Symmetric Triangular Interval Type-2 Intuitionistic Fuzzy Sets with Their Applications in Multi Criteria Decision Making


School of Mathematics, Thapar Institute of Engineering & Technology (Deemed University), Patiala 147004, India
*
Author to whom correspondence should be addressed.
Symmetry 2018, 10(9), 401; https://doi.org/10.3390/sym10090401
Submission received: 26 August 2018
/
Revised: 7 September 2018
/
Accepted: 11 September 2018
/
Published: 14 September 2018
(This article belongs to the Special Issue Fuzzy Techniques for Decision Making 2018)
Abstract
:Type-2 intuitionistic fuzzy set (T2IFS) is a powerful and important extension of the classical fuzzy set, intuitionistic fuzzy set to measure the vagueness and uncertainty. In a practical decision-making process, there always occurs an inter-relationship among the multi-input arguments. To deal with this point, the motivation of the present paper is to develop some new interval type-2 (IT2) intuitionistic fuzzy aggregation operators which can consider the multi interaction between the input argument. To achieve it, we define a symmetric triangular interval T2IFS (TIT2IFS), its operations, Hamy mean (HM) operator to aggregate the preference of the symmetric TIT2IFS and then shows its applicability through a multi-criteria decision making (MCDM). Several enviable properties and particular cases together with following different parameter values of this operator are calculated in detail. At last a numerical illustration is to given to exemplify the practicability of the proposed technique and a comparative analysis is analyzed in detail.
1. Introduction
Multiple criteria decision making (MCDM) is a hot research topic in the modern decision-making process to find the most suitable alternative(s) from the available ones. In this process, all the alternatives are to be evaluated under several attributes by both qualitatively and quantitatively [1,2]. Traditionally, the researchers offer his/her preference information towards the alternatives by using the crisp real numbers only. However, due to lack of knowledge, a time pressure, and other unavoidable factors, it is very difficult if not impossible to express the information precisely. Therefore, to handle the incomplete or incorrect information, the theory of fuzzy set (FS) also called as a type-1 fuzzy set (T1FS) [3] and its extensions as an intuitionistic FS (IFS) [4], type-2 FS (T2FS) [5] are widely used. Under these environments, authors have put forth the different techniques to solve the MCDM problems. For instance, geometric aggregation operators (AOs) for different intuitionistic fuzzy numbers (IFNs) are developed by Xu and Yager [6]. Garg [7,8] presented some Einstein norm based AOs for IFNs. Zhao et al. [9] presented some generalized AOs. Kaur and Garg [10] presented some generalized AOs using t-norm operations for cubic IFS information. However, apart from these, a comprehensive overview of the different approaches for solving the decision making (DM) problems by using aggregation operator (AOs) [11,12,13,14,15,16,17,18,19,20,21], information measures (IMs) [22,23,24] are summarized in these papers and their references.
In these existing works, authors have investigated the problem by taking quantitative environment to access the alternatives. However, not all the alternatives are accessed in terms of quantitative. For this, there exists the concept of qualitative assessment in terms of linguistic variables/terms (LVs/LTs) [25,26]. By taking the advantages of LTs, Zhang [27] presented the linguistic IF (LIF) AOs to aggregate the LIF numbers. Chen et al. [28] presented an approach to solving the MCDM problem under LIFS environment. Garg and Kumar [29] presented AOs for LIF numbers (LIFNs) by using set pair analysis theory. Garg and Kumar [30] presented new possibility degree measure for LIFNs and an AO to aggregate the different LIFNs to solve MCDM problems. In many practical problems, it is not easy for any decision maker (DM) to discover an exact membership function of an FS corresponding to its element. To overthrow this limitation, type-2 fuzzy set (T2FS), an extension of T1FS, is applied to the model and is characterized by two functions: primary membership functions (PMF) and secondary membership function (SMF). Unfortunately, T2FSs are highly complex, it is troublesome for the DMs to implement it in the real situation; hence, their use is not yet widespread. To reduce the computational complexity, Interval type-2 fuzzy (IT2F) sets (IT2FSs) [31] is the most widely used in T2FSs. In past decades, many methods have been developed to extend the theory of MCDM under IT2FS environment. Chen et al. [32] built up an expanded QUALIFLEX strategy for taking care of DM issues in view of IT2FSs and gave a contextual analysis of medicinal basic leadership. Chen [33] built up an ELECTRE-base outranking strategy for decision-making problems using IT2FSs. Wu and Mendel [34] proposed a linguistic weighted average AOs to deal with analytical hierarchical process (AHP) process under IT2F environment. Qin and Liu [35] investigated a family of type-2 fuzzy AOs in light of Frank triangular norm and built up another way to deal with MCDM problems under the IT2FSs setting. Gong et al. [36] extended the generalized Bonferroni mean (GBM) operator to the trapezoidal IT2F environment. Apart from these, some other studies under T2FS environment are conducted which are summarized in [35,36,37,38,39,40,41,42,43,44,45,46,47,48].
In all these above AOs, researchers have described the information by considering the independent of argument assumptions during the aggregation. However, the interaction between the multi-input parameters have commonly occurred and thus, it is necessary to add their features into the process. In that direction, Bonferroni mean (BM) and generalized BM (GBM)-based operators are proposed by the researchers [49,50]. But from them, it has been observed that they have considered only two or three multi-parameter at a single time. However, they are unable to analyze the effect of the multi-input argument into one analysis. Furthermore, in BM and GBM, there is a need for two and three parameters from the irrational set during the process which increases the computational complexity. An alternative to BM operators, Hamy mean (HM) [51] or Maclaurin symmetric mean (MSM) or Muirhead mean (MM) operator has advantages of capturing the inter-relationship among the multiple input arguments. Qin [46] make a correlation between the HM and the MSM and conclude that the MSM is an instance of HM [16,17]. Garg and Nancy [52] develop MCDM method by prioritized MM aggregation operators. Additionally, the HM operator involves the parameter, which can provide more flexibility and robustness during the aggregation operator. The existing - arithmetic and geometric mean- operators can be easily deduced from the HM by setting a particular value to its parameter. Be that as it may, the HM just accomplished a couple of research results on the hypothesis and application of inequality [53,54]. Therefore, it is a means to study the AOs using the HM operator.
It is noted from the above studies that T2FS or IT2FS are examined by considering only the membership degree (MD) of an element. But in practical problems, it is sometimes not possible for a DM to give their preferences in terms of MD only as there may be some amount of hesitation also. For discussing this, a type-2 IFS (T2IFS) [39] has been introduced which simultaneously considers the MDs, non-membership degrees (NMDs) and the footprint of uncertainties (FOU) between them. Later on, due to the high complexity of T2IFS, Garg and Singh [55] introduced the concept of triangular interval T2IFS (TIT2IFS) has introduced by considering the MDs and NMDs as a triangular fuzzy number.
