1. Introduction
Diabetes is a chronic condition in which body cells cannot efficiently regulate blood glucose levels. If center untreated, diabetes may result in blindness, renal failure, heart attacks, stroke, and amputation of the lower extremities. According to World Health Organization (WHO), the number of diabetic patients has risen dramatically since 1980, with a rapid prevalence of the disease and mortality rate in low and middle income countries [
1]. Diabetes causes a microvascular condition known as diabetic retinopathy (DR), which affects the retina in diabetic patients. Uncontrolled hyperglycemia may result in damage to the tiny blood vessels of the eye. This injury eventually causes fluid leaks into the retina [
2]. The accumulation of extracellular fluids in the macula causes it to enlarge as the DR progresses. Diabetic maculopathy (DM), or diabetic macular edema (DME), is a disease in which the macula swells with fluids in a DR patient [
3].
The macula is in charge of center vision in the eye. As a result, when the macula suffers from edema, vision begins to fade and may become completely lost. If DM is not recognized and treated, it is considered the most common cause of persistent visual impairment in patients with DR. Unfortunately, the early stages of DM are typically characterized by a lack of obvious symptoms, especially when the edema is not localized in the macula [
4]. Consequently, patients are typically unaware of their DM disease. As the edema spreads to the central macula, vision begins to deteriorate progressively and rapidly [
5]. Therefore, early detection of DM is essential for prompt treatment of the illness. Ophthalmologists advise diabetics to undergo routine eye exams to avoid the aforementioned complications.
Clinical eye examination is the traditional method that has been utilized for decades to diagnose diabetic maculopathy. Manual evaluation of DME via clinical examination takes time and may result in delayed diagnosis and treatment of this crucial condition. Recently, fundus photography, eye imaging through fluorescein angiography, and optical coherence tomography (OCT) have been regarded helpful technologies for assisting specialists in identifying the existence and progression of DM. Due to the increased number of diabetic patients worldwide, automated image-based diagnosis approaches are urgently needed to accelerate the process of evaluating patients’ eye scans, deliver timely diagnosis of DR-related diseases including DM, lessen the burden on eye specialists, and improve the quality of healthcare services.
Recent advancement of machine learning techniques, including deep learning, have eased the automation of services in a variety of life domains [
6,
7,
8,
9]. The most established deep learning algorithm is the convolutional neural network (CNN). CNNs have been regarded as the foundation for many computer-aided diagnosis (CAD) systems in the medical field. The CAD systems have been utilized to detect the presence of several diseases, including DR, DME [
10], various forms of malignancies [
7,
11,
12], and COVID-19 [
13], automatically. The CNN structure is intended to automatically and adaptively learn spatial hierarchies of characteristics from gridded input such as images [
14]. To fulfill this task, two sets of network variables should be carefully tuned, namely, network parameters and hyperparameters. Network weights and biases are network parameters that are tuned by minimizing the error between network outcome and data labels during the training stage. Optimization algorithms such as the adaptive moment estimation and stochastic gradient decent could be used to train the network [
15].
The training process of the network is governed through tuning another set of variables called hyperparameters. Hyperparameters include learning rate, number of neural network hidden layers, number of neurons, activation functions, number of training epochs, and others. Model hyperparameters aid ML models to customize for a specific task and dataset [
16]. They have a direct impact on the training behavior as well as the model’s performance. Therefore, tuning hyperparameters is an important step in creating robust prediction models. Although manual setting of hyperparameters is commonly utilized in the literature, it is not regarded as the best approach [
17]. Hyperparameter optimization is an emerging approach that has been utilized recently to select an optimal set of hyperparameters to guide the learning process. The optimization process includes defining a hyperparameter space and searching this space for the optimum model configuration in an iterative process. Searching the hyperparameter space could be carried out by an informed or uninformed approach. Grid Search and Random Search are the most popular uninformed optimization algorithms. These techniques are uninformed search approaches since they handle each search iteration independently [
16]. The selection of the hyperparameter set to be used in the current iteration is made by the algorithm without reference to previous iterations. The Grid Search approach evaluates each unique combination of hyperparameters in the search space to determine the optimal prediction performance. This method is simple, but it is computationally intensive, particularly for larger search spaces. Random Search evaluates at random a preset number of hyperparameter settings. This method reduces the runtime, but it may miss the optimum set of hyperparameters. An advanced informed search technique is the Bayesian optimization [
18].
