

Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems

School of Automation, Guangdong University of Technology, Guangzhou 510006, China
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(2), 221; https://doi.org/10.3390/e25020221
Submission received: 20 December 2022
/
Revised: 21 January 2023
/
Accepted: 22 January 2023
/
Published: 23 January 2023
(This article belongs to the Topic Complex Systems and Artificial Intelligence)
Abstract
:This paper focuses on the optimal containment control problem for the nonlinear multiagent systems with partially unknown dynamics via an integral reinforcement learning algorithm. By employing integral reinforcement learning, the requirement of the drift dynamics is relaxed. The integral reinforcement learning method is proved to be equivalent to the model-based policy iteration, which guarantees the convergence of the proposed control algorithm. For each follower, the Hamilton–Jacobi–Bellman equation is solved by a single critic neural network with a modified updating law which guarantees the weight error dynamic to be asymptotically stable. Through using input–output data, the approximate optimal containment control protocol of each follower is obtained by applying the critic neural network. The closed-loop containment error system is guaranteed to be stable under the proposed optimal containment control scheme. Simulation results demonstrate the effectiveness of the presented control scheme.
1. Introduction
Distributed coordination control of multiagent systems (MASs) has drawn expansive interest due to its potential application on agricultural irrigation [1], disaster rescue [2], microgrid scheduling [3], marine survey [4] and wireless communication [5]. The distributed coordination control aims to guarantee that all agents which exchange local information by communicating with their neighbors reach an agreement on some variables of interest [6]. Over the last decade, containment control has received increasing attention because of its remarkable performance in addressing the secure control issues, such as hazardous material treatment [7] and fire rescue [8]. The goal of containment control is to drive the followers to enter and keep within the convex hull spanned by multiple leaders. Numerous interesting and significant results of containment control have been presented. Reference [9] developed a fuzzy-observer-based backstepping control to achieve the containment of MASs. An adaptive funnel containment control was proposed in [10], where the containment errors converged to an adjustable funnel boundary. In practical applications, containment control has been developed for autonomous surface vehicles [4], unmanned aerial vehicles [11] and spacecrafts [12]. Notice that most of the aforementioned works have ignored the control performance with a minimum of energy consumption.
It is well-known that the Riccati equation or the Hamilton–Jacobi–Bellman equation (HJBE) are solved to acquire the optimal control for linear or nonlinear systems [13], respectively. In other words, the Riccati equation is a particular case of the HJBE. As a classical optimization algorithm, dynamic programming (DP) [14] is regarded as an effective way to obtain the optimal solution of the HJBE. However, as the dimension of state variables increases, the computation of the DP approach expands as a geometric series, which arouses the dilemma of the “curse of dimensionality”. With the success of AlphaGo, reinforcement learning (RL) has stimulated increasing enthusiasm from scholars to tackle the “curse of dimensionality” problem [15]. As is synonymous with RL, adaptive DP (ADP) [16] forward-in-time-solves the optimal control problem with the aid of neural network (NN)-based approximators. Moreover, ADP has been increasingly exploited for the optimal coordination control of MASs. Reference [17] established a cooperative policy iteration (PI) algorithm to solve the differential graphical games of linear MASs. In the nonlinear case, Reference [18] investigated the consensus problem via model-based PI with a generalized fuzzy hyperbolic critic structure. An event-triggered ADP-based optimal coordination control was proposed for the communication load and the commutation consumption was reduced [19]. To tackle the optimal containment control (OCC) problem, a finite-time fault-tolerant control was proposed via model-based PI [20]. In the presence of state constraints, Reference [21] presented a proper barrier function to transform the state constraint problem into an unconstrained case, thereafter the event-triggered OCC protocols were obtained. In Reference [22], distributed RL was applied to handle an OCC problem with collision avoidance of nonholonomic mobile robots. When the accurate model of the plant is not obtained, system identification is always employed. It should be pointed out that system identification is intractable for responding to dynamic changes of systems in time, which brings inevitable identification errors.
Recently, the integral RL (IRL) method was adopted to relax the accurate model requirement of the plant by constructing the integral Bellman equation [23,24]. An actor–critic architecture was adopted to execute the IRL algorithm, in which an actor NN learned the optimal control strategy and a critic NN was devoted to approximating the optimal value function. In the presence of heterogeneous linear MASs (HLMASs), the IRL method was developed to handle the robust OCC problem [25]. An adaptive output-feedback method was developed for the containment control for HLMASs via the IRL algorithm [26]. In Reference [27], the off-policy IRL-based OCC scheme was presented for unknown HLMASs with active leaders. However, the OCC problem of the nonlinear MASs with partially unknown dynamics has rarely been investigated via the IRL method. Moreover, the actor–critic architecture requires constructing the actor NN, which makes the control structure more complex. It is crucial to develop an IRL-based OCC scheme by implementing a simplified control structure. In addition, most of the aforementioned OCC approaches ensure the weight estimation error of the critic NN is uniformly ultimately bounded (UUB) only, which may degrade the control performance. All the above concerns motivated our research.
Inspired by the aforementioned works, we developed an IRL-based OCC scheme with asymptotically stable critic structure for partially unknown nonlinear MASs. The main contributions are reflected as follows.
- (1)
- (2)
- (3)
This paper is organized as follows. In Section 2, graph theory and its application to the containment of MASs are outlined. In Section 3, the IRL-based OCC scheme and its convergence proof are presented for nonlinear MASs. Then, the stability of the closed-loop containment error systems is analyzed in detail. In Section 4, two simulation examples demonstrate the effectiveness of the proposed scheme. In Section 5, concluding remarks are drawn.
2. Preliminaries and Problem Description
2.1. Graph Theory
For a network with N agents, the information interactions among agents are reflected by a weighted graph with the nonempty finite set of nodes , the edge set and the nonnegative weighted adjacency matrix . If node links to node , the edge is available with ; otherwise, . For a node , the node is named as a neighbor of when . In this way, represents the set of all neighbors of . Denote the Laplacian matrix as , where , and satisfies
It implies that each row sum of L equals to zero. A sequence of edges described by with is defined as a directed path. For arbitrary , a directed graph is strongly connected, if there is a directed path from to , while the directed graph is said to contain a spanning tree if there exists a directed path from a root node to every other nodes with respect to . This paper focuses on a strongly connected digraph with a spanning tree.
2.2. Problem Description
Consider the leader–follower nonlinear MASs in the form of the graph with M leaders and N followers, where the node dynamic of the ith follower is modeled by
where is the state vector for the ith follower, is the control input vector, , and the nonlinear functions and represent the unknown drift dynamic and the control input matrix, respectively. Denote the global state vector as .
Assumption 1.
and are Lipschitz continuous on the compact set with and the system (1) is controllable.
Define the node dynamic of the jth leader as
where stands for the state vector of the jth leader, and satisfies Lipschitz continuity.
Definition 1
(Convex hull [8]). A set is convex if for any and , . A convex hull of a finite set is the minimal convex set, i.e., .
The containment control aims to find a set of distributed control protocols such that all followers stay in the convex hull formed by the leaders, i.e., with . For the ith follower, the local neighborhood containment error is formulated as
where , represents the pinning gain. Define . In fact, the connection between the ith follower and the jth leader is available if and only if . Denote the communication graph as . The global containment error vector of is
where , , , represents the n-dimension identity matrix, stands for the M-dimensional column vector whose every element equals to 1 and . Considering (1), (2) and (3), for the ith follower, the local neighborhood containment error dynamic is formulated as
where and . For the ith follower, the local neighborhood containment error is dominated not only by local states and local control inputs, but also by the information from its neighbors and the leaders. In order to implement the synchronization of the partially unknown nonlinear MASs (i.e., ), an IRL-based OCC scheme is designed in the next subsection.
