1. Introduction
In the incoming era of 5G communication, there is a huge amount of data to be transmitted from IoT (Internet of Things) devices to computational data centers in order to make analytics on it. In this regard, Cisco has recently argued that, at the end of the next year (2021), more than 50 billion IoT devices will be connected to the Internet, which are estimated to consume about 850 Zettabytes of data per year [
1]. This aspect will be further stressed and taken to extremes by the future 6G communication technology [
2]. However, the global intra-data center traffic will remain limited up to 21 Zettabytes. This implies, in turn, that producers/consumers of big data will progressively move from large-scale centralized cloud-hosted data centers to a wide range of spatially distributed ones [
3], also induced by the limited bandwidth still offered by multi-hop cellular Wide Area Networks (WANs) [
4].
In order to efficiently mine the huge Big Data streams generated by IoT devices, the technological platforms supporting these analytics and the related algorithms should be: (i) powerful enough to take into account the heterogeneous and possibly noisy sensing data generated by resource-limited IoT devices; (ii) fast enough, in order to cope with the stream nature of the IoT data; and (iii) suitable for a distributed execution, in order to be compliant with the spatially distributed nature of the IoT devices.
The emerging Deep Learning (DL) paradigm of the so-called Conditional Deep Neural Networks (CDNNs) with early exits [
5,
6,
7], also known as BranchyNets [
8,
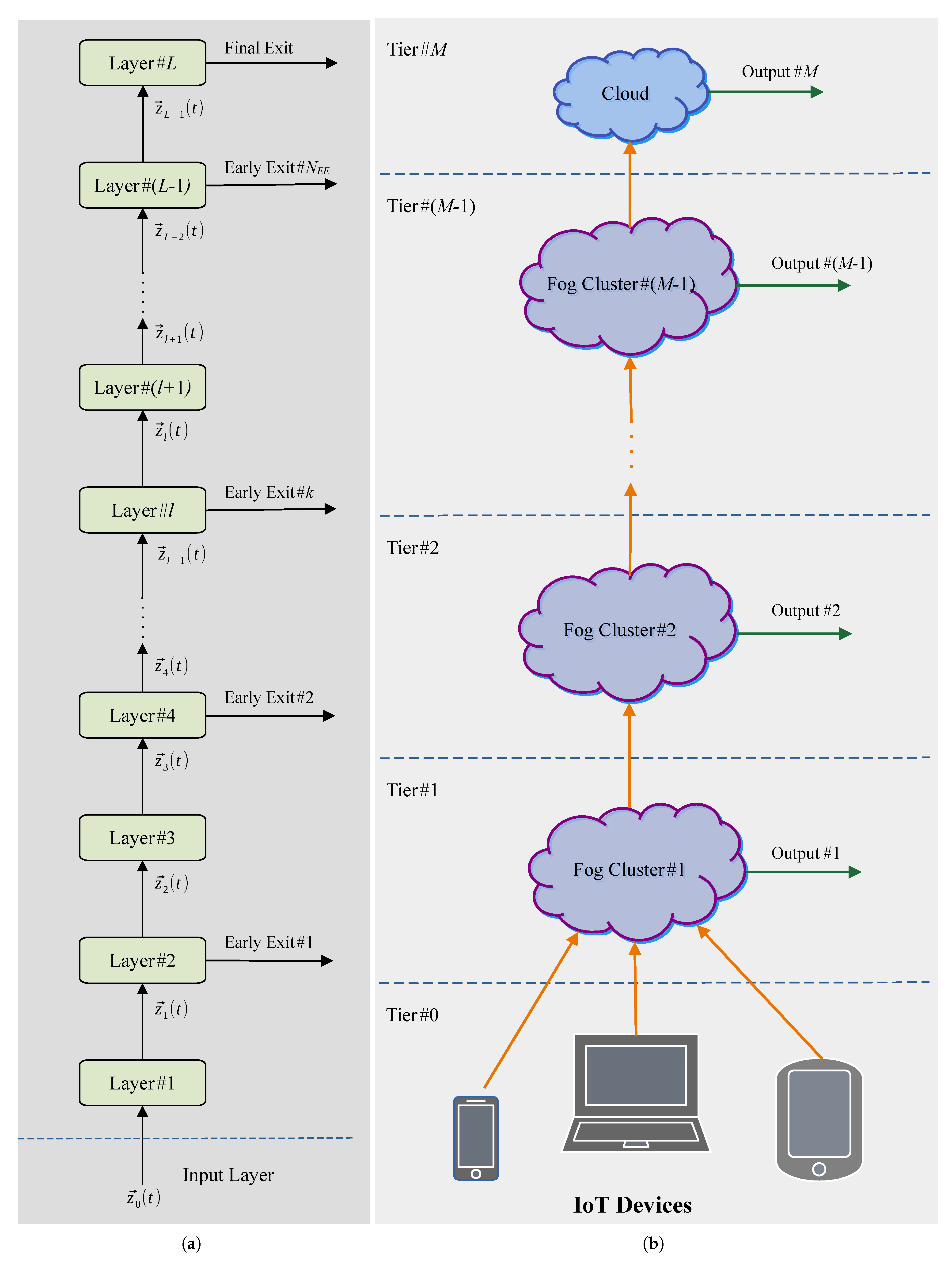
9], meets the first two requirements and provides an effective means of performing real-time analytics on structured/unstructured IoT data. As sketched in
Figure 1a, a CDNN with early exits is obtained by augmenting the stack topology of a baseline feedforward Deep Neural Network (DNN) [
10] with a number of local classifiers connected to associated intermediate output branches, called the early exits. The introduction of these auxiliary classifiers allows a fast prediction if there is enough confidence, i.e., the input data is sufficiently simple to be classified in the first layers, while more complicated data will use more or even all the CDNN layers, in order to provide reliable decisions. Both the reliability and associated delay of the local classifiers’ decisions increase, while moving from the bottom to the top of the CDNN stack. Hence, CDNNs with early exits may be capable of
self-tuning the right reliability-vs.-delay tradeoff, so as to
reduce both computing effort and inference delay, providing
distributed local exit points to the running application.
In order to guarantee such a distributed implementation, the technological platform supporting the execution of a CDNN with early exits cannot rely only on a standing-alone remote and centralized cloud data center. It should be composed, indeed, of the networked interconnection of a number of hierarchically-organized computing nodes, which are spatially scattered and operate nearby the IoT devices. This is the native layout of the emerging paradigm of Fog Computing (FC) [
11]. An FC technological platform (sketched in
Figure 1b) enables pervasive local access to a set of
clusters of virtualized small-size pools of computing resources, hierarchically-organized into tiers, which can be quickly provisioned, dynamically scaled up/down and released on an on-demand basis. Nearby resource-limited mobile devices may access these resources by establishing single-hop WiFi-supported communication links. The Fog paradigm exploits resource virtualization for supporting a set of virtualized services by distributing computing-plus-communication virtualized resources along the full path from the IoT realm to the remote Cloud data center [
11] and offers a powerful paradigm for developing DL applications [
12,
13,
14].
Interestingly enough, the IoT-CDNN-FC convergence can allow the exploitation of both the local exits of the implemented CDNNs and the per-tier aggregation of the local processing performed by the supporting FC platforms. In addition, this convergence may also allow the acquisition and joint mining of data generated by
spatially scattered IoT device and may also enable energy and bandwidth-efficient data analytics by exploiting the
scalable nature of the CDNNs and supporting FC platforms [
11].
According to these facts, to enable an energy-efficient and real-time exploitation of the FC technological platform, we need a flexible evaluation environment for the dynamic test of different distribution strategies of CDNNs under programmable (i.e., settable by the user) models for the energy-delay profiles of the virtualized computing and network blocks composing the considered FC platform of
Figure 1b.
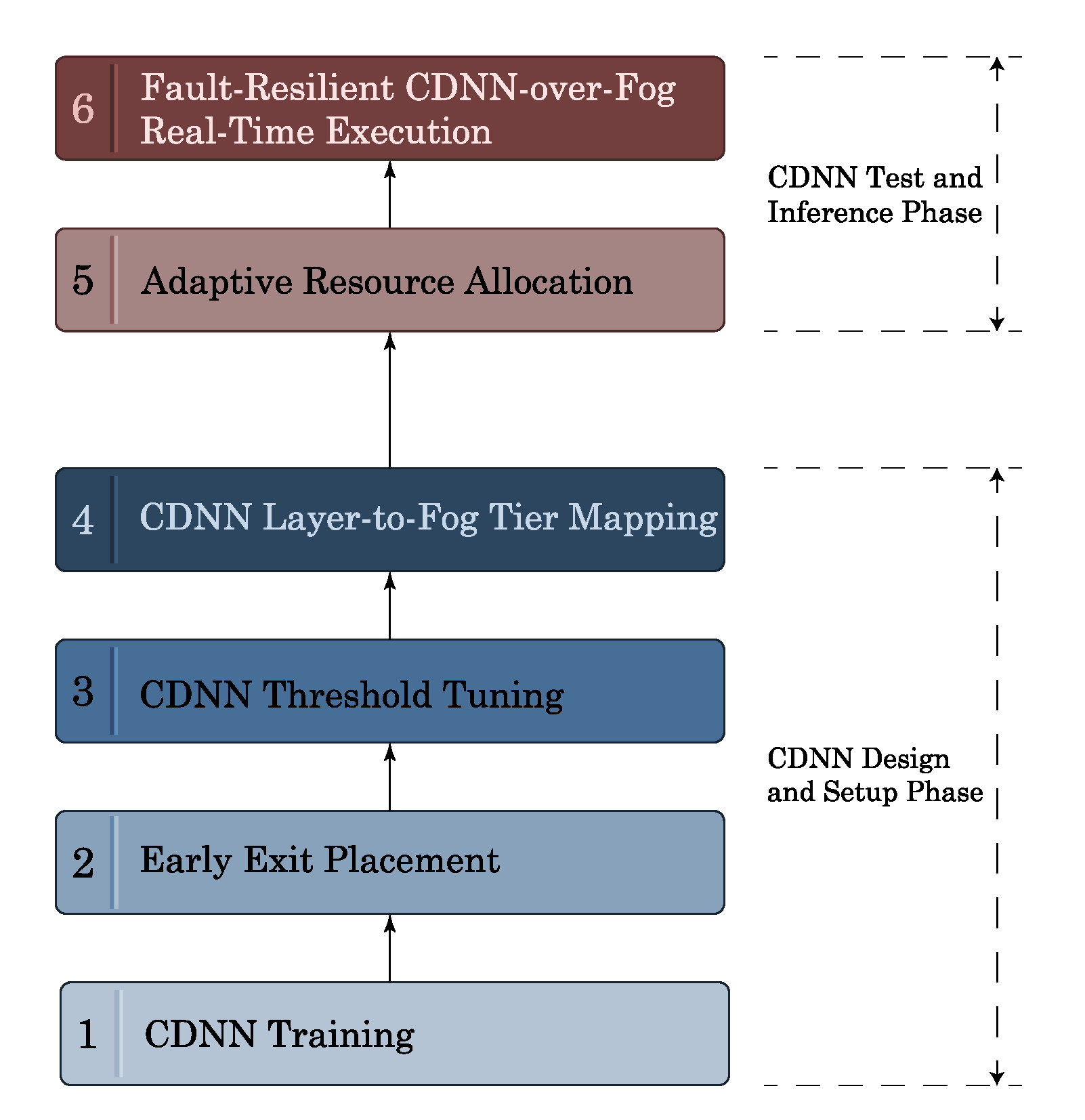
The steps to be taken for the design, training, and execution of the CDNN with early exits of
Figure 1a over the distributed Fog technological platform of
Figure 1b are sketched in
Figure 2. The first four steps of
Figure 2 concern the training/setup of the considered CDNN with early exits. All these steps have been the focus of our previous contributions in Reference [
7,
15], and will not be further considered in this paper. The last two steps of
Figure 2 concern the inference phase of the CDNN’s life-cycle and will be the
explicit focus of this contribution.
Motivated by these considerations, in this paper, we propose DeepFogSim, a toolkit supporting virtualized technological platforms for the real-time distributed execution of the inference phase of CDNNs with early exits under IoT realms.
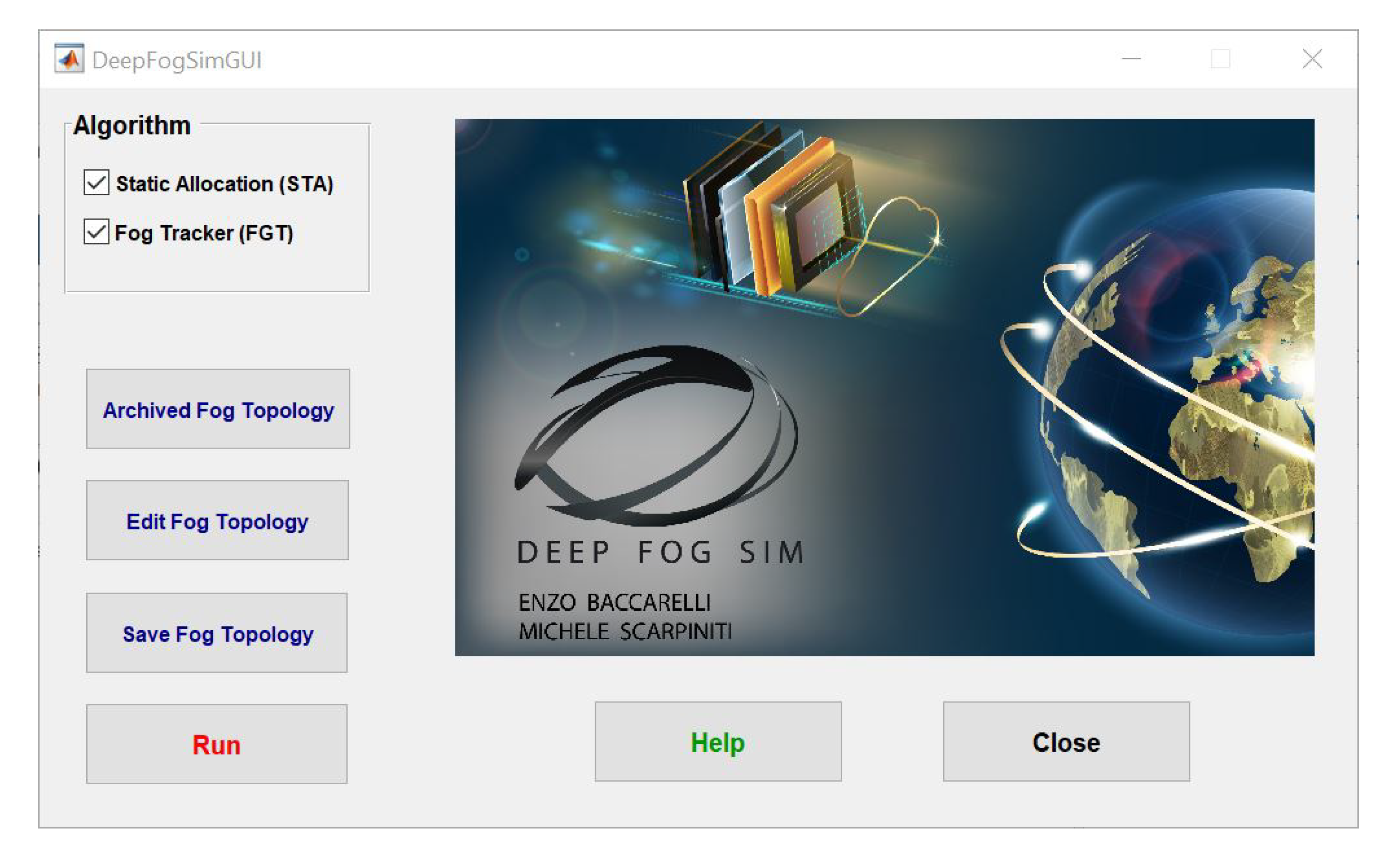
In this perspective, DeepFogSim is a new software toolbox that allows:
the simulation atop a standard PC;
the dynamic optimization;
the dynamic tracking;
the comparison; and
the graphic rendering through an ad-hoc designed Graphic Use Interface (GUI),
of the energy-vs.-delay performance of the underlying Fog-based technological platform supporting the execution of CDNNs with early exits. In particular, DeepFogSim tackles the joint CDNN inference and dynamic resource allocation problems, under hard real-time constraints on the overall (i.e., computing-plus-communication) execution time. Specifically, DeepFogSim allows the users to:
test their desired network topologies by customizing the simulation environment through the setting of the 34 input parameters of the simulator package (see
Table A2);
dynamically track the energy-delay network performance in the presence of abrupt (possibly, unpredictable) changes of the simulated environment, like mobility-induced changes of the available communication bandwidths; and
optimize the obtained performance against a number of metrics, like total consumed energy, network consumed energy, network bandwidth, computing processing speeds, execution delays, just to name a few.
