
The Formal Framework for Collective Systems


1
Department of Applied Informatics, Faculty of Management and Computer Science, Wrocław University of Science and Technology, 50-370 Wrocław, Poland
2
Facultad de Informática, Complutense University of Madrid, 28040 Madrid, Spain
*
Authors to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Axioms 2021, 10(2), 91; https://doi.org/10.3390/axioms10020091
Submission received: 8 October 2020
/
Revised: 3 May 2021
/
Accepted: 11 May 2021
/
Published: 15 May 2021
(This article belongs to the Special Issue Deductive Systems in Traditional and Modern Logic)
{kind=link}
Abstract
:Automated reasoning is becoming crucial for information systems. Building one uniform decision support system has become too complicated. The natural approach is to divide the task and combine the results from different subsystems into one uniform answer. It is the basic idea behind the system approach, where one solution is a composition of multiple subsystems. In this paper, the main emphasis is on establishing the theoretical framework that combines various reasoning methods into a collective system. The system’s formal abstraction uses graph theory and provides a discussion on possible aggregation function definitions. The proposed framework is a tool for building and testing specific approaches rather than the solution itself.
Keywords:
collective intelligence; inference system; aggregation function; butterfly effect; reasoning stop conditionMSC:
68T42; 68T051. Introduction
There are various types of problems that modern expert systems aim to solve. Some of them are simple enough that one approach is sufficient to provide adequate solutions. However, there are a number of problems for which a combination of algorithms or methods is needed. In such a case, we employ a complex system that either chooses an appropriate approach based on the insights or combines the outcomes of various methods into a uniform one. In this paper, we focus on the latter, i.e., systems fitting into the category of collective intelligence. Among many definitions of collective intelligence, some of the most often used are “the capacity of human collectives to engage in intellectual cooperation in order to create, innovate and invent” [1] and “groups of individuals acting collectively in ways that seem intelligent” [2]. The most common definition comprises deductive systems as: “A set of rules R and axioms. Since axioms can be viewed as rules without premises, we assume that a deductive system is a set of rules and a procedure for derivation such that if and only if A can be derived from by rules R” [3].
The goal of collective intelligence is to provide either decision support or decision making systems. The difference between those two approaches is slight and relates to the reliability of the system. If the ultimate goal is to eliminate the human factor, then one of the options is to employ deductive systems. In that case, the reliability of the system is derived from the proper configuration of the system and the accuracy of the data provided to it. Since there is no single system that could produce an output to all types of problems, commonly, a set of systems is used. In such a case, we might consider a complex system built from individual subsystems or a multi-agent system. However, utilising multiple deductive systems may lead to the situation where two or more of them return conflicting results. Such a situation is not unusual, since most deductive systems use sets of predefined rules to generate outputs. Those sets may not only have different numbers of elements but also differ in spite of individual rule definitions; thus, the systems lead to heterogeneous outputs. Another reason for the diversity of outputs is the fact that any human involvement creates the possibility for error to appear. In addition, the deductive systems are most commonly configured by humans. The number of rules relies on the time the designer can spend on their definition and the general aim of the system. In the case of a multitude of deductive systems, they will inevitably differ in details. Thus, for the sake of uniformity, a collective approach is introduced in this paper. The proposed solution utilises the model defined in [4], assuming each of the deductive systems as a collective member.
The remainder of the paper comprises, first, a background section that presents state of the art in the field of deductive systems and collective intelligence. The next section introduces the formal definition of the collective structure for the deductive systems to utilise. Further, the properties of such combinations are distinguished and analysed. Then, we present a discussion on the proposed framework and conclude the paper.
2. Background
This paper is the first work strictly addressing the collectives built from multiple deductive systems to the best of our knowledge. It has to be stressed out that the authors are aware of the multi-agent systems. However, they do not consider using deductive methods for agent definition in most cases. Since our work connects both the collective intelligence field and deductive systems, we discuss related research in both areas.
2.1. Collective Study
Many authors have proven that approaches based on collectives are an effective method for forming accurate judgements in an uncertain environment [5,6,7]. However, it is hard to find a straightforward answer to the question “why does collective intelligence work?”. One of the most popular is the Surowiecki explanation [8]. In his work, he proposed the following properties of a wise crowd [8]:
- Diversity: each agent should have some private information, even if it is just an eccentric interpretation of the known facts.
- Independence: the opinions of those around them do not determine agents’ opinions.
- Decentralisation of opinion: an agent can specialise on and draw on local knowledge.