3. IRL-Based OCC Scheme
3.1. Optimal Containment Control
For the local neighborhood containment error dynamic (4), define the cost function as
where is a utility function, represents a set of the local control protocols from the neighbors of node , and and are the positive definite matrices.
Definition 2
Definition 3
(Nash equilibrium [17]). An N-tuple admissible control policy is said to constitute a Nash equilibrium solution in graph , if the following N inequalities are satisfied
where .
This paper aims to find an N-tuple optimal admissible control policy to minimize the cost function (5) for each follower such that the Nash equilibrium solution in (i.e., the OCC protocols) is obtained.
For arbitrary of the ith follower, define the value function
When (6) is finite, then the Bellman equation is
where and . For the ith follower, the local Hamiltonian is
Define the optimal value function as
According to [13], the optimal value function satisfies the HJBE as follows
The local OCC protocol is
It should be mentioned that the analytical solution of the HJBE is intractable to obtain since is unknown. According to [15], the solution of the HJBE is successively approximated through a sequence of iterations with policy evaluation
and policy improvement
where represents the kth iteration index with .
From (11), we can see that the policy evaluation requires the accurate mathematical model of (1). However, the accurate mathematical model is always difficult to obtain in practice. To break this bottleneck, the IRL method is developed to relax the requirement of the accurate model in the policy evaluation.
3.2. Integral Reinforcement Learning
For , (6) can be rewritten as
Based on the integral Bellman Equation (13), and satisfy
Compared to (7), the policy evaluation (14) is not required for the accurate system dynamics in (1).
Theorem 1.
Let , and . is the solution of the integral Bellman equation
if and only if is the only solution of (11).
Proof of Theorem 1.
Integrate on both sides of (16) within , that is
According to the derivation of (16) and (17), if is the solution of (11), satisfies the integral Bellman Equation (15). Next, we verify the uniqueness of the solution .
Theorem 1 reveals that the IRL algorithm with (15) and (12) theoretically equals to the model-based PI algorithm, whose relevant convergence analysis was provided in [15]. Hence, the IRL algorithm can be guaranteed to be convergent.
Theorem 2.
Considering the nonlinear MAS with partially unknown dynamic as (1), the local neighborhood containment error dynamic as (4) and the optimal value function as (8), the closed-loop containment error system is guaranteed to be asymptotically stable under the local OCC protocol (10). Furthermore, the containment control is achieved with a set of the OCC protocols if there is a spanning tree in the directed graph.
Proof of Theorem 2.
Substituting (20) into the time derivative of , then
3.3. Critic NN Implementation
Based on the Stone–Weierstrass approximation theorem, on the compact set , the optimal function and its partial gradient can be established by a critic NN as
where represents the ideal weight, represents the activation function, represents the number of hidden neurons and stands for the reconstruction error.
Since the ideal weight vector is unknown, the approximation of and are expressed as
where and represents the estimation of . Then, the local OCC protocol (10) can be approximated by
The approximate local Hamiltonian is
Assumption 2.
is bounded by , i.e., with .
In order to tune , the steepest descent algorithm is employed to minimize . A modified updating law of is
where and , the estimation of , can be updated by
where is a design constant. Considering (26) and (27), the weight estimation error is updated by
Theorem 3.
Proof of Theorem 3.
Define . Choose the Lyapunov function candidate as
According to (28), is updated by
Considering (29) and (31), the time derivative of (30) is
where . According to Assumption 2, (32) is derived as
It indicates . Therefore, one can conclude that is ensured to be asymptotically stable. □
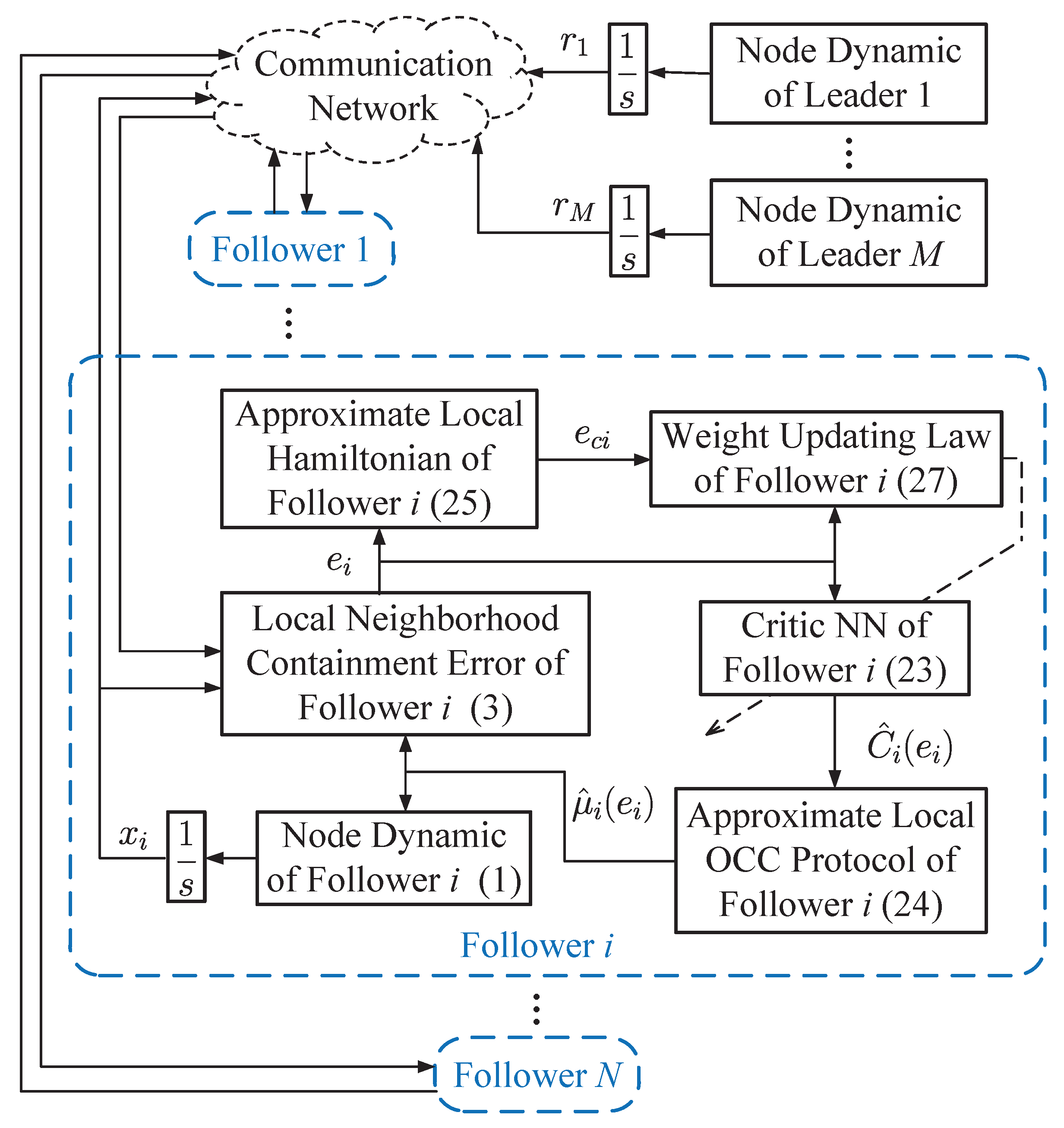
Under the framework of the critic-only architecture, the IRL-based OCC scheme is presented. For each follower, the local neighborhood containment error (3) is established by communicating with its neighbors and the leaders. The value function of each follower is approximated by the critic NN (23), whose weights are tuned by a modified weight updating law (27). Based on (1), (3) and (23), the local OCC protocol (24) is obtained. The structural diagram of the developed IRL-based OCC scheme is shown in Figure 1.
