4.1. Dataset Preparation
The proposed method is thoroughly examined using two datasets obtained from the Canadian Institute for Cybersecurity (
https://www.unb.ca/cic/datasets/index.html (accessed on 6 September 2021)). The first dataset, the Canadian Institute of Cybersecurity Android Adware and General Malware (CICAAGM2017) dataset [
36] is gathered semiautomatically by installing Android apps on authorized mobile devices. The dataset is generated using 1900 apps and is separated into three classes: adware, general malware, and benign. The adware contains 250 malicious apps, including Airpush, Dowgin, kemoge, mobidash, and shuanet. The general malware consists of 150 malicious apps, including AVpass, fakeAV, fakeflash, GGtracker, and penetho. A total of 1500 apps are included in the benign set.
Table 2 contains a detailed description of the dataset. The second dataset, CICMalDroid 2020 [
25,
37], collected over 17,341 Android samples from different sources, including the VirusTota l service, the Contagio security blog, AMD, and MalDozer between December 2017 and December 2018. The classification of Android apps as malware is critical for cybersecurity investigators to implement effective classification and detection systems. As a result, this dataset contains adware, banking, riskware, and SMS as malware, as well as benign apps. The number of adware, banking, riskware, SMS, and benign apps is 1253, 2100, 2546, 3904, and 1795, respectively. A detailed description of each app is presented in
