Modeling Expected Shortfall Using Tail Entropy


1
Department of Statistics and Econometrics, Faculty of Cybernetics, Statistics and Economic Informatics, The Bucharest University of Economic Studies, Piata Romana, nr.6, Sector 1, 010371 Bucharest, Romania
2
Henley Business School, University of Reading, ICMA Centre, Whiteknights, Reading RG6 6BA, UK
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(12), 1204; https://doi.org/10.3390/e21121204
Submission received: 10 October 2019
/
Revised: 29 November 2019
/
Accepted: 5 December 2019
/
Published: 7 December 2019
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:Given the recent replacement of value-at-risk as the regulatory standard measure of risk with expected shortfall (ES) undertaken by the Basel Committee on Banking Supervision, it is imperative that ES gives correct estimates for the value of expected levels of losses in crisis situations. However, the measurement of ES is affected by a lack of observations in the tail of the distribution. While kernel-based smoothing techniques can be used to partially circumvent this problem, in this paper we propose a simple nonparametric tail measure of risk based on information entropy and compare its backtesting performance with that of other standard ES models.
JEL Classification Codes:
C14; C22; G101. Introduction
Past banking regulation has concerned and current banking regulation concerns the measurement of risk needed for capital calculation, which can be computed based on various models. Additionally, banks and financial institutions need to estimate their own exposure to different relevant risk factors in order to understand the overall riskiness of their activities and to help them prepare for undesirable situations. While value-at-risk (VaR) is the most popular risk measure and has been widely used in the past, it is not a subadditive measure (Artzner et al. [1,2]) and it is a misleading measure for portfolio optimizers [3]. Expected shortfall (ES), which has been popularized by Artzner et al. [1,2], having the advantage of being a coherent measure [4], has increased in importance since the Basel Committee on Banking Supervision ([5,6]) began to bases its regulatory capital calculations on ES estimates at the 2.5% significance level.
The standard way to estimate ES at level α is to simply compute the weighted average of the historical returns in the α-tail of the returns’ distribution, where the weights are the probabilities associated with the returns estimated from historical data (nonparametric method). However, this often gives an estimate that is inaccurate (see McNeil et al. [7]), data-sensitive (due to the low number of observations in the tail), and often characterized by an undesirably large variability.
A comprehensive presentation of the modern techniques used in risk management, especially with regard to estimating value-at-risk, expected shortfall, and spectral risk measures, can be found in Guégan et al. [8].
Several alternatives exist to computing ES, and a comprehensive review can be found in Nadaraj et al. [9]. Starting with semiparametric methods, a strand of this approach is based on extreme value theory, as in McNeil and Frey [10], who apply the theoretical framework of Embrechts et al. [11] and employ the generalized Pareto distribution combined with an ARMA-GARCH(1,1) process. In a later paper, Embrechts et al. [12] propose an ES estimation method based on the Hill estimator. Another semiparametric ES estimation method, using expectiles, has been proposed by Taylor [13] based on an asymmetric regression methodology of Aigner et al. [14] and the CaViaR model of Engle [15]. A smoothing technique, detailed in Schnabel and Eilers [16] and based on the algorithm of Schall [17], can be employed to improve the performance of the ES estimate. Daouia et al. [18] consider expectile-based ES estimation for extreme percentiles and study their asymptotic behavior.
There are many parametric methods used to estimate ES. Nadaraj et al. [9,19] enlist more than 100 approaches, including methods that make different distributional assumptions (Gaussian, Johnson family, Student’s t, stable distributions, mixture distributions, generalized Pareto and elliptical distributions, etc.)—see also Broda and Paolella [20]. Many methods employ different econometric formulations (like GARCH, as in a recent paper by Krause and Paolella [21], or ARMA, or even Bayesian approaches); these methods are mostly applied to historical data, but they can be applied within a Monte Carlo simulation setup as well. All these parametric approaches make an assumption of a particular model, so they bear significant model risk.
Chen [22] argues that semiparametric or parametric tail-risk estimation models struggle to specify an adequate model for the tail distribution (due to a lack of data), meaning nonparametric models are preferred. In terms of nonparametric ES estimation (which has the advantage of not employing a particular model and hence not being affected by misspecification risk), in addition to the classical historical ES estimation (which is considered the gold standard), the estimator of Yamai and Yoshiba [3], the estimator of Inui and Kijma [23], the ES estimator of Chen [22], and the methodology of Jadhav et al. [24], which has been shown to perform better than an historical estimator, have all been proposed. Kernel methods based on a kernel-smoothed estimator, as in Scaillet [25], can be used as well, but as shown by Chen [22], smoothing negatively affects the accuracy of ES estimates as it introduces a bias and does not reduce the variance of the estimates. To correct this, Alemany et al. [26] have shown that a double transformed kernel estimator can, in some cases, be a good alternative. Cai and Wang [27] suggest a nonparametric ES estimator using weighted double kernels and study its finite sample performance. The trimmed kernel method of Hill [28] is a bias-corrected estimator with a small error only. Another alternative is provided by the method of Richardson [29] and the algorithm of Fan et al. [30], which reduce the bias but not the error of the estimation (see Inui and Kijma [23]). A two-stage estimation method based on extreme value theory has been proposed by Martins-Filho et al. [31]. In this paper we propose a nonparametric estimator based on tail entropy (TE) and compare it with alternatives.
As entropy is a measure of uncertainty, which is in some ways similar to volatility, it is widely used in physics and the social sciences. In general, the higher the uncertainty of a system, the larger its entropy. The central theme of this paper is risk, which is directly linked to the tail of the distribution of returns (as opposed to its full distribution), so it makes sense to compute entropy based solely on returns that determine risk (that is, the tail of the distribution), which then gives tail entropy, as discussed in detail in this paper. Roughly speaking, tail entropy is defined as the weighted sum of log probabilities in the tail, where the weights are the conditional tail probabilities themselves.
Furthermore, it has to be noted that there is a strong similarity between definitions of ES and tail entropy. While ES computes the weighted average of tail returns, tail entropy calculates the weighted average of the log probabilities of the returns (again, in the tail of the distribution), but the two calculations use the same weights (probabilities). As such, tail entropy is an estimate of tail risk, which is free of the main problem with ES, namely, its direct dependence on the actual observations in the tail, hence the motivation of our paper. Our aim was to study how tail entropy can be used as an efficient measure of risk and how it compares with alternative estimates of ES.
It is natural to compare the theoretical and empirical properties of entropy with those of variance or volatility, with both being measures of uncertainty. While volatility is often considered a measure of risk in finance, here we consider it a measure of uncertainty. To differentiate between the two types of measures, i.e., measures of risk and measures of uncertainty, measures that are symmetric by nature are measures of uncertainty, and (asymmetric) tail measures are considered measures of risk. Thus, tail entropy is a measure of risk. Philippatos and Wilson in 1972 [32], and, later, Ebrahimi et al. [33] suggested that entropy compares favorably to volatility/variance as a measure of uncertainty. The same has been shown by Dionisio et al. [34], with the authors arguing that while variance measures the concentration around the mean, entropy measures the dispersion of the density irrespective of the location of the concentration (also see Ebrahimi et al. [35] and Allen et al. [36]). Moreover, the entropy of a distribution function is strongly related to its tails, as shown by Pele et al. [37], which becomes an important feature for distributions with heavy tails or with an infinite second-order moment for which an estimator of variance is obsolete. Liu et al. [38] compare an entropy-based measure with the classical coefficient of correlation and conclude that their measure has certain superior characteristics as a descriptor of the relationship between time series when compared with the correlation measure.
The study of the relationship between entropy and financial markets goes back more than a decade. Entropy has been used as a measure of stock market efficiency in Zunino et al. [39], while Risso [40] links it to stock market crashes, arguing that the probability of having a crash increases as entropy decreases. Oh et al. [41] use entropy as a measure of the relative efficiency of the foreign exchange (FX) markets. Based on generalized entropy theory, Wang et al. [42] analyze the interactions among agents of stock markets. Entropy has also been used as a tool for the predictability of stock market returns. Maasoumi and Racine [43] show that entropy can capture nonlinear dependence between financial returns. An effective early warning indicator for crisis situations of banking systems has been built by Billio et al. [44]; this indicator considers different definitions of entropy.
Entropy has also been used in option pricing (Stutzer [45] and Stutzer and Kitamura [46]). An application of entropy-based risk measures for decision-making can be found in Yang and Qiu [47]. Applications of Tsallis entropy in risk management can be found in Gradojevic and Gencay [48], Gencay and Gradojevic [49], and Gradojevic and Caric [50]. Bowden [51] introduces directional entropy and uses it to improve the performance of VaR in capturing regime changes. Portfolio optimization based on maximum entropy has been discussed by Geman et al. [52].
