
A Narrative Literature Review of Natural Language Processing Applied to the Occupational Exposome


Abstract
:1. Introduction
- What are the most common text mining and NLP approaches used in exposure assessment research?
- What resources are used for this task?
- What are the most common NLP methods used?
- What are the main challenges and future directions of research?
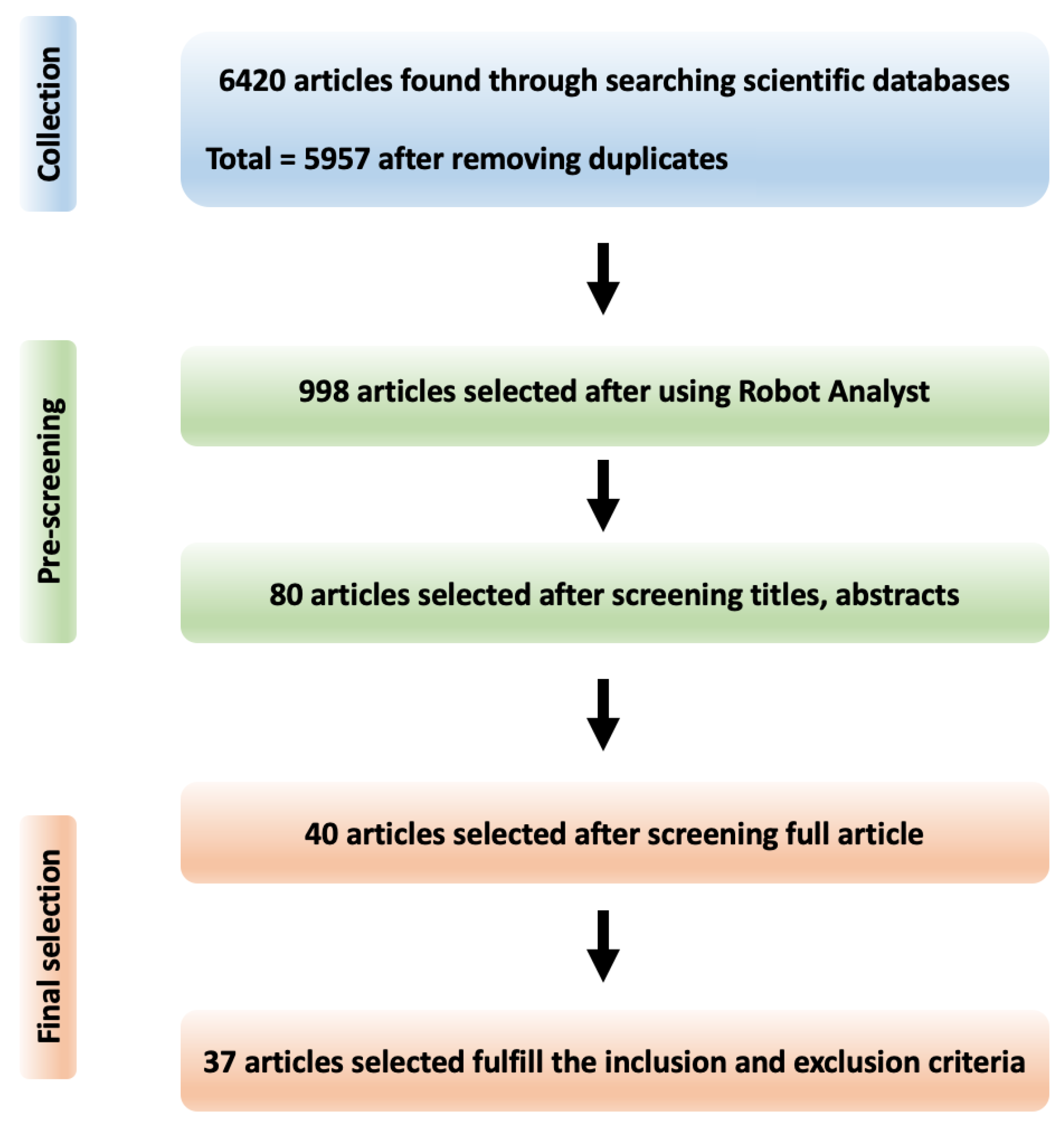
2. Review Methodology
- (“natural language processing” OR “text mining” OR “text-mining” OR “text and data mining” OR ontology OR lexic* OR corpus OR corpora) AND (exposome OR exposure OR socioexposome OR (“risk factor” AND (“work” OR “occupational” OR “environmental*”)))
- Original work;
- Study exposures concerning humans;
- Study occupational and/or environmental exposures of humans, such as airborne agents (e.g., particulates or substances and biological agents (viruses)), stressors, psycho-social and physical (e.g., muscle-skeletal) exposures as well as workplace accidents;
- Have their full texts available;
- Are written in English;
- Focus on text mining or natural language processing and their texts containing a method, experiments and result section.
- Studied animal or plant exposures;
- Studied drug, nutrition or dietary exposures on humans;
- Written in another language than English;
- Commentaries, opinion papers or editorials.
