Mapping the Distribution of Coffee Plantations from Multi-Resolution, Multi-Temporal, and Multi-Sensor Data Using a Random Forest Algorithm




Abstract
:
1. Introduction
- (1)
- Assessing the accuracy of random forest classification derived from integrating multi-sensor, multi-temporal, and multi-resolution remote sensing data from pan-sharpened GeoEye-1, multi-temporal Sentinel 2, and DEM for mapping coffee plantations.
- (2)
- Determining the most important variables derived from random forest classifications for mapping coffee plantations.
2. Materials and Methods
2.1. Description of Research Area
2.2. Data and Preprocessing
2.3. Field Surveys
2.4. Land Cover Classification Scheme
2.5. Textural Analysis
2.6. Derivation of Topography Data
2.7. Derivation of Vegetation Index
2.8. Tasseled Cap Transformation
2.9. Optimization Parameter of Random Forest Algorithm
2.10. Mapping Coffee Plantations Based on a Full Model Approach
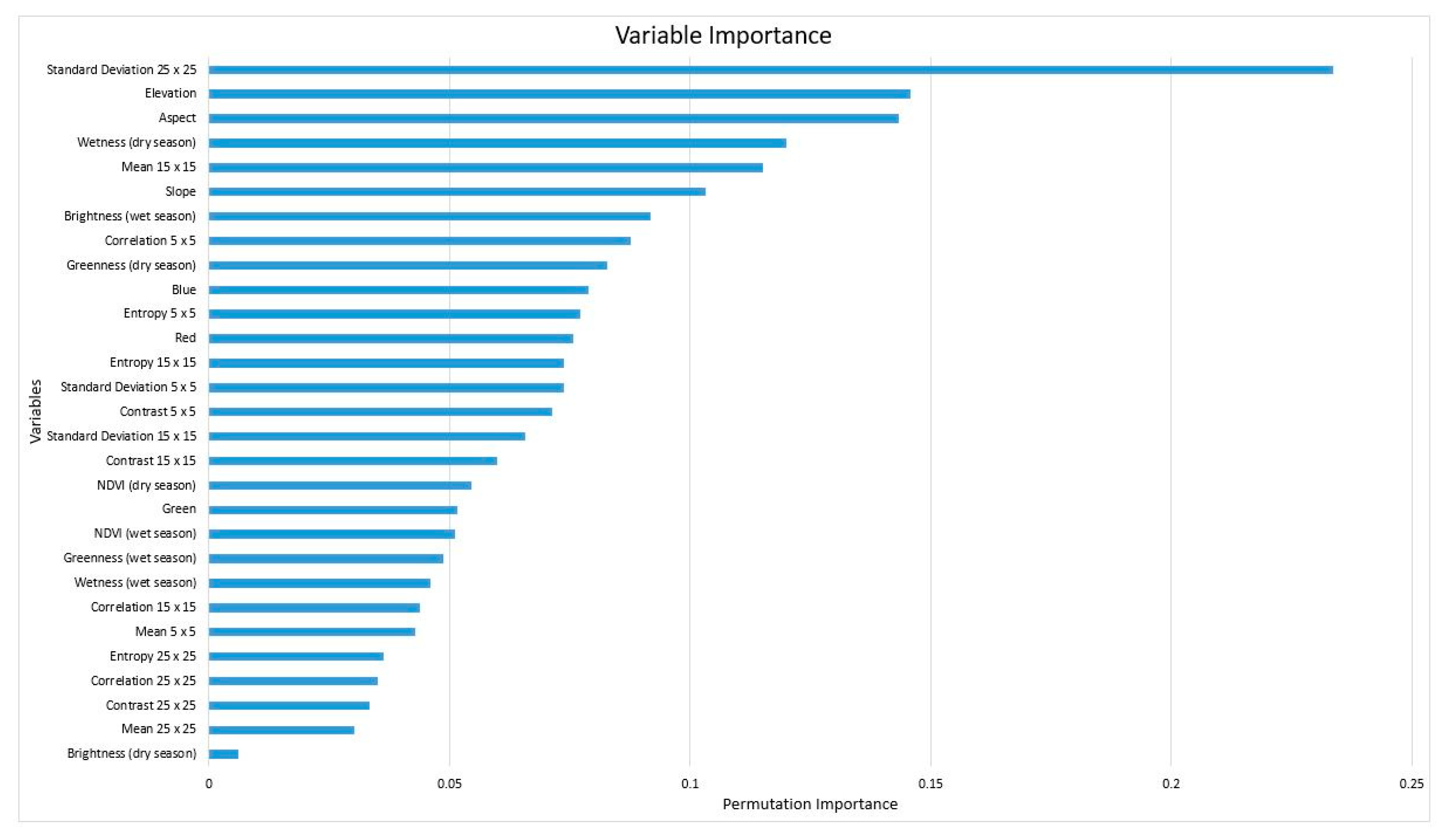
2.11. Variables of Importance
2.12. Accuracy Assessment of Classification Model
3. Results
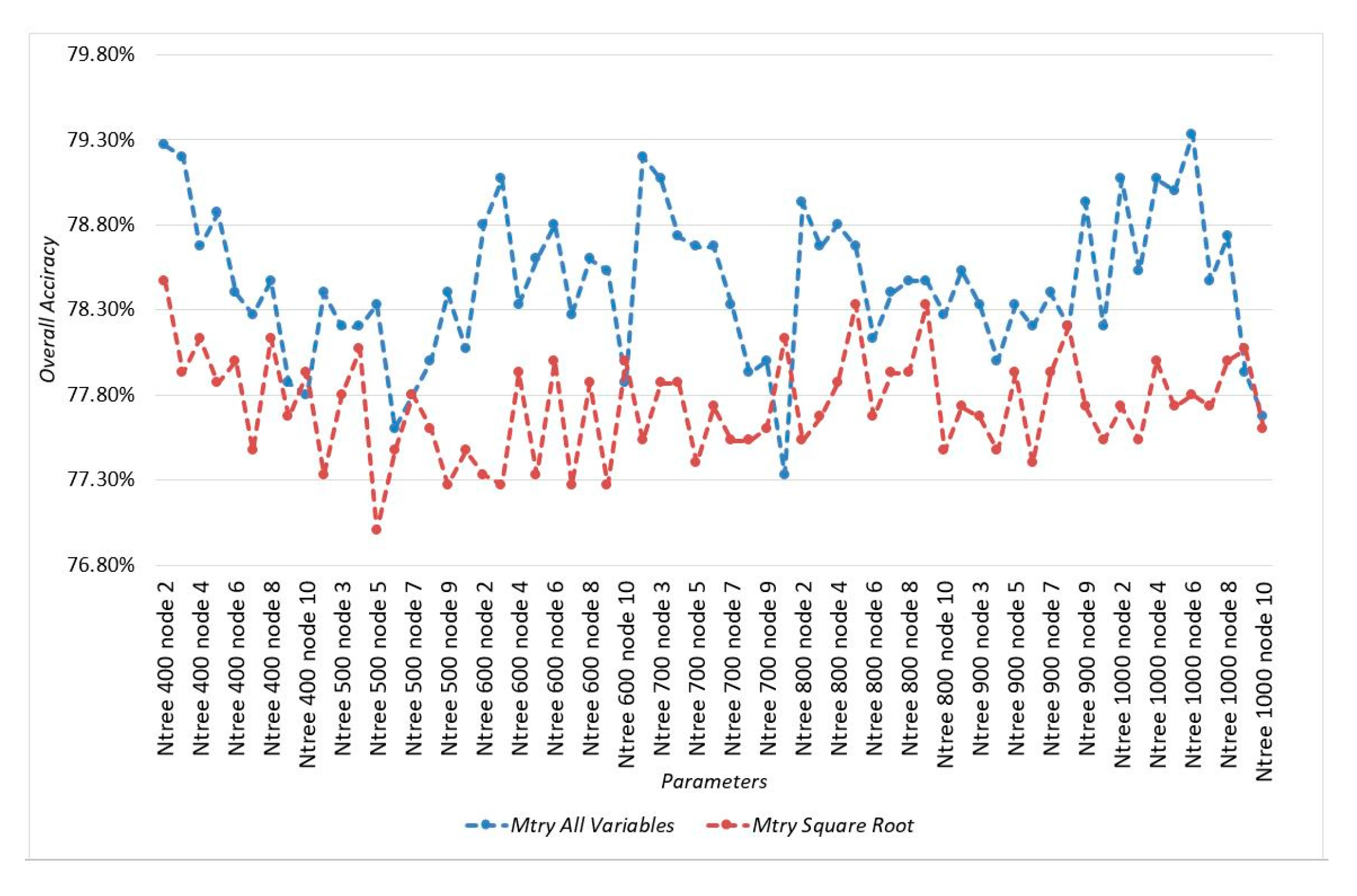
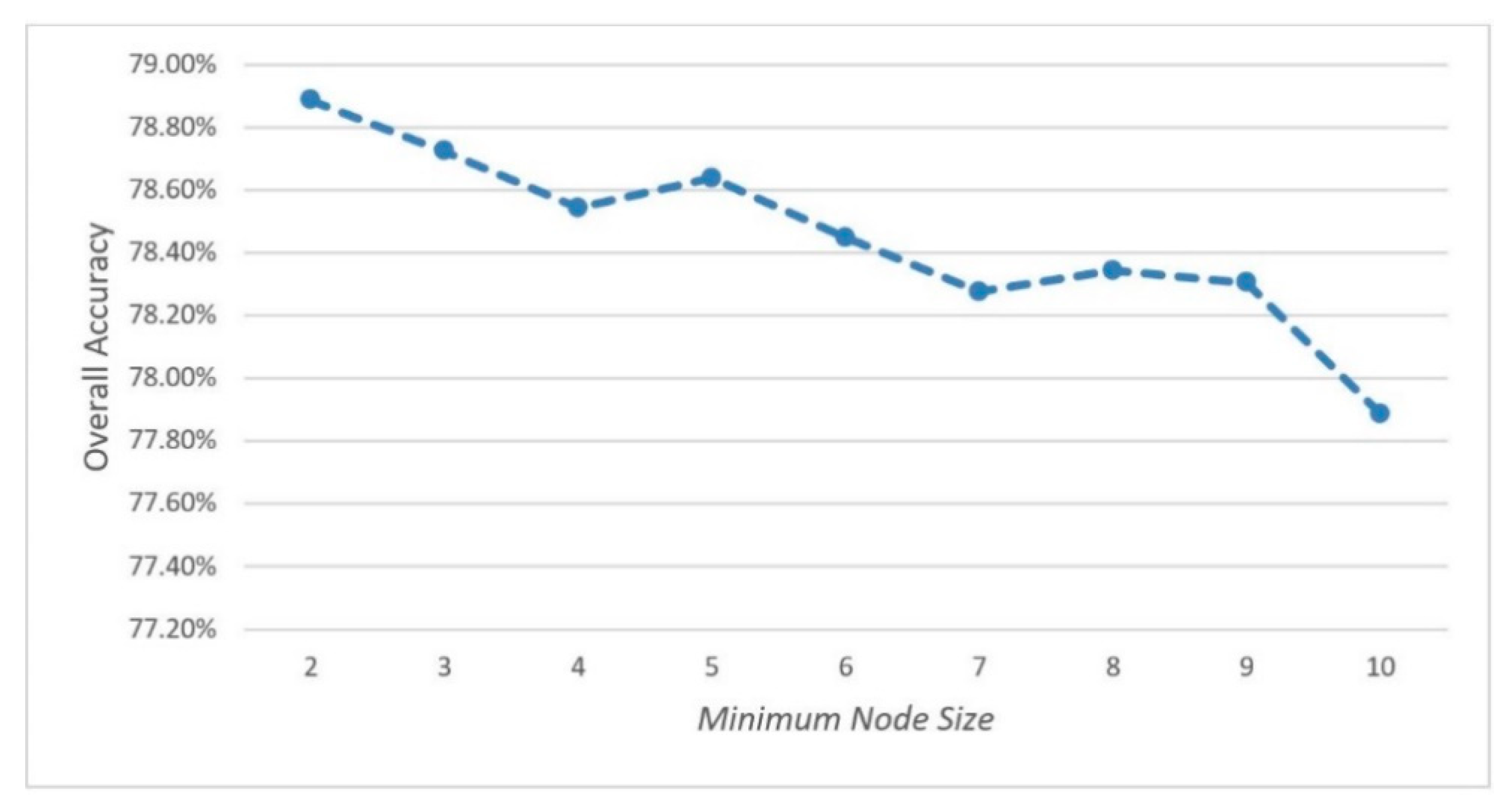
3.1. Parameter Optimal in Random Forest Algorithm
3.1.1. Mtry
3.1.2. Tree
3.1.3. Minimum Node Sizes
