Robust Regression with Density Power Divergence: Theory, Comparisons, and Data Analysis



1
Dipartimento di Scienze Economiche e Aziendale and Interdepartmental Centre for Robust Statistics, Università di Parma, l43125 Parma, Italy
2
The London School of Economics, London WC2A 2AE, UK
3
European Commission, Joint Research Centre, 21027 Ispra, Italy
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(4), 399; https://doi.org/10.3390/e22040399
Submission received: 22 February 2020
/
Revised: 26 March 2020
/
Accepted: 26 March 2020
/
Published: 31 March 2020
(This article belongs to the Special Issue Robust Procedures for Estimating and Testing in the Framework of Divergence Measures)
Abstract
:Minimum density power divergence estimation provides a general framework for robust statistics, depending on a parameter , which determines the robustness properties of the method. The usual estimation method is numerical minimization of the power divergence. The paper considers the special case of linear regression. We developed an alternative estimation procedure using the methods of S-estimation. The rho function so obtained is proportional to one minus a suitably scaled normal density raised to the power . We used the theory of S-estimation to determine the asymptotic efficiency and breakdown point for this new form of S-estimation. Two sets of comparisons were made. In one, S power divergence is compared with other S-estimators using four distinct rho functions. Plots of efficiency against breakdown point show that the properties of S power divergence are close to those of Tukey’s biweight. The second set of comparisons is between S power divergence estimation and numerical minimization. Monitoring these two procedures in terms of breakdown point shows that the numerical minimization yields a procedure with larger robust residuals and a lower empirical breakdown point, thus providing an estimate of leading to more efficient parameter estimates.
1. Introduction
Basu et al. [1] introduced a general form of robust estimation based on minimizing a density power divergence. The family of procedures, and so the robustness properties, depend on the value of a parameter . In this paper, we consider normal theory regression. We use standard methods for the analysis of robust procedures, in particular S-estimation (Riani et al. [2]), to find the theoretical breakdown point and efficiency of power divergence regression as a function of . We use these results to make comparisons with theoretical properties of other robust methods, for example, S-estimation using Tukey’s biweight. We introduce a data-driven method for the estimation of from monitoring residuals over a range of values of and so find the empirical efficiency and breakdown point of power density estimation for several regression examples. One surprising conclusion is that, for normal theory models, the rho function for the power divergence is one minus a suitably scaled standard normal density raised to the power .
The paper is structured as follows. The next section introduces minimum density power divergence estimation and the related estimating equations for normal theory linear regression. The important problem of estimating is mentioned. The first part of Section 3 reviews S-estimation in the linear regression model, and the second part, Section 3.2, rewrites power divergence estimation of the regression parameter in the form of S-estimation, derives the rho function, and so finds the asymptotic breakdown point (bdp) of the procedure. Section 3.2.2 gives the asymptotic efficiency of this S-estimation at the Gaussian model and finds the weight function used in fitting data. Comparisons are given with some well known rho and weight functions. In Section 4, plots of asymptotic efficiency against asymptotic bdp are used to compare the properties of several S-estimators, including Tukey’s biweight. Section 5 compares methods through the analysis of data. An alternative to S power divergence is the original suggestion of Basu et al. [1] to use Brute Force (BF) minimization (our acronym, not theirs). Comparisons on simulated and real data show the superiority of BF power divergence to the S-estimator. In particular, monitoring the plots of residuals as varies may lead to a clear indication of the minimum value of for which a robust fit is obtained. Thus, the empirical breakdown point of BF power divergence estimation can be found, leading to the most efficient robust estimation for each specific data set.
2. Minimum Density Power Divergence Estimation
Basu et al. [1] define the power divergence between two densities and , a function of a single parameter , as
The parameter controls the trade-off between efficiency and robustness for the power divergence estimator. The limit as is a version of the Kullback-Leibler divergence. The value leads to squared estimation, an analysis of which is given by Scott [3].
Let g be the density function of the process generating the data. Given an independent and identically distributed sample is available from G, Basu et al. [1] model the unknown with the density by minimizing . Since the third term of the divergence is independent of , the power divergence estimator of can be found by minimizing
in which the empirical distribution is used to approximate the unknown distribution G, thus avoiding the necessity for density estimation.
Basu et al. [1] develop their method only for random samples from the normal, exponential and Poisson distributions. For the normal distribution, Equation (2) is minimized over both the mean and the variance . The extension to normal theory regression models is in Ghosh and Basu [4].
As usual in a regression framework, we define to be the response variable, which is related to the values of a set of explanatory variables by the relationship
where, including an intercept, and . Let , which is assumed to be constant for all . We also take the quantities in to be fixed and assume that are not collinear. The case corresponds to that of a univariate response without predictors. We call the scale of the distribution of the error term , when its density takes the form
When f is the normal distribution with mean, as in Equation (3), and variance , Durio and Isaia [5] and Ghosh and Basu [4] show that the function, as in Equation (2), to be minimized becomes
The partial derivative of Equation (4), with respect to , provides the estimating equation for :
When , Equation (5) becomes the equation for non-robust ordinary least squares. For we have weighted least squares of the kind associated in the next section with M estimation. Ghosh and Basu [4] also give the estimating equation for which we will however not be using in our theoretical development.
An important aspect is the estimation of . Durio and Isaia [5] test for changes in the estimates of the parameters as a function of , while Warwick and Jones [6] and Ghosh and Basu [7] estimate the mean squared error of the parameter estimates as changes. In Section 5, we monitor changes in the pattern of residuals to choose the minimum value of for which a robust fit is obtained, so leading to the most efficient parameter estimates.
3. Robust Regression
3.1. M and S Estimation
Basu et al. [1] find estimates of the parameters of the linear model by simultaneous minimization of Equation (4) as a function of and . In this section, we recall the theory of M and S estimation, which we use in Section 3.2 to describe properties of the S power divergence estimator. In Section 5, we provide a numerical comparison of the BF minimization and S-estimation approaches.
The M-estimator of the regression parameters, which is scale equivariant (i.e., independent of the units of measurement), is defined by
where is the i-th residual and is a function with suitable properties and s is an estimate of . For least squares For robust estimation for sufficiently large absolute values of x. We also write to emphasize the dependence of on .
These definitions do not depend on how is estimated. Clearly, if we want to keep the M-estimate robust, s should also be a robust estimate. We assume that the same is used in the estimation of and , which is customary in practice. In order to have a consistent scale estimate for normally distributed observations, we require
where is the cdf of the standard normal distribution. To see consistency, notice that implies
Equation (8) is solved, at least in principle, among all , where . Rousseeuw and Yohai [8] defined S-estimators by minimization of the dispersion s of the residuals
with final scale estimate
The dispersion s is defined as the solution of Equation (8). The S-estimates, therefore, can be thought as self-scaled M-estimates whose scale is estimated simultaneously with the regression parameters. Note, in fact, that when the scale and the regression estimates are simultaneously estimated, S-estimators for regression also satisfy (for example, Maronna et al. [9], p. 131)
The estimator of in Equation (9) is called an S-estimator because it is derived from a scale statistic in an implicit way.
The function is the key to many important properties of M and S estimates. Rousseeuw and Leroy [10] (p. 139) show that, if the function satisfies the following conditions:
- It is symmetric and continuously differentiable, and ;
- there exists a such that is strictly increasing on and constant on ; and
- it is such that
then the asymptotic breakdown point of the S-estimator tends to bdp when . Note that if is normalized in such a way that , the constant K becomes exactly equal to the breakdown point of the S-estimator.
3.2. S Estimation for Power Divergence Regression
3.2.1. The Breakdown Point and the Rho Function
The function is used in the estimation of for a given estimate s. With it follows from the function to be minimized in Equation (4) that . If we scale this function so that and , we obtain
This is a trivial reparameterization of an otherwise unreferenced rho function attributed to Welsh.
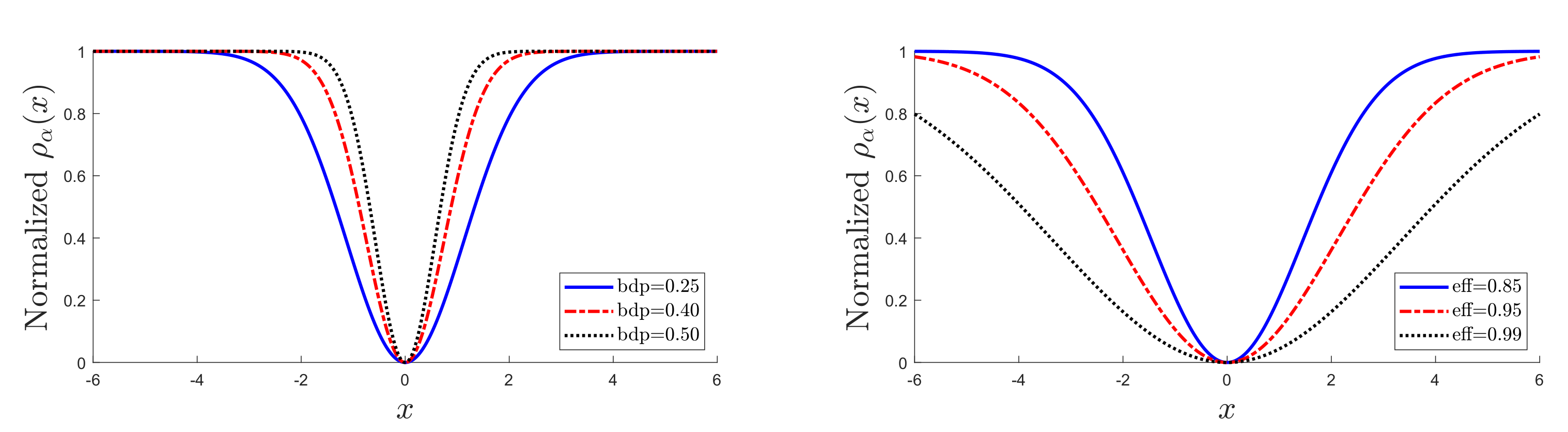
The panels of Figure 1 show plots of for several values of . For , the efficiency is 0.65, and the breakdown point is 0.29. As decreases, the procedure becomes less robust but more efficient. Table 1 gives values of , bdp, and eff for three frequently used values of each quantity; these values being given in bold. The left-hand panel of Figure 1 is for the three bold values of bdp, and the right-hand panel for the three values of eff. The rho functions for high efficiency are appreciably flatter than those for high bdp.
