State Transfer via On-Line State Estimation and Lyapunov-Based Feedback Control for a N-Qubit System


Department of Automation, University of Science and Technology of China, Hefei 230027, China
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(8), 751; https://doi.org/10.3390/e21080751
Submission received: 20 May 2019
/
Revised: 20 July 2019
/
Accepted: 29 July 2019
/
Published: 31 July 2019
(This article belongs to the Special Issue Open Quantum Systems (OQS) for Quantum Technologies)
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we propose a Lyapunov-based state feedback control for state transfer based on the on-line quantum state estimation (OQSE). The OQSE is designed based on continuous weak measurements and compressed sensing. The controlled system is described by quantum master equation for open quantum systems, and the continuous measurement operators are derived according to the dynamic equation of system. The feedback control law is designed based on the Lyapunov stability theorem, and a strict proof of proposed control laws are given. At each sampling time, the state is estimated on-line, which is used to design the control law. The simulation experimental results show the effectiveness of the proposed feedback control strategy.
1. Introduction
Quantum control theory has attracted considerable attention both theoretically [1,2,3,4,5,6] and experimentally [7,8]. Most studies of quantum control are concerned with transferring the state of the system to a desired final state [9,10]. Quantum Lyapunov control (QLC) has been widely studied to control quantum systems for state preparation [11,12], trajectory tracking [13,14] and state transfer [15,16,17] with different Lyapunov functions [18,19]. In QLC, the control laws are designed by keeping the first-order time derivative of a selected Lyapunov function less than zero. The selection of the appropriate Lyapunov function is tricky, where different Lyapunov functions make different control effects. The best approach is to use some special geometric or physical meanings of the system to design the Lyapunov function. The most common Lyapunov functions are: Lyapunov function based on the state distance, on the average value of an imaginary mechanical quantity, and on the state error [18]. In [15,20] the control laws are designed using the distance-based Lyapunov function, and the conditions are obtained for the asymptotic stability of the closed-loop system by linearizing the unitary operator of the state. Using the QLC feedback control, one can achieve more accurate control performance. However, it should use the system’s state, which needs to be estimated on-line.
Quantum state estimation (QSE) is a useful tool which describes the characterization of the state of a quantum system [21]. To estimate the state of the system, one needs to apply appropriate measurements on the system and reconstruct the state based on the results of the measurements by an estimator algorithm. Different measurements and estimation methods have been well studied in the field of QSE. For instance, projective measurement [22,23], continuous weak measurement [24,25,26] and sequential unsharp measurement [27], which have been used with estimation approaches such as maximum likelihood or Bayesian method to reconstruct the initial state of the measurement processes [28,29]. These methods have been widely used in experiments [30,31]. Compressed quantum tomography, based on techniques from compressed sensing [23,32], reduces the required number of measurements to reconstruct the state. In classical control theory, one gets the best estimation of the state of the system at each time and uses the results of the estimation for controlling a closed loop system. The same feedback control is possible for quantum feedback control by using OQSE [33]. On-line quantum state estimation (OQSE) is a continuous state estimation at any moment by using continuous weak measurements with the help of some optimization algorithms. In OQSE, the results of continuous measurements are used to reconstruct the state of the system at any time. The measurement operators should be designed based on the dynamic equation of the system which changes over time. In [34], the authors proposed a quantum state estimation scheme and employed a continuous measurement protocol to perform QSE on the seven-dimensional, atomic hyperfine spin manifold, in an ensemble of cesium atoms. Then a state-to-state quantum mapping performance estimation based on the continuous weak measurement is achieved, as well as the optimal control technology design and implementation [35]. By using non-destructive measurements and the dynamics of the system, at the end of the estimation procedure, the state of the system was reconstructed. Hence, the result of OQSE can be used for real-time state feedback control. The dynamic of the open quantum system can be described using the Lindblad-type Markovian master equation [36]. In Markovian quantum control, any time delay is ignored and a memoryless controller is assumed. The measurement record is immediately fed back onto the system to alter the system dynamics [37].
