Agglomerative Clustering of Enteric Infections and Weather Parameters to Identify Seasonal Outbreaks in Cold Climates


Abstract
:1. Introduction
2. Data and Methods
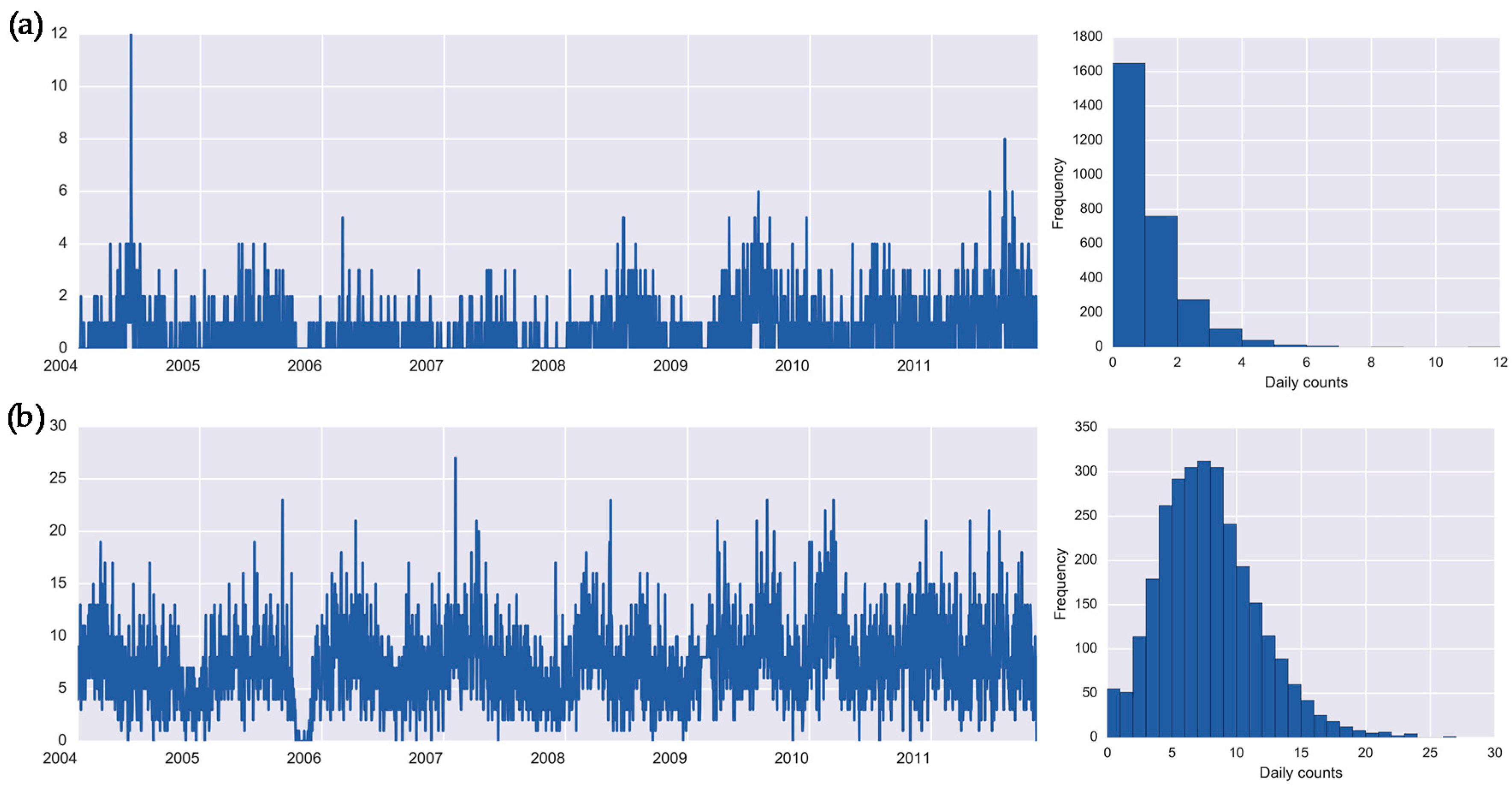
2.1. Health Outcomes
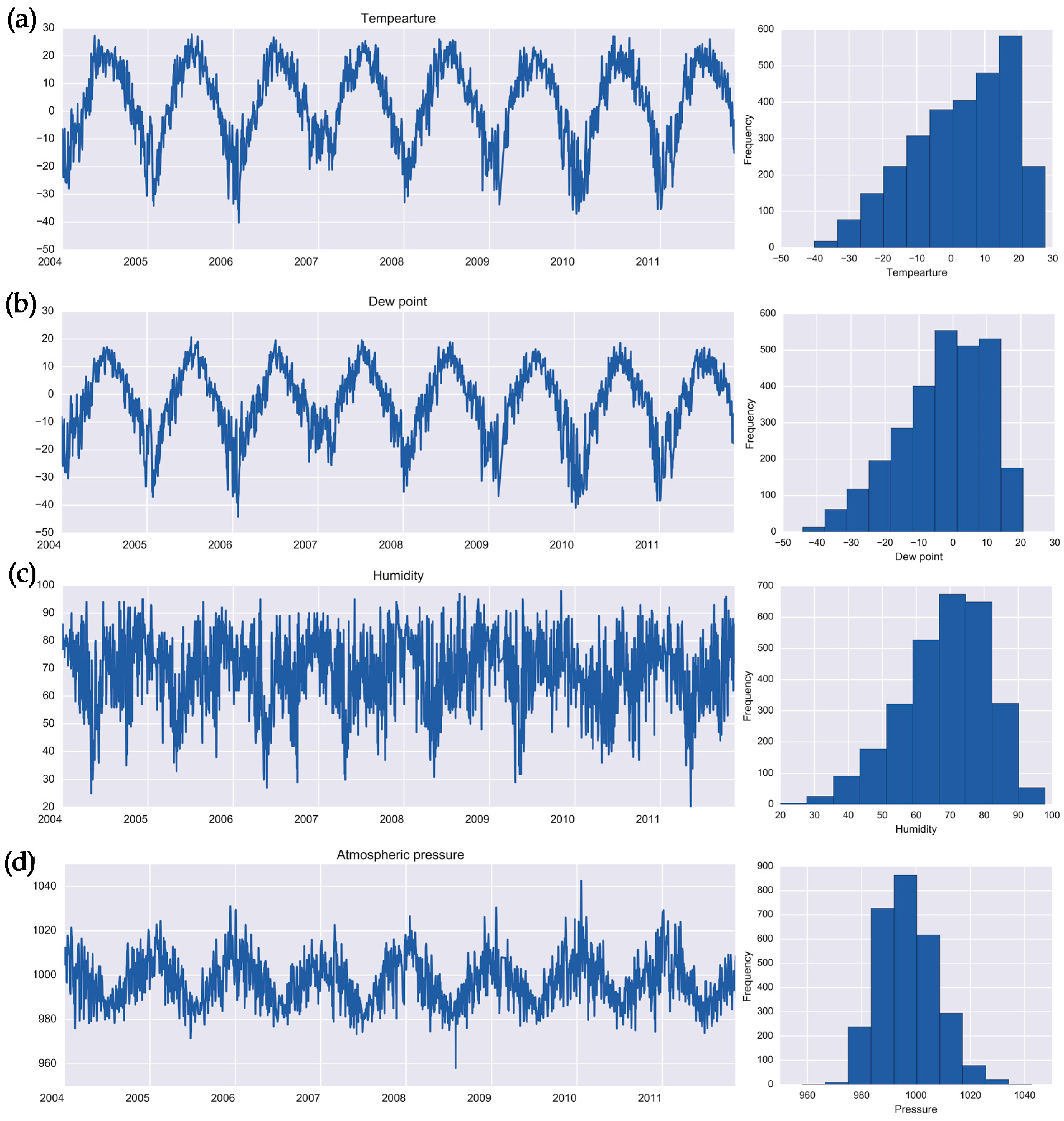
2.2. Meteorological Records
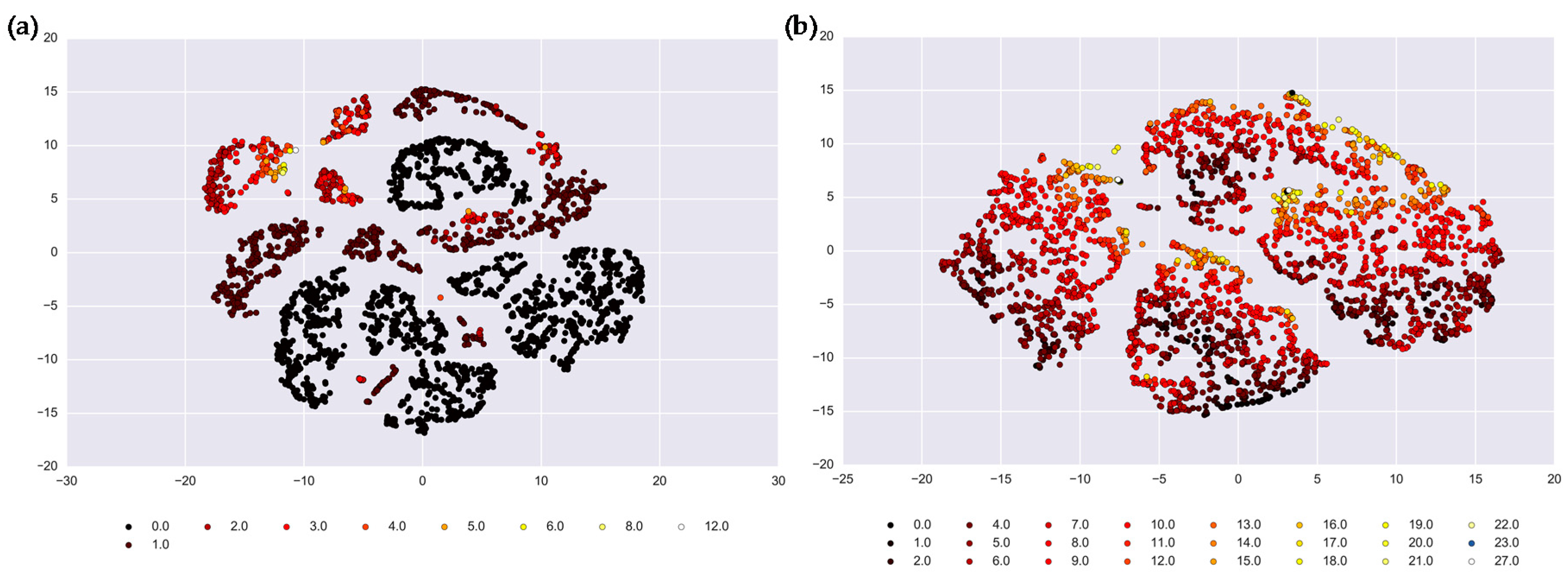
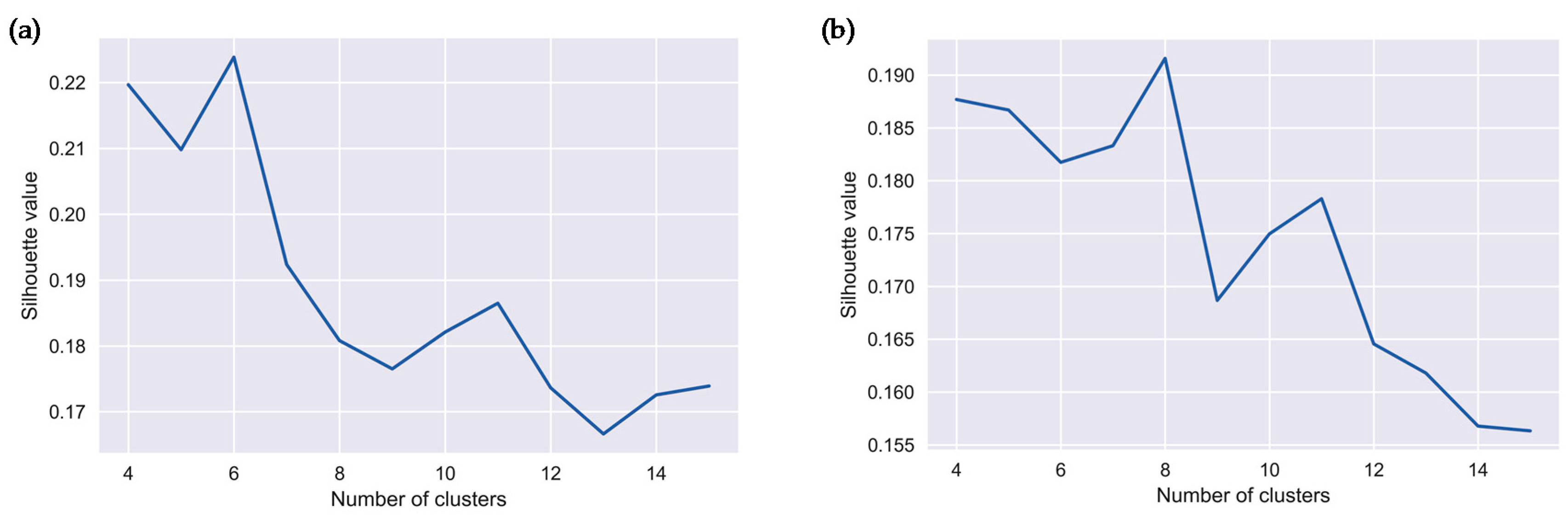
2.3. Agglomerative Clustering
2.4. Log-Linear and Harmonic Regression Models
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liss, A.; Wu, R.; Chui, K.K.; Naumova, E.N. Heat-related hospitalizations in older adults: An amplified effect of the first seasonal heatwave. Sci. Rep. 2017, 7, 39581. [Google Scholar] [CrossRef] [PubMed]
- Stratton, M.D.; Ehrlich, H.Y.; Mor, S.M.; Naumova, E.N. A comparative analysis of three vector-borne diseases across Australia using seasonal and meteorological models. Sci. Rep. 2017, 7, 40186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chui, K.K.; Webb, P.; Russell, R.M.; Naumova, E.N. Geographic variations and temporal trends of salmonella-associated hospitalization in the U.S. Elderly, 1991–2004: A time series analysis of the impact of HACCP regulation. BMC Public Health 2009, 9, 447. [Google Scholar] [CrossRef] [PubMed]
- Levy, K.; Woster, A.P.; Goldstein, R.S.; Carlton, E.J. Untangling the impacts of climate change on waterborne diseases: A systematic review of relationships between diarrheal diseases and temperature, rainfall, flooding, and drought. Environ. Sci. Technol. 2016, 50, 4905–4922. [Google Scholar] [CrossRef] [PubMed]
