Solving Competitive Location Problems with Social Media Data Based on Customers’ Local Sensitivities

Abstract
:1. Introduction
2. Background
2.1. Sina Weibo
2.2. Competitive Location Approach
3. Study Area and Data
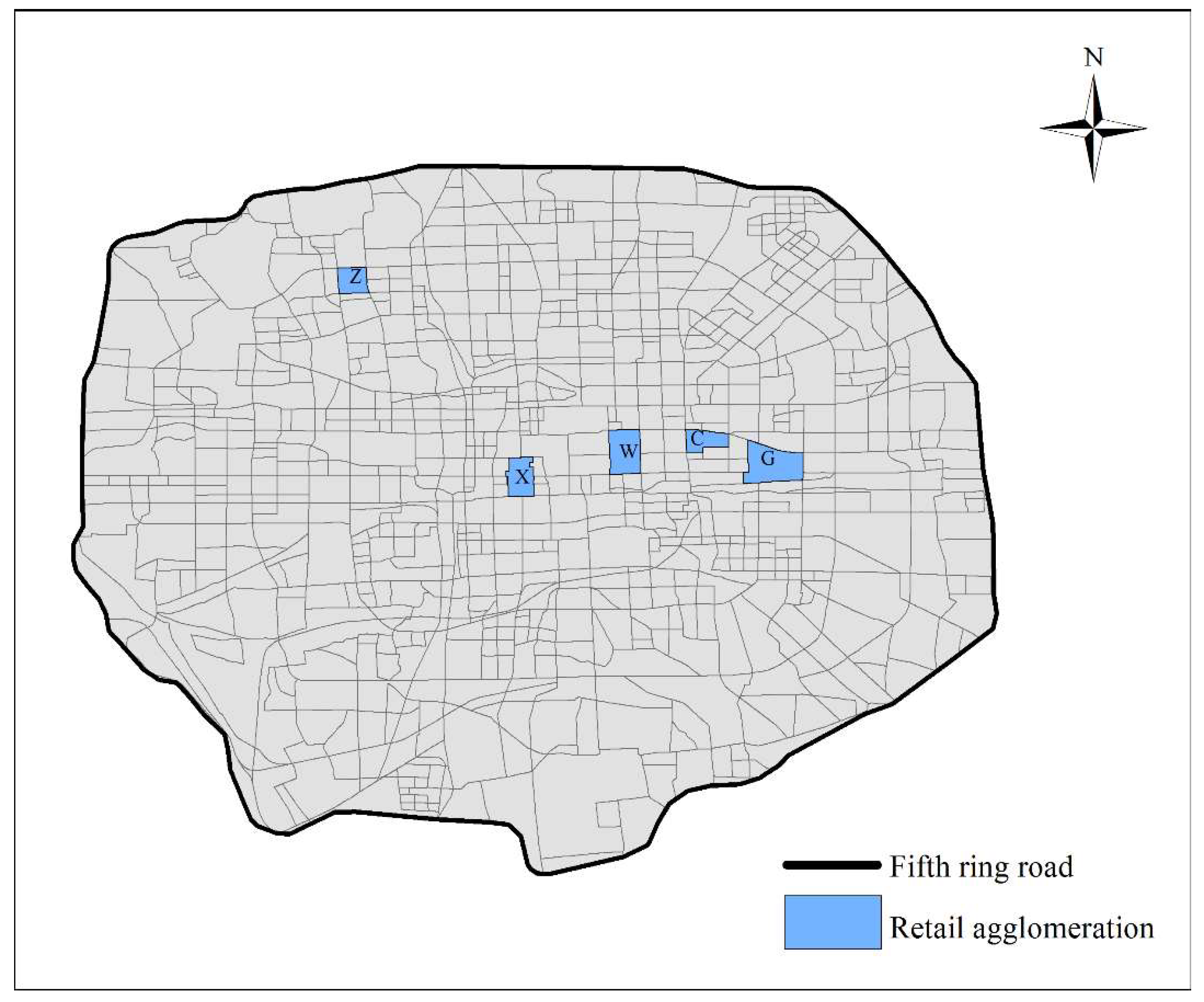
3.1. Study Area
3.2. Data Collection and Preprocessing
4. Method
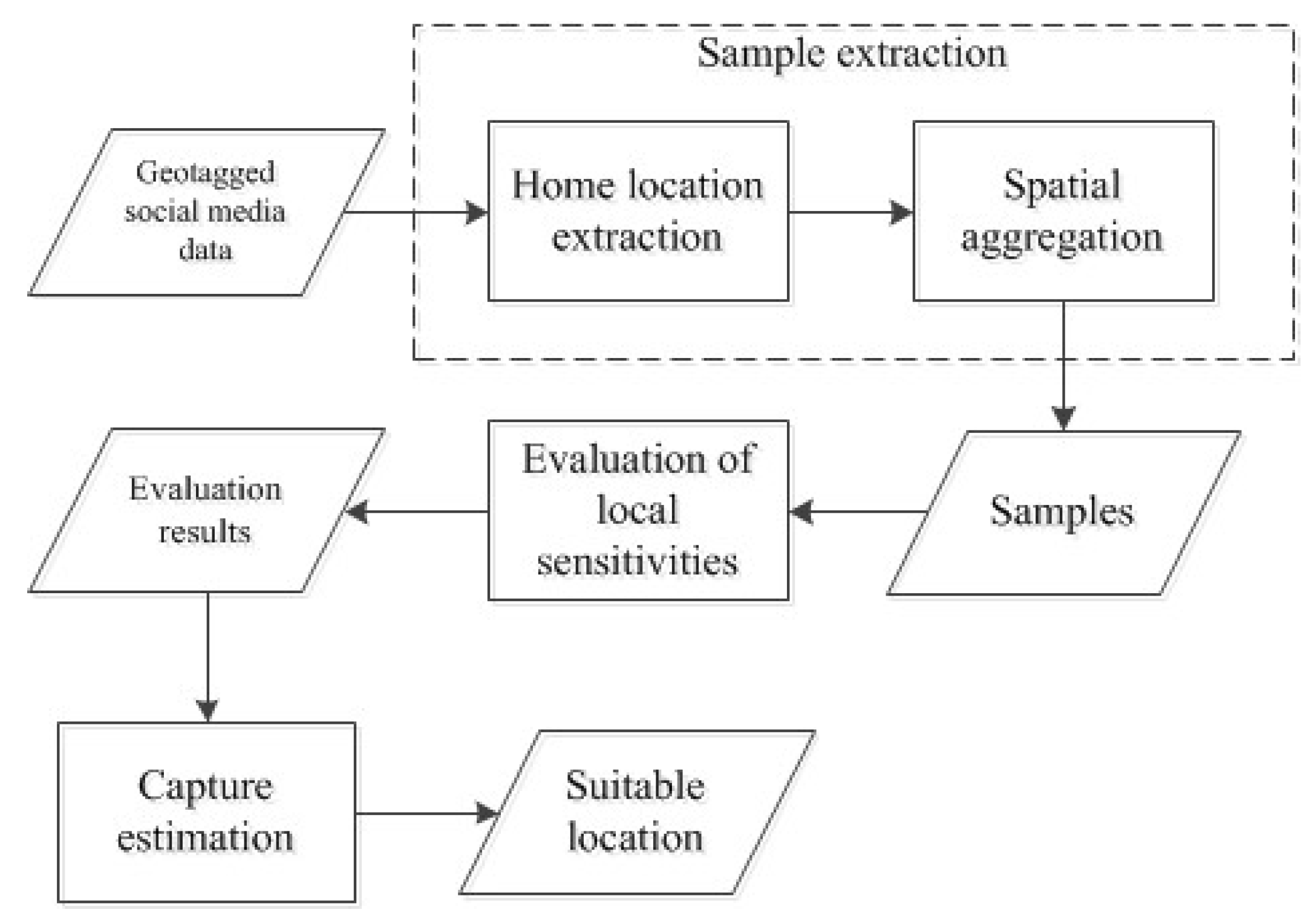
4.1. Sample Extraction
4.1.1. Home Location Extraction
4.1.2. Spatial Aggregation
4.2. Local Sensitivity Evaluation
4.3. Capture Estimation
5. Results and Analysis
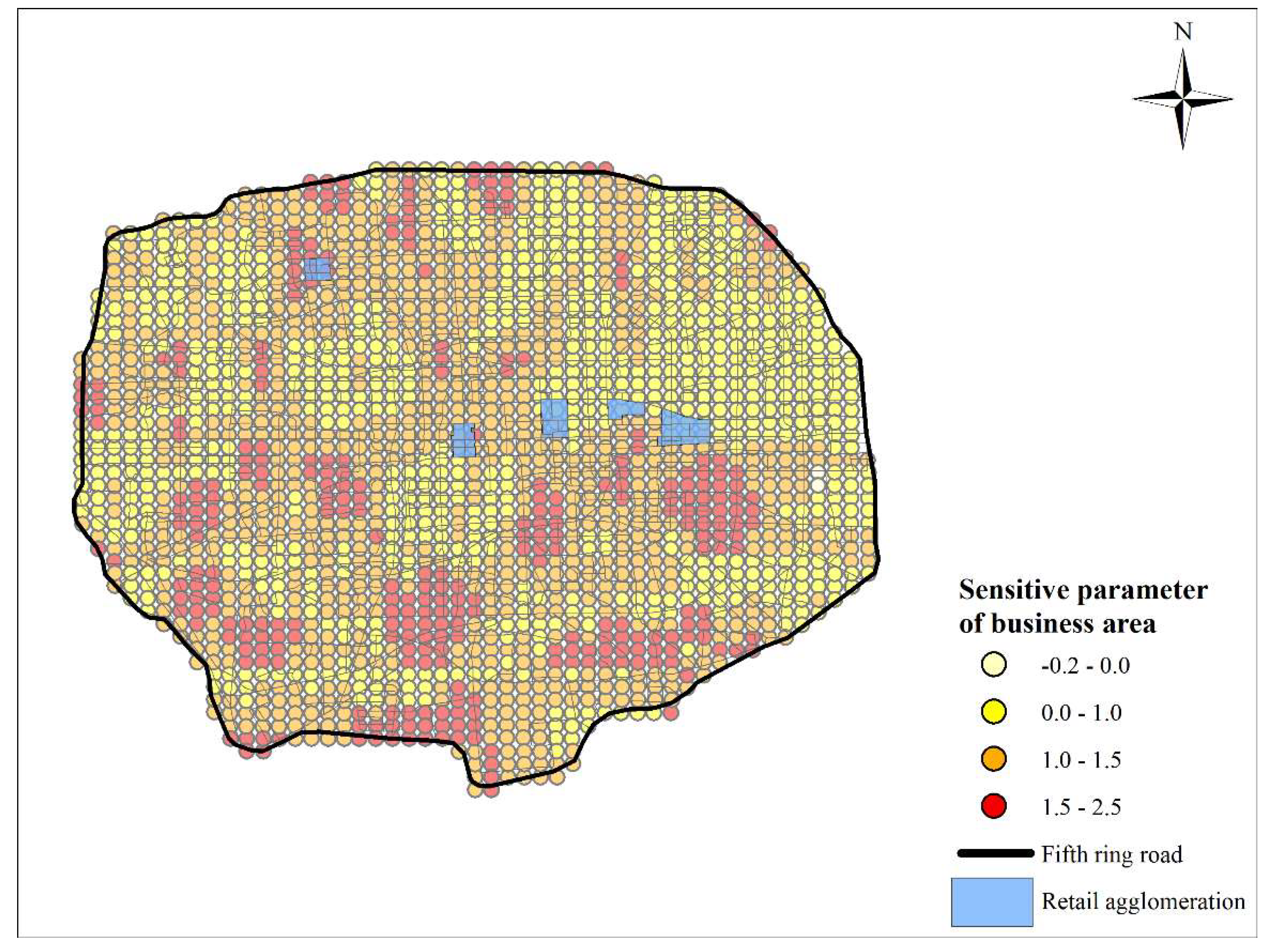
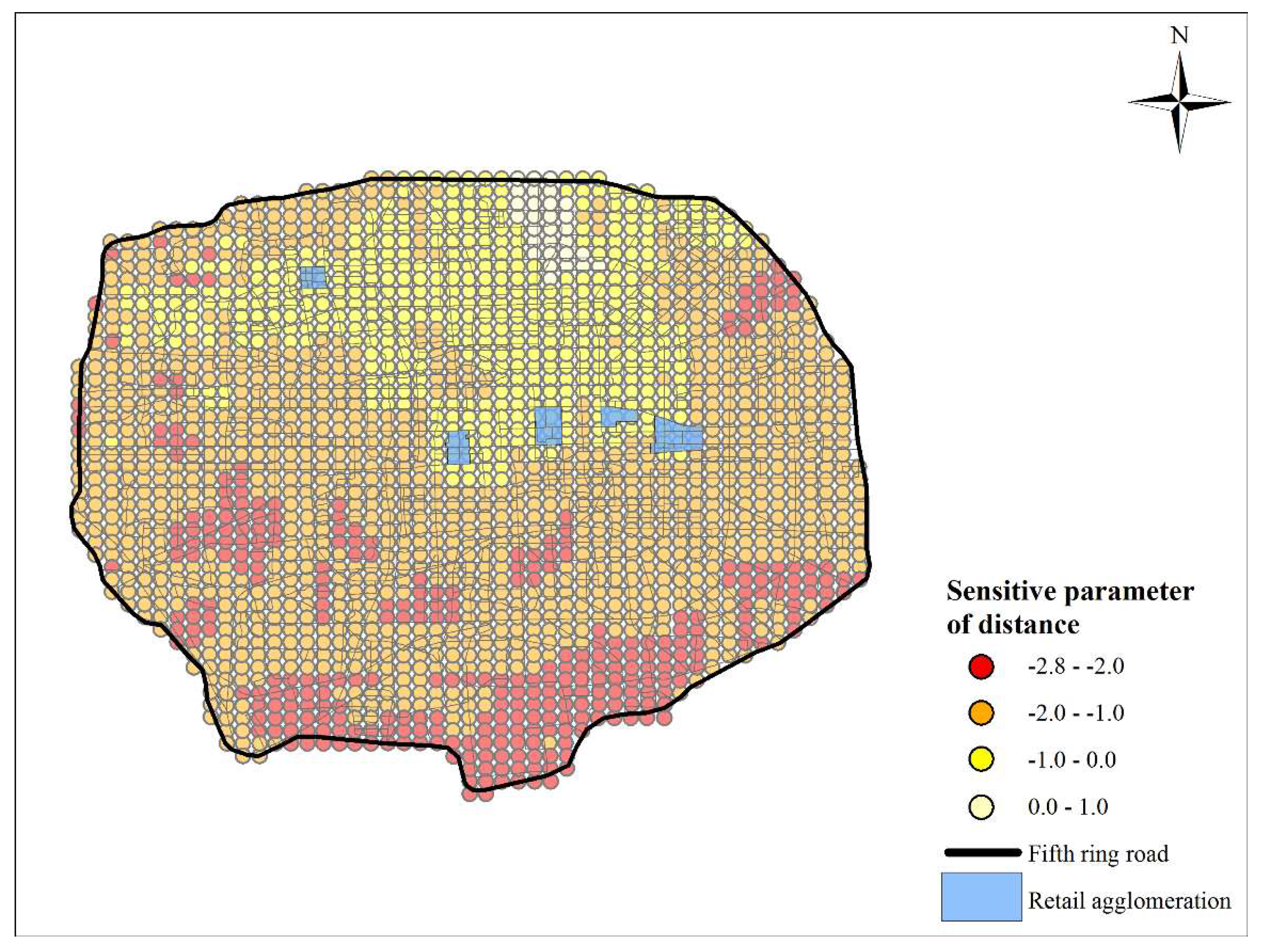
