HyRA: A Hybrid Recommendation Algorithm Focused on Smart POI. Ceutí as a Study Scenario

 , ,
, ,  , and
, and 
Abstract
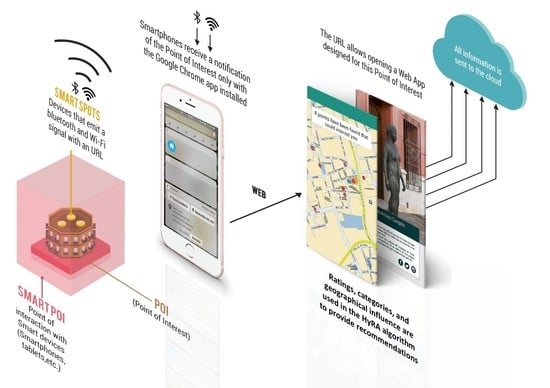
:
1. Introduction
- The use of Google’s Physical Web technology as well as the Smart Spot device in the proposal of a recommendation algorithm in the tourism sector.
- The incorporation of an average aggregation operator integrated by five similarity and distance measures, validated among a total of nine measures, into a user-based CF algorithm.
- The HyRA’s proposal and development, encoding the improved user-based CF algorithm along with the Smart POIs’ categories and the geographical influence factor.
- Two datasets built with real-world information: one dataset composed of 16 Smart POIs (Smart POIs Dataset in Ceutí) and another constituted by the 16 explicit preferences of 200 respondents (User preferences Dataset).
- One experimental dataset comprised of 13 Smart POIs’ categories (Smart POI’s Categories Dataset).
- The experimental results show that HyRA provides better recommendations against other approaches.
2. State of the Art
2.1. Traditional and POI Recommendation Algorithms
- Year (Y). It refers to the year of publication of the approach.
- Rating (R). Data that consider the recommendation algorithm to address the user’s explicit preference on POIs.
- Check-in (CI). Data that consider the recommendation algorithm to address the user’s implicit preference on POIs.
- Geographical Influence (GI). Factor that is examined in the POI recommendation approach.
- Social Influence (SI). Factor that is explored in the POI recommendation approach.
- Category (C). Data that consider the recommendation algorithm to address the POI tags, categories, or topics.
- Another context data (ACD). Some other data that the POI recommendation algorithm considers different from the data and factors mentioned in this comparison.
- Information Source (IS). Source that is employed in the collection of the data used to evaluate the POI recommender.
- Similarity and Distance Measures (SDM). Measure that is applied in the POI recommendation algorithm.
- User-based CF with Aggregation Operator (UCF+), where ✗ * indicates that the approach works with the user-based CF algorithm without an aggregation operator. Algorithm that is implemented as a POI recommender using an aggregation operator as a similarity measure.
- Physical Web, Smart Spot, and Smart POI (PSSP). Technology and device that are used to collect the input data of the POI recommendation algorithm.
- Scope (S). Field of application of the approach.
2.2. Similarity and Distance Measures
- Pearson. It is a measure of the strength of a linear association between two variables. In a broad sense, the Pearson correlation coefficient returns the distance of all data points that best fit through data. Its representation is given by Equation (2) [23].where and are single samples indexed with i; n is the sample size; and are the sample mean of x and y, respectively; and and are the sample standard deviation of x and y, respectively.
- Manhattan. It is also known as rectilinear distance and taxicab norm. It calculates several projections in the mathematical space, where the size of blocks does not affect the distances. The Manhattan distance is represented in Equation (4) [22,24].where and are components of a vector indexed with i; and n is the sample size.
2.3. POI (Point-of-Interest) and Smart POI (Smart Point of Interaction)
- Any entity can be a Smart POI when placing it on a Smart Spot.
- A Smart POI provides a smart interaction area between entities and people through a smartphone.
- A Smart POI can represent both an interesting place for a visitor and an urban infrastructure relevant for a city manager according to a certain context.
3. The HyRA’s Approach
3.1. User-Based CF: Analysis and Description
- In the POI recommendation systems, user preferences are reflected and inferred by the frequency of check-in at locations [2,6]. For this scenario, such preferences can be obtained from Smart Spot through interaction between it and the user’s smartphone. Nevertheless, since Smart Spot constantly emits signals to the mobile devices of the users [9], the user’s smartphone can receive all the signals that any Smart Spot emits. Therefore, the interaction between a user and a Smart POI (check-in) does not necessarily indicate interest on that Smart POI, but only that the user is close to it. Consequently, to get the user preferences using Smart Spot, a solution based on the traditional recommendation systems approach was proposed. This is, to have explicitly the ratings for the items [2] considering to Smart POIs as items.
- Data gathering process. The datasets that serve as input for HyRA are loaded: the Smart POIs located in Ceutí and the users’ ratings for each Smart POI. Subsequently, a ground-truth subset was built from the dataset that concentrates all users’ ratings for each Smart POI. There are randomly extracted from one to 11 rated Smart POIs from each user to compose the ground-truth subset, where only Smart POIs whose rating values oscillate between three to five are conserved. This with the aim of leaving behind Smart POIs that are not of interest for a user and that are represented with a ranked below three. By setting to 11 the maximum number of Smart POIs that can be extracted, a total maximum of 70% of the rated Smart POIs of each user is retained to represent their preferences. This ground-truth subset is taken as if the user had only rated this number of Smart POIs. The remaining Smart POIs of each user are used as not visited (not rated) Smart POIs that can be recommended by HyRA. In addition, these remaining Smart POIs and their rated values were preserved in a separate subset to compare the true rated Smart POIs against the Smart POIs recommended by HyRA. Algorithm 1 provides the pseudocode of this phase.
- Compute similarities between users. A comparison between a user with the rest of them is performed to obtain the N users who have most similar preferences with him/her. The rationale behind this is that users who have similar values to a certain user share similar preferences [2]. Thus, it is more likely that the Smart POIs recommended by these similar users matches the preferences of the specified user. To find those users that share analogous preferences with a specific user, a paired comparison of their ratings of Smart POIs is carried out. This comparison iterates through each available user in the dataset to retain all Smart POIs that are presented in the preferences of both users. Then, the ratings of the two users’ Smart POIs are compared by using one distance or similarity measure. Independent experiments are carried out using the following measures: Euclidean distance, Pearson correlation, Cosine similarity, Manhattan distance, and Chebyshev distance. After the paired comparison, a descending list of similarity values among users is obtained per each distance or similarity measure. The similarity values closer to 1 indicate that both users share more preferences in common, while similarity values closer to 0 express the opposite. Algorithm 2 provides the pseudocode of this process.
