
A Universal Routing Algorithm Based on Intuitionistic Fuzzy Multi-Attribute Decision-Making in Opportunistic Social Networks



1
School of Software, Xinjiang University, Urumqi 830000, China
2
School of Computer Science and Engineering, Central South University, Changsha 410075, China
3
School of Computer, National University of Defense Technology, Changsha 410073, China
*
Authors to whom correspondence should be addressed.
Symmetry 2021, 13(4), 664; https://doi.org/10.3390/sym13040664
Submission received: 12 March 2021
/
Revised: 31 March 2021
/
Accepted: 10 April 2021
/
Published: 12 April 2021
Abstract
:With the vigorous development of big data and the 5G era, in the process of communication, the number of information that needs to be forwarded is increasing. The traditional end-to-end communication mode has long been unable to meet the communication needs of modern people. Therefore, it is particularly important to improve the success rate of information forwarding under limited network resources. One method to improve the success rate of information forwarding in opportunistic social networks is to select appropriate relay nodes so as to reduce the number of hops and save network resources. However, the existing routing algorithms only consider how to select a more suitable relay node, but do not exclude untrusted nodes before choosing a suitable relay node. To select a more suitable relay node under the premise of saving network resources, a routing algorithm based on intuitionistic fuzzy decision-making model is proposed. By analyzing the real social scene, the algorithm innovatively proposes two universal measurement indexes of node attributes and quantifies the support degree and opposition degree of node social attributes to help node forward by constructing intuitionistic fuzzy decision-making matrix. The relay nodes are determined more accurately by using the multi-attribute decision-making method. Simulation results show that, in the best case, the forwarding success rate of IFMD algorithm is 0.93, and the average end-to-end delay, network load, and energy consumption are the lowest compared with Epidemic algorithm, Spray and Wait algorithm, NSFRE algorithm, and FCNS algorithm.
1. Introduction
Recently, because of the vigorous development of big data and 5G networks [1], the number of mobile communication devices has greatly increased. An opportunistic social network is the product of the application of opportunistic networks in social scenes. In the scenario of the opportunistic social network, people communicate through mobile devices. Imagine a scene in which people move randomly with mobile communication devices and communicate through Bluetooth or Wifi within the transmission range of the other party. Then, the mobile device in this scenario is the node in the opportunistic social network. Therefore, by analyzing the sociality of nodes [2,3], the problem of finding relay nodes can be effectively solved, and the practicability and effectiveness of routing algorithms in opportunistic social networks can be improved.
Nodes in opportunistic social networks [4,5,6] adopt the “store–carry–forward” [7,8] routing mechanism through the communication opportunities brought by the random movement of nodes [9]. This mechanism can realize normal communication in the absence of end-to-end stability. This communication mode depends on the movement of nodes and efficient routing algorithm [10,11,12,13]. More generally speaking, the source node wants to forward its stored information to the destination node. In this process, the forwarding node needs to constantly find a suitable relay node for forwarding operation [14]. The more suitable the selected relay nodes are, the fewer relay nodes undertake forwarding work in the network and the less network resources are consumed, so the higher the forwarding success rate of the algorithm will be. It can be concluded that the essence of an excellent routing algorithm is to choose more suitable relay nodes [15,16,17].
However, there is no method to build a trust list and blacklist in the proposed algorithm. The trust tendency builds a trust list and blacklist in the node through the information fed back by the node. The node can exclude the nodes recorded in the blacklist before judging the next hop node, thus saving network resources to a certain extent. In order to make routing algorithms better applied to real-life scenes, the recently proposed algorithms all focus on analyzing the social characteristics [18,19] of nodes, including interests, workplace, time, social relations, intimacy, and so on. Obviously, analyzing the social characteristics of nodes in opportunistic social networks can help us find the best next hop node. However, few algorithms consider the population status of nodes when analyzing the social characteristics of nodes. The performance of nodes in their own communication areas will directly affect their population status. In real-life situations, advice from the most important friends is more likely to be accepted. In other words, the higher the population status of a node in its own communication area, the higher the success rate of forwarding messages. There is another problem in the current algorithms. Some algorithms take into account the problem of selecting the best relay node in a single scene, which leads to the problem that some routing algorithms are not universal. We adopt the multi-attribute decision-making method in an intuitionistic fuzzy model to select the best relay node [20,21] in the opportunistic social network, which can not only express the degree of support and opposition of a certain attribute for the node’s judgment of forwarding preference, but also expresses the third case besides the two cases. These attributes define the hesitation degree of the relationship between the node and the social attribute. Besides, the multi-attribute decision-making method in intuitionistic fuzzy decision-making is just in line with the application scenario in the opportunistic social network, and the multi-attribute decision-making method is a process of evaluating and selecting the best of multiple schemes with multiple attributes. However, the process of selecting relay nodes in opportunistic social networks can actually be understood: assuming that nodes in opportunistic social networks have multiple social attributes, the source node selects the best relay node from multiple neighbor nodes for the forwarding operation.
In order to solve the above problems, we propose a routing algorithm that can be more suitable for various social scenarios. Through a large number of experiments and research in domestic and foreign papers, our algorithm selects two indicators to measure node attributes: population status and social similarity. Population status is used to score the neighbor nodes in the trust forwarding node list, and the one with the highest score is considered to be the node with the highest population status in the forwarding node area. Social similarity is a collection of all social attributes of nodes to judge the degree of similarity between nodes. Then, the measurement indexes of these two nodes are integrated to construct an intuitionistic fuzzy decision-making matrix. Finally, the best relay node is determined by making the best of the multi-attribute fuzzy decision method. In short, this algorithm is a novel routing and forwarding algorithm, which fully considers the social scene of nodes. The main contributions of this algorithm can be summarized as the following four aspects:
- In the warm-up phase, we collect and update records (trust list and blacklist) stored in nodes. After analyzing all possible social scenarios of opportunistic social networks, we propose two indicators to measure node attributes: population status and social similarity.
- In this paper, the idea of intuitionistic fuzzy sets is applied to opportunistic social networks for the first time, and intuitionistic fuzzy decision matrices are constructed for the social attributes corresponding to nodes.
- In order to effectively evaluate and select the best relay node, in this paper the entropy weight method and the weighted average operator are used to obtain the comprehensive attribute value of the nodes, and then the comprehensive score value of each node is calculated by the similarity function and sorted according to the order from large to small. Finally, the node with the highest comprehensive score value is selected as the next hop node for information forwarding.
- The experiment uses the simulation tool The One and obtains the real network topology of Stanford University from the Open Street Map. The experimental results show that the IFMD algorithm proposed in this paper is of great significance for enhancing the success rate of routing and reducing network overhead.
The rest of this paper is organized as follows. In Section 2, we will briefly introduce the related works. In Section 3, the IFMD algorithm will be proposed and analyzed in detail. In Section 4, the complexity analysis of IFMD routing-forwarding algorithm will be analyzed. The simulation results are demonstrated in Section 5. The summary of the full paper is shown in the last part.
2. Related Work
Because of the vigorous progress of big data and 5G era, people’s demand for efficient information transmission is increasing daily. In order to forward information more quickly and accurately, research into routing algorithms has always been an important research direction in the field of opportunistic social network. In order to make the designed algorithm more universal, we should start by analyzing the social environment of nodes. In the opportunistic social network, routing-forwarding algorithms can be mainly divided into two types: the social-ignorant routing algorithm and the social-aware routing algorithm. We will introduce the state-of-the-art versions of the two types of routing-forwarding algorithms.
2.1. Existing Social-Ignorant Routing Algorithm
In existing social-ignorant routing algorithms, in order to realize the purpose of improving the success rate of message forwarding, new forwarding strategies have been continuously proposed by researchers. The Epidemic routing protocol [22] adapts a flooding-based technique. The source node of Epidemic carries data packets in the process of movement and directly forwards the carried information to all nodes it encounters without judgment. Due to this, under the condition of unlimited network resources, the delivery rate is also the highest. However, the reality is that the resources of the network are limited, and unjudged forwarding will lead to memory overflow. The Spray and Wait protocol [23] creates a fixed number of message copies for each message, and forwards the fixed number of message copies to all encountered nodes during the movement process. The node that forwards the message waits for a copy of the message to arrive at the destination node. Although the algorithm reduces unnecessary waste of network resources, it will increase network delay.
