
Multi-Descriptor Random Sampling for Patch-Based Face Recognition
by
 , , , and
, , , and
Ismahane Cheheb
1,* ,
,
Noor Al-Maadeed
2,
Ahmed Bouridane
1,
Azeddine Beghdadi
3 and
Richard Jiang
4 1
Department of Computer and Information Sciences, Northumbria University, Newcastle upon Tyne NE1 8ST, UK
2
Department of Computer Science and Engineering, Qatar University, Doha 2713, Qatar
3
Institut Galilée, Université Sorbonne Paris Nord, 93430 Villetaneuse, France
4
Department of Computing and Communications, Lancaster University, Lancaster LA1 4YW, UK
*
Author to whom correspondence should be addressed.
Appl. Sci. 2021, 11(14), 6303; https://doi.org/10.3390/app11146303
Submission received: 18 May 2021
/
Revised: 3 July 2021
/
Accepted: 6 July 2021
/
Published: 8 July 2021
(This article belongs to the Special Issue Advanced Machine Learning Algorithms for Biometrics and Its Applications)
Abstract
:While there has been a massive increase in research into face recognition, it remains a challenging problem due to conditions present in real life. This paper focuses on the inherently present issue of partial occlusion distortions in real face recognition applications. We propose an approach to tackle this problem. First, face images are divided into multiple patches before local descriptors of Local Binary Patterns and Histograms of Oriented Gradients are applied on each patch. Next, the resulting histograms are concatenated, and their dimensionality is then reduced using Kernel Principle Component Analysis. Once completed, patches are randomly selected using the concept of random sampling to finally construct several sub-Support Vector Machine classifiers. The results obtained from these sub-classifiers are combined to generate the final recognition outcome. Experimental results based on the AR face database and the Extended Yale B database show the effectiveness of our proposed technique.
1. Introduction
Face images can be captured easily at a distance and can also be used in various applications including surveillance, tracking, access control, etc. Therefore, face modality has been widely investigated in the biometric research field compared to other biometric modalities such as iris, fingerprint, and palmprint counterparts.
Currently, the human face can be accurately recognised in a restricted environment. However, in an unrestricted environment, several challenges are encountered where faces are exposed to distortions. These distortions include illumination changes, pose variations, and partial occlusion. Moreover, while multiple algorithms have been proposed to tackle them in recent years, they have their limitations or requirements that cannot be met for faces in the wild.
An image-based recognition system comprises of a feature extraction and representation process followed by a classification stage. Feature extraction methods can be classified into two main approaches: holistic feature-based and local feature-based methods [1].
In holistic approaches, the features extracted from the whole images are processed using either global linear, nonlinear statistical techniques or combined. The more conventional holistic methods include the popular linear techniques such as Principal Component analysis (PCA) method [2], Independent Component Analysis (ICA) [3], and Linear Discriminant Analysis (LDA) [4]. However, these methods may not be efficient due to the nonlinear characteristics of the face images. Therefore, some nonlinear kernel-based techniques have been investigated to address the problem by exploiting the contours of face images including the information details of the curves. Kernel Principal component analysis (KPCA) and Kernel Fisher Analysis (KFA) [5,6] are widely used methods of this category.
Local feature-based approaches are proven to be more robust to deal with complex backgrounds and occlusions inherently present in real image data. Unlike global descriptors which compute features from the whole image, local descriptors [7] have been shown to be more effective. Patch-based face recognition, which was proposed in [8], is another effective technique and operates by dividing an image into multiple overlapping or non-overlapping patches using either global or local descriptors for matching. In the case of patch-based approaches, the extraction of the local features is performed for each region (or patch) of the images where each face image is divided into a number of either overlapping or non-overlapping blocks. There exists a number of approaches for patch-based face recognition in the literature. The authors in [9] have proposed a feature concatenation method including a block selection with similarity measure. On the other hand, the work described in [10] suggests the use of a weight for classification results of the patches by calculating the genuine classification rates extracted from the test set. The work [11] proposes to employ the concept of subspace by using a majority voting scheme for combining the results of classification generated from the patches using random subspaces. The work discussed in [12] proposes carrying out the training of classifiers using separate random patches of the images and suggests a combination using a two-step layer decision: (i) using a weighted summation and (ii) combining the outcome from local ensemble classifiers with that of a global classifier obtained from the whole faces. The work described in [13] proposes to determine and select face areas containing more discriminative information for use in the classification phase. Although this proposed method shows high effectiveness while being highly robust against the issues of illumination distortions and partial occlusions, the classification performances are not significant, which is mainly due to the fact that one single classifier is constructed for all the image patches. The authors in [14] propose to first determine the area having the largest matching score at each point of the face. This is then used to carry out an occlusion de-emphasis stage in order to deal with partial occlusion distortions. However, this approach has shown limitations since it can be challenging to develop such a de-emphasis procedure due to the variations and extent of the occlusions. Recently, the concept of deep learning [15,16,17] has been proposed and has gained popularity in face recognition problems. This technology gives outstanding results and clearly outperforms the conventional machine learning algorithms. However, deep learning architectures generally require a considerable amount of data, including specialised high performance hardware for the training stage especially for practical situations. This makes them hard to deploy and less suited especially for embedded and low power applications.
Therefore, this work proposes an approach for human face recognition under partial occlusion. A random patch sampling method for face recognition under various distortions is proposed in this paper. Local descriptors are deployed to capture smaller texture patterns which can be more discriminative in human faces while still keeping the spatial relations. This paper is a follow-up of our previous work [18], deploying a multi-descriptor approach instead of a single descriptor. In addition, the proposed method has been validated using a dataset with more challenging illumination and occlusion conditions.
The paper is organised as follows: Section 2 gives an overview of the method including a brief description of the concept of face patching, the multi-LBP approach, the feature extraction process using HOG and Kernel PCA and their application in the proposed method, and finally describing the proposed Random Patching method and its adaptation to the problem of face recognition. Section 3 discusses the validation process and the experiments performed and compared against existing methods. Finally, conclusions and future work are in Section 4.
2. Overview of the Proposed Method
As mentioned above, this paper proposes a random patch (RP) sampling method for face recognition under distortions targeting partial occlusion in particular. The use of multiple local descriptors helps capture smaller texture patterns. Therefore, they offer higher accuracy compared to holistic feature-based descriptors that tend to average over the given image. The local descriptors used are Local Binary Patterns (LBPs) and Histogram of Oriented Gradients (HoGs). These two descriptors provide different type of features, which are complimentary and therefore offer more discriminative power. For example, their combination would offer an advantage over using a single descriptor. For dimensionality reduction, KPCA, which is nonlinear extension of the conventional PCA, offers more refined features. For the matching process, the proposed approach uses Random Patch Sampling based on the employment of several Support Vector Machine (SVM) classifiers. It operates by considering all generated face patches equally to build multiple sub-classifiers to further improve the recognition performances.