Table 3.
4.2. Result Analysis and Performance Comparison
The trained textual features are combined with visual texture features before being fed into the designed model. We generated texture features with 229 × 229 and 256 × 256 and then combined them with textual features to analyze the impact.
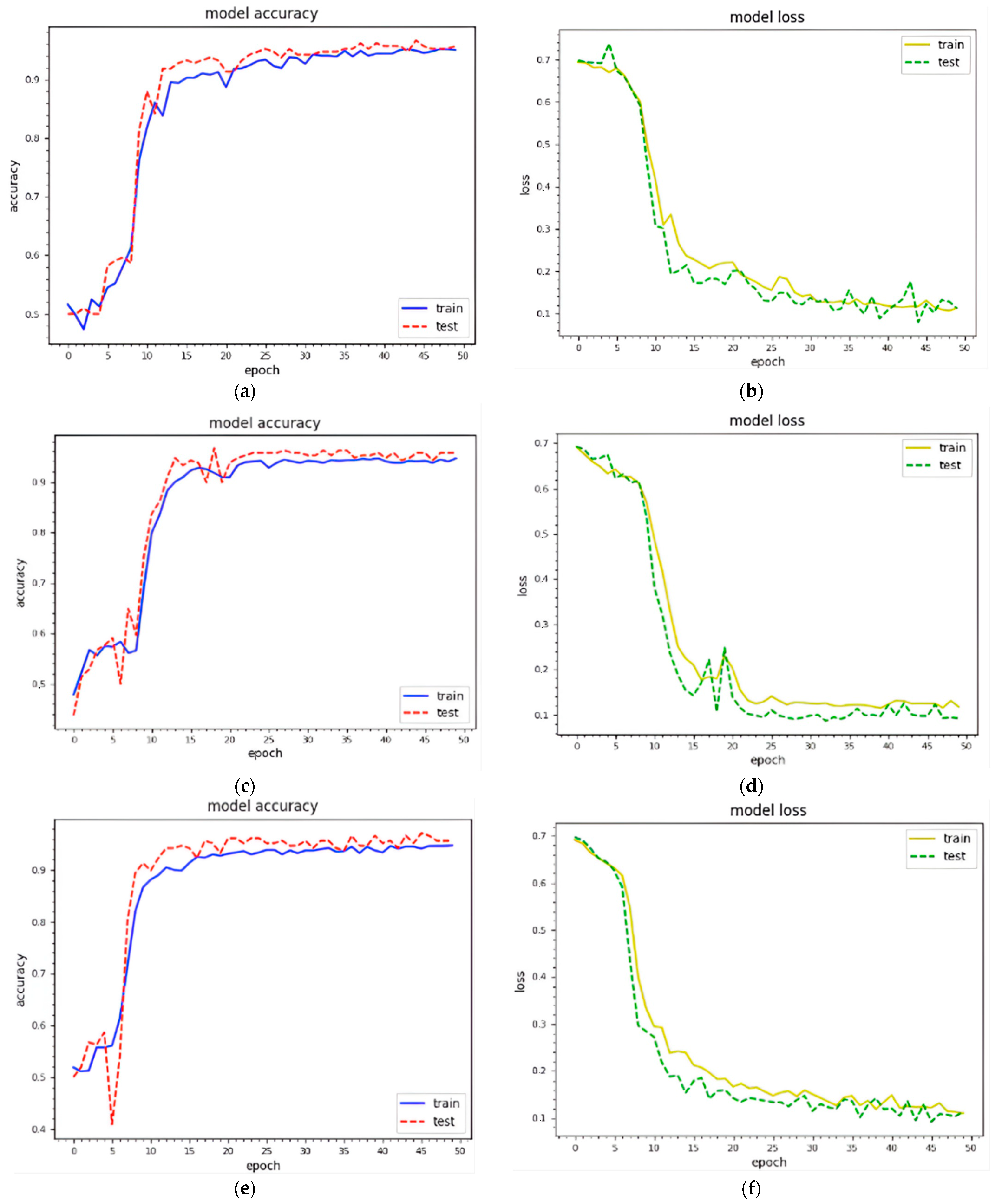
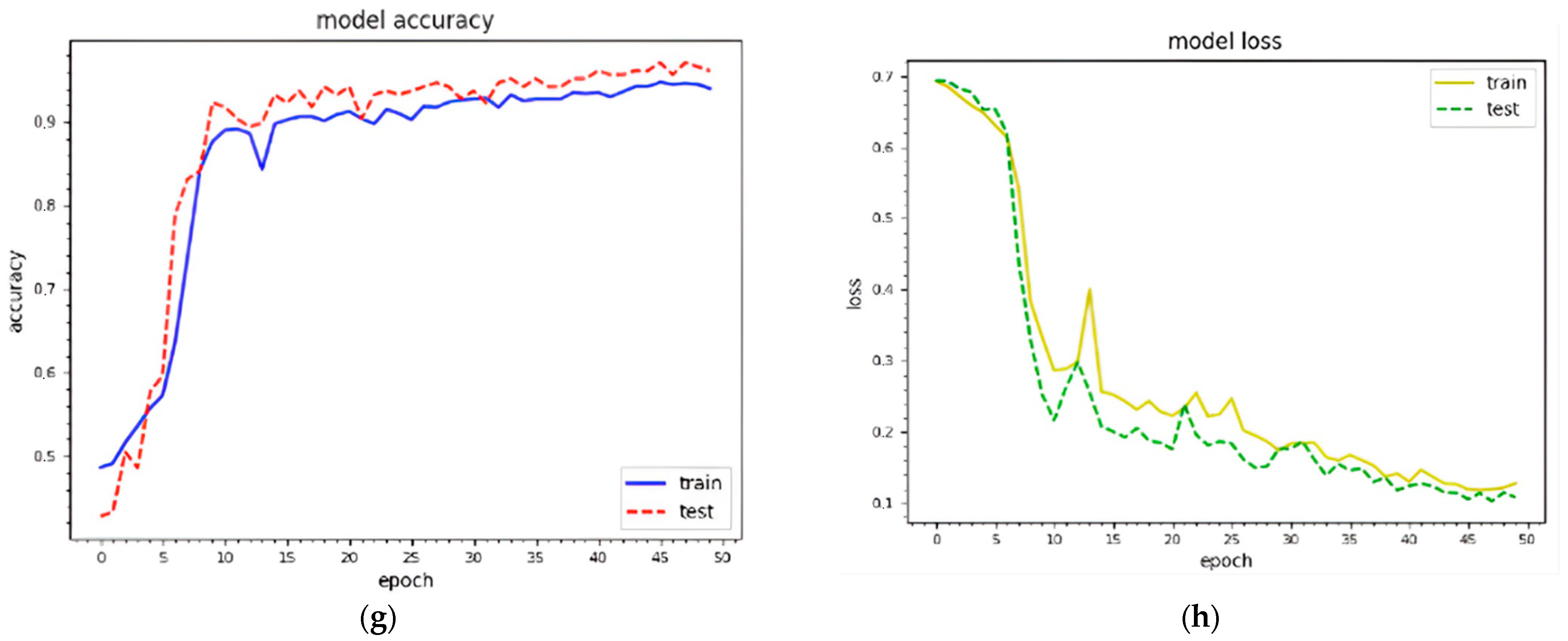
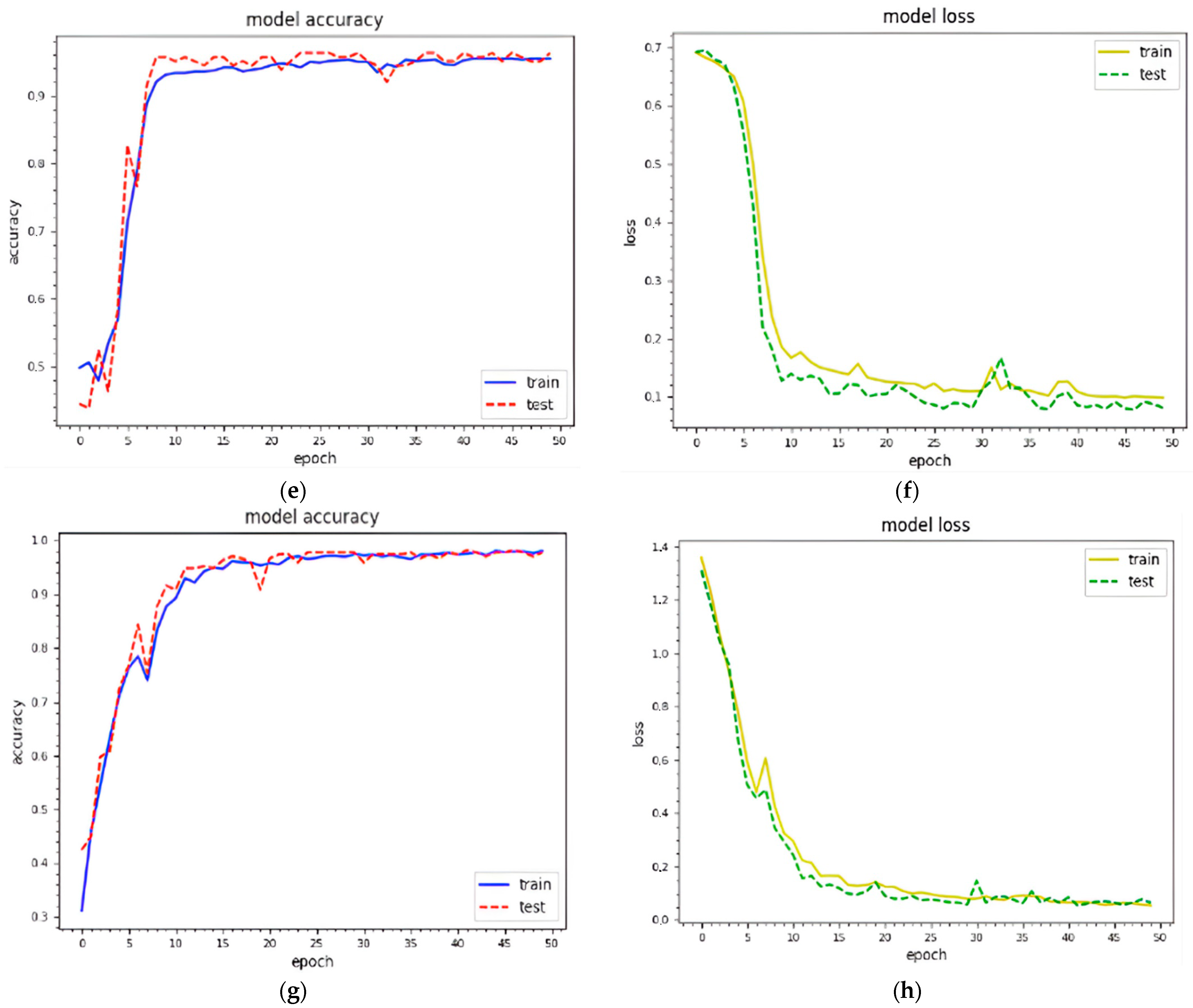
Figure 5 shows the training and testing curves for malware classification and detection using dataset 1. We utilized two standard image sizes: 229 × 229 and 256 × 256. In terms of model accuracy, the blue and red curves represent the training and testing data points, respectively. In terms of model loss, the yellow and green curves represent the training and testing points, respectively. (a–d) demonstrate classification and detection for 229 × 229 images, whereas (e–h) demonstrate classification and detection for 256 × 256 images. These curves represent the dynamic behavior of the specified model during the training phase. Using 229 × 229 texture features, the model accuracy curves range from 40% to 98% for classification and 40% to 99% for detection. The model accuracy curves for 256 × 256 texture features result in 35% to 98.1% classification and 30%to 99.16% detection accuracy. As a result, the combined features with 256 × 256 texture features outperform. The model loss is inversely proportional to the model accuracy.
