1. Introduction
Energy management plays an important role in buildings nowadays, and its interest is still rising [
1,
2,
3,
4,
5], as more and different types of sensors are being installed in existent buildings, or form part of projects when designing new buildings. Automatic meter readings are now installed in key locations of many new and retrofitted buildings, collecting information for intelligent decision making, providing different types of energy disaggregation in different building areas, and enabling access to high resolution data (half-hourly, quarter-hourly, or possibly even smaller periods).
In order to take advantage of available consumption data being continuously accessed through the Building Management Systems (BMS), new strategies should be designed to better analyze the incoming data [
6]. These types of analyses could be providential to better accompany consumptions trends, to project the effect of demand-side actions and even to rapidly identify untypical consumption patterns (operation alarmistic purposes) [
1,
5]. The accomplishment of the targets and requirements towards the implementation of neutral or positive energy buildings will also benefit from the analysis of data gathered from existing buildings to improve their design and operation [
7].
The ambition of achieving energy neutrality of a building goes beyond the improvements of energy efficient use. Energy neutrality requires that the efforts towards a better use of energy resources are complemented with the possibility of in situ renewable primary energy conversion [
8]. Feasibility studies concerning the optimized operation of renewable energy generation and efficient use of resources, including economic constraints, are needed for adequate design of nearly zero energy buildings. Often, this type of analysis requires significant computation resources, which could consequently led to long computation times, thus data-driven approaches play an important role in predicting buildings’ energy performance [
9,
10].
Mathematical models have been proposed for different applications, such as load forecasting, load profiling, load disaggregation, and anomalous consumption detection. Regarding forecasting purposes, the models can be divided into more conventional statistical approaches (linear, polynomial, and autoregressive integrated moving average (ARIMA) methods) or the latest and popular approaches based on machine learning (such as artificial neural networks and support vector regression) [
4,
5,
11,
12]. It is widely recognized that the use of building energy performance simulation software (such as
EnergyPlus) is widely disseminated [
2,
4], mainly to obtain an estimate of the consumption when buildings are being designed. With accurate parametrization, it is then possible to infer the influence of different passive elements (walls, glazing, insulation materials, natural ventilation…) and their features in the building’s energy consumptions. Furthermore, it is also quite relevant to evaluate the impact of the choice of technology for active elements (cooling and heating systems, water heating systems, lighting systems, etc.) in energy vector consumptions, as well. Building energy simulation tools can also be used when the buildings are being operated, in order to enable building benchmark comparisons to other, similar buildings, or to compare adopted parameter setups and setpoints (e.g., temperature), to support energy certification processes, or even to evaluate energy savings and environmental benefits to be obtained through demand-side actions for projected scenarios [
1]. One of the main constraints when applying these simulation tools to existent buildings is the calibration process, which mainly consists of suitable parametrization of the simulation inputs. These could be both static information, such as the building location and orientation, building envelope and adopted technology (façades, windows, thermal insulation, heating and cooling systems, lighting systems), and dynamic information, dependent on the use of the building (occupancy profile, lighting profile or heating, ventilation and air conditioning (HVAC) temperature setups). All these types of parameters must be carefully introduced, in order to get a suitable calibration that becomes validated when the simulated consumption strongly matches the actual, measured consumption. A considerable training of the user to deal with the specificities of each simulation software is an additional requirement, often pointed out as a non-negligible challenge. When incorporating exogenous variables, such as weather conditions, a careful sensitivity analysis of the influence of these variables in the energy consumptions must be undertaken, as the simulation takes into account several characteristics that can interfere in these interconnections (as the heat transmission coefficient for different surfaces, or even the effects of shadings or infiltrations that can distort the expected behavior). These relationships are expected to be easily and quickly obtained through the use of data-driven methods anchored on large historical databases, and also online or periodic training could help to follow subtle variations along the building use.
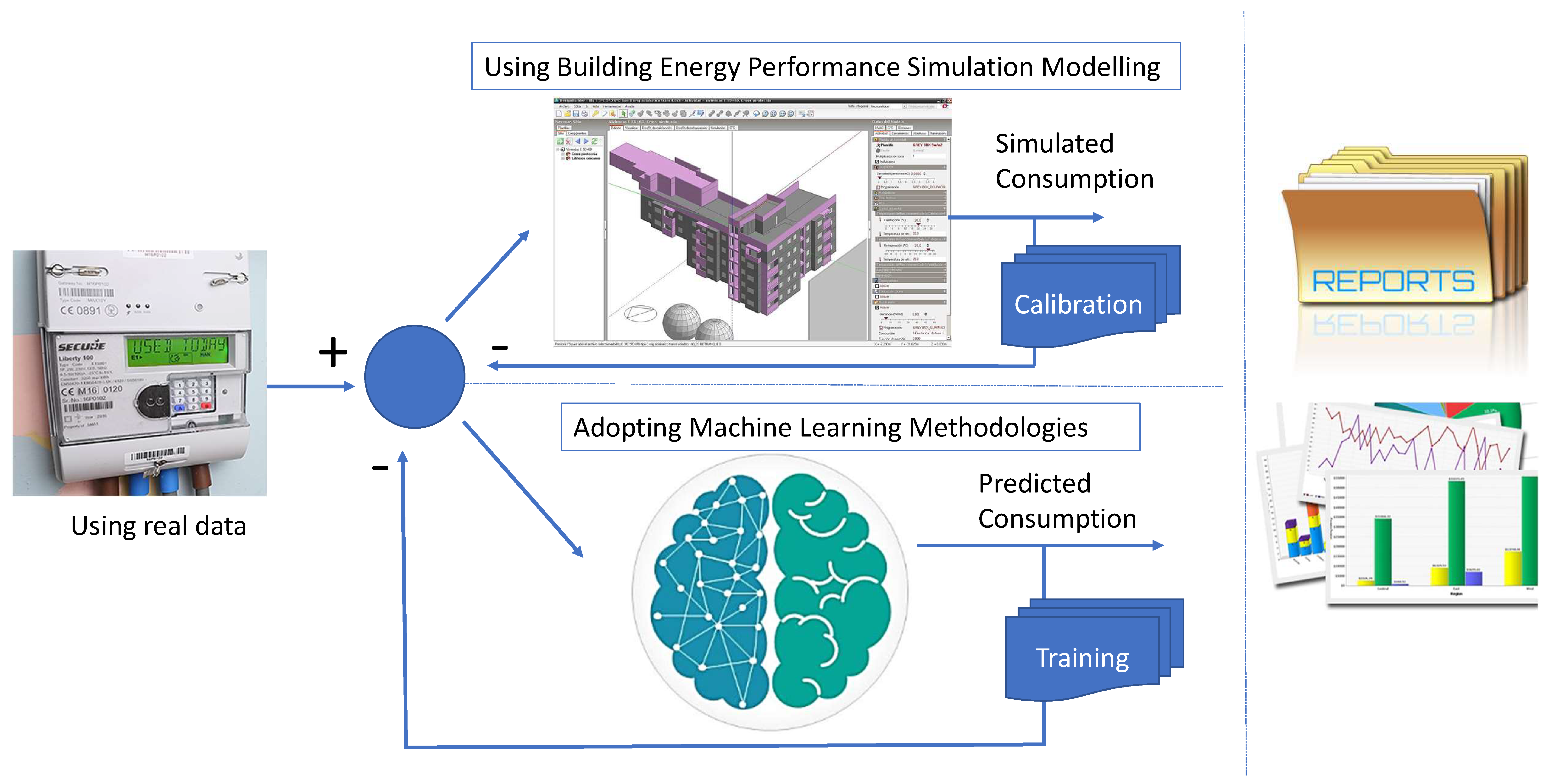
With the recent paradigm of accessing high amounts of data in buildings (energy consumptions records and also exogenous variables such as indoor/outdoor temperatures, relative humidity, or solar radiation), it becomes possible to take into account available data to predict future consumptions. In fact, it is the authors’ admitted research interest to assess whether machine learning prediction methods to estimate future load demand in buildings may provide an alternative of using common building energy simulation tools. This change in paradigm is illustrated in
Figure 1.
Machine learning approaches, often called data-driven models, require a training stage comparable to the calibration stage in traditional simulation processes, mainly to determine the relative importance of different features used to estimate future load demand. The feature selection stage will be further explored in
Section 3. While the training stage occurs, it is expected that estimated consumptions will be closer to real consumptions.
When using building energy dynamic simulation tools, sometimes the estimation of energy consumption is far from being coincident with reality when comparing simulations with measured data. The difference between these values is usually designated energy gap [
13]. Reducing energy gap is an important issue to be taken into account when designing neutral energy buildings, since small differences in assumptions may result in higher energy performance gaps. Therefore, the use of data-driven approaches appears to be an important alternative to conventional building energy performance simulation tools in reducing the energy performance gap, since they do not rely on assumptions, but on historical data coming from buildings under operation conditions [
14].
This study will focus on applying machine learning approaches to forecast thermal energy demand. Different researchers used forecasting models to predict building electricity demand [
4,
5,
11,
15]. It becomes clear that, in most cases, it is easier to obtain electrical energy as data with higher resolution, and also that quite often weather conditions can strongly influence these electricity consumptions (mainly during the summer periods, when air conditioning systems are used). Nevertheless, as the building analyzed in this article has its heating and cooling needs provided by district heating (further addressed in
Section 2.1), electricity consumptions are quite more stable and easier to predict. For similar reasons, a considerable number of researchers are tackling the challenge of estimating building heating and cooling needs [
3,
5,
15,
16,
17,
18,
19].