5.1. Comparative Analysis of Evaluation Results
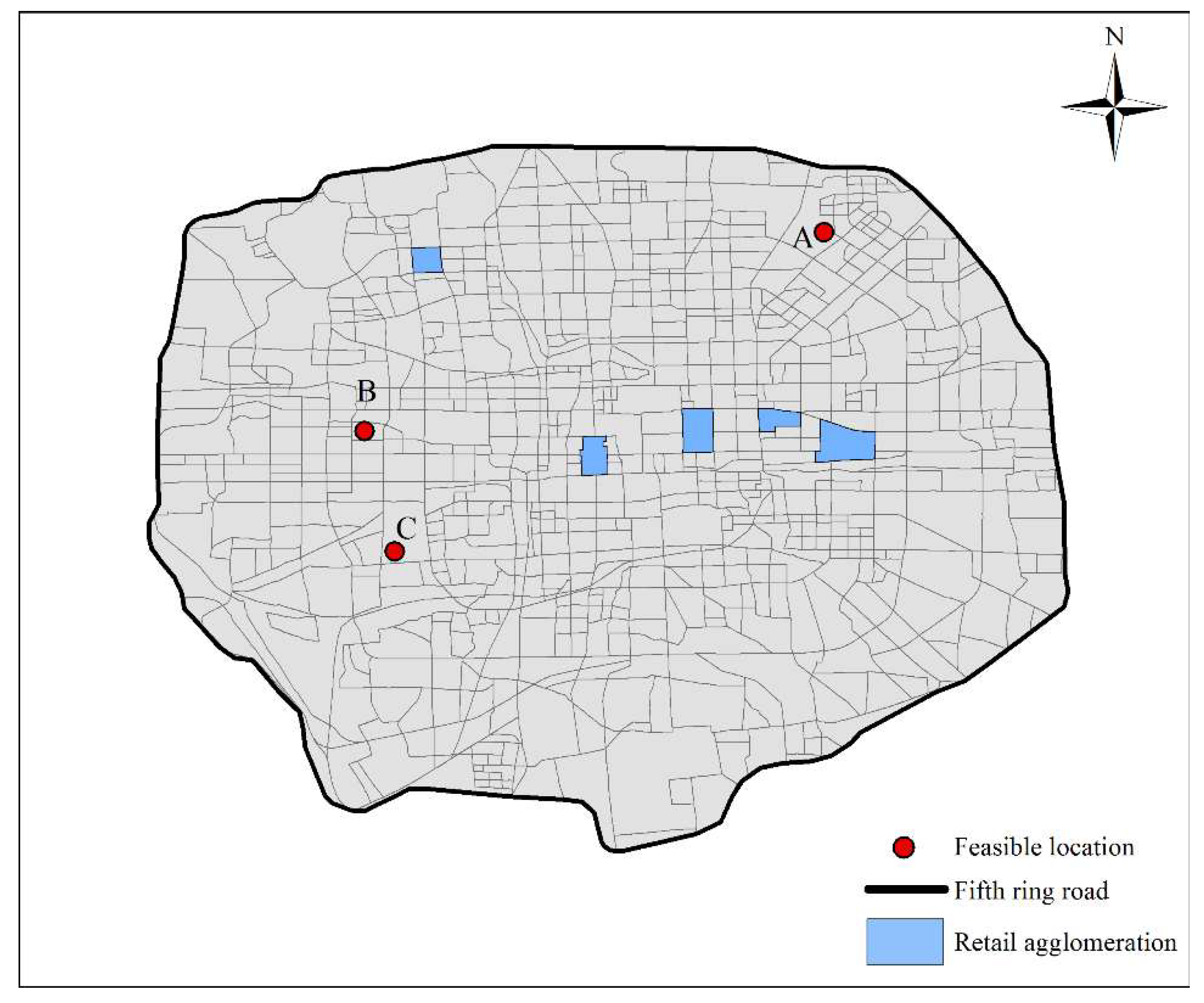
5.2. Capture Analysis
6. Conclusions
- Representability. Social media services are widely used among young people. The age structure of social media users is different from that of the real world [18]. Therefore, social media data can only be used as an approximate representation of the population density and customers’ behavior in the real world. Our research team will investigate the impact of the representability of social media data on competitive location problem.