Based on the above analysis, we can know that the decision-making problems have become more tedious these days. So in order to make a better decision in terms of selecting the best alternative(s) for the MCDM problems, it is necessary to consider the various factors such as MDs, NMDs, FOU between the alternatives. By keeping the advantages of both the AOs and the TIT2IFS, it is necessary to extend the Hamy mean AOs to process the TIT2IFNs by using linguistic features of MDs and NMDs and hence to develop some MCDM methods. Until now, we have not seen any work based on the AOs used to aggregate the TIT2IFS information. Thus, keeping in mind the advantages of T2IFS and the multiple input interaction between the argument of HM operator, this paper has presented the concept of the symmetric TIT2IFS and their desired properties. These considerations have led us to consider the main objectives of this paper:
- to propose the concept of the symmetric TIT2IFS (STIT2IFSs);
- to propose some new AOs for STIT2IFSs under the linguistic intuitionistic features;
- to develop an algorithm to solve the decision-making problems based on proposed operators;
- to present some example to validate and compare the results.
To achieve the objective (1), we combine the T2IFSs and the symmetric triangular number to build a concept of the STIT2IFSs and studied their desired properties. To complete the objective (2), we presented the averaging AOs by using HM operations and named as symmetric triangular IT2IF HM averaging (STIT2IFHM) and weighted symmetric triangular IT2IF Hamy mean averaging (WSTIT2IFHM) operator for decision-making problems by keeping in mind the advantages of T2IFS and the multiple input interaction between the argument of HM operator. Several enviable properties and particular cases together with following different parameter values of this operator are calculated in detail. To cover the objective (3), we establish an MCDM method based on these proposed operators under the STIT2IFS environment where preferences related to each alternative is expressed in terms of linguistic STIT2IFNs. A numerical illustration is to given to exemplify the practicability of the proposed technique and a comparative analysis is analyzed in detail for fulfilling the Objective 4. Finally, the advantages of the proposed method in the state of the art are highlighted and discussed in detail.
The rest of the paper is organized as follows. In Section 2, some basic concepts on T2FS, IT2FS, T2IFS, and HM are reviewed briefly. In Section 3, we present the concept of the symmetric TIT2IF set and their desirable properties. Section 4 deals with new AOs based on HM operator to accommodate the STIT2IFN information and its special cases. In Section 5, we present an approach based on the WSTIT2IFHM operator to solve the MCDM problem. A practical example is discussed in Section 6 and some concluding remarks are summarized in Section 7.
2. Basic Concepts
In this section, we overview some basic definition of T2FSs, IT2FS and T2IFSs defined over the universal set X.
Definition 1 ([42]).
A type-2 fuzzy set (T2FS) , defined as
where denotes the primary membership function (PMF) of A, is called as secondary membership function (SMF) is PMF of x.
Another equivalent expression for T2FS A is given as
Definition 2 ([20]).
The collection of all PMFs of T2FS is named as “footprint of uncertainty" (FOU), i.e., .
However, because of high computational burden of T2FSs, researchers prefer using interval type-2 (IT2) fuzzy set (IT2FS) for real-world problems.
Definition 3 ([44]).
Definition 4 ([44]).
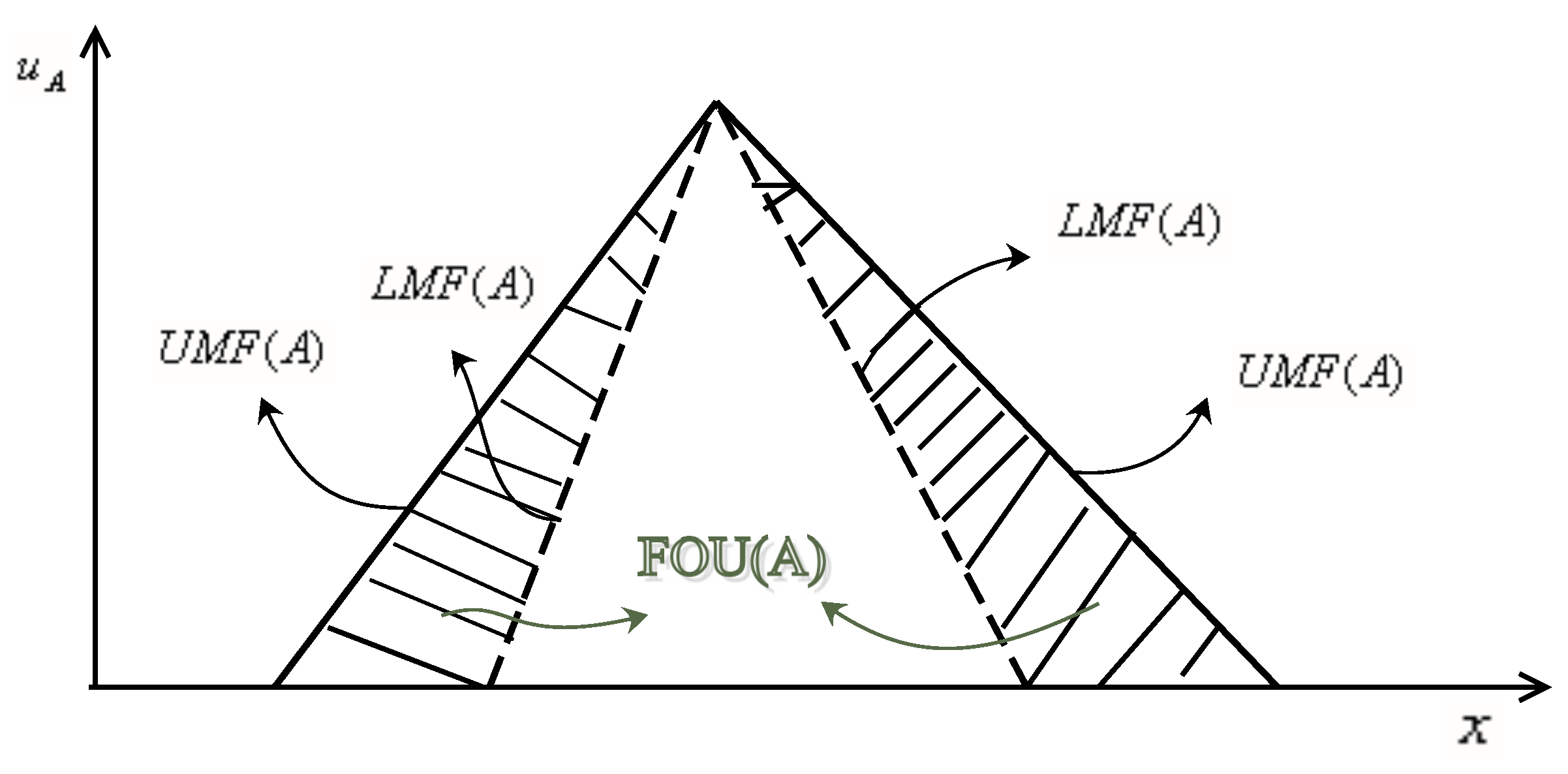
An IT2 FS is normally described by a zone called as FOU, which is limited by two membership functions (MFs), known as lower MF (LMF) and the upper MF (UMF) . That is FOU=[]. Figure 1 shows the graphical representation of IT2 fuzzy number (IT2 FN) with triangular MF shape.