A number of studies can be found in the literature that address the forecast of energy demand of non-domestic buildings (both thermal and electrical) using machine learning strategies. In [
20], artificial neural networks (ANN) are compared to a physical principle-based model (
EnergyPlus) when forecasting the amount of energy consumed by an administrative building in São Paulo, Brazil. In [
16], a load forecasting method using wavelet transform, SVM and partial least squares regression is applied to an office building in Tianjin, China. In [
21], a linear regression model on air temperature data is compared to decision trees, SVM and ANN as they attempt to forecast the total heating energy demand of a set of 52 residential buildings. In [
22], the effect of considering a single artificial intelligence based method or combining multiple single artificial intelligence based prediction models (ensemble approach) is also analyzed, trying to capture the benefits and avoid drawbacks associated with different strategies.
The article is organized as follows:
Section 2 describes the dataset used for this study and presents some background related to the used methods and the strategies adopted when applying them in this study. Additionally, the adopted error metrics and the list of features considered to predict heating and cooling energy demands are also introduced. In
Section 3 the main results are presented, with a feature selection stage followed by a detailed comparison among the proposed methods, for both seasons.
Section 4 is dedicated to the discussion, revealing the potential amongst the forecasting models tested and highlighting a comparative analysis of these selected models. Finally, in
Section 5, the main conclusions are drawn and some topics for further research are proposed.
2. Materials and Methods
In this section, the dataset information used for computing the models is presented, along with a brief overview of ANN, SVM and simulated annealing (SA) as a metaheuristic used to enhance SVM model. The work presented in this paper follows on from a previously published work by the same authors. [
23].
2.1. Dataset, Model Characterisation, and Inputs
The case-study building for this paper is an office building on the riverside of a recently modernized district in Lisbon, Portugal. Built in 2007, it has a net floor area just under 12,000 m2, with 7000 m2 over eight floors (above ground) occupied by offices and open workspace area, and 5000 m2 over three (underground) floors dedicated to parking. All building façades are mostly glazed and exposed to the elements, with partial shading installed on the south-facing façade only. The roof consists of a polystyrene insulated concrete slab covered by an outer layer of pebbles. The building is equipped with an advanced BMS, including a building automation and control system (BACS). A nearby trigeneration plant provides hot and cold fluids used to heat and/or cool the building, which are transferred through heat exchangers installed on a thermal substation located on the underground floors.
A significant amount of data was collected, including weather-related data (outdoor dry-bulb temperature, relative humidity, wind speed, direct normal solar radiation, diffuse horizontal radiation, occupation (hourly profile), and enthalpic counts of (hot and cold) fluid consumed from a complete year, obtained through simulation of a calibrated building energy performance model. In this area, the cooling period is usually April to September, while the rest of the year is the heating period. Around 4/5 of the data thus obtained was used in model training, while the remaining 1/5 was used for testing (heating and cooling) demand forecast. Both historical data (namely 7-days and 14-days prior) and exogenous variables were considered in the models. Variable normalization was performed, using training dataset maxima and minima for each variable as scaling factors.
Different combinations of inputs were tested in this study and their respective error metrics (mean absolute error, MAE, and root-mean-square error, RMSE) were compared to evaluate the most effective set of inputs to forecast heating and cooling energy demand. In
Table 1 and
Table 2, the combinations of features tested for the cooling (Cx) and heating (Hx) energy demand, respectively, are presented.
2.2. Artificial Neural Networks
ANN are a well-known strategy to predict consumptions [
24]. ANN are inspired by the way biological neurons of the human brain process information and are composed by several single and highly interconnected processors. An input node receives the contribution of adopted features and the last layer (the output layer) provides the information derived from the network (predicted values as the main goals of ANN for regression purposes). Between the input and output layer, one or more intermediate layers (hidden layers) are considered, and in these different number of neurons can be adopted, according to the real time series complexity. For each connection between elements, weights links are responsible to pass information signals from each unit to the next (respecting a feed-forward typology). A training stage is needed to provide the effectiveness of the model when comparing predicted values with the real ones. To do that, an error metric is used as an objective function that must be minimized in each iteration, sending the error to precedent layers and enabling a weights’ update (backpropagation).
Their ability to deal with non-linear relationships between inputs and outputs (possible when nonlinear transfer functions are adopted) and the option to predict different load records simultaneously (when adopting a single model multivariate forecasting) make ANN very suitable to forecast a daily load profile. For that reason, they are being adopted by several researchers to predict building energy consumptions [
3,
15,
21]. Some drawbacks that are often pointed out are the inherent empirical process (based on trial-error experiments, mostly depending on random ANN parameters’ initialization), considerable risk of reaching local minima, and high dependence on a proper structure selection or even on a feature selection/extraction stage.
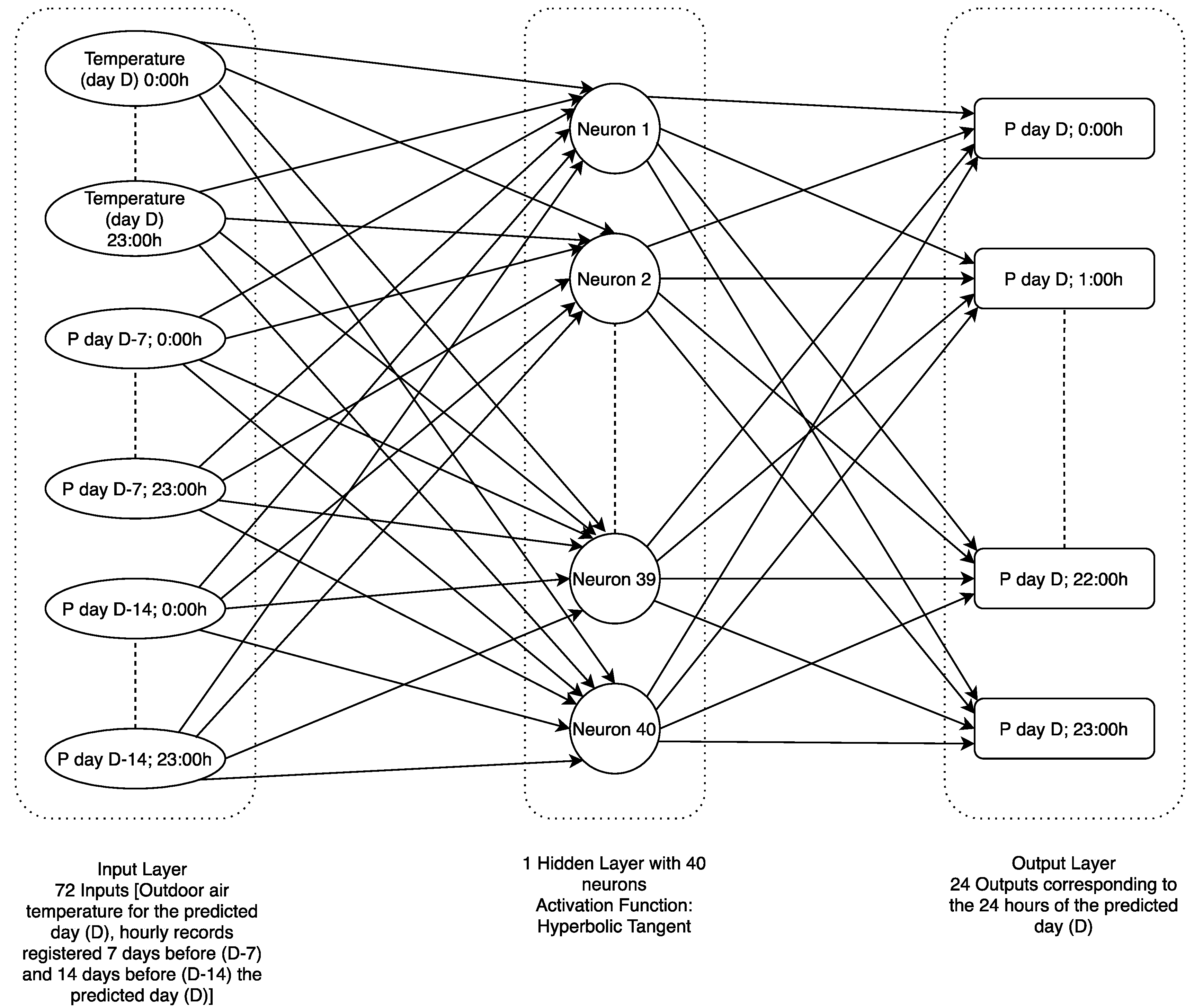
In this study, ANN were parameterized as follows:
Hidden layer activation function: hyperbolic tangent;
Weight optimization solver: “Adam”;
Number of hidden layers: 1;
Number of neurons: 40;
Data training/validation ratio: 80%/20%.
The Adam optimization algorithm, which is an alternative to classical stochastic gradient descent, was used to update network weights since it is particularly efficient when handling large datasets, with a reasonable trade-off between training times and prediction accuracy. A single hidden layer was used as that is the most widely recommended choice to represent any type of function, with the approximation ability dependent on both the choice of activation functions and the number of neurons. The number of neurons was selected after ten-time ANN training trials using ten, twenty, thirty, forty and fifty neurons, following the best results (i.e., lowest error metrics); simulations with fewer neurons led to underfitting (lower ability to estimate heating/cooling), while higher number of neurons led to overfitting (generalization loss, lower ability to estimate new values).
Figure 2 presents an example of an ANN model’s structure based only on historical records (in this case, congenerous days, one week and two weeks before) and exogenous variables (in the example, temperature).