The main objectives of this paper were to introduce a measure for expected shortfalls based on tail entropy, to study this measure’s properties, and to compare it with alternative measures of ES. The main advantage of the measure we propose is that it is less sensitive to the actual values of observations in the tail of the distribution (compared to historical ES), making it a more stable measure of tail risk. We use several ES backtests to verify the accuracy of the proposed measure. The rest of the paper is organized as follows. Section 2 derives the theoretical results specifying the steps in estimating tail entropy as a measure of market risk and details our methodology, Section 3 presents an empirical application, and Section 4 concludes.
2. Methodology
For a series of asset prices denoted by St, in the following we compute and denote log-returns by X with realizations , i.e.,
2.1. Measures of Risk: VaR and ES
Given the returns series X, with F denoting its cumulative density (or distribution) function, for an the VaR at level α is the smallest number with cumulative density at least as big as α, i.e.,
In probabilistic terms we can write that
In addition, VaR is the negative of the quantile, i.e.,
The ES at significance level α is the average of the returns below the VaR at level α, as given by
For a continuous variable with density function f, the above definition for ES can be rewritten as
where is the left α-quantile.
2.2. Entropy
Entropy is a measure of uncertainty, which is in some ways similar to volatility. Various definitions exist (e.g., Shannon entropy, Tsallis entropy, and Kullback Cross entropy etc.) based on the informational content of a discrete or continuous random variable (see Zhou et al. [53] for a comprehensive review of entropy measures used in finance). Shannon information entropy is the most commonly used definition of entropy; it quantifies the expected value of the information contained in a discrete distribution.
Definition 1 (Shannon information entropy).
For X, a discrete random variable with probability distribution , with , , and , the Shannon information entropy is defined as
For a discrete distribution, the entropy reaches its maximum value of for the uniform distribution when all the pi values are the same (i.e., when there is a high level of uncertainty). Similarly, the entropy will reach its minimum value of 0 for a distribution with zero uncertainty (i.e., one of the probabilities pi is 1 and the rest are all 0).
For X, a continuous random variable with probability density function , the differential entropy is given by
However, unlike with Shannon entropy, differential entropy does not possess certain desirable properties like invariance to linear transformations and non-negativity (Lorentz [54] and Pele [55]). A measure of entropy similar to Shannon entropy can be defined via a transformation called quantization, as defined below [54].
Definition 2 (sampled function).
For , a real valued continuous function, , a fixed number, and , , where , the sampled function for is given by (point sampling)
For, which is essentially bounded, the sampled function is (mean sampling)
Definition 3 (quantization).
The quantization of a function creates a simple function that approximates the original one. Given q > 0, a quantum, the following function defines a quantization of.
Definition 4 (entropy of a function at quantization level q).
Let be a measurable and essentially bounded real valued function defined on [a,b] and let q > 0. Let and . Then, the entropy of at quantization level q is given by
where μ denotes the Lebesgue measure.
Lorentz’s theorem given below calculates the entropy of a continuous function on a compact interval. Eventually, it helps define the entropy of a probability distribution function for a continuous random variable on a compact interval, regardless of the sampling and quantization.
Theorem (Lorentz [54]).
Let f be continuous for point sampling, measurable, and essentially bounded for mean sampling. The sampling spacing is 1/n. Let be the corresponding sampling; fix q > 0 and let be the quantization of the samples with resolution q as in Definition 3. The number of occurrences of in is and the relative probability of the occurrence of the value i is denoted by . Then, we have
In the following we assume that we are dealing with a continuous random variable X whose support is the set A with the distribution function . If the distribution function is absolutely continuous, then there exists a non-negative, Lebesgue integrable function f which is a probability density function (PDF), i.e.,
- (i)
- ;
- (ii)
- ;
- (iii)
- .
Assuming that the probability density function f is essentially bounded, we can define the entropy of the probability density function Hq(f) at the quantization level q > 0.
Definition 5 (entropy of a probability density function at quantization level q).
For a probability density function which is essentially bounded, let disjoint giving and not necessarily disjoint, with . Then, the entropy of at quantization level q is , where is the Lebesgue measure.
Of note is that in general, for a probability density function defined on set A not necessarily of finite measure, it is possible to consider this function’s restriction on a compact interval, i.e.,
Then, satisfies the conditions of Lorentz’s theorem, meaning the entropy can be defined.
The above framework can be applied to estimation of the entropy of a probability density function of a continuous random variable X.
Next, we present the estimation algorithm of the entropy of a probability density function. Let be a sample of an i.i.d. variable with probability density function f. The Algorithm 1 (see below) estimates the entropy of a probability density function (see Pele et al. [37]).
| Algorithm 1. Estimation of the entropy of a probability density function. |
|
A similar approach can be found in Miśkiewicz [56], where two possible algorithms for estimating entropy of a continuous probability density function are discussed.
The entropy of the probability density function reaches its maximum value for the uniform distribution. A dimensionless measure of uncertainty, normalized entropy, can be defined as the ratio between the entropy of the probability density function and the entropy of the uniform distribution, i.e.,
In the following we refer to the entropy of the probability density function as the normalized entropy of the probability density function, i.e., .
2.3. Tail Entropy
Similarly to the definition of entropy, we can define tail entropy as being when entropy is computed using observations in the tail only. Shannon tail entropy is defined below.
Definition 6 (Shannon tail entropy).
For X, a discrete random variable with probability distribution , with , , and , and α-level value-at-risk for 0 < α < 1, the Shannon tail information entropy at level α is defined by
The tail-adjusted probabilities are denoted by , and this normalization is required to make sure that the probabilities in the tail add up to 1. For a discrete distribution, the TE will reach its maximum value for a distribution which has uniform distribution in the α-tail, with all tail observations having the same probability. Similarly, for a given α, the tail entropy will reach its minimum for a distribution with zero uncertainty in the tail (an observation in the tail has a probability of pi = α and the rest of the tail observations have a probability of 0).
For X, the discrete random variable given above, we can compute the expected shortfall based on the variable’s probability distribution at level α; this is denoted by ESPD and given by
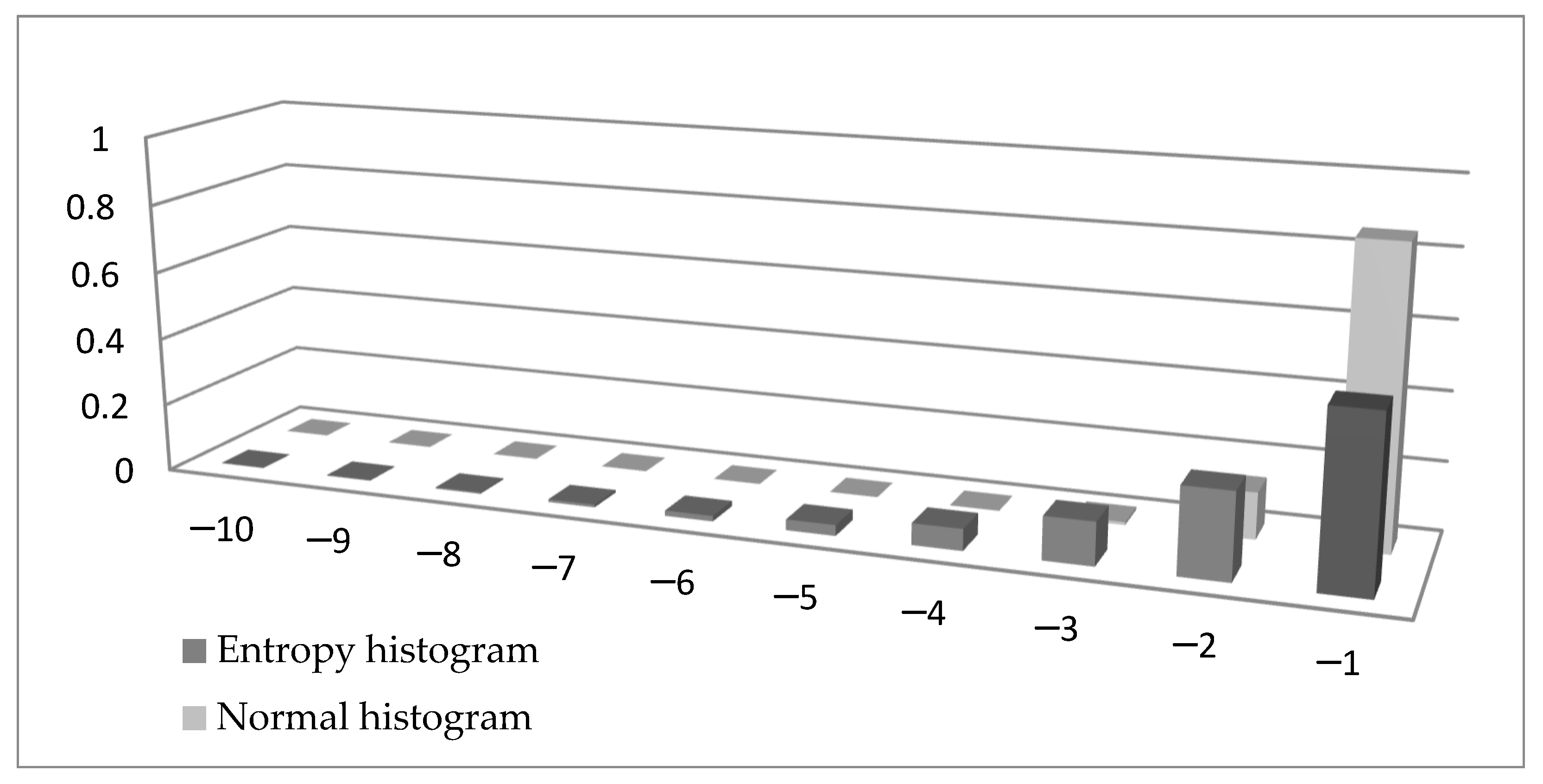
The similarity between Formulas (15) and (16) is obvious. There is a minus sign in Formula (15) to make sure the tail entropy is a positive measure. More importantly, while the entropy is a weighted sum of log probabilities, the ES is the weighted sum of observations in the tail. To visualize the difference between the two formulae, in Figure 1 we compare the left tail of a histogram of a variable distributed N (0,1) (normalized with the tail probability and using bins of width 1) with the left tail of a histogram built using the entropy measure. In Formula (15) we can denote by xi, giving , and this probability is presented in Figure 1 in the entropy histogram. It can be seen that the probabilities calculated using entropy are higher (except for when using the value −1) than the probabilities in the normal histogram.
