A Maximum-Entropy Method to Estimate Discrete Distributions from Samples Ensuring Nonzero Probabilities


1
Institute of Water Resources and River Basin Management, Karlsruhe Institute of Technology—KIT, 76131 Karlsruhe, Germany
2
Institute for Modelling Hydraulic and Environmental Systems (IWS), University of Stuttgart, 70569 Stuttgart, Germany
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(8), 601; https://doi.org/10.3390/e20080601
Submission received: 18 July 2018
/
Revised: 9 August 2018
/
Accepted: 13 August 2018
/
Published: 13 August 2018
(This article belongs to the Section Information Theory, Probability and Statistics)
{kind=link}
{kind=link}
{kind=link}
Abstract
:When constructing discrete (binned) distributions from samples of a data set, applications exist where it is desirable to assure that all bins of the sample distribution have nonzero probability. For example, if the sample distribution is part of a predictive model for which we require returning a response for the entire codomain, or if we use Kullback–Leibler divergence to measure the (dis-)agreement of the sample distribution and the original distribution of the variable, which, in the described case, is inconveniently infinite. Several sample-based distribution estimators exist which assure nonzero bin probability, such as adding one counter to each zero-probability bin of the sample histogram, adding a small probability to the sample pdf, smoothing methods such as Kernel-density smoothing, or Bayesian approaches based on the Dirichlet and Multinomial distribution. Here, we suggest and test an approach based on the Clopper–Pearson method, which makes use of the binominal distribution. Based on the sample distribution, confidence intervals for bin-occupation probability are calculated. The mean of each confidence interval is a strictly positive estimator of the true bin-occupation probability and is convergent with increasing sample size. For small samples, it converges towards a uniform distribution, i.e., the method effectively applies a maximum entropy approach. We apply this nonzero method and four alternative sample-based distribution estimators to a range of typical distributions (uniform, Dirac, normal, multimodal, and irregular) and measure the effect with Kullback–Leibler divergence. While the performance of each method strongly depends on the distribution type it is applied to, on average, and especially for small sample sizes, the nonzero, the simple “add one counter”, and the Bayesian Dirichlet-multinomial model show very similar behavior and perform best. We conclude that, when estimating distributions without an a priori idea of their shape, applying one of these methods is favorable.
1. Introduction
Suppose a scientist, having gathered extensive data at one site, wants to know whether the same effort is required at each new site, or whether already a smaller data set would have provided essentially the same information. Or imagine an operational weather forecaster working with ensembles of forecasts. Working with ensemble forecasts usually involves handling considerable amounts of data, and the forecaster might be interested to know whether working with a subset of the ensemble is sufficient to capture the essential characteristics of the ensemble. If what the scientist and the forecaster are interested in is expressed by a discrete distribution derived from the data (e.g., the distribution of vegetation classes at a site, or the distribution of forecasted rainfall), then the representativeness of a subset of the data can be evaluated by measuring the (dis-)agreement of a distribution based on a randomly drawn sample (“sample distribution”) and the distribution based on the full data set (“full distribution”). One popular measure for this purpose is the Kullback–Leibler divergence [1]. Depending on the particular interest of the user, potential advantages of this measure are that it is nonparametric, which avoids parameter choices influencing the result, and that it measures general agreement of the distributions instead of focusing on particular aspects, e.g., particular moments.
For the use cases described above, if the sample distribution is derived from the sample data via the bin-counting (BC) method, which is the most common and probably most intuitive approach, a situation can occur where a particular bin in the sample distribution has zero probability but the corresponding bin in the full distribution has not. From the way the sample distribution was constructed, we know that this disagreement is not due to a fundamental disagreement of the two distributions, but rather that this is a combined effect of sampling variability and limited sample size. However, if we measure the (dis-)agreement of the two distributions via Kullback–Leibler divergence, with the full distribution as the reference, divergence for that bin is infinite, and consequently so is total divergence. This is impractical, as an otherwise possibly good agreement can be overshadowed by a single zero probability. A similar situation occurs if a distribution constructed from a limited data set (e.g., three months of air-temperature measurements) contains zero-probability bins, but from physical considerations we know that values falling into these zero-probability bins can and will occur if we extend the data set by taking more measurements.
Assuring nonzero (NZ) probabilities when estimating distributions is a requirement found in many fields of engineering and sciences [2,3,4]. If we stick to BC, this can be achieved either by adjusting the binning to avoid zero probabilities [5,6,7,8,9], or by replacing zero probabilities with suitable alternatives. Often-used approaches to do so are (i) assigning a single count to each empty bin of the sample histogram, (ii) assigning a (typically small) preselected probability mass to each zero probability bin in the sample pdf and renormalizing the pdf afterwards, (iii) spreading probability mass within the pdf by smoothing operations such as Kernel-density smoothing (KDS) [10] (an extensive overview on this topic can be found in Reference [11]), and (iv) assigning a NZ guaranteeing prior in a Bayesian (BAY) framework. Whatever method we apply, desirable properties we may ask for are introducing as little unjustified side information as possible (e.g., assumptions on the shape of the full distribution) and, like the BC estimator, convergence towards the full distribution for large samples.
In this context, the aim of this paper is to present a new method of calculating the sample distribution estimate, which meets the mentioned requirements, and to compare it to existing methods. It is related to and draws from approaches to estimate confidence intervals of discrete distributions based on limited samples [12,13,14,15,16,17]. In the remainder of the text, we first introduce the “NZ” method and discuss its properties. Then we apply the NZ method and four alternatives to a range of typical distributions, from which we draw samples of different sizes. We use Kullback–Leibler divergence to measure the agreement of the full and the sample distributions. We discuss the characteristics of each method and their relative performance with a focus on small sample sizes and draw conclusions on the applicability of each method.
