1. Introduction
For thousands of years, Traditional Chinese Medicines (TCMs) have been widely consumed in many Asian countries. As natural products, TCMs were generally considered to be green and harmless [
1]. However, actually, as all drugs do, TCMs also possess a series of side effects. The hepatotoxicity [
2], nephrotoxicity [
3], cardiotoxicity [
4], neurotoxicity [
5], carcinogenicity [
6], and some other toxicities of TCMs have been reported in the literature. As one of the major concerns of TCMs, hepatotoxicity has gained more and more attention recently. Currently, hundreds of TCMs or their extracts have been reported to possess potential hepatotoxicity [
7,
8,
9]. Several special databases focused on TCM-induced liver injuries also have been developed, such as Hepatox (
http://www.hepatox.org) and HDS hepatotoxicity databases [
10]. Additionally, in recent studies focused on the etiology of drug-induced liver injury (DILI) in several Asian countries, TCMs were found to be the leading induction factors of DILI [
11,
12]. TCMs with hepatotoxicity always resulted in severe clinical adverse events, such as liver fibrosis, hepatitis, liver failure, and even death [
13]. Therefore, studies focused on the hepatotoxicity of TCMs are urgent and imperative.
The identification of hepatotoxic ingredients is always the first step to exploring the hepatotoxicity of TCMs. Unlike the synthetic drugs, which generally produce their efficacy based on the theory of one drug and one target, the efficacy/toxicity of TCMs relies on the comprehensive effects of multiple ingredients, multiple targets, and multiple pathways [
14]. The molecular basis of a TCM is not a single chemical entity but the combination of many chemical ingredients. Therefore, it is difficult to unveil the mechanisms of TCMs solely based on the reductionism research strategies of Western medicine [
15]. Network pharmacology, a burgeoning new field, analyzes the mechanisms of drugs by integrating the complex interactions among drugs, genes, diseases, and any other relevant entities in biological systems comprehensively. The basic theory of network pharmacology is in accordance with the holistic idea of TCMs [
16].
During the last decade, network pharmacology has been applied to identify the active/toxic ingredients of many TCMs [
17,
18,
19]. Recently, taking
Polygonum multiflorum Thunb (PmT) as a case, Wang et al. proposed a pathway-based systems toxicology approach to understand TCM-induced liver injury [
20]. As a result, a total of 54 compounds were found to be associated with the hepatotoxicity of PmT. The top seven compounds consisted of luteolin, kaempferol, gallic acid, resveratrol, apigenin, quercetin, and emodin. The hepatotoxicity of emodin has been well documented in many studies [
21,
22,
23,
24,
25]. Luteolin was reported to cause cytotoxicity in primary rat hepatocytes at dosages of 50 μM or lower levels of concentration [
26]. Apigenin was found to can significantly increase the accumulation of lipid droplets and cause fatty liver disease [
27]. However, for the other four compounds, no direct evidence focused on their hepatotoxicity was retrieved. Inversely, all of those four compounds were reported to be promising hepatoprotectors [
28,
29,
30,
31,
32]. In another study, a similar phenomenon was observed. Based on the network pharmacology framework, the authors attempted to identify the potential hepatotoxic ingredients in Xiao-Chai-Hu-Tang. As a result, kaempferol and thymol exhibited the largest number of hepatotoxic targets connections [
33]. However, neither clinical cases nor scientific reports about the hepatotoxicity of those two compounds were available. In fact, both kaempferol and thymol could significantly attenuate the liver injury induced by several hepatotoxicants [
32,
34]. In the two representative cases mentioned above, one can easily find that those potential hepatotoxic compounds identified solely based on network pharmacology were the mixtures of beneficial and toxic ingredients. Therefore, to uncover the real hepatotoxic ingredients in TCMs, research focused on differentiating hepatotoxicants and non-hepatotoxicants is required.
