1. Introduction
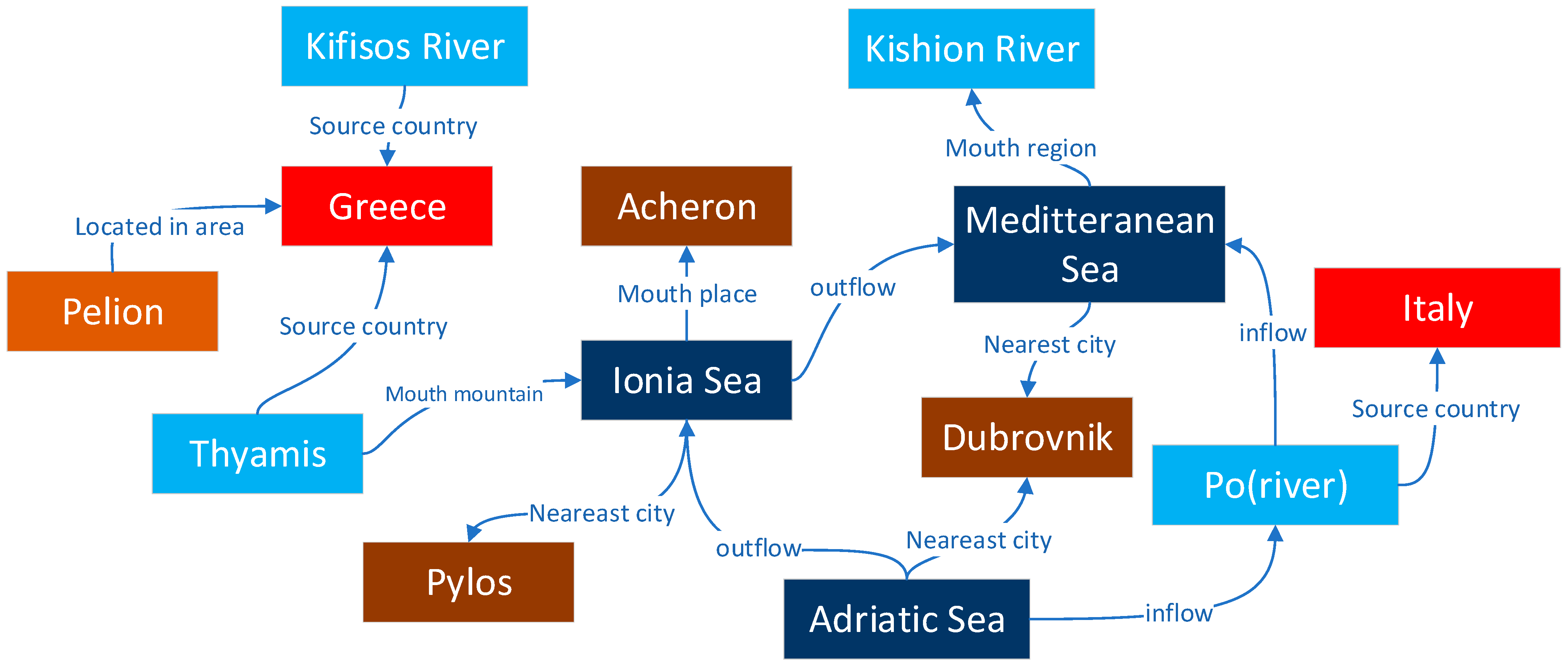
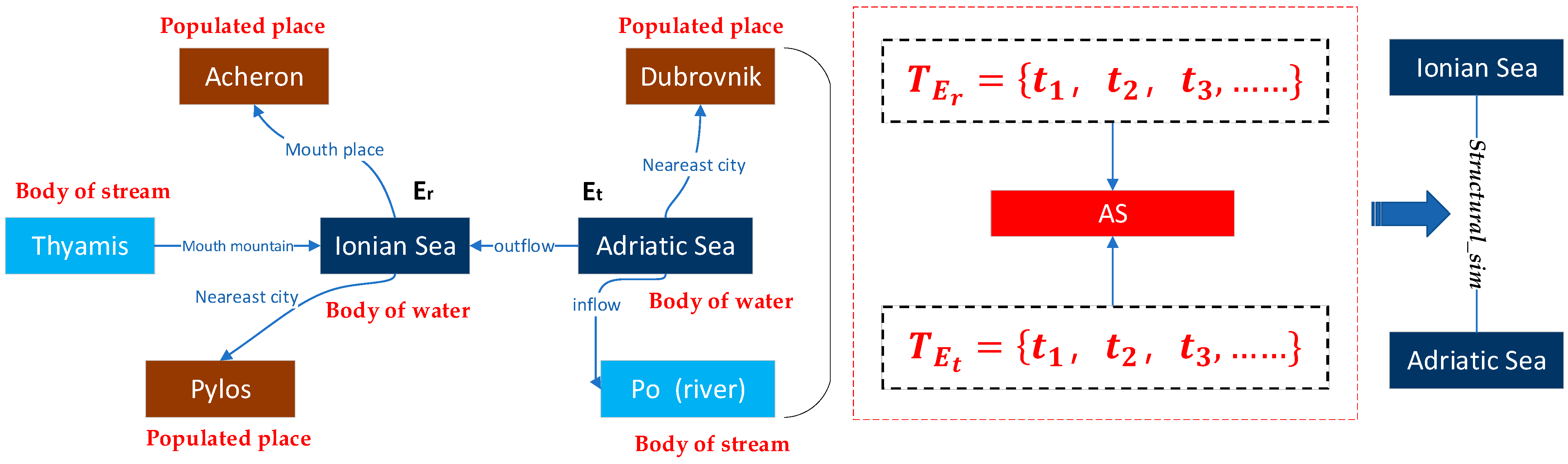
A knowledge graph (KG) contains rich descriptions of concepts, objects/places, events, and their relations in the physical world in the form of symbols. As shown in
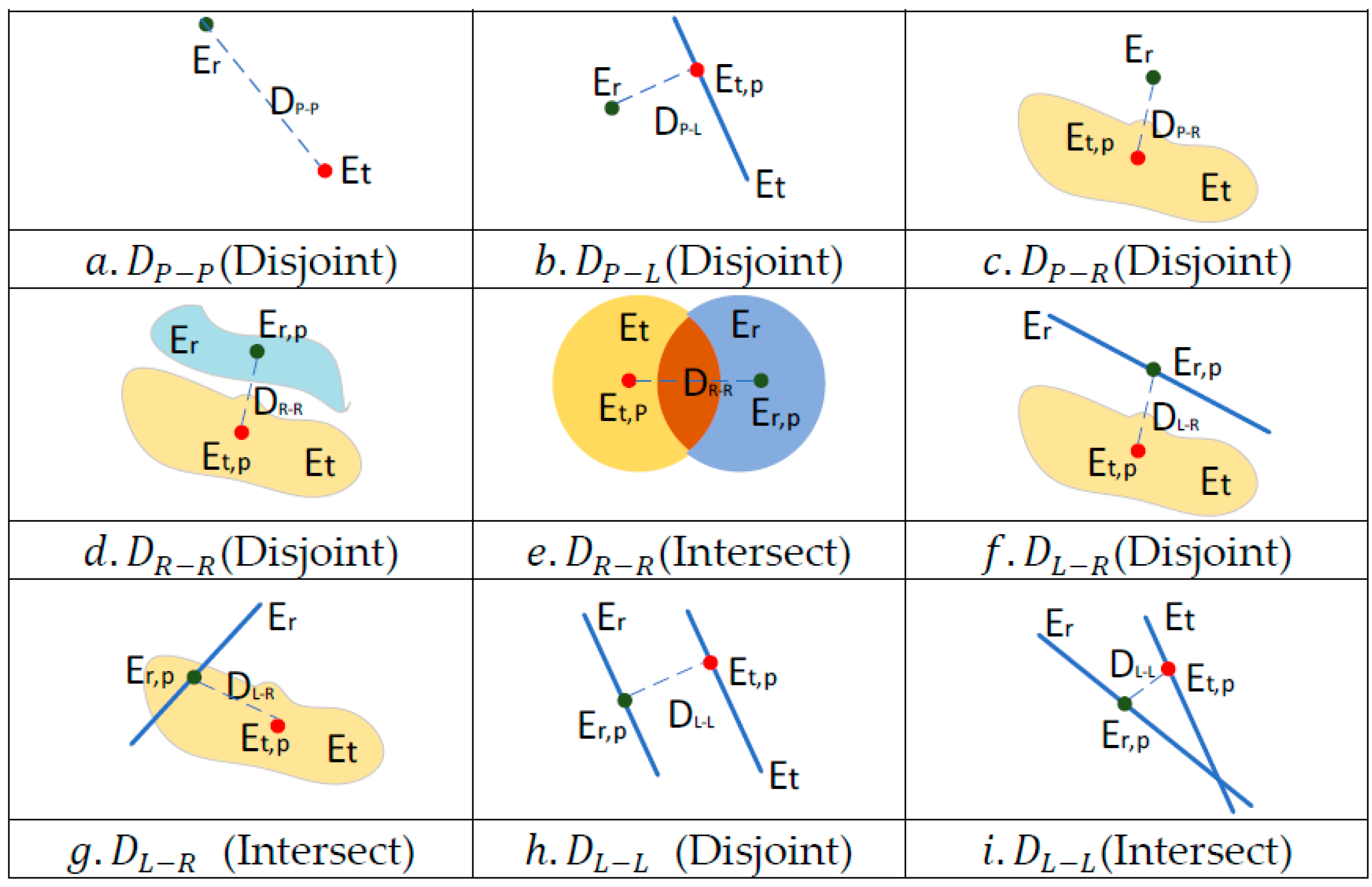
Figure 1, for example, the triplet <Ionian Sea, outflow, Meditteranean Sea>. A geographic knowledge graph (GeoKG) provides a convenient tool in the field of geography to describe geographic knowledge, depict the relations between objects, and express geographic information. Among the components of a GeoKG, a geographic entity (geo-entity from hereon) represents an object with location connotation in the real world. A geographic relation (geo-relations