1. Introduction
A road network is a system of interconnecting lines that represent the interconnecting roads in a given area [
1,
2,
3]. Traditionally, the road networks are constructed from geographic surveying through devices, such as telescopes and sextants. These mapping devices are very expensive, and doing such surveys requires a huge amount of time and effort. As a result, such maps cannot be updated frequently [
4]. With the development of Global Positioning System (GPS) technology in the last few decades, mobile mapping campaigns with GPS devices have replaced the surveying devices in urban areas and reduced the labor cost for the road map generation. Although, it is still time consuming for the campaigns to cover all streets on the map; thus, the map updates lag behind road construction substantially. Thanks to the ubiquitous use of hand-held GPS units, now we can easily obtain massive GPS trace data from a variety of road users, such as vehicle drivers, cyclists and pedestrians. This has simulated the development of automatic road network inference [
5,
6,
7,
8,
9,
10,
11,
12].
Road intersections play an important role in road networks. They can provide very useful information, such as connectivity, topology and allowable moving direction, which are not only beneficial to build the topology of the road network, but also helpful to generate the geometric representation of the road segments in the network. Based on the generated road network, we can further analyze the preferences of the travelers on route selection [
13], the transition between different transportation modes [
14], traffic density on the roads [
15,
16,
17], the delays due to traffic jams [
9,
14,
18,
19], etc.
In the literature, some indirect methods have been proposed to detect the intersections by examining the moving direction changes of the road users on their trajectories. Karagiorgou and Pfoser detected turn samples from GPS traces by thresholding the moving speed and moving direction change [
10]. The vector from the current point to its next adjacent point was used to describe the moving direction at this point. An agglomerative hierarchical clustering method was applied to cluster the turn samples into intersection nodes Wu et al. first found turning points from coarse-gained GPS traces by thresholding the moving direction changes [
20]. To improve the concentration of the turning points, they collected the intersecting points, where the turning points converged. The X-means algorithm was applied in their work to cluster the converging points to intersections [
21]. Wang et al. first detected the conflict points, where two or more traces cross, diverge or converge, through thresholding the road users’ moving direction change [
22]. They then computed the spatial position and boundary circle of each road intersection from the conflict points. In our earlier work [
23], we calculated the moving direction at each GPS point using the point ahead of it with a fixed distance to it, instead of the next point, and clustered the turning points with moving direction changes into intersection candidates. We finally checked the turn patterns to remove misdetected bends.
Although the researchers mentioned above have applied different techniques to detect the intersections, their algorithmic foundation is the same: an intersection is defined as a location or an area where the road users change their moving directions often. A limitation of these approaches is that it is difficult to determine an appropriate threshold for the moving direction change. A low threshold will lead to more spurious intersections being falsely detected, and a high threshold will result in more true intersections being undetected.
Different from the methods above, Fathi and Krumm designed a shape descriptor representing the distribution of GPS traces around a point and trained a classifier over the descriptor so as to distinguish intersection points from non-intersection points [
24]. Their results showed that the detected intersections matched their ground-truth closely. However, they need to train a new shape descriptor for each new type of intersection, which is not suitable for automatic road map updating.
In this work, an intersection is defined by its own property as a location connecting three or more road segments in different directions. Based on this definition, a novel method is proposed to detect intersections from GPS traces based on the Longest Common Subsequence (LCSS) algorithm. First, pairwise GPS traces are aligned to find the longest common subsequences between them. The nonconsecutive subsequences are then partitioned into consecutive sub-tracks. Second, the starting and ending points of the common sub-tracks are collected as connecting points, if neither of the GPS traces start or end there. The density of the connecting points are estimated, and the local maximums on the density map are detected as intersections. At last, the pattern of the GPS traces converging or diverging at the connecting points around each intersection is checked to remove the false positive detections.
The initial results were written in a four-page paper and published in the 2016 IEEE International Geo-science and Remote Sensing Symposium [
25]. In this paper, we elaborate our algorithm of intersection detection in more depth. Except the common sub-tracks in the same direction, we also find the common sub-tracks in the opposite directions by reversing one of the GPS traces and applying the LCSS algorithm to them. We improve the robustness of our algorithm against GPS errors, by checking patterns of the GPS traces meeting at the intersections and removing the intersections that are detected from one single GPS trace converging or diverging with all other traces. In addition, we evaluate the accuracy of the detected intersections thoroughly using the F-score measure, which considers both precision and recall.
The remainder of this paper is structured as follows. In the next section, we present the problem of intersection detection from GPS traces given the new intersection definition, followed by
Section 3, which elaborates how to detect the common sub-tracks between pairwise traces and utilize the starting and ending points of these sub-tracks to identify intersections.
Section 4 shows our experimental results. Lastly, the conclusion is drawn in
Section 5.
2. Problem Statement
In this work, we define a road segment as a sequence of non-intersection geographical locations that connect two intersections. The road users often traverse a sequence of road segments, instead of a single road segment, to arrive at their destinations. On their journeys, they may traverse the same road segment and then split to different road segments; or they may traverse from different road segments to the same road segment. As a result, the generated GPS traces may converge from different road segments to the shared road segment or diverge from the shared road segment to different road segments. The converging and diverging points on the GPS traces are located at the intersections. Therefore, the intersections can be detected through finding the common sub-tracks of the GPS traces recorded on the same road segments. A common sub-track is a sequence of points that appears in the same relative order and occupies consecutive positions in both GPS traces. Each common sub-track corresponds to a shared road segment.
