
MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images

 , ,
, ,
Abstract
:
1. Introduction
2. Related Work
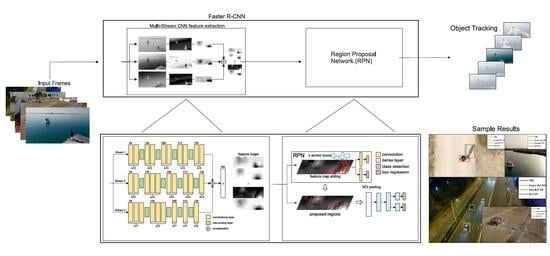
3. Materials and Methods
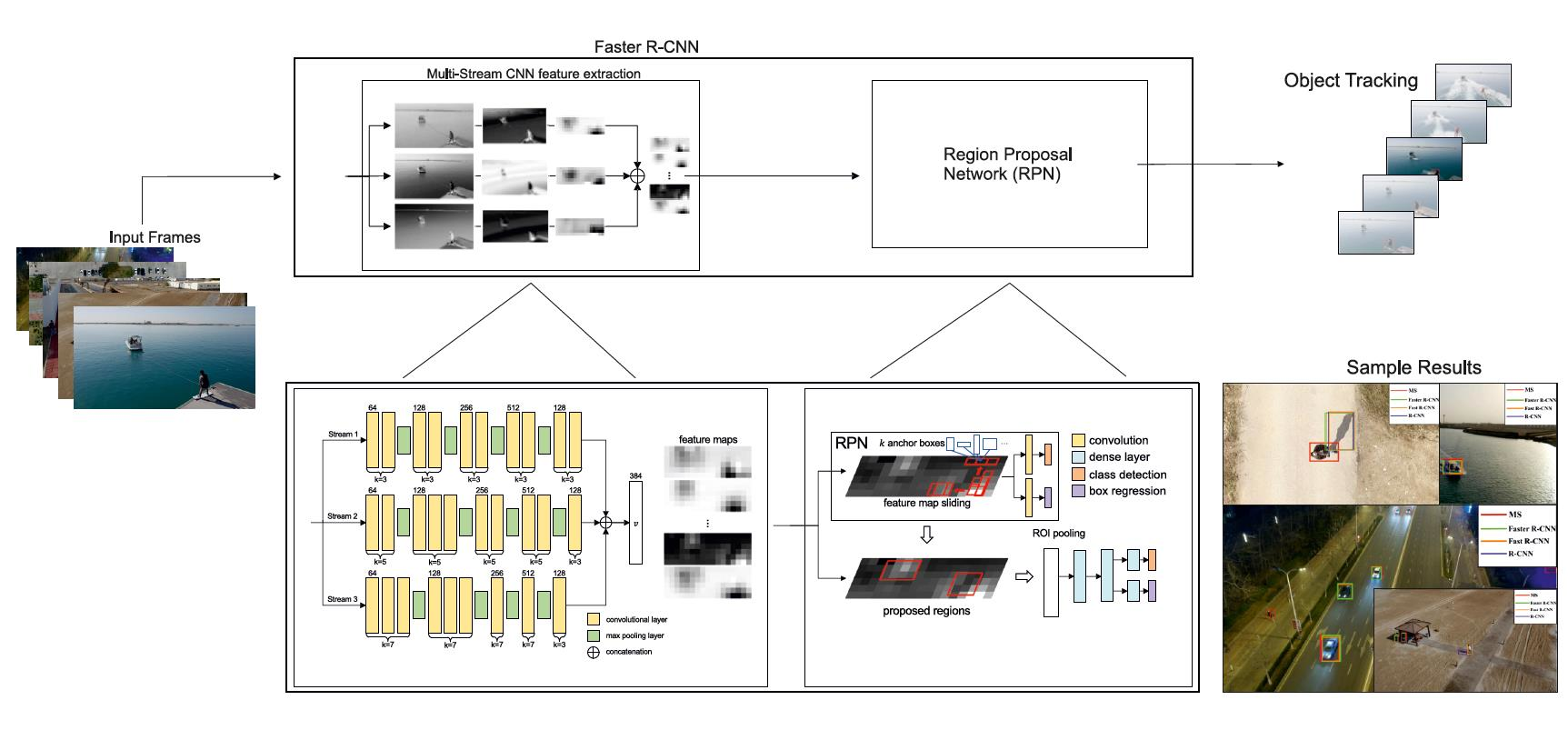
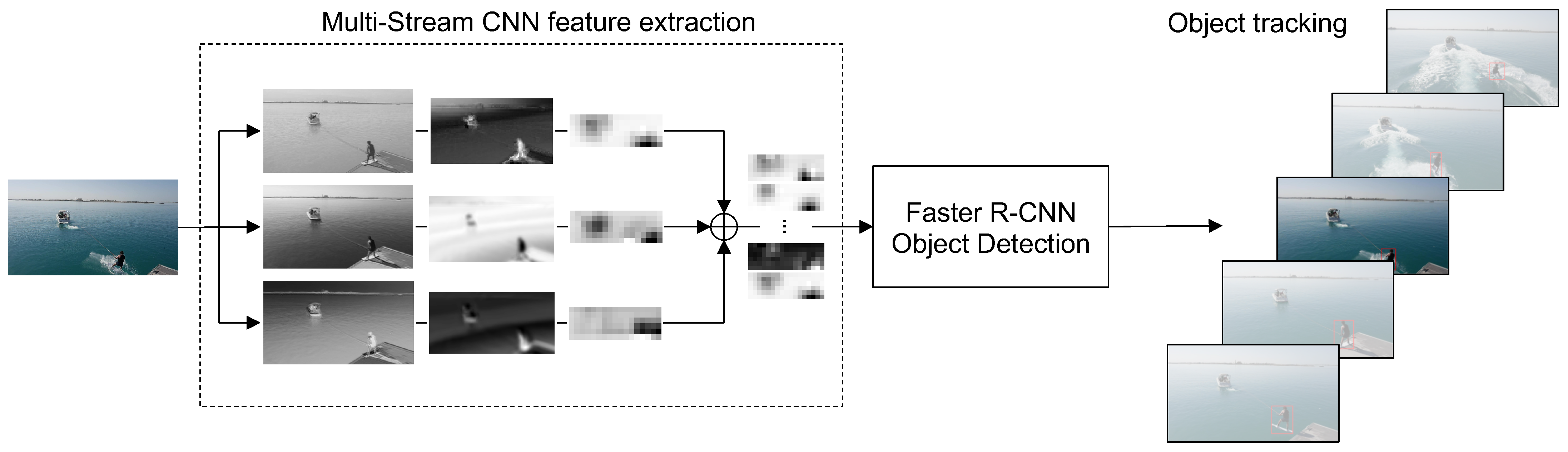
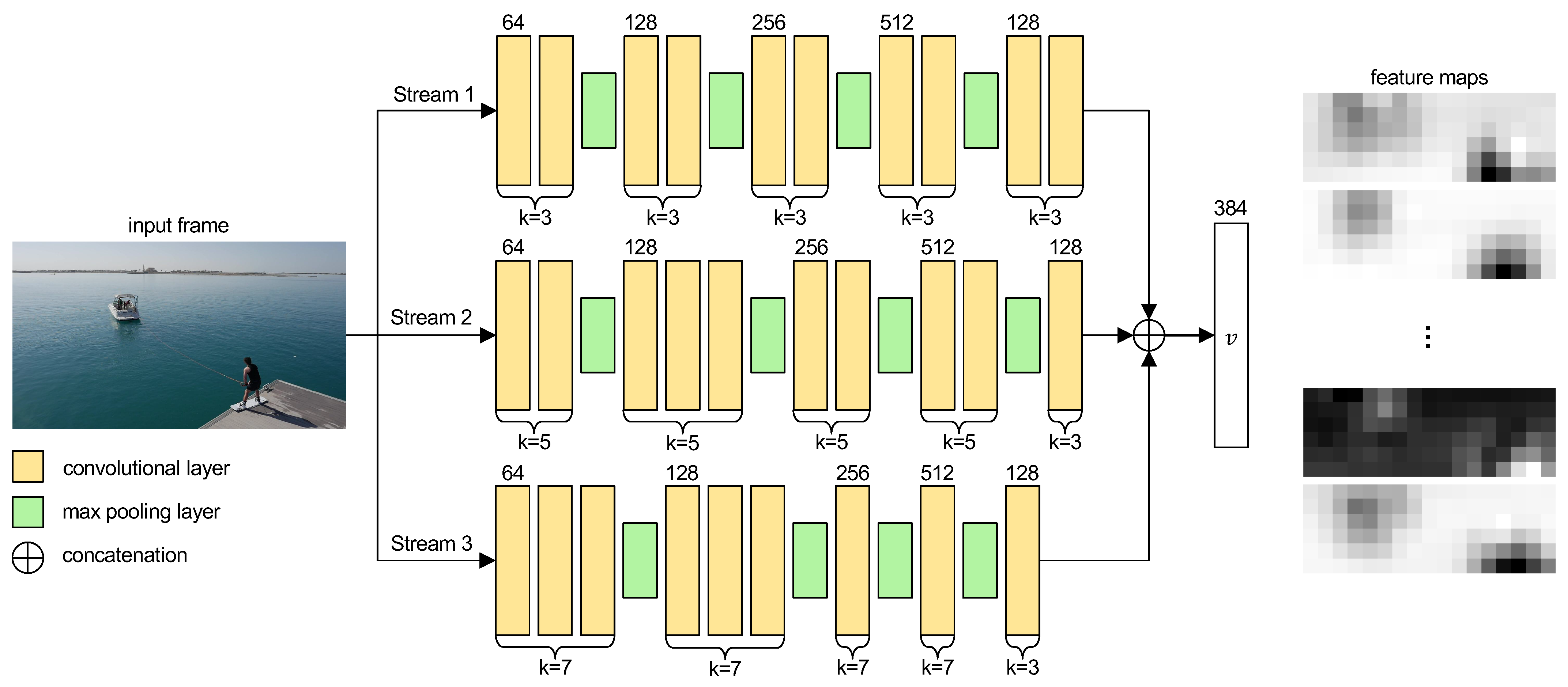
3.1. Multi-Stream CNN Feature Extractor
3.2. Object Detection
3.3. Multi-Stream Faster R-CNN Loss Functions
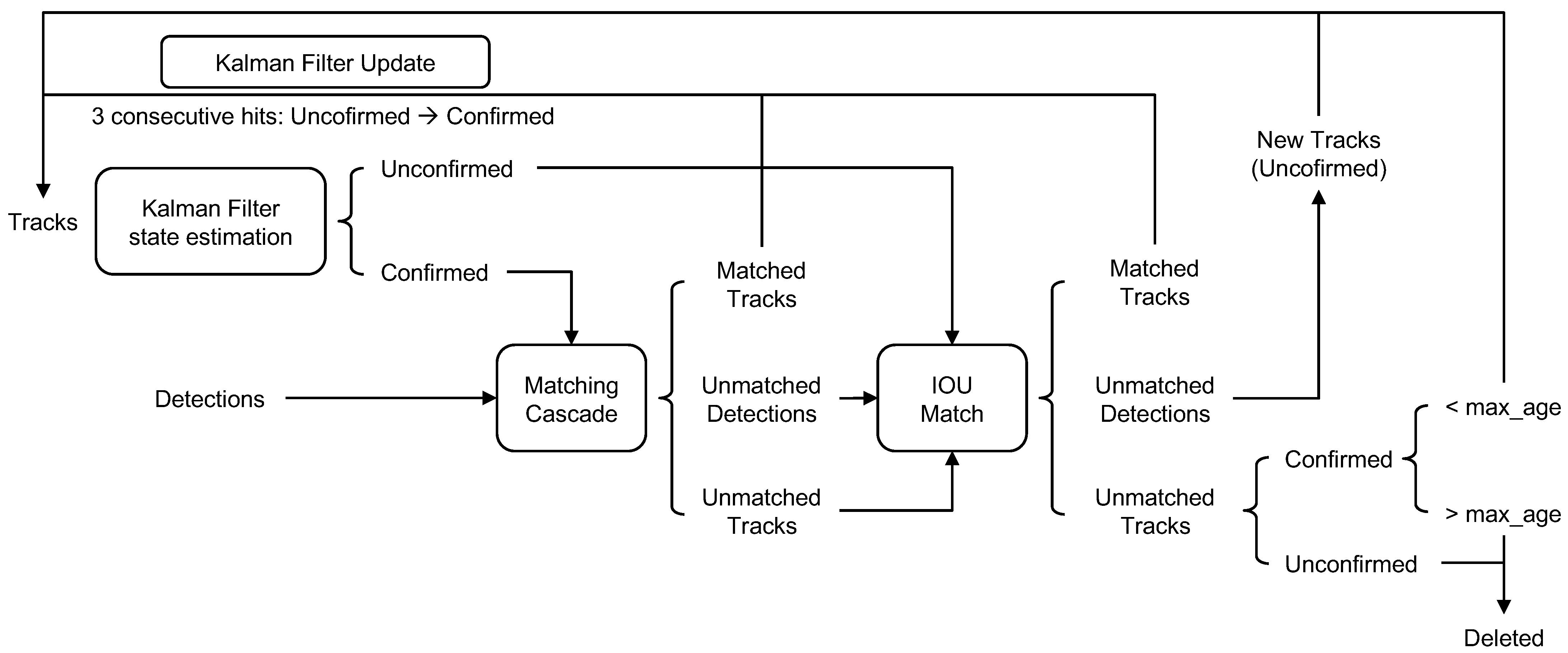
3.4. Tracking
| Algorithm 1 Hungarian Algorithm |
|
| Algorithm 2 Hungarian Algorithm (continued) |
|
4. Experimental Results
4.1. Datasets
4.1.1. UAVDT
4.1.2. UAV123 and UAV20L
4.1.3. UMCD
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Object Detection Performance Evaluation
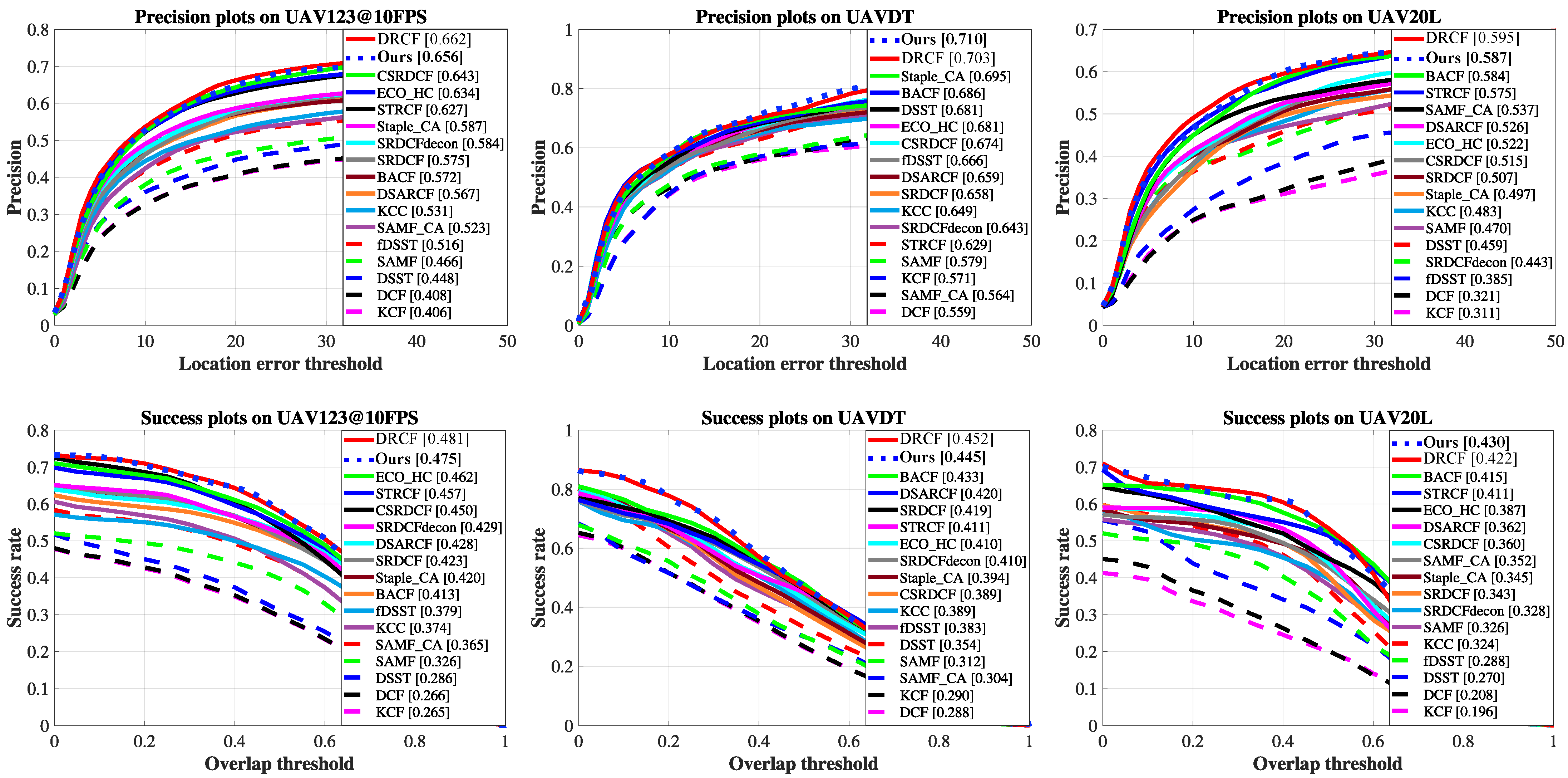
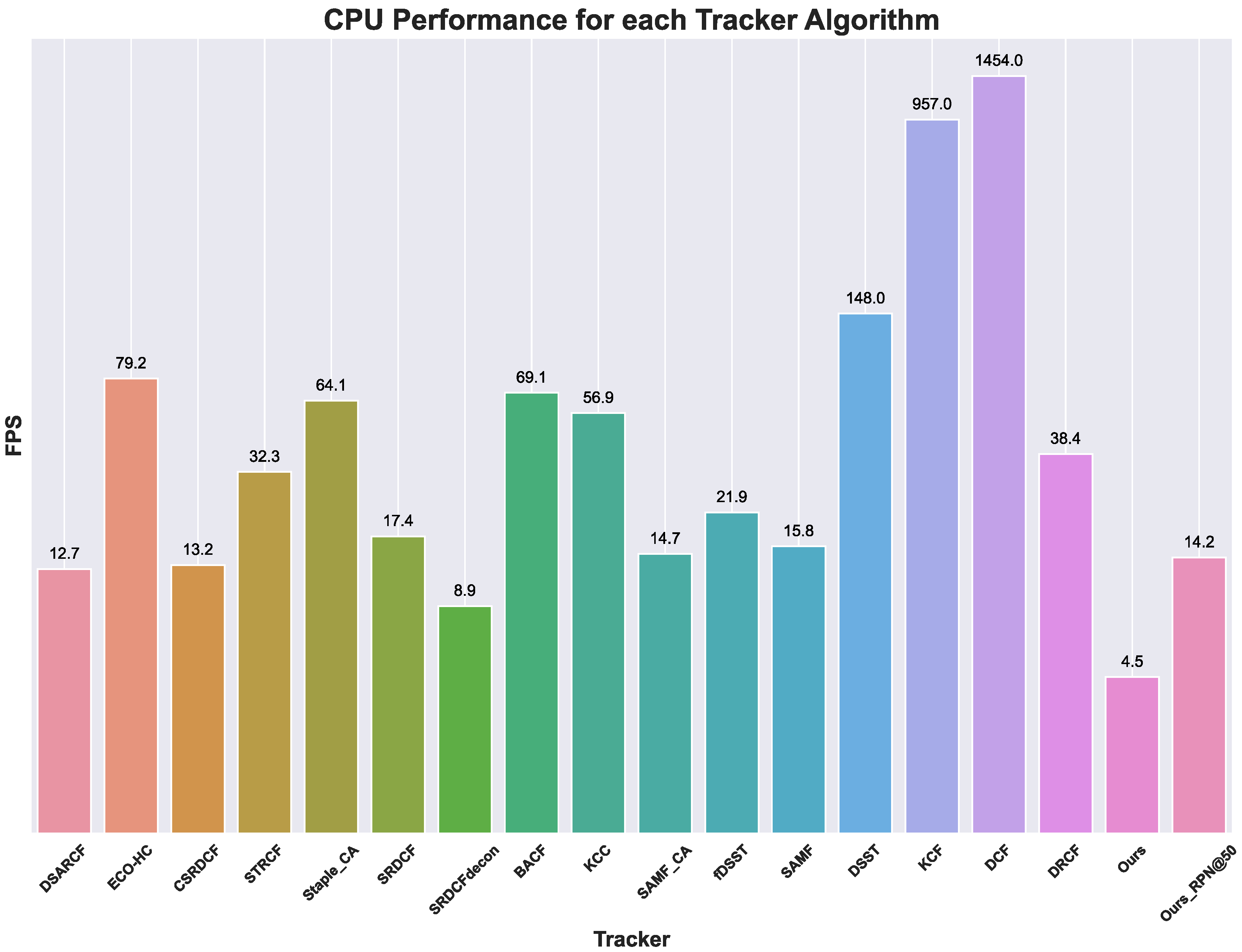
4.5. Tracking Performance Evaluation
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Avola, D.; Cinque, L.; Pannone, D. Design of a 3D Platform for Immersive Neurocognitive Rehabilitation. Information 2020, 11, 134. [Google Scholar] [CrossRef] [Green Version]
- Manca, M.; Paternò, F.; Santoro, C.; Zedda, E.; Braschi, C.; Franco, R.; Sale, A. The impact of serious games with humanoid robots on mild cognitive impairment older adults. Int. J. Hum. Comput. Stud. 2021, 145, 102509. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Marini, M.R.; Pannone, D. VRheab: A fully immersive motor rehabilitation system based on recurrent neural network. Multimed. Tools Appl. 2018, 77, 24955–24982. [Google Scholar] [CrossRef]
- Ladakis, I.; Kilintzis, V.; Xanthopoulou, D.; Chouvarda, I. Virtual Reality and Serious Games for Stress Reduction with Application in Work Environments. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies–Volume 5: HEALTHINF, Online Streaming, 11–13 February 2021; pp. 541–548. [Google Scholar]
