An Efficient and Unique TF/IDF Algorithmic Model-Based Data Analysis for Handling Applications with Big Data Streaming

 , , and
, , and
Abstract
:1. Introduction
2. Literature Review
3. Implementation for Proposed Research Methodology
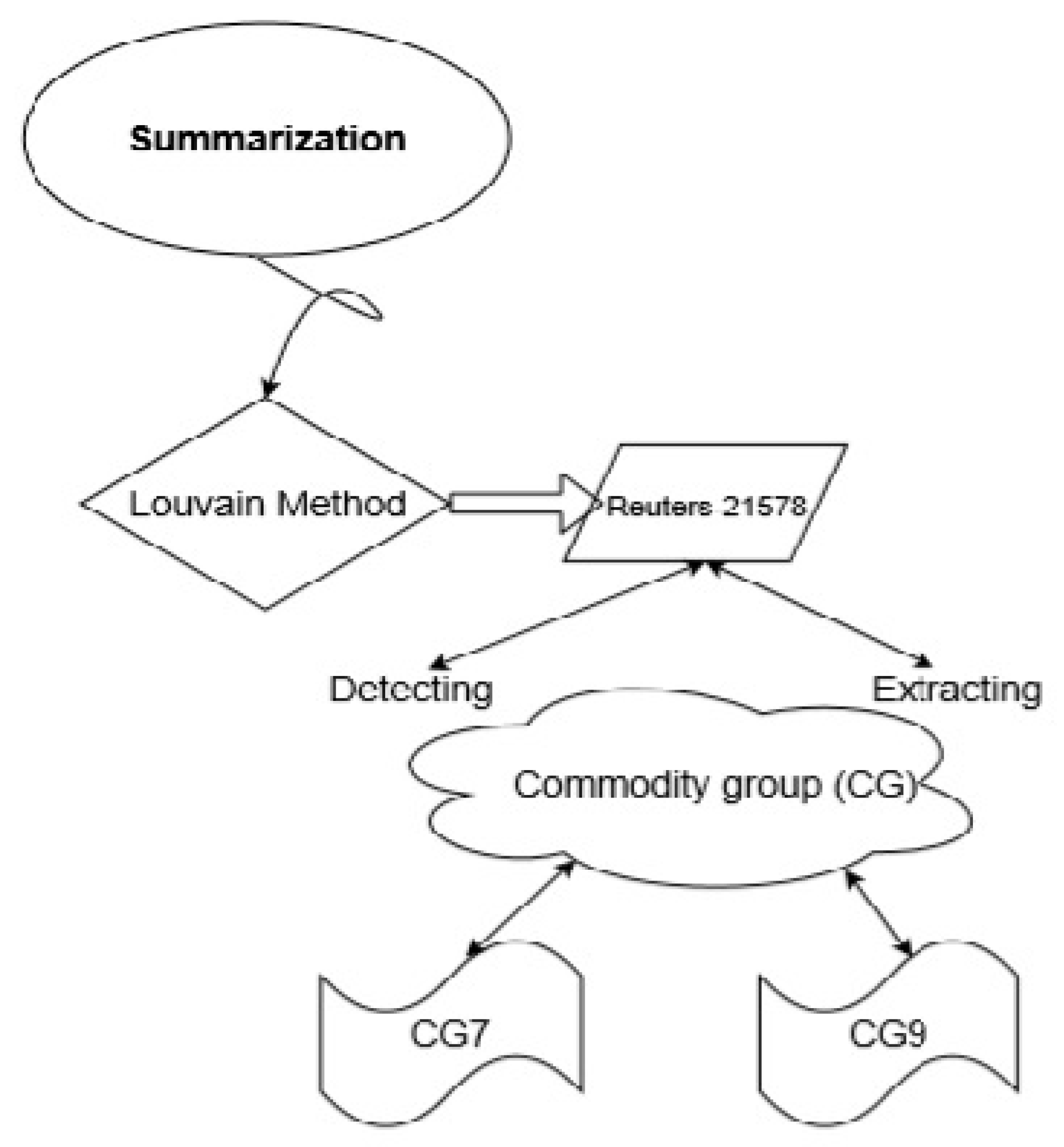
3.1. Temporal Louvain Method in Proposed Summarization
- Generally, all detections and extractions are taken into the relation of similarity weights.
- Accurate input streaming data count should be accessed with mathematical computation.
- Computation might not be as per the approximate number of results.
- To resolve the troubles in processing schemes as well as validate the Louvain method by using the application verification process i.e., first, the methods are applied to the predefined dataset corpus. Later, live streaming data is to be processed, as shown in Figure 1.
