
Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras

Abstract
:1. Introduction
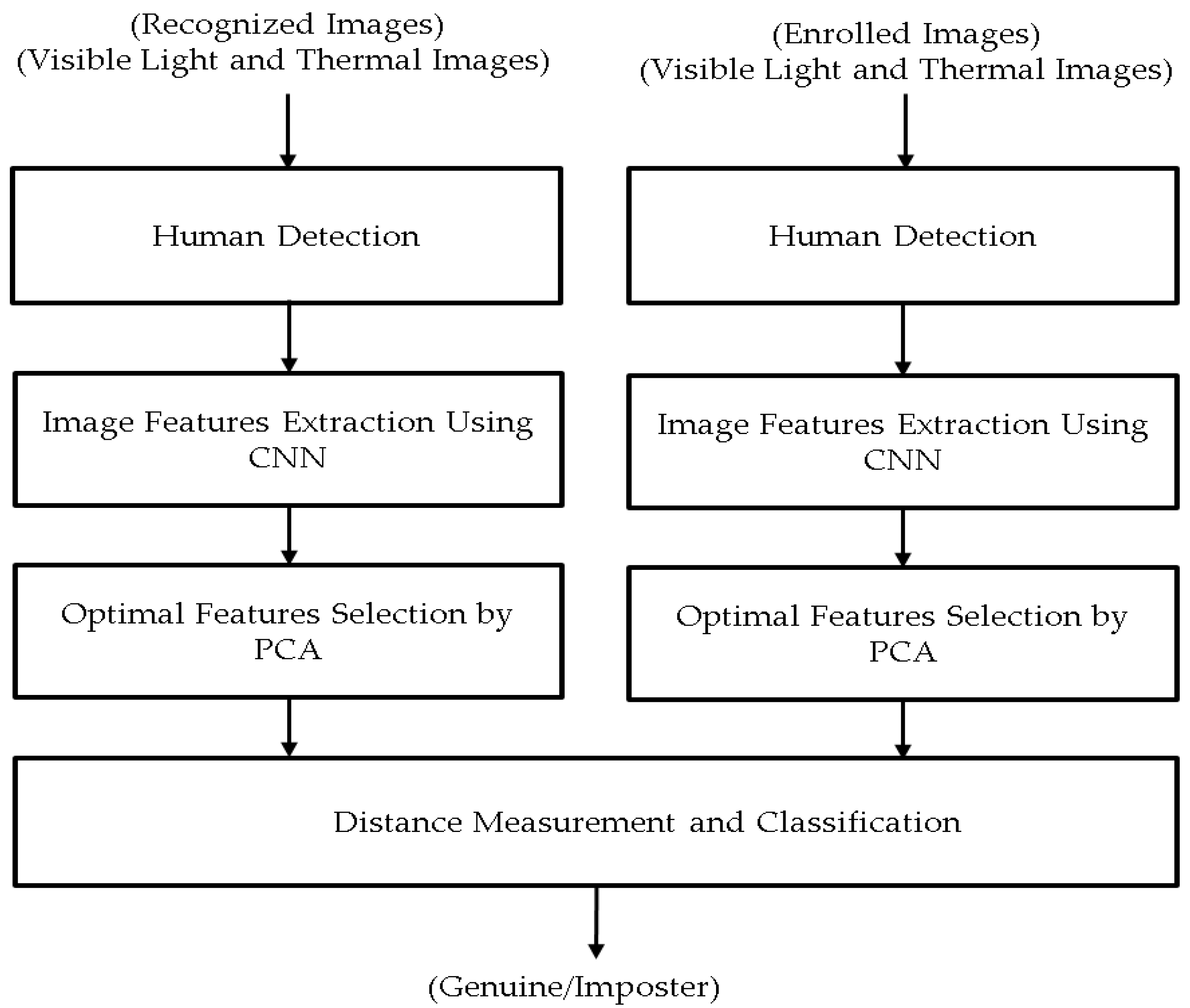
2. Proposed Method for Person Recognition Using Visible Light and Thermal Images of the Human Body
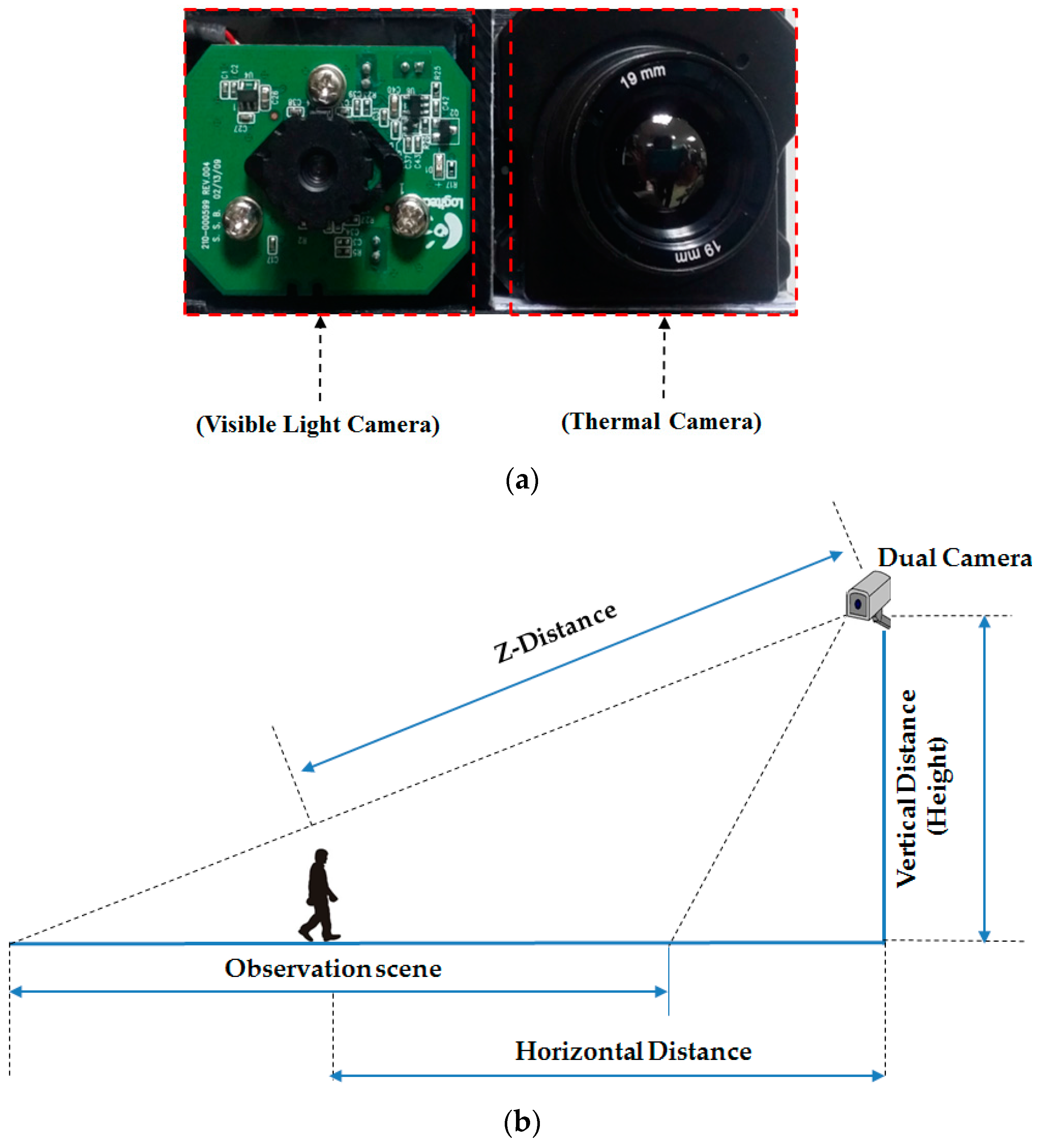
2.1. Overview of the Proposed Method
2.2. Image Feature Extraction
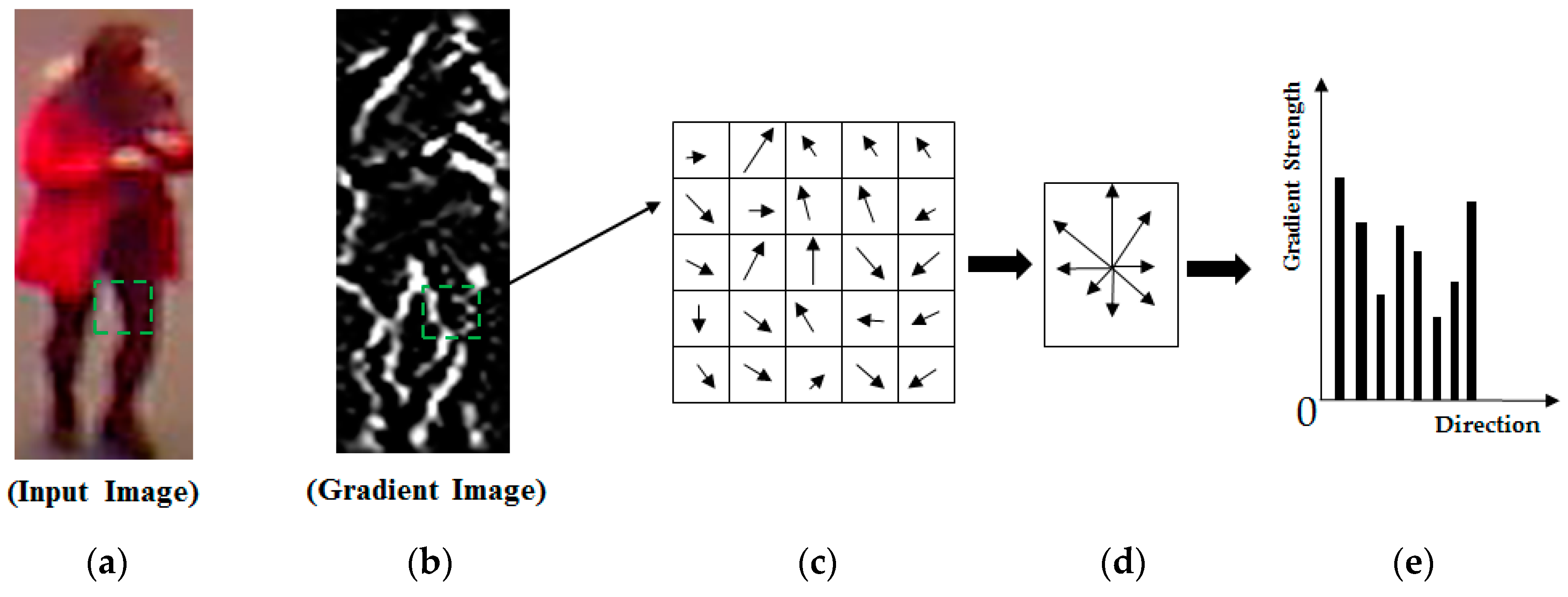
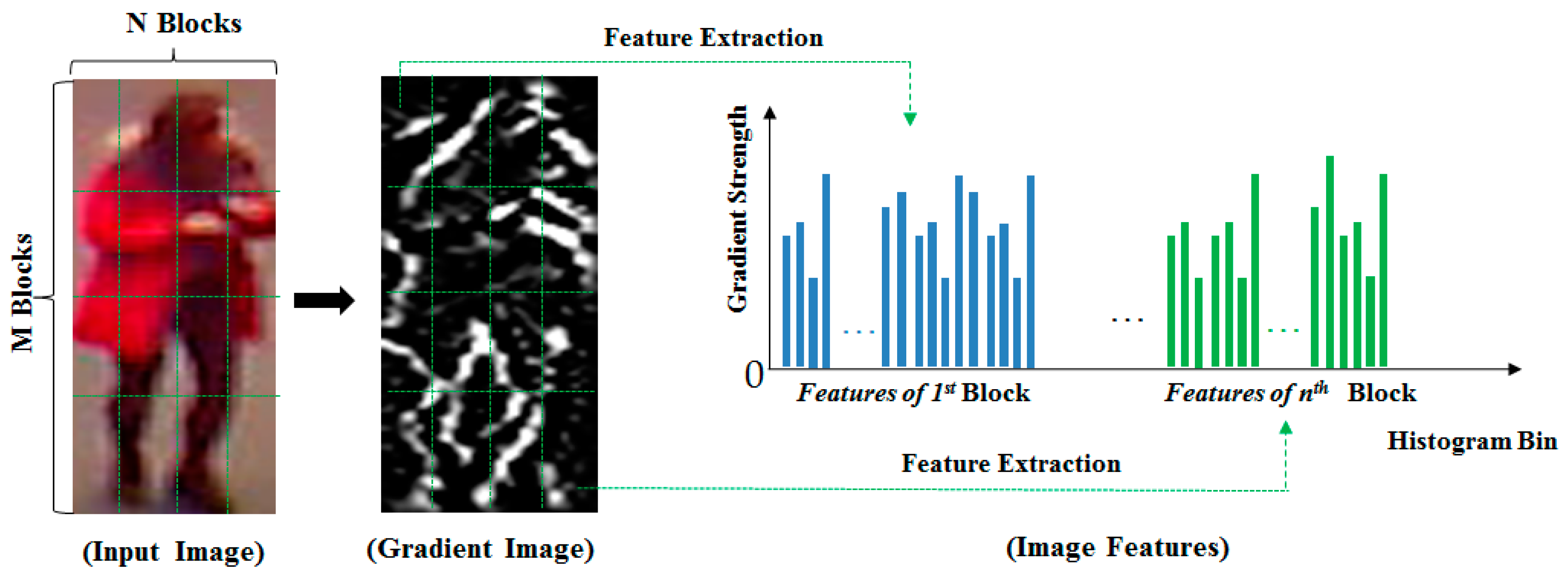
2.2.1. Histogram of Oriented Gradients
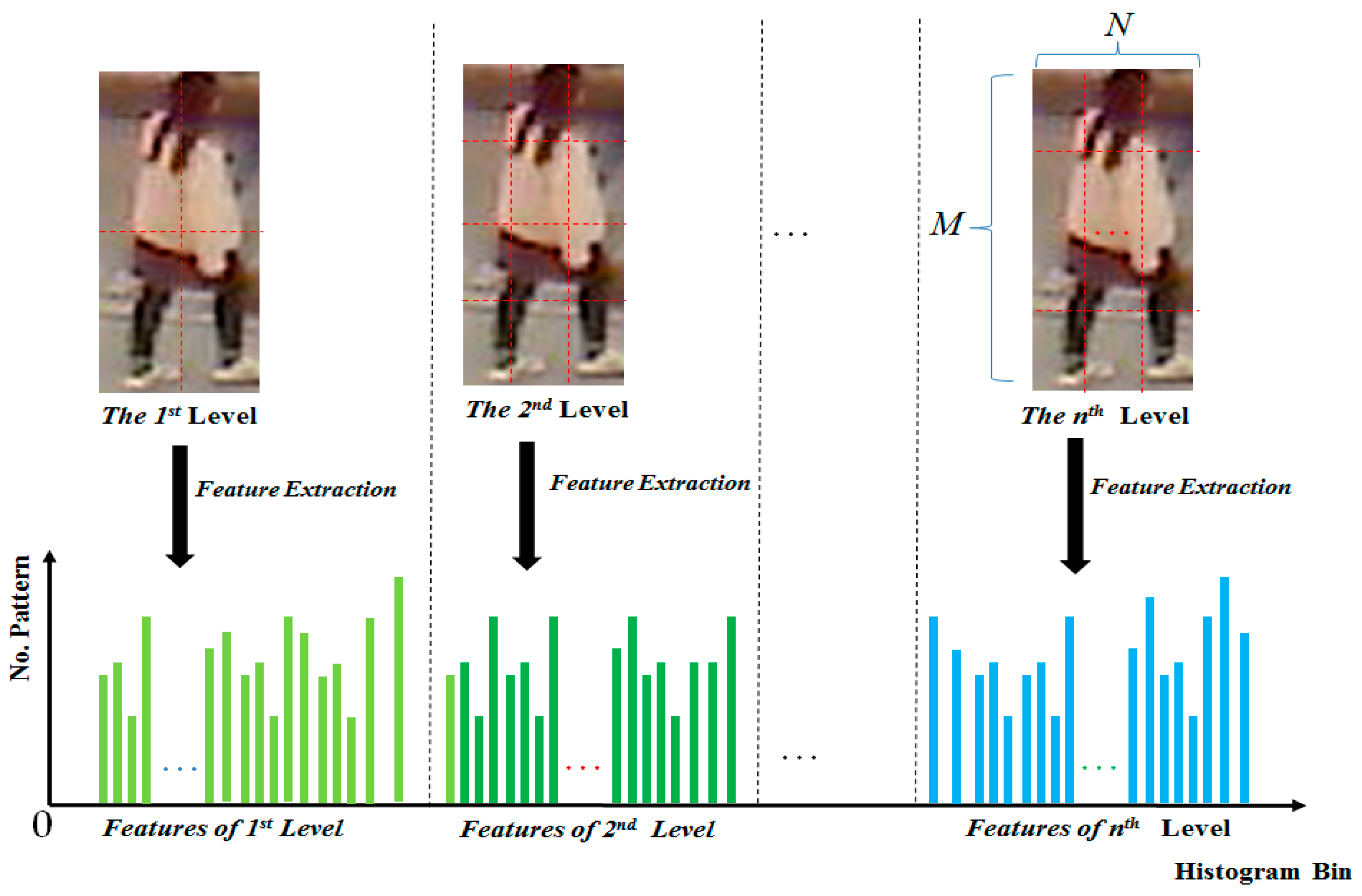
2.2.2. Multi-Level Local Binary Patterns
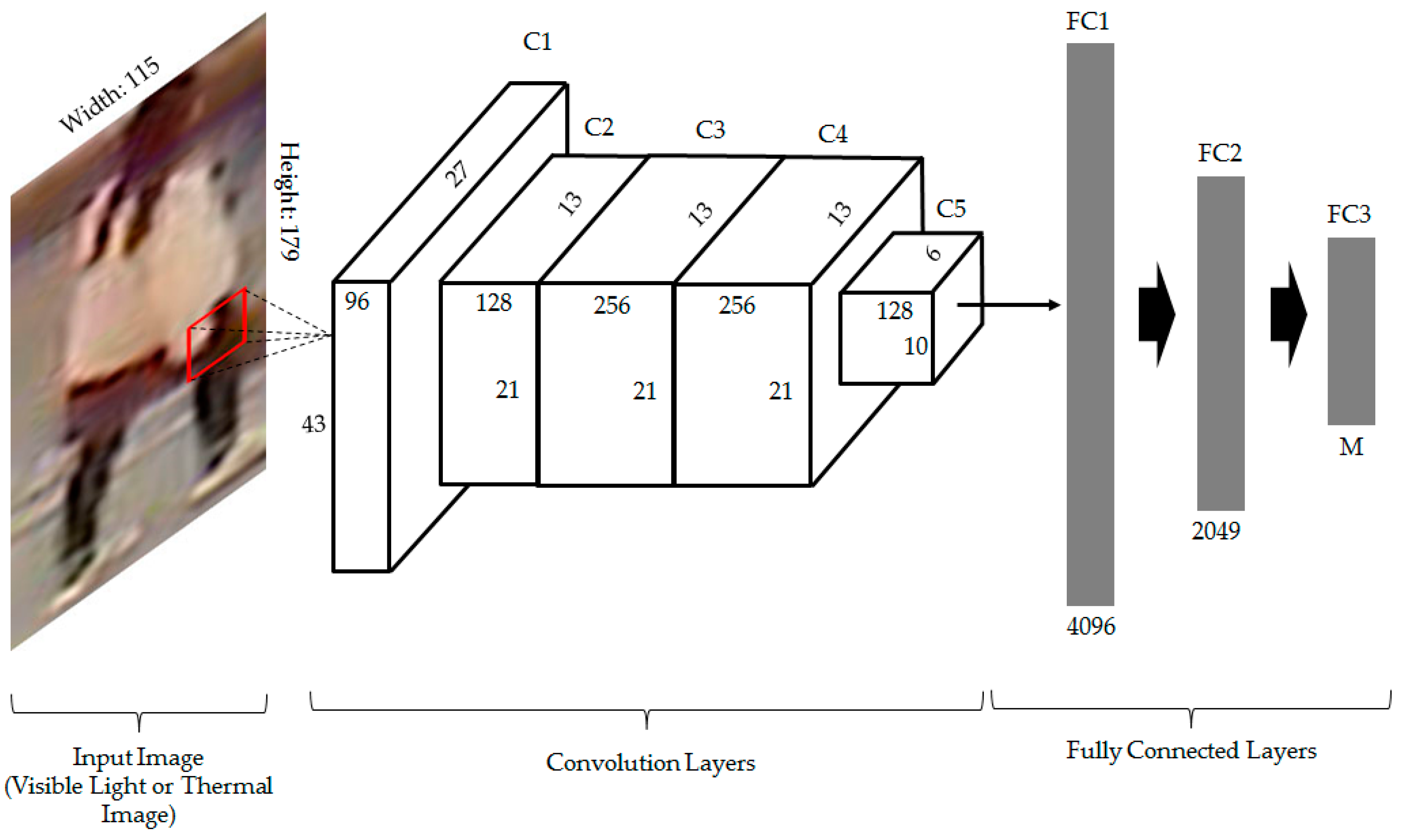
2.2.3. Convolutional Neural Networks (CNNs)
2.2.4. Optimal Feature Extraction by Principal Component Analysis and Distance Measurement
3. Experimental Results
3.1. Description of Database and Performance Measurement
3.2. Experimental Results
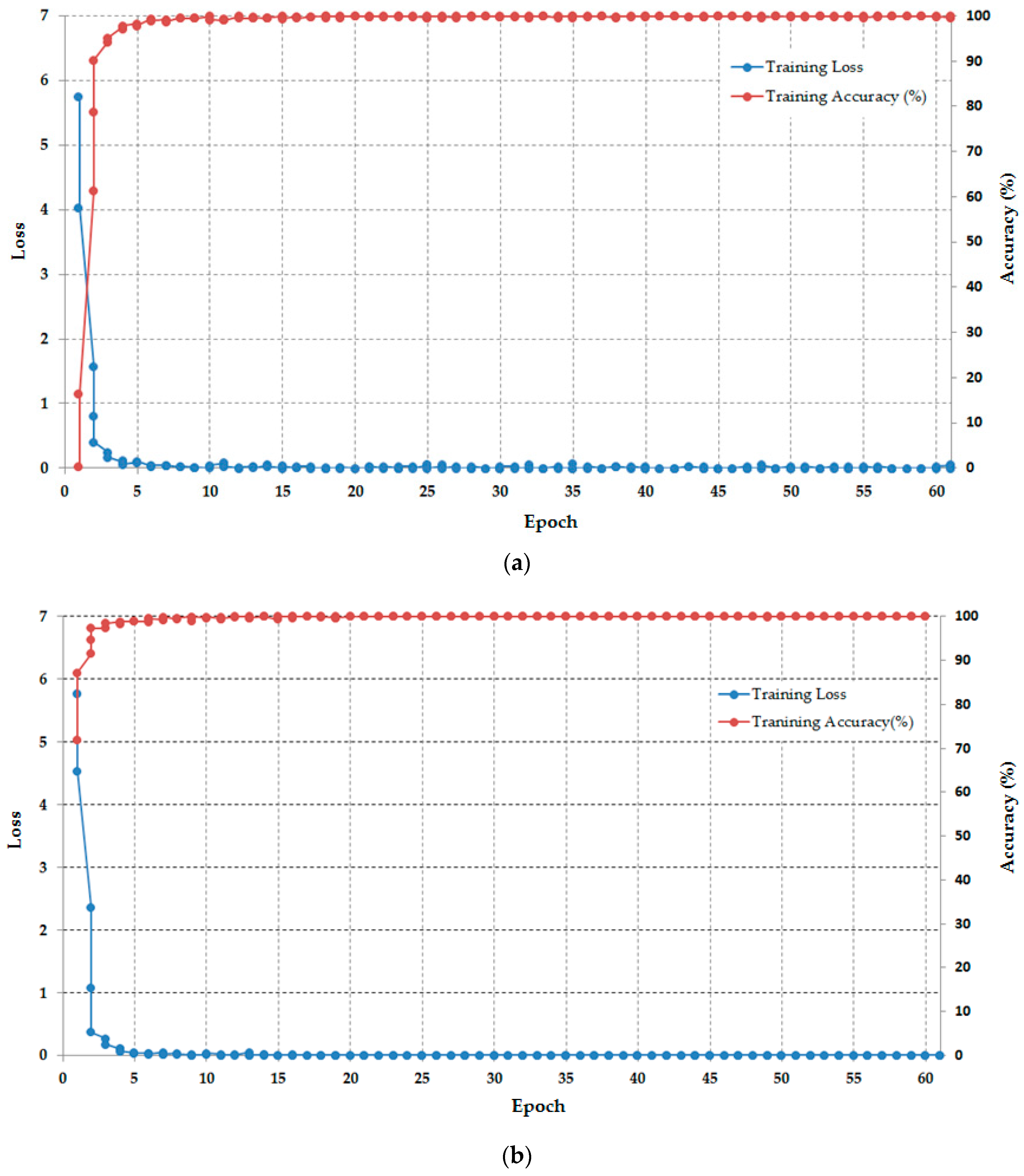
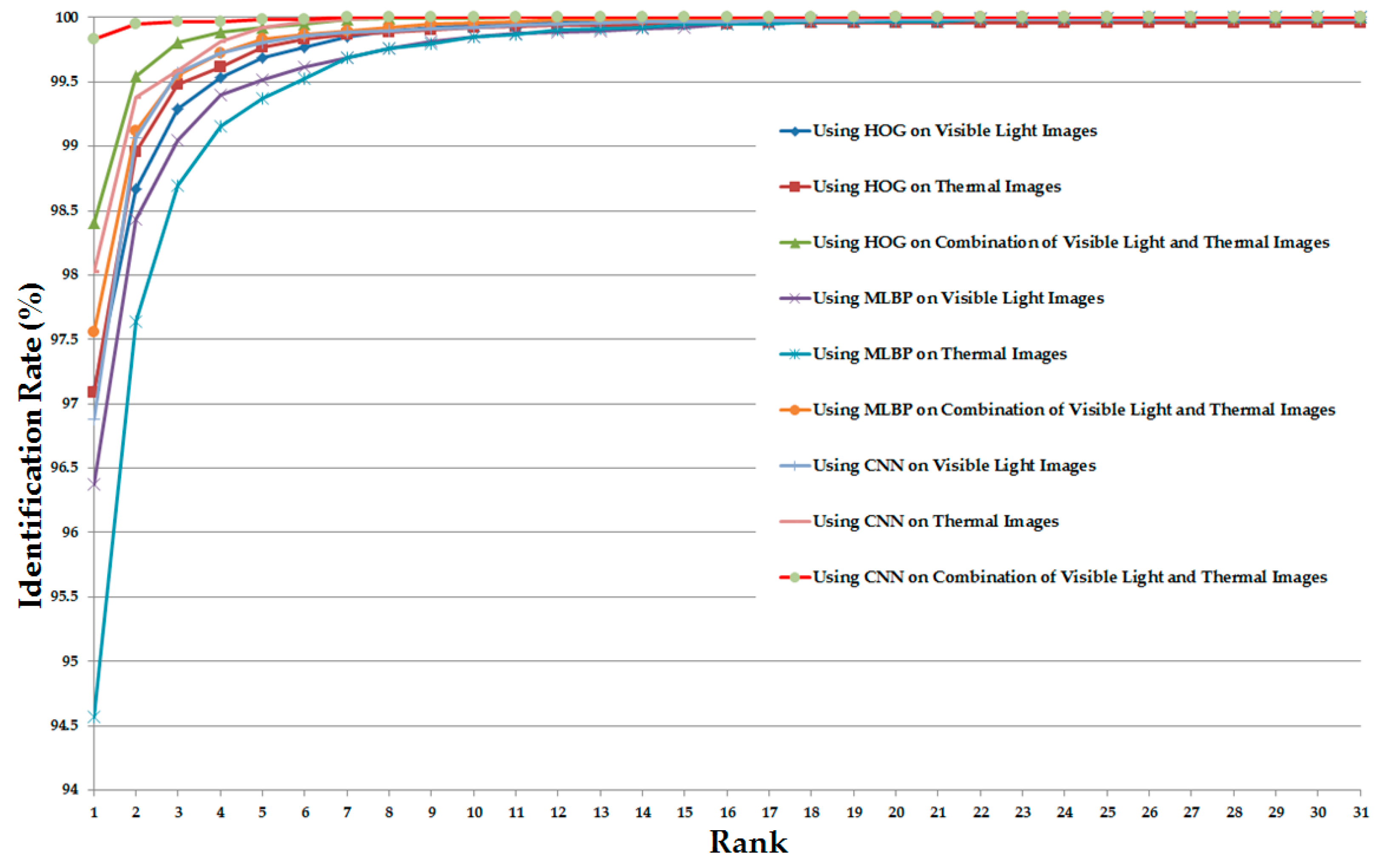
3.2.1. Optimal Feature Extraction Based on CNN
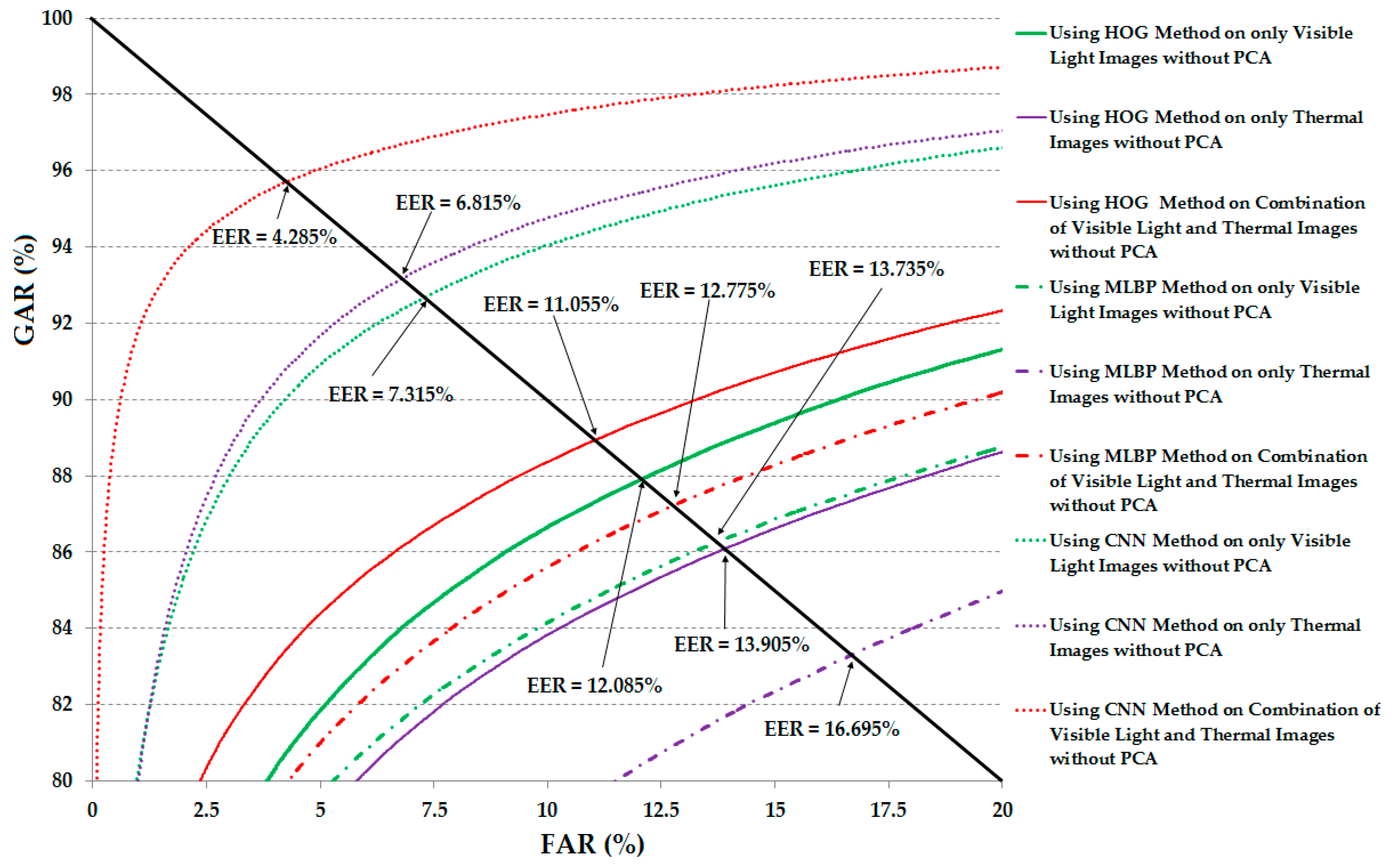
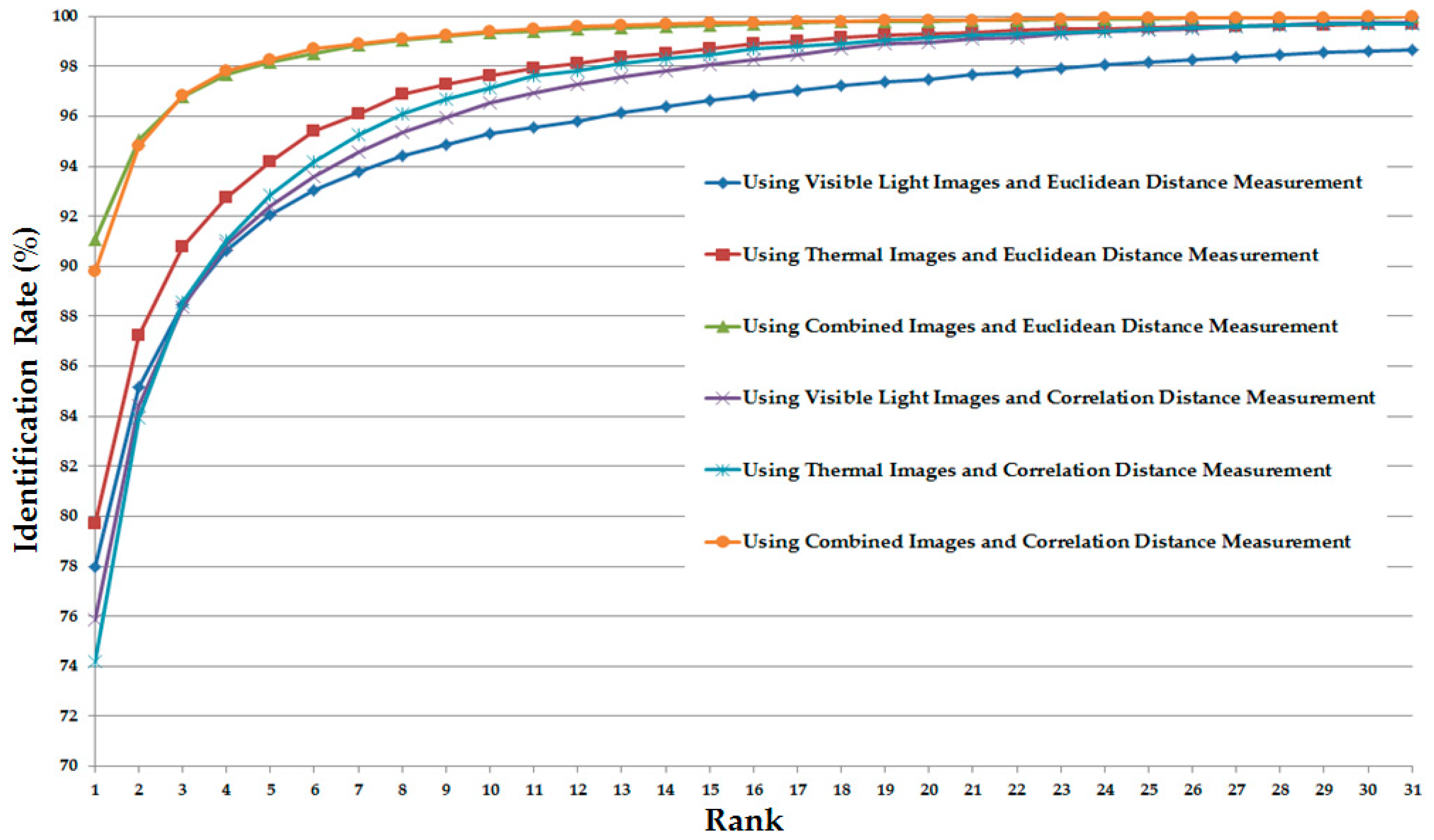
3.2.2. Experiments Using Euclidean Distance
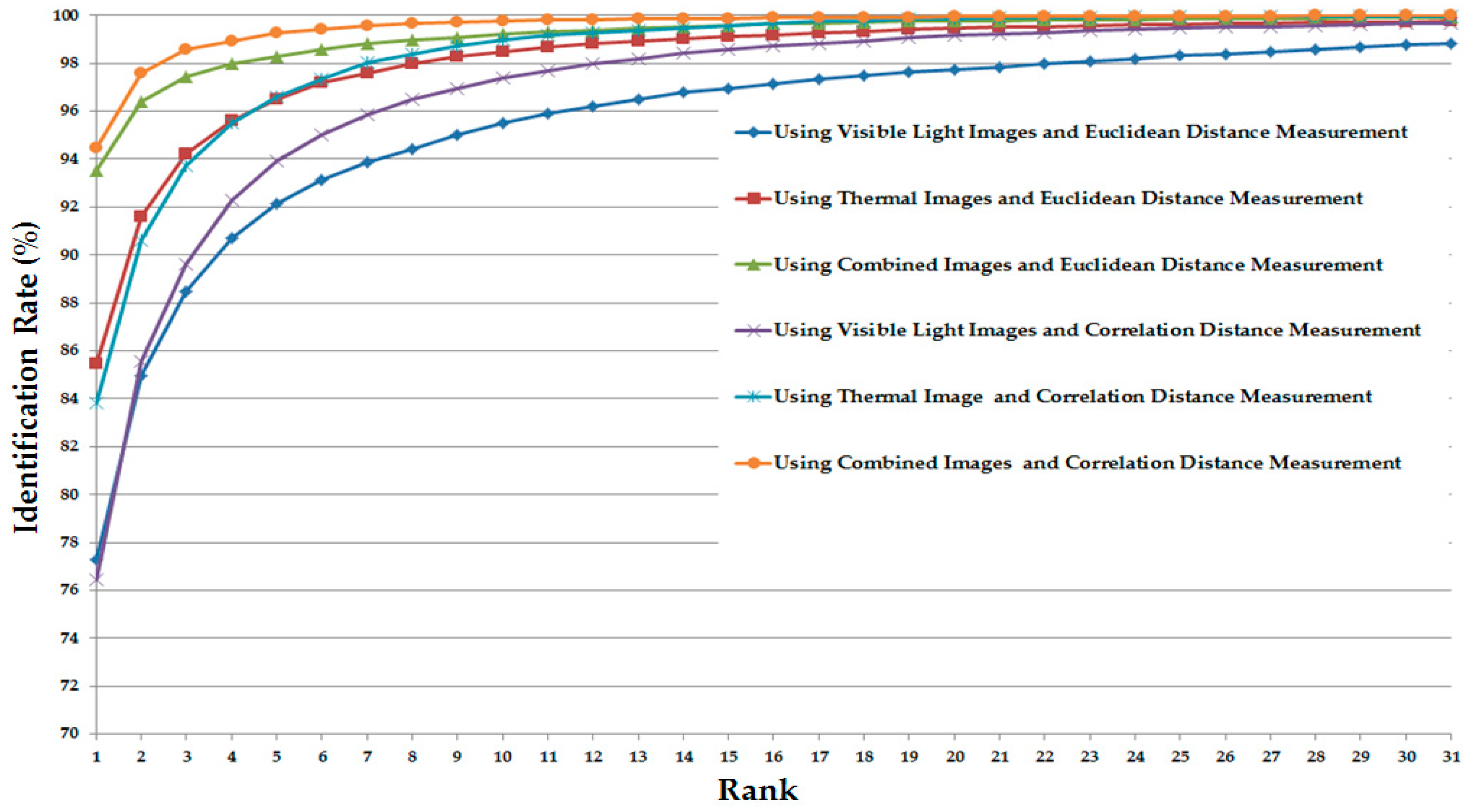
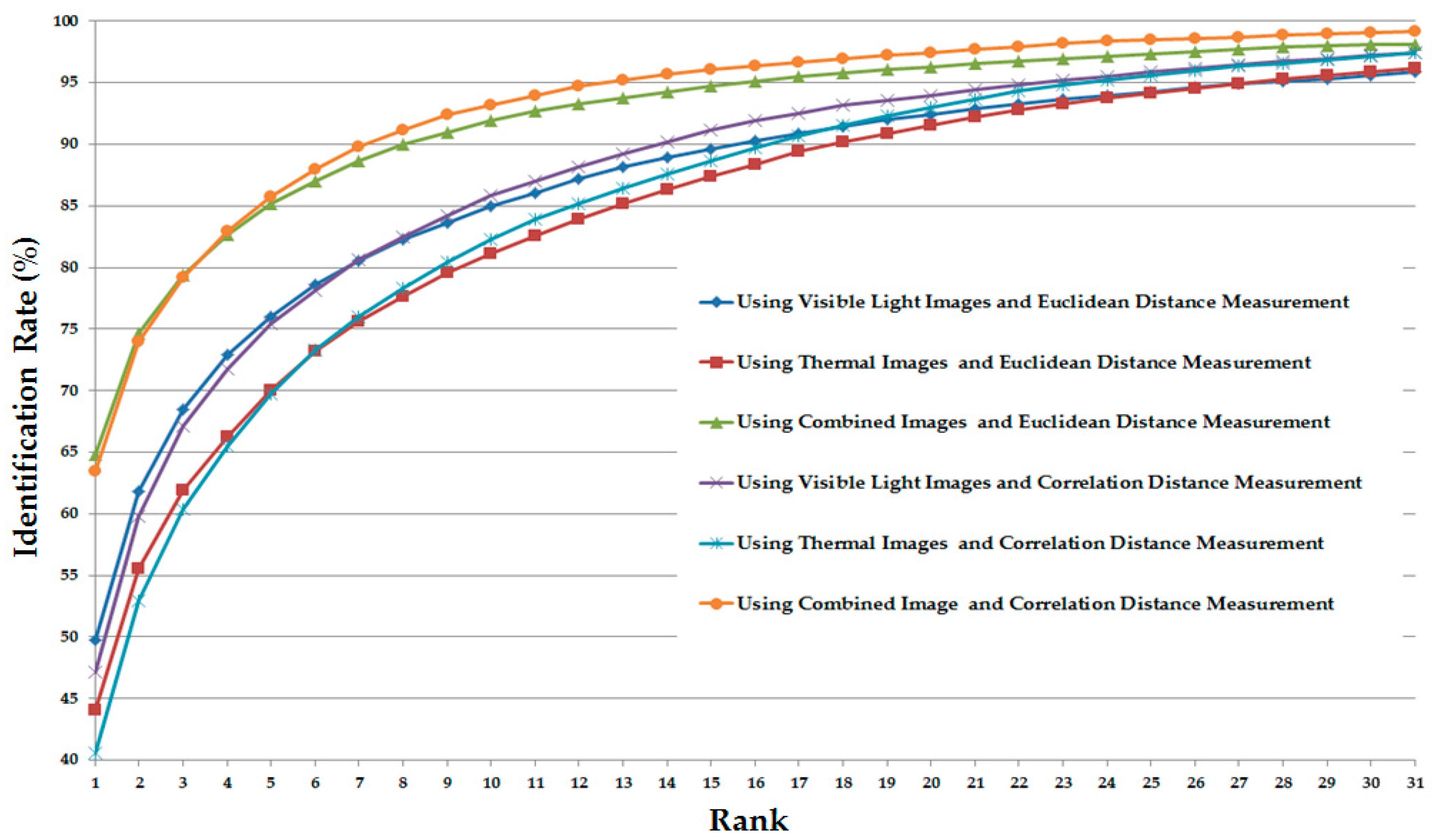
3.2.3. Experiments Using Correlation Distance
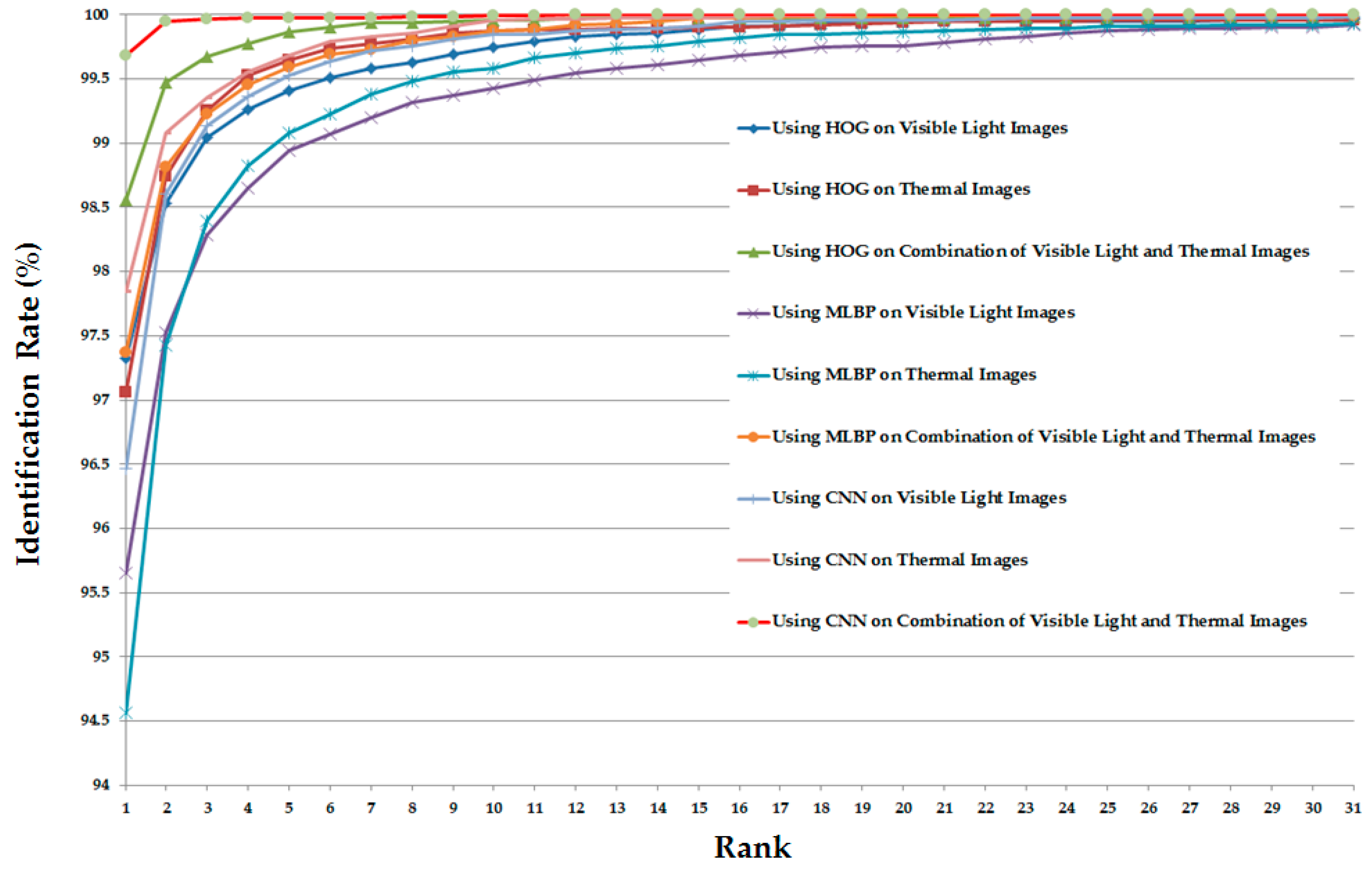
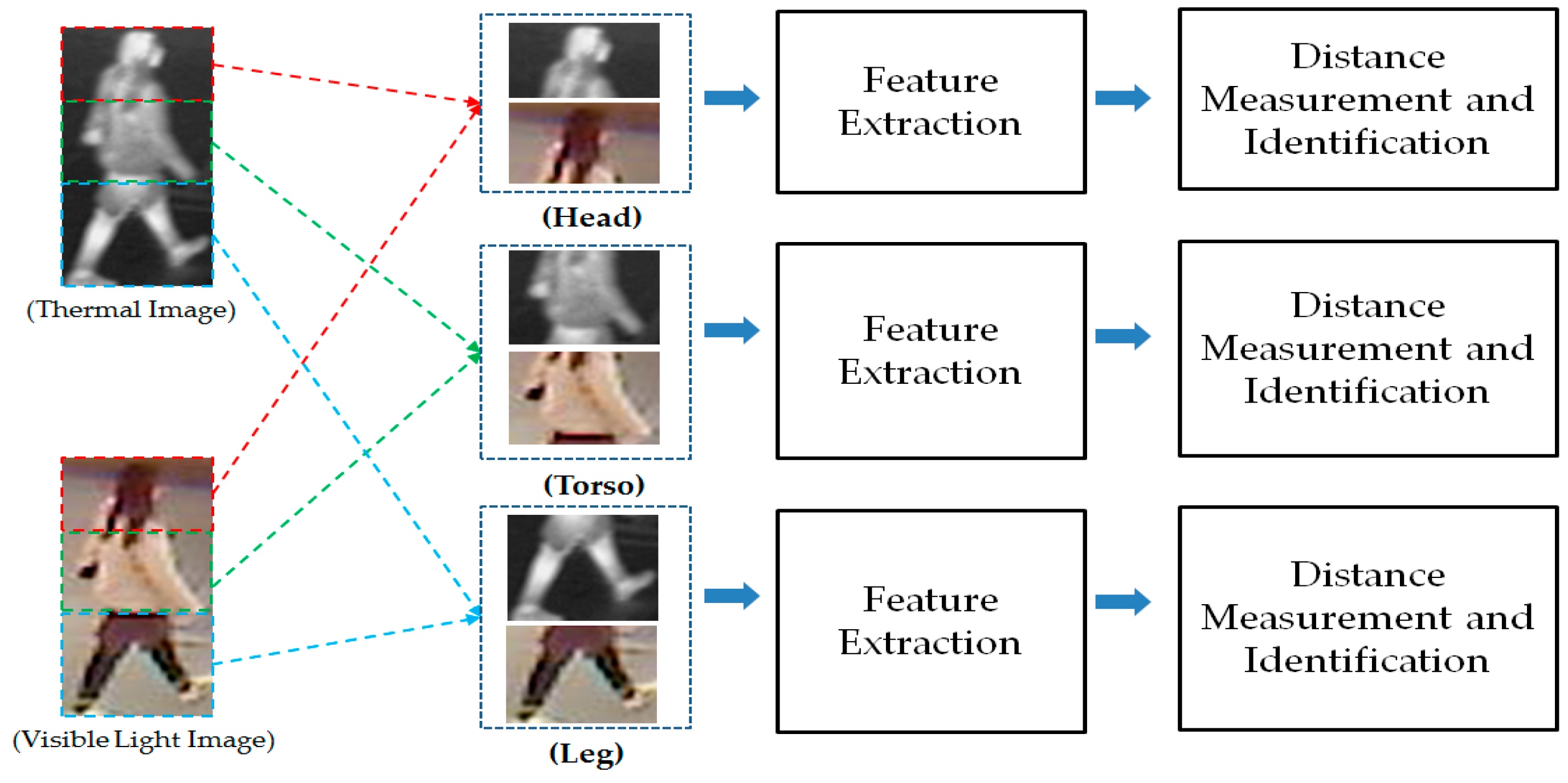
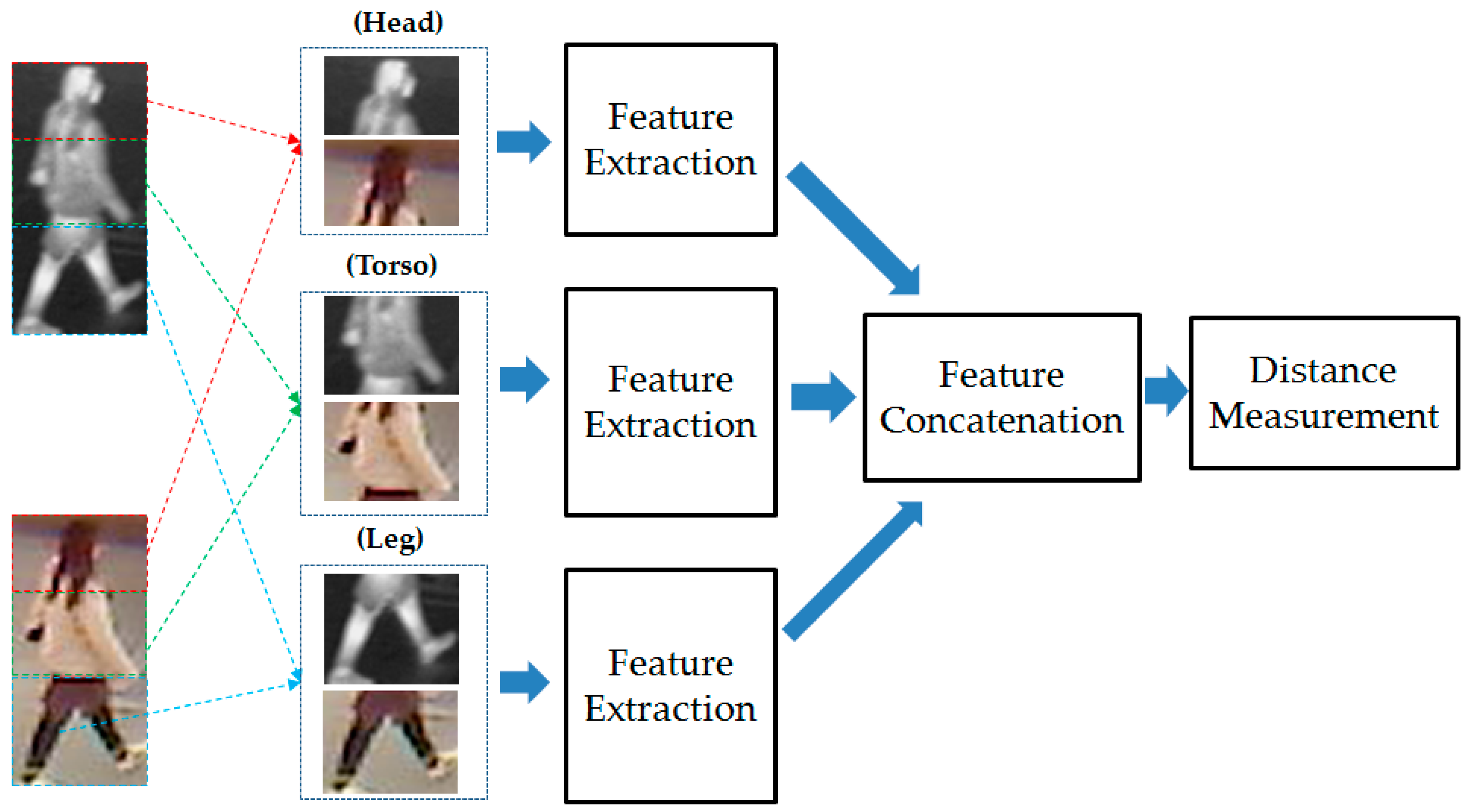
3.2.4. Part-Based Person Recognition
3.3. Discussion
4. Conclusions
Acknowledgments
Authors Contribution
Conflicts of Interest
References
