1. Introduction
Landslides represent a significant threat to human life, natural resources, infrastructure, and properties in mountainous areas [
1]. A landslide is defined as the movement of a mass of debris, rocks, or slope failures, which occurs during rainfall, runoff, rapid snowmelt, earthquakes, and volcanic eruptions [
2,
3]. As well as the physical impacts on the environment, landslides also have adverse consequences for the economy of local communities [
4,
5]. Landslides can occur for a range of reasons; for instance, they can be triggered by earthquake shocks, heavy rainfall, or road construction in hilly areas [
6,
7]. Despite some progress being obtained through scientific studies, landslide susceptibility modeling and mapping pose significant challenges for land-use planners and policymakers [
8,
9]. Regardless of the type of methodology applied for landslide susceptibility mapping, reliable inventory data sets play an essential role in this process. A landslide inventory data set, including precise boundaries, spatial locations, and distributions, can be produced by conducting field surveys using the global positioning system (GPS), which is an expensive and, in some cases, dangerous approach due to the rough topography and instability [
10,
11]. Therefore, Earth observation (EO) products are considered a low cost and useful data source for landslide inventory data set production [
12]. The two main approaches of object-based and pixel-based classification methods have been used for the classification of satellite imagery and information extraction from EO data. Based on improvements in the fields of computer vision and image processing of the last two decades, object-based image analysis (OBIA) has become more widespread [
13]. OBIA is a relatively new sub-discipline of geographic information science (GIScience) and makes it possible to produce useful geographic information based on the partitioning of EO data into meaningful image objects applicable for the class or feature of interest [
14]. OBIA is a knowledge-driven approach, which—by mimicking human perception—tries to group a set of contiguous pixels into meaningful objects through a segmentation process that represents corresponding features in an image [
15,
16]. Compared to pixel-based approaches, which depend on the digital number (DN) of pixels, OBIA integrates and employs spectral information (e.g., color) and spatial properties (e.g., size and shape), along with textural data and contextual information (e.g., association with neighboring objects) [
17], to classify objects into desired classes.
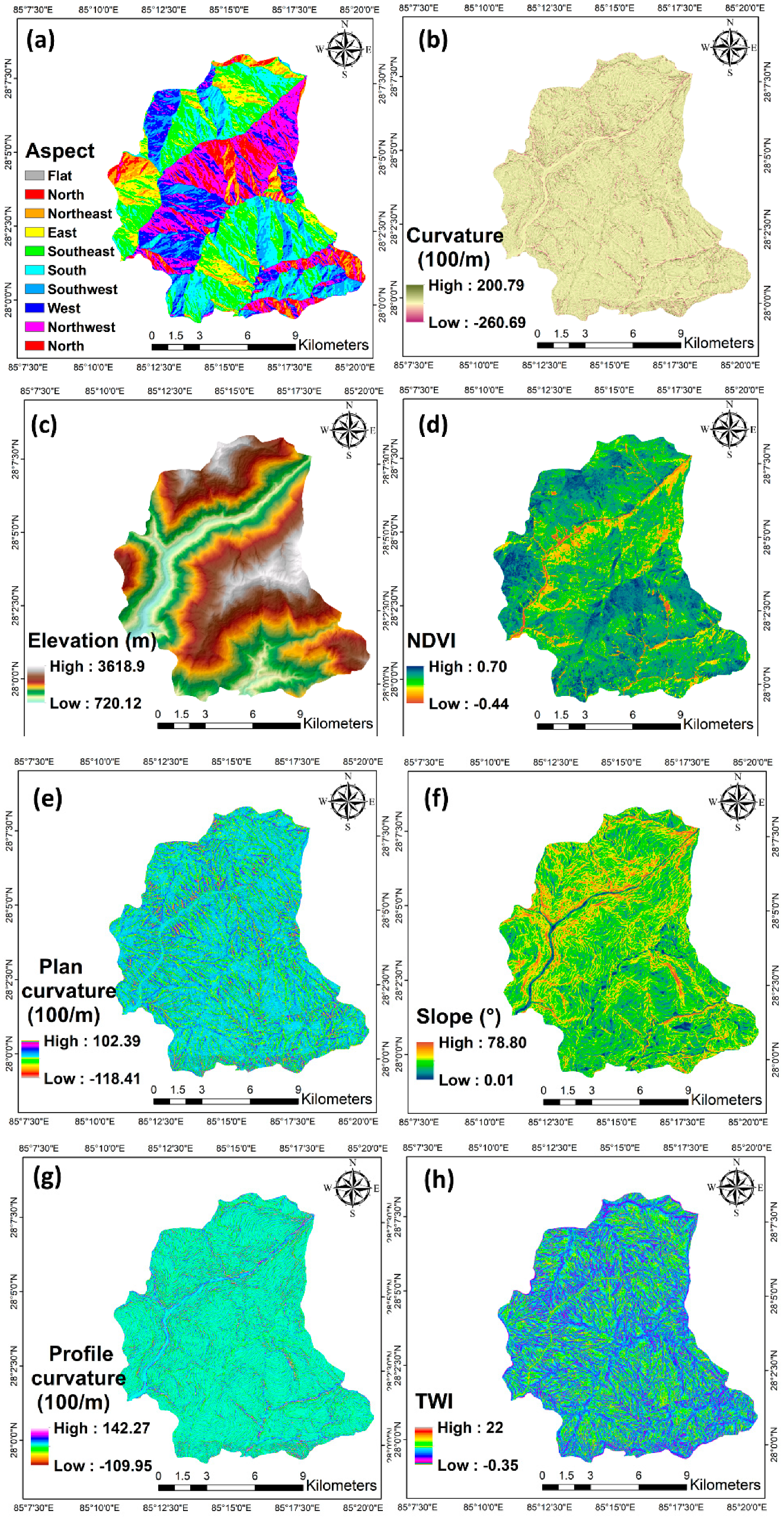
In OBIA, image segmentation is an essential pre-requisite for classification/feature extraction and further analysis with geographic information systems (GIS) [
17,
18]. The segmentation process controls the accuracy of further image analysis steps, such as classification and object detection [
19]. In other words, the segmentation procedure has a considerable influence on further processes [
20,
21], and incorrect segmentation usually results in over-segmentation and under segmentation errors [
22]. Therefore, defining the optimal parameters for object definition plays an essential role in detecting landslides through the image segmentation process. The optimal scale parameter (SP) should be considered in defining and generating meaningful segments/objects for segmentation [
