
Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents


1
School of Integrated Technology, Gwangju Institute of Science and Technology, Gwangju 61005, Korea
2
Artificial Intelligence Graduate School, Gwangju Institute of Science and Technology, Gwangju 61005, Korea
*
Author to whom correspondence should be addressed.
Appl. Sci. 2021, 11(22), 10600; https://doi.org/10.3390/app112210600
Submission received: 5 October 2021
/
Revised: 29 October 2021
/
Accepted: 8 November 2021
/
Published: 11 November 2021
(This article belongs to the Special Issue Human-Computer Interaction: Theory and Practice)
Abstract
:By providing a high degree of freedom to explore information, QA (question and answer) agents in museums are expected to help visitors gain knowledge on a range of exhibits. Since information exploration with a QA agent often involves a series of interactions, proper guidance is required to support users as they find out what they want to know and broaden their knowledge. In this paper, we validate topic recommendation strategies of system-initiative QA agents that suggest multiple topics in different ways to influence users’ information exploration, and to help users proceed to deeper levels in topics on the same subject, to offer them topics on various subjects, or to provide them with selections at random. To examine how different recommendations influence users’ experience, we have conducted a user study with 50 participants which has shown that providing recommendations on various subjects expands their interest on subjects, supports longer conversations, and increases willingness to use QA agents in the future.
1. Introduction
With the growing expectations of a high degree of freedom in questioning, QA agents have been applied to various domains, such as education, financial services, and counseling [1,2,3]. Introducing QA agents to museums has been tried to help inform visitors of background knowledge and details about exhibitions [4,5]. Due to the enormity of cultural heritage digitally archived in museum collections, people find the exploration of such a huge repository of information to be intimidating and difficult. For this reason, QA agents are considered to be a reasonable solution to guide people in navigating these knowledge spaces effectively [6]. QA agents have been developed which can answer any question posed by users, but users still encounter the basic problem of not knowing what to ask. Human docents in museums often promote conversation by giving hints or guidance to stimulate visitors’ interest and provide a better understanding of exhibits [5,7]. Similarly, QA agents are required to interact with people in order to better explore cultural information [6].
QA agents in many contexts receive natural text input from users, and prior studies have mainly focused on improving the accuracy of how to understand the intention of users’ queries [8,9]. Such interaction with user initiative is appropriate when the user knows which questions to ask, but common users may find it burdensome to type proper questions that can be interpreted by the system [6,10]. For this reason, many applications in practice employ system-initiative QA agents, which includes, for example, interactions based on canned scripts, with agents proactively guiding users to explore the knowledge space. By taking the lead in its interaction with users, a QA agent can help them progressively navigate information by providing several options from which the users can choose [11]. In this paper, we design a system-initiative QA agent that provides information related to Asian contemporary culture and art. The agent proactively suggests several canned-script questions, and the user selects the most preferred one. The interaction continues with the repetition of suggestions, selections, and answers. The questions that the agent suggests are important for helping the user gradually proceed with information exploration in successive turns. The maintenance of context between agent and user is especially important in making the interaction informative and enjoyable [12]. The issues of maintaining context in the conversation has been relatively less studied, but we notice that people often discuss a series of similar topics [13]. Thus, we classified the knowledge base (comprised of question–answer pairs) based on levels, the difficulty of questions, and topics and categories of questions. We examine three strategies to compose the suggested questions for each turn: stressing the level, presenting more topics, and random suggestion. We conducted a user test with 50 participants to investigate the effect of level and topic in expanding users’ interest across topics, engaging them in information exploration, and their willingness to use QA agents in the future.
2. Related Works
2.1. Agent Initiative Strategies for Helping Users
Posing a question to a QA agent can be difficult for users without information or guidance, so the importance of giving hints or suggestions that make it “clear what to do” has been highlighted in previous studies [11,12]. These agent initiative strategies help users progress easily to subsequent turns by providing hints as to what they can do. For example, agents can notify users of their options at the beginning of their interaction [11] or suggest options in the event of a breakdown [14]. Such strategies include giving suggestions and constantly displaying general functions on buttons and cards [11]. These “clear what to do” strategies make users confident in proceeding with their information exploration and help to increase users’ trust, satisfaction, and willingness to continue using the agents [15,16,17]. However, these strategies can only help the conversation proceed by capturing or recovering attention in a single turn of question and answer. Moreover, information exploration is a subsequential process that requires context awareness for displaying information relevant to the user’s current task [10,12] and a proper guidance strategy to expand users’ knowledge [6].
