Role of Big Data in the Development of Smart City by Analyzing the Density of Residents in Shanghai


 , , and
, , and
Abstract
:1. Introduction
2. Related Work
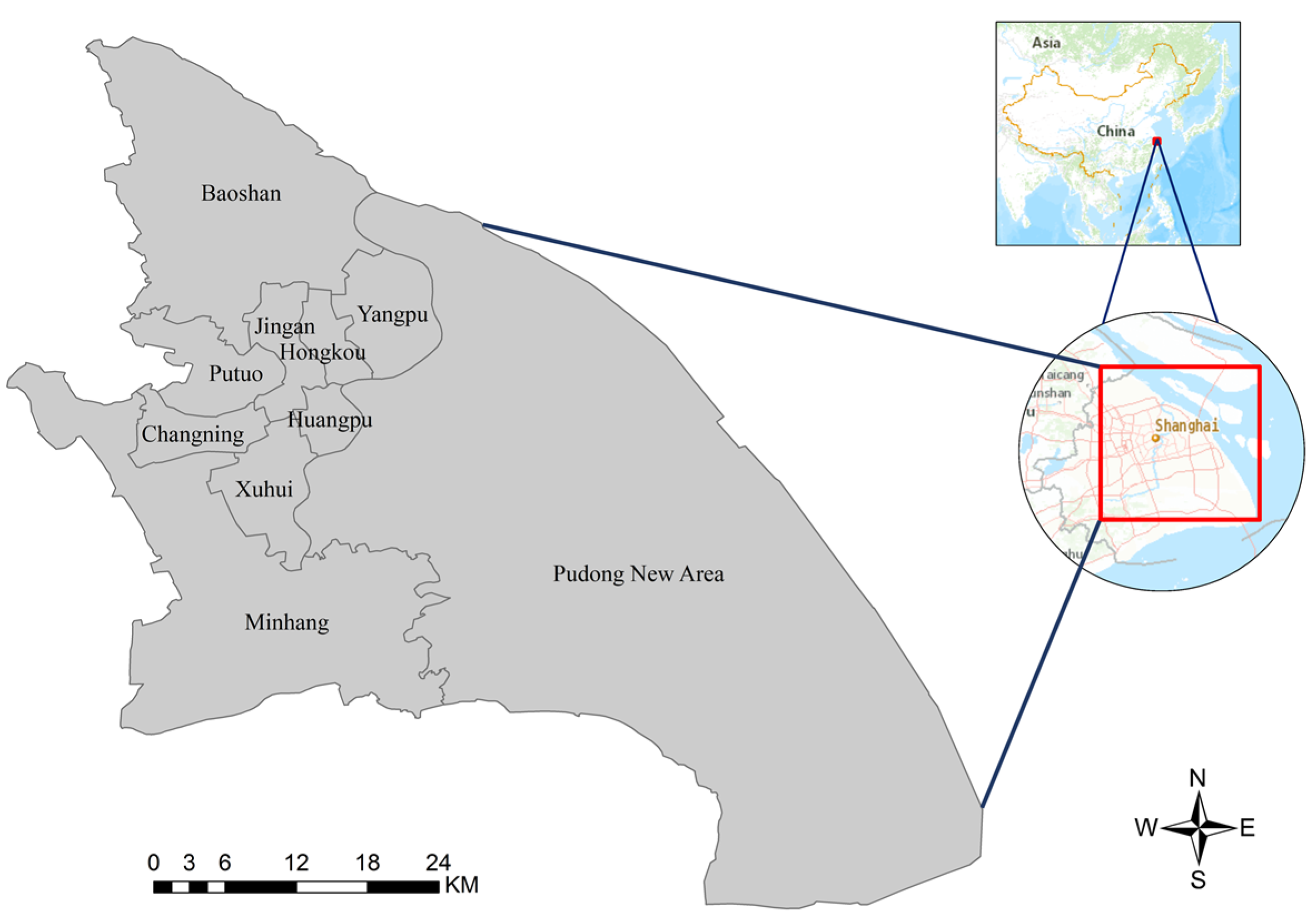
3. Study Area and Dataset
4. Methodology
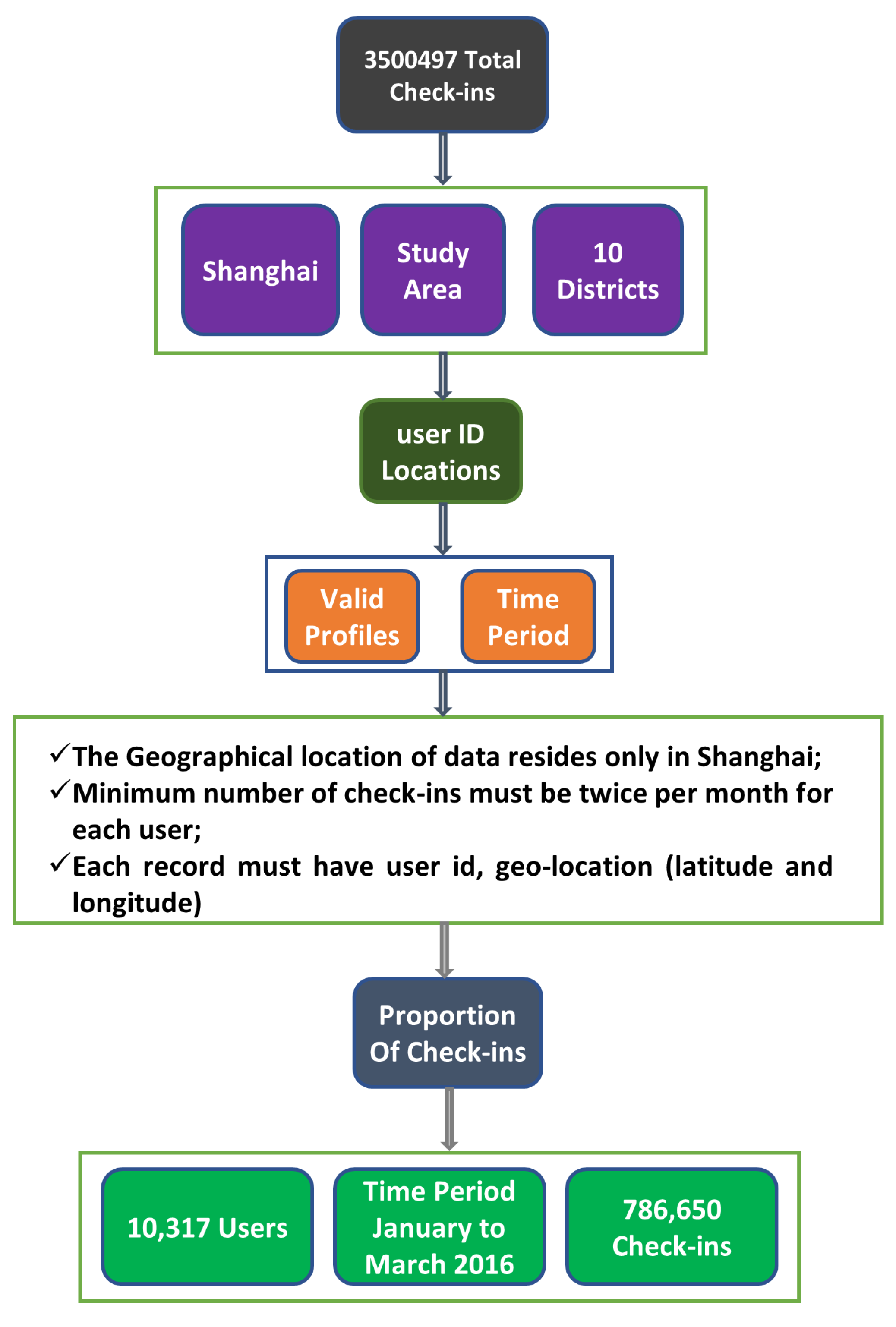
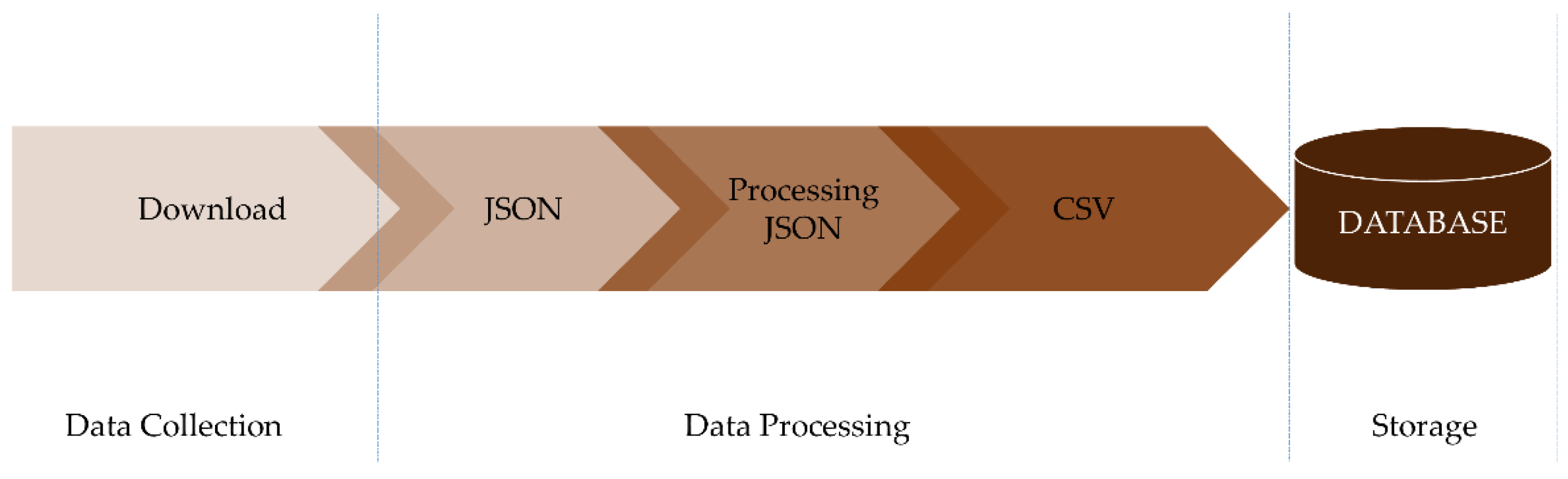
4.1. Data Acquisition and Preparation
4.2. Statistical Analysis and Parameters
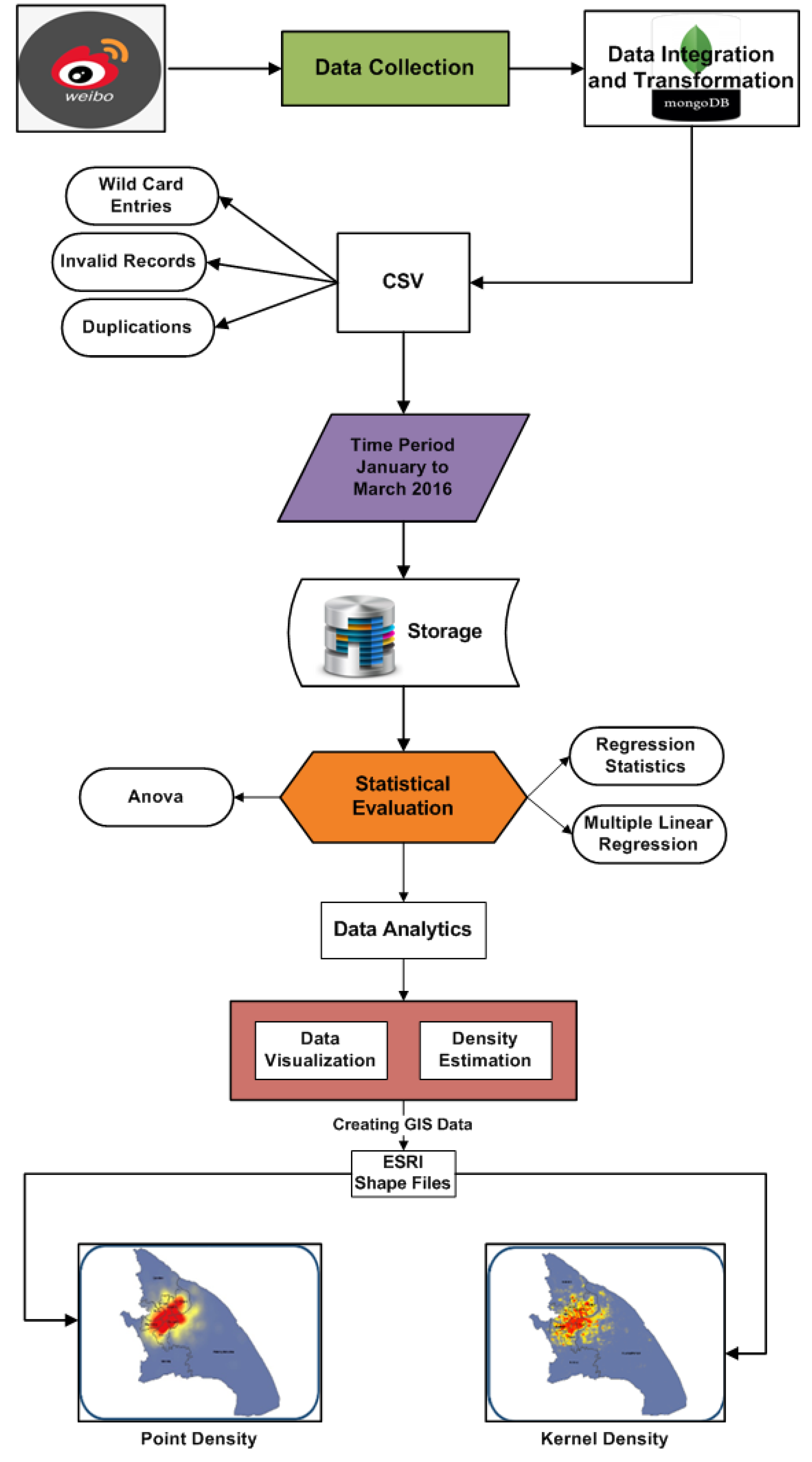
4.3. Social Media Data Analytics Framework
4.4. Analytical Method
4.4.1. Point Density
4.4.2. Kernel Density Estimation
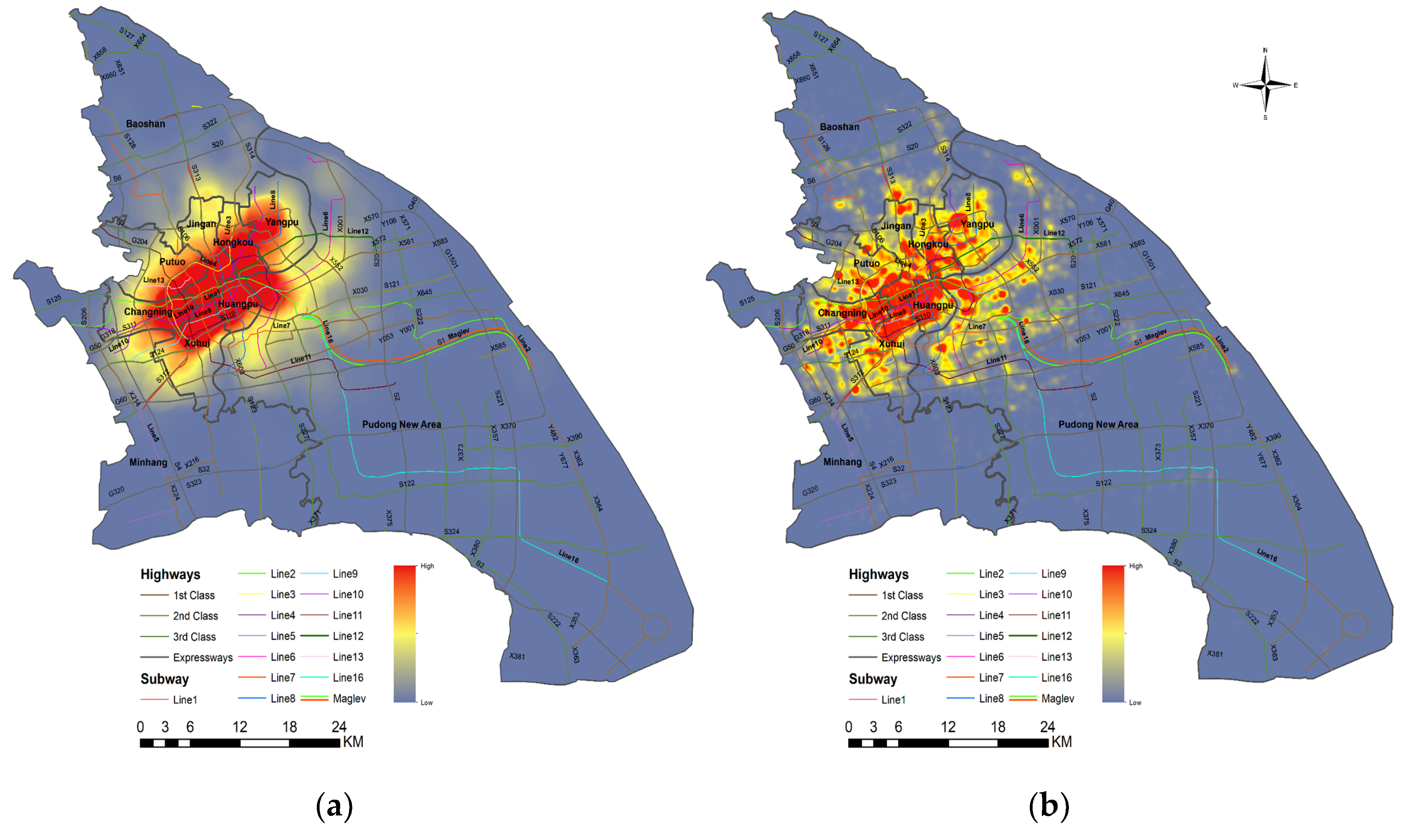
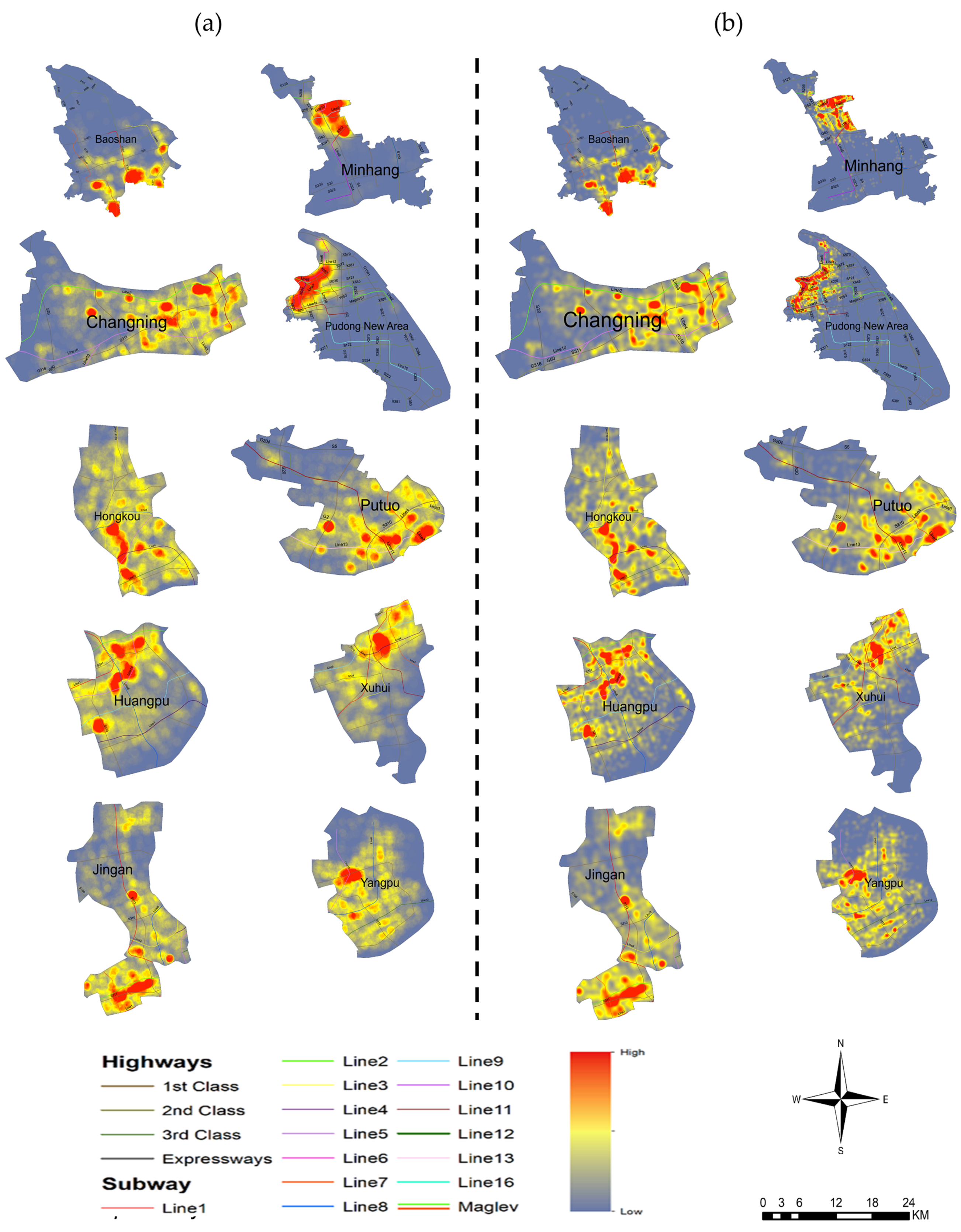
5. Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Tenkanen, H.; Di Minin, E.; Heikinheimo, V.; Hausmann, A.; Herbst, M.; Kajala, L.; Toivonen, T. Instagram, Flickr, or Twitter: Assessing the usability of social media data for visitor monitoring in protected areas. Sci. Rep. 2017, 7, 17615. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weibo. Available online: https://www.weibo.com (accessed on 25 June 2019).
- Waller, L.A.; Gotway, C.A. Applied Spatial Statistics for Public Health Data; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 368. [Google Scholar]
- Zhang, G.; Zhu, A.-X.; Huang, Q. A GPU-accelerated adaptive kernel density estimation approach for efficient point pattern analysis on spatial big data. Int. J. Geogr. Inf. Sci. 2017, 31, 2068–2097. [Google Scholar] [CrossRef]
- Haidery, S.A. Spatial Analysis To Observe Urban Functionalities Using Location-Based Social Network; Shanghai Uinversity: Shanghai, China, 2019. [Google Scholar]
- Cranshaw, J.; Schwartz, R.; Hong, J.; Sadeh, N. The livehoods project: Utilizing social media to understand the dynamics of a city. In Proceedings of the 6th International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–7 June 2012. [Google Scholar]
- Gray, A.G.; Moore, A.W. Nonparametric density estimation: Toward computational tractability. In Proceedings of the 2003 SIAM International Conference on Data Mining, San Francisco, CA, USA, 1–3 May 2003; pp. 203–211. [Google Scholar]