3.1.4. Combination of All Parameters
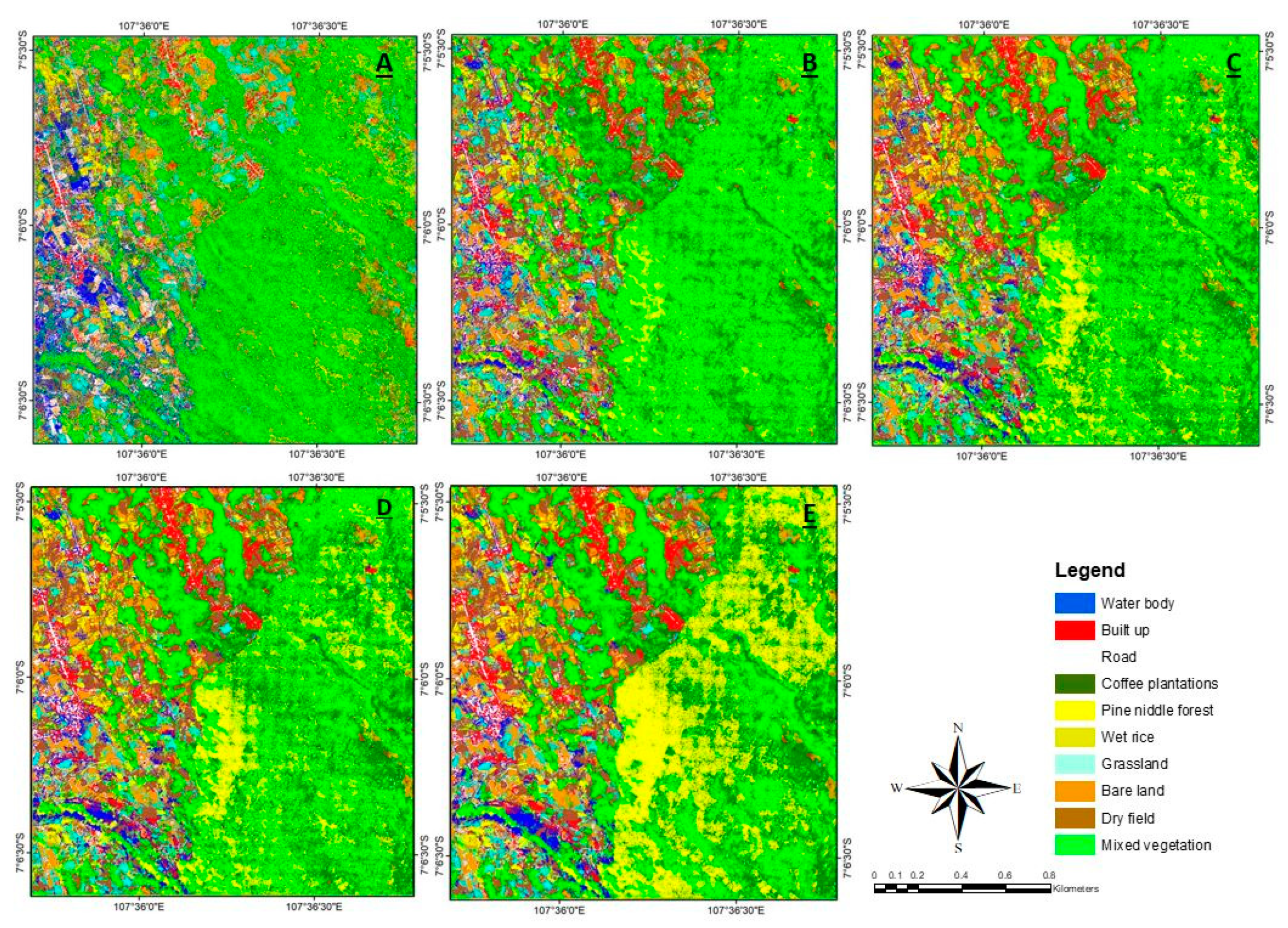
3.2. Distribution of Coffee Plantations
3.3. Mapping Coffee Plantations Using Variables of Importance
4. Discussion
4.1. Parameter of Random Forest Classifications
4.2. Distribution of Coffee Plantations
4.3. Important Variables
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Supriadi, H.; Pranowo, D. Prospek pengembangan agroforestri berbasis kopi di Indonesia. Perspektif 2016, 14, 135–150. [Google Scholar]
- ICO. Exports of All Forms of Coffee by Exporting Countries to All Destinations. 2019. Available online: http://www.ico.org (accessed on 12 September 2019).