- Recommend Smart POIs. For each available user in the dataset—excluding the user that is selected for giving recommendations—are extracted the Smart POIs that the selected user has not visited. Then, each Smart POI not visited is ranked through a weighted mean. The weighted mean contemplates the rating of Smart POI and the similarity value of the user that has been compared to the selected user. Consequently, a descending list of N ranked Smart POIs is obtained. From this list, the Top-5 Smart POIs are recommended to the specific user. As a result, only the Smart POIs that could be interesting for the specific user are recommended.
| Algorithm 1 HyRA—Data gathering process. |
|
| Algorithm 2 HyRA—Compute similarities between users. |
|
3.2. User-Based CF with the Average Aggregation Operator
- Data gathering process. Same process as described in Section 3.1 and presented in Algorithm 1.
- Compute similarities between users. Same process as described in Section 3.1 and presented in Algorithm 2.
- Recommend Smart POIs. For each available user in the dataset excluding the user that is selected for giving recommendations, the Smart POIs that the selected user has not visited are extracted. Then, each Smart POI not visited is ranked through a weighted mean. The weighted mean contemplates the rating of Smart POI and the similarity value of the user that has been compared to the selected user. Consequently, a descending list of N ranked Smart POIs is obtained. This process is carried out for all similarity and distance measures previously described in Section 2.2 as well as for the Spearman correlation, Bray–Curtis distance, Canberra metric, and Squared Euclidean distance. Thus, nine descending lists of N ranked Smart POIs are computed. Afterwards, the frequency of appearance of all Smart POIs embraced in these descending lists is calculated with the objective that all frequencies of the Smart POIs are averaged by the total number of measures used. Lastly, the Top-5 Smart POIs from the final descending list are recommended to the specific user.
3.3. User-Based CF with the Average Aggregation Operator + Smart POIs’ Categories
- Data gathering process. Same process as described in Section 3.1 and presented in Algorithm 1. Furthermore, the Smart POIs’ categories dataset is loaded. Such a dataset is described in Section 6.3.
- Compute similarities between users. Same process as described in Section 3.1 and presented in Algorithm 2.
- Recommend Smart POIs. Firstly, all categories of the Smart POIs visited by the user selected to give recommendations are extracted. Then, the Smart POIs’ categories are ranked according to their frequency of appearance. Thus, a descending frequency list of the Smart POIs’ categories is obtained. Thereupon, for each similarity or distance measure, a list of similar users is obtained, who best resemble the specified user according to the procedure described in the previous step. Afterwards, the categories of each Smart POI present in the preferences of each similar user are ranked according to the descending frequency list of the Smart POIs’ categories of the specified user. Finally, all Smart POIs of each similar user are sorted to obtain those that better resemble the specified user preferences. That is, Smart POIs whose categories are closer to the rated Smart POIs’ categories of the specified user are more likely to be recommended. Consequently, a descending list of N Smart POIs ranked by their categories is obtained. From this list, the Top-5 Smart POIs are recommended to the specific user.
3.4. HyRA
- Data gathering process. Same process as described in Section 3.3 and presented in Algorithm 1. Furthermore, the Smart POIs’ geographical location dataset is loaded. Such a dataset is described in Section 6.1.
- Address geographical influence. All Smart POIs loaded in the data gathering process are clustered using K-means with the Euclidean distance. Due to the geographical distribution of Smart POIs, only three clusters are enough to embrace them all. The calculation of the optimal number of clusters is beyond the scope of this paper. As a result, a list containing the cluster number to which each Smart POI belongs is obtained. Then, the cluster’ number of each Smart POI visited by the specific user is extracted. Subsequently, the clusters’ numbers visited by the chosen user are compared against the clusters’ numbers of the Smart POIs of the rest of users. As a result, the users that share at least N Smart POIs visited in common with the specific user are retained. Here, it is important to mention that the value of N is calculated as follows: one plus the result of the number of clusters visited by the specific user divided by two. This metric has two purposes: first, to ensure that the Smart POIs geographically closer to users location preferences are retained for a possible recommendation; and, second, to decrease the computational calculations that the recommendation algorithm has to perform. Consequently, a list of users that have visited Smart POIs geographically closer to the Smart POIs of a given user is obtained.
- Recommend Smart POIs. Finally, the procedure described in Section 3.3 is performed to obtain the Top-5 Smart POIs that are going to be recommended, except step 1. As a result, a Smart POI list that could be interesting for the specific user is recommended. Algorithm 3 provides the pseudocode of this process.
