Analysis of Information-Based Nonparametric Variable Selection Criteria


1
Institute of Computer Science, Polish Academy of Sciences, Jana Kazimierza 5, 01-248 Warsaw, Poland
2
Faculty of Mathematics and Information Science, Warsaw University of Technology, Koszykowa 75, 00-662 Warsaw, Poland
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(9), 974; https://doi.org/10.3390/e22090974
Submission received: 6 August 2020
/
Revised: 28 August 2020
/
Accepted: 28 August 2020
/
Published: 31 August 2020
(This article belongs to the Special Issue Nonparametric Statistical Inference with an Emphasis on Information-Theoretic Methods)
Abstract
:We consider a nonparametric Generative Tree Model and discuss a problem of selecting active predictors for the response in such scenario. We investigated two popular information-based selection criteria: Conditional Infomax Feature Extraction (CIFE) and Joint Mutual information (JMI), which are both derived as approximations of Conditional Mutual Information (CMI) criterion. We show that both criteria CIFE and JMI may exhibit different behavior from CMI, resulting in different orders in which predictors are chosen in variable selection process. Explicit formulae for CMI and its two approximations in the generative tree model are obtained. As a byproduct, we establish expressions for an entropy of a multivariate gaussian mixture and its mutual information with mixing distribution.
1. Introduction
In the paper, we consider theoretical properties of Conditional Mutual Information (CMI) and its approximations in a certain dependence model called Generative Tree Model (GTM). CMI and its modifications are used in many problems of machine learning including feature selection, variable importance ranking, causal discovery, and structure learning of dependence networks (see, e.g., Reference [1,2]). They are the cornerstone of nonparametric methods to solve such problems meaning that no parametric assumptions on dependence structure are imposed. However, formal properties of these criteria remain largely unknown. This is mainly due to two problems: firstly, theoretical values of CMI and related quantities are hard to calculate explicitly, especially when the conditioning set has a large dimension. Moreover, there are only a few established facts about behavior of their sample counterparts. Such a situation, however, has important consequences. In particular, a relevant question whether certain information based criteria, such as Conditional Infomax Feature Extraction (CIFE) and Joint Mutual Information (JMI), obtained as approximations of CMI, e.g., by truncation of its Möbius expansion are approximations in analytic sense (i.e., whether the difference of both quantities is negligible) remains unanswered. In the paper, we try to fill this gap. The considered GTM is a model for which marginal distributions of predictors are mixtures of gaussians. Exact values of CMI, as well as of those of CIFE and JMI, are calculated for this model, which makes studying their behavior when parameters of the model and number of predictors change feasible. In particular, it is shown that CIFE and JMI exhibit different behavior than CMI and also they may significantly differ between themselves. In particular, we show, that depending on the value of model parameters, each of considered criteria JMI and CIFE can incorporate inactive variables before active ones into a set of chosen predictors. This, of course, does not mean that important performance criteria, such as False Detection Rate (FDR), cannot be controlled for CIFE and JMI but should serve as a cautionary note that their similarity to CMI, despite their derivation, is not necessarily ensured. As a byproduct, we establish expressions for an entropy of a multivariate gaussian mixture and its mutual information with mixing distribution, which are of independent interest.
We stress that our approach is intrinsically nonparametric and focuses on using nonparametric measures of conditional dependence for feature selection. By studying their theoretical behavior for this task we also learn an average behavior of their empirical counterparts for large sample sizes.
Generative Tree Model appears, e.g., in Reference [3], a non-parametric tree structured model is also considered, e.g., in Reference [4,5]. Together with autoregressive model, it is one of the two most common types of generative models. Besides its easily explainable dependence structure, distributions of predictors in the considered model are mixed gaussians, and this facilitates calculation of explicit form of information-based selection criteria.
The paper is structured as follows. Section 2 contains information-theoretic preliminaries, some necessary facts on information based feature-selection and derivation of CIFE and JMI criteria as approximations of CMI. Section 3 contains derivation of entropy and mutual information for gaussian mixtures. In Section 4, behavior of CMI, CIFE, and JMI is studied in GTM. Section 5 concludes.
2. Preliminaries
We denote by , a probability density function corresponding to continuous variable X on . Joint density of X and variable Y will be denoted by . In the following, Y will denote discrete random response to be predicted using multivariate vector X.
Below, we discuss some information-theoretic preliminaries, which leads, at the end of Section 2.1, to Möbius decomposition of mutual information. This is used in Section 2.2 to construct CIFE approximation of CMI. In addition, properties of Mutual Information discussed in Section 2.1 are used in Section 2.2 to justify JMI criterion.
2.1. Information-Theoretic Measures of Dependence
The (differential) entropy for continuous random variable X is defined as
and quantifies the uncertainty of observing random values of X. Note that the definition above is valid regardless the dimensionality d of the range of X. For discrete X, we replace the integral in (1) by the sum and density by probability mass function. In the following, we will frequently consider subvectors of , which is a vector of all potential predictors of discrete response Y. The conditional entropy of X given discrete Y is written as
When Z is continuous, the conditional entropy is defined as , i.e.,
where and denote joint density of and density of Z, respectively. The mutual information (MI) between X and Y is
This can be interpreted as the amount of uncertainty in X (Y) which is removed when Y (respectively, X) is known, which is consistent with the intuitive meaning of mutual information as the amount of information that one variable provides about another. It determines how similar the joint distribution is to the product of marginal distributions when Kullback-Leibler divergence is used as similarity measure (cf. Reference [6], Equation (8.49)). Thus, may be viewed as nonparametric measure of dependence. Note that, as is symmetric, it only shows the strength of dependence but not its direction. In contrast to correlation coefficient MI is able to discover non-linear relationships as it equals zero if and only if X and Y are independent. It is easily seen that . A natural extension of MI is conditional mutual information (CMI) defined as
which measures the conditional dependence between X and Y given Z. When Z is a discrete random variable, the first integral is replaced by a sum. Note that the conditional mutual information is mutual information of X and Y given averaged over values z of Z, and it equals zero if and only if X and Y are conditionally independent given Z. Important property of MI is a chain rule which connects with :
For more properties of the basic measures described above, we refer to Reference [6,7]. We define now interaction information II ([8]), which is a useful tool for decomposing mutual information between multivariate random variable and Y (see Formula (13) below). The 3-way interaction information is defined as
This is frequently interpreted as the part of , which remains after subtraction of individual informations between Y and and Y and . The definition indicates in particular that is symmetric. Note that it follows from (6) that
which is consistent with the intuitive meaning of existence of interaction as a situation in which the effect of one variable on the class variable Y depends on the value of another variable. By expanding all mutual informations on RHS of (7), we obtain
The 3-way can be extended to the general case of p variables. The p-way interaction information [9,10] is
We consider two useful properties of introduced measures. We first start with 3-way information interaction, and we note that it inherits chain-rule property from MI, namely
where is defined analogously to (7) by replacing mutual informations on RHS by conditional mutual informations given . This is easily proved by writing, in the view of (6):
and using (8) in the above equalities. Namely, joining the first and the third expression together (and the second and the fourth, as well), we obtain that RHS equals .