2.2. Adapting the Scaffolding Method into the Subsequential Process of Information Exploration
Scaffolding refers to the pedagogical strategy devised by psychologist Lev Vygotsky [18]. In this theory, a scaffold is a kind of support that helps learners achieve goals which they cannot approach by themselves [18]. The central tenet of scaffolding theory is that learners and enabled to achieve a goal with the help of factors in learning, such as teachers, colleagues, or tools [19]. Prior works on computer-based learning with agents adopted the theory and its strategies for this reason [20,21], but early scaffolding theory as suggested by Vygotsky, which aimed to expand knowledge and interest from learners’ prior knowledge, deals with broader theoretical issues [22]. Previous studies tried to adopt it in practical fields, especially when investigating how to give guidance according to learners’ state of interest and comprehension [22,23]. Significantly, strategies were developed focusing on how to suggest a scaffold at the right relevance level and at the right moment [24]. Scaffolding also helps learners proceed with information exploration in a self-regulated way, whereby they can manipulate the process of learning according to their level of interest or state of understanding [24,25]. In this study, we adopt a scaffolding strategy used by teachers in classrooms and by docents in museums who give guidance and hints during conversations. Two orientations can be considered for suggesting guidance that can act as scaffolds in learning through conversation. The first one deepens the level related to the state of understanding, and the other one changes the subject according to users’ interests [22,26,27]. When developing QA agents for the study, we constructed the DB (database) in levels and subjects and designed topic recommendation strategies to direct QA agents to support users’ self-regulation during information exploration by giving recommendations as scaffolds.
3. Context-Based Database and Recommendation Strategies for QA Agents
3.1. Context-Based Database Construction
To facilitate users’ self-regulation during information exploration, we constructed the database (DB) for our QA agents with two contexts: levels and subjects. The construction of a DB with a sufficient level of complexity and subjects enables agents to map the process of information exploration. By doing so, agents can give recommendations according to the relevance of adjacent topics or deeper-level topics to the current location in the knowledge space. The levels indicate the users’ degree of understanding of subjects, while subjects indicate the elemental content in the domain. In this knowledge space, we anticipated that users can choose questions in a self-regulated way based on their comprehension and interests.
We classified the six levels according to Bloom’s taxonomy, which classifies educational objectives into levels of complexity [28]. It covers low-level educational objectives, such as factual knowledge (e.g., name, location, or year) all the way to high-level knowledge, such as meta-knowledge, e.g., comparison with other points of view [29]. Bloom’s taxonomy is used in educational fields because its classification of knowledge helps teachers deliver appropriate instruction [29]. We classified the adjacent subjects as themes based on the knowledge graph of the anonymized institution’s archive page, which contains an array of content, including background knowledge of historical events of contemporary Asia and information on the character of its architecture, urban culture, and popular culture [30]. The database configurations are shown in Figure 1. Each DB set has three themes―for example, (1) contemporary Asian architecture, (2) urban life in Asian cities and (3) Asian cinema―and two subjects for each theme―for example, the subjects of the theme “contemporary Asian architecture” are (1) styles of contemporary Asian architecture and (2) the effects of government development initiatives on contemporary Asian architecture. Six subjects were therefore constructed for each DB set. While levels and subjects are classified into six layers, we constructed 36 topics for each agent, so the maximum number of turns is 36.
3.2. Show Me the Way: Topic-Recommendation Strategies
To evaluate the effects on the process of information exploration with QA agents according to given recommendations, we designed context-based topic recommendation strategies. When our QA agent suggests four candidate questions from a pool of potential questions, it considers the level and subject of the questions. Among the suggested questions, the user may select one in a self-regulated way.
3.2.1. Depth-Oriented Strategy
The depth-oriented strategy is designed to help users manipulate the process of exploration with the self-regulation of levels according to their understanding of subjects. We expected that this would make them engage more consistently with subjects, so it provides two selections from two upper-level topics from the current position, one selection from a lower-level topic and the other from the same level (See Figure 2a). When a level five or six topic is reached, the selection that yields a higher topic gives a level one topic from the next subject.