from hereon) refers to the relation between geo-entities and related entities, mainly including their spatial (e.g., spatial adjacency, separation, orientation, and inclusion relation) relation and semantic (e.g., type, component) relation [
1]. The vast amount of ubiquitous geographic semantic information present on the Internet promotes GeoKG-related research, including geographic information extraction [
2], geographic information fusion [
3], GeoKG construction [
4,
5], and GeoKG reasoning [
6]. High-quality entities and relations are important prerequisites for intelligent computation and reasoning based on a KG, such as recalibration convolutional networks for learning interaction KG embedding, learning KG embedding with heterogeneous relation attention networks, and multi-scale dynamic convolutional networks for KG embedding. However, owing to the constraints of ambiguous semantics, variety of styles, and incomplete structures of natural language expressions, the existing geography-related knowledge bases (e.g., DBpedia [
7], Ownthink, OSM [
8], and Geonames [
9]) do not only contain massive geo-entities but also have sparse entity relations and are generally missing data. This results in an incomplete relation structure, inaccurate information, or poor timeliness, which seriously affects the intelligent reasoning and computation of the resultant GeoKG [
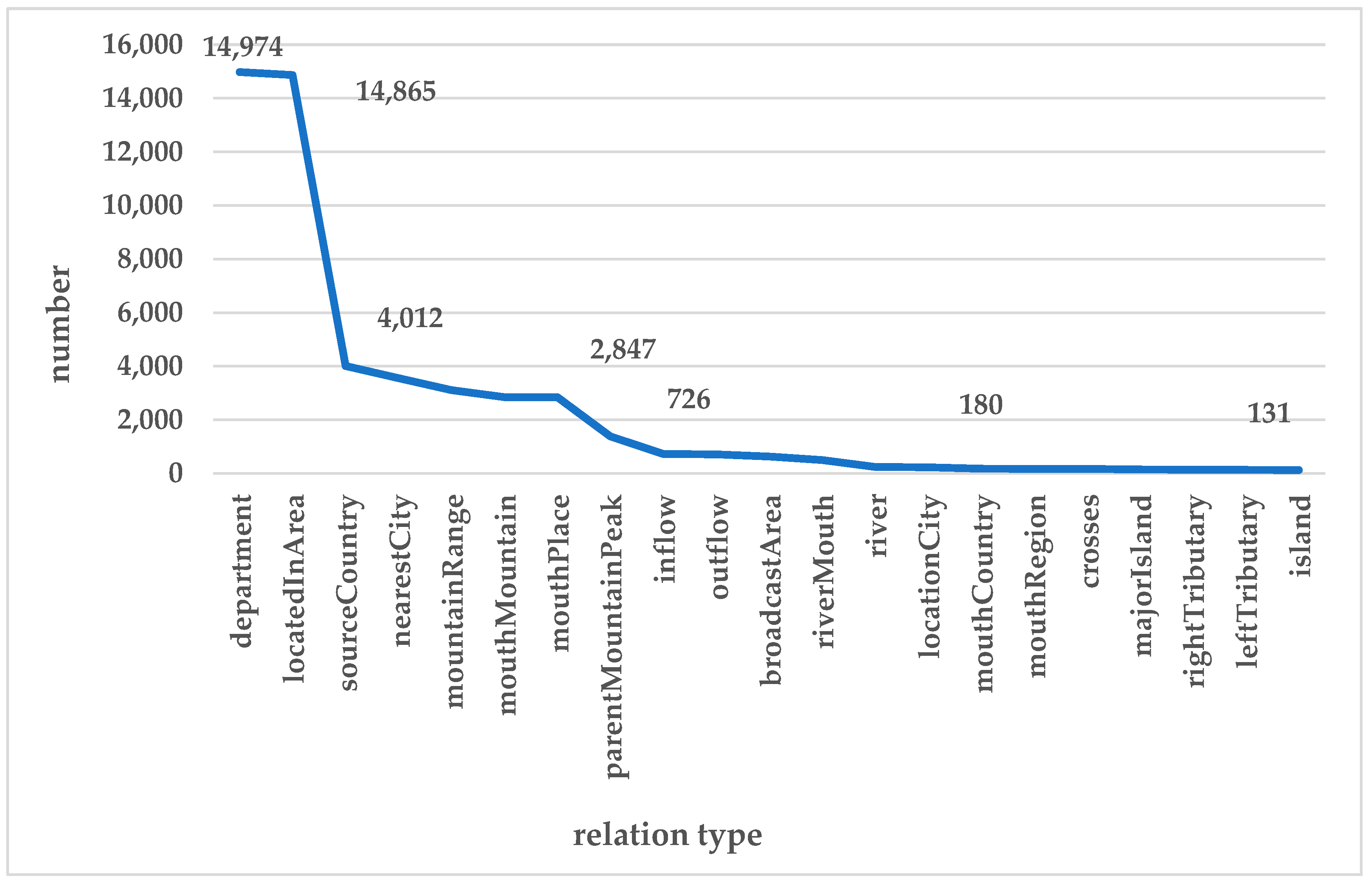
10]. Hence, geo-relation complementation has become the primary challenge of GeoKG research.