- Huang, H.-Y. Examining the beneficial effects of individual’s self-disclosure on the social network site. Comput. Hum. Behav. 2016, 57, 122–132. [Google Scholar] [CrossRef]
- Chang, J.; Sun, E. Location3: How users share and respond to location-based data on social. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: London, UK, 2018. [Google Scholar]
- Wang, Y.; Yuan, N.J.; Lian, D.; Xu, L.; Xie, X.; Chen, E.; Rui, Y. Regularity and conformity: Location prediction using heterogeneous mobility data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1275–1284. [Google Scholar]
- Sadilek, A.; Kautz, H.; Silenzio, V. Modeling spread of disease from social interactions. In Proceedings of the 6th International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–7 June 2012. [Google Scholar]
- Evangelista, P.F.; Beskow, D. Geospatial Point Density. R J. 2018, 10. [Google Scholar] [CrossRef] [Green Version]
- Gao, C.; Wang, X.; Jiang, T.; Jin, G. Spatial distribution of archaeological sites in lakeshore of Chaohu Lake in China based on GIS. Chin. Geogr. Sci. 2009, 19, 333. [Google Scholar] [CrossRef] [Green Version]
- Point Density for Geospatial Data. Available online: https://cran.r-project.org/web/packages/pointdensityP/index.html (accessed on 18 February 2019).
