
Deep Learning-Based Pedestrian Detection in Autonomous Vehicles: Substantial Issues and Challenges

 , ,
, ,  ,
,  ,
,
Abstract
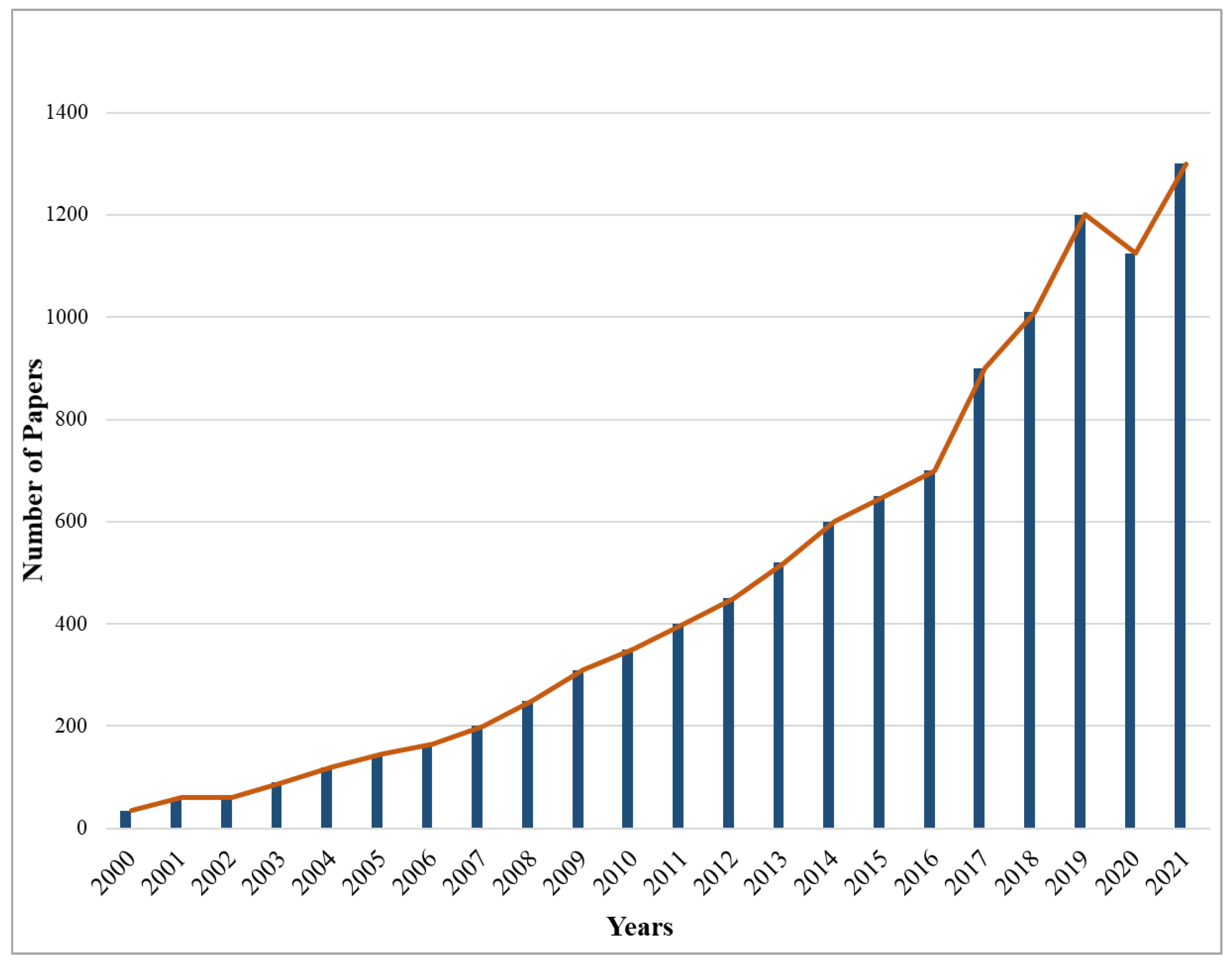
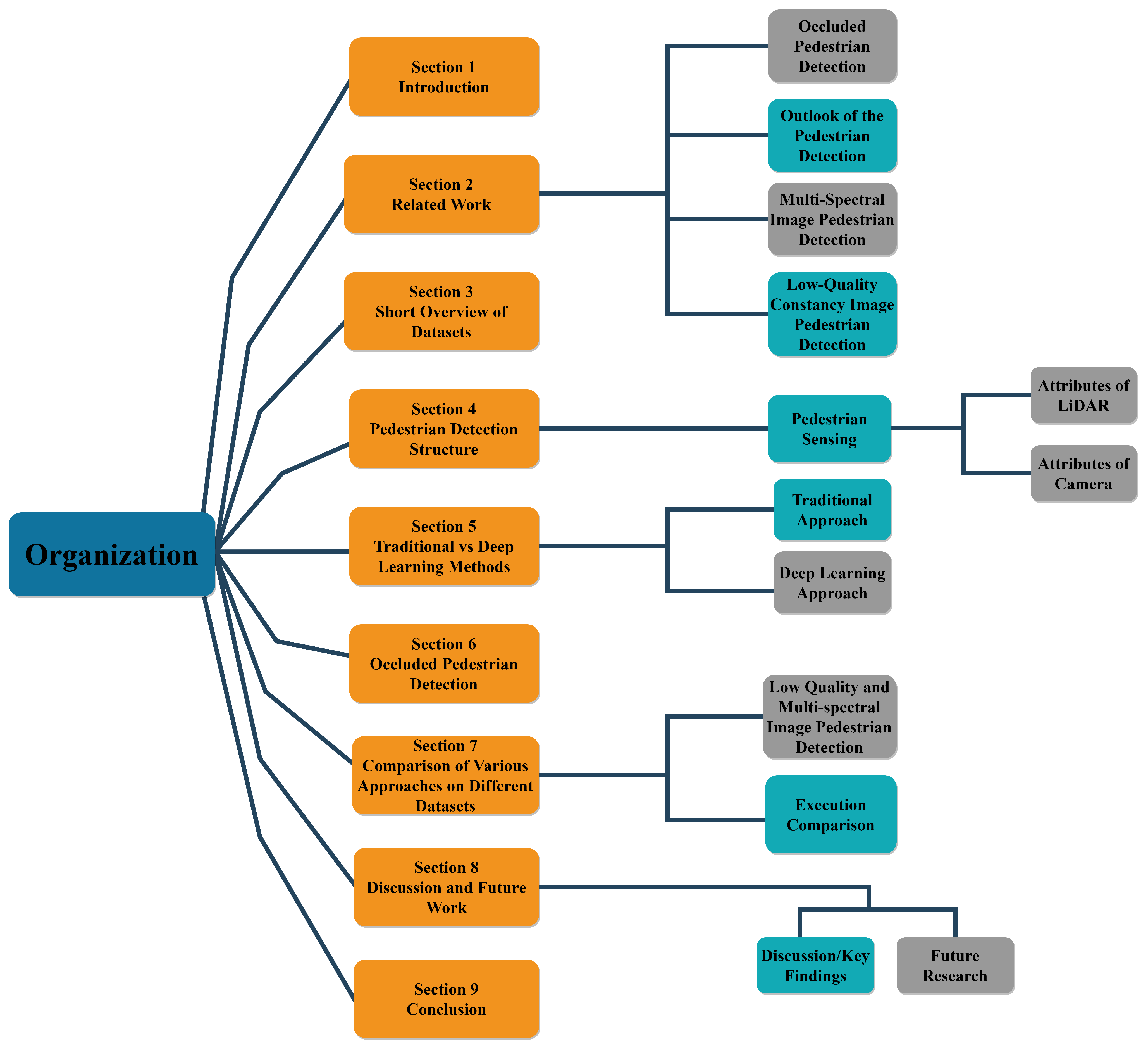
:1. Introduction
2. Related Work
2.1. Outlook of the Pedestrian Detection
2.1.1. Occluded Pedestrian Detection
2.1.2. Multi-Spectral Image Pedestrian Detection
2.1.3. Low-Quality Constancy Image Pedestrian Detection
3. Short Overview of Datasets
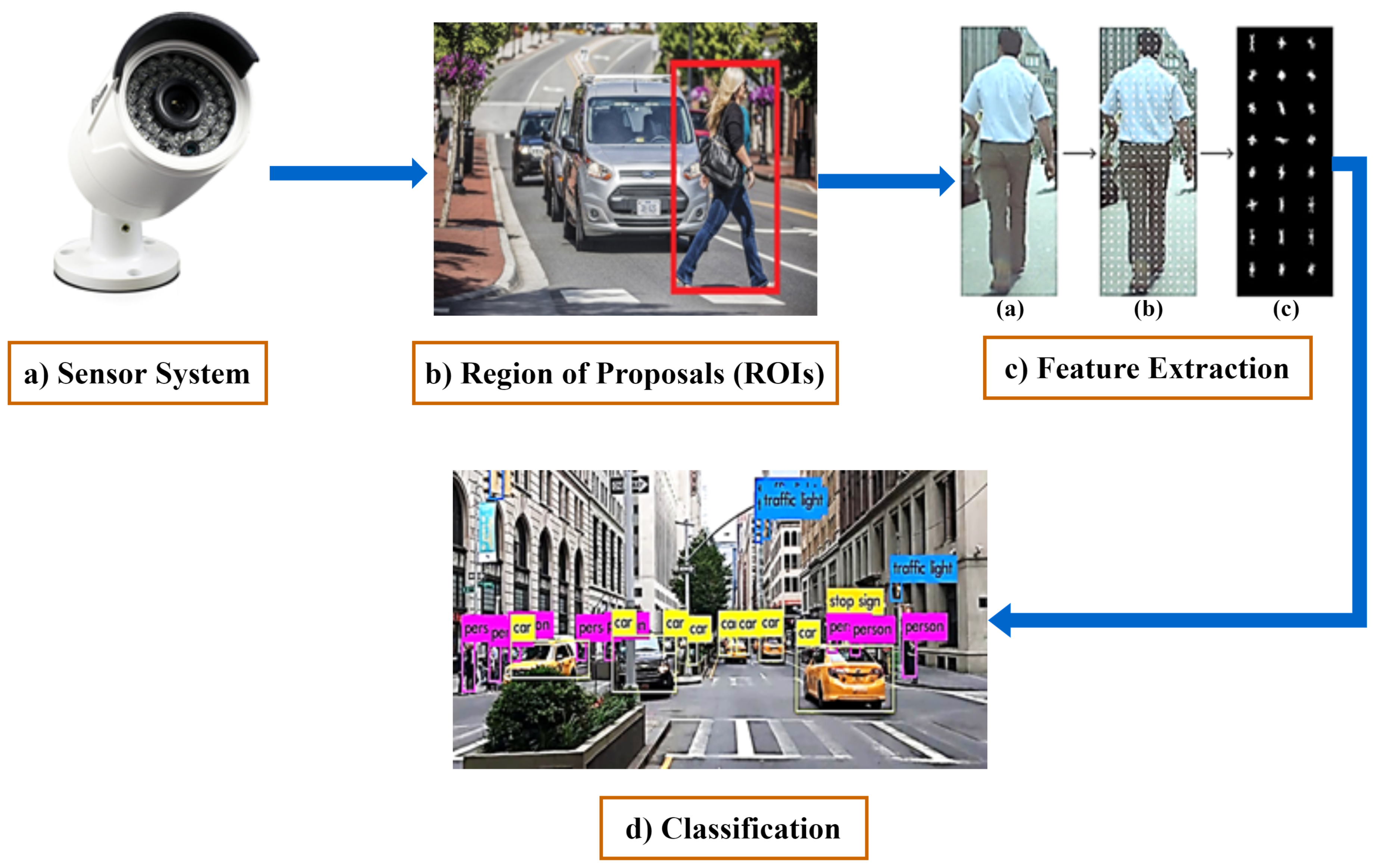
4. Pedestrian Detection Structure
4.1. Pedestrian Sensing
4.1.1. LiDAR vs. Camera
4.1.2. Benefits of LiDAR
- Among the key benefits of LiDAR are its precision and correctness. The aim is for Waymo to protect its LiDAR structure through its accuracy. Navigate reports that Waymo’s LiDAR is very up-to-date, and that it can determine the position of pedestrians and can estimate their movement. Equipped with a Waymo LiDAR, the Chrysler Pacificas can tell which way a cyclist should turn by looking at the gestures used by cyclists.
- Another advantage of LiDAR is that it provides a 3D image for autonomous vehicles. LiDAR is more accurate than cameras because the laser will not be confused by daylight, blazing, shadows, or entering the car front lights.
- In conclusion, LiDAR liberates computing capacity. LiDAR can instantly notify of the distance and direction of an object, while the camera-form program must first take pictures and then examine the images to regulate the distance and velocity of the object, which requires more computing power.
4.1.3. Limitations of LiDAR
- LiDAR also has limitations, as there are still many systems that cannot penetrate well through fog, snow, and rain weather conditions. Ford, which is extraordinarily superior in making self-driving cars, has established a design that can help its LiDAR network distinguish between isolated dewdrops and avalanches. Apart from that, the self-driving car will interpret the avalanche falling in the highway medium as a wall. Ford demonstrated their courage in the Michigan test, but its strategy still has much to comprehend.
- Furthermore, LiDAR does not provide data that the camera can normally see, such as text on signs or the shade of traffic lights. The camera is more suitable for this type of information.