Since is scaled, the breakdown point, bdp, is given by . Then,
Our expression for the breakdown point comes from S-estimation, reflecting breakdown in the estimate of under the customary assumption that is known. This is different from the value of
in Section 3.2 of Basu et al. [11], who consider the joint breakdown of the estimates of and when “location explodes” and “scale implodes”. While the expression in Equation (14) increases monotonically in the interval , Equation (15) increases monotonically in the smaller interval and then slightly decreases.
To fit a model to data, we specify the desired asymptotic breakdown point, when the value of from inverting the expression in Equation (14) is
For example, for 50% breakdown,
3.2.2. Efficiency, the Psi Function and the Influence Function
Other basic properties of the robust estimator follow from derivatives of . For power density
and
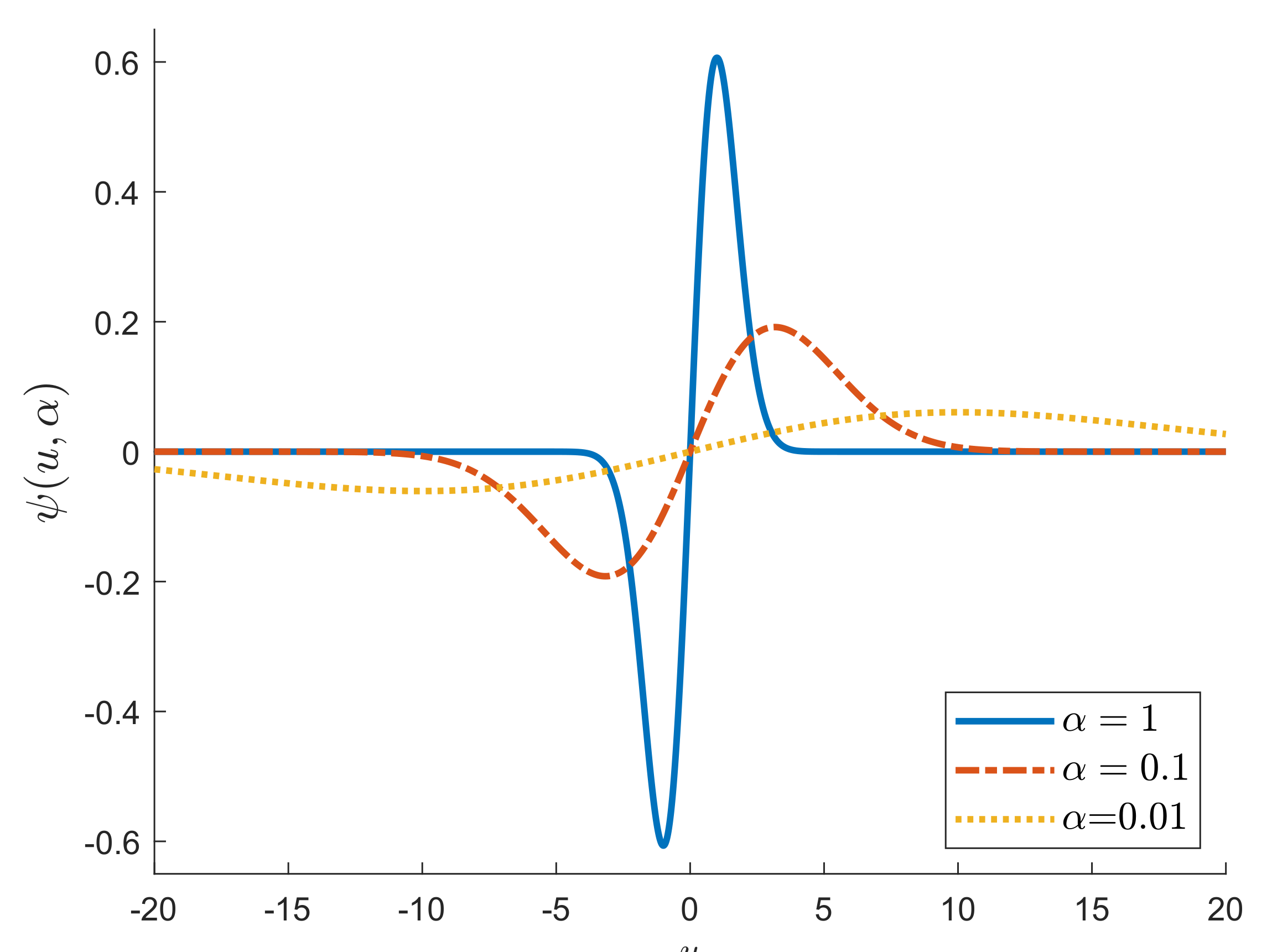
Figure 2 shows, for three values of , a plot of (which is proportional to the Influence Function, see Maronna et al. [9] (p. 123)). As decreases, the figure shows the curve becomes flatter.
From, for example, Rousseeuw and Leroy [10] (p. 142), the asymptotic efficiency eff of the S-estimator at the Gaussian model is
For ,
Since
Equation (17) becomes
To find the numerator of the efficiency
Combining these pieces, we obtain
agreeing with the expression for the asymptotic variance of the estimate of the mean of a univariate normal sample given in Section 4.2 of Basu et al. [1], a few values of which are tabulated in their Table 1. Inversion of Equation (19) yields
where .
The algorithm for S-estimation is complicated, involving weighted regression. Rousseeuw and Leroy [10] (pp. 207–208) provide a sketch. More details are in Salibian-Barrera and Yohai [12]. A central part is weighted regression, with weights
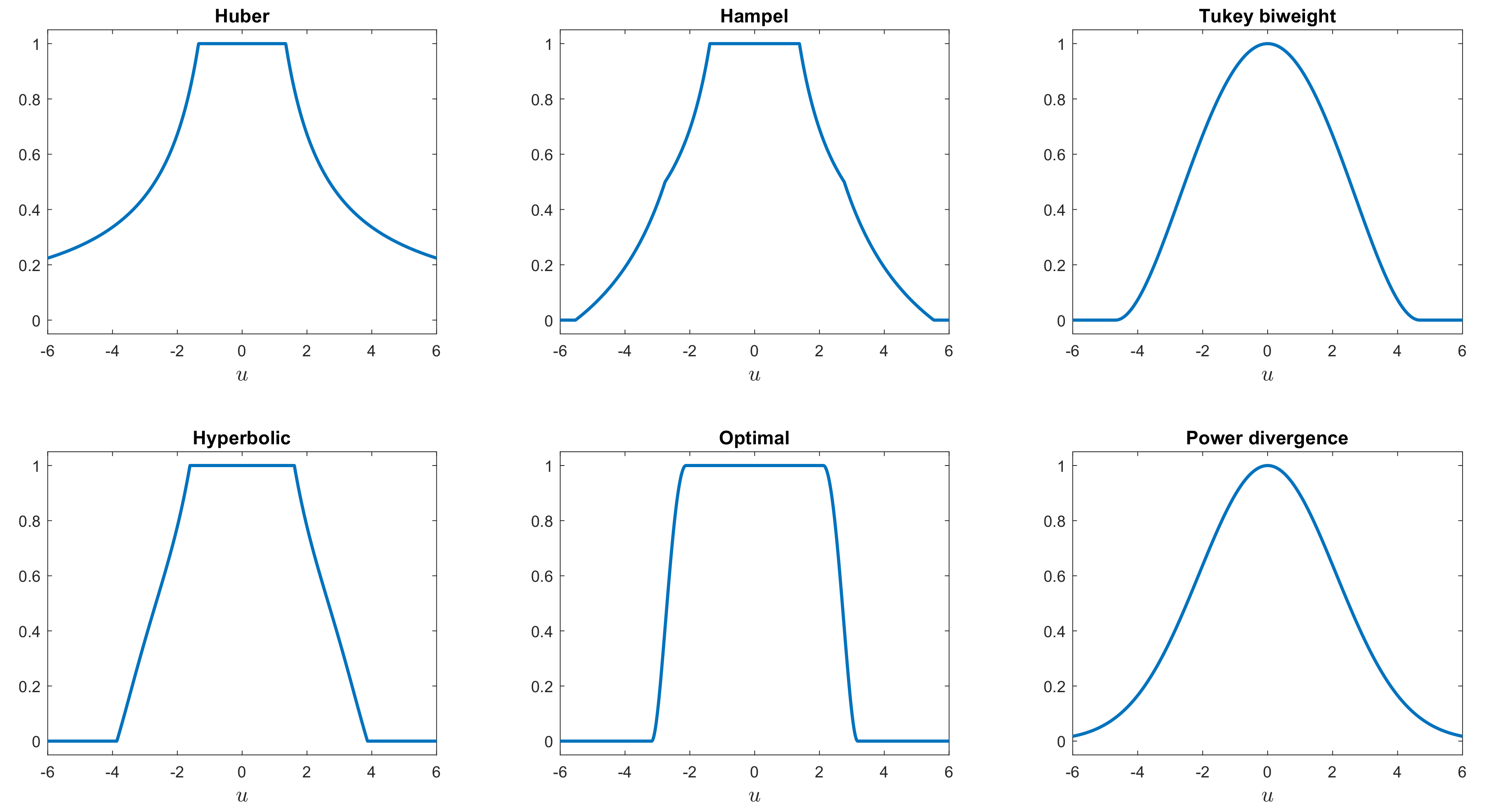
Figure 3 plots the weight functions for power divergence and five other rho functions: Tukey’s biweight [13], Hampel’s [14] (p. 150), Huber’s [15], the optimal (Yohai and Zamar [16]), and hyperbolic tangent (Hampel et al. [14] (p. 328)), all scaled to have efficiency 0.95.