Definition 5 ([38,39]).
A T2IFS is a set of ordered pairs consisting of PMFs and SMFs of the element defined as
where represents the primary membership (non-membership) of A denoted by PMF(PNMF), is secondary membership (non-membership) function of A, denoted by SMF (SNMF) and are PMF and PNMF of x, respectively. When the SMFs , and SNMF , a T2IFS translates to an IT2 IFS.
Definition 6 ([55]).
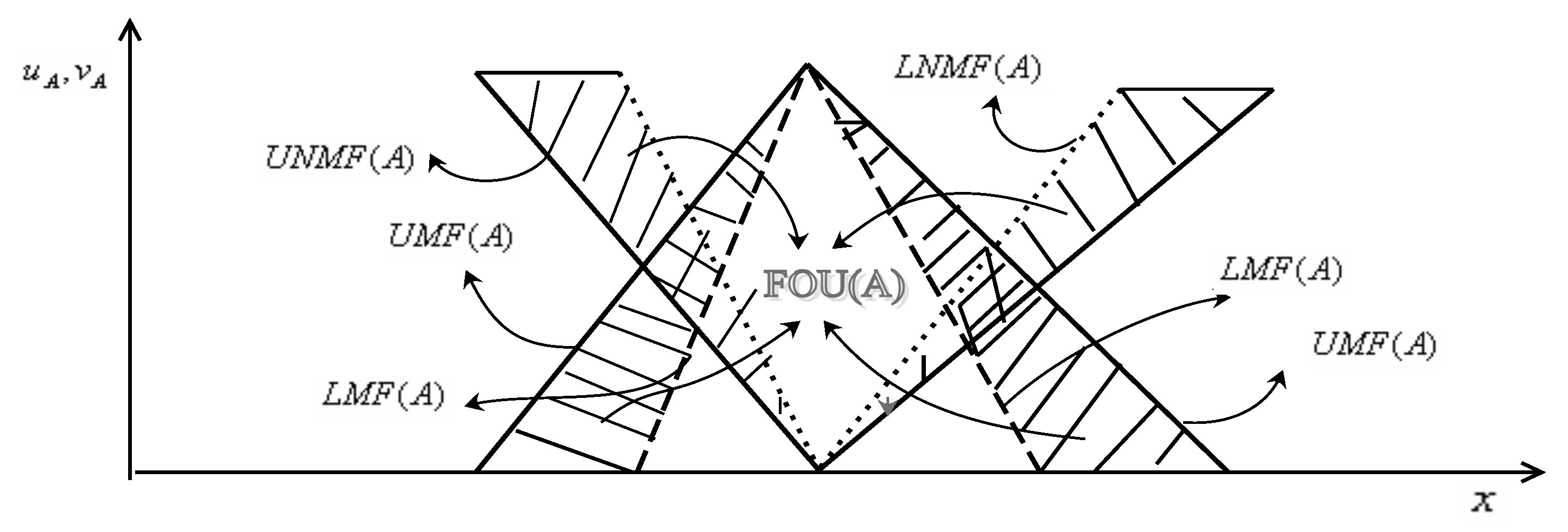
An IT2 IFS, A, is described by a bounding functions of lower and upper membership and non-membership functions denoted by LMF, UMF, LNMF and UNMF defined as , and , with conditions: and . The FOUs of an IT2IFS is illustrated in Figure 2 with triangular shape and defined mathematically as
Definition 7 ([51]).
For non-negative real numbers , the Hamy mean (HM) is given as
where k is the parameter, and crosses all the tuple mix of .
3. Proposed Symmetric Triangular Interval T2IFS
In this section, we present a symmetric triangular IT2IFS and characterize their fundamental operational laws.
Definition 8.
Let X be the universal set. A symmetric triangular interval T2 IFS (TIT2IFS) can be represented as follows:
where , are the real numbers satisfying the inequalities, , , such that and .
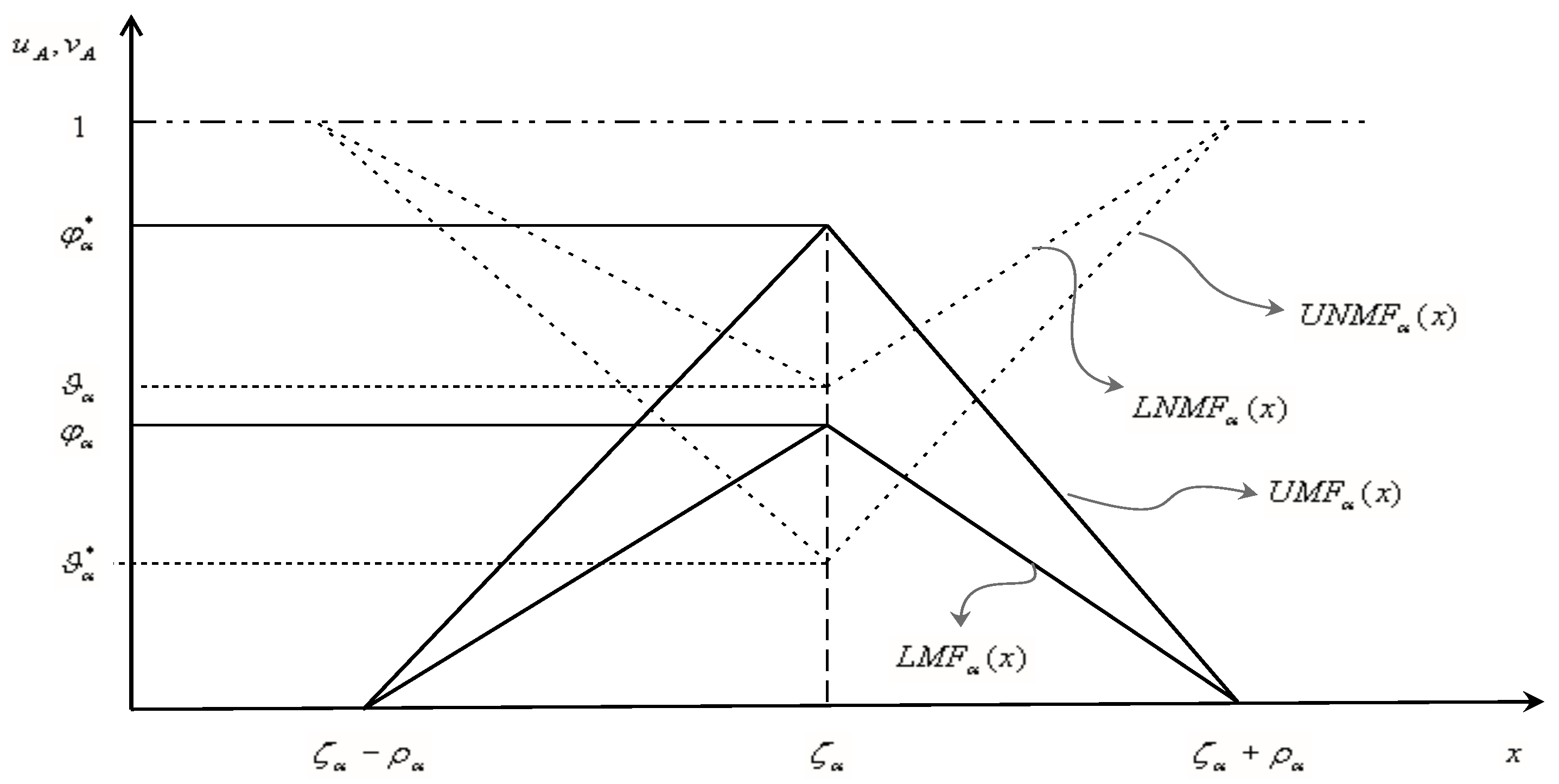
For convenience, we represent this pair as and called as symmetric triangular IT2 intuitionistic fuzzy (IT2IF) number (STIT2IFN) where , , and , . The graphical representation of STIT2IFN is given in Figure 3.