3.2. Community Group Classification
- Community group (CG)-7: there are fewer amounts of data to be tested for grouping concerning the user comment. In that case, there are 1000 comments applied to the word detection ratio test. Seemingly it gets 26.2% with the 80 document identification.
- Community group (CG)-9: there are more data to be tested for the grouping concerning the user comment. In that case, there are 9000 comments applied to the word detection ratio test. Seemingly, it gets 1.1% with the 85-document identification.
3.3. Temporal Similarity and Comparison Method
- Each time similarity has been checked with the streaming data (LinkedIn, Twitter).
- In another case, the comparison has been checked (20 Newsgroups, Reuters-21578) by the source dataset.
- The similarity and comparison are both verified by the (mobile phone network) input data.
4. Experimental Results
4.1. Datasets and Setup
4.2. News Group
4.3. LinkedIn Network
5. Performance Evaluation and Discussion
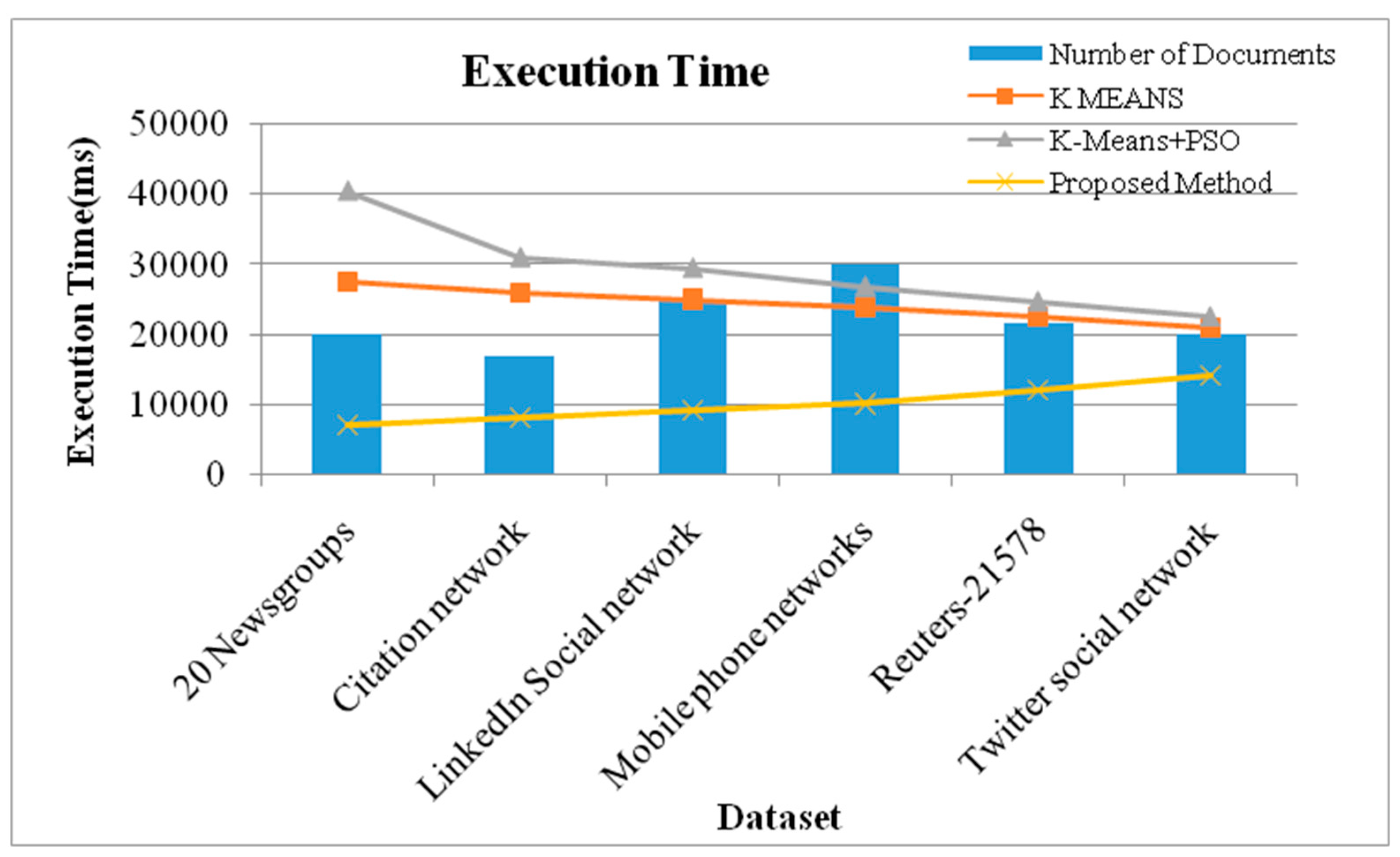
Investigation of Accuracy and Execution Time
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Judith, J.E.; Jayakumari, J. Distributed document clustering analysis based on a hybrid method. China Commun. 2017, 14, 131–142. [Google Scholar] [CrossRef]
- Xu, H.; Lau, W.C. Optimization for speculative execution in big data processing clusters. IEEE Trans. Paral. Dist. Syst. 2016, 28, 530–545. [Google Scholar] [CrossRef]
- Kumar, D.; Bezdek, J.C.; Palaniswami, M.; Rajasegarar, S.; Leckie, C.; Havens, T.C. A hybrid approach to clustering in big data. IEEE Trans. Cybern. 2016, 46, 2372–2385. [Google Scholar] [CrossRef] [PubMed]
- Xi, X.; Jiang, D.; Wu, Y.; He, L.; Song, H.; Lv, Z. Empirical analysis and modeling of the activity dilemmas in big social networks. IEEE Access 2016, 5, 967–974. [Google Scholar]
- Wei, S.; Salim, F.D.; Song, A.; Bouguettaya, A. Clustering big spatiotemporal-interval data. IEEE Trans. Big Data 2016, 2, 190–203. [Google Scholar]
- Berberidis, D.; Kekatos, V.; Giannakis, G.B. Online censoring for large-scale regressions with application to streaming big data. IEEE Trans. Signal Process. 2015, 64, 3854–3867. [Google Scholar] [CrossRef] [PubMed]