Remark 1.
In the actor–critic architecture, the optimal value function and the optimal control policy are approximated by a critic NN and an actor NN, respectively. While for the critic-only architecture, the optimal value function is approximated by a critic NN and the optimal control policy is directly obtained by combining (10) and (22). Hence, the critic-only architecture keeps the same performance as the actor–critic one. In contrast, the critic-only architecture utilizes a single critic NN only, which implies that the control structure is simplified and the computation burden is reduced.
3.4. Stability Analysis
Assumption 3.
, , and are norm-bounded, i.e.,
where , , , and are positive constants.
Theorem 4.
Considering the nonlinear MAS with partially unknown dynamics as (1), the local neighborhood containment error dynamic as (4), the optimal value function as (8) and the critic NN which is updated by (27) and (28), the local containment control protocol (24) can guarantee the closed-loop containment error system (4) to be UUB.
Proof of Theorem 4.
The Lyapunov function candidate is chosen as
Notice that
Then, (34) becomes
Let . Thus, (35) turns to
It shows if lies outside the compact set
Remark 2.
In Assumption 1, we know that the nonlinear functions and are Lipschitz continuous on a compact set containing the origin, . It indicates that the developed control scheme is effective in a compact set . If the system states are outside this compact set, this scheme might be invalid. In Theorem 4, we analyzed the system stability within such a compact set via the Lyapunov direct method, which means the closed-loop system is stable in the compact set under the developed IRL-based OCC scheme.
4. Simulation Study
This section provides two simulation examples to support the developed IRL-based OCC scheme.
4.1. Example 1
Consider a six-node graph network connected by three leader nodes. The directed topology of the graph is displayed in Figure 2.
As displayed in Figure 2, nodes 1–3 stand for the leaders 1–3 and nodes 4–6 represent the followers 1–3. In (3), the edge weights and pinning gains were set to 0.5. The node dynamic of the jth leader is described as , where represents the state vector, and
For the ith follower, the node dynamic is formulated as , where and with , , and . The local neighborhood containment error vector is calculated by (3).
In the simulation, was reconstructed by a critic NN with a 2–5–1 structure. The activation function was described as . The initialization of the node dynamics were characterized as , , , , and . The related parameters were chosen as , , and .
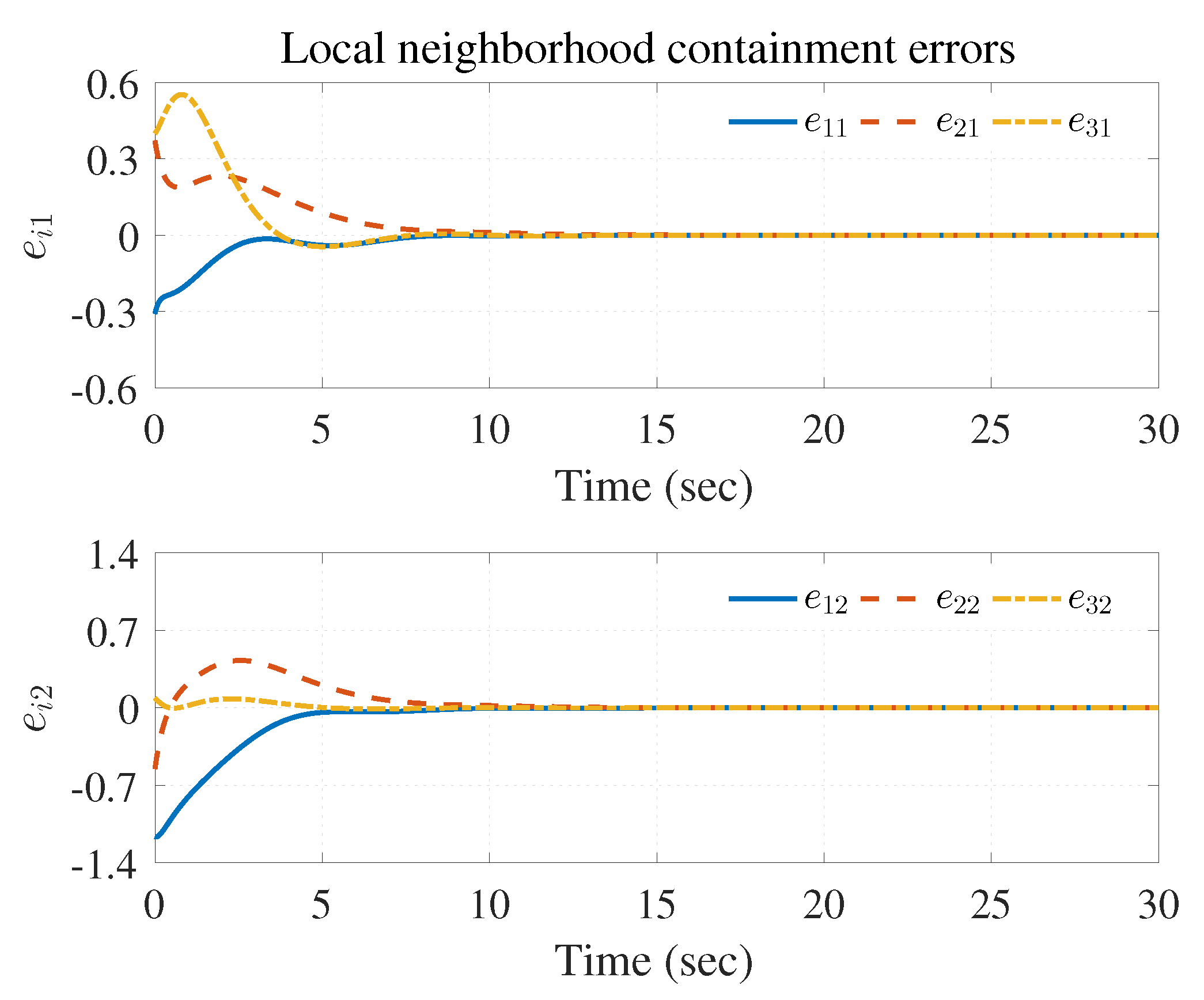
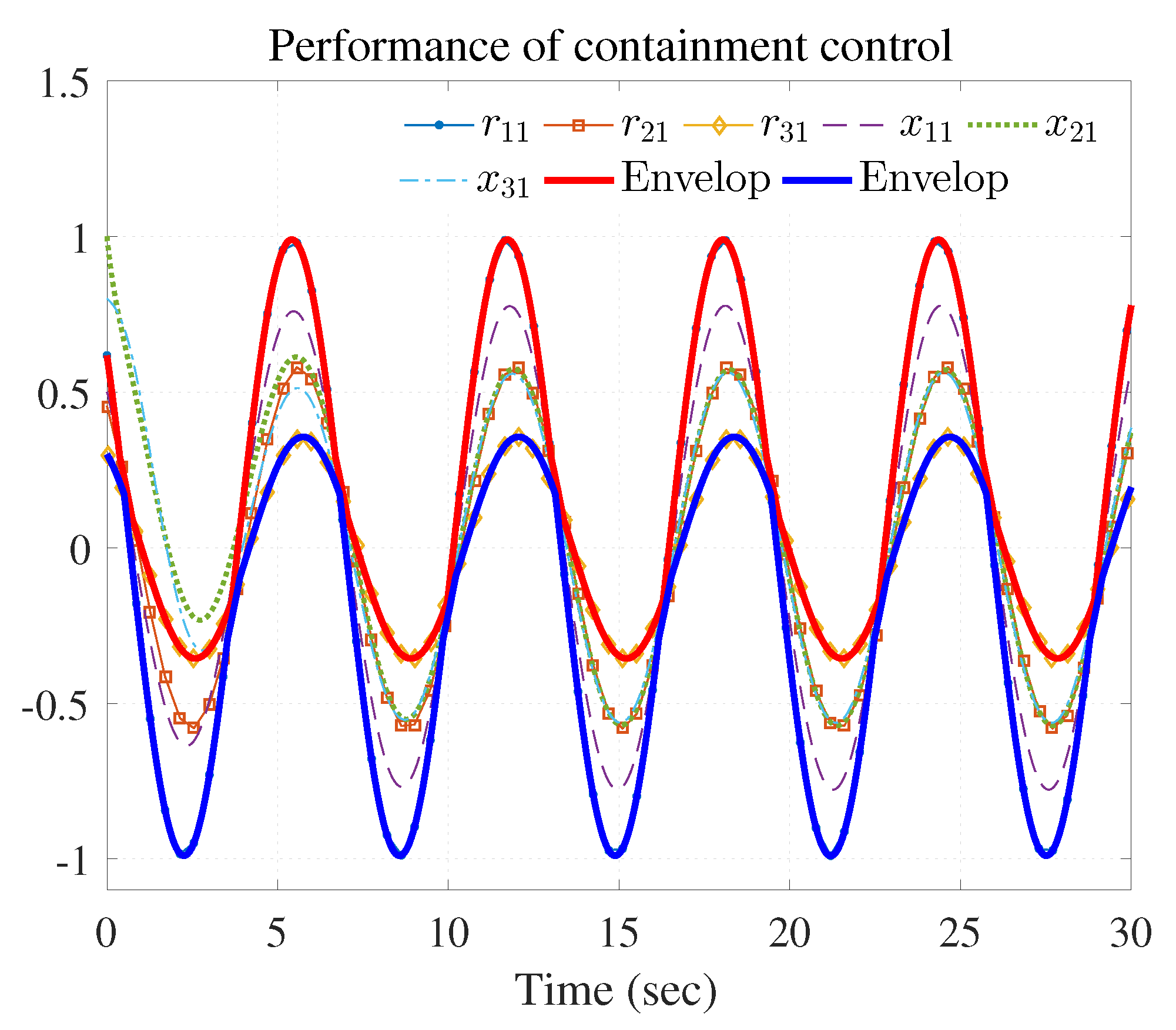
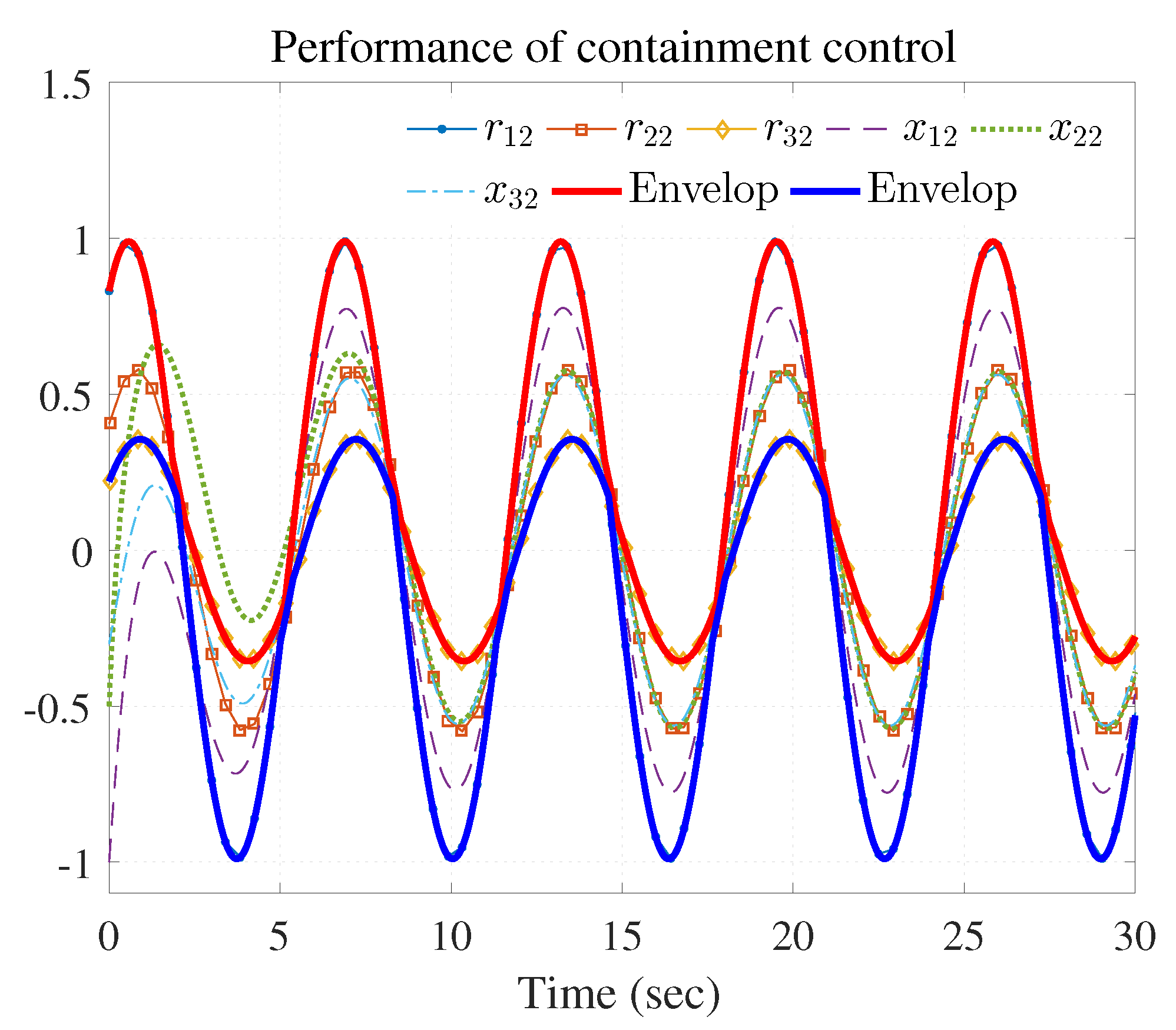
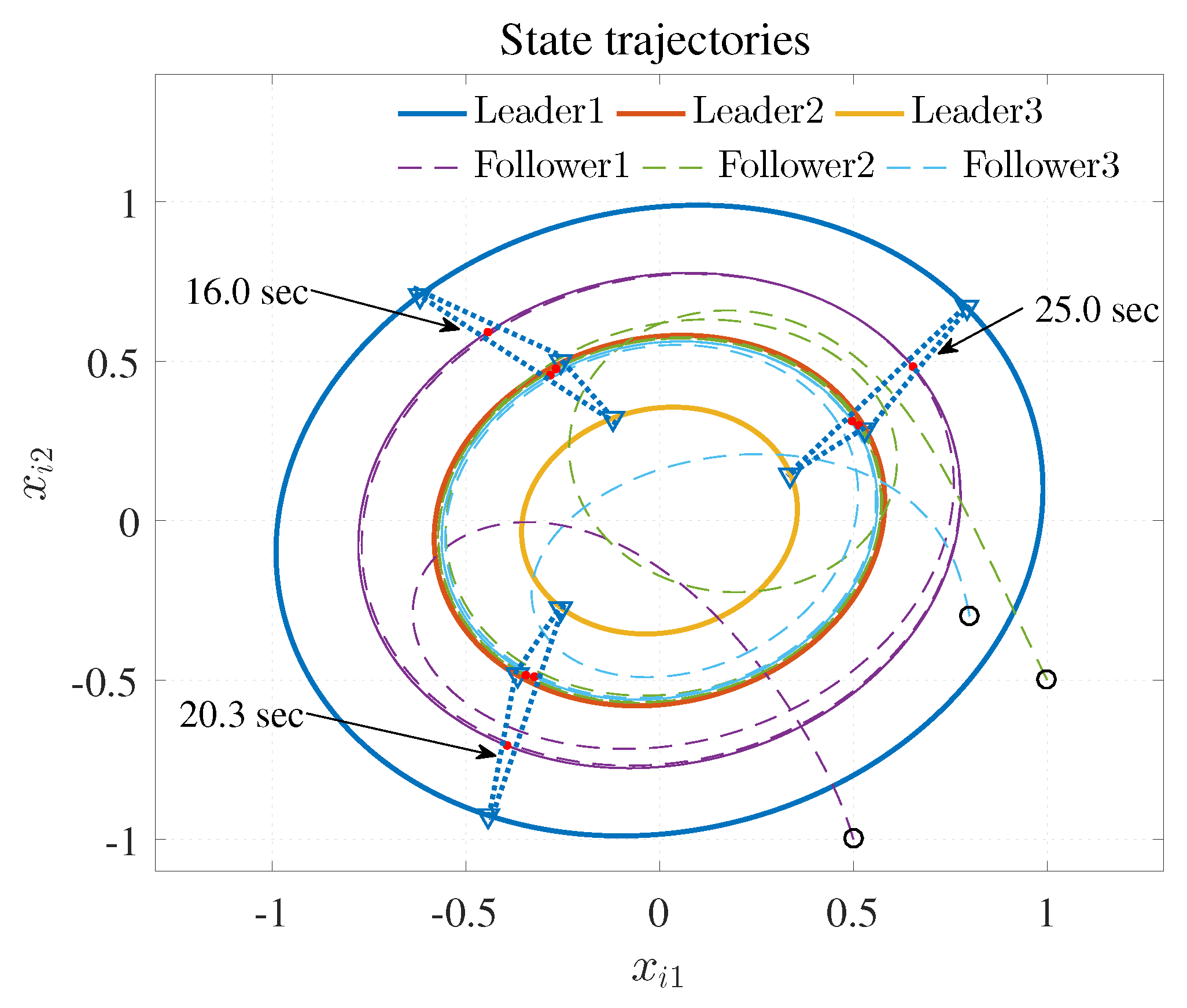
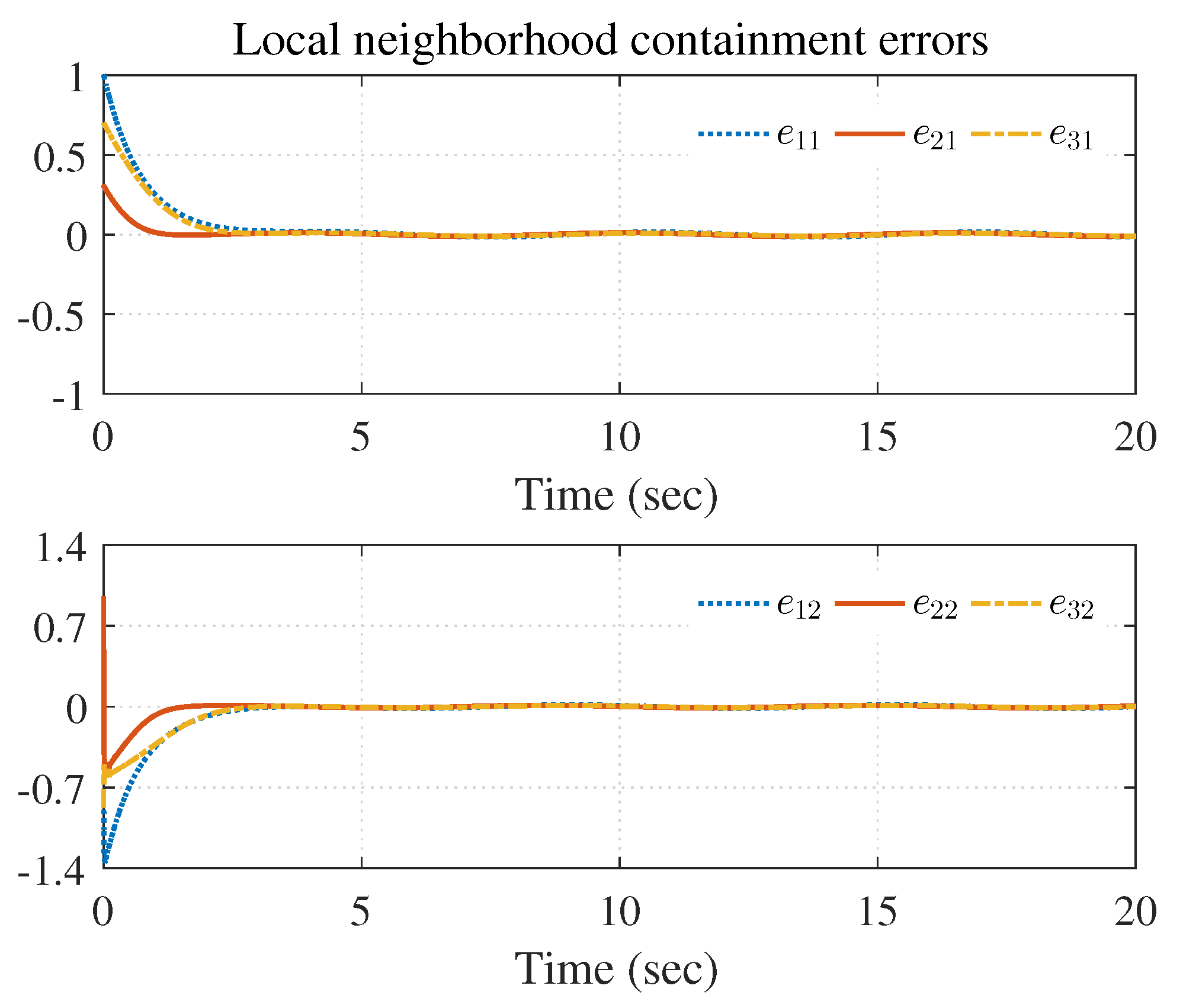
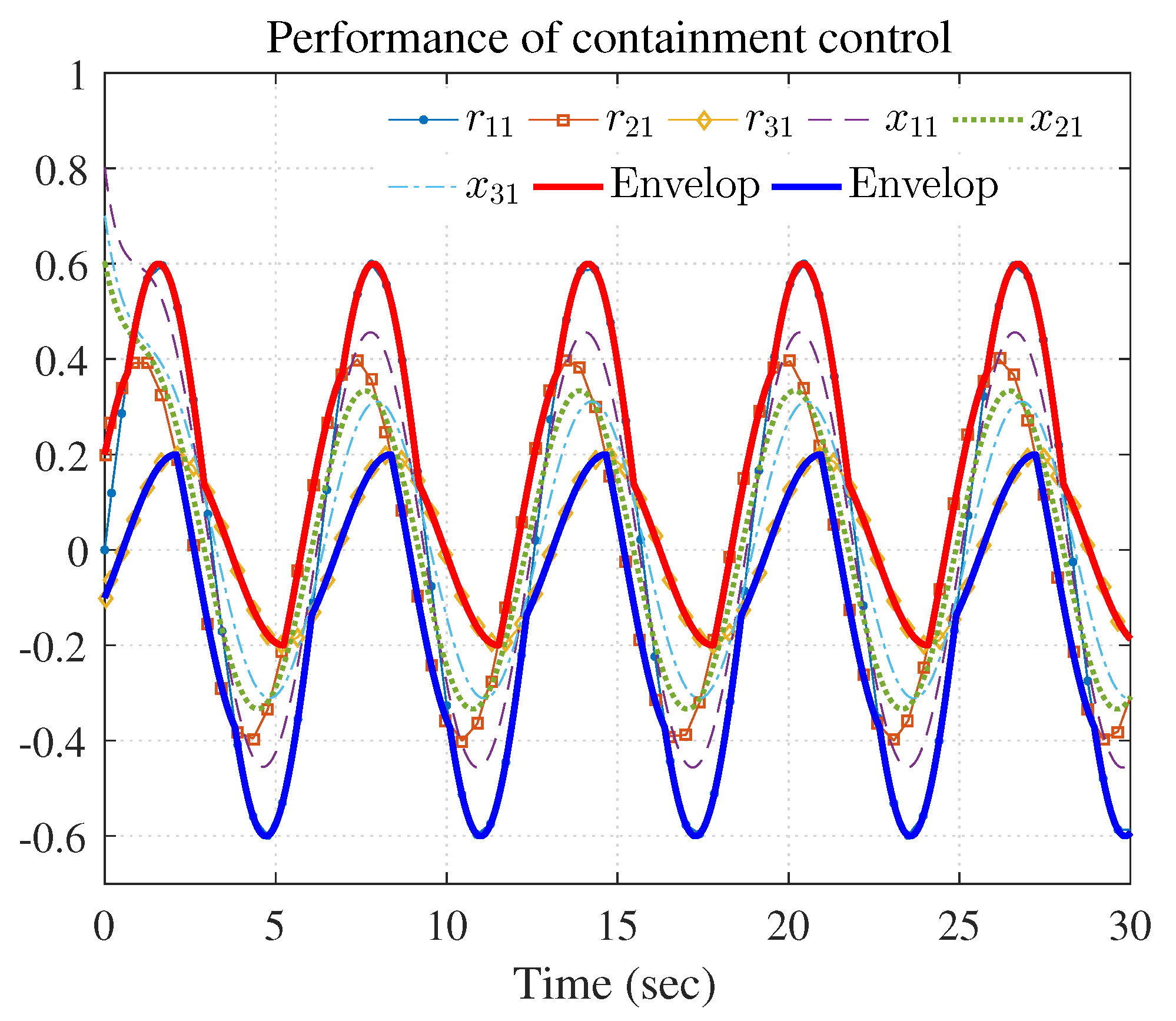
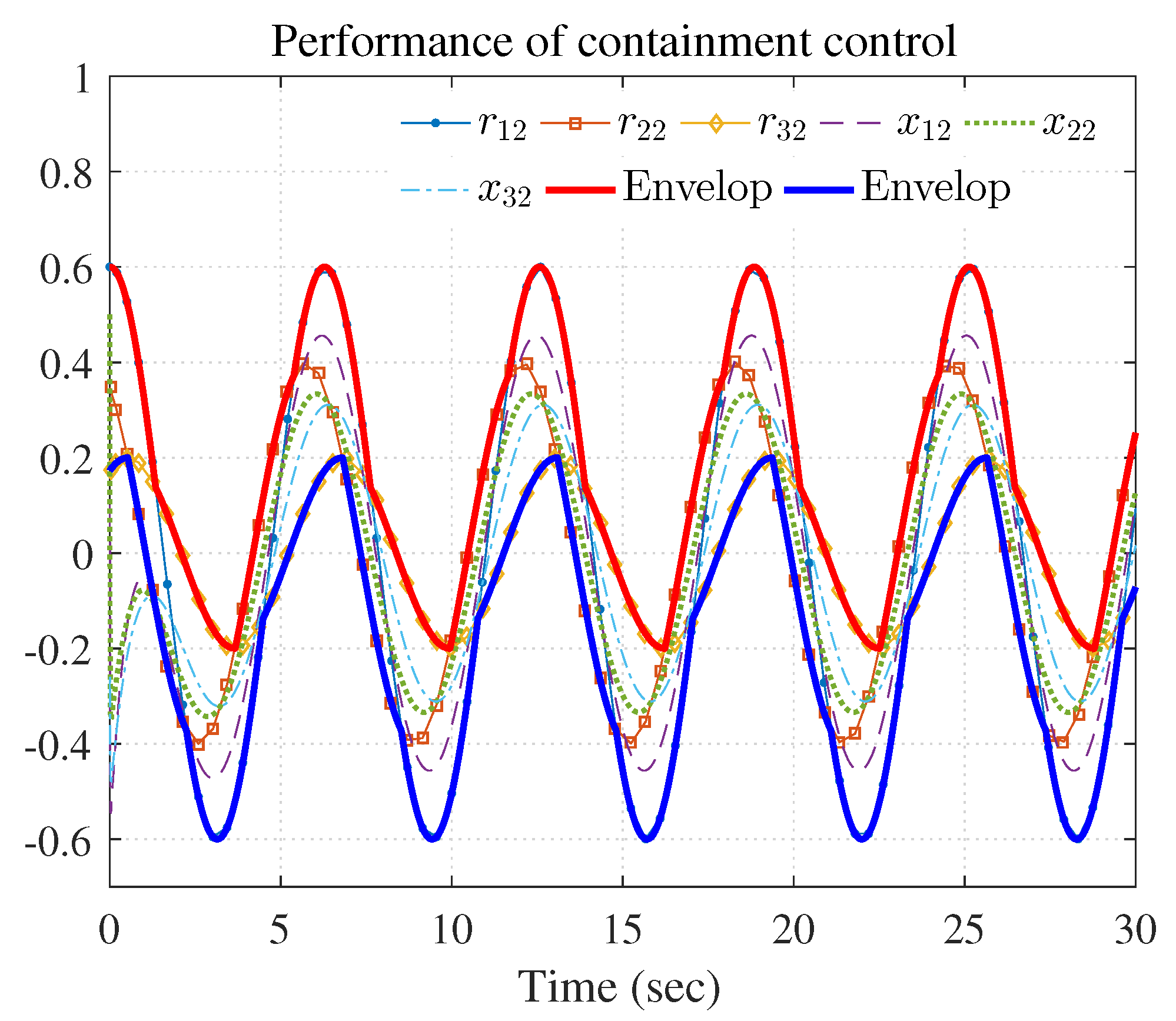
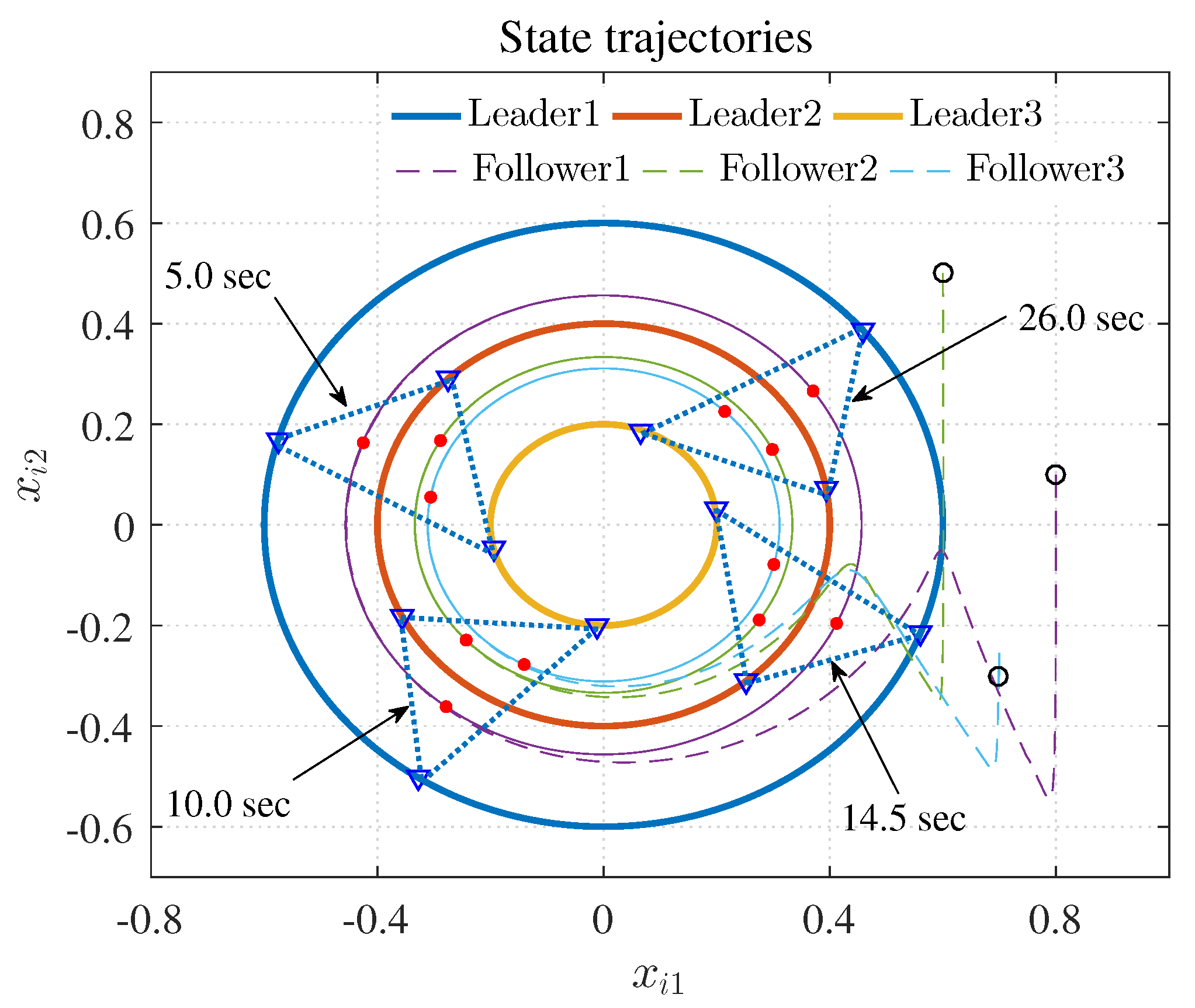