Definition 9.
For a STIT2IFN , the lower and upper membership and non-membership functions denoted by LMF, UMF, LNMF and UNMF are defined as
Definition 10.
The score function of STIT2IFN is defined as
Definition 11.
For two STIT2IFNs α and β, an order relation “” to compare them is defined as
- If , then ;
- If
Definition 12.
For two STIT2IFNs and , , then the operational laws of it are shown as follows:
- ;
- ;
- ;
Theorem 1.
For STIT2IFNs α and β, the operations defined in Definition 12 are again STIT2IFNs.
Proof.
Consider two STIT2IFNs and . So by Definition 8, we have , , , , , , , , .
Let and thus by Definition 12, we get , , , , , . Now, to show is again an STIT2IFN, we need to prove that , , , , .
As and which implies that . Further , , , , , which gives that
and
Finally, and .
Therefore, we conclude that becomes STIT2IFN. Similarly, we can prove that , and are also STIT2IFNs.
4. TIT2IF Hamy Mean Aggregation Operators
Let be the gathering of all non-empty STIT2IFNs . Here, we present HM-based AOs for STIT2IFNs.
4.1. STIT2IFHM Operator
Definition 13.
A STIT2IFHM is a mapping defined as
then is called the symmetric triangular IT2IF Hamy mean operator, where is the parameter and represent the binomial coefficient.
Theorem 2.
The aggregated value for n STIT2IFNs by using Definition 13 is again STIT2IFN which is given as
Proof.
The first part of the result can be easily obtained from Theorem 1. So, there is a need to prove only that Equation (12) is kept.
According to the operational laws of STIT2IFNs, we get
and
Therefore,
Subsequently, we have
□
In what follows, we investigate the certain property of STIT2IFHM operator.
Theorem 3.
(Idempotency) If for all i, then
□
Proof.
Since for all i then based on Theorem 2, we have
Theorem 4.
(Commutativity) Let be a collection of STIT2IFNs, and be any permutation of . Then
Proof.
Based on the Definition 13, we have
□
Theorem 5.
(Monotonicity) For two different STIT2IFNs , and , . If , , , , and for all i, then
Proof.
Let and . Then according to Theorem 2, we get
and
Since which implies that
Also, implies that
Similarly for , and for all i, we have
and
Therefore, by using these inequalities and Definition 11, we get
□
Theorem 6.
(Boundedness) For n STIT2IFNs , , and , we have
Proof.
Clearly, we get . Thus, based on Theorems 4 and 5, we have
□
Lemma 1 ([51]).
For n non-negative real numbers , we have
with equality holding iff .
Lemma 2 ([54]).
Let and . Then
Theorem 7.
For given STIT2IFNs , the operator STIT2IFHM is monotonically decreasing with parameter k.
Proof.
For STIT2IFNs and , we denote
Based on Theorem 2, we have
Following Definition 10 and Lemma 1, we obtained
Then, two cases are arisen:
- Case 1
- If , following the Definition 11 we get
- Case 2
- If . Then, by Lemmas 1 and 2, we get
To check the monotonic behavior of , we assume that it is increasing with k, i.e.,
Also since
which implies that
which contradict the Lemma 2. Hence with parameter k, is monotonically decreasing. Similarly, we can get is also monotonically decreasing with parameter k. Also, the functions and are monotonically increasing with parameter k.
Therefore,
Thus, by both the cases, we get . □
Furthermore, we will talk about a few special cases of the STIT2IFHM operator concerning the parameter the k.
- When , Equation (12) reduces to the triangular IT2IF averaging operator.
4.2. WSTIT2IFHM Operator
Definition 14.
For a collection of n STIT2IFNs, , is weight vector of , where and , we define WSTIT2IFHM operator as
then is stated as weighted symmetric triangular IT2IF Hamy mean operator.
Theorem 8.
Proof.
Similar to the proof of Theorem 2. □
Theorem 9.
The operator STIT2IFHM is a special case of the WSTIT2IFHM operator.
Proof.
Assume that , then by Theorem 5, we have
- if , we have
- If , we have□
5. An Approach to MCDM Based on the Proposed WSTIT2IFHM Operator
In this section, an MCDM approach is developed under the triangular IT2IF (TIT2IF) environment. The description of the problem, as well as the procedure steps, are explained as below.
Assume an MCDM problem which consists of ‘n’ different alternatives and a set of ‘m’ attributes whose weight vector is , satisfying and . An expert has evaluated these given alternatives and rate them under TIT2IF environment denoted by where represent the linguistic information about the alternatives. Furthermore, the importance of the attributes plays a dominant role during the decision-making process. During handling the MCDM problems, if the sum of the relative coefficient w.r.t. each criterion is small, it relates that such criteria demonstrate a major impact on the overall values of the alternative. Similarly, if the relative coefficient sum is large then it shows such criterion play a less significant role. Hence, the relative coefficient of the alternative under the certain criteria is inversely proportional to the corresponding weights of criteria. Therefore, the weight of the criteria is determined by using the Spearman method [56] which main steps are summarized in Algorithm 1.
| Algorithm 1 Weight determination using Spearman coefficient method. |
|
By using this weight vector, we summarized the following steps based on the proposed AO to rank the alternatives under TIT2IFS environment.