- At last, LiDAR systems are very heavy because they need a laser rotation system to be installed throughout the vehicle, whereas the camera system used in existing Tesla cars is almost invisible.
4.1.4. What Are the Main Reasons for Camera’s Popularity?
4.1.5. Limitation of Cameras
- When the lighting conditions change so that the subject becomes blurred, the camera encounters the same problem that humans face, e.g., a situation where intense shadows or glare from the sun or upcoming cars can create chaos. This is a common reason for which Tesla is still adding radar to the forefront of its car to provide further input (which, compared to LiDAR systems radar, is much cheaper).
- Cameras are also relatively “dumb” sensors because they lay out the system with only raw image data, without the exact distance and location of objects as LiDAR does. This means that the camera system must depend on strong machine learning (such as neural network or DL approach) computers that can operate these images to precisely regulate where to place them. As our human brain acts on stereo perception with the eyes to regulate the distance and position.
- To date, neural networks and machine learning systems are not strong enough to transfer massive amounts of data from cameras so that all the information could be prepared in time to make management decisions. Nevertheless, the growth of neural networks has become increasingly complex and can handle real-world inputs better than LiDAR.
5. Traditional vs. DL Approaches
5.1. Traditional Approach
5.2. DL Approaches
6. Occluded Pedestrian Detection
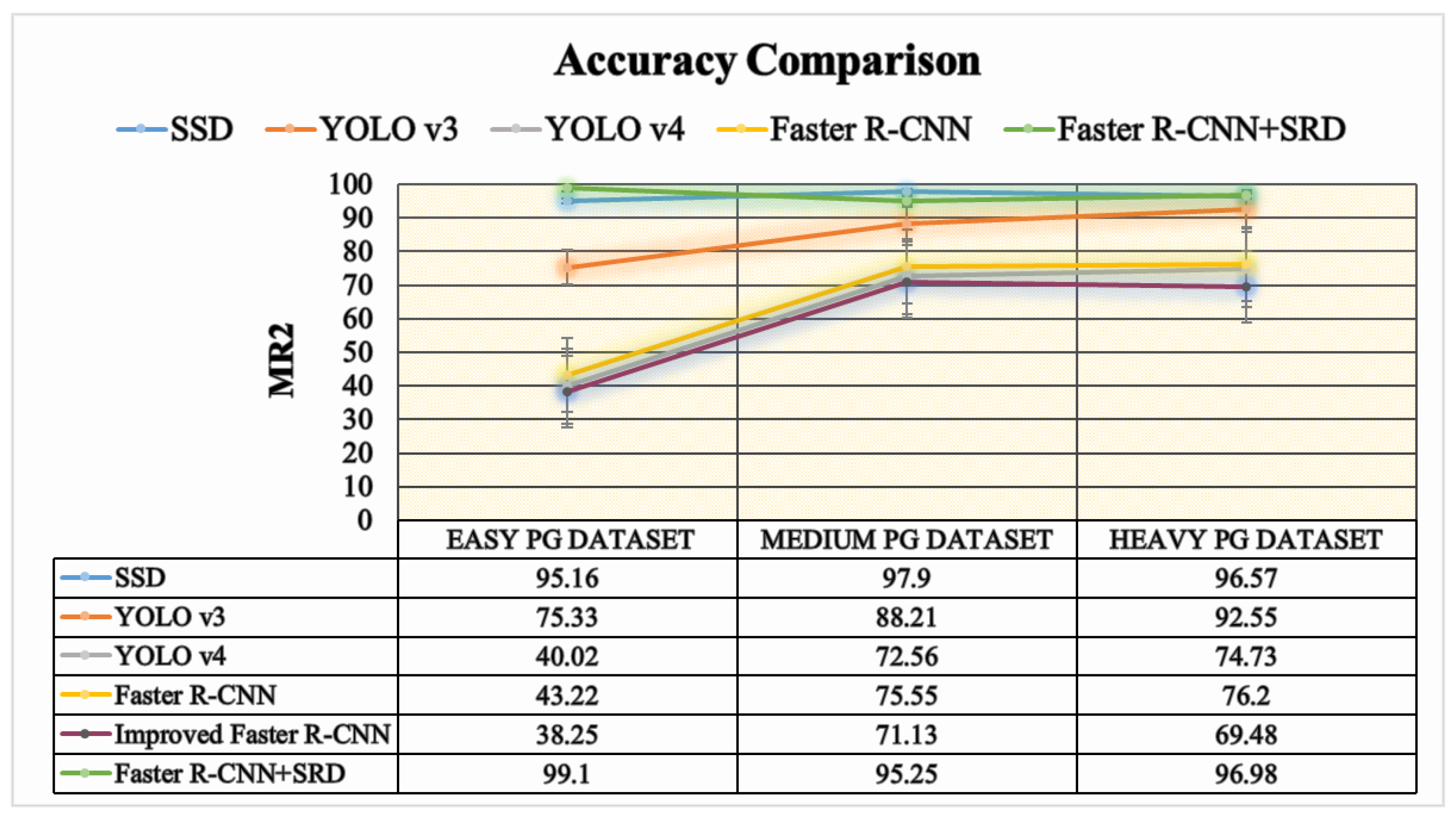
7. Comparison of Various Approaches on Different Datasets
7.1. Low Quality and Multi-Spectral Image Pedestrian Detection
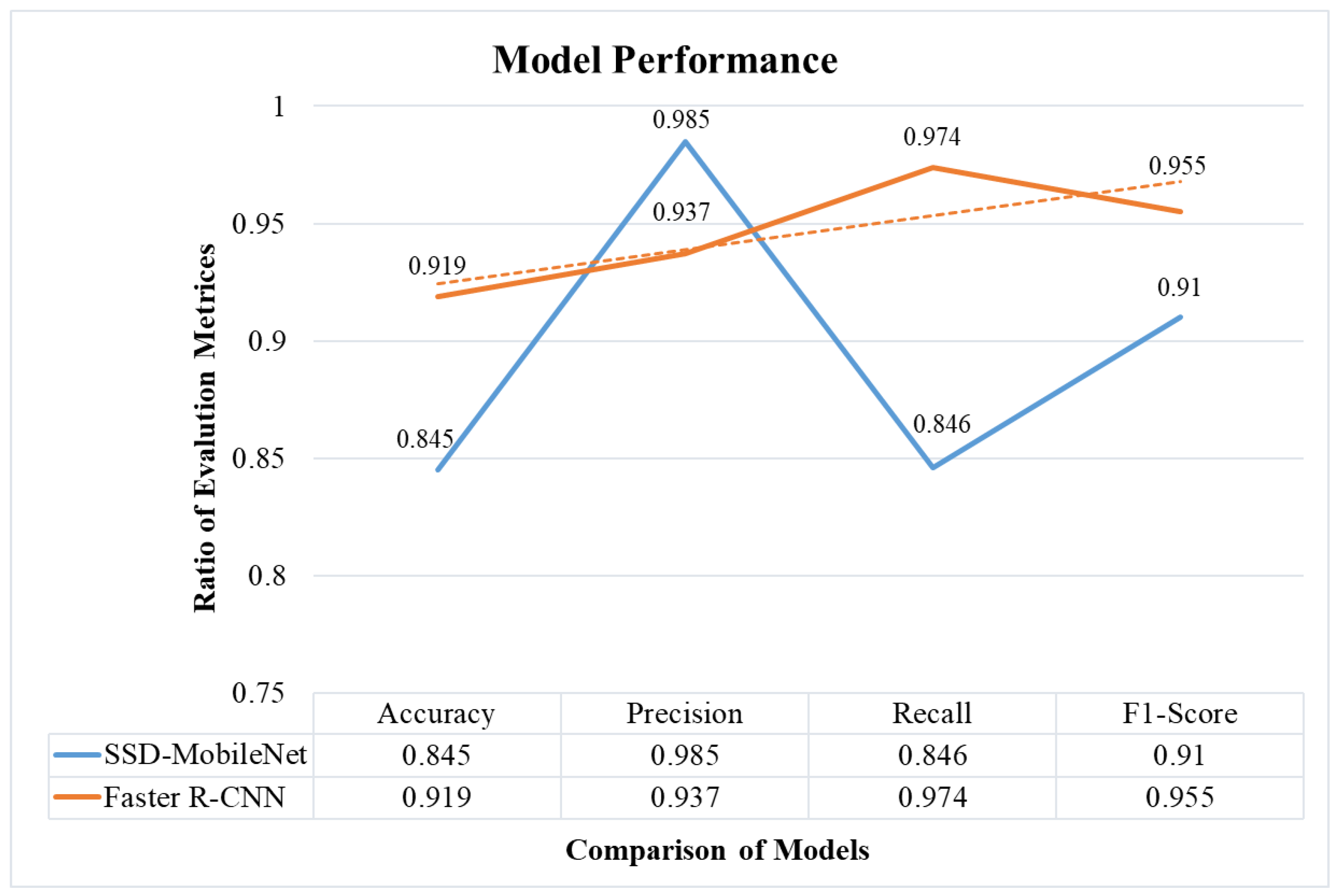
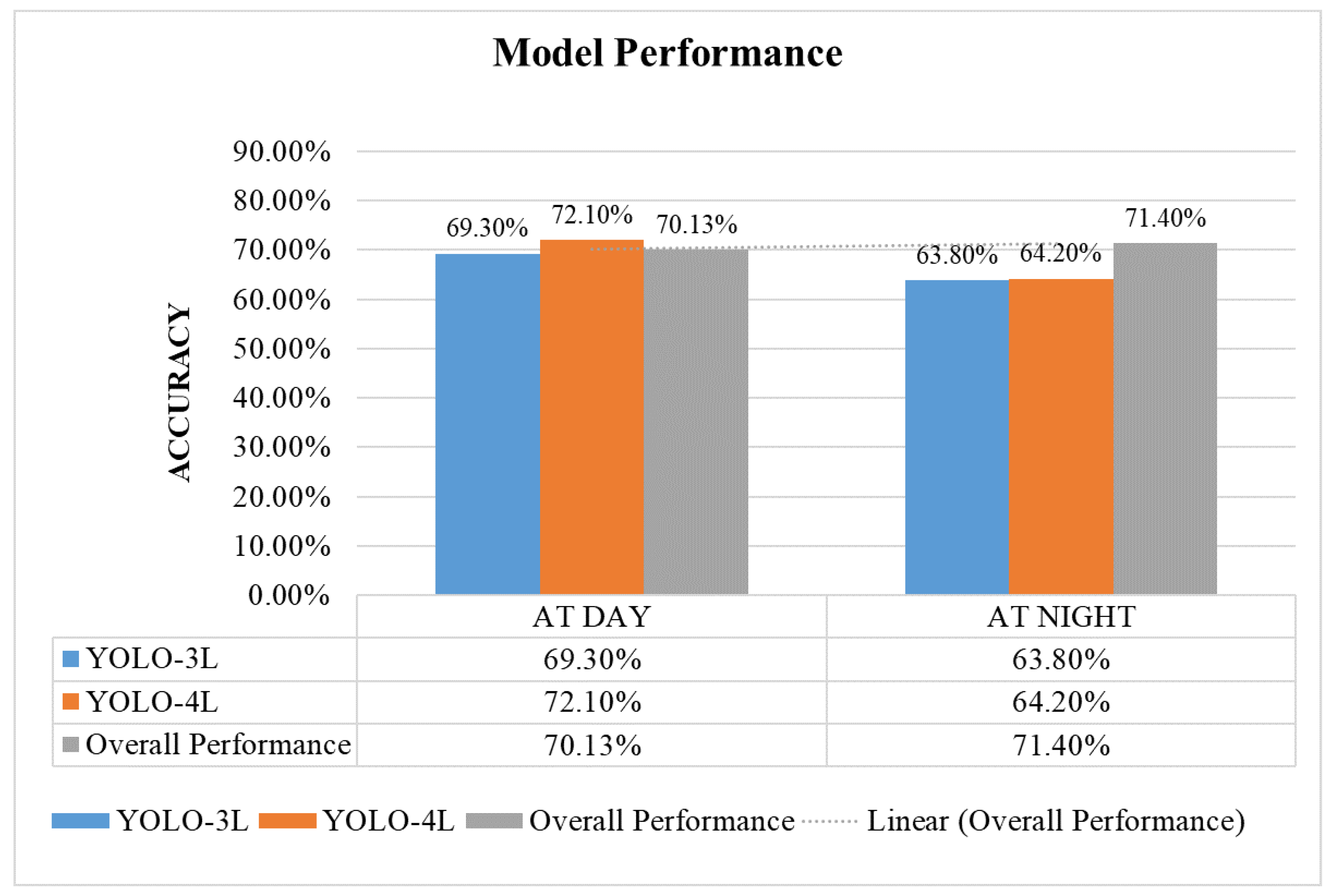
7.2. Execution Comparison
8. Discussion and Future Work
8.1. Discussion/Key Findings
8.2. Future Research
- For pedestrian detection, better outcomes have been attained with the help of DL approaches. However, to date, the present algorithms are still facing the issue of the detection of small, moderate, and occluded objects. In the future, one can consider/address the aforementioned issues.
- In addition, there is still insufficient work examining how to enhance the detection production under bad lighting and weather conditions. In the future, this problem can be tackled by training both models with daytime and nighttime models as one paradigm and thus increase the generalization abilities.
- Furthermore, there is a need to investigate more techniques that are put together into the detection algorithms to improve the accuracy enhancement. In the future, some powerful techniques can be combined to improve the accuracy of pedestrian detection systems.