The simulation results are shown in Figure 3, Figure 4 and Figure 5 using the developed IRL-based OCC protocols. The evolution procedure of the local neighborhood containment errors for triple followers is shown in Figure 3, which indicates that the local neighborhood containment errors were regulated to zero under the developed control protocols. Thus, the containment control of MAS could be reached. Figure 4 and Figure 5 depict the state curves of the leaders and the followers, where all followers moved and stayed within the region formed by the envelope curves. It implies that the satisfactory performance of the containment control was acquired. The state curves of the followers and the leaders are displayed as 2-D phase plane plot in Figure 6 and the region enveloped by the three leaders and is shown at three different instants ( and ). We can observe from Figure 6 that the followers converged to the convex hull.
4.2. Example 2
Consider the nonlinear MAS consisting of three single-link robot arms and triple leader nodes. A rigid link is attached to each robot arm via a gear train to a direct current motor [28]. In Figure 2, the directed topology among these robot arms is shown. We chose the values of all edge weights and pinning gain as 1.
The state trajectories of the leaders is given by , and . The single-link robot arm for each follower can be described as
where , , , , and . The notations of the model (36) are defined in Table 1.
Similar to Example Section 4.1, the local neighborhood containment error vector was given as .
The critic NN structures and the related activation functions were initialized as in Example Section 4.1. The critic NN weights were initialized as the random values within and the parameters of initialization and control were chosen as , , , , , , , , , and .
Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11 show the simulation results. The local neighborhood containment errors converged to a small region around zero as depicted in Figure 7, which shows that the containment control of the nonlinear MAS was achieved. In Figure 8 and Figure 9, it can be found that the state trajectories of single-link robot arms (36) entered and stayed within the region enveloped by the leader nodes as the time progressed, which indicated the satisfactory performance of the developed scheme. The evolution curves of all agents are illustrated as the 2-D phase plane plot in Figure 10. We can see that the convex hull formed by the leaders and contains the followers at the time instants and , which implies that the followers converged to the convex hull. Figure 11 describes the curves of the containment control inputs, which shows the regulation process of the containment error system.
5. Conclusions