- Step 1:
- Arrange the information of each alternative in decision matrix aswhere be the STIT2IFNs provided by an expert.
- Step 2:
- Compute the normalized decision matrix L from by using the normalized formula
- Step 3:
- Compute the weight vector to each criteria by using Algorithm 1.
- Step 4:
- Combine the different values of STIT2IFNs into the single one of each alternative by using WSTIT2IFHM operator as follows:
- Step 5:
- Compute the score value of the by using Equation (10).
- Step 6:
- Rank all the alternatives by using an order relation defined in Definition 11 and hence select the most feasible alternative(s).
6. Illustrative Example
The above mentioned approach has been illustrate with a numerical example which is stated as below.
6.1. A Case Study
Jharkhand is the eastern state of the India, which has the 40 percent mineral resources of the country and second leading state of the mineral wealth after Chhattisgarh state. It is also known for its vast forest resources. Jamshedpur, Bokaro and Dhanbad cities of the Jharkhand are famous for industries in all over the world. After that, it is the widespread poverty state of the India because it is the primarily a rural state as 76 percent of the population live in the villages which depend on the agriculture and wages. Only 30 percent villages are connected by roads while only 55 percent villages have accessed to electricity and other facilities. But in the today’s life, everyone is changing fast to himself for a better life, therefore, everyone moves to the urban cities for a better job. To stop this emigration, Jharkhand government wants to set up the industries based on the agriculture in the rural areas. For this, the government has been organized “MOMENTUM JHARKHAND” global investor submit 2017 in Ranchi to invite the companies for investment in the rural areas. Government announced the various facilities for setup the five food processing plants in the rural areas and consider the six attributes required for company selection to setup them, namely, project cost , completion time , technical capability , financial status , company background , reference from previous project and assign the weights of relative importance of each attributes. The six companies taken as in the form of the alternatives, namely, Surya Food and Agro Pvt. Ltd. , Mother Dairy Fruit and Vegetable Pvt. Ltd. , Parle Products Ltd. , Heritage Food Ltd. , Verka Pvt. Ltd. and Reliance Pvt. Ltd. interested for these projects. Then the main object of the government is to choose the best company among them for the task. In order to find the best feasible alternative(s) for the required task, the authority called an expert to evaluate these alternatives and rate their preferences in terms of linguistic terms (LTs). The standardized LTs such as “Very High” (VH), “High”(H), “Medium”(M), “Medium Low”(ML), “Low”(L), “Very Low”(VL) are defined in terms of STIT2IFNs given in Table 1. Furthermore, the complementary relation corresponding to LTs is presented in Table 2.
The above mentioned steps are executed to locate the best alternative(s).
- Step 1:
- An expert has evaluated each alternative and present their rating values in terms of LTs which are summarized as
- Step 2:
- Step 3:
- Apply the Algorithm 1 to compute the weight vector to each criteria. For it, we follows the steps of the algorithm and summarized as below
- Step 4:
- Aggregate all the values by using WSTIT2IFHM operator into a collective one . Here, without loss of generality, we take and the obtained results areSimilarly, we have
- Step 5:
- The score values of are computed by Equation (10) and get
- Step 6:
- Since and thus by Definition 11, we get the ranking order of the alternatives as . Here “≻” means “preferred to”. Therefore, is the best alternative.
6.2. Influence of k on Alternatives
Keeping in mind the end goal to investigate the impact of the parameter k on to the final positioning order of the alternatives, we use an alternate estimation of k in our test. Here n is 7 in our case, so we shift k from 1 to 7 and their outcomes relating to the proposed technique have been outlined in Table 3. From this table, it is seen that with the expansion of the interaction of the multi-input options, the general score estimations of it diminishes which recommend that the proposed operator reflect the risk preferences to the decision makers. This examination will propose the distinctive decisions to the analyst as indicated by his/her decision. For example, in the event that he will cover the risk parameters during the aggregation then they will allocate a little incentive to the parameter k with the goal that score esteems increments while, if the analyst is pessimistic in nature towards the choice then the bigger estimation of k can be allocated during the procedure.
Furthermore, in some other existing Bonferroni mean (BM) and generalized Bonferroni mean (GBM) operators, the information takes only two or three arguments during an aggregation. Also, in BM operator there is need of two additional parameters while the three parameters for GBM from an infinite rational set. Thus, the computational complexity is too high in such cases. On the other hand, in the proposed operator, there is only one parameter k from a finite integer set and hence the computational complexity is low and easier to understand. Finally, the several operators such as averaging, BM and geometric for the T2IFNs can be deduced from the proposed ones by setting , and respectively. Subsequently, our proposed operator and the strategy are more summed up and adaptable to tackle the decision-making problems.
6.3. Comparative Study
In this section, we perform some comparative analysis of the proposed method result with some of the existing approaches results in [36,46,47,48] under the uncertain environment. The results computed from them on to the considered problem are summarized as below:
- In [36], authors proposed the weighted geometric Bonferroni mean operator under the type-2 fuzzy environment, denoted by IT2FWGBM, which is defined asBy applying Equation (28) on to the considered data, we get the aggregated value corresponding to each alternative asTherefore, the score values of these aggregated numbers are , , , , , and and hence the final ranking of all alternatives is found as
- If we use the existing WSTIT2FHM operator as proposed by Qin [46] under the T2FS environmentthen, the aggregated values corresponding to each alternative (by taking ) are obtained asThus, the score values areand hence ordering is
From the above examinations, it is revealed that the ranking order of the alternatives stays same yet the computational procedure is altogether unique. For instance, in [36,46] authors have introduced AOs under TIT2FNs by considering just the degree of membership during an examination. But it is quite recognizable that the level of non-membership likewise assumes a predominant part during the aggregation process. Thus, the outcomes processes by these methodologies [36,46] might be unreasonable under some specific constraints where the degree of non-membership pays a more significance than the degree of agreement.
However, apart from these, we give some characteristics comparison of our proposed method and the aforementioned methods, which are listed in Table 4.