- Rahmani, M.; Atia, G.K. Randomized robust subspace recovery and outlier detection for high dimensional data matrices. IEEE Trans. Signal Process. 2016, 65, 1580–1594. [Google Scholar] [CrossRef]
- Shi, W.; Zhu, Y.; Philip, S.Y.; Huang, T.; Wang, C.; Mao, Y.; Chen, Y. Temporal dynamic matrix factorization for missing data prediction in large scale coevolving time series. IEEE Access 2016, 4, 6719–6732. [Google Scholar] [CrossRef]
- Godfrey, P.; Gryz, J.; Lasek, P. Interactive visualization of large data sets. IEEE Trans. Knowl. Data Eng. 2016, 28, 2142–2157. [Google Scholar] [CrossRef]
- Hideyuki, S.; Shirahata, K.; Drozd, A.; Sato, H.; Matsuoka, S. GPU-accelerated large-scale distributed sorting coping with device memory capacity. IEEE Trans. Big Data 2016, 2, 57–69. [Google Scholar]
- Huan, K.; Li, P.; Guo, S.; Guo, M. On traffic-aware partition and aggregation in map reduce for big data applications. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 818–828. [Google Scholar]
- Wasi-ur-Rahman, M.D.; Islam, N.; Lu, X.; Panda, D. A comprehensive study of MapReduce over lustre for intermediate data placement and shuffle strategies on HPC clusters. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 633–646. [Google Scholar] [CrossRef]
- Fegaras, L. Incremental query processing on big data streams. IEEE Trans. Knowl. Data Eng. 2016, 28, 2998–3012. [Google Scholar] [CrossRef]
- Xia, D.; Li, H.; Wang, B.; Li, Y.; Zhang, Z. A map reduce-based nearest neighbor approach for big-data-driven traffic flow prediction. IEEE Access 2016, 4, 2920–2934. [Google Scholar] [CrossRef]
- Andriy, M.; Hamou-Lhadj, A.; Cialini, E.; Larsson, A. Operational-log analysis for big data systems: challenges and solutions. IEEE Softw. 2016, 33, 52–59. [Google Scholar]
- Jun, Z.; Zhuang, E.; Fu, J.; Baranowski, J.; Ford, A.; Shen, J. A framework-based approach to utility big data analytics. IEEE Trans. Power Syst. 2016, 31, 2455–2462. [Google Scholar]
- Ge, S.; Rochas, J.; El Beze, L.; Huet, F.; Magoules, F. K nearest neighbour joins for big data on MapReduce: A theoretical and experimental analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 2376–2392. [Google Scholar]
- Hao, W.; Chen, H.; Du, Z.; Hu, F. BeTL: MapReduce checkpoint tactics beneath the task level. IEEE Trans. Serv. Comput. 2015, 9, 84–95. [Google Scholar]