23]. Although segmentation and primary object definition are never considered perfect, it is possible to use spectral and spatial indexes to obtain the optimal scale parameter (SP) for segmentation. Besides, many landslides that we can detect with EO data have a multi-scale character: along with their various sizes, they are composites of different entities, such as landslide bodies and affected areas, which are usually defined as the landslide area [
1]. An optimal scale out of multiple scales results in less internal heterogeneity concerning particular parameters compared to the adjacent areas [
15].
Since landslides in the real world come in a wide range of shapes and sizes and are embedded within different land cover types, expert knowledge plays a vital role in the accuracy of landslide detection with conventional rule-based approaches in OBIA. However, determining the appropriate thresholds to group segments into landslide classes based on each landslide diagnostic parameter is a difficult task. Another challenge is that the conventional approaches are mostly time-consuming and labor-intensive, and are often criticized because of their weakness regarding transferability [
24]. Currently, OBIA has been integrated with different machine learning (ML) methods and used in various applications [
25]. Generally, ML methods are considered valid methods for remote sensing (RS) applications with an emphasis on image classification and object recognition [
26]. Different ML methods and classifiers have already been integrated with OBIA and used for extracting landslides in different studies. For example, the ML method of support vector machines (SVMs) was used by [
24] to classify the segments employed to extract forested landslides. The authors trained their semi-automatic method using old and densely vegetated landslides and derived their extent using LiDAR products. Their method was then tested in the Flemish Ardennes (Belgium) and resulted in landslide extraction accuracies of almost 70%. In another study, [
27] used the same ML method, but applied the RBF kernel along with OBIA to propose an automatic landslide extraction approach for rainfall-induced landslides on Madeira Island. Furthermore, [
28] integrated the K-means clustering method with both pixel-based and OBIA approaches to compare their performance in landslide detection. The integrated approaches were implemented using very high-resolution (VHR) remotely sensed images for their case study area of the San Juan La Laguna, Guatemala. The comparative study revealed that the integration of the K-means clustering method with OBIA was able to identify most of the landslides with less false positives compared to the pixel-based approach.
Although using single ML methods provides acceptable accuracies in landslide extraction and modeling, the combination of two or more ML methods has achieved higher accuracies [
29]. Chen et al. [
30] applied an ensemble method to stack the weights of evidence (WoE) and evidential belief function (EBF) methods with a logistic model tree (LMT) ML classifier for landslide susceptibility mapping. Their results proved that the prediction capability of the ensemble methods was better than that of single methods.