Contrary to the aforementioned search strategies, the Bayesian optimization algorithm is an educated search strategy that leverages information from prior iterations to select the hyperparameters for subsequent iterations [
16]. It balances reasonable run duration and search efficiency to give optimal hyperparameter settings for the machine learning model. It is supposed that utilizing such an informed optimization algorithm to select the structure and training configuration of a custom CNN would improve the model’s classification performance. Therefore, this study investigates the impact of using the Bayesian approach for hyperparameter optimization of deep learning networks (DLNs) on the model’s performance in classifying diabetic maculopathy. In this article, we propose two custom CNN models to detect DM in two types of retinal photography; fundus retinography and OCT images. The Bayesian optimization algorithm is used to decide the best architectures of the presented CNNs and optimize their hyperparameters. The main contributions of the present work are:
Developing two new custom CNNs for the diagnosis of diabetic maculopathy in two distinct retinal images; the OCT and fundus photography.
Utilizing the Bayesian optimization technique to select the optimal architecture and hyperparameters of the proposed DLNs.
Preparing the datasets through image enhancement and data augmentation approaches.
Comparing the error behavior and classification performance of the Bayesian optimized CNNs (BO-CNN) with non-optimized CNNs (NO-CNN) to investigate the significance of employing the Bayesian-based hyperparameter optimization on the model’s ability to distinguish between normal and pathological images.
Deducting insights from comparing the performance of the fundus-based BO-CNN with that of the OCT-based DLN model.
Comparing the study findings with the state-of-the-art models.
The rest of the paper is structured as follows:
Section 2 presents research conducted on the DM diagnosis in the literature.
Section 3 describes the datasets, the proposed framework, and methods.
Section 4 presents the conducted experiments, discusses the study’s findings and results, while
Section 5 draws the main conclusion of the work.
2. Literature Review
In light of the recent increase in diabetes prevalence, automatic DM diagnosis in retinal images has become a pressing need. Numerous research papers have approached the issue of automatic DM identification in retinal screening images [
19,
20,
21]. Image processing-based methods and classification-based approaches were utilized to diagnose DM in the literature. Methods based on image processing basically seek for exudates in the retinal image to diagnose DM [
10,
11]. Using image improvement and noise removal techniques, these technologies improve the retinal image quality [
10]. Retinal images are improved through image enhancement and noise removal techniques and then are segmented to detect objects of retinal, including the blood vessels, macula, and optic disc. After that, lesions caused by DM are segmented from processed images. The presence or absence of DM is determined by the segmentation results of the lesion.
Sánchez et al. [
22] devised a dynamic thresholding strategy to segregate exudates using a mixture model computed from an RGB retinal image-enhanced green component histogram. Despite achieving a sensitivity of 90.2%, several bright markings, such as blood vessels and optical aberrations, were incorrectly identified as exudates. Walter et al. [
23] established a mathematical morphology-based system for detecting exudates. To locate and exclude the optic disc, they utilized watershed transformation and morphological filtering. The variation in gray level intensity was used to locate exudates. Sopharak et al. [
24] created an algorithm employing fuzzy C-means (FCM) clustering and morphological operations to segment exudates from the low-contrast retinal images. Several features were retrieved from the images and supplied into an FCM clustering-based coarse segmentation stage. By utilizing Sobel edge detection, morphological operations, and thresholding, the necessary features were extracted. Their algorithm reported a sensitivity of 87.2% and a specificity of 99.2%.
Classification-based algorithms employ machine learning techniques to differentiate between normal and DM-affected images. Classification algorithms assign a class to an input image using image-based attributes. Image features such as the mean, perimeter, region of interest area, and variance of pixel intensity, could be extracted manually or automatically [
10]. On the basis of the classification algorithm employed in machine learning (ML), classification-based approaches can be categorized into conventional ML approaches and deep learning approaches. Conventional classifiers, such as k-nearest neighbors, random forest, and support vector machines (SVMs), are typically fed by hand-crafted features. With a small dataset size and a moderate computing cost, these classifiers could perform adequately well. Nevertheless, the performance of conventional classifiers is significantly influenced by the selection of manually-crafted features. Deep neural networks, on the other hand, demand larger training datasets, automatically extract features, and deliver a higher classification performance [
25,
26,
27]. Shengchun et al. [
28] employed an SVM classifier for hard exudate categorization. They utilized a fuzzy C-means clustering and dynamic threshold to identify potential hard exudate candidates. The hard exudate candidates’ collected features were then fed to an SVM classifier. The results recorded a precision of 97.7% on the DIARETDB1 database [
29] and an F1-score of 76.7% on the e-ophtha EX database [
30]. In a separate study [
31], a DM classification system was created using the local binary pattern features extracted from spectral domain OCT images and the histogram of directed gradients. Principal component analysis (PCA) was used to pick features, and a linear SVM was employed to conduct classification. The sensitivity and specificity of this method were 87.5%.