- Meullenet, J.F.; Lovely, C.; Threlfall, R.; Morris, J.; Striegler, R. An ideal point density plot method for determining an optimal sensory profile for Muscadine grape juice. Food Qual. Prefer. 2008, 19, 210–219. [Google Scholar] [CrossRef]
- Ruckthongsook, W.; Tiwari, C.; Oppong, J.R.; Natesan, P.R. Evaluation of threshold selection methods for adaptive kernel density estimation in disease mapping. Int. J. Health Geogr. 2018, 17, 10. [Google Scholar] [CrossRef] [Green Version]
- Lichman, M.; Smyth, P. Modeling human location data with mixtures of kernel densities. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 35–44. [Google Scholar]
- Qasim, A.A.; Hina, M.; Imran, M.; Muhammad Hammad, M.; Riaz Ahmed, S.; Farman Ali, M. Intelligent travel information platform based on location base services to predict user travel behavior from user-generated GPS traces. Int. J. Comput. Appl. 2017, 39, 155–168. [Google Scholar]
- Carlos, H.A.; Shi, X.; Sargent, J.; Tanski, S.; Berke, E.M. Density estimation and adaptive bandwidths: A primer for public health practitioners. Int. J. Health Geogr. 2010, 9, 39. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.O. A cross-validation bandwidth choice for kernel density estimates with selection biased data. J.Multivar. Anal. 1997, 61, 38–60. [Google Scholar] [CrossRef] [Green Version]
- Ullah, H.; Wan, W.; Haidery, S.A.; Khan, N.U.; Ebrahimpour, Z.; Muzahid, A.A.M. Muzahid. Spatiotemporal Patterns of Visitors in Urban Green Parks by Mining Social Media Big Data based upon WHO reports. IEEE Access 2020, 8, 39197–39211. [Google Scholar] [CrossRef]
- Rizwan, M.; Wan, W.; Cervantes, O.; Gwiazdzinski, L. Using location-based social media data to observe check-in behavior and gender difference: Bringing weibo data into play. ISPRS Int. J. Geo-Inf. 2018, 7, 196. [Google Scholar] [CrossRef] [Green Version]
- Khan, N.U.; Wan, W.; Yu, S. Spatiotemporal Analysis of Tourists and Residents in Shanghai Based on Location-Based Social Network’s Data from Weibo. ISPRS Int. J. Geo-Inf. 2020, 9, 70. [Google Scholar] [CrossRef] [Green Version]
- Ebrahimpour, Z.; Wan, W.; Velázquez García, J.L.; Cervantes, O.; Hou, L. Analyzing Social-Geographic Human Mobility Patterns Using Large-Scale Social Media Data. ISPRS Int. J. Geo-Inf. 2020, 9, 125. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Ge, Y.; Hong, R.; Zhu, H. Point-of-interest recommendations: Learning potential check-ins from friends. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 975–984. [Google Scholar]
- Bao, M.; Yang, N.; Zhou, L.; Lao, Y.; Zhang, Y.; Tian, Y. The Spatial Analysis of Weibo Check-in Data: The Case Study of Wuhan. In Proceedings of the International Conference on Geo-Informatics in Resource Management and Sustainable Ecosystem, Ypsilanti, MI, USA, 3–5 October 2014; pp. 480–491. [Google Scholar]
- Rizwan, M.; Wan, W. Big Data Analysis to Observe Check-in Behavior Using Location-Based Social Media Data. Information 2018, 9, 257. [Google Scholar] [CrossRef] [Green Version]
- Lazzari, M.; Murgante, B. Kernel density estimation methods for a geostatistical approach in seismic risk analysis: The case study of potenza hilltop town (Southern italy). In Proceedings of the International Conference on Computational Science and Its Applications, Saint Petersburg, Russia, 1–4 July 2019; pp. 415–429. [Google Scholar]
- O’Sullivan David, W.D.W. A surface-based approach to measuring spatial segregation. Geogr. Anal. 2007, 39, 147–168. [Google Scholar] [CrossRef]
- Li, J.; Fang, W.; Wang, T.; Qureshi, S.; Alatalo, J.; Bai, Y. Correlations between socioeconomic drivers and indicators of urban expansion: Evidence from the heavily urbanised shanghai metropolitan area, China. Sustainability 2017, 9, 1199. [Google Scholar] [CrossRef] [Green Version]
- Hidayat Ullah, W.W.; Wan, W.; Ali Haidery, S.; Khan, N.U.; Ebrahimpour, Z.; Luo, T. Analyzing the Spatiotemporal Patterns in Green Spaces for Urban Studies Using Location-Based Social Media Data. ISPRS Int. J. Geo-Inf. 2019, 8, 506. [Google Scholar] [CrossRef] [Green Version]
- Guo, R. Regional China: A Business and Economic Handbook; Springer: Berlin, Germany, 2013. [Google Scholar]
- Shanghai’s GDP. Available online: http://www.xinhuanet.com/english/2019-01/22/c_137765564.htm (accessed on 29 December 2019).