Details of the functions are in the Appendix A. The similarity of the power divergence weights to those of the Tukey biweight is outstanding, although the biweight is exactly zero at , which in this case is equal to 4.6851. For this x coordinate, the power divergence weight (when eff = 0.95) is 0.0851. Both have a curved shape for small values of , unlike the Hampel and hyperbolic weights. We note that the procedure for finding the tuning constant for the power divergence estimator, given a prefixed value of breakdown point or efficiency, is not iterative. This is distinct from all the other rho functions listed above (apart from that of Huber), for which iterative procedures are required.
4. Comparisons of Asymptotic Properties
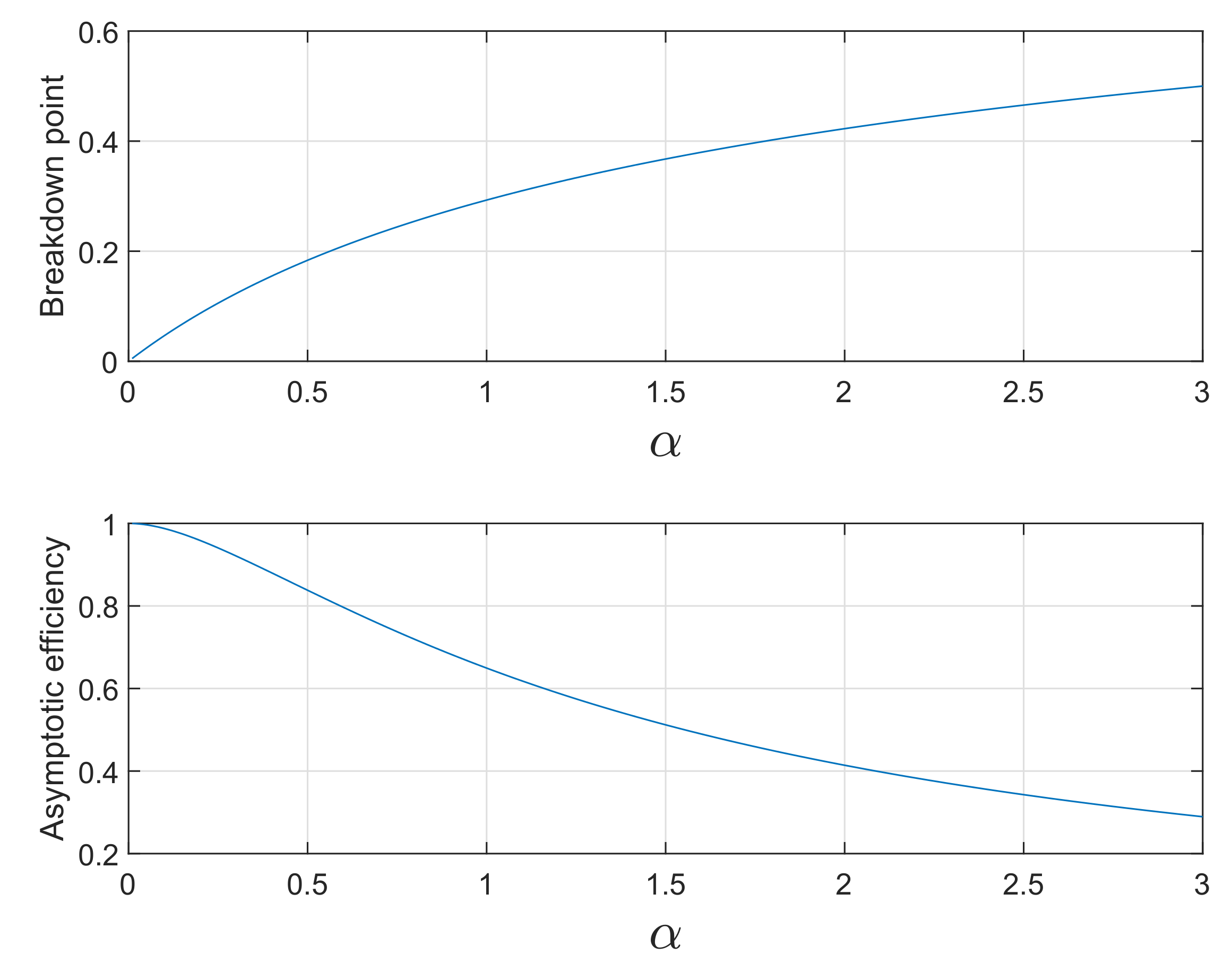
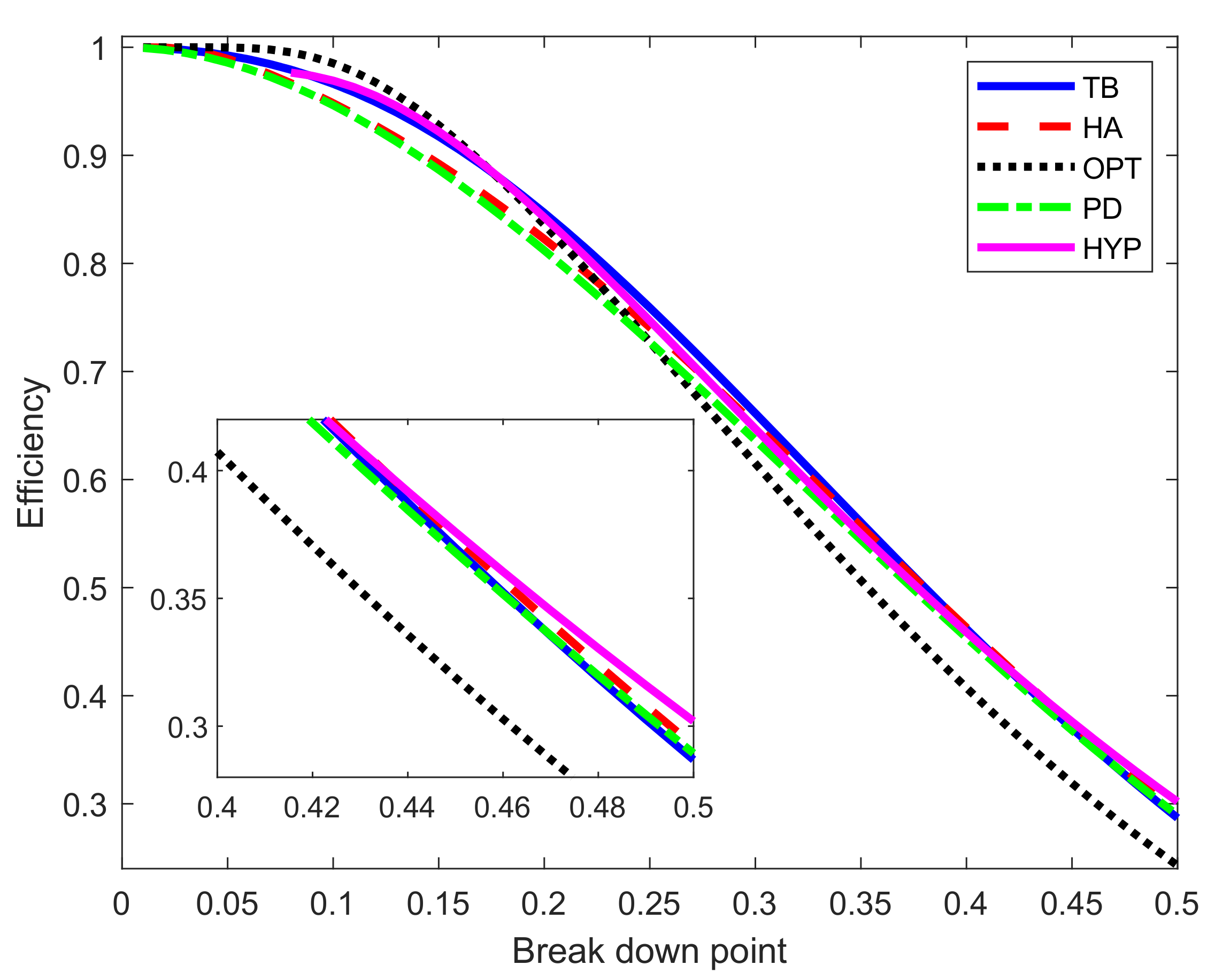
The basic properties of S power divergence are the asymptotic breakdown point, as in Equation (14), and the asymptotic efficiency, as in Equation (19). Figure 4 shows these two properties as functions of over the range . As bdp increases from zero towards 0.5, eff decreases from 1 to 0.2894. These are generic shapes for robust estimators, quantifying the trade-off between robustness and efficiency. Figure 5 shows plots of efficiency against breakdown point for S power divergence and four of the other functions of Figure 3 (the Huber function being excluded because it has a zero breakdown point). In order to generate these curves, we fix a particular value of breakdown point and find the associated tuning constant for PD or c for the other estimators (the details are in the Appendix). In the case of the Hampel functions, the three extra parameters , , and have been set equal to 2, 4, and 8. For the hyperbolic tangent estimator the extra parameter k, which reflects the log of the change of variance sensitivity of the M-estimator, has been set equal to 4.5. Given the value of the tuning constant, we found the corresponding value of the efficiency.