We also state Möbius representation of mutual information which plays an important role in the following development. For , let be a random vector coordinates of which have indices in S. Möbius representation [10,11,12] states that can be recovered from interaction informations
where denotes number of elements of set S.
2.2. Information-Based Feature Selection
We consider discrete class variable Y and p features . We do not impose any assumptions on dependence between Y and , i.e., we view its distributional structure in a nonparametric way. Let denote a subset of features, indexed by set . As does not decrease when S is replaced by its superset , the problem of finding has a trivial solution . Thus, one usually tries to optimize mutual information between and Y under some constraints on the size of S. The most intuitive approach is an analogue of k-best subset selection in regression which tries to identify a feature subset of a fixed size that maximizes the joint mutual information with a class variable Y. However, this is infeasible for large k because the search space grows exponentially with the number of features. As a result, various greedy algorithms have been developed including forward selection, backward elimination and genetic algorithms. They are based on observation that
where is a complement of S. The equality in (14) follows from (6). In each step, the most promising candidate is added. In the case of ties in (14), the variable satisfying it with the smallest index is chosen.
2.3. Approximations of CMI: CIFE and JMI Criteria
Observe that it follows from (13)
Direct application of the above formula to find the maximizer in (14) is infeasible as estimation of a specific information interaction of order k requires observations. The above formula allows us, however, to obtain various natural approximations of CMI. The first order approximation does not take interactions between features into account and that is why the second order approximation obtained by taking first two terms in (15) is usually considered. The corresponding score for candidate feature is
The acronym CIFE stand for Conditional Infomax Feature Extraction, and the measure has been introduced in Reference [13]. Observe that if interactions of order 3 and higher between predictors are 0, i.e., for and then CIFE coincides with CMI. In Reference [2], it is shown that CMI also coincides with CIFE if certain dependence assumptions on vector are satisfied. In view of the discussion above, CIFE can be viewed as a natural approximation to CMI.
Observe that, in (16), we take into account not only relevance of the candidate feature, but also the possible interactions between the already selected features and the candidate feature. The empirical evaluation indicates that (16) is among the most successful MI-based methods; see Reference [2] for an extensive comparison of several MI-based feature selection approaches. We mention in this context, Reference [14], in which stopping rules for CIFE-based methods are considered.
Some additional assumptions lead to other score functions. We show now reasoning leading to Joint Mutual Information Criterion JMI (cf. Reference [12], on which the derivation below is based). Namely, if we define , we have for
Summing these equalities over all and dividing by , we obtain
and analogously
Subtracting the two last equations and using (8), we obtain
Moreover, it follows from (8) that when is independent of given and these quantities are independent given and Y the last sum is 0 and we obtain equality
This is Joint Mutual Information Criterion (JMI) introduced in Reference [15]. Note that (18) together with (8) imply another useful representation
JMI can be viewed as an approximation of CMI when independence assumptions on which the above derivation was based are satisfied only approximately. Observe that differs from in that the influence of the sum of interaction informations is down weighted by factor instead of 1. This is sometimes interpreted as coping with ‘redundancy over-scaled’ problem (cf. Reference [2]). When the terms are omitted from the sum above then minimal redundancy maximal relevance (mRMR) criterion is obtained [16]. We note that approximations of CMI, such as CIFE or JMI, can be used in place of CMI in (14). As the derivation in both cases is quite intuitive, it is natural to ask how the approximations compare when used for selection. This is the primary aim of the present paper. Theoretical behavior of such methods will be investigated in the following sections. Note that we do not consider empirical counterparts of the above selection rules and investigate how they would behave provided their values have been known exactly.
3. Auxiliary Results: Information Measures for Gaussian Mixtures
In the following section, we will prove some results on information-theoretic properties of gaussian mixtures which are necessary to analyze the behavior of CMI, CIFE, and JMI in Generative Tree Model defined below.
In the next section, we will consider a gaussian Generative Tree Model, in which the main components have marginal distributions being mixtures of normal distributions. Namely, if Y has Bernoulli distribution (i.e., it admits values 0 and 1 with probability 1/2) and distribution of X is defined as , then X is a mixture of two normal distributions: and with equal weights. Thus, in this section, we state auxiliary results on entropy of such random variable and its mutual information with its mixing distribution. The result for entropy of multivariate gaussian mixture, to the best of our knowledge, is new; for univariate case, it was derived in Reference [17]. Bounds and approximations of the entropy of a gaussian mixture are used, e.g., in signal processing; see, e.g., Reference [18,19]. Consider d-dimensional gaussian mixture X defined as
where ‘∼’ signifies ‘distributed as’.
Theorem 1.
Differential entropy of X in (20) equals
where is the differential entropy of one-dimensional gaussian mixture for .
Proof.
In order to avoid burdensome notation, we prove the theorem for only. By the definition of differential entropy, we have
where X is defined in (20) for , and denotes the density of normal distribution with a mean and a covariance matrix .
We calculate the integral above changing the variables according to the following rotation
Transformed densities and are equal
and
Applying above transformation, we can decompose into sum of two integrals as follows:
where in the last equality the value for variable Z is used. This ends the proof. □
The result above is now generalized to the case of arbitrary covariance matrix . The general case will follow from Theorem 1 and the scaling property of differential entropy under linear transformations.
Theorem 2.
Differential entropy of
equals
Proof.
We apply Theorem 1 to multivariate random variable . We obtain
Using the scaling property of differential entropy [6], we have
which completes the proof. □
Similarly, we obtain the formula for mutual information of gaussian mixture and its mixing distribution. We use shorthand to denote random variable defined as having distribution coinciding with conditional distribution .
Theorem 3.
Mutual information of X and Y where and equals
Proof.