- Fuzzy logic-based algorithms can be combined with DL algorithms to improve the pedestrian detection process.
- An interesting future work may be to consider/combine 3D measures with 2D information in order to improve detection and classifications.
- Multi-class approaches should be incorporated, not only to consider different pedestrian models but also to check for other targets (e.g., vehicles) and increase the robustness of the system.
- A DL algorithm-based pedestrian detection has overcome many issues in pedestrian detection, however, these are very slow, and interpretability is very low. As such, the major issue in pedestrian detection is speed and accuracy. Future research may focus on improving the speed of computation and accuracy in detection.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liem, M.C.; Gavrila, D.M. Joint multi-person detection and tracking from overlapping cameras. Comput. Vis. Image Underst. 2014, 128, 36–50. [Google Scholar] [CrossRef]
- Cao, X.; Guo, S.; Lin, J.; Zhang, W.; Liao, M. Online tracking of ants based on deep association metrics: Method, dataset and evaluation. Pattern Recognit. 2020, 103, 107233. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, Y.; Chen, J.; Kan, S.; Cen, Y.; Cao, Q. PGAN: Part-based nondirect coupling embedded GAN for person reidentification. IEEE Multimed. 2020, 27, 23–33. [Google Scholar] [CrossRef]
- Han, C.; Ye, J.; Zhong, Y.; Tan, X.; Zhang, C.; Gao, C.; Sang, N. Re-id driven localization refinement for person search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9814–9823. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Antonio, J.A.; Romero, M. Pedestrians’ Detection Methods in Video Images: A Literature Review. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 354–360. [Google Scholar]
- Zhu, Y.; Yang, J.; Xieg, X.; Wang, Z.; Deng, X. Long-distanceinfrared video pedestrian detection using deep learning and backgroundsubtraction. J. Phys. Conf. Ser. 2020, 1682, 012012. [Google Scholar] [CrossRef]
- Iftikhar, S.; Asim, M.; Zhang, Z.; El-Latif, A.A.A. Advance generalization technique through 3D CNN to overcome the false positives pedestrian in autonomous vehicles. Telecommun. Syst. 2022, 80, 545–557. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian detection based on YOLO network model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1547–1551. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Stutz, D.; Geiger, A. Learning 3d shape completion under weak supervision. Int. J. Comput. Vis. 2020, 128, 1162–1181. [Google Scholar] [CrossRef] [Green Version]
- Neumann, L.; Karg, M.; Zhang, S.; Scharfenberger, C.; Piegert, E.; Mistr, S.; Prokofyeva, O.; Thiel, R.; Vedaldi, A.; Zisserman, A.; et al. Nightowls: A pedestrians at night dataset. In Proceedings of the Asian Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 691–705. [Google Scholar]
- Chebrolu, K.N.R.; Kumar, P. Deep learning based pedestrian detection at all light conditions. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 4–6 April 2019; pp. 838–842. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://proceedings.neurips.cc/paper/2016/hash/7c9d0b1f96aebd7b5eca8c3edaa19ebb-Abstract.html (accessed on 13 October 2022).
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 714–722. [Google Scholar]
- Navarro, P.J.; Fernandez, C.; Borraz, R.; Alonso, D. A machine learning approach to pedestrian detection for autonomous vehicles using high-definition 3D range data. Sensors 2016, 17, 18. [Google Scholar] [CrossRef] [Green Version]
- Divvala, S.K.; Hoiem, D.; Hays, J.H.; Efros, A.A.; Hebert, M. An empirical study of context in object detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1271–1278. [Google Scholar]
- Koo, B.; Jung, S.P. Improvement of air cathode performance in microbial fuel cells by using catalysts made by binding metal-organic framework and activated carbon through ultrasonication and solution precipitation. Chem. Eng. J. 2021, 424, 130388. [Google Scholar] [CrossRef]
- Pawar, A.A.; Karthic, A.; Lee, S.; Pandit, S.; Jung, S.P. Microbial electrolysis cells for electromethanogenesis: Materials, configurations and operations. Environ. Eng. Res. 2022, 27, 200484. [Google Scholar] [CrossRef]
- Zahid, M.; Savla, N.; Pandit, S.; Thakur, V.K.; Jung, S.P.; Gupta, P.K.; Prasad, R.; Marsili, E. Microbial desalination cell: Desalination through conserving energy. Desalination 2022, 521, 115381. [Google Scholar] [CrossRef]
- Kang, H.; Kim, E.; Jung, S.P. Influence of flowrates to a reverse electro-dialysis (RED) stack on performance and electrochemistry of a microbial reverse electrodialysis cell (MRC). Int. J. Hydrogen Energy 2017, 42, 27685–27692. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.; Santhosh, R.; Sabari, A. Enhanced pedestrian detection using optimized deep convolution neural network for smart building surveillance. Soft Comput. 2020, 24, 17081–17092. [Google Scholar] [CrossRef]
- Chen, L.; Ma, N.; Wang, P.; Li, J.; Wang, P.; Pang, G.; Shi, X. Survey of pedestrian action recognition techniques for autonomous driving. Tsinghua Sci. Technol. 2020, 25, 458–470. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Dinakaran, R.K.; Easom, P.; Bouridane, A.; Zhang, L.; Jiang, R.; Mehboob, F.; Rauf, A. Deep learning based pedestrian detection at distance in smart cities. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 6–9 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 588–593. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep learning strong parts for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Wang, K.; Li, G.; Chen, J.; Long, Y.; Chen, T.; Chen, L.; Xia, Q. The adaptability and challenges of autonomous vehicles to pedestrians in urban China. Accid. Anal. Prev. 2020, 145, 105692. [Google Scholar] [CrossRef]
- Hbaieb, A.; Rezgui, J.; Chaari, L. Pedestrian detection for autonomous driving within cooperative communication system. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Srivastava, G. Multimodal machine learning for pedestrian detection. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–7. [Google Scholar]
- Han, J.; Bhanu, B. Fusion of color and infrared video for moving human detection. Pattern Recognit. 2007, 40, 1771–1784. [Google Scholar] [CrossRef]
- Socarrás, Y.; Ramos, S.; Vázquez, D.; López, A.M.; Gevers, T. Adapting pedestrian detection from synthetic to far infrared images. In Proceedings of the ICCV Workshops, Beijing, China, 21 October 2013; Volume 3. [Google Scholar]
- Han, J.; Bhanu, B. Human activity recognition in thermal infrared imagery. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 20–25 June 2005; p. 17. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Angelova, A.; Krizhevsky, A.; Vanhoucke, V.; Ogale, A.; Ferguson, D. Real-Time Pedestrian Detection with Deep Network Cascades. 2015. Available online: http://www.bmva.org/bmvc/2015/papers/paper032/index.html (accessed on 13 October 2022).