- Aggregation: some mechanism exists for turning private judgements into a collective decision.
A multitude of research seems to confirm Surowiecki’s work. Due to Surowiecki’s background as a journalist, in his work, he mainly focused on human crowds. Nevertheless, collective intelligence has proven its effectiveness for various types of agents, even artificial ones [9]. Therefore it is used in many disciplines—e.g., in deep learning where it is called ensembling [10]. The use of collectives allows us to achieve far more accurate results with the use of simple solutions.
For the sake of uniformity, Jodłowiec et al. [4] proposed the universal definition of collective suitable for the identification of its features regardless of the implementation area. They assumed the collective to be a graph defined as a tuple:
where
- M
- is a set of collective members;
- E
- is a set of edges;
- t
- is collective , which can be understood as either a pursued value or a quality.
There exist other approaches to the definition of collectives, such as [11,12,13]. However, they lack the flexibility of the aforementioned model. Thus, we decided to rely on the approach presented in [4].
The model used allows the distinction of the following measure types describing the collective properties:
- Distribution metrics (DM)—used to assess the one-dimensional distribution of attribute values among collective members.
- Clustering metrics (CM)—used to analyse multidimensional aspects of attribute value distribution in the member society.
- Collective’s structure metrics (CSM)—used to analyse the structure of collective connections.
- Members’ social relations metrics (MSRM)—used to analyse social connections among members of the crowd.
- Collective information flow metrics (CIF)—used to determine the information flow (propagation) among members of the collective.
- Collective aggregation function (CAF)—used to transform answers (opinions or recommendations) given by members of the collective into one unified response.
Each of those metrics is important and provides information crucial for the collective analysis. However, in the authors’ opinion, the aggregation function is highly underestimated for its role in the study of collective intelligence phenomena.
The diversity of collective structures and aims forces the creation of a variety of aggregation function types. Inputs and outputs can be distinguished for the functions [14]:
- Aggregation functions whose inputs are of the same types as the outputs;
- Aggregation functions whose inputs are of different types to their outputs.
Beliakov et al. [15] proposed another approach to the aggregation function classification, where we can distinguish the following types:
- Averaging—aggregation function f has an averaging behaviour (or is averaging) if for every x it is bounded by:
- Conjunctive—aggregation function f has conjunctive behaviour (or is conjunctive) if for every x it is bounded by:
- Disjunctive—aggregation function f has disjunctive behaviour (or is disjunctive) if for every x it is bounded by:
- Mixed—aggregation function f is mixed if it does not belong to any of the above classes, i.e., it exhibits different types of behaviour on different parts of the domain [15].
If we consider the aggregation function in terms of the mathematical formulas used, the following families can be distinguished [15]:
- Minimum and maximum;
- Means;
- Medians;
- Ordered weighted averaging;
- Choquet and Sugeno integrals;
- Conjunctive and disjunctive functions;
- Mixed aggregation functions.
Minimum and maximum are the main aggregation functions used in fuzzy set theory and fuzzy logic [16]. That comes from the fact that they are the only two operations consistent with several theoretical set properties, i.e., mutual distribution. The standard definition of minimum and maximum is as follows:
where is a property of a collective member.
The next type of aggregation function is mean and median, with the arithmetic mean being the most popular one to use.
where:
- J
- is the collective judgement;
- is a judgement of a collective member i;
- N is a number of collective members.
It is a baseline for most of the other methods [17]. Research proved that the unweighted average guarantees the outcome to be more accurate than the typical individual judgement [18,19]. Nevertheless, various authors have proposed enhancements, mainly by adding a weight to each opinion, whose value usually represents the certainty or trustworthiness of collective member’s opinion.
Thus, another type of aggregation function that is worth mentioning is ordered weighted averaging (OWA) functions [20]. OWA are also averaging aggregation functions, which associate weights not with a particular input, but rather with its value. They were introduced by Yager [20], and since then have become very popular in the fuzzy sets community. OWA could be defined based on vector as:
where,
- is a subsequent value from the vector containing individuals judgements in non-increasing order ;
- is a subsequent value from the vector of weights w.
Choquet and Sugeno integrals are considered another aggregation function category [21,22,23]. They are mainly used in a situation when we can convert the problem of estimation by the use of fuzzy sets and scale it to become the Choquet and Sugeno problem [24]. The standard definition of this function defined for vector is as follows:
where:
- and are subsequent values from the vector containing individuals’ judgements in non-increasing order ,
- v is a fuzzy measure.