- FAO. Food and Agriculture Organization of the United Nations: FAOSTAT Statistical Database. Available online: http://www.fao.org/faostat/en/#data (accessed on 30 July 2020).
- ICO. Historical Data. 2017. Available online: http://www.ico.org (accessed on 6 June 2017).
- Lu, Y.C.; Daughtry, C.; Hart, G.; Watkins, B. The current state of precision farming. Food Rev. Int. 1997, 13, 141–162. [Google Scholar]
- LeBoeuf, J. Practical applications of remote sensing technology—An industry perspective. HortTechnology 2000, 10, 475–480. [Google Scholar]
- Cordero-Sancho, S.; Sader, S.A. Spectral analysis and classification accuracy of coffee crops using Landsat and a topographic-environmental model. Int. J. Remote Sens. 2007, 28, 1577–1593. [Google Scholar]
- Martínez-Verduzco, G.C.; Galeana-Pizaña, J.M.; Cruz-Bello, G.M. Coupling community mapping and supervised classification to discriminate Shade coffee from Natural vegetation. Appl. Geogr. 2012, 34, 1–9. [Google Scholar]
- Dos Santos, J.A.; Gosselin, P.-H.; Philipp-Foliguet, S.; Torres, R.d.S.; Falao, A.X. Multiscale classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3764–3775. [Google Scholar]
- Souza, C.G.; Arantes, T.B.; Carvalho, L.M.T.d.; Aguiar, P. Multitemporal variables for the mapping of coffee cultivation areas. Pesqui. Agropecuária Bras. 2019, 54, e00017. [Google Scholar]
- Ortega-Huerta, M.A.; Komar, O.; Price, K.P.; Ventura, H.J. Mapping coffee plantations with Landsat imagery: An example from El Salvador. Int. J. Remote Sens. 2012, 33, 220–242. [Google Scholar]
- Langford, M.; Bell, W. Land cover mapping in a tropical hillsides environment: A case study in the Cauca region of Colombia. Int. J. Remote Sens. 1997, 18, 1289–1306. [Google Scholar]
- Arias, S.B. Using Image Analysis and GIS for Coffee Mapping; McGill University Libraries: Montreal, QC, Canada, 2007. [Google Scholar]
- Kelley, L.C.; Pitcher, L.; Bacon, C. Using Google Earth engine to map complex shade-grown coffee landscapes in Northern Nicaragua. Remote Sens. 2018, 10, 952. [Google Scholar]
- Schowengerdt, R.A. Remote Sensing: Models and Methods for Image Processing; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Sisodia, P.S.; Tiwari, V.; Kumar, A. Analysis of supervised maximum likelihood classification for remote sensing image. In Proceedings of the International conference on recent advances and innovations in engineering (ICRAIE-2014), Jaipur, India, 9–11 May 2014; pp. 1–4. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Chica-Olmo, M.; Abarca-Hernandez, F.; Atkinson, P.M.; Jeganathan, C. Random Forest classification of Mediterranean land cover using multi-seasonal imagery and multi-seasonal texture. Remote Sens. Environ. 2012, 121, 93–107. [Google Scholar] [CrossRef]
- Sartono, B.; Syafitri, U.D. Metode pohon gabungan: Solusi pilihan untuk mengatasi kelemahan pohon regresi dan klasifikasi tunggal. Indones. J. Stat. Appl. 2010, 15, 1–7. [Google Scholar]
- Van Beijma, S.; Comber, A.; Lamb, A. Random forest classification of salt marsh vegetation habitats using quad-polarimetric airborne SAR, elevation and optical RS data. Remote Sens. Environ. 2014, 149, 118–129. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Ghosh, A.; Joshi, P.K. A comparison of selected classification algorithms for mapping bamboo patches in lower Gangetic plains using very high resolution WorldView 2 imagery. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 298–311. [Google Scholar] [CrossRef]
- Gao, T.; Zhu, J.; Zheng, X.; Shang, G.; Huang, L.; Wu, S. Mapping spatial distribution of larch plantations from multi-seasonal Landsat-8 OLI imagery and multi-scale textures using random forests. Remote Sens. 2015, 7, 1702–1720. [Google Scholar] [CrossRef] [Green Version]
- Coltri, P.P.; Zullo, J.; do Valle Goncalves, R.R.; Romani, L.A.S.; Pinto, H.S. Coffee crop’s biomass and carbon stock estimation with usage of high resolution satellites images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1786–1795. [Google Scholar] [CrossRef]
- Aguilar, M.; Saldaña, M.; Aguilar, F. GeoEye-1 and WorldView-2 pan-sharpened imagery for object-based classification in urban environments. Int. J. Remote Sens. 2013, 34, 2583–2606. [Google Scholar] [CrossRef]