2.3. Support Vector Machines
While SVM have been widely used for classification purposes, the metaheuristic may also be applied to regression based on the same principles. It is consensual in the research community that this approach relies more on a structural risk minimization principle rather than an empirical risk minimization principle [
16,
25,
26], quite common, for example, in ANN. Other particularity is that its training derives from quadratic programming, resulting in a global optimal solution. As it addresses a regression problem, SVM attempt to find an optimal hyperplane such that distance to data is minimized. The original input space is usually nonlinearly related to the predictor variable. Therefore, it is mapped onto a higher dimensional feature space through a nonlinear mapping function (kernel function) to deal with these nonlinearities. The kernel transformation allows the handling of nonlinear relationships in the data as a higher dimensional space is obtained, in which a linear regression model can be built.
An SVM model may be optimized by tuning the kernel function, the kernel parameter (gamma), the cost parameter, and the error margin (epsilon). The Radial Basis Function (RBF), which is commonly used in energy demand problems, is the kernel function best fit to deal with non-linearities. The level of non-linearity of an SVM model is defined, according to the width of the ensuing bell-shaped function (RBF). The cost parameter (C), used to apply a penalty on individual errors, is also important to avoid model overfitting.
The selection of the three non-negative parameters (epsilon, C, and gamma) is determinant to forecasting accuracy. The use of a combinatorial method is often suggested to optimize the parameter selection procedure [
18,
25,
26,
27,
28]. The authors selected simulated annealing (SA) to approach the parameter selection stage.
A number of combinations were tested in an attempt to find the best-performing combination for the given dataset. The lowest values for error metrics MAE and RMSE were obtained for C = 500, gamma = 0.5 and epsilon = 0.5.
2.4. Simulated Annealing as a Metaheuristic Used to Enhance SVM Model Accuracy
SA is one of the oldest metaheuristics with an explicit strategy to avoid the problem of the local minima [
26]. The subjacent idea is to allow the acceptance of some solutions that can eventually deteriorate the objective function, in order to keep away from local minima. The current solution is replaced by a new solution in a random neighborhood, and the extent of the search is based on a probability distribution with a scale that is proportional to the “temperature”. An annealing schedule is used to decrease the temperature as the algorithm proceeds. As the temperature decreases, the extent of its search is reduced to enable an approximation to a minimum. However, it is difficult to conclude whether this is the global minimum or an undesired local minimum. Thus, a reannealing process is often required. This reannealing process can be viewed as a supplementary strategy to a global search because the temperature in each dimension (for each variable) is raised, depending on temperature sensitivity, giving a wider opportunity to accept solutions that are distant from the aforementioned ones.
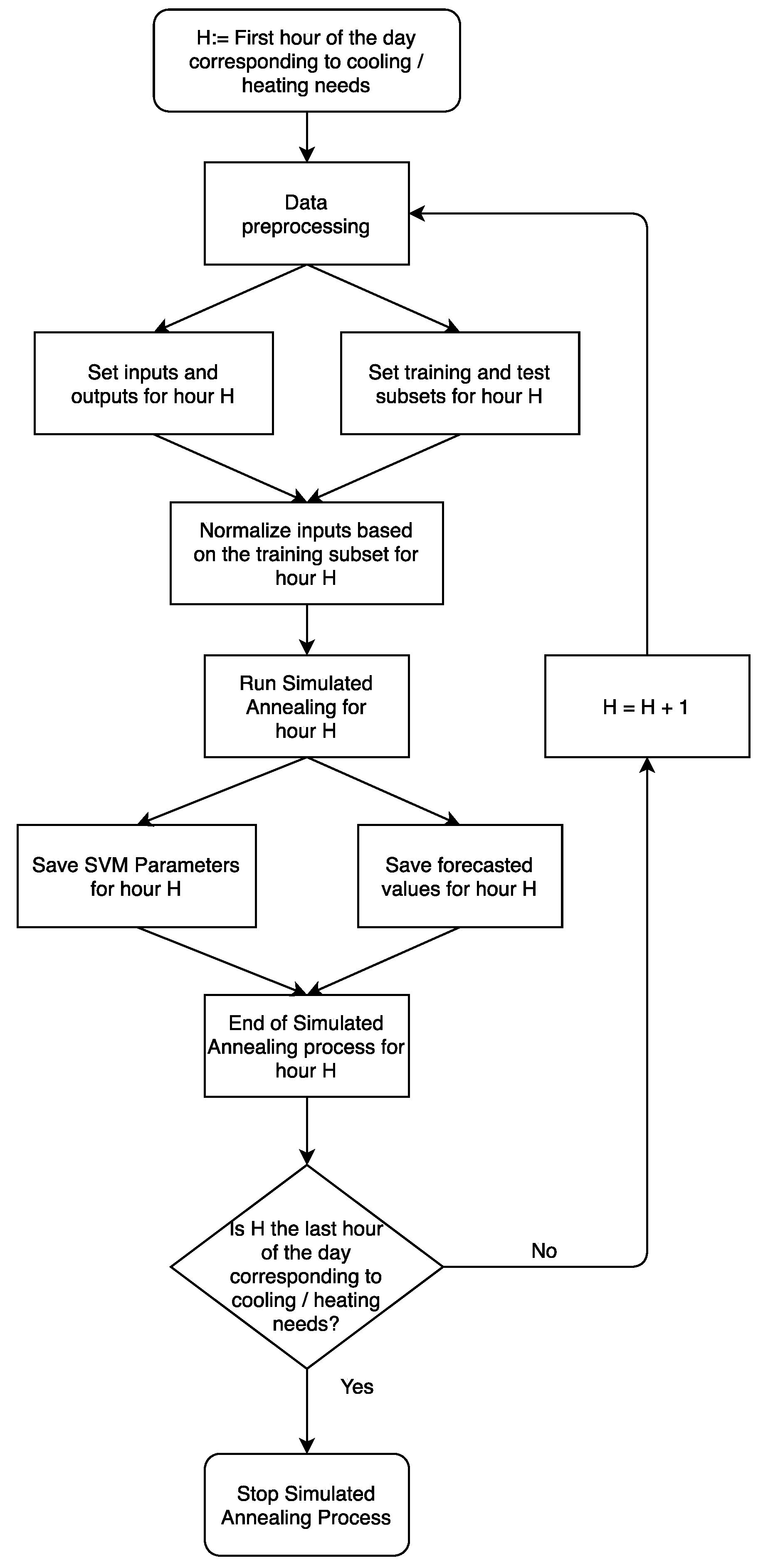
For this study, the SA approach to improve SVM models had some variations compared to the SVM models. Firstly, in order to be able to properly normalize the training and test subsets, only the hours in which heating and cooling systems were actually working were considered for the predictions; secondly, instead of a single combination of SVM parameters for all hours being predicted, each individual hour had its own combination, in order to allow SVM models to adapt to the time of the day at which prediction were made; and thirdly, also associated with the previous assumption, each hour being predicted is normalized using the minimum and maximum values registered in the training subset (unlike SVM, based on overall maximum and minimum).
Figure 3 shows the flowchart followed in this study when using SA to forecast hourly heating and cooling energy demand.
For the SA technique, thirty cycles (iterations) were used for each hour. In each cycle, fifteen trials, i.e., fifteen random initial combinations of SVM parameters were tested, and at the end of each cycle, the temperature would drop to narrow the range of options of each SVM parameter. The cost parameter C was tested in a range between 0 and 700, epsilon was tested between 0.0001 and 3, and gamma was tested between 0.0001 and 10. Other Simulated Annealing parameters were set as:
Probability to accept a worst solution in the beginning (p1) = 0.5;
Probability to accept a worst solution in the last cycle (p30) = 0.001;
Initial temperature (t1) = −1.0/log (p1);
Final temperature (t30) = −1.0/log (p30);
Temperature for a new cycle (tn) = (t30/t1)[(1/(n−1)]·tn−1, n being the number of the cycle.
The assumed objective function was based on the Root Mean Square Error (described in
Section 2.5) verified in the validation subset (20% of the data, similar to the approach followed for ANN). An example of the optimization model being evaluated during thirty iterations is shown in
Figure 4, where the objective function being minimized can be evaluated, while the acceptance of worse solutions and the exploitation of different parameters’ combination can also be appreciated.
2.5. Error Metrics
This section describes the error metrics used to evaluate the performance of the models. In this work, two error metrics were used to score and compare forecast values to reference values [
29,
30].
The mean absolute error (MAE) is obtained by computing the average absolute error between the reference values (y) and the predicted values (ŷ) through n observations (1):
The root mean squared error (RMSE) represents the mean standard deviation of the predicted values when compared to the reference values (2):
4. Discussion
After scrutinizing the results for the developed models in both cooling and heating periods, it is now convenient to evaluate which are the most accurate models overall in forecasting cooling and heating energy demand, respectively.