| Algorithm 3 HyRA—Recommend Smart POIs. |
|
4. Experimental Scenario Based on Surveys
4.1. Project Background
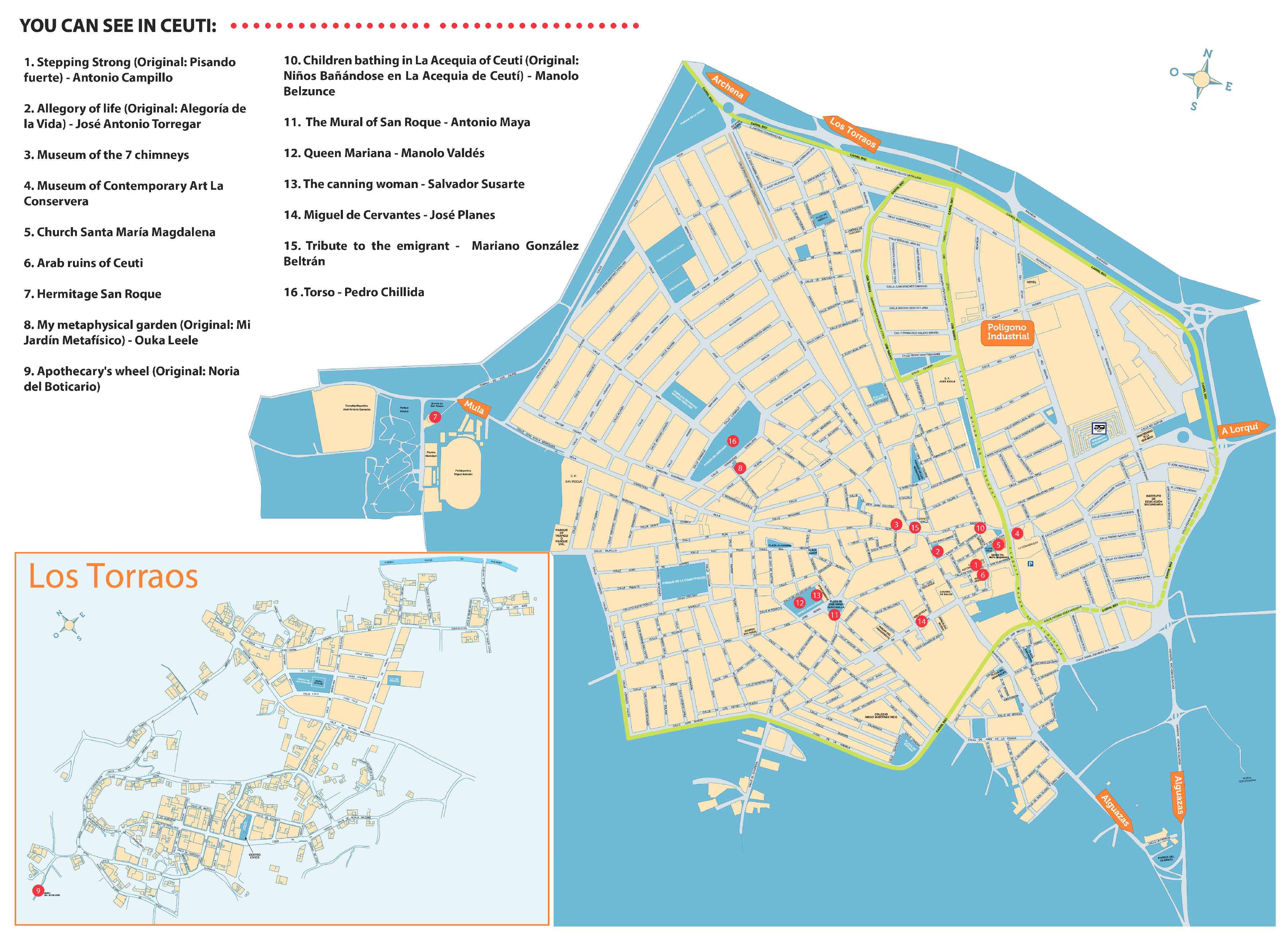
- Selection of POIs. 16 POIs in Ceutí were defined as Smart POIs. Information about these Smart POIs is presented in Section 6.1.
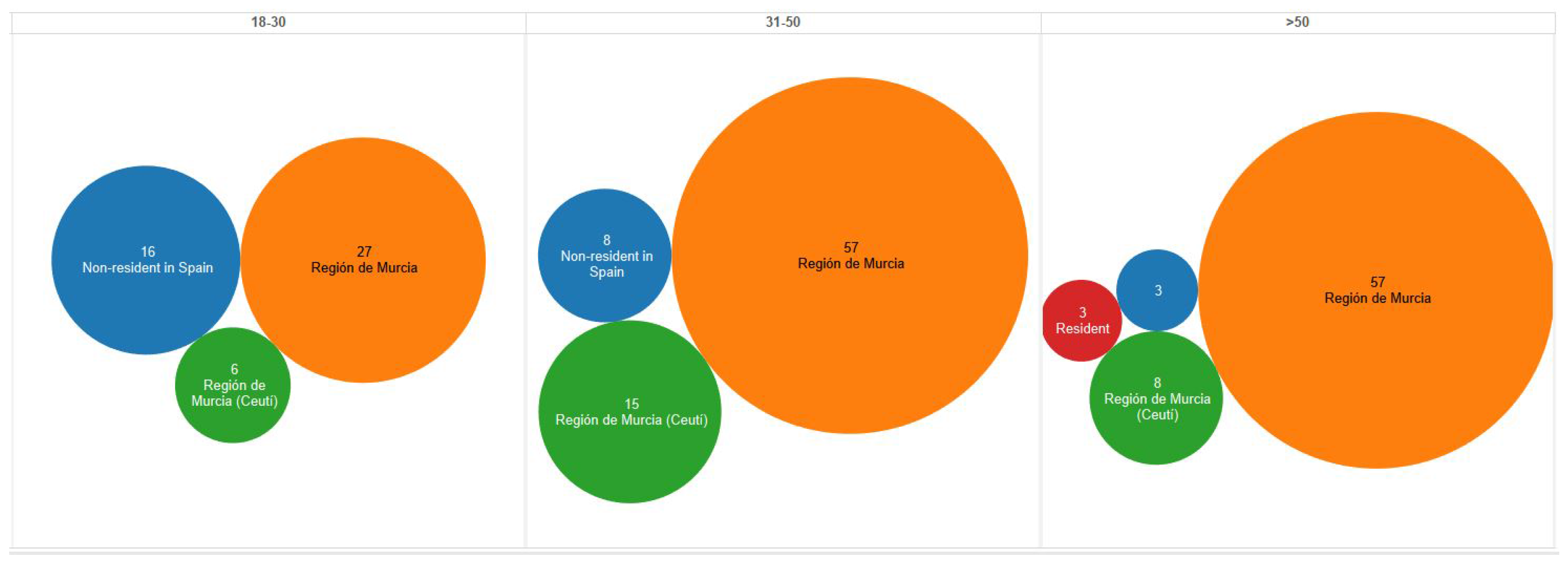
- Definition of the target audience. Two types of tourists were included in the total target audience: Residents in Spain (86.4%) and Non-residents in Spain (13.6%). On the one hand, the resident target audience was the population of the Región de Murcia ≥18 years old. On the other hand, the non-resident target audience was defined as non-resident travelers in Spain.
- Definition of representative sampling (surveys). The conditions to ensure the building of a database representative of the target audience were defined as follows:
- -
- The non-probabilistic and cluster-based sampling methods were selected to conduct the surveys. This decision was based on the target audience is hard to identify and the sample is a pilot study [32].
- -
- The 6.75% margin of error was defined to ensure a representative sample of the target audience. Therefore, the number of surveys to be collected was estimated at 200, of which 173 people must be resident travelers in Spain (86.4%) and 27 people must be non-resident travelers in Spain (13.6%).
- -
- The 27 surveys for non-resident travelers in Spain were collected globally while the 173 surveys for resident travelers in Spain were divided into clusters. That is, three clusters were considered for this scenario, i.e. 18–30, 31–50, and >50, which also were divided into women and men. Hence, the number of surveys per cluster is shown in Table 2.
- -
- The survey was designed and managed online via Google Forms (https://www.google.com/intl/en/forms/about/), and structured in both Spanish (https://goo.gl/VrC0ve) and English (https://lnkd.in/dzqVyJD) language to facilitate its dissemination.