2. The NZ Method
2.1. Method Description
For a variable with discrete distribution with bins, and a limited data sample , thereof of size , we derive a NZ estimator for based on as follows: For the occurrence probability of each bin (), we calculate a BC estimator and its confidence interval on a chosen confidence level (e.g., 95%).
Based on the fact that the occurrence probability of a given bin from -repeated trials follows a binomial distribution with parameters and , there exist several ways to determine a confidence interval for this situation [18]. Several of these methods approximate the binomial distribution with a normal distribution, which is only reasonable for large , or use other assumptions. To avoid any of these limitations and to keep the methods especially useful for cases of small (here the probability of observing zero probability bins is the highest), we calculate using the conservative yet exact Clopper–Pearson method [19]. It applies a maximum-likelihood approach to estimate given the sample of size . The required conditions for the method to apply are:
- there are only two possible outcomes of each trial,
- the probability of success for each trial is constant, and
- all trials are independent.
In our case, this is assured by distinguishing the two outcomes “the trial falls within the bin or not”, keeping the sample constant and random sampling.
In practice, there are two convenient ways to compute the confidence Interval . One way is to look it up, for example, in the original paper by Clopper and Pearson [19], where they present graphics of confidence intervals for different sample sizes , different numbers of observations , and different confidence levels. The second option is to compute the intervals using the Matlab function [~, CI] = binofit(x, n, alpha) (similar functions exist for R or python) with 1 − alpha defining the confidence level. This function uses a relation between the binomial and the Beta-distribution, for more details see e.g., Reference [20] (Section 7.3.4) and Appendix A.
For each , the NZ estimate is then calculated as the normalized mean value of the confidence interval according to Equation (1). Normalization with the sum of all for is required to assure that the total sum of probabilities in equals . For this reason, the normalized values of can differ a little from the mean of the confidence intervals.
Two text files with Matlab code (Version 2017b, MathWorks Inc., Natick, MA, USA) of the NZ method and an example application are available as Supplementary Material.
2.2. Properties
There are four properties of the NZ estimate that are important for our application:
- Maximum Entropy by default: For an increasing number of zero probability bins in , converges towards a uniform distribution. For any zero probability bin we get , assign the same confidence interval, and, hence, the same NZ estimate. Consequently, estimating on a size-zero sample results in a uniform distribution with for all , which is a maximum-entropy (or minimum-assumption) estimate. For small samples, the NZ estimate is close to a uniform distribution.
- Positivity: As probabilities are restricted to the interval , and it always holds , the mean value of the confidence interval is strictly positive. This also applies to the normalized mean. This is the main property we were seeking to be guaranteed by .
- Convergence: Since is a consistent estimator (Reference [21], Section 5.2), it converges in probability towards for growing sample size . Moreover, the ranges of the confidence intervals approach zero with increasing sample size (Reference [19], Figures 4 and 5) and hence, the estimates converge towards .
- As described above, due to the normalization in the method, the NZ estimate does not exactly equal the mean of the confidence interval. However, the interval’s mean tends towards with growing and, hence, the normalizing sum in the denominator tends towards one. Consequently, for growing sample size , the effect of the normalization is of less and less influence.
2.3. Illustration of Properties
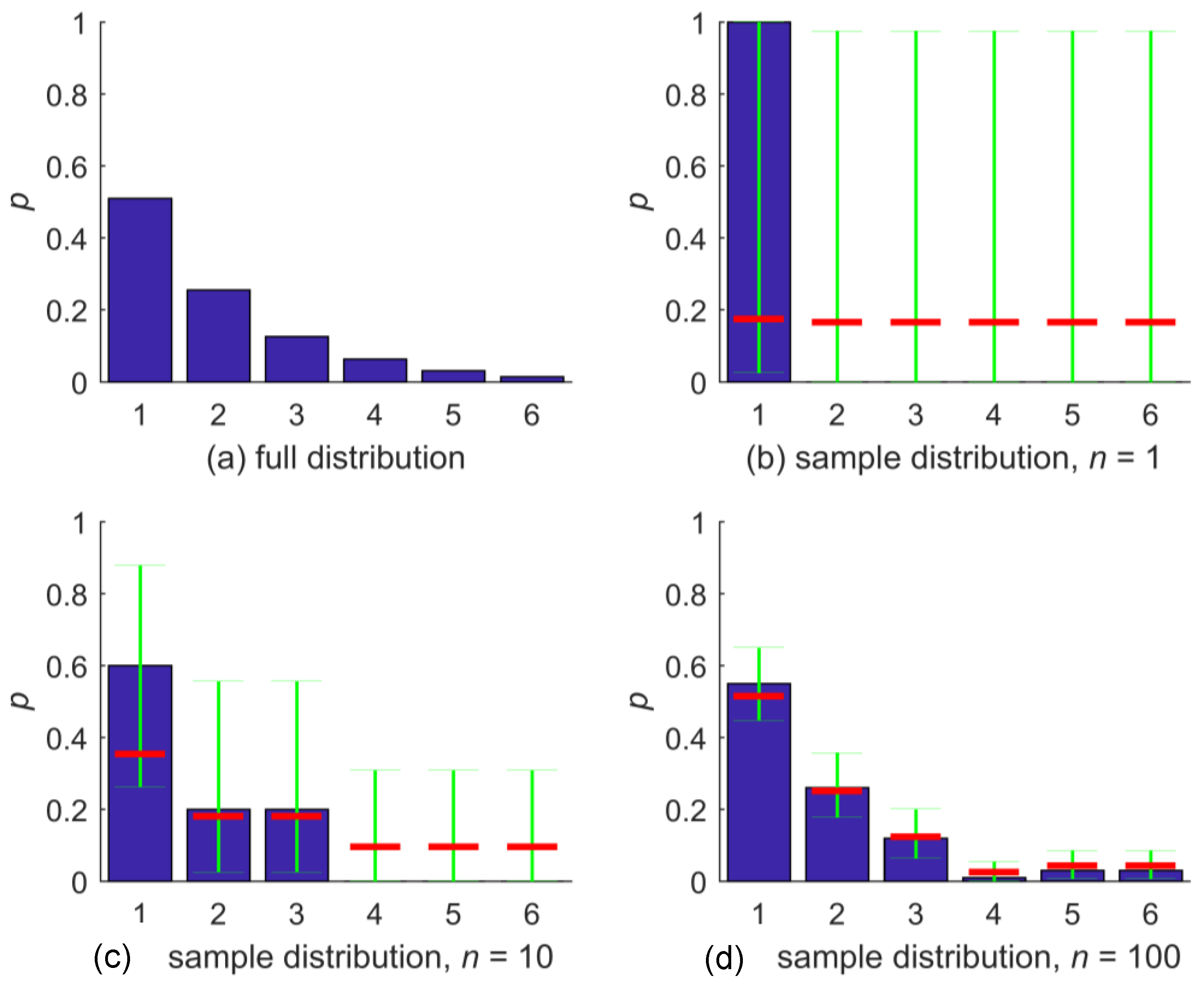