- Gao, K.; Zhu, Y. Deep data stream analysis model and algorithm with memory mechanism. IEEE Access 2016, 5, 84–93. [Google Scholar] [CrossRef]
- Iwendi, C.; Zhang, Z.; Du, X. ACO based key management routing mechanism for WSN security and data collection. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 19–22 February 2018; pp. 1935–1939. [Google Scholar] [CrossRef]
- Kutia, S.; Chauhdary, S.H.; Iwendi, C.; Liu, L.; Yong, W.; Bashir, A.K. Socio-technological factors affecting user’s adoption of ehealth functionalities: A case study of China and Ukraine eHealth Systems. IEEE Access 2019, 7, 90777–90788. [Google Scholar] [CrossRef]
- Lo’ai, A.; Rashid Mehmood, T.; Benkhlifa, E.; Song, H. Mobile cloud computing model and big data analysis for healthcare applications. IEEE Access 2016, 4, 6171–6180. [Google Scholar]
- Ranjan, R. Streaming big data processing in datacenter clouds. IEEE Cloud Comput. 2014, 1, 78–83. [Google Scholar] [CrossRef]
- Adrian, B.; She, Y.; Ding, L.; Gramajo, G. Feature selection with annealing for computer vision and big data learning. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 272–286. [Google Scholar]
- Xia, X.G. Small data, mid data, and big data versus algebra, analysis, and topology. IEEE Signal Process. Mag. 2017, 34, 48–51, perspectives. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, J.; Liu, J.; Xu, C.; Guo, H.; Liu, Y. A survey on emerging computing paradigms for big data. Chin. J. Electron. 2017, 26, 1–12. [Google Scholar] [CrossRef]
- Rysavy, S.J.; Bromley, D.; Daggett, V. DIVE: A graph-based visual-analytics framework for big data. IEEE Comput. Graph. Appl. 2014, 34, 26–37. [Google Scholar] [CrossRef] [PubMed]
- Wei, T.; Blake, M.B.; Saleh, I.; Dustdar, S. Social-network-sourced big data analytics. IEEE Internet Comput. 2013, 17, 62–69. [Google Scholar]
- Zhang, X.; Yang, L.T.; Liu, C.; Chen, J. A scalable two-phase top-down specialization approach for data anonymization using mapreduce on cloud. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 363–373. [Google Scholar] [CrossRef]
- Peng, S.; Wang, G.; Xie, D. Social influence analysis in social networking big data: Opportunities and challenges. IEEE Netw. 2016, 31, 11–17. [Google Scholar] [CrossRef]