We will use here the fact that the entropy of multidimensional normal distribution equals (cf. Reference [6], Theorem 8.4.1)
Therefore, we have
as
where stands for the entropy of X on the stratum . We notice that , as the distribution of X on stratum is normal with covariance matrix , and its entropy does not depend on the mean. □
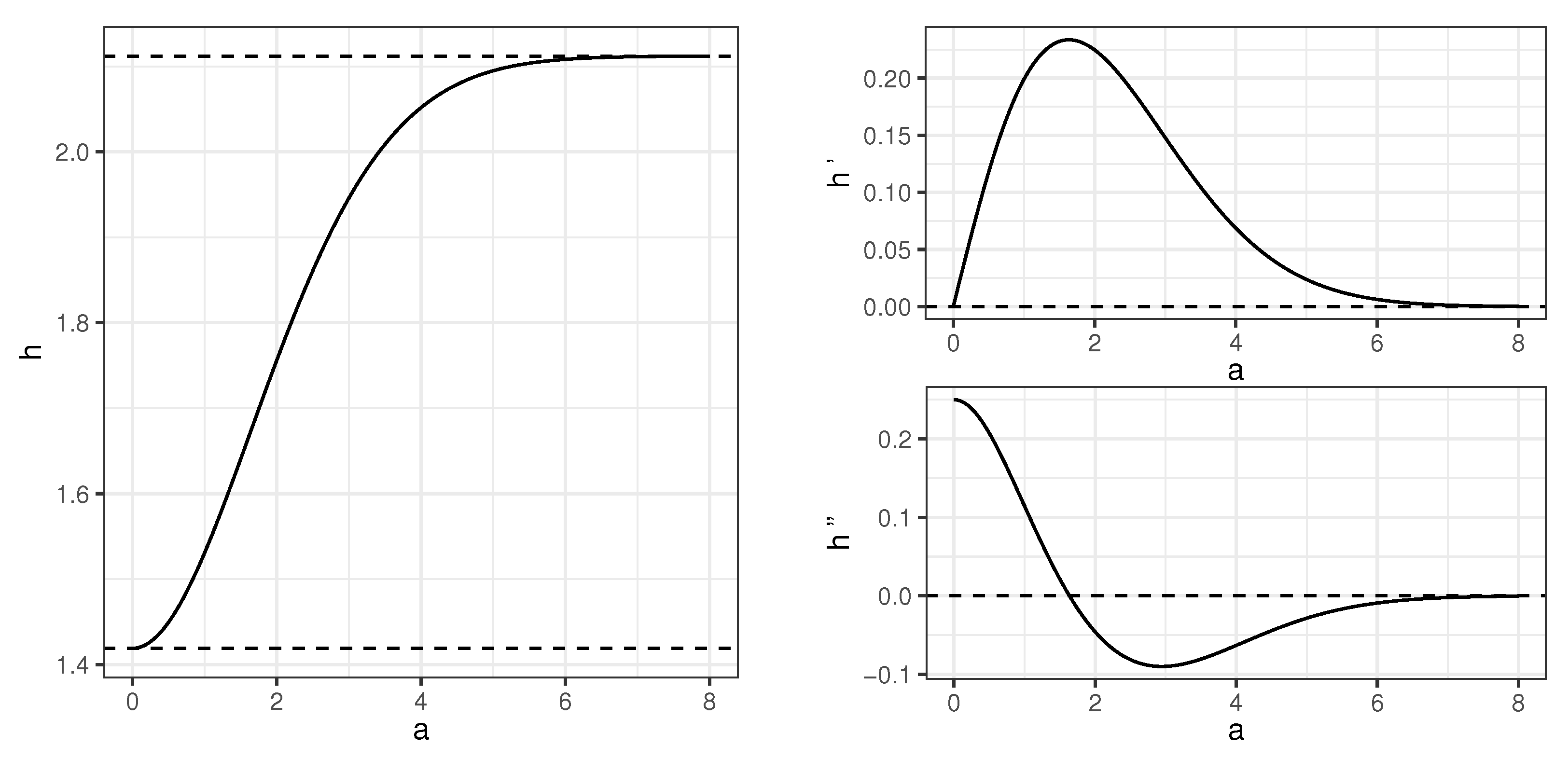
We note that, in Reference [17], entropy of one-dimensional Gaussian mixture is calculated as , where is given in an integral form. As the entropy is invariant with respect to translation, function defined above equals . The behavior of h and its two first derivatives is shown in Figure 1. It indicates that the function h is strictly increasing, and this fact is also stated in Reference [17] without proof. This is proved formally below. Strict monotonicity of h plays a crucial role in determining the order in which variables are included in a set of active variables. Note that , which is the entropy of the standard normal variable. Values of h need to be calculated numerically.
Lemma 1.
Differential entropy of gaussian mixture defined in Theorem 1 is strictly increasing function of a.
Proof.
It is easy to see that h is differentiable and for calculation of its derivative, integration in (21) and taking derivatives can be interchanged. We show that derivative of h is positive. We have by standard manipulations, using the fact that is an odd function for the second equality below, that
We have used change of variables for the third and the fifth equality above. It follows from the last expression that as for and , and, therefore, h is increasing. □
Remark 1.
Note that Theorems 2 and 3 in conjunction with Lemma 1 show that entropy of mixture of two gaussians with the same covariance matrix and its mutual information with mixing distribution is strictly increasing function of the norm . In particular, for , entropy increases as the distance between centers of two gaussians increases. In addition, it follows from (22) and that for any .
4. Main Results: Behavior of Information-Based Criteria in Generative Tree Model
In the following, we define a special gaussian Generative Tree Model and investigate how greedy procedure based on (14), as well as its analogues when CMI is replaced by JMI and CIFE, behaves in this model. Theorem 22 proved in the previous section will yield explicit formulae for CMIs in this model, whereas strict monotonicity of function proved in Lemma 1 will be essential to compare values of for different candidates .
4.1. Generative Tree Model