4.2. The Surveys and the HyRA Evaluation Scenario
- Extraction of a ground-truth subset of ratings on Smart POIs of each user. With the aim of counting on a ground-truth to assess the recommendation algorithm, the Smart POIs dataset is divided into two. The ground-truth subset is obtained by randomly select up to 11 Smart POIs from each user whose rates vary from three to five stars. By doing this, we can capture approximately the 70% from the 16 Smart POIs ratings given by the users. The aim of this subset is to serve as a ground-truth dataset that allows the recommendation algorithm to have a representation of the preferences of each user. The remaining Smart POIs of each user are used as not visited (not rated) Smart POIs that can be recommended by the recommendation algorithm. The original ratings that each user gives to each Smart POI—which belong to this last subset—are preserved to later compare the recommendations provided by the recommendation algorithm.
- Selection and implementation of a set of similarity and distance measures to provide the Smart POI recommendation. The objective of this activity is to calculate the first recommendations for this scenario. Experiments are carried out by using each similarity and distance measure described in Section 2.2. Furthermore, the following measures were also tested: Spearman correlation, Bray–Curtis distance, Canberra metric, and Squared Euclidean distance. First, the ground-truth subset is obtained as described above. Then, for each user, his/her recommendations are calculated with each similarity and distance measure. The procedure and description of the algorithm is found in Section 3.1.
- Incorporation of the validated similarity and distance measures into the average aggregation operator. The aim of this activity is to increase the proposed recommendation algorithm precision. For this experiment, all similarity and distance measures described in Section 2.2 are concentrated into an average aggregation operator as described in Section 3.2. In this experimental phase, one hundred executions are performed in order to compare the user-based CF algorithm with the average aggregation operator against its counterpart with one similarity or distance measure at a time. Each execution is independent of the others, that is, each execution calculated its own random ground-truth subset that is used at that time in both versions of the proposed algorithm.
- Definition and integration of the Smart POIs’ categories to the proposed recommendation algorithm. The aim of this activity is to increase the proposed recommendation algorithm precision. In this test scenario, the Smart POIs’ categories are taken into account and added to the recommendation algorithm supplemented with the average aggregation operator as described in Section 3.3. In addition, one hundred executions are performed in order to compare the proposed recommendation algorithm supplemented with the average aggregation operator against its counterpart that adds Smart POIs’ categories. Each execution is independent of the others, that is, each execution calculated its own random ground-truth subset that is used at that time in both versions of the proposed algorithm.
- Implementation of the geographical influence factor in the proposed recommendation algorithm. The aim of this activity is to increase the proposed recommendation algorithm precision. In this phase, the Smart POIs’ locations are integrated into the proposed recommendation algorithm that considers the Smart POIs’ categories. The algorithm description can be reviewed in Section 3.4. Consistently, one hundred executions are performed to compare the proposed recommendation algorithm supplemented with both the average aggregation operator and the Smart POIs’ categories against the recommendation algorithm that adds the geographical influence factor (HyRA). In addition to carrying out the same executions, the results of the recommendation algorithm supplemented with the average aggregation operator against the results of HyRA are compared. Each execution is independent of the others, that is, each execution calculated its own random ground-truth subset that is used at that time in the three versions of the proposed algorithm.
- Compare the different approaches of the recommendation algorithm. To provide the version of the recommendation algorithm that delivers better recommendations to all users, the results of all implementations previously described are compared. The first step is to sort in descending order the Smart POIs preferences of each user contained in the not visited (not rated) dataset, this with the purpose of obtaining the preferences of each user from the highest to the lowest. Subsequently, the original rating that users granted to each Smart POI recommended by each algorithm per each user is extracted. Consequently, a list that concentrates the Smart POI recommendations with the original ratings for each version of the recommendation algorithm is obtained. Thus, the algorithm whose lists of recommendations deliver the Smart POIs with higher ratings for all users stands as the best approach for this study.
5. Results and Discussion
5.1. Surveys: Dissemination and Analysis
- Spanish version
- -
- “Age” question. In the first surveys, the birthdate was asked to the respondents. However, this field was changed to the four age ranges established (<18, 18–30, 31–50, and >50) to directly do the clustering of each participant.
- -
- “Residence” question. The type of format to introduce this answer was specified since sometimes, only the city, country, or locality was typed by the respondent, entailing possible issues to determine the residence of the participant.
- -
- Sort the questions. The questions related to the tourism in the Región de Murcia and Ceutí “Do you usually tour the Region of Murcia (Spain)?”, “Have you ever visited Ceutí?”, and “if you visited Ceutí, what was the reason for the visit?” were realigned. Firstly, these questions were located between the personal information questions and the SNS questions; thus, some respondents asked if the questions related to the tourism in the Región de Murcia as well as Ceutí and the questions about the usage of SNS were associated, due to their answers could change according to this condition. Hence, to clarify that questions corresponding to the usage of SNS were formulated to know the user preferences in general, these three questions were located after the SNS questions.
- -
- New options for the answers. Two situations were presented: people from Ceutí and people who had never visited Ceutí answered the survey. Therefore, respondents suggested incorporating “I am from Ceutí” for the “have you ever visited Ceutí?” and “what was the reason for the visit?” questions, as well as “I have not visited Ceutí” for the last question. In addition, in the “what social networks do you use to publish your location during your travels or visits?” question was proposed to add the Twitter option. Such suggestions were integrated into the survey.
- -
- Information about Ceutí. A brief introduction about Ceutí was described in the have you ever visited Ceutí? question to contextualize foreign respondents.
- English version
- -
- “Residence” question. The type of format was modified to indicate to the user only writing his/her country.
- -
- Re-formulated question. “Do you usually tour the Region of Murcia (Spain)? was rephrased to have you ever visited the Region of Murcia?”
- -
- Points of tourist attraction. The names of these points were translated for their identification, although the original name was also maintained.
- SNS: HOP Ubiquitous, town council of Ceutí, and Tecnologico de Monterrey.
- Instant messaging (WhatsApp): people involved in the project (HOP Ubiquitous and Tecnologico de Monterrey).
- E-mail: people involved in the project (HOP Ubiquitous, Tecnologico de Monterrey, and town council of Ceutí).
- People related to the Spanish members of the project located in different geographical locations from the Región de Murcia.
- People related to the Mexican members of the project located in Mexico.
- People identified by the town council of Ceutí.
- -
- Members of transnational meetings of the town council of Ceutí’s European projects.
