Local Feature Extraction and Information Bottleneck-Based Segmentation of Brain Magnetic Resonance (MR) Images


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. IB-Based Segmentation Method

2.1. Feature Extraction in Brain MR Images
2.2. IB-Based Clustering
2.3. Brain Tissue Classification
3. Results and Discussion
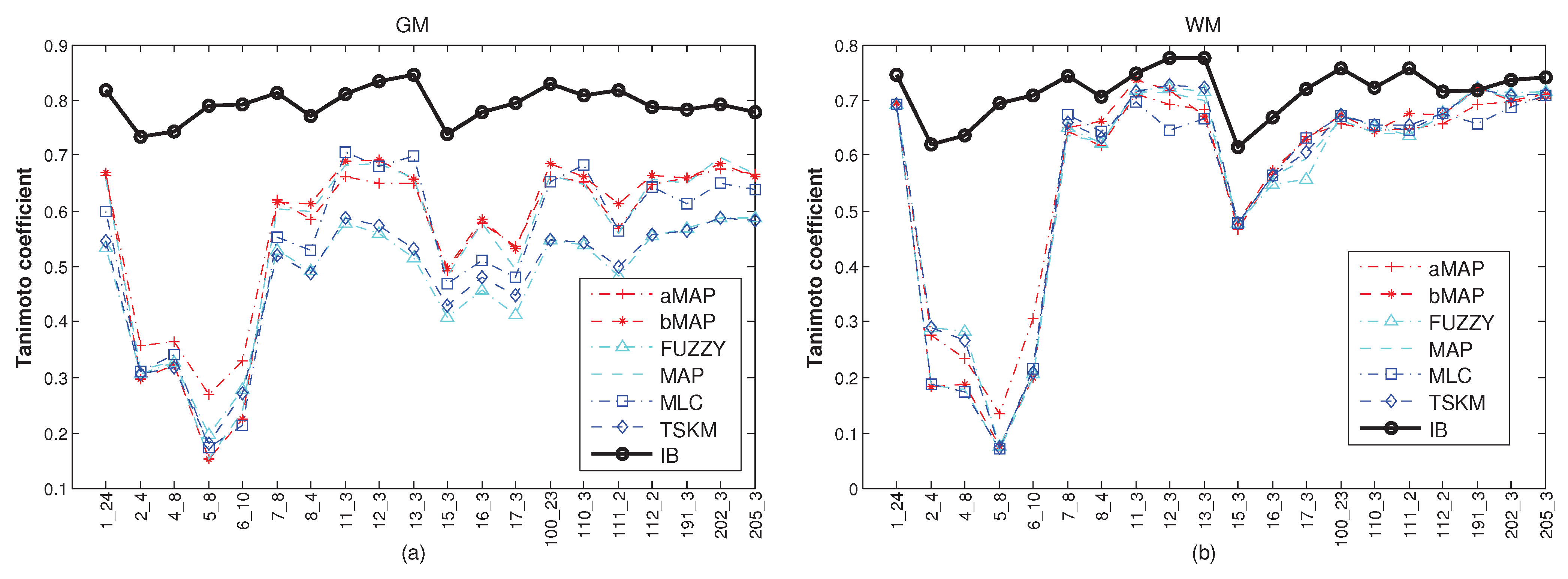
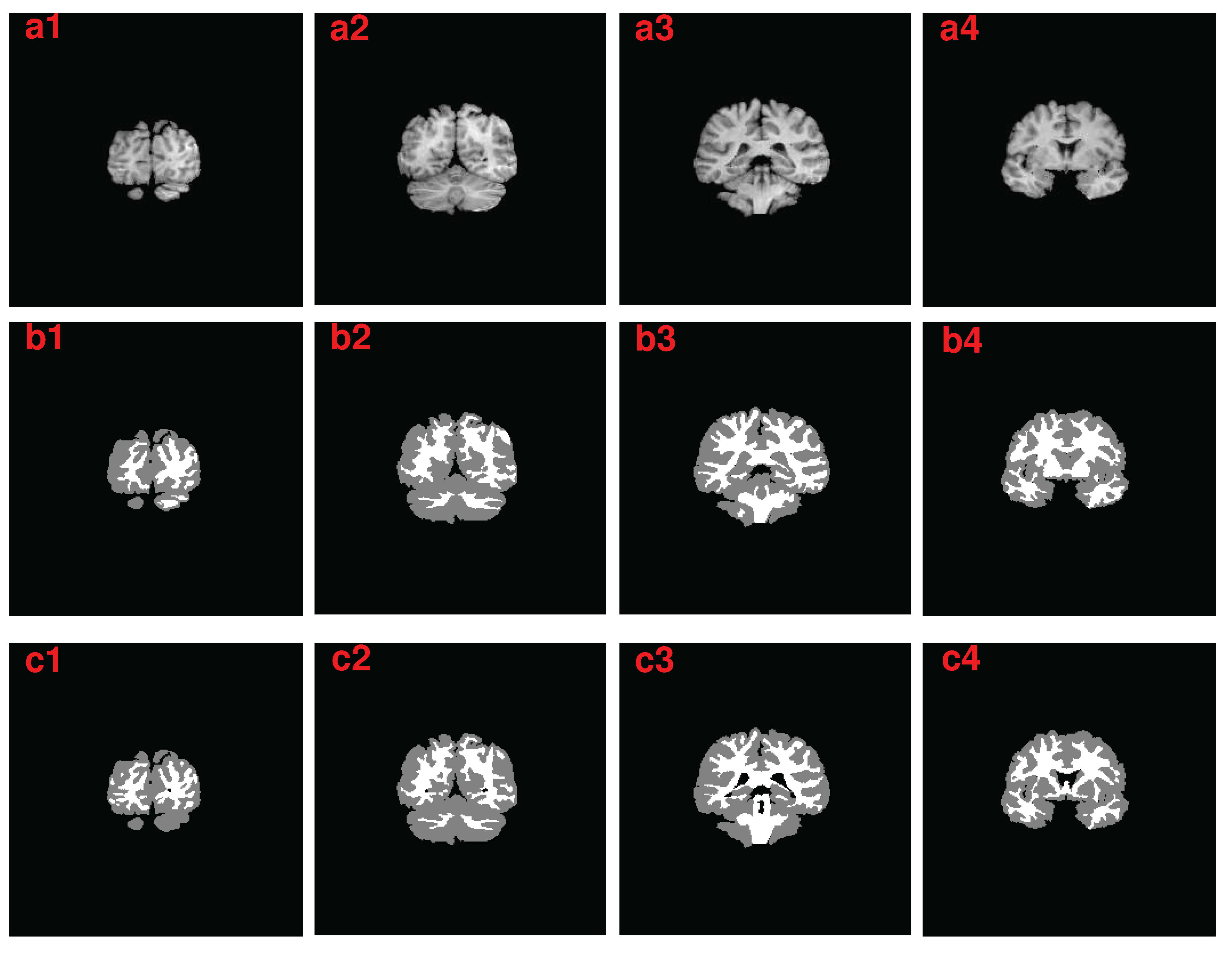
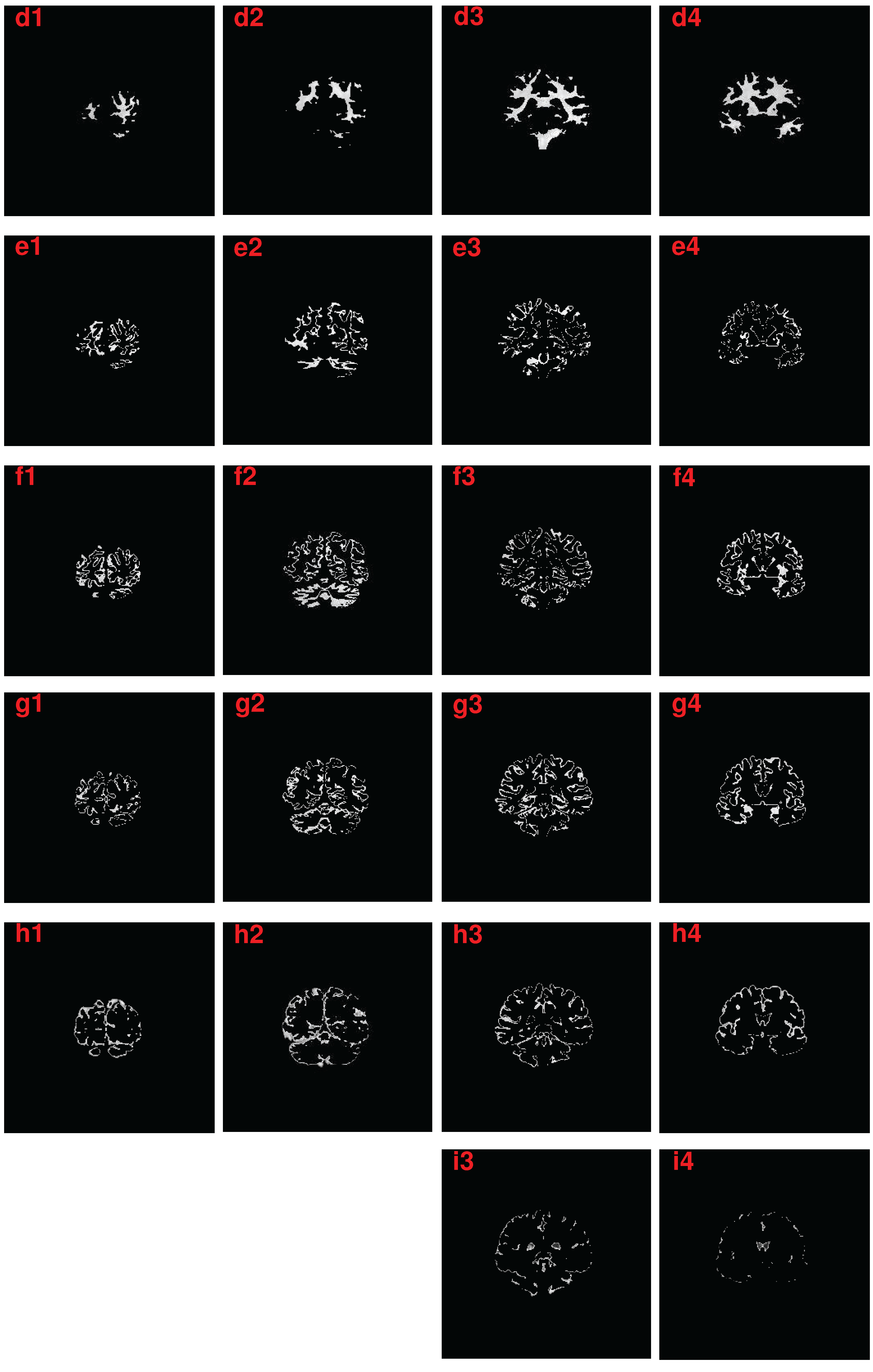
3.1. Performance of the Algorithm under Empirical Parameters




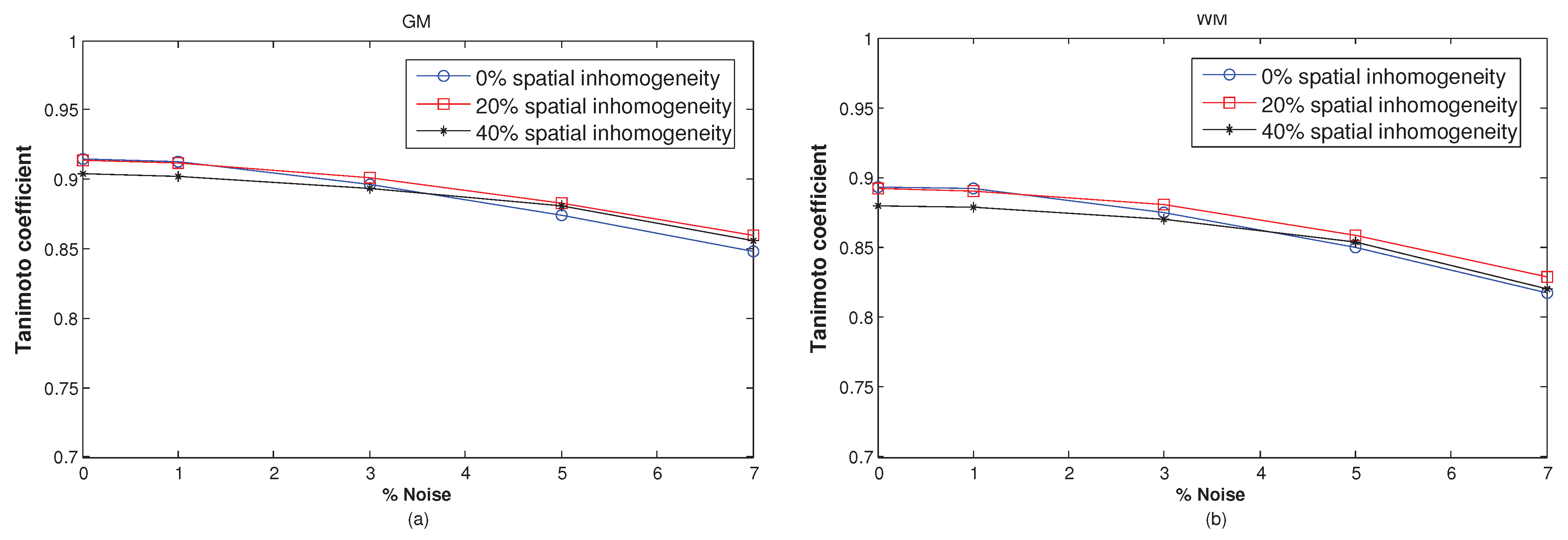
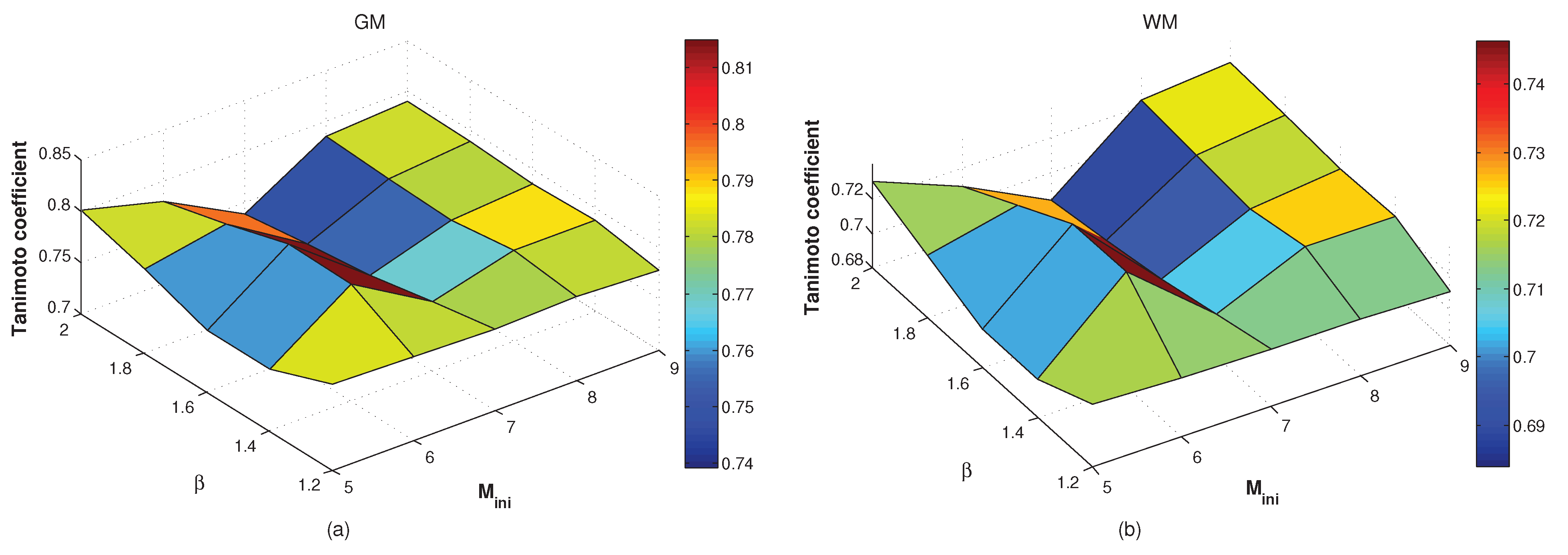
3.2. Effect of the Free Parameters on the Algorithm’s Performance


4. Conclusions
Acknowledgments
Conflict of Interest
References
- Ji, Z.X.; Xia, Y.; Sun, Q.S.; Chen, Q.; Xia, D.S.; Feng, D.D. Fuzzy local gaussian mixture model for brain MR image segmentation. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 339–337. [Google Scholar] [PubMed]