The major peculiar features of the proposed DeepFogSim toolbox are the following:
it allows the numerical performance evaluation arising from the delay-constrained minimization of the overall computing-plus-network energy consumed by the execution of the CDNN with early exits. For this purpose, the DeepFogSim toolbox relies on a gradient-based primal-dual iterative procedure that implements a set of ad-hoc designed adaptive (i.e., time-varying) step-sizes;
the resource allocation is performed by explicitly accounting for the virtualized nature of the utilized Fog platform;
it allows the user to compare the energy-delay performance under a number of user-defined optimization strategies;
it allows the display of the dynamic time-behavior of the performed resource allocation under the time-varying simulation environment set by the user; and
it allows the rendering of the data output by the simulator in tabular, bar plot, and colored graph formats.
In this respect, we remark that the proposed DeepFogSim extends and complements our previous simulator VirtFogSim. Both these toolkits allow the dynamic joint optimization and tracking of the energy and delay performance of Mobile-Fog-Cloud systems. However, the VirtFogSim is designed for the execution of applications described by general Directed Application Graphs (DAGs), while the DeepFogSim aims at simulating the performance of CDNNs with early exits on a customizable networked Fog topology.
The rest of the paper is organized as follows.
Section 2 overviews the literature about other simulation toolkits on Fog environment.
Section 3 introduces the architecture of the main simulated building blocks, and, then,
Section 4 describes the underlying optimization problem.
Section 5 illustrates the general software architecture of the
DeepFogSim toolkit, while
Section 6 shows the supported formats for the rendered data.
Section 7 presents several numerical results, and
Section 8 concludes the work and provides some hints for future developments. Finally, the
DeepFogSim user interface and the full list of all the parameters used by the simulator are described in
Appendix A and
Appendix B, respectively.
2. Related Work
Although the FC paradigm is a relatively recent field of research, there are already several tools for its software simulation [
16,
17,
18]. This is because the most part of the current contributions constitute the follow-up of some toolkits designed for the simulation of the (more conventional) Cloud environment.
An overview of the current literature points out that the research on the development of simulation tools for Cloud-Fog computing platforms proceeded along three main research lines, i.e.,
software for simulation of networked large-scale Cloud data centers;
toolkits that explicitly account for the specific features of Fog platforms for the support of IoT-based sensor applications; and
software toolkits for the simulation and performance evaluation of general multi-tier Cloud-Fog computing platforms.
Starting to overview the first more traditional research line, we point out that CloudSim [
19] is a general-purpose simulation toolkit that allows modeling and simulation of applications atop remote Cloud platforms according to the Infrastructure-as-a-Service provisioning model. It allows the user to setup a customized modeling of the major building blocks of conventional Cloud infrastructures. However, it shows some deficiencies when applied to FC scenarios. Specifically, it does not allow the customized setup of network-related parameters (like the per-link wireless access bandwidths and the round-trip-times of Transport-layer TCP/IP connections), it relies only on Virtual Machine (VM)-based virtualization and does not allow the modeling of emerging Container (CNT)-based virtualization, the implemented resource allocation policies are of static-type and no support for dynamic resource tracking is provided. Similarly, the main focus of GreenCloud [
20] is on the modeling and simulation of the energy profiles of some main computing and network components of the Cloud ecosystem. GreenCloud allows the customized setting and simulation of the full TCP/IP protocol stacks equipping the switches of the intra-cloud network, but it does not account for the Device-to-Cloud wireless links. Stemming from an extension of the traditional OMNeT++ platform, the iCanCloud [
21] focuses on the simulation of Cloud-supported large ecosystems with thousands of served devices. Hence, being scalability the main concern of this toolkit, it does not support dynamic resource tracking and per-device performance optimization. Although based on the virtualization, these works, differently from the proposed one, do not explicitly consider Fog platforms.
About the second and more recent research line, we cite the SimIOT [
22], which extends the (previously developed) SimIC [
23] simulator by including a bottom IoT layer, in order to allow the user to model the request of Cloud resources by a settable number of sensor/actuator devices. Similarly, IOTSim [
24] is implemented as an extension of the (aforementioned) CloudSim. Its goal is the simulation of FC environments in which sensor-acquired big data streams have to be quickly processed. For this purpose, the IOTSim platform is MapReduce-compliant, so that it implements batch processing models for the support of delay-tolerant big-data applications. iFogSim [
25] is another JAVA-based toolbox in which implementation is an extension of CloudSim. It aims at simulating IoT-based Fog platforms by providing a set of suitable primitives for modeling the energy-delay performances of sensors, actuators, Fog and Cloud nodes, two service models and two heuristic task allocation policies. More recently, MyiFogSim [
26] has extended the iFogSim simulator to support virtual machine migration policies for mobile users. Moreover, MobFogSim [
27] has currently improved MyiFogSim by taking into account for the modeling of device mobility and service migration in FC. A different philosophy has been pursued by the EmuFog toolkit [
28], which, instead of performing the simulation of large-scale topologies, generates networks that can be easily emulated by specific software designed for SDN (like MaxiNet, which extends the seminal Mininet emulation environment). Based on the OMNeT++ framework, the FogNetSim++ toolkit [
29] allows simulation of a large Fog network with several user configurations. It also enables users to incorporate customized mobility models and FN scheduling algorithms so as to manage handover mechanisms. The goal of the Edge-Fog toolkit [
30] is to distribute different processing tasks on the available Cloud resources. The assignment of the processing tasks to different cloud nodes is pursued by a customized cost function that jointly optimizes the processing time and networking costs. The Python-based simulator YAFS (Yet Another Fog Simulator) [
31] aims at designing discrete-event Fog applications. It also allows the users to incorporate strategies for placement, scheduling and routing. The software toolkit EdgeCloudSim [
32] is designed for the simulation and performance evaluation of general multi-tier Cloud-FC platforms. It provides the user with a software environment for the setting and dynamic simulation of the profiles of WLAN/WAN networks, wireless network traffic, device mobility, Fog nodes and Cloud nodes. A comprehensive comparative analysis between iFogSim, MyiFogSim, EdgeCloudSim, and YAFS simulators is provided in Reference [
33]. In a similar manner, PureEdgeSim [
34] allows the evaluation of the performance related to Cloud, Edge, and Mist computing environments by taking account of a number of resource management strategies. It shows a high scalability, since it is suitable for thousands of devices and it supports the devices heterogeneity. The toolkits of this second group consider distributed FC environments and resource management techniques. However, unlike the proposed work, they do not allow the dynamic tracking of the performed resource allocation under time-varying operating conditions and/or failure events affecting the underlying Fog execution platform.
Regarding the third research line, we start with the FogTorch toolkit [
35]. It is a Java-based software simulator that allows the development of network models supporting the Quality of Service (QoS)-aware deployment of multicomponent IoT applications atop Fog infrastructures. The FogBus simulator [
36] offers a platform independent interface to IoT applications. It also allows users to run multiple applications at a time and to manage network resources. In addition, FogBus takes care of security of sensitive data by applying Blockchain, authentication and encryption techniques. FogDirSim simulator [
37] allows the user to analyze and compare different application management policies according to a set of user-defined performance indexes (like delay time, energy consumption, resource usage, etc.). It also allows us to model random resource fluctuations and infrastructure failures. FogWorkFlowSim [
38] is a general-purpose toolkit that is developed to model and simulate the workflow scheduling in IoT, Edge, and FC environments. After the execution of the user submitted workflow, FogWorkFlowSim is capable of automatically evaluating and comparing the performance of different computation offloading and task scheduling strategies with respect to time delay, energy and cost performance. Our previous simulator, VirtFogSim [
39], is a MATLAB-supported software toolbox that allows the dynamic joint optimization and tracking of the energy and delay performance of Mobile-Fog-Cloud systems for the execution of applications described by general Directed Application Graphs (DAGs). Specifically, it allows the joint dynamic energy-aware optimization of the placement of the application tasks and the allocation of the needed computing-networking resources under hard constraints on the allowed overall execution times, and it also allows the dynamic tracking of the performed resource allocation under time-varying operational environments. Although this group of toolkits tackles the joint optimization of energy and delay performance of IoT-Fog-Cloud environments, differently from
DeepFogSim, they do not support the execution of CDNNs.
A summary of the mentioned simulators and their main targets is reported in
Table 1.
Overall, on the basis of the carried out review summarized in
Table 1, the main new features of the proposed
DeepFogSim toolkit are the following:
DeepFogSim provides a software platform for the simulation of the energy-vs.-delay performance featuring the execution of CDNNs with early exits atop multi-tier distributed networked virtualized Fog technological platforms;
DeepFogSim allows the user to explicitly model the joint effects on the resulting performance of the underlying Fog execution platform of both the fraction of the input data that undergoes early exits and the user-dictated constraints on the per-exit maximum tolerated inference delays; and
DeepFogSim allows the dynamic tracking of the performed resource allocation under time-varying operating conditions and/or failure events affecting the underlying Fog execution platform.
This leads, indeed, to two main conclusions. First, the main pro of the proposed
DeepFogSim toolkit is that it allows us to properly account for the impact of the multiple per-exit inference delays on the resulting minimum-energy allocation of the computing-plus-networking resources over the multi-tier Fog execution platform of
Figure 1b. In this regard, we note that, to the best of our knowledge, up to date, there is no competing simulation toolbox which natively retains this feature, and the synoptic overview of the related work of
Table 1 supports, indeed, this conclusion. Second, a possible limitation of the current version of the
DeepFogSim toolkit may arise from the fact that the implemented optimization engine inherently exploits the hierarchically-organized stack topology featuring the overall family of the here considered feedforward DNNs (see
Figure 1a). This precludes, indeed, the application of the proposed toolkit for the simulation of the inference phase of neural networks which do not retain stacked-type topologies, such as, for example, the family of the so-called Recurrent Neural Networks (RNNs) [
10].
We finally remark that, by design, the
DeepFogSim toolkit refers to the simulation of the
inference phase of the CDNN with early exits of
Figure 1a over the multi-tier Fog execution platform of
Figure 1b. Hence, topics related to: (i) the optimized design and placement of the CDNN early exits; (ii) the CDNN training; and (iii) the optimized mapping of the CDNN layers of
Figure 3 onto the Fog tiers of
Figure 1b are not the focus of this paper. All these topics have been afforded in our previous contribution in Reference [
15].
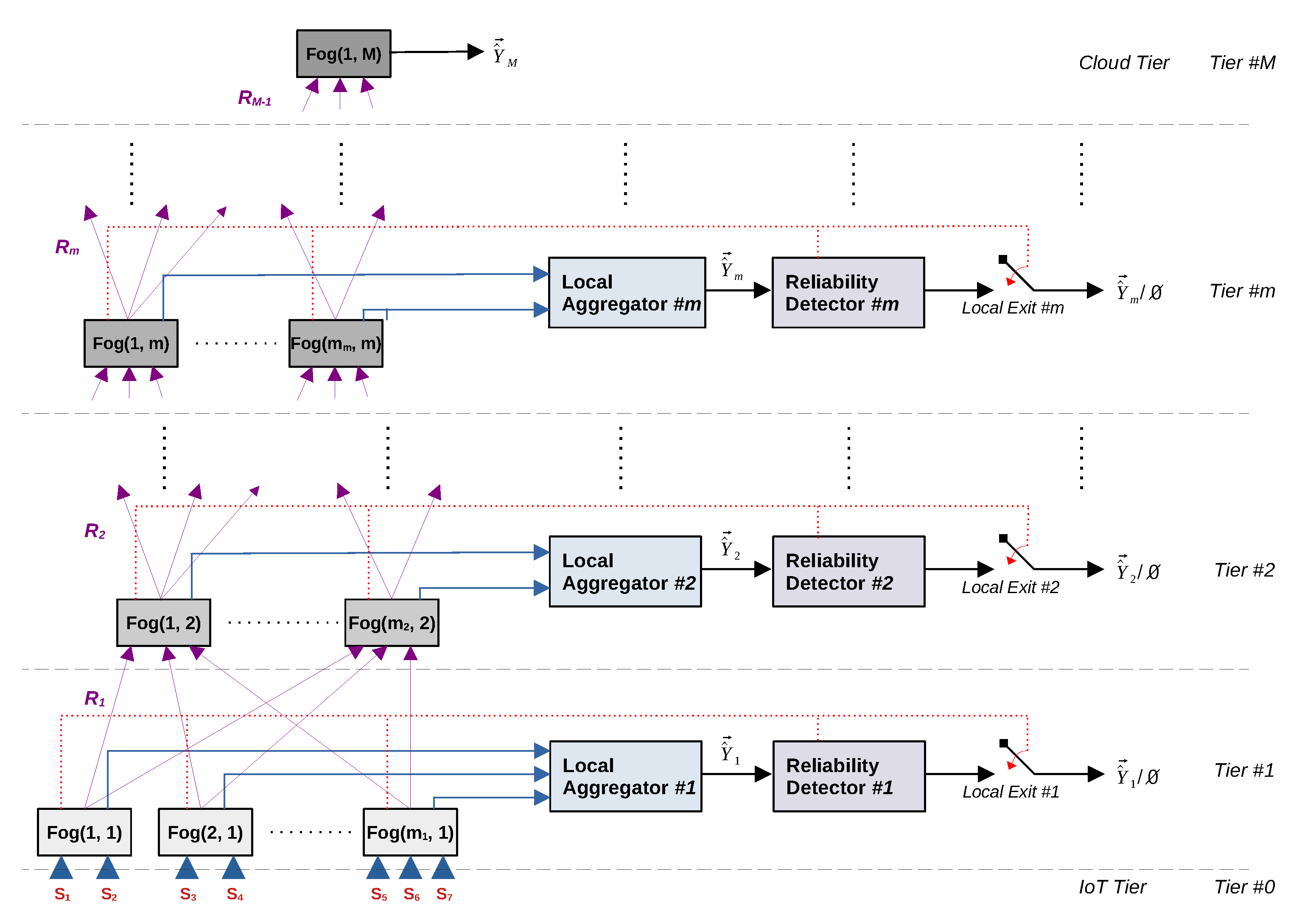
4. DeepFogSim: The Considered System Model
In this section, we introduce the basic definitions and formal assumptions about the constrained resource optimization problem tackled by the DeepFogSim.