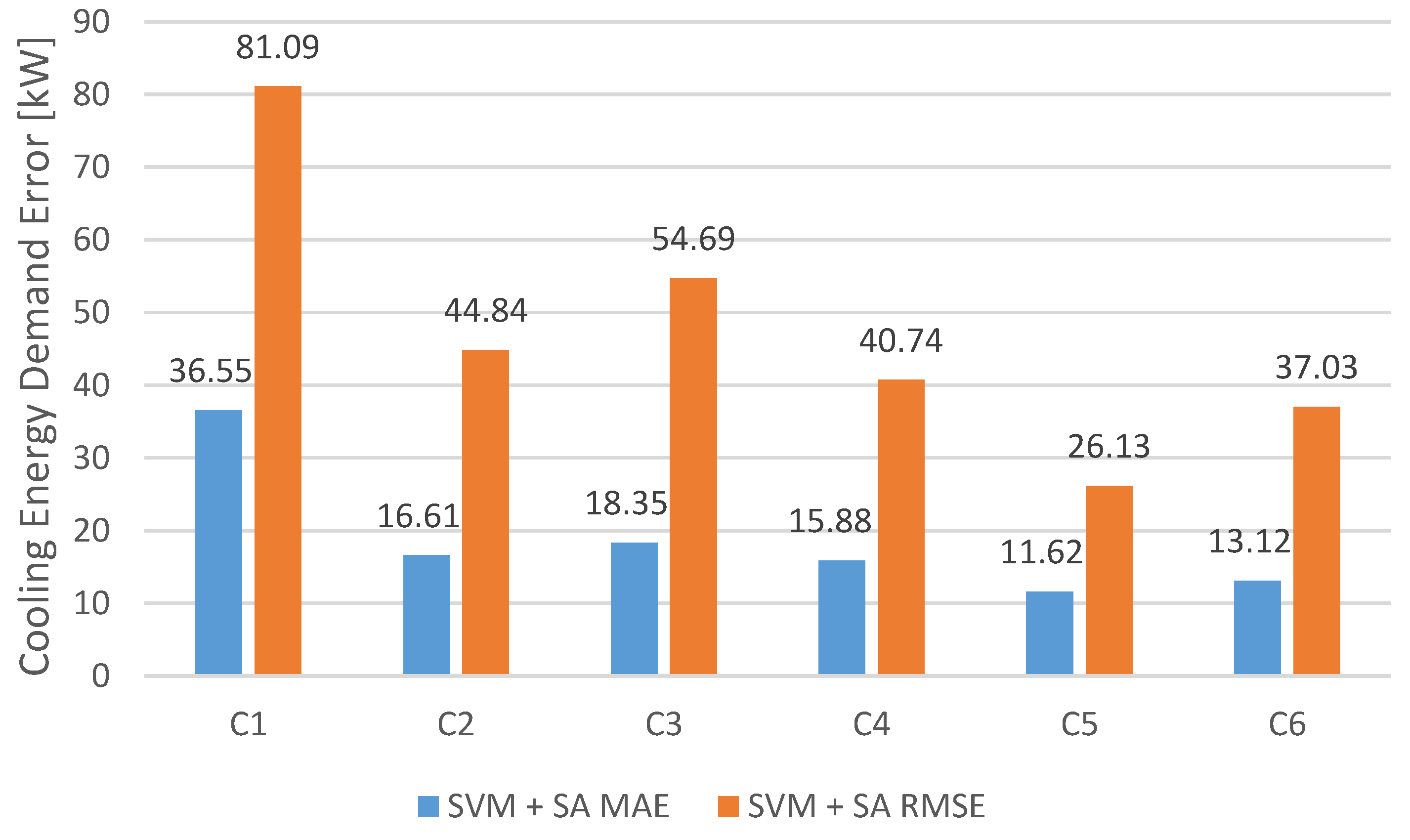
Concerning cooling energy demand, from the six models tested (represented in
Table 1 using ANN, SVM and SVM with SA, the most accurate model, i.e., the one with the lowest MAE and RMSE, was C6 using SVM with SA. This means that the set of features that included historical cooling load, outdoor air temperature, relative humidity and estimated occupancy profile was the most effective in forecasting cooling energy demand.
4.1. Comparative Analysis
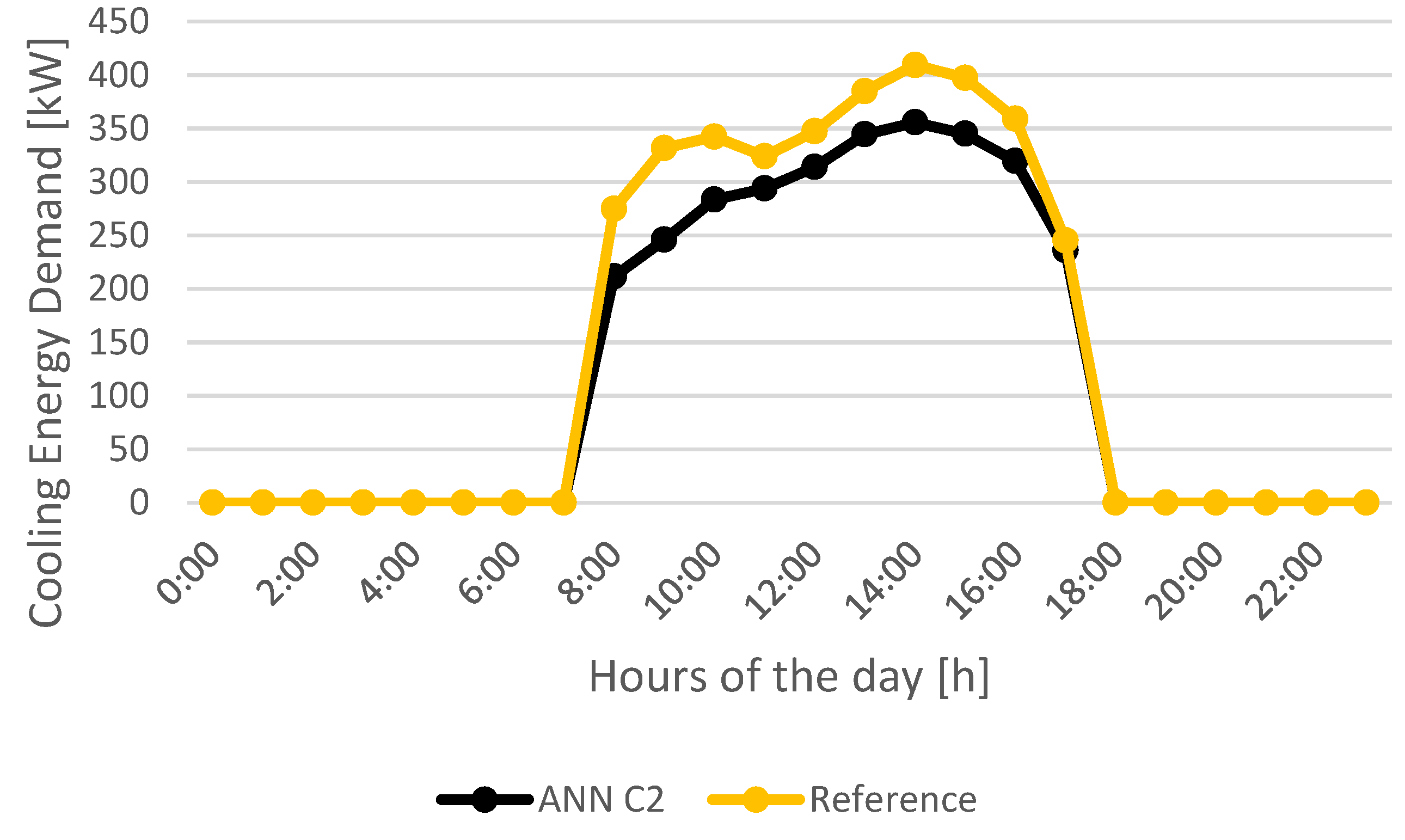
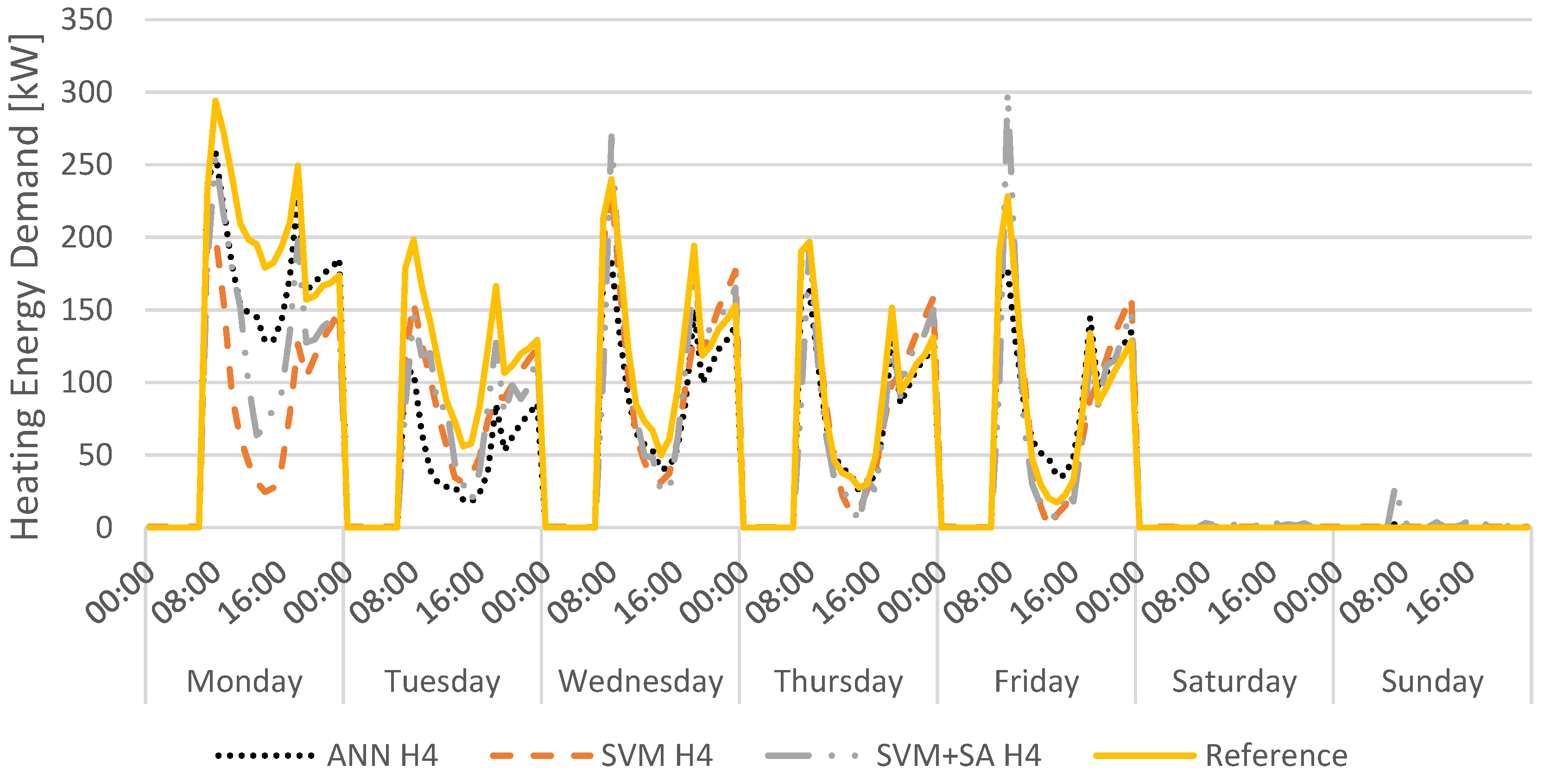
To compare the best performing models retrieved from each of the three different techniques studied (ANN, SVM and SVM+SA) in forecasting cooling and heating energy demand, a weekly load profile corresponding to the test subset was created in order to evaluate the aptitude of those models in fulfilling their goal.