For a continuous random variable with density function, the differential tail entropy is given by
Similarly to differential entropy, tail differential entropy does not possess the properties of invariance to linear transformations and non-negativity. Using quantization, a measure of entropy similar to Shannon tail entropy can be defined as follows.
Definition 7 (tail entropy of a probability density function at quantization level q).
For the probability density function , let disjoint giving and not necessarily disjoint, with . Then, the tail entropy of f at level α with quantum q (using the notation * for the Lebesgue measure divided by α and [.] for the integer part of a number) is
Of note is that as in Definition 5, for a probability density function defined on set A which is not necessarily of finite measure, we can consider its restriction on a compact interval, i.e.,
The tail entropy of the returns’ distribution can be interpreted as the expected shortfall of the returns, if in the tail of the distribution the probability of losses can be expressed as an exponential function of the size of the losses. The tail entropy is a measure of uncertainty in the tail, with low values of tail entropy being associated with a lower risk in the tail.
This framework can be used to estimate the tail entropy of a distribution function of a continuous random variable X, defined on the support set of X, with values on [0, 1]. The distribution function can be estimated using the histogram estimator of a probability density or kernel density estimation methods as described in the previous section. We proceed by presenting an estimation algorithm of the tail entropy of a distribution function.
Let be a sample of an i.i.d. variable with probability density function f. The Algorithm 2 (see below) estimates the tail entropy of a distribution function.
| Algorithm 2. Estimation of the tail entropy of a distribution function. |
|
The tail entropy of a distribution function reaches its maximum value for a distribution which has uniform distribution in the α-tail.
Property (maximum value of the tail entropy of a probability density function):
The α-tail entropy of a distribution function reaches its maximum for a distribution with F(x) = x for x ≤ α, and this maximum value is .
Proof.
This is similar to the proof of the maximum Shannon entropy. Indeed, when all probabilities are equal for the observations in the α-tail (= 1/m), the tail probability can be written as:
□
As such, a dimensionless measure of uncertainty, the normalized tail entropy, can be defined as the ratio between the entropy of the probability density function and its maximum value, i.e.,
We refer below to the tail entropy of the probability density function as the normalized tail entropy of the probability density function: .
In practical applications, the estimated tail entropy may be severely biased for small samples (Liu et al. [57]). In order to correct for small sample bias we propose a bootstrapping method, following DeDeo et al. [58]. Thus, we generate B independent samples of volume k from a multinomial distribution with probabilities , and for each sample we estimate the normalized tail entropy . The unbiased estimator of the normalized tail entropy has the form
The estimated entropy can be influenced by the quantum value q > 0; as there is no canonical quantum/level of quantization, apparently all results depend on an arbitrarily chosen quantum/quantization level. However, the Lorentz theorem ([54]) shows that the entropy estimator is consistent regardless of the choice of q; in practical applications, such as stock market data, we have used q = 0.2 (see Section 3). For q = 0.2, the number of bins used to compute the tail entropy is 1/q = 5; a smaller value of the quantum q will increase the number of bins and also the likelihood of having zero probability bins. For example, when the window used for estimation has 1000 observations (roughly 4 years of daily observations) and α = 5%, there are 50 observations in the left tail of the distribution; by decreasing the quantum level and increasing the number of bins, there is a high chance of having bins with zero probability where the term is undefined.
Unlike expected shortfall, which is not well-defined when the expectation fails to exist (for instance for the Pareto family when the parameter a ≤ 1), tail entropy does exist for the Pareto distribution for any tail parameter value a. In general, under the hypothesis of the Lorentz theorem ([54]), tail entropy exists for any probability density function with bounded support. Even if the probability density function is not bounded, we can consider its restriction on a compact interval in order to fulfil the conditions of the Lorentz theorem. Indeed, tail entropy is sensitive to the choice of the level of the quantum, but in the next section we show how it can be transformed (via normalizing it and using a linear adjustment) into an expected-shortfall-type measure which will be less sensitive to the choice of quantum.
2.3.1. Tail Entropy Expected Shortfall
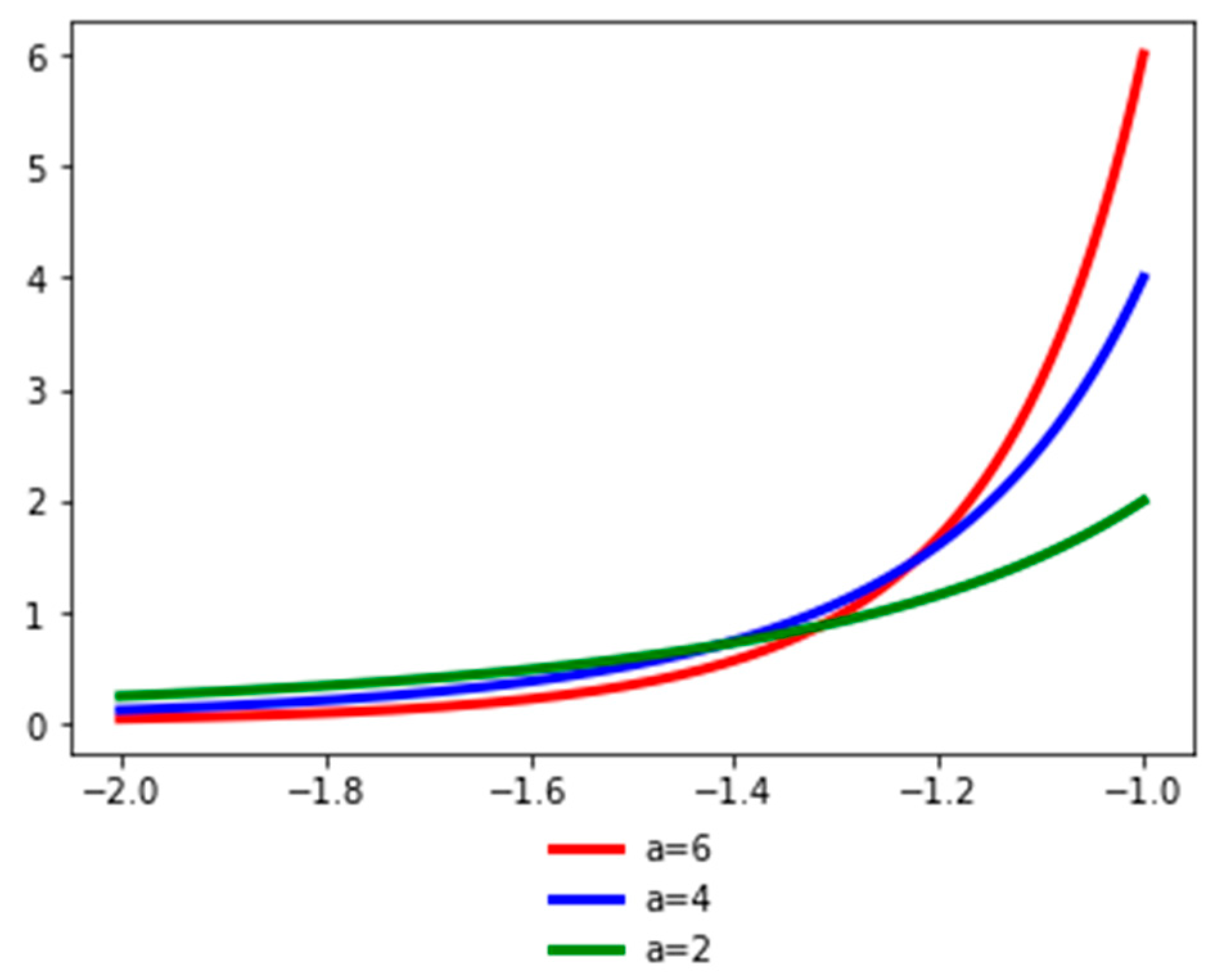
Next, we turn our attention to the link between tail entropy and measures of risk and uncertainty, seeking to propose a tail-entropy-enhanced ES estimator. First, we perform a Monte Carlo experiment, estimating and comparing tail entropy and historical expected shortfall for several simulated Pareto-like distributions; we report our results for different tail probabilities. Here we use the random variable Y = −X~Pareto(a), which has the following characteristics:
- (i)
- Cumulative distribution function: .