- -
- Members of transnational meetings of the European projects in which the Ceutí’s IES is involved.
- -
- Members of the relations between families with the St Berthevin City in France.
5.2. HyRA: Analysis and Discussion
- Pearson correlation
- Euclidean distance
- Cosine similarity
- Spearman correlation
- Manhattan distance
- Bray–Curtis distance
- Canberra metric
- Chebyshev distance
- Squared Euclidean distance
- Smart POIs used for the similarity calculation = {Stepping Strong, Allegory of Life, Arabic Ruins of Ceuti, Hermitage of San Roque, My Metaphysical Garden, Queen Mariana, The Canning Woman, Torso}—eight Smart POIs
- Smart POIs available for the recommendations = {Apothecary’s Noria, “7 Chimneys” Museum, Tribute to the Emigrant, The Mural of San Roque, “Santa Maria Magdalena” Church, Children bathing in La Acequia of Ceuti, “La Conservera” Contemporary Art Museum, “Miguel de Cervantes” Sculpture}—eight Smart POIs
- 5—“La Conservera" Contemporary Art Museum
- 4—”Santa Maria Magdalena” Church
- 3—”7 Chimneys” Museum
- 2— Apothecary’s Noria
- 1—Children bathing in La Acequia of Ceuti
5.3. Smart POI Recommendation through User-Based CF with an Average Aggregation Operator
5.4. Smart POI Recommendation through User-Based CF with an Average Aggregation Operator + Smart POIs’ Categories
5.5. Smart POI Recommendation through Geographical Influence + User-Based CF with an Average Aggregation Operator + the Smart POIs’ Categories (HyRA)
6. Materials and Methods
6.1. Smart POIs Dataset in Ceutí
- Smart POI Identifier. The field that identifies the Smart POI and allows establishing a relationship with the user dataset to extract the ratings assigned by each user to these Smart POIs as well as with the Smart POI’s categories dataset to obtain the tags that describe them.
- Name. The Smart POI’s title in both English and Spanish language.
- Location. The column that indicates the Smart POI’s coordinate in decimal degrees, whose format is [latitude, longitude].
6.2. User Preferences Dataset
- User Identifier. The field that identifies the respondent, solely for purposes of the algorithm because no personal information was collected.
- Smart POI Identifier. The key to extracting the information from the Smart POIs dataset.
- Rating. The given numerical value by the respondent to the Smart POI according to his/her preferences. This value is within the range from 1 to 5, being 1 not interesting and 5 very interesting.
6.3. Smart POIs’ Categories Dataset
- Smart POI Identifier. The key to extracting the information from the Smart POIs dataset.
- Category-X. The fields that indicate the category name.
7. Conclusions and Further Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| CF | Collaborative Filtering |
| CRTCF | Cross-Region Topic-based Collaborative Filtering |
| Geo-PFM | Geographical Probabilistic Factor Model |
| GPS | Global Positioning System |
| GTAG | Geographical-Temporal influences Aware Graph |
| GT-BNMF | Geographical-Topical Bayesian Non-negative Matrix Factorization |
| HyRA | Hybrid Recommendation Algorithm |
| IoT | Internet of Things |
| LTSCR | Location and Time aware Social Collaborative Retrieval model |
| MDPI | Multidisciplinary Digital Publishing Institute |
| MSE | Mean Squared Error |
| POI | Point-Of-Interest |
| Smart POI | Smart Point Of Interaction |
| SNS | Social Networking Sites |
| UG | User preference/Geographical influence based recommendation |
| UPOI-Mine | Urban POI-Mine |
| URL | Uniform Resource Locator |
| USG | Unified collaborative recommendation algorithm |
| VISIT | Virtual Intelligent System for Informing Tourists |
| WBPR-FD | Weighted Bayesian Personalized Ranking model with visit Frequency and Distance |
Appendix A. Smart POIs Dataset in Ceutí

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Smart POI Identifier | Name | Location |
|---|---|---|
| Heritage-ES-Ceuti-1 | Stepping Strong | 38.078472, −1.270139 |
| Original: Pisando fuerte | ||
| Heritage-ES-Ceuti-2 | Allegory of Life | 38.078889, −1.271444 |
| Original: Alegoría de la Vida | ||
| Heritage-ES-Ceuti-3 | “7 Chimneys” Museum | 38.079417, −1.272889 |
| Original: Museo “7 Chimeneas” | ||
| Heritage-ES-Ceuti-4 | “La Conservera” Contemporary Art Museum | 38.079194, −1.269000 |
| Original: Museo de Arte Contemporáneo “La Conservera” | ||
| Heritage-ES-Ceuti-5 | “Santa Maria Magdalena” Church | 38.079056, −1.269528 |
| Original: Iglesia “Santa María Magdalena” | ||
| Heritage-ES-Ceuti-6 | Arabic Ruins of Ceuti | 38.078417, −1.27016 |
| Original: Ruinas Árabes de Ceutí | ||
| Heritage-ES-Ceuti-7 | Hermitage of San Roque | 38.082111, −1.28466 |
| Original: Ermita de San Roque | ||
| Heritage-ES-Ceuti-8 | My Metaphysical Garden | 38.080722, −1.276806 |
| Original: Mi Jardín Metafísico | ||
| Heritage-ES-Ceuti-9 | Apothecary’s Noria | 38.100167, −1.287722 |
| Original: Noria del Boticario | ||
| Heritage-ES-Ceuti-10 | Children bathing in La Acequia of Ceuti | 38.079389, −1.270056 |
| Original: Niños Bañándose en La Acequia de Ceutí | ||
| Heritage-ES-Ceuti-11 | The Mural of San Roque | 38.079833, −1.273306 |
| Original: El Mural de San Roque | ||
| Heritage-ES-Ceuti-12 | Queen Mariana | 38.077806, −1.274861 |
| Original: Reina Mariana | ||
| Heritage-ES-Ceuti-13 | The Canning Woman | 38.077778, −1.274194 |
| Original: La Mujer Conservera | ||
| Heritage-ES-Ceuti-14 | “Miguel de Cervantes” Sculpture | 38.077306, −1.271722 |
| Original: Escultura “Miguel de Cervantes” | ||
| Heritage-ES-Ceuti-15 | Tribute to the Emigrant | 38.079472, −1.271917 |
| Original: Homenaje al Emigrante | ||
| Heritage-ES-Ceuti-16 | Torso | 38.081444, −1.276944 |
| Original: Torso |

Appendix B. User Preferences Dataset
| User Identifier | Smart POI Identifier | Rating |
|---|---|---|
| User-CEUTI-1 | Heritage-ES-Ceuti-1 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-2 | 2 |
| User-CEUTI-1 | Heritage-ES-Ceuti-3 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-4 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-5 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-6 | 3 |
| User-CEUTI-1 | Heritage-ES-Ceuti-7 | 5 |
| User-CEUTI-1 | Heritage-ES-Ceuti-8 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-9 | 3 |
| User-CEUTI-1 | Heritage-ES-Ceuti-10 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-11 | 3 |