Recent studies have examined the problem of diagnosing DM with deep neural networks. Research in this area included the development of custom CNN-based systems and transfer learning-based systems. Transfer learning enables the use of pre-trained CNNs as automatic feature extractors or image classifiers. Pre-trained networks are CNNs that have been trained using a huge dataset of natural images such as the ImageNet database. Transfer learning involves fine-tuning the last layers of a pretrained network to solve a defined classification problem on a new dataset. For instance, Abbas [
27] created a modified dense convolutional neural network (DCNN) model for DM diagnosis. Five convolutional layers and one dropout layer were added to the original pretrained Dense CNN network to create the DCNN model. The DCNN model achieved 91.2% accuracy, 94.4% specificity, and 87.5% sensitivity on the Hamilton HEI-MED dataset. Atteia et al. [
10] created a deep learning-based DM model that integrates multiple pretrained CNNs with a stacked autoencoder network for the classification of DM in fundus images. The autoencoder network was trained using deep features extracted by four pre-trained CNNs; GoogLeNet, Inception-v3, ResNet-50, and SqueezeNet. On the IDRiD dataset, that study achieved an accuracy of 96.8%. Other studies designed custom deep learning models to tackle the problem of DM classification. The study in [
26] constructed a custom CNN trained using the MESSIDOR dataset to detect the severity of the DM disease. Their results demonstrated an accuracy of 88.8%, a sensitivity of 74.70%, and a specificity of 96.50%. Singh et al. [
31] created a hierarchical ensemble CNN model for the detection of DM. They adopted a preprocessing step employing a morphological opening and Gaussian kernel for color fundus images. For the IDRiD and MESSIDOR datasets, their findings demonstrated an average of 96.1% accuracy. Mo et al. [
20] created a system consisting of two cascaded deep residual networks in order to recognize DM. In that study, the first fully convolutional residual network integrated multi-level hierarchical information to accurately segregate exudates from input images. The region centered on the pixel with the highest likelihood was clipped and fed into the second deep residual network, which was utilized for DM classification, based on the segmentation results. On the HEI-MED dataset, this model achieved a sensitivity of 96.3%, a specificity of 93.04%, and an accuracy of 94.08%.
The study of Srinivasan et al. [
32] developed a classification method to differentiate between normal, DM, and age-related macular degeneration (AMD) in OCT images. They first denoised the OCT images, flattened the retinal curvature, and extracted edge information of the retina using the histogram of the oriented gradient method. The classification task was performed using a linear SVM classifier. They evaluated their algorithm on a dataset of 45 patients with a balanced number of images in the three classes, and obtained a classification accuracy of 100%, 100%, and 86.7% for normal, DME and AMD, respectively. Venhuizen et al. [
33] proposed a bag of words (BoW) model classify normal and AMD normal in OCT images. A set of keypoints detected in the input image were used to extract features. An area of
pixels was extracted around each selected keypoint and the principal component analysis (PCA) was used to reduce the feature dimension. Histograms were created for the extracted features and used to train a random forest (RF) classifier. This algorithm recorded an area under the curve (AUC) of 0.984 on 384 OCT scans. Liu et al. [
34] proposed a method for diagnosing retinal disease using local binary pattern (LBP) and gradient information. Each scan was aligned and flattened, and a three-level, multi-scale spatial pyramid was produced. Edges were spotted on the pyramid using the Canny detector. Subsequently, an LBP histogram was extracted for each pyramidal layer. All resulting histograms were concatenated into a global descriptor whose dimensions were decreased using principal component analysis. A Support Vector Machine (SVM) with a Radial Basis Function (RBF) kernel was used as a classifier. A dataset of 326 OCT images yielded an AUC of 0.93 for the detection of several diseases, including DME and AMD, with the approach achieving favorable outcomes.