Moreover, to improve image classification and feature extraction, there are relevant probability concepts such as Dempster–Shafer theory (DST). The DST has been applied to classifier models to find the best match between the inventory data set and the resulting classification [
31]. This probability concept has been used in RS data fusion [
32] and landslide susceptibility mapping [
33] to deal with uncertainty associated with the results. The DST has been successfully used for combining classifiers in a wide range of applications, such as target identification and object tracking [
34,
35]. In the field of landslide detection, Mezaal et al. [
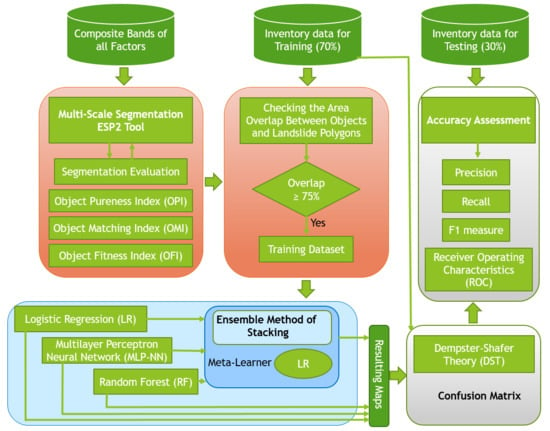
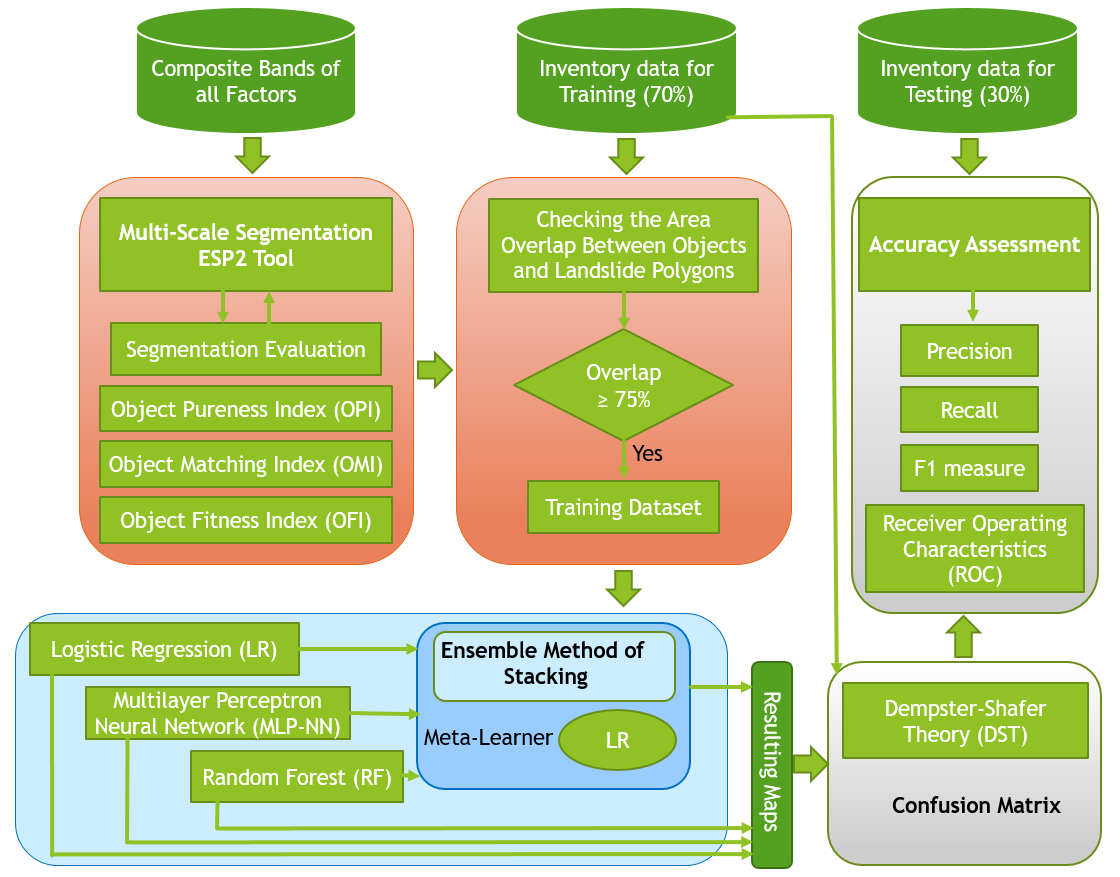
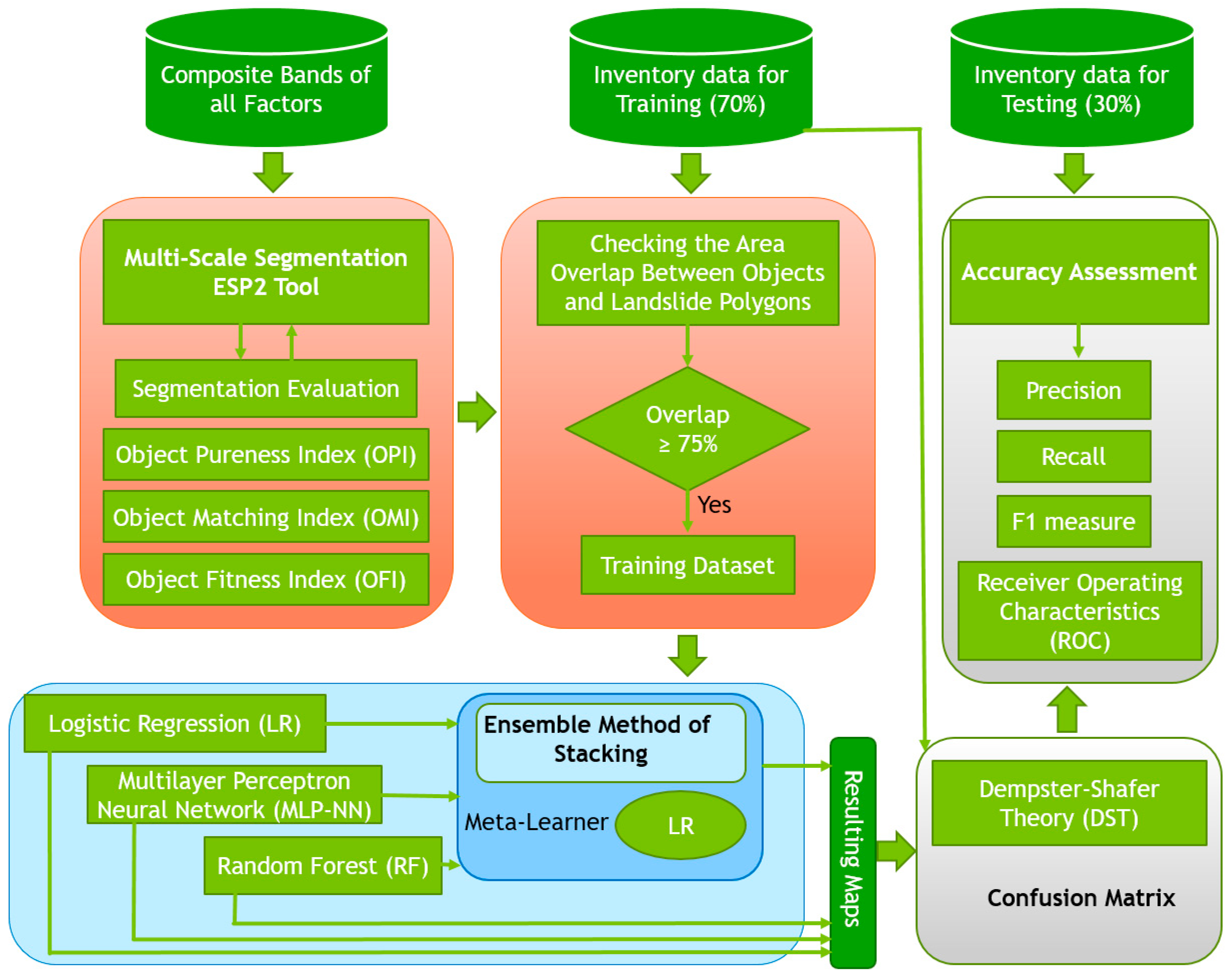
12] used the DST to enhance the results of the integration of OBIA with various ML methods, including SVM, random forest (RF), and K-nearest neighbor (KNN). The DST method performed well in landslide detection in their tropical study area. These pieces of evidence from previously published papers motivated us to apply the DST probability concept to improve the ML classification accuracy through integration with different classifiers. Therefore, in the present study, we integrate the widely used ML methods of logistic regression (LR), the multilayer perceptron neural network (MLP-NN), and RF with OBIA for landslide detection, based on optical data and topographic factors resulting from PlanetScope satellite images and Digital Elevation Model (DEM) data, respectively. To improve the performance of the applied ML methods, the ensemble method of stacking is used to combine them and produce a new result. The optimal scale for image segmentation is derived using the estimation of scale parameters (ESP2) tool [
23]. Multiple scales are selected using interval values based on the optimal scale. The maps resulting from the multi-scale segmentation by each ML method are then fused using DST to demonstrate the advantages of working in a multi-scale environment. All resulting landslide detection maps are then validated using standard RS accuracy metrics and the validation method of receiver operating characteristics (ROC).