Figure 23 presents weekly load profiles for ANN_C2, SVM_C5, and SVM+SA_C5 and reference for the cooling period.
By analyzing
Figure 23, model SVM+SA_C5 provides the most accurate of the load profiles when compared to the reference.
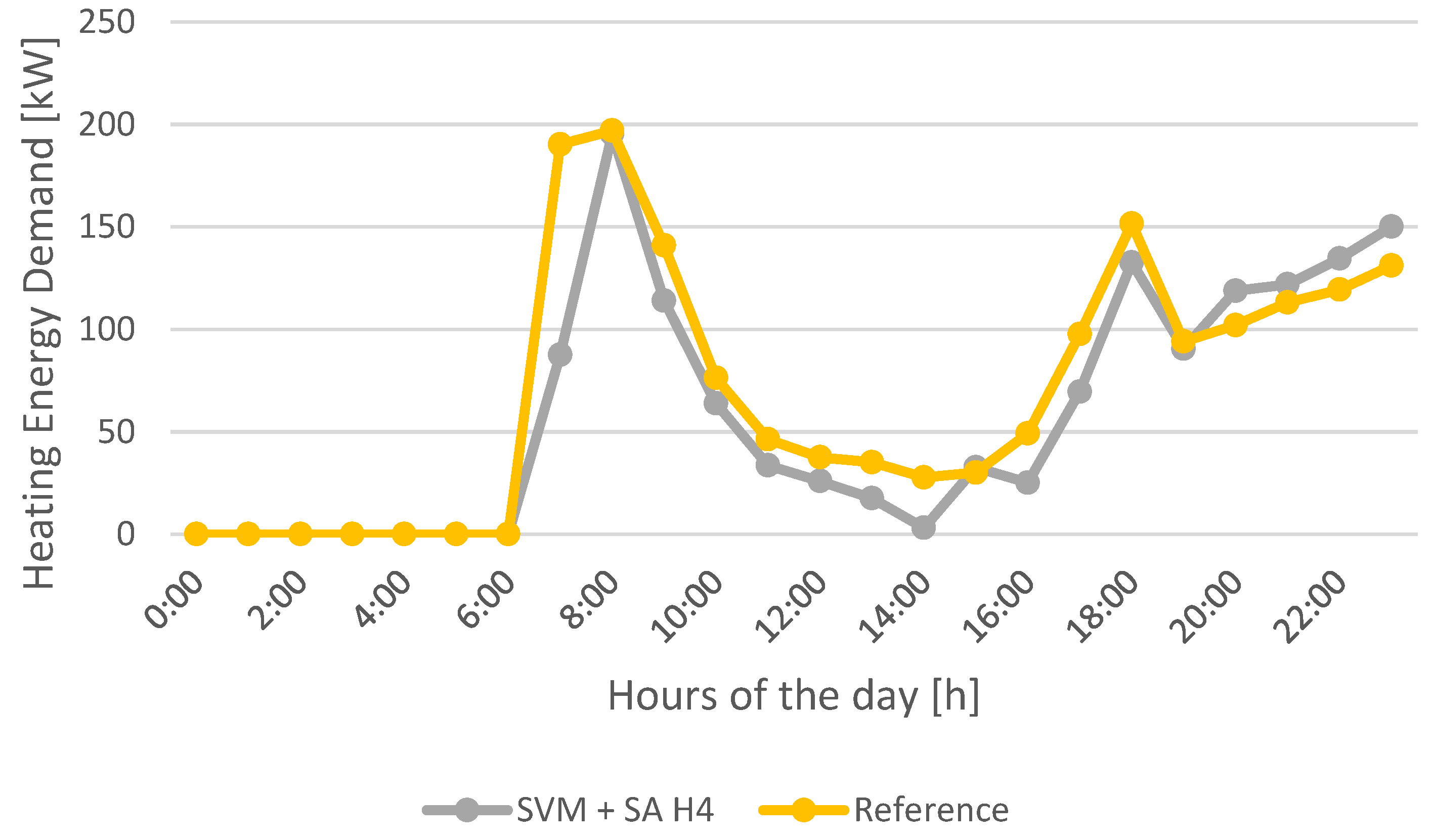
The weekly load profiles regarding heating energy demand for the best performing models in each machine learning technique studied are presented in
Figure 24.
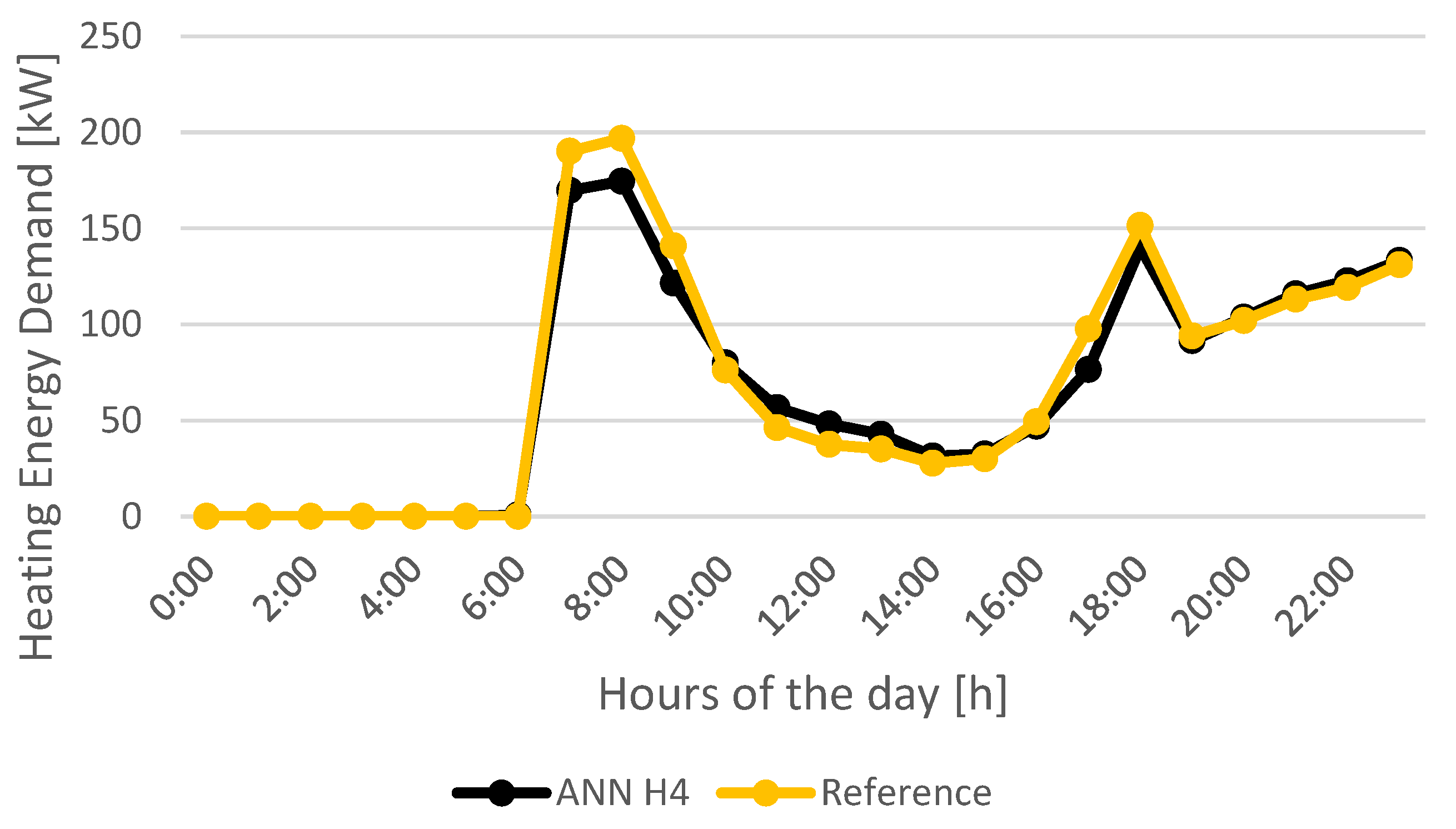
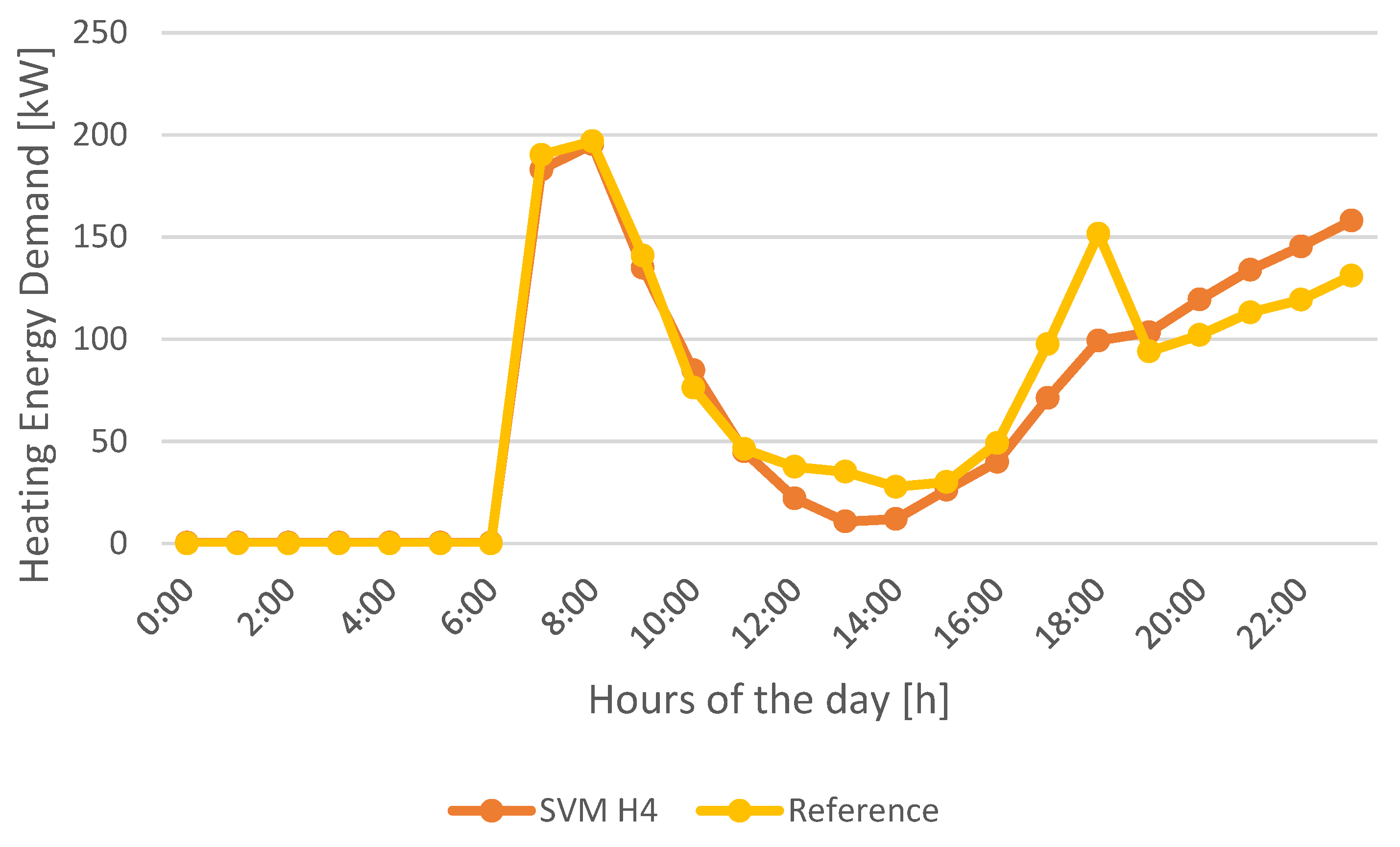
Analyzing the weekly load profiles for heating energy demand forecast (
Figure 24), the most precise model is ANN_H4. Especially when analyzing the peaks registered in the morning and afternoon from Monday to Friday, model ANN_H4 is the model that best fits the reference profile.
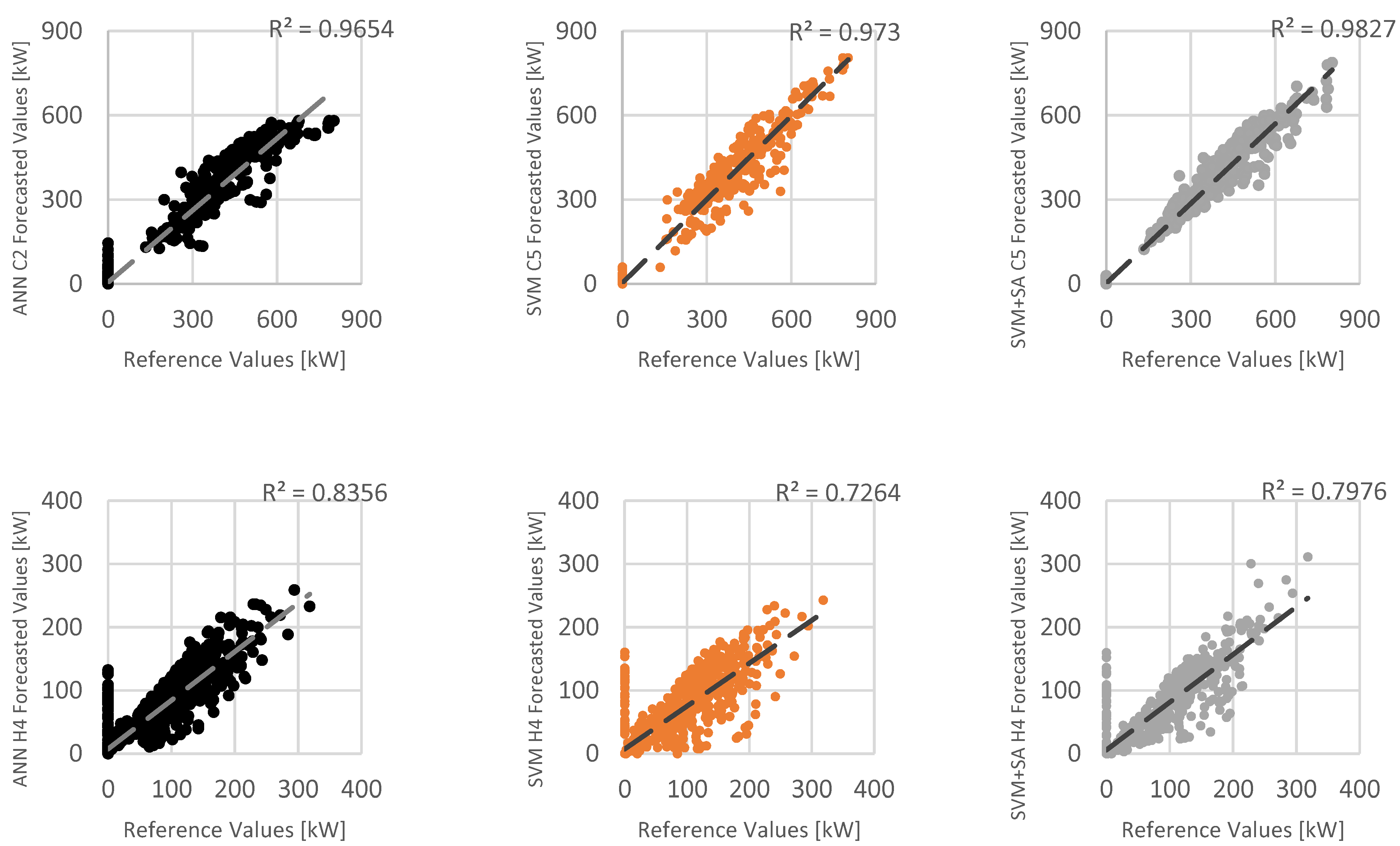
4.2. Forecast vs. Reference
In this section, a detailed comparison, for the full testing subset, between the forecasted values for all three models and the respective reference values is presented, using a dispersion chart.
Figure 25 presents the dispersion chart for the cooling energy demand (ANN_C2, SVM_C5 and SVM+SA_C5) and the heating energy demand (ANN_H4, SVM_H4 and SVM+SA_H4) and the corresponding correlation factors (R
2).
For the cooling period (the top three charts), all models have a very high correlation between the forecasted values and the reference values. The dispersion is slightly higher for ANN_C2, while SVM+SA_C5 presents a very high concentration of the points around the trendline with a R2 of 0.9879.
For the heating period, the correlation factors are lower than in the cooling period. This may be partly due to the fact that the Christmas season is part of the testing subset and the models are not configured to detect holidays, considering them as normal working days. The highest correlation factor is obtained for the ANN_H4 model, which confirms it as the most effective model in forecasting heating energy demand. Moreover, the trendlines for the three bottom models are considerably below the bisector of the chart, meaning that, in all these models, most of the forecasted values for heating energy demand are lower than the respective reference values.
