
Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns

1
School of International Business, Zhejiang International Studies University, Hangzhou 310023, China
2
School of Management and E-Business, Zhejiang Gongshang University, Hangzhou 310018, China
3
Modern Business Research Center, Zhejiang Gongshang University, Hangzhou 310018, China
4
Sprott School of Business, Carleton University, Ottawa, ON K1S 5B6, Canada
*
Author to whom correspondence should be addressed.
Systems 2022, 10(6), 198; https://doi.org/10.3390/systems10060198
Submission received: 15 September 2022
/
Revised: 7 October 2022
/
Accepted: 13 October 2022
/
Published: 29 October 2022
(This article belongs to the Section Complex Systems)
Abstract
:Aiming at the problem of data sparsity, cold start, and privacy concerns in complex information recommendation systems, such as personalized marketing on Alibaba or TikTok, this paper proposes a mobile social recommendation model integrating users’ personality traits and social relationship strength under privacy concerns (PC-MSPR). Firstly, PC-MSPR focuses on specific personality traits, including openness, extraversion, and agreeableness, and their impacts on mobile users’ online behaviors. A personality traits calculation method that incorporates privacy preferences (PP-PTM) is then introduced. Secondly, a novel method for calculating the users’ relationship strength, based on their social network interactive activities and domain ontologies (AI-URS) is proposed. AI-URS divides the interactive activities into activity domains and calculates the strength of relationships between users belonging to the same activity domain; at the same time, the comprehensive relationship strength of users in the same domain, including direct relationships and indirect relationships, is calculated based on interactive activity documents. Finally, social recommendations are derived by integrating personality traits and social relationships to calculate user similarity. The proposed model is validated using empirical data. The results show the model’s superiority in alleviating data sparsity and cold-start problems, obtaining higher recommendation precision, and reducing the impact of privacy concerns regarding the users’ adoption of personalized recommendation services.
1. Introduction
As new information and communication technologies (ICT) infrastructure construction grows rapidly in fields such as 5G, big data, and artificial intelligence (AI), business intelligence applications are deeply involved in the complex information systems necessary for social commerce [1]. At the same time, the COVID-19 epidemic has created a situation where social media users post more and more content, such as text posts, short videos, and live-streams through social media platforms (i.e., Weibo, WeChat, TikTok, and Facebook). A rapid increase in data volume, variety, and velocity (3Vs) presents both opportunities for and challenges to users and service providers, due to the prevalence of social media software and user-generated content (UGC), which often results in “information overload” [2] for users and unique challenges for systems designers. As such, the recommendation system (RS) has been introduced and is now in use by large commercial vendors, such as Amazon. The goal of the RS is to utilize user information to obtain user preferences, realize personalized service recommendations, and convert casual viewers into potential buyers. The essence of the social recommendation system is to use various types of information, such as user personal attributes and social behaviors, to recommend personalized services for users. The integration of basic user attributes and friend relationship information effectively relieves the pressure of data sparseness when the system recommends and efficiently improves the recommendation accuracy. A well-designed mobile social recommendation system allows mobile commerce enterprises to target individual marketing and lock on the target customers, based on the users’ demographic and social characteristics, including gender, age, address, etc., as well as social relationships, interests, and behaviors, and to achieve more relevant, participatory, and efficient personalized services on social platforms [3]. As a result, mobile personalized information recommendation systems that incorporate social relations are becoming an important system design challenge.
The strength of the user relationship can represent the degree of intimacy between different users, including both direct and indirect relationships. The higher the degree of closeness in a connection, the greater the responsibility toward the people with whom we share it. Moreover, the relationship strength among different users is different and can change rapidly for various reasons. Therefore, examining the strength of the user relationship in social networks is of great significance in many aspects, such as personalized recommendations, behavior prediction, link prediction [4], etc. [5]. At present, most studies estimate the strength of relationships among different users in social networks by utilizing the users’ personal information and interaction information [6]. In general, users with similar personal information are likely to have more similar interests and will have stronger relationship strengths. In addition, more frequent interactions between users may indicate a closer relationship between the two [7]. However, the methods proposed by these researchers for calculating the strength of user relationships are rather one-sided. Either the strength of the relationship between all users is calculated in a general way, or only direct links are considered, while the importance of indirect relationships is ignored; therefore, the results of these methods are less accurate.
Furthermore, privacy issues in mobile personalized services have sparked panic among users. In the case of customization as well as privacy, there’s a constant conflict between a firm’s need for consumer information to tailor consumer experiences and the need to protect a customer’s privacy. The existing online privacy protection mechanisms are mostly unilaterally formulated by service providers, ignoring the privacy preferences of individual users. Users must either directly refuse to use the service, or, in order to access the service, must passively accept all these privacy policies, without having a choice about the types of private information that are disclosed [8]. Therefore, the impact of “privacy concerns” regarding the performance of recommendations has to be considered when service providers offer personalized information services. In addition, an individual’s personality traits have been found to influence user behavior in social networks. People who are high in extraversion tend to be better at communicating with friends and are relatively less concerned about their privacy [9]; those who are high in openness tend to have a broad range of interests and be more adventurous and creative; those who are high in conscientiousness have high levels of thoughtfulness, have good impulse control, and show goal-directed behaviors; those who are high in agreeableness are more selfless, cooperative and harmonious with others, and are more likely to trust others; people high in neuroticism are characterized by sadness, moodiness, and emotional instability [10]. The above can be summarized thus: individual personality traits will have a significant impact on users’ psychological preferences, online social styles, privacy concerns, etc. [11].
The main contribution of the paper is to develop a mobile social recommendation model (PC-MSPR) that takes the user’s privacy and their social relationship into account in design considerations. Firstly, a novel personality traits metric integrating privacy preference for users’ privacy concerns is presented. Secondly, a relationship strength calculation based on activity domain classification and indirect relationship fusion is proposed. On this basis, a hybrid collaborative filtering recommendation method considering privacy concerns and integrating users’ personality traits and social relationship strength is proposed, to achieve a high-quality mobile personalized intelligent recommendation service. Finally, in order to verify the superiority of the method proposed in this paper, we conducted experiments using both simulated and public datasets. The experimental results show that compared with the traditional collaborative filtering recommendation algorithm, the proposed method achieves a higher performance. In addition, it is superior in terms of alleviating data sparsity and cold-start problems and can reduce the impact of privacy issues on users’ adoption of personalized recommendation services.
The structure of this paper is as follows. Section 2 provides an overview of the relevant literature and previous work. Section 3 introduces a hybrid collaborative filtering recommendation method that integrates personality traits and relationship strength in light of privacy concerns. Section 4 presents the initial test results, based on empirical data analysis. A summary presenting our comments and suggestions for future work is provided in Section 5.
2. Related Work
2.1. The Relationship between the Big Five Personality Traits and Users’ Online Behavior
Personality trait theory has long attempted to determine how many personality traits exist [12]. The theory suggests that personality traits are the basic characteristics of people; they determine the basic characteristics of behavior, and the relative strengths of different traits explain personality differences, which are the commonly used basic units for personality assessment [13]. The Big Five personality model quantifies some personality traits. Researchers have summarized the Big Five personality model, thus: individual personality traits can be represented by openness, extraversion, agreeableness, conscientiousness, and neuroticism, and all five dimensions can be quantified [14]. Moreno [15] first proposed the statistical analysis method to assess the personality traits of users and called it a sociometric technique. As the current mainstream method of personality trait measurement, this technology can directly use the scores in the experiment to quantify abstract user psychological traits and measure the interpersonal relationships among members of social groups. Compared with the traditional subjective measurement method, its advantage lies in revealing information on individual or group adaptation and studying the stable relationship between individuals in the group. Selfhout et al. [16] used Moreno’s sociometric technique to collect the required data, and then collected subjective scoring data about personality traits through questionnaires. Through the hypothesis of the types of extraversion (frequently spelled as extroversion), directness, neuroticism, agreeableness, and conscientiousness, the five general personality traits are defined. Lu et al. [17] studied the relationship between the Big Five personality traits and online user trust. It revealed that the Big Five personality traits have an impact on trust between users and indirectly influence the success rate of transactions. Quercia et al. [18] studied the interesting topic of analyzing whether there are similarities between users who are popular in real life and those who are popular in the virtual world. It suggests that the Big Five personality traits are related to users’ openness and extraversion on social networks. Moreover, an even more important contribution is the discovery that real and virtual users share similar personality traits. Golbeck et al. [19] analyzed the relationship between users’ online behaviors and personality traits using text-mining techniques and predicted personality traits by using online behavior data, based on Gaussian processes and machine learning algorithms. Similarly, numerous studies [20,21,22] have demonstrated the feasibility of using data on users’ online social behavior to predict their personality traits. Some results have also shown that the Big Five personality traits are mainly characterized by extraversion, openness, and agreeableness [23]. Xiao et al. [24] used users’ online social information and selected different indicator dimensions for different personality traits to calculate users’ extraversion, openness, and agreeableness. On this basis, with the emergence of social platforms and formats such as short videos in recent years, we further optimize the indicator dimensions in this paper to improve the accuracy in predicting users’ personality traits.
2.2. The Strength of the User Relationship and Personality Traits in Social Networks
At present, research on user relationship strength in social networks mainly focuses on the analysis of users’ interaction information. Xiang et al. [25] calculated user relationship strength on Facebook and LinkedIn by analyzing user interaction activities and user similarity. Viswanath et al. [26] discussed the relationships between users through Facebook “wall posts”; Lin et al. [27] evaluated the user relationship strength by proposing a weighted network graph model based on trust propagation strategy and indirect relationships. The weighted network graph can clearly reflect the relationship between users. In the graph, nodes represent users, edges represent connections between users, and edge weights represent the strength of user connections. By considering the length and edge weights of a relationship path and the number of relationship paths, we can use them to estimate the user relationship strength. Feng et al. [28] estimated the relationship strength between users through a predictive model by using a large amount of social network data. However, the above studies ignore the distinction between users and interactive activities in terms of activity domains. Users who belong to the same area generally have a greater number of similar interests and stronger relationship strength. Based on this, Zhao et al. [29] estimated the strength of the relationship between users by analyzing personal data and information on the interactions between users. However, this approach ignores the strength of the indirect relationships between users. In addition, scholars have focused on the use of personality traits to study relationship strength. Su et al. [30] examined the impact of “homogeneity” formed by user personality traits on the strength of social relationships on Myspace and LinkedIn. Singla and Richardson [31] studied the influence mechanism of users’ similar personality traits on user relationships. Based on the basic principles of personality traits in social psychology, Anusic and Schimmack [32] proposed a method for calculating the strength of social relationships that integrates both personality and behavioral interactions. Based on the works reviewed, this paper considers the activity domains of users when calculating the user relationship strength and divides the relationship strength between users into direct relationship strength and indirect relationship strength.
2.3. Recommendation Services and Privacy Protection in Social Networks
The recommendation services process in social networks generally includes the collection of multi-source social network data, the calculation of user relationship strength, the calculation of user interests, the generation of recommendation results integrating into the social network relationship, and the continuous revision of recommendation results, based on user feedback [33,34,35]. At present, the research on the recommendation method mainly focuses on two approaches: the heuristic/memory-based and model-based approaches [36,37,38]. The memory-based social network recommendation system uses the known “user–user” relationship matrix and “user-item” rating matrix to build the recommendation model [39,40,41]. Conversely, the model-based social network recommendation system uses heuristic or K-nearest neighbor approaches for social recommendation [42,43,44].