- Chen, B.-W.; Chen, C.-Y.; Wang, J.-F. Smart homecare surveillance system: Behavior identification based on state-transition support vector machines and sound directivity pattern analysis. IEEE Trans. Syst. Man Cybern.-Syst. 2013, 43, 1279–1289. [Google Scholar] [CrossRef]
- Sanoob, A.H.; Roselin, J.; Latha, P. Smartphone enabled intelligent surveillance system. IEEE Sens. J. 2016, 16, 1361–1367. [Google Scholar] [CrossRef]
- Haritaoglu, I.; Harwood, D.; Davis, L.S. W4: Real-time surveillance of people and their activities. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 809–830. [Google Scholar] [CrossRef]
- Namade, B. Automatic traffic surveillance using video tracking. Procedia Comput. Sci. 2016, 79, 402–409. [Google Scholar] [CrossRef]
- Bagheri, S.; Zheng, J.Y.; Sinha, S. Temporal mapping of surveillance video for indexing and summarization. Comput. Vis. Image Underst. 2016, 144, 237–257. [Google Scholar] [CrossRef] [Green Version]
- Ng, C.B.; Tay, Y.H.; Goi, B.-M. Recognizing human gender in computer-vision: A survey. Lect. Notes Comput. Sci. 2012, 7458, 335–346. [Google Scholar]
- Lee, W.O.; Kim, Y.G.; Hong, H.G.; Park, K.R. Face recognition system for set-top-box-based intelligent TV. Sensors 2014, 14, 21726–21749. [Google Scholar] [CrossRef] [PubMed]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus Convention Center, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708.
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2012, 21, 2228–2244. [Google Scholar] [CrossRef] [PubMed]