4. Accuracy Assessment and Comparison
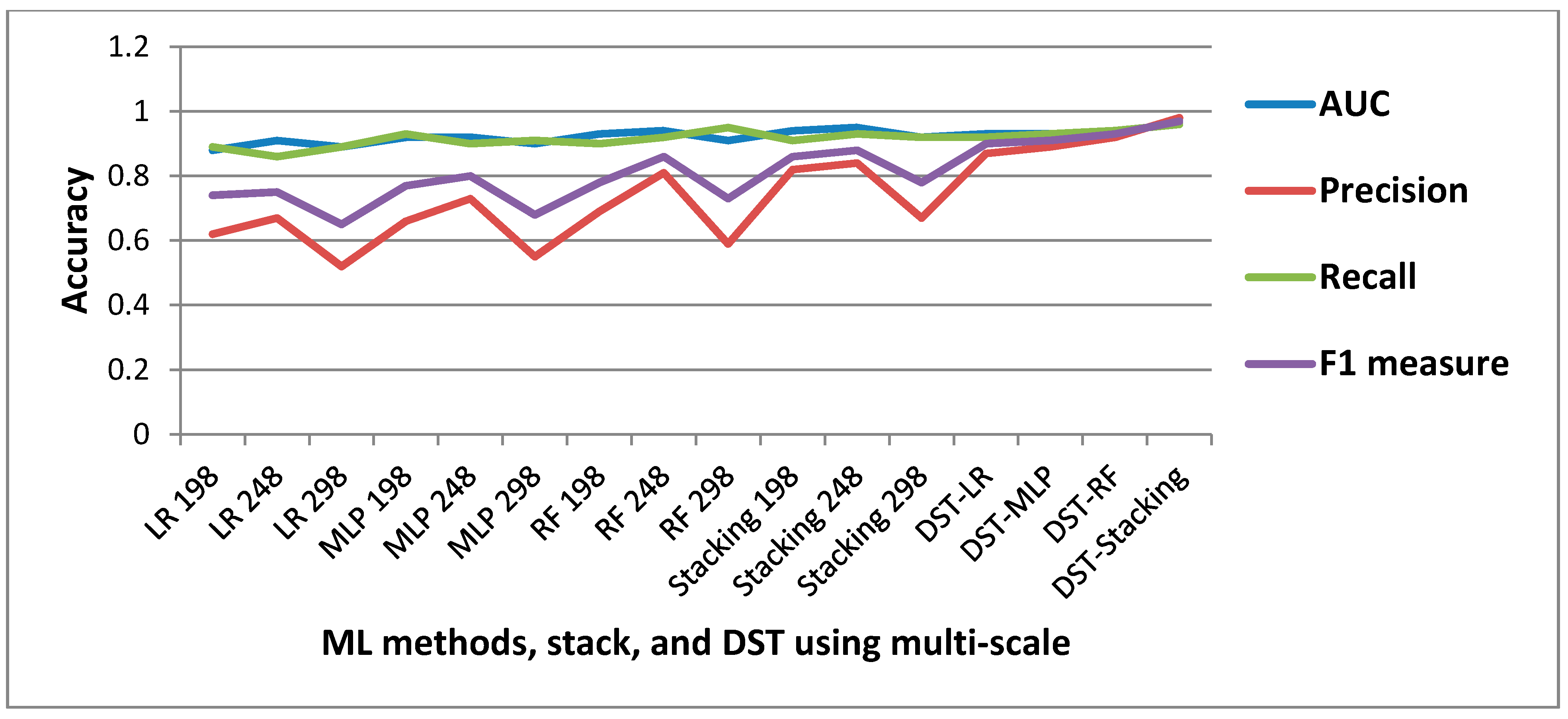
In this section, we outline the most common accuracy assessment methods, which were used to validate the performance of the applied ML methods and the improvements made by using the stacking and DST methods. The accuracy assessment was made by comparing the resulting landslide detection maps with the landslide inventory dataset. The accuracy assessment was conducted using a confusion matrix, precision, recall F1 measure, and the receiver operating characteristics (ROC), to determine the accuracy of the landslides detected by each method. The user accuracy was calculated based on dividing correctly mapped objects by the total number of classified objects. In this regard, the study area was divided into two classes called landslide areas and non-landside areas, and for each class, this measure was calculated. We used the confusion matrix based on a comparison of the inventory dataset and the resulting maps based on a pixel-based environment. The Kappa coefficient was derived from the confusion matrix [
76], and the coefficient was calculated using Equation (16):
where
denotes the ratio of correctly detected areas, whereas
denotes the proportion of agreement by randomness [
12].