However, while enjoying the convenience of a mobile personalized intelligent recommendation service, the risks of users’ private information being exposed and inappropriately or illegally used are also gradually increasing. More and more researchers have proposed new methods from the perspective of privacy protection to solve user privacy problems [45]. For example, Zhao et al. [46] conducted a questionnaire survey with structural equation relationship research into the adoption of location-based services (LBS) to verify the impact of privacy on users’ online behavior. Mousavi et al. [47] used a questionnaire to complete their study on the privacy protection behavior of online users, suggesting that mobile social platforms allow users to set their own privacy preference mechanisms. Christian et al. [48] integrated the impact of individuals and systems on the privacy of online users and quantified the privacy influences.
The above works show that users’ online behaviors are highly correlated with their personality traits, and it is feasible to use users’ online social behavior data to predict their personality traits. However, most of the current models fail to address users’ privacy concerns fully and fail to analyze the relationship between privacy concerns, personality traits, and the online behavior of users. In addition, the current calculation methods of user relationship strength in social networks mainly rely on the calculation of direct user similarity, based on online interaction data. Therefore, this paper takes important factors, such as domain knowledge and users’ indirect relationships, into account to improve the measurement of user relationship strength in social networks, and innovatively integrates privacy preference into the user personality traits calculation model. Finally, personality traits, privacy concerns, and the relationship strength of users are integrated into the user-based collaborative filtering recommendation model, and psychology and computer sciences are likewise integrated to study the online behaviors of mobile users and their willingness to make use of recommendation services.
3. Methodology
3.1. The Implementation Mechanism of the Methodology
In the field of recommender system frameworks, a technique has been broadly applied that is commonly known as collaborative filtering (CF) [49]. The main idea is to determine similar users, based on group behavior, and use multiple user information to give users decision-making recommendations. The theoretical basis of collaborative filtering is that the more similar things are, the easier it is to make the same choice, which is mainly reflected in two aspects. One is that users are more likely to adopt recommendations that are similar to historical services, and the other is that users are more likely to receive recommendations from users similar to themselves. The inspiration for communitarian separation comes from the latter, the idea that individuals frequently get the best suggestions from somebody with tastes similar to their own. Most of the traditional hybrid collaborative filtering systems simply combine several methods and do not use additional user data to improve the accuracy of user portraits. For example, the recommendation results of various technologies are weighted and mixed; the one with the highest accuracy is selected from multiple recommendations; alternatively, the recommendation result of one method is used as the input of another method, and so on. To improve accuracy, the hybrid collaborative filtering method proposed in this paper incorporates personality traits and relationship strength while addressing privacy concerns.
The method proposed in this paper integrates various types of information on users, including user attributes, social behaviors, interests, preferences, etc., so as to obtain a more accurate sense of similarity between users. The use of multiple information types can improve recommendation accuracy and alleviate the problems of cold starts and data sparseness. Privacy preferences enable social media platforms to assess an individual user’s privacy preferences and then provide this reaction to the service provider. With their control of the social media platforms, the service provider can apply an appropriate degree of privacy protection, based on the different levels of privacy preferred by their users. Personality characteristics shape the patterns of thoughts, actions, and feelings that people choose. Firstly, users with certain privacy preferences are more likely to be surrounded by the same type of friends. Therefore, the model for a personality traits measurement method, combined with privacy preference (PP-PTM), is proposed to study the impact of users’ personality traits on privacy preference and the correlation between personality traits, online behaviors, and the privacy preferences of social network users. Secondly, a user relationship strength estimation method combining activity field classification and indirect relationships (AI-URS) is proposed to estimate the comprehensive relationship strength of users in the same field, based on their interaction activity data, including their direct and indirect relationships. Through the calculation of the user relationship strength, it is not only possible to know whether there is a relationship between users in the social network but also to further obtain information on the closeness of the relationship between users. Finally, an improved collaborative filtering recommendation method considering privacy concerns is proposed, which integrates user personality traits and social relationships. Figure 1 shows the framework of the model. Traditional mobile social recommendation methods use basic user attributes and friend relationships to alleviate the data sparsity problem and enhance the reliability of recommendations. The method proposed in this paper fully incorporates user privacy preferences, personality traits, interactive activities, and other types of information on this basis, effectively alleviates the cold-start problem of new users and data sparseness in new systems, and helps to address user privacy concerns, to a certain extent. On the basis of the above methods, it calculates the nearest similar neighbor set of target users by integrating information such as privacy preferences, personality traits, and social network relationship strength.
3.2. Personality Trait Measurement Method Integrating Privacy Preferences
3.2.1. User Privacy Preferences Measurement
Privacy settings in social networks (taking Sina-Weibo as an example) include: “How can I be found?” (account number or mobile number), “Who is allowed to comment on my posts?” (all people, followers only, or people I follow), “Should I recommend contacts?”, “Who is allowed to personally message me?” (all people, followers only, or people I follow), “Who is allowed to mention me?” (people I follow, everyone), “Binding other accounts”, “My location” (all people, followers only, or people I follow), etc. Henson et al. [50] and Xiao et al. [23,24] both found a strong correlation between user activity, personality traits, and the user’s privacy behavior. Mobile social users’ activity is significantly correlated at the level of “Who is allowed to comment on me?”, “Who is allowed to personally message me”, and “My location”. Therefore, the above three elements are selected as measurement items of users’ privacy preferences. One statistical technique for predicting the value of one variable that depends on the value of another is known as linear regression analysis. When the dependent variable is affected by multiple variables, the multiple linear regression model is usually used to predict the dependent variable. Using this model for prediction is relatively effective and it is simple to operate. Taking Sina-Weibo or TikTok as examples, the multiple linear regression model is adopted, and three evaluation indexes are assumed that are all within a certain time period (taking half a year as an example): (1) whether to tick: “Who is allowed to personally message me?” (AM); (2) whether to tick “Who is allowed to comment on me?” (AC); (3) whether to allow “My location” to be marked (AG). The privacy preference strength of mobile users can be calculated by the above three indexes and is expressed in Equation (1):
The preferences in terms of privacy concerns of user is expressed by a vector ; represents the quantitative value of user and their privacy preference for private messages sent by other users; represents the quantitative value of user and their privacy preference for other users to comment on his or her own posts; represents the quantitative value of user and their privacy preference for location information being marked on social media platforms. Quantifying the privacy vector can obtain the degree value that can be used to represent the privacy preference of the user . This paper defines it as privacy preference intensity (PPI). The value of user PPI () can be calculated by these three related measurement items, which is expressed as:
The probability values of the three measurement items can be 0 (fully agree with allowing “private messages”, allowing “comments”, and allowing “location annotations”), or 1 (fully disagree with allowing “private messages”, allowing “comments”, and allowing “location annotations”). This value represents the specific preferences of different mobile users in terms of privacy settings.
3.2.2. Personality Traits Measurement
The model proposed in this paper treats the user’s ratings on the “Big five personality questionnaire” as continuous data showing the user’s personality traits. The questionnaire we used was proposed by Hellriegel et al. [51], “The big five personality traits measurement short form”, which contains 25 measurement questions on five dimensions of personality traits, and a total of 421 people completed the questionnaire. The Big Five personality traits test includes five dimensions: openness, conscientiousness, extraversion, agreeableness, and neuroticism, which can be used to describe personality generally and is suitable for the measurement of personality traits in this paper. In addition, it uses vectors to characterize the data of users’ social network behaviors. Based on an analysis of the representation variables of mobile user activity, this method obtains information representing the originality, dissemination, and popularity of a mobile social platform, and the interaction information in the user network is used to measure the user relationship strength. Originality refers to the degree of platform users’ original activity, which is measured by the number of posts, photos, short videos, and updated comments on the network; dissemination refers to the connection role of users in social networks, which is measured by the number of comments, photos, music, short videos, and shared blogs published by users, mainly reflecting the sharing and relaying of information by users; popularity refers to the popularity of users, measured by the number of friends, followers, and visitors.
Selfhout et al. [16] believe that not all five dimensions have an impact on the user’s online behavior and social network relationships. At the same time, Xiao et al. [23,24] have suggested that the extraversion, openness, and agreeableness of users can affect their privacy concerns behavior. In addition, previous works [19,24] both argue that users’ personality traits can be characterized according to their online behaviors. Therefore, the paper chooses these three dimensions and users’ online behavior representation information about originality, dissemination, and popularity, as mentioned above. Based on a multiple linear regression model used to measure personality traits, the model selects 15 independent variables, including the number of followers, visitors, blog posts, photos, short videos, private messages, and comments, as well as the number of comments retweeted and shared, photos, trending topics, short videos, music, etc.:
The vector represents the personality traits of each user, is the user’s openness rating (the number of followers (), the number of shares (), the number of likes or comments (), the number of mentions ()), is the users’ conscientiousness rating, is the users’ extraversion rating(the number of followers (), the number of posts (), the number of likes or comments (), the number of following ()), is the user agreeableness rating (the number of followers (), the number of shares (), the number of likes or comments (, and the number following ()), while is the users’ neuroticism rating. Quantifying the mobile user’s personality traits vector can obtain the value that represents the user’s personality traits. This paper defines it as the personality traits reference value (PTPV). Therefore, the PTPV, which integrates privacy preferences, is calculated as follows:
- , where the vector variables of , , and are calculated by a multiple linear regression model, respectively.
3.3. A Method for Calculating the Strength of a User Relationship Based on Social Network Interaction Activities and Domain Ontologies
3.3.1. Construction of the AI-URS Method
Step 1: Allocation of activity domains. Since the strength of the relationship expressed by user interaction behavior in different activity domains is different, the activity domains need to be divided according to interaction activity documents. Therefore, this paper utilizes natural language processing (NLP) to deal with this problem. LDA is an important unsupervised machine learning algorithm in terms of text semantic analysis. We use it as a generation probability model of text collections to model the generation process of documents. Each word in the text is assigned a subject in LDA, which assumes that interaction activity documents are made up of words that help determine their themes. As a collection of works, the model treats documents in the same way. “Google distance” is a common method for evaluating semantic similarity. This method assumes that words with the same or a similar meaning are closer, and words with different meanings are relatively far apart. We use this method for the calculation of text content distance. According to the standard Google distance algorithm, the semantic distance of each result cluster and the name of each activity field is calculated; this is also known as the correlation calculation. If the correlation exceeds the pre-set threshold, the activity domain with the highest correlation will be considered the activity domain of the result cluster; otherwise, the result cluster belongs to the “other” class. Then, based on domain ontology [52], this paper further calculates the correlation between each social platform interaction activity document in the cluster and the activity domain name that the result cluster belongs to. If the correlation is higher than the pre-set threshold, the activity domain name of the interactive activity document of the social platform is the activity domain name of the result cluster; otherwise, the interactive activity document belongs to the “other” class.
Step 2: User relationship strength measurement. Based on the interactive activity document, this paper calculates the comprehensive strength of relationships between the target users and the node user in the same field, including the strength between users with direct and indirect relationships. At the same time, in order to facilitate expression and interaction, each activity domain is represented by ontology knowledge, while user relationships are represented by the social network weight graph. Considering the characteristics of mobile social networks, this paper calculates the indirect relationship strength based on the number, length, and edge weight of the relationship paths; it calculates the direct relationship strength, based on time and interaction frequency.
3.3.2. User Relationship Strength Measurement
- Allocation of Activity Domains
This paper proposes an ontology-based method for the allocation of activity domains, using Microblog (Sina-Weibo) as an example. The relevant information is collected from social network platforms, such as user information, microblog information, user friendship, and retweets. Then, each piece of information data is converted into a dataset, including a user dataset, an activity document dataset, and a user-interactive relationship set.