In [47], authors presented an analytical method for solving the problems by using the fuzzy weighted average. In [36], the authors have presented the BM by considering simultaneously the values of UMF and LMF to aggregate IT2FS information. On the other hand, the present study is based on the HM operator which is more adaptable and robustness in process of information fusion than others such as BM, GBM. The outstanding characteristic of the HM operator is to catch the inter-relationship between more than two input arguments with a parameter k from the finite integer set. Furthermore, in [46], the author developed HM operator by taking into account the membership degree only but in practical problems, it is sometimes not possible for DM to give their preferences in terms of acceptance degree only. Therefore, the non-membership degree is required for handling the problems in which rejection degree is not equal to one minus acceptance degree. Also by comparing with the AHP-based method [48], the proposed method does not require any software package to compute the results while the technique proposed in [48] requires it. Thus, the computation complexity of the proposed technique is comparatively easy. Furthermore, the AHP-based technique is usually dependent on various parameters and thus the final ranking may some time suffers from inconsistency, in the case of inappropriate parameter selection. On the other hand, the proposed method draws up a more authentic ranking result as it can terminate the difference, draws up for the flaws of already existing aggregation methods that do not capture experts utility or decision preference and achieves more stationary and commendable interrelationships result with less information loss. The proposed method takes into consideration the uniformity of the alternatives as well as highlights the significance and interactions in association with any solutions of alternatives. On the other hand, the AHP-based technique is good at calculating only the optimal ranking values of the alternatives beyond inter-relationships.
7. Conclusions
In this paper, an endeavor has been made to exhibit the some new AOs to accommodate the IT2IF conditions. IT2IFS is one of the augmentations of the conventional FS, IFS by considering grades of the primary membership functions also. On the other hand, in practical application problems, the criteria interrelationship phenomenon occurs frequently. To address it, Hamy means (HM) operator is a standout among the most critical operators that catches the inter-relationship together with the multi-input arguments. Furthermore, to diminish the computational complexity of the IT2IFS, we introduce symmetric IT2IFS and characterize some operation laws. Then, keeping the advantages of STIT2IFS and HM operators, we exhibit the symmetric TIT2 intuitionistic fuzzy HM (STIT2IFHM) operator and weighted symmetric TIT2 intuitionistic fuzzy HM (WSTIT2IFHM) operator under a provision of type-2 intuitionistic uncertain situation. Various beneficial characteristics of these operators have endorsed. Furthermore, in light of these operators, a decision-making approach is introduced to solve the MCDM problems. The presented approach has been tried and clarified with a numerical illustration and registered that it can efficiently deal with the available information by eliminating more amount of fuzziness as compared to the existing approaches. The major advantages of the proposed operator with respect to the existing ones are that it need only one parameter k from a finite integer set while other needs more than one from an infinite rational set such as BM and GBM etc., and hence the computational complexity is low and easier to understand. Additionally, a portion of the existing studies can be effectively concluded from the proposed operators by setting , and . Thus, it expresses a better technique for taking care of the decision-making problems with additional benefits.
Author Contributions
Conceptualization, H.G. and S.S.; Methodology, H.G.; Validation and Investigation, S.S. and H.G.; Writing-Original Draft Preparation, H.G.; Writing-Review and Editing, H.G.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Garg, H.; Kumar, K. An advanced study on the similarity measures of intuitionistic fuzzy sets based on the set pair analysis theory and their application in decision making. Soft Comput. 2018, 22, 4959–4970. [Google Scholar] [CrossRef]
- Garg, H.; Arora, R. Dual hesitant fuzzy soft aggregation operators and their application in decision making. Cogn. Comput. 2018, 1–21. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning: Part-1. Inf. Sci. 1975, 8, 199–251. [Google Scholar] [CrossRef]
- Xu, Z.S.; Yager, R.R. Some geometric aggregation operators based on intuitionistic fuzzy sets. Int. J. Gen. Syst. 2006, 35, 417–433. [Google Scholar] [CrossRef]
- Garg, H. Novel intuitionistic fuzzy decision making method based on an improved operation laws and its application. Eng. Appl. Artif. Intell. 2017, 60, 164–174. [Google Scholar] [CrossRef]
- Garg, H. Generalized intuitionistic fuzzy interactive geometric interaction operators using Einstein t-norm and t-conorm and their application to decision making. Comput. Ind. Eng. 2016, 101, 53–69. [Google Scholar] [CrossRef]
- Zhao, H.; Xu, Z.; Ni, M.; Liu, S. Generalized aggregation operators for intuitionistic fuzzy sets. Int. J. Intell. Syst. 2010, 25, 1–30. [Google Scholar] [CrossRef]
- Kaur, G.; Garg, H. Generalized cubic intuitionistic fuzzy aggregation operators using t-norm operations and their applications to group decision-making process. Arab. J. Sci. Eng. 2018. [Google Scholar] [CrossRef]
- Garg, H. Generalized interaction aggregation operators in intuitionistic fuzzy multiplicative preference environment and their application to multicriteria decision-making. Appl. Intell. 2018, 48, 2120–2136. [Google Scholar] [CrossRef]
- Xu, Z.S.; Yager, R.R. Intuitionistic fuzzy bonferroni means. IEEE Trans. Syst. Man Cybern. 2011, 41, 568–578. [Google Scholar]
- Xia, M.; Xu, Z.; Zhu, B. Geometric bonferroni means with their application in multi criteria decision making. Knowl.-Based. Syst. 2013, 40, 88–100. [Google Scholar] [CrossRef]
- Garg, H. New exponential operational laws and their aggregation operators for interval-valued Pythagorean fuzzy multicriteria decision-making. Int. J. Intell. Syst. 2018, 33, 653–683. [Google Scholar] [CrossRef]