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection using Deep Fusion Convolutional Neural Networks. In Proceedings of the ESANN Conference, Bruges, Belgium, 27–29 April 2016; Volume 587, pp. 509–514. [Google Scholar]
- Nguyen, D.T.; Li, W.; Ogunbona, P.O. Human detection from images and videos: A survey. Pattern Recognit. 2016, 51, 148–175. [Google Scholar] [CrossRef]
- Ragesh, N.; Rajesh, R. Pedestrian detection in automotive safety: Understanding state-of-the-art. IEEE Access 2019, 7, 47864–47890. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 428–441. [Google Scholar]
- Oren, M.; Papageorgiou, C.; Sinha, P.; Osuna, E.; Poggio, T. Pedestrian detection using wavelet templates. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 193–199. [Google Scholar]
- Mu, Y.; Yan, S.; Liu, Y.; Huang, T.; Zhou, B. Discriminative local binary patterns for human detection in personal album. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware R-CNN: Detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Zhou, C.; Yuan, J. Multi-label learning of part detectors for heavily occluded pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3486–3495. [Google Scholar]
- Ouyang, W.; Wang, X. Joint deep learning for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 1–8 December 2013; pp. 2056–2063. [Google Scholar]
- Choi, H.; Kim, S.; Park, K.; Sohn, K. Multi-spectral pedestrian detection based on accumulated object proposal with fully convolutional networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 621–626. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Hou, Y.L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M.; Chen, H. Multispectral pedestrian detection based on deep convolutional neural networks. Infrared Phys. Technol. 2018, 94, 69–77. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster R-CNN doing well for pedestrian detection? In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–457. [Google Scholar]
- Chen, Y.; Shin, H. Pedestrian detection at night in infrared images using an attention-guided encoder-decoder convolutional neural network. Appl. Sci. 2020, 10, 809. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Braun, M.; Krebs, S.; Flohr, F.; Gavrila, D.M. The eurocity persons dataset: A novel benchmark for object detection. arXiv 2018, arXiv:1805.07193. [Google Scholar]
- Ess, A.; Leibe, B.; Van Gool, L. Depth and appearance for mobile scene analysis. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Wang, S.; Cheng, J.; Liu, H.; Wang, F.; Zhou, H. Pedestrian detection via body part semantic and contextual information with DNN. IEEE Trans. Multimed. 2018, 20, 3148–3159. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/hash/14bfa6bb14875e45bba028a21ed38046-Abstract.html (accessed on 13 October 2022). [CrossRef] [Green Version]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Subcategory-aware convolutional neural networks for object proposals and detection. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 924–933. [Google Scholar]
- You, M.; Zhang, Y.; Shen, C.; Zhang, X. An extended filtered channel framework for pedestrian detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1640–1651. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Dp kingma and j. ba, adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Najila, A.L.; Shijin Knox, G.U. A Study on Automatic Pedestrian Detection Using Computer Vision; IEEE: New York City, NY, USA, 2021; Volume 8, pp. 4553–4557. [Google Scholar]
- Tsai, C.Y.; Su, Y.K. MobileNet-JDE: A lightweight multi-object tracking model for embedded systems. Multimed. Tools Appl. 2022, 81, 9915–9937. [Google Scholar] [CrossRef]
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Generalizable pedestrian detection: The elephant in the room. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11328–11337. [Google Scholar]
- Wang, L.; Shi, J.; Song, G.; Shen, I.f. Object detection combining recognition and segmentation. In Proceedings of the Asian Conference on Computer Vision, Tokyo, Japan, 18–22 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 189–199. [Google Scholar]
- Zheng, A.; Zhang, Y.; Zhang, X.; Qi, X.; Sun, J. Progressive End-to-End Object Detection in Crowded Scenes. arXiv 2022, arXiv:2203.07669. [Google Scholar]
- Ding, M.; Zhang, S.; Yang, J. Improving Pedestrian Detection from a Long-tailed Domain Perspective. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2918–2926. [Google Scholar]
- Gilroy, S.; Glavin, M.; Jones, E.; Mullins, D. Pedestrian Occlusion Level Classification using Keypoint Detection and 2D Body Surface Area Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3833–3839. [Google Scholar]
- Sun, H.; Zhang, W.; Runxiang, Y.; Zhang, Y. Motion planning for mobile Robots–focusing on deep reinforcement learning: A systematic Review. IEEE Access 2021, 9, 69061–69081. [Google Scholar] [CrossRef]
- Bigas, M.; Cabruja, E.; Forest, J.; Salvi, J. Review of CMOS image sensors. Microelectron. J. 2006, 37, 433–451. [Google Scholar] [CrossRef]
- Pinggera, P.; Pfeiffer, D.; Franke, U.; Mester, R. Know your limits: Accuracy of long range stereoscopic object measurements in practice. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 96–111. [Google Scholar]
- Fleming, W.J. New automotive sensors—A review. IEEE Sens. J. 2008, 8, 1900–1921. [Google Scholar] [CrossRef]
- Hurney, P.; Waldron, P.; Morgan, F.; Jones, E.; Glavin, M. Review of pedestrian detection techniques in automotive far-infrared video. IET Intell. Transp. Syst. 2015, 9, 824–832. [Google Scholar] [CrossRef]
- Carullo, A.; Parvis, M. An ultrasonic sensor for distance measurement in automotive applications. IEEE Sens. J. 2001, 1, 143. [Google Scholar] [CrossRef] [Green Version]