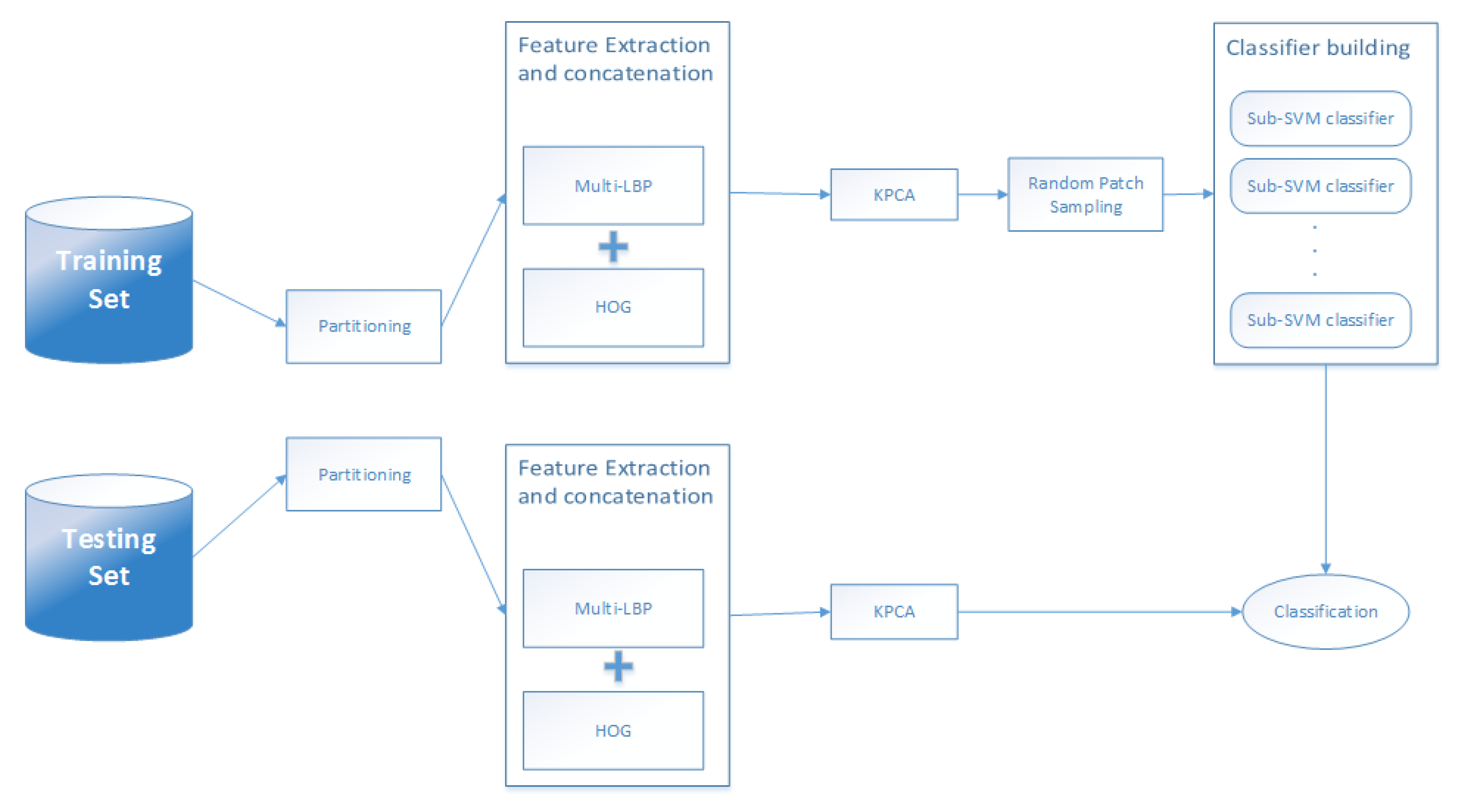
The proposed algorithm works as follows: First, each image is partitioned into several 50% overlapping regions/blocks. Then, the LBP and HOG descriptors are used to individually extract features from the generated image patches. Since the previous step generates high dimensionality descriptors, potentially including redundancies, the KPCA method is used in order to extract the most significant feature patterns of the descriptors. Next, the reduced descriptors of the image patches are normalised and fed to the classification module. Finally, a number of patches are randomly sub-sampled within each image training set in order to build multiple SVM classifiers from each subset. The validation of the proposed algorithm was performed through extensive experiments using a single sample per person as per real world conditions. A combination of the final results of the performances generated from all the sub-classifiers is performed with a union rule. Figure 1 depicts the process.
2.1. Face Patching
Let S be a greyscale image. S can be defined as a collection of k patches. The blocks can be overlapping, non-overlapping, covering, or non-covering. The shapes and sizes can vary as well. Figure 2 is an illustration of overlapping blocks.
Selecting the optimum patch size is an important step since the recognition performances can be significantly affected. This is mainly due to the fact that the extracted features may adversely correlate in small blocks while the more discriminative ones may not be captured especially in large patches. In this work, the face patches are selected in rectangular shape and each overlapping by 50%. This is because, as explained above, the features may correlate in small blocks and, thus, an overlap of 50% would help to capture more distinguishing features while avoiding excessive redundancies. As for determining the appropriate patch size, initial experiments were carried out by varying the block size [18] and noting the performances, a size of 33 × 30 was found to be the best and it is noted that it relates to the image’s original size of 165 × 120.
2.2. Multi-Scale Local Binary Patterns
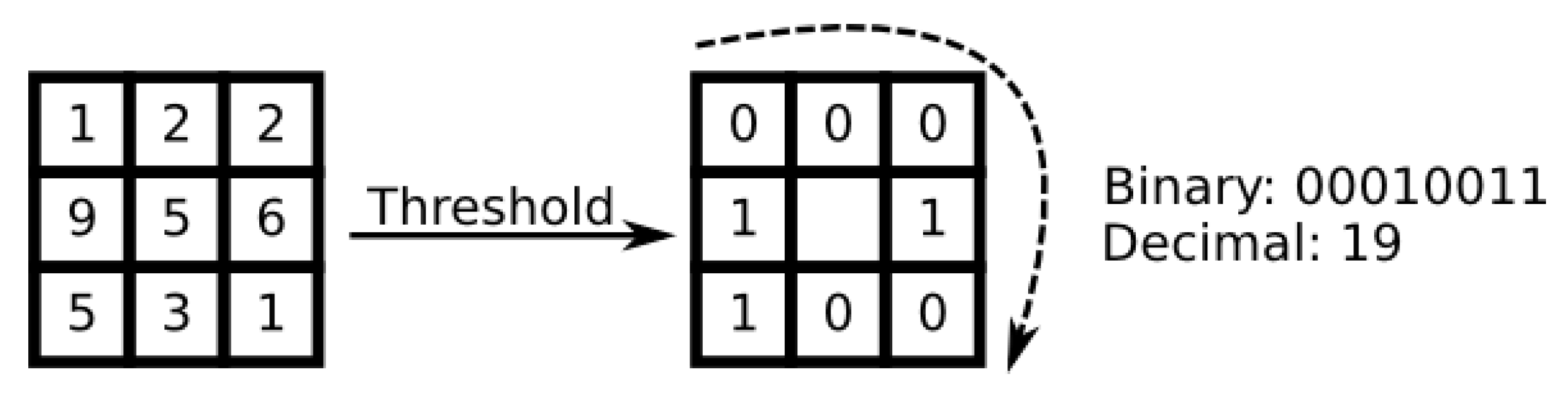
The LBP operator has gained much popularity as a local texture descriptor for various computer vision and biometric security applications including face recognition [19]. It is based on a combination of greyscale invariants and works by thresholding and labelling a pixel of an image neighbourhood (P, R) (P sampling points on a circle of radius R) against the central pixel value. This results in a binary number and the histogram of the labels can the be used as a texture descriptor.