- Garg, H. Some robust improved geometric aggregation operators under interval-valued intuitionistic fuzzy environment for multi-criteria decision-making process. J. Ind. Manag. Optim. 2018, 14, 283–308. [Google Scholar] [CrossRef]
- Qin, J.; Liu, X. An approach to intuitionistic fuzzy multiple attribute decision making based on Maclaurin symmetric mean operators. J. Intell. Fuzzy Syst. 2014, 27, 2177–2190. [Google Scholar]
- Qin, J.; Liu, X. Approaches to uncertain linguistic multiple attribute decision making based on dual Maclaurin symmetric mean. J. Intell. Fuzzy Syst. 2015, 29, 171–186. [Google Scholar] [CrossRef]
- Garg, H.; Arora, R. Novel scaled prioritized intuitionistic fuzzy soft interaction averaging aggregation operators and their application to multi criteria decision making. Eng. Appl. Artif. Intell. 2018, 71, 100–112. [Google Scholar] [CrossRef]
- Garg, H. Generalized Pythagorean fuzzy geometric interactive aggregation operators using Einstein operations and their application to decision making. J. Exp. Theor. Artif. Intell. 2018, 1–32. [Google Scholar] [CrossRef]
- Mendel, J.M. Uncertain Rule-Based fuzzy Logic System: Introduction and New Directions; Prentice-Hall: Englewood Cliffs, NJ, USA, 2001. [Google Scholar]
- Xu, Z.S. Intuitionistic fuzzy aggregation operators. IEEE Trans. Fuzzy Syst. 2007, 15, 1179–1187. [Google Scholar]
- Kumar, K.; Garg, H. Connection number of set pair analysis based TOPSIS method on intuitionistic fuzzy sets and their application to decision making. Appl. Intell. 2018, 48, 2112–2119. [Google Scholar] [CrossRef]
- Peng, X.; Dai, J.; Garg, H. Exponential operation and aggregation operator for q-rung orthopair fuzzy set and their decision-making method with a new score function. Int. J. Intell. Syst. 2018, 1–28. [Google Scholar] [CrossRef]
- Kumar, K.; Garg, H. TOPSIS method based on the connection number of set pair analysis under interval-valued intuitionistic fuzzy set environment. Comput. Appl. Math. 2018, 37, 1319–1329. [Google Scholar] [CrossRef]
- Herrera, F.; Martínez, L. A model based on linguistic 2-tuples for dealing with multigranular hierarchical linguistic contexts in multi-expert decision-making. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2001, 31, 227–234. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z. An approach based on similarity measure to multiple attribute decision making with trapezoid fuzzy linguistic variables. In Proceedings of the 2nd International Conference on Fuzzy Systems and Knowledge Discovery, Changsha, China, 27–29 August 2005; pp. 110–117. [Google Scholar]
- Zhang, H. Linguistic Intuitionistic fuzzy sets and application in MAGDM. J. Appl. Math. 2014, 2014, 432092. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, P.; Pei, Z. An approach to multiple attribute group decision making based on linguistic intuitionistic fuzzy numbers. J. Comput. Intell. Syst. 2015, 8, 747–760. [Google Scholar] [CrossRef] [Green Version]
- Garg, H.; Kumar, K. Some aggregation operators for linguistic intuitionistic fuzzy set and its application to group decision-making process using the set pair analysis. Arab. J. Sci. Eng. 2018, 43, 3213–3227. [Google Scholar] [CrossRef]
- Garg, H.; Kumar, K. Group decision making approach based on possibility degree measures and the linguistic intuitionistic fuzzy aggregation operators using einstein norm operations. J. Mult.-Valued. Log. Soft Comput. 2018, 31, 175–209. [Google Scholar]
- Mendel, J.M.; John, R.I.; LIu, F. Interval type-2 fuzzy logic systems made simple. IEEE Trans. Fuzzy Syst. 2006, 14, 808–821. [Google Scholar] [CrossRef]
- Chen, T.Y.; Chang, C.H.; Lu, J.F.R. The extended QUALIFLEX method for multiple criteria decision analysis based on interval type-2 fuzzy sets and applications to medical decision making. Eur. J. Oper. Res. 2013, 226, 615–625. [Google Scholar] [CrossRef]
- Chen, T.Y. An ELECTRE-based outranking method for multiple criteria group decision making using interval type-2 fuzzy sets. Inf. Sci. 2014, 263, 1–21. [Google Scholar] [CrossRef]
- Wu, D.; Mendel, J.M. Aggregation using the linguistic weighted average and interval type-2 fuzzy sets. IEEE Trans. Fuzzy Syst. 2007, 15, 1145–1161. [Google Scholar] [CrossRef]
- Qin, J.; Liu, X. Frank aggregation operators for triangular interval type-2 fuzzy set and its application in multiple attribute group decision making. J. Appl. Math. 2014, 2014, 923213. [Google Scholar] [CrossRef]
- Gong, Y.; Hu, N.; Zhang, J.; Liu, G.; Deng, J. Multi-attribute group decision making method based on geometric Bonferroni mean operator of trapezoidal interval type-2 fuzzy numbers. Comput. Ind. Eng. 2015, 81, 167–176. [Google Scholar] [CrossRef]
- Lee, L.W.; Chen, S.M. Fuzzy multiple attributes group decision-making based on the extension of TOPSIS method and interval type-2 fuzzy sets. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 2–15 July 2008; pp. 3260–3265. [Google Scholar]
- Zhao, T.; Xia, J. Type-2 intuitionistic fuzzy sets. Control Theory Appl. 2012, 29, 1215–1222. [Google Scholar]
- Singh, S.; Garg, H. Distance measures between type-2 intuitionistic fuzzy sets and their application to multicriteria decision-making process. Appl. Intell. 2017, 46, 788–799. [Google Scholar] [CrossRef]
- Mendel, J.M.; Wu, H. Type-2 fuzzistics for symmetric interval type-2 fuzzy sets: Part 1, forward problems. IEEE Trans. Fuzzy Syst. 2006, 14, 781–792. [Google Scholar] [CrossRef]
- Jana, D.K. Novel arithmetic operations on type-2 intuitionistic fuzzy and its applications to transportation problem. Pac. Sci. Rev. A Nat. Sci. Eng. 2016, 18, 178–189. [Google Scholar] [CrossRef]
- Mendel, J.M.; Mouzouris, G.C. Type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 1999, 7, 643–658. [Google Scholar]
- Mendel, J.M.; Wu, H. Type-2 fuzzistics for symmetric interval type-2 fuzzy sets: Part 2, inverse problems. IEEE Trans. Fuzzy Syst. 2007, 15, 301–308. [Google Scholar] [CrossRef]
- Chiao, K.P. Multiple criteria group decision making with triangular interval type-2 fuzzy sets. In Proceedings of the 2011 IEEE International Conference on Fuzzy Systems, Taipei, Taiwan, 27–30 June 2011; pp. 2572–2582. [Google Scholar]