Quantitative structure–activity relationship (QSAR) is aimed at correlating structure with activity [
35]. In recent years, it has been widely applied to assess the hepatotoxic risks of the synthetic drugs [
36,
37,
38]. However, QSAR research focused on evaluating the hepatotoxicity of TCMs is very rare. Huang et al. [
39], Shi et al. [
40], Liu et al. [
41], and Wu et al. [
42] have attempted to develop QSAR models to evaluate the hepatotoxic risks of ingredients from TCMs. However, all of those models were built solely based on the synthetic drugs. As we all know, the chemical environment of natural products is quite different from that of the synthetic drugs [
43,
44]. Therefore, in silico models developed solely based on the synthetic drugs are always not applicable to natural products. Based on the Liver Toxicity Knowledge Base, Zhao et al. [
45] and Ye et al. [
46] have attempted to develop QSAR models to evaluate the hepatotoxic risks of ingredients from TCMs. Although the training sets of those two studies were relatively small (
n ≤ 350), they still indicated that QSAR models developed based on both TCMs and the synthetic drugs outperformed those only relying on the synthetic drugs.
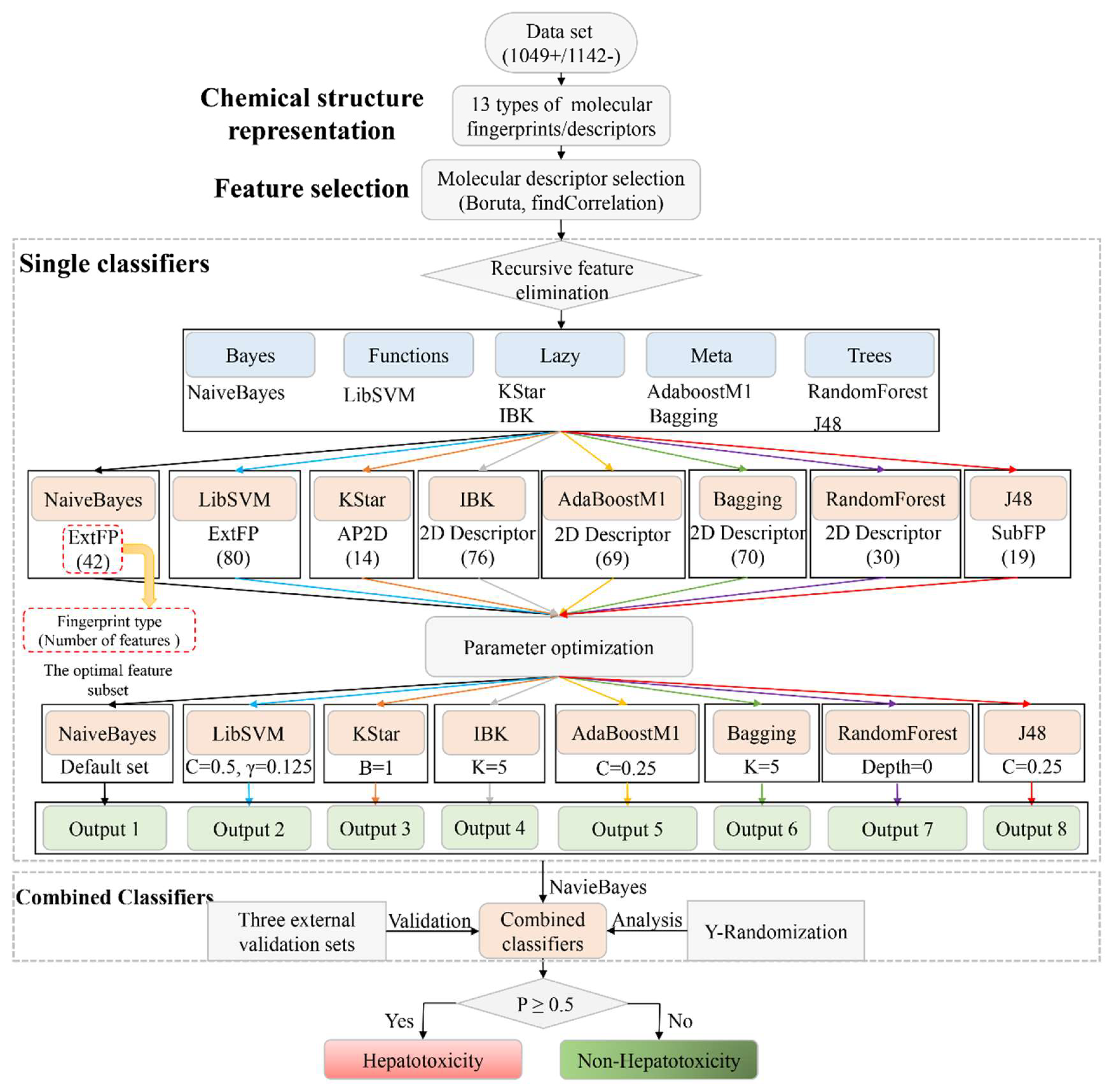
In our previous studies, we collected two hepatotoxic datasets, among which, one was specially focused on herb-induced liver injury (HILI) [
47,