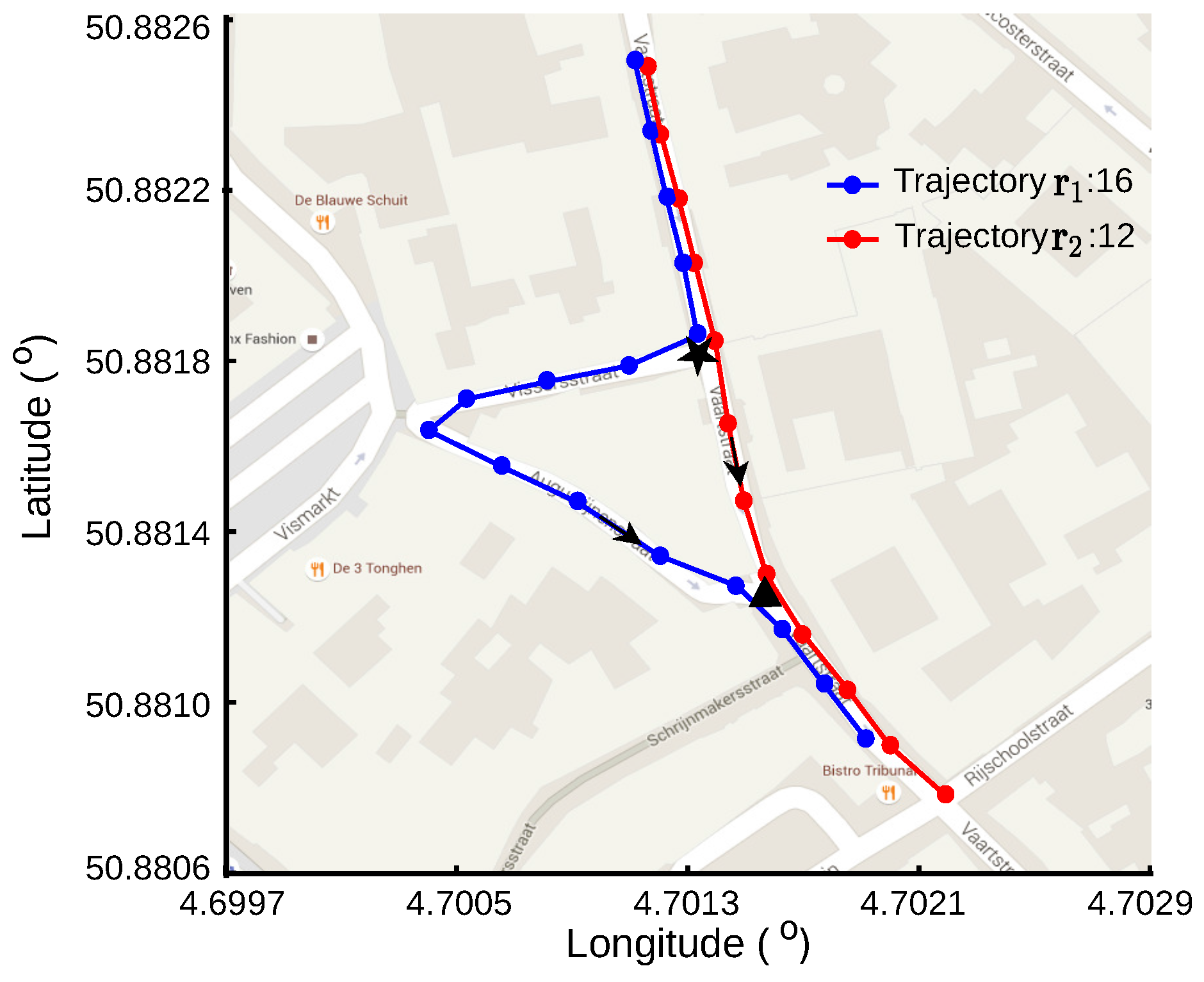
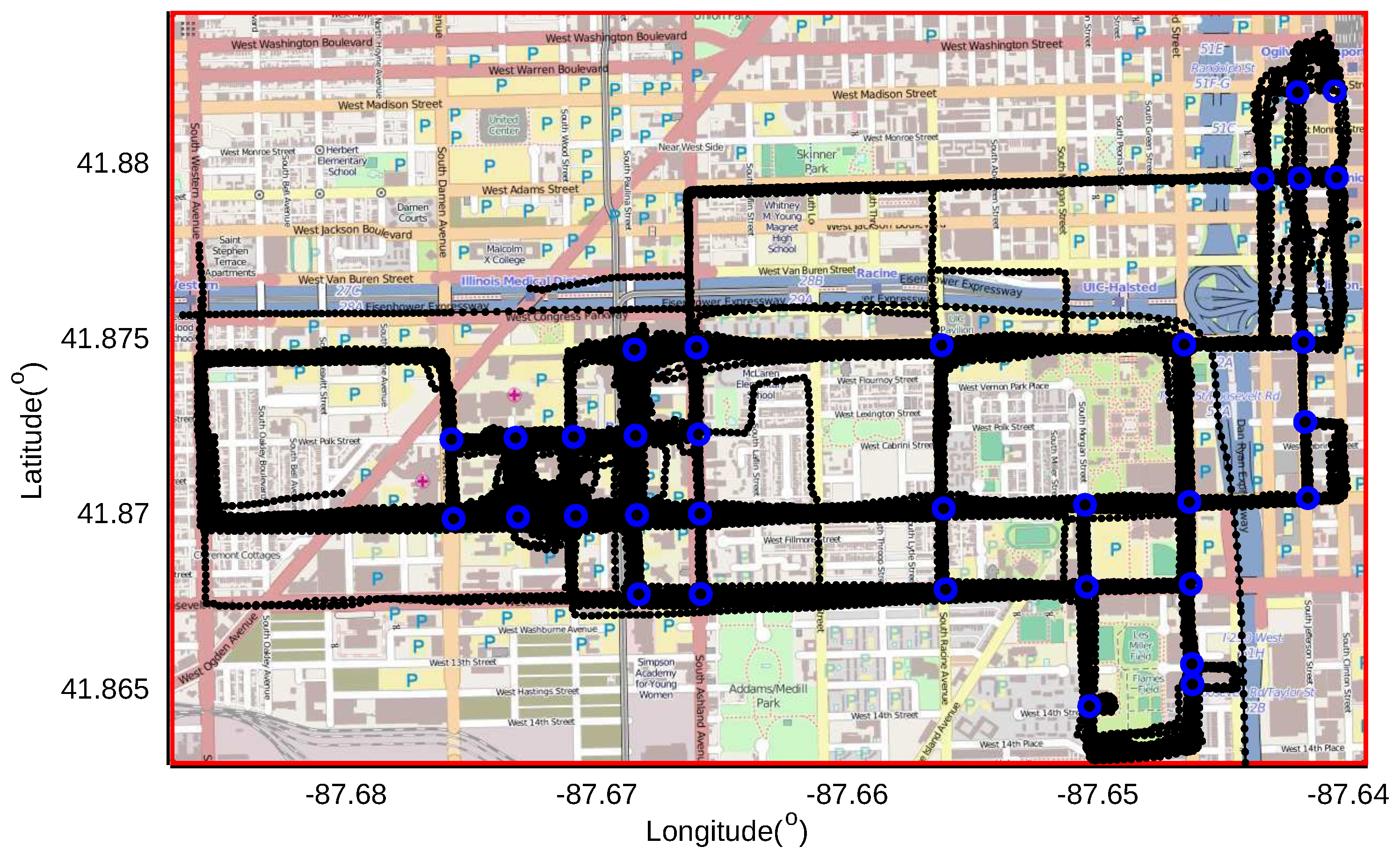
Figure 1 shows an example of two GPS traces diverging at one intersection and then converging at another intersection. The first GPS trace, which contains 16 points, is shown using blue lines with blue dots, indicating the point locations. There are 12 points in the second trace, shown in red lines with dots. The arrows show that the road users move from a higher latitude area to a lower latitude area in both traces. Both of the road users start their journeys on the same road segment, split to different road segments at the first intersection indicated using a black star, come together to another road segment at the second intersection indicated using a black triangle and end their journeys on this road segment. The generated GPS traces diverge at the first intersection and converge at the second intersection. We aim to find the common sub-tracks of the GPS traces, which correspond to the shared road segments both road users traverse, and identify the intersections from the starting and ending points of these sub-tracks.