- Wang, W.; Liu, X.; Qin, Y. Multi-attribute group decision making models under interval type-2 fuzzy environment. Knowl.-Based. Syst. 2012, 30, 121–128. [Google Scholar] [CrossRef]
- Qin, J. Interval type-2 fuzzy Hamy mean operators and their application in multiple criteria decision making. Granul. Comput. 2017, 2, 249–269. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Y.M. An analytical solution method for the generalized fuzzy weighted average problem. Int. J. Uncertain. Fuzz. Knowl.-Based Syst. 2013, 21, 455–480. [Google Scholar] [CrossRef]
- Pedrycz, W.; Song, M. A granulation of linguistic information in AHP decision-making problems. Inf. Fusion 2014, 17, 93–101. [Google Scholar] [CrossRef]
- Garg, H.; Arora, R. Bonferroni mean aggregation operators under intuitionistic fuzzy soft set environment and their applications to decision-making. J. Oper. Res. Soc. 2018, 1–14. [Google Scholar] [CrossRef]
- Kaur, G.; Garg, H. Multi-Attribute decision-making based on bonferroni mean operators under cubic intuitionistic fuzzy set environment. Entropy 2018, 20, 65. [Google Scholar] [CrossRef]
- Hara, T.; Uchiyama, M.; Takahasi, S.E. A refinement of various mean inequalities. J. Inequal. Appl. 1998, 1998, 932025. [Google Scholar] [CrossRef]
- Garg, H.; Nancy. Multi-criteria decision-making method based on prioritized Muirhead mean aggregation operator under Neutrosophic set environment. Symmetry 2018, 10, 280. [Google Scholar] [CrossRef]
- Guan, K. The Hamy symmetric function and its generalization. Math. Inequal. Appl. 2006, 9, 797–805. [Google Scholar] [CrossRef]
- Jiang, W.D. Some properties of dual form of the Hamy’s symmetric function. J. Math. Inequal. 2007, 1, 117–125. [Google Scholar] [CrossRef]
- Garg, H.; Singh, S. A novel triangular interval type-2 intuitionistic fuzzy sets and their aggregation operators. Iran. J. Fuzzy Syst. 2018. [Google Scholar] [CrossRef]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Garg, H.; Arora, R. A nonlinear-programming methodology for multi-attribute decision-making problem with interval-valued intuitionistic fuzzy soft sets information. Appl. Intell. 2018, 48, 2031–2046. [Google Scholar] [CrossRef]
- Peng, X.D.; Garg, H. Algorithms for interval-valued fuzzy soft sets in emergency decision making based on WDBA and CODAS with new information measure. Comput. Ind. Eng. 2018, 119, 439–452. [Google Scholar] [CrossRef]
- Garg, H.; Rani, D. Some generalized complex intuitionistic fuzzy aggregation operators and their application to multicriteria decision-making process. Arab. J. Sci. Eng. 2018, 1–20. [Google Scholar] [CrossRef]
- Garg, H. Linguistic Pythagorean fuzzy sets and its applications in multiattribute decision-making process. Int. J. Intell. Syst. 2018, 33, 1234–1263. [Google Scholar] [CrossRef]
- Selvachandran, G.; Garg, H.; Alaroud, M.H.S.; Salleh, A.R. Similarity measure of complex vague soft sets and its application to pattern recognition. Int. J. Fuzzy Syst. 2018, 20, 1901–1914. [Google Scholar] [CrossRef]
- Selvachandran, G.; Garg, H.; Quek, S.G. Vague entropy measure for complex vague soft sets. Entropy 2018, 20, 403. [Google Scholar] [CrossRef]
Figure 1.
LMF (dashed), UMF (solid), FOU (shaded) for IT2FS A.

Figure 2.
LMF (dashed), UMF (solid), LNMF (doted), UNMF (solid), FOU (shaded) for IT2IFS A.

Figure 3.
Representation of STIT2IFN .


{kind=link}
{kind=link}
{kind=link}
Table 1.
Linguistic grade and coressponding values.
| LTs | Triangular IT2IFNs |
|---|---|
| VL | (0.20,0.10,0.60,0.65,0.35,0.30) |
| L | (0.30,0.10,0.65,0.70,0.30,0.25) |
| ML | (0.40,0.20,0.70,0.75,0.20,0.18) |
| M | (0.50,0.20,0.75,0.80,0.16,0.15) |
| MH | (0.60,0.30,0.80,0.85,0.13,0.12) |
| H | (0.70,0.30,0.85,0.90,0.10,0.08) |
| VH | (0.80,0.40,0.90,0.95,0.07,0.03) |
Table 2.
Linguistic grades and compliments.
| LT | VL | L | ML | M | MH | H | VH |
|---|---|---|---|---|---|---|---|
| Complemented LT | VH | H | MH | M | ML | L | VL |
Table 3.
Effect of k on to ranking of alternatives.
| Value of k | Score Values () of the Alternatives | Ranking Order | |||||
|---|---|---|---|---|---|---|---|
| 1 | (0.3615, 0.0762) | (0.5627, 0.0523) | (0.2268, 0.0872) | (0.3953, 0.0677) | (0.1577, 0.0702) | (0.3836, 0.0856) | |
| 2 | (0.3404, 0.0375) | (0.5550, 0.0396) | (0.2046, 0.0392) | (0.3770, 0.0362) | (0.1455, 0.0412) | (0.3579, 0.0402) | |
| 3 | (0.3324, 0.0241) | (0.5526, 0.0840) | (0.1997, 0.0250) | (0.3702, 0.0268) | (0.1427, 0.0321) | (0.3484, 0.0240) | |
| 4 | (0.3285, 0.0177) | (0.5507, 0.0329) | (0.1976, 0.0181) | (0.3656, 0.0203) | (0.1415, 0.0275) | (0.3437, 0.0161) | |
| 5 | (0.3260, 0.0138) | (0.5498, 0.0314) | (0.1964, 0.0141) | (0.3631, 0.0170) | (0.1409, 0.0247) | (0.3408, 0.0115) | |
| 6 | (0.3244, 0.0113) | (0.5492, 0.0304) | (0.1957, 0.0114) | (0.3613, 0.0148) | (0.1405, 0.0228) | (0.3389, 0.0086) | |
| 7 | (0.3232, 0.0095) | (0.5488, 0.0298) | (0.1952, 0.0094) | (0.3601, 0.0131) | (0.1402, 0.0215) | (0.3376, 0.0064) | |
Table 4.
The characteristic comparisons of different methods.
| Methods | Whether Captures | Whether Captures | Whether It Makes the | Whether Criteria Weights | Whether Describe | Whether Flexible to |
|---|---|---|---|---|---|---|
| Interrelationship of Two | Interrelationship of Multiple | Method Flexible by | Are Depends on the | Information Using | Express a Wider | |
| Aggregated Arguments | Aggregated Arguments | the Parameter Vector | Collective Information | Linguistic Features | Range of Information | |
| Gong et al. [36] | ✓ | × | × | × | × | × |
| Liu and Wang [47] | × | × | × | × | × | × |
| Pedrycz and Song [48] | × | × | × | ✓ | ✓ | × |
| Qin [46] | ✓ | ✓ | ✓ | × | ✓ | × |
| The proposed method | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Singh, S.; Garg, H. Symmetric Triangular Interval Type-2 Intuitionistic Fuzzy Sets with Their Applications in Multi Criteria Decision Making. Symmetry 2018, 10, 401. https://doi.org/10.3390/sym10090401
AMA Style
Singh S, Garg H. Symmetric Triangular Interval Type-2 Intuitionistic Fuzzy Sets with Their Applications in Multi Criteria Decision Making. Symmetry. 2018; 10(9):401. https://doi.org/10.3390/sym10090401
Chicago/Turabian StyleSingh, Sukhveer, and Harish Garg. 2018. "Symmetric Triangular Interval Type-2 Intuitionistic Fuzzy Sets with Their Applications in Multi Criteria Decision Making" Symmetry 10, no. 9: 401. https://doi.org/10.3390/sym10090401
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.