In order to increase the success rate of information forwarding as much as possible on the premise of reducing the consumption of network resources, some machine learning methods have been applied to the design of routing algorithms for opportunistic networks, such as Markov chains, decision trees, etc. Dhurandher et al. [24] used Markov chain to predict the position of nodes in the network and the probability of nodes meeting. However, in the real scene, the movement of nodes is random and irregular. Yang et al. [25] use the number of multicasts to achieve lower communication costs. Nahideh et al. [26] proposed the CPTR method by using conditional probability tree. The CPTR method not only records the probability of forwarding information and the probability of forwarding information by meeting nodes, but also includes the probability of forwarding messages after meeting. Although these algorithms improve the efficiency of message forwarding, they are not suitable for our algorithm scenario.
2.2. Existing Social-Aware Routing Algorithm
The existing social-aware routing algorithms make full use of the social characteristics of nodes to design routing algorithms suitable for more scenarios. Yeqing et al. [27] proposed an effective data transmission algorithm based on social relationship (ESR). The ESR algorithm divides communities according to the social characteristics of nodes and reduces useless nodes in the community to achieve the purpose of improving information forwarding efficiency. The FSMF [28] algorithm was proposed by Ying et al. They used the Markov chain model to evaluate users’ social relations and solve the problem of unfair traffic distribution and unfair delivery success ratio. In order to improve fairness, FSMF imposes restrictions on the number of message copies and forwarding copies according to human relations in society. Yuan et al. [29] proposed the SSR algorithm, which uses the social importance of node encounter records to calculate the similarity between two nodes. By dynamically adjusting the encounter sequences stored in nodes, SSR considers that the more similar the encounter sequences are, the more similar the social behaviors of two nodes will be, and selects the node with the maximum similarity as the relay node. The MILECER [30] algorithm was proposed by Sheng et al. The MILECER algorithm fully considers the energy of nodes and the importance of messages, and solves the problem of priority forwarding of important messages. Then, the cache replacement strategy is used to solve the problem of insufficient cache space. Although these methods all consider the social attributes of nodes and the designed algorithm has a certain improvement in forwarding performance, these algorithms do not take into account the different social scenes in which the nodes are located, so the performance of the algorithms will also be different. In order to design routing algorithms suitable for various social scenarios, some algorithms consider the idea of fuzzy decision-making.
Moreover, many newly proposed algorithms incorporate the idea of fuzzy decision-making. Genghua et al. [31] proposed the node social features relationship evaluation method (NSFRE). The NSFRE algorithm constructs a multidimensional similarity matrix according to the trust level to further quantify the social relations of nodes. Kanghuai et al. [32] established a fuzzy routing-forwarding algorithm (FCNS). The FCNS algorithm uses the social similarity and mobile similarity of nodes to make a fuzzy evaluation to determine the forwarding preference of nodes. Although, these algorithms all consider using a fuzzy decision to design a more universal routing algorithm. In the design of the routing algorithm, whether the contribution of social attributes to the forwarding operation can be accurately quantified will directly affect the forwarding efficiency of nodes. None of these algorithms has proposed a reasonable method to quantify the contribution degree of social attributes of nodes, so there is still space for advancement.
Unlike the routing algorithms listed above, the algorithm we propose has a preheating stage. Nodes can form a trust tendency in the preheating stage. In the subsequent calculation of the social attributes (population status and social similarity) of nodes, nodes in the blacklist can be excluded first. Next, an entropy weight method is used to quantify the contribution degree of social attributes to the forwarding operation, and a multi-attribute decision-making method in intuitionistic fuzzy model is used to help the algorithm select the best relay node.
3. Model Design
Nodes in opportunistic social networks are composed of mobile devices carried by human beings. The storage function of mobile devices is equivalent to the cache space of nodes, while the movement of mobile devices is equivalent to the movement of nodes. Nodes that have human characteristics and move are nodes in the network. Figure 1 depicts the real-life scenarios of human beings. Teena has different routes for entertainment, work, and medical treatment from home. The mobile device he carries with him will record his movement track and habits. The circle in the Figure 1 indicates Teena’s communication range. When other people move to Teena’s communication range, it is possible to communicate with Teena.
In order to accurately quantify the social attributes of nodes and make the proposed algorithm more universal, our algorithm constructs the trust tendency of nodes in the preheating stage and quantifies the social attributes of nodes through population status and social similarity. The intuitionistic fuzzy decision-making model is used to obtain the best relay node in the network. In order to accurately quantify the social attributes of nodes and make the proposed algorithm more universal, our algorithm constructs the trust tendency of nodes in the preheating stage and quantifies the social attributes of nodes through population status and social similarity. The decision-making method in the intuitionistic fuzzy model is used to obtain the best relay node in the network.
3.1. The Establishment Stage of Trust Tendency
In the message forwarding model established by this algorithm, there is an early information collection stage, which is called the preheating stage. At this stage, each node has its own trust list and blacklist, and the neighbor nodes in the blacklist are excluded first before calculating node attributes, which can save network resources. To give a vivid example, Teena originally planned to go to the hospital to send information before going to work in the factory. However, the temporary factory has an emergency meeting, and Teena is required to preside over the meeting. However, the hospital also needs the information urgently. Therefore, Teena first excludes employees with bad records and then selects the most trusted employees in the factory to send the information to the hospital. It can be seen that the formation of trust tendency is usually determined by the individual’s historical experience. It is the nodes in the network that record the past communication process and form their own trust node list and blacklist. Unfriendly nodes that only receive information and do not forward it will be recorded in the blacklist, while those nodes that receive information and forward it successfully will be recorded in the trusted list. Moreover, the communication list in the node will change dynamically according to the communication sequence, and the node that has successfully communicated recently will be ranked first in the communication list. In the communication process, assume that the trust list and blacklist formed by node i are
where n indicates that n nodes are recorded in the trust list, and m indicates that m nodes are recorded in the blacklist. Set a time threshold and record the result of its forwarding success or failure to the source node into the blacklist within this time. In the next forwarding process of the source node, the nodes in the blacklist are excluded first, which can greatly reduce the network overhead. As shown in Figure 2, node A forwards the message to node B, and node B continues to forward after receiving the message. If node B is successful in forwarding and feedbacks its successful forwarding information to node A, node A will record node B into the trust list. Node A also forwards its own information to node C, and node C does not feedback the message of whether it has successfully forwarded to node A within the specified time threshold, then node A will record node C into blacklist. After node B forwards its own information to node C, it receives a message sent by node C within a specified time threshold, but this message tells node B that forwarding failed, so node B will still record node C in its blacklist. At the time of the next communication, the nodes that are recorded into the blacklist. Nodes A and B will first compare the neighbor nodes with their blacklists, and first exclude the untrusted nodes in the neighbor nodes, in order to fulfill the purpose of saving network overhead.
In fact, the warm-up stage is the process of the formation of trust tendency, which is the stage of data collection and update. At this stage, the construction of node trust tendency is a periodic activity, and the length of the preheating stage is usually set according to the real activity cycle of human beings. In a real social scene, Teena may go home and work from the same route every day, and he is likely to meet the same people at the same time. Therefore, the optimal value of preheating stage should be obtained through experiments. After the formation of trust tendency, the routing algorithm began to use a multi-attribute decision-making method to evaluate the population status and social similarity of nodes in the network and make the optimal data forwarding decision. After the whole data transmission process is completed, the trust list and blacklist stored in the node storage space will be emptied and enter the next warm-up stage.
3.2. Calculate the Social Attributes of Nodes
In the process of information transmission in an opportunistic social network, the source node chooses the best relay node to forward information. The choice of relay nodes will affect the forwarding efficiency of the whole network, so it is very important to choose appropriate social attributes for nodes to quantify their behaviors in routing strategies. Each node has different importance in its own communication area, which is called population status in this paper. Specifically, after the source node excludes the untrusted nodes in the blacklist, it scores the neighbor nodes in the trusted list, selects several nodes with high positive scores, and then calculates the social similarity between the nodes. Social similarity can describe all the social characteristics of nodes in detail, including the role, interest, age, etc. Using social similarity to compare the similarity between nodes is a social attribute with wider applicability. In the following sections, this chapter will introduce the calculation process of node population status and social similarity.