3. Proposed Method
In this section, we first find the longest common subsequences between pairwise GPS traces, then segment them into common sub-tracks. The starting and ending points of the common sub-tracks, i.e., the converging and diverging points of the traces, are collected as connecting points. We then identify the intersections from the connecting points through KDE. Lastly, we examine the patterns of the GPS traces meeting at the intersections, so as to remove the false-positive intersections detected from one single trace converging or diverging with all other traces.
3.1. Longest Common Subsequence
A trace subsequence is a sequence of data points that appears in the same relative order within the original trace as a sub-track does, but does not necessarily occupy consecutive positions as a sub-track does. A common subsequence of two GPS traces is a subsequence present in both of them. A longest common subsequence is a common subsequence of maximal length. The most naive approach to find the longest subsequence would be to enumerate all subsequences common to both GPS traces and select the one of maximal length. However, it is very time consuming to apply this approach. To overcome this challenge, dynamic programming is employed to find the longest subsequence efficiently [
26].
Dynamic programming is an algorithm for breaking a complex problem into a collection of simpler subproblems, solving each of those subproblems firstly and then using them to find the solution to the complex problem [
27,
28,
29]. In our case, rather than finding the LCSS between two whole traces, we first find the LCSS between smaller prefixes of the traces and use them to find the LCSS between larger prefixes, until we find the LCSS between the whole traces.
We adopt the following notations. Suppose we have two GPS traces
and
. Let
,
and
,
be points of
and
, where
and
are the numbers of points in each trace, respectively. The first stage of implementing dynamic programming is to create a two-dimensional (2D)
length matrix
L. The value at each cell,
, represents the length of the longest common subsequences between the prefixes of the given traces,
,
and
,
. It depends on the similarity of the points
and
and the values of its adjacent cells
. We also create a 2D
arrow matrix
B. The arrow at each cell,
, indicates which of the adjacent cells
is calculated from, as shown Equation (
2).
where
and
. The geographical distance between two points,
, is used to measure their local dissimilarity. The distance threshold
should be chosen based on the road width and the expected GPS error.
where
and
.
| Algorithm 1 FindPath. |
| Input: L, B |
| Output: , , , , |
| Initialization , , |
| 2: while do |
| if then |
| 4: |
| else if then |
| 6: |
| else |
| 8: switch do |
| case |
| 10: , |
| , |
| 12: |
| , |
| 14: case |
| |
| 16: case |
| |
| 18: end if |
| |
| 20: end while |
| if then |
| 22: , |
| , |
| 24: end if |
| , |
| 26: , |
Once the length matrix L and direction matrix B are built, the longest common subsequences are deduced by following the arrows backwards through matrix B. It starts from the last cell and ends at the first cell . If the length decreases, the traces must have had similar data points. These two data points are added to the longest subsequences, and , for each trace, respectively, and their time indexes in the original traces are added to and , i.e., and . Algorithm 1 elaborates the procedure.
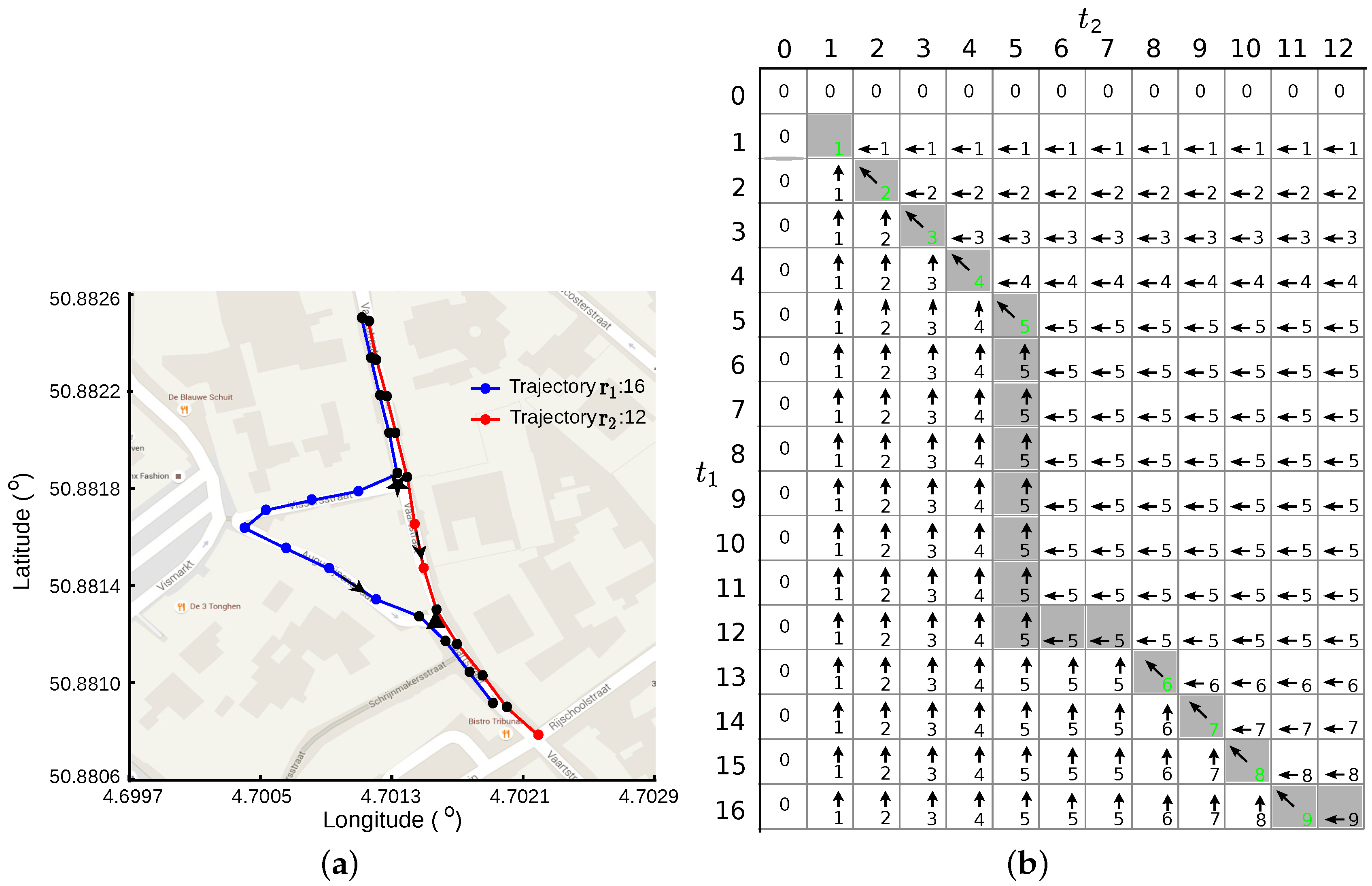
Figure 2 illustrates the procedure of finding the LCSSs between two GPS traces.