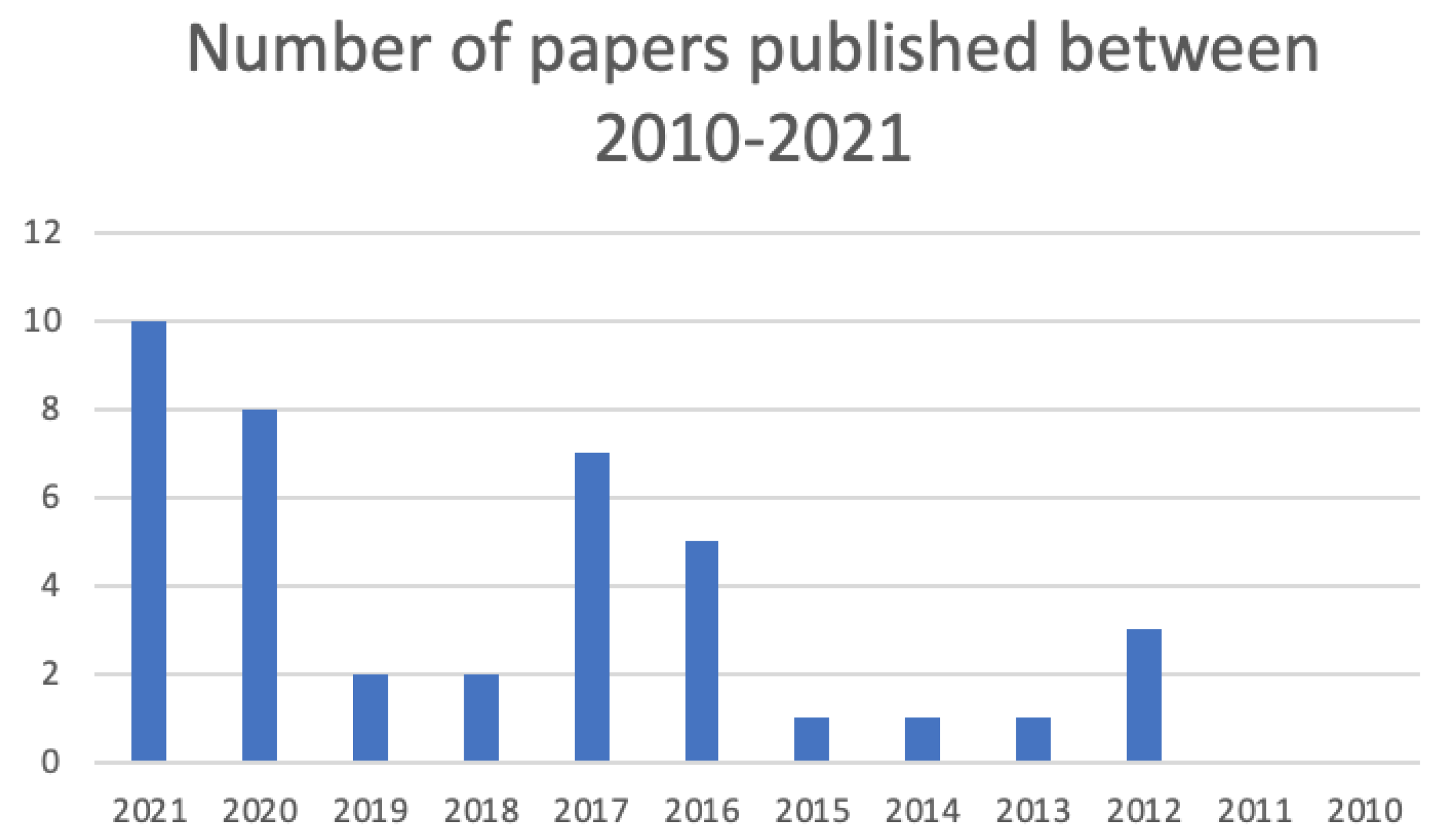
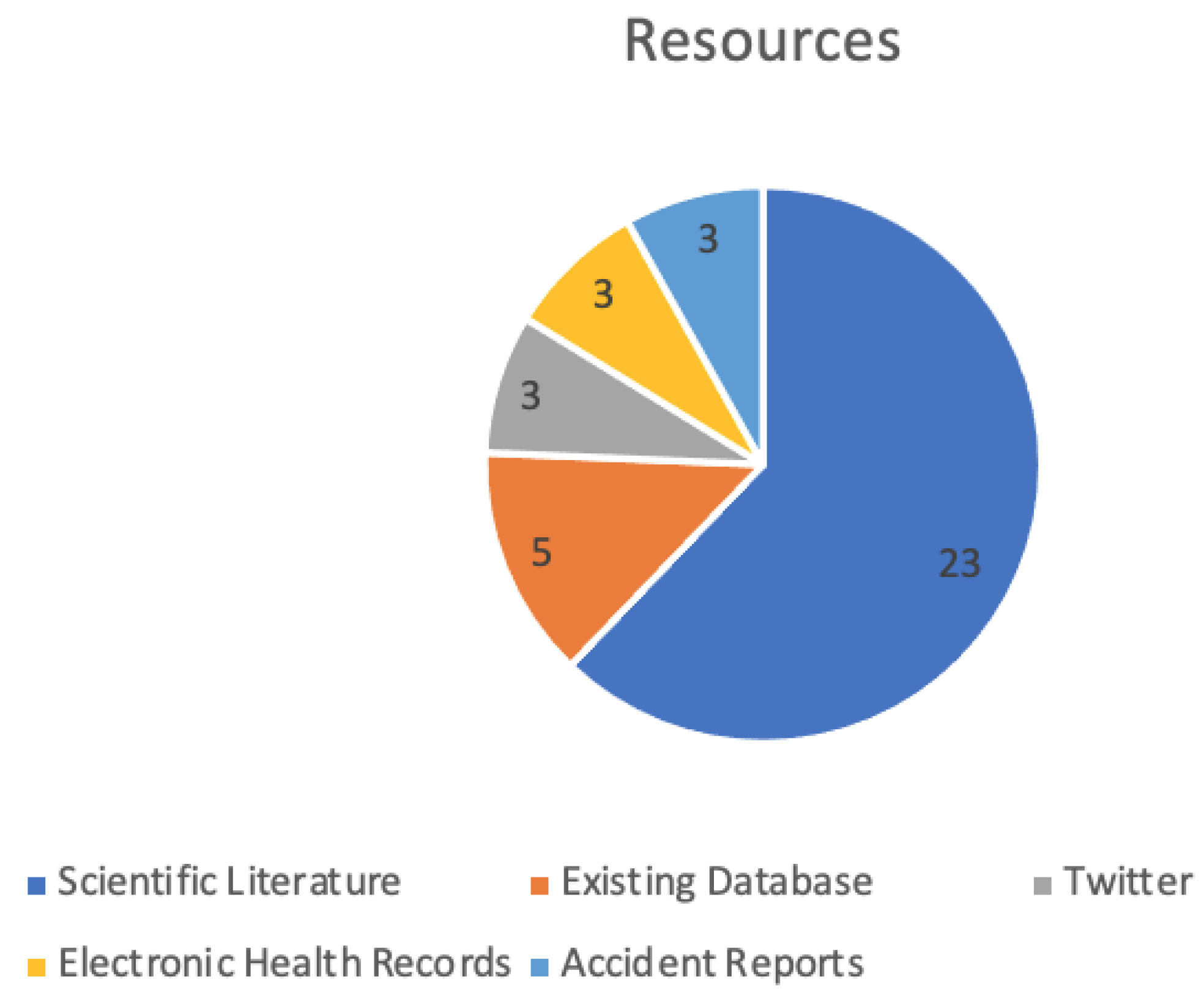
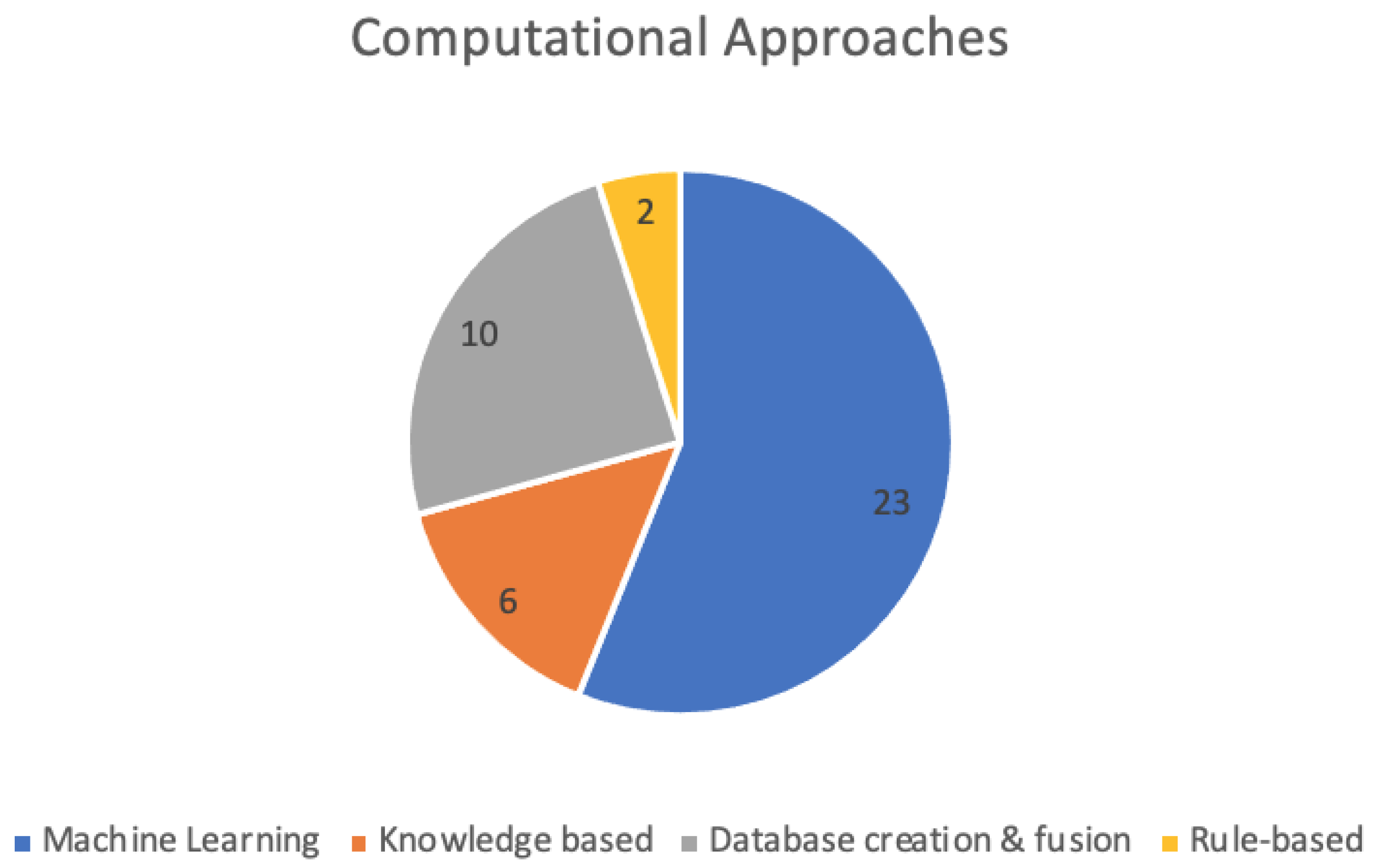
3. Results
- A.
- Resources
- B.
- Computational Methods
- C.
- Existing NLP tools
3.1. Machine Learning Methods
3.2. Knowledge-Based Methods
3.3. Database Creation and Fusion
3.4. Literature Reviews and Qualitative Research
4. Discussion
- Data volume and quality Whilst there has been some use of unsupervised machine learning methods (e.g., clustering via LDA) in the selected studies, a majority use supervised machine learning. One downside of this is that the latter approach requires human annotated data, which usually requires expert knowledge and is therefore a time-consuming and costly process. To overcome this issue, the use of semi-supervised or unsupervised learning methods might be explored, because it requires either significantly less annotated training data or none at all. An example of this is the use of topic modelling techniques to cluster jobs and exposures from the existing literature. Another opportunity lies in using semi-supervised Named Entity Recognition to increase the coverage of annotated literature.