This paper investigated the OCC problem of nonlinear MASs with partially unknown dynamics via the IRL method. Based on the IRL method, the integral Bellman equation was constructed to relax the requirement of the drift dynamics. The proposed control algorithm was guaranteed to converge by analyzing the convergence of IRL. With the aid of the universal approximation capability of the NN, the solution of the HJBE was acquired by a critic NN with a modified weight-updating law which guaranteed the asymptotical stability of the weight error dynamics. By using the Lyapunov stability theorem, we showed that the closed-loop containment error system was UUB. From the simulation results of two examples, the effectiveness of the proposed IRL-based OCC scheme was illustrated. In the considered MASs, the information among all agents was transmitted by a desired communication network, which is always confronted with some security issues, such as attacks and packet dropouts. The focus of our future work is to develop a novel distributed resilient containment control for the MASs subjected to attacks and packet dropouts.
Author Contributions
Conceptualization, Q.W. and Y.W. (Yonghua Wang); methodology, Q.W.; software, Q.W.; investigation, Q.W.; writing—original draft preparation, Q.W.; writing—review and editing, Y.W. (Yongheng Wu); visualization, Y.W. (Yongheng Wu); supervision, Y.W. (Yonghua Wang); funding acquisition, Y.W. (Yonghua Wang). All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Open Research Fund of The State Key Laboratory for Management and Control of Complex Systems under grant no. 20220118.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within this manuscript.
