Large Margin and Local Structure Preservation Sparse Representation Classifier for Alzheimer’s Magnetic Resonance Imaging Classification
 Runmin Liu
Runmin Liu Guangjun Li1*
Guangjun Li1*  Ming Gao
Ming Gao Weiwei Cai
Weiwei Cai Xin Ning
Xin Ning- 1College of Sports Engineering and Information Technology, Wuhan Sports University, Wuhan, China
- 2College of Sports Science and Technology, Wuhan Sports University, Wuhan, China
- 3School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi, China
- 4AiTech Artificial Intelligence Research Institute, Changsha, China
- 5Institute of Semiconductors, Chinese Academy of Sciences, Beijing, China
Alzheimer’s disease (AD) is a progressive dementia in which the brain shrinks as the disease progresses. The use of machine learning and brain magnetic resonance imaging (MRI) for the early diagnosis of AD has a high probability of clinical value and social significance. Sparse representation classifier (SRC) is widely used in MRI image classification. However, the traditional SRC only considers the reconstruction error and classification error of the dictionary, and does not consider the global and local structural information between images, which results in unsatisfactory classification performance. Therefore, a large margin and local structure preservation sparse representation classifier (LMLS-SRC) is developed in this manuscript. The LMLS-SRC algorithm uses the classification large margin term based on the representation coefficient, which results in compactness between representation coefficients of the same class and a large margin between representation coefficients of different classes. The LMLS-SRC algorithm uses local structure preservation term to inherit the manifold structure of the original data. In addition, the LMLS-SRC algorithm imposes the ℓ2,1-norm on the representation coefficients to enhance the sparsity and robustness of the model. Experiments on the KAGGLE Alzheimer’s dataset show that the LMLS-SRC algorithm can effectively diagnose non AD, moderate AD, mild AD, and very mild AD.
Introduction
Alzheimer’s disease (AD) is a chronic progressive neurodegenerative disease that usually progresses slowly in the early stages and gets worse over time (Katabathula et al., 2021). AD often occurs in the elderly. The initial symptoms are easy to forget recent events. With the development of the disease, the symptoms may include language problems, disorientation, mood swings, loss of self-care ability, etc., which will eventually seriously affect the daily life of the elderly. Currently, about 90 million people worldwide suffer from AD of varying degrees. It is estimated that by 2050, the number of AD patients will reach 300 million (Wong, 2020). The specific symptoms of very mild AD are progressive decline in memory or other cognitive functions, but do not affect the ability of daily living. According to statistics, about 10–15% of very mild AD will eventually transform into AD (Porsteinsson et al., 2021). Current scientific and clinical research has not yet clearly identified the pathogenesis and etiology of AD, and there is no fully effective treatment drug. AD is uncontrollable and irreversible after being diagnosed. However, if patients can be intervened and treated in the early stage of mild cognitive impairment (MCI), it is hoped that the onset of AD will be delayed by 5 years, and even stop the progression of AD in the stage of MCI, and no longer worsen into AD, reducing the number of patients with AD by 40% (Venugopalan et al., 2021).
In the past decade, neuroimaging techniques have been widely used in the classification and prediction of AD. Among them, magnetic resonance imaging (MRI) is a non-contact imaging technology that can provide detailed three-dimensional anatomical images of the brain and provide effective information for the classification and prediction of AD (Al-Khuzaie and Duru, 2021). The AD classification algorithms based on machine learning usually extract the required features from the collected medical images by manual or semi-manual methods. Various parts of the brain regions of AD patients will atrophy to varying degrees due to the progression of the disease process. The volume, shape and texture information of the hippocampus, gray matter, white matter, and cerebral cortex of the brain are important features to distinguish AD and healthy people (Lee et al., 2020; Gao, 2021). To classify AD MRI images, some studies extract the volume information of the whole brain or part of the brain. Some scholars segment different regions of the brain and take the volume of each segment as features. According to the anatomical automatic labeling brain region template, some researchers divide the entire brain or part of the brain region into multiple regions and then obtain the features for each region. AD Patients often experience cerebral cortex atrophy and ventricular enlargement, and early AD patients usually have hippocampal atrophy (van Oostveen and de Lange, 2021). Therefore, some scholars use the volume information of different regions of interest such as the hippocampus as features based on medical prior knowledge. Another common feature extraction method is the morphometric measurement method, which is often implemented based on MRI images and PET images. For example, Al-Khuzaie and Duru (2021) took the overall shape of the brain in MRI images as features. Katabathula et al. (2021) used the shape information of the hippocampus as features. Brain gully dilation is often seen in AD patients. Furthermore, texture features are also widely used in MRI images. Gao (2021) extracted the grayscale co-occurrence matrix of images as features. Hett et al. (2018) used 3D Gabor filter to extract and classify multi-directional texture features of MRI images.