One of the earliest LBP neighbourhoods introduced is (8, 1) and is generated by the 8 neighbouring pixels in a radius of 1, as shown in Figure 3. This scheme was later extended to other neighbourhoods having larger sizes. As can be seen in Figure 3, the threshold value is generally the value of the central pixel which can be used for comparing the neighbourhood pixels . The result of applying the operator would give 1 if the is larger than and 0 otherwise. The final form of the LBP is an integer value and the features extracted by the LBP operator can be represented as histograms. Mathematically, this can be expressed as:
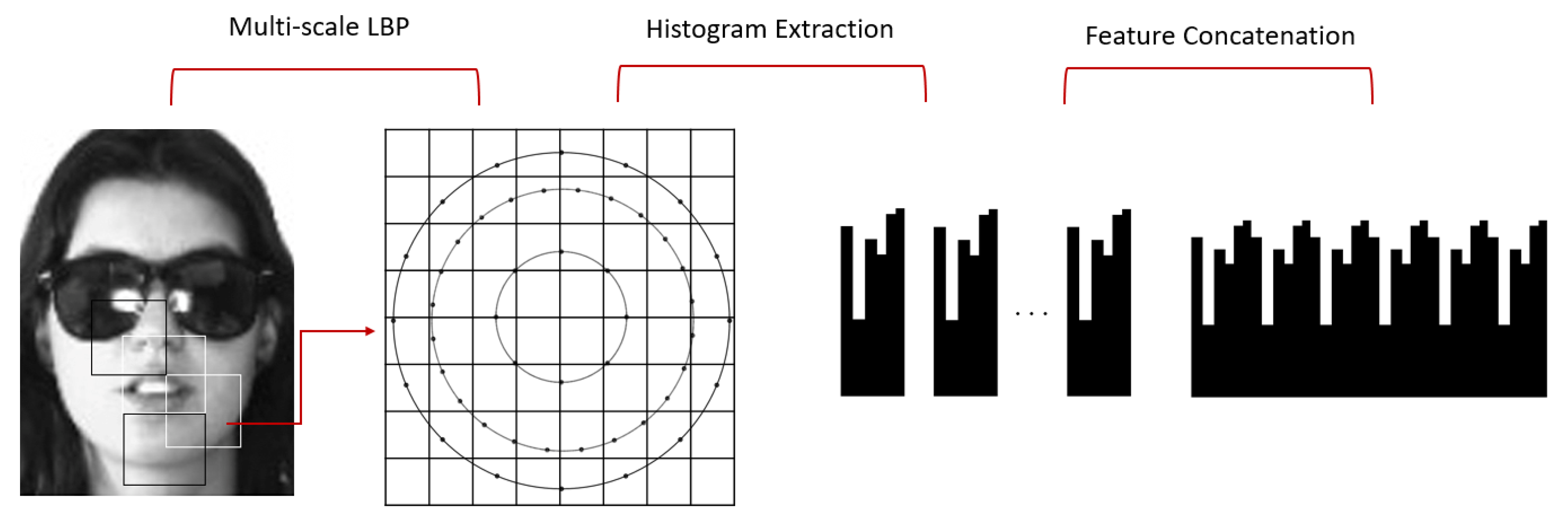
The local neighbourhood (P, R) is a set of evenly spaced sampling points P on a circle of radius R centred at a fixed pixel. Uniform patterns [20] were inspired from the fact that some binary patterns occur more commonly in facial images than others. LBP is called uniform when the binary pattern contains at most two bitwise transitions from 0 to 1 or vice versa when the bit pattern is considered circular. By using uniform patterns and computing the occurrence histogram, structural and statistical approaches are effectively combined. The distribution of micro structures-like edges, lines, and flat areas is estimated by the uniform histogram. LBP histograms have been introduced for face description in [21], where the face images are divided into a number of local regions allowing for the texture descriptors to be extracted from each region. The descriptors are then combined into one uniform histogram representing the face image as depicted in Figure 4.
Uniform histograms were proposed as a result of the observation that some binary patterns do occur more commonly in face images than others and are therefore used to reduce the usual length of 256-bins patterns to smaller 59 patterns [20]. In addition, since the area covered by a conventional LBP algorithm is usually small, a uniform multi-scale LBP has been chosen in our work. This ensures that neighbourhoods with varying sizes can be used. Therefore, an LBP is carried out using various sample points , , and . The extracted feature vectors from each neighbourhood are then concatenated to form one uniform LBP histogram having 857 bins. This method covers a larger area, thus providing a much larger range of discriminative descriptors. The choice of LBP neighbourhoods is based on the best results obtained from initial experiments. The neighbourhoods LBP(3, 8), LBP(8, 16), and LBP(6, 24) offer a different range of features on different levels.
2.3. Histograms of Oriented Gradients
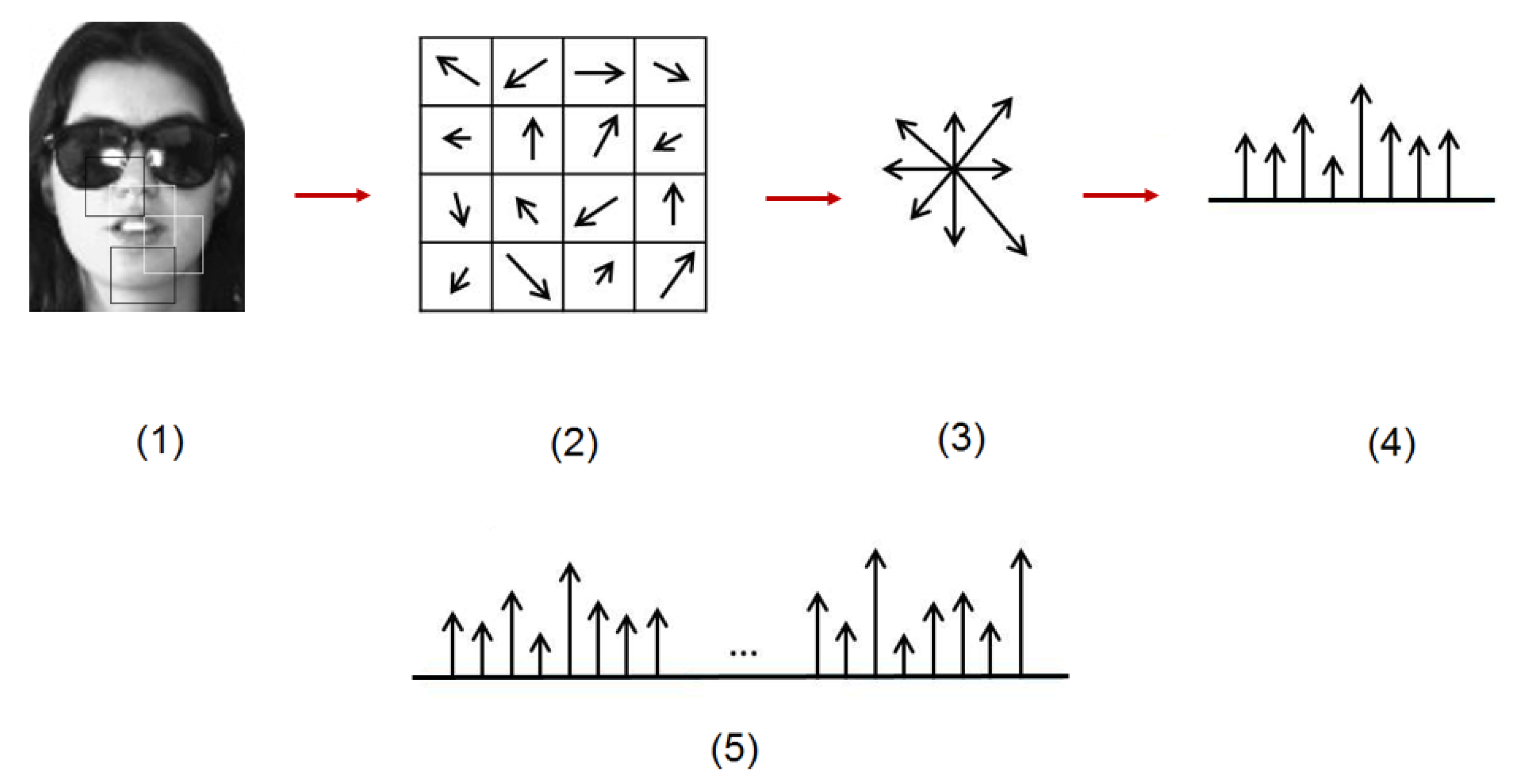
Histograms of Oriented Gradients is a representation that captures edge or gradient structures/patterns that are very characteristic to local shapes (counts occurrences of edge orientations). They are also invariant to geometric transformations when they are smaller than the local spatial or orientation bin size. They have been used mainly in human detection [22,23] and later for recognition [24]. HOG features are calculated by taking orientation histograms of the edge intensity in local regions. An image can be divided into N local regions called ‘blocks’. Each block can then be divided into smaller spatial areas called ‘cells’. Consequently, each block is defined as a set of cells.