Next, activity domain is assigned to each activity document, . There are two main steps. Firstly, the activity documents are clustered using the LDA algorithm, followed by calculating the relevance of each cluster to the activity domain, and an activity domain is assigned to each cluster. The second step is to further assign activity domains to each document in each cluster, based on ontology knowledge. Given the activity document set and the number of clusters to be obtained, m, the LDA algorithm is used to cluster the activity document and output the result cluster set, where . The normalized word frequency of each activity document cluster is marked as the vector of the R dimension, where the r-th element represents the standard frequency of the word wr in words W.
The “allocate activity field” (AAF) algorithm is as follows:
Step 1 represents the correlation between clusters and activity domain names with:
where google_distance(wr, Al) represents the standardized Google distance of the word wr to the domain . The definition of the standardized Google distance between the two search topics, and , is shown in Equation (8):
Among them, represents the total number of pages, and represent the number of clicks to search topic and topic , respectively, and represents the number of pages where and exist at the same time.
Step 2: The correlation between each cluster and each activity domain is calculated, and the threshold is determined in advance. Here, we take the activity domain name that exceeds the threshold, and that has the highest correlation, to be the activity name of the cluster. If it is less than the threshold, it is classified as the “other” class. After that, based on the correlation between the cluster and the activity domain, the domain of the document in the cluster is further determined. is used to represent the correlation between the document in the cluster and the name of the activity domain:
where represents the similarity between and , where and are standardized word frequency vectors in cm and dn.
It calculates the correlation between each document in the cluster and the activity domain name to which the cluster belongs.
- 2
- User relationship strength measurement
It is necessary to comprehensively consider the direct and indirect relationship strength. This paper uses the social network weight graph to express and calculate the relationship strength.
The social network weight graph is represented by where represents the set of users of the social network graph. In this set, represents the i-th user. is the set of edges of the social network, in which denotes the edges between and . is the set of edge weights of the social network graph, in which denotes the weights of the edges . The weight of each edge represents the direct relationship strength between the two users connected to this edge.
- (a)
- Calculation of the direct relationship strength
The strength of the direct relationship is calculated using the social activity information of users, which describes the closeness of the source user to the target user . The relationship between users will be affected by numerous factors, such as frequency and time of interaction. is used to denote the strength of the direct relationship of to .
- Among them, represents the weight of the relationship between and , users who are in the same activity domain, as determined by the frequency of interaction,. represents the number of interactions between and in this activity domain, and represents the total number of interactions of with other users in this activity domain. Here, l represents the count of interaction instances between two users in a specific activity domain. represents the count of instances where the source-target user in a specific activity domain interacts with all other users, and is a temporal factor, expressed as a function.
- (b)
- Calculation of the indirect relationship strength
The strength of the indirect relationship is calculated by the length and the number of the relationship path and the edge weight of the relationship path between two users. In addition, the closeness of the source user to the target user is described through multiple intermediate users. The strength of the indirect relationship of the source user ui to the target user uj is represented by RSid(ui,uj):
- Among them, is the length of the relationship path and is its attenuation coefficient. is the weight of the j-th relationship path. denotes an attenuation function with a value varying continuously between 0 and 1, representing the weight coefficient of a relationship path among all paths. As the path length d increases, the value of the function will decrease. The calculation of the attenuation coefficient can reflect the phenomenon that the relationship strength between users will decrease with an increase in distance. There are often multiple relationship paths between two users. This paper assumes that the number of relationship paths between user and user is n. Pij = {P1, P2, …, Pn} is used to represent the set of relationship paths between two users, and represents the set of weights of each path.
The indirect relationship strength of the source user to the target user on all paths can be expressed as follows:
- (c)
- Calculation of the comprehensive relationship strength
The comprehensive relationship strength is a combination of the direct and indirect relationship strengths. RS(ui,uj) is used to represent the comprehensive relationship strength of the source user to the target user :
where α represents the weight factor of the direct relationship strength, β represents the weight factor of the indirect relationship strength. [0,1]. From the perspective of social relationships, in the process of user interaction, the relationship strength obtained by direct interaction is higher than that obtained by indirect interaction. Therefore, as the number of indirect interactions between users increases, the strength of the direct relationship will become stronger. When β is larger and α is smaller, it means that as the number of indirect interactions increases, the proportion of indirect relationship strength will be larger and larger, and the proportion of direct relationship strength will be smaller and smaller. If the relationship strength of two users is strong in [0.5,1] and weak in [0,0.5], there is a half-probability that their relationship strength is strong or weak. Therefore, this paper introduces the relationship strength impact function, which is expressed in the following Equation (14):
where is the dynamic change function, with the number of interactions k as the variable. When n − k = 0, i.e., k = n, this indicates that the comprehensive relationship strength contains only the direct relationship strength and no indirect relationship strength, at which point α(k) = 1. In contrast, when k = 0, α(k) = 0, this indicates that there is no direct connection.
3.4. A Collaborative Filtering Recommendation Method Integrating Users’ Personality Traits and Social Relationship Strengths, Considering Privacy Concerns
3.4.1. Generation of a User Similarity Set
Knowing how to construct the K-nearest neighbor (K-NN) (the first k users with the most closely similar preferences to the target users) is the key to collaborative filtering recommendation systems. Considering the fact that the impact of different privacy preferences on users may be different, this paper proposes the concept of “personality traits integrating with privacy preferences” and quantifies it to improve the collaborative filtering method, based on user similarity. Then, a personality traits vector matrix integrating privacy preferences and a mobile social network relationship vector matrix are used to calculate user similarity separately, after which, a hybrid collaborative recommendation is completed by fusing these two methods of generating the user’s nearest-neighbor set.
- Calculating user similarity based on personality traits, integrating with privacy preferences
Users with similar privacy preferences or the same personality traits generally have the same interest preferences. Therefore, in constructing the set of K-nearest neighbors of the target user u, this paper uses the ‘user-personality traits’ matrix, . The matrix scores are calculated by the personality traits measurement method that best integrates with privacy preferences. Each score in the matrix is a measured value of user in terms of “openness”, “extraversion”, “agreeableness”, and “privacy preferences”. Each row represents the personality trait score vector that integrates privacy preferences:
where represents the comprehensive value of the four dimensions of personality traits, integrating with privacy preferences.
The personality traits vector of users is obtained by the PP-PTM proposed in Section 3.1, while the user similarity is calculated based on the personality trait score matrix, integrating privacy preferences. Firstly, the basic personality traits data of users are obtained through the questionnaire completed by users. Secondly, the personality traits under the influence of privacy concerns are calculated using social network behavior data. Finally, based on the “user-personality traits” scoring matrix, the user similarity calculation is completed using Equation (16), where and represent the personality traits vectors of user u and user v, respectively, integrating privacy concerns:
- 2
- Calculating user similarity, based on the social relationship strength
This paper suggests that users with close social ties (high social relationship strength) tend to share similar interests with each other. This paper uses the calculation of social network relationship strength to find the nearest neighbors to the target user. On the one hand, using the social network relationship strength value instead of the item score can solve the problem of data sparsity in collaborative filtering. On the other hand, it also helps to improve the recommendation authenticity. The process of user similarity based on social relationship strength is as follows. Firstly, the comprehensive relationship strength of mobile users is obtained in the same activity domain, and the “user-user” comprehensive relationship strength matrix is constructed. Secondly, each value in the matrix is calculated directly, using the user relationship strength method AI-URS, based on social network interaction and domain ontology. Finally, the user similarity is calculated using the Pearson correlation coefficient. By using the “user-user” comprehensive relationship strength matrix, the Pearson correlation coefficient of each pair of users is calculated, and this is used to represent the user similarity based on the social relationship strength.
We calculate the similarity between user u and user v, as shown in Equation (17):
This shows a direct or indirect social relationship between user and user . represents the number of users who have social relationships in the matrix. Due to the complexity and dynamics of user relationships in social networks, it averages the strength of the user relationship in the matrix, which is represented by and .
- 3
- Fusion calculation of user similarity
The user similarity based on personality traits, and the user similarity based on relationship strength, are weighted and fused to calculate the mixed-user similarity, then the comprehensive similarity calculated in Equation (18) is used to search the K-NN user set of the target user:
In real mobile personalized intelligent recommendation applications, the recommender system will dynamically adjust the weight of personality traits and social relationships to meet the actual needs of mobile commerce service providers. Therefore, this paper introduces the differential adjustment parameter, , which is determined by the five-fold cross-validation method in the experiment. The different values of indicate what factor plays a greater role in user-based hybrid collaborative recommendation. When or 1, the similarity between users becomes or .
3.4.2. Predicting User Preferences and Generating Recommendations
We use Equation (19) to predict user preferences and rank the Top-N according to preference values. The K-NN user set () of personality traits and the K-NN user set () of social network relationships are fused, where the adjustment parameter of weights is for personality traits and social relations.
4. Experiments and Analysis
4.1. Data Collection and Evaluation Criteria
4.1.1. Data Collection
This paper uses the dataset from the data-sharing platform, Data Hall (http://www.datatang.com/ (accessed on 15 January 2021)). It includes a number of datasets, such as the comments and retweets of microblog data, personal information, and the user attention data of microblog users, microblog user relationship data, and the Amazon Commerce reviews dataset (Amazon-Book and Amazon-Movie). This paper uses two datasets, Amazon-Book and Amazon-Movie, to evaluate the classification results of the user’s personality traits for the proposed recommendation model. The Amazon-Book dataset is made of three components, including users, books, and ratings. The Amazon-Movie dataset is made of users, movies, and ratings. The above datasets were collected from January to December 2020. The data statistics of these two datasets are listed in Table 1.
Another source for the dataset is to capture the dataset needed for the users’ social relationship strength experiments by using the microblog, open API. The basic user information includes the nickname, location, gender, emotional status, birthday, personal labels, and other information; the microblog activity information includes the user ID, microblog release time, microblog content, the number of retweets, the retweeters, the number of comments, the commenters, information on the rating of the content, the number of likes and the likers, etc. User-friend relationship information is also present in the data. Each record shows the attention relationship between two users, including both the followed and the follower. Based on this, the relationship between users in the social network weight map is calculated. Finally, the data includes a total of 14,168 pieces of data collected from January to August 2019. The experimental dataset is divided into the training set (80%) and test set (20%).
4.1.2. Evaluation Standard of Experimental Results
- Normalized Discounted Cumulative Gain (NDCG)
Social recommendation models need to find out which users are related to the target user, and also sort them in order, according to the user relationship strength. Therefore, this paper introduces the normalized discounted cumulative gain (NDCG) to evaluate the experimental results of the user relationship strength ranking. According to the ranking of scores, the relationship between users appearing at the front of the list and the target users is stronger. Using the NDCG ensures that higher-quality results are ranked higher when the overall quality is good. The calculation equation is shown in Equation (20).
Among them, IDCG is the ideal DCG. After sorting the search results manually and ranking them according to the best state, the DCG of the query in this arrangement is calculated, namely, IDCG.
- 2
- P@R
P@R represents the correlation between the top R products/services in the recommendation list and the user’s real preferences (in the experimental test, this paper determines the R-value based on the number of mobile personalized information recommendation services).
- 3
- Mean Average Precision (MAP)
MAP is used to evaluate the average ranking accuracy of our method in recommending related products/services. The higher the value of MAP, the more accurate the recommendation method will be:
- represents the number of products/services recommended by the recommendation system for the i-th user; represents the ranking of the j-th product/service recommended by the system for the i-th user in the test set.