- Tian, G.J.; Xia, Y.; Zhang, Y. Hybrid genetic and variational expectation-maximization algorithm for GMM based brain MR image segmentation. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 373–380. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.X.; Sun, Q.S.; Xia, D.S. A modified possibilistic fuzzy C-means clustering algorithm for bias field estimation and segmentation of brain MR image. Comput. Med. Imag. Graph. 2011, 35, 383–397. [Google Scholar] [CrossRef] [PubMed]
- Liao, L.; Lin, T.; Li, B. MRI brain image segmentation and bias field correction based on fast spatially constrained kernel clustering approach. Pattern Recog. Lett. 2008, 29, 1580–1588. [Google Scholar] [CrossRef]
- Sfikas, G.; Nikou, C.; Galatsanos, N.; Heinrich, C. MR brain tissue classification using an edge-preserving spatially variant bayesian mixture model. Med. Image. Comput. Comput. Assist. 2008, 11, 43–50. [Google Scholar]
- Song, T.; Jamshidi, M.M.; Lee, R.R.; Huang, M. A modified probabilistic neural network for partial volume segmentation in brain MR image. IEEE Trans. Neural Netw. 2007, 18, 1424–1432. [Google Scholar] [CrossRef] [PubMed]
- Chang, H.; Valentino, D.J.; Duckwiler, G.R.; Toga, A.W. Segmentation of brain MR images using a charged fluid model. IEEE Trans. Biomed. Eng. 2007, 54, 1798–1813. [Google Scholar] [CrossRef] [PubMed]
- Greenspan, H.; Ruf, A.; Goldberger, J. Constrained gaussian mixture model framework for automatic segmentation of MR brain images. IEEE Trans. Med. Imag. 2006, 25, 1233–1245. [Google Scholar] [CrossRef]
- Li, X.; Li, L.; Lu, H.; Liang, Z. Partial volume segmentation of brain magnetic resonance images based on maximum a posteriori probability. Med. Phys. 2005, 32, 2337–2345. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Huang, T.S.; Liang, Z.P. Segmentation of Brain MR Images Using Hidden Markov Random Field Model with Weighting Neighborhood System. In Proceedings of the IEEE 2004 Nuclear Science Symposium Conference Record, Rome, Italy, 16–22 October 2004; Volume 5, pp. 3209–3212.
- Liew, A.; Yan, H. An adaptive spatial fuzzy clustering algorithm for 3-D MR image segmentation. IEEE Trans. Med. Imag. 2003, 22, 1063–1075. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Yamany, S.; Mohamed, N.; Farag, A.; Moriarty, T. A modified fuzzy C-means algorithm for bias field estimation and segmentation of MRI data. IEEE Trans. Med. Imag. 2002, 21, 193–199. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden markov random field model and the expectation maximization algorithm. IEEE Trans. Med. Imag. 2001, 20, 45–57. [Google Scholar] [CrossRef] [PubMed]
- Pham, D.L.; Xu, C.; Prince, J.L. Current methods in medical image segmentation. Ann. Rev. Biomed. Eng. 2000, 2, 315–337. [Google Scholar] [CrossRef] [PubMed]
- Wells, W.; Grimson, E.; Kikinis, R.; Jolesz, F. Adaptive segmentation of MRI data. IEEE Trans. Med. Imag. 1996, 15, 429–442. [Google Scholar] [CrossRef] [PubMed]
- Macovski, A. Noise in MRI. Magn. Reson. Med. 1996, 36, 494–497. [Google Scholar] [CrossRef] [PubMed]
- Kapur, T.; Grimson, W.E.; Wells, W.M.; Kikinis, R. Segmentation of brain tissue from magnetic resonance images. Med. Image Anal. 1996, 1, 109–127. [Google Scholar] [CrossRef]
- Gupta, L.; Sortrakul, T. A gaussian-mixture-based image segmentation algorithm. Pattern Recog. 1998, 31, 315–325. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Annual Allerton Conference Communicaiton, Control and Computing, Monticello, IL, USA, September 1999; pp. 368–377.