- Novel deep learning techniques The present studies predominantly utilise traditional machine learning techniques (e.g., SVMs); however, the field has drastically evolved over recent years with more advanced techniques known as deep learning methods producing scaleable and accurate results. This includes but is not limited to transfer learning [76] or adversarial learning [77], which include a variety of neural networks structures or knowledge graphs that have been at the core of NLP research.This also includes Transformer-based methods [78] (e.g., large pre-trained language models such as BERT [79]), which have made a significant impact on the field of NLP over recent years and could prove to be useful in NLP for occupational exposure research. This type of deep learning method is based on attention [80], which has been shown to improve results in a variety of other domains that have utilised NLP (e.g., healthcare). These advances could be used to improve tasks such as Named Entity Recognition (NER) [81] or Relation Extraction (RE) [82] in occupational exposure research, which up until this point have relied on traditional machine learning only. Both tasks could prove useful in the context of occupational exposure research to automatically identify key concepts (e.g., types of exposures, jobs or work environments) but also how they relate to one another (e.g., a particular role is in a specific work place). Other advances could be made through the use of unsupervised methods, which thus far have also relied on traditional machine learning only. More recent methods such as Neural Topic Models (NTM) have become increasingly popular for different tasks, including document summarisation and text generation [83] due to their flexibility and capability. These methods could also be applied to occupational exposure research to uncover new topics and concepts at a larger scale or draw new connections between exposures and work environments. Similarly, NTM methods could also be coupled with pre-trained language models to further boost performance and result in more accurate representations of new topics [83].
- Extrapolating existing research to other domains of exposure research Most of the research explored in this review is specific to a particular type of exposure, databases or enhancement of literature reviews. The domain-specificity and different needs/requirements for each type of exposure make it therefore hard to extrapolate these existing works to other fields, link and scale up existing approaches.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AOP | Adverse Outcome Pathways |
| BERT | Bidirectional Encoder Representations from Transformers |
| CTD | Comparative Toxicogenomics Database |
| DRS | Document relevancy score |
| LDA | Latent Dirichlet Allocation |
| LSA | Latent semantic analysis |
| LSTM | Long Short Term Memory |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| NLTK | Natural Language Toolkit |
| NTM | Neural topic models |
| PCA | Principal component analysis |
| RE | Relation Extraction |
| SVM | Support Vector Machine |
| TF-IDF | frequency–inverse document frequency |
| UMLS | Unified Medical Language System |
References
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall: Hoboken, NJ, USA, 2002. [Google Scholar]
- Wild, C.P. The exposome: From concept to utility. Int. J. Epidemiol. 2012, 41, 24–32. [Google Scholar] [CrossRef] [PubMed]
- Haddad, N.; Andrianou, X.D.; Makris, K.C. A scoping review on the characteristics of human exposome studies. Curr. Pollut. Rep. 2019, 5, 378–393. [Google Scholar] [CrossRef] [Green Version]
- Kreimeyer, K.; Foster, M.; Pandey, A.; Arya, N.; Halford, G.; Jones, S.F.; Forshee, R.; Walderhaug, M.; Botsis, T. Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review. J. Biomed. Inform. 2017, 73, 14–29. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef] [Green Version]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Przybyła, P.; Brockmeier, A.J.; Kontonatsios, G.; Le Pogam, M.A.; McNaught, J.; von Elm, E.; Nolan, K.; Ananiadou, S. Prioritising references for systematic reviews with RobotAnalyst: A user study. Res. Synth. Methods 2018, 9, 470–488. [Google Scholar] [CrossRef]
- Balasubramanian, V.; Vivekanandhan, S.; Mahadevan, V. Pandemic tele-smart: A contactless tele-health system for efficient monitoring of remotely located COVID-19 quarantine wards in India using near-field communication and natural language processing system. Med. Biol. Eng. Comput. 2021, 60, 61–79. [Google Scholar] [CrossRef]