- Borra, S.R.; Reddy, G.J.; Reddy, E.S. A broad survey on fingerprint recognition systems. In Proceedings of the International Conference on Wireless Communications, Signal Processing and Networking, Sri Sivasubramaniya Nadar College of Engineering Rajiv Gandhi Salai (OMR), Kalavakkam, Chennai, India, 23–25 March 2016; pp. 1428–1434.
- Marsico, M.D.; Petrosino, A.; Ricciardi, S. Iris recognition through machine learning techniques: A survey. Pattern Recognit. Lett. 2016, 82, 106–115. [Google Scholar] [CrossRef]
- Hu, Y.; Sirlantzis, K.; Howells, G. Optimal generation of iris codes for iris recognition. IEEE Trans. Inf. Forensic Secur. 2017, 12, 157–171. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A.; Parbhakar, S. An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hynes Convention Center, Boston, MA, USA, 7–12 June 2015; pp. 3908–3916.
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344.
- Zhao, R.; Ouyang, W.; Wang, X. Person re-identification by salience matching. In Proceedings of the IEEE International Conference on Computer Vision, Sydney Convention and Exhibition Centre, Sydney, NSW, Australia, 1–8 December 2013; pp. 2528–2535.
- Khamis, S.; Kuo, C.-H.; Singh, V.K.; Shet, V.D.; Davis, L.S. Joint learning for attribute-consistent person re-identification. Lect. Notes Comput. Sci. 2015, 8927, 134–146. [Google Scholar]
- Kostinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large scale metric learning from equivalence constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence Rhode Island Convention Center, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295.