For this purpose, let us denote by Fog
the
j-th FN located at
, with
and
, where
is the total number of FNs present in the
m-th tier, while
M is the total number of tiers. By definition, the last
M-th tier is the Cloud one. Moreover, let us denote by
the data vector arriving at the input of the CDNN of
Figure 3 at time
t that will be processed in a layer-wise way, moving from
. In a similar way, we denote by
the feature vector extracted by
and passed to the next
for further processing.
4.1. Container-Based Virtualized Fog Node Architecture
In principle, the technological platform of
Figure 3 may run, in parallel,
multiple CDNNs which carry out different analytics on the same set of sensed data by resorting to the virtualization of the full spectrum of available physical resources [
40].
Hence, according to this consideration, we assume that all Fog/Cloud nodes of
Figure 3 are equipped with software clones of the run CDNNs. The number of clones simultaneously hosted by each FN equates to the number of (possibly, multiple) CDNNs which are running in parallel over the technological platform of
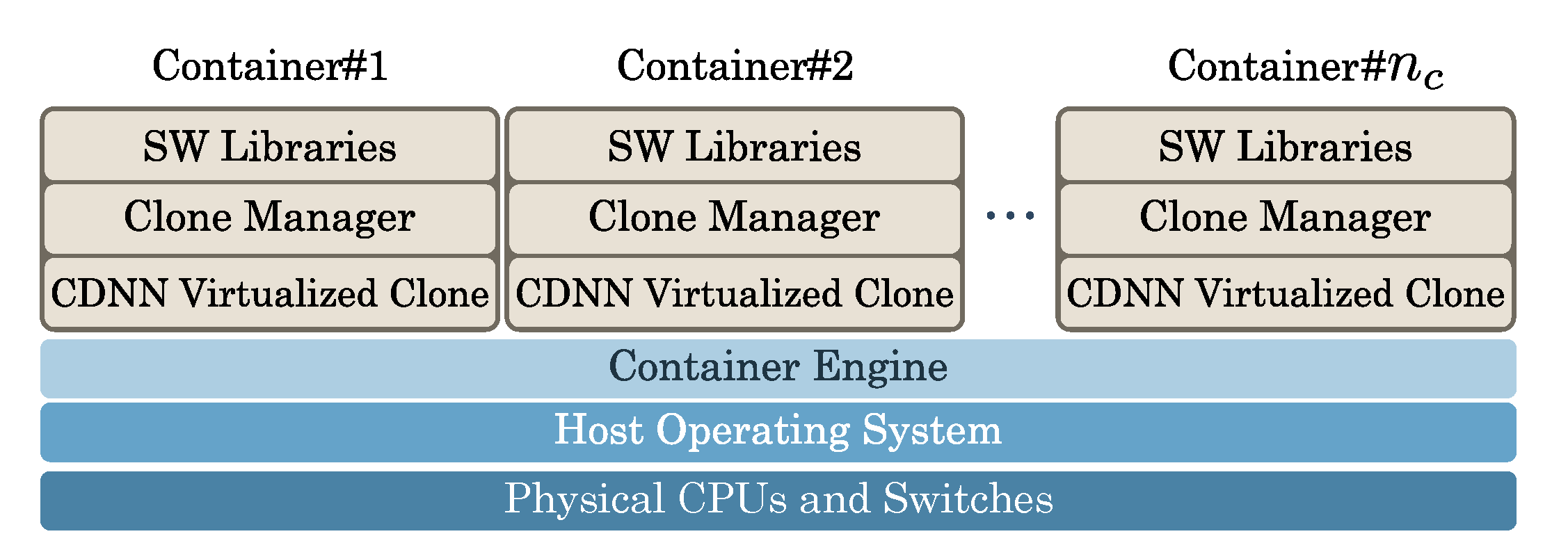
Figure 3. Doing so, each clone is fully dedicated to the execution of a single associated CDNN, and then it acts as a virtual “server” by providing resource augmentation to the tied “client” CDNN. For this purpose, each clone is executed by a container (CNT) that is instantiated atop the hosting FN. The container is capable of using (through resource multiplexing) a slice of the physical computing and networking resources of the hosting FN. The logical view of the resulting virtualized container-based FN is detailed in
Figure 5.
All containers hosted by Fog
in
Figure 5 share: (i) a same Host Operating System (HOS); and (ii) the pool of computing (i.e., CPU cycles) and networking (i.e., bandwidth and I/O Network Interface Cards (NICs) and switches) physical resources available on the hosting FN. The task of the Container Engine of
Figure 5 is to allocate these physical resources to the requiring containers by performing dynamical multiplexing.
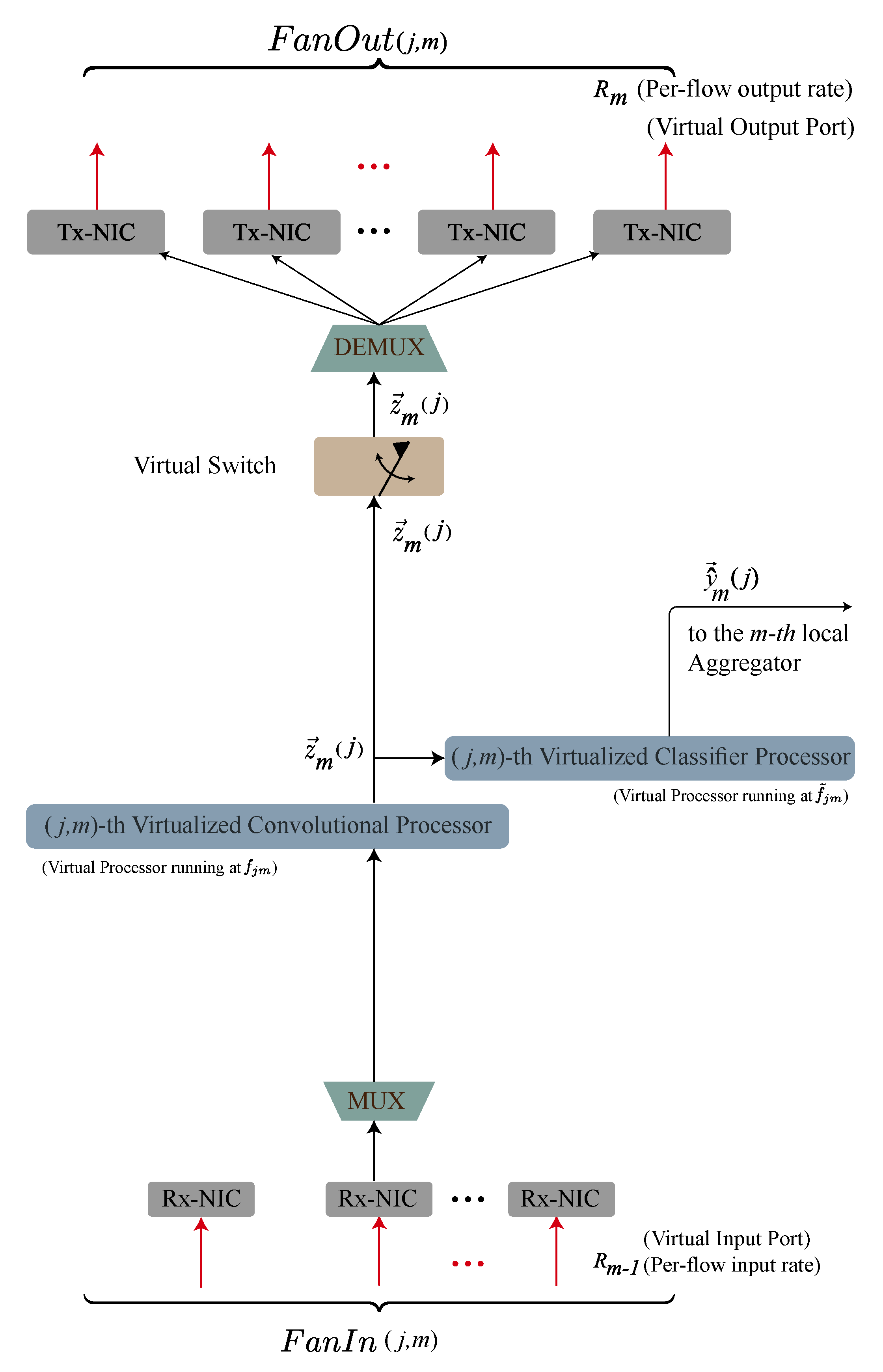
The resulting virtualized architecture of Fog
is sketched in
Figure 6. Specifically, in
Figure 6 we have that:
the -th Virtualized Convolutional Processor, running at frequency , provides the computing support for the execution of the set of consecutive convolutional and pooling layers of the supported CDNN to be executed on . In the envisioned architecture, the input data at the Virtualized Convolutional Processor is a feature vector received from the FNs working at the previous , while the corresponding output data is provided to the associated Virtualized Classifier Processor, as well as forwarded to the FNs operating at the next ;
the
-th
Virtualized Classifier Processor, running at frequency
, provides the computing support for the execution of the local classifier of the CDNN. Its task is to process the feature vector generated by the corresponding
Virtualized Convolutional Processor, so as to produce the output vector
to be delivered to the corresponding
m-th
Local Aggregator of
Figure 3 for the (possible) generation of an early-exit;
Fog
is also equipped with a number
of virtualized input ports. Hence, the task of the
MUltipleXer (
MUX) at the bottom of
Figure 6 is to merge the corresponding information flows received by the FNs operating at the previous
, so as to generate a (single) aggregate feature vector
. All input flows at the bottom of
Figure 6 are assumed to operate at a same bit-rate
(bit/s);
the main task of the
De-MUltipleXer (
DEMUX) at the top of
Figure 6 is to replicate the received feature vector
over the
virtualized output ports equipping Fog
. Each output flow is forwarded to the FNs at the next
at a bit-rate
(bit/s); and
the task of the
Virtual Switch (
VS) of
Figure 6 is to enable the transmission of the output feature
to the FNs at the next
only when early-exit does not occur at
.
4.2. Featuring the Average Traffic and Workload
Since all FNs of a same tier of
Figure 3 cooperate, by definition, in performing the same type of processing, all flows output by FNs of
have the same throughput
(bit/s), with
.
In the case that consecutive layers of the supported CDNN collapse into a single component layer at the m-th tier, the corresponding layer interior architecture becomes composed of the cascade of convolutional blocks followed by a single nonlinearity and a single soft-decisor that sits atop the last convolutional blocks. As a consequence of these architecture features, we have that:
the processing density of each -th Fog convolutional processor passes from to ;
the processing density of each -th Fog classifier processor is , regardless of the number of CDNN layers, which are executed by the FNs at ;
the average volume of data
(bit) received in input by Fog
during each sensing period is:
where
denotes the expectation and
is the size (in bit) of the vector
;
the average volume of data
(bit) output by Fog
is:
4.3. Per-Node Execution Times
Since we assume that the transmit Network Interface Cards (NICs) of Fog
, at the top of
Figure 6, may operate in parallel, the per-node execution time
can be expressed as the summation of three terms, i.e., the computation time
, the classification time
and the network transmission time
. Hence, it equates:
where
(respectively,
) is the processing speed (in (bit/s)) of the convolutional processor (respectively, the classifier processor) equipping Fog
(see
Figure 6).
Furthermore, since the Cloud does not perform transmission but only convolutional and classify tasks, its execution time comprises only the first two terms of the above expression, that is:
4.4. Per-Tier Execution Times
Since the
m-th local aggregator in
Figure 3 must receive all the
-dimensional vectors
before performing its final operation, the (per-tier) execution time
at
equates to the execution time of the
slowest FN, so that we have:
By definition, the multi-tier Fog architecture of
Figure 3 processes the data generated by IoT devices of
Figure 3 in a
sequential way. Hence, the aggregate execution time
needed to generate the local exit at
equates to:
so that the resulting time constraint on the allowed local decision at
reads as follows:
where
is the tolerated upper bound on the time needed for the generation of the local decision at
.
4.5. Models of the Per-Node Computing Power and Energy
In this subsection, we provide the formal relationships modeling the power and energy consumption of each FN. Specifically, we analyze separately the contributions of the convolutional and classifier processors equipping each FN in
Figure 6.
4.5.1. Power and Energy Wasted by the Convolutional Processor
The power wasted by the convolutional processor of Fog
in
Figure 6 is composed of a static part
(Watt), with
and
, and a dynamic one:
where [
41]:
is a dimensionless power exponent that depends on the power profile of the underlying CPU;
(CPU cycle/bit) is the so called processing density of the computation operations performed by the underlying CPU when a single layer of the CDNN must be executed. It depends on the number of convolutional neurons that compose a single layer of the considered CDNN and the average number of summations/multiplications performed by each neuron [
15];
(bit/s) is the processing frequency of the -th convolutional processor;
is the number of layers of the underlying CDNN to be executed by Fog
. This term accounts for the fact that the workload to be processed by the
-th convolutional processor scales (more or less) linearly with the number
of convolutional layers of CDNN to be executed by the Fog
[
15]; and
, measured in (Watt/(CPU cycle/s)), is a power scaling factor that depends on the power profile of the CPU supporting the -th convolutional processor.
In order to compute the (average) energy
(Joule) consumed by the
-th convoultional processor during each sensing interval, we note that: (i) the
-th convolutional processor must remain turned ON for a time
equal to the execution time required by the Cloud node of
Figure 3, i.e., the
maximum time needed for the processing of the data generated by the server in a sensing period; and (ii) since the
-th convolutional processor works at the processing speed
(bit/s) and the workload to be executed is
in (
1), the resulting processing time is
in (
3). Hence, we have the following relationship for
:
where
is the full (i.e, worst case) execution time of the supported CDNN of
Figure 1a.