3.2.2. Various Subjects Strategy
The various subjects strategy focuses on self-regulation according to users’ interests, where we designed it to allow users to switch subjects easily. As shown in Figure 2b, selections consist of two adjacent subjects at the same level as the current position and one higher- and lower-level topic in the same subject from the current position. When it reaches a level six topic, the selection that yields a higher topic gives a level one topic from the next subject.
3.2.3. Random
For comparison with the context-based recommendation strategies, we also developed a QA agent that gives selections randomly. It gives four selections randomly without considering topics that users have already chosen and examined the answers for (see Figure 2c).
4. Methodology
To see the effects of the topic recommendation strategies, we conducted a model comparison user test. We recruited 50 participants (25 males and 25 females) of ages ranging from 19 to 33 (M = 24.36) years. Due to COVID-19 and enhanced precautions against the pandemic, 20 participants took the test live in the laboratory and 30 participants took the test online. Note that we confirm that there is no significant difference between them. Table 1 shows the participant’s demographic information. The experiment was conducted mostly on people who have never visited the museum or who are not familiar with it. Therefore, the possibility that prior knowledge would affect the experimental results was excluded. To provide background, the participants watched a video depicting a virtual tour of the museum which gave them context of the QA agents on the day before the test. Then they checked the topics in which they were interested and wanted to know more about. In the main study, the participants took a model comparison test. In the model comparison, the number of times the user checked the question–answer set was regarded as a turn taken, and the results of logging were compared. The order of agents differed among participants and the DB sets were allocated differently from among three DB sets. To compare the engagement with the agents, participants were told that they could finish their information exploration with the agents whenever they wanted by clicking the finish button, which was displayed along with the four suggested selections at every turn. After finishing with the QA agents, they took a survey based on the technology acceptance model (TAM) [30]. In addition, the participants had to check the topics in which they were newly interested or wanted to see related exhibits of. The user test took 40 min on average, and each participant was compensated $10 for his/her time. The overall process, including the experimental setting, user study procedure, and results analysis, is visualized in Figure 3.
5. Result
5.1. Questionnaire Analysis
The TAM evaluates a user’s acceptance based on three sections: perceived usefulness, perceived ease of use, and intention to use [30]. The questionnaire and its results are shown in Table 2. For all participants, there was no significant difference between giving depth-oriented options and giving options from various subjects. We notated mean value with M and standard deviation with SD. Against the random strategy (M = 3.56, SD = 1.265), specifically, both the depth-oriented strategy (M = 3.96, SD = 0.879; p < 0.05) and strategy of various subjects (M = 4.02, SD = 1.059; p < 0.05) resulted in participants wanting to visit the museum, and to explore the information introduced by the agents in general (Q12). Participants recognized that the depth-oriented strategy was better than that of the random one for three reasons (Q1, Q5, Q9). Moreover, all three of these reasons were related to the participants’ self-regulated choosing of questions from given selections. In the case of selections given from various subjects, participants replied that it was better than the random strategy for two reasons (Q3, Q4). Q3′s result is related to the will to explore more information. Q4′s results signified that participants’ exploration of diverse subjects (M = 3.86, SD = 0.947) made them feel more knowledgeable about the subject compared to the random strategy (M = 3.28, SD = 1.143; p < 0.01).
In addition, we divided all the participants into three groups according to model preference. We scored the preference of each participant by the sum of their “willingness to use” (Q10, Q11, Q12). We named them: ‘Keep going’ (a group of 25 participants who preferred the depth-oriented model), ‘What else’ (a group of 31 participants who preferred the various subjects model), and ‘Whatever’ (a group of 23 participants who preferred the random model) for each group. There were tied scores between models for individual participants (15 tied scores between the depth-oriented and various subjects models, 13 between the depth-oriented and random models, and 11 between the various subjects and random models), and we excluded ties from the analysis on each preference group. ‘Keep going’ had a strong preference for depth-oriented exploration over the others (Q3) and they felt that agents with other strategies do not reflect well what they wanted to ask (Q8). Moreover, ‘Keep going’ felt easy about selecting next turns from depth-oriented (M = 4.1, SD = 0.737) rather than various subjects (M = 3.1, SD = 0.875; p < 0.01) models (Q9). For ‘What else,’ significant differences between various subjects and others were related to helping the information exploration with focused subjects (Q1) and the ease of selecting the next turns (Q9). Moreover, they responded that the various-subjects model (M = 3.777, SD = 0.666) helped them get to know subjects on a deeper level than the depth-oriented model (M = 3.222, SD = 0.441; p < 0.05) (Q4). Aside from the differences between context-based strategies, ‘Whatever’ show significant differences between random and others in the perceived ease of use section. They responded that others suggested more difficult questions than they expected (Q6) and that randomly given suggestions reflected well what they wanted to know (Q5) and that it was easy to select questions for the next turns (Q9).