48]. In the current study, by integrating those two datasets and Comparative Toxicogenomics Database (CTD), we built a novel hepatotoxic dataset. Then, we attempted to develop QSAR models to predict the hepatotoxic risks of compounds by incorporating the use of 13 types of molecular fingerprints/descriptors and eight machine learning algorithms (NaiveBayes, LibSVM, IBK, KStar, AdaboostM1, Bagging, J48, and RandomForest). The recursive feature elimination (RFE) method was utilized to identify the optimal feature subset of each machine learning algorithm. As a result, the best model of each machine learning algorithm was attained. We then used the NaiveBayes algorithm to develop a combined classifier based on the eight best single classifiers. By integrating the three external validation sets collected by Ai et al. [
37], Zhang et al. [
49], and Kotsampasakou et al. [
38], an integrated external validation set was acquired and utilized to test the reliability of the combined classifier. In addition, comparisons between the combined classifier and prior studies were conducted against the three external validation sets separately. Finally, taking PmT as a case, we proposed a computational toxicology approach to screen the hepatotoxic ingredients in TCMs by combining the combined classifier constructed in this work and the herb-hepatotoxic ingredient network and HILI dataset published in our prior studies [
47,
48].
4. Discussion
During the past few decades, a series of adverse effects caused by TCMs have been reported, among which hepatotoxicity is one of the major concerns. Identification of toxic ingredients is always considered to be the first step to illustrating the hepatotoxicity