- Slonim, N.; Tishby, N. Agglomerative information bottleneck. Adv. Neural Inf. Process. Syst. 1999, 12, 617–623. [Google Scholar]
- Gordon, S.; Greenspan, H.; Goldberger, J. Applying the Information Bottleneck Principle to Unsupervised Clustering of Discrete and Continuous Image Representations. In Proceedings of the Ninth IEEE 2003 International Conference Computer Vision, Nice, France, 13–16 October 2003; Volume 1, pp. 370–377.
- Slonim, N.; Tishby, N. Document Clustering Using Word Clusters via The Information Bottleneck Method. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 208–215.
- Thirion, B.; Faugeras, O. Feature characterization in fMRI data: The information bottleneck approach. Med. Image Anal. 2003, 8, 403–419. [Google Scholar] [CrossRef] [PubMed]
- Bardera, A.; Rigau, J.; Boada, I.; Feixas, M.; Sbert, M. Image segmentation using information bottleneck method. IEEE Trans. Image Process. 2009, 18, 1601–1612. [Google Scholar] [CrossRef] [PubMed]
- Bardera, A.; Feixas, M.; Boada, I. Registration-Based Segmentation Using the Information Bottleneck Method. In Proceedings of the Iberian Conference on Patern Recognition and Image Analisys, Girona, Spain, 6–8 June 2007; Volume 2. pp. 190–197.
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley and Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Still, S.; Bialek, W.; Bottou, L. Geometric clustering using the information bottleneck method. Adv. Neural Inf. Process. Syst. 2003, 16, 1165–1172. [Google Scholar]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imag. 2004, 13, 146–165. [Google Scholar]
- Nobuyuki, O. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man. Cybern. 1979, 9, 62–66. [Google Scholar]
- Cocosco, C.A.; Kollokian, V.; Kwan, R.K.; Evans, A.C. BrainWeb: Online interface to a 3D MRI simulated brain database. NeuroImage 1997, 5. No. 4. [Google Scholar]
- Center for Morphometric Analysis, IBSR Internet Brain Segmentation Repository. Available online: http://neurowww.mgh.harvard.edu/cma/ibsr/ (accessed on 23 May 2013).
- Kennedy, D.N.; Filipek, P.A.; Caviness, V.S. Anatomic segmentation and volumetric calculations in nuclear magnetic resonance imaging. IEEE Trans. Med. Imag. 1989, 8, 1–7. [Google Scholar] [CrossRef] [PubMed]
© 2013 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Shen, P.; Li, C. Local Feature Extraction and Information Bottleneck-Based Segmentation of Brain Magnetic Resonance (MR) Images. Entropy 2013, 15, 3205-3218. https://doi.org/10.3390/e15083295
Shen P, Li C. Local Feature Extraction and Information Bottleneck-Based Segmentation of Brain Magnetic Resonance (MR) Images. Entropy. 2013; 15(8):3205-3218. https://doi.org/10.3390/e15083295
Chicago/Turabian StyleShen, Pengcheng, and Chunguang Li. 2013. "Local Feature Extraction and Information Bottleneck-Based Segmentation of Brain Magnetic Resonance (MR) Images" Entropy 15, no. 8: 3205-3218. https://doi.org/10.3390/e15083295