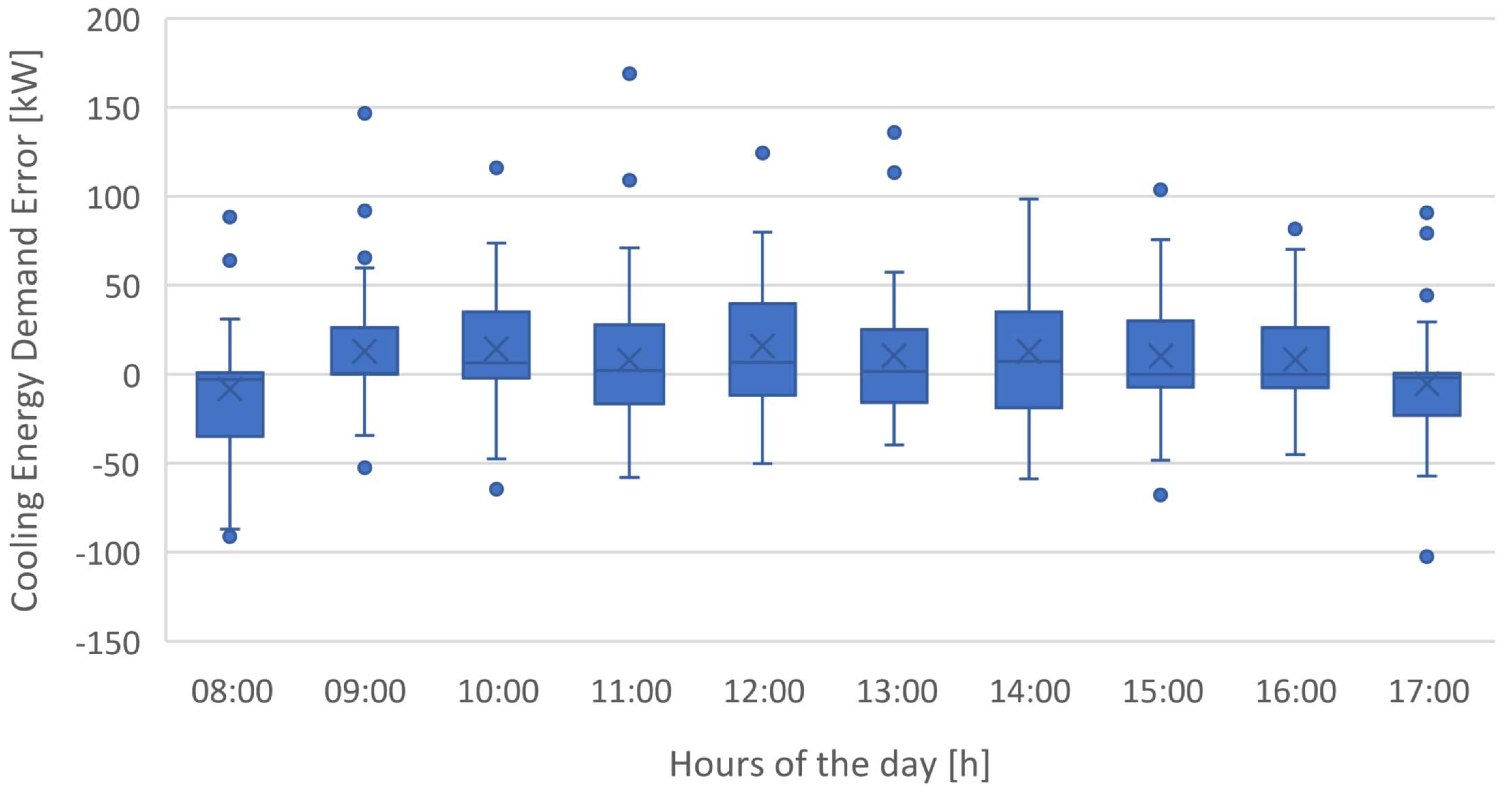
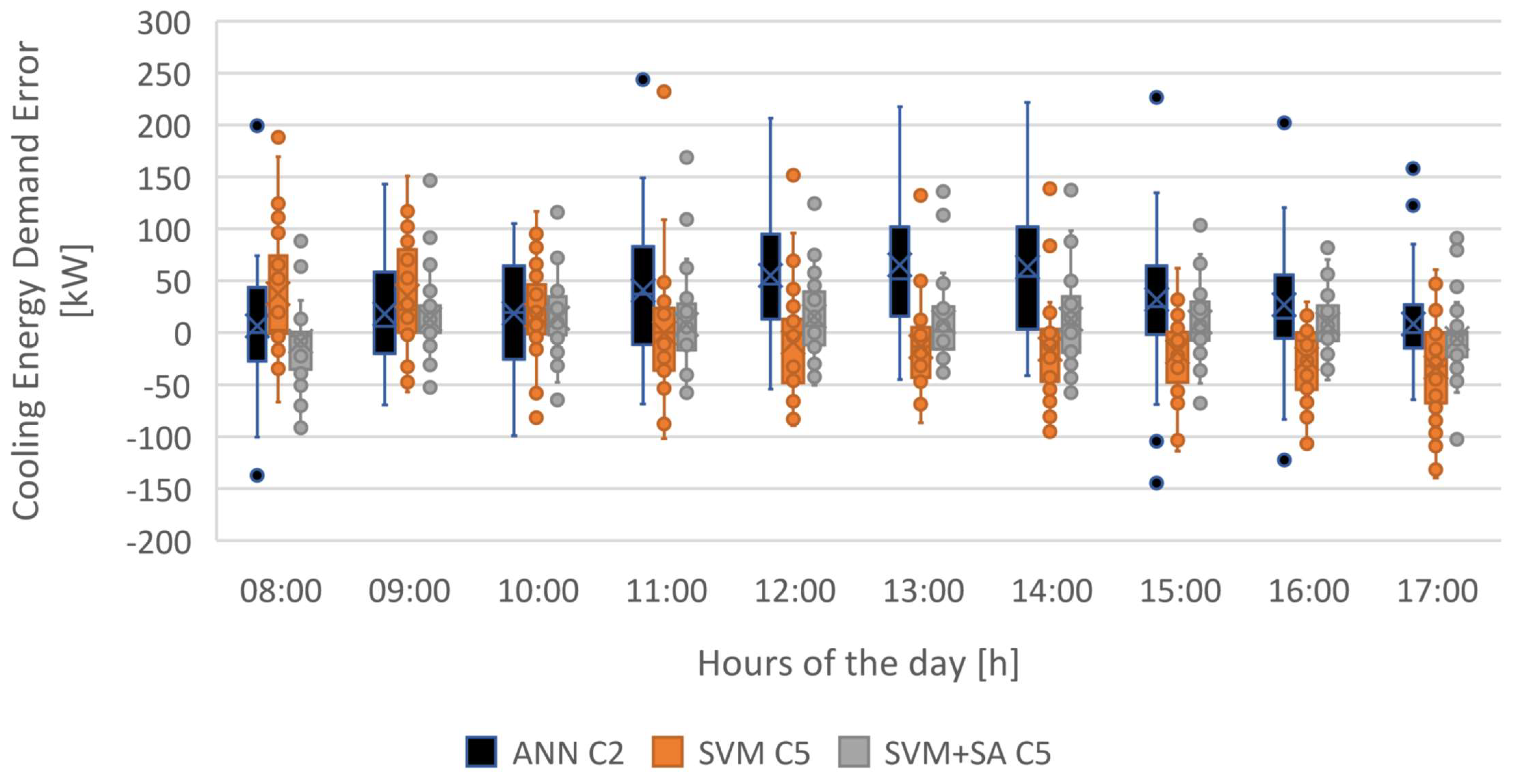
4.3. Boxplot Analysis
In this section, the error distributions for the best performing models of each machine learning strategy studied are presented and compared.