- Text. Text information is an important attribute of social media data. People can post text that expresses their feelings and opinions about a retail facility. Therefore, from the text, we can find more factors that can attract customers. Based on text analysis, more facility attractions can be added to the competitive location models to further improve accuracy of the evaluation of the customers’ sensitivities.
- Modifiable area unit problem (MAUP). In our case, 600 meter * 600 meter grids were applied to divide the study area based on previous studies. Different sizes of spatial units can generate different results, and the optimal size needs to be investigated. In the future, we will reveal the effect of the size of spatial units in competitive location problems and obtain the best-fit size.
- Noise filtering. Based on the manual analysis of noises, we investigated the characteristics of noises in Sina Weibo dataset. The microblogs with particular symbols and “source” were identified as noises and filtered out. Although this process can filter out noises effectively, it is very time consuming and labor intensive. We need to develop machine learning procedures to remove noises.
- Home location extraction. In this case, we applied the method proposed by Qu et al. for extracting the home locations of Sina Weibo users [12]. In the study of Qu et al, the home locations extracted from geotagged social media data were compared to the real homes. Although the accuracy of the proposed method has been proved to be higher than many other methods in their study, the accuracy was not evaluated in our dataset. In the future work, the electronic questionnaires will be sent to the Sina Weibo users and the accuracy of this method will be further investigated.