- Torner, J.; Skouras, S.; Molinuevo, J.L.; Gispert, J.D.; Alpiste, F. Multipurpose virtual reality environment for biomedical and health applications. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1511–1520. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Cinque, L.; Foresti, G.L.; Mercuri, C.; Pannone, D. A Practical Framework for the Development of Augmented Reality Applications by Using ArUco Markers. In Proceedings of the 5th International Conference on Pattern Recognition Applications and Methods, Rome, Italy, 24–26 February 2016; pp. 645–654. [Google Scholar]
- Ikbal, M.S.; Ramadoss, V.; Zoppi, M. Dynamic Pose Tracking Performance Evaluation of HTC Vive Virtual Reality System. IEEE Access 2021, 9, 3798–3815. [Google Scholar] [CrossRef]
- Blut, C.; Blankenbach, J. Three-dimensional CityGML building models in mobile augmented reality: A smartphone-based pose tracking system. Int. J. Digit. Earth 2021, 14, 32–51. [Google Scholar] [CrossRef] [Green Version]
- Choy, S.M.; Cheng, E.; Wilkinson, R.H.; Burnett, I.; Austin, M.W. Quality of Experience Comparison of Stereoscopic 3D Videos in Different Projection Devices: Flat Screen, Panoramic Screen and Virtual Reality Headset. IEEE Access 2021, 9, 9584–9594. [Google Scholar] [CrossRef]
- Izard, S.G.; Méndez, J.A.J.; Palomera, P.R.; García-Peñalvo, F.J. Applications of virtual and augmented reality in biomedical imaging. J. Med. Syst. 2019, 43, 1–5. [Google Scholar]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Automatic Deception Detection in RGB Videos Using Facial Action Units. In Proceedings of the 13th International Conference on Distributed Smart Cameras, Trento, Italy, 9–11 September 2019; pp. 1–6. [Google Scholar]