In [
35,
36], Lemaitre et al. developed a classification strategy based on LBP features taken from OCT images and vocabulary learning using BoW models. Instead of the OCT scans, BoW and dictionary learning were utilized for classification. In this technique, OCT images were pre-processed to decrease speckle noise. The scans were mapped into discrete sets of local and global structures. Different mapping approaches, such as LBP and three orthogonal planes (LBP-TOP) were used to extract texture features, which were subsequently represented using histogram, PCA, or BoW. Using an RF classifier, the final feature descriptors per volume were classified. On a balanced dataset of 32 OCT volumes, the classification performance in terms of sensitivity (SE) and specificity (SP) was 87.5% and 75%, respectively, for DME versus normal scans. Albarrak et al. [
37] provided a classification scheme to distinguish between AMD and normal OCT volumes. Each OCT scan is subjected to two pre-processing steps; a joint denoising and cropping phase, and a fattening step fitting a second-order polynomial using a least-squares technique. Ten LBP-TOP and HoG features were combined and concatenated into a single feature vector per OCT volume, and PCA was used to minimize the dimension of this feature vector. A Bayesian network classifier is employed to classify the volumes as a final step. The classification performance of the framework in terms of SE and SP was 92.4% and 90.5%, respectively.
As presented, deep learning technologies have shown promising outcomes into identifying diabetic-related eye diseases. Few studies, however, have concentrated on using optimization techniques to improve the performance of deep learning-based classifiers in this field. Two important elements that affect the performance of deep learning networks are hyperparameter setting and feature selection. In a number of applications, optimization methods have been shown to be useful tools for selecting the best features and optimizing the hyperparameters of ML models yielding substantial improvement in model’s performance [
15]. The Grey Wolf algorithm [
38], the Sine Cosine algorithm [
39], the Sine Cosine dynamic group algorithm [
40], hybrid Sine Cosine and grey wolf optimizer algorithm [
41], the chimp optimization algorithm [
42], Dragonfly algorithm [
43], the whale optimization algorithm [
44], and guided whale optimization algorithm [
45] are recent optimization techniques employed for improving the classification performance of DLNs in the medical field. To detect diabetic-related eye diseases, recently, some studies employed optimization algorithms for optimizing the selection process and hyperparameters of DLNs. For instance, the Harris hawks optimization (HHO) algorithm was used in [
46] to optimize the classification of diabetic retinopathy in fundus images. A dimensionality reduction method utilizing the Harris hawks optimization algorithm was utilized after a features selection step using the principal component analysis (PCA) to further enhance the feature set. DR classification was performed using a DNN. The PCA and HHO, were combined with deep neural networks (DNN), and a number of ML models, including the XGBOOT, KNN, and SVM. They found that the classification performance of the PCA, HHO, and DNN combination outperforms the other ML-based systems with an accuracy of 97%, and a recall of 91%, on the DR Debrecen dataset.
A hybrid deep-learning CNN-based modified grey-wolf optimizer with variable weights (DLCNN-MGWO-VW) was proposed in [
47] to detect signs of DR and DM in fundus images. The ResNet50 was used to extract features of DR and DM from the IDRiD dataset. Two independent modules were developed to extract the disease-specific features for the DR and DM. These features were then separately fed to the MGWO-VW algorithm to conduct classification using CNN. The DLCNN-MGWO-VW algorithm recorded an accuracy of 96.0%, and 93.2% for the classification of DR and DM, respectively. In [
48], transfer learning of a pre-trained CNN was examined to detect retinal abnormalities in OCT images. The VGG16, DenseNet201, InceptionV3, and Xception were utilized to categorize seven distinct retinal disorders from images with and without retinal diseases. The data have eight classes namely, AMD, CNV, DM, DRUSEN, CSR, DR, MH, and Normal. The pre-trained networks were used as feature extractors of image features. The authors replaced the final layers of the pre-trained network with custom classification layers to adapt to the OCT images. The Bayesian optimization was employed to select optimal hyperparameter values for the proposed classification layers. The optimizer, the number of neurons in specific layers, the learning rate, the activation function, and the batch size were the hyperparameters that were optimized in that study. Using an OCT dataset posted on the Kaggle platform [
49], the accuracy attained using the aforementioned pre-trained CNNs ranged from 95% to 99%, which was much higher than that obtained from associated non-optimized models.