It is clear from the figure that the general asymptotic performance of the five methods is similar. The optimal function is best for small bdp but worst for values slightly larger than 0.25. The situation for Hampel is the reverse, being worst for small bdp and best for bdp values above approximately 0.4. For small bdp, the power divergence is the second worst but behaves much like the hyperbolic and biweight functions for larger values of bdp. For 50% bdp (as the inset in the figure shows), the ordering is (we give the exact numbers in parenthesis) hyperbolic (0.3019), Hampel (0.2924), power divergence (0.2894), biweight (0.2868), and last the optimal (0.2428). Hössjer [17] proves that, for normal theory linear models, the maximum efficiency when bdp = 0.5 is 0.329.
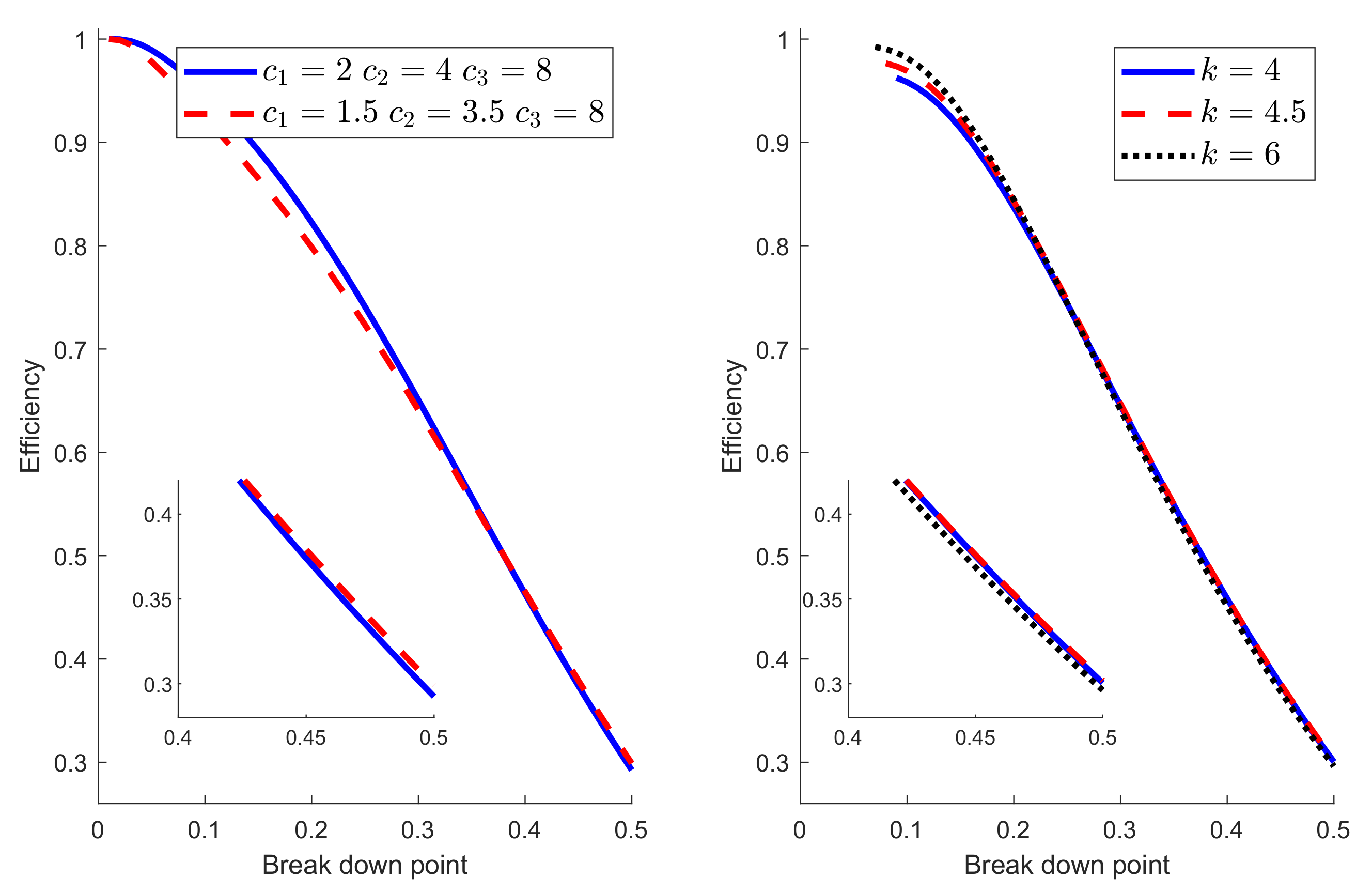
Some further insight into the balance between breakdown point and efficiency comes from varying the parameters of the Hampel and hyperbolic functions. In Figure 5, the parameters for the Hampel were , , and . The left-hand panel of Figure 6 compares the breakdown point and efficiency of Hampel’s rho function with these values to those when , , and . The original procedure is better for breakdown point less than around 0.3, with the modified version being slightly better for larger values. For the hyperbolic rho function in the right-hand panel the freely variable parameter, other than c, is k. The curves for three values of k are shown in the right-hand panel of Figure 6. The difference is largest for small values of bdp, when has the highest efficiency. In other words, imposing a looser constraint in the change of variance parameter produces higher efficiency for small values of bdp. For breakdown points near 0.5, the order is reversed, with being the least efficient, although, in this region, the differences are less than for low bdp. The conclusion from this figure reinforces that from Figure 5; no one rho function has the highest breakdown point and efficiency over the whole range of bdp from 0 to 0.5. These results also implicitly show that the choice of the function is not a crucial aspect since all (provided they are bounded) have similar behavior in terms of breakdown point and efficiency. These theoretical results are in line with the empirical findings in Salini et al. [18], where it is shown that the size of the test for outlier detection is much more affected by the choice of the requested level of efficiency or breakdown point than by the choice of the function.
It is hard to reconcile the conclusions from these graphs with the statement in the opening paragraph of Jones et al. [19] that “quite small values of were found to afford considerable robustness while retaining very high efficiency relative to maximum likelihood”. Although it may be argued that S power divergence has good properties as a robust procedure, the figure shows that these fully agree with those for other S estimators. We now turn from asymptotics to data analysis to allow non-asymptotic comparisons and analysis of the ‘brute force’ approach to power divergence estimation.
5. Monitoring and Comparisons with Data
In order to compare the finite sample properties of robust estimators in regression, Riani et al. [20] introduced the idea of monitoring the properties of robust analyses as tuning constants are changed. For power divergence, this would be the value of , or equivalently changes in nominal values of bdp or eff, which are how the range of monitored values was specified for other functions. The most incisive information comes from looking at displays of residuals. Typically, for contaminated data, these display many outliers for very robust analyses, which suddenly are much reduced in magnitude at a specific value of the tuning constant. At this point, the procedure becomes close to maximum likelihood including the outliers. The sharp transition between the two regions allows estimation of the empirical breakdown point and so to the robust analysis with the highest efficiency. The monitoring process starts with bdp=0.5, which is the maximum fraction of contamination that an affine equivariant estimator can resist.
To illustrate this structure, we re-analyze regression data from Atkinson and Riani [21] (Table A2) comparing S power divergence with the BF version, using numerical minimization. We start monitoring from a bdp of 50% and use the very robust version of Least Median of Squares regression (Rousseeuw [22]) to provide initial estimates of and . After this initial minimization for , successive minimizations for lower values of start from the estimates for the immediately higher value of .