- Naumova, E.N.; Christodouleas, J.; Hunter, P.R.; Syed, Q. Effect of precipitation on seasonal variability in cryptosporidiosis recorded by the North West England surveillance system in 1990–1999. J. Water Health 2005, 3, 185–196. [Google Scholar] [CrossRef]
- Naumova, E.N.; Jagai, J.S.; Matyas, B.; DeMaria, A., Jr.; MacNeill, I.B.; Griffiths, J.K. Seasonality in six enterically transmitted diseases and ambient temperature. Epidemiol. Infect. 2007, 135, 281–292. [Google Scholar] [CrossRef]
- Chui, K.K.; Jagai, J.S.; Griffiths, J.K.; Naumova, E.N. Hospitalization of the elderly in the United States for nonspecific gastrointestinal diseases: A search for etiological clues. Am. J. Public Health 2011, 101, 2082–2086. [Google Scholar] [CrossRef]
- Gubarev, V.V.; Aksenova, V.; Alsova, O.; Belova, T.; Belozertseva, N.; Brusnitsyna, L.; Vaneeva, G.; Grazhdantseva, A.; Egorov, A.; Ivanova, L.; et al. Climate and infectious disease databank (CliWaDIn) for examining associations between weather, water quality and infectious diseases. In Proceedings of the 22nd Annual Conference of the International Environmetrics Society, Hyderabad, India, 3–6 January 2012; pp. 82–83. [Google Scholar]
- Egorov, A.I.; Naumova, E.N.; Tereschenko, A.A.; Kislitsin, V.A.; Ford, T.E. Daily variations in effluent water turbidity and diarrhoeal illness in a Russian city. Int. J. Environ. Health Res. 2003, 13, 81–94. [Google Scholar] [CrossRef]
- Alarcon Falconi, T.M.; Cruz, M.S.; Naumova, E.N. The shift in seasonality of legionellosis in the USA. Epidemiol. Infect. 2018, 146, 1824–1833. [Google Scholar] [CrossRef] [Green Version]