4.5.2. Power and Energy Wasted by the Classifying Processor
Let
(Watt) be the idle power consumed by the CPU of the
-th classifying processor in
Figure 6. Then, the corresponding dynamic power component may be modeled as [
41]:
where:
is a dimensionless power exponent that depend on the power profile of the underlying CPU;
(bit/s) is the processing frequency of the -th classifying processor;
(CPU cycle/bit) is the processing density of the computation operations performed by the underlying CPU [
15]; and
, measured in (Watt/(CPU cycle/s)), is a positive scaling factor that depends on the power consumption of the CPU that supports the -th classifier.
Hence, the energy
(Joule) consumed by the
-th classifier during a sensing interval equates to:
with
being still the full (i.e, worst case) execution time.
4.6. Models of the Per-Flow Networking Power and Energy
Before developing the power/energy network models, some remarks about the network aspects of the Fog platform of
Figure 3 are in order.
First, we assume that the
m-th bit-rate
(bit/s),
in
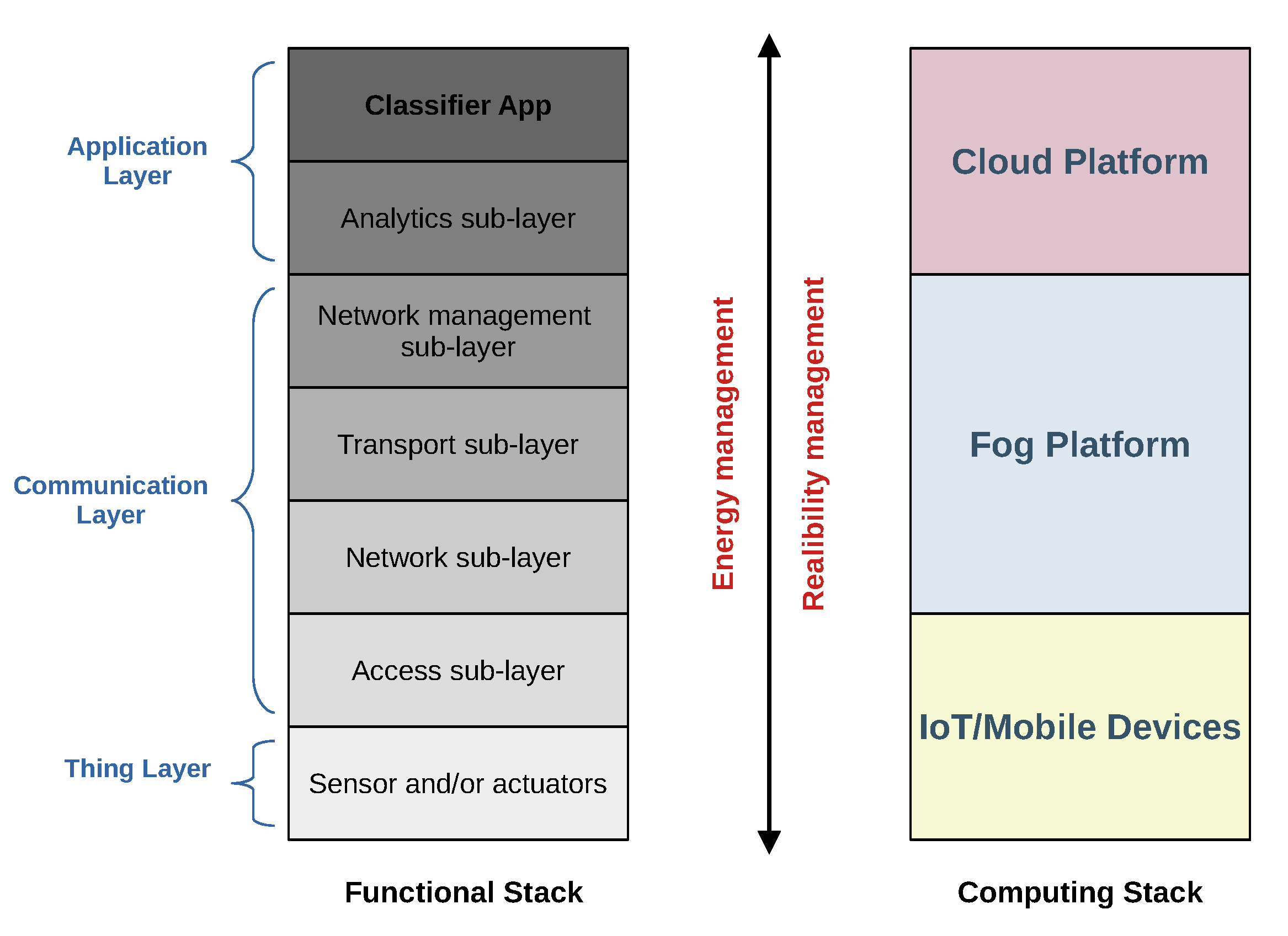
Figure 3 is a per-flow transport-layer throughput. However, both the consumed network power and energy depend on the corresponding bit-rate
measured at the physical layer of the protocol stack of
Figure 4. In general, the (average values of the) above communication rates may be related as:
where
is a dimensionless coefficient that accounts for the communication overhead incurred by passing from the Transport layer to the Physical one of the underlying protocol stack of
Figure 4. Typical values of
are in the range:
[
40].
Second, each FN Fog
must act as both a computing and a (wireless) network switch. Furthermore, depending on the actual network topology, in general, its fan-in and fan-out may be different, i.e.,
. According to this consideration, Fog
in
Figure 6 is equipped with two distinct sets of input and output NICs.
Third, since all FNs that compose the same tier cooperate in the execution of the same set of CDNN layers, it is reasonable to retain that the total volume of data received in input by Fog is balanced over its input ports.
The mentioned features of the networking infrastructure of the envisioned Fog execution platform of
Figure 3 will be exploited in the sequel for developing the corresponding network power and energy models.
4.6.1. Power Wasted for Receiving Network Operations
Let
(Watt) be the idle power consumed by each receive port of Fog
in
Figure 6. Hence, the corresponding receive dynamic power can be modeled as [
41]:
Now, the idle time is still
. However, the receive time is:
because the overall workload
received by Fog
is evenly split over its
input ports, each one working at
. Hence, the total network energy
consumed by Fog
for receiving operations over a sensing interval equates to:
The above expression holds for
because, in our framework, sensors are co-located with FNs at
(see
Figure 3).
and
in (
15) depend on the communication technology employed at the Physical layer and can be modeled as follows [
41]:
is a positive dimension-less exponent, in which the actual value depends on the transmission technology actually implemented at the Access sub-layer of the functional stack of
Figure 4 [
42,
43];
is a positive coefficient (measured in Watt/((bit/s)
)), which accounts for the effect of the round-trip-time
of the received flows. Specifically, in the case of single-hop connections, it can be formally modeled as in the following [
41,
44]:
where: (i)
is a dimension-less positive exponent; (ii)
is the length (i.e., coverage, measured in meter (m)) of the wireless connections in
Figure 3 going from
to
; (iii)
is a fading-induced path-loss exponent; and (iv) the positive coefficient
accounts for the power profile of the receive ports.
4.6.2. Power Wasted by Fog in the Transmit Mode
Let
(Watt) be the idle power consumed by a single transmit port of Fog
. Hence, the corresponding per-port dynamic transmit power can be modeled as [
41]:
Now, the idle time is still
. However, since the overall data
generated by Fog
is entirely replicated over each output port (see
Figure 6), the corresponding transmit time equates to:
Hence, the total energy
wasted by Fog
over a sensing interval for transmission purpose can be modeled as follows:
The above expression holds for
because, by design, the last node (i.e., the Cloud) in
Figure 3 does not transmit. The parameters
and
in Equation (
19) play the same roles and then assume the same formal expressions to the receive counterparts in Equations (
15) and (
16).
4.7. Total Energy Wasted by the Overall Networked Virtualized Fog Computing Platform
Let
(Joule) be the (average) overall energy wasted by the virtualized networked computing platform of
Figure 3 over a (single) sensing period for both network and computing operations. Hence, by definition, we have that:
where the overall computing energy
equates to (see
Figure 6):
while the overall network energy
is given by:
Equation (
22) is the summations of three terms, i.e., (i) the energy wasted by
for transmission; (ii) the energy consumed by all intermediate tiers for receive and network operations; and (iii) the energy consumed by the uppermost Cloud node for receiving purposes.
Before proceeding, a remark about the formal meaning of
is in order. Specifically, according to the virtualized nature of the proposed
DeepFog technological platform of
Figure 5,
in (
20) is the total (i.e., computing-plus-communication) energy wasted over a (single) sensing period by
all and only Fog clones that actually support the execution of the considered CDNN. Hence,
considers
only the energy consumed for the execution of the supported CDNN of
Figure 1a and does
not represent the total energy wasted by the full hardware infrastructure of
Figure 1b, which can be used for the simultaneous support of
multiple jobs and/or CDNNs. This meaning of
is in agreement with the virtualized architecture of each FN that has been previously detailed in
Figure 5 and
Figure 6.
4.8. The Underlying Resource Allocation Problem
From a formal point of view, the proposed
DeepFogSim toolkit numerically computes the solution and evaluates the resulting performance of an optimization problem that is concerned with the
joint allocation of the available computing-plus-networking resources to the FNs of the virtualized execution platform of
Figure 3 under per-exit constraints on the tolerated inference delays.
In order to introduce this problem, let
be the number of FNs of the platform of
Figure 3. Let:
,
and
be the vectors of the convolutional and classifier processing frequencies and the vector of the inter-tier network throughputs, respectively. Finally, let
be the resulting compound vector. Hence, the tackled constrained resource allocation problem is formally defined as follows:
where:
(s),
(bit/s),
(bit/s) and
(bit/s) are the set of the
assigned constraints on the maximum allowed resources and tolerated per-exit inference delays.
The box constraints in (23c)–(23e) upper bound the computing frequencies at the FN and the inter-tier network throughput, respectively. The M constraints in (23b) guarantee that each local exit is generated within a maximum inference delay. In the case in which no delay constraint is enforced to the m-th local exit, we set .
The problem in (23) is a continuous-valued optimization problem that embraces non-negative continuous optimization variables and constraints. The constraints in (23c)–(23e) are of box-type, while the M delay constraints in (23b) are nonlinear constraints involving the optimization vector .
After indicating by
the Lagrangian function of the problem in Equation (23), and by
the Lagrange multipliers associated to the delay constraints in (23b), let:
be a solution of the optimization problem. In order to compute it, we implement the iteration-based primal-dual approach recently customized in Reference [
45] for broadband networked application scenarios. The primal-dual algorithm is an iterative procedure that updates on per-step basis both the primal
and the dual
variables, in order to throttle the corresponding Lagrangian function
towards its saddle point. Hence, after introducing the dummy position
, the
-th update of the
i-th scalar component
,
of the resource vector
reads as:
while the
-th update of the
m-th scalar component of the Lagrange multiplier vector
is:
In order to guarantee fast responses to abrupt (and possibly unpredictable) changes of the operating conditions, as well as (asymptotic) convergence to the steady state of the iterations in (
24) and (
25), we implemented the following “clipped” relationships for updating the step sizes in (
24) and (
25):
and
The goal of the clipping factor
is to avoid both too small and too large values of the step-size in (
24) and (
25), in order to guarantee a quick self-response to operative changes and small oscillations in the steady state.
Remark—On the generality of the considered resource allocation problem and coverage area of the related DeepFogSim
toolbox. Regarding the generality of the resource allocation problem in Equation (23), and then the related coverage area of the implementing
DeepFogSim toolbox, we stress that the proposed toolkit is flexible enough to be applied for the calculation of the optimized resource allocation and simulation of the inference phase of the overall family of the conventional (that is, early exit-free) family of the feedforward (convolutional or dense) DNNs [
10]. In fact, a direct examination of the tackled optimization problem of Equation (23) leads to the conclusion that it suffices to set:
the per-classifier maximum processing frequencies: in Equation (23d) to zero; and
the per-exit maximum tolerated inference delays: in Equation (23b) to infinite,
in order to turn out the afforded resource allocation problem over the CDNN with early exits of
Figure 1a into the corresponding resource allocation problem over a conventional early-exit-free DNN equipped with
L (convolutional or dense) layers. Furthermore, by setting the constraint:
on the tolerated inference delay of the uppermost
M-th tier in
Figure 1b to infinite, then all the delay constraints in Equation (23b) are relaxed. As a consequence, the solutions of the afforded resource allocation problems returned by the
DeepFogSim toolbox under this setting are capable of featuring delay-tolerant application scenarios.
Overall, the above considerations lead to the conclusion that the proposed DeepFogSim toolbox is capable of properly covering a broad spectrum of delay-sensitive and delay-tolerant resource allocation problems involving both feedforward CDNNs with early exits and conventional early-exit-free DNNs.
5. The DeepFogSim Toolkit: Software Architecture and Supported Resource Allocation Strategies
The core of the
DeepFogSim simulator is built up by three software routines that implement a number of strategies (i.e., optimization policies), in order to numerically solve the constrained optimization problem in (23). MATLAB is the native environment under which the optimization routines are developed and run. Differently from our previous simulator [
39], the problem solved here is intrinsically sequential; hence, the current version of
DeepFogSim does not exploit the parallel programming on multi-core hardware platforms supported by the
Parallel Tool Box of MATLAB, which is utilized by the
VirtFogSim package.
5.1. The General SW Architecture of DeepFogSim
The main functionalities of
DeepFogSim are implemented by the functions listed in
Table 2. In the following of the paper, these functions are briefly described. A detailed explanation about the usage of such functions is found in the
DeepFogSim User Guide, which can be downloaded along with the software package (see
Section 9). The main functions in
Table 2 use some auxiliary functionalities implemented by the set of additional routines listed in
Table 3.
To describe the general software architecture of the simulator, we note that DeepFogSim acts as the main program that:
allows the user to setup 34 input parameters (refer to
Table A2), which characterize the scenario to be simulated by the user (see
Figure 3);
optionally calls the Static_Allocation function to simulate the same scenario where all the resources are set to their maximum values (bit/s);
optionally, calls the DynDeFog_TRACKER function. It returns the time plots over the interval: of the:
- (a)
total energy
consumed by the overall proposed platform of
Figure 3;
- (b)
the corresponding energy
consumed by the convolutional and classifier processors of
Figure 3;
- (c)
the corresponding energy
consumed by the network connections of
Figure 3; and
- (d)
the behavior of the first and last (
M-th)
lambda multipliers in (
25) associated to the constraints in Equation (23),
when unpredicted and abrupt changes in the operating conditions of the simulated Fog platform of
Figure 3 occur. The user may set the magnitude of these changes, in order to test various time-fluctuations of the simulated environment of
Figure 3 (see
Section 5.4 for a deeper description of the
DynDeFog_TRACKER function and its supported options).
The current version of the DeepFogSim simulator is equipped with a (rich) Graphical User Interface (GUI) that displays:
the numerical values of the best optimized frequencies for the convolutional and classifier processors and the network throughputs; and
the numerical values of the optimal energy consumption, which are returned by the DynDeF_RAS function.