Although the aforementioned papers have yielded impressive results, the topic of deep learning-based DM detector hyperparameter optimization has not been comprehensively investigated. Moreover, it is noticeable that most hyperparameter optimization-related research was for the OCT images; however, there is a shortage of research for the fundus images. It is worth mentioning that fundus photography of the retina is the most affordable eye screening for patients, particularly in low-income communities. This article proposes two new custom CNNs for detecting diabetic maculopathy in two distinct retinal image types, namely, the fundus and OCT retinal photography. This research investigates using the Bayesian optimization algorithm for hyperparameter-tuning a deep learning-based DM detector. The Bayesian optimization technique selects the optimal architecture and hyperparameters of the presented deep networks. The impact of using the Bayesian optimization approach on the proposed DLNs datasets classification performance is studied in this work.
5. Results
In this work, two experiments were conducted to investigate the efficiency of using Bayesian optimized-DNL for detecting DME in two different types of images: fundus images and OCT scans of the retina. Based on the introduced framework, at first, the architecture of the DNL is set as described in the methodology section. The optimization variables are then set, the network is trained, validated, and the Bayesian optimization algorithm evaluates the objective function in search for the optimum hyperparameters. The ranges of the optimization hyperparameters are unified for both experiments and set as in
Table 1. To adjust variables during iterations, the search functions are given in
Table 1. The SGDM momentum and initial learning rate are sought on a logarithmic scale. In both experiments, the proposed network is trained using the training subset with a piecewise drop rate for 0.1 learning rate within 40 iterations and 0.1 mean and variance batch normalization decay rates. In order to prevent overfitting, a dropout strategy with a probability of 0.5 was implemented. The number of objective function assessments was fixed at 30.
During the initial iteration of optimization, the optimization variables, or hyperparameters, are set arbitrarily within the defined ranges. Accordingly, the proposed CNN’s number of convolutional blocks is specified, the network is trained, evaluated, and the objective is computed and stored. The Bayesian optimizer chooses the next set of hyperparameters for the second iteration based on the acquisition function’s maximization. The chosen hyperparameters are employed to configure the structure of CNN, train and assess the model, and compute the objective function during the second iteration. The Bayesian optimizer determines the next set of hyperparameters based on the outcomes of the previous iteration. The procedure continues until the maximum number of iterations, 30, is reached. The model that achieved the lowest objective score is deemed optimal and tested on the test set. Experiments’ specific settings and results are presented in detail in this section.
5.1. Experiment 1: DM Detection in Fundus Retinographs
The proposed BO-CNN is trained, validated, and tested in this experiment using fundus color images from the IDRiD dataset. Two steps for this dataset have been adopted for data pre-processing as depicted in
Figure 5. Degraded image quality has been noticed for a considerable number of images in the dataset. Therefore, an image enhancement step has been utilized to sharpen the contrast between the image background and foreground. The RGB image is initially converted to an HSV image in this pre-processing step. Then, contrast-limited adaptive histogram equalization (CLAHE) was used to enhance the contrast of the V channel. The original S and H channels are left unchanged before blended with the enhanced V channel to produce the enhanced HSV image, which is then translated to the RGB domain. The CLAHE parameters are configured with 64 tiles and a clip limit of 0.005. These values were determined experimentally to produce the needed contrast enhancement.