3.2.1. Population Status
Each node in the network has its own influence area. When there are multiple neighbor nodes around node i, it is necessary to calculate which of these nodes has the highest population status. At this time, source node i needs to score the forwarding effect of these neighbor nodes. The scoring rules are shown in the following formula: the first formula represents the ratio of the number of times the neighbor node j helps node i forward to the total number of times the node i forwards. In this paper, is called the positive fraction, and the higher , the higher the population status of node j. The second formula represents the ratio of the number of times node j failed to help node i forward messages to the total number of times node i forwarded messages. Then, is called the negative score in this paper. The higher the score of , the lower the population status of node j is proved.
Because the setting of social attributes of nodes will affect the forwarding preference of nodes when forwarding operations, intuitionistic fuzzy numbers contain two kinds of information: one is to express the forwarding preference of nodes, and the other is to express the relationship between nodes and social attributes. It can be seen that intuitionistic fuzzy numbers are used to represent the population status of node j. denotes a degree of membership of the node j to the community status attribute , denotes a degree of non-membership of the node j to the community status attribute , and denotes a degree of hesitation.
Among them, represents the total number of times that node j helps node i forward, and represents the number of times that node j fails to help node i forward messages. represents the connection times of all nodes that help node i successfully forward information recorded in the trust list of node i.
3.2.2. Social Similarity
The social similarity of node attributes in an opportunistic social networks is the key factor affecting the success probability of network forwarding. Experiments show that comparing the social similarity of node attributes can accurately predict the forwarding path of messages in opportunistic social networks. The set contains all the social attributes measured by the social similarity of nodes: , the decisive attributes that determine the forwarding of different nodes will also be different. In order to more accurately compare the social similarity between nodes, we also define sub-vectors for the social attributes of each node. For example, individuals play different roles in society, as fathers in families, as employees in work, etc. Each individual has at least three or more roles in society, where , respectively, represents the roles played by nodes in the community (e.g., father, employee, son, etc.). If node i plays the role or owns the attribute in the sub-vector, the corresponding value is initialized to 1, otherwise it is set to 0. For example, if the node is in the workplace, its role sub-vector is . In addition, the difference between a pair of nodes i and j are measured by the following equation:
where and express the sub-vector model of the a-th feature of nodes i and j, respectively. is calculated by Euclidean distance formula. represents the difference between nodes i and j. The Euclidean distance is inversely proportional to the similarity, so the smaller the Euclidean distance, the greater the similarity between the two nodes. In order to ensure that the similarity value between two nodes is limited to between 0 and 1, we define the similarity as
It can be seen that social similarity uses intuitionistic fuzzy number to represent the social similarity of node j, where represents the membership degree of node j to the social similarity attribute, represents the non-membership degree of node j to the social similarity attribute, and represents the hesitation degree.
3.3. Intuitionistic Fuzzy Decision-Making Model
The intuitionistic fuzzy decision-making model is an adaptive technology based on a multi-attribute decision method and intuitionistic fuzzy set, which has been widely used in machine learning and AI intelligent system in recent years. It is expected that the system will be utilized to offer more precise decision-making for data forwarding. On account of the relationship between the nodes and their social attributes there exists indetermination, and we adopt an multi-attribute decision-making method in the intuitionistic fuzzy model to select the best relay node. The multi-attribute decision-making method consists of three parts: the construction of intuitionistic fuzzy decision-making matrix, the determination of node attribute weights, and the determination of intuitionistic fuzzy sets.
3.3.1. Principle of Intuitionistic Fuzzy Sets
In 1986, K. Atanassov proposed a new fuzzy theory for dealing with fuzzy information-Intuitionistic Fuzzy Sets (IFS). Multi-attribute decision-making method analyzes the forwarding preference of nodes on the basis of using intuitionistic fuzzy sets. Using intuitionistic fuzzy sets in opportunistic social networks, each node has its corresponding attribute’s true membership degree, false membership degree, and hesitation degree. Thus, this not only gives the support degree of a certain attribute to the node’s judgment forwarding preference, but also gives the opposition degree of a certain attribute to the node’s judgment forwarding preference. At the same time, in addition to support and opposition, the third situation is the degree of neutrality. For example, suppose that the degree of social attribute A judgment forwarding preference for node i is , that is, its true membership degree , false membership degree , and neutrality degree . Specifically, it means that the support degree of the attribute A to the node judgment forwarding preference is 0.6, the opposition degree of the attribute A to the node judgment forwarding preference is 0.3, and the neutrality degree is 0.1. The general definition of basic intuitionistic fuzzy sets used in this paper is as follows.
Definition 1.
Let be a non-empty finite set. For any element x, an intuitionistic fuzzy set A in E is defined as
where and denote the degree of membership and the degree of non-membership of an element to the set A, respectively. In an opportunistic social network, E represents a set of all nodes in the network. represents n nodes in the network. represents the degree of support of attribute for nodes to judge forwarding preferences, and represents the degree of opposition of attribute A to nodes to judge forwarding preferences. Among them, the degree of support and the degree of opposition are limited between .
Definition 2.
is the intuitionistic index (or intuitionistic term) of the element x in A, which indicates the uncertainty of whether x belongs to the set A or the neutrality relative to A.
Obviously, for every , there is . In particular, for each general fuzzy set A in the universe E, . From this, we can see the advantages of intuitionistic fuzzy sets over fuzzy sets. It can represent the third situation besides the degree of support of attribute A for a node to judge the forwarding preference and the degree of opposition of attribute A for a node to the judge forwarding preference. That is to say, the degree of uncertainty of the relationship between the node and attribute A, which can also be regarded as the degree of neutrality. It is more convincing to measure the utility of forwarding decision by using the degree of neutrality to measure the social attributes of nodes.
Definition 3.
Suppose that is a group of in intuitionistic fuzzy number, and set IFWA: .
As indicated by the above definition, IFWA is an intuitionistic fuzzy weighted average operator, where is the weight vector of , and , . By observing the above formula, it is not difficult to find that the integrated value calculated by the IFWA operator is still an intuitionistic fuzzy number, which can effectively avoid the loss of information. In an opportunistic social network, it can be expressed as multiple attribute values owned by a node, multiplied by the corresponding weight of each attribute value, and finally added. This method can perfectly consider all social attributes contained in the node.
Definition 4.
Use the similarity function of intuitionistic fuzzy numbers to sort the nodes in the network and select the best relay node, as shown in the following formula:
Only paying attention to the membership degree of nodes can easily lead to decision-making mistakes. The similarity function constructed by the hesitation degree and non-membership degree can avoid this problem to a certain extent. Hesitation degree more accurately expresses the neutrality of a certain social attribute to node forwarding preference. If only the membership degree of a certain attribute in a node is measured, there may be a situation that the best relay node cannot be judged when the membership degree of the nodes is the same.
3.3.2. Constructing Intuitionistic Fuzzy Decision Matrix
A multi-attribute decision-making method is a research direction of applying intuitionistic fuzzy set theory to real-life scenes. Multi-attribute decision-making is a process of evaluating and selecting the best of multiple schemes with multiple attributes, which consists of a scheme set, attribute set, and fuzzy decision-making matrix. Therefore, its application in opportunistic social networks can screen out the best next hop node from many neighbor nodes and achieve the purpose of improving network throughput and reducing network delay. In an opportunistic social network, the node set composed of many neighbor nodes is the scheme set in the multi-attribute decision-making method, and let the node set be . Each node has social attributes, which are called attribute sets in intuitionistic fuzzy theory. Let the attribute set of the nodes be , and let be the weight vector of attributes, where . From Definition 1, it is assumed that the feature information of nodes is expressed by intuitionistic fuzzy sets as follows:
where represents the degree of support of the attribute to the node in judging the forwarding preference, represents a degree of opposition of the attribute to the node in judging the forwarding preference, and .