- Qiao, Y.; Cheng, Y.; Yang, J.; Liu, J.; Kato, N. A mobility analytical framework for big mobile data in densely populated area. IEEE Trans. Veh. Technol. 2016, 66, 1443–1455. [Google Scholar] [CrossRef]
- Sakr, S. Big data processing stacks. IT Prof. 2017, 19, 34–41. [Google Scholar] [CrossRef]
- Lena, M.; Movahed Nejad, M.; Grosu, D.; Zhang, Q.; Shi, W. Energy-aware scheduling of mapreduce jobs for big data applications. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 2720–2733. [Google Scholar]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graphs over time: Densification laws, shrinking diameters and possible explanations. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Chicago, IL, USA, 21–24 August 2005. [Google Scholar]
- Hall, B.H.; Jaffe, A.B.; Trajtenberg, M. The NBER Patent Citation Data File: Lessons, Insights and Methodological Tools; NBER Working Paper 8498; NBER: Cambridge, MA, USA, 2001. [Google Scholar]
- Depeng, D.; Liu, Y.; Zhang, X.; Huang, S. A crowdsourcing worker quality evaluation algorithm on MapReduce for big data applications. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1879–1888. [Google Scholar]
- Srinivasan, K.; Chang, C.-Y.; Huang, C.-H.; Chang, M.-H.; Sharma, A.; Ankur, A. An efficient implementation of mobile raspberry Pi hadoop clusters for robust and augmented computing performance. J. Inf. Process. Syst. 2018, 14, 989–1009. [Google Scholar]
- Hua, K.; Dai, B.; Srinivasan, K.; Hsu, Y.-H.; Sharma, V. A hybrid NSCT domain image watermarking scheme. J. Image Video Process. 2017, 2017, 10. [Google Scholar] [CrossRef]
- Chang, C.Y.; Chang, C.W.; Kathiravan, S.; Lin, C.; Chen, S.T. DAG-SVM based infant cry classification system using sequential forward floating feature selection. Multidimens. Syst. Signal Process. 2017, 28, 961–976. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set Community Group | Total Number of Documents To Be Analyzed per minutes | Total Number of Documents To Be Identified per minutes | Word Occurrence Ratio | Approximate Time Interval per Analysis (Duration of Processing) | Word Detection Ratio | Approximate Time Interval per Analysis (Duration of Detection) | Approximation of Final Result (Duration of Processing)≈(Duration of Detection) | Total Comments Per File |