The completion of geo-relations is realized by predicting the relation in GeoKG. for example, obtaining the value of “r” in the triplet <Ionian Sea, r, Meditteranean Sea> through relation prediction modeling, or predicting the value of “h” in <h, outflow, Meditteranean Sea> or the value of “t” in <Ionian Sea, outflow, t>. Existing relation prediction methods include inference methods based on deductive reasoning, inductive reasoning, and representation learning. Methods based on deductive reasoning [
11] require clearly defined prior information, such as defining axiomatic rules of (province, contains, city) and (country, contains, province) then (province, contains, city), to complete the “contains” relation between the province and city category entities in a KG. This type of method has high accuracy, but also high labor cost. Methods based on inductive reasoning [
12] can effectively mine axiomatic rules with high confidence from large-scale KGs, which reduces the cost of manually defining rules, to a certain extent, and also eliminates potential subjective errors made by the rule makers. However, these two types of methods remain difficult to apply to the open GeoKGs that have a large scale of data and many types of relations. The reasoning method based on representation learning can map the entities and relations in a KG to the vector space, and transform the geo-relations prediction problem into the direct calculation between vectors, which makes it possible to complete more relations in a large-scale KG.
The reasoning method based on representation learning has become a research hotspot in intelligent computing and relation completion for large-scale KGs, it mainly comprises the distanced-based method, semantic matching-based method, and neural network method. The distanced-based method (e.g.,TransE [
13], TranR [
14], TransD [
15]) maps geo-entities and geo-relations into low-dimensional vector space, and treat relations as translation operations from head entities to tail entities in vector space, so that h +r ≈ t. The semantic matching-based method (e.g., RESCAL [
16], DisMult [
17]) uses vectors to represent entities and matrices to represent their relations. The internal interaction of triplets is captured by a self-defined scoring function, as shown in Equation (12). The neural network method (e.g., ProjE [
18], GNN [
19], R-GCN [
20]) learns the vectorial expression of new entities by using related entities and relations with the help of neural network models. All of the above methods aim to mine the features of geo-entities and relations from an existing GeoKG. However, the relations are often so sparse that the sample data cannot provide sufficient and comprehensive characteristics of geo-entities and relations in large-scale GeoKGs.
Therefore, an increasing number of researchers are finding that the aforementioned methods of mining internal structural features cannot cope with incomplete structural information in the sparse KG. Using external information to enhance the semantics of entities or relations, or learning intervention may promote the improved vectorial expression of entities and relations. TKRL [
21] states that different types of entities should have different vectorial expressions, so the type information of entities is added as a constraint, the hierarchical type is taken as the projection matrix of entities, and the distance-based method is used to model different types of entities. TransEA [
22] states that entity attributes will help to optimize the vectorial expression of entities. Based on using a distance model to model the triplet structure in the body of data, a linear regression model is used to model the quantitative attributes of entities. DKRL [
23] states s that similar entities have similar descriptions, and uses a convolution network to encode the description information and integrate it into a distance-based model. All of the above methods, without changing the structure of the sample data, optimize the quantitative expression of entities and their relations by enhancing the external semantic information. To a certain extent, this overcomes the sparse problem of the sparsity of entities and relations in the sample data set.