An illustration of the NZ method and its properties is shown in Figure 1. The first plot, Figure 1a, shows a discrete distribution, constructed for demonstration purposes such that it covers a range of different bin probabilities. Possible outcomes are the six integer values , where and all further probabilities are half of the previous, such that . Figure 1b shows a random sample of size one taken from the distribution; here, the sample took the value “1”. The BC estimator for the distribution for outcomes is shown with blue bars. Obviously, we encounter the problem of zero-probability bins here. In the same plot, the confidence intervals for the bin-occupation probability based on the Clopper–Pearson method on confidence level are shown in green. Due to the small sample size, the confidence intervals are almost the same for all outcomes, and so is the NZ estimate for bin-occupation probability shown in red. Altogether, the NZ estimate is close to a uniform distribution, which is the maximum entropy estimate, except that the bin-occupation probability for the observed outcome “1” is slightly higher than for the others: The NZ estimate of the distribution is . We can also see that the positivity requirement for bin occupation probability is met.
In Figure 1c,d, BC and NZ estimates of the bin-occupation probability are shown for random samples of size 10 and 100, respectively. For sample size 10, the BC method still yields three zero-probability bins, which are filled by the NZ method. The NZ estimates for this sample still gravitate towards a uniform distribution (red bars) but, due to the increased sample size, to a lesser degree than before. For sample size 100, both the BC and the NZ distribution estimate of bin-occupation probability closely agree with the full distribution, which illustrates the convergence behavior of the NZ method. Compared to the size-10 sample, the Clopper–Pearson confidence intervals for the bin-occupation probabilities have narrowed considerably, and, as a result, the NZ estimates are close to those from BC.
3. Comparison to Alternative Distribution Estimators
3.1. Test Setup
How does the NZ method compare to established distribution estimators that also assure NZ bin-occupation probabilities? We address this question by applying various estimation methods to several types of distributions. In the following, we will explain the experimental setup, the evaluation method, the estimation methods, and the distributions used.
We start by taking samples of size by i.i.d. picking (random sampling with replacement) from each distribution . Each estimation method we want to test applies this sample to construct a NZ distribution estimate . The (dis-)agreement of the full distribution with each estimate is measured with the Kullback–Leibler divergence as shown in Equation (2).
with : Kullback–Leibler divergence [bit];: reference distribution; : distribution estimate; : set taking discrete values (“bins”) for .
Note that, for our application, the full distribution of the variable is the reference , since the observations actually occur according to this distribution; the distribution estimate is derived from the sample and is our assumption about the variable. We chose Kullback–Leibler divergence as it conveniently measures, in a single number, the overall agreement of two distributions, instead of focusing on particular aspects, e.g., particular moments. Kullback–Leibler divergence is also zero if and only if the two distributions are identical, while, for instance, two distributions with identical mean and variance can still differ in higher moments.
We tested sample sizes from to 150, increasing in steps of one. We found an upper limit of 150 to be sufficient for two reasons: Firstly, the problem of zero-probability bins due to the combined effect of sampling variability and limited sample size mainly occurs for small sample sizes; secondly because, for large samples, the distribution estimates by the tested methods quickly become indistinguishable. To eliminate effects of sampling variability, we repeated the sampling for each sample size 1000 times, calculated Kullback–Leibler divergence for each and then took the average. As a result, we get mean Kullback–Leibler divergence as a function of sample size, separately for each estimation method and test distribution.