5.2. Supported Resource Allocation Strategies
In this subsection, we describe the supported resource allocation strategies provided by the
DeepFogSim toolkit and listed in
Table 2.
(a) The RAS function
The
DynDeF_RAS function implements the primal-dual adaptive iterations in (
25) and (
27) for the numerical evaluation of the solution of the optimization problem in (23). The goal is to perform the optimized constrained allocation of the computing and networking resources needed by the simulated hierarchical Fog platform of
Figure 3 for sustaining the inference phase of the CDNN of
Figure 1a running atop it. The input parameters of this function are the following four vectors:
, which are needed for the initialization of the primal-dual iterations in (
24) and (
25). The values of these vectors are set by calling the main script of the
DeepFogSim simulator.
The DynDeF_RAS function returns, by saving the values to the corresponding global variables, the following output variables:
(bit/s): the matrix collecting the frequencies of the convolutional processors on a per-iteration basis;
(bit/s): the matrix collecting the frequencies of the classifier processors on a per-iteration basis;
(bit/s): the matrix collecting the frequencies of the network throughputs on a per-iteration basis;
(Joule): the matrix collecting the lambda multipliers on a per-iteration basis;
(Joule): the vector collecting the total energy in (
20) on a per-iteration basis;
(Joule): the vector collecting the computing energy in (
21) on a per-iteration basis; and
(Joule): the vector collecting the network energy in (
22) on a per-iteration basis,
where the parameter fixes the maximum number of the allowed primal-dual iterations.
The last column of the previous matrices and vectors are the optimized (best) values of the allocated resources and consumed energy, respectively: , , , , , , and , which represent the final output of the DynDeF_RAS function.
Algorithm 1 presents a pseudo-code of the
DynDeF_RAS function. An examination of this code points out that the asymptotic computational complexity of the
DynDeF_RAS function scales linearly with
.
| Algorithm 1DynDeF_RAS function |
function: .
Input: The initialized values: .
Output: , , and vectors of the best resource allocation; scalar total energy (Joule), scalar computing energy (Joule), and network energy (Joule) consumed under the optimized allocation vectors.
|
|
▹ Begin DynDeF_RAS function |
- 1:
fordo - 2:
for do - 3:
Compute with Equation ( 1) - 4:
Compute with Equation ( 2) - 5:
end for - 6:
end for - 7:
fordo ▹RAS iterations - 8:
for do - 9:
for do - 10:
Compute the with Equations ( 3) and ( 4) - 11:
end for - 12:
Compute with Equation ( 5) - 13:
end for - 14:
Compute with Equation ( 6) - 15:
Compute with Equations ( 9), ( 11), and ( 21) - 16:
Compute with Equation ( 22) - 17:
Compute with Equation ( 20) - 18:
Compute all the derivatives of the Lagrangian function - 19:
Update , , and
with Equations ( 24) and ( 25) - 20:
Update , , and with Equations ( 26) and ( 27) - 21:
end for - 22:
Obtain , , and - 23:
Compute with Equations ( 9), ( 11), and ( 21) - 24:
Compute with Equation ( 22) - 25:
Compute with Equation ( 20) - 26:
return. ▹End DynDeF_RAS function
|
(b) The Static Allocation strategy
The Static Allocation strategy, implemented by the
Static_Allocation function, calculates the computing, networking, and total energy consumed by the simulated Fog platform of
Figure 3 for sustaining the delay-constrained inference phase of the considered CDNN under the (static) maximal allocation vectors:
.
Hence, the Static_Allocation function returns:
: the maximum total energy consumed by the the simulated Fog platform of
Figure 3 under the maximal resource vectors;
: the maximum computing energy consumed by the the simulated Fog platform of
Figure 3 under the maximal resource vectors; and
: the maximum network energy consumed by the the simulated Fog platform of
Figure 3 under the maximal resource vectors.
Algorithm 2 presents a pseudo-code of the implemented
Static_Allocation function. An examination of this code points out that the asymptotic computational complexity of the
Static_Allocation function scales linearly with the sum of
M of tiers and the total number
Q of Fog nodes, i.e.,
.
| Algorithm 2Static_Allocation function |
function: .
Input: , , , , and .
Output: scalar total energy (Joule), scalar computing energy (Joule), and network energy (Joule) consumed under the maximal allocation vectors. |
|
▹Begin Static_Allocation function |
- 1:
fordo - 2:
for do - 3:
Compute with Equation ( 1) - 4:
Compute with Equation ( 2) - 5:
Compute the with Equations ( 3) and ( 4) - 6:
end for - 7:
Compute with Equation ( 5) - 8:
end for - 9:
Compute with Equation ( 6) - 10:
Compute with Equations ( 9), ( 11), and ( 21) - 11:
Compute with Equation ( 22) - 12:
Compute with Equation ( 20) - 13:
return. ▹End Static_Allocation function
|
5.3. Auxiliary Functions of DeepFogSim
In this subsection, we provide the description of some auxiliary functions called from the previous main routines. These auxiliary functions are listed in
Table 3.
The Check_convexity function checks for the (strict) convexity of the optimization problem in (23). If the problem is not strictly convex, the function returns an error message and then exits the program.
The Check_feasibility function tests the (strict) feasibility of the underlying constrained optimization problem in (23) by checking M delay-induced constraints in (23b). If at least one of these M constraints fails, the function generates an error message indicating the failed delay constraint and then stops the overall program.
In a similar way, the Check_input function checks for the formal validity of the input data set by the user. If any input variable is not formally valid, the function returns an error message and then exits the program.
The init_other_global function initializes all the output and dummy (global) variables that have not been directly set by the user in the configuration script.
Finally, the
oneDtotwoD and
twoDtooneD functions allow transformation of the mono-dimensional (i.e., string type) representation of the network topology of
Figure 3 to the corresponding bi-dimensional one. Specifically, these functions are used to map the bi-dimensional index of the
i-th Fog node lying in the
j-th tier into a sequential scalar number falling in the range
. In more detail:
The function [tier, column] = oneDtotwoD(oneDindex) converts the 1D indexing of a Fog node to the corresponding 2D row/column one. The input parameter must be an integer and fall in the range: . The returned parameter is an integer and falls in the range: . The returned corresponding parameter is an integer and falls in the range: .
The function oneDindex = twoDtooneD(tier, column) evaluates the 1D equivalent index of the 2D indexing of a Fog node. The returned is integer-valued and falls in the range: . The value of the tier parameter must be an integer and fall in the range: . The value of the column parameter must be an integer and fall in the interval: .
5.4. DynDeFog_TRACKER: The Dynamic Performance Tracking Function
The goal of the
DynDeFog_TRACKER function is to test the convergence rate to the steady state and the steady-state stability of the primal-dual iterations performed by the
DynDeF_RAS function when unpredicted and abrupt changes in the operating conditions of the simulated Fog platform of
Figure 3 happen. These changes are formally dictated by the scaling vectors:
and
(see
Table A2), which multiply the scalar components of the input maximal resource allocation vector:
. Specifically, at the time indexes multiple of
, with
, the initial values of the sliced resource vector:
, undergo changes. These changes are obtained by multiplying (on a per scalar entry-basis) the components of the sliced vector
by:
and
.
The input parameters of the DynDeFog_TRACKER function are the same ones of the DynDeF_RAS function, namely , , , and . The outputs of the DynDeFog_TRACKER function are the resulting time-traces of the computing energy, network energy, total energy, multiplier and multiplier over the time interval , evaluated for three values of the speed-up factor (stored into the input vector ).
The feasibility of the operating conditions induced by and are explicitly tested by the DynDeFog_TRACKER function, and suitable terminating error messages are generated if infeasible operating conditions occur.
Graphic plots of the time traces of the returned output matrices are displayed at the end of the DynDeFog_TRACKER run. A detailed description of each of the steps performed by the DynDeFog_TRACKER can be found in the User Guide of the DeepFogSim package. From the previous description, it follows that the asymptotic complexity of the DynDeFog_TRACKER function scales up as in: .
Overall,
Table 4 presents a synoptic view of the asymptotic computational complexities of the described
DynDeF_RAS,
Static_Allocation, and
DynDeFog_TRACKER functions.
6. DeepFogSim: Supported Formats of the Rendered Data
Under the current version of the simulator, both the
DeepFogSim and
DeepFogSimGUI interfaces (see
Appendix A) support four main formats, in order to render the results output by the three main routines of
Table 4. The functions, used to obtain these formats, are listed in
Table 5 and are described in depth in the
DeepFogSim User Guide (see
Section 9). These rendering formats are:
the Tabular format, which is enabled by the print_solution graphic function;
the Colored Graphic Plot format, which is enabled by the plot_solution graphic function;
the Colored Time-tracker Plot format, which is enabled by the plot_FogTracker graphic function; and
the Fog Topology format, which is enabled by the plot_Topology graphic function.
Specifically, the
print_solution function prints on the MATLAB prompt the result obtained by running the tested strategies under the selected topology and given input parameters (see
Table A2). This function has an optional input parameter that allows the print of the results obtained by the
DynDeF_RAS function and the
Static_Allocation function, respectively. The function prints, in a numerical form, the results related to the optimized frequencies of the convolutional and classifier processors, the optimized energies
,
, and
, and the ratio
. If the
Static_Allocation is selected in the main script, it also prints the maximum energies
,
, and
consumed by the maximal resource allocation strategy and the ratio
. In addition, the
print_solution function prints on the MATLAB prompt the total computing time needed for running all the selected strategies.
The plot_solution function opens a number of figure windows, which graphically display the numerical results obtained by the DeepFogSim simulator. This function accepts two optional input parameters, i.e., (i) the number of figure from which to start and (ii) a flag used to choose whether the results returned by the Static_Allocation function must be also plotted. A maximum of eleven different figures may be opened. Specifically, this function displays the traces of the resources allocated by the DynDeF_RAS function (and eventually by the Static_Allocation one) and the related consumed total, computing and networking energy. A figure showing a bar plot of the per-exit actual-vs.-maximum tolerated delay ratio is also provided.
The
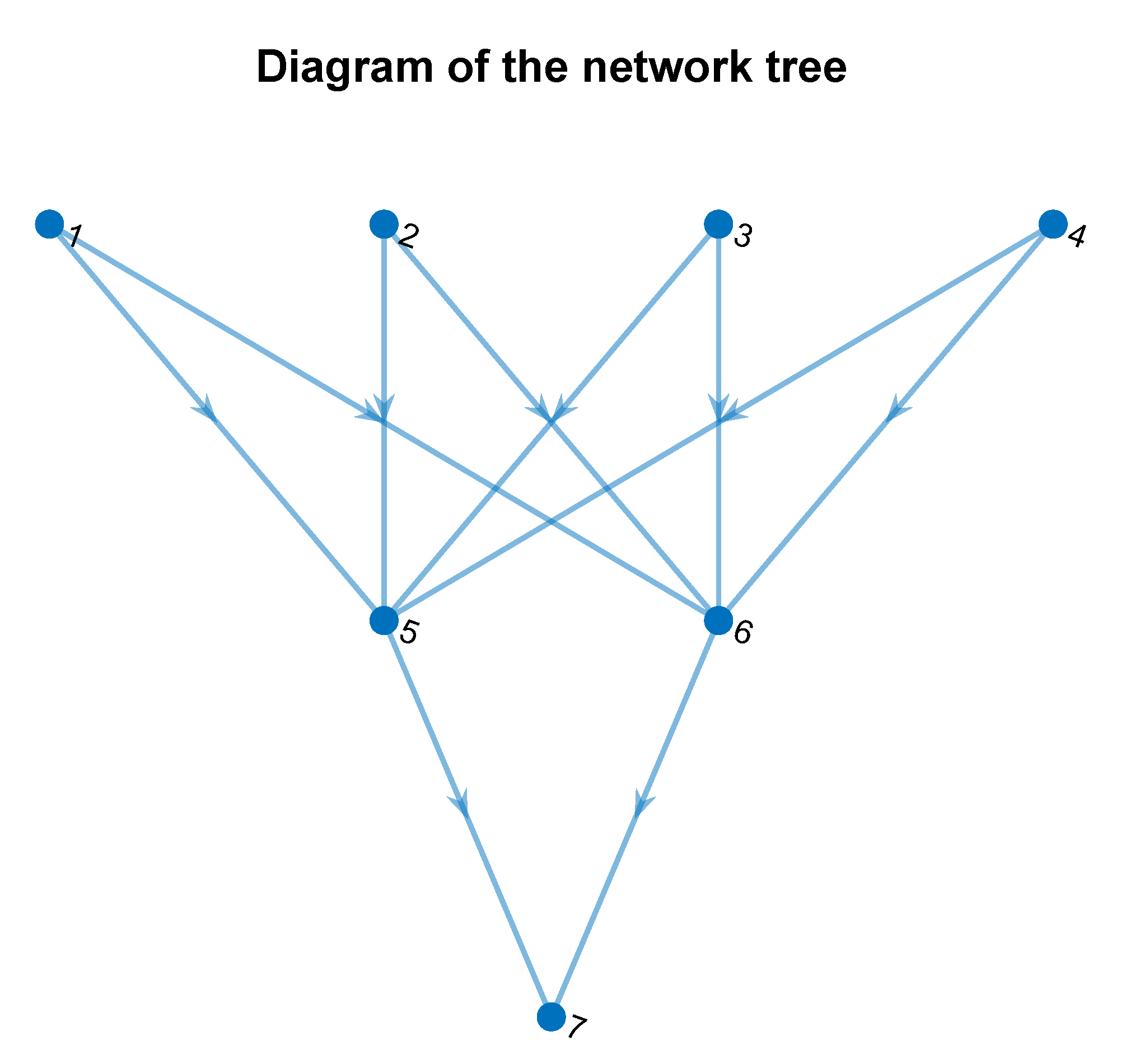
plot_Topology function returns a graphic representation of the Fog topology set in the input configuration for the Fog platform to be simulated. This function reads the global matrix variable
, which represents the
adjacency matrix of the tree. An illustrative screenshot of the network tree plot by this function is shown in
Figure 7.
Finally, the
plot_FogTracker function provides the graphic capabilities needed for a proper plot of the time-traces of the total energy, computing energy and networking energy, and the first and last lambda multipliers generated by the
DynDeFog_TRACKER function under the three values of step-size that are stored by the input vector
(see
Table A1). Its input parameter is the number of figure from which to start, to be sequential from the last plotted figure. Specifically, the function renders five figures that orderly report: the total (computing-plus-networking), computing, and networking energy, and the first and last lambda multiplier. All curves have been evaluated under the three step-size values stored by the input
vector. Some illustrative screenshots of the dynamic plots rendered by the
FogTracker function are shown in Figures 15 and 16 of
Section 7.3.
In the current version of the DeepFogSim package, it is available an archive that stores several test setups, together with the related sets of (suitably tuned) input parameters. These Fog topologies are ready-for-the-use, i.e., they may be retrieved by the user and then run under both the (previously described) interfaces of the simulator. The archived set-ups cover several topologies, with different number of tiers and per-tier nodes. Specifically, the number of Fog nodes ranges from , to , the number of tiers ranges from to , while the number of links varies in the range .