Figure 2a shows the LCSS for each GPS trace using blue lines with black dots and red lines with black dots, respectively. In total, there are nine points in the LCSS for each trace. The LCSS for the first trace is expressed as
,
, and
,
is for the second one.
Figure 2b shows the length matrix
L and arrow matrix
B in grids. The “backtrack” procedure starts at cell
and follows the direction of the arrows to the first cell at
. The path through the matrix is indicated using cells with a gray background. Only the corresponding points to the cells with decreasing length are saved for the LCSS. The lengths of these cells are shown in green numbers.
3.2. Connecting Point Collection
A subsequence is a sequence of points that appear in the same relative order and do not have to occupy consecutive positions in the original trace. The longest common subsequence may correspond to more than one road segment. However, we are more interested in the common sub-tracks to both GPS traces, whose points do occupy consecutive positions in the original traces. Each common sub-track corresponds to one road segment that the road users traverse in both traces. Therefore, the starting and ending points of the sub-track correspond to the two ends of the road segment, i.e., intersections. The common sub-tracks between two GPS traces can be obtained by partitioning the longest common subsequences.
We first check the consecutiveness of the points of the longest common subsequences. Given the k-th points of the LCSSs for both traces, and , and their time indexes in the original traces and , they are nonconsecutive points if the next points and occupy positions far ahead of them in the original traces, i.e., and , where ξ is a predefined threshold. In this work, we set ξ larger than one to avoid the deviating points on the trace, which are caused by GPS errors, being falsely detected as nonconsecutive points.
The longest common subsequence is segmented by these nonconsecutive points into common sub-tracks. If all points of the LCSSs are consecutive, we directly take the starting and ending points of the LCSSs as connecting points if they are not the starting and ending points of these two GPS traces.
As shown in
Figure 2, the fifth points of the LCSSs are not consecutive in the original traces. For trace
, the sixth point of its LCSS occupies the thirteenth position in
. The fifth and sixth points of the LCSS are separated by seven blue dots. For trace
, the sixth point of its LCSS occupies the eighth position in
. The fifth and sixth points of the LCSS are separated by two red dots. Therefore, each LCSS is partitioned into two sub-tracks by the fifth point: the first sub-track containing five points and the second one containing four points. For the first trace, the detected common sub-tracks are
,
and
,
. The common sub-tracks for the second trace are
,
and
,
. The ending points of the first common sub-track for each trace,
and
, are connecting points, and the starting points of the second sub-track for each trace,
and
, are also connecting points. The starting points of the first common sub-track for each trace,
and
, are not connecting points because they are also the starting points of the GPS traces. The ending points of the second sub-track for each trace,
and
, are not connecting points because
is the ending point of trace
.
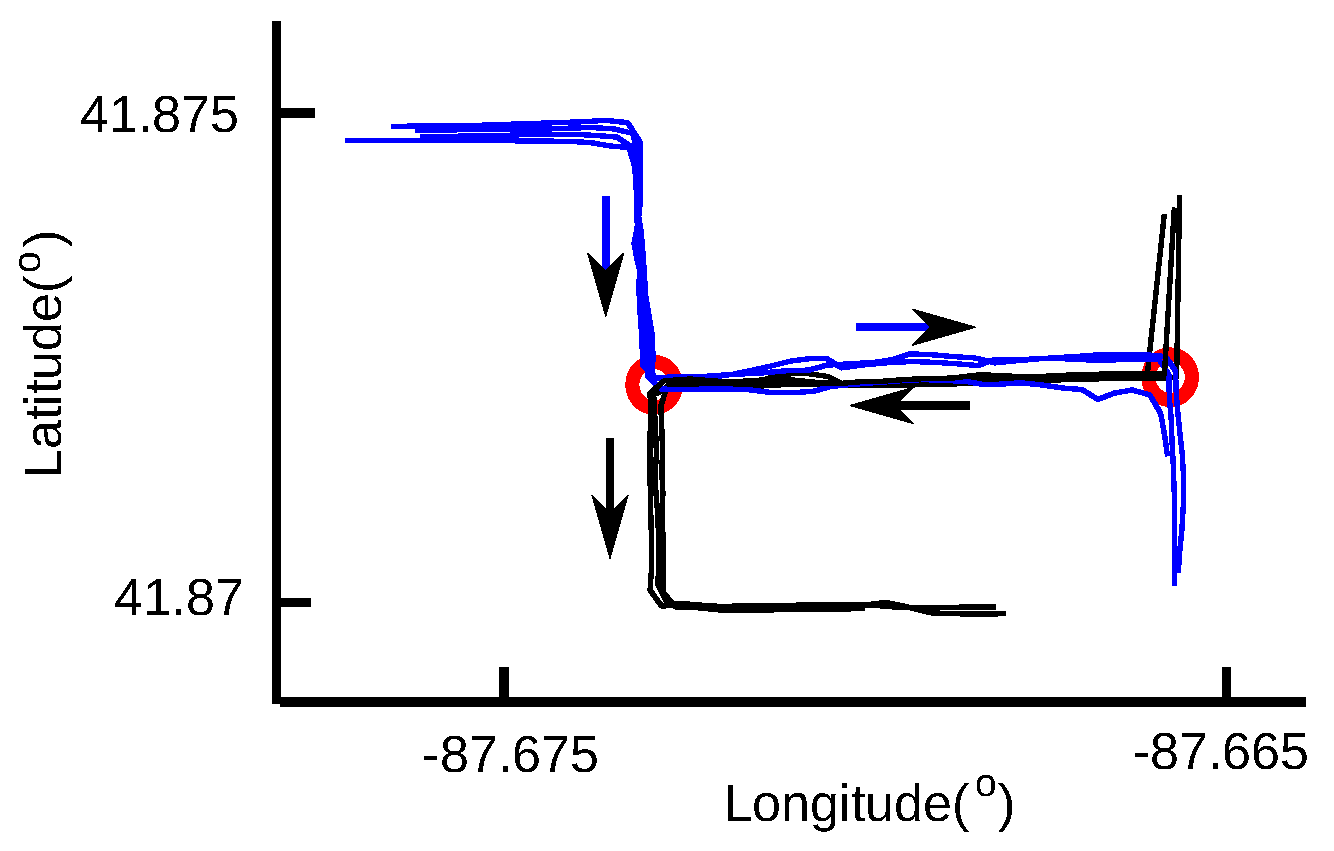
The procedure of detecting the LCSSs processes two GPS traces directionally, which start from the beginning of both traces and end at the ending of both traces. Therefore, only the common sub-tracks in the same direction can be detected. If the road users traverse the same road segment, producing two traces, but in the opposite directions, no common sub-tracks will be found between them. As shown in
Figure 3, all of the GPS traces share the same road segment between two intersections, which are indicated by red circles. On this road segment, the road users travel from left to right in the blue traces, but from right to left in the black traces. No common sub-tracks will be found between the blue and black traces, although they do share the same road segment. Therefore, the connecting points at the ends of the common sub-tracks in the opposite directions will not be detected, leading to intersection detection being inaccurate. This can be solved by reversing the data points of the black traces.