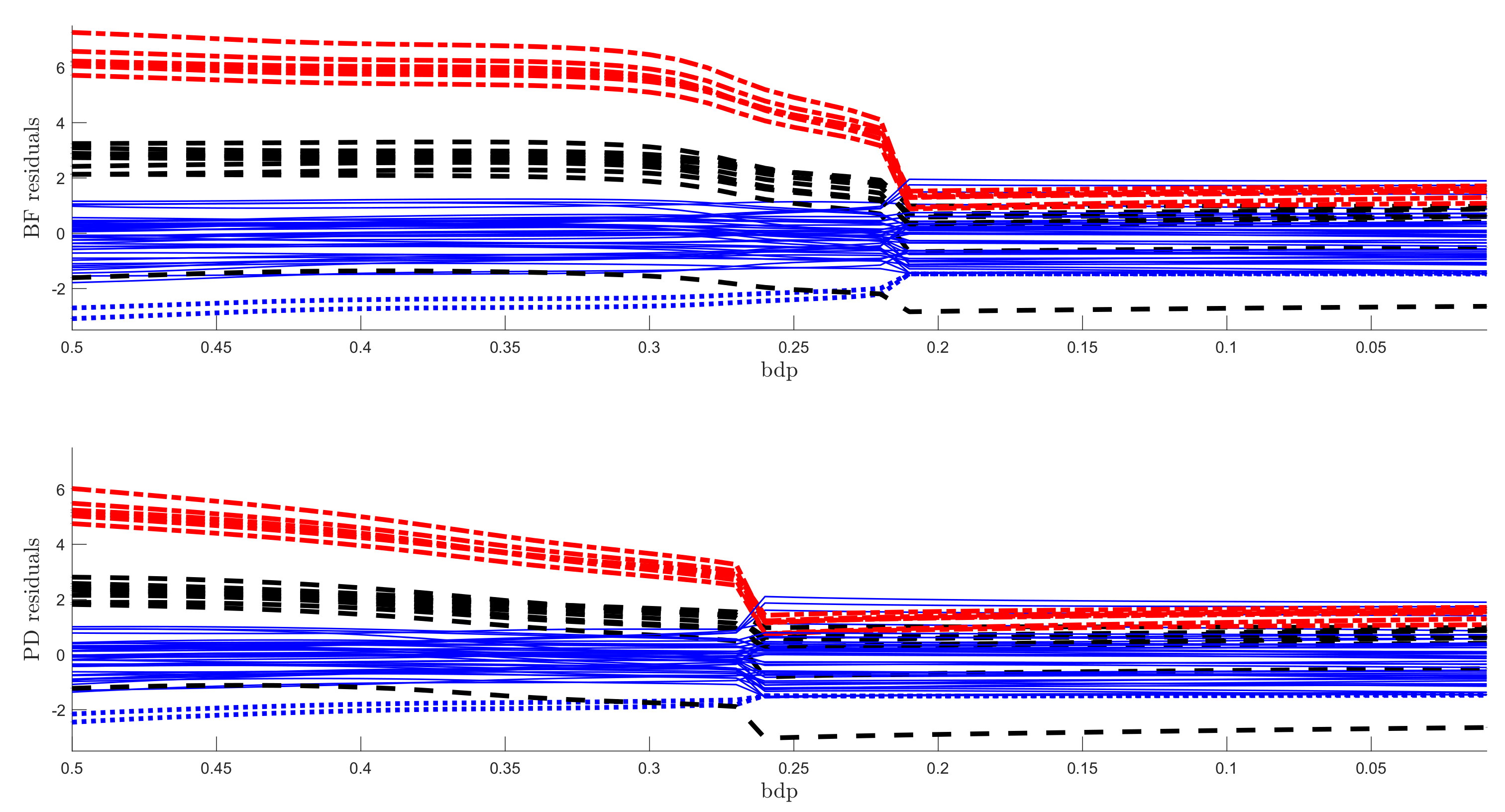
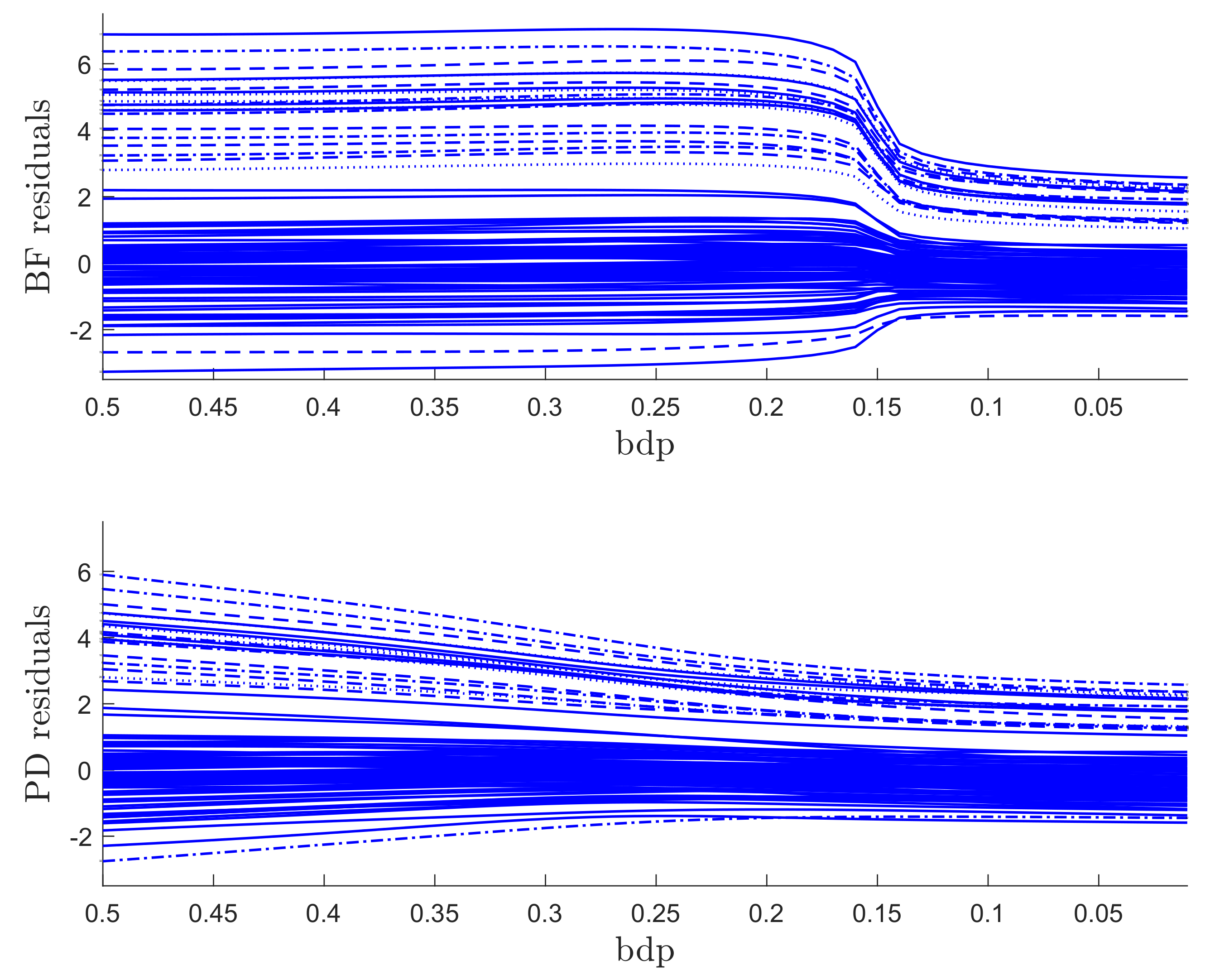
The regression data consist of 60 response observations and three explanatory variables. The scatter-plot matrix of the data does not reveal any outlying observations. The upper panel of Figure 7 is the monitoring plot of the residuals for BF power divergence as goes from 3 to 0. There is a very clear transition from the robust analysis in the left-hand part of the plot to the non-robust analysis in the right-hand part, which occurs just before bdp = 0.21, giving an empirical breakdown point of 0.23. What is striking about this figure, apart from the clear transition point, is the distinct near constancy of the residuals in the two parts of the plot.