7. Performance Evaluation
This section aims at showing the actual capabilities of the developed
DeepFogSim toolkit by numerically testing and comparing the energy-delay-tracking performance of its natively supported optimization tools of
Section 5 under some use cases of practical interest.
The peculiar features of the considered CDNN with early exits is the presence of a number of hierarchically organized delay-constraints (see Equation (23b)) on the allowed per-exit maximum tolerated inference times. To the best of authors’ knowledge, neither resource allocation algorithms nor related simulation packages are currently present in the open literature, which explicitly consider these multiple inference delays featuring the considered operating framework. Hence, motivated by this consideration, the proposed DeepFogSim simulator natively supports, as a benchmark for performance comparison, the so-called Maximal Resource Allocation strategy of Algorithm 2. This is a not adaptive resource allocation strategy that takes fixed at their allowed maximum values all the components of the resource allocation vectors . The performance comparisons against this benchmark allow us to appreciate, indeed, the actual resources savings arising from the implementation of the adaptive resource allocation engine of Algorithm 1 which is the core of the proposed DeepFogSim simulator.
A joint examination of the volumes of the input and output workloads in Equations (
1) and (
2) processed by the
-th FN, and the related model for the dynamic power profile
of the
-th convolutional processor in Equation (
8), points out that the information about the CDNN with early exits, needed for running the
DeepFogSim simulator are [
15]: (i) the vector of the per-layer compression factors
, where
,
, is the ratio between the size (in bit) of the workload at the output from
with respect to that at its input (i.e.,
takes account of the fraction of the workload that does not undergo early exit); and (ii) the vector of the Layer-to-Tier mappings featured by the actually performed partition
, where
,
, is the number of (adjacent) CDNN layers in
Figure 1a mapped onto the
m-the tier in
Figure 1b.
An in-depth analysis and evaluation of the overall topic of the optimized design of CDNNs with early exits is presented in Reference [
15], together with numerical examples of the vectors
and
for some CDNNs of practical interest (see, in particular, Tables 4–6 of Reference [
15] and the related texts). As already detailed in Reference [
15], we note that, in practice, the actual values of these vectors depend on a number of design factors, like the topology of the considered CDNN, the number and placement of the corresponding early exits, the sets of examples used to train and validate the CDNN, just to name a few.
All the simulations have been carried out by exploiting an hardware execution platform equipped with: (i) an Intel 10-core i9-7900X processor; (ii) 32 GB of RAM DDR 4; (iii) an SSD with 512 GB plus an HDD with 2TB; and (iv) a GPU ZOTAC GeForce GTX 1070. The release R2020a of MATLAB provided the underlying software execution platform.
We remark that, unless otherwise stated, all the simulations have been carried out under the parameter setting reported in the last column of the final
Table A2 in
Appendix B.
7.1. Use Cases and Simulated Fog Topologies
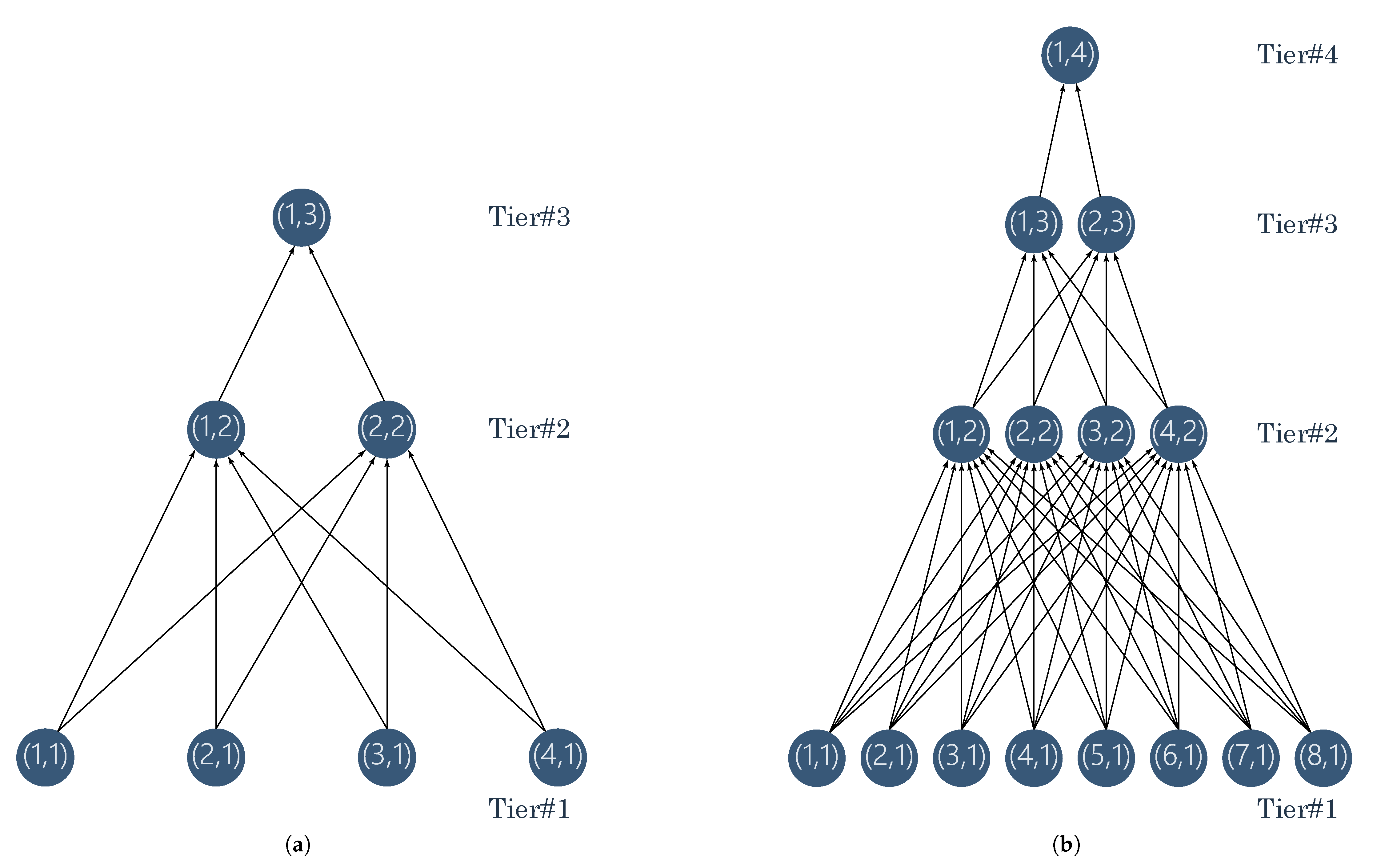
The reported tests of the
DeepFogSim package refer to the Fog topologies sketched in
Figure 8, hereinafter referred to as
and
, respectively. Specifically:
topology is composed of nodes, which are arranged onto tiers. Each node at is connected to every node at ; hence, the topology embraces 10 transmission links;
topology is composed of nodes, which are arranged onto tiers. Each node at is connected to every node at ; hence, the resulting topology embraces 42 transmission links.
Due to space constraints, we have decided to limit to report the performance results under and topologies. However, the archived set-ups in the DeepFogSim package cover several topologies, with different number of tiers and per-tier nodes.
In the carried out simulations, we refer to a CDNN with
layers to be suitably scattered over the available
M tiers of the Fog platform of
Figure 1b. In particular, we assume the following default numerical settings:
for the compression vector;
and for the mapping vectors under the two considered Fog topologies and , respectively; and
(s) and
(s) for the per-tier maximum allowed inference times under the two considered topologies in
Figure 8.
In addition, in the carried out simulations, we set the maximum allowable resources to: (Mbit/s), (Mbit/s), (Mbit/s), and (Mbit/s) under topology and to: (Mbit/s), (Mbit/s), and (Mbit/s) under topology . These values are the same for every node, i.e., for all and .
7.2. Resource and Energy Distribution Returned by DeepFogSim
In this subsection, we provide results obtained by the DynDeF_RAS function in terms of both resource allocation and energy performance.
To begin with, the
DeepFogSim has been tested under topology
and the obtained plots are shown in
Figure 9. Specifically,
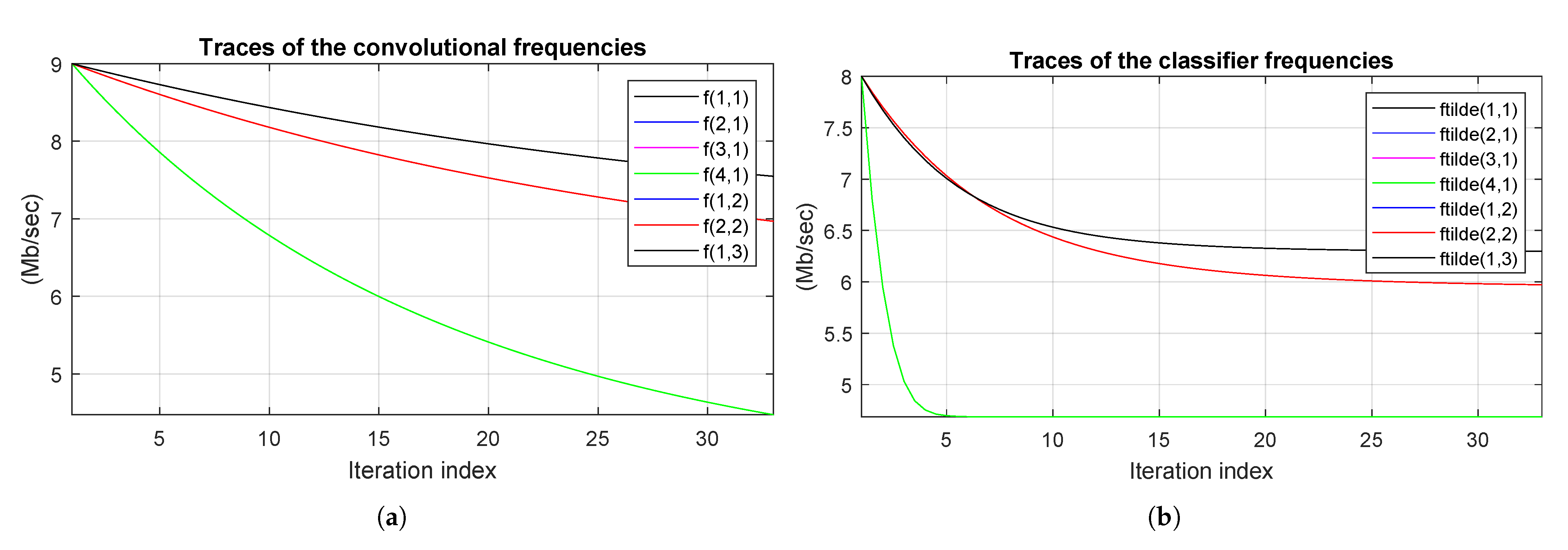
Figure 9a,b illustrate the traces of the optimized frequencies of the convolutional and the classifier processors, respectively. Although the total number of iteration
of the
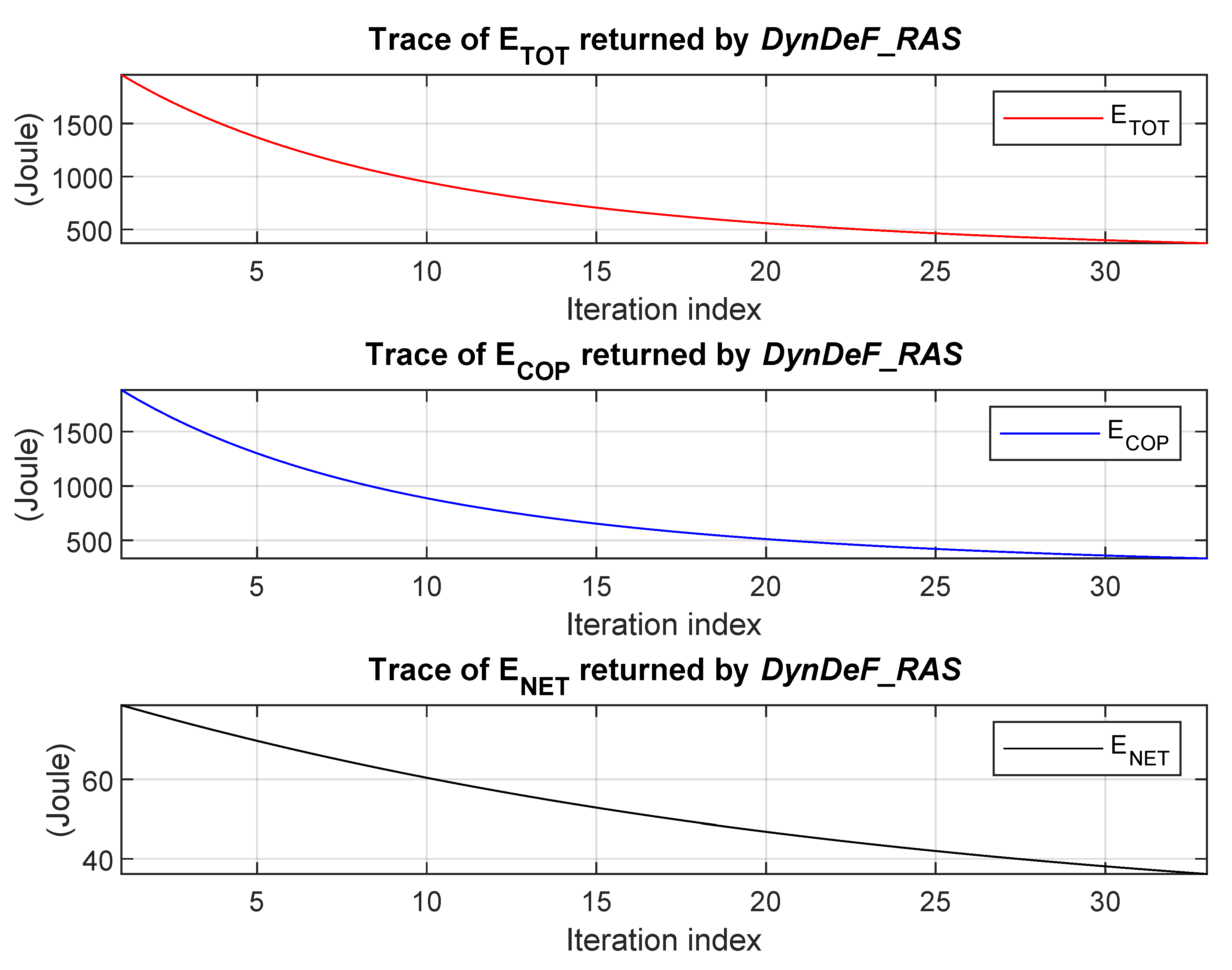
DynDeF_RAS function in Algorithm 1 is set to 450, these figures clearly show that the
DeepFogSim simulator stops Algorithm 1 after only 33 iteration. An examination of the traces and legends shown in
Figure 9a,b also suggests that all the involved frequencies (both for the convolutional and classifier processors) are clustered into three groups, which correspond to the FNs allocated over each of the three tiers of the considered Fog topology. This behavior is justified by the fact that, at each tier, each FN has to process the same volume of the input workload.