- (ii)
- Probability density function: .
- (iii)
- .
Figure 2 presents the probability density function of the random variable Y for different values of the a parameter. The a parameter (the tail index) is a measure of tail probability: higher values of a correspond to lower probability in the tail.
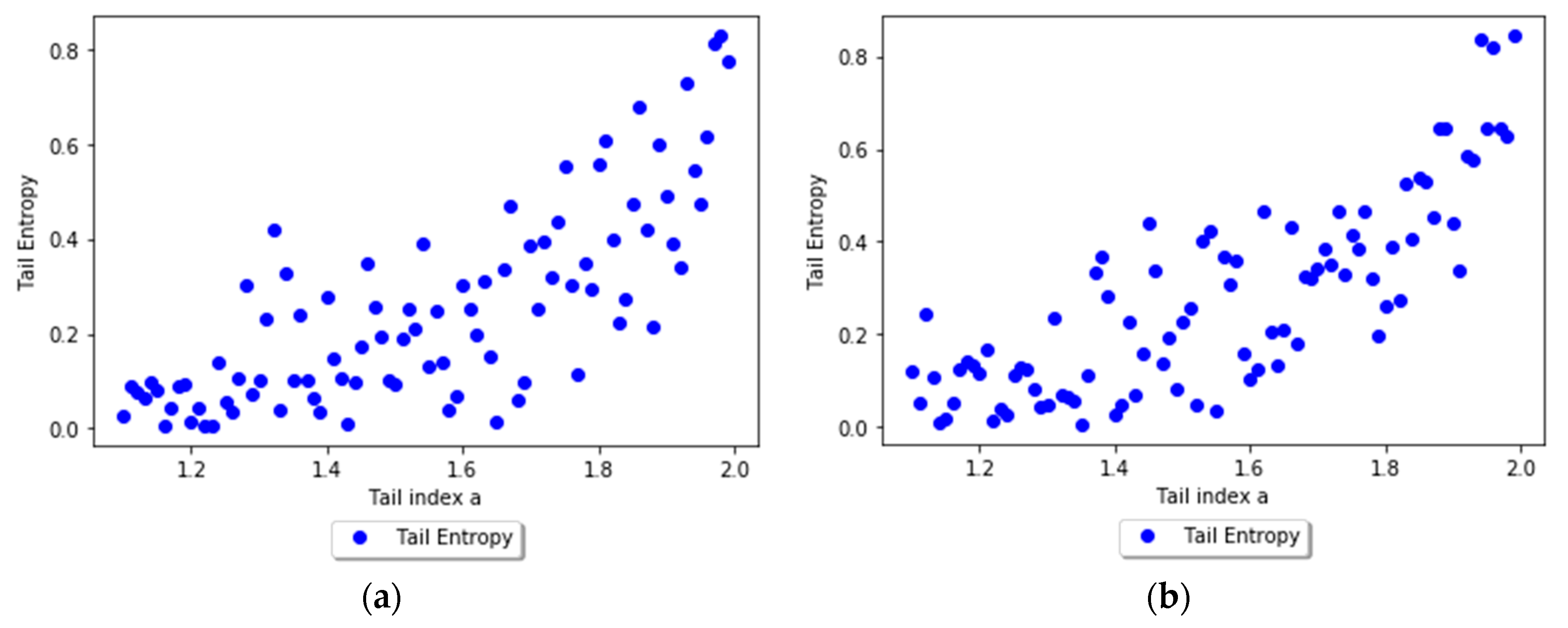
In order to assess the relationship between the tail entropy and the historical expected shortfall (ESH), we simulate random variables , with . Figure 3 presents the relationship between TE and tail index a using scatterplots for different levels, i.e., 1% and 2.5%, of α. As the a parameter of the simulated distribution decreases, the tail entropy of the distribution decreases, too; as expected, high tail entropy values are associated with heavy-tailed distributions. Figure 4 presents the relationship between TE and historical ES, as functions of the a parameter of the simulated distribution, for 1% and 2.5% levels of α.
Additionally, we regress the historical ES estimates of the simulated returns above on tail entropy; the results are reported in Table 1. We estimate the historical ES using the formula
It can be seen that there is a strong linear negative relationship between the tail entropy and ESH, with higher values of tail entropy corresponding to lower values of expected shortfall. The validity of this regression approach depends on the tail behavior of the underlying distribution; without this explicit assumption, one would need regularly varying tails and a particular tail behavior in order to make the regression approach sound. Indeed, for some distributions the relationship between historical ES and tail entropy might not be exactly linear, but we show below how assuming a linear relationship helps us define a new measure of expected shortfall.
A multiple regression with several tail entropies of varying tail levels was also estimated in order to explicitly assess the relationship between historical ES and TE for a Pareto-like simulated distribution, as in the above examples.
Thus, we estimated the following regression model, where the historical ES (1% and 2.5%) is regressed against the tail entropy for significance levels 1%, 2.5%, and 5%, i.e.,
The results of the regression as calculated using Formula (23) are reported in Table 2. By including varying tail levels for entropy, the performance of the model is significantly improved, with increasing for α = 1% from 51% (see Table 1, left panel) to 55%, and for α = 2.5% from 48% (see Table 1, right panel) to 60%.
A second simulation using α-stable distributions can help understand this behavior. We chose α-stable distributions because they have several interesting properties: they allow for heavy tails and any linear combination of independent stable variables follows a stable distribution for up to a scale and location parameter (Nolan [59]); additionally, the Gaussian distribution is a particular case of a stable distribution.
We have that a random variable X which follows an α-stable distribution if its characteristic function is
In the above expression is the tail index (we obtain for a normal distribution and lower values correspond to heavier tails), is the skewness parameter, is the scale parameter, and is the location parameter. We simulate 1000 observations from an α-stable distribution for and study the relationship between tail index and tail entropy.
The tail entropy reaches its maximum value for a distribution that has uniform distribution in the tail, and as the a parameter decreases, the tail entropy of the stable distribution decreases, too. As expected, low tail entropy values are associated with heavier-tailed distributions. Figure 5 presents the relationship between TE and tail index, while Table 3 present the regression results between TE and tail index.
Based on the results above (and taking into consideration that the tail entropy is between 0 and 1), we perform a linear adjustment on the tail entropy to obtain the tail entropy expected shortfall, i.e.,
where b0 is the mid-point of the first bin B0 and bm is the mid-point of the last bin in the α-tail of the distribution Bm.
The justification for Formula (25) lies in the following points.
- If the entropy reaches its maximum (), which corresponds to the highest uncertainty level, then we have , i.e., the tail entropy expected shortfall is the average of losses below the value-at-risk.
- If the entropy reaches its minimum (), which corresponds to the lowest uncertainty level, then we have , i.e., the tail entropy expected shortfall is the minimum value of the distribution.
2.3.2. Tail Entropy Expected Shortfall as a Spectral Risk Measure
According to Guégan et al. [8], a spectral risk measure can be defined as the function , where is a functional space and
In Formula (26) is a positive or null, non-increasing, right-continuous, integrable function defined on [0, 1] such as .
Following Formula (25), the tail entropy expected shortfall can be written as a linear function of the tail entropy (even though for some distributions this is only an approximation), i.e.,
where and .
Thus, according to Formula (27), the tail entropy expected shortfall is a spectral risk measure and satisfies the conditions of coherence (see Artzner [1,2]), any spectral risk measure being law-invariant and comonotonic additive (see [8]).
The tail entropy expected shortfall can have interpretability in terms of monetary units, being a linear combination of the expected shortfall and the adimensional normalized entropy which takes values between [0,1], as can be seen from Formula (27).