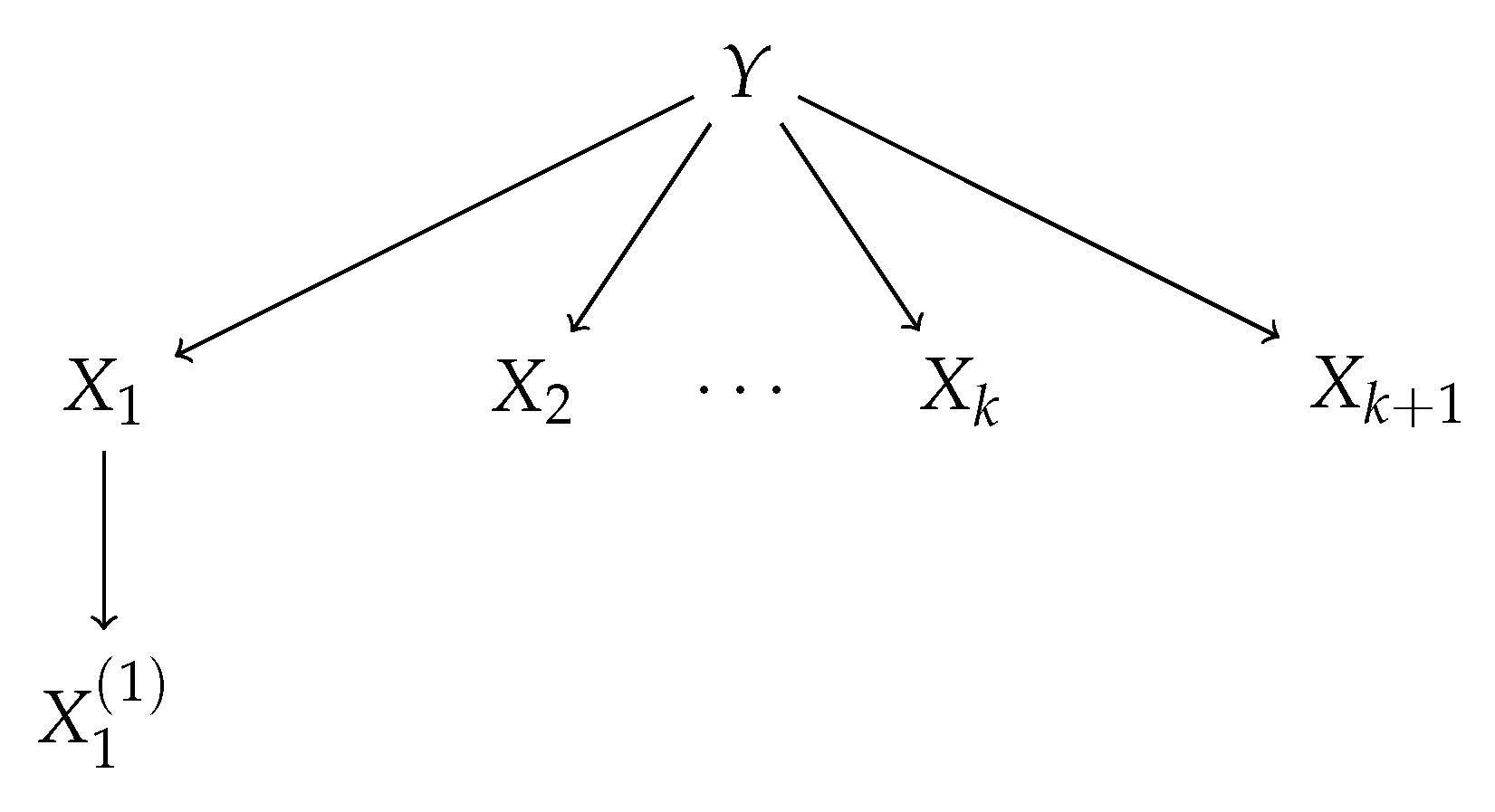
We will consider the Generative Tree Model with tree structure illustrated in the Figure 2. Data Generating Process described by this model yields the distribution of the random vector such that:
where is the parameter. Thus, first the value is generated with both values 0 and 1 having the same probability 1/2; then, are generated as normal variables with the variance 1 and the mean equal to Y. Finally, once the value of is obtained, is generated from normal distribution with the variance 1 and the mean equal to . Thus, in the sense specified above, are the children of Y and is the child of . Parameter controls how difficult the problem of feature selection is. Namely, the smaller the parameter is, the less information holds about Y for . We will refer to the model defined above as . We denote by, abusing slightly the notation, bivariate densities and by marginal densities. With this notation, the joint density equals
which can be more succinctly written as
after renaming the variables to and E and V standing for edges and vertices in the graph shown in Figure 2 (cf. formula (4.1) in Reference [4]).
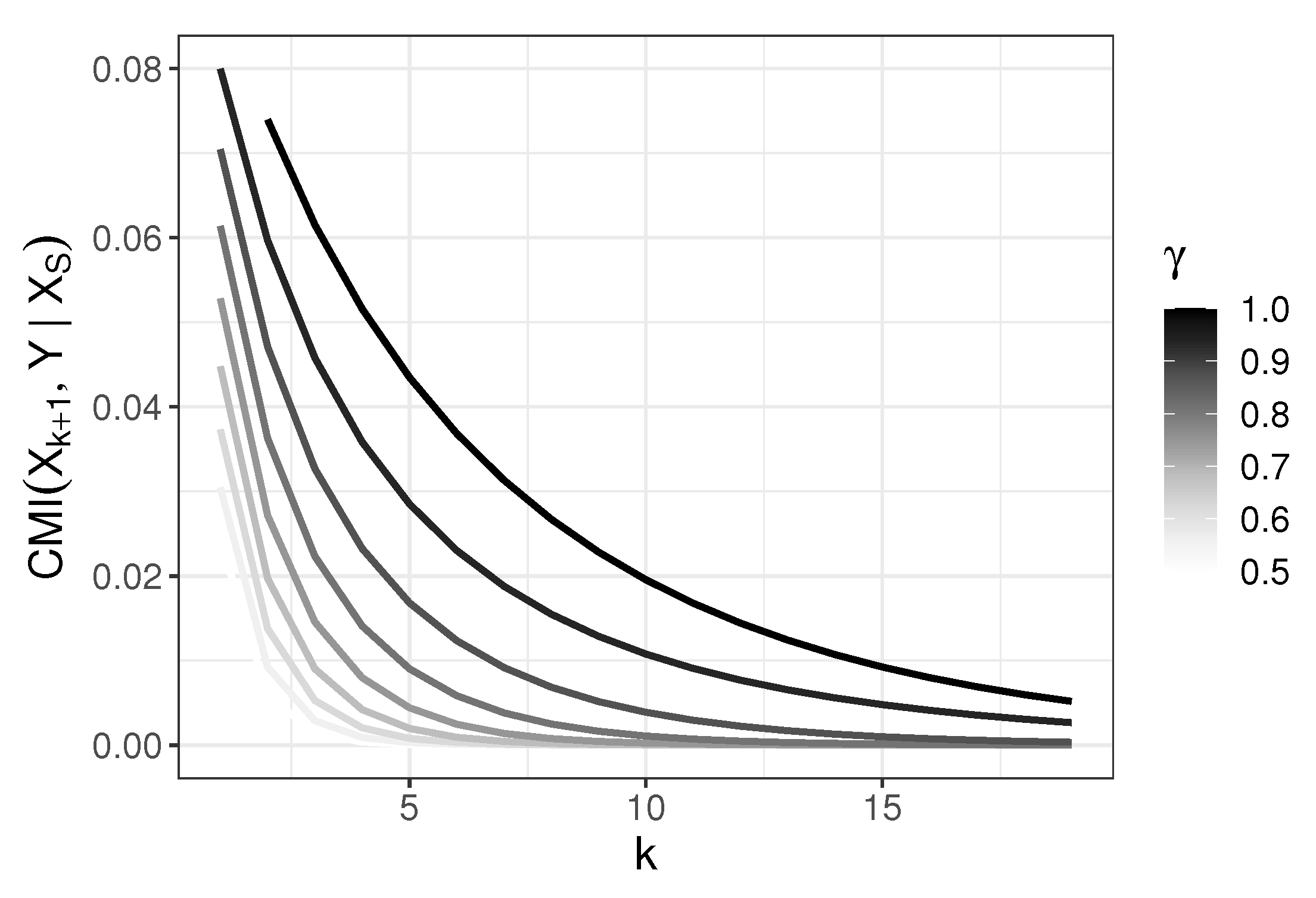
The above model generalizes the model discussed in Reference [3], but some branches which are irrelevant in our considerations are omitted. The values of conditional mutual information in the model, where for different as a function of k are shown in the Figure 3. We prove in the following that ; thus, carries non-null predictive information about Y even when variables are already chosen as predictors. We note that for every and containing . Thus, is the Markov Blanket (cf., e.g., Reference [22]) of Y among predictors and is sufficient for Y (cf. Reference [23]). A more general model may be considered which incorporates children of every vertex , and several levels of progeny. Here, we show how one variable which does not belong to Markov Blanket of Y is treated differently by the considered selection rules.
Intuitively, for and carry more information about Y than and, moreover, is redundant once has been chosen. Thus, predictors should be chosen in order . For , the order of selection of is also in concordance with our convention of breaking ties, but should not be chosen. We show in the following that CMI chooses variables in this order; however, the order with respect to its approximations, CIFE, and JMI may be different. We also note that alternative way of representing predictors is
for , where are i.i.d. . Thus, in particular
with . Moreover, it is seen that .