The last values of the traces in
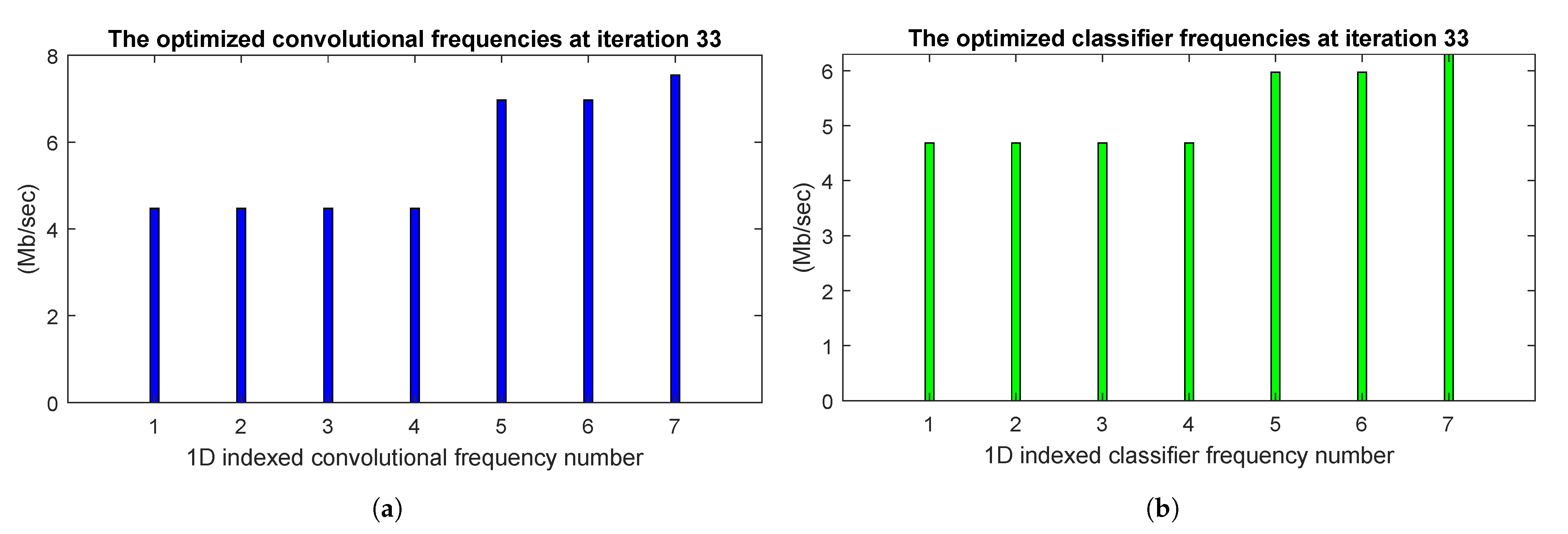
Figure 9a,b, i.e., the optimized frequencies of the convolutional and the classifier processors returned by the Algorithm 1, are shown in the bar plots of
Figure 10a,b, respectively. These plots confirm the clusterization of the optimized frequencies of both the convolutional and the classifier processors: the four frequencies of the first tier converge to the same value, and a similar behavior holds for the two frequencies of the second tier.
In a similar way,
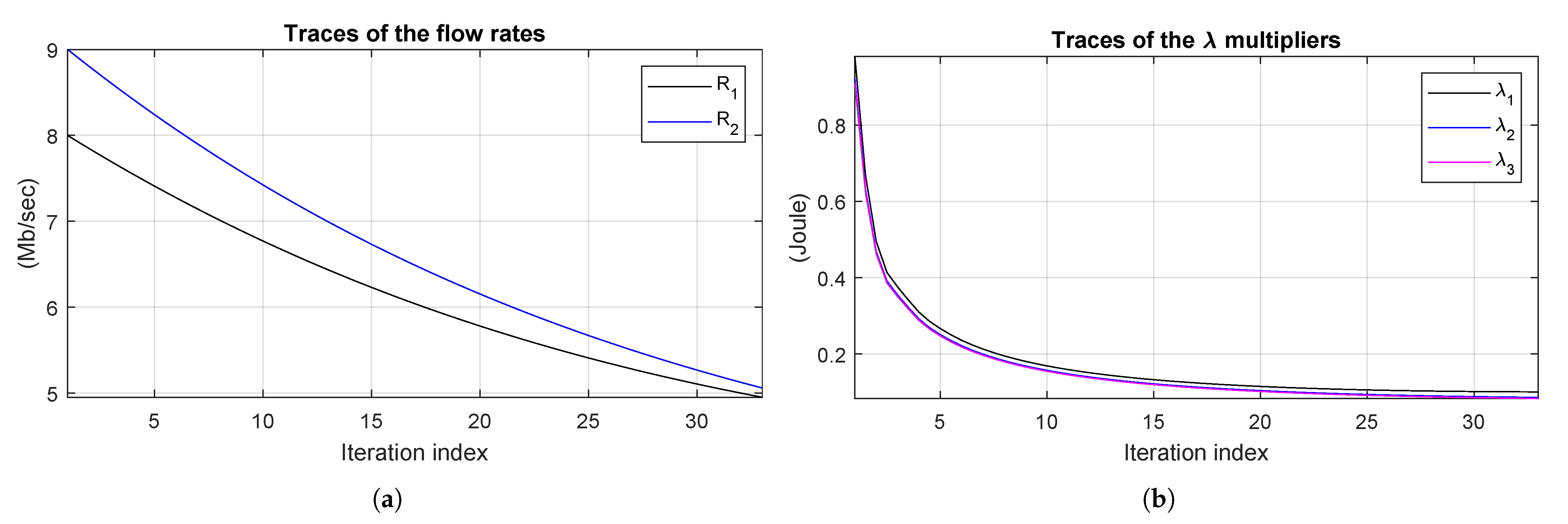
Figure 11a shows the traces of the optimized flow rates
and
between
and
, and between
and
, respectively. This figure shows that, although the rates start from different values, they converge to similar values at the steady state.
Figure 11b illustrates the convergence of the lambda multipliers in (
25) and supports the conclusion that a very limited number of iterations is sufficient to converge to a feasible solution.
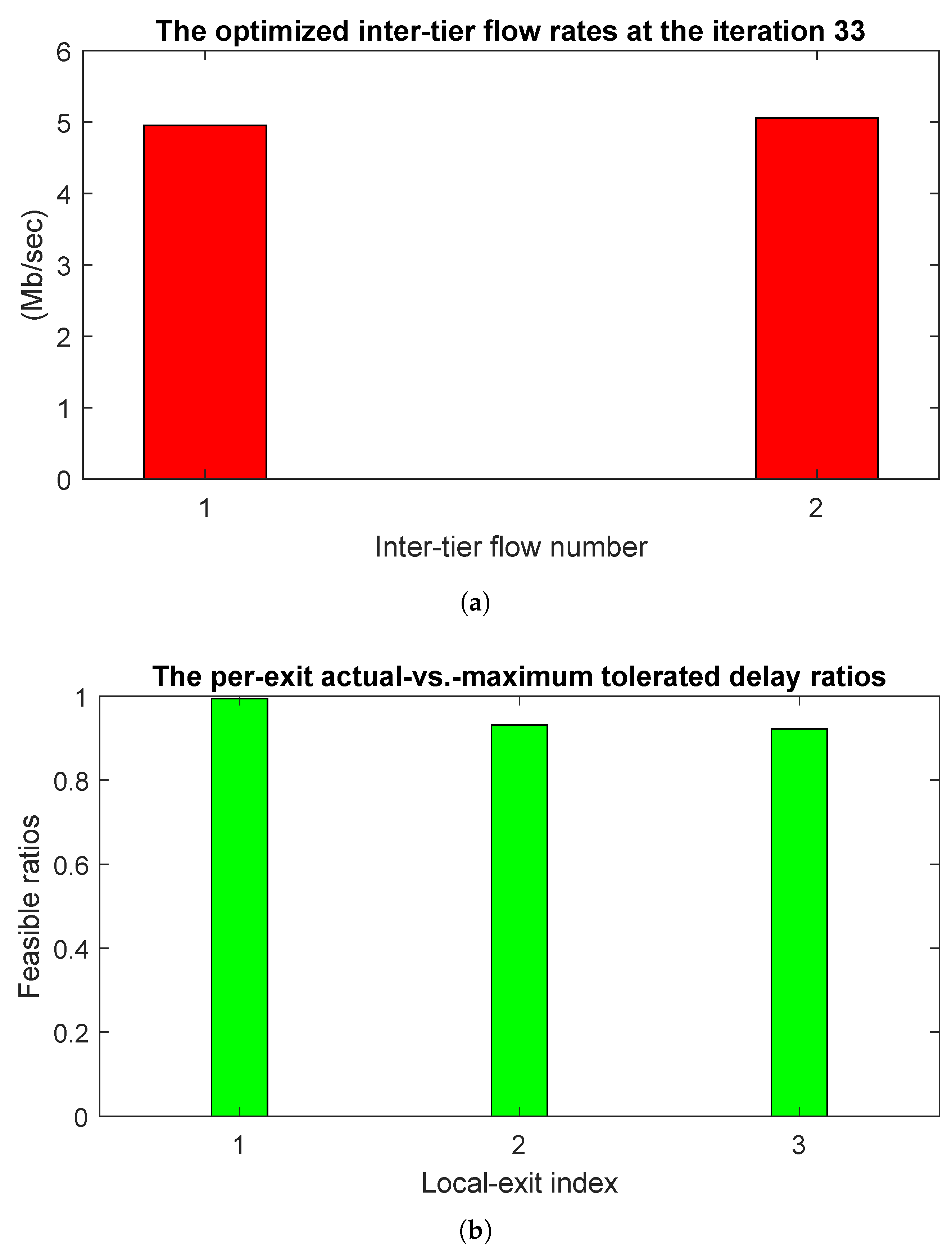
The values of the optimized values of the flow rates
and
are presented in
Figure 12a, once again highlighting the similar optimized values.
Figure 12b, instead, shows the ratio between the actual delay needed to perform the computation-plus-communi cation task at each tier in (
6) and the maximum tolerated delays
. By definition, the returned optimized solution is feasible if all these rates are not greater than the unit.
Figure 12b clearly shows that this constraint is met in all the three cases; hence, the presented steady-state resource allocations are, indeed, feasible.
In order to describe the energy plots returned by the
DeepFogSim toolkit,
Figure 13 presents the returned traces of the total energy
(top plot), computing energy
(middle plot), and network energy
(bottom plot). In addition, for the energy consumption, it is evident that
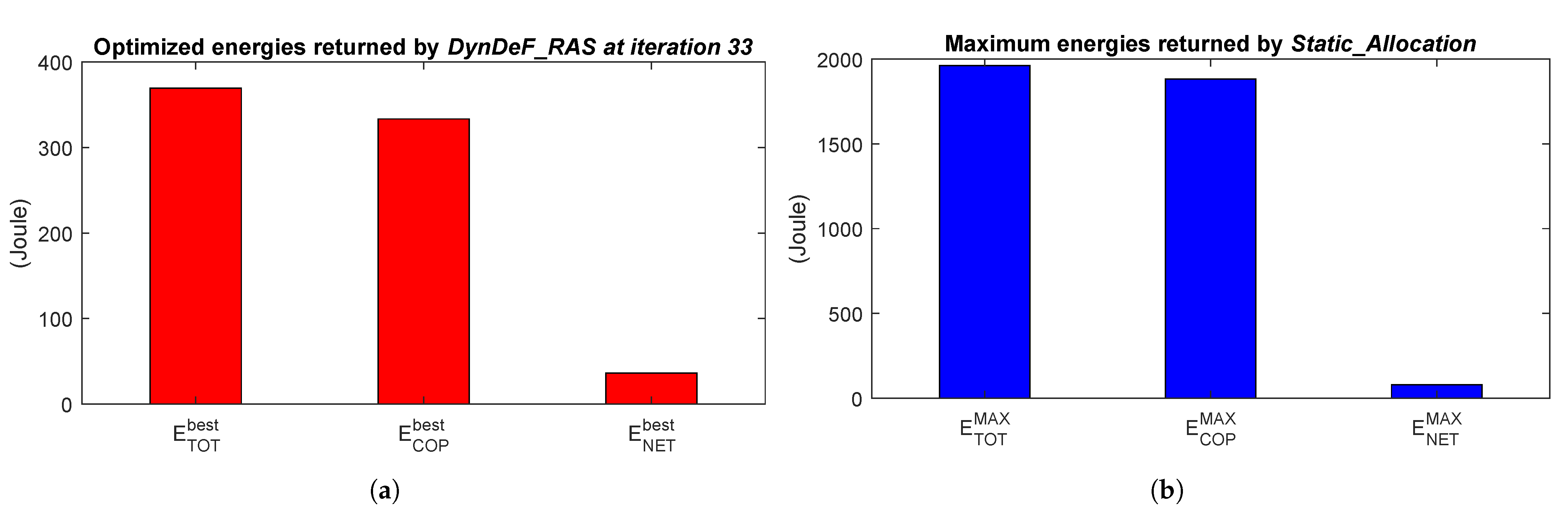
DeepFogSim allows a considerable saving after only 33 iteration of Algorithm 1. The final optimized values for these energies are shown by the bar plots of
Figure 14a, which explicitly illustrate that the main fraction of the total consumed energy is due to the computing part, while the network one is limited up to about 10%.
In order to provide fair comparisons,
Figure 14b presents the bar plots of the total energy
, computation energy
, and network energy
consumed in the case that all the available resources are set to their maximum values:
,
, and
. These energies are evaluated by the
Static_Allocation function described in
Section 5.2 and presented in Algorithm 2. A comparison of plots in
Figure 14a,b demonstrates the noticeable energy saving offered by the adaptive Algorithm 1 implemented by the
DeepFogSim toolkit.
A synoptic view of the energy consumption under topology
, compared to the static allocation solution and the ratios between these two solutions, is analytically presented in the first row of
Table 6. This table also shows the ratio between the optimized network energy and the total one:
.
Regarding the network topology
, we have numerically ascertained that traces similar to those of the previous
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 are obtained; hence, we do not show them here. However under topology
, Algorithm 1 converges within only 23 iterations. Once again, the number of needed iterations is very small.
The energy performance under the network topology
is also summarized in
Table 6 (see the second row). Moreover, this table also presents the energy performance under topologies
and
by using a different Layer-to-Tier mapping vector
and different maximum allowable resources. We named this new tested settings as
and
, respectively (see the 3rd and 4th rows in
Table 6). The new sets of values are:
,
(Mbit/s),
(Mbit/s), and
(Mbit/s) under topology
; and
,
(Mbit/s),
(Mbit/s), and
(Mbit/s) under topology
.