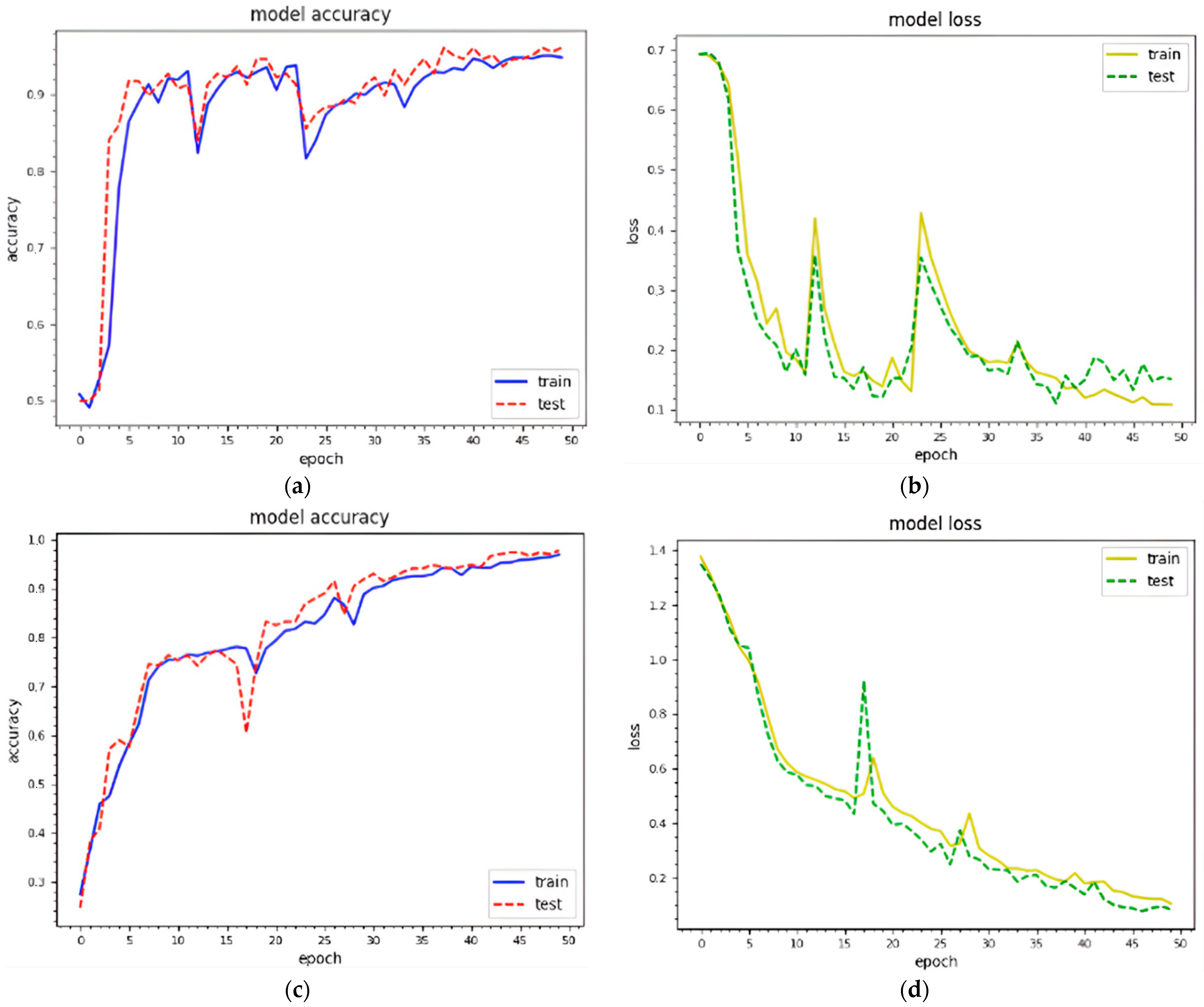
Figure 6 depicts the training and testing curves for model accuracy and loss using dataset 2. The model accuracy curves achieve between 50% and 98.1% accuracy for classification and between 40% and 99.1% for detection using dataset 1. Similarly, the same curves provide performance accuracy ranging from 30% to 98.11% for classification and from 40% to 99% for detection. It is clear that textual features with 256 × 256 work better for malware detection.