- Liu, J.; Liu, H.; Lv, Y.; Xue, X. Classification of high resolution imagery based on fusion of multiscale texture features. In Proceedings of the 35th International Symposium on Remote Sensing of Environment, Beijing, China, 22–26 April 2013; pp. 22–26. [Google Scholar]
- Hurni, K.; Hett, C.; Epprecht, M.; Messerli, P.; Heinimann, A. A texture-based land cover classification for the delineation of a shifting cultivation landscape in the Lao PDR using landscape metrics. Remote Sens. 2013, 5, 3377–3396. [Google Scholar] [CrossRef] [Green Version]
- Moreira, M.A.; Adami, M.; Rudorff, B.F.T. Análise espectral e temporal da cultura do café em imagens Landsat. Pesqui. Agropecuária Bras. 2004, 39, 223–231. [Google Scholar] [CrossRef]
- Jia, K.; Liang, S.; Zhang, N.; Wei, X.; Gu, X.; Zhao, X.; Yao, Y.; Xie, X. Land cover classification of finer resolution remote sensing data integrating temporal features from time series coarser resolution data. ISPRS J. Photogramm. Remote Sens. 2014, 93, 49–55. [Google Scholar] [CrossRef]
- Hunt, D.A.; Tabor, K.; Hewson, J.H.; Wood, M.A.; Reymondin, L.; Koenig, K.; Schmitt-Harsh, M.; Follett, F. Review of Remote Sensing Methods to Map Coffee Production Systems. Remote Sens. 2020, 12, 2041. [Google Scholar] [CrossRef]
- Camargo, Â.P.d.; Camargo, M.B.P.d. Definição e esquematização das fases fenológicas do cafeeiro arábica nas condições tropicais do Brasil. Bragantia 2001, 60, 65–68. [Google Scholar] [CrossRef] [Green Version]
- Chavez, P.S. Image-based atmospheric corrections-revisited and improved. Photogramm. Eng. Remote Sens. 1996, 62, 1025–1035. [Google Scholar]
- Kuester, M. Absolute Radiometric Calibration: 2016v0; Digital Globe: Westminster, CO, USA, 2017. [Google Scholar]
- Dorren, L.K.; Maier, B.; Seijmonsbergen, A.C. Improved Landsat-based forest mapping in steep mountainous terrain using object-based classification. For. Ecol. Manag. 2003, 183, 31–46. [Google Scholar] [CrossRef]
- Minnaert, M. The reciprocity principle in lunar photometry. Astrophys. J. 1941, 93, 403–410. [Google Scholar] [CrossRef]
- Riaño, D.; Chuvieco, E.; Salas, J.; Aguado, I. Assessment of different topographic corrections in Landsat-TM data for mapping vegetation types (2003). IEEE Trans. Geosci. Remote Sens. 2003, 41, 1056–1061. [Google Scholar] [CrossRef] [Green Version]
- Hantson, S.; Chuvieco, E. Evaluation of different topographic correction methods for Landsat imagery. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 691–700. [Google Scholar] [CrossRef]
- Nedkov, R. Orthogonal transformation of segmented images from the satellite Sentinel-2. Comptes Rendus De L’academie Bulg. Des. Sci. 2017, 70, 687–692. [Google Scholar]
- Shi, T.; Xu, H. Derivation of Tasseled Cap Transformation Coefficients for Sentinel-2 MSI At-Sensor Reflectance Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4038–4048. [Google Scholar] [CrossRef]
- Rousel, J.; Haas, R.; Schell, J.; Deering, D. Monitoring vegetation systems in the great plains with ERTS. In Proceedings of the Third Earth Resources Technology Satellite—1 Symposium, Washington, DC, USA, 10–14 December 1973; NASA SP-351. pp. 309–317. [Google Scholar]
- Patro, S.; Sahu, K.K. Normalization: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Al Shalabi, L.; Shaaban, Z.; Kasasbeh, B. Data mining: A preprocessing engine. J. Comput. Sci. 2006, 2, 735–739. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and tuning strategies for random forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef] [Green Version]
- Agisoft. Agisoft Metashape User Manual: Professional Edition, Version 1.5; Agisoft: St. Petersburg, Russia, 2019. [Google Scholar]
- Sevilla, C.G. Research Methods Slovin; Rex Print. Co.: Quezoncity, Philippines, 2007. [Google Scholar]
- Fitzpatrick-Lins, K. Comparison of sampling procedures and data analysis for a land-use and land-cover map. Photogramm. Eng. Remote Sens. 1981, 47, 343–351. [Google Scholar]
- International Organization for Standardization. ISO 19157: 2013, Geographic Information-Data Quality. 2013. Available online: http://www.iso.org/iso/iso_catalogue (accessed on 2 April 2015).
- Margono, D.S. Metodologi Penelitian Pendidikan; PT Rineka Cipta: Jakarta, Indonesia, 2004. [Google Scholar]
- Sugiyono, D. Statistika Untuk Penelitian; CV ALFABETA: Bandung, Indonesia, 2006. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Mohanaiah, P.; Sathyanarayana, P.; GuruKumar, L. Image texture feature extraction using GLCM approach. Int. J. Sci. Res. Publ. 2013, 3, 1. [Google Scholar]