- Schlegl, T.; Bretterklieber, T.; Neumayer, M.; Zangl, H. Combined capacitive and ultrasonic distance measurement for automotive applications. IEEE Sens. J. 2011, 11, 2636–2642. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, J. RFID localization algorithms and applications—A review. J. Intell. Manuf. 2009, 20, 695. [Google Scholar] [CrossRef]
- Fernandez-Llorca, D.; Minguez, R.Q.; Alonso, I.P.; Lopez, C.F.; Daza, I.G.; Sotelo, M.Á.; Cordero, C.A. Assistive intelligent transportation systems: The need for user localization and anonymous disability identification. IEEE Intell. Transp. Syst. Mag. 2017, 9, 25–40. [Google Scholar] [CrossRef]
- Zhao, F.; Jiang, H.; Liu, Z. Recent development of automotive LiDAR technology, industry and trends. In Proceedings of the Eleventh International Conference on Digital Image Processing (ICDIP 2019), Guangzhou, China, 10–13 May 2019; Volume 11179, p. 111794A. [Google Scholar]
- Schalling, F.; Ljungberg, S.; Mohan, N. Benchmarking lidar sensors for development and evaluation of automotive perception. In Proceedings of the 2019 4th International Conference and Workshops on Recent Advances and Innovations in Engineering (ICRAIE), Kedah, Malaysia, 28–29 November 2019; pp. 1–6. [Google Scholar]
- de Ponte Müller, F. Survey on ranging sensors and cooperative techniques for relative positioning of vehicles. Sensors 2017, 17, 271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ohguchi, K.; Shono, M.; Kishida, M. 79 GHz band ultra-wideband automotive radar. Fujitsu Ten Tech. J. 2013, 39, 9–14. [Google Scholar]
- Hasch, J.; Topak, E.; Schnabel, R.; Zwick, T.; Weigel, R.; Waldschmidt, C. Millimeter-wave technology for automotive radar sensors in the 77 GHz frequency band. IEEE Trans. Microw. Theory Tech. 2012, 60, 845–860. [Google Scholar] [CrossRef]
- Gresham, I.; Jenkins, A.; Egri, R.; Eswarappa, C.; Kinayman, N.; Jain, N.; Anderson, R.; Kolak, F.; Wohlert, R.; Bawell, S.P.; et al. Ultra-wideband radar sensors for short-range vehicular applications. IEEE Trans. Microw. Theory Tech. 2004, 52, 2105–2122. [Google Scholar] [CrossRef]
- Kuutti, S.; Fallah, S.; Katsaros, K.; Dianati, M.; Mccullough, F.; Mouzakitis, A. A survey of the state-of-the-art localization techniques and their potentials for autonomous vehicle applications. IEEE Internet Things J. 2018, 5, 829–846. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part C Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Altay, F.; Velipasalar, S. The Use of Thermal Cameras for Pedestrian Detection. IEEE Sens. J. 2022. [Google Scholar] [CrossRef]
- Jabłoński, P.; Iwaniec, J.; Zabierowski, W. Comparison of pedestrian detectors for LiDAR sensor trained on custom synthetic, real and mixed datasets. Sensors 2022, 22, 7014. [Google Scholar] [CrossRef] [PubMed]
- Bakheet, S.; Al-Hamadi, A. A framework for instantaneous driver drowsiness detection based on improved HOG features and naïve Bayesian classification. Brain Sci. 2021, 11, 240. [Google Scholar] [CrossRef]
- Buongiorno, D.; Cascarano, G.D.; De Feudis, I.; Brunetti, A.; Carnimeo, L.; Dimauro, G.; Bevilacqua, V. Deep learning for processing electromyographic signals: A taxonomy-based survey. Neurocomputing 2021, 452, 549–565. [Google Scholar] [CrossRef]
- Zhang, L.; Yuan, M.; Zheng, D.; Li, X.Y. M&M: Recognizing Multiple Co-evolving Activities from Multi-Source Videos. In Proceedings of the 2021 17th International Conference on Distributed Computing in Sensor Systems (DCOSS), Pafos, Cyprus, 14–16 July 2021; pp. 75–82. [Google Scholar]
- Asim, M.; Wang, Y.; Wang, K.; Huang, P.Q. A Review on Computational Intelligence Techniques in Cloud and Edge Computing. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 742–763. [Google Scholar] [CrossRef]
- Sighencea, B.I.; Stanciu, R.I.; Căleanu, C.D. A Review of Deep Learning-Based Methods for Pedestrian Trajectory Prediction. Sensors 2021, 21, 7543. [Google Scholar] [CrossRef] [PubMed]
- Weina, Z.; Lihua, S.; Zhijing, X. A Real-time Detection Method for Multi-scale Pedestrians in Complex Environment. J. Electron. Inf. Technol. 2021, 43, 2063–2070. [Google Scholar]
- Shivappriya, S.; Priyadarsini, M.J.P.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B. Cascade object detection and remote sensing object detection method based on trainable activation function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K. Multiscale object detection from drone imagery using ensemble transfer learning. Drones 2021, 5, 66. [Google Scholar] [CrossRef]
- Indapwar, A.; Choudhary, J.; Singh, D.P. Survey of Real-Time Object Detection for Logo Detection System. In Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 61–72. [Google Scholar]
- Fu, X.B.; Yue, S.L.; Pan, D.Y. Camera-based basketball scoring detection using convolutional neural network. Int. J. Autom. Comput. 2021, 18, 266–276. [Google Scholar] [CrossRef]
- Rundo, F.; Leotta, R.; Battiato, S.; Conoci, S. Intelligent Saliency-based Deep Pedestrian Tracking System for Advanced Driving Assistance. In Proceedings of the 2021 AEIT International Conference on Electrical and Electronic Technologies for Automotive (AEIT AUTOMOTIVE), Online, 17–19 November 2021; pp. 1–6. [Google Scholar]
- Xiao, X.; Wang, B.; Miao, L.; Li, L.; Zhou, Z.; Ma, J.; Dong, D. Infrared and visible image object detection via focused feature enhancement and cascaded semantic extension. Remote Sens. 2021, 13, 2538. [Google Scholar] [CrossRef]
- Do, T.N.; Tran-Nguyen, M.T.; Trang, T.T.; Vo, T.T. Deep Networks for Monitoring Waterway Traffic in the Mekong Delta. In Proceedings of the International Conference on Modelling, Computation and Optimization in Information Systems and Management Sciences; Springer: Berlin/Heidelberg, Germany, 2021; pp. 315–326. Available online: https://link.springer.com/book/10.1007/978-981-16-5685-9 (accessed on 13 October 2022).