5.2. Search Behavior Analysis
5.2.1. Exploration on the Same Subject
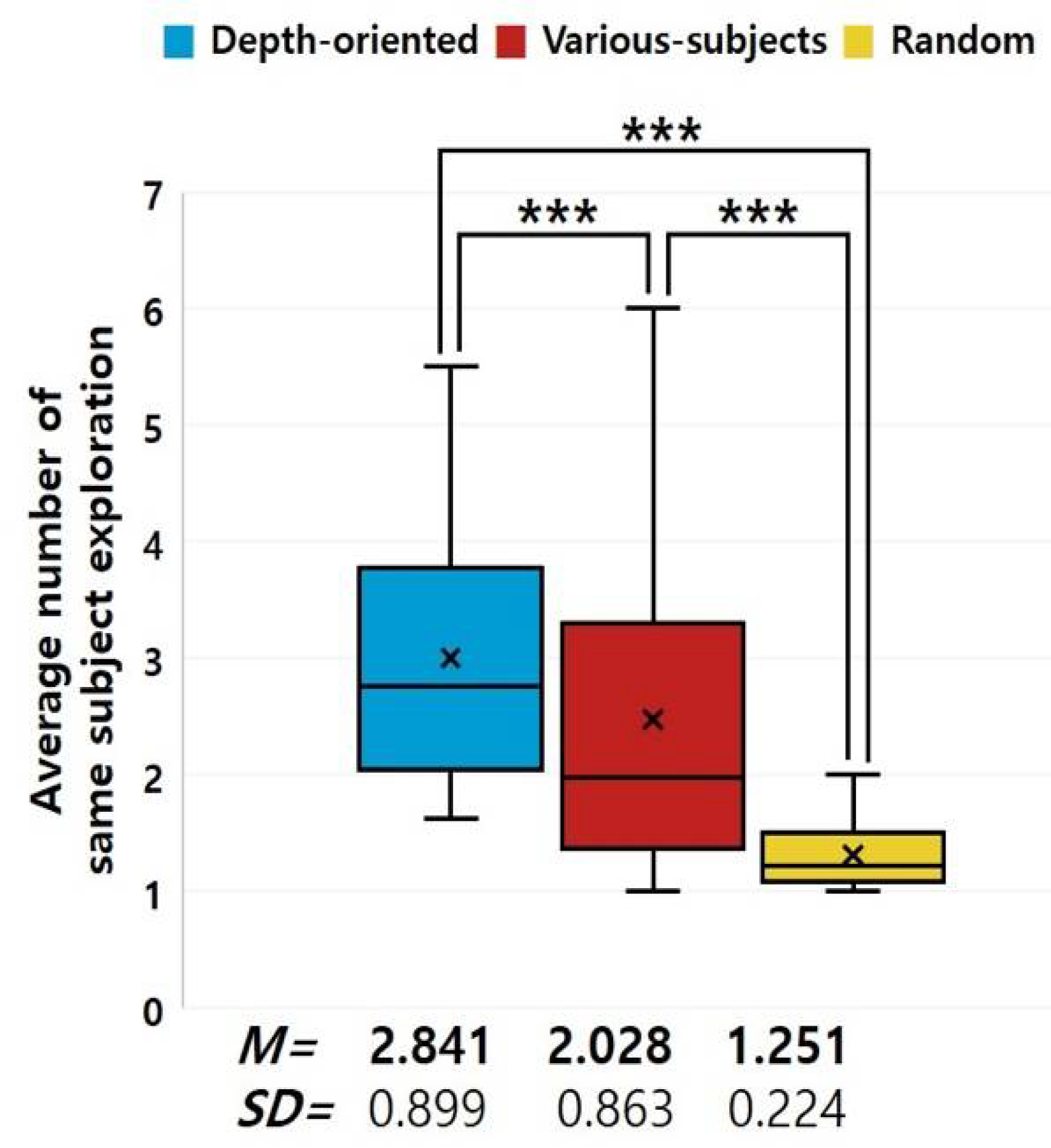
For how many turns did users continue with questions on the same subjects? We compared the average number of questions selected from the same subjects for each strategy. As shown in Figure 4, both the depth-oriented (M = 2.841, SD = 0.899) and various subjects (M = 2.028, SD = 0.863) models led to more same-subject exploration than the random model (M = 1.251, SD = 0.224; p < 0.001). Users also recognized that they maintained the same subjects more according to the questionnaire (Q1). The replies for the depth-oriented model were significantly higher than that of the random model. Even in each of the three preference groups, we found out that the depth-oriented model led to greater subsequent same-subject exploration than others. However, users from each group replied to Q1 that they perceived that their preferred strategy helped with same-subject exploration the most.