- Maillard, P. Comparing texture analysis methods through classification. Photogramm. Eng. Remote Sens. 2003, 69, 357–367. [Google Scholar] [CrossRef] [Green Version]
- Weszka, J.S.; Dyer, C.R.; Rosenfeld, A. A comparative study of texture measures for terrain classification. IEEE Trans. Syst. ManCybern. 1976, 4, 269–285. [Google Scholar] [CrossRef]
- Conners, R.W.; Harlow, C.A. A theoretical comparison of texture algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1980, 2, 204–222. [Google Scholar] [CrossRef] [PubMed]
- Marceau, D.J.; Howarth, P.J.; Dubois, J.-M.M.; Gratton, D.J. Evaluation of the grey-level co-occurrence matrix method for land-cover classification using SPOT imagery. IEEE Trans. Geosci. Remote Sens. 1990, 28, 513–519. [Google Scholar] [CrossRef]
- Wikantika, K. Integration of spectral and textural features from IKONOS image to classify vegetation cover in mountainous area. J. Manaj. Hutan Trop. 2006, 12, 51–62. [Google Scholar]
- Baraldi, A.; Panniggiani, F. An investigation of the textural characteristics associated with gray level cooccurrence matrix statistical parameters. IEEE Trans. Geosci. Remote Sens. 1995, 33, 293–304. [Google Scholar] [CrossRef]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Karjono. Klasifikasi Tutupan Lahan Berbasis Rona Dan Tekstur Dengan Menggunakan Citra Alos Prism; Institut Pertanian Bogor: Bogor, Indonesia, 2015. [Google Scholar]
- Franklin, S.; Wulder, M.; Gerylo, G. Texture analysis of IKONOS panchromatic data for Douglas-fir forest age class separability in British Columbia. Int. J. Remote Sens. 2001, 22, 2627–2632. [Google Scholar] [CrossRef]
- Hailu, B.T.; Maeda, E.E.; Hurskainen, P.; Pellikka, P.P. Object-based image analysis for distinguishing indigenous and exotic forests in coffee production areas of Ethiopia. Appl. Geomat. 2014, 6, 207–214. [Google Scholar] [CrossRef]
- Liu, W.; Kogan, F. Monitoring regional drought using the vegetation condition index. Int. J. Remote Sens. 1996, 17, 2761–2782. [Google Scholar] [CrossRef]
- Kauth, R.J.; Thomas, G. The Tasselled Cap—A Graphic Description of the Spectral-Temporal Development of Agricultural Crops as Seen by Landsat; LARS Symposia: West Lafayette, IN, USA, 1976; p. 159. [Google Scholar]
- Gilbertson, J.K.; Van Niekerk, A. Value of dimensionality reduction for crop differentiation with multi-temporal imagery and machine learning. Comput. Electron. Agric. 2017, 142, 50–58. [Google Scholar] [CrossRef]
- Mišurec, J.; Kopačková, V.; Lhotáková, Z.; Campbell, P.; Albrechtová, J. Detection of spatio-temporal changes of Norway spruce forest stands in Ore Mountains using Landsat time series and airborne hyperspectral imagery. Remote Sens. 2016, 8, 92. [Google Scholar] [CrossRef] [Green Version]
- Allen, H.; Simonson, W.; Parham, E.; Santos, E.d.B.e.; Hotham, P. Satellite remote sensing of land cover change in a mixed agro-silvo-pastoral landscape in the Alentejo, Portugal. Int. J. Remote Sens. 2018, 39, 4663–4683. [Google Scholar] [CrossRef]
- Baig, M.H.A.; Zhang, L.; Shuai, T.; Tong, Q. Derivation of a tasselled cap transformation based on Landsat 8 at-satellite reflectance. Remote Sens. Lett. 2014, 5, 423–431. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Chapman, M.; Deng, F.; Ji, Z.; Yang, X. Integration of orthoimagery and lidar data for object-based urban thematic mapping using random forests. Int. J. Remote Sens. 2013, 34, 5166–5186. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping invasive plants using hyperspectral imagery and Breiman Cutler classifications (RandomForest). Remote Sens. Environ. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree species classification with random forest using very high spatial resolution 8-band WorldView-2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Colditz, R.R. An evaluation of different training sample allocation schemes for discrete and continuous land cover classification using decision tree-based algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef] [Green Version]