Conjunctive and disjunctive functions are so-called triangular norms and conorms, respectively (t-norms and t-conorms) [25]. An example of a conjunctive extended aggregation function could be:
where:
- is a i-th collective member judgement;
- n is a number of collective members.
Last, but not least important, is the mixed aggregation function. An example of such a function is function defined after [26]:
where:
- is a i-th collective member judgement;
- n is a number of collective members.
One of the ideas is the approach that takes the assumption that outliers may affect the result too heavily [27]. Therefore, those methods aim at removing appropriate (unneeded) individual values. Let us take the median absolute deviation (MAD) filtering method as an example, where each judgement is considered an unneeded outlier, iff:
where,
- t is a parameter that controls the sensitivity of the trimming;
- are dummy variables,
and is removed from the set. Following the filtering, usually one of the above-mentioned methods is applied, e.g., the average aggregation function. However, the potential drawback of any filtering is the potential to ignore strong dissenting voices. It proved to be a problem in situations of group thinking, where the process of forming a collective judgement neglects well-justified outlier opinions and is biased towards a consensus judgement, irrespective of the evidence for that judgement [14].
2.2. Deductive Systems
Automated reasoning is one of the most promising research fields in computer science. The multitude of approaches available are aimed at solving a straightforward issue, i.e., how to conclude according to the information and data available at the moment. One class of solutions uses a black box architecture, where the exact execution rules are independent and often unknown to the operator. This approach is widespread in such tasks as automated classification systems, and screening or prediction in image, text, sound or video processing. In general, the black-box approach is a mixture of artificial neural networks and genetic algorithms and other nondeterministic techniques. In most cases, a black-box system needs a short time to employ. However, there is a need for sufficient training data or periodical fine-tuning. While they prove efficient in computational aspects, they nearly never reach complete reliability.
Contrary to the nondeterministic approach, some systems aim at reliability in the first place. They utilise, among others, parts of the classical mathematical apparatus, i.e., deduction and induction. In this paper, we focus on the latter approach, with particular emphasis on the deductive systems, since they are one of the primary solutions for many problems, e.g., program synthesis problems [28]. The most basic definition sets the deductive system as “a set of rules R and axioms. Since axioms can be viewed as rules without premises, we assume that a deductive system is a set of rules and a procedure for derivation such that if and only if A can be derived from by rules R” [3].
The definition mentioned above allows the creation of multiple systems with the same set of premises. Thus, we may assume that when having a bunch of solutions defined with the same set of assumptions but with an orthogonal set of rules, we will receive heterogeneous outcomes. That raises a new problem, i.e., how to measure the reliability or accuracy of the outcome. Since we are focused on deductive systems, it is safe to assume that the accuracy of such a system relies on its complexity. In perfect conditions, the complexity is irrelevant, but in real-life, we need to take into account the constraints—maximum answer time expectancy, minimum accuracy, etc. Thus, having the accuracy as the primary evaluation function, we will aim at producing such a system which provides an accurate output with adequate resource (time) consumption. Sets of rules used in deductive systems are mainly defined by human operators, rather than automatically generated. With complex tasks, it is virtually impossible to test the system against all possible situations (inputs). Thus, we need to assume that even if the system returns the correct value, it might not be the most accurate one. Instead of solving the accuracy issue by introducing more rules into the system, in this article, we will focus on the approach that solves the problem by combining responses from various deductive systems into a uniform one. Our solution uses a collective intelligence approach, in particular, a model defined in [4] that utilises graph theory to describe the complexity of the collective structure.
3. Method
In this research, we have focused on two main steps needed to adopt the model defined in [4]. At first, we checked if the node definition is suitable to represent individual deductive systems. Since the framework is flexible, we are not limited to any specific system, either deductive or not. Secondly, we have defined the aggregation principles to use with multiple systems and combined them into a uniform system. In the following sections, we present those steps in detail.
3.1. A Deductive System as a Collective Member
The definition of the collective member presented in [4] is a complex one. First of all, we need to make sure that a set of members, e.g., deductive systems, is a collective. That means all of its members should share the same target, as defined in Equations (14) and (15). The target might be understood as either the pursued value or a quality of any sort. It is only crucial we can evaluate reaching it.
where
- M is a set of collective members;
- is a subsequent collective member;
- t is a target;
- i is a collective member number;
- n is a number of collective members.
Once we ensure that the set of deductive systems is a collective, we may investigate their characteristics. Each collective member has a type assigned, which is defined in (16) as a tuple .
where
- a is an attribute characterised by name and type;
- i is an index of an attribute;
- is number of attributes;
- is a set of all attributes.