In this paper, we propose a Lyapunov-based state feedback control based on the OQSE, to transfer the state of a N-qubit system to a desired final state for a Markovian open quantum system. The measurement operators for the N-qubit system are derived, which are indirectly acted on the controlled system and change as the time. The quantum state is estimated on-line based on the continuous weak measurements and compressed sensing, and the state feedback control law is designed based on the Lyapunov stability theorem, which is used to transfer the state of N-qubit Markovian system from an initial state to a desired final state. The control laws based on the Lyapunov stability theorem are designed with variable control parameters.
2. N-Qubit OQSE Establishment
In OQSE, the results of continuous weak measurements are used to reconstruct the state of the system in real time with compressed sensing theory. The measurement operators are derived by means of the weak measurement and the dynamic equation of the system. At each instant time, one can obtain the records of the expectation values with some measurement operators by the indirect results of continuous weak measurements. The estimated state can be obtained by solving convex optimization problem with physical constraints.
The n-dimensional dynamics of open quantum system can be described as
where is the density matrix of the system which is a matrix, N the number of qubits and the dimension of the system; the total Hamiltonian of the system, and ; is the free Hamiltonian of the system, and is the control Hamiltonian. Let , which is the decoherence effect of the measurement process, and manifests as the drift term of the Lindblad form.
For the continuous weak measurements of a two-level quantum systems, the measurement operator group contains two operators: and as [33]
where is the time for measurement and L is a Lindblad operator as
where is the strength of the measurement, and the operator B is chosen from the Stokes measurements set in this paper as:
where is horizontal polarization, is vertical polarization, is diagonal polarization, and is right-circular polarization.
The discrete-time dynamic equation of the open quantum system is:
For N-qubit state estimation, one usually needs to use measurement operators, which are calculated by tensor products of and given in Equation (2):
The corresponding discrete-time dynamic equation of continuous weak measurement operators for N-qubit is:
The reconstruction problem of density matrix is transformed into the following optimization problem: , where is the nuclear-norm of estimated density matrix , represents the transformation from a matrix to a vector by stacking the matrix’s columns in order on the top of one another. The vector y and matrix A can be expressed according to the current measurement configurations as:
and
where , is the corresponding measurement value in the l-th measurement; the sampling vector y is the vector form of the corresponding observation values ; and K is the selected number of measurements to estimate the state of the system accurately at each sampling time. The estimator needs to estimate density matrix parameters, which are elements of density matrix for a d-dimensional Hilbert space. Hence the maximum amount of K is . To limit the number of measurements, we define the measurement rate as:
where K is the number of measurements used in the state estimation and d is the dimension of Hilbert space. Hence, at each sampling time, we choose the last K number of measurements and discards the others. The measurement rate is proportional to the number of measurements and when the measurement set is an informationally complete set; and when the number of measurement outcomes is less than the number of elements , the measurement set is called an informationally incomplete set.
To solve the optimization problem, we use the non-negative least squares estimator of minimizing the 2-norm under the positive definite constraint:
In this paper, we use fidelity as the performance of OQSE which is defined as the trace between actual state and estimated state as:
where is the estimated state and the actual state of the system at sampling time t. Generally, fidelity measures how much two states overlap each other. A fidelity of 1 means the states are identical, whereas the fidelity of 0 means the states are orthogonal.
3. Lyapunov-Based State Feedback Control
In this section, we propose the Lyapunov-based state feedback control to transfer the state from given initial state to the desired final state of Markovian open quantum systems. The control laws are designed based on the Lyapunov stability theorem and the theoretical proof is given.
Theorem 1.
For the dynamics equation of controlled system Equation (1), letwhereis the estimated state by OQSE,is the desired final state, m is the number of control fields which is,anda small positive number.
The first control Hamiltonian is set equal to free Hamiltonian of the system, with control law. The other control laws are designed as:
(1) If, then the designed control law isCUj≠1,2 = −Kj.Tj Kj .
(j) If, … and, we designed the control lawbto counteract the drift C. Therefore, the control laws, which can make the control system asymptotically stable, become:
(m) If, …, and, we designed the control lawto counteract the drift C. In this case, the control system becomes asymptotically stable by setting control laws as:
(m+1) If, …, and, the control laws which can make the control system asymptotically stable are:
where g is a small positive number.