- Akar, Ö.; Güngör, O. Integrating multiple texture methods and NDVI to the Random Forest classification algorithm to detect tea and hazelnut plantation areas in northeast Turkey. Int. J. Remote Sens. 2015, 36, 442–464. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Waske, B.; Benediktsson, J.A.; Árnason, K.; Sveinsson, J.R. Mapping of hyperspectral AVIRIS data using machine-learning algorithms. Can. J. Remote Sens. 2009, 35, S106–S116. [Google Scholar] [CrossRef]
- Köthe, U. The VIGRA Image Analysis Library; University of Heidelberg: Heidelberg, Germany, 2013. [Google Scholar]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Ghosh, A.; Sharma, R.; Joshi, P. Random forest classification of urban landscape using Landsat archive and ancillary data: Combining seasonal maps with decision level fusion. Appl. Geogr. 2014, 48, 31–41. [Google Scholar] [CrossRef]
- Kulkarni, V.Y.; Sinha, P.K. Pruning of random forest classifiers: A survey and future directions. In Proceedings of the 2012 International Conference on Data Science & Engineering (ICDSE), Cochin, India, 18–20 July 2012; pp. 64–68. [Google Scholar]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Vosselman, G. Identification of damage in buildings based on gaps in 3D point clouds from very high resolution oblique airborne images. ISPRS J. Photogramm. Remote Sens. 2015, 105, 61–78. [Google Scholar] [CrossRef]
- Moran, M.S.; Inoue, Y.; Barnes, E. Opportunities and limitations for image-based remote sensing in precision crop management. Remote Sens. Environ. 1997, 61, 319–346. [Google Scholar] [CrossRef]
- Mukashema, A.; Veldkamp, A.; Vrieling, A. Automated high resolution mapping of coffee in Rwanda using an expert Bayesian network. Int. J. Appl. Earth Obs. Geoinf. 2014, 33, 331–340. [Google Scholar] [CrossRef]
- Chen, D.; Stow, D.; Gong, P. Examining the effect of spatial resolution and texture window size on classification accuracy: An urban environment case. Int. J. Remote Sens. 2004, 25, 2177–2192. [Google Scholar] [CrossRef]
- Rewh, I.C.; Stoep, A.V.; Kearney, A.; Smith, N.L.; Dunbar, M.D. Validation of the normalized difference vegetation index as a measure of neighborhood greenness. Ann. Epidemiol. 2011, 21, 946–952. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | Use (Variables) | Source |
|---|---|---|---|
| Pan-sharpened GeoEye-1 | Spatial: 0.46 m Date: 18 June 2019 | (1) band red | Digital Globe |
| (2) band green | |||
| (3) band blue | |||
| (4) entropy 5 × 5 | |||
| (5) entropy 15 × 15 | |||
| (6) entropy 25 × 25 | |||
| (7) mean 5 × 5 | |||
| (8) mean 15 × 15 | |||
| (9) mean 25 × 25 | |||
| (10) standard deviation 5 × 5 | |||
| (11) standard deviation 15 × 15 | |||
| (12) standard deviation 25 × 25 | |||
| (13) correlation 5 × 5 | |||
| (14) correlation 15 × 15 | |||
| (15) correlation 25 × 25 | |||
| (16) contrast 5 × 5 | |||
| (17) contrast 15 × 15 | |||
| (18) contrast 25 × 25 | |||
| Sentinel 2 (Dry season) | Spatial: 10 m Date: 21 May 2019 | (19) NDVI | USGS |
| (20) brightness (dry season) | |||
| (21) greenness (dry season) | |||
| (22) wetness (dry season) | |||
| Sentinel 2 (Wet season) | Spatial: 10 m Date: 19 November 2019 | (23) NDVI | USGS |
| (24) brightness (wet season) | |||
| (25) greenness (wet season) | |||
| (26) wetness (wet season) | |||
| Digital Elevation Model (DEM) | Spatial: 8.3 m | (27) elevation | BIG |
| (28) slope | |||
| (29) aspect | |||
| Aerial Photograph | Spatial: 3 cm Date: 31 August 2019 | Validation | Field Survey |
| Area 1 | Area 2 | Area 3 | Area 4 | Area 5 | |
|---|---|---|---|---|---|
| RMSE | 0.0286 | 0.0274 | 0.01970 | 0.03478 | 0.0381 |
| Class (Id) | Description |
|---|---|
| Water body (1) | Inland water bodies, including river |
| Built-up (2) | Land used as a temporary or permanent residence environment, residential environment, or places such as homes, schools, or offices |
| Road (3) | Area dominated by roads |
| Coffee plantations (4) | Coffee plantations mostly in agroforestry area |
| Pine neddle forest (5) | Forested area predominantly covered with mixed species of pine needle trees |
| Wet rice (6) | Irrigated agricultural fields including rice fields |
| Grassland (7) | Areas where vegetation is dominated by grasses |
| Bare land (8) | Land with no crops being grown |
| Dry field (9) | Dry land planted with seasonal or annual crops, such as corn, onions, secondary crops |
| Mixed vegetation (10) | Forested area predominantly covered with mixed species of vegetation |
| Tasseled Cap | Blue | Green | Red | NIR | MIR-1 | MIR-2 |