Each collective member can be thus understood as a tuple of values v defined in (19). Each value of collective member corresponds to appropriate attribute of .
Considering a collective built from deductive systems, we identify the minimum set of attributes characterising them. In our study, we assumed that it is sufficient to define:
- A set of input values ;
- Output value ;
- Confidence factor .
Depending on the approach taken, can be defined as one attribute a or represented by several attributes . We believe that the internal member’s rules should not be part of its description in the collective definition, since they are part of the deductive system configuration. The presented approach does not focus on the reasoning of individual members but rather on their aggregated outcome.
The common target is not the only special thing about the collective. It is the set of relationships among members that makes it unique. If we had only a set of unrelated members, we could investigate any kind of aggregation but only look for their outcomes’ statistical significance. Following to the model from [4], the authors use the definition of relations between collective members as graph edges.
where
- is the edge connecting members ;
- is number of edges;
- is relation kind and is a set of kinds of relations;
- is a level of influence member has on member ;
- is a edge property for which .
The definitions mentioned above apply to all possible collectives, but for the sake of this article, we will narrow them down. The first and most obvious move is to put a constraint on the member set to only allow it to contain deductive systems.
where
- is a set of deductive systems.
Limiting the collective members set does not change the obligation to have a common target. In the case of a system built up from deductive systems, we assume this target to be providing a uniform answer to the query. As for the attributes, we take into account only those that might give any insight into the creation of a shared collective response. It might be wise to focus on the input each member uses for generating the response. Each deductive system is independent in its decision making. However, it can take into account the outcome from other connected systems. It is not yet the aggregation, but rather part of the individual decision making process of each member. Probably the most important aspect of collective building is the possibility to define aggregation function based on the relations between members. As stated in (21) and (22), each edge representing the connection between two members has information on the level of influence and type of relationship. That information is crucial for the setting up of the whole system. It not only affects the analysis of individual outcomes but also allows better definition of the aggregation function.
3.2. Collective Decision Making
The goal of the presented framework is to deliver a way for solving problems when several deductive systems infer a heterogeneous outcome. We have proved that the model we chose is capable of describing the complexity of the collective structure. The next step is to define the proper aggregation approach. Let us define the aggregation function y.
where
- y is the collective decision for a given vector of members’ decisions x;
- x is a vector of members’ decisions.
In the proposal, the authors strive to present a universal solution. Thus there will be no universal aggregation function shown, but rather an approach on how to define one for a specific case. The authors focus on three baseline families of functions, i.e.,
- Average aggregation function;
- Weighed average aggregation function;
- Combined measure.
3.2.1. Average Aggregation Function
The first type of aggregation neglects any connections between collective members. So each deduction equally influences the general outcome. We will follow the arithmetic average function defined as (7).
Since this function does not use any information concerning relationships, we might assume it is not a full-fledged aggregation. However, it is a good idea to use simplification for the sake of, e.g., prototyping or processing time. It is particularly essential in the case of highly complex systems, where the proper definition of more sophisticated methods might be time demanding. There is no simple guide to use this simplest approach. However, we can assume that a large number of members, a dense relationship network and low centralisation are pre-requirements.
3.2.2. Weighed Average Aggregation Function
Another approach involves distinguishing member opinions by a chosen factor. Unlike the simple arithmetic average, the weighted one (26) assumes that the outcome of every member has a measurable and diverse impact on the final decision of collective.
where
- is the decision of the i-th member;
- n is the number of members;
- is the weight for i-th deductive system.
This method is quite simple once we know how to obtain the vector of weights. However, the definition of the latter is a fundamental difficulty. Values of the vector can be calculated based on the members’ attributes or the properties of relationships, e.g.,
- Confidence in the inferred answer,
- Influences of interconnected deductive systems—a calculation is based on the incoming and outgoing edges to/from the node;
- With respect to other deductive systems—calculated as an average of the weights assigned by the deductive systems to the output generated by a given system.
Generation of the weight vector might be tedious work involving many repetitions and fine-tuning. The standard procedure would include setting the initial vector and challenging results obtained from aggregating collective members’ opinions with the expected outcome. The process might rely on expert knowledge and on any automated technique.