- Khan, W.; Crockett, K.; O’Shea, J.; Hussain, A.; Khan, B.M. Deception in the eyes of deceiver: A computer vision and machine learning based automated deception detection. Expert Syst. Appl. 2021, 169, 114341. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; De Marsico, M.; Fagioli, A.; Foresti, G.L. LieToMe: Preliminary study on hand gestures for deception detection via Fisher-LSTM. Pattern Recognit. Lett. 2020, 138, 455–461. [Google Scholar] [CrossRef]
- Wu, Z.; Singh, B.; Davis, L.; Subrahmanian, V. Deception detection in videos. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Visual Cryptography for Detecting Hidden Targets by Small-Scale Robots. In Proceedings of the Pattern Recognition Applications and Methods, Funchal, Madeira, Portugal, 16–18 January 2019; pp. 186–201. [Google Scholar]
- Roy, S.; Hazera, C.T.; Das, D.; Rahman Pir, R.M.S.; Ahmed, A.S. A computer vision and artificial intelligence based cost-effective object sensing robot. Int. J. Intell. Robot. Appl. 2019, 3, 457–470. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Homography vs similarity transformation in aerial mosaicking: Which is the best at different altitudes? Multimed. Tools Appl. 2020, 79, 18387–18404. [Google Scholar] [CrossRef]
- Manzanilla, A.; Reyes, S.; Garcia, M.; Mercado, D.; Lozano, R. Autonomous Navigation for Unmanned Underwater Vehicles: Real-Time Experiments Using Computer Vision. IEEE Robot. Autom. Lett. 2019, 4, 1351–1356. [Google Scholar] [CrossRef]