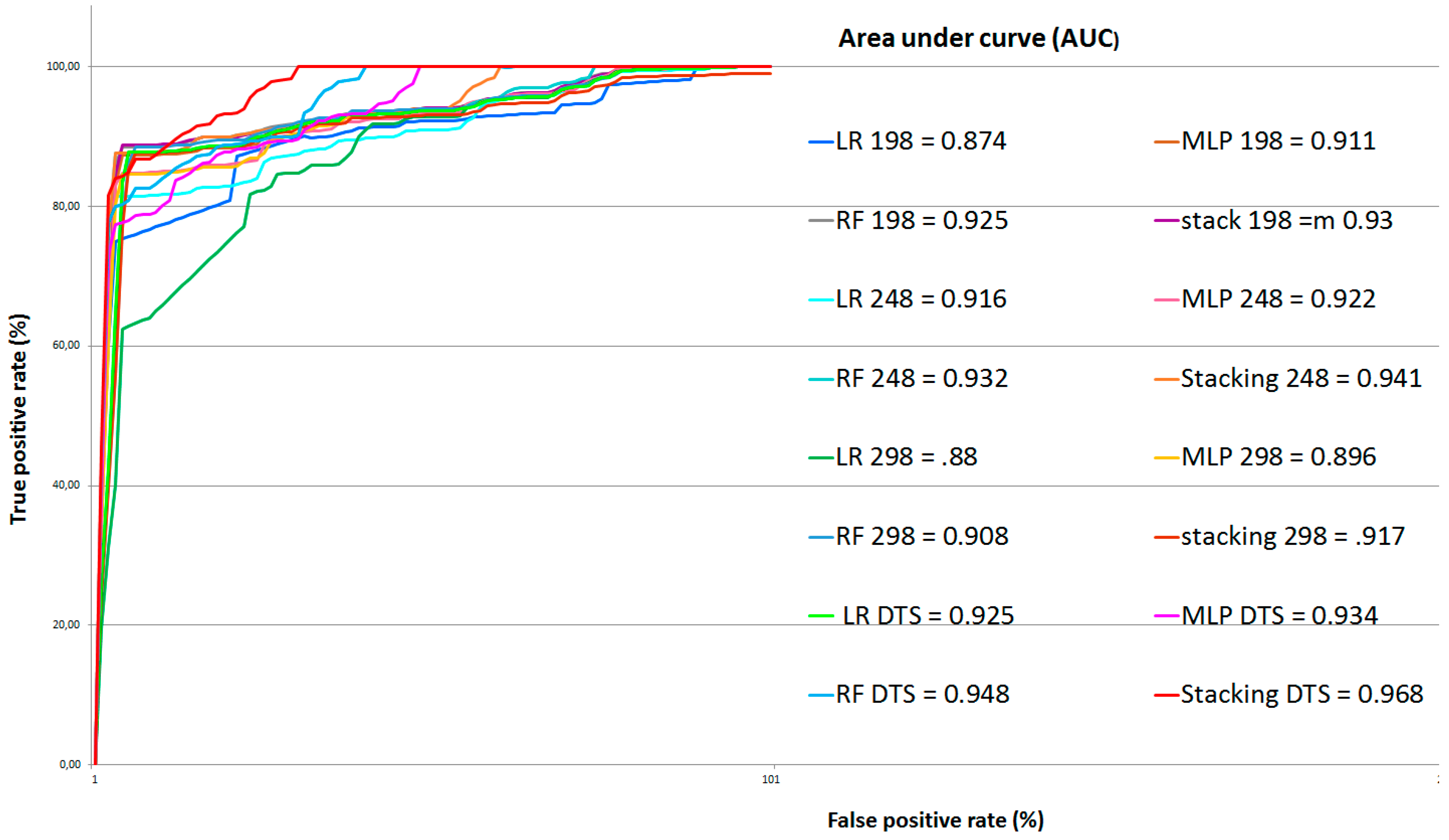
The ROC is a graphical plot used to evaluate the validity of a method that predicts the location of the occurrence of events by comparing the probabilistic map of the event with a reference map [
77]. This assessment method has been applied in many fields, in particular, in the Geosciences [
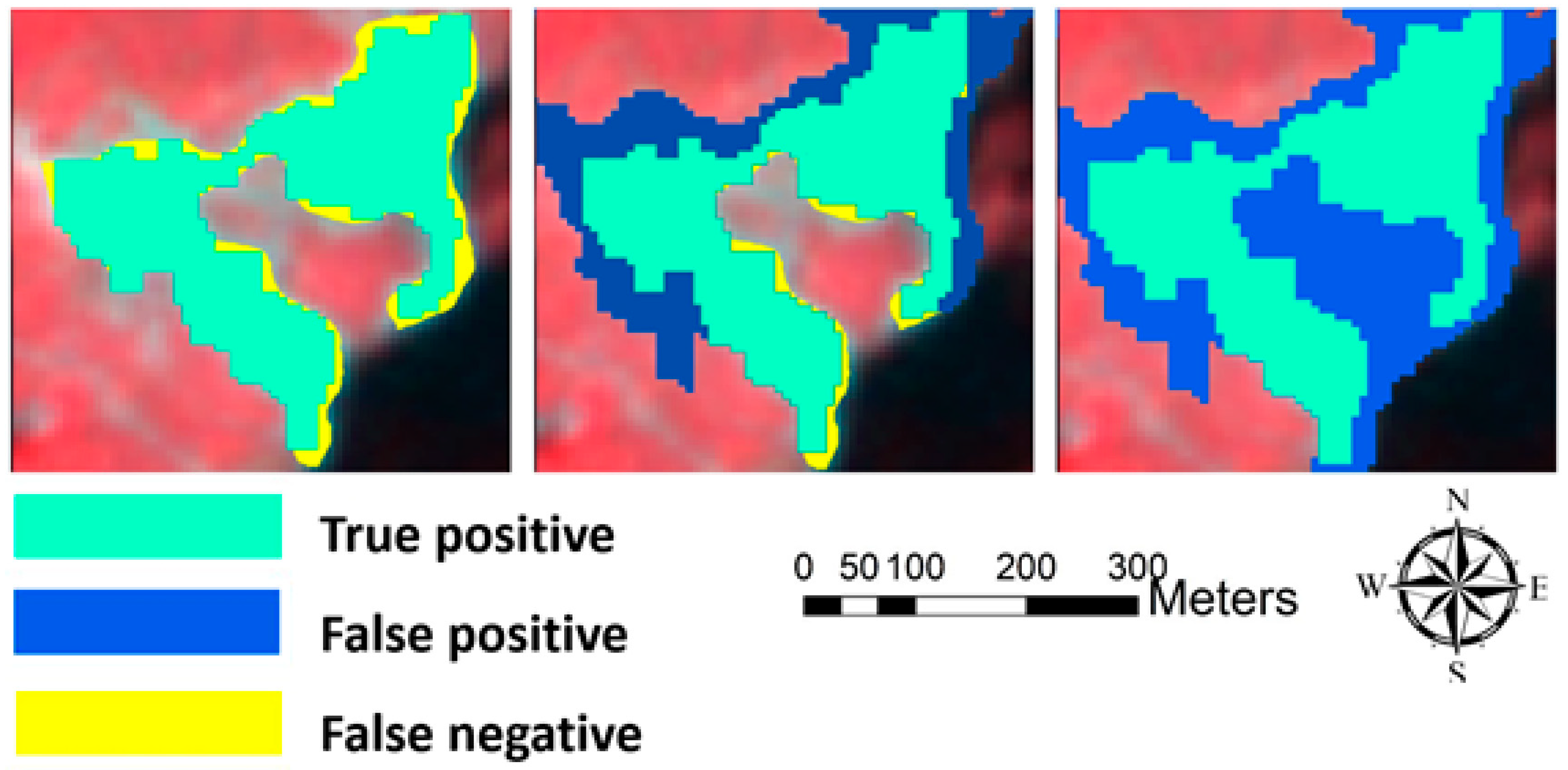
78]. The ROC measure is based on three metrics: true positive (TP), false positive (FP), and false-negative (FN) (see
Figure 5 and Equations (17)–(19)). In this case, the landslide events that were correctly detected were TPs, areas that were incorrectly classified as landslides were FPs, and FNs represented landslide areas that were not detected. Using these metrics, the three parameters of Precision, Recall, and F1 measure could be calculated to assess the results. Precision shows the proportion of landslide events that were detected, Recall indicates how many of the inventory landslide events were detected, and the F1 measure was used to balance the Precision and Recall.