Proof of Theorem 1.
Based on the Lyapunov stability theorem, one needs to select a scalar function with continuous partial derivatives which satisfies following conditions: (a) is a positive definite, ; (b) the first order time derivative of the Lyapunov function is negative: . We select the trace distance as the Lyapunov function
Trace distance measures the closeness of two quantum states and . In the feedback control system, we need to make the amount of trace distance as small as possible to make sure that the system reaches the desired final state .
The first time derivative of the Lyapunov function V can be calculated as:
where is a real function of the real time estimated state at time t; is a drift term which its sign cannot be determined.
By setting first control Hamiltonian equal to free Hamiltonian of the system , with control law , the effects of free Hamiltonian of the system is compensated . Now one needs to design the control laws to transfer the state to the desired final state.
In each case of control law design, two crucial tasks should be done. (i) to compensate the influence of the drift term C. (ii) make sure that holds. Hence, in each case of control law design, we compare with a small positive number . If the control law choose to counteract the drift term C, as ; , as Uj(t) = −Kj.Tj where Kj is a positive tunable number that satisfies . By applying the designed control laws, the first time derivative of the Lyapunov
function V in Equation (18) becomes:
If none of the conditions in cases satisfied, we need to apply a disturbance to the system. In case where , …, and , means and the system is in a stable point. In N-qubit system, there are two stable points and . When the system is in one of these stable points or , the first derivative of the Lyapunov function becomes always equal to zero . In this case, we apply a disturbance to the system to bring it out of the stable point as given in Equation (16). □
The detailed control procedure is given in Algorithm 1.
| Algorithm 1 Pseudocode of state transfer based on OQSE and QLC |
Require: Initialize variables L in Equation (3), Hamiltonians H0, H1, H2 and Lyapunov control parameter Kj in Equation (19).
|
Steps 3 to 7 are related to OQSE and steps 8 to 10 are related to QLC. We note that at each sampling time, according to the designed control laws, a new Hamiltonian is defined (step 2 of the algorithm). Otherwise, the decoherence effect of the measurement process as defined in Equation (1), reduces the off-diagonal elements of the density matrix and leads the state to a maximally mixed state.
4. Numerical Simulations and Results Analyses
In this section, the experimental simulation results and analysis for N-qubit state transfer based on OQSE are given. In the simulation experiments we assume that each qubit is in the initial eigenstate , and the desired final eigenstate is . The initial and final states of N-qubit system are:
The free Hamiltonian and control Hamiltonians are defined as:
where are Pauli matrices as , and .
To compensate for the effects of the free Hamiltonian of the system , we design the first control Hamiltonian equal to free Hamiltonian of the system with control law . The other control Hamiltonians are set along x and y axis with designed Lyapunov control laws, given in Theorem 1 to transfer the state to the desired final state.
The weak measurement initial operator is set as:
where are chosen from stokes measurement set given in Equation (4).
First, we do the experiment for a two-qubit system. The parameters for OQSE and Lyapunov control of two-qubit system are set as: the number of control fields is , with the free Hamiltonian and the control Hamiltonians as ; the first control law is fixed as at all sampling times to compensate the effects of free Hamiltonian of the system; the control law parameters are set as ; the measurement strength is set as , the Lindblad operator as , and the initial weak measurement operator as . The measurement rate is set as , which means at each sampling time, the last four measurements and corresponding results are used in the optimization algorithm.