5.2.2. Analysis of Topic Precision
To evaluate the precision rate of the strategies for increasing self-regulation according to users’ interests, we analyzed the proportion of selected questions that paralleled the topics that users stated that they were interested in during their exploration. According to the results shown in Figure 5, topics from the various subjects model (M = 51.33, SD = 24.082) afforded users more ease to explore their topics of interest than both the depth-oriented (M = 43.42, SD = 27.172; p < 0.01) and random (M = 35.71, SD = 21.96; p < 0.001) strategies. The depth-oriented model still gave better interest-based selections than that of the random model (p < 0.05). However, the users’ feedback was slightly different than the precision rate analysis. In the results of Q5, “Composition of selections were well reflected with what I want to ask,” the only significant result found was in the comparison between the depth-oriented and random models (p < 0.01). For each preference group, the only significant differences were that the various subjects model give more chances of exploration based on users’ interests than that of the random model from ‘What else’ (p < 0.001) or ‘Whatever’ (p < 0.01). Nevertheless, ‘Whatever’ still felt that randomly given selections (M = 4, SD = 0.707) reflected their interests better than the depth-oriented (M = 3.222, SD = 0.971; p < 0.05) and various subjects (M = 3.09, SD = 0.943; p < 0.05) models (Q5). The analysis of the precision rate shows that giving selections from various subjects helps the exploration of what users wanted to ask before.
5.2.3. Analysis of Topic Exploration
To find out when users showed high engagement with agents, we compared the average number of turns taken (see Figure 6). More turn taking means users explore more topics with agents, which increases their chance of exploring all topics. For the various subjects model (M = 19.46, SD = 10.526), all participants proceeded with more turn taking compared to the random model (M = 17.02, SD = 9.5333; p < 0.05), but no statistical significance is shown for differences with the depth-oriented model (M = 18.4, SD = 9.8). From the perceived usefulness section, users perceived that suggestions made by the various subjects model made them proceed with more exploration (Q3) than the suggestions made by the random model (p < 0.05). Additionally, we evaluated the correlation between the preference of strategy and the turn taking number by group. Although there were no significant differences between strategies for each group, we found that users explored more with their preferred strategy, with the exception of one case in ‘What else’. In addition, users also replied that their preferred strategy made them proceed with more exploration (Q3). Significantly, ‘Keep going’ perceived that suggestions from the depth-oriented model made them proceed with more exploration than the various subjects (p < 0.01) and random (p < 0.01) models. Moreover, ‘What else’ recognized that suggestions from the various subjects model made them want to explore more than the random model (p < 0.001).
To see which factors affect the turn taking number, we conducted a survey on why users stopped information exploration after using each agent. In general, participants stopped the interaction because the agent did not suggest what they want to know in selections (27% on average). Users felt fatigue during exploration with the random model (18%) more than with the depth-oriented (4%; p < 0.01) and various subjects (6%; p < 0.05) models. This interview shows that this is related to the absence of context awareness for selections:
“Unlike other agents, in this case (using random), most of the questions that gave selections were not related to subjects that I have explored. And some questions were from subjects that I explored already. It made it difficult to choose questions for the next-turn.”—a ‘What else’ user.
Therefore, for engagement in information exploration with QA agents, giving random recommendations can make users confused, and can cause fatigue, which makes them quit earlier.