- 4
- Degree of Agreement (DOA)
The degree of agreement (DOA) is also one of the most common evaluation indicators to measure the accuracy of recommendation ranking.
- Among them, if,, otherwise . Thus, represents the predicted position of in the recommendation list. represents the potential predictive ranking products/services, and indicates that the products/services have been rated by in the test set.
4.2. Experimental Results of Personality Traits Measurement Integrating Privacy Preferences
Based on the stepwise multivariable linear regression model, this paper measures the personality traits integrating privacy preferences. Each variable (the F probability is less than the set value of 0.05) is selected for the model. Each time, the highest significant level of the variable coefficient is retained and the insignificant variables are excluded, so that the significant regression equation of coefficients is finally obtained through multiple selections and exclusions.
- Based on the stepwise multivariable linear regression model, it can be found from the results in Table 2 (the confidence interval is set to 0.05) that there is a linear regression relationship between openness (the dependent variable) and the number of likes or comments of independent variables (the regression coefficient is −0.006), the number of followers (the regression coefficient is 0.125), the number of mentions (the regression coefficient is 0.594) and the number of shares (the regression coefficient is 0.087). At the same time, by analyzing the regression coefficient, it is found that there is a positive linear relationship between openness and the number of followers, the number of mentions and the number of shares, and the number of mentions in the social platform has the greatest impact on openness (the absolute value of the regression coefficient is the largest), which is in line with common sense. Finally, the multi-correlation coefficient and the coefficient of determination of the openness dimension regression model in personality traits are and respectively, indicating that openness is positively correlated with the number of likes or comments, the number of followers, the number of mentions, and the number of shares, and the model fits the data well.
The regression equation is:
- (2)
- Based on the stepwise multivariable regression model, it can be seen from the results in Table 3 that there is a linear regression relationship between extraversion (the dependent variable) and the number of followers (the regression coefficient 0.104), the number of likes or comments (the regression coefficient is 0.876), the number of following (the regression coefficient is −0.004) and the number of posts (the regression coefficient is 0.125) of the independent variable. At the same time, the multi-correlation coefficient and the coefficient of determination of the extraversion dimension regression model in personality traits are and , respectively, indicating that the extraversion is positively correlated with the number of followers, the number of posted works, the number of likes or comments, and the number of concerns, and the model fits the data well.
The regression equation is:
- (3)
- Based on the stepwise multivariable regression model, it can be seen from the results in Table 4 that there is a linear regression relationship between agreeableness (the dependent variable) and the number of followers (the regression coefficient is 0.145), the number of shares (the regression coefficient is 0.087), the number of likes or comments (the regression coefficient is −0.008) and the number of follows (the regression coefficient 1.161) of the independent variable. At the same time, the multi-correlation coefficient and the coefficient of determination of the agreeableness dimension regression model in terms of personality traits are and respectively, indicating that the agreeableness is positively correlated with the number of followers, the number of shares, the number of likes or comments, and the number of concerns, and the model fits the data well.
The regression equation is:
- (4)
- Based onthe stepwise multivariable regression model, it can be seen from the results in Table 5 that there is a linear regression relationship between the privacy preference (the dependent variable) and “Who is allowed to personally message me?” (the regression coefficient is −0.820), “Who is allowed to comment on me?” (the regression coefficient is −0.138), and whether to allow “My location” to be marked (the regression coefficient is −0.136) of the independent variable. In addition, the regression coefficients of “Who is allowed to personally message me?”, ”Who is allowed to comment on me?” and of whether to allow “My location” to be marked are all less than 0, indicating that with the increase in the user’s allowing personal messages, allowing comments, and allowing location information, the lower the resulting privacy preferences are, which is consistent with common sense. In this model, the absolute value of the standard coefficient “Who is allowed to personally message me?” is the largest. The multi-correlation coefficient and the coefficient of determination of the privacy preference dimension regression model in personality traits are and respectively, indicating that the privacy preference is positively correlated with “Who is allowed to personally message me?”, “Who is allowed to comment on me?” and whether to allow “My location” to be marked, and the model fits the data well.
The regression equation is:
From the experimental results of the personality traits measurement, personality traits can better reflect the online behavior of mobile users. This objective network behavior can be used to quantify the “Big Five Personality” tests, and obtain more accurate and objective “Personality” scores on the questionnaire, which improves the accuracy of user similarity calculation in collaborative filtering recommendations.
In addition, this paper embeds the personality traits analysis module in a personalized recommender system, and users fill in the “mobile user social behavior personality assessment” questionnaire when they first register on the system. Then, the data in the above questionnaire is expressed numerically. The personality trait of user is expressed as . For the convenience of calculation, this paper uses to correspond to the five dimensions of personality traits. User scores item j in the questionnaire as , , and the original score of personality dimension is expressed as (as shown in Equation (29)); in order to distinguish the personality traits of the different measurement items, we set .
To validate the method proposed in this paper, the questionnaire of the “Mobile User Social Behavior Personality Assessment” is designed to obtain the personality traits of users, and in this way, the user’s Big Five personality score table and privacy preference strength are collected. Finally, 421 valid questionnaires were recovered, and the respondents covered different age groups, educational backgrounds, occupations, etc., and the distribution was reasonable. It compares the subjective data of the above questionnaire survey with the calculation data of the personality traits measurement method integrating privacy concerns (PP-PTM) to measure the accuracy of the PP-PTM. Table 6 shows the results.
4.3. Experimental Results of the Method for Calculating the Strength of User Relationship Based on Social Network Interactive Activities and Domain Ontologies
4.3.1. Evaluation Results of Activity Domains Allocation
Firstly, the activity domains need to be accurately divided, and the accuracy of the allocation of activity domains needs to rely on the optimal number of clusters. Therefore, this paper uses the appropriate degree index of cluster number to evaluate the accuracy of domain allocation. The proportion of documents in the cluster that correctly belong to the activity domain Al to which the cluster belongs is the appropriateness of the number of clusters, known as accuracy. This paper takes several different cluster number inputs, using the LDA algorithm to cluster; the effect is shown in Figure 2.
It can be seen in Figure 2 that when the number of clusters is fewer than 400, the accuracy gradually increases with the increase in the number of clusters. When the number of clusters is 300, the highest accuracy is 0.8. When the number of clusters is greater than 300, as the number of clusters increases, the accuracy decreases. Therefore, 300 is the optimum number of clusters.
4.3.2. Evaluation Results of the Relationship Strength Calculation
The method proposed in the paper comprehensively evaluates using calculations and comparing the average NDCG. Profoundly useful records are more helpful at the time of showing up, prior in the web search tool results this list. It uses the average NDCG of all users in a specific activity domain. This paper compares the proposed method with two traditional methods for calculating the strength of the relationship. During the experiment, AI-URS only considers the top 25 friends of each user. For method (b), this paper attempts to combine different weights, and the best results of this method and the results of AI-URS are shown in Figure 3.
- (a)
- AI-URS: The relationship strength is calculated using the method proposed in 3.3.
- (b)
- The linear combination method: This method obtains the strength of the relationship between two users in the same activity domain by calculating the personal data similarity of two users with direct connection and the linear combination of interactive activities. Compared with other methods, the biggest advantage of this method is its simple operation and low computational complexity.
- (c)
- The common framework model method. The strength of the direct relationship between users in the same interest activity domain is calculated by using the personal information of users and the interaction activity information between users.
In the process of comparing with method (c), this paper compares the average NDCG in each activity domain, the results of which are shown in Figure 4.
Figure 3 shows that AI-URS is superior to the linear combination method at different depths. Figure 4 shows that AI-URS is also superior to the general framework model method in each activity domain. This indicates that the user relationship strength in social networks, as calculated by AI-URS, is more accurate. Therefore, this paper divides the interaction domains of users in social networks and calculates the user relationship strength in each domain. Moreover, it considers both the direct relationship strength and the indirect relationship strength.
4.4. Experimental Results of a Collaborative Filtering Recommendation Method Integrating User Personality Traits and Social Relationship Strengths, Considering Privacy Concerns
- (a)
- Comparison of the influence of different values on the hybrid collaborative filtering method based on user similarity fusion
The different values of α indicate the importance weights of the two factors of social relationship and personality traits in a user-based hybrid collaborative recommendation. This paper sets for experiments. The hybrid collaborative filtering method PC-MSPR, based on user similarity fusion, includes the user collaborative filtering method, based on personality traits (PT-UCF) () which calculates user similarity under personality traits that incorporate the user’s privacy preferences, while the user collaborative filtering method is based on the user relationship (UR-UCF) (), which calculates user similarity based on the social relationship strengths. The parameter α is mainly used to set the importance of PT-UCF and UR-UCF. In the MAP, DOA, P@10, and P@5 establish the evaluation index, then the degree of PC-MSPR affected by the weighted coefficient α is compared; the results are shown in Table 7 and Table 8. We set , and . The comparison of multiple sets of experimental results shows that the PC-MSPR has a higher sorting accuracy and the value of α is nonlinearly increasing and decreasing with the sorting accuracy. When α = 0.6, the performance is the best. The experiment verifies that in the process of calculating user similarity in PC-MSPR, the user similarity based on personality traits of PP-PTM, and the user similarity based on the social relationship of AI-URS can obtain a more accurate nearest-neighbor set. Therefore, PC-MSPR improves the accuracy of the recommendation ranking.
- (b)
- Performance comparison between the different collaborative filtering methods
To verify the influence of privacy preferences, personality traits, and social relationship strength on a mobile personalized intelligent recommendation system, this paper compares the collaborative filtering recommendation methods that incorporate the above information. Figure 5 shows that PC-MSPR is superior to the traditional collaborative filtering algorithm, based on the user (UCF). The importance weight was set for the experiment, and the evaluation indexes were P@10 and MAP. The results show that the sparsity of the actual rating data is a serious problem, but this paper improves the quality of the generation of the nearest neighbor set through the comprehensive user similarity calculation integrating personality traits, and social relations so that the final accuracy performance is less affected by the sparse dimension. It also shows that the introduction of privacy concerns, personality traits and user social relations is of great significance to the calculation of user similarity.
The “mobile social recommend method, combining with privacy concerns” is either based on personality traits (PT-MSPR) or based on user relationship intensity (UI-MSPR) and is compared with the traditional user collaborative filtering method (UCF), with a parameter of. The experimental results are shown in Figure 6. When the user relationship strength is introduced into the recommendation system, if the impact of different privacy preferences on user behavior is not considered, the improvement of recommendation accuracy is not particularly obvious. By introducing the privacy preference factor alone, it can be seen that privacy preference has a significant impact on recommendation performance. This shows that in the recommendation of mobile personalized intelligent services, the influencing factors of privacy concerns may be more important than social network factors. In addition, when the model includes any influences related to privacy concerns (such as personality traits or social relationships), the recommendation results outperform traditional user-based collaborative filtering methods. This shows that integrating privacy preference and user relationship strength into the collaborative filtering method will alleviate the data sparsity and cold-start problems and improves the recommendation performance.
4.5. Discussion
Firstly, when the multiple linear regression model was used to calculate the users’ personality traits while integrating privacy concerns, the values of the multi-correlation coefficient and the coefficient of determination were both greater than 0.7, indicating that personality traits could be easily predicted by users’ online behaviors. Moreover, this paper compared this method with the traditional method of using questionnaires to calculate personality traits and finds that the method proposed in this paper is more accurate and objective. This is because the questionnaire comes from users’ self-ratings of their personality traits, and the reliability of the data is uncertain. In contrast, it is more objective and reliable to use online behaviors to predict personality traits.