| User-CEUTI-1 | Heritage-ES-Ceuti-12 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-13 | 4 |
| User-CEUTI-1 | Heritage-ES-Ceuti-14 | 3 |
| User-CEUTI-1 | Heritage-ES-Ceuti-15 | 3 |
| User-CEUTI-1 | Heritage-ES-Ceuti-16 | 5 |
Appendix C. Smart POIs’ Categories Dataset
| Smart POI Identifier | Category-1 | Category-2 | Category-3 | Category-4 |
|---|---|---|---|---|
| Heritage-ES-Ceuti-1 | Sculpture | Outdoors | Human | |
| Heritage-ES-Ceuti-2 | Mural | Outdoors | Human | Art |
| Heritage-ES-Ceuti-3 | Museum | Building | Architecture | Art |
| Heritage-ES-Ceuti-4 | Museum | Building | Architecture | Art |
| Heritage-ES-Ceuti-5 | Church | Building | Architecture | Art |
| Heritage-ES-Ceuti-6 | Museum | Building | Architecture | Outdoors |
| Heritage-ES-Ceuti-7 | Church | Building | Architecture | Outdoors |
| Heritage-ES-Ceuti-8 | Mural | Outdoors | Nature | Art |
| Heritage-ES-Ceuti-9 | Noria | Outdoors | Architecture | Nature |
| Heritage-ES-Ceuti-10 | Mural | Outdoors | Human | Art |
| Heritage-ES-Ceuti-11 | Mural | Outdoors | Human | Art |
| Heritage-ES-Ceuti-12 | Sculpture | Outdoors | Human | |
| Heritage-ES-Ceuti-13 | Sculpture | Outdoors | Human | Square |
| Heritage-ES-Ceuti-14 | Sculpture | Outdoors | Human | |
| Heritage-ES-Ceuti-15 | Sculpture | Outdoors | Human | Square |
| Heritage-ES-Ceuti-16 | Sculpture | Outdoors | Human | Park |
References
- Physical Web. Walk Up and Use Anything. Available online: https://google.github.io/physical-web/ (accessed on 13 March 2017).
- Yu, Y.; Chen, X. A Survey of Point-of-Interest Recommendation in Location-Based Social Networks. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 53–60. [Google Scholar]
- Meehan, K.; Lunney, T.; Curran, K.; McCaughey, A. Context-aware Intelligent Recommendation System for Tourism. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), San Diego, CA, USA, 18–22 March 2013; pp. 328–331. [Google Scholar]
- Meehan, K.; Lunney, T.; Curran, K.; McCaughey, A. Aggregating social media data with temporal and environmental context for recommendation in a mobile tour guide system. J. Hosp. Tour. Technol. 2016, 7, 281–299. [Google Scholar] [CrossRef]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning Geographical Preferences for Point-of-Interest Recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Liu, B.; Xiong, H.; Papadimitriou, S.; Fu, Y.; Yao, Z. A General Geographical Probabilistic Factor Model for Point of Interest Recommendation. IEEE Trans. Knowl. Data Eng. 2015, 27, 1167–1179. [Google Scholar] [CrossRef]
- Yuan, Q.; Cong, G.; Sun, A. Graph-based Point-of-interest Recommendation with Geographical and Temporal Influences. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 659–668. [Google Scholar]
- SmartSDK. Smart POIs: A FIWARE-based Technology to Engage Users and Make Cities More Sustainable. Available online: https://www.smartsdk.eu/2017/02/16/smartpoi/ (accessed on 13 March 2017).
- HOP Ubiquitous. SMART POI. Available online: https://storage.googleapis.com/smartcity/SmartPOI_A4_lr.pdf (accessed on 23 March 2017).
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting Geographical Influence for Collaborative Point-of-Interest Recommendation. In Proceedings of the 34th International ACM SIGIR Conference On Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 325–334. [Google Scholar]
- Alvarado-Uribe, J.; Gómez-Oliva, A.; Molina, G.; Gonzalez-Mendoza, M.; Parra-Meroño, M.C.; Jara, A.J. Towards the Development of a Smart Tourism Application Based on Smart POI and Recommendation Algorithms: Ceutí as a Study Case. In Innovative Mobile and Internet Services in Ubiquitous Computing. IMIS 2017. Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2018; Volume 612, pp. 904–916. [Google Scholar]
- Yahoo Answers. All Categories. Available online: https://answers.yahoo.com/dir/index (accessed on 11 November 2017).
- Amoretti, M.; Belli, L.; Zanichelli, F. UTravel: Smart mobility with a novel user profiling and recommendation approach. Pervasive Mob. Comput. 2017, 38, 474–489. [Google Scholar] [CrossRef]
- Xie, B.; Tang, X.; Tang, F. Hybrid recommendation base on Learning to Rank. In Proceedings of the IEEE 9th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Blumenau, Brazil, 8–10 July 2015; pp. 53–57. [Google Scholar]
- Guo, L.; Jiang, H.; Wang, X.; Liu, F. Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs. Information 2017, 8, 20. [Google Scholar] [CrossRef]
- Zheng, N.; Jin, X.; Li, L. Cross-Region Collaborative Filtering for New Point-of-Interest Recommendation. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 45–46. [Google Scholar]
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized Point-of-Interest Recommendation by Mining Users’ Preference Transition. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 733–738. [Google Scholar]
- Zhang, W.; Wang, J. Location and Time Aware Social Collaborative Retrieval for New Successive Point-of-Interest Recommendation. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1221–1230. [Google Scholar]
- Kang, E.Y.; Kim, H.; Cho, J. Personalization Method for Tourist Point of Interest (POI) Recommendation. In Knowledge-Based Intelligent Information and Engineering Systems, Proceedings of the 10th International Conference (KES 2006), Bournemouth, UK, 9–11 October 2006; Gabrys, B., Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4251, pp. 392–400. [Google Scholar]
- Ying, J.J.C.; Lu, E.H.C.; Kuo, W.N.; Tseng, V.S. Urban Point-of-Interest Recommendation by Mining User Check-in Behaviors. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12 August 2012; pp. 63–70. [Google Scholar]
- Yu, Z.; Xu, H.; Yang, Z.; Guo, B. Personalized Travel Package With Multi-Point-of-Interest Recommendation Based on Crowdsourced User Footprints. IEEE Trans. Hum.-Mach. Syst. 2016, 46, 151–158. [Google Scholar] [CrossRef]
- Cha, S.H. Comprehensive Survey on Distance/Similarity Measures between Probability Density Functions. Int. J. Math. Model. Methods Appl. Sci. 2007, 1, 300–307. [Google Scholar]
- Laerd Statistics. Pearson Product-Moment Correlation. Available online: https://statistics.laerd.com/statistical-guides/pearson-correlation-coefficient-statistical-guide.php (accessed on 29 April 2017).