5.2.4. Analysis of Topic Introduction
To measure which recommendation strategy helped users to expand their interests, as aligned with the scaffolding method, we compared the ‘newly interested in’ topics for each QA agent as shown in Figure 7. ‘Newly interested in’ topics are defined as topics that were not in the ‘interested in’ topics that were subsequently explored and checked as ‘interested in’ topics after using the agents. For the various subjects model (M = 35.547, SD = 29.416), users became interested in new topics more than with the depth-oriented (M = 27.255, SD = 26.674; p < 0.05) and random (M = 25.398, SD = 24.869; p < 0.05) models. From the precision rates in Figure 5, we can assume that showing suggestions randomly has a higher chance of topic exploration for topics that were not in the users’ interests. However, this may lead to users choosing the new topics with little purpose.
6. Conclusions
In this paper, we compared different QA agent recommendation strategies for information exploration. The depth-oriented and various subjects strategies showed better performance metrics than that of giving recommendations randomly. The depth-oriented strategy was better for self-regulated information exploration, while the various subjects strategy showed better results in information exploration more related to expanding one’s interests in different subjects, aligned with the scaffolding method.
While evaluating how recommendation strategies affect users’ search behavior, we ran into a few limitations. In terms of the depth-oriented strategy and various subjects strategy, some of the participants barely noticed the differences between the two strategies. Three out of four selections of the two strategies are the same, thus we may need to emphasize the feature of each strategy, e.g., the depth-oriented strategy suggests topics of the same subject only, and the various subjects model suggests topics of the same level only. We had another limitation related to the environment and circumstances. Due to the COVID-19 pandemic and enhanced precautions, we were unable to test our QA agents in a real museum that is physically related to the information recommended by the QA agents. In the future, we hope that we can conduct further studies by using QA agents in coordination with a real museum.
Author Contributions
Conceptualization, J.-H.H.; Formal analysis, A.D.-Y.Y.; Methodology, J.-H.H.; Software, Y.-G.N.; Supervision, J.-H.H.; Validation, A.D.-Y.Y.; Writing—original draft, A.D.-Y.Y.; Writing—review&editing, Y.-G.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported the National Research Foundation of Korea (NRF) and funded by the MSIT (2021R1A4A1030075).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mendonça, V.; Melo, F.S.; Coheur, L.; Sardinha, A. A Conversational Agent Powered by Online Learning. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, Richland, SC, USA, 8–12 May 2017; pp. 1637–1639. [Google Scholar]
- Li, C.-H.; Yeh, S.-F.; Chang, T.-J.; Tsai, M.-H.; Chen, K.; Chang, Y.-J. A Conversation Analysis of Non-Progress and Coping Strategies with a Banking Task-Oriented Chatbot. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Hu, T.; Xu, A.; Liu, Z.; You, Q.; Guo, Y.; Sinha, V.; Luo, J.; Akkiraju, R. Touch Your Heart: A Tone-aware Chatbot for Customer Care on Social Media. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Kopp, S.; Gesellensetter, L.; Krämer, N.C.; Wachsmuth, I. A conversational agent as museum guide: Design and evaluation of a real-world application. In Proceedings of the Advances in Autonomous Robotics, Kos, Greece, 12–14 September 2005; pp. 329–343. [Google Scholar]
- Schaffer, S.; Gustke, O.; Oldemeier, J.; Reithinger, N. Toward chatbot in the museum. In Proceedings of the 2nd Workshop on Mobile Access to Cultural Heritage, Barcelona, Spain, 3 September 2018; pp. 1–10. [Google Scholar]
- Machidon, O.-M.; Tavčar, A.; Gams, M.; Duguleană, M. CulturalERICA: A conversational agent improving the exploration of European cultural heritage. J. Cult. Herit. 2020, 41, 152–165. [Google Scholar] [CrossRef]
- Grinder, A.L.; McCoy, E.S. The Good Guide: A Sourcebook for Interpreters, Docents, and Tour Guides; Ironwood Press: Schottsdale, AZ, USA, 1985. [Google Scholar]