of TCMs. However, until now, an effective method to predict the hepatotoxicity of TCMs was unavailable. QSAR aims at finding the relationship between structure and activity/toxicity. In recent years, it has been widely used to predict the hepatotoxicity of the synthetic drugs. However, relevant research focused on TCMs is very rare. The major obstacle for such a situation is that dataset on the hepatotoxicity of TCMs is very limited. In our prior study, we collected a dataset on HILI, which laid the foundation for assessing the hepatotoxicity of TCMs based on the QSAR methods [
48].
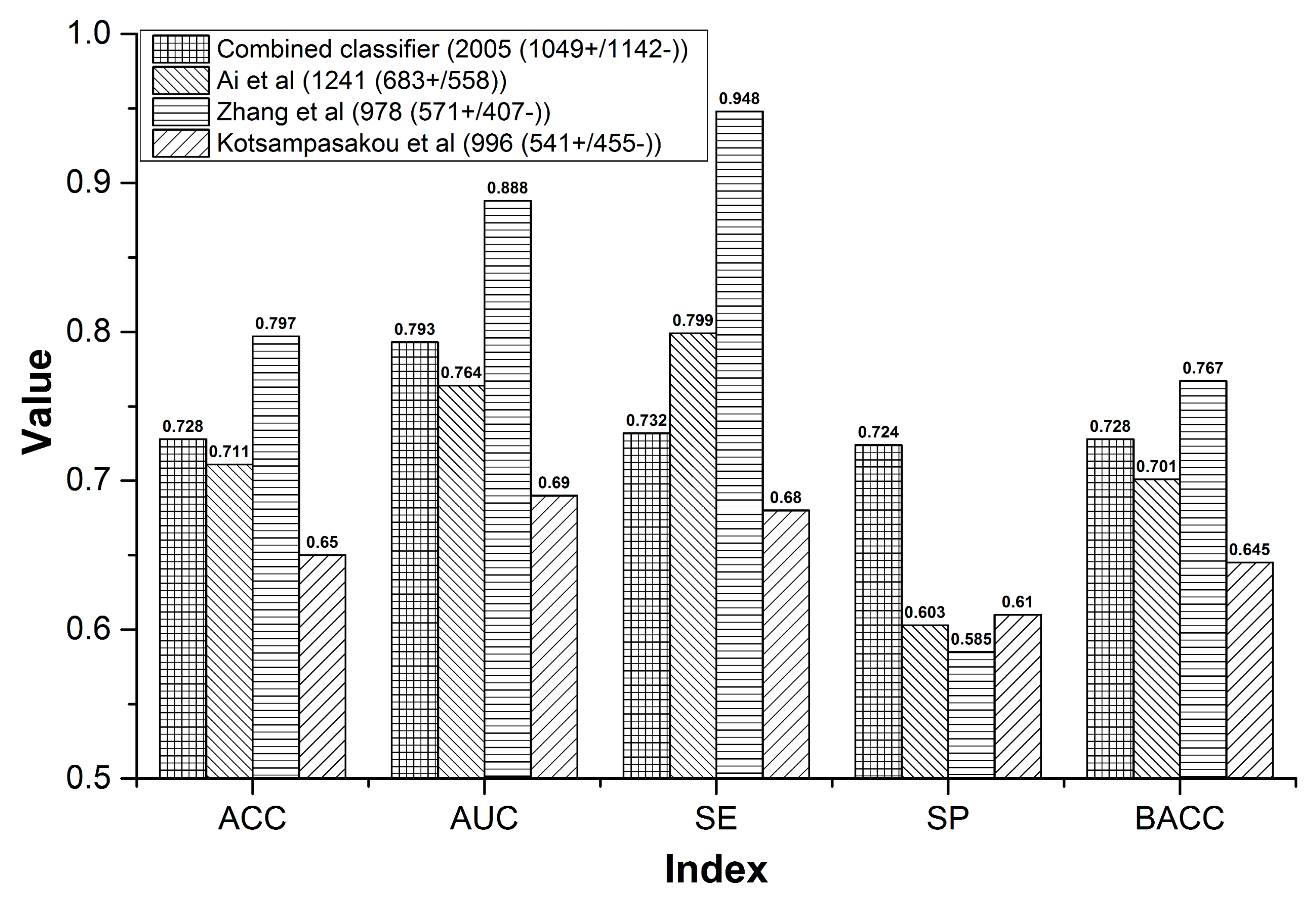
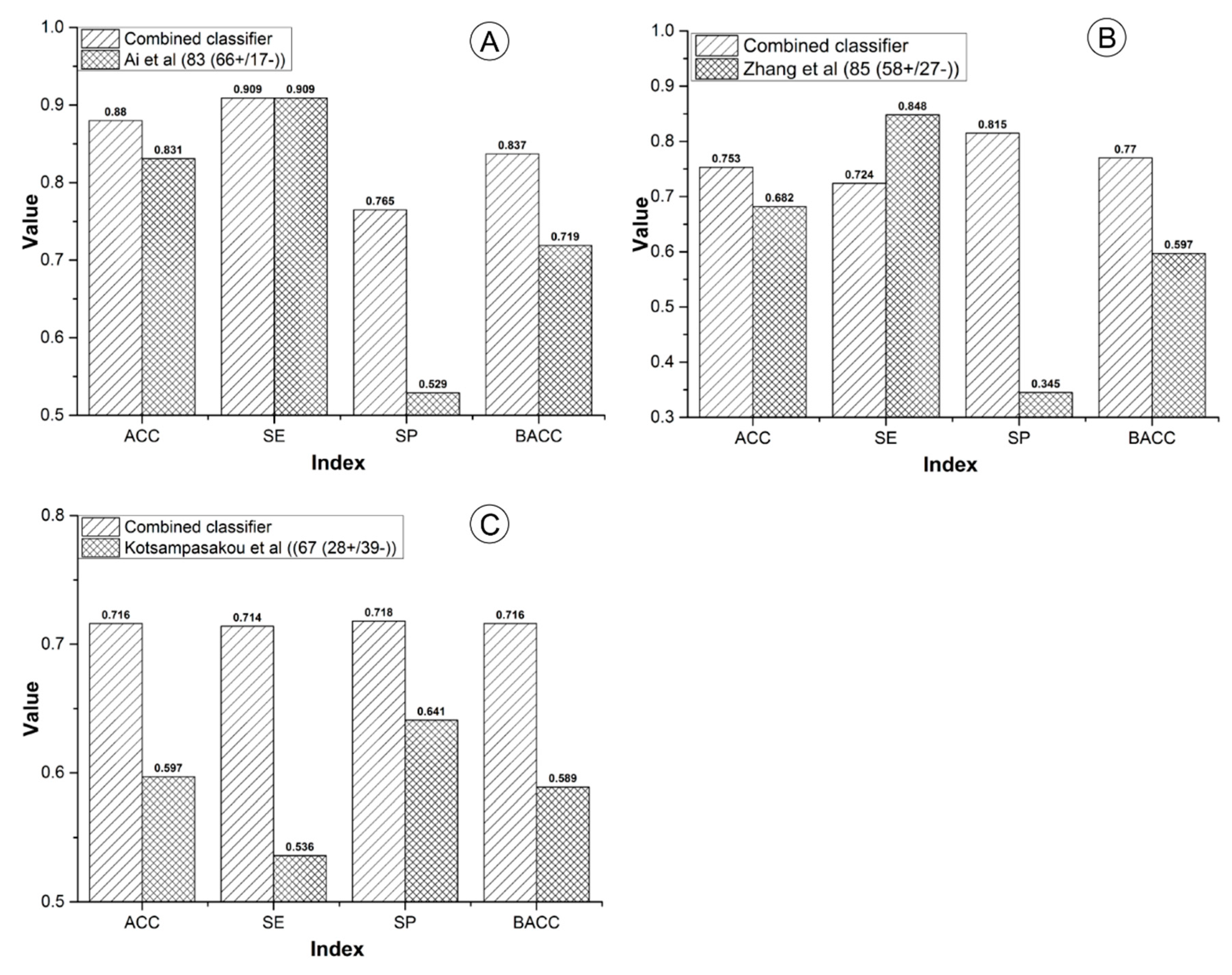
In this work, by utilizing eight machine learning algorithms and 13 types of molecular fingerprints/descriptors, a combined classifiers strategy was utilized to develop QSAR models for predicting the hepatotoxicity of TCMs. A total of 5416 single classifiers and one combined classifier were developed. For validation, an integrated external validation set was utilized to test the combined classifier. As a result, our combined classifier resulted in better performance than several prior studies both in cross validation and external validation. Within 10-fold cross validation, ACC of the combined classifier was 72.798, which was significantly higher than that of the Y-randomization model (ACC = 50.8507 ± 0.9103). The results mentioned above indicated that our combined classifier was stable and reliable. Another advantage of our combined classifier is the large scale of its training set. Our training set included 1049 positives and 1142 negatives. To the best of our knowledge, so large a DILI dataset is very rare. In addition, when predicting the hepatotoxicity of a compound, our combined classifier outputs the probability that the compound belongs to hepatotoxicants simultaneously. In this work, we set the threshold of the probability to 0.500. In other words, only those compounds with probabilities of hepatotoxicity greater than 0.500 would be categorized as hepatotoxicants, and all of the other compounds would be classified as non-hepatotoxicants. In practical applications, researchers can adjust the threshold of the probability according to their requirements. In our prior study, based on a training set consisting of 1254 compounds, we developed an in-silico model for predicting DILI by utilizing a voting method. Compared to our prior study, the advantages of this work include, but are not limited to, several aspects, as follows. Firstly, we built the combined classifier using 2191 unique compounds, 1.75 times more compounds than that used in our prior study. Secondly, a complex feature selection strategy was utilized to identify the optimal feature set for each machine learning algorithm. Thirdly, parameter optimization was performed in this work. Fourthly, the ACC, SE, SP, and BACC values of the combined classifier against the integrated external validation set were 78.922, 0.813, 0.750, and 0.782, which are higher than those of our prior work by 5.9%, 4.0%, 9.2%, and 6.6%, respectively.