- Li, W.; Wang, X. Locally aligned feature transforms across views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Oregon Convention Center, Portland, OR, USA, 23–28 June 2013; pp. 3594–3601.
- Xiong, F.; Gou, M.; Camps, O.; Sznaier, M. Person re-identification using kernel-based learning methods. Lect. Notes Comput. Sci. 2014, 8695, 1–16. [Google Scholar]
- Zhang, Z.; Troje, N.F. View-independent person identification from human gait. Neurocomputing 2005, 69, 250–256. [Google Scholar] [CrossRef]
- Li, W.; Wu, Y.; Mukunoki, M.; Kuang, Y.; Minoh, M. Locality based discriminative measure for multiple-shot human re-identification. Neurocomputing 2015, 167, 280–289. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Z.; Wu, Q.; Wang, Y. Enhancing person re-identification by integrating gait biometric. Neurocomputing 2015, 168, 1144–1156. [Google Scholar] [CrossRef]
- Yogarajah, P.; Chaurasia, P.; Condell, J.; Prasad, G. Enhancing gait based person identification using joint sparsity model and l1-norm minimization. Inf. Sci. 2015, 308, 3–22. [Google Scholar] [CrossRef]
- Ding, S.; Lin, L.; Wang, G.; Chao, H. Deep feature learning with relative distance comparison for person re-identification. Pattern Recognit. 2015, 48, 2993–3003. [Google Scholar] [CrossRef]
- Shi, S.-C.; Guo, C.-C.; Lai, J.-H.; Chen, S.-Z.; Hu, X.-J. Person re-identification with multi-level adaptive correspondence models. Neurocomputing 2015, 168, 550–559. [Google Scholar] [CrossRef]