- Privacy issues. Social media data contains a large amount of personal information (such as registration locations, age, friends and attitudes). Most users did not notice that their post information could be publicly obtained on the Internet and was applied to published research. More studies are needed to explore the protection of the privacy of social media users and provide guidance on developing academic ethical standards in social media data application.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gentile, J.; Pessoa, A.A.; Poss, M.; Roboredo, M.C. Integer programming formulations for three sequential discrete competitive location problems with foresight. Eur. J. Oper. Res. 2018, 265, 872–881. [Google Scholar] [CrossRef]
- Kung, L.C.; Liao, W.H. An Approximation Algorithm for a Competitive Facility Location Problem with Network Effects. Eur. J. Oper. Res. 2018, 267, 176–186. [Google Scholar] [CrossRef]
- Fernández, J.; Pelegri, N.B.; Plastria, F.; Boglárka, T. Solving a Huff-like competitive location and design model for profit maximization in the plane. Eur. J. Oper. Res. 2007, 179, 1274–1287. [Google Scholar] [CrossRef]
- Blanquero, R.; Carrizosa, E.; Hendrix, M.T. Locating a competitive facility in the plane with a robustness criterion. Eur. J. Oper. Res. 2011, 215, 21–24. [Google Scholar] [CrossRef]
- Suárezvega, R.; Gutiérrezacuña, J.L.; Rodríguezdíaz, M. Locating a supermarket using a locally calibrated Huff model. Int. J. Geogr. Inf. Sci. 2015, 29, 217–233. [Google Scholar] [CrossRef]
- Drezner, T. A review of competitive facility location in the plane. Logist. Res. 2014, 7, 114–129. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Y.; Tsou, M.H.; Fu, X. Using social media to detect outdoor air pollution and monitor air quality index (aqi): A geo-targeted spatiotemporal analysis framework with Sina Weibo (Chinese Twitter). PLoS ONE 2015, 10, e0141185. [Google Scholar] [CrossRef]
- Lin, M.; Lucas, H.C.; Shmueli, G. Research Commentary—Too Big to Fail: Large Samples and the p-Value Problem. Inf. Syst. Res. 2013, 24, 906–917. [Google Scholar]
- O’Kelly, M.E. Trade-Area Models and Choice-based Samples: Methods. Environ. Plan. A 2008, 31, 613–627. [Google Scholar]
- Lu, S.; Shaw, S.L.; Fang, Z.; Zhang, X.; Yin, L. Exploring the Effects of Sampling Locations for Calibrating the Huff Model Using Mobile Phone Location Data. Sustainability 2017, 9, 159. [Google Scholar] [CrossRef]
- Yue, Y.; Wang, H.D.; Hu, B.; Li, Q.Q.; Li, Y.G.; Yeh, A.G.O. Exploratory calibration of a spatial interaction model using taxi GPS trajectories. Comput. Environ. Urban Syst. 2012, 36, 140–153. [Google Scholar] [CrossRef]
- Qu, Y.; Zhang, J. Trade area analysis using user generated mobile location data. In Proceedings of the 22nd International Conference on World Wide Web, New York, NY, USA, 13–17 May 2013; pp. 1053–1064. [Google Scholar]
- Hu, Q.; Wang, M.; Li, Q. Urban Hotspot and Commercial Area Exploration with Check-in Data. Acta Geod. Cartogr. Sin. 2014, 43, 314–321. [Google Scholar]
- Wang, Y.; Jiang, W.; Liu, S.; Ye, X.; Wang, T. Evaluating Trade Areas Using Social Media Data with a Calibrated Huff Model. ISPRS Int. J. Geo-Inf. 2016, 5, 112. [Google Scholar] [CrossRef]
- Huff, D.L. Defining and Estimating a Trading Area. J. Mark. 1964, 28, 34–38. [Google Scholar] [CrossRef]
- Markham, F.; Doran, B.; Young, M. Estimating gambling venue catchments for impact assessment using a calibrated gravity model. Int. J. Geogr. Inf. Sci. 2014, 28, 326–342. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, H.; Lin, M.; Lv, S. Comparision of microblogging service between Sina Weibo and Twitter. In Proceedings of the 2011 International Conference on Computer Science and Network Technology (ICCSNT), Guangzhou, China, 24–26 December 2011; pp. 2259–2263. [Google Scholar]
- The Number of Sina Weibo Users Has Reached 411 Million. Available online: http://tech2ipo.com/10037717 (accessed on 9 May 2018).