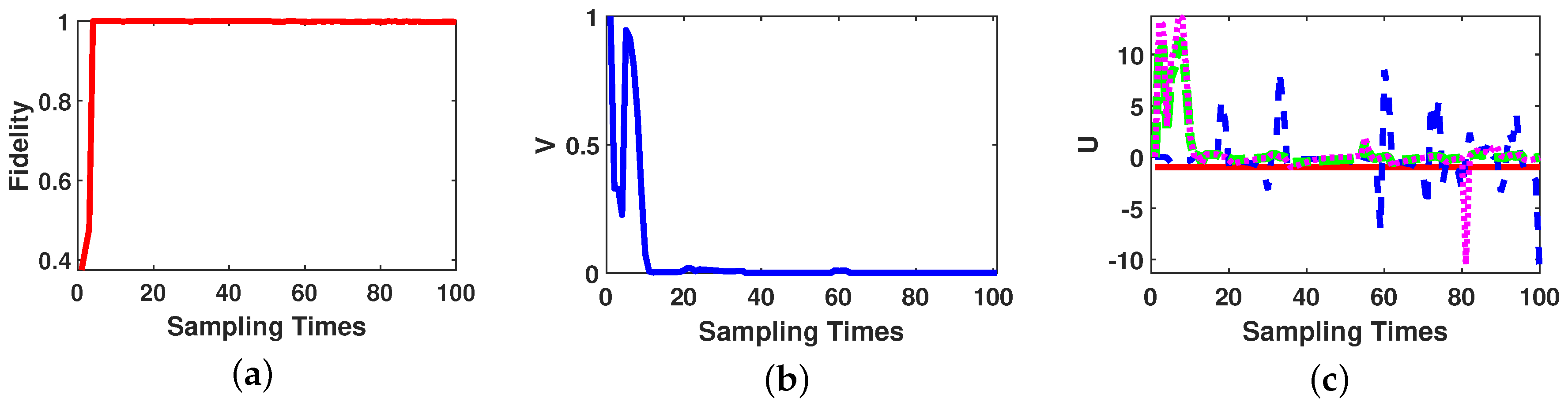
Fidelity between actual state and estimated state is calculated according to Equation (12), and trace distance between estimated state and the desired final state as Equation (17). The behavior of fidelity, state distance and the control law parameters are given in Figure 1. We note that the fidelity evaluates the performance of the state estimation by comparing actual state and estimated state, and trace distance evaluates the performance of the transfer control by comparing the estimated state and the desired final state.
As Figure 1 shows, at sampling time 4, the amount of fidelity is close to 1, which means the OQSE estimates the state accurately; but the amount of trace distance is 0.22, which means the system could not reach the desired final state yet. After sampling time 11, the trace distance between the estimated state and the desired final state becomes less than 0.01; and after sampling time 40 the trace distance becomes less than 0.001. As Figure 1c depicted, the amount of first control law is always equal to −1 to compensate the effects of free Hamiltonian of the system and the other control laws are designed according to Lyapunov control method in Theorem 1.
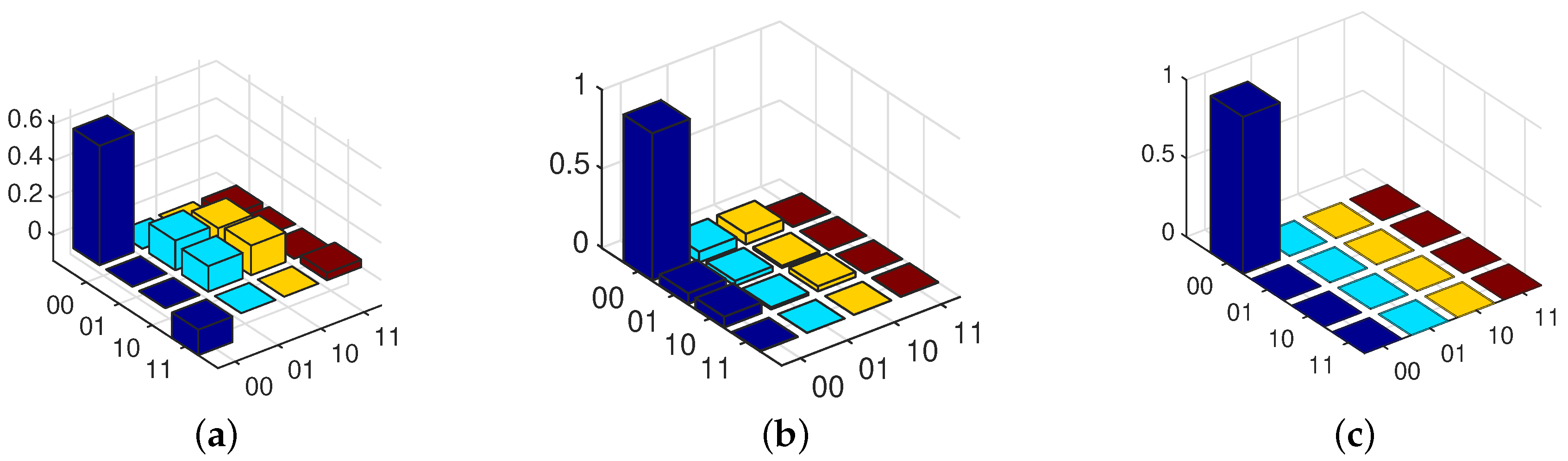
To show the evolution of the state during the sampling times, Figure 2 shows the density matrix of the two-qubit system at 8, 20 and 100 sampling times.