- Iwashita, Y.; Uchino, K.; Karazume, R. Gait-based person identification robust to changes in appearance. Sensors 2013, 13, 7884–7901. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Huang, C.; Luo, B.; Meng, F.; Song, T.; Shi, H. Person re-identification based on multi-region-set ensembles. J. Vis. Commun. Image Represent. 2016, 40, 67–75. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hynes Convention Center, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520.
- Qin, H.; Yan, J.; Li, X.; Hu, X. Joint training of cascaded CNN for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3456–3465.
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye tracking for everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2176–2184.
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. DeepLanes: End-to-end lane position estimation using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 38–45.
- Lee, J.H.; Choi, J.-S.; Jeon, E.S.; Kim, Y.G.; Le, T.T.; Shin, K.Y.; Lee, H.C.; Park, K.R. Robust pedestrian detection by combining visible and thermal infrared cameras. Sensors 2015, 15, 10580–10615. [Google Scholar] [CrossRef] [PubMed]
- Dhamecha, T.I.; Nigam, A.; Singh, R.; Vatsa, M. Disguise detection and face recognition in visible and thermal spectrums. In Proceedings of the International Conference on Biometrics, Madrid, Spain, 4–7 June 2013; pp. 1–8.
- Hermosilla, G.; Gallardo, F.; Farias, G.; Martin, C.S. Fusion of visible and thermal descriptors using genetic algorithms for face recognition systems. Sensors 2015, 15, 17944–17962. [Google Scholar] [CrossRef] [PubMed]
- Ghiass, R.S.; Arandjelovic, O.; Bendada, H.; Maldague, X. Infrared face recognition: A literature review. In Proceedings of the International Joint Conference on Neural Networks, Fairmont Hotel Dallas, Dallas, TX, USA, 4–9 August 2013; pp. 1–10.
- Martin, R.; Arandjelovic, O. Multiple-object tracking in cluttered and crowded public spaces. Lect. Notes Comput. Sci. 2010, 6455, 89–98. [Google Scholar]
- Dalal, N.; Triggs, B. Histogram of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893.
- Hajizadeh, M.A.; Ebrahimnezhad, H. Classification of age groups from facial image using histograms of oriented gradients. In Proceedings of the 7th Iranian Conference on Machine Vision and Image Processing, Iran University of Science and Technology (IUST), Tehran, Iran, 16–17 November 2011; pp. 1–5.
- Karaaba, M.; Surinta, O.; Schomaker, L.; Wiering, M.A. Robust face recognition by computing distances from multiple histograms of oriented gradients. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town International Convention Center, Cape Town, South Africa, 7–10 December 2015; pp. 203–209.
- Cao, L.; Dikmen, M.; Fu, Y.; Huang, T.S. Gender recognition from body. In Proceedings of the 16th ACM International Conference on Multimedia, Vancouver, BC, Canada, 26–31 October 2008; pp. 725–728.