- Eiselt, H.A.; Laporte, G.; Thisse, J.F. Competitive Location Models: A Framework and Bibliography. Transp. Sci. 1993, 27, 44–54. [Google Scholar] [CrossRef]
- Hotelling, H. Stability in Competition. Econ. J. 1929, 39, 41–57. [Google Scholar] [CrossRef]
- Yang, H.; Wong, S.C. A Continuous Equilibrium Model for Estimating Market Areas of Competitive Facilities with Elastic Demand and Market Externality. Transp. Sci. 2000, 34, 216–227. [Google Scholar] [CrossRef]
- Hodgson, M.J. Toward More Realistic Allocation in Location Allocation Models: An Interaction Approach. Environ. Plan. A 1978, 10, 1273–1285. [Google Scholar] [CrossRef]
- Wong, S.C.; Yang, H. Determining Market Areas Captured by Competitive Facilities: A Continuous Equilibrium Modeling Approach. J. Reg. Sci. 2010, 39, 51–72. [Google Scholar] [CrossRef]
- Leonardi, R.T. Random utility demand models and service location. Reg. Sci. Urban Econ. 2006, 14, 399–431. [Google Scholar] [CrossRef]
- Kress, D.; Pesch, E. Competitive Location and Pricing on Networks with Random Utilities. Netw. Spat. Econ. 2016, 16, 837–863. [Google Scholar] [CrossRef]
- Drezner, T.; Drezner, Z. Competitive facilities: Market share and location with random utility. J. Reg. Sci. 2010, 36, 1–15. [Google Scholar] [CrossRef]
- Baray, J.; Cliquet, G. Delineating store trade areas through morphological analysis. Eur. J. Oper. Res. 2007, 182, 886–898. [Google Scholar] [CrossRef]
- Gautschi, D.A. Specification of patronage models for retail center choice. J. Mark. Res. 1981, 18, 162–174. [Google Scholar] [CrossRef]
- Kryvasheyeu, Y.; Chen, H.; Obradovich, N.; Moro, E.; Van Hentenryck, P.; Fowler, J.; Cebrian, M. Rapid Assessment of Disaster Damage Using Social Media Activity. Sci. Adv. 2016, 2, e1500779. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Huang, B.; Song, Y. Using multi-source geospatial big data to identify the structure of polycentric cities. Remote Sens. Environ. 2017, 24, 906–917. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Tsou, M.H.; Li, H.; Jiang, W.; Gao, F. Mapping Dynamic Urban Land Use Patterns with Crowdsourced Geo-Tagged Social Media (Sina-Weibo) and Commercial Points of Interest Collections in Beijing, China. Sustainability 2016, 8, 1202. [Google Scholar] [CrossRef]
- Laylavi, F.; Rajabifard, A.; Kalantari, M.A. Multi-Element Approach to Location Inference of Twitter: A Case for Emergency Response. ISPRS Int. J. Geo-Inf 2016, 5, 56. [Google Scholar] [CrossRef]
- Wang, Y.; Fu, X.; Jiang, W.; Wang, T.; Tsou, M.H.; Ye, X. Inferring urban air quality based on social media. Comput. Environ. Urban Syst. 2017, 66, 110–116. [Google Scholar] [CrossRef]
- Rzeszewski, M.; Beluch, L. Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production. ISPRS Int. J. Geo-Inf. 2017, 6, 236. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically Weighted Regression: A Method for Exploring Spatial Nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Charlton, M.; Brunsdon, C. The geography of parameter space: An investigation of spatial non-stationarity. Geogr. Inf. Syst. 1996, 10, 605–627. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M. Some Notes on Parametric Significance Tests for Geographically Weighted Regression. J. Reg. Sci. 1999, 39, 497–524. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Charlton, M.E.; Brunsdon, C. Geographically weighted regression: A natural evolution of the expansion method for spatial data analysis. Environ. Plan. A 1998, 30, 1905–1927. [Google Scholar] [CrossRef]
- Nakanishi, M.; Cooper, L.G. Parameter Estimation for a Multiplicative Competitive Interaction Model: Least Squares Approach. J. Mark. Res. 1974, 11, 303–311. [Google Scholar]
- Loader, C.R. Bandwidth Selection: Classical or Plug-In? Ann. Stat. 1999, 27, 415–438. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Proceedings of the 2nd International symposium on information theory, Tsahkadsor, Armenian SSR, 2–8 September 1971; pp. 267–281. [Google Scholar]