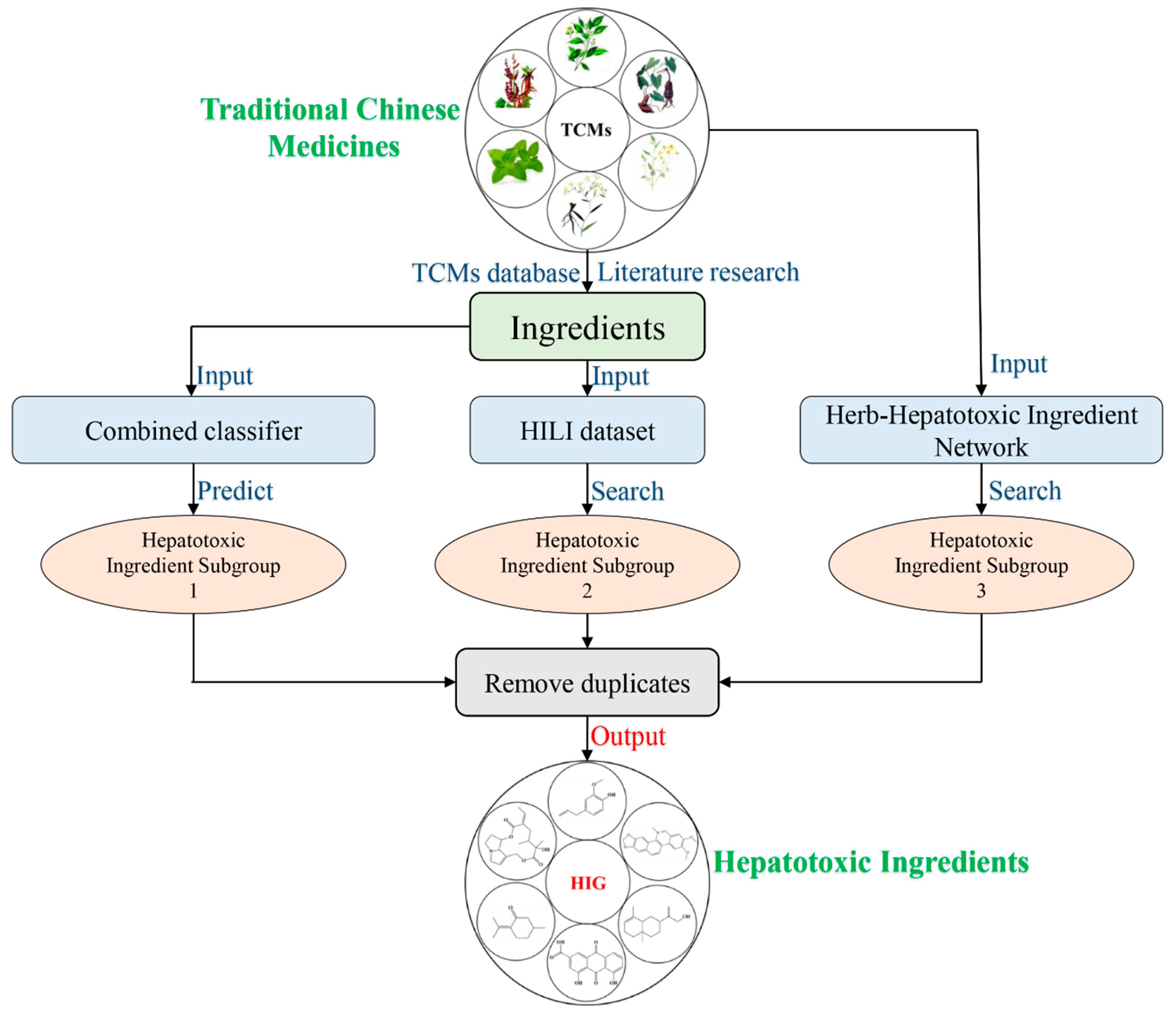
Relying on a pathway-based systems toxicology approach, Wang et al. attempted to explore the hepatotoxicity of Pmt [
20]. Firstly, the authors assessed the intestinal absorption properties of 98 compounds in PmT. Compounds with very poor intestinal absorption were discarded, and the remaining compounds were used for further analyses. Finally, a total of 44 compounds (
Figure 7, Wang “−”) with very poor intestinal absorption were filtered off, and the other 54 compounds (
Figure 7, Wang “+”) with good intestinal absorption were identified to be associated with the liver toxicity of PmT. In this work, taking PmT as a case, we proposed a computational toxicology approach to screen the heapotoxic ingredients in TCMs. The heapotoxic ingredients consisted of three heapotoxic ingredient subgroups which originated from the combined classifier, HILI dataset, and herb-hepatotoxic ingredient network, respectively. As a result, a total of 25 compounds in Pmt were identified as hepatotoxicants, among which 20 ingredients (
Figure 7, module 2) exhibited good intestinal absorption. For the 44 compounds with very poor intestinal absorption, only 2 (Module 1 in
Figure 7) of them were classified as hepatotoxicants. The most popular administration route of TCMs is oral administration. Therefore, chemical ingredients with good oral absorption are more likely to distribute in the liver and lead to liver injury. Therefore, we may speculate that screening focused on the oral absorption properties may help to narrow the range of screening hepatotoxic ingredients in TCMs. In introduction section, we highlighted that the potential hepatotoxicants identified by Wang et al. were the mixtures of toxic and beneficial ingredients. Thus, studies focused on differentiating hepatotoxicants and non-hepatotoxicants are required. In this work, for the 54 potential hepatotoxic compounds identified by Wang et al, twenty (
Figure 7, module 2) of them were identified as hepatotoxicants by our computational toxicology approach. According to records in the literature, eight (Emodin, chrysophanol, rhein, danthron, aloe emodin, luteolin, physcion, and apigenin) out of those 20 hepatotoxic ingredients could cause varying degrees of liver injury. For the other 12 hepatotoxic ingredients, although direct evidence focused on their hepatotoxicity was not available, no one of them was reported to be a potential hepatoprotector. For the 34 non-hepatotoxic compounds (