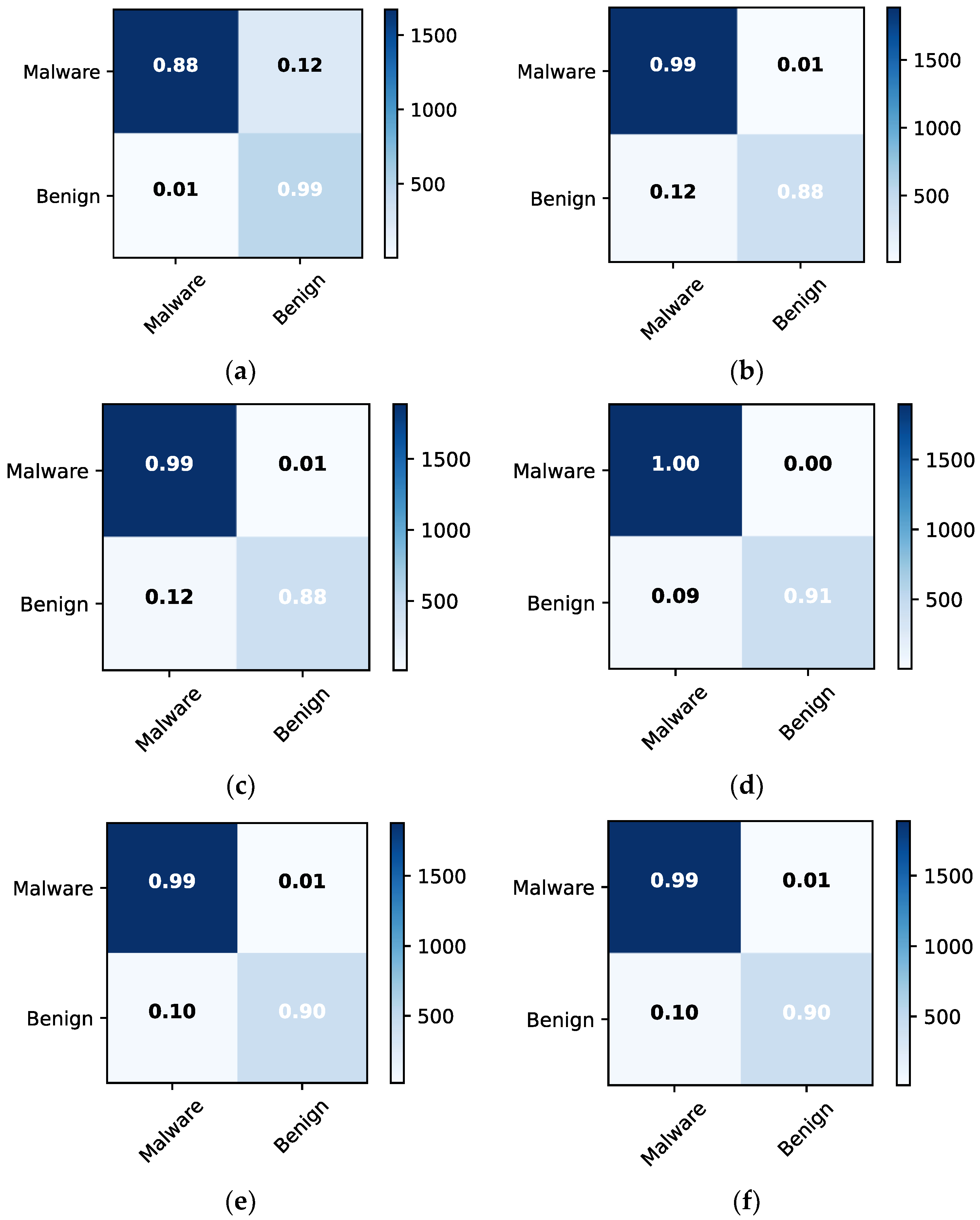
The confusion matrices for malware detection are obtained to examine misclassification errors for each class, such as malware and benign.
Figure 7 depicts the confusion matrices for the individual approaches and the ensemble model, allowing for detailed comparison. The ensemble model outperforms RF in terms of classification. For instance, both approaches had 99% classification and 12% misclassification accuracy for malware and 90% and 10% for benign, respectively. The LR model behaves similarly to ensemble learning but with different results. For example, LR has a 100% classification accuracy and 0% misclassification for malware and 91% classification and 9% misclassification for benign.
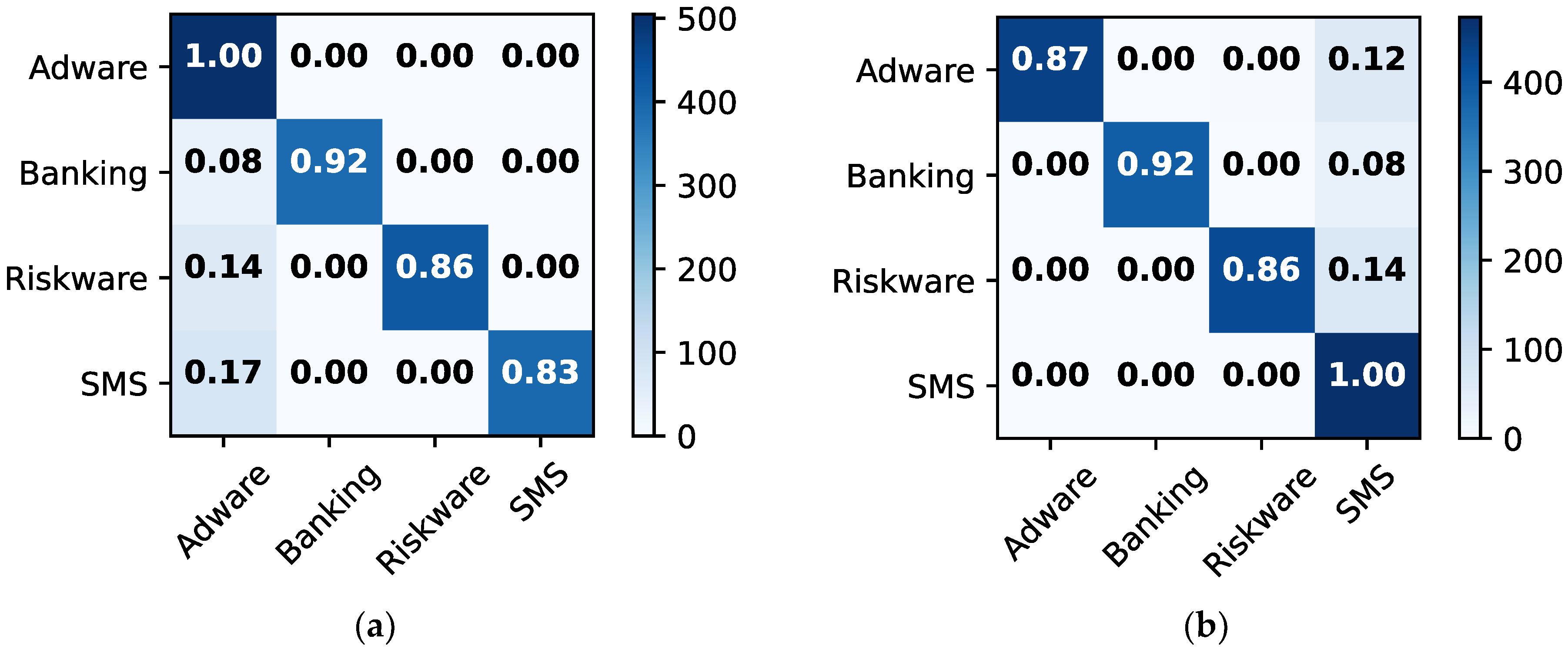
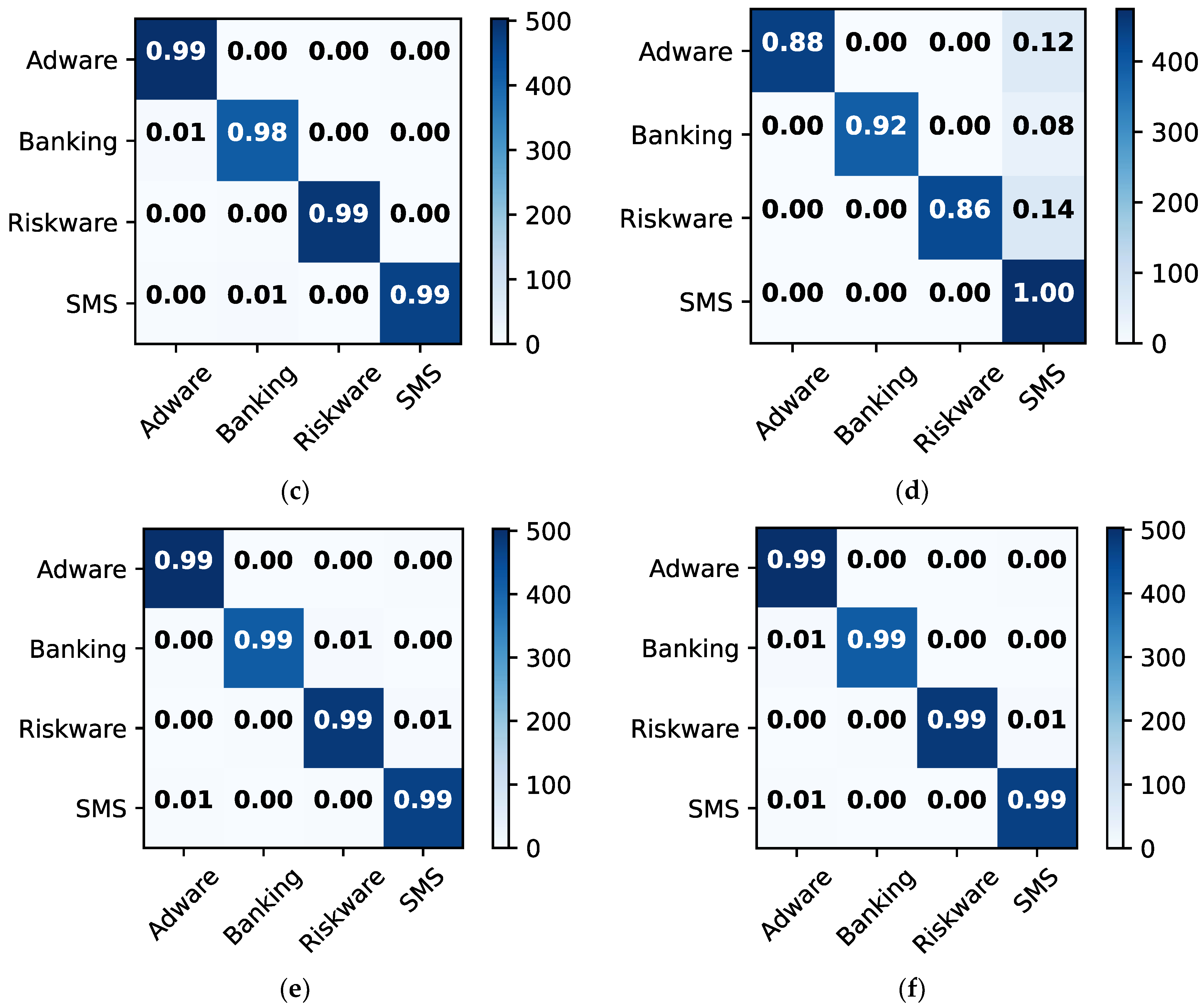
Figure 8 depicts the confusion matrices for malware classification using 256 × 256 dataset 2. Ensemble and RF models outperform other methods. For instance, they provide classification and misclassification rates of 99% and 1%, respectively, for each class, such as adware, banking, riskware, and SMS.
Table 4 shows the precision, recall, f1-score, and accuracy measures for both datasets using 229 × 229. Performance matrices are provided for each approach, as well as for the ensemble. The ensemble model outperforms the other models in terms of malware classification and detection when utilizing dataset 1. For malware classification, the precision, recall, f1-score, and accuracy measures are 98%, 97, 98%, and 98.18%, respectively. The same performance measures achieve 99%, 99%, 99%, and 99.02% accuracy for malware and detection, respectively. Using dataset 2, the ensemble approach performs better for malware classification; however, the RF approach works better for malware detection. Malware categorization performance measures are 98, 98%, 98%, and 98.1%, respectively. Similarly, the performance measures for malware detection are 99%, 99%, 99%, and 99.04%, respectively.
Table 5 shows the performance measures for malware classification and detection using both 256 × 256 datasets. The proposed approach achieves the best classification results using both datasets with 256 × 256 dimensions.
Table 6 shows the malware classification performance measures for each class label using dataset 1.
Table 7 shows the performance measures for each class label using dataset 2. The methods with a bold style demonstrate that they outperform others for the designed experiment.
