Throughout this section, recent works addressing network attack detection using ML-based NIDS techniques are described in detail, especially the methodology and steps followed to address the problem of network attack classification.
All works studied here are summarized in
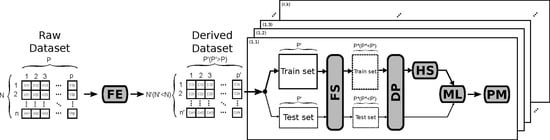
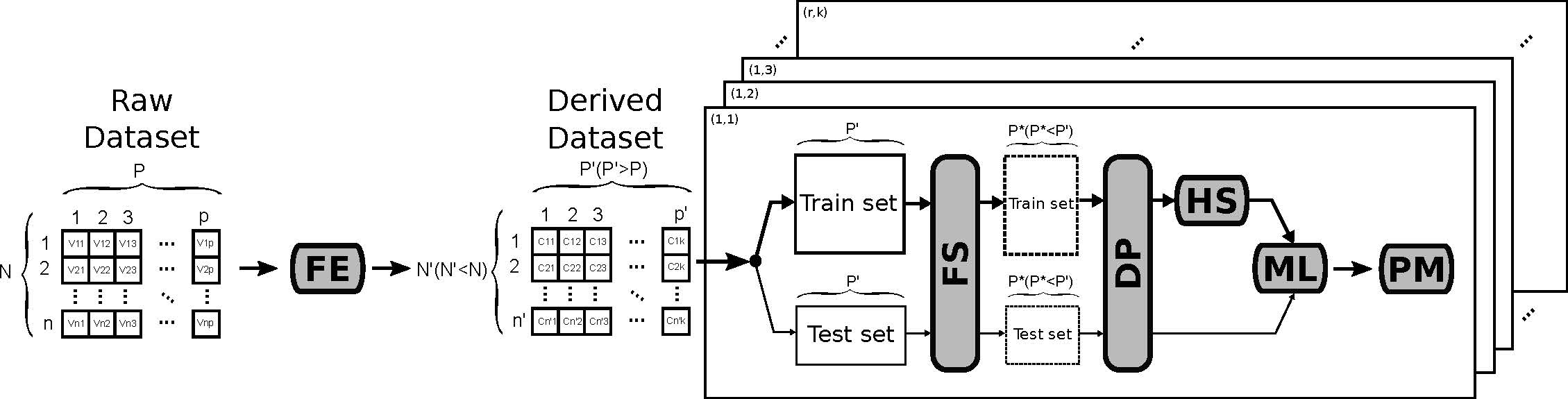
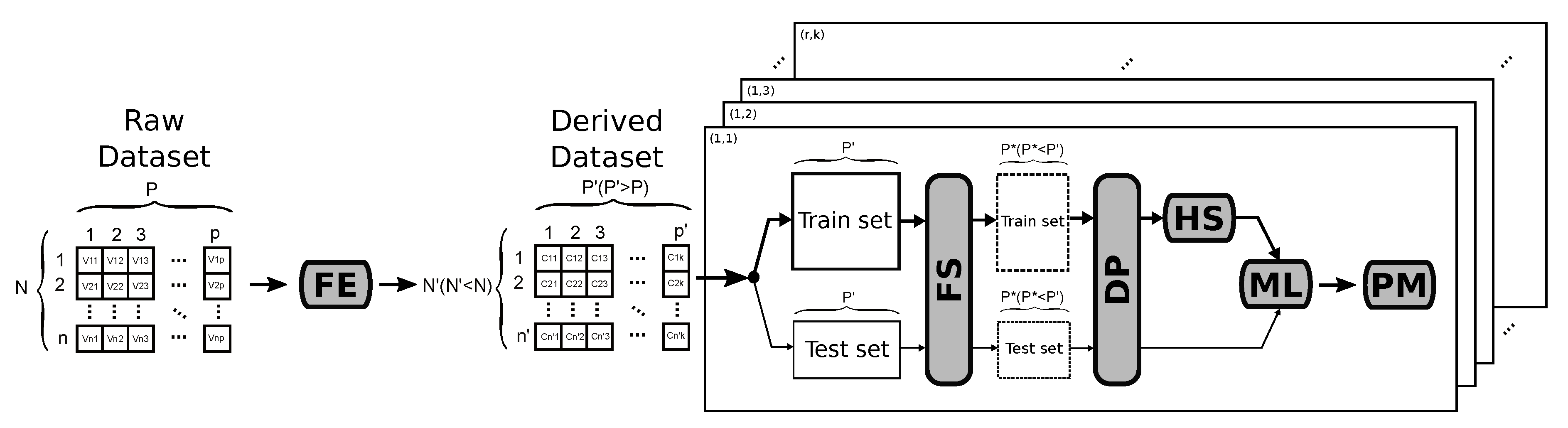
Table 1. It shows the involved dataset and the proposed solution according to what we consider should be the standard steps to be performed in network attack detection using ML-based solutions. This way, the whole detection procedure should comprise, at least, the following steps: Feature Engineering (FE), Data Pre-processing (DP), Feature Selection (FE), Hyper-parameter Selection (HS), Machine Learning method (ML) and Performance Metrics (PM). In the table, symbol ‘–’ denotes the involved step could not be found in the referred work, which does not mean that the authors did not use any technique or procedure to accomplish the related task. Finally, the specific steps used in this work to test the proposed methodology are highlighted in bold in the last row of
Table 1.