Given a dataset of N GPS traces, we first find the common sub-tracks between each pair of GPS traces as elaborated above and collect the starting and ending points of the common sub-tracks as connecting points, if they are not the starting and ending points of these two GPS traces. We then reverse one trace in the each pair of the GPS traces and repeat the procedure again to find more connecting points.
3.3. Intersection Extraction from Connecting Points
In this section, intersections are detected using the connecting points by estimating their density over the area covered by the GPS traces. We first discretize the geographical area into a two-dimensional (2D) grid of cells and count the number of the connecting points in each cell, producing a 2D histogram [
5,
30]. We then convolve this 2D histogram with a Gaussian smoothing function
, resulting in an approximation of the Kernel Density Estimation (KDE). The parameter
σ exhibits a strong influence on the resulting estimate. A small
σ can cause the 2D histogram to be undersmoothed, resulting in more than one intersection detected at the location of one true intersection. A big
σ may lead to oversmoothing, then two adjacent intersections merge together on the density map. Therefore, the choice of
σ should be made depending on the intersection size and the minimum distance between adjacent intersections.
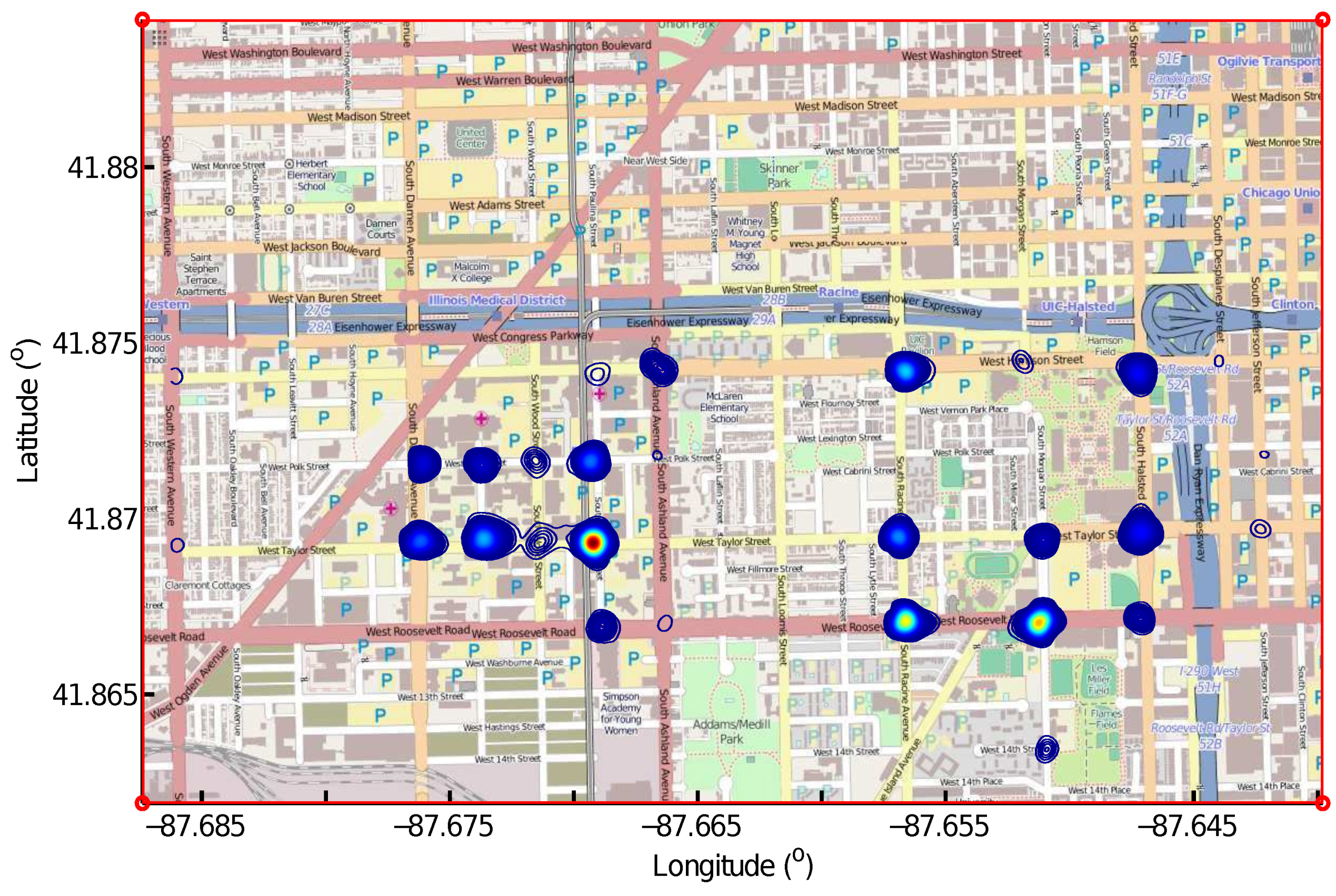
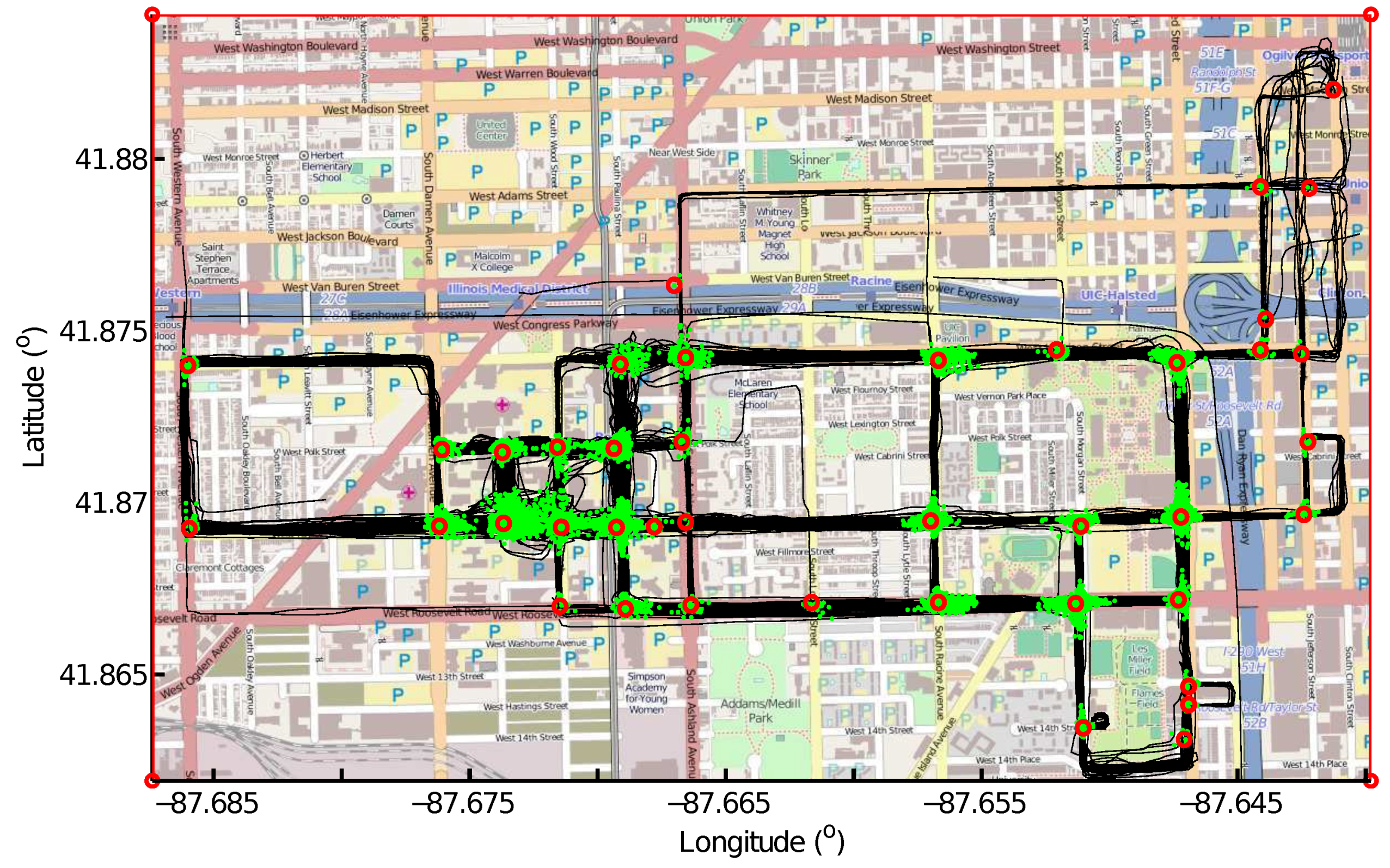
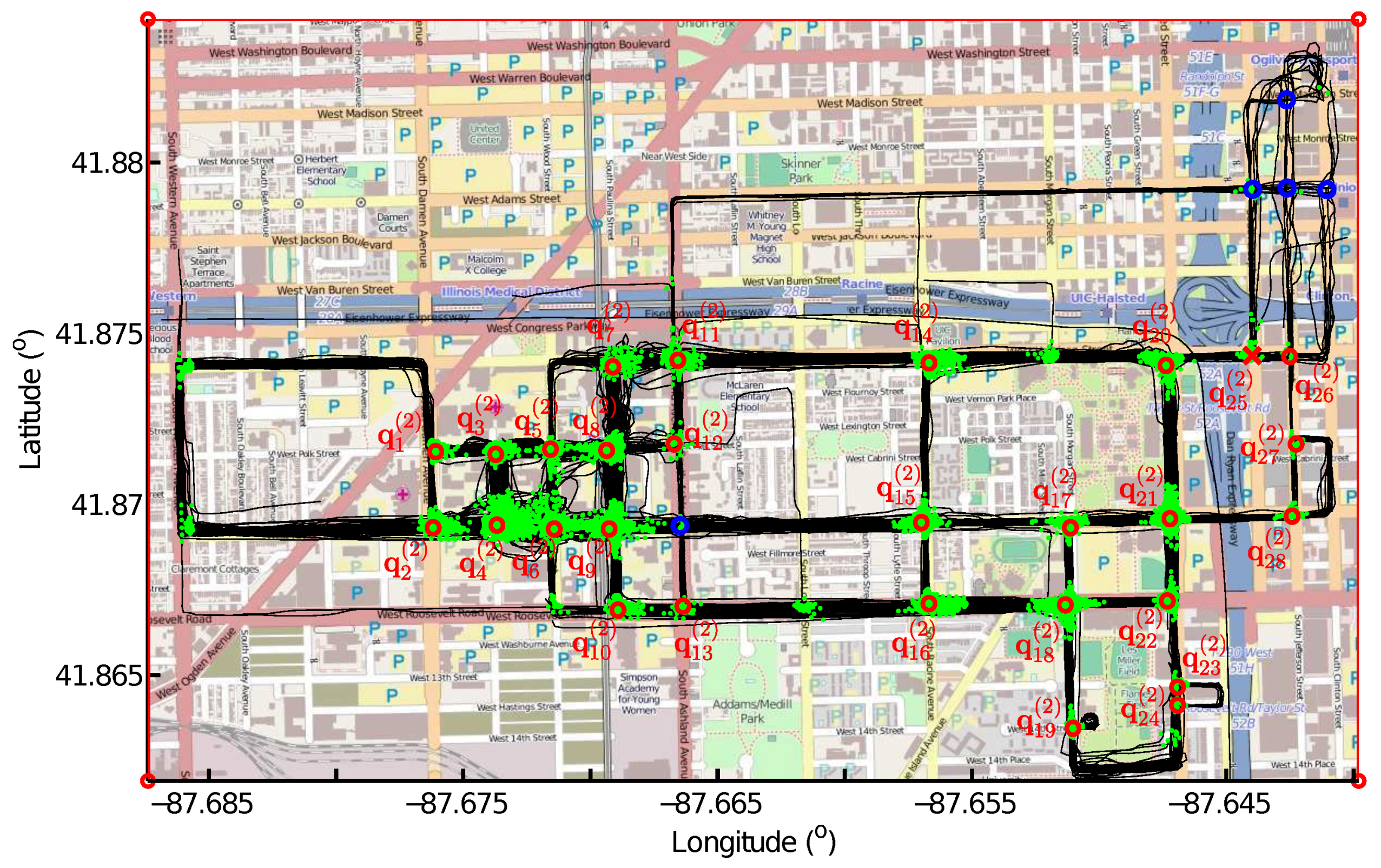
The local maximums on the density map, i.e., the cells that have greater values than their neighbors, are detected as intersections. The outputs of this step are the geographical locations of the detected intersections and the connecting points that belong to each intersection.