In order to clearly demonstrate the social attributes of nodes, the characteristics of node about attribute are expressed by intuitionistic fuzzy number , that is, represents the degree of support of attribute for node to judge forwarding preferences, and represents the degree of opposition of attribute to node to judge forwarding preferences. Therefore, the characteristic information of all nodes about attributes can be represented by an intuitionistic fuzzy matrix , where , . The intuitionistic fuzzy decision-making matrix D is expounded as
3.3.3. Determine the Attribute Weights of Nodes by Entropy Weight Method
In classical multi-attribute decision-making, the weight allocation methods suitable for unknown decision matrix include the eigenvector method and weighted least square method, and the entropy weight method is suitable for a known decision-making matrix. Therefore, we use the entropy weight method to determine the attribute weights of nodes. The basic idea of the entropy weight method is that the greater the degree to which the attribute value of each node in the network jumps on a certain attribute in a certain period of time, the smaller the information entropy of the attribute, indicating that the greater the amount of information provided by the attribute, that is, the more important the attribute is when judging relay nodes, the greater the weight should also be. On the contrary, the smaller the jump value of a certain attribute value of a node in a certain time, the larger the information entropy of the attribute, indicating that the amount of information provided by the attribute is larger, that is, the attribute is less important when judging the relay node, and the weight should also be smaller.
Assuming that the opportunistic social network contains n nodes and m attributes, the entropy weight method is used to determine the weight of each fuzzy number in the intuitionistic fuzzy decision matrix as follows. First, the fuzzy number formed by the attribute value corresponding to the i-th node in the intuitionistic fuzzy matrix needs to be standardized. Assuming that the normalized value is , denotes the value of the -th attribute of the i-th node. Then, use the following formula to calculate the proportion of the i-th node in the attribute of the item.
Next, calculate the information entropy of each attribute, where . If , it is considered , and the formula is defined as
Then, information entropy redundancy is obtained by subtracting information entropy from 1. The formula is
Finally, the weight of each attribute can be obtained by using the ratio of the information entropy redundancy of the attribute of node i to the information entropy redundancy of all attributes in node i. The formula is
3.3.4. Ranking of Intuitionistic Fuzzy Sets
The weighted average operator formula is used to integrate all the elements of the i-th row in the decision matrix D. The comprehensive attribute values of n nodes in the opportunistic social network can be obtained. Next, the comprehensive score values of each node are calculated by using the similarity function of intuitionistic fuzzy numbers. Finally, the comprehensive score values of each node are sorted from large to small and two to three nodes, and the same score or the closest score is selected as the next hop nodes.
In order to understand the whole calculation process of this algorithm more intuitively, let us give an example. The example is as follows: The source node needs Teena to preside over the emergency meeting held by the factory, but the hospital urgently needs the information prepared by Teena. Teena needs to choose a responsible employee to deliver the information to the hospital instead of himself. Now, the employees with bad reputation around him are removed, leaving five employees to choose from. Teena judges whether the employee can timely and safely deliver the documents to the hospital. The chosen employee needs to meet three criteria: degree of responsibility, degree of contribution, and degree of trustworthiness. The weight vector of the selection criteria is . An intuitionistic fuzzy decision-making matrix is used for the characteristic information of the employees to be selected that meets the selection criteria , as shown in Table 1.
First, the weight vector of the candidate standard given in question is used to weigh the attribute values of the employees to be selected, and the weighted attribute values are obtained. The weighted intuitionistic fuzzy decision matrix decision-making is shown in Table 2.
Then, the IFWA operator is used to obtain the comprehensive attribute value of the employee to be selected :
Then, according to the similarity function of the formula (–), the score values are calculated and sorted:
Due to
Therefore,
Finally, it is concluded that node 5 is the best relay node.
4. Complexity Analysis
In brief, a high-efficiency routing algorithm based on an intuitionistic fuzzy decision-making model is proposed. We comprehensively think about various communication scenarios in real-life and propose a more universal routing algorithm suitable for various life scenarios. In order to enhance the understanding and readability of the algorithm, the processes of the IFMD algorithm are displayed as follows.
Step 1: In the warm-up phase, each node in the network collects information to build its own trust list and blacklist, and in order to make the application scope of the routing algorithm more extensive and more universal. In the process of designing the routing algorithm, we determined two social attributes to quantify the characteristics of nodes: population status and social similarity.
Step 2: In order to determine the best relay node, we construct a intuitionistic fuzzy decision-making matrix and calculate the intuitionistic fuzzy number of the characteristic attribute value of each node in the network. Then, we transform the intuitionistic fuzzy number into intuitionistic fuzzy set.
Step 3: The entropy weight method is utilized to confirm the weight of each intuitionistic fuzzy set in the intuitionistic fuzzy decision-making matrix. Then, the weighted average operator is used to integrate all elements of each row in the intuitionistic fuzzy decision-making matrix D, so that the comprehensive attribute values of n nodes are obtained.
Step 4: Finally, the comprehensive score value of each node is calculated by using the similarity function, and the comprehensive score value is sorted from big to small. The node with the highest comprehensive score value is selected as the next hop node for information forwarding.
In order to increase the readability and understandability of IFMD algorithm, we constructed Algorithm 1 and Figure 3 rigorously and objectively. Specifically, after the nodes form a trust tendency in the warm-up phase, each node has its own trust list and blacklist. Nodes that successfully help forward are recorded in the trust list through node feedback, and nodes that fail to help forward are recorded in the blacklist. Then, after calculating the population status and social similarity, a fuzzy decision-making matrix is constructed, and the entropy weight method is utilized to confirm the weight of each intuitionistic fuzzy set in the intuitionistic fuzzy decision-making matrix. The time complexity of this stage is . Then, the weighted average operator IFWA is used to calculate the comprehensive attribute values of n nodes, and the time complexity of this process is . Finally, the similarity function is used to calculate the comprehensive score value of each point, and the best relay node is selected by sorting the nodes. The time complexity of this stage is . In conclusion, after rigorous mathematical analysis, we get that the time complexity of IFMD algorithm is .
The fuzzy decision-making system is a new adaptive technology based on fuzzy inference and mathematics, which has emerged as a decision support system in recent years. This system is expected to be used to provide more accurate decisions for route selection and data transmission in 5G networks and big data. The time complexity of the Epidemic algorithm is . The time complexity of the Spary and Wait algorithm is . The time complexity of NSFRE algorithm is . The time complexity of FCNS algorithm is . By comparing the time complexity of IFMD algorithm with two classical algorithms and two new algorithms, we can draw the conclusion that although the time complexity will be very high when a large number of calculation methods are used in the restrictive scenario of opportunistic social network, the performance of the algorithm can be improved on the premise of maximizing the time complexity of the control nodes. Experimental results show that the IFMD algorithm achieves a good balance between time complexity and performance.
| Algorithm 1 Routing Forwarding Algorithm Based on Intuitionistic Fuzzy |
| Decision-Making Model |
| Input: all nodes in the opportunistic social network; |
| Output: the optimal next hop nodes; |
| 1. Begin |
| 2. //Social feature analysis; |
| 3. Calculate population status and social similarity; |
| 4. //Intuitionistic fuzzy decision-making matrix is constructed |
| 5. For each node |
| 6. The intuitionistic fuzzy number of the characteristic attributes corresponding to |
| each node is calculated and transformed into an intuitionistic fuzzy set; |
| 7. End for |
| 8. //The weight of each intuitionistic fuzzy set in intuitionistic fuzzy decision-making |
| matrix is determined by using entropy weight method |
| 9. For each intuitionistic fuzzy set |
| 10. Convert to the corresponding intuitionistic fuzzy number; |
| 11. The standardized intuitive fuzzy number is ; |
| 12. Get the proportion of the i-th node in the -th attribute by ; |
| 13. Get the information entropy of each attribute ; |
| 14. Calculate the information entropy redundancy rate ; |
| 15. Get the weight of each attribute ; |
| 16. All the elements of i-th line in the decision-making matrix D are integrated |
| utilizing IFWA; |
| 17. Get the comprehensive attribute values of n nodes |
| 18. End for |
| 19. The similarity function is used to calculate the comprehensive score of |
| each node ; |
| 20. If then |
| 21. If then |
| 22. get the optimal next hop node is ; |
| 23. End if |
| 24. End if |
| 25. End |
5. Simulations
We adopt The One simulation tool to simulate the IFMD routing algorithm proposed in this paper, and compare it with two classical routing algorithms and two novel routing algorithms. Among them, the two classical routing algorithms are the Epidemic algorithm [22] and Spray and Wait algorithms [23], and the two novel routing algorithms are the NSFRE [31] and FCNS algorithms [32]. The Epidemic algorithm is a flooding algorithm in which the source node is regarded as the pathogen and the other nodes as the susceptible population, and it passes its stored messages to neighboring nodes whenever there is an opportunity. The Spray and Wait algorithm is divided into two stages: In the Spray stage, the source node injects a fixed number of message copies into the network, and then transmits the message copies to all relay nodes it encounters during the movement. In the Wait phase, if the copy of the message is not transmitted to the target node, the node carrying the information will complete the information transfer through direct transfer. FCNS algorithm makes use of the similarity of node movement and society, and uses fuzzy reasoning method to determine the relay node in the process of node forwarding. The NSFRE algorithm establishes a fuzzy similarity matrix based on various characteristics of nodes. Each node in the network iterates and deletes useless features according to the confidence level, and then further quantifies social characteristics to achieve the purpose of improving the network forwarding rate.