- Naumova, E.N.; MacNeill, I.B. Time-distributed effect of exposure and infectious outbreaks. Environmetrics 2008, 20, 235–248. [Google Scholar] [CrossRef] [Green Version]
- Tol, R.S.J. Estimates of the damage costs of climate change, Part II. Dynamic estimates. Environ. Resour. Econ. 2002, 21, 135–160. [Google Scholar] [CrossRef]
- Watson, R.T.; Zinyowera, M.C.; Moss, R.H. The Regional Impacts of Climate Change: An Assessment of Vulnerability; Cambridge University Press: Cambridge, UK; New York, NY, USA, 1998; p. 517. [Google Scholar]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series clustering—A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Ghassempour, S.; Girosi, F.; Maeder, A. Clustering multivariate time series using hidden Markov models. Int. J. Environ. Res. Public Health 2014, 11, 2741–2763. [Google Scholar] [CrossRef] [PubMed]
- Izakian, H.; Pedrycz, W.; Jamal, I. Fuzzy clustering of time series data using dynamic time warping distance. Eng. Appl. Artif. Intell. 2015, 39, 235–244. [Google Scholar] [CrossRef]
- Sadahiro, Y.; Kobayashi, T. Exploratory analysis of time series data: Detection of partial similarities, clustering, and visualization. Comput. Environ. Urban Syst. 2014, 45, 24–33. [Google Scholar] [CrossRef]
- Climate, Water, Diseases, Infections (CliWaDIn): Establishment of a Data Analysis and Modeling Center to Assess the Associations between Weather and Waterborne Infections and the Probable Impacts of Forecast Climate Changes on These Infections in Russia. Available online: https://www.nstu.ru/science/innovation_ip/certificate/?god=2011&nomenu=1 (accessed on 29 March 2019).