- Nguyen, D.T.; Park, K.R. Body-based gender recognition using images from visible and thermal cameras. Sensors 2016, 16, 156. [Google Scholar] [CrossRef] [PubMed]
- Tapia, J.E.; Perez, C.A. Gender classification based on fusion of different spatial scale features selected by mutual information from histogram of LBP, intensity and shape. IEEE Trans. Inf. Forensic Secur. 2013, 8, 488–499. [Google Scholar] [CrossRef]
- Choi, S.E.; Lee, Y.J.; Lee, S.J.; Park, K.R.; Kim, J. Age estimation using a hierarchical classifier based on global and local facial features. Pattern Recognit. 2011, 44, 1262–1281. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Cho, S.R.; Pham, T.D.; Park, K.R. Human age estimation method robust to camera sensor and/or face movement. Sensors 2015, 15, 21898–21930. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional neural networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural network. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December2012.
- Li, W.; Zhao, R.; Wang, X. Human re-identification with transferred metric learning. In Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Volume I, pp. 31–44.
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus Convention Center, Columbus, OH, USA, 23–28 June 2014; pp. 152–159.
- Gray, D.; Brennan, S.; Tao, H. Evaluating appearance models for recognition, reacquisition, and tracking. In Proceedings of the IEEE International Workshop on Performance Evaluation for Tracking and Surveillance, Rio de Janeiro, Brazil, 14 October 2007.
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. Person re-identification by video ranking. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014.
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bishof, H. Person re-identification by descriptive and discriminative classification. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 23–27 May 2011; pp. 91–102.
- C600 Webcam Camera. Available online: https://support.logitech.com/en_us/product/5869 (accessed on 28 November 2016).
- Tau2 Thermal Imaging Camera. Available online: http://www.flir.com/cores/display/?id=54717 (accessed on 28 November 2016).
- Dongguk Body-Based Person Recognition Database (DBPerson-Recog-DB1). Available online: http://dm.dongguk.edu/link.html (accessed on 23 February 2017).
- Lu, Y.; Yoon, S.; Xie, S.J.; Yang, J.; Wang, Z.; Park, D.S. Finger-vein recognition using histogram of competitive Gabor responses. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1758–1763.
- Yang, B.; Chen, S. A comparative study on local binary pattern (LBP) based face recognition: LBP histogram versus LBP image. Neurocomputing 2013, 120, 365–379. [Google Scholar] [CrossRef]
- Manjunath, N.; Anmol, N.; Prathiksha, N.R.; Vinay, A. Performance analysis of various distance measures for PCA based face recognition. In Proceedings of the National Conference on Recent Advances in Electronics & Computer Engineering, Roorkee, India, 13–15 February 2015; pp. 130–133.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Strength | Weakness |
|---|---|---|---|
| Using only visible light images of the human body for the person identification problem | Extracts the image features by using traditional feature extraction methods such as color histogram [17,18], local binary pattern [17,18], Gabor filters [19], and HOG [19]. | Easy to implement image features extraction by using traditional feature extraction methods [17,18,19]. | - The identification performance is strongly affected by random noise factors such as background, clothes, and accessories. - It is difficult for the surveillance system to operate in low illumination environments such as rain or nighttime because of the use of only visible light images. |
| - Uses a sequence of images to obtain body gait information [23,24]. | - Higher identification accuracy than the use of single images [23,24]. | ||
| - Uses deep learning framework to extract the optimal image features and/or learn the distance measurement metrics [14,15,25]. | - Higher identification accuracy can be obtained; the extracted image features are slightly invariant to noise, illumination conditions, and misalignment because of the use of deep learning method [14,15,25]. | ||
| Using a combination of visible light and thermal images of the human body for the person verification and identification problem (our proposed method) | - Combines the information from two types of human body images (visible light and thermal images) for the person verification and identification problem. - Uses CNN and PCA methods for optimal image features extraction of visible light and thermal images of human body. | - Verification/identification performance is higher than that of only visible light images or only thermal images. - The system can work in poor illumination conditions such as rain or nighttime. | - Requires two different kinds of cameras to acquire the human body images, including a visible light camera and a thermal camera. - Requires longer processing time than the use of a single kind of human body image. |