Secondly, when calculating the strength of the user relationship, the activity domains were first divided. In this paper, the appropriate number of clusters was determined by the change in accuracy. It can be seen that as the number of clusters increases, the accuracy shows a trend of increasing and then decreasing. Because too many or too few people in the active domain will lead to uncertainty regarding the topic to a certain extent, when the accuracy reaches the highest point, this is an optimal number of clusters. In addition, compared with the traditional methods of calculating user relationship strength, it can be seen that the NDCG is higher, and the estimation of user relationship strength is more accurate after considering both the user activity domains and the indirect relationship strength; this result is in line with the ideas presented in the previous section.
In the previous section, we proposed that considering personality traits integrating both privacy concerns and user relationship strength would improve the effectiveness of social recommendation. In this paper, the importance weights of the two factors, the social relationship and personality traits, in the hybrid user-based collaborative recommendation were first obtained by determining the value of α. The best α = 0.6 was obtained by comparing the P@R at different values of α. On this basis, the experimental results show that PC-MSPR is superior to the traditional user-based collaborative filtering algorithm (UCF). This is mainly because, by incorporating multiple types of user information, the user portrait is more accurate, and the user similarity is more in line with the actual behavior obtained. In this way, potential services that are preferred by target users can be obtained, so that the recommendation precision can be improved. In addition, by adding privacy concerns alone, it can be found that users’ privacy preferences have a significant impact on recommendation performance. Because users have different levels of willingness to adopt the marketing model that recommends different goods or services to them because of different privacy concerns, considering users’ privacy preferences can better meet their needs for personalized recommendations and achieve better results. What is more, because of the complexity of the recommended service context, the drift of user interests, and the dynamic nature of privacy concerns, the results achieved in this paper can meet the users’ needs for the recommended model.
5. Conclusions and Future Work
Aiming to address privacy concerns in mobile social recommendations, this paper proposes a social recommendation model that integrates personality traits and relationship strength with privacy concerns for mobile business marketing. This model can be used for “Guess your favorite”, “Home channel recommendation”, “Today’s personalized recommendations”, and “Personalized sorting of category list” under mobile business platforms, such as B2C e-commerce platforms and social e-commerce platforms and other scenarios. It will help digital business enterprises in the “post-epidemic era” to improve service quality and meet users’ personalized needs for recommendation services. The main conclusions are as follows:
- This paper offers the rationality of personality traits for user preference mining and focuses on the analysis of the influence of openness, extraversion, and agreeableness on mobile users’ online behavior, innovatively integrating privacy concerns into the individual personality traits calculation model. The four influencing factors are quantified, and a personality trait calculation method integrating privacy concerns, i.e., PP-PTM, is proposed.
- A method for calculating user relationship strength, AI-URS, based on social network interactive activities and domain ontologies is proposed. AI-URS divides interactive activities into activity domains and calculates the strength of relationships between users belonging to the same activity domain. At the same time, the comprehensive relationship strength of users in the same domain is calculated based on interactive activity documents, including direct and indirect relationships, which overcomes the limitation of previous studies that could only calculate the strength of the relationship for directly related users and improves the accuracy of the calculation results.
- In the collaborative filtering recommendation process, user similarity is calculated by combining personality traits and user relationship strength according to privacy concerns. This paper uses simulated datasets and public datasets to conduct experiments to verify the superiority of the model. The experimental results show that the model proposed in this paper can help alleviate the cold-start and data sparsity problems in recommendations. In addition, this model can reduce the negative impact of current privacy issues on users’ adoption of mobile personalized intelligent recommendation services from the user’s subjective perspective.
The research in this paper mainly focuses on the personalized recommendation problem in a single domain. However, with the development of mobile Internet information technology, users will participate in activities on multiple platforms, such as shopping on Taobao and establishing social relations with friends on Weibo. Therefore, how to utilize users’ behaviors in e-commerce, social networking, and other fields to design cross-domain personalized recommendation methods will become a research focus in the future. In addition, future research can be conducted to dynamically adjust the indicator weights and eigenvalues according to privacy concerns, offering contextual changes and adjusting privacy protection methods and mechanisms in a timely manner.