- Van der Maaten, L.; Hinton, G.E. Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- De Amorim, R.C.; Hennig, C. Recovering the number of clusters in data sets with noise features using feature rescaling factors. Inf. Sci. 2015, 324, 126–145. [Google Scholar] [CrossRef] [Green Version]
- De Amorim, R.C. Feature relevance in Ward’s hierarchical clustering using the lp-norm. J. Classif. 2015, 32, 46–62. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. Cure: An efficient clustering algorithm for large databases. Inf. Syst. 2001, 26, 35–58. [Google Scholar] [CrossRef]
- Fefferman, N.H.; Naumova, E.N. Innovation in observation: A vision for early outbreak detection. Emerg. Health Threats J. 2010, 3, 7103. [Google Scholar] [CrossRef]
- Noufaily, A.; Enki, D.G.; Farrington, P.; Garthwaite, P.; Andrews, N.; Charlett, A. An improved algorithm for outbreak detection in multiple surveillance systems. Stat. Med. 2013, 32, 1206–1222. [Google Scholar] [CrossRef] [PubMed]
- Shmueli, G.; Burkom, H. Statistical challenges facing early outbreak detection in biosurveillance. Technometrics 2010, 52, 39–51. [Google Scholar] [CrossRef]
- Honaker, J.; King, G. What to do about missing values in time-series cross-section data. Am. J. Political Sci. 2010, 54, 561–581. [Google Scholar] [CrossRef]
- Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. Density-based clustering in spatial databases: The algorithm gdbscan and its applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Gallegos, M.T.; Ritter, G. Trimming algorithms for clustering contaminated grouped data and their robustness. Adv. Data Anal. Classif. 2009, 3, 135–167. [Google Scholar] [CrossRef] [Green Version]
- Gubarev, V.V.; Loktev, V.B.; Naumova, E.N.; Khizenko, V.E. The possibilities of factor and cluster analysis to study the system “environment-infections”. In Proceedings of the International Congress on Computer Science: Information Systems and Technologies, Shanghai, China, 4–7 December 2011; pp. 65–69. [Google Scholar]