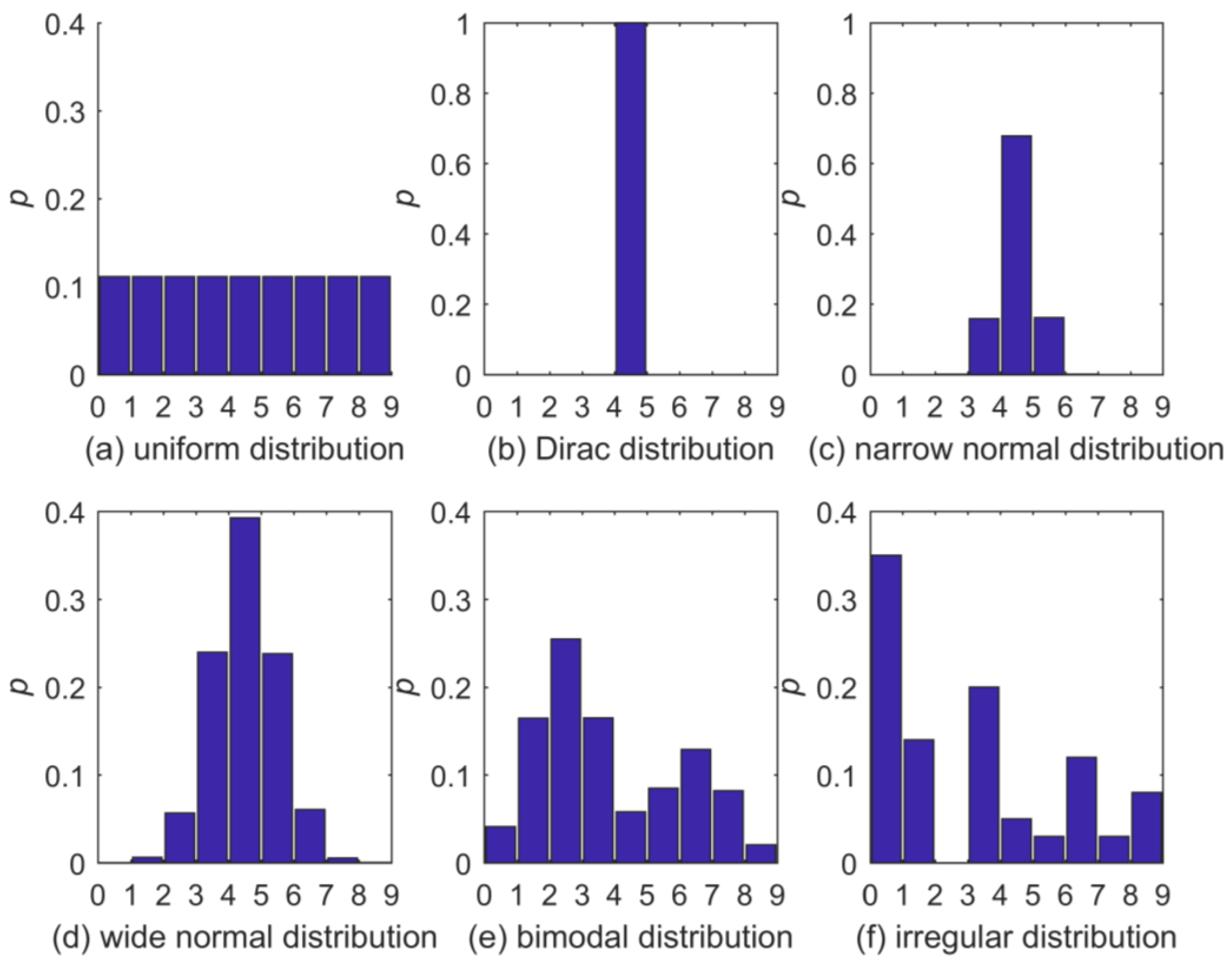
The six test distributions are shown in Figure 2. We selected them to cover a wide range of shapes. Please note that two of the distributions, Figure 2b,f, actually contain bins with zero . It may seem that, in such a case, the application of a distribution estimator assuring NZ ’s is inappropriate; however, in our targeted scenarios (e.g., comparison of two distributions via Kullback–Leibler divergence), it is the zero ’s due to limited sample size that we need to avoid, while we accept the adverse effect of falsely correcting true zeros. If the existence and location of true-zero bins were known a priori, this knowledge could be easily incorporated in the distribution estimators discussed here to only produce actual NZ ’s.
Finally, we selected a range of existing distribution estimators to compare to the NZ method:
- BC: The full probability distribution is estimated by the normalized BC frequencies of the sample taken from the full data set. This method is just added for completeness, and as it does not guarantee NZ bin probabilities its divergences are often infinite, especially for small sample sizes.
- Add one (AO): With a sample taken from the full distribution, a histogram is constructed. Any empty bin in the histogram is additionally filled with one counter before converting it to a pdf by normalization. The impact of each added counter is therefore dependent on sample size.
- BAY: This approach to NZ bin-probability estimation places a Dirichlet prior on the distribution of bin probabilities and updates to a posterior distribution in the light of the given sample via a multinomial-likelihood function [22]. We use a flat uniform prior (with the Dirichlet distribution parameter alpha taking a constant value of one over all bins) as a maximum-entropy approach, which can be interpreted as a prior count of one per bin. Since the Dirichlet distribution is a conjugate prior to the multinomial-likelihood function, the posterior again is a Dirichlet distribution with analytically known updated parameters. We take the posterior mean probabilities as distribution estimate and, for our choice of prior, they correspond to the observed bin counts increased by the prior count of one. Hence, BAY is very similar to AO with the difference that a count of one is added to all bins instead of only to empty bins; like for AO, the impact of the added counters is dependent on sample size. Like the NZ method, BAY is by default a strictly positive and convergent maximum-entropy estimator (see Section 2.2).