3.2.3. Combined Aggregation Function
The proposed framework introduces a sophisticated solution, namely, the combined aggregation function. The idea is simple and relies on the usage of various measures to create a single collective response. The functions and properties to combine include averages, centralisation measure, distributions of properties or members, etc. An example of combined aggregation is:
where
- is the decision of a i-th member;
- is the weight for i-th deductive system;
- n is the number of collective members;
- is the maximum number of edges connected to any of nodes in G;
- is the average number of edges connected to nodes in G;
- f is centralisation value for a given collective; in a case where centralisation is low (lover than given value f), each node could be treated equally, and otherwise some weight should be introduced.
It is not only possible to use a centralisation function, but we can also rely on the collective prediction as below.
where
- is a the centralisation value for i-th collective member;
- is the decision of a i-th member.
The aforementioned centralisation measures are not the only possible solutions to use. Having the complexity of collective description, we can choose from a variety of functions either to define the weight system or to introduce a discrimination factor for the aggregation. Those functions can rely on members’ attributes or properties of the collective as such.
One of the critical factors that we need to take into account is the idea of joint answer creation in the collective of deductive systems. At one point, we could stop at a simple calculation of the answer using any arithmetic aggregation function. However, we assume that each member of the collective can use the responses of interconnected systems as an input for their calculations. Thus, we will seek the state in which the collective stabilises and provides a countable output. What we need to take into account is so-called “butterfly effect” when a small change in one system could influence significantly on the response of other [30]. With infinite repetitions, this effect might be even more disastrous, causing an inability to reach consensus. To cease such a situation in the proposed framework, the authors introduce a method based on two conditions along with parameters that allow for its customisation, namely:
- q a quantified value representing the smallest change in response accepted by the system;
- m a quantified value representing the number of iterations resulting in the same outcome.
The method aims at stopping the concluding process before it gets out of the balance [31]. The first condition uses the individual deductive system outcome and checks if subsequent repetitions alter their values. The iteration of the procedure seeking the collective’s consensus should stop once it meets the condition (30).
where
- x is collective member;
- is the decision of a member x in an iteration i;
- q is the value of the stop condition.
With this definition, it is easy to connect the value of q with the overall accuracy of the collective. The accuracy of the system returning numerical outcomes is defined as:
- A is the accuracy of the system;
- J is a value concluded by the collective (collective’s prediction);
- is the real value of the target information.