Figure 7, module 3), no direct evidence about their hepatotoxicity was retrieved. In addition, totals of 11 and one ingredients among these 34 non-hepatotoxic compounds were reported to be potential hepatoprotectors and a non-hepatotoxicant, respectively. Results provided by our integrated toxicity approach were highly consistent with reports in the literature. Summing up the above, we can conclude that the computational toxicity approach proposed in this work can differentiate non-hepatotoxic and hepatotoxic ingredients effectively. In addition, our computational toxicology approach also provided three (Chrysarobin, polygonumnolide C2, and emodin dianthrone) additional hepatotoxic ingredients in PmT which were not included in the 98 ingredients collected by Wang et al. Of note, among the 25 potential hepatotoxic ingredients in PmT, a total of 11 ingredients (
Table 5, 1–11) have been reported to possess potential liver toxicity in the literature. For the other 14 ingredients, their hepatotoxicity has not been investigated. Therefore, experimental verification focused on the hepatotoxicity of these potential hepatotoxic ingredients is urgently needed in the future.
The major limitation of the study is that the majority of the HILI data used in this work was derived from animal/cell experiments rather than clinical case reports. The reason for such a situation is that studies on most ingredients from TCMs are still at the stage of animal-testing. Therefore, clinical data for these ingredients are generally unavailable. Nevertheless, we cannot deny the value of these data. After all, animal/cell experiments are often necessary in the discovery and development phases of novel drugs. Generally, researchers test new therapies through animal studies, and drug candidates which exhibit the most significant efficacy are moved on to clinical trials. Therefore, we must acknowledge the value of animal/cell experiments. Of course, if the HILI data used in this work were clinical, the value of this work would be greatly enhanced.
In summary, the advantages of this work can be summarized as, but not limited to, the following several aspects: Firstly, a large scale and high quality dataset for DILI was built, which will be a valuable resource for modeling/data mining in the future. Secondly, QSAR models developed solely based on the synthetic drugs often failed to assess the hepatotoxicity of natural products. Hundreds of hepatotoxic/non-hepatotoxic ingredients from medicinal plants were added into the modeling dataset, which led to our combined classifier, applicable to both natural products and synthetic drugs. Thirdly, the computational toxicology approach proposed in this work will assist in the screening of the hepatotoxic ingredients in TCMs, which will further lay the foundation for exploring the hepatotoxic mechanisms of TCMs. In addition, the method proposed in this work can be applied to research focused on other adverse effects of TCMs/synthetic drugs.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}