5.1. Simulation Parameters
In this paper, the Open Street Map tool is used to edit the city map, and different numbers of pedestrians, vehicles, streets, and shops are designed in the map. Constructing a real living environment in this way can be used to effectively simulate the influence of the number of nodes, simulation time, and node cache on simulation results. As shown in Figure 4, the simulation scene adopts the real topological structure derived from the map by Stanford University, and the data set adopts the real data set of Stanford University. The relevant parameters set in the simulation environment in this paper include the following: simulation time: 12 h, the number of simulation nodes is 120 to 1000 nodes, and all nodes are randomly distributed in Stanford University’s network topology. The maximum transmission area of each node is 20 m, and the speed of the node is set to 5 km/h and 60 km/h for pedestrians and cars, respectively. The initial energy of each node is 100 J, and each node always consumes 0.25 J in the processes of node storage, carrying, and forwarding. The cache space of each node is set to 5, 10, 15, 20, 25, 30, 35, and 40 Mb, and the initial value is 5 Mb. For the purpose of improving the readability of relevant configurations, we established Table 3 to show the relevant configurations in the experiment.
5.2. Evaluation Indicators
The nodes in opportunistic networks are sparse and moving constantly, which leads to constant changes in the topology of the network, and the connectivity of the network is also random and constantly changing. In this case, it is particularly important to enhance the forwarding success rate of routing algorithm, reduce network delay, and improve network throughput. Therefore, how to judge the adaptability and forwarding ability of routing algorithms in network scenarios has become a problem that must be studied. By consulting the literature, the evaluation indexes [33] of routing protocols commonly used in opportunistic networks are summarized. The following evaluation indexes are used to assess the behavior of the IFMD algorithm.
- Delivery ratio: Delivery ratio refers to the proportion of the number of messages successfully received by the destination node to the number of messages sent by the source node. As shown in Equation (13), is the number of messages obtained by the destination node and is the number of messages transmitted by the source node.
- Average end-to-end delay: This index analyzes the delays caused by routing, such as waiting delay and transmission delay of relay nodes. The formula of average end-to-end delay is shown in (14), where refers to the total delay in the process of messages arriving from the source node to the destination node and the number of nodes in the communication area that successfully obtain messages.
- Overhead on average: The indicator represents the network load of a pair of nodes successfully forwarding messages, which can be formally expressed as shown in Formula (15), where represents the total time of data forwarding and represents the total time of data forwarding between nodes:
- Surplus energy: The index describes the residual energy of nodes in the process of forwarding. Because the energy in mobile communication devices carried by human beings is a limited resource, it is very useful to consider the residual energy of nodes to enhance the performance of routing policies.
5.3. Analysis of Simulation Results
The Influence of Moving Model on IFMD Algorithm
This section mainly describes the performance of IFMD algorithm with various mobile models. Simulation experiments make use of various mobile models to show the performance of IFMD algorithm. In this section, the following three mobility models are selected to evaluate the message forwarding efficiency of the algorithm: RW, RWP, and SPMBM. First, Figure 5 shows the forwarding rate of IFMD algorithm in different mobility models. Our algorithm has the best effect when SPMBM is used as the mobile model. Delivery ratio in SPMBM is the highest, at 12, and the forwarding success rate of our algorithm can reach 0.91. Nevertheless, the delivery ratio in RWP is only 0.8 at 12 h, and in RW is only 0.68.
Second, Figure 6 displays the average end-to-end delay of IFMD algorithm under various movement models. Average end-to-end delay in SPMBM is the lowest, at 12, and the average end-to-end delay of our algorithm can reach 173. Nevertheless, average end-to-end delay in RWP is 186 at 12 h, and in RW is 181.
Then, Figure 7 shows the overhead on average of IFMD algorithm under different movement models. The IFMD algorithm has the best effect when SPMBM is used as the mobile model. Overhead, on average, in SPMBM is the lowest, at 12, and the overhead on average of our algorithm can reach 114.3. Nevertheless, average end-to-end delay in RWP is 116.4 at 12 h, and in RW is 119.2.
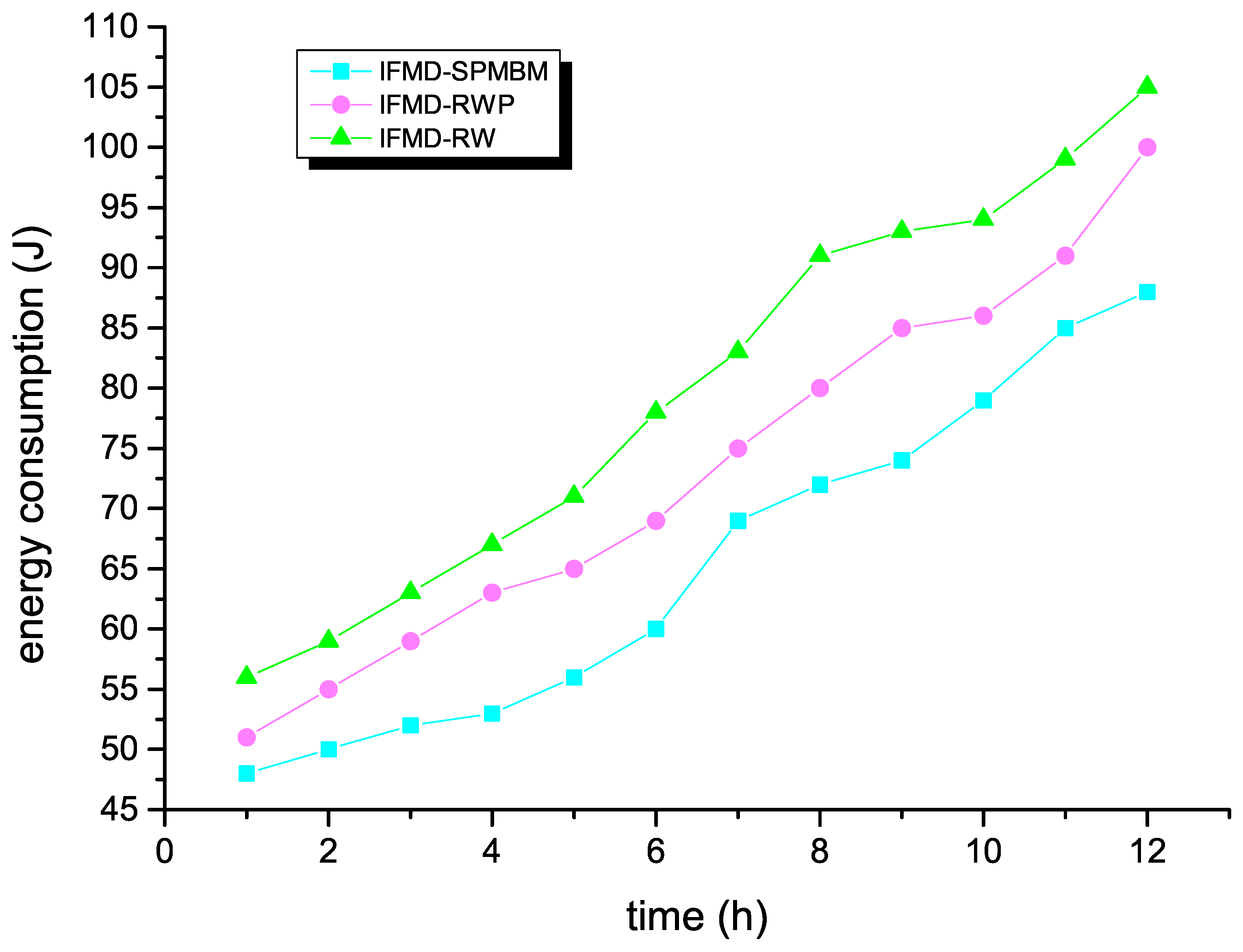
Finally, Figure 8 shows the energy consumption of IFMD under different movement models. The IFMD algorithm has the best effect when SPMBM is used as the mobile model. Energy consumption in SPMBM is the lowest, at 12, and the overhead on average of our algorithm can reach 88. Nevertheless, energy consumption in RWP is 100 at 12 h, and in RW is 105.