An examination of the related rows of
Table 6 shows that the adaptive Algorithm 1, in all tested cases, allows a considerable energy saving with respect to the benchmark static one of Algorithm 2. In addition,
Table 6 suggests that Fog topologies with higher numbers of tiers generally allow greater savings with respect to topologies with fewer numbers of tiers. This is justified by the fact that better distributions of the workload may be attained over a greater number of nodes at the first tier and greater fractions of the workload undergo to early exit for increasing number of the topology tiers.
The energy sensitivity of the resource allocation returned by
DeepFogSim is measured at different values of the vector
(s) of the maximum allowed inference times under topology
and the results are comparatively presented in
Table 7. We consider values of the vector
in the range of
—
.
An examination of
Table 7 confirms that, since, by design, the static allocation strategy fixes at their maxima all the available resources regardless of the actually enforced constraints, then, the corresponding consumed total energy
does not depend, indeed, on the allowed maximum inference times.
Table 7 also shows that the total energy
of the optimized resource allocation returned by Algorithm 1 increases when the constraints on the inference times become more stressed (see the 3rd column of
Table 7). Finally, the 7th column of the
Table 7 shows that the total energy
consumed by the optimized solution returned by Algorithm 1 is a small fraction of the corresponding energy
consumed by the static allocation strategy when the constraints on the inference times are very broad, but it converges to higher fractions if these constraints become stricter.
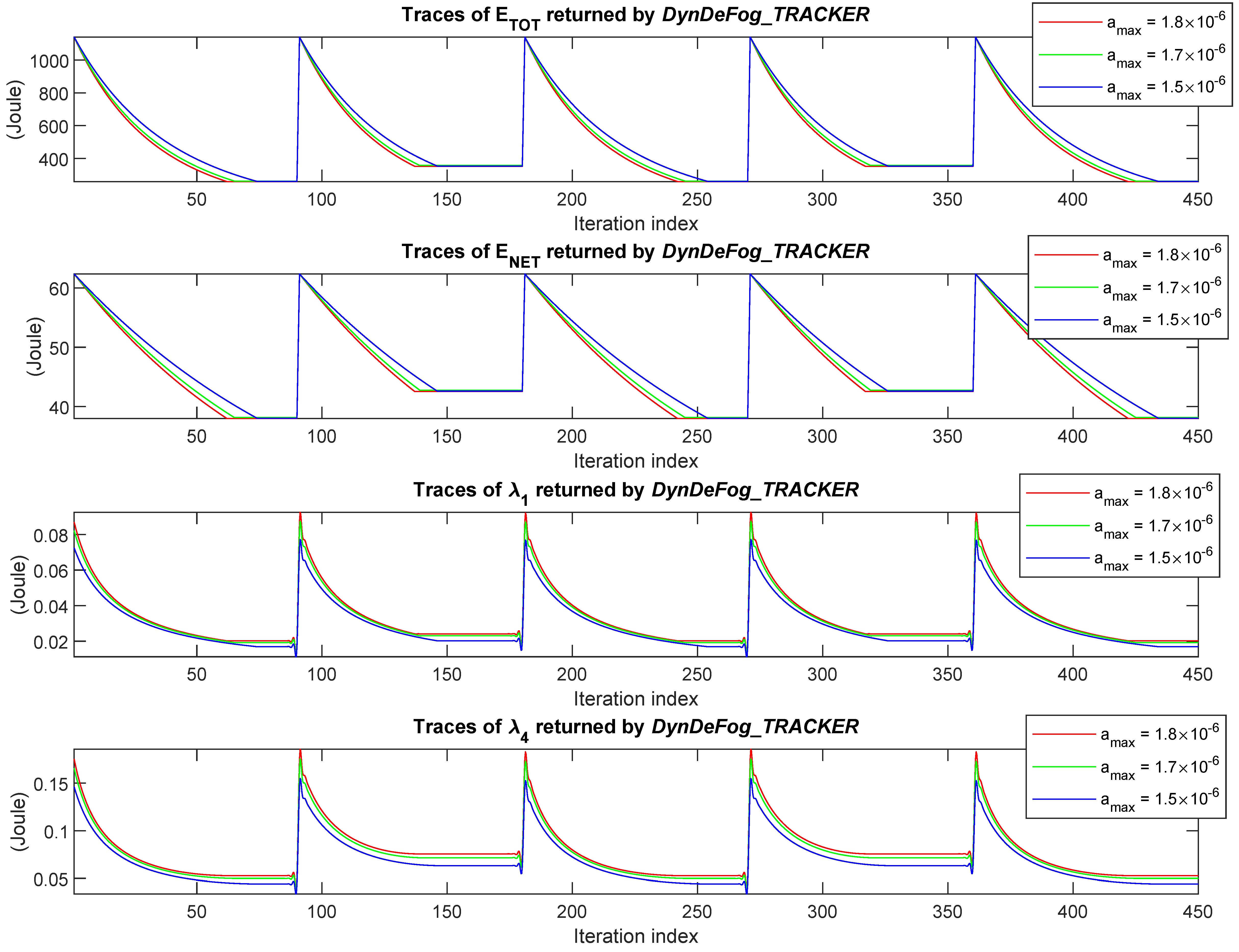
7.3. Comparative Tracking Performance Returned by DeepFogSim
The goal of this subsection is to test the convergence speed to the steady state and the steady-state stability of the primal-dual iterations implemented by the
DynDeF_RAS function of
Section 5.4 when abrupt changes in the operating conditions of the Fog platform of
Figure 3 occur. For this purpose, we ran the
DynDeFog_TRACKER function of
Section 5.4 under the (previously described) Fog topology of
Figure 8b. The obtained dynamic behaviors of the total consumed energy
, network energy
, and first and last (i.e., the
M-th)
lambda multipliers are presented in
Figure 15 and
Figure 16. The plots of these figures refer to three values of the clipping factor
in Equations (
26) and (
27).
Specifically, we have simulated a failure-affected scenario in which some nodes of the considered topology sequentially fail and then resume at the iteration indexes
, 90, 180, 270, and 360 according to the following pattern: (i) at
, all nodes and links are ON; (ii) at
, a FN fails, i.e., both the operating frequencies of its convolutional and classifier processors vanish; (iii) at
, the failed FN resumes its normal operating conditions; (iv) at
, the convolutional and classifier processors of a second FN fail; and, finally, (v) at
, the failed FN turns to be operative. After each change in the operating conditions, Algorithm 1
self-reacts by
re-computing the components of the resource vector, in order to suitably reconfigure the underlying technological platform of
Figure 3, so as to attempt to still meet the constraints in (23b) on the inference times.
The first scenario, presented in
Figure 15, refer to the case in which Fog
and Fog
nodes sequentially fail under
topology. This figure illustrates the obtained dynamic behaviors of the total and networking energy
and
, as well as the Lagrange multipliers
and
associated to the first and last constraints on the inference times in (23b).
Figure 15 shows that increasing values of the
clipping factor speed-up the convergence of Algorithm 1 and the Fog platform of
Figure 3 self-adapts its resources in within 70 iterations (see the third and fourth plots in
Figure 15). In addition, we can argue that the tracking behavior is robust to the settings of the
parameter, so that the resulting technological platform of
Figure 3 is capable of self-react and promptly adapt to abrupt failures of some of FNs composing the execution platform within a broad range of values of the
clipping factor. A careful examination of the second and fourth tracts of the curves of
Figure 15 (i.e., the index intervals 90–180 and 270–360) shows that the energy assumes the same steady-state values. This behavior is justified by the symmetry of the considered topology after failure events. In fact, in both the segments, the failure event involves one of the two FNs located at
of
in
Figure 8 that share the same values of the underlying resources. In both cases, after the failure,
remains with a single active FN, and then it consumes the same energy.
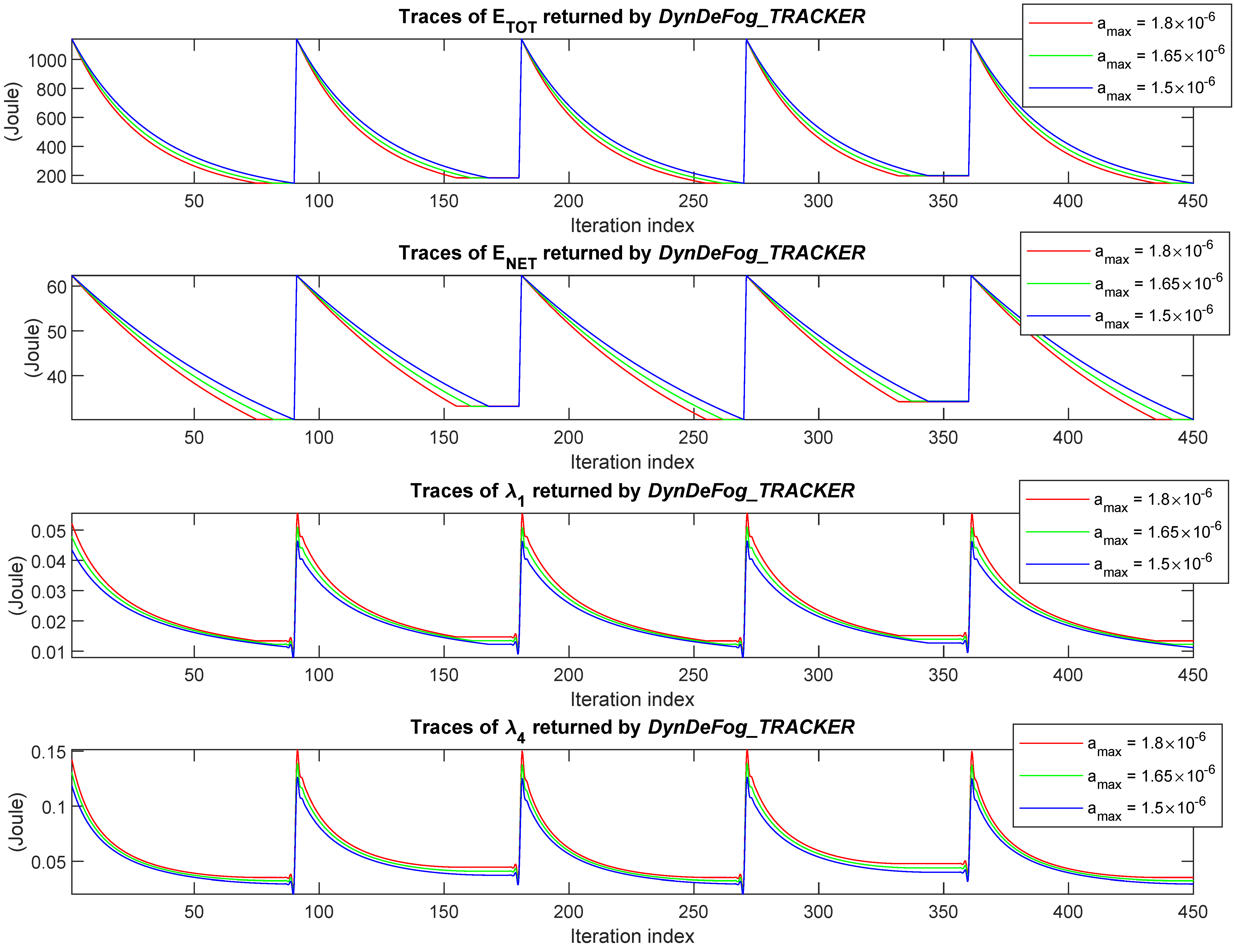
Finally, the second scenario featured by
Figure 16 refers to the case in which Fog
and Fog
nodes of the topology
sequentially fail. This figure suggests a convergence behavior similar to the previous scenario, and once again the platform is capable of automatically and promptly adapting its resource allocation for coping with the experienced failure event. However, in this case, differently from the first scenario, the failures involve nodes located at different tiers of the
topology, and this gives rise to asymmetric steady-state behaviors. In fact, a careful examination of the curves in
Figure 16, specifically in the second and fourth tracts (i.e., over the index intervals 90–180 and 270–360), shows that the steady-state energy assumes different values. Specifically, the total energy
after the failure of Fog
is about 17 (Joule) greater than the corresponding one after the failure of Fog
. This behavior is justified by both the convexity of the energy model introduced in
Section 4 and the fact that the workload to be processed at each tier reduces going up in the topology, towards the Cloud node, since a considerable fraction of the workload undergone early exits. This observation implies, in turn, that the failure of FNs at lower tiers (such as Fog
) causes a greater energy consumption than the failure of FNs at higher tiers (such as Fog
).
To summarize, the proposed DeepFogSim toolkit can be considered as an effective software tool for simulating and testing the energy-vs.-delay performance of the technological Fog platform supporting the distributed execution of the inference phase of CDNNs with early exits.
8. Conclusions and Hints for Future Research
It is expected that the convergence of Conditional Deep Neural Networks, Fog Computing and IoT allows the energy-efficient and real-time distributed mining of big volumes of data generated by resource-limited sensing devices, possibly scattered over large geographically areas. Motivated by this expectation, in this paper, we present DeepFogSim, a MATLAB-supported software toolbox aiming at simulating and testing the performance of Fog-based technological platforms supporting the real-time execution of the inference phase of CDNNs with early exits. The DeepFogSim toolkit provides a new software environment that accounts for the main system parameters featuring the computing and network aspects of the underlying Fog-Cloud execution platforms. The core engine of the DeepFogSim toolbox allows the optimized allocation, simulation, and tracking of the computing-plus-networking resources wasted by the dynamic execution of the inference phase of CDNNs with early exits under hard constraints on the allowed per-exit inference delays. The GUI equipping the DeepFogSim package allows a user-friendly rendering of the simulated data under a number of easy-to-understand graphic formats.
The current version of the
DeepFogSim package could be extended along four main directions. First at all, the stack topology the considered CDNNs with early exits of
Figure 1a could be augmented by inter-layer feedback connections, so as to give rise to recurrent-type CDNNs which are capable of exploiting the time correlations possibly present in some IoT input streams, such as those typically featuring video/audio sequences, as well as multi-view scenes, to name just a few. Second, the networking energy models of
Section 4 can be extended by accounting of the effects of spatial coding and multiplexing [
46,
47] operating over Terahertz communication channels, in order to exploit a massive number of terminal antennas as envisioned by the future 6G communication paradigm [
2]. Third, suitable algorithms for the forecast of the inter-tier network traffic and the automatic start/stop of the carried out iterations of Equations (
24) and (
25) could be introduced, in order to allow the simulated platform of
Figure 3 to cope with failure events in a pro-active (instead of re-active) way. Finally, new functions could be introduced in the current version of the
DeepFogSim toolkit, in order to simulate the effects of inter-thing social relationships, such as those featuring the emerging paradigm of the so-called Social IoT (SIoT) [
48].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