- Imai, C.; Armstrong, B.; Chalabi, Z.; Mangtani, P.; Hashizume, M. Time series regression model for infectious disease and weather. Environ. Res. 2015, 142, 319–327. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Mean | SD | Median | Minimum | Maximum | IR | Kurtosis |
|---|---|---|---|---|---|---|---|
| Salmonellosis (A02.8) | 0.67 | 1.01 | 0.00 | 0.00 | 12.00 | 1.00 | 9.77 |
| Enteritis (A04.9) | 7.38 | 3.80 | 7.00 | 0.00 | 27.00 | 5.00 | 0.85 |
| Temperature, °C | 2.96 | 14.55 | 4.83 | −40.16 | 27.81 | 22.61 | −0.61 |
| Dew point, °C | −2.74 | 12.88 | −0.97 | −44.16 | 20.69 | 18.60 | −0.32 |
| Humidity, % | 68.56 | 12.82 | 70.00 | 20.00 | 98.00 | 18.00 | −0.09 |
| Pressure, hPa | 997.02 | 10.44 | 996.25 | 958.11 | 1042.55 | 14.68 | −0.01 |
| Cluster | Daily Number of Cases | Confidence Interval for Number of Cases | Temperature, °C | Dew Point, °C | Humidity, % | Pressure, hPa | Seasonal Distribution, Number of Days | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Spring | Summer | Autumn | Winter | Total Number of Days | |||||||
| Set 1 | |||||||||||
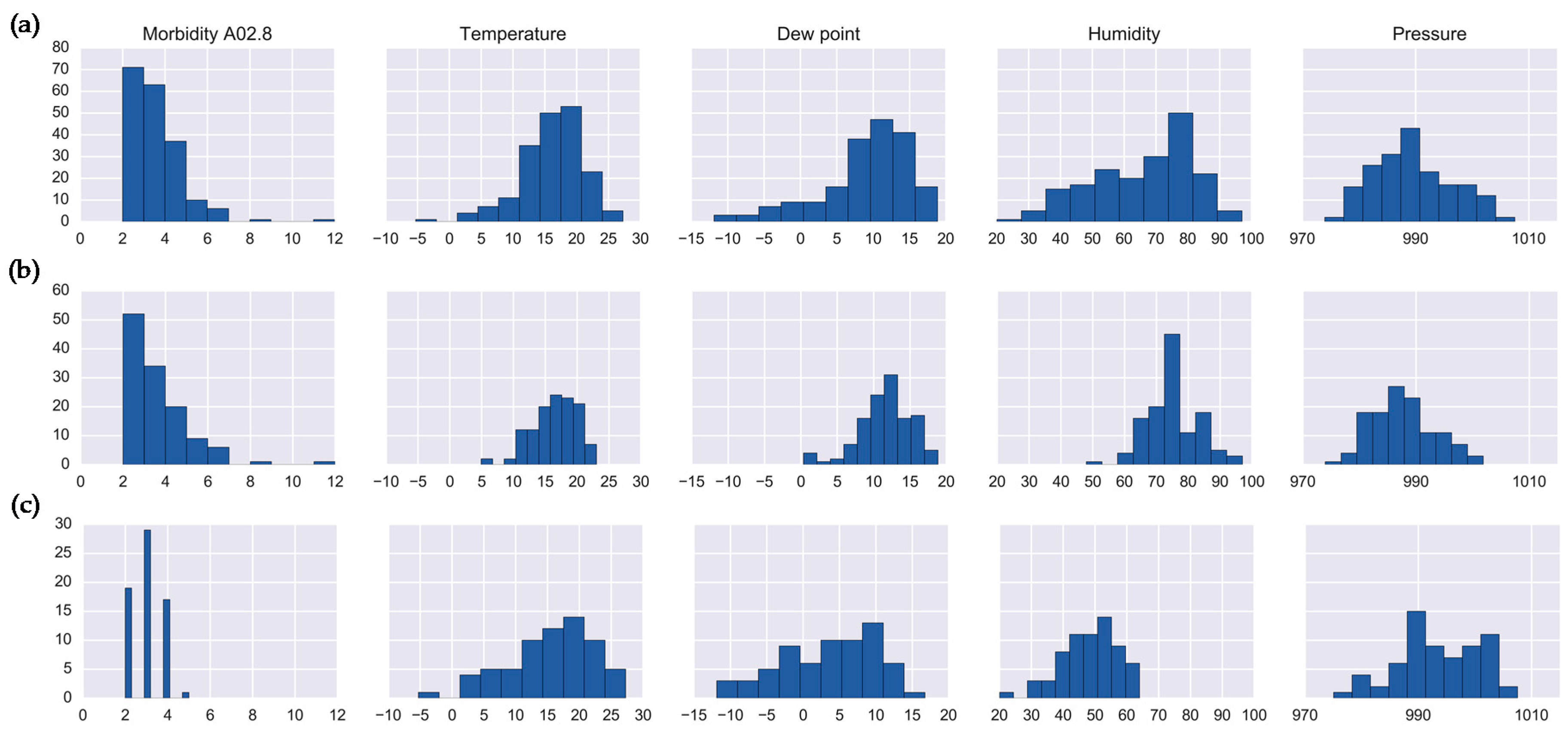
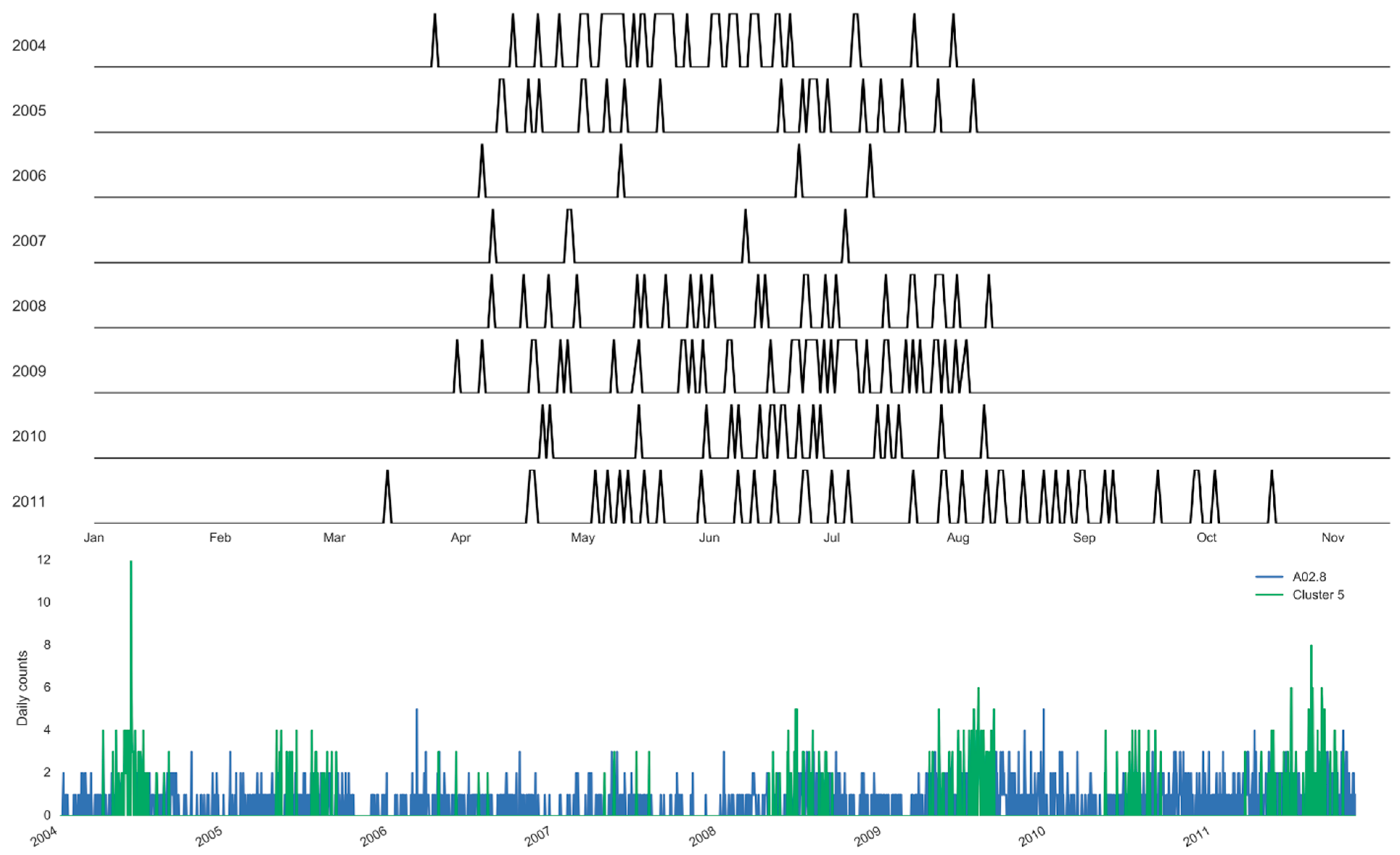
| Cluster 1 | 0.72 | [0.66;0.77] | 16.51 | 9.14 | 64.70 | 988.94 | 19 | 606 | 209 | - | 834 |
| Cluster 2 | 0.48 | [0.41;0.54] | −18.41 | −22.28 | 70.26 | 1010.65 | 122 | - | - | 407 | 529 |
| Cluster 3 | 0.27 | [0.22;0.32] | 1.16 | −2.76 | 75.71 | 1000.56 | - | - | 489 | - | 489 |
| Cluster 4 | 0.33 | [0.27;0.38] | −4.86 | −8.03 | 77.48 | 997.34 | 232 | - | - | 265 | 497 |
| Cluster 5 | 3.10 | [2.91;3.28] | 16.09 | 8.87 | 65.82 | 989.65 | 50 | 127 | 12 | - | 189 |
| Cluster 6 | 0.55 | [0.47;0.63] | 10.32 | 0.10 | 52.10 | 993.90 | 310 | - | - | 310 | |
| Set 2 | |||||||||||
| Cluster 1 | 0.27 | [0.22;0.32] | 1.17 | −2.77 | 75.71 | 1000.57 | - | - | 489 | - | 489 |
| Cluster 2 | 0.33 | [0.27;0.38] | −4.86 | −8.03 | 77.48 | 997.34 | 232 | - | - | 265 | 497 |