| Layer Name | No. Filters | Filter Size | Stride | Padding | Output Size |
|---|---|---|---|---|---|
| Input Layer | n/a | n/a | n/a | n/a | 115 × 179 × 1 |
| Convolutional Layer 1 & ReLU (C1) | 96 | 7 × 7 | 2 × 2 | 0 | 55 × 87 × 96 |
| Cross-Channel Normalization Layer | n/a | n/a | n/a | n/a | 55 × 87 × 96 |
| MAX Pooling Layer 1 (C1) | n/a | 3 × 3 | 2 × 2 | 0 | 27 × 43 × 96 |
| Convolutional Layer 2 & ReLU (C2) | 128 | 5 × 5 | 1 × 1 | 2 × 2 | 27 × 43 × 128 |
| Cross-Channel Normalization Layer | n/a | n/a | n/a | n/a | 27 × 43 × 128 |
| MAX Pooling Layer 2 (C2) | n/a | 3 × 3 | 2 × 2 | 0 | 13 × 21 × 128 |
| Convolutional Layer 3 & ReLU (C3) | 256 | 3 × 3 | 1 × 1 | 1 × 1 | 13 × 21 × 256 |
| Convolutional Layer 4 & ReLU (C4) | 256 | 3 × 3 | 1 × 1 | 1 × 1 | 13 × 21 × 256 |
| Convolutional Layer 5 & ReLU (C5) | 128 | 3 × 3 | 1 × 1 | 1 × 1 | 13 × 21 × 128 |
| MAX Pooling Layer 5 (C5) | n/a | 3 × 3 | 2 × 2 | 0 | 6 × 10 × 128 |
| Fully Connected Layer 1 & ReLU (FC1) | n/a | n/a | n/a | n/a | 4096 |
| Fully Connected Layer 2 & ReLU (FC2) | n/a | n/a | n/a | n/a | 2048 |
| Dropout Layer | n/a | n/a | n/a | n/a | 2048 |
| Fully Connected Layer 3 (FC3) | n/a | n/a | n/a | n/a | M |
| Database | Males | Females | Total | |
|---|---|---|---|---|
| Training Database | Number of Persons | 204 (persons) | 127 (persons) | 331 (persons) |
| Number of Original Images | 4080 images (204 × 20) | 2540 images (127 × 20) | 6620 (images) | |
| Number of Artificial Images | 20400 images (204 × 20 × 5) | 10160 images (127 × 20 × 5) | 33100 images | |
| Testing Database | Number of Persons | 50 (persons) | 31 (persons) | 81 (persons) |
| Number of Original Images | 1000 images (50 × 20) | 620 images (31 × 20) | 1620 images | |
| Number of Artificial Images | 5000 images (50 × 20 × 5) | 3100 images (31 × 20 × 5) | 8100 images | |
| Feature Extraction Method | Using Only Visible Light Images | Using Only Thermal Images | Using Combination of Visible Light and Thermal Images |
|---|---|---|---|
| HOG [19] | 12.085 | 13.905 | 11.055 |
| MLBP [17,18] | 13.735 | 16.695 | 12.775 |
| CNN | 7.315 | 6.815 | 4.285 |
| Feature Extraction Method | Using Only Visible Light Images | Using Only Thermal Images | Using Combination of Visible Light and Thermal Images |
|---|---|---|---|
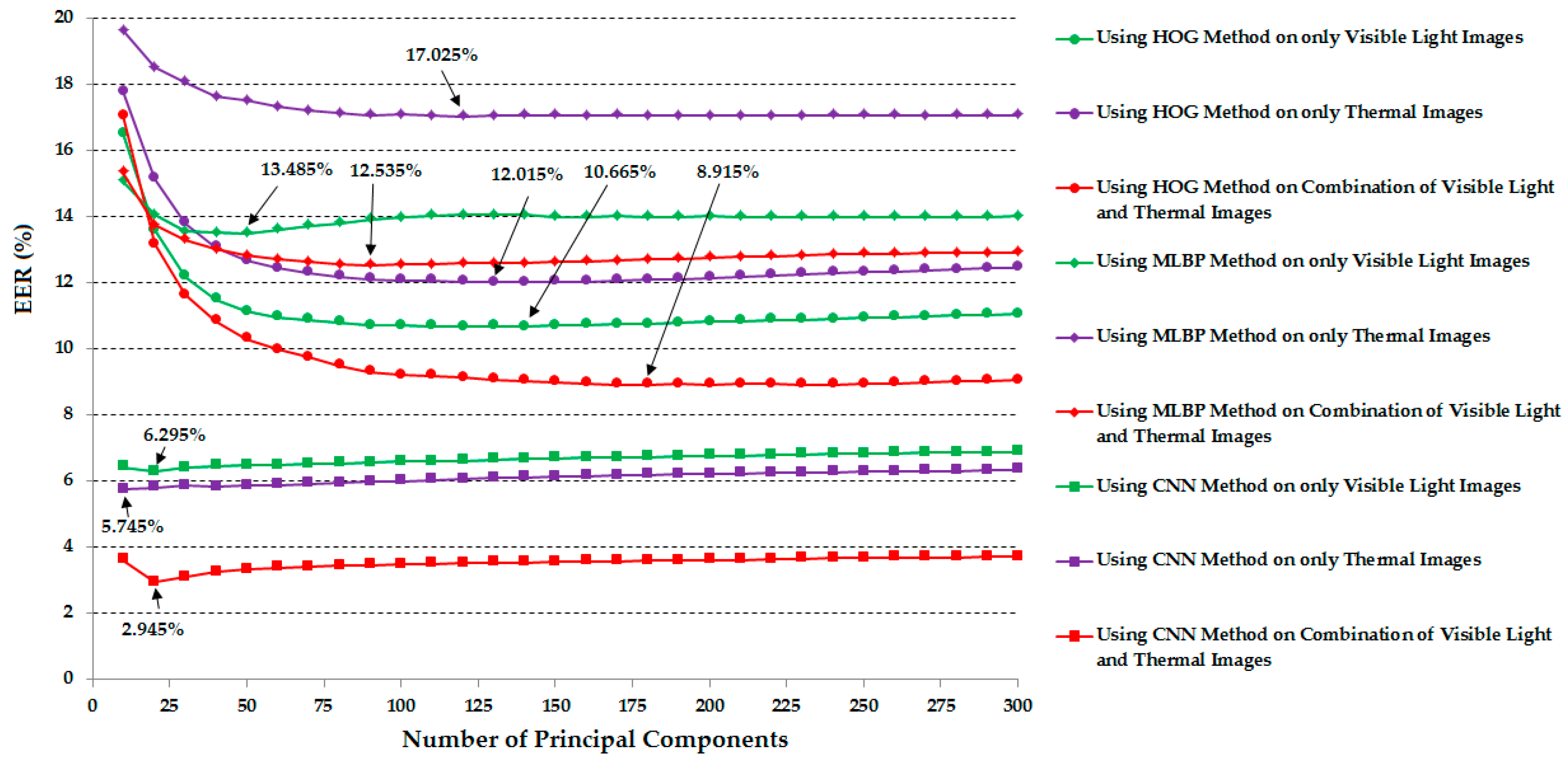
| HOG [19] | 10.665 | 12.015 | 8.915 |
| MLBP [17,18] | 13.485 | 17.025 | 12.535 |
| CNN | 6.295 | 5.745 | 2.945 |
| Feature Extraction Method | Using Only Visible Light Images | Using Only Thermal Images | Using Combination of Visible Light and Thermal Images |
|---|---|---|---|
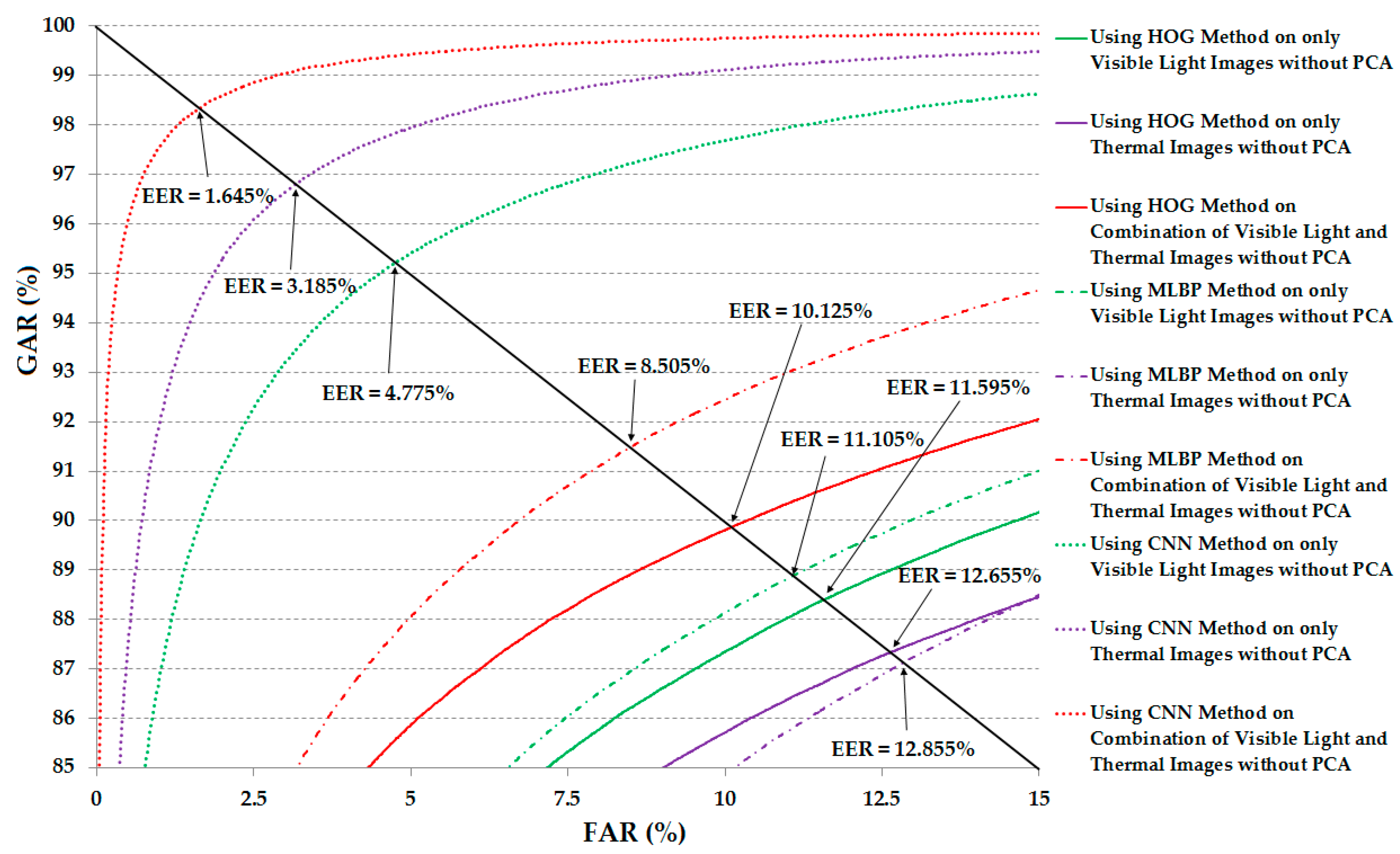
| HOG [19] | 11.595 | 12.655 | 10.125 |
| MLBP [17,18] | 11.105 | 12.855 | 9.885 |
| CNN | 4.775 | 3.185 | 1.645 |
| Feature Extraction Method | Using Only Visible Light Images | Using Only Thermal Images | Using Combination of Visible Light and Thermal Images |
|---|---|---|---|
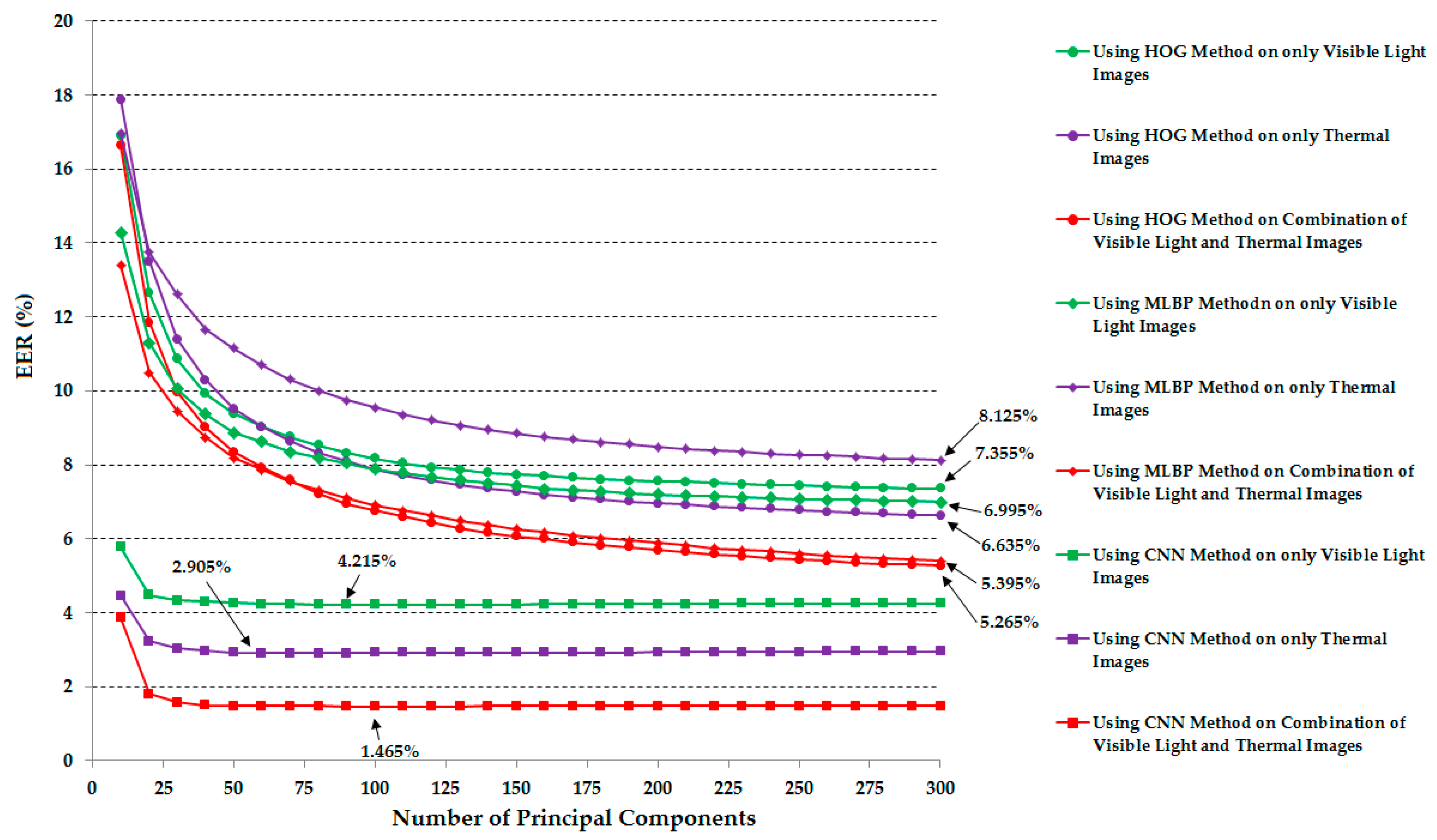
| HOG [19] | 7.355 | 6.635 | 5.265 |
| MLBP [17,18] | 6.995 | 8.125 | 5.395 |
| CNN | 4.215 | 2.905 | 1.465 |
| Body Part | Distance Method | PCA Method | Using Only Visible Light Images | Using Only Thermal Images | Using Combination of Visible Light and Thermal Images |
|---|---|---|---|---|---|
| Head | Euclidean Distance | Without PCA | 20.494 | 17.145 | 16.064 |
| With PCA | 19.265 | 16.585 | 14.725 | ||
| Correlation Distance | Without PCA | 18.485 | 17.605 | 14.875 | |
| With PCA | 14.985 | 13.335 | 9.875 | ||
| Torso | Euclidean Distance | Without PCA | 17.654 | 12.465 | 10.815 |
| With PCA | 16.465 | 11.845 | 9.755 | ||
| Correlation Distance | Without PCA | 14.695 | 10.684 | 7.925 | |
| With PCA | 11.515 | 8.905 | 5.995 | ||
| Leg | Euclidean Distance | Without PCA | 22.454 | 25.134 | 20.025 |
| With PCA | 23.145 | 25.895 | 21.235 | ||
| Correlation Distance | Without PCA | 24.224 | 26.505 | 22.305 | |
| With PCA | 20.705 | 23.675 | 18.375 |
| Distance Methods | Using Only Visible Images | Using Only Thermal Images | Using Combination of Visible and Thermal Images |
|---|---|---|---|
| Using Euclidean Distance | 13.724 | 11.915 | 9.165 |
| Using Correlation Distance | 9.155 | 8.405 | 5.265 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras. Sensors 2017, 17, 605. https://doi.org/10.3390/s17030605
Nguyen DT, Hong HG, Kim KW, Park KR. Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras. Sensors. 2017; 17(3):605. https://doi.org/10.3390/s17030605
Chicago/Turabian StyleNguyen, Dat Tien, Hyung Gil Hong, Ki Wan Kim, and Kang Ryoung Park. 2017. "Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras" Sensors 17, no. 3: 605. https://doi.org/10.3390/s17030605