2.3.3. Backtesting ES
In order to forecast daily ES, non-parametric and parametric models are used based on a rolling window approach. Thus, we compare the ES forecasting ability of the following six models.
- Historical ES forecasts: , where is the α-quantile of the daily log-returns distribution;
- Tail entropy ES forecasts: ;
- Normal GARCH(1,1) ES forecasts: , where , being the Gaussian quantile;
- Student’s t GARCH(1,1) ES forecasts: , where , being the Student’s t quantile with df being the estimated degrees of freedom;
- Gaussian ES forecasts: , where is the α-quantile of the estimated Gaussian distribution of log-returns;
- Student’s t ES forecasts: , where is the α-quantile of the estimated Student’s t distribution of log-returns.
In the above formulae, every risk measure is estimated using a rolling window of length w, with , , and T the number of daily log-returns. To see the ES forecasting performance of the above models, we run several backtests to compare the ES estimates. These are the unconditional exception frequency (UC) test and the conditional independence (CC) test of Du and Escanciano [60], and the exception frequency and magnitude test of Acerbi and Szekely [61]. These are described in Appendix A and Appendix B.
3. Empirical Analysis
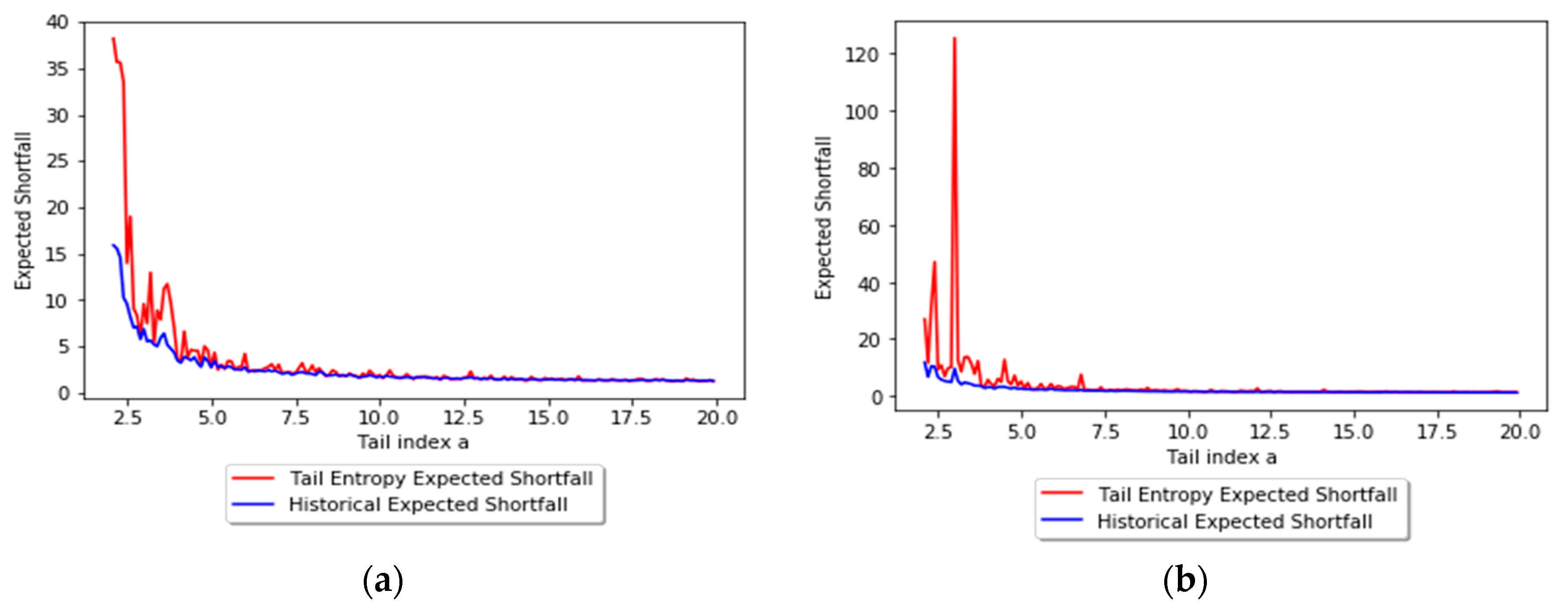
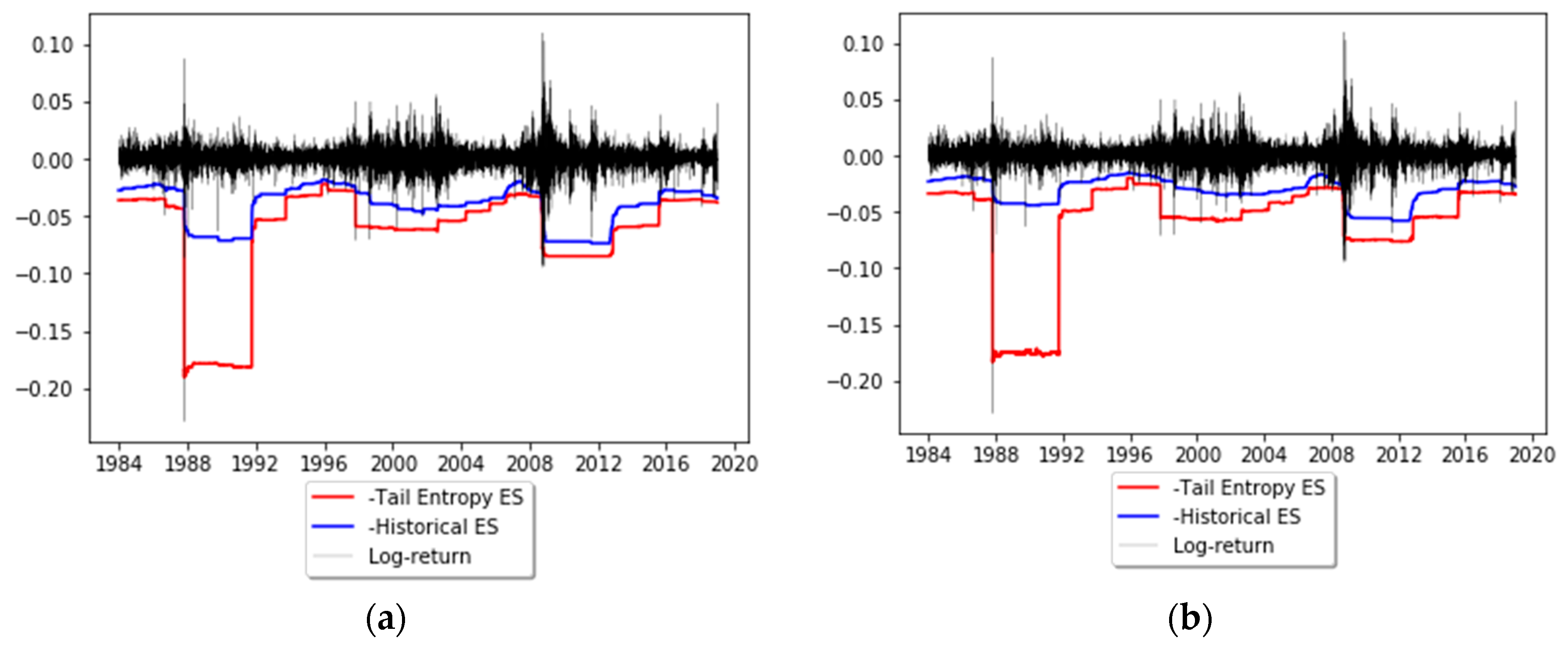
In order to illustrate the application of tail entropy in financial risk management, we consider S&P500 daily log-returns (sourced from Bloomberg). The time period considered is January 1 1980 to December 12 2018 (9835 observations). The estimators of expected shortfall described in Section 2 are computed on a rolling basis using a length of w = 1000 days for the estimation windows; these forecasts are later subjected to ES backtests. Tail entropy is estimated using a quantum q = 0.2 (see the theorem in Section 2). Figure 6 depicts the dynamics of tail-entropy-based ES versus historical ES estimated at 1% and 2.5% significance levels. It can be noted that the tail-entropy-based ES gives higher estimates of risk compared to the historical ES for both significance levels, as this model assigns a higher probability to large losses when compared to the historical ES model. However, it is not straightforward to comment on the correctness of these risk estimates as the level of true risk is not observable, meaning no direct comparisons can be made for true risk. Statistical backtests, performed in the next section, can be used to verify the correctness of VaR and ES forecasts.