| Cluster 3 | 0.55 | [0.47;0.63] | 10.32 | 0.10 | 52.10 | 993.90 | 310 | - | - | - | 310 |
| Cluster 4 | 3.14 | [2.88;3.41] | 16.43 | 11.66 | 75.21 | 987.59 | 7 | 109 | 7 | - | 123 |
| Cluster 5 | 0.54 | [0.45;0.63] | −22.27 | −25.27 | 74.44 | 1012.24 | 12 | - | - | 352 | 364 |
| Cluster 6 | 1.52 | [1.42;1.62] | 11.92 | 4.01 | 61.37 | 994.62 | - | 50 | 134 | - | 184 |
| Cluster 7 | 0.36 | [0.30;0.43] | 15.95 | 11.76 | 77.69 | 987.23 | 9 | 207 | 6 | - | 222 |
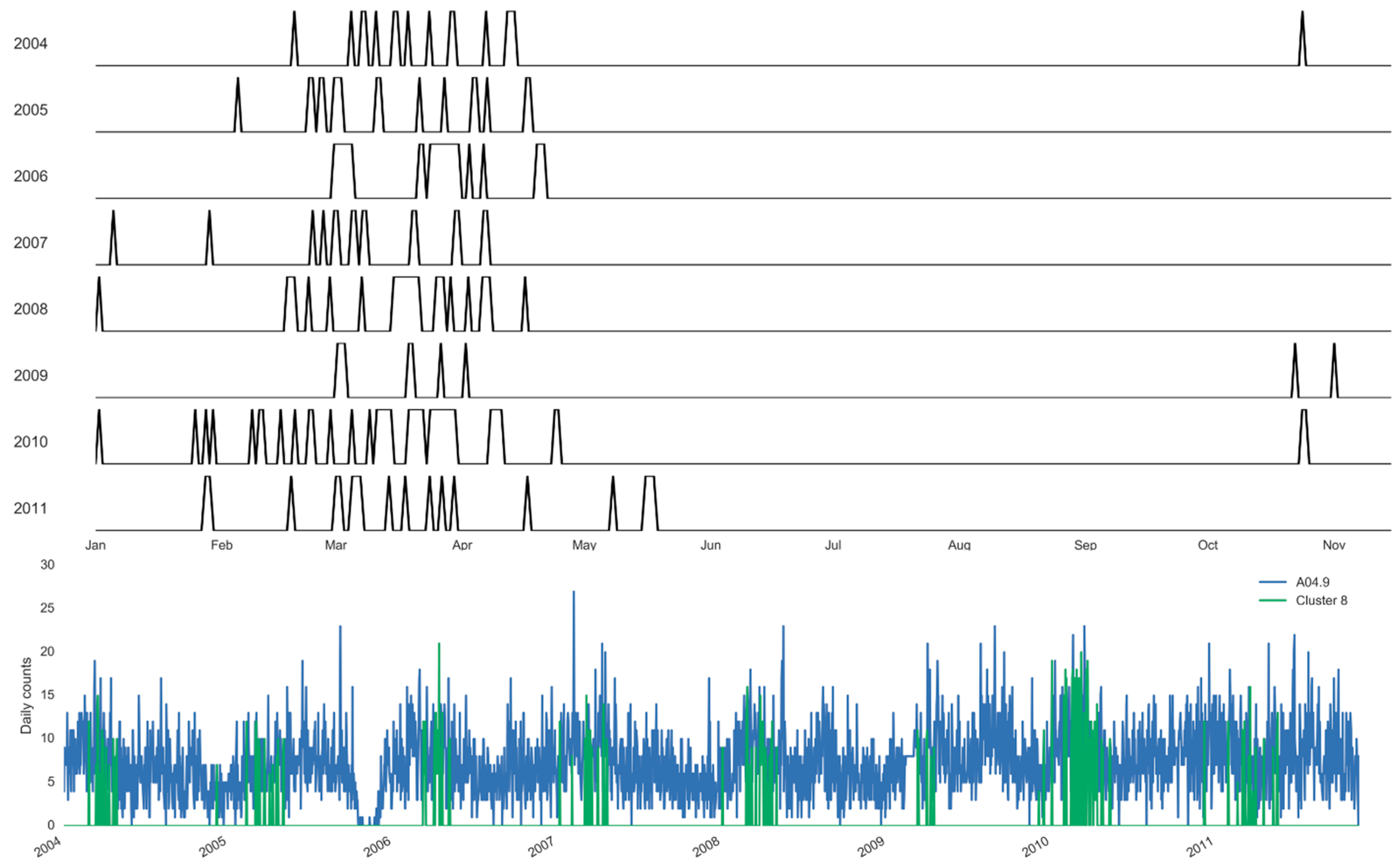
| Cluster 8 | 0.33 | [0.26;0.41] | −9.88 | −15.71 | 61.05 | 1007.13 | 110 | - | - | 55 | 165 |
| Cluster 9 | 0.02 | [0.00;0.03] | 17.28 | 8.06 | 57.48 | 989.78 | - | 168 | 69 | - | 237 |
| Cluster 10 | 3.00 | [2.81;3.19] | 15.47 | 3.69 | 48.32 | 993.51 | 43 | 18 | 5 | - | 66 |
| Cluster 11 | 1.23 | [1.14;1.32] | 20.65 | 12.41 | 61.80 | 984.41 | 10 | 181 | - | - | 191 |
| Set | Cluster | Disease Counts | Temperature | Dew Point | Humidity | Pressure | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| IR | K | IR | K | IR | K | IR | K | IR | K | ||
| Set 1 | Cluster 5 | 2.00 | 12.22 | 6.02 | 1.97 | 6.25 | 0.94 | 21.0 | −0.44 | 9.04 | −0.50 |
| Set 2 | Cluster 4 | 2.00 | 9.76 | 4.80 | 0.25 | 4.65 | 0.74 | 9.50 | 0.69 | 7.82 | −0.44 |
| Cluster 10 | 2.00 | −0.86 | 8.70 | 0.23 | 10.73 | −0.60 | 13.00 | 0.03 | 9.98 | −0.31 | |
| Cluster | Daily Number of Cases | Confidence Interval for Number of Cases | Temperature, °C | Dew Point, °C | Humidity, % | Pressure, hPa | Seasonal Distribution, Number of Days | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Spring | Summer | Autumn | Winter | Total Number of Days | |||||||
| Set 1 | |||||||||||
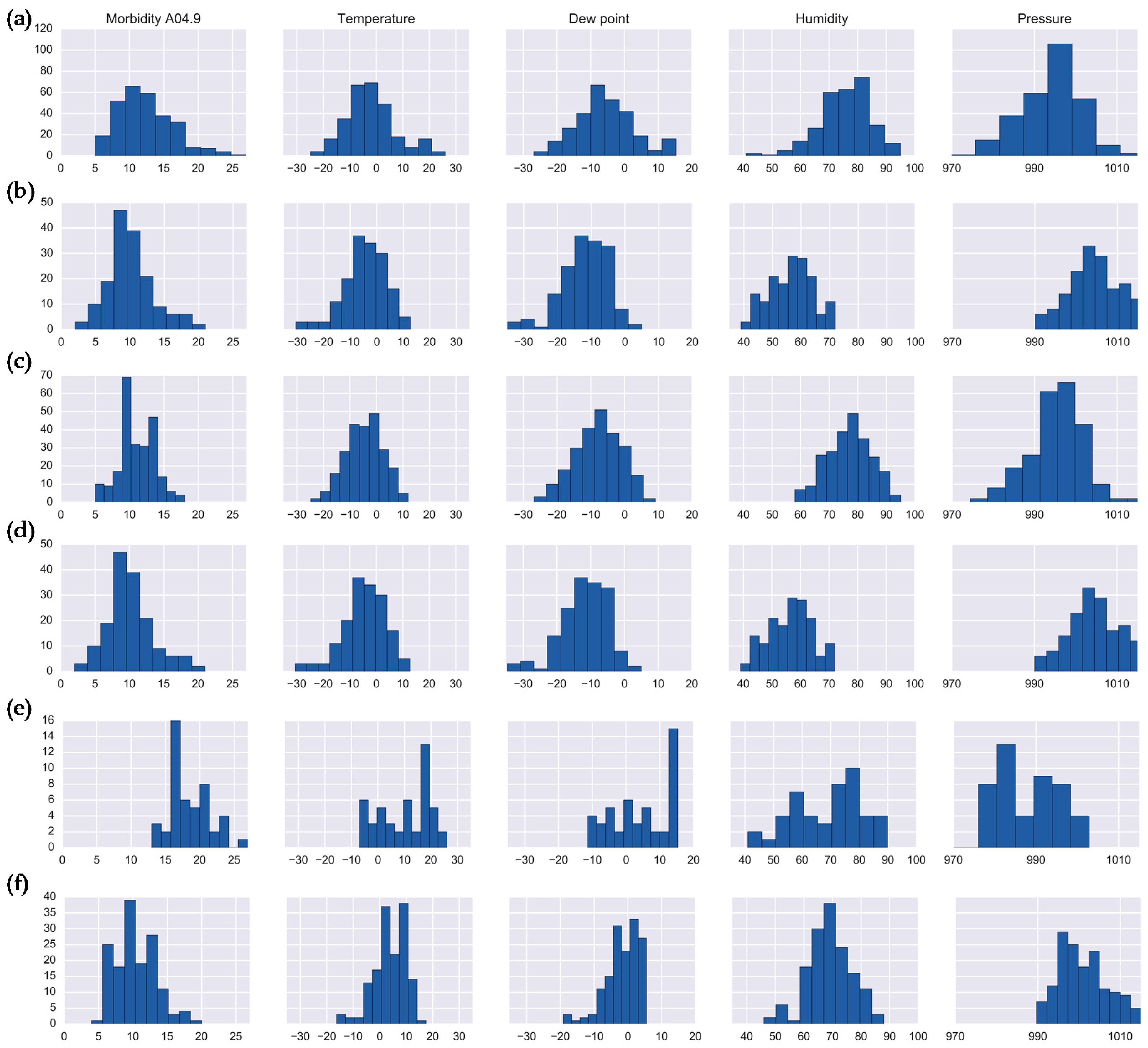
| Cluster 1 | 7.21 | [6.99;7.43] | 17.60 | 11.10 | 68.47 | 987.33 | 24 | 702 | 48 | - | 774 |
| Cluster 2 | 12.26 | [11.82;12.70] | −2.11 | −5.79 | 75.62 | 993.98 | 137 | 17 | 4 | 128 | 286 |
| Cluster 3 | 7.62 | [7.25;8.01] | 8.43 | 1.02 | 62.56 | 997.18 | - | - | 332 | - | 332 |