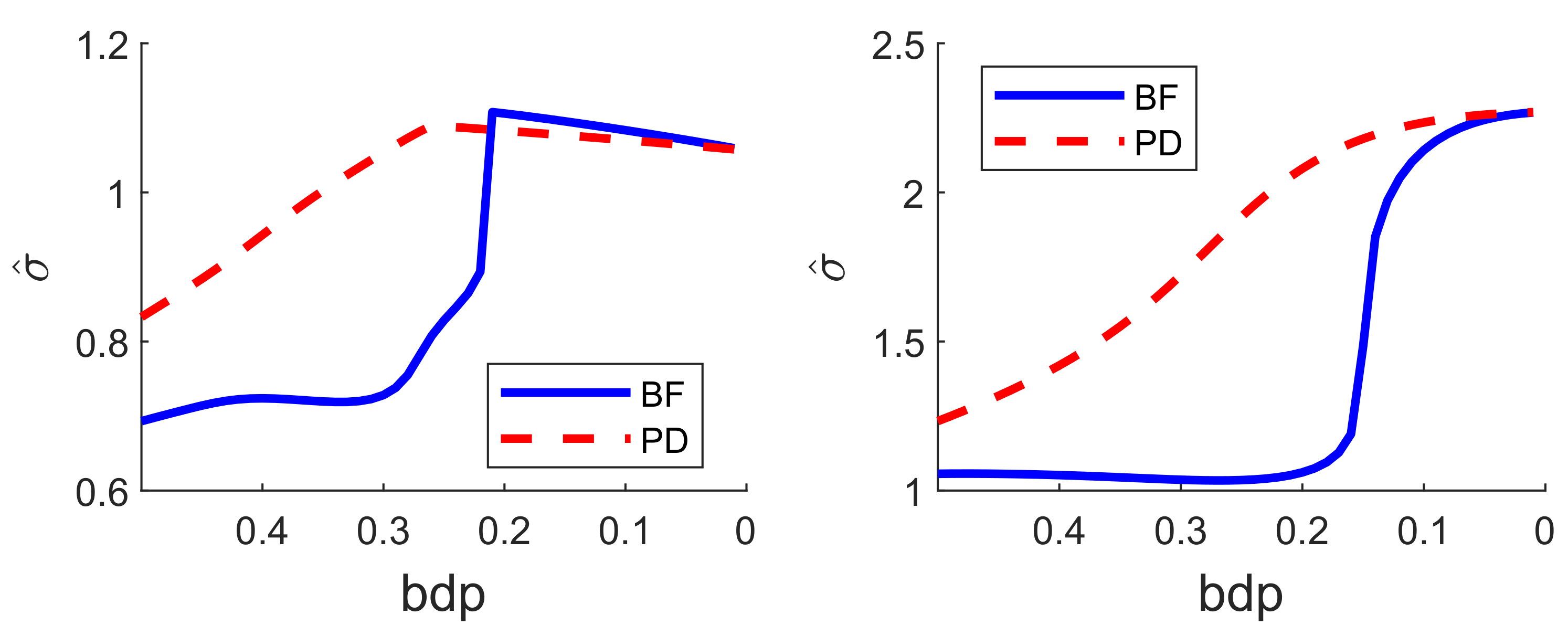
The lower panel of Figure 7 is the same plot but for the analysis using S power divergence. The conclusion is similar, with an empirical breakdown point of 0.27, higher than that in the upper panel; BF therefore provides more efficient estimates. Although the residuals in the non-robust right-hand part are constant, those from the robust analysis decrease in magnitude as the analysis becomes less robust. This effect is caused by the gradual increase in the estimate of as the analysis becomes less robust. A monitoring plot of the two estimates of is in the left-hand panel of Figure 8. The BF estimate is indeed virtually constant up to a bdp of nearly 0.3, increasing more rapidly to bdp = 0.2 with a jump corresponding to the switch from robust to non-robust analysis. At this point, it is close to that from S-estimation, which has been continually increasing. Both estimates of course coincide when bdp = 0, that is, for non-robust least squares.
These plots show the importance of the empirical breakdown point, found as , and hence bdp, decrease. We monitor at values , corresponding to breakdown values bdp. In our examples, At each i, we calculate a property of the fit, and find the difference |. Let the empirical breakdown point be bdp. Then,
Definition 1.
The empirical breakdown point bdp = bdp, where
Some choices of the property are
- The residual sum of squares.
- Changes in the parameter estimates or .
- Measures of correlation between successive sets of residuals, rather than the sum of squares (Riani et al. [20]).
This definition is for fixed finite n. If there are m outliers with responses , determination of bdp is sharp as As a threshold should be applied in the calculation of .
We ran a number of simulations and studied the monitoring plots. For a data set of 100 observations without outliers, the trajectories of the residuals were smooth and uneventful, although a similar structure was observed to that of Figure 7: the residuals from BF were sensibly constant until around and then began gently to become less extreme. On the other hand, the S residuals steadily decreased in magnitude. The plot of the estimates of was similar to that of the left-hand panel of Figure 8. As is correct in the absence of outliers, neither plot of residuals nor indicated the need for robust analysis.
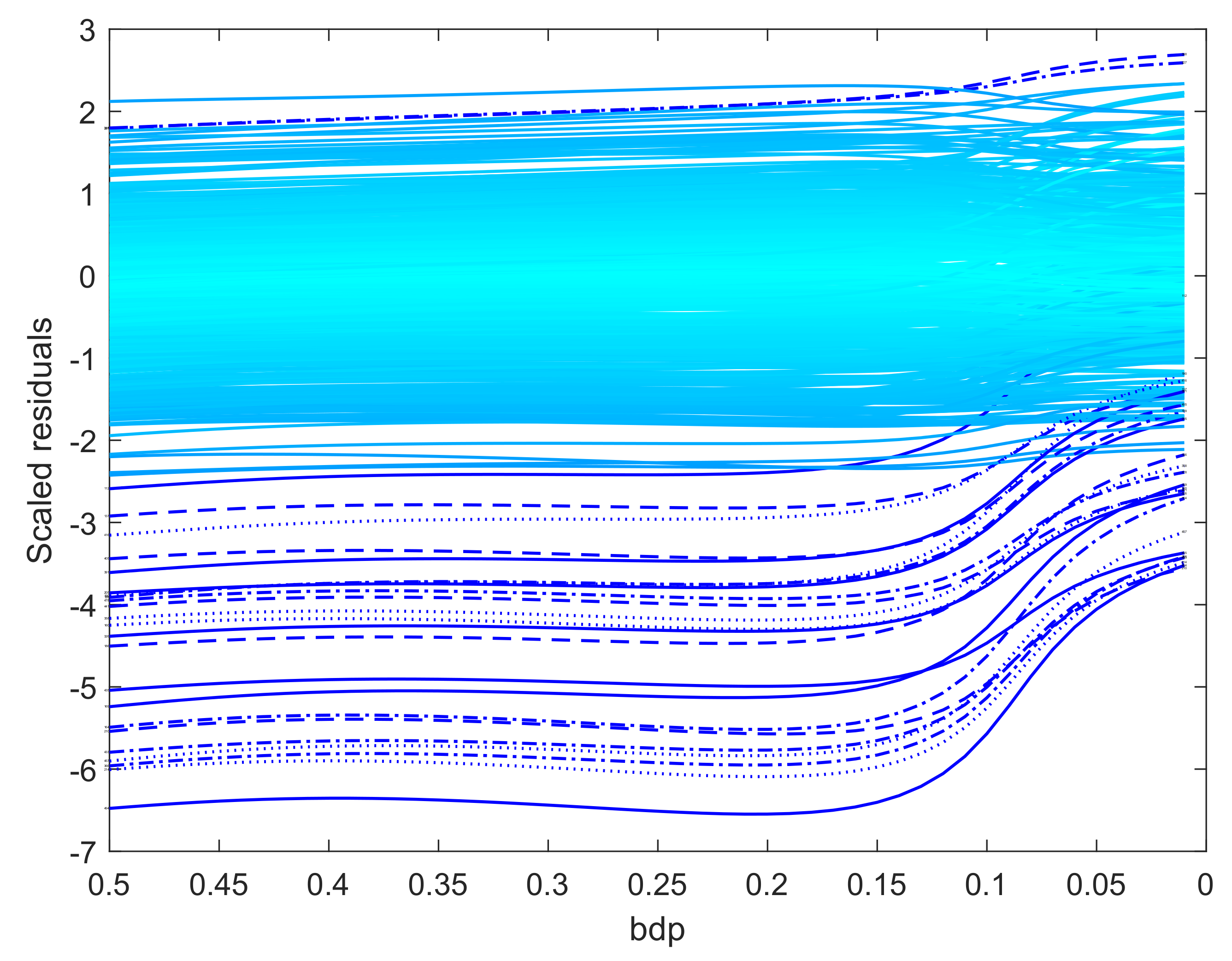
When the outliers in our simulations were very remote, both methods clearly indicated the outliers, although the monitoring plot for S estimation, unlike that using BF, did not show a sharp transition between two regions. The challenge for robust methods is when the outliers are less remote. As an example, we again simulated 100 observations with , but now a value of 5 was added to 20 responses. The two panels of Figure 9 show the resulting monitoring plots. Both display the same set of scaled residuals for 50% bdp, although those from BF are larger in magnitude. BF shows relatively sharp transitions at a breakdown point of 0.16, whereas S estimation shows a gradual decrease in the magnitude of the residuals as bdp () decreases. The right-hand panel of Figure 8 plots the two estimates of . As in the results for the regression data, the estimate from S-estimation increases gradually as bdp decreases, but the BF estimates are sensibly constant until a bdp around 0.16, when there is a distinct increase due to non-robust estimation.
Our results in Section 3.2.1 and Section 4 indicate the close relationship between Tukey’s biweight and the power density rho functions. This is illustrated by the plot for S estimation using the biweight on these data, which we do not show here, which is indistinguishable from that using the power divergence .