Backtesting ES
Backtesting of the ES forecasts based on the models given in Section 2.3 was performed using a window length of 1000 trading days and for α = 1% and 2.5%. Table 4 presents the percentage of times each model passed the given backtest for each significance level α. Based on these statistics, it can be concluded that for the unconditional ES test, the t-GARCH(1,1) ES forecasts perform best for both levels of α. Looking at the rejection rates for the conditional coverage ES backtest, it can be seen that at the 2.5% level the t-GARCH(1,1) model performs best but at the 1% level the rejection rate of the tail entropy ES is comparable with the same rate within the t-GARCH(1,1) model. Also, according to the test, the rejection rates are the lowest for tail entropy ES for α = 2.5%, and stand at around 10%. Based on these results the t-GARCH(1,1) and tail entropy ES show similar performances and overperform the other models considered. Table 5 presents the test statistics of each backtest over the entire testing period and for α levels of 1% and 2.5%. The tail entropy ES, like the other ES models considered, fails both the unconditional and conditional backtests at the 5% level, but it passes the test at the 5% level, which the t-GARCH(1,1) ES forecasts fail to pass.
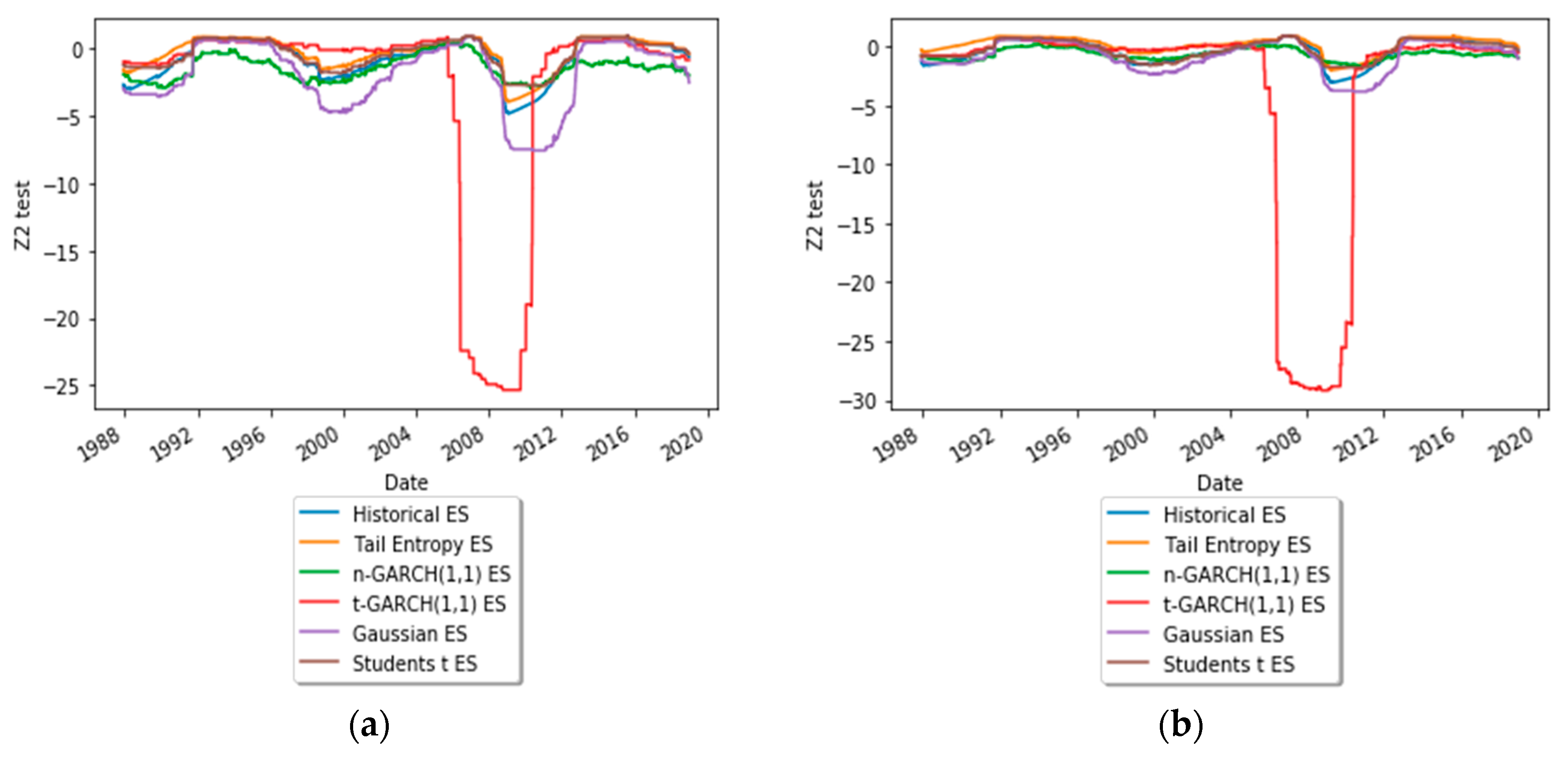
To get an insight into the dynamic behavior of the test statistics of the backtest, Figure 7 depicts time-varying test statistics (using a rolling window of length 1000) for ES estimated at significance levels α = 1% and 2.5%. As can be seen, the expected shortfall estimated with the Student’s t-GARCH(1,1) model underperformed, for both α levels, during the financial crisis of 2008.
The illustration of tail-Entropy-based ES in Figure 6 indicates that at similar backtesting rejection rates tail-entropy-based ES seems to lead to overly high risk quantifications; in addition, the time to recover from a bad shock (like Black Monday on 19 October 1987) is much longer than for historical expected shortfall (which itself usually leads to long recovery times). These two observations seem to indicate that the proposed entropy-based version of expected shortfall tends to react fiercely in the presence of outlying observations. This may be a sign that tail-entropy-based ES is a more conservative risk measure than traditional ones due to the way it is defined, as it takes into account the tail distribution, which has a higher inertia and a longer recovery time from a negative shock.
4. Conclusions
In this paper we propose a nonparametric estimator of ES based on TE, as well as an extension of this model based on kernel smoothing, and compare it with the classical estimates of ES, i.e., historical ES, Gaussian ES, Student’s t ES, Gaussian GARCH(1,1) ES and Student’s t-GARCH(1,1) ES. The main advantage of the measure we propose is that it has a low dependency on the actual values of observations in the tail of the distribution, making it a more stable measure of tail risk.
We illustrate an application of tail entropy in financial risk management based on S&P 500 daily log-returns between 1980 and 2018 (9835 observations). Comparing backtest rejection rates based on rolling windows, it can be concluded that the performance of tail entropy ES is comparable with the performance of the t-GARCH(1,1) model. However, when we backtest over the entire sample period, tail-entropy-based ES is the only model which passed the backtest.
Further research is needed to fully acknowledge the efficiency of the tail entropy ES estimator. This new measure may be beneficial for risk measurement as it is fully non-parametric and has a reduced sensitivity to actual observations in the tail. One possible extension of this approach will be to assess the predictive performance of tail entropy ES in a non-standard environment, for example by assuming a fat-tailed distribution of the returns as the generalized error distribution (see Cerqueti et al., 2019 [62]). In addition, our approach can be applied to other fields such as operational risk, where distributions are usually fat-tailed and highly skewed.
Our research can be easily reproduced using the Python codes uploaded to www.github.com.
Author Contributions
All authors are contributed equally to this paper.
Funding
This research received no external funding.
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions to improve the quality of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Unconditional and Conditional Backtests for ES (Du and Escanciano)
Let xt, t = 1 to T and denote the returns series, which are assumed to follow a model with estimated cdf and estimated parameters . Denoting by Ωt the information available at time t, we define the cumulative probability under the estimated distribution and the cumulative violations, i.e.,
The null hypothesis for the unconditional backtest is
If the estimation period is much larger than the evaluation period, the unconditional test statistic and its distribution will be
For the conditional backtest the null hypothesis is:
The conditional test statistic (for first order dependence) and its distribution is
Appendix B. Exception Frequency and Magnitude Test for ES (Acerbi and Szekely)
Let xt, t = 1 to T and denote the returns series with unknown tail distribution cdf . When forecasting the risk of the returns, namely and , we obtain a predictive tail distribution .
The hypotheses to be tested are
for all t and > for some t
, for all t.
The test statistic is computed as
Under the null hypothesis we have and . If the test statistic is below −0.7 then the null hypothesis is rejected and the model fails the ES backtest.