- McCune, B.; Grace, J.B.; Urban, D.L. Analysis of Ecological Communities, 2nd ed.; MjM Software Design: Washington, DC, USA, 2002. [Google Scholar]
- AENOR. Sistema de Gestión de Los Destinos Turísticos Inteligentes. Requisitos; Asociación Española de Normalización y Certificación: Madrid, Spain, 2016. [Google Scholar]
- HOP Ubiquitous. Smart Solutions Designed for Cities and Citizens. Available online: http://smartcities.hopu.eu/ (accessed on 26 February 2018).
- Dooms, S.; De Pessemier, T.; Martens, L. An online evaluation of explicit feedback mechanisms for recommender systems. In Proceedings of the 7th International Conference on Web Information Systems and Technologies (WEBIST-2011), Ghent, Belgium; 2011; pp. 391–394. [Google Scholar]
- Caraciolo, M. Collaborative Filtering: Implementation with Python! Available online: http://aimotion.blogspot.com.es/2009/11/collaborative-filtering-implementation.html (accessed on 27 April 2017).
- NumPy Developers. NumPy. Available online: http://www.numpy.org/ (accessed on 27 April 2017).
- SciPy Developers. SciPy.org. Available online: https://scipy.org/ (accessed on 27 April 2017).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kitchenham, B.; Pfleeger, S.L. Principles of survey research: Part 5: Populations and samples. ACM SIGSOFT Softw. Eng. Notes 2002, 27, 17–20. [Google Scholar] [CrossRef]
- Gómez Oliva, A.; Server Gómez, M.; Jara, A.J.; Parra-Meroño, M.C. Turismo Inteligente y Patrimonio Cultural: Un sector a explorar en el desarrollo de las Smart Cities. Int. J. Sci. Manag. Tour. 2017, 3, 389–411. [Google Scholar]
- Ceutí Turístico. Plano—Museo 7 Chimeneas. Available online: http://www.ceutituristico.es/al/es/plano.asp (accessed on 20 April 2017).


| Author | Y | R | CI | GI | SI | C | ACD | IS | SDM | UCF+ | PSSP | S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ye et al. [10] | 2011 | ✗ | ✔ | ✔ | ✔ | ✗ | ✗ | LBSN | ✔ | ✗ * | ✗ | LBSN |
| Zheng et al. [16] | 2013 | ✗ | ✔ | ✗ | ✔ | ✔ | ✗ | LBSN | ✔ | ✗ | ✗ | LBSN |
| Liu et al. [5] | 2013 | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | LBSN | ✗ | ✗ | ✗ | LBSN |
| Liu et al. [17] | 2013 | ✗ | ✔ | ✔ | ✗ | ✔ | ✔ | LBSN | ✗ | ✗ | ✗ | LBSN |
| Yuan et al. [7] | 2014 | ✗ | ✔ | ✔ | ✗ | ✗ | ✔ | LBSN | ✗ | ✗ | ✗ | LBSN |
| Liu et al. [6] | 2015 | ✗ | ✔ | ✔ | ✗ | ✗ | ✗ | LBSN | ✗ | ✗ | ✗ | LBSN |
| Zhang and Wang [18] | 2015 | ✗ | ✔ | ✔ | ✔ | ✗ | ✔ | LBSN | ✔ | ✗ | ✗ | LBSN |
| Guo et al. [15] | 2017 | ✗ | ✔ | ✔ | ✗ | ✗ | ✗ | LBSN | ✗ | ✗ | ✗ | LBSN |
| Kang et al. [19] | 2006 | ✔ | ✗ | ✗ | ✗ | ✔ | ✗ | Jeju-do Tourist Association from Republic of Korea and surveys from the Internet | ✔ | ✗ * | ✗ | Tourism |
| Ying et al. [20] | 2012 | ✗ | ✔ | ✗ | ✔ | ✔ | ✔ | LBSN | ✔ | ✗ | ✗ | Urban areas |
| Meehan et al. [3] | 2013 | ✗ | ✗ | ✗ | ✗ | ✗ | ✔ | WorldWeatherOnline API, Twitter, and users themselves | ✗ | ✗ | ✗ | Tourism |
| Yu et al. [21] | 2016 | ✔ | ✔ | ✔ | ✗ | ✔ | ✔ | LBSN | ✔ | ✗ * | ✗ | Tourism |
| HyRA | 2018 | ✔ | ✗ | ✔ | ✗ | ✔ | ✗ | Surveys through the Web (test) and Smart Spot in the real-world | ✔ | ✔ | ✔ | Tourism |
| Cluster | Age Range | Men | % Men | Women | % Women |
|---|---|---|---|---|---|
| 1 | 18–30 | 17 | 9.8266 | 16 | 9.2486 |
| 2 | 31–50 | 37 | 21.3873 | 35 | 20.2312 |
| 3 | >50 | 32 | 18.4971 | 36 | 20.8092 |
| Total | 86 | 49.7110 | 87 | 20.2890 |
| Smart POI Name | Rating |
|---|---|
| Stepping Strong | 4 |
| Allegory of Life | 2 |
| “7 Chimneys" Museum | 4 |
| "La Conservera” Contemporary Art Museum | 4 |
| “Santa Maria Magdalena” Church | 4 |
| Arabic Ruins of Ceuti | 3 |
| Hermitage of San Roque | 5 |
| My Metaphysical Garden | 4 |
| Apothecary’s Noria | 3 |
| Children bathing in La Acequia of Ceuti | 4 |
| The Mural of San Roque | 3 |
| Queen Mariana | 4 |
| The Canning Woman | 4 |
| “Miguel de Cervantes” Sculpture | 3 |
| Tribute to the Emigrant | 3 |
| Torso | 5 |
| Smart POI | Pearson | Euclidean | Cosine | Spearman | Manhattan |
|---|---|---|---|---|---|
| Stepping Strong | |||||
| Allegory of Life | |||||
| “7 Chimneys” Museum | 4 | 3 | 3 | ||
| “La Conservera” Contemporary Art Museum | 1 | 5 | 5 | 1 | 5 |
| “Santa Maria Magdalena” Church | 4 | 2 | 4 | 2 | 4 |
| Arabic Ruins of Ceuti | |||||
| Hermitage of San Roque | |||||
| My Metaphysical Garden | |||||
| Apothecary’s Noria | 3 | 3 | 2 | 2 | |
| Children bathing in La Acequia of Ceuti | 5 | 1 | 1 | 3 | 1 |
| The Mural of San Roque | 2 | 4 | |||
| Queen Mariana | |||||
| The Canning Woman | |||||