As a final larger data example, we analyze 509 observations on the amount spent by loyalty card holders at a supermarket chain in Northern Italy, introduced by Atkinson and Riani [23], who recommended a Box-Cox transformation for the response with . Perrotta et al. [24] showed that a value of is to be preferred. We used this value in our analysis. The monitoring plot of residuals from BF power divergence is in Figure 10. It shows stable trajectories of the residuals for many values of . A change starts around bdp = 0.17, indicating this as the empirical bdp. Again, S power divergence, which we do not show, reveals the same extreme observations, but fails to provide a sharp transition, so that the empirical breakdown point for efficient analysis is again not easily determined.
6. Discussion
We have used the estimating equation for the linear parameters to recast power divergence estimation in the context of S-estimation. This leads straightforwardly to calculations of asymptotic bdp and efficiency. This form of the power density estimate has asymptotic properties close to those of S estimation using Tukey’s biweight.
An alternative to power divergence S-estimation is brute-force numerical minimization. The non-asymptotic comparison of the two procedures has been performed with monitoring plots of residuals as bdp varies, providing fits changing from very robust to maximum likelihood. S power divergence estimation has properties very similar to those of S-estimation with Tukey’s biweight. In both, there is often a smooth decrease in the magnitude of the residuals as bdp decreases. On the other hand, BF minimization produces monitoring plots which show a clearer break between robust and non-robust fits, leading to estimation of an empirical breakdown point and so to the most efficient robust estimates.
One conclusion is that BF estimation provides more informative analyses than power density S-estimation. However, the results of monitoring regression in Riani et al. [20] show that the comparative behavior of estimators depends on the particular data set being analyzed. Figure 7 shows that S-estimation may produce monitoring plots with a sharp change, and further examples are in Riani et al. [20]. Other methods providing a sharp change, and so guidance to efficient analysis, are the Forward Search [25] and Least Trimmed Squares [22]. It remains to be seen how BF power divergence compares with these other methods, both statistically and on larger, more complicated models, such as linear mixed models, generalized linear models, or nonlinear models.
Author Contributions
All authors contributed equally to the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research benefits from the HPC (High Performance Computing) facility of the University of Parma. We acknowledge financial support from the University of Parma project “Statistics for fraud detection, with applications to trade data and financial statement”, from the Department of Statistics of the London School of Economics and from the 2014-2020 Institutional Research Programme of the Joint Research Centre of the European Commission.
Acknowledgments
We are grateful to Leandro Pardo and Nirian Martin for the invitation to contribute to the special issue of Entropy on ‘Robust Procedures for Estimating and Testing in the Framework of Divergence Measures’.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Rho Functions
In this appendix, we summarize the characteristics of the functions which have been used in the paper. Since the hyperbolic tangent estimator is rarely used and, as far as we know, is not implemented in any statistical package, we describe this estimator in greater detail.
The first -function was proposed in Huber (1964):
It is easily seen that this function is unbounded and, therefore, the corresponding estimator has a zero breakdown point.
Perhaps the most popular function for redescending M and S-estimates is Tukey’s Biweight function [13]:
the first derivative of which vanishes outside the interval . Therefore, for this function c is the crucial tuning constant, determining the efficiency or, equivalently, the breakdown point.
Hampel’s function [14] (p. 150) has a similar, but less smooth, shape.
The first derivative is piece-wise linear and vanishes outside the interval . The crucial tuning constant is . Huber and Ronchetti [26] (p. 101) suggest that the slope between and should not be too steep.
Yohai and Zamar [16] introduced a function which minimizes the asymptotic variance of the regression M-estimate, subject to a bound on a robustness measure called contamination sensitivity. Therefore, this function is called the optimal function.
Now, the first derivative vanishes outside the interval . The resulting M-estimate minimizes the maximum bias under contamination distributions (locally for a small fraction of contamination), subject to achieving a desired nominal asymptotic efficiency when the data are normally distributed.
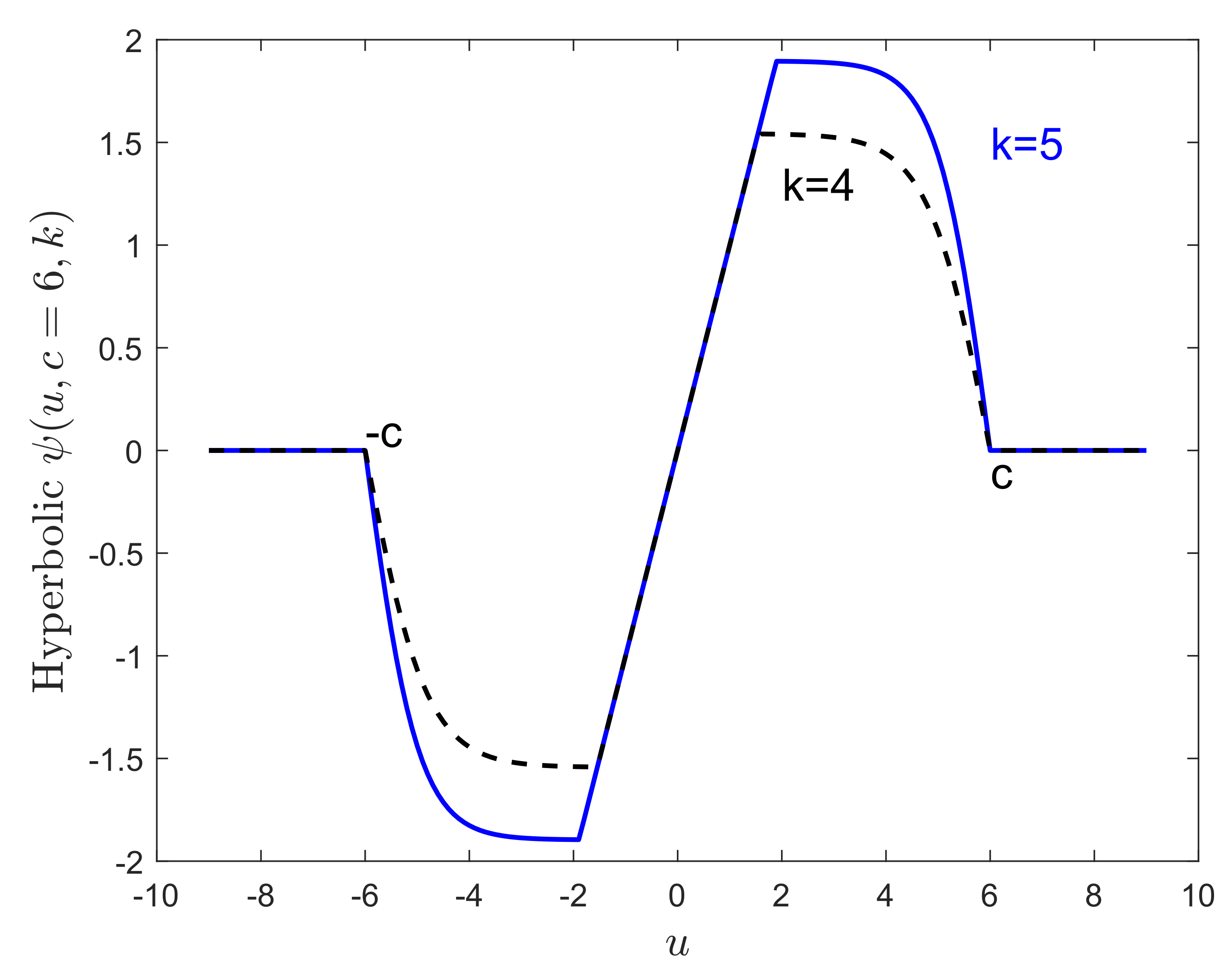
Hampel et al. [14] (p. 328) considered another optimization problem, by minimizing the asymptotic variance of the regression M-estimate, subject to a bound on the supremum of the Change of Variance Curve (CVC) of the estimate. The describes the infinitesimal increment of the logarithm of the variance of the M estimator—that is by the reciprocal of Equation (16)—in the vicinity of the null normal model, in the same way that the influence function reflects the infinitesimal asymptotic bias. This leads to the Hyperbolic Tangent function, which, for suitable constants c, k, A, B, and d, is defined as
where is such that
Parameters A and B are found as:
The value of d is found by applying the Newton-Raphson method to Equation (A5). New values of A and B are obtained (through numerical integration) and the procedure is iterated to convergence. For additional details, see Hampel et al. [27]. The parameter k is defined as
In Figure 3 and Figure 5, we used a value of 4.5 for k. The right-hand panel of Figure 6 shows that, for values of bdp close to 0.5, higher efficiencies are obtained when stronger constraints are imposed on the value of CVC by decreasing k. Conversely, smaller efficiencies result for small values of bdp. Figure A1 shows the function of the hyperbolic tangent estimator for two different values of k. Note that A, B, and d (and, consequently, also bdp and eff) are automatically determined after fixing k and c.
Figure A1.
Hyperbolic tangent function for two values of the parameter k.

We have illustrated the use of the power divergence function in regression. But all these functions can also be used for the estimation of robust location and covariance in the analysis of multivariate data. In this case, the scaled residuals u are replaced by scaled Mahalanobis distances.