References
- Artzner, P.F.; Delbaen, F.; Eber, J.-M.; Heath, D. Thinking coherently. Risk 1997, 10, 68–71. [Google Scholar]
- Artzner, P.; Delbaen, F.; Eber, J.-M.; Heath, D. Coherent measures of risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Yamai, Y.; Yoshiba, T. Comparative analyses of expected shortfall and value-at-risk: Their estimation error, decomposition, and optimization. Monet. Econ. Stud. 2002, 20, 87–122. [Google Scholar]
- Föllmer, H.; Schied, A. Convex measures of risk and trading constraints. Financ. Stoch. 2002, 6, 429–447. [Google Scholar] [CrossRef]
- Basel Committee on Banking Supervision. Fundamental Review of the Trading Book; ICMA: Basel, Switzerland, 2012. [Google Scholar]
- Basel Committee on Banking Supervision. Fundamental Review of the Trading Book: A Revised Market Risk Framework; Bank for International Settlements: Basel, Switzerland, 2013. [Google Scholar]
- McNeil, A.; Frey, R.; Embrechts, P. Quantitative Risk Management; Princeton University Press: Princeton, NJ, USA, 2005. [Google Scholar]
- Guégan, D.; Hassani, B.K. Risk Measurement. From Quantitative Measures to Management Decisions; Springer: Cham, Germany, 2019. [Google Scholar]
- Nadaraj, S.; Zhang, B.; Chang, S. Estimation methods for Expected Shortfall. Quant. Financ. 2014, 14, 271–291. [Google Scholar] [CrossRef]
- McNeil, A.; Frey, R. Estimation of tail-related risk measures for heteroscedastic financial time series: An extreme value approach. J. Empir. Financ. 2000, 7, 271–300. [Google Scholar] [CrossRef]
- Embrechts, P.; Klueppelberg, C.; Mikosch, T. Modeling Extremal Events for Insurance and Finance; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Embrechts, P.; Kaufmann, R.; Patie, P. Strategic long-term financial risks: Single risk factors. Comput. Optim. Appl. 2005, 32, 61–90. [Google Scholar] [CrossRef]
- Taylor, J. Estimating value at risk and expected shortfall using expectiles. J. Financ. Econom. 2008, 6, 231–252. [Google Scholar] [CrossRef]
- Aigner, D.T.A.; Poirier, D. On the estimation of production frontiers: Maximum likelihood estimation of the parameters of a discontinuous density function. J. Econom. Rev. 1976, 17, 377–396. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Schnabel, S.K.; Eilers, P.H. Optimal expectile smoothing. Comput. Stat. Data Anal. 2009, 53, 4168–4177. [Google Scholar] [CrossRef]
- Schall, R. Estimation in generalized linear models with random effects. Biometrika 1991, 78, 719–727. [Google Scholar] [CrossRef]
- Daouia, A.; Girard, S.; Stupfler, G. Estimation of Tail Risk based on Extreme Expectiles. J. R. Stat. Soc. Ser. B 2018, 80, 263–292. [Google Scholar] [CrossRef] [Green Version]
- Nadaraj, S.; Chan, S.; Afuecheta, E. Tabulations for Value at Risk and Expected Shortfall. Commun. Stat.–Theory Methods 2017, 46, 5956–5984. [Google Scholar] [CrossRef]
- Broda, S.A.; Paolella, M.S. Expected Shortfall for Distributions in Finance; Statistical Tools for Finance and Insurance; Cížek, P., Härdle, W., Rafał, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 57–99. [Google Scholar]
- Krause, J.; Paolella, M. A fast, accurate method for value-at-risk and expected shortfall. Econometrics 2014, 2, 98–122. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.X. Nonparametric estimation of Expected Shortfall. J. Financ. Econom. 2008, 6, 87–107. [Google Scholar] [CrossRef] [Green Version]
- Inui, K.; Kijima, M. On the significance of expected shortfall as a coherent risk measure. J. Bank. Financ. 2005, 29, 853–864. [Google Scholar] [CrossRef]
- Jadhav, D.; Ramanathan, T.V.; Naik-Nimbalkar, U.V. Modified estimators of the expected shortfall. J. Emerg. Mark. Financ. 2009, 8, 87–107. [Google Scholar] [CrossRef]
- Scaillet, O. Nonparametric estimation and sensitivity analysis of expected shortfall. Math. Financ. 2004, 14, 115–129. [Google Scholar] [CrossRef]
- Alemany, R.; Bolancé, C.; Guillén, M. A nonparametric approach to calculating value-at-risk. Insur. Math. Econ. 2013, 52, 255–262. [Google Scholar] [CrossRef]
- Cai, Z.; Wang, X. Nonparametric estimation of conditional VaR and expected shortfall. J. Econom. 2008, 147, 120–130. [Google Scholar] [CrossRef]
- Hill, J.B. Expected shortfall estimation and Gaussian inference for infinite variance time series. J. Financ. Econom. 2015, 13, 1–44. [Google Scholar] [CrossRef]
- Richardson, L.F. The approximate arithmetical solution by finite differences of physical problems including differential equations, with an application to the stresses in a masonry dam. Philos. Trans. R. Soc. A 1911, 210, 307–357. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Li, G.; Zhang, M. Expected shortfall and its application in credit risk measurement. In Proceedings of the 2010 International Conference on Business Intelligence and Financial, Engineering, Hong Kong, China, 13–15 August 2010; pp. 359–363. [Google Scholar]
- Martins-Filho, C.; Yao, F.; Torero, M. Nonparametric estimation of conditional Value-at-Risk and Expected Shortfall based on Extreme Value Theory. Econom. Theory 2018, 34, 23–67. [Google Scholar] [CrossRef] [Green Version]
- Philippatos, G.C.; Wilson, C. Entropy, Market Risk and the Selection of Efficient Portfolios. Appl. Econ. 1972, 4, 209–220. [Google Scholar] [CrossRef]
- Ebrahimi, N.; Maasoumi, E.; Soofi, E.S. Ordering Univariate Distributions by Entropy and Variance. J. Econom. 1999, 90, 317–336. [Google Scholar] [CrossRef]
- Dionisio, A.; Menezes, R.; Mendes, D.A. An econophysics approach to analyse uncertainty in financial markets: An application to the Portuguese stock market. Eur. Phys. J. B 2006, 50, 161–164. [Google Scholar] [CrossRef] [Green Version]
- Ebrahimi, N.; Maasoumi, E.; Soofi, E.S. Measuring Informativeness of Data by Entropy and Variance. In Advances in Econometrics: Income Distribution and Methodolgy of Science, Essays in Honor of Camilo Dagumi; Slottje, D., Ed.; Springer: Berlin/Heidelberg, Germany, 1999; Chapter 5. [Google Scholar]
- Allen, D.E.; McAleer, M.; Powell, R.; Singh, A.K. A non-parametric and entropy based analysis of the relationship between the VIX and S&P 500. J. Risk Financ. Manag. 2013, 6, 6–30. [Google Scholar]
- Pele, D.T.; Lazar, E.; Dufour, A. Information entropy and measures of market risk. Entropy 2017, 19, 226. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.Z.; Qian, X.Y.; Lu, H.Y. Cross-sample entropy of foreign exchange time series. Phys. A Stat. Mech. Appl. 2010, 389, 4785–4792. [Google Scholar] [CrossRef]
- Zunino, L.; Zanin, M.; Tabak, B.M.; Pérez, D.G.; Rosso, O.A. Forbidden patterns, permutation entropy and stock market inefficiency. Phys. A Stat. Mech. Appl. 2009, 388, 2854–2864. [Google Scholar] [CrossRef]
- Risso, A. The Informational Efficiency and the Financial Crashes. Res. Int. Bus. Financ. 2008, 22, 396–408. [Google Scholar] [CrossRef]
- Oh, G.; Kim, S.; Eom, C. Market efficiency in foreign exchange markets. Phys. A Stat. Mech. Appl. 2007, 382, 209–212. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Feng, Q.; Chai, L. Structural Evolutions of Stock Markets Controlled by Generalized Entropy Principles of Complex Systems. Int. J. Mod. Phys. B 2010, 24, 5949–5971. [Google Scholar] [CrossRef]
- Maasoumi, E.; Racine, J. Entropy and predictability of stock market returns. J. Econom. 2002, 107, 291–312. [Google Scholar] [CrossRef]
- Billio, M.; Casarin, R.; Costola, M.; Pasqualini, A. An entropy-based early warning indicator for systemic risk. J. Int. Financ. Mark. Inst. Money 2016, 45, 42–59. [Google Scholar] [CrossRef] [Green Version]
- Stutzer, M.J. Simple entropic derivation of a generalized Black-Scholes option pricing model. Entropy 2000, 2, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Stutzer, M.J.; Kitamura, Y. Connections between entropic and linear projections in asset pricing estimation. J. Econom. 2002, 107, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Qiu, W. A measure of risk and a decision-making model based on expected utility and entropy. Eur. J. Oper. Res. 2005, 164, 792–799. [Google Scholar] [CrossRef]