- Add (AP): With a sample taken from the full distribution, a histogram is constructed and normalized to yield a pdf. Afterwards, each zero-probability bin is filled with a small probability mass (here: 0.0001) and the entire pdf is then renormalized. Unlike in the “AO” procedure, the impact of each probability mass added is therefore virtually independent of .
- KDS: We used the Matlab Kernel density function ksdensity as implemented in Matlab R2017b with a normal kernel function, support limited to [0, 9.001], which is the range of the test distributions, and an iterative adjustment of the bandwidth: Starting from an initially very low value of 0.05, the bandwidth (and with it the degree of smoothing across bins) was increased in 0.001 increments until each bin had NZ probability. We adopted this scheme to avoid unnecessarily strong smoothing while at the same time guaranteeing NZ bin probabilities.
- NZ: We applied the NZ method as described in Section 2.1.
3.2. Results and Discussion
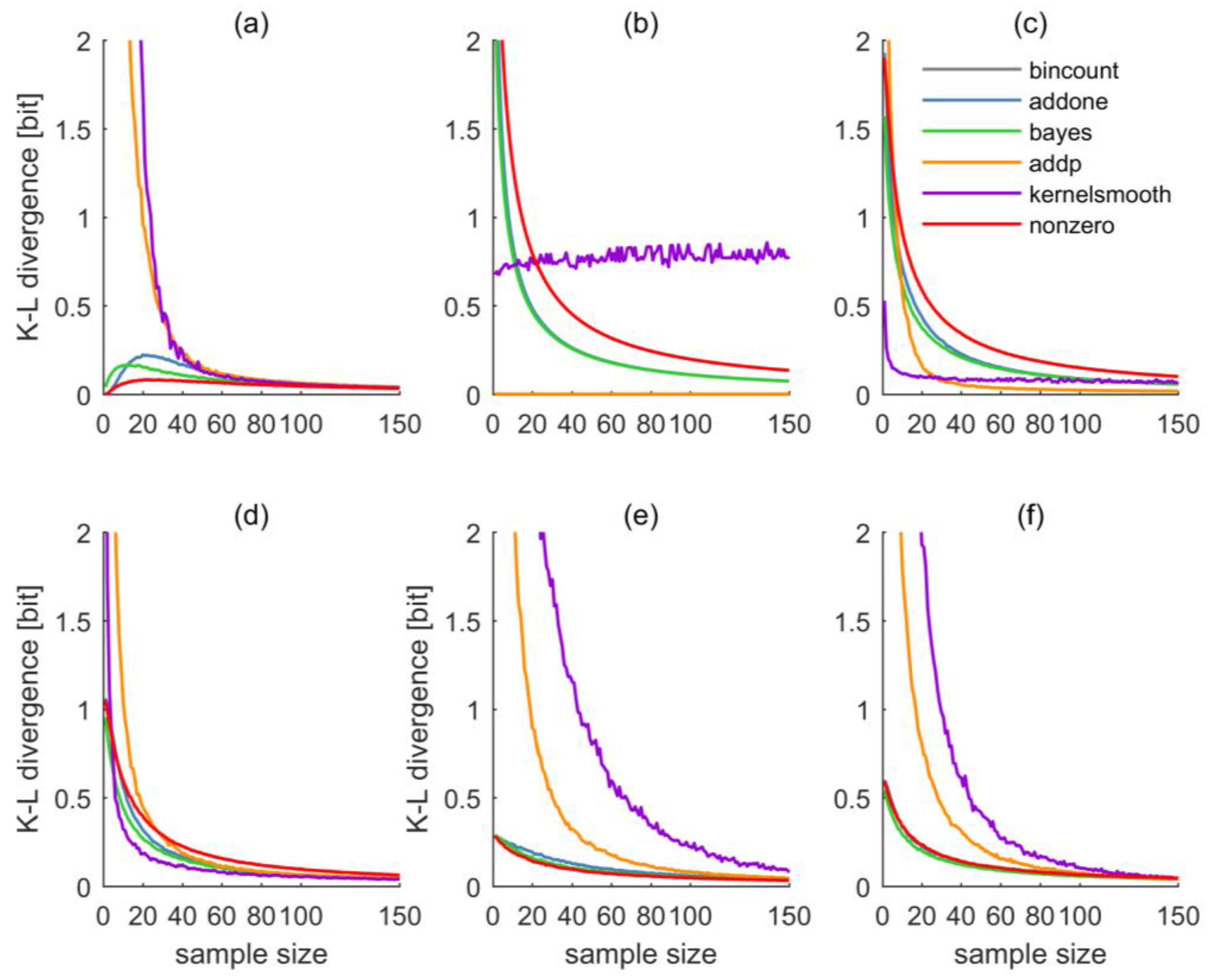
The results of all tests, separately for each test distribution and estimation method are shown in Figure 3. We will discuss them first individually for each distribution and later summarize the results.
For the uniform distribution as shown in Figure 2a, the corresponding Kullback–Leibler divergences are shown in Figure 3a. For small sample sizes up to approximately 40, both AP and KDS show very large divergences, AO, BAY, and NZ perform considerably better, with a slight advantage of NZ. This order clearly reflects the methods’ different estimation strategies, and how capable they are to reproduce a uniform distribution: For small sample sizes, both AP and KDS will maintain “spiky” distribution estimates, while AO, BAY, and NZ gravitate towards uniform distribution or maximum-entropy estimates. For larger sample sizes, beyond 80, the performance differences among the methods quickly vanish. For the small sample sizes as shown in the figure, the BC approach was still frequently afflicted with zero-probability bins, resulting in infinite divergence.