- Dong, T.; Yang, Q.; Ebadi, N.; Luo, X.R.; Rad, P. Identifying Incident Causal Factors to Improve Aviation Transportation Safety: Proposing a Deep Learning Approach. J. Adv. Transp. 2021, 2021, 5540046. [Google Scholar] [CrossRef]
- Medina Sada, D.; Mengel, S.; Gittner, L.S.; Khan, H.; Rodriguez, M.A.P.; Vadapalli, R. A Preliminary Investigation with Twitter to Augment CVD Exposome Research. In Proceedings of the Fourth IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, Austin, TX, USA, 5–8 December 2017; pp. 169–178. [Google Scholar]
- Lee, S.W.; Kwon, J.H.; Lee, B.; Kim, E.J. Scientific Literature Information Extraction Using Text Mining Techniques for Human Health Risk Assessment of Electromagnetic Fields. Sens. Mater. 2020, 32, 149–157. [Google Scholar] [CrossRef] [Green Version]
- Lamurias, A.; Jesus, S.; Neveu, V.; Salek, R.M.; Couto, F.M. Information Retrieval using Machine Learning for Biomarker Curation in the Exposome-Explorer. bioRxiv 2020, 6, 689264. [Google Scholar] [CrossRef]
- Larsson, K.; Baker, S.; Silins, I.; Guo, Y.; Stenius, U.; Korhonen, A.; Berglund, M. Text mining for improved exposure assessment. PLoS ONE 2017, 12, e0173132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tewari, S.; Toledo Margalef, P.; Kareem, A.; Abdul-Hussein, A.; White, M.; Wazana, A.; Davidge, S.T.; Delrieux, C.; Connor, K.L. Mining Early Life Risk and Resiliency Factors and Their Influences in Human Populations from PubMed: A Machine Learning Approach to Discover DOHaD Evidence. J. Pers. Med. 2021, 11, 1064. [Google Scholar] [CrossRef] [PubMed]
- Varghese, A.; Cawley, M.; Hong, T. Supervised clustering for automated document classification and prioritization: A case study using toxicological abstracts. Environ. Syst. Decis. 2018, 38, 398–414. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Xu, N.; Hu, Y.; Cui, C. Importance degree research of safety risk management processes of urban rail transit based on text mining method. Information 2018, 9, 26. [Google Scholar] [CrossRef] [Green Version]
- Leroy, G.; Harber, P.; Revere, D. Public sharing of medical advice using social media: An analysis of Twitter. Grey J. (TGJ) 2016, 12, 104–113. [Google Scholar]
- Karystianis, G.; Buchan, I.; Nenadic, G. Mining characteristics of epidemiological studies from Medline: A case study in obesity. J. Biomed. Semant. 2014, 5, 22. [Google Scholar] [CrossRef] [Green Version]
- Karystianis, G.; Thayer, K.; Wolfe, M.; Tsafnat, G. Evaluation of a rule-based method for epidemiological document classification towards the automation of systematic reviews. J. Biomed. Inform. 2017, 70, 27–34. [Google Scholar] [CrossRef]
- Fan, J.w.; Li, J.; Lussier, Y.A. Semantic modeling for exposomics with exploratory evaluation in clinical context. J. Healthc. Eng. 2017, 2017, 3818302. [Google Scholar] [CrossRef] [Green Version]
- Ali, I.; Guo, Y.; Silins, I.; Högberg, J.; Stenius, U.; Korhonen, A. Grouping chemicals for health risk assessment: A text mining-based case study of polychlorinated biphenyls (PCBs). Toxicol. Lett. 2016, 241, 32–37. [Google Scholar] [CrossRef]
- Davis, A.P.; Wiegers, T.C.; Johnson, R.J.; Lay, J.M.; Lennon-Hopkins, K.; Saraceni-Richards, C.; Sciaky, D.; Murphy, C.G.; Mattingly, C.J. Text mining effectively scores and ranks the literature for improving chemical-gene-disease curation at the comparative toxicogenomics database. PLoS ONE 2013, 8, e58201. [Google Scholar] [CrossRef] [Green Version]
- Vishnyakova, D.; Pasche, E.; Gobeill, J.; Gaudinat, A.; Lovis, C.; Ruch, P. Classification and prioritization of biomedical literature for the comparative toxicogenomics database. In Proceedings of the MIE, Pisa, Italy, 26–29 August 2012; pp. 210–214. [Google Scholar]
- Lu, Y.; Xu, H.; Peterson, N.B.; Dai, Q.; Jiang, M.; Denny, J.C.; Liu, M. Extracting epidemiologic exposure and outcome terms from literature using machine learning approaches. Int. J. Data Min. Bioinform. 2012, 6, 447–459. [Google Scholar] [CrossRef] [PubMed]
- Giummarra, M.J.; Lau, G.; Gabbe, B.J. Evaluation of text mining to reduce screening workload for injury-focused systematic reviews. Inj. Prev. 2020, 26, 55–60. [Google Scholar] [CrossRef]
- Warth, B.; Spangler, S.; Fang, M.; Johnson, C.H.; Forsberg, E.M.; Granados, A.; Martin, R.L.; Domingo, X.; Huan, T.; Rinehart, D.; et al. Exposing the Exposome with Global Metabolomics and Cognitive Computing. bioRxiv 2017, 145722. [Google Scholar] [CrossRef]