- Hurvich, C.M.; Simonoff, J.S.; Tsai, C. Smoothing parameter selection in nonparametric regression using an improved Akaike information criterion. J. R. Stat. Soc. Ser. B Stat. Methodol. 2010, 60, 271–293. [Google Scholar] [CrossRef]
- Lu, B.; Charlton, M.; Harris, P.; Fotheringham, A.S. Geographically weighted regression with a non-Euclidean distance metric: a case study using hedonic house price data. Int. J. Geogr. Inf. Sci. 2014, 28, 660–681. [Google Scholar] [CrossRef]
- Wheeler, D.C. Diagnostic Tools and A Remedial Method for Collinearity in Geographically Weighted Regression. Environ. Plan. A 2007, 39, 2464–2481. [Google Scholar] [CrossRef]
- Belsley, D.A.; Kuh, E.; Welsch, R.E. Regression Diagnostics—Identifying Influential Data and Sources of Collinearity. J. Oper. Res. Soc. 1981, 32, 157–158. [Google Scholar]
- Adnan, M.; Leak, A.; Longley, P. A geocomputational analysis of Twitter activity around different world cities. Geo-Spat. Inf. Sci. 2014, 17, 145–152. [Google Scholar] [CrossRef]
- Puntanen, S.; Styan, G.P.H. The Equality of the Ordinary Least Squares Estimator and the Best Linear Unbiased Estimator. Am. Stat. 1989, 43, 153–161. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Created_at | Text | User_ID | Geo | Retweet_Status | POI_ID | POI_Title | Source |
|---|---|---|---|---|---|---|---|---|
| xx | 2014-02-06 09:45:53 | #孕期运动##辣妈健身##孕期瑜伽##【享孕无忧】 (#pregnancy exercises##hot mum fitness## pregnancy yoga#【safe pregnancy program】) | xx | 116.70063; 39.91037 | 0 | Null | Null | PP时光机 (PP time machine) |
| xx | 2014-04-19 11:27:51 | 如果你是单身狗,千万不要点开! (If you are single, do not click this Sina Weibo!) | xx | 116.657333; 39.9077 | 0 | xx | 通州新城 (Tongzhou new town) | 未通过审核的应用 (unapproved application) |
| xx | 2014-09-01 18:28:14 | 在北京王府井这里,感觉也没什么好玩的,一条商业街而已。 (In Wangfujing, I find nothing interesting. There is just a commercial street.) | xx | 116.342531; 39.73123 | 0 | xx | 王府井百货 (Wangfujing department store) | MI 3 |
| xx | 2015-01-04 16:12:47 | 这个点在西单大悦城,和朋友一起吃下午茶。 (Have afternoon tea with friends at Xidan Joy City.) | xx | 116.37326; 39.91082 | 0 | xx | 西单大悦城 (Xidan Joy City) | iPhone 5 |
| Geotagged Microblogs | Users | |
|---|---|---|
| Original dataset | 16,682,330 | 2,428,946 |
| After filtering out noises | 16,669,258 | 2,428,294 |
| After filtering out outliers | 16,664,073 | 2,428,294 |
| Local Sensitive Parameter | Global Sensitive Parameter | |
|---|---|---|
| Min αi | −0.19 | |
| Mean αi | 1.04 | 0.97 |
| Max αi | 2.27 | |
| % sig par. for αi | 21.61 | |
| Min λi | −2.68 | |
| Mean λi | −1.16 | −1.04 |
| Max λi | 0.18 | |
| % sig par. for λi | 90.42 | |
| AICc | 4761.90 | 7039.26 |
| R2 | 0.73 | 0.51 |
| Bandwidth | 118 |
| Feasible Location | 40,000 m2 | 60,000 m2 | 80,000 m2 | |||
|---|---|---|---|---|---|---|
| Global Capture | Local Capture | Global Capture | Local Capture | Global Capture | Local Capture | |
| A | 2141.94 | 2059.88 | 2989.50 | 2820.12 | 3748.45 | 3727.14 |
| B | 1872.52 | 2101.76 | 2648.23 | 2905.03 | 3352.15 | 3642.59 |
| C | 1482.11 | 1770.39 | 2127.68 | 2463.27 | 2719.40 | 3103.61 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Wang, Y.; Dou, M.; Liu, S.; Shao, S.; Liu, H. Solving Competitive Location Problems with Social Media Data Based on Customers’ Local Sensitivities. ISPRS Int. J. Geo-Inf. 2019, 8, 202. https://doi.org/10.3390/ijgi8050202
Jiang W, Wang Y, Dou M, Liu S, Shao S, Liu H. Solving Competitive Location Problems with Social Media Data Based on Customers’ Local Sensitivities. ISPRS International Journal of Geo-Information. 2019; 8(5):202. https://doi.org/10.3390/ijgi8050202
Chicago/Turabian StyleJiang, Wei, Yandong Wang, Mingxuan Dou, Senbao Liu, Shiwei Shao, and Hui Liu. 2019. "Solving Competitive Location Problems with Social Media Data Based on Customers’ Local Sensitivities" ISPRS International Journal of Geo-Information 8, no. 5: 202. https://doi.org/10.3390/ijgi8050202