Quite expectedly, the relative performance of the estimators for the Dirac distribution (Figure 2b and Figure 3b) is almost opposite from the uniform distribution. BC shows zero and AP almost-zero divergence for all sample sizes. The reason is that even a very small sample from a Dirac distribution yields a perfect estimate of the full distribution, and both methods do not interfere much with this estimate (in fact, BC not at all). AO and BAY show almost identical performance, NZ is similar but slightly worse. All of them show high divergences for small samples and a gradual decrease with sample size. The reason lies in the methods’ tendency towards a uniform spreading of probabilities, which is clearly unfavorable if the true distribution is a Dirac. Interestingly, the KDS estimator performs constantly poorly over the entire range of sample sizes, which can be explained by its tendency of locally distributing probability mass around the BC estimate. In particular, as the kernel function was chosen to be normal, the observed divergence of about 0.8 bit corresponds to the divergence of a Dirac and a normal distribution extending over the nine bins covering the codomain.
For the narrow normal distribution as shown in Figure 2c and Figure 3c, obviously the normal kernel of KDS is of advantage, such that, for small sample sizes, divergence is smaller than for any other estimator. The performance of AP varies greatly with sample size: For small samples it is poor, for sample sizes beyond about thirty it scores best. AO and BY are almost identical, NZ is similar to them but shows worse performance; altogether it is the worst estimator. Beyond sample sizes of about 80, all methods perform almost equally well, except for BC, whose divergence is infinite due to the occasional occurrence of zero-probability bins.
For the wide normal distribution as shown in Figure 2d and Figure 3d, KDS remains the best estimator except for very small sample sizes. AO and BAY are similar and perform better than the NZ method. AP performs worst for sample sizes smaller about thirty; for larger samples, NZ performs worst.
For the bimodal distribution as shown in Figure 2e and Figure 3e things look differently: Both KDS and AP show poor performance even for large sample sizes; AO, BAY, and NZ are almost indistinguishable and they perform well even for small sample sizes.
Finally, results for the application to the irregular distribution as shown in Figure 2f are shown in Figure 3f. As this distribution shows no pattern in the distribution of probabilities across the value domain, any approach assuming a particular shape of pattern (like KDS) will have difficulties, at least for small sample sizes. This is clearly reflected in the large divergences of KDS. Interestingly, AP also struggles to reproduce the irregular distribution, but not because of the absence of a probability pattern across the value domain, but because filling a bin that has zero probability due to chance with always the same small probability mass, irrespective of the sample size, here is less effective than filling it with an adaptive probability mass as done by AO. AO, BAY, and NZ, again, perform almost equally well and better than the other methods (BC again has infinite divergences).
4. Summary and Conclusions
We started by describing use cases that involve estimation of discrete distributions with the additional requirement that all bins of the estimated distribution should have NZ probabilities. As the standard BC approach does not guarantee this, we proposed an alternative approach based on the Clopper–Pearson method, which makes use of the binominal distribution. Based on the BC-distribution estimate, confidence intervals for bin-occupation probability are calculated. The mean of each confidence interval is a strictly positive estimator of the true bin-occupation probability and is convergent with increasing sample size. For small samples, it converges towards a uniform distribution, i.e., the method effectively applies a maximum-entropy approach. We compared the capability of this “NZ” method to estimate different distributions (uniform, Dirac, narrow normal, wide normal, bimodal, and irregular) based on i.i.d. samples thereof of different sizes. For comparison, we applied four alternative estimators guaranteeing NZ bin probabilities (adding one counter to each empty bin of the sample histogram, a BAY approach applying a Dirichlet prior, and a multinomial likelihood function, adding a small probability to the sample pdf, and KDS). We measured the agreement of the distributions and their respective estimates via Kullback–Leibler divergence. The most obvious result is that the relative performance of the estimators strongly depends on whether their estimation strategy matches the shape of the test distribution or not. So if the latter is known (or can be reasonably guessed) a priori, a case-specific choice should be made. However, if this is not the case, it is reasonable to select an estimator that performs, on average, well across all distributions. For the range of distributions tested here, this could be either the straightforward method of adding one counter to each empty bin of a sample histogram, the BAY method, or the NZ method. As could be expected by their design, the first two show almost identical behavior and performance. The NZ method is similar to them in overall performance and its dependency of performance on sample size, except that it performs better for close-to-uniform distributions and worse for spiky distributions. Each of the three methods (AO, NZ, and BAY) is straightforward to implement and computationally inexpensive, so from a practical viewpoint, there is no preference for one method or the other. The main differences are in the formal background: The “AO” method lacks a formal justification; the NZ method is based on a statistical/frequentist background, while the BAY method applies a BAY perspective. Although the NZ and the BAY methods are formulated in different formal frameworks, they are in fact very similar (both are maximum-entropy estimators by construction), and so is their performance. Their main differences are that the NZ method applies the binominal distribution to evaluate each bin separately, while the BAY method applies the multinomial distribution simultaneously to all bins. The second difference is that the NZ method uses the normalized mean of the confidence interval of bin probability as the best estimate of bin probability; the BAY method uses the posterior mean. An advantage of the NZ and the BAY over the AO method is that, in addition to the distribution estimate, they also provide confidence intervals that offer additional avenues of analysis or conditioning. An additional advantage of the BAY method is that it offers adaptability: If a priori estimates of the distribution shape are available, they can be considered via the choice of the Dirichlet distribution parameter alpha. Overall, users may make a choice according to the formal setting they are most comfortable with.