- Berrang-Ford, L.; Sietsma, A.J.; Callaghan, M.; Minx, J.C.; Scheelbeek, P.F.; Haddaway, N.R.; Haines, A.; Dangour, A.D. Systematic mapping of global research on climate and health: A machine learning review. Lancet Planet. Health 2021, 5, e514–e525. [Google Scholar] [CrossRef]
- Minet, E.; Haswell, L.E.; Corke, S.; Banerjee, A.; Baxter, A.; Verrastro, I.; e Lima, F.D.A.; Jaunky, T.; Santopietro, S.; Breheny, D.; et al. Application of text mining to develop AOP-based mucus hypersecretion genesets and confirmation with in vitro and clinical samples. Sci. Rep. 2021, 11, 6091. [Google Scholar] [CrossRef]
- Taboureau, O.; El M’Selmi, W.; Audouze, K. Integrative systems toxicology to predict human biological systems affected by exposure to environmental chemicals. Toxicol. Appl. Pharmacol. 2020, 405, 115210. [Google Scholar] [CrossRef]
- Russ, D.E.; Ho, K.Y.; Colt, J.S.; Armenti, K.R.; Baris, D.; Chow, W.H.; Davis, F.; Johnson, A.; Purdue, M.P.; Karagas, M.R.; et al. Computer-based coding of free-text job descriptions to efficiently identify occupations in epidemiological studies. Occup. Environ. Med. 2016, 73, 417–424. [Google Scholar] [CrossRef] [Green Version]
- Semenza, J.C.; Herbst, S.; Rechenburg, A.; Suk, J.E.; Höser, C.; Schreiber, C.; Kistemann, T. Climate change impact assessment of food-and waterborne diseases. Crit. Rev. Environ. Sci. Technol. 2012, 42, 857–890. [Google Scholar] [CrossRef] [Green Version]
- Zhao, F.; Li, L.; Chen, Y.; Huang, Y.; Keerthisinghe, T.P.; Chow, A.; Dong, T.; Jia, S.; Xing, S.; Warth, B.; et al. Risk-Based Chemical Ranking and Generating a Prioritized Human Exposome Database. Environ. Health Perspect. 2021, 129, 047014. [Google Scholar] [CrossRef]
- Dong, Z.; Fan, X.; Li, Y.; Wang, Z.; Chen, L.; Wang, Y.; Zhao, X.; Fan, W.; Wu, F. A Web-Based Database on Exposure to Persistent Organic Pollutants in China. Environ. Health Perspect. 2021, 129, 057701. [Google Scholar] [CrossRef]
- Rugard, M.; Coumoul, X.; Carvaillo, J.C.; Barouki, R.; Audouze, K. Deciphering adverse outcome pathway network linked to bisphenol F using text mining and systems toxicology approaches. Toxicol. Sci. 2020, 173, 32–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barupal, D.K.; Fiehn, O. Generating the blood exposome database using a comprehensive text mining and database fusion approach. Environ. Health Perspect. 2019, 127, 097008. [Google Scholar] [CrossRef] [PubMed]
- Wishart, D.; Arndt, D.; Pon, A.; Sajed, T.; Guo, A.C.; Djoumbou, Y.; Knox, C.; Wilson, M.; Liang, Y.; Grant, J.; et al. T3DB: The toxic exposome database. Nucleic Acids Res. 2015, 43, D928–D934. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Hu, H.; Diller, M.; Hogan, W.R.; Prosperi, M.; Guo, Y.; Bian, J. Semantic Standards of External Exposome Data. Environ. Res. 2021, 197, 111185. [Google Scholar] [CrossRef]
- Ekenga, C.C.; McElwain, C.A.; Sprague, N. Examining public perceptions about lead in school drinking water: A mixed-methods analysis of Twitter response to an environmental health hazard. Int. J. Environ. Res. Public Health 2018, 15, 162. [Google Scholar] [CrossRef] [Green Version]
- Hollister, B.M.; Restrepo, N.A.; Farber-Eger, E.; Crawford, D.C.; Aldrich, M.C.; Non, A. Development and performance of text-mining algorithms to extract socioeconomic status from de-identified electronic health records. In Pacific Symposium on Biocomputing 2017; World Scientific: Singapore, 2017; pp. 230–241. [Google Scholar]
- Hartmann, J.; Wuijts, S.; van der Hoek, J.P.; de Roda Husman, A.M. Use of literature mining for early identification of emerging contaminants in freshwater resources. Environ. Evid. 2019, 8, 33. [Google Scholar] [CrossRef] [Green Version]
- Cawley, M.; Beardslee, R.; Beverly, B.; Hotchkiss, A.; Kirrane, E.; Sams II, R.; Varghese, A.; Wignall, J.; Cowden, J. Novel text analytics approach to identify relevant literature for human health risk assessments: A pilot study with health effects of in utero exposures. Environ. Int. 2020, 134, 105228. [Google Scholar] [CrossRef]
- Jornod, F.; Rugard, M.; Tamisier, L.; Coumoul, X.; Andersen, H.R.; Barouki, R.; Audouze, K. AOP4EUpest: Mapping of pesticides in adverse outcome pathways using a text mining tool. Bioinformatics 2020, 36, 4379–4381. [Google Scholar] [CrossRef]