However, those methods have the following problems:
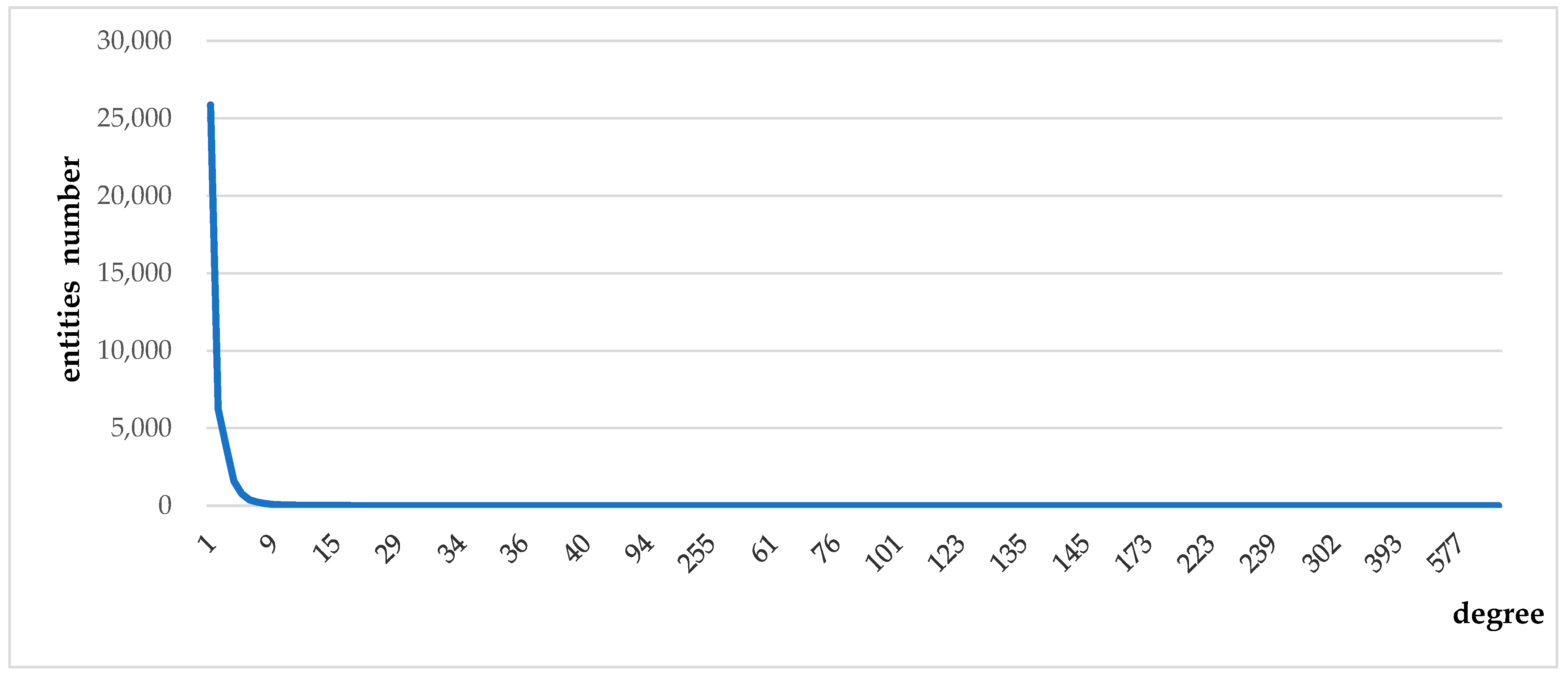
Although TransE, DisMult, ProjE, and other methods can learn the features of entities, relation transformation, and graph structure, the geo-entities, and geo-relations in a GeoKG dataset often have evident unbalanced distribution characteristics, which results in the model being unable to obtain sufficient relevant features if they do not have an explicit relational connection during the learning process, but actually, a lot of entities has implicit relation with each other.
Methods that add external information (entity types, entity attributes, textual descriptions of entities) can only improve the embedding of geo-entities theoretically, it is not clear which external information can make embedding better or worse without selected valid information, and such methods still increase the complexity and reduce the efficiency of learning.