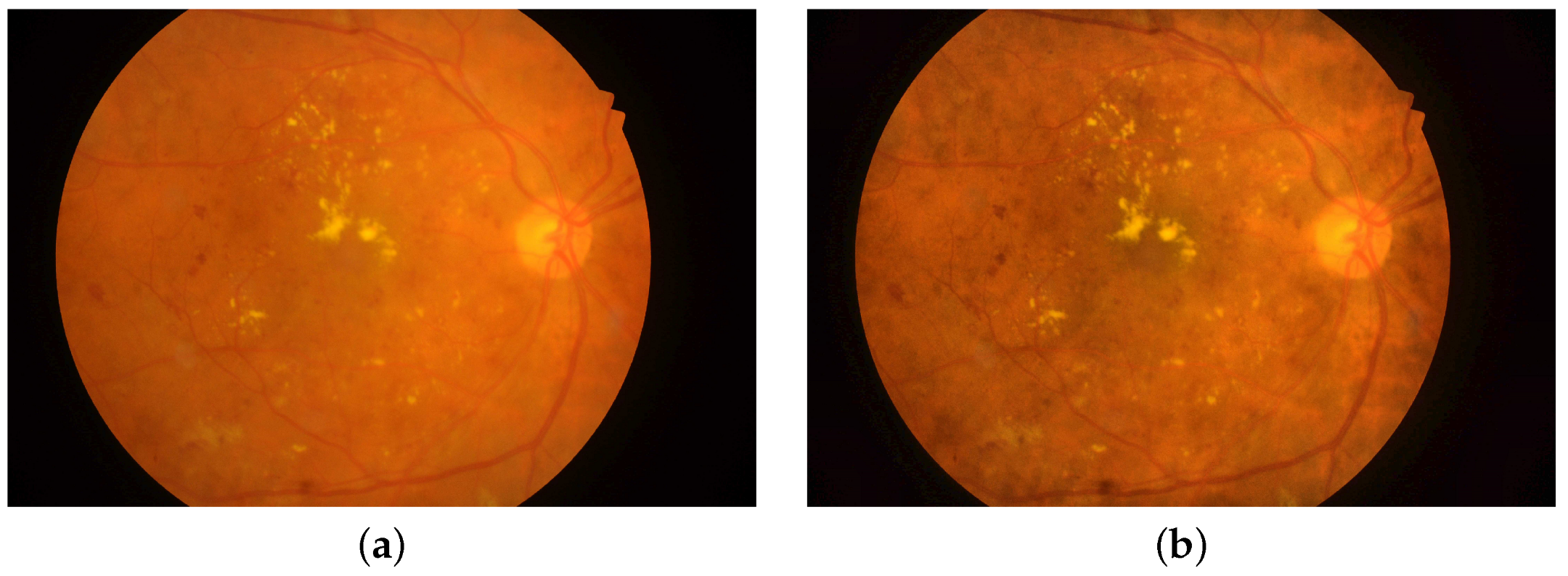
Figure 6 depicts the original colored fundus image versus the enhanced one.
The number of images in the IDRiD dataset is deemed insufficient for a deep learning network to deliver acceptable performance. Therefore, a data augmentation step is adopted in this experiment to reduce potential overfitting and improve DLN generalization. Cropping, translating, mirroring, and rotating images are efficient methods for supplementing datasets. The horizontal reflection, rotation by and are selected to augment the data as they are reasonable types of transformations that provide semi-realistic views of the retina. The expanded dataset is created by combining the original and transformed images together. The augmented dataset includes 2580 images, comprising 1110 healthy and 1470 DM-diseased images. To suit the size of the proposed CNN input layer, the images are scaled to pixels. The dataset is then divided into three sections: 80% for training, 10% for validation, and 10% for testing.
The outcomes of the Bayesian-based optimization of the proposed CNN hyperparameters are presented in
Table 2.
Table 2 demonstrates the observed objective value, the NSD, the starting learning rate, the SGDM momentum, and the regularization coefficient. In this table, the best CNN model is highlighted in bold text. The mini-batch size was set to 64, and each objective function evaluation, i.e., optimization iteration, took 100 epochs to complete. At the 21st iteration, the optimal model achieved a minimum validation error of 0.0387. The hyperparameters of the best model are
M = 0.84988,
= 0.012841,
= 0.00015666, and
of 4. In light of this, the optimal DLN is made up of 12 convolutional layers, 12 batch normalization layers, 12 Relu layers, two average-pooling layers, a single max-pooling layer, and a single softmax layer. The optimum structure of the proposed DLN in this experiment is shown in
Figure 7.
The relationship between the estimated objectives versus the optimization iterations is depicted in
Figure 8. The minimum observed objective recorded is also displayed on the same graph. The optimal CNN model was evaluated using a holdout test set. The optimum model recorded a test error of 0.0583, test accuracy of 94.17%, a generalization error rate at 95% confidence interval of [0.0321, 0.0844], and a validation accuracy of 96.13%.