Table 8 depicts the analysis of the optimum features used to determine the best feature selection. The proposed method is tested with a variety of feature counts, such as 100, 150, 200, 250, etc., corresponding to classification accuracy. Dataset 1 is used to examine feature selection with various feature counts. The NB, SVM, DT, LR, RF, and ensemble models provide the highest classification accuracy for 250 features. The classification accuracy increases from 100 to 200 features but decreases after 250. With 400 classification features, classification accuracy increases slightly but then decreases. According to this analysis, 250 is the optimal number of features for the proposed approach.
Generally, classification models produce different results after each execution. To evaluate performance, the datasets are randomly divided into train and test models. As a result, each execution produces unique results for each classification model. We used the same random seed on all classification models with 10 executions to test the scalability and reliability of the proposed ensemble model.
Table 9 shows the classification model performance using the same random seeds. On 8 of 10 random seeds, the ensemble model outperforms other classification models, demonstrating that the ensemble model configuration is more reliable than a single classification model. At execution times 2 and 10, the RF slightly outperforms other models relative to the ensemble. Surprisingly, the average performance of 10 executions demonstrates that the ensemble model is more scalable and reliable than the random forest, and it is adopted as the best solution for malware detection and classification. Furthermore, the ensemble model has an accuracy range of 98.98% to 99.02%, whereas the RF has an accuracy range of 98.86% to 99.02%.
Table 10 compares the proposed approach to previously published studies. These studies mostly made use of network traffic to classify Android malware. Aresu et al. [
14], showed how analysis of mobile botnets’ HTTP traffic can be utilized to classify them into families. To do so, it analyzes HTTP traffic data to create malware clusters. This method also extracts signatures that can be used to detect new clustered malware with an accuracy of 98.66%. Li et al. [
20] presented the Droid Classifier, which automatically builds multiple models over a set of annotated malware apps. Each model is built using common identifiers collected from network traffic. Adaptive threshold settings are designed to represent diverse virus traits with an accuracy of 94.66%. Shanshan et al. [
38] proposed identifying infected files by their URLs. Multi-view neural networks provide depth and breadth of information when analyzing malware, in addition to creating and distributing soft attention-weighting elements for use with specific data. The accuracy of URL-based malware classification is 95.74%. Shyong et al. [
39] combined static authorization with dynamic network monitoring to classify Android apps. During the dynamic evaluation step, malicious network traces are used to obtain various attributes, and Random Forest is then used to identify malware samples. The average Android malware performance is 98.86%. Shanshan et al. [
28] presented a method to detect Android malware using URLs. Multi-view neural networks are used to construct malware detection models that focus on feature depth. The weights of the features are dispersed to work on certain inputs. The suggested approach has an accuracy of 98%. Our technique outperforms this method, with a 99% malware detection accuracy.