Supplementary Materials
The following are available online at https://www.mdpi.com/1099-4300/20/8/601/s1. Two text files with Matlab code (version 2017b) are available as supplementary material. File “f_NonZero_method.m” is a function to compute the NZ estimate of a pdf given its histogram, file “apply_NonZero_method.m” is an application example calling the function. The files are also available on Github at https://github.com/KIT-HYD/NonZero_method (accessed on 13 August 2018).
Author Contributions
P.D. and U.E. jointly developed the NZ method and jointly wrote the paper. A.G. contributed the Dirichlet-Multinomial tests and interpretations.
Funding
This research received no external funding.
Acknowledgments
The third author acknowledges support by Deutsche Forschungsgemeinschaft DFG and Open Access Publishing Fund of Karlsruhe Institute of Technology (KIT). We gratefully acknowledge the fruitful discussions about the NZ method with Manuel Klar, Grey Nearing, Hoshin Gupta, and Wolfgang Nowak. Further we acknowledge comments by an anonymous referee of the first version of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. The Clopper–Pearson Method
Let be a discrete random variable that may take values in and a set of realisations of . For each , we estimate the probability of an observation from to fall into bin by the BC probability
The aim is to develop a confidence interval for to the confidence level .
We derive a confidence interval for each individually; for the sake of readability, we neglect the index in the following and only write , . Let be the random variable that counts all the observations in which actually fall into bin . This has a binominal distribution with parameters and , , i.e., for
Based on the result (“The bin is observed times in ”), we want to give a 95% confidence interval for around .
Property A1.
Consider a random variable. Based on the observation ofsuccesses out of thetrials, a confidence interval forto the confidence levelis given by, such that
Proof.
These confidence intervals were introduced by Reference [19]. The following proof is based on Reference [20] (Theorem 7.3.4).
For any and corresponding , take the largest with and the smallest with . For these values we get
Since the functions are monotonically increasing discontinuous step functions, we can define as the minimal , such that ; analogously, is the maximal with . With these definitions, the events and are equivalent, so we have
We have shown that for the observation and for , , is a confidence interval for . For it holds
Hence, the upper limit fulfills the following equation:
With and since we are looking for the smallest-possible upper bound, has to satisfy (A4). Similarly, we can show that has to satisfy (A3).
Of course, for , we have and easily compute
In the same way, for , we get . For all other , there is no such easy closed solution to compute. Reference [19] and others give tables that list the solutions for these equations for some . For our purposes (i.e., for use in Matlab codes), however, it is more convenient to use the relation between the binomial and the beta distribution to compute the confidence interval limits and [23,24]. ☐
Property A2
(see e.g., Reference [25], Equation (3.37), Chapter 3). For a random variable and , it holds
where is the regularized incomplete beta function with the beta function .
Proof.
First of all, with the property
for , (e.g., (olver), Equation (8.17.4)), it holds
Moreover, for the beta function with , we have
(e.g., Reference [26], Equation (5.12.1)). Using this, Equation (A13) can be derived by integration by parts:
For , the claim simplifies to
so Equation (A11) follows by induction. From there, Equation (A10) follows directly
The beta distribution Beta(), , is defined by its probability density function (for )
and on the interval , the cumulative distribution function is
Hence, from all the considerations above results the following theorem, which we use to compute the Clopper–Pearson confidence intervals for the binominal distribution parameter . ☐
Theorem A1.
Consider the random variablewith values in. If binis observedtimes in a data setof length, theconfidence interval for the probability of binis, where
- (a)
- for:
- (i)
- is thequantile of the beta distribution,
- (ii)
- is thequantile of the beta distribution;
- (b)
- for:
- (i)
- ,
- (ii)
- ;
- (c)
- for:
- (i)
- ,
- (ii)
- .
References
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Beck, J.L.; Au, S.-K. Bayesian Updating of Structural Models and Reliability using Markov Chain Monte Carlo Simulation. J. Eng. Mech. 2002, 128, 380–391. [Google Scholar] [CrossRef] [Green Version]
- Au, S.K.; Beck, J.L. Important sampling in high dimensions. Struct. Saf. 2003, 25, 139–163. [Google Scholar] [CrossRef]
- Kavetski, D.; Kuczera, G.; Franks, S.W. Bayesian analysis of input uncertainty in hydrological modeling: 1. Theory. Water Resour. Res. 2006, 42. [Google Scholar] [CrossRef] [Green Version]
- Pechlivanidis, I.G.; Jackson, B.; McMillan, H.; Gupta, H.V. Robust informational entropy-based descriptors of flow in catchment hydrology. Hydrol. Sci. J. 2016, 61, 1–18. [Google Scholar] [CrossRef]
- Knuth, K.H. Optimal Data-Based Binning for Histograms. arXiv, 2013; arXiv:physics/0605197v2. [Google Scholar]
- Fraser, A.M.; Swinney, H.L. Independent coordinates for strange attractors from mutual information. Phys. Rev. A 1986, 33, 1134–1140. [Google Scholar] [CrossRef]
- Darbellay, G.A.; Vajda, I. Estimation of the information by an adaptive partitioning of the observation space. IEEE Trans. Inf. Theory 1999, 45, 1315–1321. [Google Scholar] [CrossRef] [Green Version]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Blower, G.; Kelsall, J.E. Nonlinear Kernel Density Estimation for Binned Data: Convergence in Entropy. Bernoulli 2002, 8, 423–449. [Google Scholar]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Good, I.J. The Population Frequencies of Species and the Estimation of Population Parameters. Biometrika 1953, 40, 237–264. [Google Scholar] [CrossRef]