As one can see from Figure 2, at sampling time 8, the state is far from the desired state (the trace distance is 0.61); however, as the sampling times increase, the state becomes closer to the desired final state. In a way, the density matrix at sampling time 20 becomes closer to the desired final state with trace distance 0.02; and at sampling time 100, the state is exactly same as the desired final state with trace distance 0.001.
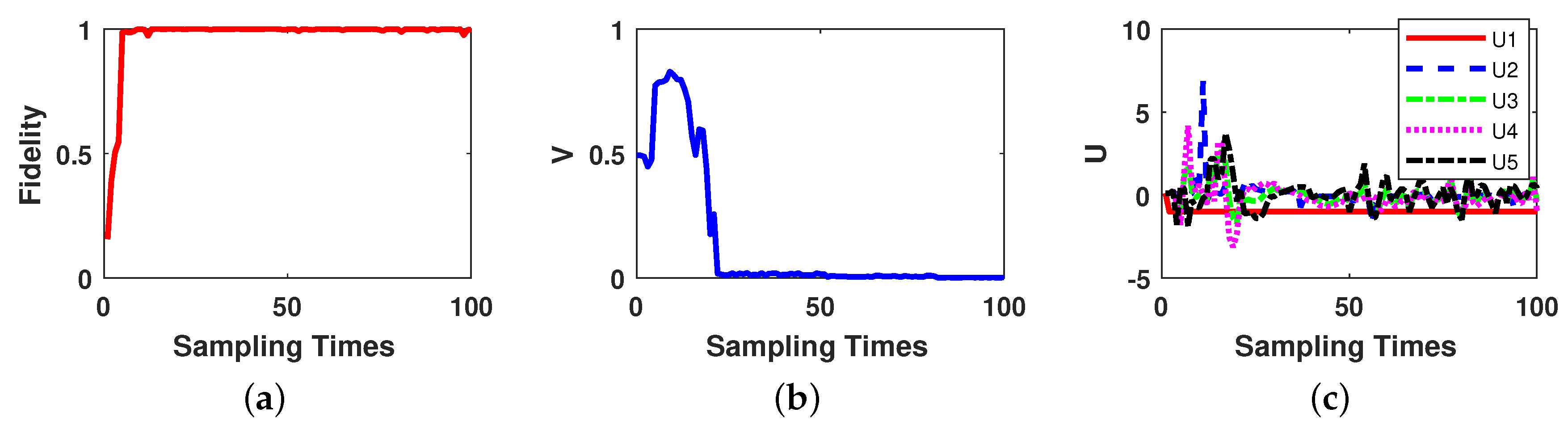
Now we do the simulation experiment for a three-qubit system. The parameters for OQSE and Lyapunov control of three-qubit system are set as: the number of control fields , where the free Hamiltonian is and the control Hamiltonians are set as , which is same as free Hamiltonian with to compensate the effects of free hamiltonian, ; the control law parameters are set as ; the measurement strength is set as , the Lindblad operator as , and the initial weak measurement operator as . The measurement rate is set as , which means at each sampling time, the last 16 measurements and corresponding results are used in the optimization algorithm. The behavior of three-qubit state transfer control performance is given in Figure 3.
As Figure 3 depicts, the OQSE reaches the amount of fidelity more than 99% at sampling time 8; and the trace distance between estimated state and the desired final state becomes less than 0.01 at sampling time 24, and becomes less than 0.001 after sampling time 80. Compare with two-qubit system, for three-qubit system the feedback control needs longer sampling times to bring the state close to the desired final state. Two-qubit system trace distance is less than 0.01 after sampling time 11, but for three-qubit system, it happens after sampling time 24. Hence, we can conclude that for higher number of qubits, one can reach the desired final state in longer sampling times.