Figure 5 describes a step-by-step overview of the method. Each image patch is first divided into blocks of A × B pixels, then each block is divided into a number of a × b cells from which histograms of oriented gradients with k orientations are computed. After that, histograms from each cell are concatenated into one histogram representing the whole block. These histograms are then concatenated together to represent each patch.
2.4. Kernel Principal Component Analysis
Kernel PCA, which remains one of the most effective nonlinear dimensionality reduction techniques [25], is a nonlinear extension of conventional PCA that uses second order statistics to take into account partial statistical information of the face image at hand. In addition, higher order statistics have become a useful tool resulting from the extension of PCA using kernels. This works by mapping texture patterns of the original input space to a higher nonlinear dimensional feature vector space [25]. Its appearance is due mainly to the need to carry out PCA in the feature space. Previously, it was not possible to perform PCA in the feature space due to the high computational expense of the dot product computation in the high dimensional feature space [26] and, thus, the appearance of kernel PCA. Ultimately, KPCA is implemented and performed in the input space by using various kernels without the need to perform the mapping explicitly [27], thus overcoming the initial issue. Let the set be the data in the input space and there exists a nonlinear mapping between the input and the feature space.
KPCA has been used extensively in various face recognition applications [28,29,30], including facial expression under illumination variations and proven to give satisfactory results as compared to other feature reduction techniques, thus its use in this work. Furthermore, this work uses the polynomial kernel since it has shown to effectively extract discriminative facial features.
2.5. Random Patch-Based SVM
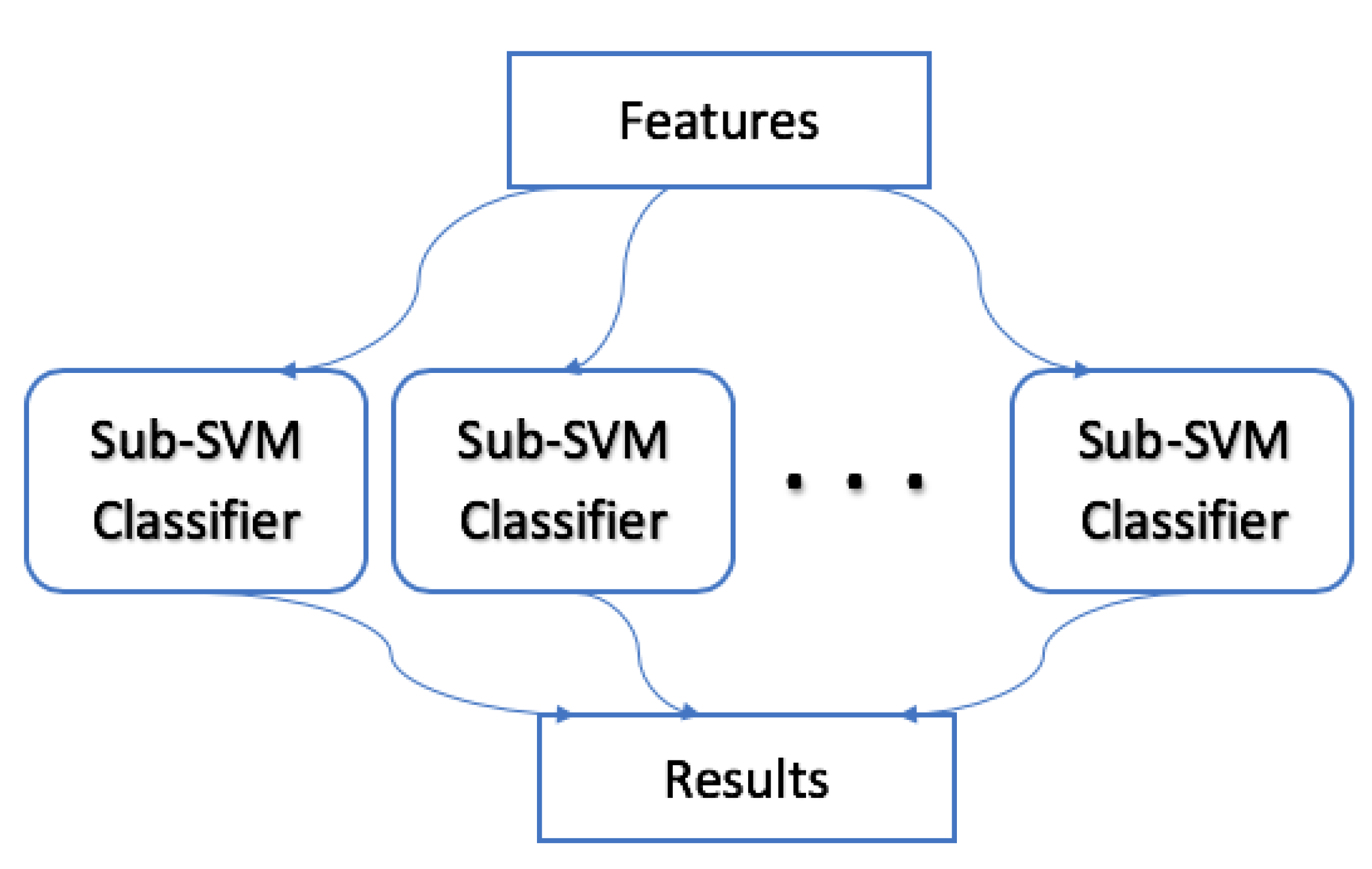
In previous papers employing patched faces, researchers have either deployed all the patches or have selected only a smaller number of blocks to construct a global classifier. In our approach described in [18], we have chosen the use of a random sampling method to construct more than one classifier to improve the recognition performances. In this case, a random sample can be seen as a subset of a population selected by considering that all samples have an equal occurrence probability. Support Vector Machine [31], which has been selected at the matching stage, has been found to be very effective. SVM is a type of binary supervised learning algorithm where the classification module is trained by mapping the training set feature vectors in a space that efficiently separates them using some kernel function (for example, polynomial, Gaussian…). Once done, the test set is mapped onto the same space. Typically, an SVM classifier determines an optimal hyperplane for use as a decision function in a high-dimensional space, thus predicting the optimum class using an in-between maximum distance. The novelty of our approach relates to the new approach of training multiple SVM classifiers based on the sub-training sets, and combining the individual results with a union rule to obtain the final score as illustrated in Figure 6. SVM has shown clear advantages in different applications [32] dealing with nonlinear data as well as high dimensionality and small samples, thus making it ideal for the problem at hand.
3. Experiments and Analysis
In order to assess the effectiveness of the proposed approach, experiments were carried out using two different and well known datasets.
3.1. AR Face Dataset
The first dataset used, the cropped AR face database [27], contains 2600 images generated from 100 individuals (26 different images per person) taken in two sessions under various distortions including facial expression, lighting, and occlusions. A resizing of the images into 165 × 160 pixels has been performed in this experiment. Some sample images of this dataset are shown in Figure 7.