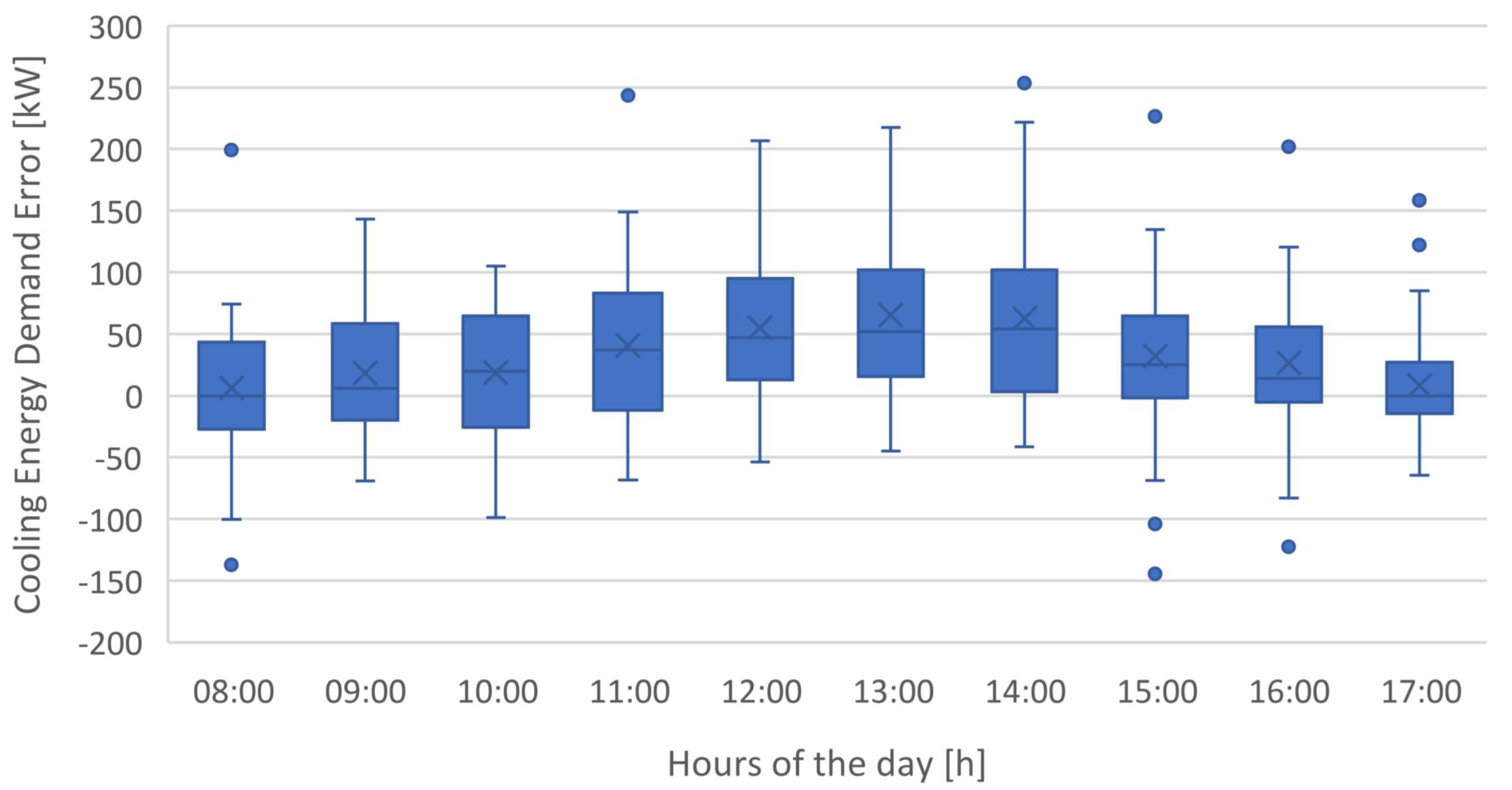
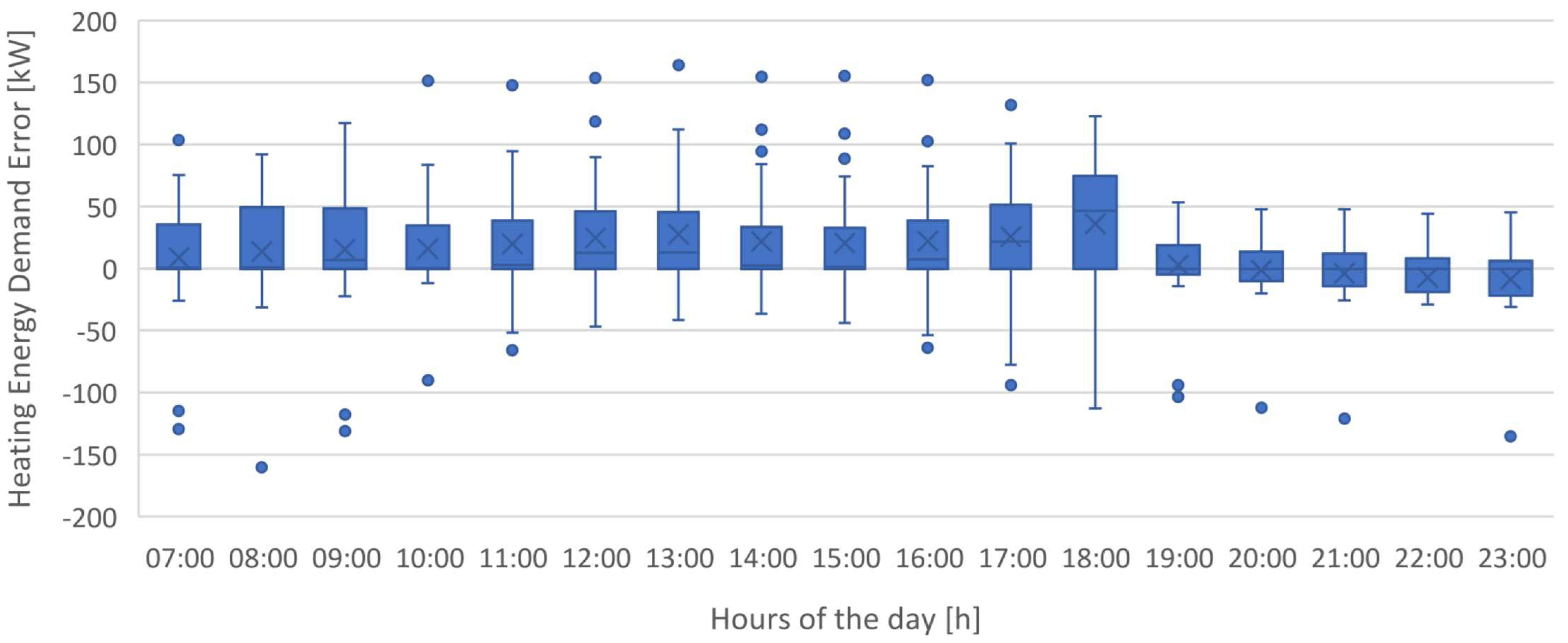
Figure 26 presents the boxplot chart containing the error distributions for models ANN_C2, SVM_C5 and SVM+SA_C5 in forecasting cooling energy demand, while
Table 3 highlights some statistical parameters for particular hours of the day.
Once again, and confirming the information given by
Figure 23 and
Figure 25, the error distribution shows that the most effective model in forecasting cooling energy demand is model C5, using SVM+SA.
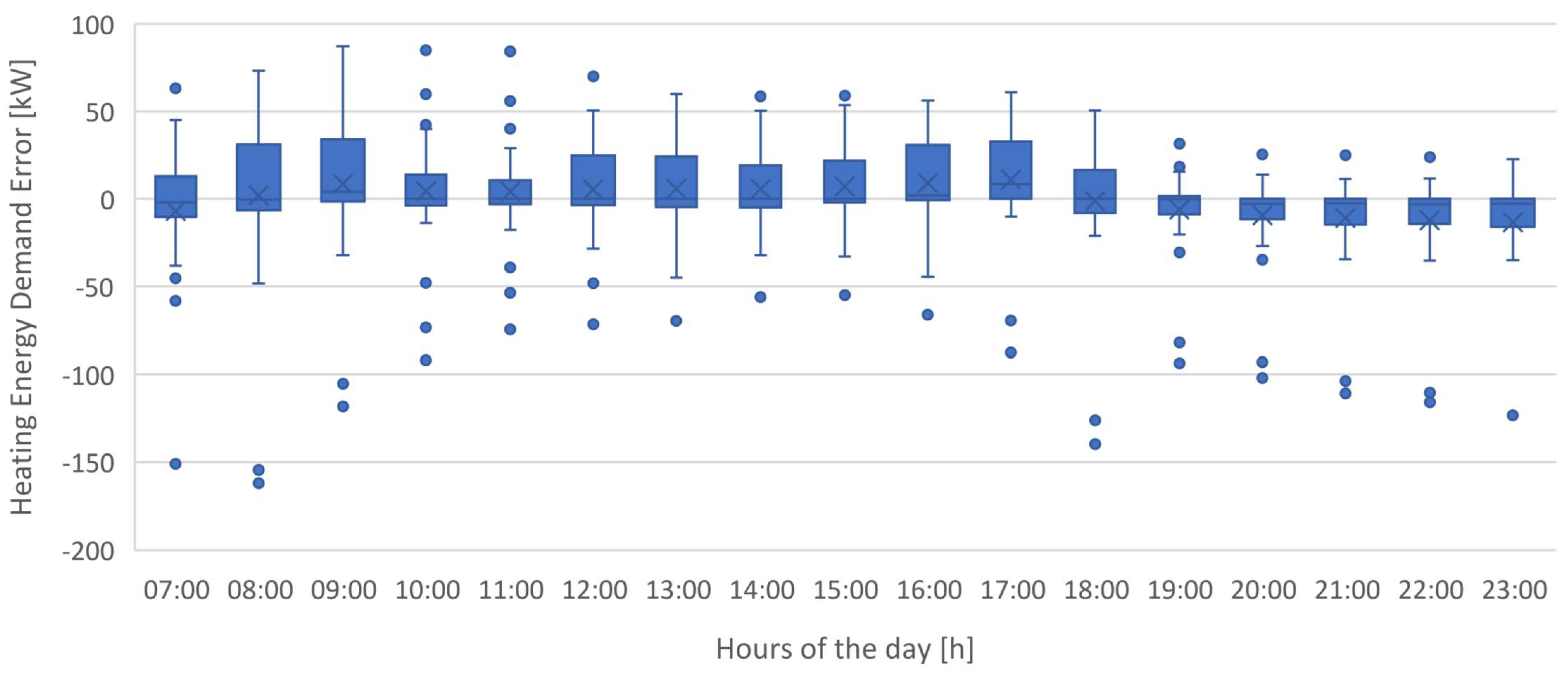
Figure 27 presents the error distribution for models ANN_H4, SVM_H4 and SVM+SA_H4 in forecasting heating energy demand, while
Table 4 highlights some statistical parameters for particular hours of the day.
Figure 27 and
Table 4 show that model ANN_H4 has an overall more satisfactory error distribution than models SVM_H4 and SVM+SA_H4, confirming the information given by
Figure 24 and
Figure 25.
It must also be pointed out that a generalized improvement in prediction accuracy occurs when SA is adopted in SVM models.
5. Conclusions
This article presents the application of different machine learning methodologies to estimate thermal energy demands in an office building. The proposed methodology was tested using a real office building located in Lisbon, Portugal, as a case study.
The demand forecast obtained from these methods proved to be an interesting alternative to the use of dynamic simulation tools, since it is certainly a quicker and more straightforward approach (less dependent on calibration processes and on expertise level of the user). Based on these results, there is a potential for faster, yet accurate machine-learning based forecasting methods to actually replace well-established, very accurate but time-consuming multi-zone dynamic simulation tools, allowing new possibilities of obtaining quick building energy consumption forecasts.
One of the contributions to the research field is related to the integration of SA as a strategy to support the fine-tuning of SVM’ parameters. In the previous sections, this addition proved to be quite effective, as it contributes to reduce prediction errors when compared to the SVM model (for both cooling and heating periods). Another relevant contribution is the evaluation on the impact of different sets of features, contributing to infer the most relevant ones for each season.
Future work may include the adoption of pre-processing techniques (e.g., the wavelet transform) in an attempt to improve model accuracy, particularly concerning the cooling period.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}