It is worth noting that the proposed state transfer control is applicable for any arbitrary initial and final states. However, one needs to find the suitable control parameters: control law parameters, Hamiltonians, measurement operators, measurement strength, Lindbald operator and initial measurement operator, for each initial and final states.
5. Conclusions
We designed the N-qubit state transfer control via OQSE and Lyapunov feedback control. The continuous weak measurement operators are designed based on the dynamic evolution of the system to estimate the state of the system in real time by compress sensing estimator. The control laws have been designed based on the Lyapunov stability theorem. The designed control laws can effectively achieve the state transfer of a N-qubit Markovian system from a given initial state to the desired target state. Fidelity between actual state and estimated state is defined to study the performance of the OQSE; and trace distance between estimated state and the desired final state is defined to study the performance of the state transfer control. The numerical simulation experiments show the effectiveness of the feedback control of N-qubit open quantum systems based on OQSE.
Author Contributions
S.H. and S.C. developed the methodology, S.H. wrote the manuscript text, performed the experiments and analyzed the results, S.C. conceived and supervised the project. S.C. and S.H. contributed to review the manuscript.
Funding
This research was supported by the National Natural Science Foundations of China under Grant No. 61573330 and 61720106009.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Werschnik, J.; Gross, E.K.U. Quantum optimal control theory. J. Phys. B 2007, 40, R175–R211. [Google Scholar] [CrossRef] [Green Version]
- Clark, J.W.; Lucarelli, D.G.; Tarn, T.-J. Control of quantum systems. Int. J. Mod. Phys. B 2003, 17, 5397–5411. [Google Scholar] [CrossRef]
- Cong, S. Control of Quantum Systems: Theory and Methods; John Wiley & Sons, Singapore Pte. Ltd.: Singapore, 2014. [Google Scholar]
- Watts, P.; O’Connor, M.; Vala, J. Metric structure of the space of two-qubit gates, perfect entanglers and quantum control. Entropy 2013, 15, 1963–1984. [Google Scholar] [CrossRef]
- Liuzzo-Scorpo, P.; Correa, L.; Schmidt, R.; Adesso, G. Thermodynamics of quantum feedback cooling. Entropy 2016, 18, 48. [Google Scholar] [CrossRef]
- Harraz, S.; Cong, S.; Kuang, S. Optimal Noise Suppression of Phase Damping Quantum Systems via Weak Measurement. J. Syst. Sci. Complex. 2018, 1–16. [Google Scholar] [CrossRef]
- Press, D.; Ladd, T.D.; Zhang, B.; Yamamoto, Y. Complete quantum control of a single quantum dot spin using ultrafast optical pulses. Nature 2008, 456, 218. [Google Scholar] [CrossRef] [PubMed]
- Gillett, G.G.; Dalton, R.B.; Lanyon, B.P.; Almeida, M.P.; Barbieri, M.; Pryde, G.J.; O’Brien, J.L.; Resch, K.J.; Bartlett, S.D.; White, A.G. Experimental feedback control of quantum systems using weak measurements. Phys. Rev. Lett. 2010, 104, 3–6. [Google Scholar] [CrossRef] [PubMed]
- Harraz, S.; Yang, J.; Li, K.; Cong, S. Quantum state transfer control based on the optimal measurement. Optim. Control Appl. Methods 2017, 38, 744–753. [Google Scholar] [CrossRef]
- Wang, D.; Hoehn, R.; Ye, L.; Kais, S. Generalized remote preparation of arbitrary m-qubit entangled states via genuine entanglements. Entropy 2015, 17, 1755–1774. [Google Scholar] [CrossRef]
- Shi, Z.C.; Wang, L.C.; Yi, X.X. Preparing entangled states by Lyapunov control. Quantum Inf. Process. 2016, 15, 4939–4953. [Google Scholar] [CrossRef]