- Kiossogloua, P.; Bordaa, A.; Graya, K.; Martin-Sancheza, F.; Verspoora, K.; d Lopez-Camposa, G. Characterising the Scope of Exposome Research: A Generalisable Approach; IOS Press: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. Comparative toxicogenomics database (CTD): Update 2021. Nucleic Acids Res. 2021, 49, D1138–D1143. [Google Scholar] [CrossRef]
- Zgheib, E.; Kim, M.J.; Jornod, F.; Bernal, K.; Tomkiewicz, C.; Bortoli, S.; Coumoul, X.; Barouki, R.; De Jesus, K.; Grignard, E.; et al. Identification of non-validated endocrine disrupting chemical characterization methods by screening of the literature using artificial intelligence and by database exploration. Environ. Int. 2021, 154, 106574. [Google Scholar] [CrossRef]
- Ayadi, A.; Auffan, M.; Rose, J. Ontology-based NLP information extraction to enrich nanomaterial environmental exposure database. Procedia Comput. Sci. 2020, 176, 360–369. [Google Scholar] [CrossRef]
- Schwartz, K.L.; Achonu, C.; Buchan, S.A.; Brown, K.A.; Lee, B.; Whelan, M.; Wu, J.H.; Garber, G. Epidemiology, clinical characteristics, household transmission, and lethality of severe acute respiratory syndrome coronavirus-2 infection among healthcare workers in Ontario, Canada. PLoS ONE 2020, 15, e0244477. [Google Scholar] [CrossRef] [PubMed]
- Loper, E.; Bird, S. Nltk: The natural language toolkit. arXiv 2002, preprint. arXiv:cs/0205028. [Google Scholar]
- Rani, J.; Shah, A.R.; Ramachandran, S. pubmed. mineR: An R package with text-mining algorithms to analyse PubMed abstracts. J. Biosci. 2015, 40, 671–682. [Google Scholar] [CrossRef] [PubMed]
- Howard, J.; Ruder, S. Transfer Learning over Text Using ULMFiT. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Christensen, H.E.; Luginbyhl, T.T. Registry of Toxic Effects of Chemical Substances; Technical Report; Tracor JITCO, Inc.: Rockville, MD, USA, 1975. [Google Scholar]
- Neveu, V.; Nicolas, G.; Salek, R.M.; Wishart, D.S.; Scalbert, A. Exposome-Explorer 2.0: An update incorporating candidate dietary biomarkers and dietary associations with cancer risk. Nucleic Acids Res. 2020, 48, D908–D912. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Korhonen, A.; Ó Séaghdha, D.; Silins, I.; Sun, L.; Högberg, J.; Stenius, U. Text mining for literature review and knowledge discovery in cancer risk assessment and research. PLoS ONE 2012, 7, e33427. [Google Scholar] [CrossRef]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; McMorran, R.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. The comparative toxicogenomics database: Update 2019. Nucleic Acids Res. 2019, 47, D948–D954. [Google Scholar] [CrossRef]
- Settles, B. ABNER: An open source tool for automatically tagging genes, proteins and other entity names in text. Bioinformatics 2005, 21, 3191–3192. [Google Scholar] [CrossRef]
- Aronson, A.R. Effective mapping of biomedical text to the UMLS Metathesaurus: The MetaMap program. In Proceedings of the AMIA Symposium, Washington, DC, USA, 3–7 November 2001; American Medical Informatics Association: Bethesda, MD, USA, 2001; p. 17. [Google Scholar]
- Corbett, P.; Copestake, A. Cascaded classifiers for confidence-based chemical named entity recognition. BMC Bioinform. 2008, 9, S4. [Google Scholar] [CrossRef] [Green Version]
- Carvaillo, J.C.; Barouki, R.; Coumoul, X.; Audouze, K. Linking bisphenol S to adverse outcome pathways using a combined text mining and systems biology approach. Environ. Health Perspect. 2019, 127, 047005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ananiadou, S.; Rea, B.; Okazaki, N.; Procter, R.; Thomas, J. Supporting systematic reviews using text mining. Soc. Sci. Comput. Rev. 2009, 27, 509–523. [Google Scholar] [CrossRef] [Green Version]
- Lopez-Campos, G.; Kiossoglou, P.; Borda, A.; Hawthorne, C.; Gray, K.; Verspoor, K. Characterizing the Scope of Exposome Research Through Topic Modeling and Ontology Analysis. In MEDINFO 2019: Health and Wellbeing e-Networks for All; IOS Press: Amsterdam, The Netherlands, 2019; pp. 1530–1531. [Google Scholar]
- Cunningham, H.; Tablan, V.; Roberts, A.; Bontcheva, K. Getting more out of biomedical documents with GATE’s full lifecycle open source text analytics. PLoS Comput. Biol. 2013, 9, e1002854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nenadic, G.; Ananiadou, S.; McNaught, J. Enhancing automatic term recognition through recognition of variation. In Proceedings of the 20th International Conference on Computational Linguistics, COLING 2004, Geneva, Switzerland, 23–27 August 2004; pp. 604–610. [Google Scholar]