In order to evaluate the impact of the hyperparameter optimization using the Bayesian technique on the classification performance of the proposed CNN model, we trained a non-optimized version of the proposed model to compare the results. The non-optimized model is denoted as NO-CNN throughout the paper. To have a meaningful comparison, we set the NSD to be four as in the optimal model selected by the Bayesian optimizer in iteration #21 and the same training options, such as the number of epochs, mini-batch size, and learning rate drop factor, are used as for the optimization iteration. The other hyperparameters are set automatically to the default setting in Matlab, and the network is trained using the SGDM algorithm.
Table 3 depicts the hyperparameter settings and the performance measures on the validation and test sets for the optimal and non-optimized models of the proposed CNN. It is clear that the optimal CNN records lower error and higher classification performance than the non-optimized CNN on both the validation and test sets. It is noticed that the optimal hyperparameter set is close to the default setting of the NO-CNN. However, the improvement in the classification performance due to Bayesian-based hyperparameter optimization is significant in all performance metrics for the networks trained on the fundus images. This reveals that a fine alteration in the hyperparameters causes a dramatic change in the fundus-based model’s classification performance and error behavior. This could be referred to as the limited size of the fundus dataset and the low quality of its images.
Figure 9 shows the training progress plot of the optimal and non-optimized model in Experiment 1.
Figure 9 depicts the accuracy of the training and validation subsets and the corresponding loss. It is noticed that no overfitting was identified during the training process for both models. The time for training and validating the NO-CNN and BO-CNN is also comparable.
5.2. Experiment 2: DM Detection in OCT Scans
The proposed BO-CNN is trained, validated, and evaluated in this experiment utilizing OCT grey images. Images in the OCT dataset are of high quality and there is a sufficient number to train the deep learning model. Therefore, unlike the IDRiD dataset, no image enhancement or augmentation steps are applied to the OCT dataset. The images are resized to [64 × 64] pixels, and the dataset is partitioned into 80% for training, 10% for validation, and 10% for testing. The mini-batch size was set to 500 images, and the optimization iteration was executed in 60 epochs.
Table 4 displays the results of Bayesian-based optimization of the proposed CNN hyperparameters. The best CNN model in this experiment is indicated in bold font. At the 6th iteration, the best model attained the lowest validation error of 0.025909. The best model’s hyperparameters are
M = 0.84805,
= 0.024665,
, and
of 5. In light of this, the ideal DLN consists of 15 convolutional layers, 15 batch normalization layers, 15 Relu layers, two average-pooling layers, one max-pooling layer, and one softmax layer.
Figure 10 depicts the optimal structure of the suggested DLN in Experiment 2.
The estimated objective function values plot over the optimization iterations is depicted in
Figure 11. The optimum model recorded a test error of 0.0418, test accuracy of 95.8%, and a generalization error rate of [0.0335, 0.0502] at a 95% confidence interval.
Following a similar strategy as in Experiment 1, we trained a non-optimized version of the proposed model and assessed the classification performance. We set the NSD to be five as in the optimal model selected by the Bayesian optimizer in iteration #6, and the same training options are used for the optimization settings. The other hyperparameters are set automatically to the default setting in Matlab, and the network is trained using the SGDM algorithm.
Table 5 depicts the hyperparameter settings and the performance measures on the validation and test sets for the optimal and non-optimized models of the proposed CNN. It is observed that the optimal CNN records lower error and higher classification performance than the non-optimized CNN on both the validation and test sets. The improvement in the model’s validation accuracy and testing specificity is more prominent than the testing accuracy and sensitivity. The optimal hyperparameter set selected by the Bayesian optimizer is different from the NO-CNN default setting.
Figure 12 illustrates the training progress plot of the optimal and non-optimal versions of the proposed CNN. No overfitting was observed during the training process, and both models spent comparable training time.
5.3. Proposed versus Pretrained-CNN
Convolutional neural networks (CNNs) are mathematical constructions that typically feature three types of layers: convolutional, pooling, and fully connected. Inspired by the structure of the image visual cortex, Pre-trained-CNN is a deep learning model for processing grid-structured data l such as photographs, with the goal of automatically and adaptively learning spatial hierarchies of information, from low- to high-level patterns. We compared 5 models, as shown below, to demonstrate the superiority of our proposed model: AlexNet, VGG16Net, VGG19Net, GoogleNet, and ResNet-50.