- Pan, Y.; Ugrinovskii, V.; James, M.R. Ground-state stabilization of quantum finite-level systems by dissipation. Automatica 2016, 65, 147–159. [Google Scholar] [CrossRef]
- Sahebi, Z.; Yarahmadi, M. Switching optimal adaptive trajectory tracking control of quantum systems. Optim. Control Appl. Methods 2018, 39, 1323–1336. [Google Scholar] [CrossRef]
- Cong, S.; Liu, J. Trajectory tracking theory of quantum systems. J. Syst. Sci. Complex. 2014, 27, 679–693. [Google Scholar] [CrossRef]
- Cong, S.; Hu, L.; Yang, F.; Liu, J. Characteristics analysis and state transfer for non-Markovian open quantum systems. Acta Autom. Sin. 2013, 39, 360–370. [Google Scholar] [CrossRef]
- Hu, J.; Ke, Q.; Ji, Y. Lyapunov-based state transfer and maintenance for non-Markovian quantum system. Int. J. Mod. Phys. B 2016, 30, 1650177. [Google Scholar] [CrossRef]
- Shi, Z.C.; Zhao, X.L.; Yi, X.X. Robust state transfer with high fidelity in spin-1/2 chains by Lyapunov control. Phys. Rev. A 2015, 91, 32301. [Google Scholar] [CrossRef]
- Kuang, S.; Cong, S. Lyapunov control methods of closed quantum systems. Automatica 2008, 44, 98–108. [Google Scholar] [CrossRef]
- Cong, S.; Meng, F. A survey of quantum lyapunov control methods. Sci. World J. 2013, 2013, 967529. [Google Scholar] [CrossRef]
- Shuang, C.; Kuang, S. Quantum control strategy based on state distance. Acta Autom. Sin. 2007, 33, 28–31. [Google Scholar]
- Koyama, T.; Matsuda, T.; Komaki, F. Minimax estimation of quantum states based on the latent information priors. Entropy 2017, 19, 618. [Google Scholar] [CrossRef]
- de Burgh, M.D.; Langford, N.K.; Doherty, A.C.; Gilchrist, A. Choice of measurement sets in qubit tomography. Phys. Rev. A 2008, 78, 52122. [Google Scholar] [CrossRef] [Green Version]
- Gross, D.; Liu, Y.K.; Flammia, S.T.; Becker, S.; Eisert, J. Quantum state tomography via compressed sensing. Phys. Rev. Lett. 2010, 105, 150401. [Google Scholar] [CrossRef] [PubMed]
- Shojaee, E.; Jackson, C.S.; Riofrio, C.A.; Kalev, A.; Deutsch, I.H. Optimal pure-state qubit tomography via sequential weak measurements. arXiv, 2018; arXiv:1805.01012. [Google Scholar]
- Six, P.; Campagne-Ibarcq, P.; Dotsenko, I.; Sarlette, A.; Huard, B.; Rouchon, P. Quantum state tomography with noninstantaneous measurements, imperfections, and decoherence. Phys. Rev. A 2016, 93, 12109. [Google Scholar] [CrossRef] [Green Version]
- Riofrío, C.A.; Jessen, P.S.; Deutsch, I.H. Quantum tomography of the full hyperfine manifold of atomic spins via continuous measurement on an ensemble. J. Phys. B At. Mol. Opt. Phys. 2011, 44, 154007. [Google Scholar]
- Bassa, H.; Goyal, S.K.; Choudhary, S.K.; Uys, H.; Diósi, L.; Konrad, T. Process tomography via sequential measurements on a single quantum system. Phys. Rev. A 2015, 92, 32102. [Google Scholar] [CrossRef]
- Blume-Kohout, R. Optimal, reliable estimation of quantum states. New J. Phys. 2010, 12, 43034. [Google Scholar] [CrossRef]
- Hradil, Z.; Řeháček, J.; Fiurášek, J.; Ježek, M. 3 maximum-likelihood methodsin quantum mechanics. In Quantum State Estimation; Springer: Berlin/Heidelberg, Germany, 2004; pp. 59–112. [Google Scholar]
- Home, J.P.; Hanneke, D.; Jost, J.D.; Amini, J.M.; Leibfried, D.; Wineland, D.J. Complete Methods Set forScalable Ion Trap QuantumInformation Processing. Science 2009, 325, 1227. [Google Scholar] [CrossRef] [PubMed]
- Barreiro, J.T.; Müller, M.; Schindler, P.; Nigg, D.; Monz, T.; Chwalla, M.; Hennrich, M.; Roos, C.F.; Zoller, P.; Blatt, R. An open-system quantum simulator with trapped ions. Nature 2011, 470, 486–491. [Google Scholar] [CrossRef] [Green Version]