The second condition takes into consideration the outcome of the system as a whole. The parameter m limits the iteration based on the value of the aggregation function. At first, when the process of estimating the collective outcome starts, there is no simple way of stopping the iteration. One approach would be to stop it after a fixed number of repetitions. However, this number might be different for various systems. In the proposed method, the authors recommend relying on more sophisticated conditions. The idea is to investigate the subsequent outcomes of the aggregation function and count those that return the same value. If this number reaches the limit set by m, then it is assumed that the system reached the consensus. The only tricky part lies in checking the equality of outcomes. In this case, we can use the parameter q. It sets the margin of error and defines the accuracy of the system.
For the sake of uniformity, the proposed solution applies not only to systems focused on numeric operations. In the case of quality-based aggregation, we can omit the first condition and rely only on the second one.
3.2.4. Example
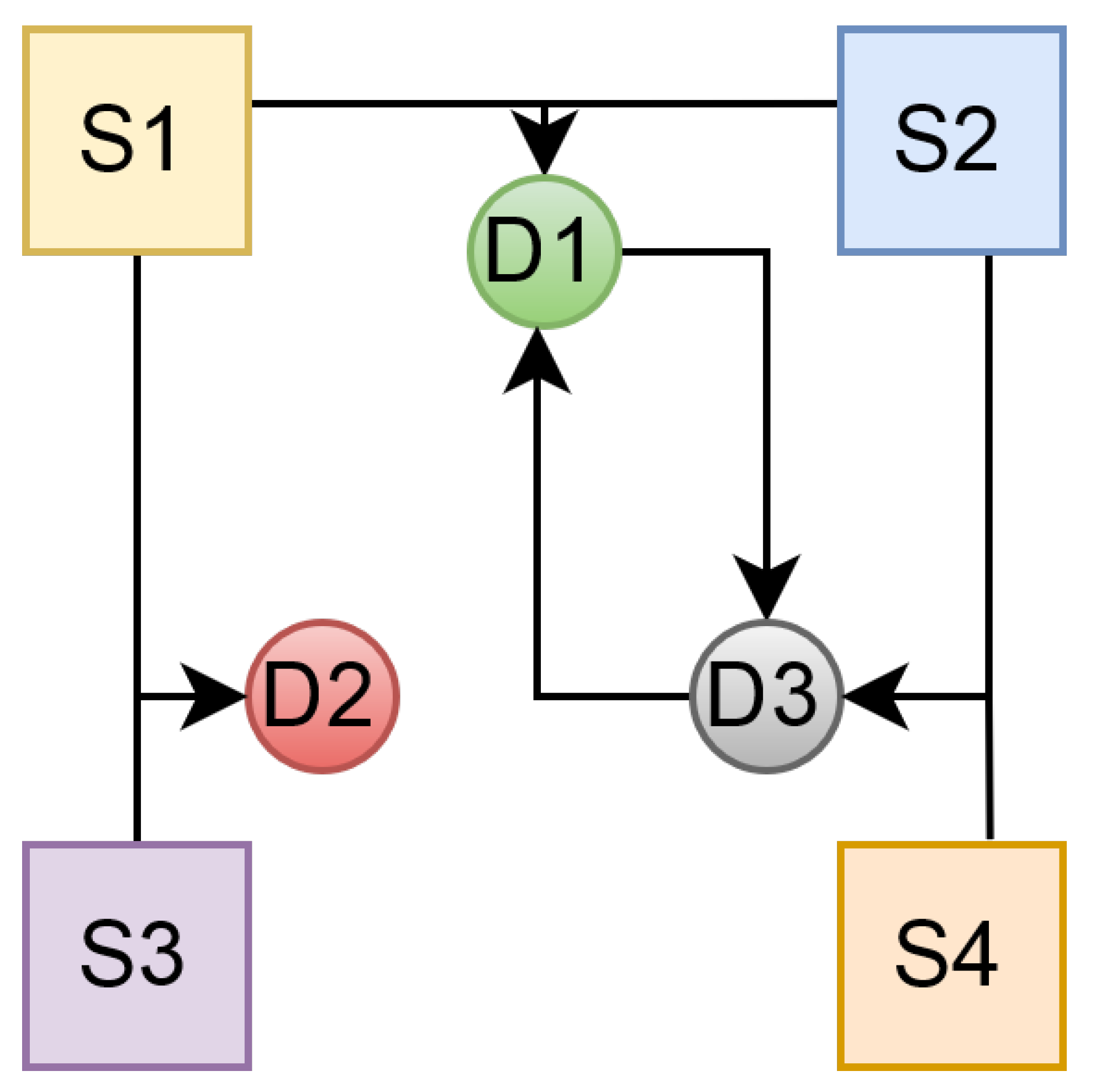
Let us consider the example shown in Figure 1 to clarify aforementioned idea. The example comprises three deductive systems, , and ; and four sources of information , , and . Each deductive system has access to exactly two information sources. However, the sources differ for each of them. Moreover, has access to the output of , and uses the output of . At first, and use only information provided by the sources. In the next iterations, both deductive systems take each other’s predictions into account. The systems return numeric value by , and respectively. Such a configuration makes systems have an orthogonal view of the current state. Since and might return unequal values and use each other output for computation, there is a need for repetition until they reach consensus. Thus, the system conducts multiple iterations for the and to stabilise, and one of the stopping conditions defined in Section 3.2.3 is triggered. Meeting the stopping conditions does not guarantee that values returned by deductive systems are the same. Nevertheless, the system is expected to return one value. Thus, the framework introduces the use of the aggregation functions. With one of them, we can determine the response r. In this example, we use a simple average aggregation function, so response r of the whole system equals:
Depending on the application, the aggregation function might vary; thus, the result value r could also be different. Additionally, the introduction of an additional information source may lead to a different response from any system. Therefore, even deterministic solutions such as deductive systems finally may not act deterministically at all.
4. Discussion
The authors proposed a theoretical framework introduced in the previous section based on a collective model from [4]. It enables working on strong foundations and presents a universal model for the complex expert system. The approach is holistic, with a minimal number of constraints in case of implementation. Therefore, universality and flexibility are the most significant advantages of the proposed solution. The authors also elaborated on “the butterfly effect”, suggesting an appropriate answer to it. The proposed approach is fully decentralised. Therefore, it does not have problems that may occur with centralised solutions, e.g., difficulties with resource allocation planning that quickly reach a point where the design of satisfying solutions becomes too complicated. Another advantage of the proposed approach is easy scaling.