It is shown in Reference [2] that maximization of is equivalent to maximization of provided that selected features in are independent and class-conditionally independent given unselected features . It is easily seen that these properties do not hold in the considered GTM for and for . It can also be seen by a direct calculation that CMI differs from CIFE in GTM. Take and . Then, note that the difference between these quantities equals
Moreover, using conditional independence, we have
and
thus, plugging the above equalities into (27) and using , we obtain that expression there equals , which is strictly positive in the considered GTM.
Similar considerations concerning conditions stated above (18) show that maximization of JMI is not equivalent to maximization of CMI in GTM. Namely, if and , then it is easily seen that and for ; thus, the last term in (17) is negative.
In order to support this numerically for a specific case, consider . In the first column of the Table 1a, MI values are shown for this value of . They were calculated in Reference [3] using simulations, while here they are based on (23) and numerical evaluation of . Additionally, in Table 1, CMI values from subsequent steps and JMI and CIFE values in such a model are shown. As a foretaste of the analysis which follows, note that, in view of panel (b) of the table, JMI chooses erroneously in the third step instead of in contrast to CIFE (cf. part (c) of the table) which chooses in the right order. Note also that, in this case, is the second largest mutual informations with Y; thus, when the filter based solely on this information is considered, then is chosen at the second step (after ).
We note that analysis of behavior of CMI and its approximations including CIFE and JMI has been given in Reference [24], Section 6, for a simple model containing 4 predictors. We analyze here the behavior of these measures of conditional dependence for the general model , which involves arbitrary number of predictors having varying dependence with Y.
4.2. Behavior of CMI
First of all, we show that the criterion based on conditional mutual information CMI without any modifications chooses correct variables in the right order. It has been previously noticed that for . Now, we show that for every k. Namely, applying Theorem 3 and the chain rule for mutual information
we obtain
where the inequality follows as h is an strictly increasing function. Thus, we proved that for for every k. Whence we have for and that
thus CMI chooses predictors in a correct order. Figure 3 shows behavior of as the function of k for various . Note that it follows from Figure 3 that is decreasing. This means that the additional information on Y obtained when is incorporated gets smaller with k. Now, we study the order in which predictors are chosen with respect to JMI and CIFE.
4.3. Behavior of JMI
The main objective of this section is to examine performance of JMI criterion in the Generative Tree Model for different values of parameter . We will show that:
- For active predictors are chosen in the right order and is not chosen before them;
- For , variable is chosen at a certain step before all are chosen, and we evaluate a moment when this situation occurs.
Consider the model above and assume that the set of indices of currently chosen variables equals . For we apply chain rule (6) and Theorem 3 with the following covariance matrices and mean vectors for (cf. (26)):
respectively, for and . Then, we have
The last equation follows from the fact that and Y are conditionally independent given .
From the definition of , abbreviated from now on to to simplify notation, we obtain
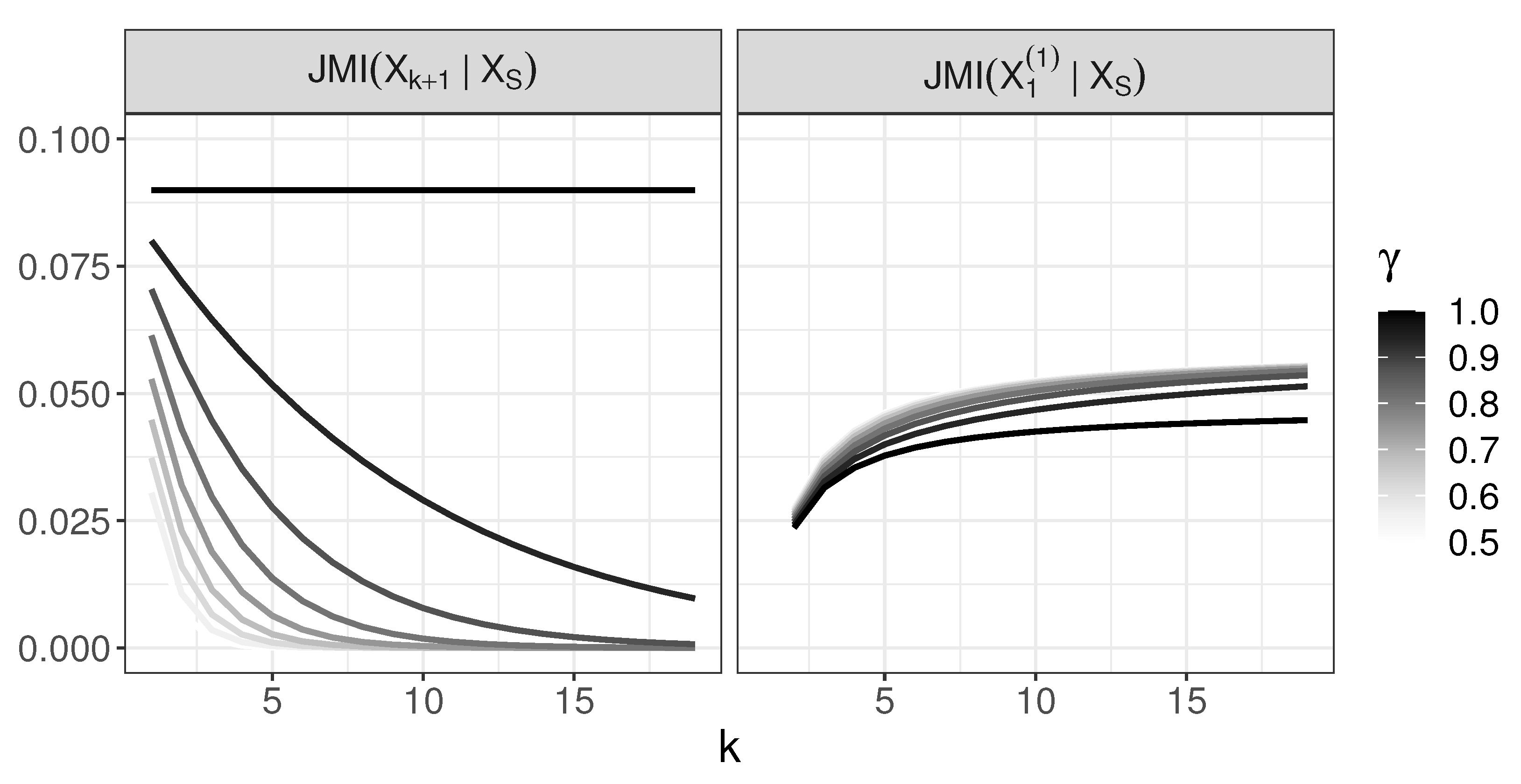
We observe that the variables are chosen in order according to JMI, as for and , we have . For , the right-hand sides of the last two expressions equal and , respectively. Thus, for , we have , which means that variables are chosen in the order and is not chosen before them when JMI criterion is used. Although, for , JMI criterion does not select this redundant feature, we note that, for , , and
which differs from for all . We note also that, in this case, does not depend on k in contrast to .