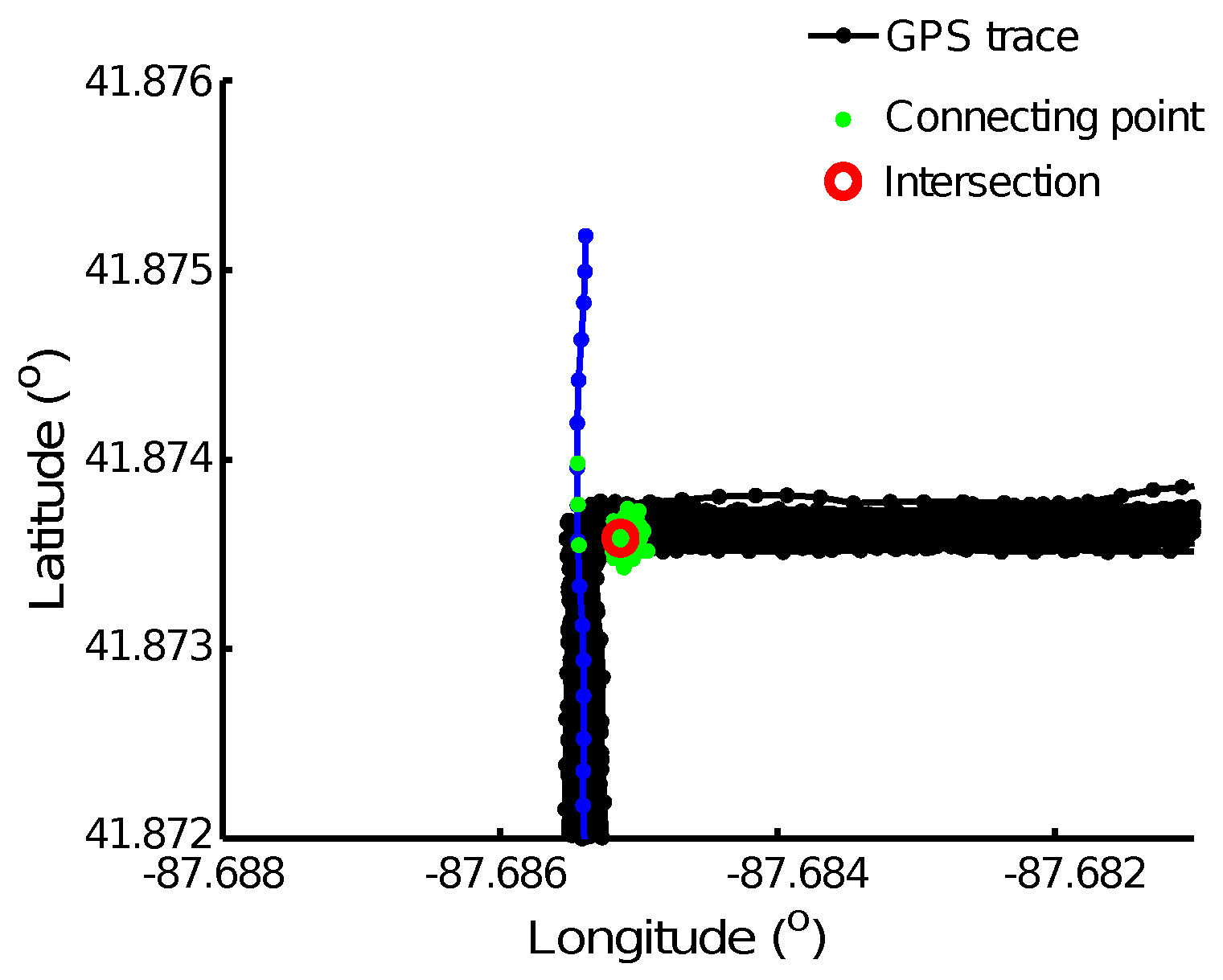
The connecting points are detected from GPS trace alignment using the LCSS algorithm. One single trace meeting with many other similar GPS traces at the same location can produce a large number of connecting points, resulting in a local maximum on the density map. However, this GPS trace can be an abnormal trace that deviates from the road because of GPS errors. An example is shown in
Figure 4. This will lead to an intersection being falsely detected. Therefore, we need to check the patterns of the GPS traces meeting at one intersection and remove this kind of misdetected intersection, so as to make our algorithm more robust to GPS errors.
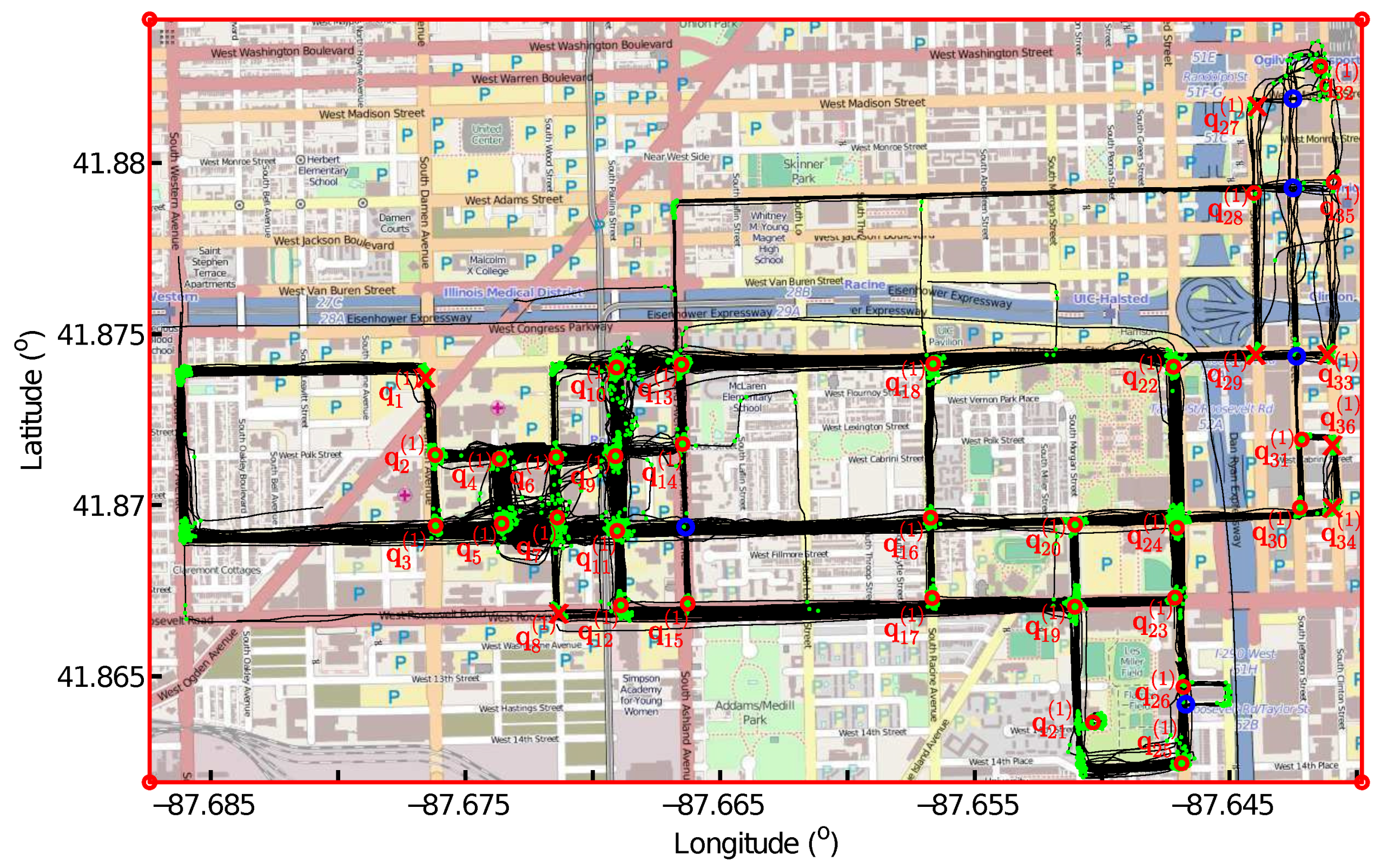
Given an intersection candidate , there are M connecting points belonging to this intersection and , , , , , , where N is the number of the GPS traces in the dataset and and are the indexes of the traces producing the connecting points and . Let be the number of connecting points that are detected by aligning trace with other traces using LCSS, . The connecting points are detected in pairs, one from and the other one from the other trace. Every connecting point is detected by aligning two traces; therefore , where . If all connecting points are detected from aligning trace with every other trace, . In this case, an intersection will be falsely detected from these connecting points if trace is an abnormal trace. For each GPS trace, we calculate , , and remove this intersection candidate if any of equals M.