Recent Works and Methods
The study published in [
13] highlighted the deficiencies found in many previous works addressing network attacks classification when they consider an outdated dataset such as KDDCup’99 for performance evaluation. Other works similar to this one usually achieve high classification performance rates, although this is mainly motivated by the flaws found in KDDCup’99 dataset. This assumption is confirmed by comparing accuracy results obtained in [
15] through classical ML algorithms against the ones obtained by using the same ML methods but, in this case, considering a recent and realistic dataset: NGIDS-DS [
16]. Although the same ML algorithms were used for comparison, no specific details were mentioning the methodology followed by the authors.
The authors in [
15] proposed an IDS architecture addressing new challenges on managing vast volumes of network traffic in real time. To evaluate the system, attack classification performance was tested by using very well known ML algorithms on the old-fashion KDDCup’99 dataset. Additionally, an interesting study about the impact of specific feature selection techniques on the classification performance is provided. Finally, a proposed FS method combining manual exploratory feature analysis and two of the considered FS techniques (FSR (Forward Selection Ranking) and BER (Backward Selection Ranking)), got the best results in terms of modelling and detection time. However, the authors did not mention anything about FE, DP and HS, making the reported results hard to reproduce and compare.
A realistic network dataset comprising up-to-date attack and normal traffic patterns from an emulated network environment is introduced by Sharafaldin et al. [
17]. They corroborated the feasibility of the dataset in order to detect network-based attack with up to seven classical ML algorithms. To this end, they extracted several network traffic flow-based characteristics employing a specific tool. Then, they performed an FS procedure called Random Forest Regressor for relevance feature weighting depending on the attack. However, neither HS nor DP methods were described.
A deep learning approach for network anomaly detection is introduced by Li et al. [
18]. In this work, authors evaluated an LSTM (Long Short-Term Memory) neural network and BLS (Broad Learning Techniques) deep learning-based techniques for anomaly detection. In this sense, two network datasets were used: NSL-KDD and a BGP (Border Gateway Protocol)-based dataset. A manual HS process was carried out to select the optimal neural network architecture. On the other hand, a dataset normalization and a dummy FE approach were done as part of their methodology. Finally, they supported the BLS technique as a feasible alternative to sophisticated deep learning methods since it offered similar performance rates with less training time. Although this solution almost contemplated all the stages according to our recommended procedure, an important step such as FS was not taken into account and should not be eluded.
A novel greedy FS approach was proposed in [
19] to improve the attack detection classification performance in communication networks. NSL-KDD and ICSX12 datasets were considered to evaluate their proposal together with several deep learning and ML classical approaches. The authors concluded the feasibility of the approach in terms of classification performance and memory consumption. However, no FE, DP and HS steps were mentioned nor proposed in this work.
A tool to enhance previously generated network datasets was introduced by Cordero et al. [
20]: the I2DT tool. I2DT can add a diverse type of attacks to existing datasets, thus providing a useful tool that, as the authors claim, hardly reduces the time spent in building an adequate dataset for NIDSs evaluation. This way, I2DT was used to enhance MAWI dataset and later used in an RNN (Replicator Neural Networks)-based approach for DoS and port scan attack detection [
28]. RNN-based solutions provide an anomaly score such that values exceeding a certain threshold are marked as an anomaly. As with other works, there were no mentions to DP and FS techniques.
The authors in [
12] improve the MSNM (Multivariate Statistical Network Monitoring) [
29] for anomaly detection. In this sense, a semi-supervised approach of MSNM that relies on the use of PLS (Partial Least Squares) optimization techniques was proposed to adjust features’ weights according to the targeted attack dynamically. MSNM is based on statistical ML models (namely PCA). The FaaC (Feature as a Counter) that transforms original variables into counters in a specific time interval is validated here as a promising FE method (see
Section 4 for a detailed explanation). Altogether, it improves the MSNM detection capabilities on the diversity of attacks provided in the UGR’16 dataset [
14].