At first glance, the proposed approach is similar to the well-known multi-agent method. In a multi-agent system (MAS) [32] agents are computational abstractions encapsulating control along with a criterion to drive control (task, goal). The MAS collects agents interacting (communicating, coordinating, competing, cooperating) in a computational system. In a multi-agent system, individual agents contribute to some part of the system through their private actions. Since part of the core conception of multi-agent systems is competing, there is a risk that agents in the system work at cross-purposes. For example, agents can reach sub-optimal solutions by competing for scarce resources or having inefficient task distribution, as they only consider their own goals. The most significant difference between the proposed solution and multi-agents systems is that each collective member solves the whole problem, not only a small part of it. The collective intelligence framework aims to promote the agent’s actions that lead to increasingly influential emergent behaviour of the collective while discouraging agents from working at cross-purposes. This is an enormous advantage possessed by the proposed solution.
The universal character of the system is derived from the possibility to model various types of systems. A solution designer has to undertake two crucial decisions. The first one relates to the communication among the deductive systems defined, whether it is possible or not. A further step is only valid if the systems can exchange information, especially regarding answers. If the deductive systems are to communicate, the designer has to define the degree and types of this communication. The second one is the choice of the aggregation function and later its thorough definition. The flexibility of the framework also lies in the fact that the aggregation can be another deductive system. The use of graph theory makes the solution intuitive; thus, it allows the creation of complex structures comprising many individual systems that are still easy to comprehend. The authors are aware that their universal approach and such flexibility as described might be a source of undiscovered issues. Therefore, further research involving the implementation of various design patterns is needed.
5. Conclusions
The paper introduces a novel approach towards the definition of collectives comprising deductive systems. The theoretical framework presents the solution to collaborative decision making, mainly in the case when individual peers give heterogeneous answers. Small constraints allow the flexible and universal design of the collective. However, it is essential to intentionally and reasonably define the degree of individual system communication and the type of aggregation function. Since the design promotes the exchange of information among peers that any of them can use as an input for their operation, the authors introduced a sophisticated stop mechanism. The proposed solution mainly aims to simplify the compound solution description; thus, it allows for better interchangeability.
The future work mainly will focus on providing various design patterns for collective systems utilising the proposed framework, and proving its effectiveness.
Author Contributions
Conceptualisation, R.P.; methodology, K.W.; validation, R.P. and K.W.; formal analysis, R.P.; writing—original draft preparation, R.P. and K.W.; writing—review and editing, R.P. and K.W.; supervision, K.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Region of Madrid grant number FORTE-CM, S2018/TCS-4314 and the Spanish MCIU-FEDER grant number FAME, RTI2018-093608-B-C31.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lévy, P. From social computing to reflexive collective intelligence: The IEML research program. Inf. Sci. 2010, 180, 71–94. [Google Scholar] [CrossRef]
- Malone, T.W.; Bernstein, M.S. Handbook of Collective Intelligence; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Citkin, A. Deductive Systems with Multiple-Conclusion Rules and the Disjunction Property. Axioms 2019, 8, 100. [Google Scholar] [CrossRef] [Green Version]
- Jodłowiec, M.; Krótkiewicz, M.; Palak, R.; Wojtkiewicz, K. Graph-Based Crowd Definition for Assessing Wise Crowd Measures. In Proceedings of the International Conference on Computational Collective Intelligence; Springer: Cham, Switzerland, 2019; pp. 66–78. [Google Scholar]
- Armstrong, J.S. Combining forecasts: The end of the beginning or the beginning of the end? Int. J. Forecast. 1989, 5, 585. [Google Scholar] [CrossRef] [Green Version]
- Clemen, R.T. Combining forecasts: A review and annotated bibliography. Int. J. Forecast. 1989, 5, 559–583. [Google Scholar] [CrossRef]
- Nielsen, M. Reinventing Discovery: The New Era of Networked Science; Princeton University Press: Prinston, NJ, USA, 2011; Volume 70. [Google Scholar]