The proposed method is thoroughly compared to existing methods using the same datasets.
Table 11 shows a performance comparison with state-of-art methods using the same datasets with different strategies. Texture, text, or a combination of both can be used to classify malware. Furthermore, some researchers used a CNN model to classify malware images without using descriptors to select special features. Alani et al. [
21] introduced AdStop, a machine-learning-based method that identifies malware in data traffic. The proposed method classified malware using textual features from the CIC-AAGM2017 dataset and a multi-layer perceptron with an accuracy of 98.02%. Acharya et al. [
22] proposed a framework
that extracts clusters using latent Dirichlet allocation and hierarchical clustering techniques. They used a CNN model, which has a precision of 98.3%, to classify malware without relying on any special features. In [
22,
24,
41,
42] CNN and TCN models were used to classify malware with texture features. The proposed deep learning models directly collect the malware images for classification without selecting the special features using descriptors. In [
21,
23,
25] multi-layer perceptron (MLP), gradient boosting, and ensemble methods were used to classify malware with textual features. To classify malware, we propose a method that combines textual and texture features from both datasets. When compared to state-of-the-art methods, the proposed approach outperforms, with a classification accuracy of 99%.
4.3. Model Interpretation and Validation Using Explainable AI and t-SNE
To interpret and validate the proposed approach, we extracted a chunk of the most important features from the embedded matrix.
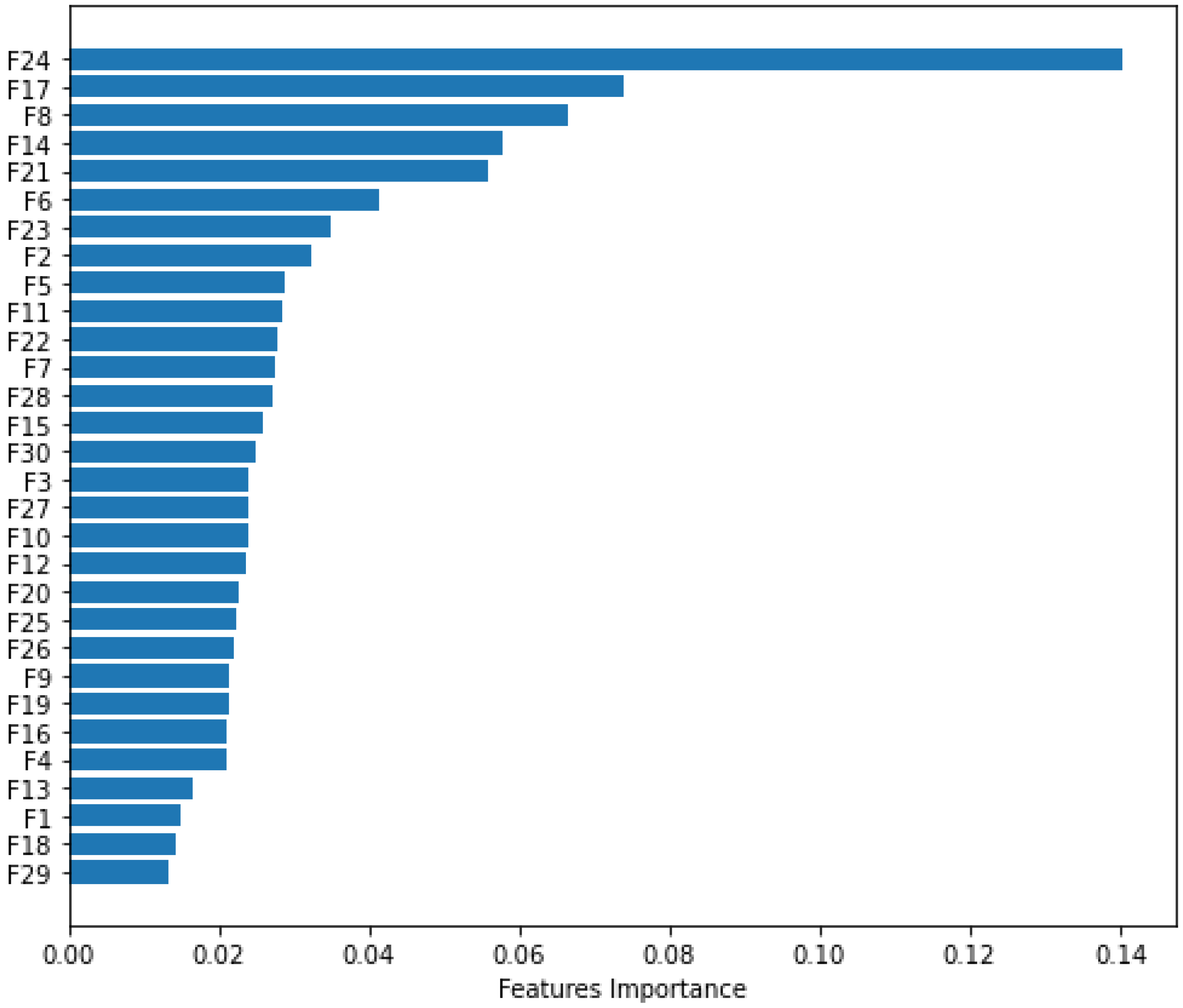
Figure 9 depicts the importance of the features among the 30 features. The feature “F24” is the most effective, indicating that it makes the most contribution to malware classification detection. However, the “F29” feature is the least effective and may perform the worst for the proposed strategy. The “F17” feature is the next most effective feature. Thus, we can readily determine which features are the most and least important. To explain the impact of each feature on the model output, we used the Local Interpretable Model-agnostic Explanation (LIME) and SHapley Additive exPlanations (SHAP) libraries [
43].
Figure 10 illustrates the proportionate contribution of features to from the average of samples with a base value of 0 (malware) to the output value of 1 (benign). The values for this sample are indicated by numbers at the bottom of the figure. In our case, the base value is 0.22. The red values are those that are moving underneath the base value, whereas the blue values are those that are moving above the base value. The base value is a threshold, and values less than the base value can contribute to the malware class. Values that are greater than the base value can contribute to the benign class. This allows us to evaluate the contribution of each feature to a specific class.
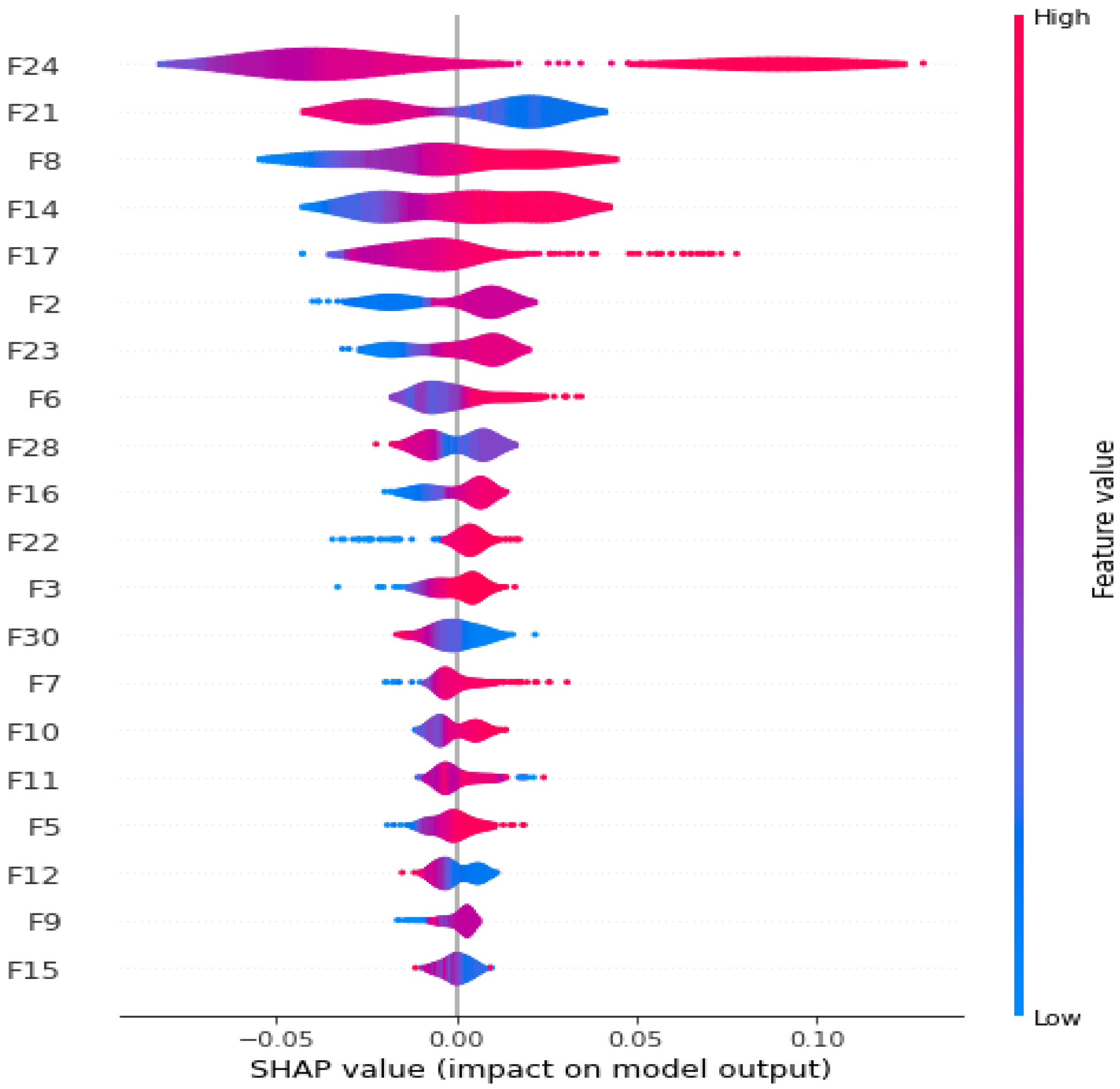
Figure 11 depicts the effect of combined features on model output. The red color represents a higher contribution of each feature, whereas the green color represents smaller contributions. The combined effect of the “F24” feature is significant, whereas that of F15 is the smallest. This allows us to easily describe the impact of each feature on a certain class, such as malware or benign. This experiment evaluates the effectiveness of each feature, providing a clear picture of how each attribute affects the model output.