5.4. Analysis of Experimental Result
The content of this chapter is mainly consists of the comparison and analysis of the above five different algorithms. In the environment of big data and 5G, people’s demand for data forwarding is increasing. Nodes in opportunistic social networks must carry, store, and forward many text messages. Choosing the appropriate relay node is very important to improve the success rate of data forwarding. Nevertheless, in the process of massive data forwarding, the cache space of nodes will also impact the forwarding success rate of nodes. For this reason, in this chapter, the cache space is reasonably set as a variable for the IFMD algorithm to study the forwarding performance of each algorithm. Generally speaking, the larger the cache space of the node, the higher the delivery success rate of all algorithms, because the nodes in the opportunistic social network can deal with the more complicated tasks and store more information.
First of all, as shown in Figure 9, the delivery rate of traditional routing algorithms Epidemic and Spray and Wait is lower than the FCNS and NSFRE algorithms. This is because the traditional routing algorithm does not consider the social attributes possessed by nodes, but only carries and forwards the information of nodes to other information through the encounter opportunities brought by random motion. This method of blindly forwarding the information of the source node to all meeting nodes without selecting the relay nodes will consume a lot of network resources, thus reducing the forwarding success rate of nodes. The other two newly proposed algorithms are NSFRE and FCNS. Together with the IFMD algorithm proposed in this paper, these three algorithms fully consider the social attributes of nodes, so they are obviously superior to the two traditional routing algorithms in forwarding efficiency. NSFRE further quantifies the social relations of nodes by constructing a fuzzy similarity matrix of node features, which provides some help for eliminating distrustful nodes in the network. The FCNS algorithm adopts the social similarity of nodes to divide nodes in the network into different groups, and nodes in the same group may have higher mobility similarity. When the nodes in the same group have high social similarity and high mobile similarity, the forwarding success rate of nodes will increase. Nevertheless, when the node cache increases from 25 Mb to 30 Mb, it is found that the forwarding success of FCNS algorithm is reduced a little, because the movement similarity between node pairs is not high, and there may be cases where abnormal nodes do not help forward messages. We can see that these two algorithms still send information to some unrelated nodes, resulting in a waste of network resources. When the node cache is 40M, the transmission efficiency of IFMD algorithm is 0.93, which is the highest transmission success rate compared with the other four algorithms. The critical factor is that IFMD algorithm synthetically analyzes and selects two node social characteristics with more universal significance through a large number of experiments and research in domestic and foreign papers. The IFMD algorithm adopts a multi-attribute decision-making method in intuitionistic fuzzy theory to determine the best relay node.
Second, Figure 10 exhibits a relationship between the average end-to-end delay and cache space of the node. We can see that the average end-to-end delay of each algorithm gradually increases as the cache space of node increases. More specifically, the maximum delays of Epidemic and Spray and Wait algorithms can reach 525 and 497, respectively, because these two traditional algorithms generate many message copies and consume a large number of network resources, thus dramatically increasing the routing and message forwarding delays. The average end-to-end delay of NSFRE algorithm and FCNS algorithm is obviously lower than that of the two traditional algorithms, because both algorithms effectively restrain the number of message copies. In addition, the NSFRE algorithm improves the trust model, establishes a multidimensional similarity matrix, and reasonably quantifies the social attributes of nodes. The FCNS algorithm takes advantage of the mobile similarity and social similarity of nodes to assist nodes in making decisions on forwarding preferences. Compared with other algorithms, the average end-to-end delay of the IFMD algorithm is the lowest in different cache spaces of node, which also indicates that the intuitionistic fuzzy decision-making theory of the IFMD algorithm is better than the FCNS algorithm, and the selected node social attribute is also better than the node attribute measurement method proposed by NSFRE. The average end-to-end delay of IFMD algorithm is roughly stable at 135, which is due to the algorithm considers the concept of hesitation degree in nodes. By analyzing the hesitation degree of nodes, the nodes in the network can be more accurately excluded from forwarding unintentional nodes, thereby effectively reducing the end-to-end delay.
Then, Figure 11 exhibits a relationship between the average overhead and cache space of the node. We can see that the average overhead of each algorithm gradually decreases as the cache space of node increases. More specifically, the maximum load of the Epidemic and Spray and Wait algorithms can reach 200 and 175, respectively, because the redundant message copy groups in opportunistic social networks will consume a lot of network resources. This method dramatically increases the load of nodes in routing. The load of the NSFRE algorithm and FCNS algorithm is lower than two traditional routing algorithms, because both algorithms do a better job of controlling the number of message copies. Besides, the NSFRE algorithm effectively solves the problem of resource waste caused by uncooperative nodes. The FCNS algorithm takes advantage of the mobile similarity and social similarity of nodes to assist nodes in making decisions on forwarding preferences. These two new routing algorithms reduce the amount of network resources occupied by nodes through their own processing methods, so the average load is also reduced. The average load of IFMD algorithm is the lowest compared with other algorithms in different node cache spaces. Furthermore, it shows that the relay node selected by IFMD algorithm performs better than that selected by FCNS algorithm and NSFRE algorithm.