|---|---|---|---|---|---|---|
| Brightness | 0.3510 | 0.3813 | 0.3437 | 0.7196 | 0.2396 | 0.1949 |
| Greenness | −0.3599 | −0.3533 | −0.4734 | 0.6633 | 0.0087 | −0.2856 |
| Wetness | 0.2578 | 0.2305 | 0.0883 | 0.1071 | −0.7611 | −0.5308 |
| Model (Dataset) | Bands |
|---|---|
| M1 (RGB) | 3 |
| M2 (RGB + multi-scale texture) | 18 |
| M3 (RGB + multi-scale texture + Topography) | 21 |
| M4 (RGB + multi-scale texture + Topography + multi-temporal NDVI) | 23 |
| M5 (RGB + multi-scale texture + Topography + multi-temporal NDVI + multi-temporal Tasseled cap) | 29 |
| Tree | The Average of Overall Accuracy |
|---|---|
| 400 | 78.533% |
| 500 | 78.111% |
| 600 | 78.541% |
| 700 | 78.437% |
| 800 | 78.533% |
| 900 | 78.348% |
| 1000 | 78.644% |
| Tree | The Highest Overall Accuracy (%) | Computation Time (Minutes) | The Lowest Overall Accuracy (%) | Computation Time (Minutes) |
|---|---|---|---|---|
| 400 | Node size 2 (79.267%) | 20 | Node size 10 (77.800%) | 23 |
| 500 | Node size 9 (78.400%) | 23 | Node size 6 (77.600%) | 22 |
| 600 | Node size 3 (79.067%) | 21 | Node size 10 (77.876%) | 26 |
| 700 | Node size 2 (79.200%) | 24 | Node size 10 (77.333%) | 27 |
| 800 | Node size 2 (78.933%) | 27 | Node size 6 (78.133%) | 29 |
| 900 | Node size 9 (78.933%) | 32 | Node size 4 (78.000%) | 30 |
| 1000 | Node size 6 (79.333%) | 31 | Node size 10 (77.677%) | 38 |
| 29 Variables | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Total | UA (%) |
| 1 | 100 | 2 | 0 | 0 | 0 | 0 | 4 | 0 | 21 | 0 | 127 | 78.74 |
| 2 | 23 | 116 | 12 | 2 | 0 | 14 | 0 | 23 | 3 | 0 | 193 | 60.10 |
| 3 | 0 | 29 | 112 | 0 | 0 | 1 | 0 | 27 | 0 | 0 | 169 | 66.27 |
| 4 | 0 | 0 | 0 | 138 | 0 | 0 | 0 | 0 | 0 | 14 | 152 | 90.79 |
| 5 | 0 | 0 | 0 | 0 | 136 | 0 | 0 | 0 | 0 | 7 | 143 | 95.10 |
| 6 | 1 | 0 | 3 | 0 | 0 | 111 | 7 | 0 | 4 | 0 | 126 | 88.10 |
| 7 | 18 | 0 | 0 | 0 | 0 | 13 | 139 | 0 | 5 | 1 | 176 | 78.98 |
| 8 | 0 | 0 | 22 | 0 | 0 | 8 | 0 | 97 | 0 | 0 | 127 | 76.38 |
| 9 | 6 | 3 | 0 | 4 | 0 | 0 | 0 | 3 | 117 | 4 | 137 | 85.40 |
| 10 | 2 | 0 | 1 | 6 | 14 | 3 | 0 | 0 | 0 | 124 | 150 | 82.67 |
| Total | 150 | 150 | 150 | 150 | 150 | 150 | 150 | 150 | 150 | 150 | OA | 79.33 |
| PA (%) | 66.67 | 77.33 | 74.67 | 92.00 | 90.67 | 74.00 | 92.67 | 64.67 | 78.00 | 80.67 | Kappa | 0.77 |
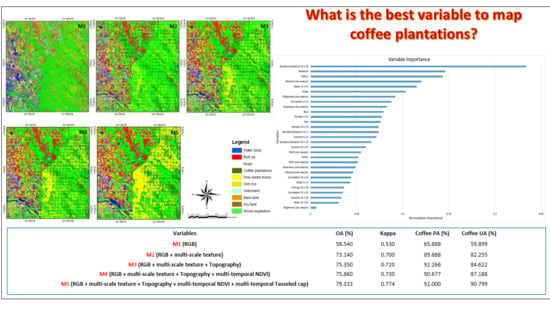
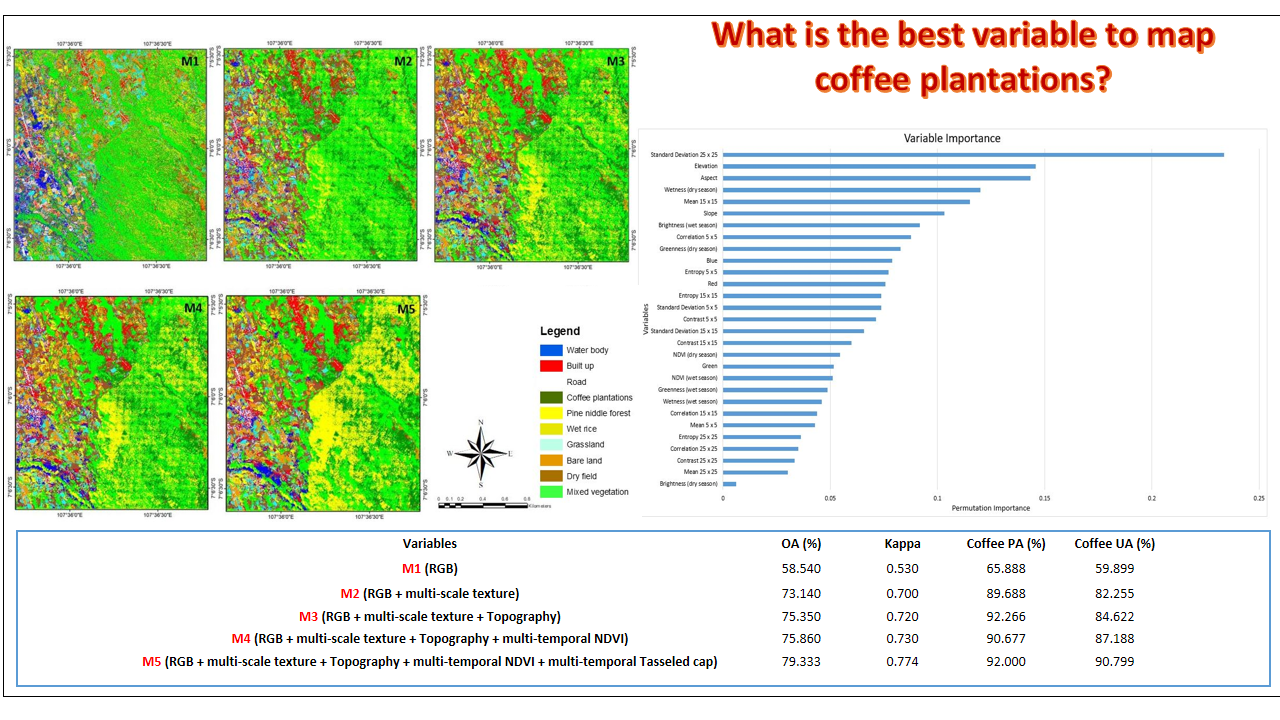
| No. | Variables | OA (%) | Kappa | Coffee PA (%) | Coffee UA (%) |
|---|---|---|---|---|---|
| 1 | M1 (RGB) | 58.540 | 0.530 | 65.888 | 59.899 |
| 2 | M2 (RGB + multi-scale texture) | 73.140 | 0.700 | 89.688 | 82.255 |
| 3 | M3 (RGB + multi-scale texture + Topography) | 75.350 | 0.720 | 92.266 | 84.622 |
| 4 | M4 (RGB + multi-scale texture + Topography + multi-temporal NDVI) | 75.860 | 0.730 | 90.677 | 87.188 |
| 5 | M5 (RGB + multi-scale texture + Topography + multi-temporal NDVI + multi-temporal Tasseled cap) | 79.333 | 0.774 | 92.000 | 90.799 |
| Variables | Overall Accuracy (%) | Kappa Statistic | Coffee PA (%) | Coffee UA (%) |
|---|---|---|---|---|
| 10 most important variables | 67.733% | 0.585 | 80.670% | 87.055% |
| 12 most important variables | 79.333% | 0.770 | 91.333% | 84.571% |
| 15 most important variables | 77.600% | 0.751 | 92.676% | 87.422% |
| 20 most important variables | 77.860% | 0.754 | 91.333% | 90.133% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tridawati, A.; Wikantika, K.; Susantoro, T.M.; Harto, A.B.; Darmawan, S.; Yayusman, L.F.; Ghazali, M.F. Mapping the Distribution of Coffee Plantations from Multi-Resolution, Multi-Temporal, and Multi-Sensor Data Using a Random Forest Algorithm. Remote Sens. 2020, 12, 3933. https://doi.org/10.3390/rs12233933
Tridawati A, Wikantika K, Susantoro TM, Harto AB, Darmawan S, Yayusman LF, Ghazali MF. Mapping the Distribution of Coffee Plantations from Multi-Resolution, Multi-Temporal, and Multi-Sensor Data Using a Random Forest Algorithm. Remote Sensing. 2020; 12(23):3933. https://doi.org/10.3390/rs12233933
Chicago/Turabian StyleTridawati, Anggun, Ketut Wikantika, Tri Muji Susantoro, Agung Budi Harto, Soni Darmawan, Lissa Fajri Yayusman, and Mochamad Firman Ghazali. 2020. "Mapping the Distribution of Coffee Plantations from Multi-Resolution, Multi-Temporal, and Multi-Sensor Data Using a Random Forest Algorithm" Remote Sensing 12, no. 23: 3933. https://doi.org/10.3390/rs12233933