- Gradojevic, N.; Gencay, R. Overnight interest rates and aggregate market expectations. Econ. Lett. 2008, 100, 27–30. [Google Scholar] [CrossRef] [Green Version]
- Gencay, R.; Gradojevic, N. Crash of ′87—Was it expected? Aggregate market fears and long-range dependence. J. Empir. Financ. 2010, 17, 270–282. [Google Scholar] [CrossRef] [Green Version]
- Gradojevic, N.; Caric, M. Predicting systemic risk with entropic indicators. J. Forecast. 2017, 36, 16–25. [Google Scholar] [CrossRef] [Green Version]
- Bowden, R.J. Directional entropy and tail uncertainty, with applications to financial hazard. Quant. Financ. 2011, 11, 437–446. [Google Scholar] [CrossRef]
- Geman, D.; Geman, H.; Taleb, N.N. Tail risk constraints and maximum entropy. Entropy 2005, 17, 3724–3737. [Google Scholar] [CrossRef] [Green Version]
- Zhou, R.; Cai, R.; Tong, G. Applications of entropy in finance: A review. Entropy 2013, 15, 4909–4931. [Google Scholar] [CrossRef]
- Lorentz, R. On the entropy of a function. J. Approx. Theory 2009, 158, 145–150. [Google Scholar] [CrossRef]
- Pele, D.T. Information Entropy and Occurrence of Extreme Negative Returns. J. Appl. Quant. Methods 2011, 6, 23–32. [Google Scholar]
- Miśkiewicz, J. Improving quality of sample entropy estimation for continuous distribution probability functions. Phys. A Stat. Mech. Appl. 2016, 450, 473–485. [Google Scholar] [CrossRef]
- Liu, D.; Wang, D.; Wang, Y.; Wu, J.; Singh, V.P.; Zeng, X. Entropy of hydrological systems under small samples: Uncertainty and variability. J. Hydrol. 2016, 532, 163–176. [Google Scholar] [CrossRef]
- DeDeo, S.; Hawkins, R.X.D.; Klingenstein, S.; Hitchcock, T. Bootstrap Methods for the Empirical Study of Decision-Making and Information Flows in Social Systems. Entropy 2013, 15, 2246–2276. [Google Scholar] [CrossRef] [Green Version]
- Nolan, J.P. Stable Distributions—Models for Heavy Tailed Data; Birkhauser: Boston, MA, USA, 2011. [Google Scholar]
- Du, Z.; Escanciano, J.C. Backtesting expected shortfall: Accounting for tail risk. Manag. Sci. 2017, 63, 940–958. [Google Scholar] [CrossRef] [Green Version]
- Acerbi, C.; Szekely, B. Backtesting expecting shortfall. Risk 2014, 27, 76–81. [Google Scholar]
- Cerqueti, R.; Giacalone, M.; Panarello, D. A Generalized Error Distribution Copula-based method for portfolios risk assessment. Phys. A Stat. Mech. Appl. 2019, 524, 687–695. [Google Scholar] [CrossRef]
Figure 1.
Comparison between a normal histogram and a histogram built using entropy.

Figure 2.
Probability density function for Y. See the Github page SFM_Sim_Pareto_like.
Figure 2.
Probability density function for Y. See the Github page SFM_Sim_Pareto_like.

Figure 3.
Tail Entropy and tail index a of the simulated distributions: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_ES_Pareto.
Figure 3.
Tail Entropy and tail index a of the simulated distributions: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_ES_Pareto.

Figure 4.
Tail entropy and historical expected shortfall of the simulated distributions: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_ES_Pareto.
Figure 4.
Tail entropy and historical expected shortfall of the simulated distributions: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_ES_Pareto.

Figure 5.
Tail Entropy and tail index of the simulated distributions: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_ES_Stable.
Figure 5.
Tail Entropy and tail index of the simulated distributions: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_ES_Stable.

Figure 6.
Dynamics of tail-entropy-based ES versus historical ES: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_TE_ES.
Figure 6.
Dynamics of tail-entropy-based ES versus historical ES: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_TE_ES.

Figure 7.
Dynamics of the test statistic: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_TE_ES.
Figure 7.
Dynamics of the test statistic: (a) α = 1% and (b) α = 2.5%. See the Github page SFM_TE_ES.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Relationship between historical ES (ESH) and tail entropy (TE) for simulated distributions.
Table 1.
Relationship between historical ES (ESH) and tail entropy (TE) for simulated distributions.
| Dependent Variable: ESHα;t | ||
|---|---|---|
| Significance Level | α = 1% | α = 2.5% |
| Hα,q;t | −12.95 *** | −8.32 *** |
| [0.94] | [0.64] | |
| 0.51 | 0.48 | |
Note: standard errors are given in brackets. *** denotes significance at 1%.
Table 2.
The results of the multivariate regression model obtained using Formula (23).
| Dependent Variable: ESHα;t | ||
|---|---|---|
| Significance Level | α = 1% | α = 2.5% |
| Intercept | 5.75 *** | 4.32 *** |
| [0.13] | [0.08] | |
| H0.01,q;t | −3.69 *** | −2.48 *** |
| [0.37] | [0.23] | |
| H0.025,q;t | −3.64 *** | −2.57 *** |
| [0.38] | [0.24] | |
| H0.05,q;t | −3.07 *** | −2.20 *** |
| [0.37] | [0.23] | |
| 0.55 | 0.60 | |
Note: standard errors are given in brackets. *** denotes significance at 1%.
Table 3.
Relationship between tail index and TE of simulated distributions.
| Dependent Variable: TEα;t | ||
|---|---|---|
| Significance Level | α = 1% | α = 2.5% |
| a | 0.51 *** | 0.63 *** |
| [0.05] | [0.05] | |
| 0.50 | 0.65 | |
Note: standard errors are given in brackets. *** denotes significance at 1%.
Table 4.
Backtesting rejection rates of the null hypothesis from January 1980 to December 2018. Legend: UC, unconditional exception frequency; CC, conditional independence.
Table 4.
Backtesting rejection rates of the null hypothesis from January 1980 to December 2018. Legend: UC, unconditional exception frequency; CC, conditional independence.
| α = 1% | α = 2.5% | |||||
|---|---|---|---|---|---|---|
| Model | Du’s UC Test | Du’s CC Test | Du’s UC Test | Du’s CC Test | ||
| Gaussian ES | 62.56% | 56.43% | 55.55% | 74.74% | 59.17% | 43.93% |
| Students’s t ES | 65.93% | 42.80% | 38.04% | 73.41% | 66.03% | 34.35% |
| Historical ES | 59.02% | 38.14% | 39.82% | 73.39% | 69.79% | 33.00% |
| n-GARCH(1,1) ES | 74.83% | 33.05% | 77.03% | 66.91% | 46.57% | 45.77% |
| t-GARCH(1,1) ES | 29.30% | 23.17% | 26.73% | 27.44% | 41.97% | 23.32% |
| Tail Entropy ES | 58.35% | 24.11% | 28.29% | 69.50% | 69.22% | 10.25% |
Note: rolling windows of length 1000 were used to carry out the backtests.
Table 5.
Test statistics of ES backtests from January 1980 to December 2018.
| α = 1% | α = 2.5% | |||||
|---|---|---|---|---|---|---|
| Model | Du’s UC Test | Du’s CC Test | Du’s UC Test | Du’s CC Test | ||
| Gaussian ES | 18.26 | 97.55 | −1.88 | 11.18 | 84.61 | −0.73 |
| Student’s t ES | 5.24 | 45.58 | −0.33 * | 5.48 | 74.74 | −0.19 * |
| Historical ES | 5.50 | 44.70 | −0.62 * | 4.56 | 81.62 | −0.32 * |
| n-GARCH(1,1) ES | 11.43 | 22.88 | −1.39 | 7.78 | 18.39 | −0.73 |
| t-GARCH(1,1) ES | 2.82 | 16.21 | −2.78 | 3.39 | 22.37 | −3.37 |
| Tail Entropy ES | 6.11 | 20.58 | −0.23 * | 20.71 | 66.28 | 0.20 * |
Note: critical values for each test are the following. Du’s UC test (5%, two-sided, normal): −1.96, 1.96. Du’s CC test (5%, one-sided, Chi-squared): 3.84. test (5%, one-sided, normal): −0.70. * stands for test statistics that passed the backtests at the 5% level.
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pele, D.T.; Lazar, E.; Mazurencu-Marinescu-Pele, M. Modeling Expected Shortfall Using Tail Entropy. Entropy 2019, 21, 1204. https://doi.org/10.3390/e21121204
AMA Style
Pele DT, Lazar E, Mazurencu-Marinescu-Pele M. Modeling Expected Shortfall Using Tail Entropy. Entropy. 2019; 21(12):1204. https://doi.org/10.3390/e21121204
Chicago/Turabian StylePele, Daniel Traian, Emese Lazar, and Miruna Mazurencu-Marinescu-Pele. 2019. "Modeling Expected Shortfall Using Tail Entropy" Entropy 21, no. 12: 1204. https://doi.org/10.3390/e21121204
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.