|---|---|---|---|---|---|---|---|---|
| CG1 | 1866 | 70 | 0.95 | 88 | 17 | 85 | 75 | 4000 |
| CG 2 | 3400 | 75 | 0.9 | 84 | 1.2 | 85 | 77 | 10,000 |
| CG 3 | 260 | 70 | 0.94 | 86 | 1.4 | 96 | 95 | 2000 |
| CG 4 | 335 | 69 | 0.91 | 82 | 14 | 97 | 88 | 1000 |
| CG 5 | 593 | 75 | 0.77 | 70 | 1.5 | 98 | 93 | 5000 |
| CG 6 | 146 | 64 | 0.74 | 90 | 16.2 | 90 | 85 | 1000 |
| CG 7 | 354 | 70 | 0.67 | 95 | 26.2 | 75 | 70 | 1000 |
| CG 8 | 546 | 55 | 1 | 90 | 1.85 | 70 | 70 | 5000 |
| CG 9 | 937 | 60 | 1 | 85 | 1.1 | 90 | 86 | 9000 |
| CG 10 | 714 | 89 | 0.85 | 85 | 18 | 96 | 89 | 1000 |
| CG 11 | 235 | 78 | 0.76 | 75 | 1.7 | 88 | 87 | 2000 |
| CG 12 | 312 | 65 | 0.7 | 70 | 2.7 | 73 | 68 | 2000 |
| CG 13 | 549 | 70 | 0.75 | 80 | 4.4 | 93 | 85 | 2000 |
| CG 14 | 455 | 65 | 0.8 | 65 | 13.5 | 40 | 35 | 4000 |
| CG 15 | 335 | 70 | 0.88 | 90 | 12.9 | 72 | 65 | 2000 |
| CG 16 | 615 | 55 | 0.66 | 75 | 1.2 | 86 | 80 | 2000 |
| CG 17 | 3610 | 60 | 0.74 | 60 | 1.4 | 96 | 90 | 10,000 |
| CG 18 | 356 | 77 | 0.69 | 75 | 15.1 | 72 | 70 | 2000 |
| CG 19 | 712 | 80 | 0.8 | 95 | 3.6 | 42 | 35 | 1000 |
| CG 20 | 482 | 73 | 0.82 | 87 | 16 | 85 | 75 | 4000 |
| CG 21 | 3321 | 73 | 0.88 | 83 | 1.4 | 89 | 79 | 10,000 |
| CG 22 | 255 | 67 | 0.92 | 85 | 1.3 | 98 | 98 | 3000 |
| CG 23 | 315 | 67 | 0.9 | 80 | 13.5 | 96 | 86 | 1000 |
| CG 24 | 875 | 75 | 0.608 | 50 | 2.7 | 90 | 80 | 8000 |
| Total | 21,578 | 1672 | 19.538 | 1925 | 189.85 | 2002 | 1861 | 92,000 |
| Data Set Community Group | Total Comments per File | Total Number of Documents To Be Analyzed Per Minutes | Total Number of Documents To Be Identified Per Minutes | Words Occurrence Ratio | Approximate Time Interval Per Analysis (Duration of Processing) | Approximate Time Interval Per Analysis (Duration of Detection) | Word Detection Ratio | Approximation of Final Result |
|---|---|---|---|---|---|---|---|---|
| CG 7 | 1000 | 354 | 80 | 0.760 | 95 | 75 | 26.2 | 70 |
| CG 10 | 1000 | 714 | 194 | 0.760 | 85 | 96 | 18 | 89 |
| CG1 | 4000 | 1866 | 70 | 0.951 | 88 | 85 | 17 | 75 |
| CG 6 | 1000 | 146 | 64 | 0.581 | 90 | 90 | 16.2 | 85 |
| CG 20 | 4000 | 482 | 73 | 0.825 | 87 | 85 | 16 | 75 |
| CG 18 | 2000 | 356 | 77 | 0.767 | 75 | 72 | 15.1 | 70 |
| CG 4 | 1000 | 335 | 69 | 0.770 | 82 | 97 | 14 | 88 |