The training step used a single clean image per person from the first session. The training set has been divided into two sets depending on the type of occlusions present in each image. ‘set1’: sunglasses-occluded faces and ‘set2’: scarf-occluded faces from both sessions. See Figure 8
3.1.1. Experiments Part 1: Single Descriptor
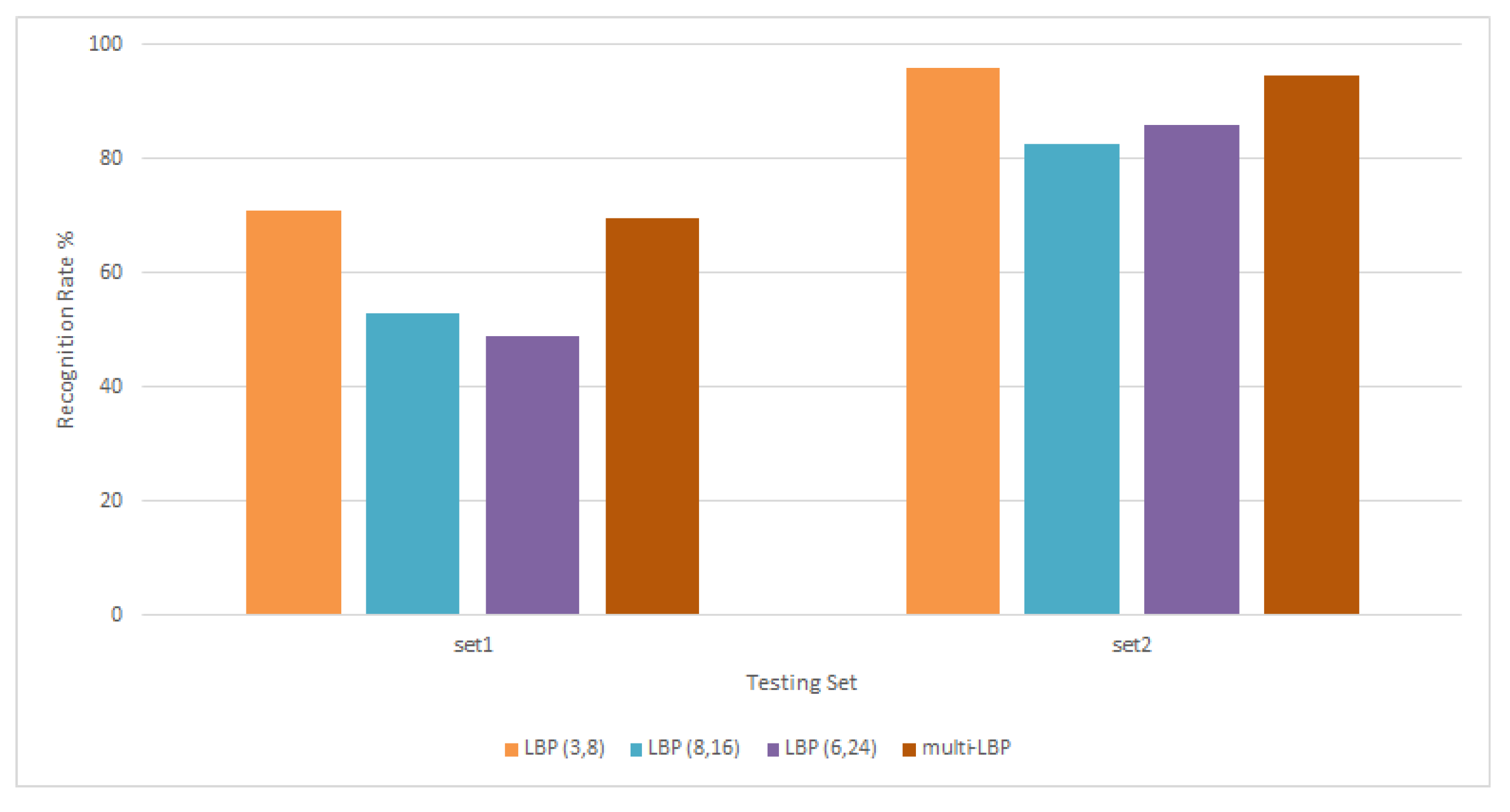
Experiments started out by testing the proposed approach using LBP and HOG separately. First, the following LBP neighbourhoods have been used: LBP(8, 3), LBP(16, 8), and LBP(24, 6). After extracting the features using each scale separately, the resulting feature vectors are then concatenated into one big feature set. Following the LBP algorithm, Figure 9 presents the accuracy rate of each neighbourhood separately and when the features are concatenated before classification.
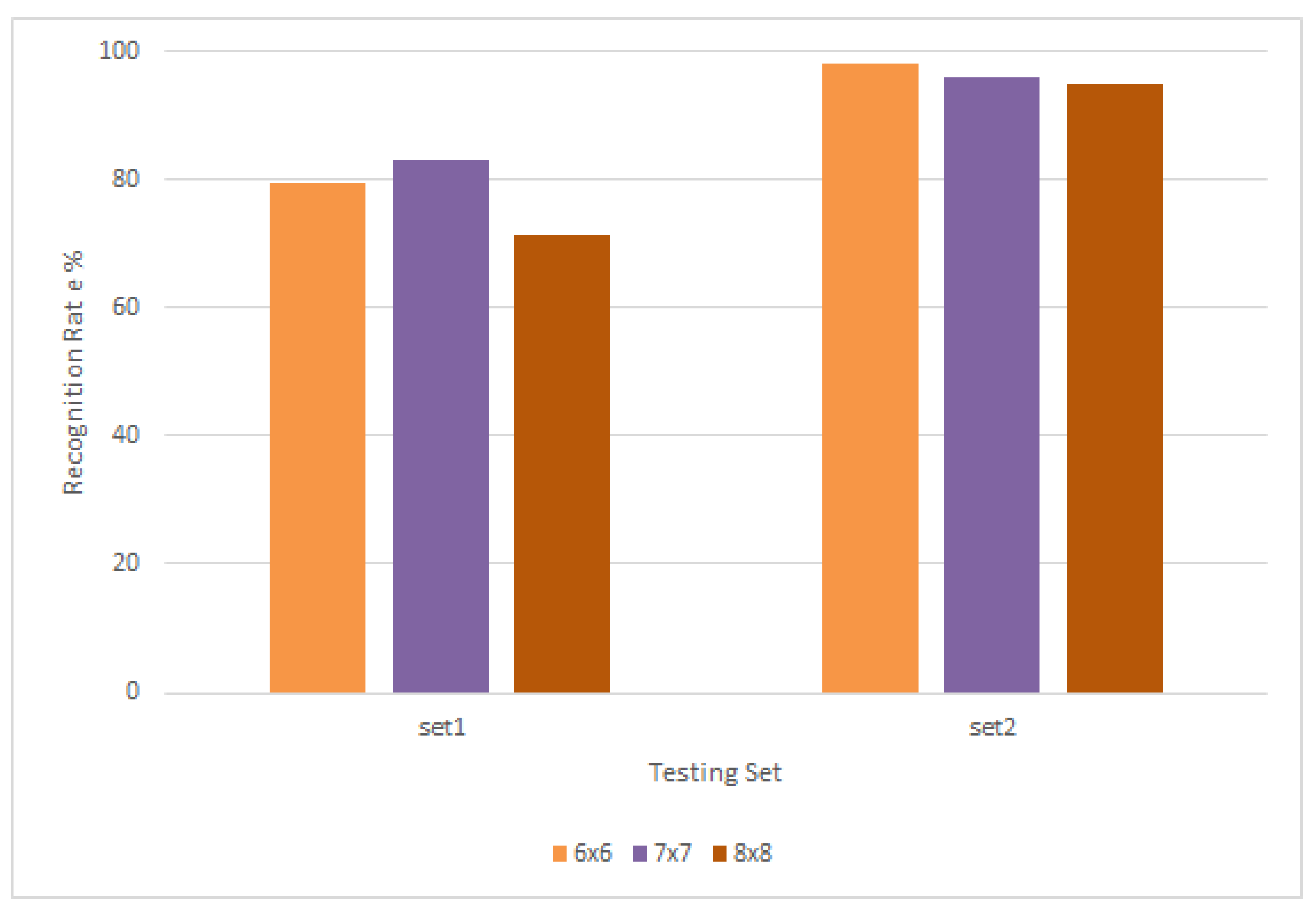
It is observed that each LBP neighbourhood gives different results depending on the testing set and type of occlusion present in the images, with scoring the highest rate for both sets. It is therefore concluded that the combination will tackle different types of challenges as compared to single-scale. From the same figure, it is seen that the multi-LBP goes as high as 95% for set2 and averaging around 70% for set1. Next, when extracting HOG features, the following cell sizes have been used: 6 × 6, 7 × 7, and 8 × 8 as seen in Figure 10. The results show that each cell size works differently for each testing set. In the same figure it could be seen that the recognition rate for set1 goes up to 83% and 96% for set2 with cell size 7 × 7. The last rate is lower compared to cell size 6 × 6, which reaches 98%. Cell size 8 × 8 records lower recognition rate than both smaller cells. It is to be noted that the smaller the cell, the more features HOG produces as their number increases.