Author Contributions
Conceptualization, Q.L. and F.G.; methodology, Q.L.; software, Q.L. and F.G.; validation, F.G., W.Z. and Z.W.; formal analysis, F.G.; investigation, W.Z.; resources, S.J.; data curation, F.G.; writing—original draft preparation, Q.L. and F.G.; writing—review and editing, Q.L., F.G., W.Z., Z.W. and S.J.; visualization, Z.W.; supervision, S.J.; project administration, Q.L.; funding acquisition, F.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Zhejiang Provincial Philosophy and Social Sciences Planning Project (No. 21NDJC017Z); the Soft Science Research Program of Zhejiang (No. 2022C35018); the National Natural Science Foundation of China (No. 71802180); the Basic and Public Welfare Research Project of Zhejiang Province, China (No. LGJ21G010001); the Fundamental Research Funds for the Provincial Universities of Zhejiang, China (No. XR202203).
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, X.; Wang, H.; Zhang, C. A Literature Review of Social Commerce Research from a Systems Thinking Perspective. Systems 2022, 10, 56. [Google Scholar] [CrossRef]
- Nawaz, Z.; Zhao, C.H.; Nawaz, F.; Safeer, A.A.; Irshad, W. Role of Artificial Neural Networks Techniques in Development of Market Intelligence: A Study of Sentiment Analysis of eWOM of a Women’s Clothing Company. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1862–1876. [Google Scholar] [CrossRef]
- García-Sánchez, F.; Colomo-Palacios, R.; Valencia-García, R. A social-semantic recommender system for advertisements. Inf. Process. Manag. 2020, 57, 1–16. [Google Scholar] [CrossRef]
- Guo, F.P.; Zhou, W.; Lu, Q.B.; Zhang, C. Path extension similarity link prediction method based on matrix algebra in directed networks. Comput. Commun. 2022, 187, 83–92. [Google Scholar] [CrossRef]
- Song, C.Y.; Ge, Y.; Ge, T.J.; Wu, H.X.; Lin, Z.T.; Kang, H.; Yuan, X.J. Similar but Foreign: Link Recommendation Across Communities. Inf. Sci. 2021, 552, 142–166. [Google Scholar] [CrossRef]
- Zhao, Y.L.; Tarus, S.K.; Yang, L.T.; Sun, J.Y.; Ge, Y.F.; Wang, J.K. Privacy-preserving Clustering for Big Data in Cyber-physical-social Systems: Survey and Perspectives. Inf. Sci. 2020, 515, 132–155. [Google Scholar] [CrossRef]
- Lin, X.L.; Sarker, S.; Featherman, M. Users’ Psychological Perceptions of Information Sharing in the Context of Social Media: A Comprehensive Model. Int. J. Electron. Commer. 2019, 23, 453–491. [Google Scholar] [CrossRef]
- Al-Natour, S.; Cavusoglu, H.; Benbasat, I.; Aleem, U. An Empirical Investigation of the Antecedents and Consequences of Privacy Uncertainty in the Context of Mobile Apps. Inf. Syst. Res. 2020, 31, 1037–1063. [Google Scholar] [CrossRef]
- Wang, H.F.; Zuo, Y.; Li, H.; Wu, J.J. Cross-domain recommendation with user personality. Knowl. Based Syst. 2021, 213, 106664. [Google Scholar] [CrossRef]
- Power, R.A.; Pluess, M. Heritability estimates of the Big Five personality traits based on common genetic variants. Transl. Psychiatry 2015, 5, e604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taddicken, M. The Privacy Paradox in the Social Web: The Impact of Privacy Concerns, Individual Characteristics, and the Perceived Social Relevance on Different Forms of Self-disclosure. J. Comput. Mediat. Commun. 2014, 19, 248–273. [Google Scholar] [CrossRef]
- Goldberg, L.R. The structure of phenotypic personality traits. Am. Psychol. 1993, 48, 26–34. [Google Scholar] [CrossRef]
- McCrae, R.R.; John, O.P. An introduction to the five-factor model and its applications. J. Pers. 1992, 60, 175–215. [Google Scholar] [CrossRef]
- Kwantes, P.J.; Derbentseva, N.; Lam, Q.; Vartainian, O.; Marmurek, H.H.C. Assessing the big five personality traits with latent semantic analysis. Pers. Individ. Differ. 2016, 102, 229–233. [Google Scholar] [CrossRef]
- Moreno, J.L. Who Shall Survive?: A New Approach to the Problem of Human Interrelations; Nervous and Mental Disease Publishing Co.: Washington, DC, USA, 1934. [Google Scholar]
- Selfhout, M.; Burk, W.; Branje, S.; Denissen, J.J.A.; van Aken, M.; Meeus, M. Emerging late adolescent friendship networks and big five personality traits: A social network approach. J. Person. 2010, 78, 509–538. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, Y.B.; Zhao, L.; Wang, B. From virtual community members to C2C e-commerce buyers: Trust in virtual communities and its effect on consumers’ purchase intention. Electro. Commer. Res. Appl. 2010, 9, 346–360. [Google Scholar] [CrossRef]
- Quercia, D.; Lambiotte, R.; Stillwell, D.; Kosinski, M.; Crowcroft, J. The personality of popular facebook users. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 11–15 February 2013; pp. 955–964. [Google Scholar]
- Golbeck, J.; Robles, C.; Turner, K. Predicting personality with social media. In Proceedings of the International Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 7–12. [Google Scholar]
- Zhao, Y.L.; Li, Y.B. Research on forecasting personality traits and relationship strngth of social network users. In Proceedings of the 7th (2012) China Management Annual Conference on Business Intelligence (Selected), Tianjin, China, 13–14 October 2012; pp. 4–13. [Google Scholar]
- Shi, G.H. Behaviors of Weibo Use Predict the Big-Five Personality Traits. Master’s Thesis, Huazhong Normal University, Wuhan, China, 2014. [Google Scholar]
- Lin, L.; Li, A.; Hao, B.; Guan, Z.; Zhu, T. Predicting Active Users’ Personality Based on Micro-Blogging Behaviors. PLoS ONE 2014, 9, e84997. [Google Scholar]