| CG 14 | 4000 | 455 | 65 | 0.829 | 65 | 40 | 13.5 | 35 |
| CG 23 | 1000 | 315 | 67 | 0.762 | 80 | 96 | 13.5 | 86 |
| CG 15 | 2000 | 335 | 70 | 0.768 | 90 | 72 | 12.9 | 65 |
| CG 13 | 2000 | 549 | 70 | 0.848 | 80 | 93 | 4.4 | 85 |
| CG 19 | 1000 | 712 | 80 | 0.869 | 95 | 42 | 3.6 | 35 |
| CG 12 | 2000 | 312 | 65 | 0.764 | 70 | 73 | 2.7 | 68 |
| CG 24 | 8000 | 875 | 75 | 0.896 | 50 | 90 | 2.7 | 80 |
| CG 8 | 5000 | 546 | 44 | 0.885 | 90 | 70 | 1.85 | 70 |
| CG 11 | 2000 | 235 | 125 | 0.586 | 75 | 88 | 1.7 | 87 |
| CG 5 | 5000 | 593 | 75 | 0.852 | 70 | 98 | 1.5 | 93 |
| CG 3 | 2000 | 260 | 70 | 0.715 | 86 | 96 | 1.4 | 95 |
| CG 17 | 10,000 | 3610 | 119 | 0.962 | 60 | 96 | 1.4 | 90 |
| CG 21 | 10,000 | 3321 | 73 | 0.971 | 83 | 89 | 1.4 | 79 |
| CG 22 | 3000 | 255 | 67 | 0.717 | 85 | 98 | 1.3 | 98 |
| CG 2 | 10,000 | 3400 | 12 | 0.989 | 84 | 85 | 1.2 | 77 |
| CG 16 | 2000 | 615 | 55 | 0.882 | 75 | 86 | 1.2 | 80 |
| CG 9 | 9000 | 937 | 85 | 0.893 | 85 | 90 | 1.1 | 86 |
| Total | 92,000 | 21,578 | 1672 |
| URL. | Time Delta | n_tokens_title | n_tokens_content | abs_title_subjectivity | abs_title_sentiment_polarity | Shares |
|---|---|---|---|---|---|---|
| http://mashable.com/2013/01/07/amazon-instant-video-browser/ | 731 | 12 | 219 | 0 | 0 | 593 |
| http://mashable.com/2013/01/07/ap-samsung-sponsored-tweets/ | 731 | 9 | 255 | 1 | 0 | 711 |
| http://mashable.com/2013/01/07/apple-40-billion-app-downloads/ | 731 | 9 | 211 | 1 | 0 | 1500 |
| http://mashable.com/2014/12/27/son-pays-off-mortgage/ | 8 | 10 | 442 | 0 | 0 | 1900 |
| http://mashable.com/2014/12/27/ukraine-blasts/ | 8 | 6 | 682 | 1 | 0 | 1100 |
| Procedure | Criterion | Dataset | Access | Update | Schema Structure | Integrity | Speed |
|---|---|---|---|---|---|---|---|
| Occurrence | Data Size | 20 Newsgroups | Constant data | Depends on version | Static schema | High | MB/Sec |
| Citation network | Partial Streaming data | depends on database | Dynamic schema | Low | GB/sec | ||
| LinkedIn Social network | Streaming data | Depends on user input | Dynamic schema | High | GB/sec | ||
| Mobile phone networks | Ad-hoc data | depends on database | Dynamic schema | Low | GB/sec | ||
| Reuters-21578 | Constant data | Depends on version | Static schema | High | MB/Sec | ||