- Cohen, W.W. Minorthird: Methods for Identifying names and Ontological Relations in Text Using Heuristics for Inducing Regularities from Data. In Proceedings of the 6th International Workshop on Knowledge Discovery on the Web, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- High, R. The era of cognitive systems: An inside look at IBM Watson and how it works. IBM Corp. Redbooks 2012, 1, 16. [Google Scholar]
- Schultheisz, R.J. TOXLINE: Evolution of an online interactive bibliographic database. J. Am. Soc. Inf. Sci. 1981, 32, 421–429. [Google Scholar] [CrossRef]
- Barupal, D.K.; Schubauer-Berigan, M.K.; Korenjak, M.; Zavadil, J.; Guyton, K.Z. Prioritizing cancer hazard assessments for IARC Monographs using an integrated approach of database fusion and text mining. Environ. Int. 2021, 156, 106624. [Google Scholar] [CrossRef]
- Grondin, C.J.; Davis, A.P.; Wiegers, T.C.; King, B.L.; Wiegers, J.A.; Reif, D.M.; Hoppin, J.A.; Mattingly, C.J. Advancing exposure science through chemical data curation and integration in the Comparative Toxicogenomics Database. Environ. Health Perspect. 2016, 124, 1592–1599. [Google Scholar] [CrossRef]
- Coletti, M.H.; Bleich, H.L. Medical subject headings used to search the biomedical literature. J. Am. Med Inform. Assoc. 2001, 8, 317–323. [Google Scholar] [CrossRef] [Green Version]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [Green Version]
- Maglott, D.; Ostell, J.; Pruitt, K.D.; Tatusova, T. Entrez Gene: Gene-centered information at NCBI. Nucleic Acids Res. 2010, 39, D52–D57. [Google Scholar] [CrossRef]
- Davi, A.; Haughton, D.; Nasr, N.; Shah, G.; Skaletsky, M.; Spack, R. A review of two text-mining packages: SAS TextMining and WordStat. Am. Stat. 2005, 59, 89–103. [Google Scholar] [CrossRef]
- Lewis, R.B.; Maas, S.M. QDA Miner 2.0: Mixed-model qualitative data analysis software. Field Methods 2007, 19, 87–108. [Google Scholar] [CrossRef]
- Wallace, B.C.; Small, K.; Brodley, C.E.; Lau, J.; Trikalinos, T.A. Deploying an interactive machine learning system in an evidence-based practice center: Abstrackr. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 819–824. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial attacks and defences: A survey. arXiv 2018, arXiv:1810.00069. [Google Scholar] [CrossRef]
- Singh, S.; Mahmood, A. The NLP cookbook: Modern recipes for transformer based deep learning architectures. IEEE Access 2021, 9, 68675–68702. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Kumar, S. A survey of deep learning methods for relation extraction. arXiv 2017, arXiv:1705.03645. [Google Scholar]
- Zhao, H.; Phung, D.; Huynh, V.; Jin, Y.; Du, L.; Buntine, W. Topic modelling meets deep neural networks: A survey. arXiv 2021, arXiv:2103.00498. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Papers | |
|---|---|
| Tool used | |
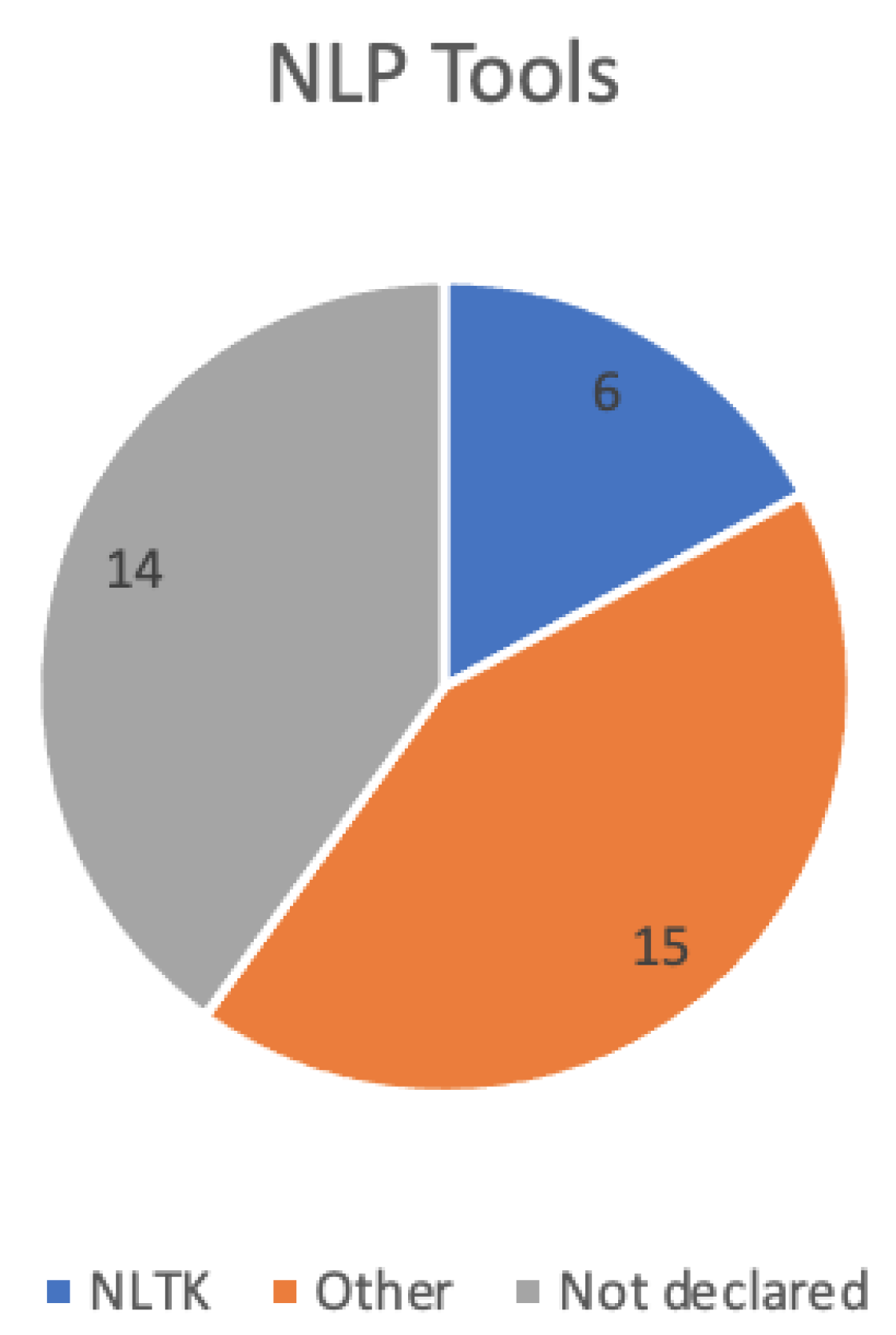
| NLTK | [9,10,11,12,13], |
| [14] | |
| Other | [9,15,16,17,18], |
| [19,20,21], | |
| [13,22,23,24], | |
| [25,26,27] | |
| Not declared | [15,28,29,30,31,32], |
| [33,34,35,36,37], | |
| [38,39,40] | |
| Resources | |
| Scientific literature | [12,15,28,29,41,42], |
| [14,22,23,31], | |
| [24,43,44], | |
| [19,20,21,33,34,45], | |
| [35,36,46,47] | |
| Existing Database | [13,30,35,37,45] |
| [11,18,39] | |
| EHR | [9,21,48] |
| Accident reports | [10,17,25] |
| Computational Method | |
| Machine learning | [9,15,28,41], |
| [10,12,28,29], | |
| [13,17,30,42,48], | |
| [11,14,18,22,31], | |
| [23,24,25,27] | |
| Knowledge based | [19,20,21,43,44] |
| Database creation and fusion | [27,33,34,35,45,46], |
| [36,37,47] | |
| Rule-based algorithms | [27,40] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schoene, A.M.; Basinas, I.; van Tongeren, M.; Ananiadou, S. A Narrative Literature Review of Natural Language Processing Applied to the Occupational Exposome. Int. J. Environ. Res. Public Health 2022, 19, 8544. https://doi.org/10.3390/ijerph19148544
Schoene AM, Basinas I, van Tongeren M, Ananiadou S. A Narrative Literature Review of Natural Language Processing Applied to the Occupational Exposome. International Journal of Environmental Research and Public Health. 2022; 19(14):8544. https://doi.org/10.3390/ijerph19148544
Chicago/Turabian StyleSchoene, Annika M., Ioannis Basinas, Martie van Tongeren, and Sophia Ananiadou. 2022. "A Narrative Literature Review of Natural Language Processing Applied to the Occupational Exposome" International Journal of Environmental Research and Public Health 19, no. 14: 8544. https://doi.org/10.3390/ijerph19148544