Acknowledgments
We appreciate all the authors for their contributions and the support of the foundation.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jimenez, A.F.; Cardenas, P.F.; Jimenez, F. Intelligent IoT-multiagent precision irrigation approach for improving water use efficiency in irrigation systems at farm and district scales. Comp. Electr. Agric. 2022, 192, 106635. [Google Scholar] [CrossRef]
- Vallejo, D.; Castro-Schez, J.; Glez-Morcillo, C.; Albusac, J. Multi-agent architecture for information retrieval and intelligent monitoring by UAVs in known environments affected by catastrophes. Eng. Appl. Artif. Intell. 2020, 87, 103243. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Li, Y.; Gooi, H.B.; Xin, H. Multi-agent based optimal scheduling and trading for multi-microgrids integrated with urban transportation networks. IEEE Trans. Power. Syst. 2021, 36, 2197–2210. [Google Scholar] [CrossRef]
- Deng, Q.; Peng, Y.; Qu, D.; Han, T.; Zhan, X. Neuro-adaptive containment control of unmanned surface vehicles with disturbance observer and collision-free. ISA Trans. 2022, 129, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Hamani, N.; Jamont, J.P.; Occello, M.; Ben-Yelles, C.B.; Lagreze, A.; Koudil, M. A multi-cooperative-based approach to manage communication in wireless instrumentation systems. IEEE Syst. J. 2018, 12, 2174–2185. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R.W. Consensus seeking in multiagent systems under dynamically changing interaction topologies. IEEE Trans. Autom. Control 2005, 50, 655–661. [Google Scholar] [CrossRef]
- Luo, K.; Guan, Z.H.; Cai, C.X.; Zhang, D.X.; Lai, Q.; Xiao, J.W. Coordination of nonholonomic mobile robots for diffusive threat defense. J. Frankl. Inst. 2019, 356, 4690–4715. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, Z.; Zhang, Y.; Qu, Y.; Su, C.Y. Distributed finite-time fault-tolerant containment control for multiple unmanned aerial vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2077–2091. [Google Scholar] [CrossRef]
- Li, Y.; Qu, F.; Tong, S. Observer-based fuzzy adaptive finite-time containment control of nonlinear multiagent systems with input delay. IEEE Trans. Cybern. 2021, 51, 126–137. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Xue, H.; Pan, Y.; Liang, H. Distributed adaptive event-triggered containment control for multi-agent systems under a funnel function. Int. J. Robust Nonlinear Control 2022. [Google Scholar] [CrossRef]
- Li, Y.; Liu, M.; Lian, J.; Guo, Y. Collaborative optimal formation control for heterogeneous multi-agent systems. Entropy 2022, 24, 1440. [Google Scholar] [CrossRef]
- Zhao, L.; Yu, J.; Shi, P. Command filtered backstepping-based attitude containment control for spacecraft formation. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 1278–1287. [Google Scholar] [CrossRef]
- Liu, D.; Wei, Q.; Wang, D.; Yang, X.; Li, H. Adaptive Dynamic Programming with Applications in Optimal Control; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Bellman, R.E. Dynamic Programming; Princeton Univ. Press: Trenton, NJ, USA, 1957. [Google Scholar]
- Abu-Khalaf, M.; Lewis, F.L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica 2005, 41, 779–791. [Google Scholar] [CrossRef]
- Liu, D.; Xue, S.; Zhao, B.; Luo, B.; Wei, Q. Adaptive dynamic programming for control: A survey and recent advances. IEEE Trans. Syst. Man. Cybern. Syst. 2021, 51, 142–160. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L.; Hudas, G.R. Multi-agent differential graphical games: Online adaptive learning solution for synchronization with optimality. Automatica 2012, 48, 1598–1611. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, J.; Yang, G.; Luo, Y. Leader-based optimal coordination control for the consensus problem of multiagent differential games via fuzzy adaptive dynamic programming. IEEE Trans. Fuzzy. Syst. 2015, 23, 152–163. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Zhang, H. Distributed optimal coordination control for nonlinear multi-agent systems using event-triggered adaptive dynamic programming method. ISA Trans. 2019, 91, 184–195. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Pan, Y.; Xue, H.; Tan, L. Simplified optimized finite-time containment control for a class of multi-agent systems with actuator faults. Nonlinear Dyn. 2022, 109, 2799–2816. [Google Scholar] [CrossRef]
- Xu, J.; Wang, L.; Liu, Y.; Xue, H. Event-triggered optimal containment control for multi-agent systems subject to state constraints via reinforcement learning. Nonlinear Dyn. 2022, 109, 1651–1670. [Google Scholar] [CrossRef]
- Xiao, W.; Zhou, Q.; Liu, Y.; Li, H.; Lu, R. Distributed reinforcement learning containment control for multiple nonholonomic mobile robots. IEEE Trans. Circuits Syst. I Reg. Papers 2022, 69, 896–907. [Google Scholar] [CrossRef]
- Chen, C.; Lewis, F.L.; Xie, K.; Xie, S.; Liu, Y. Off-policy learning for adaptive optimal output synchronization of heterogeneous multi-agent systems. Automatica 2020, 119, 109081. [Google Scholar] [CrossRef]
- Yu, D.; Ge, S.S.; Li, D.; Wang, P. Finite-horizon robust formation-containment control of multi-agent networks with unknown dynamics. Neurocomputing 2021, 458, 403–415. [Google Scholar] [CrossRef]
- Zuo, S.; Song, Y.; Lewis, F.L.; Davoudi, A. Optimal robust output containment of unknown heterogeneous multiagent system using off-policy reinforcement learning. IEEE Trans. Cybern. 2018, 48, 3197–3207. [Google Scholar] [CrossRef] [PubMed]
- Mazouchi, M.; Naghibi-Sistani, M.B.; Hosseini Sani, S.K.; Tatari, F.; Modares, H. Observer-based adaptive optimal output containment control problem of linear heterogeneous Multiagent systems with relative output measurements. Int. J. Adapt. Control Signal Process. 2019, 33, 262–284. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Modares, H.; Wunsch, D.C.; Yin, Y. Optimal containment control of unknown heterogeneous systems with active leaders. IEEE Trans. Control Syst. Technol. 2019, 27, 1228–1236. [Google Scholar] [CrossRef]
- Zhang, H.; Lewis, F.L.; Qu, Z. Lyapunov, adaptive, and optimal design techniques for cooperative systems on directed communication graphs. IEEE Trans. Ind. Electron. 2012, 59, 3026–3041. [Google Scholar] [CrossRef]
Figure 1.
Structural diagram of the developed IRL-based OCC scheme.

Figure 2.
The directed topology of example 1.

Figure 3.
Local neighborhood containment errors .

Figure 4.
Performance of containment control ( and ).

Figure 5.
Performance of containment control ( and ).

Figure 6.
State trajectories.

Figure 7.
Local neighborhood containment errors of triple followers.

Figure 8.
Performance of containment control ( and ).

Figure 9.
Performance of containment control ( and ).

Figure 10.
State trajectories.

Figure 11.
Containment control inputs of triple followers.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Notations of the single-link robot arm.
| Symbol | Notation |
|---|---|
| Link angle | |
| Angular velocity of the link | |
| Total rotational inertia of the link and motor | |
| Overall damping coefficient | |
| Total mass of the link | |
| l | Distant from joint axis to mass center of the link |
| Command generator |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wu, Q.; Wu, Y.; Wang, Y. Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems. Entropy 2023, 25, 221. https://doi.org/10.3390/e25020221
AMA Style
Wu Q, Wu Y, Wang Y. Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems. Entropy. 2023; 25(2):221. https://doi.org/10.3390/e25020221
Chicago/Turabian StyleWu, Qiuye, Yongheng Wu, and Yonghua Wang. 2023. "Integral Reinforcement-Learning-Based Optimal Containment Control for Partially Unknown Nonlinear Multiagent Systems" Entropy 25, no. 2: 221. https://doi.org/10.3390/e25020221
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.