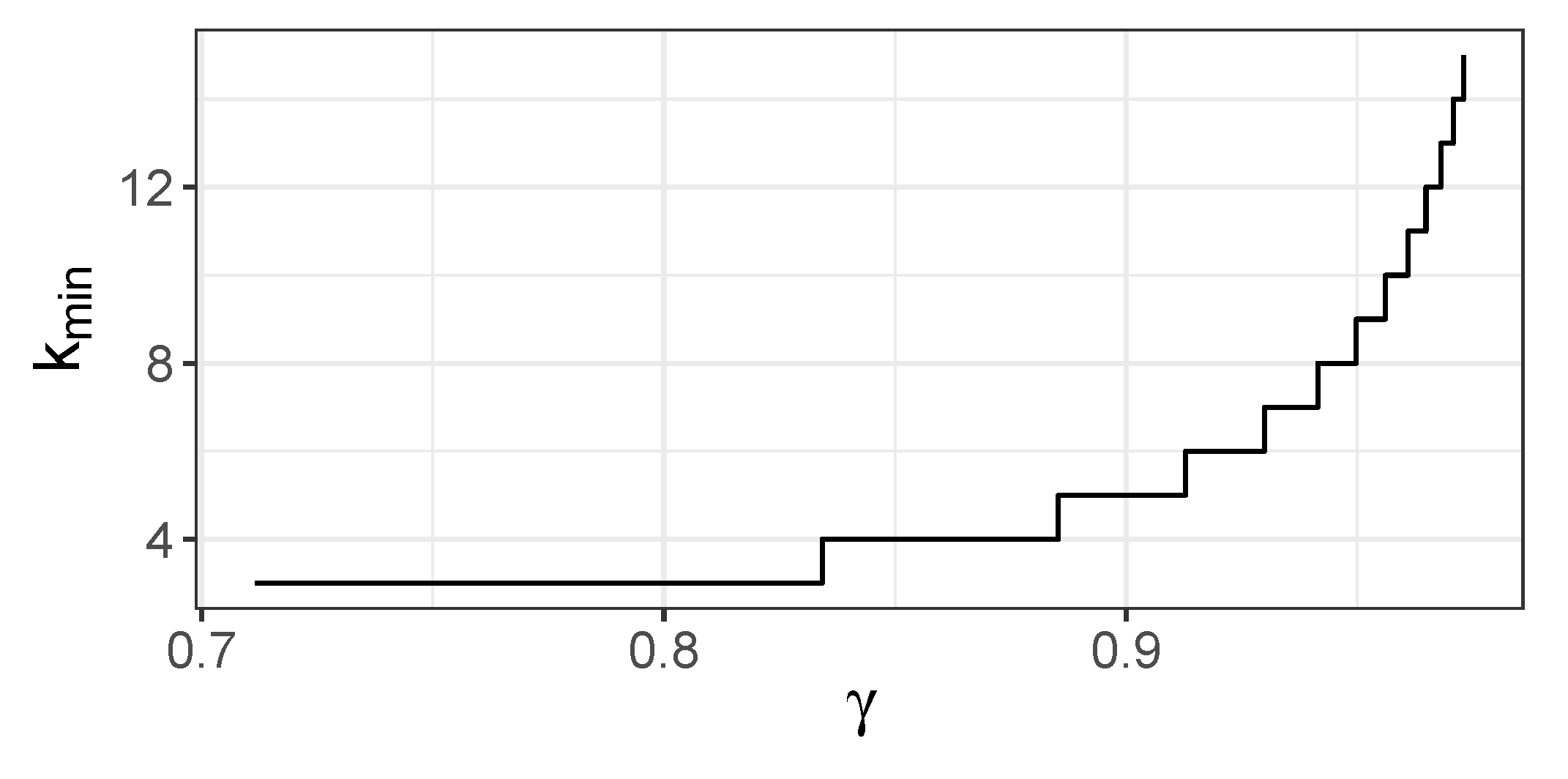
Now, we will consider the case . We want to show that, for sufficiently large k and , JMI criterion chooses since
The last inequality is equivalent to
The right-hand side tends to 0 when . For the left-hand side, note that, for , we have , and all summands of the sum above are positive, as h is an increasing function. Thus, bounding the sum by its first term, we have
4.4. Behavior of CIFE and Its Comparison with JMI
The aim of this section is to show that, although both JMI and CIFE criteria are developed as approximations to conditional mutual information, their behavior in the tree generative model differs. We will show that:
- For , CIFE incorrectly chooses at some point;
- For , CIFE selects variables in the right order.
Thus, CIFE behaves very differently from JMI in Generative Tree Model.
Analogously to formulae for JMI, we have the following formulae for CIFE ():
For , we have
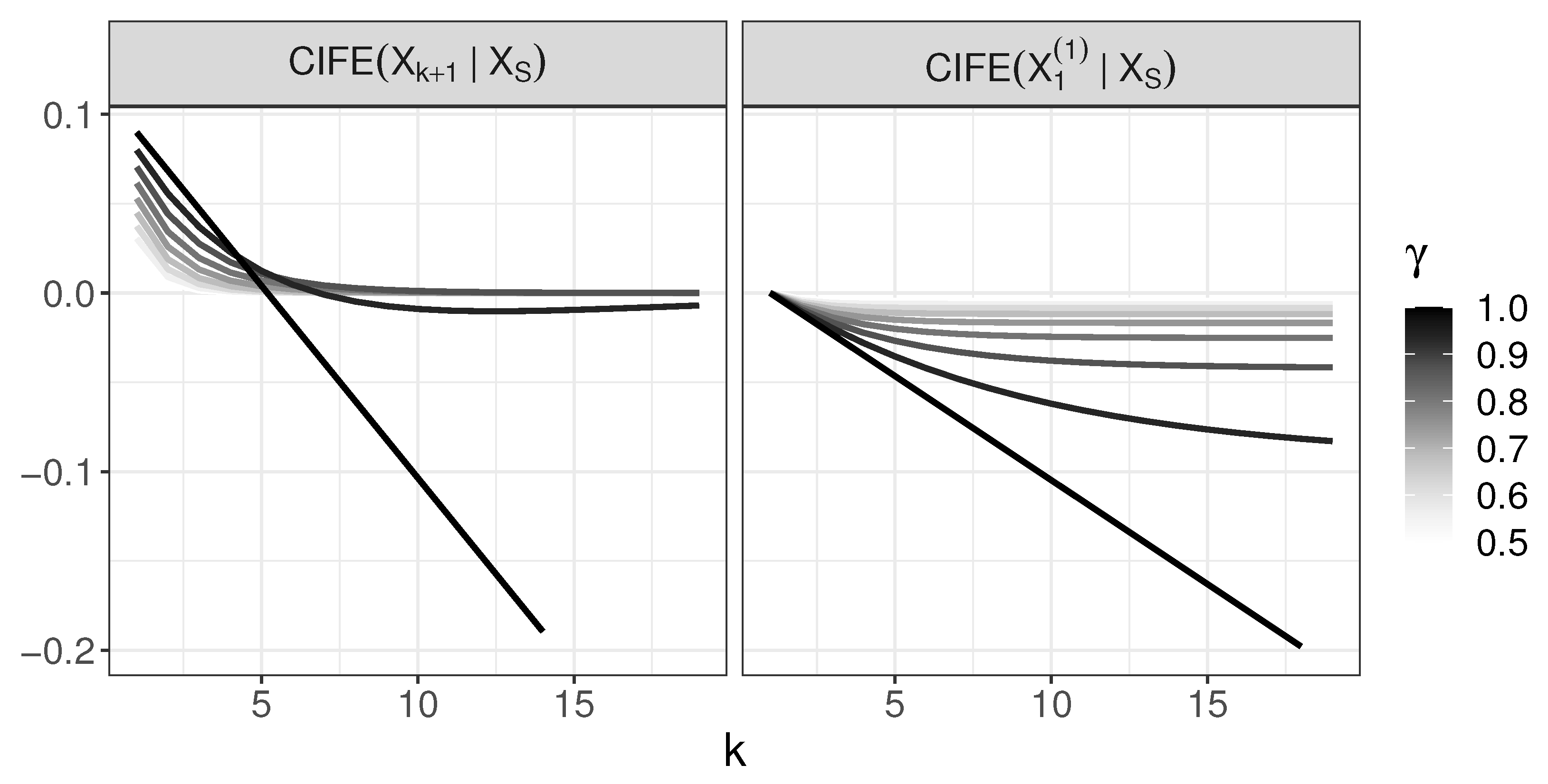
Note that both expressions above are linear functions with respect to k. Comparison of their slopes, in view of as h is an increasing function, yields that, for sufficiently large k, we obtain . The behavior of CIFE for in case of and is shown in Figure 6 and the difference between and in Figure 7. The values below 0 in the last plot occur for ; only, thus, for , we have for any k.