3.1.2. Experiments Part 2: Multi-Descriptor
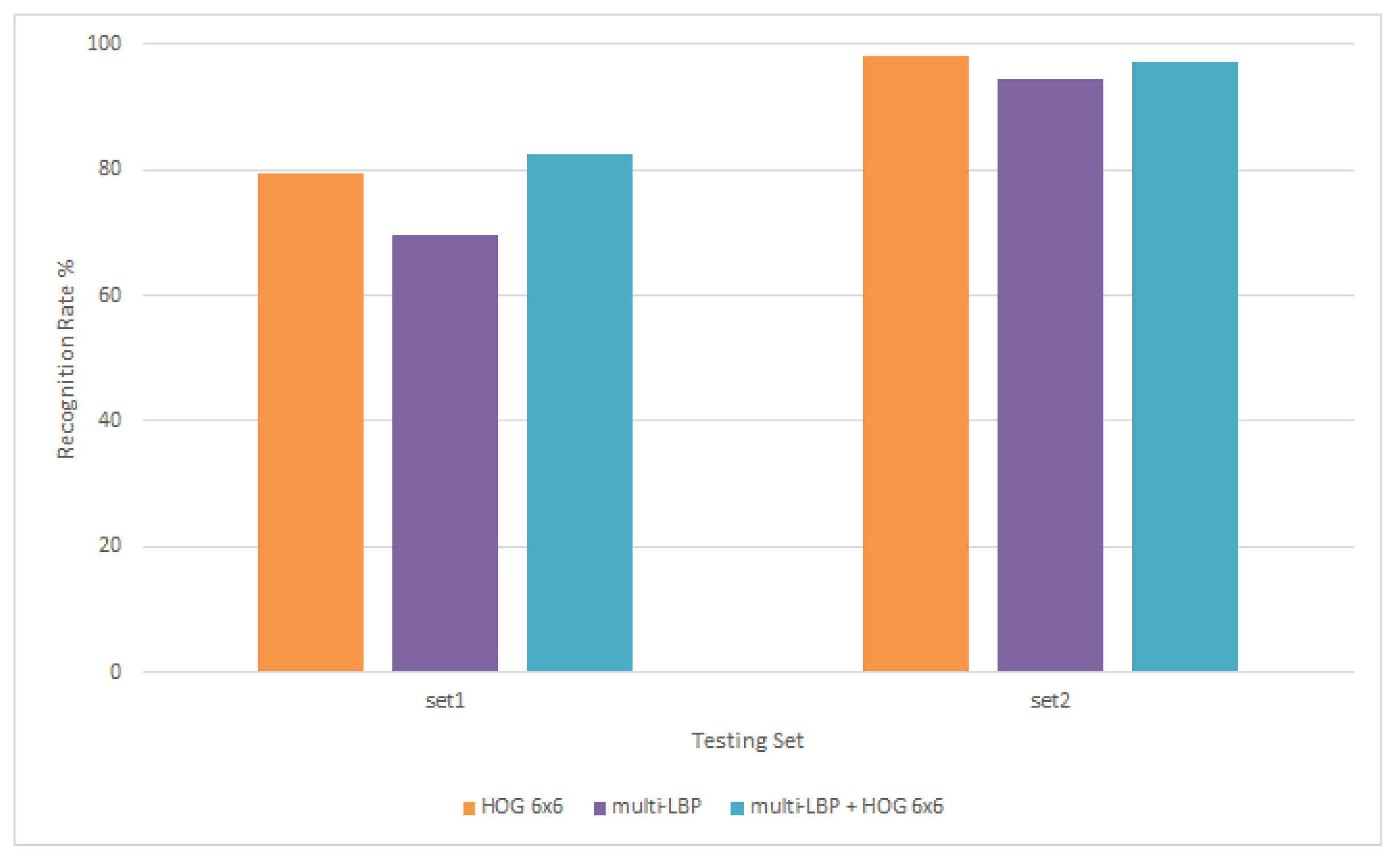
The second set of experiments focused on the combination of both HOG and LBP features for classification. First, multi-LBP features used previously (see Figure 9) are concatenated with HOG features from Figure 11. Results in Figure 11 show that although the recognition rate for the combination is higher, especially for test set1 reaching as high as 81%, the improvement is slight and insignificant.
Another experiment was carried out to validate the approach using different HOG features using a cell size of 8 × 8. The results are depicted in Figure 12, where it clearly shows a significant improvement for test set1, increasing sharply and reaching an outstanding 91% as compared to previous results that fall below 83%. Test set2 sees an increase as well to a high rate of 98.5%.
Although the HOG features used in the last experiments have lower recognition rates separately compared to when using different HOG cell sizes (see Figure 10), their combination with LBP features has given superior results. It can be concluded that both types of features are complimentary for both testing sets making them more robust against different partial-occlusion types.
3.1.3. Experiments Part 3: Classifier Size
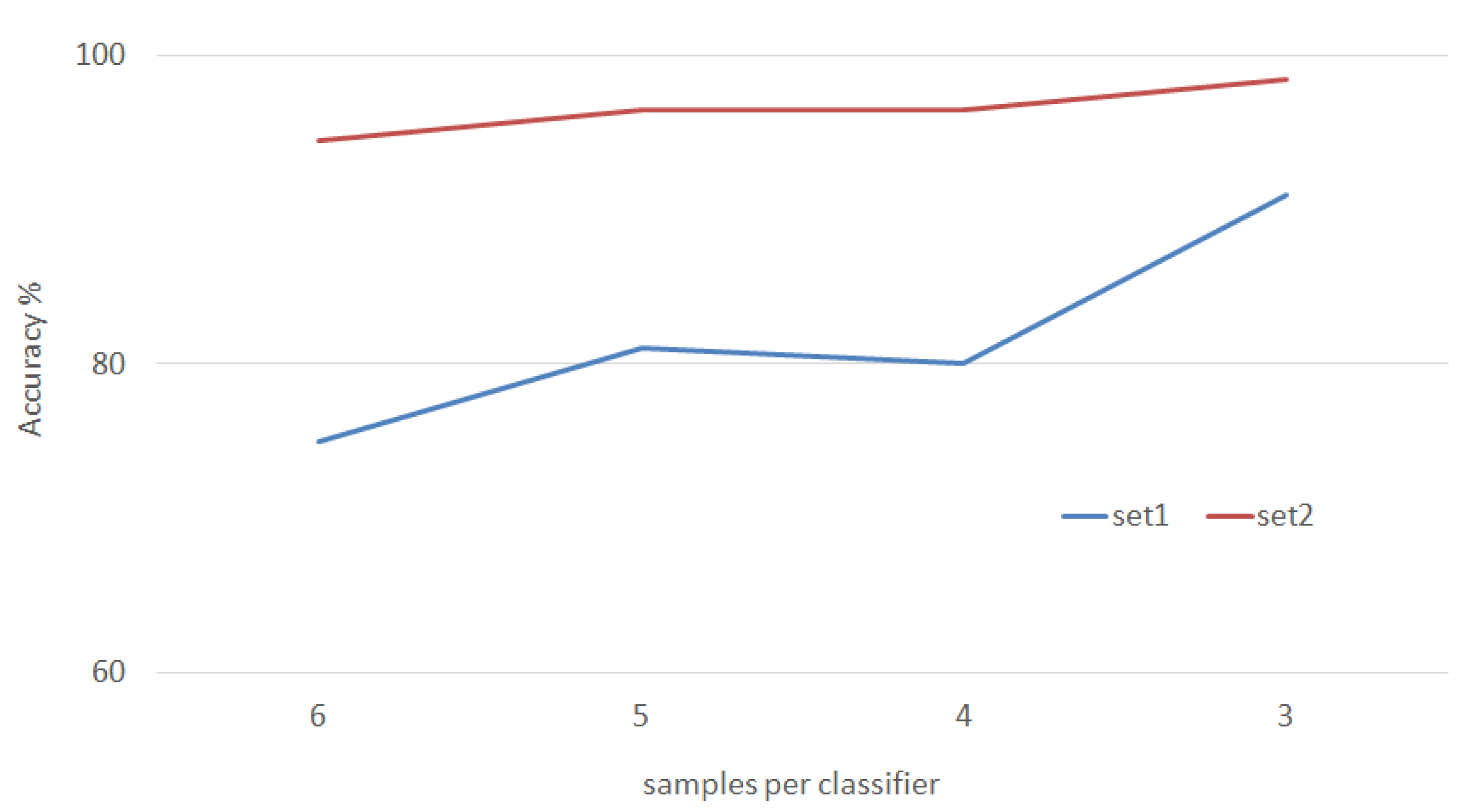
In the third set of experiments, the number of samples used per SVM classifier is varied in order to find the best subset. Figure 13 presents the results of the conducted experiments decreasing the number of samples each time. For testing set1, the accuracy rate sees a noticeable increase as the number of samples used decreases, starting from 75% when the number samples p = 6 and going to a highest of 91% when p = 3. The same observation for testing set2, as it starts from 94.5% when p = 6 going up as p decreases and rating 98.5% when p = 3.