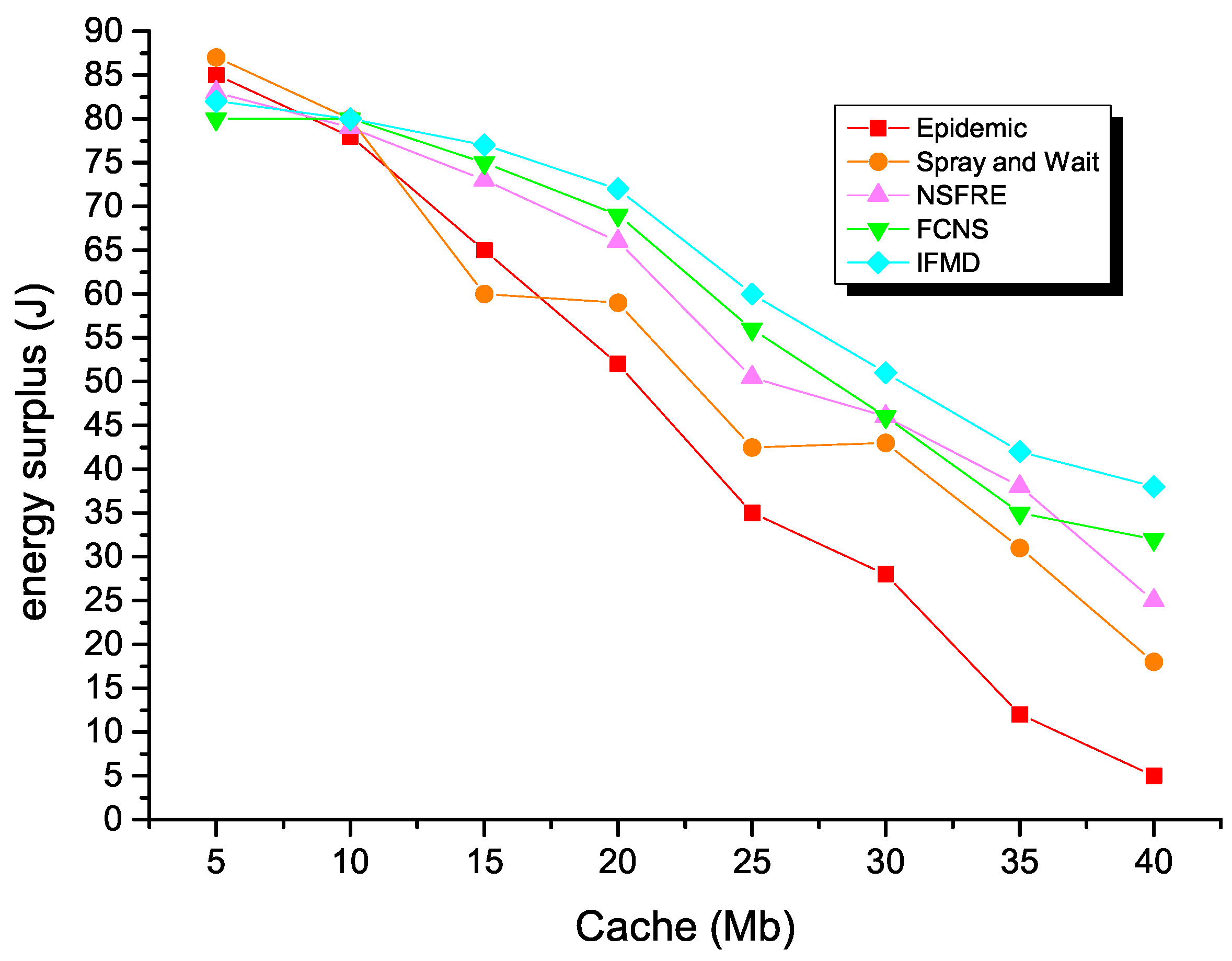
Finally, Figure 12 exhibits a relationship between the residual energy and cache space of the node. We can see that the residual energy of each algorithm gradually decreases as the cache space of node increases. More specifically, the Epidemic algorithm and Spray and Wait algorithms have the least residual energy, because the redundant message copy groups in opportunistic social networks will consume a lot of network resources. Both traditional routing algorithms consume the energy in the network sharply, making the residual energy of the node very small after completing the forwarding task. The residual energy of the NSFRE and FCNS algorithms is higher than the two traditional routing algorithms, because both algorithms do a better job of controlling the number of message copies. Besides, the NSFRE algorithm effectively solves the problem of resource waste caused by uncooperative nodes. The FCNS algorithm takes advantage of the mobile similarity and social similarity of nodes to assist nodes in making decisions on forwarding preferences. Compared with other algorithms, the IFMD algorithm has the most residual energy in different node cache spaces. Furthermore, it shows that the relay node selected by the IFMD algorithm performs better than that selected by the FCNS and NSFRE algorithms.
In summary, the experimental results show that the algorithm proposed in this paper effectively reduces network delay, load, and energy consumption, and increases the success rate of message delivery. The IFMD algorithm proposed in this paper is compared with two typical algorithms and two newly proposed routing algorithms. Surprisingly, in the best case, the forwarding success rate of the algorithm proposed in this paper is as high as 0.93, and the average end-to-end delay is reduced by 21. Compared with FCNS algorithm, the network load is reduced by 390. Compared with the Epidemic algorithm, the residual energy is increased by 33J compared with the NSFRE algorithm.
6. Conclusions
We propose a routing algorithm that can be more suitable for various social scenarios. The IFMD algorithm establishes trust lists and blacklists through the warm-up stage, and selects two universal indicators to measure node attributes through a large number of experiments and research in domestic and foreign papers: population status and social similarity. In the warm-up stage, the node constructs the trust list and blacklist of the node inside the node by forwarding the information fed back by the node. When the node judges the next hop node, it can first exclude the nodes recorded in the blacklist; population status is to score the neighbor nodes existing in the trust list in the forwarding node, and the node with the highest score is considered as the node with the highest community status in the forwarding node area. Social similarity is a collection of all social attributes of nodes to judge the degree of similarity between nodes. Then, the measurement indexes of these two nodes are integrated to construct an intuitionistic fuzzy decision-making matrix. Finally, the best relay node is determined by using the multi-attribute fuzzy decision method. In the future, we will build a more perfect node social attribute judgment mechanism and devote ourselves to studying how to apply the idea of algorithm to solve practical problems in real life. When 5G networks cover every corner of our lives, we believe that routing algorithms can provide convenience for our lives.
Author Contributions
Y.Y. (Yao Yu), J.Y., Z.C., and J.W. conceived the idea of the paper; Y.Y. (Yao Yu), Y.Y. (Yeqing Yan), J.Y., Z.C., and J.W. designed and performed the experiments; Y.Y. (Yao Yu) and Y.Y. (Yeqing Yan) analyzed the data; Z.C. contributed reagents/materials/analysis tools; Y.Y. (Yao Yu) wrote and revised the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by National Natural Science Foundation of China (Grant Nos. 61462079, 61562086, 61562078, 61862060), Science and Technology Support Project of Ministry of National Science and Technology of China (Grant No. 2015BAH02F01).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ONE | Opportunistic Networking Environment |
| FCNS | Fuzzy Routing-Forwarding Algorithm |
| IFMD | A Universal Routing Algorithm Based on Intuitionistic Fuzzy Multi-attribute Decision-making |
| NSFRE | an adaptive control scheme based on intelligent fuzzy decision-making system |
References
- Lucas-Estañ, M.C.; Gozalvez, J. Mode Selection for 5G Heterogeneous and Opportunistic Networks. IEEE Access 2019, 7, 113511–113524. [Google Scholar] [CrossRef]
- Li, X.; Wu, J. Node-oriented secure data transmission algorithm based on IoT system in social networks. IEEE Commun. Lett. 2020, 24, 2898–2902. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z. Human Activity Optimal Cooperation Objects Selection Routing Scheme in Opportunistic Networks Communication. Wirel. Pers. Commun. 2017, 95, 3357–3375. [Google Scholar] [CrossRef]
- Wu, J.; Qu, J.; Yu, G. Behavior prediction based on interest characteristic and user communication in opportunistic social networks. Peer-to-Peer Netw. Appl. 2021, 14, 1006–1018. [Google Scholar] [CrossRef]
- Xiao, Y.; Wu, J. Data transmission and management based on node communication in opportunistic social networks. Symmetry 2020, 12, 1288. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z.; Zhao, M. Weight distribution and community reconstitution based on communities communications in social opportunistic networks. Peer-to-Peer Netw. Appl. 2019, 12, 158–166. [Google Scholar] [CrossRef]
- Liu, K.; Chen, Z.; Wu, J.; Xiao, Y.; Zhang, H. Predict and Forward: An Efficient Routing-Delivery Scheme Based on Node Profile in Opportunistic Networks. Future Internet 2018, 10, 74. [Google Scholar] [CrossRef] [Green Version]
- Yu, G.; Chen, Z.; Wu, J. Predicted Encounter Probability Based on Dynamic Programming Proposed Probability Algorithm in Opportunistic Social Network. Comput. Netw. 2020, 181, 107465. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, H.; Zhu, C.; Leung, V.C.M. Freshness-aware initial seed selection for traffic offloading through opportunistic mobile networks. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Lenando, H.; Alrfaay, M. EpSoc: Social-Based Epidemic-Based Routing Protocol in Opportunistic Mobile Social Network. Mob. Inf. Syst. 2018, 2018, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Leung, V.C.; Zhu, C.; Xu, S.; Fan, J. Predicting Temporal Social Contact Patterns for Data Forwarding in Opportunistic Mobile Networks. IEEE Trans. Veh. Technol. 2017, 66, 10372–10383. [Google Scholar] [CrossRef]
- Wang, R.; Wang, X.; Hao, F.; Zhang, L.; Liu, S.; Wang, L.; Lin, Y. Social identity–aware opportunistic routing in mobile social networks. Trans. Emerg. Telecommun. Technol. 2018, 29, e3297. [Google Scholar] [CrossRef]
- Xia, F.; Liu, L.; Jedari, B.; Das, S.K. PIS: A Multi-dimensional Routing Protocol for Socially-aware Networking. IEEE Trans. Mob. Comput. 2016, 15, 2825–2836. [Google Scholar] [CrossRef]