All the functions , , , , and described in this appendix have been implemented in the FSDA MATLAB toolbox, which is freely downloadable from the file exchange of Mathworks. Each .m file has associated HTML documentation which is also present at web address “http://rosa.unipr.it/FSDA”. The prefixes of the different links which have been used are “HU”, “TB”, “OPT”, “HA”, “HYP”, and “PD”. The suffixes for the different ingredients are “rho”, “psi”, “wei”, “psider”, and “psix”. For example, to see the corresponding documentation for the hyperbolic ρ function, visit “http://rosa.unipr.it/FSDA/HYPrho.html”. For the corresponding documentation of the derivative of the ψ function of Hampel, see “http://rosa.unipr.it/FSDA/HApsider.html”. The routines for finding the constant c associated with a particular value of the breakdown point end with the suffix bdp. For example, to compute the constant c associated with the Tukey biweight for a given bdp, type “http://rosa.unipr.it/FSDA/TBbdp.html”. The routines to find the constant c associated with a particular value of the efficiency end with the suffix eff. Finally, the routines which, given a particular value of c compute bdp and eff, end with the suffix c. For example, to compute bdp and eff for the power divergence estimator given c, call function PDc (the corresponding documentation is on the web at “http://rosa.unipr.it/FSDA/PDc.html”).
References
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and efficient estimation by minimizing a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef] [Green Version]
- Riani, M.; Cerioli, A.; Torti, F. On consistency factors and efficiency of robust S-estimators. TEST 2014, 23, 356–387. [Google Scholar] [CrossRef]
- Scott, D.W. Parametric Statistical Modeling by Minimum Integrated Square Error. Technometrics 2001, 43, 274–285. [Google Scholar] [CrossRef]
- Ghosh, A.; Basu, A. Robust estimation for independent non-homogeneous observations using density power divergence with applications to linear regression. Electron. J. Stat. 2013, 7, 2420–2456. [Google Scholar] [CrossRef]
- Durio, A.; Isaia, E.D. The minimum density power divergence approach in building robust regression models. Informatica (Lithuania) 2011, 22, 43–56. [Google Scholar]
- Warwick, J.; Jones, M.C. Choosing a robustness tuning parameter. J. Stat. Comput. Simul. 2005, 75, 581–588. [Google Scholar] [CrossRef]
- Ghosh, A.; Basu, A. Robust estimation for non-homogeneous data and the selection of the optimal tuning parameter: The density power divergence approach. J. Appl. Stat. 2015, 42, 2056–2072. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Yohai, V.J. Robust regression by means of S-estimators. In Robust and Nonlinear Time Series Analysis: Lecture Notes in Statistics 26; Franke, J., Härdle, W., Martin, R.D., Eds.; Springer: New York, NY, USA, 1984; pp. 256–272. [Google Scholar]
- Maronna, R.A.; Martin, R.D.; Yohai, V.J. Robust Statistics: Theory and Methods; Wiley: Chichester, UK, 2006. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and Efficient Estimation by Minimising a Density Power Divergence; Technical Report, 7; Department of Mathematics, University of Oslo: Oslo, Norway, 1997. [Google Scholar]
- Salibian-Barrera, M.; Yohai, V. A fast algorithm for S-regression estimates. J. Comput. Graph. Stat. 2006, 15, 414–427. [Google Scholar] [CrossRef]
- Beaton, A.E.; Tukey, J.W. The fitting of power series, meaning polynomials, illustrated on band-spectroscopic data. Technometrics 1974, 16, 147–185. [Google Scholar] [CrossRef]
- Hampel, F.; Ronchetti, E.M.; Rousseeuw, P.; Stahel, W.A. Robust Statistics; Wiley: New York, NY, USA, 1986. [Google Scholar]
- Huber, P.J. Robust Regression: Asymptotics, Conjectures and Monte Carlo. Ann. Stat. 1973, 1, 799–821. [Google Scholar] [CrossRef]
- Yohai, V.J.; Zamar, R.H. Optimal locally robust M-estimates of regression. J. Stat. Plan. Inference 1997, 64, 309–323. [Google Scholar] [CrossRef]
- Hössjer, O. On the optimality of S-estimators. Stat. Probabil. Lett. 1992, 14, 413–419. [Google Scholar] [CrossRef]
- Salini, S.; Cerioli, A.; Laurini, F.; Riani, M. Reliable Robust Regression Diagnostics. Int. Stat. Rev. 2015, 84, 99–127. [Google Scholar] [CrossRef]
- Jones, M.C.; Hjort, N.L.; Harris, I.R.; Basu, A. A comparison of related density-based minimum divergence estimators. Biometrika 2001, 88, 865–873. [Google Scholar] [CrossRef]
- Riani, M.; Cerioli, A.; Atkinson, A.C.; Perrotta, D. Monitoring Robust Regression. Electron. J. Stat. 2014, 8, 642–673. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Riani, M. Robust Diagnostic Regression Analysis; Springer: New York, NY, USA, 2000. [Google Scholar]
- Rousseeuw, P.J. Least median of squares regression. J. Am. Stat. Assoc. 1984, 79, 871–880. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Riani, M. Distribution theory and simulations for tests of outliers in regression. J. Comput. Graph. Stat. 2006, 15, 460–476. [Google Scholar] [CrossRef]
- Perrotta, D.; Riani, M.; Torti, F. New robust dynamic plots for regression mixture detection. Adv. Data Anal. Classi. 2009, 3, 263–279. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Riani, M.; Cerioli, A. The Forward Search: Theory and data analysis (with discussion). J. Korean Stat. Soc. 2010, 39, 117–134. [Google Scholar] [CrossRef]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Hampel, F.; Rousseeuw, P.; Ronchetti, E. The change-of-variance curve and optimal redescending M-estimators. J. Am. Stat. Assoc. 1985, 76, 643–648. [Google Scholar] [CrossRef]
Figure 1.
Dependence of on , for frequently used values of robustness properties in Table 1. Left-hand panel, three values of breakdown point (bdp); right-hand panel, three values of eff.
Figure 1.
Dependence of on , for frequently used values of robustness properties in Table 1. Left-hand panel, three values of breakdown point (bdp); right-hand panel, three values of eff.

Figure 2.
S power divergence; function, proportional to the influence function.

Figure 3.
The weight function for six S-estimators.

Figure 4.
S power divergence: breakdown point and efficiency as functions of .

Figure 5.
Breakdown point and efficiency as parameters vary for five rho functions: TB = Tukey biweight; HA = Hampel; OPT = optimal; PD = power divergence and HYP = hyperbolic. The inset is a zoom of the main figure for high breakdown point.
Figure 5.
Breakdown point and efficiency as parameters vary for five rho functions: TB = Tukey biweight; HA = Hampel; OPT = optimal; PD = power divergence and HYP = hyperbolic. The inset is a zoom of the main figure for high breakdown point.

Figure 6.
Breakdown point and efficiency as parameters vary for the Hampel and hyperbolic rho functions.
Figure 6.
Breakdown point and efficiency as parameters vary for the Hampel and hyperbolic rho functions.

Figure 7.
Regression data: residuals as bdp decreases. Upper panel, Brute Force (BF)-estimation, lower panel S-estimation.
Figure 7.
Regression data: residuals as bdp decreases. Upper panel, Brute Force (BF)-estimation, lower panel S-estimation.

Figure 8.
Comparison of estimates of as bdp decreases. Left-hand panel, regression data: right-hand panel, data with moderate outliers.
Figure 8.
Comparison of estimates of as bdp decreases. Left-hand panel, regression data: right-hand panel, data with moderate outliers.

Figure 9.
Data with moderate outliers: residuals as bdp decreases. Upper panel, BF-estimation; lower panel S-estimation.
Figure 9.
Data with moderate outliers: residuals as bdp decreases. Upper panel, BF-estimation; lower panel S-estimation.

Figure 10.
Loyalty card data: residuals for BF-estimation as bdp decreases.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
S power divergence. Values of , bdp, and eff for three frequently used values of each in bold.
Table 1.
S power divergence. Values of , bdp, and eff for three frequently used values of each in bold.
| bdp | ||
|---|---|---|
| 0 | 0 | 1 |
| 0.5 | 0.1835 | 0.8381 |
| 1 | 0.2929 | 0.6495 |
| 0.7778 | 0.25 | 0.7271 |
| 1.7778 | 0.4 | 0.4536 |
| 3 | 0.5 | 0.2894 |
| 0.4715 | 0.1756 | 0.85 |
| 0.3522 | 0.14 | 0.9 |
| 0.2245 | 0.0963 | 0.95 |
| 0.089 | 0.0417 | 0.99 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Riani, M.; Atkinson, A.C.; Corbellini, A.; Perrotta, D. Robust Regression with Density Power Divergence: Theory, Comparisons, and Data Analysis. Entropy 2020, 22, 399. https://doi.org/10.3390/e22040399
AMA Style
Riani M, Atkinson AC, Corbellini A, Perrotta D. Robust Regression with Density Power Divergence: Theory, Comparisons, and Data Analysis. Entropy. 2020; 22(4):399. https://doi.org/10.3390/e22040399
Chicago/Turabian StyleRiani, Marco, Anthony C. Atkinson, Aldo Corbellini, and Domenico Perrotta. 2020. "Robust Regression with Density Power Divergence: Theory, Comparisons, and Data Analysis" Entropy 22, no. 4: 399. https://doi.org/10.3390/e22040399
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.