| Twitter social network | Streaming data | Depends on user input | Dynamic schema | Low | GB/sec | ||
| Detection | Mapping | 20 Newsgroups | 43.3MB(.srt) | Standard | Yes | - | Fast |
| Citation network | 250 GB | Fixed | No | - | Moderate | ||
| LinkedIn Social network | ≈1 TB | Streaming | No | - | Slow down | ||
| Mobile phone networks | ≈500 GB | Fixed- Streaming | No | - | Moderate | ||
| Reuters-21578 | 26.6(.sgm) | Standard | Yes | - | Fast | ||
| Twitter social network | ≈1 TB | Streaming | No | - | Slow down |
| Various Citation-Network Version | Total Number of Papers | Citation Relationship |
|---|---|---|
| Citation-network V1, V2, DBLP-Citation-network V3, V4, V5, V6, V7, V8, and ACM-Citation-network V8 | 16,725,563 | 33,069,449 |
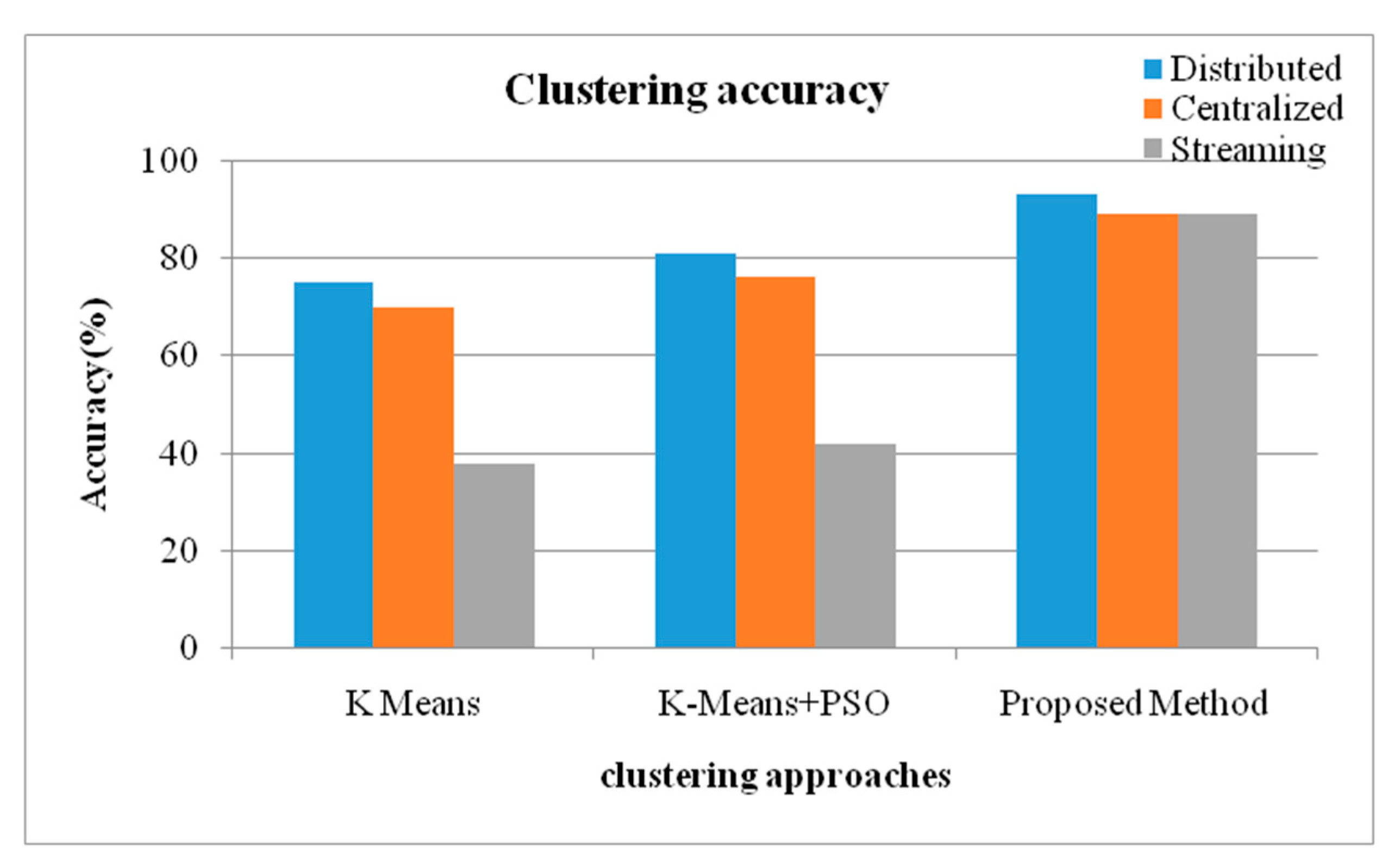
| Methods | Distributed | Centralized | Streaming |
|---|---|---|---|
| K Means | 75 | 70 | 38 |
| K-Means + PSO | 81 | 76 | 42 |
| Proposed Method | 93 | 89 | 89 |
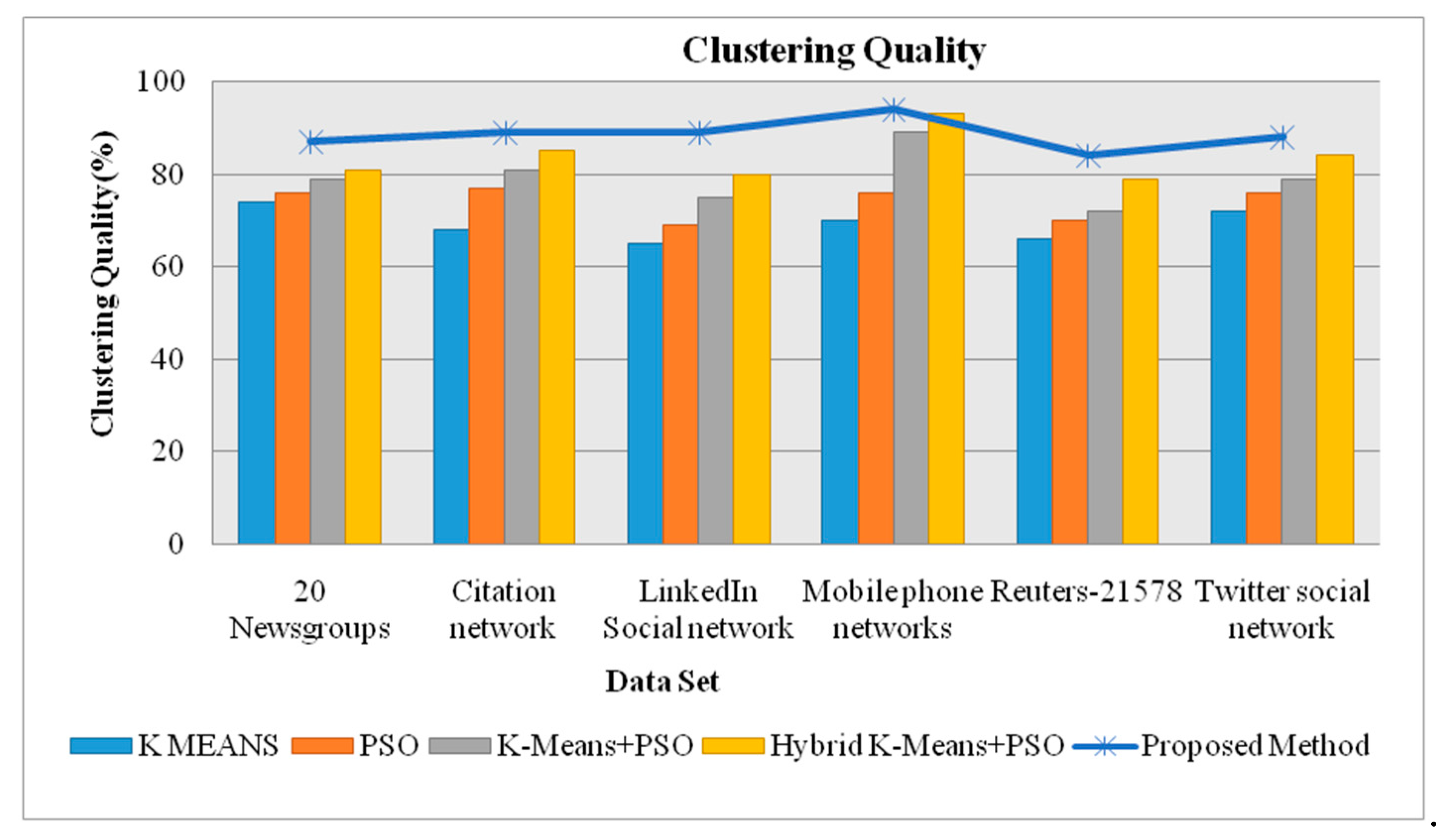
| Dataset | K Means | PSO | K-Means + PSO | Hybrid K-Means + PSO | Proposed Method |
|---|---|---|---|---|---|
| 20 Newsgroups | 74 | 76 | 79 | 81 | 87 |
| Citation network | 68 | 77 | 81 | 85 | 89 |
| LinkedIn Social network | 65 | 69 | 75 | 80 | 89 |
| Mobile phone networks | 70 | 76 | 89 | 93 | 94 |
| Reuters-21578 | 66 | 70 | 72 | 79 | 84 |
| Twitter social network | 72 | 76 | 79 | 84 | 88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iwendi, C.; Ponnan, S.; Munirathinam, R.; Srinivasan, K.; Chang, C.-Y. An Efficient and Unique TF/IDF Algorithmic Model-Based Data Analysis for Handling Applications with Big Data Streaming. Electronics 2019, 8, 1331. https://doi.org/10.3390/electronics8111331
Iwendi C, Ponnan S, Munirathinam R, Srinivasan K, Chang C-Y. An Efficient and Unique TF/IDF Algorithmic Model-Based Data Analysis for Handling Applications with Big Data Streaming. Electronics. 2019; 8(11):1331. https://doi.org/10.3390/electronics8111331
Chicago/Turabian StyleIwendi, Celestine, Suresh Ponnan, Revathi Munirathinam, Kathiravan Srinivasan, and Chuan-Yu Chang. 2019. "An Efficient and Unique TF/IDF Algorithmic Model-Based Data Analysis for Handling Applications with Big Data Streaming" Electronics 8, no. 11: 1331. https://doi.org/10.3390/electronics8111331