- Viejo, C.G.; Fuentes, S.; Howell, K.; Torrico, D.; Dunshea, F.R. Robotics and computer vision techniques combined with non-invasive consumer biometrics to assess quality traits from beer foamability using machine learning: A potential for artificial intelligence applications. Food Control 2018, 92, 72–79. [Google Scholar] [CrossRef]
- Lauterbach, H.A.; Koch, C.B.; Hess, R.; Eck, D.; Schilling, K.; Nüchter, A. The Eins3D project—Instantaneous UAV-Based 3D Mapping for Search and Rescue Applications. In Proceedings of the 2019 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Würzburg, Germany, 2–4 September 2019; pp. 1–6. [Google Scholar]
- Ruetten, L.; Regis, P.A.; Feil-Seifer, D.; Sengupta, S. Area-Optimized UAV Swarm Network for Search and Rescue Operations. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 613–618. [Google Scholar]
- Alotaibi, E.T.; Alqefari, S.S.; Koubaa, A. Lsar: Multi-uav collaboration for search and rescue missions. IEEE Access 2019, 7, 55817–55832. [Google Scholar] [CrossRef]
- Zhou, S.; Yang, L.; Zhao, L.; Bi, G. Quasi-polar-based FFBP algorithm for miniature UAV SAR imaging without navigational data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7053–7065. [Google Scholar] [CrossRef]
- López, A.; Jurado, J.M.; Ogayar, C.J.; Feito, F.R. A framework for registering UAV-based imagery for crop-tracking in Precision Agriculture. Int. J. Appl. Earth Obs. Geoinf. 2021, 97, 102274. [Google Scholar] [CrossRef]
- Mazzia, V.; Comba, L.; Khaliq, A.; Chiaberge, M.; Gay, P. UAV and Machine Learning Based Refinement of a Satellite-Driven Vegetation Index for Precision Agriculture. Sensors 2020, 20, 2530. [Google Scholar] [CrossRef] [PubMed]