The purpose of the t-distributed stochastic neighbor embedding (t-SNE) visualization method is to identify whether features possess high or sparse knowledge. Furthermore, the t-SNE method is intended to evaluate the efficiency of the suggested approach. Maaten et al. [
44] proposed the t-SNE method to visualize high-dimensional data.
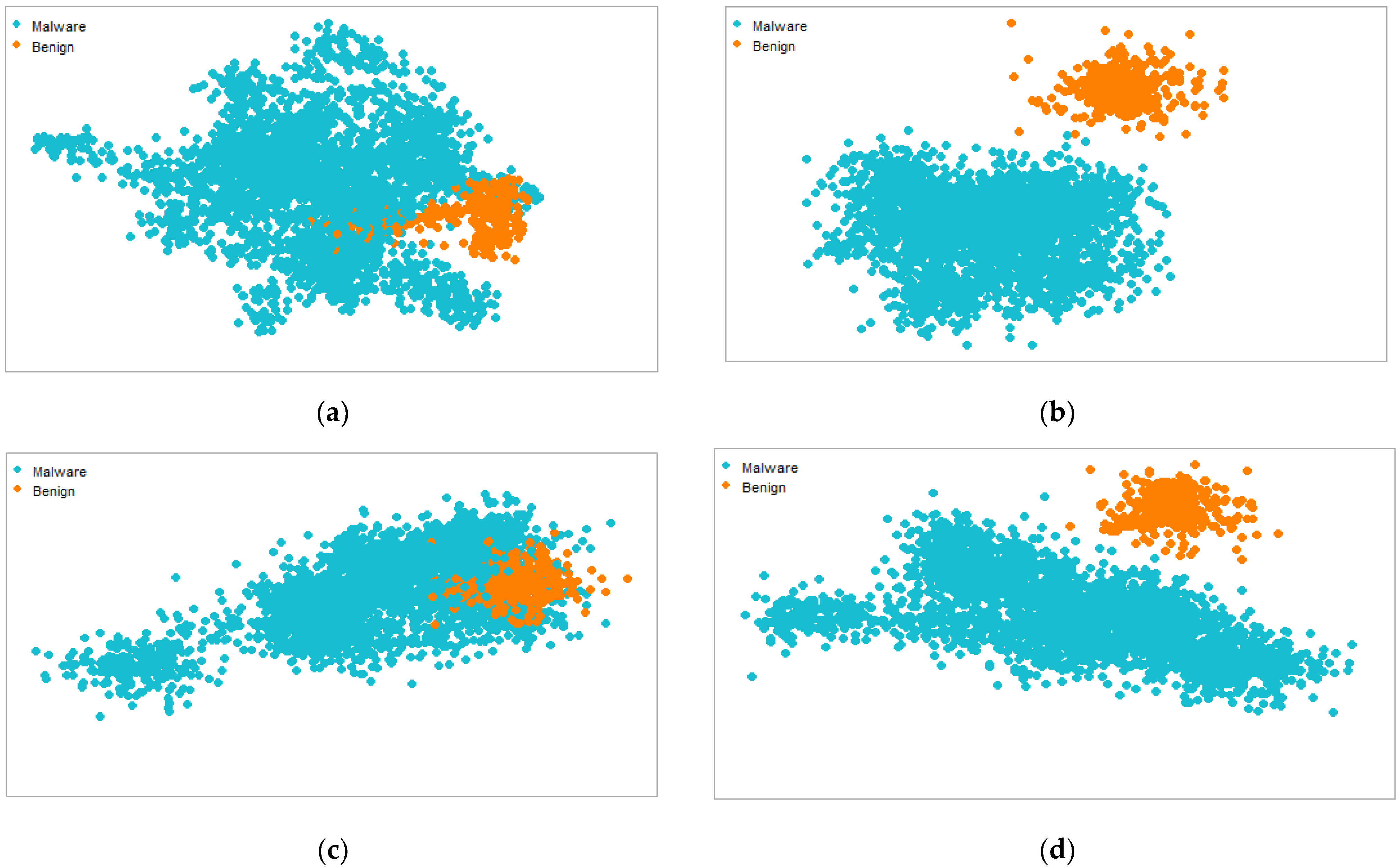
Figure 12 shows the attentive ratio of semantic and syntactic feature local and global scores for various perplexity values. Using the R programming language, we designed two t-SNE visual studies. In the first experiment, we attempted to determine how much perplexity is required to distinguish between the benign and malicious classes. The best Android malware clusters are distinguished by the highest perplexity scores in the second experiment. For instance, (a,c) have the lowest perplexity values, whereas (b,d) have the highest values. t-SNE makes use of iterations to distinguish between different types of samples. We utilized 400 iterations for each perplexity factor to display the distinct malware and benign groupings. The dataset density has a significant impact on the overall classification results. Because more qualitative data are presented for training, a higher density usually improves accuracy. To improve classification outcomes, the t-SNE visual clusters are better segregated using optimal perplexity settings. A dataset can be divided into sections using an acceptable perplexity value and classified using important hyperparameters. This method is used to demonstrate the efficacy of the presented strategy because semantic aspects can be extracted and classified as malware or benign to improve classification performance.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}