- Surowiecki, J. The Wisdom of Crowds; Anchor: New York, NY, USA, 2005. [Google Scholar]
- Ferber, J.; Weiss, G. Multi-Agent Systems: An Introduction to Distributed Artificial Intelligence; Addison-Wesley: Boston, MA, USA, 1999; Volume 1. [Google Scholar]
- Zhou, Z.H.; Wu, J.; Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intell. 2002, 137, 239–263. [Google Scholar] [CrossRef] [Green Version]
- DeGroot, M.H. Reaching a consensus. J. Am. Stat. Assoc. 1974, 69, 118–121. [Google Scholar] [CrossRef]
- Wagner, C. Consensus through respect: A model of rational group decision-making. Philos. Stud. 1978, 34, 335–349. [Google Scholar] [CrossRef] [Green Version]
- Golub, B.; Jackson, M.O. Naive learning in social networks and the wisdom of crowds. Am. Econ. J. Microeconomics 2010, 2, 112–149. [Google Scholar] [CrossRef] [Green Version]
- Lyon, A.; Wintle, B.C.; Burgman, M. Collective wisdom: Methods of confidence interval aggregation. J. Bus. Res. 2015, 68, 1759–1767. [Google Scholar] [CrossRef]
- Beliakov, G.; Pradera, A.; Calvo, T. Aggregation Functions: A Guide for Practitioners; Springer: Berlin, Germany, 2007; Volume 221. [Google Scholar]
- Bellman, R.; Giertz, M. On the analytic formalism of the theory of fuzzy sets. Inf. Sci. 1973, 5, 149–156. [Google Scholar] [CrossRef]
- Yaniv, I. Weighting and trimming: Heuristics for aggregating judgments under uncertainty. Organ. Behav. Hum. Decis. Process. 1997, 69, 237–249. [Google Scholar] [CrossRef] [Green Version]
- Herzog, S.M.; Hertwig, R. The wisdom of many in one mind: Improving individual judgments with dialectical bootstrapping. Psychol. Sci. 2009, 20, 231–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larrick, R.P.; Soll, J.B. Intuitions about combining opinions: Misappreciation of the averaging principle. Manag. Sci. 2006, 52, 111–127. [Google Scholar] [CrossRef] [Green Version]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Choquet, G. Theory of capacities. Annales de L’institut Fourier. 1954, 5, 131–295. [Google Scholar] [CrossRef] [Green Version]
- Schmeidler, D. Integral representation without additivity. Proc. Am. Math. Soc. 1986, 97, 255–261. [Google Scholar] [CrossRef]
- Grabisch, M.; Labreuche, C. A decade of application of the Choquet and Sugeno integrals in multi-criteria decision aid. Ann. Oper. Res. 2010, 175, 247–286. [Google Scholar] [CrossRef]
- Rakus-Andersson, E.; Jogreus, C. The Choquet and Sugeno Integrals as Measures of Total Effectiveness of Medicines. In Theoretical Advances and Applications of Fuzzy Logic and Soft Computing; Castillo, O., Melin, P., Ross, O.M., Sepúlveda Cruz, R., Pedrycz, W., Kacprzyk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 253–262. [Google Scholar] [CrossRef] [Green Version]
- DenĹ“ux, T. Conjunctive and disjunctive combination of belief functions induced by nondistinct bodies of evidence. Artif. Intell. 2008, 172, 234–264. [Google Scholar] [CrossRef] [Green Version]
- Yager, R.R.; Rybalov, A. Uninorm aggregation operators. Fuzzy Sets Syst. 1996, 80, 111–120. [Google Scholar] [CrossRef]
- Jose, V.R.R.; Winkler, R.L. Simple robust averages of forecasts: Some empirical results. Int. J. Forecast. 2008, 24, 163–169. [Google Scholar] [CrossRef]
- Polozov, O.; Gulwani, S. FlashMeta: A framework for inductive program synthesis. In Proceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, Pittsburgh, PA, USA, 25–30 October 2015; pp. 107–126. [Google Scholar]
- Palak, R.; Wojtkiewicz, K. The Time Efficient Centralisation Measure for Social Networks Assessment. In Proceedings of the 33th International Conference on Industrial, Engineering & Other Applications of Applied Intelligent Systems, Kitakyushu, Japan, 22–25 September 2020. [Google Scholar]
- Lorenz, E.N. Deterministic Nonperiodic Flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef] [Green Version]
- Schut, M.C. On model design for simulation of collective intelligence. Inf. Sci. 2010, 180, 132–155. [Google Scholar] [CrossRef]
- Omicini, A.; Ricci, A.; Viroli, M. Artifacts in the A&A meta-model for multi-agent systems. Auton. Agents -Multi-Agent Syst. 2008, 17, 432–456. [Google Scholar]
Figure 1.
An example of a collective built from deductive systems.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Palak, R.; Wojtkiewicz, K. The Formal Framework for Collective Systems. Axioms 2021, 10, 91. https://doi.org/10.3390/axioms10020091
AMA Style
Palak R, Wojtkiewicz K. The Formal Framework for Collective Systems. Axioms. 2021; 10(2):91. https://doi.org/10.3390/axioms10020091
Chicago/Turabian StylePalak, Rafał, and Krystian Wojtkiewicz. 2021. "The Formal Framework for Collective Systems" Axioms 10, no. 2: 91. https://doi.org/10.3390/axioms10020091
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.