These results and observations can be explained by the fact that a smaller training set decreases the possibility of error, thus making the accuracy higher and the approach more robust in general.
Another observation relates to the difference between the performance rates of test set1 and test set2. Even though in set2, the scarf used as partial occlusion hides a larger chunk of the face as compared to set1 where only the eyes are invisible (see Figure 8), set2 gives higher performance accuracy when tested under the proposed approach. This can be concluded that the features extracted from the eyes and eyebrows using the proposed method play a significant role in recognition as compared to other parts of the face.
Table 1 shows the results of our comparative study of our approach against some existing and similar approaches available in literature including our previous work [18]. From the results shown in the table, one can observe that our proposed method clearly compares favourably when compared against some of the best performing algorithms. For example, our proposed technique attains 98% performance accuracy, thus matching [14,33] using the scarf-occluded set. It is also worth mentioning that the authors in [33] have used more than one training sample in their analysis, unlike the proposed method which uses a single training sample, thus making it more recommendable as it operates under real world conditions.
3.2. Extended Yale B Dataset
The Extended Yale B database [34] consists of 2414 frontal face images generated from 38 persons using 64 different illumination conditions. In addition, an image with ambient illumination was also captured for every subject in all poses. Then, the images are grouped into four different subsets depending on the lighting angle with respect to the axis of the camera. Typically, subset1 and subset2 cover the range of 0° to 25° while subset3 covers the angular range of 25° to 50°. subset4 covers 50° to 77° and subset5 covers angles which are larger than 78°. To allow a simulation of different levels of contiguous occlusions, the most widely used technique described in [35] is used to replace a randomly located square patch from each test image with a baboon image, this is because it has a texture similar to that of the human face. Moreover, the location of the occlusion is randomly selected. The sizes of the synthetic occlusions vary in the range of 10% to 80% of the original image size. Figure 14 shows some samples of randomly occluded faces generated from the Extended Yale B database.
For this set of experiments, subset1 was used for training while the remaining 4 subsets were used for testing. For the other parameters, the best performing ones from the previous experiments were used. First, the original image size of 192 × 168 was kept, and 50% overlapping patches were sized equally at 32 × 28 each. The classifier size was set to p = 3, the HOG cell size to 6 × 6 combined with multi-LBP.
The average recognition accuracy for each subset for an occlusion level ranging between 10% and 80% is depicted in Figure 15.
The obtained results have been evaluated and compared against some state-of-the-art algorithms and Table 2 depicts the accuracy percentages. From the table, it can be observed that our proposed method achieves consistent results throughout the experiments. Despite not reaching a higher accuracy at small occlusions, its increase does not affect it as does the SSR-P/W method proposed in [36]. Finally, it eventually outperforms it when occlusion is at 50%, reaching 90.58% as compared to 88.6% for SSR-W, in subset5.
Further results can be seen in Table 3, which are consistent even when occlusion increases. The accuracy remains above 85% for any occlusion level and under different lighting conditions. This could also be seen in Figure 15, where the average accuracy for each of the four testing sets has been illustrated.
4. Conclusions
This paper has proposed a novel face recognition algorithm using the concept of random patching. The method operates by dividing the face images into a number of non-overlapping patches. Next, LBP operator is employed as a local descriptor and then combined with HOG technique to extract a concatenated descriptor of the image patches. A dimensionality reduction step using KPCA method is then applied to the inherent high dimensional descriptors. Once done, a random patch sampling operation is employed allowing us to build a number of sub-SVM classifiers. Finally, the results from the classification obtained from the SVMs are fused using a simple union rule. The experiments carried out suggest that the proposed algorithm performs favourably when compared against conventional global SVM face classifiers when the lower part of the face is missing (up to 98.5%). Furthermore, the algorithm outperforms other similar state-of-the-art techniques, thus clearly demonstrating its potential recognition performances, even when working in an under-sampled and challenging operational environment.