- Xiao, L.; Guo, F.P.; Lu, Q.B. Mobile Personalized Service Recommender Model Based on Sentiment Analysis and Privacy Concern. Mobile Inf. Syst. 2018, 2018, 8071251. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, Q.B.; Guo, F.P. Mobile personalized recommendation model based on privacy concerns and context analysis for the sustainable development of M-commerce. Sustainability 2020, 12, 3036. [Google Scholar] [CrossRef] [Green Version]
- Xiang, R.; Neville, J.; Rogati, M. Modeling relationship strength in online social networks. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 981–990. [Google Scholar]
- Viswanath, B.; Mislove, A.; Cha, M.; Gummadi, P.K. On the evolution of user interaction in facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks, Barcelona, Spain, 17 August 2009; pp. 37–42. [Google Scholar]
- Lin, X.; Shang, T.; Liu, J.W. An estimation method for relationship strength in weighted social network graphs. J. Comput. Commun. 2014, 2, 82–89. [Google Scholar] [CrossRef] [Green Version]
- Feng, J.; Yang, L.T.; Gati, N.J.; Xie, X.; Gavuna, B.S. Privacy-preserving Computation in Cyber-physical-social Systems: A Survey of the State-of-the-art and Perspectives. Inf. Sci. 2020, 527, 341–355. [Google Scholar] [CrossRef]
- Zhao, X.J.; Yuan, J.; Li, G.D.; Chen, X.M.; Li, Z.J. Relationship strength estimation for online social networks with the study on Facebook. Neurocomputing 2012, 95, 89–97. [Google Scholar] [CrossRef]
- Su, Z.; Zheng, X.L.; Ai, J.; Shen, Y.M.; Zhang, X.X. Link prediction in recommender systems based on vector similarity. Phys. A Stat. Mech. Appl. 2020, 560, 125154. [Google Scholar] [CrossRef]
- Singla, P.; Richardson, M. Yes, there is a correlation: From social networks to personal behavior on the web. Environ. Geol. 2008, 58, 1627–1628. [Google Scholar] [CrossRef]
- Anusic, I.; Schimmack, U. Stability and change of personality traits, self-esteem, and well-being: Introducing the meta-analytic stability and change model of retest correlations. J. Person. Soc. Psychol. 2016, 110, 766–781. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Ma, X.; Wan, S.H.; Abbas, H.; Guizani, M. CrossRec: Cross-Domain Recommendations Based on Social Big Data and Cognitive Computing. Mob. Netw. Appl. 2018, 23, 1610–1623. [Google Scholar] [CrossRef]
- Lu, Q.B.; Guo, F.P. Personalized information recommendation model based on context contribution and item correlation. Measurement 2019, 142, 30–39. [Google Scholar] [CrossRef]
- Yang, G.L.; Yang, Q.; Jin, H.X. A novel trust recommendation model for mobile social network based on user motivation. Electron. Commer. Res. 2021, 21, 809–830. [Google Scholar] [CrossRef]
- He, J.N.; Fang, X.; Liu, H.Y.; Li, X.D. Mobile App Recommendation: An Involvement-Enhanced Approach. MIS Q. 2019, 43, 827–849. [Google Scholar] [CrossRef]
- Do, Q.; Liu, W.; Fan, J.; Tao, D.C. Unveiling Hidden Implicit Similarities for Cross-Domain Recommendation. IEEE Trans. Knowl. Data Eng. 2021, 33, 302–315. [Google Scholar] [CrossRef]
- Guo, F.P.; Lu, Q.B. Contextual Collaborative Filtering Recommendation Model Integrated with Drift Characteristics of User Interest. Hum. Cent. Comput. Inf. Sci. 2021, 11, 1–18. [Google Scholar] [CrossRef]
- Wang, T.; Manogaran, G.; Wang, M.H. Framework for social tag recommendation using Lion Optimization Algorithm and collaborative filtering technique. Clust. Comput. 2020, 23, 2009–2019. [Google Scholar] [CrossRef]
- Ma, H.; Zhou, D.Y.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Fourth International Conference on Web Search and Web Data Mining, WSDM, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Fernández-Tobías, I.; Cantador, I.; Tomeo, P.; Anelli, V.W.; Di Noia, T. Addressing the User Cold Start with Cross-domain Collaborative Filtering: Exploiting Item Metadata in Matrix Factorization. User Model. User Adapt. Interact. 2019, 29, 443–486. [Google Scholar] [CrossRef]
- Guy, I.; Zwerdling, N.; Carmel, D.; Ronen, I.; Uziel, E.; Yogev, S.; Ofek-Koifman, S. Personalized recommendation of social software items based on social relations. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 53–60. [Google Scholar]
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24. [Google Scholar] [CrossRef]
- Sahu, A.K.; Dwivedi, P. Knowledge Transfer by Domain-independent User Latent Factor for Cross-domain Recommender Systems. Future Gener. Comput. Syst. 2020, 108, 320–333. [Google Scholar] [CrossRef]
- Tang, W.J.; Zhang, K.; Ren, J.; Zhang, Y.X.; Shen, X.M. Privacy-preserving Task Recommendation with Win-win Incentives for Mobile Crowdsourcing. Inf. Sci. 2020, 527, 477–492. [Google Scholar] [CrossRef]
- Zhao, C.; Yang, S.S.; Mccann, J.A. On the Data Quality in Privacy-Preserving Mobile Crowdsensing Systems with Untruthful Reporting. IEEE Trans. Mob. Comput. 2021, 20, 647–661. [Google Scholar] [CrossRef] [Green Version]
- Mousavi, R.; Chen, R.; Kim, D.J.; Chen, K.C. Effectiveness of Privacy Assurance Mechanisms in Users’ Privacy Protection on Social Networking Sites from the Perspective of Protection Motivation Theory. Decis. Support Syst. 2020, 135, 113323. [Google Scholar] [CrossRef]
- Christian, F.L.; Wong, S.F.; Chang, Y.; Bravo, E.R. The Effect of Fair Information Practices and Data Collection Methods on Privacy-Related Behaviors: A Study of Mobile Apps. Inf. Manag. 2021, 58, 103284. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Henson, B.; Reyns, B.W.; Fisher, B.S. Security in the 21st Century: Examining the link between online social network activity, privacy, and interpersonal victimization. Crim. Justice Rev. 2011, 36, 253–268. [Google Scholar] [CrossRef]
- Hellriegel, D.; Slocum, J.W.; Woodman, R.W. Organizational Behavior, 9th ed.; East China Normal University Press: Shanghai, China, 2001. [Google Scholar]