Furthermore, as , we have, for ,
and as , we have
In order to understand the consequences of this property, let us momentarily assume that one introduces an intuitive stopping rule which says that candidate such that is appended only when . Then, Positive Selection Rate (PSR) of such selection procedure may become arbitrarily small in model for fixed and sufficiently large k. PSR is defined as , where is a set of indices of Markov Blanket of Y and is a set of indices of the chosen variables.
5. Conclusions
We have considered , a special case of Generative Tree Model and investigated behavior of CMI and related criteria JMI and CIFE in this model. We have shown that, despite the fact that both of these criteria are derived as approximations of CMI under certain dependence conditions, their behavior may greatly differ from that of CMI in the sense that they may switch the order of variable importance and treat inactive variables as more relevant than active ones. In particular, this occurs for JMI when and CIFE for . We have also shown a drawback of CIFE procedure which consists in disregarding significant part of active variables so that PSR may become arbitrarily small in model for large k. As a byproduct, we obtain formulae for the entropy of multivariate gaussian mixture and its mutual information with mixing variable. We have also shown that the entropy of the gaussian mixture is a strictly increasing function of the euclidean distance between two centers of its components. Note that, in this paper, we investigated behavior of theoretical CMI and its approximations in GTM; for their empirical versions, we may expect exacerbation of effects described here.
Author Contributions
Conceptualization, M.Ł.; Formal analysis, J.M. and M.Ł.; Methodology, J.M. and M.Ł.; Supervision, J.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
Comments of two referees which helped to improve presentation of the original version of the manuscript are gratefully acknowledged.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Guyon, I.; Elyseeff, A. An introduction to feature selection. In Feature Extraction, Foundations and Applications; Springer: Berlin/Heidelberger, Germany, 2006; Volume 207, pp. 1–25. [Google Scholar]
- Brown, G.; Pocock, A.; Zhao, M.; Luján, M. Conditional likelihood maximisation: A unifying framework for information theoretic feature selection. J. Mach. Learn. Res. 2012, 13, 27–66. [Google Scholar]
- Gao, S.; Ver Steeg, G.; Galstyan, A. Variational Information Maximization for Feature Selection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 487–495. [Google Scholar]
- Lafferty, J.; Liu, H.; Wasserman, L. parse nonparametric graphical models. Stat. Sci. 2012, 27, 519–537. [Google Scholar] [CrossRef]
- Liu, H.; Xu, M.; Gu, H.; Gupta, A.; Lafferty, J.; Wasserman, L. Forest density estimation. J. Mach. Learn. Res. 2011, 12, 907–951. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing); Wiley-VCH: Hoboken, NJ, USA, 2006. [Google Scholar]
- Yeung, R.W. A First Course in Information Theory; Kluwer: South Holland, The Netherlands, 2002. [Google Scholar]
- McGill, W.J. Multivariate information transmission. Psychometrika 1954, 19, 97–116. [Google Scholar] [CrossRef]
- Ting, H.K. On the Amount of Information. Theory Probab. Appl. 1960, 7, 439–447. [Google Scholar] [CrossRef]
- Han, T.S. Multiple mutual informations and multiple interactions in frequency data. Inform. Control 1980, 46, 26–45. [Google Scholar] [CrossRef] [Green Version]
- Meyer, P.; Schretter, C.; Bontempi, G. Information-theoretic feature selection in microarray data using variable complementarity. IEEE J. Sel. Top. Signal Process. 2008, 2, 261–274. [Google Scholar] [CrossRef]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural. Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Lin, D.; Tang, X. Conditional infomax learning: An integrated framework for feature extraction and fusion. In European Conference on Computer Vision 2006 May 7; Springer: Berlin/Heidelberg, Germany, 2006; pp. 68–82. [Google Scholar]
- Mielniczuk, J.; Teisseyre, P. Stopping rules for information-based feature selection. Neurocomputing 2019, 358, 255–274. [Google Scholar] [CrossRef]
- Yang, H.H.; Moody, J. Data visualization and feature selection: New algorithms for nongaussian data. Adv. Neural. Inf. Process Syst. 1999, 12, 687–693. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Michalowicz, J.; Nichols, J.M.; Bucholtz, F. Calculation of differential entropy for a mixed gaussian distribution. Entropy 2008, 10, 200–206. [Google Scholar] [CrossRef] [Green Version]
- Moshkar, K.; Khandani, A. Arbitrarily tight bound on differential entropy of gaussian mixtures. IEEE Trans. Inf. Theory 2016, 62, 3340–3354. [Google Scholar] [CrossRef]
- Huber, M.; Bailey, T.; Durrant-Whyte, H.; Hanebeck, U. On entropy approximation for gaussian mixture random vectors. In Proceedings of the 2008 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, Seoul, Korea, 20–22 August 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 181–189. [Google Scholar]
- Singh, S.; Póczos, B. Nonparanormal information estimation. arXiv 2017, arXiv:1702.07803. [Google Scholar]
- Watanabe, S. Iformation theoretical analysis of multivariate correlation. IBM J. Res. Dev. 1960, 45, 211–232. [Google Scholar]
- Pena, J.M.; Nilsson, R.; Bjoerkegren, J.; Tegner, J. Towards scalable and data efficient learning of Markov boundaries. Int. J. Approx. Reason. 2007, 45, 211–232. [Google Scholar] [CrossRef] [Green Version]
- Achille, A.; Soatto, S. Emergence of invariance and disentanglements in deep representations. J. Mach. Learn. Res. 2018, 19, 1948–1980. [Google Scholar]
- Macedo, F.; Oliveira, M.; Pacecho, A.; Valadas, R. Theoretical foundations of forward feature selection based on mutual information. Neurocomputing 2019, 325, 67–89. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Behavior of function h and its two first derivatives. Horizontal lines in the left chart correspond to bounds of h and equal and , respectively.