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F.Y. Deep neural network based vehicle and pedestrian detection for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Ozdemir, C.; Gedik, M.A.; Kaya, Y. Age Estimation from Left-Hand Radiographs with Deep Learning Methods. Trait. Signal 2021, 38, 1565–1574. [Google Scholar] [CrossRef]
- Jia, W.; Gao, J.; Xia, W.; Zhao, Y.; Min, H.; Lu, J.T. A performance evaluation of classic convolutional neural networks for 2D and 3D palmprint and palm vein recognition. Int. J. Autom. Comput. 2021, 18, 18–44. [Google Scholar] [CrossRef]
- Wang, I.S.; Chan, H.T.; Hsia, C.H. Finger-Vein Recognition Using a NASNet with a Cutout. In Proceedings of the 2021 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hualien, Taiwan, 16–19 November 2021; pp. 1–2. [Google Scholar]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A real time DNN-based face mask detection system using single shot multibox detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef] [PubMed]
- Pawlowski, P.; Piniarski, K.; Dąbrowski, A. Highly Efficient Lossless Coding for High Dynamic Range Red, Clear, Clear, Clear Image Sensors. Sensors 2021, 21, 653. [Google Scholar] [CrossRef] [PubMed]
- Nataprawira, J.; Gu, Y.; Goncharenko, I.; Kamijo, S. Pedestrian detection using multispectral images and a deep neural network. Sensors 2021, 21, 2536. [Google Scholar] [CrossRef] [PubMed]
- Paigwar, A.; Sierra-Gonzalez, D.; Erkent, Ö.; Laugier, C. Frustum-pointpillars: A multi-stage approach for 3d object detection using rgb camera and lidar. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 11–17 October 2021; pp. 2926–2933. [Google Scholar]
- Ding, M.; Zhang, S.; Yang, J. Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9076–9082. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Guided attentive feature fusion for multispectral pedestrian detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 72–80. [Google Scholar]
- Ding, L.; Wang, Y.; Laganière, R.; Huang, D.; Luo, X.; Zhang, H. A robust and fast multispectral pedestrian detection deep network. Knowl.-Based Syst. 2021, 227, 106990. [Google Scholar] [CrossRef]
- Jin, Y.; Zhang, Y.; Cen, Y.; Li, Y.; Mladenovic, V.; Voronin, V. Pedestrian detection with super-resolution reconstruction for low-quality image. Pattern Recognit. 2021, 115, 107846. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Challenges | Area | Models | Results |
|---|---|---|---|---|
| Kim et al. [23] 2020 | Pedestrian detection issues in smart towns | Facing issues due to complex environmental components, parameters, and discord in images | Utilized CNN to build up the advance VGG-16 and vision-based techniques | High accuracy up to 98.8% |
| Chen et al. [24] 2020 Su Hang et al. [25] 2015 | Difficult to identify the pedestrian because the images are captured from one position; no paradigm to stimulate the operations against the movements operated by pedestrians | Pedestrian detection evolution in intelligent transport design | Used the support vector machine (SVM) R-CNN to identify the one- and two-step patterns with the help of Google AVA, Hollywood2, KTH, and UCF sequence | The accuracy rate is 85.5% |
| Dinakaran et al. [26] 2019 Tian et al. [27] 2015 | Reduce long-distance low-resolution problems and control the occlusion handling in pedestrian detection | Detection of vehicles, cyclists, and pedestrians in smart towns due to security issues in transmission generated in IoT systems | Presented a new DCGAN model with cascaded single short detectors (SSD) based on Canadian Institute for Advanced Research (CIFAR) datasets; presented a DeepParts model to handle the occlusion issue based on KITTI and Caltech datasets | Accuracy rates are 80.7% and 70.49% |
| Wang et al. [28] 2020 | An occluded pedestrian resulting in missing information leading to the identification of a false negative pedestrian | The bad reaction of pedestrians to traffic conditions in urban areas of China | Proposed different methods such as FichaDL, THICV-YDM, DH-ARI, and EM-FPS based on KITTI and Caltech datasets | The accuracy rate on the KITTI dataset is 88.27% while that on the Caltech dataset is 81.73% |
| Hbaieb et al. [29] 2019 | To overcome the time response issues in pedestrian detection during the change of weather situations and various road circumstances | Camera quality effects in urban areas | Detection was performed based on support vector machine (SVM), histogram of oriented gradients (HOG), and Haar cascade techniques | The accuracy rate is up to 90% to 93.43% |
| Navarro et al. [17] 2016 | To reduce the pedestrian detection challenges based on a sensors system under real driving circumstances | Perceptions were performed in crowded places | Proposed machine learning (ML) approaches such as SVM, k-nearest neighbors (kNN), Naïve Bayes classifier (NBC) | The accuracy rate is 96.2% |
| Aledhari et al. [30] 2021 | To reduce the poor performance of algorithmic bias in the detection of human skin for instance poor detection due to a darker skin color under a complex situation such as variations in images and illuminations; moreover, a darker skin color also causes occlusion and other issues | Darker skin tones cause serious accidents in some areas of America | Proposed K-Means Cluster, YOLOv3, and CNN for the classification of skin tones based on the Caltech pedestrian detection dataset | The mAP is 43% |
| Datasets | Methods | Training Images | Testing Images |
|---|---|---|---|
| KITTI | PCN [62], ECP faster R-CNN [58], faster R-CNN [63], Sub-CNN [64] | 7481 images | 7518 images |
| INRIA | PCN [62], SAF R-CNN [34] 2LDCF [65], RF3 + LDCF [65] | 614 is used as a positive image and 1218 used as a negative image | 288 images |
| Caltech | PCN [62], RPN + FRCNN [63] SAF R-CNN [34], HOG [10] | 350,000 images | 2300 images |
| CityPersons | Adam solver ImageNet Model [66] | 2975 images | 500 images |
| TUD-Brussels | Part-based model [67] | 218 images used as negative | 508 images used as positive |
| ETH | Part-based model [67] Faster RCNN [68,69] | 499 used as positive images | 1804 negative images |
| Sensors | Range | Accuracy |
|---|---|---|
| STEREO CAMERAS | Ranges from five hundred centimeters to various tens of centimeters [75] Several tens of meters [75] | Divergence delusion of 1/10 pixels (corresponds to approximately 1 m range delusion if the target is 100 m out of the way) [76] |
| INFRARED | From a minor centimeter to various centimeters [77,78] | Temperature precision of +/−10 °C, can calculate the temperature up to 3000 °C [77] |
| ULTRANSONIC | Starting from 20 mm up to 5000 mm [79,80] | Approximately 0.03 cm [79,80] |
| RFID | Certain meters [81,82] | Certain centimeters [81,82] |
| LIDAR | Starts range onward 300 m [83,84] | Starts onward from 2 cm [84,85] |
| RADAR | Short range: 40 m, angle 130° [86,87,88] Middle range: 70–100 m, angle 90° [86,87] Long-range automotive radar: From below 1 m onwards to 300 m (beginning gradient onward +/−30°, a comparative velocity scale of onward +/−260 km/h) [85,86,89] | Short range: below than 15 cm or 1% [86,87,88] Middle range: below than 30 cm or 1% [86,87] Long range: 10 cm such as Long-Range-Radar LRR3 Bosch 77 GHz, scale from 250 m [85] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iftikhar, S.; Zhang, Z.; Asim, M.; Muthanna, A.; Koucheryavy, A.; Abd El-Latif, A.A. Deep Learning-Based Pedestrian Detection in Autonomous Vehicles: Substantial Issues and Challenges. Electronics 2022, 11, 3551. https://doi.org/10.3390/electronics11213551
Iftikhar S, Zhang Z, Asim M, Muthanna A, Koucheryavy A, Abd El-Latif AA. Deep Learning-Based Pedestrian Detection in Autonomous Vehicles: Substantial Issues and Challenges. Electronics. 2022; 11(21):3551. https://doi.org/10.3390/electronics11213551
Chicago/Turabian StyleIftikhar, Sundas, Zuping Zhang, Muhammad Asim, Ammar Muthanna, Andrey Koucheryavy, and Ahmed A. Abd El-Latif. 2022. "Deep Learning-Based Pedestrian Detection in Autonomous Vehicles: Substantial Issues and Challenges" Electronics 11, no. 21: 3551. https://doi.org/10.3390/electronics11213551