- Mesas-Carrascosa, F.J.; Clavero Rumbao, I.; Torres-Sánchez, J.; García-Ferrer, A.; Peña, J.; López Granados, F. Accurate ortho-mosaicked six-band multispectral UAV images as affected by mission planning for precision agriculture proposes. Int. J. Remote Sens. 2017, 38, 2161–2176. [Google Scholar] [CrossRef]
- Popescu, D.; Stoican, F.; Stamatescu, G.; Ichim, L.; Dragana, C. Advanced UAV–WSN system for intelligent monitoring in precision agriculture. Sensors 2020, 20, 817. [Google Scholar] [CrossRef] [Green Version]
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A review on UAV-based applications for precision agriculture. Information 2019, 10, 349. [Google Scholar] [CrossRef] [Green Version]
- Avola, D.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Pannone, D.; Piciarelli, C. Automatic estimation of optimal UAV flight parameters for real-time wide areas monitoring. Multimed. Tools Appl. 2021, 1–23. [Google Scholar]
- Avola, D.; Foresti, G.L.; Martinel, N.; Micheloni, C.; Pannone, D.; Piciarelli, C. Aerial video surveillance system for small-scale UAV environment monitoring. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Piciarelli, C.; Foresti, G.L. Drone swarm patrolling with uneven coverage requirements. IET Comput. Vis. 2020, 14, 452–461. [Google Scholar] [CrossRef]
- Padró, J.C.; Muñoz, F.J.; Planas, J.; Pons, X. Comparison of four UAV georeferencing methods for environmental monitoring purposes focusing on the combined use with airborne and satellite remote sensing platforms. Int. J. Appl. Earth Obs. Geoinf. 2019, 75, 130–140. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Massaroni, C.; Pannone, D. Feature-based SLAM algorithm for small scale UAV with nadir view. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; pp. 457–467. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar]