- Abu-Salih, B.; Chan, K.Y.; Al-Kadi, O.; Al-Tawil, M.; Wongthongtham, P.; Issa, T.; Saadeh, H.; Al-Hassan, M.; Bremie, B.; Albahlal, A. Time-aware domain-based social influence prediction. J. Big Data 2020, 7, 1–37. [Google Scholar] [CrossRef]
Figure 1.
A framework for a hybrid collaborative filtering recommendation model integrating personality traits and relationship strength in accordance with privacy concerns.
Figure 1.
A framework for a hybrid collaborative filtering recommendation model integrating personality traits and relationship strength in accordance with privacy concerns.

Figure 2.
Accuracy comparison of different cluster numbers.

Figure 3.
Average NDCG for calculating the user relationship strength at different depths.

Figure 4.
Average NDCG for calculating user relationship strength in different activity domains.

Figure 5.
Comparison of the accuracy of PC-MSPR and UCF.

Figure 6.
Comparison of the MAP of PI-MSPR, UI-MSPR, and UCF.


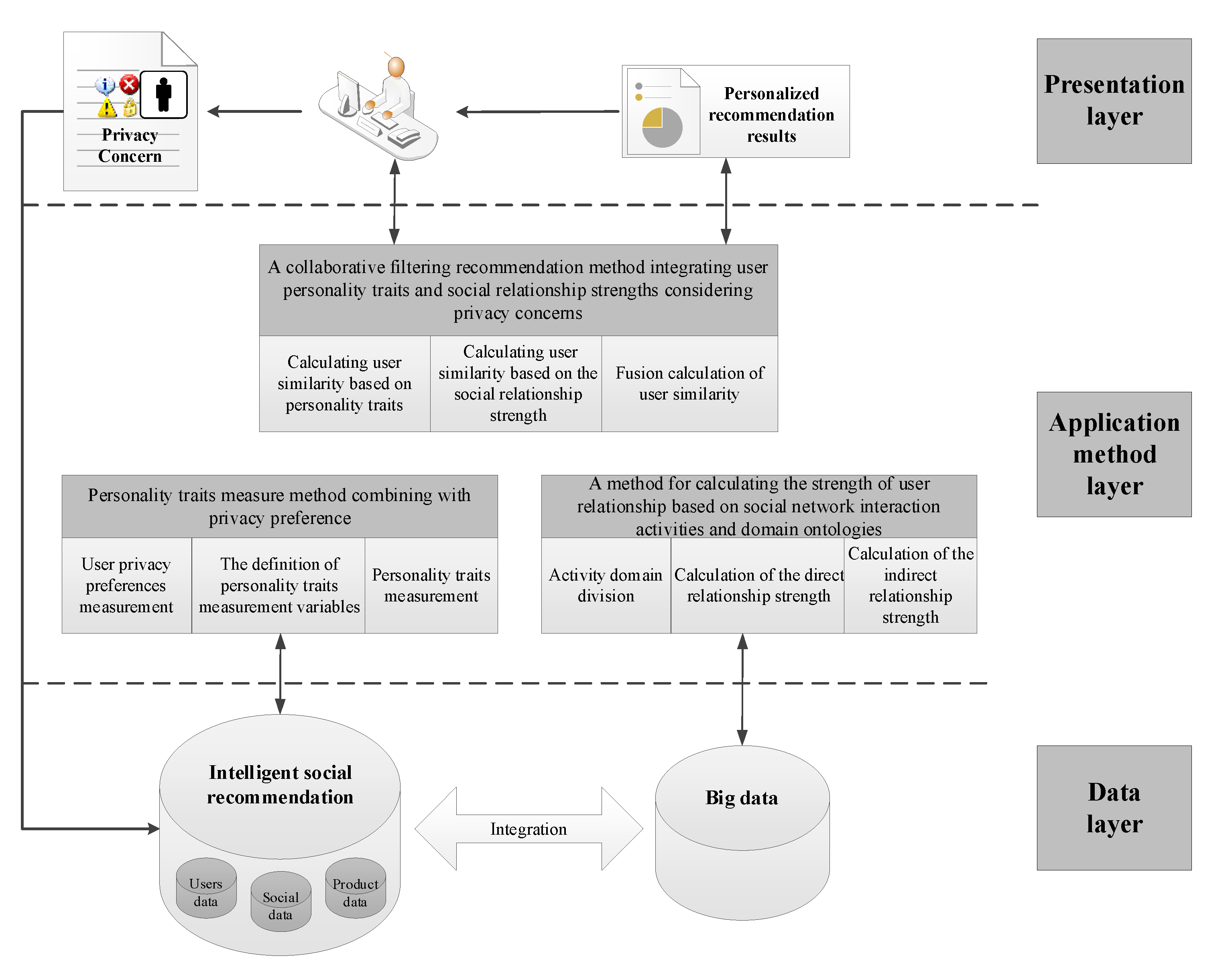{kind=link}
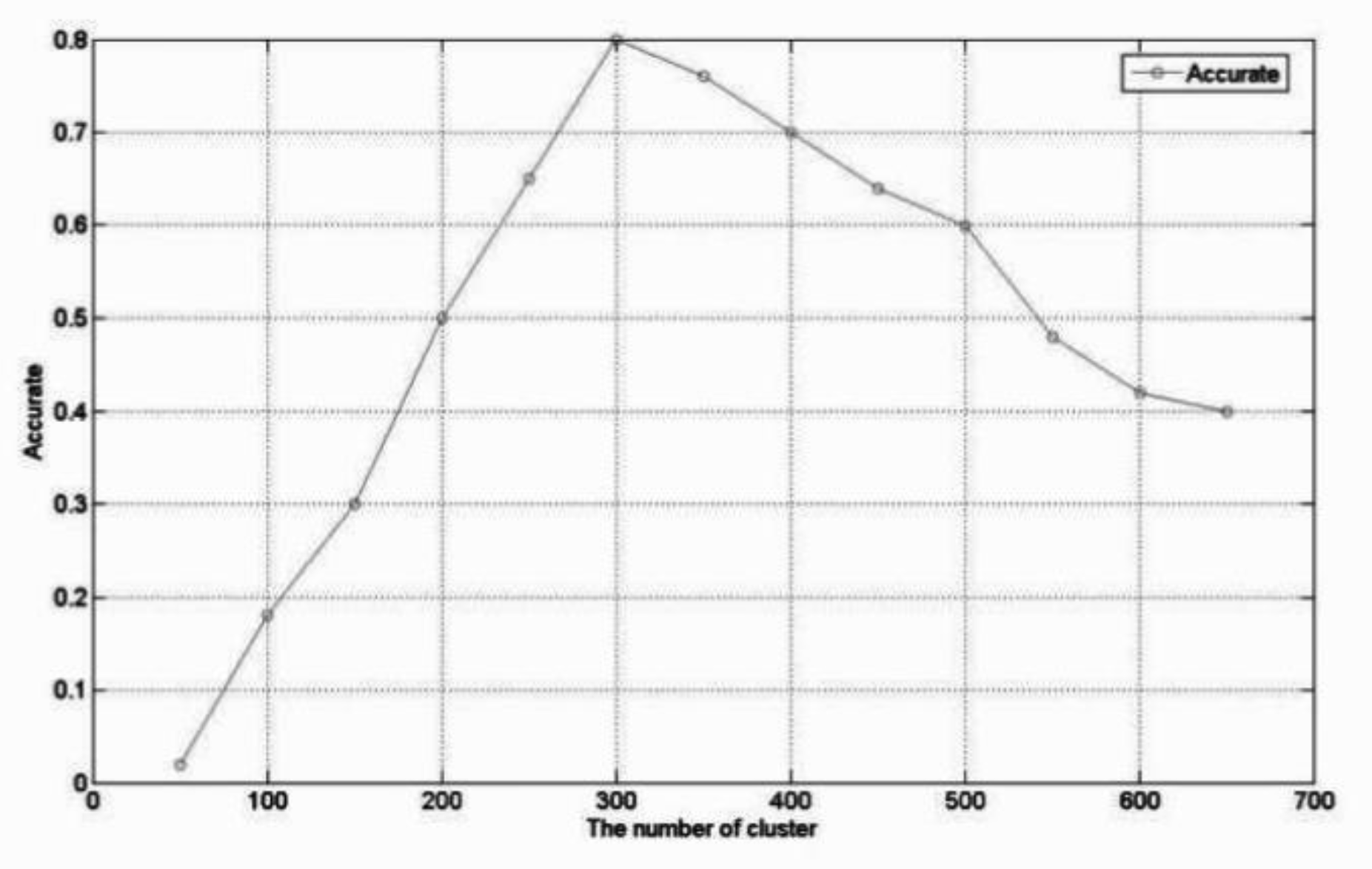{kind=link}
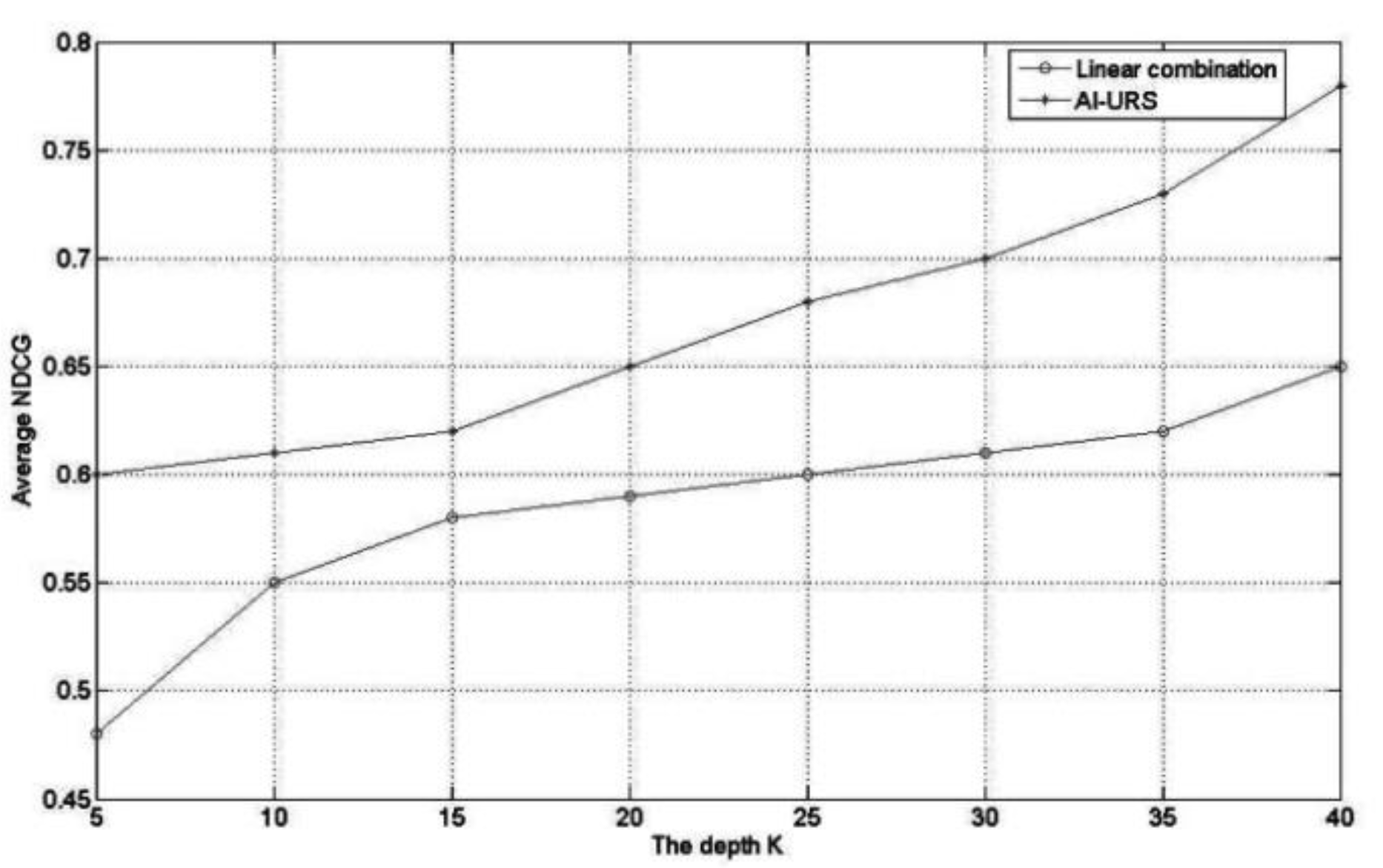{kind=link}
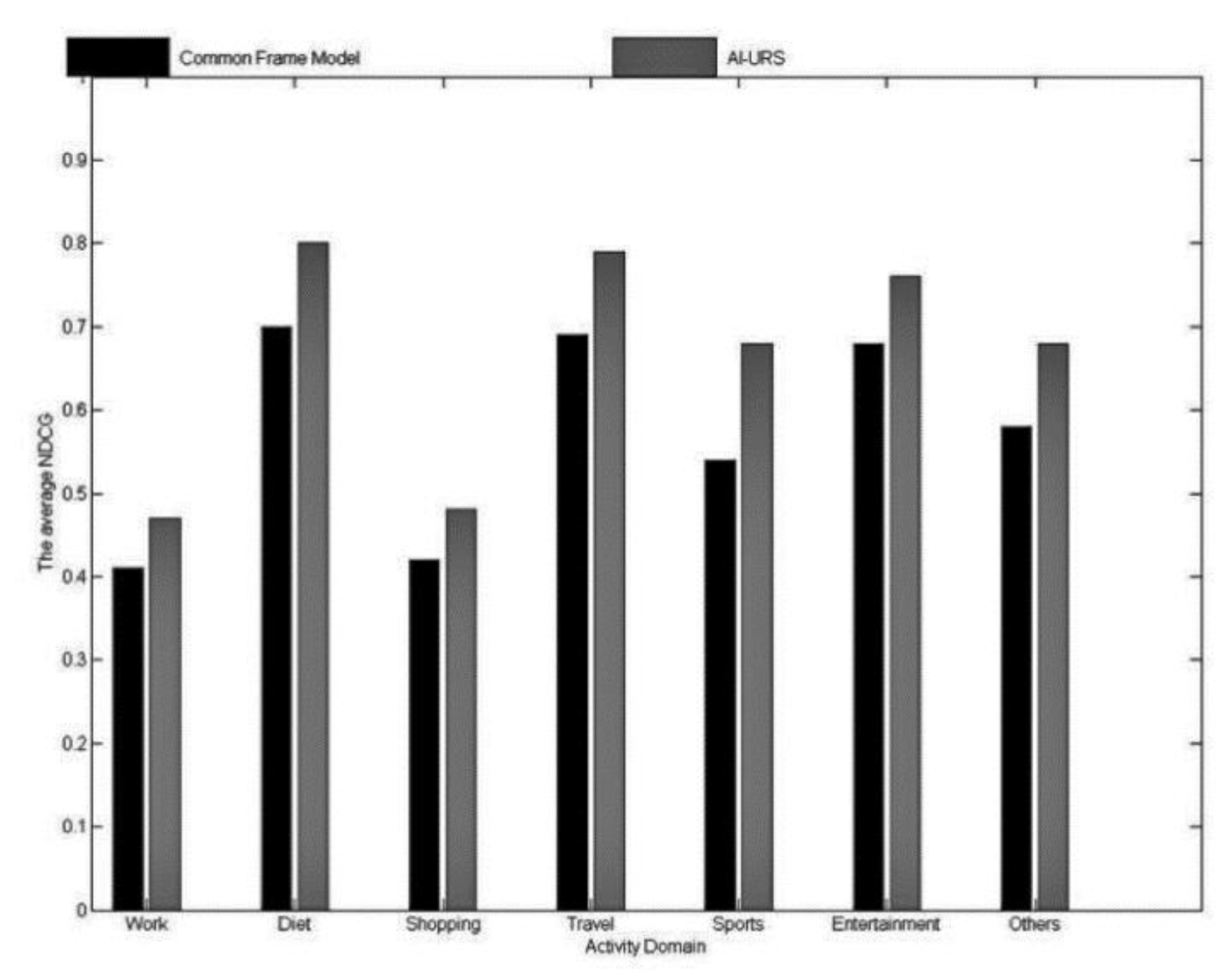{kind=link}
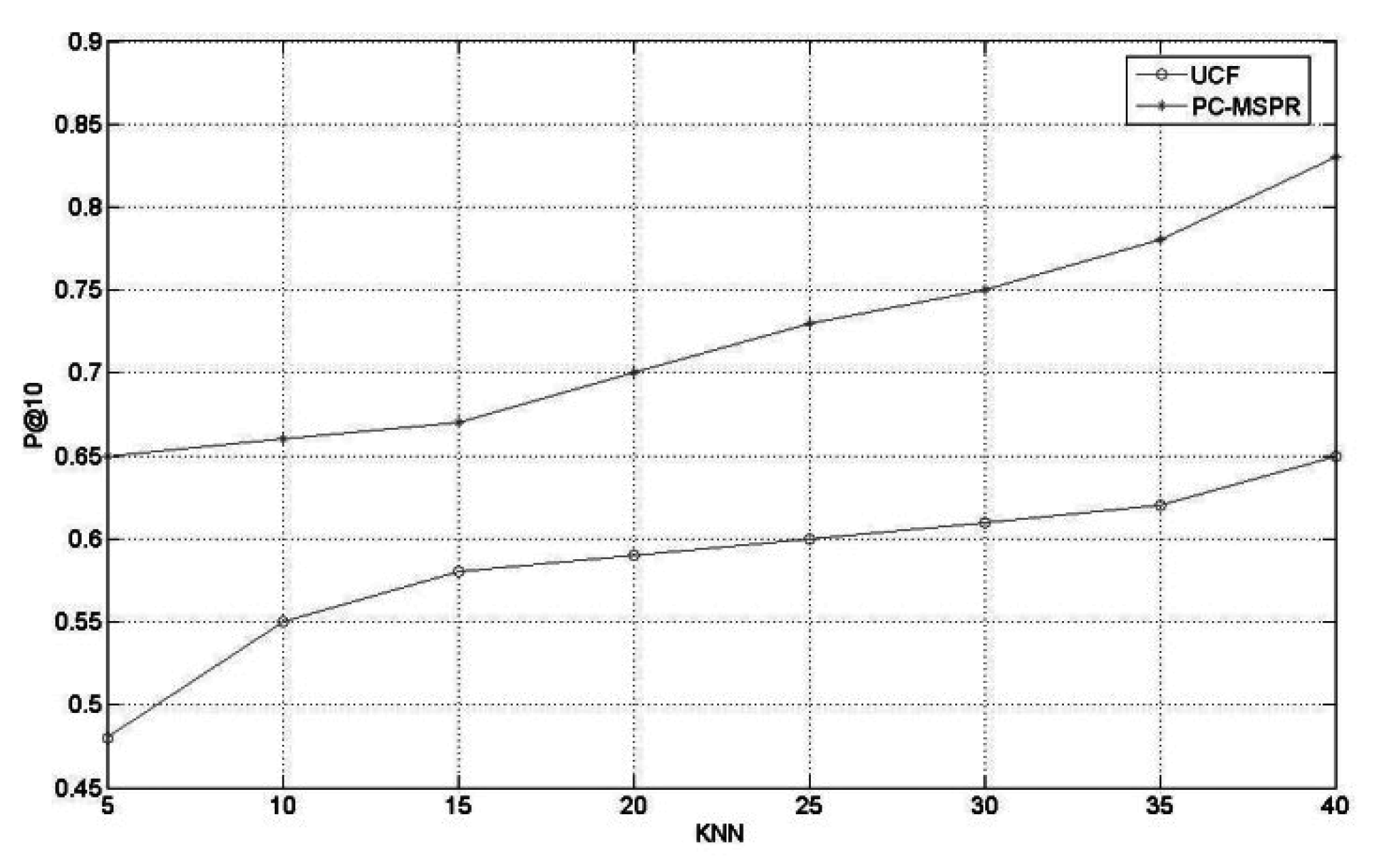{kind=link}
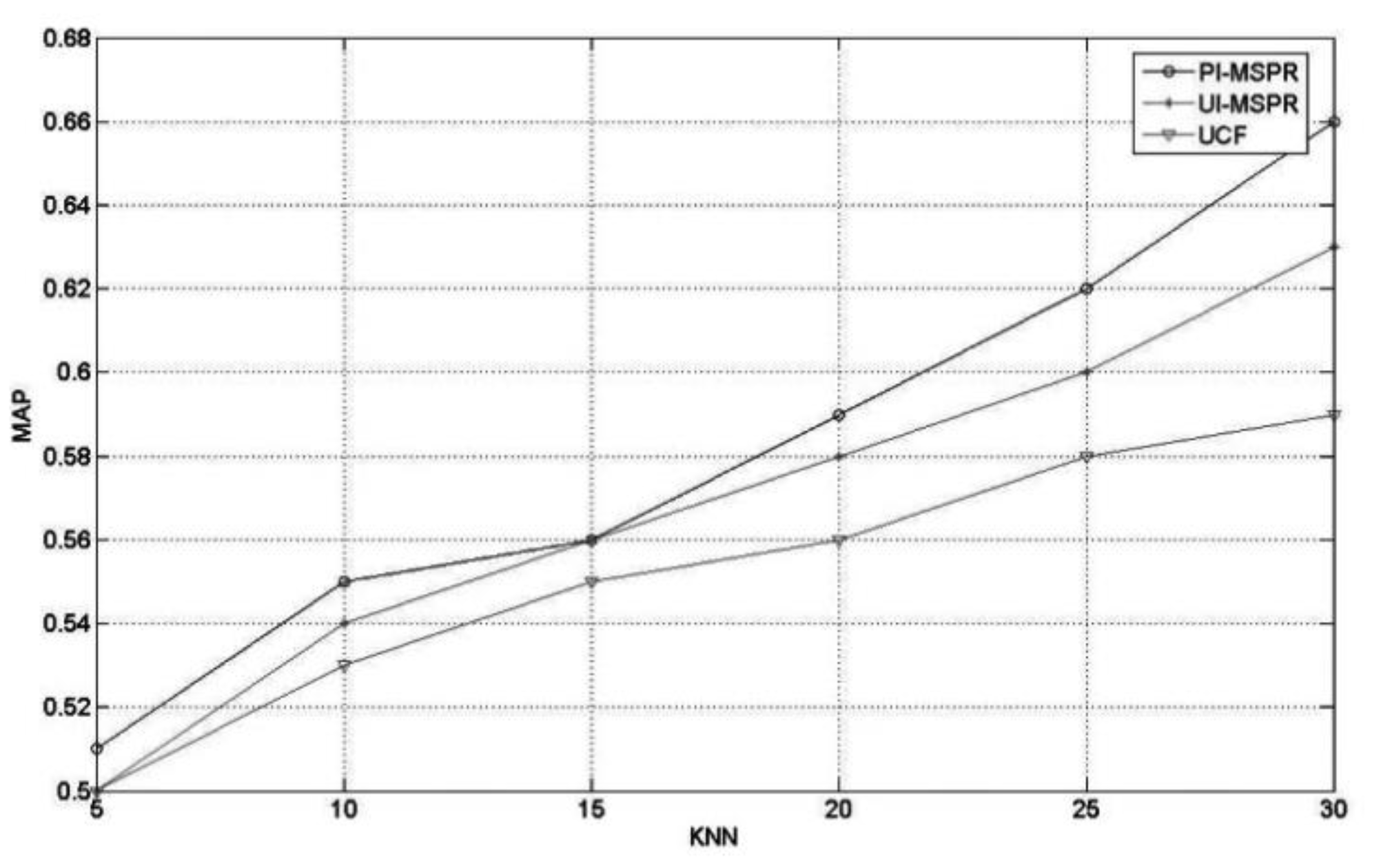{kind=link}
Table 1.
Data statistics.
| Dataset | Users | Items | Ratings | Density |
|---|---|---|---|---|
| Amazon-Movie | 9870 | 41,058 | 232,110 | 0.057% |
| Amazon-Book | 12,137 | 40,232 | 314,409 | 0.064% |
Table 2.
Regression model (openness).
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| The number of followers | 0.125 | 0.806 | 11.104 | 0.000 |
| The number of shares | 0.087 | 0.121 | 2.489 | 0.014 |
| The number of likes or comments | −0.006 | −0.144 | −2.457 | 0.013 |
| The number of mentions | 0.594 | 0.918 | 2.162 | 0.030 |
Table 3.
Regression model (extraversion).
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| The number of followers | 0.104 | 0.654 | 11.941 | 0.000 |
| The number of posts | 0.125 | 0.166 | 3.747 | 0.000 |
| The number of likes or comments | 0.876 | 0.170 | 3.398 | 0.001 |
| The number of follows | −0.004 | −0.134 | −2.658 | 0.026 |
Table 4.
Regression model (agreeableness).
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| The number of followers | 0.145 | 0.777 | 10.571 | 0.000 |
| The number of shares | 0.087 | 0.098 | 2.003 | 0.045 |
| The number of likes or comments | −0.008 | −0.170 | −2.877 | 0.003 |
| The number of follows | 1.161 | 0.193 | 3.471 | 0.001 |
Table 5.
Regression model (privacy preference).
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| Who is allowed to personally message me | −0.820 | −0.653 | −11.942 | 0.000 |
| Who is allowed to comment on me | −0.138 | −0.165 | −3.746 | 0.030 |
| Whether to allow “My location” to be marked | −0.136 | −0.171 | −3.398 | 0.021 |
Table 6.
Classification results of the user’s personality traits (F1 scores).
| Method | Extraversion | Openness | Agreeableness |
|---|---|---|---|
| A (Amazon-movie) | 0.73 | 0.77 | 0.71 |
| B (Amazon-movie) | 0.86 | 0.86 | 0.85 |
| A (Amazon-Book) | 0.72 | 0.78 | 0.70 |
| B (Amazon-Book) | 0.85 | 0.86 | 0.85 |
A: Measurement of personality traits, based on the questionnaire survey; B: personality traits measurement based on a multivariable linear regression model.
Table 7.
Comparison results of hybrid collaborative filtering methods, based on user similarity fusion under different P@R.
Table 7.
Comparison results of hybrid collaborative filtering methods, based on user similarity fusion under different P@R.
| The Hybrid Collaborative Filtering Method Based on User Similarity Fusion | P@5 (k = 10,20,30,50) | P@10 (k = 10,20,30,50) | ||||||
|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | |
| 0.0 | 0.47 | 0.52 | 0.54 | 0.57 | 0.45 | 0.48 | 0.52 | 0.53 |
| 0.2 | 0.49 | 0.55 | 0.56 | 0.58 | 0.48 | 0.51 | 0.53 | 0.55 |
| 0.4 | 0.51 | 0.56 | 0.57 | 0.58 | 0.50 | 0.53 | 0.54 | 0.56 |
| 0.6 (Demarcation point) | 0.53 | 0.57 | 0.58 | 0.59 | 0.51 | 0.54 | 0.55 | 0.57 |
| 0.8 | 0.52 | 0.55 | 0.57 | 0.58 | 0.49 | 0.53 | 0.54 | 0.55 |
| 1.0 | 0.48 | 0.52 | 0.54 | 0.57 | 0.47 | 0.51 | 0.52 | 0.54 |
Table 8.
Comparison results of hybrid collaborative filtering methods based on user similarity fusion under different (MAP, DOA).
Table 8.
Comparison results of hybrid collaborative filtering methods based on user similarity fusion under different (MAP, DOA).
| The Hybrid Collaborative Filtering Method Based on User Similarity Fusion | MAP (k = 10,20,30,50) | DOA (n = 2–8,3–7,4–6,5–5) | ||||||
|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 80%-20% | 70%-30% | 60%-40% | 50%-50% | |
| 0.0 | 0.51 | 0.55 | 0.58 | 0.60 | 0.77 | 0.80 | 0.82 | 0.83 |
| 0.2 | 0.54 | 0.57 | 0.60 | 0.61 | 0.79 | 0.82 | 0.84 | 0.84 |
| 0.4 | 0.55 | 0.58 | 0.61 | 0.62 | 0.80 | 0.83 | 0.85 | 0.85 |
| 0.6 (Demarcation point) | 0.56 | 0.59 | 0.62 | 0.63 | 0.81 | 0.83 | 0.85 | 0.86 |
| 0.8 | 0.54 | 0.58 | 0.60 | 0.62 | 0.80 | 0.82 | 0.84 | 0.85 |
| 1.0 | 0.52 | 0.56 | 0.59 | 0.61 | 0.78 | 0.81 | 0.83 | 0.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lu, Q.; Guo, F.; Zhou, W.; Wang, Z.; Ji, S. Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns. Systems 2022, 10, 198. https://doi.org/10.3390/systems10060198
AMA Style
Lu Q, Guo F, Zhou W, Wang Z, Ji S. Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns. Systems. 2022; 10(6):198. https://doi.org/10.3390/systems10060198
Chicago/Turabian StyleLu, Qibei, Feipeng Guo, Wei Zhou, Zifan Wang, and Shaobo Ji. 2022. "Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns" Systems 10, no. 6: 198. https://doi.org/10.3390/systems10060198
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.