As shown in
Figure 4, the intersection candidate shown in the red circle is removed from the true intersections because all of its connecting points shown in green dots are detected from aligning the GPS trace, indicated using blue lines with dots, with every of the other 152 GPS traces shown in black lines with dots. We admit that we will also remove true intersections connecting three road segments, in which the road users traverse two of the road segments very frequently, but through the third road segment only once. This detected intersection candidate will be removed until we have more GPS traces to confirm the existence of this third road segment.
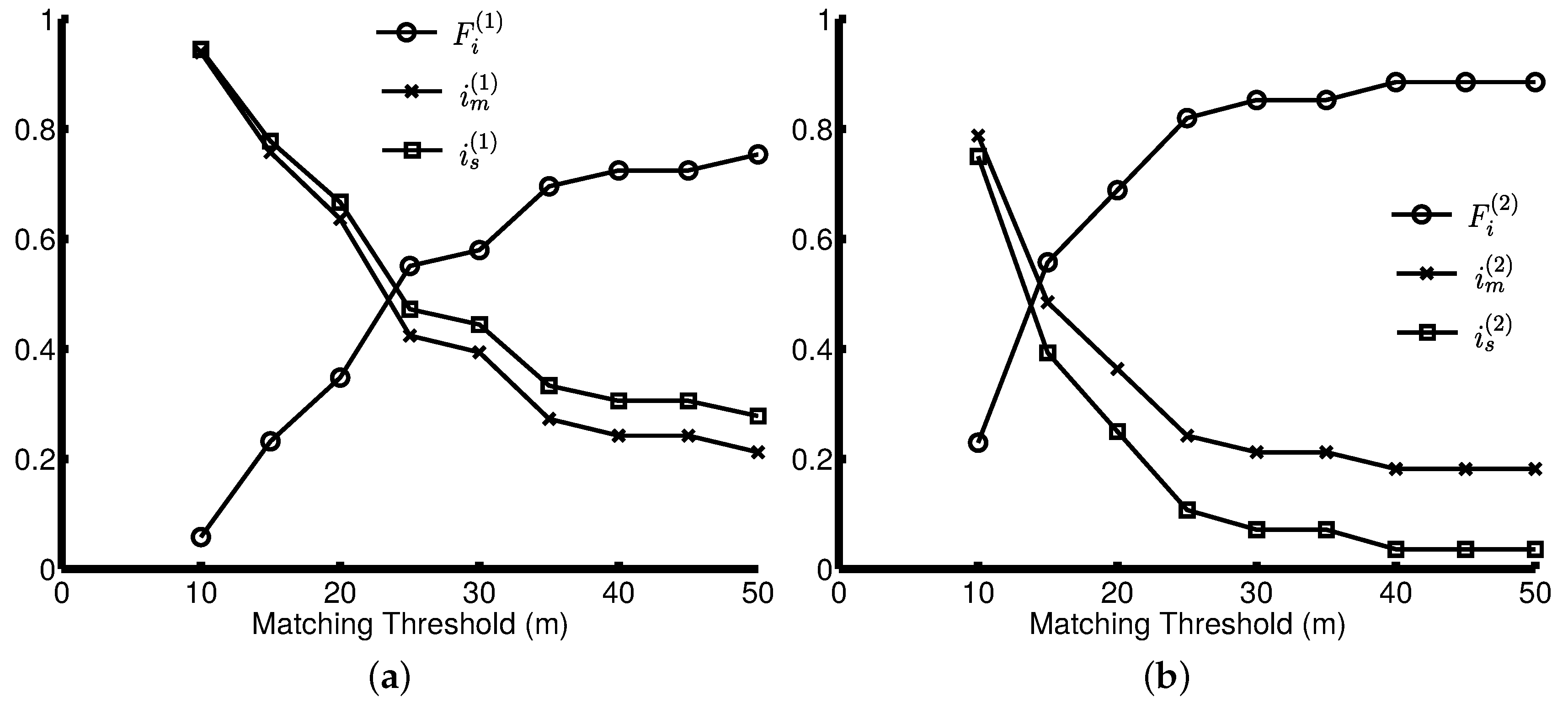
3.4. Accuracy Measure
Because of the limited accuracy of the GPS traces, we may detect “spurious” intersections that are not matched to any intersection on the ground-truth map. Due to the low coverage of the GPS traces in some area, we may not detect all of the ground-truth intersections. An efficient intersection detection method is supposed to identify as many ground-truth intersections as possible and as few “spurious” and “missing” intersections as possible. Therefore, we measure recall, precision and the F-score of the intersection detection methods. The recall represents the proportion of the “matched” intersections among the “matched” intersections and the “missing” intersections, i.e.,
, where
and
are the number of “missing” intersections and the number of “matched” intersections, respectively. The precision specifies the proportion of the “matched” intersections among all detected intersections, i.e.,
, where
is the number of “spurious” intersections. We use the well-known F-score [
31,
32], calculated using both precision and recall, as an overall accuracy measure:
5. Conclusions
We have presented a novel approach to identify intersections from GPS traces by detecting the common sub-tracks between pairwise traces using LCSS. The starting and ending points of these consecutive sub-tracks are collected as connecting points and used to find the intersections through KDE. The patterns of the GPS traces meeting at the intersections are checked so as to remove the false positive detections. Experimental results show that our proposed method achieves higher accuracy than the turning point-based method. Especially, we successfully differentiate true intersections from bends.
A drawback of our proposed method is the computational cost. Given N GPS traces, pairwise traces are processed to detect the common sub-tracks using our method, while N traces are processed separately to find the turning points using the turning point-based method. Therefore, our computational cost is more expensive. In the future, we will pre-process the GPS traces to reduce the computational cost. For instance, the pairwise GPS traces will not go to the LCSS procedure if there are no overlapping points found between them. Additionally, we will work on inferring the existence and coverage of intersections statistically using a probabilistic method, instead of the two-valued logic in our current method. We will also test our algorithm in road networks with non-orthogonal road segments.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