- Shanghai National Economic and Social Development Statistics. Available online: http://tjj.sh.gov.cn/html/sjfb/201903/1003219.html (accessed on 29 December 2019).
- Xiong, X.; Jin, C.; Chen, H.; Luo, L. Using the fusion proximal area method and gravity method to identify areas with physician shortages. PLoS ONE 2016, 11, e0163504. [Google Scholar] [CrossRef]
- Shen, J.; Kee, G. Shanghai: Urban development and regional integration through mega projects. In Development and Planning in Seven Major Coastal Cities in Southern and Eastern China; Springer: Berlin, Germany, 2017; pp. 119–151. [Google Scholar]
- Weibo Report. Available online: http://ir.weibo.com/news-releases/news-release-details/weibo-corporation-report-fourth-quarter-and-fiscal-year-2018 (accessed on 10 June 2019).
- Rizwan, M.; Wan, W.; Gwiazdzinski, L. Visualization, Spatiotemporal Patterns, and Directional Analysis of Urban Activities Using Geolocation Data Extracted from LBSN. ISPRS Int. J. Geo-Inf. 2020, 9, 137. [Google Scholar] [CrossRef] [Green Version]
- Weibo API. Available online: https://open.weibo.com/wiki/API (accessed on 14 July 2019).
- Batrinca, B.; Treleaven, P. Social media analytics: A survey of techniques, tools and platforms. AI Soc. 2015, 30, 89–116. [Google Scholar] [CrossRef] [Green Version]
- JavaScript Object Notation. Available online: https://en.wikipedia.org/wiki/JSON (accessed on 29 December 2019).
- Savitch, W.; Mock, K. Java: An Introduction to Problem Solving and Programming, 6th ed.; Pearson Education: London, UK, 2011. [Google Scholar]
- CSV Format. Available online: https://en.wikipedia.org/wiki/Comma-separated_values (accessed on 26 December 2019).
- Abidi, S.; Hussain, M.; Xu, Y.; Zhang, W. Prediction of Confusion Attempting Algebra Homework in an Intelligent Tutoring System through Machine Learning Techniques for Educational Sustainable Development. Sustainability 2019, 11, 105. [Google Scholar] [CrossRef] [Green Version]
- R Language. Available online: https://cran.rproject.org (accessed on 12 May 2019).
- R Studio. Available online: https://www.rstudio.com (accessed on 12 May 2019).
- Mougiakou, E.; Photis, Y.N. Urban green space network evaluation and planning: Optimizing accessibility based on connectivity and raster GIS analysis. Eur. J. Geogr. 2014, 5, 19–46. [Google Scholar]
- Wu, C.; Ye, X.; Ren, F.; Wan, Y.; Ning, P.; Du, Q. Spatial and Social Media Data Analytics of Housing Prices in Shenzhen, China. PLoS ONE 2016, 11, e0164553. [Google Scholar] [CrossRef]
- Rizwan, M.; Mahmood, S.; Wanggen, W.; Ali, S. Location based social media data analysis for observing check-in behavior and city rhythm in shanghai. In Proceedings of the 4th International Conference on Smart and Sustainable City (ICSSC), Shanghai, China, 5–6 June 2017. [Google Scholar]
- Silverman, B. Density Estimation for Statistics and Data Analysis; CRC Press, Inc.: Boca Raton, FL, USA, 1986. [Google Scholar]
- Sun, Y.; Fan, H.; Li, M.; Zipf, A. Identifying the city center using human travel flows generated from location-based social networking data. Environ. Plan. B Plan. Design 2016, 43, 480–498. [Google Scholar] [CrossRef]
- Hasan, S.; Zhan, X.; Ukkusuri, S.V. Understanding urban human activity and mobility patterns using large-scale location-based data from online social media. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, Chicago, IL, USA, 11 August 2013; p. 6. [Google Scholar]
- Li, L.; Goodchild, M.F.; Xu, B. Spatial, temporal, and socioeconomic patterns in the use of Twitter and Flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Kirby, R.S.; Delmelle, E.; Eberth, J.M. Advances in spatial epidemiology and geographic information systems. Ann. Epidemiol. 2017, 27, 1–9. [Google Scholar] [CrossRef]
- Mukherjee, A. Characterizing Product Lifecycle in Online Marketing: Sales, Trust, Revenue, and Competition Modeling. arXiv 2017, arXiv:1704.02993. [Google Scholar]