Figure 1.
Behavior of function h and its two first derivatives. Horizontal lines in the left chart correspond to bounds of h and equal and , respectively.

Figure 2.
Generative Tree Model under consideration.

Figure 3.
Behavior of conditional mutual information as a function of k for different values.

Figure 4.
Minimal k for which , .

Figure 5.
The behavior of JMI in the generative tree model: and .

Figure 6.
The behavior of CIFE in the generative tree model: and .

Figure 7.
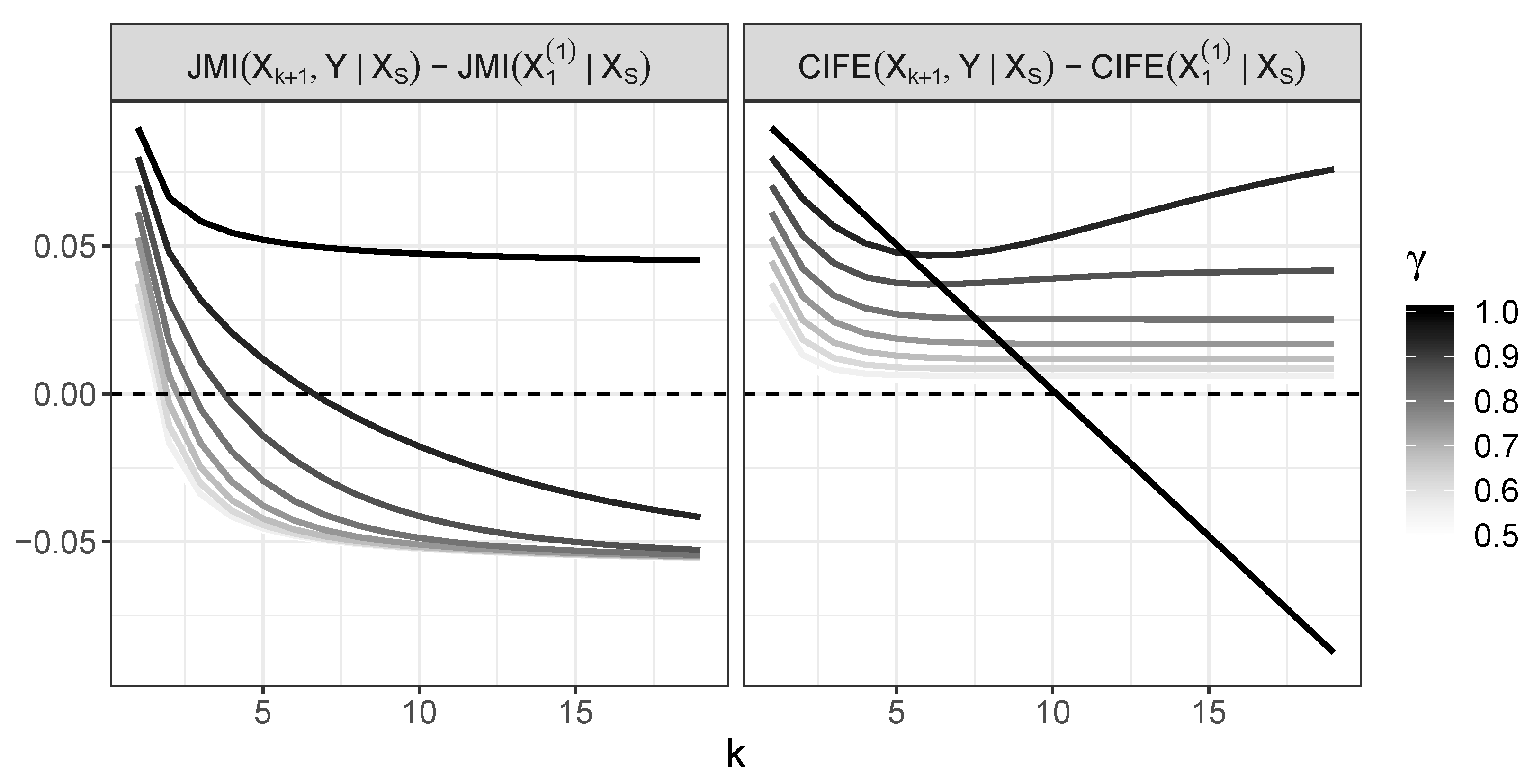
Difference between values of JMI for and (left panel) and analogous difference for CIFE (right panel). Values below 0 mean that the variable is chosen.
Figure 7.
Difference between values of JMI for and (left panel) and analogous difference for CIFE (right panel). Values below 0 mean that the variable is chosen.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The criteria (Conditional Mutual Information (CMI), Joint Mutual Information (JMI), Conditional Infomax Feature Extraction (CIFE)) values for and . A value of the chosen variable in each step and for each criterion is in bold.
Table 1.
The criteria (Conditional Mutual Information (CMI), Joint Mutual Information (JMI), Conditional Infomax Feature Extraction (CIFE)) values for and . A value of the chosen variable in each step and for each criterion is in bold.
| (a) , , | ||||
| 0.1114 | ||||
| 0.0527 | 0.0422 | |||
| 0.0241 | 0.0192 | 0.0176 | ||
| 0.0589 | 0.0000 | 0.0000 | 0.0000 | |
| (b) , , | ||||
| 0.1114 | ||||
| 0.0527 | 0.0422 | |||
| 0.0241 | 0.0192 | 0.0205 | 0.0208 | |
| 0.0589 | 0.0000 | 0.0266 | ||
| (c) , , | ||||
| 0.1114 | ||||
| 0.0527 | 0.0422 | |||
| 0.0241 | 0.0192 | 0.0169 | ||
| 0.0589 | 0.0000 | −0.0083 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Łazęcka, M.; Mielniczuk, J. Analysis of Information-Based Nonparametric Variable Selection Criteria. Entropy 2020, 22, 974. https://doi.org/10.3390/e22090974
AMA Style
Łazęcka M, Mielniczuk J. Analysis of Information-Based Nonparametric Variable Selection Criteria. Entropy. 2020; 22(9):974. https://doi.org/10.3390/e22090974
Chicago/Turabian StyleŁazęcka, Małgorzata, and Jan Mielniczuk. 2020. "Analysis of Information-Based Nonparametric Variable Selection Criteria" Entropy 22, no. 9: 974. https://doi.org/10.3390/e22090974
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.