| Cluster 4 | 7.12 | [6.82;7.44] | −21.02 | −24.10 | 74.10 | 1011.89 | 17 | - | - | 399 | 416 |
| Cluster 5 | 6.99 | [6.67;7.32] | 11.49 | 1.05 | 52.10 | 992.94 | 324 | 14 | - | - | 338 |
| Cluster 6 | 5.01 | [4.70;5.31] | −6.89 | −9.76 | 78.64 | 1000.65 | 94 | - | - | 120 | 214 |
| Cluster 7 | 4.17 | [3.90;4.45] | −0.96 | −4.27 | 78.06 | 1001.58 | - | - | 326 | 326 | |
| Cluster 8 | 10.08 | [9.53;10.63] | −4.60 | −11.86 | 56.44 | 1004.68 | 137 | - | - | 25 | 162 |
| Set 2 | |||||||||||
| Cluster 1 | 7.13 | [6.82;7.44] | −21.02 | −24.10 | 74.10 | 1011.89 | 17 | - | - | 399 | 416 |
| Cluster 2 | 6.99 | [6.67;7.32] | 11.49 | 1.05 | 52.10 | 992.94 | 324 | 14 | - | - | 338 |
| Cluster 3 | 4.17 | [3.90;4.45] | −0.96 | −4.27 | 78.06 | 1001.58 | - | - | 326 | - | 326 |
| Cluster 4 | 5.77 | [5.51;6.02] | 15.80 | 10.93 | 74.84 | 986.96 | 24 | 369 | 33 | - | 426 |
| Cluster 5 | 5.45 | [5.11;5.79] | 12.14 | 3.18 | 57.37 | 994.13 | - | - | 183 | - | 183 |
| Cluster 6 | 5.01 | [4.70;5.31] | −6.89 | −9.76 | 78.64 | 1000.65 | 94 | - | - | 120 | 214 |
| Cluster 7 | 11.05 | [10.72;11.38] | −4.52 | −7.79 | 76.84 | 995.25 | 114 | 1 | - | 124 | 239 |
| Cluster 8 | 10.08 | [9.53;10.63] | −4.60 | −11.86 | 56.44 | 1004.68 | 137 | - | - | 25 | 162 |
| Cluster 9 | 8.99 | [8.70;9.27] | 19.81 | 11.30 | 60.67 | 987.80 | - | 333 | 15 | - | 348 |
| Cluster 10 | 18.43 | [17.58;19.27] | 10.17 | 4.35 | 69.44 | 987.50 | 23 | 16 | 4 | 4 | 47 |
| Cluster 11 | 10.30 | [9.83;10.77] | 3.87 | −1.63 | 68.93 | 1000.93 | - | - | - | 149 | 149 |
| Set | Cluster | Disease Counts | Temperature | Dew Point | Humidity | Pressure | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| IR | K | IR | K | IR | K | IR | K | IR | K | ||
| Set 1 | Cluster 2 | 4.00 | 0.74 | 10.48 | 0.35 | 10.13 | 0.11 | 11.00 | 0.78 | 9.07 | 1.43 |
| Cluster 8 | 4.00 | 0.68 | 9.84 | 0.51 | 9.45 | 0.80 | 11.00 | −0.63 | 8.06 | −0.41 | |
| Set 2 | Cluster 7 | 4.00 | −0.38 | 9.79 | −0.36 | 9.76 | −0.37 | 10.00 | −0.39 | 7.86 | 0.55 |