- Avola, D.; Cinque, L.; Foresti, G.L.; Martinel, N.; Pannone, D.; Piciarelli, C. A UAV Video Dataset for Mosaicking and Change Detection From Low-Altitude Flights. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 2139–2149. [Google Scholar] [CrossRef] [Green Version]
- Yao, R.; Lin, G.; Xia, S.; Zhao, J.; Zhou, Y. Video object segmentation and tracking: A survey. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–47. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhong, B.; Zhang, Y.; Li, J.; Fu, Y. Deep alignment network based multi-person tracking with occlusion and motion reasoning. IEEE Trans. Multimed. 2018, 21, 1183–1194. [Google Scholar] [CrossRef]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-time multiple people tracking with deeply learned candidate selection and person re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Tang, Z.; Wang, G.; Xiao, H.; Zheng, A.; Hwang, J.N. Single-camera and inter-camera vehicle tracking and 3D speed estimation based on fusion of visual and semantic features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 108–115. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, S.; Wang, S.; Shi, W.; Liu, H.; Li, Z.; Mao, T. Vehicle tracking by detection in UAV aerial video. Sci. China Inf. Sci. 2019, 62, 24101. [Google Scholar] [CrossRef] [Green Version]
- Zhu, M.; Zhang, H.; Zhang, J.; Zhuo, L. Multi-level prediction Siamese network for real-time UAV visual tracking. Image Vis. Comput. 2020, 103, 104002. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, X.; Dong, M.; Xu, H. Multiple objects tracking in the UAV system based on hierarchical deep high-resolution network. Multimed. Tools Appl. 2021, 1–19. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Feng, W.; Han, R.; Guo, Q.; Zhu, J.; Wang, S. Dynamic Saliency-Aware Regularization for Correlation Filter-Based Object Tracking. IEEE Trans. Image Process. 2019, 28, 3232–3245. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–9. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M. Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4904–4913. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-Aware Correlation Filter Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 4310–4318. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Adaptive Decontamination of the Training Set: A Unified Formulation for Discriminative Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June –1 July 2016; pp. 1430–1438. [Google Scholar]
- Galoogahi, H.K.; Fagg, A.; Lucey, S. Learning Background-Aware Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1144–1152. [Google Scholar]
- Wang, C.; Zhang, L.; Xie, L.; Yuan, J. Kernel Cross-Correlator. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 4179–4186. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the Computer Vision—ECCV Workshops, Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Danelljan, M.; Häger, G.; Shahbaz Khan, F.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, C.; Xu, J.; Lin, F.; Guo, F.; Liu, T.; Zhang, Z. Object Saliency-Aware Dual Regularized Correlation Filter for Real-Time Aerial Tracking. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8940–8951. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Task (s) | # Sequences | #Frames (Approx) |
|---|---|---|---|
| UAVDT [38] | Object Detection Single Object Tracking Multiple Object Tracking | 100 | 80,000 |
| UAV123 [39] UAV20L [39] | Short-Term Tracking Long-Term Tracking | 123 | 110,000 |
| UMCD [40] | Object Detection (Very Low Altitudes) | 50 (challenging) | 48,765 |
| Used in this work | Object Detection Object Tracking | 273 | more than 190,000 |
| Streams | mAP | Precision | Success | ||||
|---|---|---|---|---|---|---|---|
| UMCD | UAV123 | UAVDT | UAV20L | UAV123 | UAVDT | UAV20L | |
| Stream 1 | 0.153 | 0.146 | 0.110 | 0.111 | 0.098 | 0.135 | |
| Stream 2 | 0.112 | 0.097 | 0.092 | 0.074 | 0.071 | 0.067 | |
| Stream 3 | 0.105 | 0.098 | 0.088 | 0.072 | 0.069 | 0.064 | |
| Streams 1, 2 | 0.452 | 0.568 | 0.392 | 0.273 | 0.295 | 0.238 | |
| Streams 1, 3 | 0.443 | 0.555 | 0.386 | 0.264 | 0.245 | 0.227 | |
| Streams 2, 3 | 0.438 | 0.513 | 0.381 | 0.259 | 0.223 | 0.215 | |
| Full Model | 0.656 | 0.710 | 0.587 | 0.475 | 0.445 | 0.430 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avola, D.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Mecca, A.; Pannone, D.; Piciarelli, C. MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images. Remote Sens. 2021, 13, 1670. https://doi.org/10.3390/rs13091670
Avola D, Cinque L, Diko A, Fagioli A, Foresti GL, Mecca A, Pannone D, Piciarelli C. MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images. Remote Sensing. 2021; 13(9):1670. https://doi.org/10.3390/rs13091670
Chicago/Turabian StyleAvola, Danilo, Luigi Cinque, Anxhelo Diko, Alessio Fagioli, Gian Luca Foresti, Alessio Mecca, Daniele Pannone, and Claudio Piciarelli. 2021. "MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images" Remote Sensing 13, no. 9: 1670. https://doi.org/10.3390/rs13091670