The proposed BO-CNN model is compared with the pre-trained-CNN models for the IDRiD and OCT datasets in
Table 6 and
Table 7, respectively. Statistical descriptive of the proposed BO-CNN model compared to the pre-trained-CNN models for the IDRiD and OCT datasets is shown in
Table 8 and
Table 9, respectively. ANOVA test results of the proposed BO-CNN model compared to the pre-trained-CNN models for the IDRiD and OCT datasets are described in
Table 10 and
Table 11, respectively. These tables confirm the quality of the BO-CNN model.
Figure 13 and
Figure 14 show the box plot of the proposed BO-CNN model versus the pre-trained-CNN models for the IDRiD and OCT datasets based on accuracy. The histograms of the proposed BO-CNN model versus the pre-trained-CNN models for the IDRiD and OCT datasets based on a number of values are shown in
Figure 15 and
Figure 16, respectively.
Figure 17 and
Figure 18 show the Residual, QQ plots, and heat map of the proposed BO-CNN model versus Pretrained-CNN models for the IDRiD and OCT datasets. Finally, the ROC curves of the proposed BO-CNN model versus the ResNet-50 model for the IDRiD and OCT datasets are shown in
Figure 19 and
Figure 20, respectively. These figures confirm the quality of the BO-CNN model.
5.4. Discussion
The results of the experiments conducted in this research reveal that Bayesian-based hyperparameter optimization yields improved classification performance of the suggested CNN models in detecting DM in fundus and OCT retinography images. Nevertheless, it has been noticed that the classification performance and error behavior improvement are more significant for the fundus-based CNN than for the OCT-based model. As the input images from the IDRiD and OCT datasets are not equivalent in size or quality, the comparison between the BO-based DLNs in Experiments 1 and 2 would be unfair so far. Nevertheless, general insights could be deduced.
Table 12 summarizes the results obtained for the optimal BO-CNNs of Experiments 1 and 2. The size of the dataset affects the depth of the network as well as the classification performance. Deeper networks are required to extract deep features from large datasets. It is apparent that the BO-CNN trained on the OCT dataset provides the lowest validation and test classification errors and a lower error rate with a 95% confidence interval. The OCT-based CNN achieves higher classification accuracy and specificity than the fundus-based network. This could reflect the OCT-based CNN’s higher ability to recognize the disease’s absence in images than the fundus-based network. On the other hand, the fundus-based CNN records a slightly higher sensitivity value than the OCT-based network. Nonetheless, both CNNs generally exhibit a high capability of detecting the existence of the DM in input images.
We further compare our work to relevant studies in the literature. Given the huge number of deep learning networks developed in the literature for diagnosing DM in eye scans and the vast variability between these models, we only consider comparing our work with the studies that emphasize optimizing algorithms for DM detection.
Table 13 compares our results with state-of-the-art methods, used dataset, performance metrics, and used optimization method. These studies were selected because they utilized the same fundus and OCT datasets as in our study. For the fundus-based CNN, we compared our work to the study of Reddy et al. [
47] in which a hybrid deep-learning convolutional neural network-based modified grey-wolf optimizer with variable weights was proposed to detect signs of diabetic retinopathy and maculopathy in the IDRiD dataset. Our proposed BO-CNN records higher classification accuracy than the DLCNN-MGWO-VW developed in [
47]. No other studies used optimization algorithms to improve DM classification performance using the IDRiD dataset. Pertaining to the OCT dataset, the work in [
58] is considered suitable to compare our work with as it used the Bayesian optimization for hyperparameter optimization and images from the same OCT dataset we used. However, there are some differences between our work and theirs.
In [
48], a hybrid transfer learning-based approach is developed to detect several retinal abnormalities in OCT images. They classified OCT images into eight classes; AMD, CNV, DM, DRUSEN, CSR, DR, MH, and Normal. They employed several pre-trained CNNs for the feature extraction and developed customized classification layers for their multi-class classification problem. The VGG16, DenseNet201, InceptionV3, and Xception were utilized to extract image features. They utilized the Bayesian optimization technique to fine-tune the hyperparameters of the classification layers. They compared the optimized versus non-optimized models. Their results showed various classification accuracies for the pre-trained CNNs, ranging from 95% to 99% averaged over all retinal diseases. They reported superior performance of the Bayesian-optimized transfer learning-based networks over the non-optimized ones. Although we employed the Bayesian optimization to fine-tune an entirely customized deep learning model, which is not based on transfer learning, for detecting merely the DM, our findings confirm their observation.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}