| Cluster 8 | 4.00 | 0.68 | 9.84 | 0.51 | 9.45 | 0.80 | 11.00 | −0.63 | 8.06 | −0.41 | |
| Cluster 10 | 4.50 | 0.21 | 16.83 | −1.14 | 15.49 | −1.28 | 18.50 | −0.63 | 11.65 | 1.31 | |
| Cluster 11 | 4.00 | 0.17 | 7.86 | 0.67 | 6.25 | 1.51 | 9.00 | 0.18 | 8.00 | −0.53 | |
| Infection | Peak Timing Estimates | Model A | Model A1 | Model A2 |
|---|---|---|---|---|
| Salmonellosis (A02.8) | RR (SE) | 187.0 (7.4) | 186.6 (8.6) | 186.5 (8.6) |
| LCI; UCI | [179.7;194.4] | [178.0;195.3] | [177.9;195.0] | |
| Enteritis (A04.9) | RR (SE) | 103.0 (9.5) | 105.4 (12.3) | 104.7 (11.9) |
| LCI; UCI | [93.5;112.5] | [93.1;117.8] | [92.9;116.6] |
| Infection | Risk Estimates | Temperature | Dew Point | Humidity | Pressure |
|---|---|---|---|---|---|
| Salmonellosis (A02.8) | RR | 1.278 | 1.309 | 0.915 | 0.772 |
| LCI; UCI | [1.228;1.330] | [1.252;1.370] | [0.877;0.954] | [0.731;0.815] | |
| Enteritis (A04.9) | RR | 0.994 | 0.986 | 0.965 | 0.986 |
| LCI; UCI | [0.981;1.007] | [0.972;1.001] | [0.950;0.979] | [0.968;1.004] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stashevsky, P.S.; Yakovina, I.N.; Alarcon Falconi, T.M.; Naumova, E.N. Agglomerative Clustering of Enteric Infections and Weather Parameters to Identify Seasonal Outbreaks in Cold Climates. Int. J. Environ. Res. Public Health 2019, 16, 2083. https://doi.org/10.3390/ijerph16122083
Stashevsky PS, Yakovina IN, Alarcon Falconi TM, Naumova EN. Agglomerative Clustering of Enteric Infections and Weather Parameters to Identify Seasonal Outbreaks in Cold Climates. International Journal of Environmental Research and Public Health. 2019; 16(12):2083. https://doi.org/10.3390/ijerph16122083
Chicago/Turabian StyleStashevsky, Pavel S., Irina N. Yakovina, Tania M. Alarcon Falconi, and Elena N. Naumova. 2019. "Agglomerative Clustering of Enteric Infections and Weather Parameters to Identify Seasonal Outbreaks in Cold Climates" International Journal of Environmental Research and Public Health 16, no. 12: 2083. https://doi.org/10.3390/ijerph16122083