Author Contributions
Conceptualisation, I.C. and A.B. (Ahmed Bouridane); methodology, I.C.; formal analysis, I.C.; implementation, I.C.; writing–original draft preparation, I.C.; writing–review and editing, I.C., A.B. (Ahmed Bouridane); supervision, A.B. (Ahmed Bouridane), N.A.-M. and R.J.; funding acquisition, N.A.-M., A.B. (Ahmed Bouridane) and A.B. (Azeddine Beghdadi). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by NPRP grant # NPR 8-140-2-065 from the Qatar National Research Fund (a member of Qatar Foundation). The statements made herein are solely the responsibility of the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hassaballah, M.; Aly, S. Face recognition: Challenges, achievements and future directions. IET Comput. Vis. 2015, 9, 614–626. [Google Scholar] [CrossRef]
- Turk, M.A.; Pentland, A.P. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1991; pp. 586–591. [Google Scholar]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [Green Version]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Plataniotis, K.N.; Venetsanopoulos, A.N. Face recognition using kernel direct discriminant analysis algorithms. IEEE Trans. Neural Netw. 2003, 14, 117–126. [Google Scholar] [PubMed] [Green Version]
- Kim, K.I.; Jung, K.; Kim, H.J. Face recognition using kernel principal component analysis. IEEE Signal Process. Lett. 2002, 9, 40–42. [Google Scholar]
- Hadid, A.; Ylioinas, J.; López, M.B. Face and texture analysis using local descriptors: A comparative analysis. In Proceedings of the 2014 4th International Conference on Image Processing Theory, Tools and Applications (IPTA), Paris, France, 14–17 October 2014; pp. 1–4. [Google Scholar]
- Gottumukkal, R.; Asari, V.K. An improved face recognition technique based on modular {PCA} approach. Pattern Recognit. Lett. 2004, 25, 429–436. [Google Scholar] [CrossRef]
- Ekenel, H.K.; Stiefelhagen, R. Local appearance based face recognition using discrete cosine transform. In Proceedings of the 13th European Signal Processing Conference (EUSIPCO 2005), Antalya, Turkey, 4–8 September 2005. [Google Scholar]
- Tan, K.; Chen, S. Adaptively weighted sub-pattern PCA for face recognition. Neurocomputing 2005, 64, 505–511. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Liu, J.; Chen, S. Semi-random subspace method for face recognition. Image Vis. Comput. 2009, 27, 1358–1370. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Shan, S.; Chen, X.; Gao, W. Hierarchical ensemble of global and local classifiers for face recognition. IEEE Trans. Image Process. 2009, 18, 1885–1896. [Google Scholar] [CrossRef] [PubMed]
- Sapkota, A.; Boult, T. Context-patch for difficult face recognition. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 59–66. [Google Scholar]
- McLaughlin, N.; Ming, J.; Crookes, D. Largest Matching Areas for Illumination and Occlusion Robust Face Recognition. IEEE Trans. Cybern. 2017, 47, 796–808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the BMVC 2015, Swansea, UK, 7–10 September 2015; Volume 1, p. 6. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- Cheheb, I.; Al-Maadeed, N.; Al-Madeed, S.; Bouridane, A.; Jiang, R. Random sampling for patch-based face recognition. In Proceedings of the 2017 5th International Workshop on Biometrics and Forensics (IWBF), Coventry, UK, 4–5 April 2017; pp. 1–5. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face recognition with local binary patterns. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2004; pp. 469–481. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face Description with Local Binary Patterns: Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar]
- Déniz, O.; Bueno, G.; Salido, J.; De la Torre, F. Face recognition using histograms of oriented gradients. Pattern Recognit. Lett. 2011, 32, 1598–1603. [Google Scholar] [CrossRef]
- Liu, C. Gabor-based kernel PCA with fractional power polynomial models for face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 572–581. [Google Scholar] [PubMed]
- Meshgini, S.; Aghagolzadeh, A.; Seyedarabi, H. Face recognition using Gabor filter bank, kernel principle component analysis and support vector machine. Int. J. Comput. Theory Eng. 2012, 4, 767. [Google Scholar] [CrossRef]
- Martínez, A.M.; Kak, A.C. Pca versus lda. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhang, Y. The facial expression recognition based on KPCA. In Proceedings of the 2010 International Conference on Intelligent Control and Information Processing, Dalian, China, 13–15 August 2010; pp. 365–368. [Google Scholar]
- Xie, X.; Zheng, W.S.; Lai, J.-H.; Suen, C.Y. Restoration of a Frontal Illuminated Face Image Based on KPCA. In Proceedings of the 2010 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 2150–2153. [Google Scholar]
- Ebied, H.M. Feature extraction using PCA and Kernel-PCA for face recognition. In Proceedings of the 2012 8th International Conference on Informatics and Systems (INFOS), Giza, Egypt, 14–16 May 2012; pp. MM-72–MM-77. [Google Scholar]
- Guo, G.; Li, S.Z.; Chan, K. Face recognition by support vector machines. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 28–30 March 2000; pp. 196–201. [Google Scholar]
- Zhang, Y. Support vector machine classification algorithm and its application. In International Conference on Information Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 179–186. [Google Scholar]
- Wei, X.; Li, C.T.; Hu, Y. Face recognition with occlusion using dynamic image-to-class warping (DICW). In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Lee, K.; Ho, J.; Kriegman, D. Acquiring Linear Subspaces for Face Recognition under Variable Lighting. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 684–698. [Google Scholar] [PubMed]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, X.; Li, C.T.; Hu, Y. Robust face recognition under varying illumination and occlusion considering structured sparsity. In Proceedings of the 2012 International Conference on Digital Image Computing Techniques and Applications (DICTA), Fremantle, WA, Australia, 3–5 December 2012; pp. 1–7. [Google Scholar]
Figure 1.
Diagram explaining Random Patch SVM for face recognition.

Figure 2.
Example of overlapping patches of an image from the AR dataset.

Figure 3.
Illustration of the original LBP operator.

Figure 4.
The process of extracting multi-LBP features from face images.

Figure 5.
The process of extracting HOG features from face images: (1) Original face image after patching (2) partition of each patch into cells (3) extraction of HOG features from each cell (4) Concatenation of HOG features of each cell (5) Concatenation of HOG histograms of all cells into a single histogram.
Figure 5.
The process of extracting HOG features from face images: (1) Original face image after patching (2) partition of each patch into cells (3) extraction of HOG features from each cell (4) Concatenation of HOG features of each cell (5) Concatenation of HOG histograms of all cells into a single histogram.

Figure 6.
Illustration of the classification process using multiple sub-SVM classifiers.

Figure 7.
Sample images from the AR Face Dataset.

Figure 8.
Example of testing images from the AR dataset.

Figure 9.
Results of experiments conducted using different LBP neighbourhoods.

Figure 10.
Results of experiments conducted using different HOG descriptors.

Figure 11.
Results of experiments carried out by combining HOG (with a cell size of 6 × 6) and LBP.

Figure 12.
Experiments carried out using HOG with a cell size of 8 × 8 and LBP.

Figure 13.
Obtained recognition rates with varying numbers of samples per sub-SVM classifier.

Figure 14.
Sample images from the Extended Yale B dataset with randomly located occlusions.

Figure 15.
Results for each Extended Yale B dataset subset averaged over the different levels of occlusion.
Figure 15.
Results for each Extended Yale B dataset subset averaged over the different levels of occlusion.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparing Random Patching approach results on the AR dataset to the literature.
| Test Conditions | Sunglasses % | Scarf % |
|---|---|---|
| Previous work [18] | 73∼89 | 92∼98 |
| Our approach | 91 | 98.5 |
| LMA/LMA-UDM [14] | 96∼98 | 97∼98 |
| DICW [33] | 99.5 | 98 |
Table 2.
Comparative analysis of the proposed approach using the Extended Yale B Datatset.
| Occlusion % | 10 | 20 | 30 | 40 | 50 | |
|---|---|---|---|---|---|---|
| subset3 | SSR-P [36] | 100 | 100 | 100 | 97.8 | 85.4 |
| Our Method | 94.26 | 94.53 | 94.57 | 94.89 | 90.78 | |
| subset4 | SSR-W [36] | 99.8 | 99.4 | 99.4 | 99.6 | 98.1 |
| Our Method | 87.04 | 85.52 | 90.90 | 89.96 | 90.29 | |
| subset5 | SSR-W [36] | 98.0 | 97.3 | 95.8 | 95.4 | 88.6 |
| Our Method | 89.38 | 86.53 | 90.54 | 90.02 | 90.58 |
Table 3.
Further Results on the Extended Yale B Datatset.
| Occlusion % | 60 | 70 | 80 |
|---|---|---|---|
| subset3 | 90.07 | 89.17 | 90.08 |
| subset4 | 89.03 | 93.85 | 89.85 |
| subset5 | 90.58 | 86.66 | 86.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cheheb, I.; Al-Maadeed, N.; Bouridane, A.; Beghdadi, A.; Jiang, R. Multi-Descriptor Random Sampling for Patch-Based Face Recognition. Appl. Sci. 2021, 11, 6303. https://doi.org/10.3390/app11146303
AMA Style
Cheheb I, Al-Maadeed N, Bouridane A, Beghdadi A, Jiang R. Multi-Descriptor Random Sampling for Patch-Based Face Recognition. Applied Sciences. 2021; 11(14):6303. https://doi.org/10.3390/app11146303
Chicago/Turabian StyleCheheb, Ismahane, Noor Al-Maadeed, Ahmed Bouridane, Azeddine Beghdadi, and Richard Jiang. 2021. "Multi-Descriptor Random Sampling for Patch-Based Face Recognition" Applied Sciences 11, no. 14: 6303. https://doi.org/10.3390/app11146303
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.