- Gross, D. Recovering low-rank matrices from few coefficients in any basis. IEEE Trans. Inf. Theory 2011, 57, 1548–1566. [Google Scholar] [CrossRef]
- Shuang, C.; Yaru, T.; Sajede, H.; Kezhi, L.; JIngbei, Y. On-line quantum state estimation using continuous weak measurement and compressed sensing. Sci. China Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Silberfarb, A.; Jessen, P.S.; Deutsch, I.H. Quantum state reconstruction via continuous measurement. Phys. Rev. Lett. 2005, 95, 030402. [Google Scholar] [CrossRef] [PubMed]
- Smith, G.A.; Silberfarb, A.; Deutsch, I.H.; Jessen, P.S. Efficient quantum-state estimation by continuous weak measurement and dynamical control. Phys. Rev. Lett. 2006, 97, 180403. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2010; ISBN 1139495488. [Google Scholar]
- Dong, D.; Petersen, I.R. Quantum control theory and applications: A survey. IET Control Theory Appl. 2010, 4, 2651–2671. [Google Scholar] [CrossRef]
- Grant, M.C.; Boyd, S.P. Graph implementations for nonsmooth convex programs. In Recent Advances in Learning and Control; Springer: London, UK, 2008; pp. 95–110. [Google Scholar]
- Grant, M.; Boyd, S.; Ye, Y. CVX: Matlab Software For Disciplined Convex Programming. Available online: http://cvxr.com/cvx/ (accessed on 31 July 2019).
Figure 1.
Two-qubit state transfer based on on-line estimation performance. (a) Fidelity between actual state and estimated state. (b) Trace distance between estimated state and the desired final state over the number of sampling times. (c) Variation curves of control law parameters. (The red solid line: , the blue dashed line: , the green dash-dotted line: and the pink dotted line: ).
Figure 1.
Two-qubit state transfer based on on-line estimation performance. (a) Fidelity between actual state and estimated state. (b) Trace distance between estimated state and the desired final state over the number of sampling times. (c) Variation curves of control law parameters. (The red solid line: , the blue dashed line: , the green dash-dotted line: and the pink dotted line: ).

Figure 2.
Two-qubit density matrix during sampling times. (a) Estimated state at sampling time 8. (b) Estimated state at sampling time 20. (c) Estimated state at sampling time 100.
Figure 2.
Two-qubit density matrix during sampling times. (a) Estimated state at sampling time 8. (b) Estimated state at sampling time 20. (c) Estimated state at sampling time 100.

Figure 3.
Three-qubit state transfer based on on-line estimation performance. (a) Fidelity between actual state and estimated state. (b) Trace distance between estimated state and the desired final state over the sampling times. (c) Variation curves of control law parameters.
Figure 3.
Three-qubit state transfer based on on-line estimation performance. (a) Fidelity between actual state and estimated state. (b) Trace distance between estimated state and the desired final state over the sampling times. (c) Variation curves of control law parameters.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Harraz, S.; Cong, S. State Transfer via On-Line State Estimation and Lyapunov-Based Feedback Control for a N-Qubit System. Entropy 2019, 21, 751. https://doi.org/10.3390/e21080751
AMA Style
Harraz S, Cong S. State Transfer via On-Line State Estimation and Lyapunov-Based Feedback Control for a N-Qubit System. Entropy. 2019; 21(8):751. https://doi.org/10.3390/e21080751
Chicago/Turabian StyleHarraz, Sajede, and Shuang Cong. 2019. "State Transfer via On-Line State Estimation and Lyapunov-Based Feedback Control for a N-Qubit System" Entropy 21, no. 8: 751. https://doi.org/10.3390/e21080751
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.