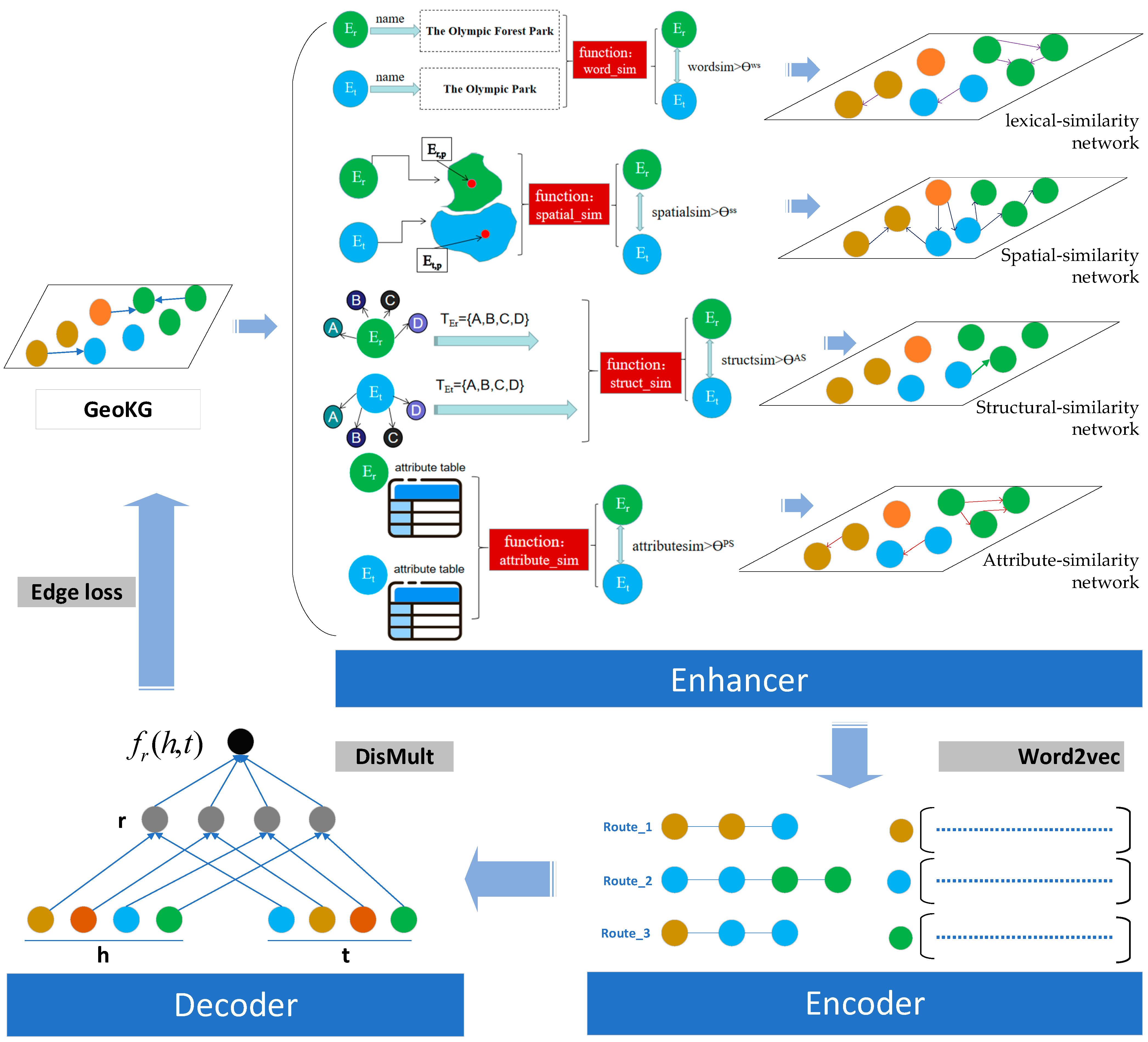
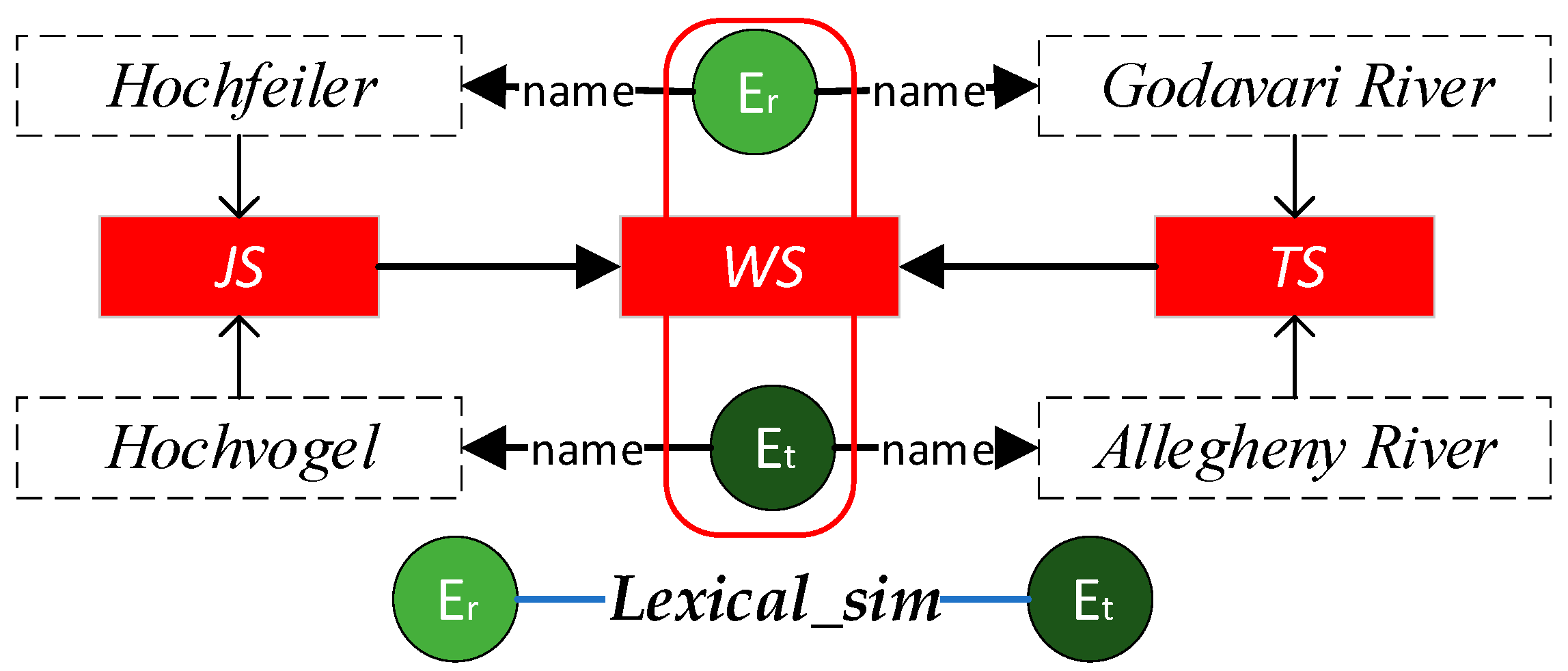
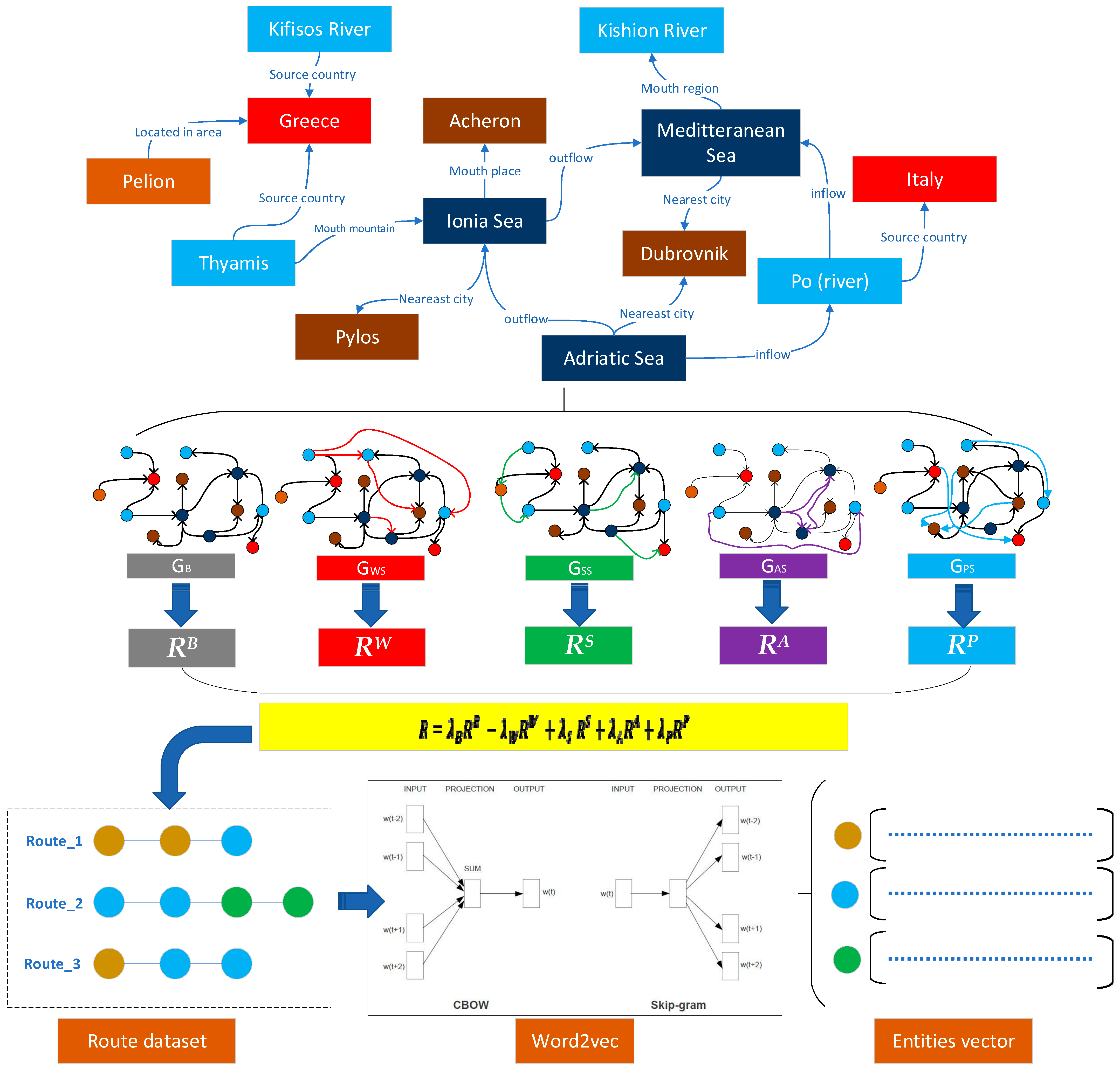
To address the above problems, a geo-relations prediction method based on multi-layer similarity enhanced networks (MSEN-GRP) is proposed, which incorporates an enhancer, encoder, and decoder to alleviate the difficulties caused by sparse relation connections between entities in the GeoKG corpus. This method has the following advantages: (1) By calculating the multi-level similarity of geo-entities, the enhancer can explicitly preserve the multi-level similarity relations between geo-entities to a certain extent, which enhances the connection of entities in the training dataset and also takes into account the enhancement of effective semantics; (2) In the encoder, different sampling ratios can be used to realize the process of vector chemistry learning of geo-entities, eliminate the added interference and enhance the semantic part, and realize the embedding of the optimally enhanced semantics. In addition, the path feature collection method can better obtain the long path dependency features between entities in a KG; 3) The model adopts a semantic enhancement method of limited display, which not only displays and increases the multi-level explicit semantic relations among geo-entities but also improves the effectiveness of the model in relation prediction.
The remainder of this paper is organized as follows:
Section 2 presents details of the proposed methodology. In
Section 2.1, we describe the construction of multi-layer similarity networks of geo-entities to achieve the semantic enhancement of a KG. We describe the process of realizing the vectorization expression of geo-entities in
Section 2.2, and we introduce the prediction of geo-relations based on the vectorization of geo-entities in