| “Miguel de Cervantes” Sculpture | 5 | ||||
| Tribute to the Emigrant | |||||
| Torso |
| Smart POI | Bray–Curtis | Canberra | Chebyshev | Squared Euclidean |
|---|---|---|---|---|
| Stepping Strong | ||||
| Allegory of Life | ||||
| “7 Chimneys” Museum | 3 | 3 | 3 | 3 |
| “La Conservera” Contemporary Art Museum | 5 | 5 | 5 | 5 |
| “Santa Maria Magdalena” Church | 4 | 4 | 4 | 4 |
| Arabic Ruins of Ceuti | ||||
| Hermitage of San Roque | ||||
| My Metaphysical Garden | ||||
| Apothecary’s Noria | 2 | 2 | 2 | 2 |
| Children bathing in La Acequia of Ceuti | 1 | 1 | 1 | 1 |
| The Mural of San Roque | ||||
| Queen Mariana | ||||
| The Canning Woman | ||||
| “Miguel de Cervantes” Sculpture | ||||
| Tribute to the Emigrant | ||||
| Torso |
| Counts of Winning Comparisons | Percentage of Winning Comparisons | |
|---|---|---|
| Wins of CF across all executions | 72,968 | 44.00% |
| Winning distance of CF across all executions | Euclidean distance | NA |
| with 68/100 executions | ||
| Wins of CF + AO across all executions | 55,445 | 33.43% |
| Draws across all executions | 35,848 | 21.61% |
| No comparisons across all executions | 1599 | 0.96% |
| Similarity and Distance Measures, or Algorithm | MSE |
|---|---|
| Euclidean distance | 0.85 |
| Cosine similarity | 1.07 |
| Chebyshev distance | 1.37 |
| Pearson correlation | 1.54 |
| Manhattan distance | 1.62 |
| Bray–Curtis distance | 1.63 |
| Canberra metric | 1.80 |
| Squared Euclidean distance | 1.82 |
| Spearman correlation | 14.68 |
| User-based CF + AO | 2.16 |
| Number of Measures | MSE |
|---|---|
| Nine | 2.16 |
| Eight | 1.69 |
| Seven | 1.67 |
| Six | 1.60 |
| Five | 1.57 |
| Four | 1.60 |
| Three | 1.22 |
| Two | 1.13 |
| Counts of Winning Comparisons | Percentage of Winning Comparisons | |
|---|---|---|
| Wins of CF across all executions | 65,636 | 42.53% |
| Winning distance of CF across all executions | Euclidean distance | NA |
| with 60/100 executions | ||
| Wins of CF + AO across all executions | 55,159 | 35.74% |
| Draws across all executions | 31,977 | 20.72% |
| No comparisons across all executions | 1562 | 1.01% |
| Similarity and Distance Measures, or Algorithm | MSE |
|---|---|
| Euclidean distance | 0.84 |
| Cosine similarity | 1.08 |
| Chebyshev distance | 1.38 |
| Pearson correlation | 1.55 |
| Manhattan distance | 1.62 |
| Bray–Curtis distance | 1.64 |
| Canberra metric | 1.80 |
| Squared Euclidean distance | 1.81 |
| Spearman correlation | 14.70 |
| CF + AO | 1.57 |
| Counts of Winning Comparisons | Percentage of Winning Comparisons | |
|---|---|---|
| Wins of CF + AO across all executions | 6164 | 22.06% |
| Wins of CF + AO + C across all executions | 9170 | 32.82% |
| Wins of CF + AO + C across all executions (Euclidean) | 8849 | 31.67% |
| Draws across all executions | 3760 | 13.45% |
| Counts of Winning Comparisons | Percentage of Winning Comparisons | |
|---|---|---|
| Wins of CF + AO + C across all executions | 27 | 0.14% |
| Wins of HyRA across all executions | 36 | 0.18% |
| Draws across all executions | 19,630 | 99.68% |
| Counts of Winning Comparisons | Percentage of Winning Comparisons | |
|---|---|---|
| Wins of CF + AO across all executions | 6129 | 31.12% |
| Wins of HyRA across all executions | 9653 | 49.02% |
| Draws across all executions | 3911 | 19.86% |
| Counts of Winning Comparisons | Percentage of Winning Comparisons | |
|---|---|---|
| Wins of UG [10] across all executions | 5707 | 28.99% |
| Wins of HyRA across all executions | 11,099 | 56.38% |
| Draws across all executions | 2879 | 14.63% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvarado-Uribe, J.; Gómez-Oliva, A.; Barrera-Animas, A.Y.; Molina, G.; Gonzalez-Mendoza, M.; Parra-Meroño, M.C.; Jara, A.J. HyRA: A Hybrid Recommendation Algorithm Focused on Smart POI. Ceutí as a Study Scenario. Sensors 2018, 18, 890. https://doi.org/10.3390/s18030890
Alvarado-Uribe J, Gómez-Oliva A, Barrera-Animas AY, Molina G, Gonzalez-Mendoza M, Parra-Meroño MC, Jara AJ. HyRA: A Hybrid Recommendation Algorithm Focused on Smart POI. Ceutí as a Study Scenario. Sensors. 2018; 18(3):890. https://doi.org/10.3390/s18030890
Chicago/Turabian StyleAlvarado-Uribe, Joanna, Andrea Gómez-Oliva, Ari Yair Barrera-Animas, Germán Molina, Miguel Gonzalez-Mendoza, María Concepción Parra-Meroño, and Antonio J. Jara. 2018. "HyRA: A Hybrid Recommendation Algorithm Focused on Smart POI. Ceutí as a Study Scenario" Sensors 18, no. 3: 890. https://doi.org/10.3390/s18030890