- Ronbinson, S.; Traum, D.R.; Ittycheriah, M.; Henderer, J. What would you Ask a conversational Agent? Observations of Human-Agent Dialogues in a Museum Setting. In Proceedings of the Sixth International Conference on Language Resources and Evaluation, Marrakech, Morocco, 28–30 May 2008; pp. 1125–1131. [Google Scholar]
- Liao, Q.V.; Mas-ud Hussain, M.; Chandar, P.; Davis, M.; Khazaeni, Y.; Crasso, M.P.; Wang, D.; Muller, M.; Shami, N.S.; Geyer, W. All Work and No Play? In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Gregory, D.; Anind, A.; Dey, K.; Peter, J.; Nigel Davies, B.; Smith, M.; Steggles, P. Towards a Better Understanding of Context and Context-Awareness. In Proceedings of the 1st international symposium on Handheld and Ubiquitous Computing, Karlsruhe, Germany, 27–29 September 1999; pp. 304–307. [Google Scholar]
- Francisco, A.M.; Tatiane, V.; Guimarães, G.; Prates, R.O.; Candello, H. Here’s What I Can Do: Chatbots’ Strategies to Convey Their Features to Users. In Proceedings of the XVI Brazilian Symposium on Human Factors in Computing Systems, Joinville, Brazil, 23–27 October 2017; pp. 1–10. [Google Scholar]
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for Human-AI Interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Walker, J.P.; Walker, M.I. Centering Theory in Discourse; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Ashktorab, Z.; Jain, M.; Liao, Q.V.; Weisz, J.D. Resilient Chatbots: Repair Strategy Preferences for Conversational Breakdowns. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Jain, M.; Kumar, P.; Kota, R.; Patel, S.N. Evaluating and Informing the Design of Chatbots. In Proceedings of the 2018 Designing Interactive Systems Conference, Hong Kong, China, 8 June 2018; pp. 895–906. [Google Scholar]
- Lee, M.K.; Kielser, S.; Forlizzi, J.; Srinivasa, S.; Rybski, P. Gracefully mitigating breakdowns in robotic services. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), Osaka, Japan, 22 April 2010; pp. 203–210. [Google Scholar]
- Thies, I.M.; Menon, N.; Magapu, S.; Subramony, M.; O’Neill, J. How do you want your chatbot? An exploratory Wizard-of-Oz study with young, urban Indians. In Proceedings of the Advances in Autonomous Robotics, Mumbai, India, 20 September 2017; pp. 441–459. [Google Scholar]
- Vygotsky, L.S. Mind in Society: The Development of Higher Psychological Processes; Harvard University Press: Cambridge, MA, USA, 1980. [Google Scholar]
- van de Pol, J.; Volman, M.; Oort, F.; Beishuizen, J. Teacher scaffolding in small-group work: An intervention study. J. Learn. Sci. 2014, 23, 600–650. [Google Scholar] [CrossRef]
- Winkler, R.; Hobert, S.; Salovaara, A.; Söllner, M.; Leimeister, J.M. Sara, the Lecturer: Improving Learning in Online Education with a Scaffolding-Based Conversational Agent. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 21 April 2020; pp. 1–14. [Google Scholar]
- Griol, D.; Callejas, Z. An Architecture to Develop Multimodal Educative Applications with Chatbots. Int. J. Adv. Robot. Syst. 2013, 10, 175. [Google Scholar] [CrossRef] [Green Version]
- van de Pol, J.; Elbers, E. Scaffolding student learning: A micro-analysis of teacher–student interaction. Learn. Cult. Soc. Interact. 2013, 2, 32–41. [Google Scholar] [CrossRef]
- Gonda, D.E.; Luo, J.; Wong, Y.-L.; Lei, C.-U. Evaluation of Developing Educational Chatbots Based on the Seven Principles for Good Teaching. In Proceedings of the 2018 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Wollongon, Australia, 4–7 December 2018; pp. 446–453. [Google Scholar]
- Delen, E.; Liew, J.; Willson, V. Effects of interactivity and instructional scaffolding on learning: Self-regulation in online video-based environments. Comput. Educ. 2014, 78, 312–320. [Google Scholar] [CrossRef]
- Azevedo, R.; Hadwin, A.F. Scaffolding Self-regulated Learning and Metacognition—Implications for the Design of Computer-based Scaffolds. Instr. Sci. 2005, 33, 367–379. [Google Scholar] [CrossRef]
- Graves, M.F. Scaffolded Reading Experiences for Inclusive Classes. Educ. Leadersh. 1996, 53, 14–16. [Google Scholar]
- Wood, D.; Bruner, J.S.; Ross, G. The Role of Tutoring in Problem Solving. J. Child Psychol. Psychiatry 1976, 17, 89–100. [Google Scholar] [CrossRef] [PubMed]
- Bloom, B.S. Taxonomy of Educational Objectives, Handbook 1: Cognitive Domain, 2nd ed.; David McKay Company: New York, NY, USA, 1956. [Google Scholar]
- Asia Culture Archive of Asia Culture Center. Available online: http://archive.acc.go.kr/ (accessed on 8 November 2021).