- Blaker, H. Confidence curves and improved exact confidence intervals for discrete distributions. Can. J. Stat. 2000, 28, 783–798. [Google Scholar] [CrossRef] [Green Version]
- Agresti, A.; Min, Y. On Small-Sample Confidence Intervals for Parameters in Discrete Distributions. Biometrics 2001, 57, 963–971. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vollset, S.E. Confidence intervals for a binomial proportion. Stat. Med. 1993, 12, 809–824. [Google Scholar] [CrossRef] [PubMed]
- Escobar, M.D.; West, M. Bayesian Density Estimation and Inference Using Mixtures. J. Am. Stat. Assoc. 1995, 90, 577–588. [Google Scholar] [CrossRef]
- Argiento, R.; Guglielmi, A.; Pievatolo, A. Bayesian density estimation and model selection using nonparametric hierarchical mixtures. Comput. Stat. Data Anal. 2010, 54, 816–832. [Google Scholar] [CrossRef] [Green Version]
- Leemis, L.M.; Trivedi, K.S. A Comparison of Approximate Interval Estimators for the Bernoulli Parameter. Am. Stat. 1996, 50, 63–68. [Google Scholar] [Green Version]
- Clopper, C.J.; Pearson, E.S. The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial. Biometrika 1934, 26, 404–413. [Google Scholar] [CrossRef]
- Larson, H.J. Introduction to Probability Theory and Statistical Inference; Wiley: Hoboken, NJ, USA, 1982. [Google Scholar]
- Bickel, P.J.; Doksum, K.A. Mathematical Statistics; CRC Press: Boca Raton, FL, USA, 2015; Volume 1. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Brown, L.D.; Cai, T.T.; DasGupta, A. Interval estimation for a binomial proportion. Stat. Sci. 2001, 16, 101–133. [Google Scholar]
- Blyth, C.R. Approximate binomial confidence limits. J. Am. Stat. Assoc. 1986, 81, 843–855. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Olver, F.W.; Lozier, D.W.; Boisvert, R.F.; Clark, C.W. NIST Handbook of Mathematical Functions, 1st ed.; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
Figure 1.
(a) Full distribution and (b–d) samples drawn thereof for different sample sizes n shown as blue bars. Green bars are the sample-based confidence intervals on 95% confidence level for bin-occupation probability based on the Clopper–Pearson method, and the red bar is the nonzero estimate for bin-occupation probability.
Figure 1.
(a) Full distribution and (b–d) samples drawn thereof for different sample sizes n shown as blue bars. Green bars are the sample-based confidence intervals on 95% confidence level for bin-occupation probability based on the Clopper–Pearson method, and the red bar is the nonzero estimate for bin-occupation probability.

Figure 2.
Test distributions: (a) Uniform, (b) Dirac, (c) narrow normal, (d) wide normal, (e) bimodal and (f) irregular. Possible outcomes are divided in nine bins of uniform width. Note that for (b,c), the y-axis limit is 1.0, but for all others it is 0.4.
Figure 2.
Test distributions: (a) Uniform, (b) Dirac, (c) narrow normal, (d) wide normal, (e) bimodal and (f) irregular. Possible outcomes are divided in nine bins of uniform width. Note that for (b,c), the y-axis limit is 1.0, but for all others it is 0.4.

Figure 3.
(a) Kullback–Leibler divergences of test distributions uniform, (b) Dirac, (c) narrow normal, (d) wide normal, (e) bimodal, and (f) irregular and size- samples thereof. Sample-based distribution estimates are based on bin counting (grey), “Add one counter” (blue), “Bayesian” (green), “Add probability” (orange), “Kernel-density smoothing” (violet), and the “nonzero method” (red). In all plots except (b), the “bincount” line is invisible as its divergence is infinite, and in plot (b) it is invisible as it is zero and almost completely overshadowed by the “addp” line. In plots (b,f), the “addone” line is almost completely overshadowed by the “bayes” line. For better visibility, all y-axes are limited to a maximum divergence of 2 bit, although this limit is sometimes clearly exceeded for small sample sizes.
Figure 3.
(a) Kullback–Leibler divergences of test distributions uniform, (b) Dirac, (c) narrow normal, (d) wide normal, (e) bimodal, and (f) irregular and size- samples thereof. Sample-based distribution estimates are based on bin counting (grey), “Add one counter” (blue), “Bayesian” (green), “Add probability” (orange), “Kernel-density smoothing” (violet), and the “nonzero method” (red). In all plots except (b), the “bincount” line is invisible as its divergence is infinite, and in plot (b) it is invisible as it is zero and almost completely overshadowed by the “addp” line. In plots (b,f), the “addone” line is almost completely overshadowed by the “bayes” line. For better visibility, all y-axes are limited to a maximum divergence of 2 bit, although this limit is sometimes clearly exceeded for small sample sizes.

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Darscheid, P.; Guthke, A.; Ehret, U. A Maximum-Entropy Method to Estimate Discrete Distributions from Samples Ensuring Nonzero Probabilities. Entropy 2018, 20, 601. https://doi.org/10.3390/e20080601
AMA Style
Darscheid P, Guthke A, Ehret U. A Maximum-Entropy Method to Estimate Discrete Distributions from Samples Ensuring Nonzero Probabilities. Entropy. 2018; 20(8):601. https://doi.org/10.3390/e20080601
Chicago/Turabian StyleDarscheid, Paul, Anneli Guthke, and Uwe Ehret. 2018. "A Maximum-Entropy Method to Estimate Discrete Distributions from Samples Ensuring Nonzero Probabilities" Entropy 20, no. 8: 601. https://doi.org/10.3390/e20080601
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.