An Optimal Allocation Least Square SVM (or OA-LS-SVM) method was proposed in [
21] for incremental datasets. When working with incremental datasets, the size of the dataset may eventually be too large to train the models in a reasonable time. To handle this problem, the proposed method first used the Optimal Allocation technique to select representative samples from the dataset, and then applied an LS-SVM model to learn the classification problem, just using the selected samples. This technique was tested to detect anomalies in the KDDCup’99 dataset [
6]. The authors compared two versions of the method: using all features available in the dataset, or just a subset of them obtained through PCA [
30]. Avoiding critical stages, such as FE, DP and HS, is not recommended for fair NIDS comparison.
In [
22], the authors proposed a hybrid approach for anomaly-based IDS consisting of two different evolutionary algorithms, namely Artificial Bee Colony (ABC) and Artificial Fish Swarm (AFS). The hybrid algorithm was used to create rules for anomaly detection, based on a reduced subset of features which were generated with a primary correlation method. In this sense, bio-inspired alternatives may overcome classical and deep learning-based techniques for network attack detection, but the lack of details concerning the methodology or steps used makes comparison harder to perform.
Divekar et al. [
23] pointed out some flaws in KDDCup’99 [
6] for the evaluation of modern NIDS, and proposed a study on the performance of several classical ML models on two alternatives to the mentioned benchmark, as an attempt to analyze its suitability for modern NIDS. Mean Decrease Impurity technique was used to discard irrelevant features (the string values of some features were mapped onto integer numbers). Besides SMOTE was used for oversampling, followed by a random undersampling method in order to generate a dataset of reasonable size with a balanced number of samples of every class. ML models’ hyper-parameters were configured using randomized grid search and 5-fold cross-validation. Once more, no mention of FE methods was provided.
In [
24], the authors proposed the application of several classical ML models for NIDS on the UNSW-NB15 dataset, considering all available features. The performance of the considered models was evaluated using Apache Spark. Naïve Bayes was the fastest method to train, while Random Forest provided the most accurate predictions. The authors provided some numbers on the obtained run times, although they did not provide any details about the computation platform used or most of the recommended steps (FE, FS, etc.).
The authors in [
25] evaluated an extensive set of classical ML-based algorithms for anomaly detection in networks. To this end, well-known network datasets were used: KDDCup’99 and NSL-KDD. Besides, the influence of adding noise to data in NSL-KDD was also tested. On the one hand, almost all algorithms performed better with more realistic datasets, i.e., with NSL-KDD and its noisy versions. On the other hand, every algorithm had its own relevant set of features leading to better results. For that, a Performance-based Method of Ranking (PMR) FS algorithm was also proposed. As with previous works, FE, DP and FS were not considered nor mentioned.
The CTU-13 dataset for botnet anomaly detection was created and introduced by Garcia et al. [
26]. The authors compared three NIDS methods in their work: Cooperative Adaptive Mechanism for Network Protection (CAMNEP), BCplus and BotHunter. Besides, a methodology for comparison of the previous methods and NIDS solutions was proposed, which are, in general, fed with NetFlow-based data sources. Such a methodology just compares predictions obtained by the methods under evaluation for each observation in terms of standard and well-known metrics such as F1, precision, accuracy, etc., and another one proposed by the authors: the error metric. However, a common way to do crucial tasks in network attack detection such as FE, DP, or FS is also not proposed.
Through the work in [
27], the authors consider all the steps we claim as mandatory for network attack detection and remark the importance of feature extraction and feature selection steps for DoS, DDoS and network attacks classification in general. Firstly, they chose and extracted a vast number of network traffic features from previous works in the field. Secondly, they proposed a new feature selection method that mixes the Random Forest and Pearson’s correlation coefficient, called Random Forest and Pearson wrap (RFPW) algorithm. Their approach was tested through the MAWI dataset with a Gradient Boosted Decision Tree (GBDT) algorithm and some other classical ML algorithms, showing improvements introduced not only in the performance of the algorithms but also in the time required for the training phases.
In summary, almost all studied proposals avoid, elude or do not mention critical steps to evaluate ML-based algorithms for network attack detection. Therefore, the authors of this paper claim that it is hard and, sometimes, impossible to reproduce the obtained performance. Additionally, carrying out a fair comparison between different NIDS solutions only having information about the performance results is questionable. It is also worth noting that one of the most used datasets is the obsolete KDDCup’99 and its derived and improved version NSL-KDD which could be a handicap when evaluating NIDSs. In conclusion, some standard procedures or methodologies comprising all necessary steps, from the considered raw data to the outcome, should be proposed allowing honest and equitable comparisons.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}