Section 2.3. In
Section 3, we report comparative experiments that prove the effectiveness of the method. We discuss the usefulness of the method and its limitations in
Section 4 and summarize our work in
Section 5.
4. Discussion
At present, the main knowledge completion methods (e.g., TransE, RESCAL, ProjE, TKRL) are all based on the connection characteristics between existing entities to obtain a reliable and effective vectorized representation of entities, which is then applied to knowledge completion. Therefore, the connectivity of entities is closely related to the representation learning of a KG. Thus, when those methods such as TransE and DisMult were used in GeoDBpedia21 for testing, and the MRR was lower than 0.2, Hits@10 is lower than 0.33, and the overall effect was not ideal [
26]. The proposed MSEN-GRP method converts the implicit geo-relations between geo-entities to explicit geo-relations with specific meaning by constructing multi-layer similarity networks, which compensates for the weak connectivity between geo-entities and improves the learning effect of geo-entity representation(as long as the accuracy of knowledge completion based on representation learning is improved). The experimental results shown in
Table 7 verify the effectiveness of the proposed MSEN-GRP method in improving geo-relations prediction.
The MSEN-GRP method attempts to build those similarity networks, which theoretically enhances the effect of representation learning, but there are differences in the contribution of different layers of similarity networks to the representation learning of geo-entities. Therefore, the MSEN-GRP method also provides a mixed-path sampling method to test the effect of the MSEN-GRP method under different sampling modes, and evaluate the impact of different levels of similarity networks on the learning of geo-entity representation. The experimental results (
Table 6) show that the lexical-similarity network and the spatial-similarity network provide a greater contribution to the prediction of the relations between geo-entities; this is mainly because the spatial characteristics and structural similarity characteristics of geo-entities are relatively evident. However, owing to the complexity of geo-entity attribute types, the effect of the attribute similarity network remains unclear. the good effect of the structural-similarity network is verified that the simplified and captured structural feature of GeoKG would contribute to the geo-entity embedding. MSEN-GRP method can adjust the sampling ratio according to the contribution of each layer of the similarity network to the relation completion, to achieve the optimization of efficiency and effect. Therefore, the mixed sampling strategy results in the MSEN-GRP method being more interpretable, and also provides greater flexibility for method optimization and scene applicability.
However, the MSEN-GRP method still has some limitations: (1) The time complexity of the enhancer increases as the scale of the KG becomes larger. For large-scale GeoKG applications, the construction of a geo-entity similarity network requires the calculation of the similarity between each pair of geo-entities; (2) The vectorized representation of geo-relations still needs to be improved. Although this method uses DisMult in the decoder to realize the vectorized expression of the geo-relations between geo-entities, the distance calculated by the vectors cannot be used to evaluate the similarity of the geo-relations because of their uneven distribution in GeoKG datasets.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}