- Kafaie, S.; Chen, Y.; Dobre, O.A.; Ahmed, M.H. Joint Inter-Flow Network Coding and Opportunistic Routing in Multi-Hop Wireless Mesh Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2018, 20, 1014–1035. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Jia, X.; Lv, X.; Han, Z.; Liu, J.; Hao, J. Opportunistic routing with data fusion for multi-source wireless sensor networks. Wirel. Netw. 2019, 25, 3103–3113. [Google Scholar] [CrossRef]
- Zeng, Y.; Chen, G.; Li, K.; Zhou, Y.; Zhou, X.; Li, K. M-Skyline: Taking sunk cost and alternative recommendation in consideration for skyline query on uncertain data. Knowl. Based Syst. 2019, 163, 204–213. [Google Scholar] [CrossRef]
- Chen, G.; Lu, Y.; Meng, Y.; Li, B.; Tan, K.; Pei, D.; Cheng, P.; Luo, L.; Xiong, Y.; Zhao, Y.; et al. FUSO: Fast Multi-Path Loss Recovery for Data Center Networks. IEEE/ACM Trans. Netw. 2018, 26, 1–14. [Google Scholar] [CrossRef]
- Pirozmand, P.; Wu, G.; Jedari, B.; Xia, F. Human mobility in opportunistic networks: Characteristics, models and prediction methods. J. Netw. Comput. Appl. 2014, 42, 45–58. [Google Scholar] [CrossRef]
- Wang, L.; Yu, Z.; Xiong, F.; Yang, D.; Pan, S.; Yan, Z. Influence spread in geo-social networks: A multiobjective optimization perspective. IEEE Trans. Cybern. 2019, 2019, 2168–2267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stanujkic, D.; Zavadskas, E.K.; Karabasevic, D.; Urosevic, S.; Maksimovic, M. An approach for evaluating website quality in hotel industry based on triangular intuitionistic fuzzy numbers. Informatica 2017, 28, 725–748. [Google Scholar] [CrossRef] [Green Version]
- Urena, R.; Chiclana, F.; Melancon, G.; Herrera-Viedma, E. A social network based approach for consensus achievement in multiperson decision making. Inf. Fusion 2019, 47, 72–87. [Google Scholar] [CrossRef] [Green Version]
- Xchitra, M.; Siva Sathya, S. Selective epidemic broadcast algorithm to suppress broadcast storm in vehicular ad hoc networks. Egy. Inf. J. 2017, 19, 1–9. [Google Scholar]
- Sisodiya, S.; Sharma, P.; Tiwari, S.K. A new modifified spray and wait routing algorithm for heterogeneous delay tolerant network. In Proceedings of the 2017 International Conference on International Conference on I-Smac, Coimbatore, India, 10–11 February 2017; pp. 843–848. [Google Scholar]
- Dhurandher, S.K.; Borah, S.J.; Woungang, I.; Bansal, A.; Gupta, A. A location prediction-based routing scheme for opportunistic networks in an IoT scenario. J. Parallel Distrib. Comput. 2018, 118, 369–378. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, H.; Xia, Y.; Wang, Y.; Li, F.; Yang, P. Optimal online data dissemination for resource constrained mobile opportunistic networks. IEEE Trans. Veh. Technol. 2016, 66, 5301–5315. [Google Scholar] [CrossRef]
- Derakhshanfard, N.; Sabaei, M.; Rahmani, A.M. CPTR: Conditional probability tree based routing in opportunistic networks. Wirel. Netw. 2017, 23, 43–50. [Google Scholar] [CrossRef]
- Yan, Y.; Chen, Z.; Wu, J.; Wang, L. An effective data transmission algorithm based on social relationships in opportunistic mobile social networks. Algorithms 2018, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Ying, B.; Xu, K.; Nayak, A. Fair and social-aware message forwarding method in opportunistic social networks. IEEE Commun. Lett. 2019, 23, 720–723. [Google Scholar] [CrossRef]
- Yuan, P.; Pang, X.; Song, M. SSR: Using the social similarity to improve the data forwarding performance in mobile opportunistic networks. IEEE Access 2019, 7, 44840–44850. [Google Scholar] [CrossRef]
- Yin, S.; Wu, J.; Yu, G. Low energy consumption routing algorithm based on message importance in opportunistic social networks. Peer-to-Peer Netw. Appl. 2021, 14, 948–961. [Google Scholar] [CrossRef]
- Yu, G.; Chen, Z.G.; Wu, J. Quantitative social relations based on trust routing algorithm in opportunistic social network. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 83. [Google Scholar] [CrossRef]
- Liu, K.; Chen, Z.; Wu, J.; Wang, L. FCNS: A Fuzzy Routing-Forwarding Algorithm Exploiting Comprehensive Node Similarity in Opportunistic Social Networks. Symmetry 2018, 10, 338. [Google Scholar] [CrossRef] [Green Version]
- Yu, G.; Wu, J. Content Caching Based on Mobility Prediction and Joint User Prefetch in Mobile Edge Networks. Peer-to-Peer Netw. Appl. 2020, 13, 1–11. [Google Scholar] [CrossRef]
Figure 1.
Real-life scenarios.

Figure 2.
The formation process of trust tendency.

Figure 3.
Flow chart of IFMD routing algorithm.

Figure 4.
Simulation scene diagram.

Figure 5.
Delivery ratio and time for IFMD in different models.

Figure 6.
Average end-to-end delay and time for IFMD in different models.

Figure 7.
Average overhead and time for IFMD in different models.

Figure 8.
Energy consumption and time for IFMD in different models.

Figure 9.
Delivery ratio of the IFMD algorithm in different buffer spaces.

Figure 10.
Average end-to-end delay of the IFMD algorithm in different buffer spaces.

Figure 11.
Average overhead with various cache space.

Figure 12.
Energy surplus with various cache space.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Intuitionistic fuzzy decision-making matrix D.
| (0.3, 0.6) | (0.6, 0.2) | (0.4, 0.3) | |
| (0.5, 0.2) | (0.4, 0.1) | (0.3, 0.2) | |
| (0.4, 0.4) | (0.5, 0.3) | (0.7, 0.1) | |
| (0.6, 0.3) | (0.2, 0.4) | (0.5, 0.4) | |
| (0.3, 0.0) | (0.8, 0.1) | (0.5, 0.3) |
Table 2.
Weighted intuitionistic fuzzy decision-making matrix D.
| (0.133, 0.815) | (0.240, 0.617) | (0.142, 0.697) | |
| (0.242, 0.525) | (0.142, 0.501) | (0.101, 0.617) | |
| (0.185, 0.693) | (0.188, 0.697) | (0.303, 0.501) | |
| (0.350, 0.618) | (0.065, 0.760) | (0.188, 0.760) | |
| (0.602, 0.000) | (0.383, 0.501) | (0.188, 0.697) |
Table 3.
The experimental configurations of the simulation environment.
| Simulation Parameters | Values |
|---|---|
| Simulator | Opportunistic Network Environment (ONE) |
| Mobility model | Shortest Path Map Based Movement |
| Communication area | 2500 m × 3600 m |
| Nodes’ speed (pedestrians, cars) | 5 (km/h), 60 |
| Number of nodes | 1000 |
| Simulation time | 12 h |
| Initial energy | 100 J |
| Transmit range | 20 m |
| Nodes’ buffer | 5 (MB), 10, 15, 20, 25, 30, 35, 40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yu, Y.; Yu, J.; Chen, Z.; Wu, J.; Yan, Y. A Universal Routing Algorithm Based on Intuitionistic Fuzzy Multi-Attribute Decision-Making in Opportunistic Social Networks. Symmetry 2021, 13, 664. https://doi.org/10.3390/sym13040664
AMA Style
Yu Y, Yu J, Chen Z, Wu J, Yan Y. A Universal Routing Algorithm Based on Intuitionistic Fuzzy Multi-Attribute Decision-Making in Opportunistic Social Networks. Symmetry. 2021; 13(4):664. https://doi.org/10.3390/sym13040664
Chicago/Turabian StyleYu, Yao, Jiong Yu, Zhigang Chen, Jia Wu, and Yeqing Yan. 2021. "A Universal Routing Algorithm Based on Intuitionistic Fuzzy Multi-Attribute Decision-Making in Opportunistic Social Networks" Symmetry 13, no. 4: 664. https://doi.org/10.3390/sym13040664
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.