- Estes, L.; Elsen, P.R.; Treuer, T.; Ahmed, L.; Caylor, K.; Chang, J.; Choi, J.J.; Ellis, E.C. The spatial and temporal domains of modern ecology. Nat. Ecol. Evol. 2018, 2, 819–826. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Latitude | Longitude |
|---|---|---|
| 1987068471 | 121.5012107 | 31.2605724 |
| 3292139955 | 121.530461 | 31.334979 |
| 2425639602 | 121.5399461 | 31.27232846 |
| 5404478798 | 121.544449 | 31.268159 |
| Status_ID | User_ID | User_Name | Month | Date | Time | Year | Gender | Longitude | Latitude | Address |
|---|---|---|---|---|---|---|---|---|---|---|
| 3943172612597320 | ### * | ### * | 03 | 13 | 3:02:12 | 2016 | M | 121.3969 | 31.3984 | ### *, Jufengyuan Road, Baoshan District |
| Min 1Q Median 3Q Max −23.7348 −0.6238 0.2834 0.8349 2.0153 | |||||
|---|---|---|---|---|---|
| Coefficients | Estimate | Std. Error | t Value | Pr (>|t|) | |
| Intercept | 4.8421088 | 0.0164305 | 294.703 | <2 × 10−16 | *** |
| Baoshan | 0.0159932 | 0.0029441 | 5.432 | 5.69 × 10−8 | *** |
| Changning | 0.0065855 | 0.0021546 | 3.056 | 0.002245 | ** |
| Hongkou | 0.0079145 | 0.0024644 | 3.211 | 0.001325 | ** |
| Huangpu | 0.0147966 | 0.0019293 | 7.669 | 1.88 × 10−14 | *** |
| Jingan | 0.0016087 | 0.001976 | 0.814 | 0.415602 | |
| Minhang | 0.014982 | 0.0028092 | 5.333 | 9.86 × 10−8 | *** |
| Pudong New Area | 0.0039008 | 0.0013275 | 2.938 | 0.003307 | ** |
| Putuo | 0.0084851 | 0.0022825 | 3.717 | 0.000202 | *** |
| Xuhui | 0.0091736 | 0.0019475 | 4.71 | 2.50 × 10−6 | *** |
| Yangpu | 0.0089936 | 0.0021494 | 4.184 | 2.89 × 10−5 | *** |
| Residual Standard Error | Degrees of Freedom | Multiple R-Squared | Adjusted R-Squared | F-Statistics | p-Value |
|---|---|---|---|---|---|
| 1.19 | 10299 | 0.3916 | 0.3951 | 397.3 | <2.2 × 10−6 |
| Response: Number of Check-ins | ||||||
|---|---|---|---|---|---|---|
| Df | Sum Sq | Mean Sq | F Value | Pr (>F) | ||
| Baoshan | 1 | 7238.2 | 7238.2 | 5109.7946 | <2.2 × 10−16 | *** |
| Changning | 1 | 1251 | 1251 | 883.1285 | <2.2 × 10−16 | *** |
| Hongkou | 1 | 307.7 | 307.7 | 217.2498 | <2.2 × 10−16 | *** |
| Huangpu | 1 | 339.1 | 339.1 | 239.3547 | <2.2 × 10−16 | *** |
| Jingan | 1 | 35.9 | 35.9 | 25.3324 | 4.91 × 10−7 | *** |
| Minhang | 1 | 77.7 | 77.7 | 54.8639 | 1.39 × 10−13 | *** |
| Pudong New Area | 1 | 34.2 | 34.2 | 24.1414 | 9.09 × 10−7 | *** |
| Putuo | 1 | 31.7 | 31.7 | 22.3638 | 2.29 × 10−6 | *** |
| Xuhui | 1 | 30.4 | 30.4 | 21.4392 | 3.70 × 10−6 | *** |
| Yangpu | 1 | 19.9 | 19.9 | 14.068 | 0.0001773 | *** |
| Residuals | 10299 | 14588.9 | 1.4 | |||
| District | No. of Users | No. of Check-Ins | % Check-Ins |
|---|---|---|---|
| Baoshan | 5074 | 39,603 | 5.02% |
| Changning | 6722 | 70,026 | 8.88% |
| Hongkou | 5978 | 53,983 | 6.84% |
| Huangpu | 7503 | 92,195 | 11.69% |
| Jingan | 7276 | 85,401 | 10.83% |
| Minhang | 5466 | 43,739 | 5.55% |
| Pudong | 8802 | 173,938 | 22.06% |
| Putuo | 6521 | 64,023 | 8.12% |
| Xuhui | 7432 | 91,188 | 11.56% |
| Yangpu | 6811 | 72,556 | 9.20% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali Haidery, S.; Ullah, H.; Khan, N.U.; Fatima, K.; Rizvi, S.S.; Kwon, S.J. Role of Big Data in the Development of Smart City by Analyzing the Density of Residents in Shanghai. Electronics 2020, 9, 837. https://doi.org/10.3390/electronics9050837
Ali Haidery S, Ullah H, Khan NU, Fatima K, Rizvi SS, Kwon SJ. Role of Big Data in the Development of Smart City by Analyzing the Density of Residents in Shanghai. Electronics. 2020; 9(5):837. https://doi.org/10.3390/electronics9050837
Chicago/Turabian StyleAli Haidery, Saqib, Hidayat Ullah, Naimat Ullah Khan, Kanwal Fatima, Sanam Shahla Rizvi, and Se Jin Kwon. 2020. "Role of Big Data in the Development of Smart City by Analyzing the Density of Residents in Shanghai" Electronics 9, no. 5: 837. https://doi.org/10.3390/electronics9050837