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Data configuration: theme and subject.

Figure 2.
Examples of recommendations presented by the three strategies.

Figure 3.
Experiment process flowchart.

Figure 4.
Comparison of information exploration for the same subject.

Figure 5.
Precision rate of prior interested topic selected during the turn taking process.

Figure 6.
Average turn taking number by each model.

Figure 7.
Proportion of newly introduced topics that QA agents sparked interest in for users.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Participants’ demographic and background information.
| Mode | Percentage | ||
|---|---|---|---|
| Gender | |||
| Male | 25 | 50 | |
| Female | 25 | 50 | |
| Visit Experience of Anonymised Museum | |||
| Never visited | 39 | 78 | |
| 1 to 3 times | 7 | 14 | |
| Above 4 times | 4 | 8 | |
| The Frequency of Visiting Museum | |||
| Once a month | 0 | 0 | |
| Once every 2–3 months. | 8 | 16 | |
| Once every 6 months. | 9 | 18 | |
| Once a year | 17 | 34 | |
| Less than once a year. | 16 | 32 | |
| The Purpose of Visiting Museum | (Duplicate check allowed) | ||
| To consume exciting content | 38 | 76 | |
| To share own feelings with company | 27 | 54 | |
| To acquire knowledge | 13 | 26 | |
| To get some ideas from museum | 20 | 40 | |
| To appreciate the exhibits and relax | 36 | 72 |
Table 2.
Results from questionnaire after using each model.
| TAM Sections | No. | Questionnaires | All Participants (n = 50) | Keep Going (n = 25) | What Else (n = 31) | Whatever (n = 23) |
|---|---|---|---|---|---|---|
| Perceived Usefulness | 1 | Selections help the subsequential information exploration with themes I focused on |  |  |  | A>C>B |
| 2 | Selections help to explore topics with various subjects | B>A>C | A=B>C | B>A=C | B=C>A | |
| 3 | Suggested selections make me want to explore more turns |  |  |  | C>A>B | |
| 4 | By using the agent, I explored subjects profoundly |  |  |  | B>C>A | |
| Perceived Easy of Use | 5 | Questions in suggested selections reflected well what I want to ask |  |  | B>A>C | C>B=A |
| 6 | Questions in suggested selections were difficult than what I wanted to ask | B>C>A | A>B>C | C>B>A | A>B>C | |
| 7 | Questions in suggested selections were easier than what I wanted to ask | A>B>C |  |  | A>B=C | |
| 8 | There were times that I wanted to ask other questions than that of suggested selections | C>B>A |  |  | C>A>B | |
| 9 | It was easy to choose questions for the next turns |  |  |  | C>A>B | |
| Intention to Use | 10 | Want to use the QA agent when I visit the museum | B>A>C |  |  |  |
| 11 | Want to recommend the QA agent to acquaintances who will visit the exhibition | B>A>C |  |  |  | |
| 12 | Want to visit the exhibition related with subjects I explored with the QA agent |  |  |  |  |
Notes: A, B, and C in the table refer depth-oriented, various subjects, and random strategies, respectively (*: p < 0.05, **: p < 0.01, ***: p < 0.001).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yang, A.D.-Y.; Noh, Y.-G.; Hong, J.-H. Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents. Appl. Sci. 2021, 11, 10600. https://doi.org/10.3390/app112210600
AMA Style
Yang AD-Y, Noh Y-G, Hong J-H. Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents. Applied Sciences. 2021; 11(22):10600. https://doi.org/10.3390/app112210600
Chicago/Turabian StyleYang, Albert Deok-Young, Yeo-Gyeong Noh, and Jin-Hyuk Hong. 2021. "Topic Recommendation to Expand Knowledge and Interest in Question-and-Answer Agents" Applied Sciences 11, no. 22: 10600. https://doi.org/10.3390/app112210600
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.