6. Conclusions
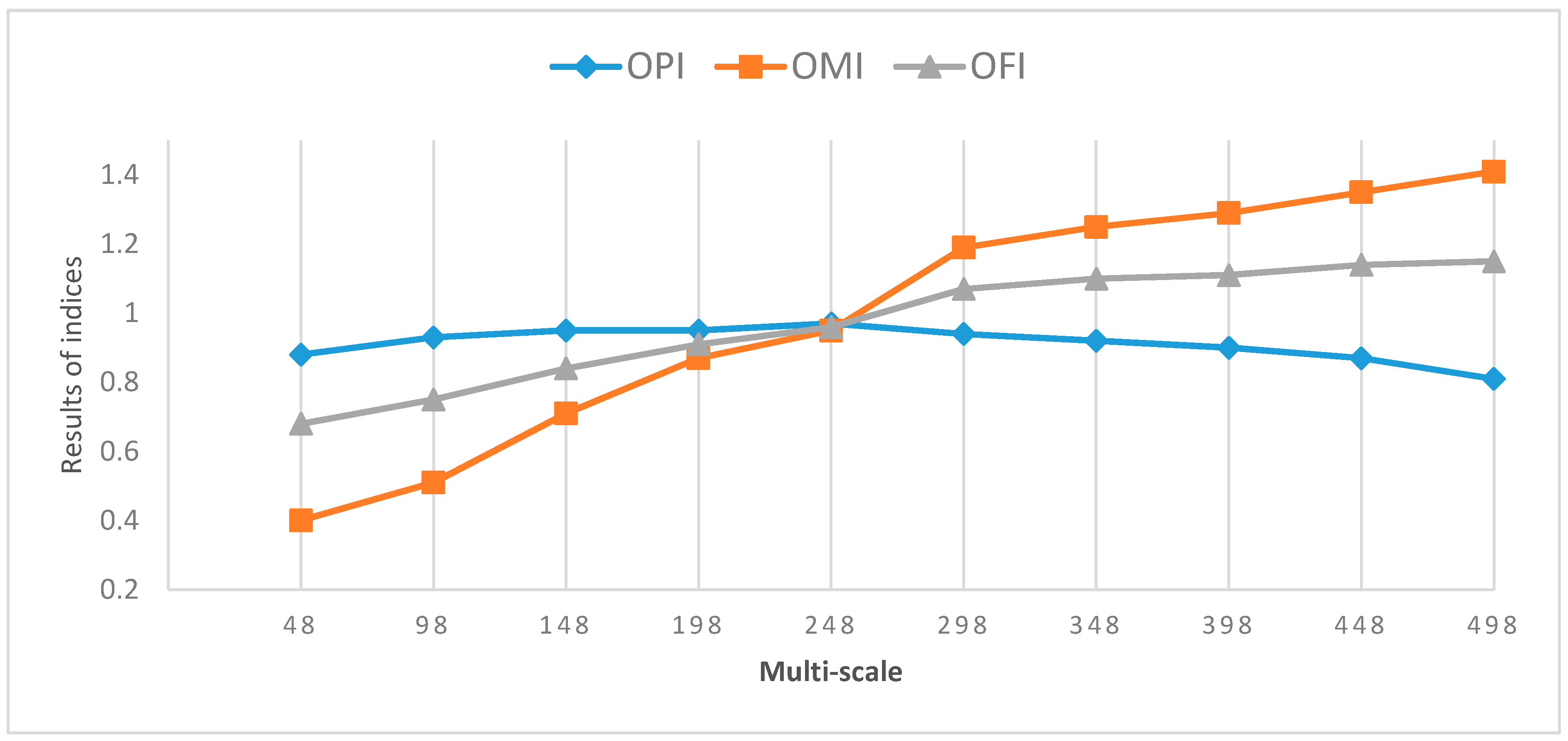
We have developed a methodology that incorporates OBIA with three machine learning methods, namely, logistic regression (LR), the multilayer perceptron neural network (MLP-NN), and random forest (RF), for landslide detection. Our multi-scale methodology identifies the optimal scale parameters (SP) and uses them for multi-scale segmentation and further analysis. The presented landslide mapping study showed that the integrated method improves the performance and accuracy. Most notably, the stacking method for landslide detection outperformed every single ML method. Furthermore, the validation results show that using DST could optimize and improve the outcomes of all applied methods. However, it should be noted that the results of an object-based ML method strongly depend on the segmentation quality. Therefore, optimal segmentation parameters result in a higher segmentation accuracy and, consequently, better results. Although there are no standard methods for selecting segmentation parameters and for accuracy assessment, we used the two measures of OPI and OMI to identify ideal segmentation parameters in terms of spectral and spatial quality. Therefore, as a result, both measures were combined to create the OFI, which allowed us to identify the best segmentation parameters, as well as to identify over-segmentation and under-segmentation errors. Therefore, we believe that a challenge for object-based ML methods is improving the segmentation accuracy, which requires new reliable automatic methods dealing with intra-class heterogeneity and inter-class homogeneity. This study shows that using high-resolution satellite imagery data does not guarantee a good accuracy. Several measures and parameters should be identified based on the target object detection or classification. In this regard, we used an ensemble method of stacking and DST to enhance the landslide detection results based on multi-scale segmentation. Different accuracy assessment results proved that the performance of landslide detection can be increased using these two methods. Moreover, all resulting maps yielded the highest accuracies using the optimal SP. Therefore, finding the optimal SP for the applied satellite image and ML method for the classification is crucial for accurate landslide detection. Based on the results of the present study, our future work will focus more on improving both segmentation and classification using relative mathematical and probability concepts, such as the central limit theorem (CLT) and fuzzy set theory (FST).


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}