Classifiers such as sparse representation classifier (SRC), logistic regression (LR), support vector machine (SVM), and decision tree (DT) are widely used in AD MRI image classification. For example, Kruthika et al. (2019) used a multi-level classifier to classify AD MRI images. They first used a naive Bayes classifier, and then used SVM as secondary classification to classify the data with confidence lower than the threshold. Liu et al. (2015) proposed a multi-view learning algorithm based on inherent structure of mild cognitive impairment (MCI) MRI images, which used the multi-view features of MCI images to train multiple SVMs, and then fused and discriminated each classifier result. Altaf et al. (2018) used SVM, random forest, and K-nearest neighbor (KNN) to train AD classifiers, respectively, and the final classification result was the weighted sum of the results of each classifier. Yao et al. (2018) used the idea of hierarchical classification to classify AD MRI images. They initially classified samples into four classes (AD, healthy, MCI, converted MCI), then they trained several binary classifiers (AD and converted MCI, healthy and MCI), and finally got a classifier that can classify all samples into four classes. Pan et al. (2019) proposed an algorithm to integrate multi-level features based on FDG-PET images, and simultaneously considered the region features and connectivity between regions to classify AD or MCI from healthy people. Finally, multiple SVMs were used for voting classification, and good results had been achieved in multiple binary classification tasks.
Magnetic resonance imaging image features usually suffer from high dimensionality and small sample size, which may lead to overfitting in data-driven machine learning methods (Jiang et al., 2019). To solve this problem, most existing methods adopt feature selection or feature representation to exploit the potential knowledge of data. Sparse representation is one of the widely used feature representation methods. Sparse representation can explore potential relationships within the data (Gu et al., 2021). Chang et al. (2015) proposed a dictionary learning algorithm based on sparse decomposition of stacked prediction. They used the spatial pyramid matching method to encode representation coefficients, and used SVM to classify the pathological state of tumors. Shi et al. (2013) developed a multi-modal SRC algorithm for lung histopathological image classification, which used genetic algorithm to guide the learning of three sub-dictionaries of color, shape and texture, and then combined sparse reconstruction error and majority voting algorithm for classification of lung histopathology images. He (2019) proposed a spatial pyramid matching algorithm based on joint representation coefficient, which utilized the three color channel information of RGB, and converted the grayscale description operator into a color description operator, which improved the image classification performance. Jiang et al. (2019) extracted features from breast cancer histopathological images based on stacked sparse autoencoder, and used Softmax function to detect cell nuclei in histopathological images. Zhang et al. (2016) realized the fusion of global and local features of the nuclear image, and then combined the ranking and majority voting algorithm to classify the histopathological images of breast cancer. The above algorithms can effectively extract image features by introducing the sparsity of the image, and the extracted features have good reconstruction properties, but they do not have good discriminative ability.
To improve the diagnosis of MCI and AD based on MRI images, we propose large margin and local structure preservation sparse representation classifier (LMLS-SRC) in this manuscript. The traditional SRC only uses the classification error term to control the classification accuracy, and does not fully consider the class label information of the representation coefficients. Different from the traditional SRC, the LMLS-SRC algorithm introduces the classification margin term of representation coefficients into the sparse representation classifier, so that the similar representation coefficients are compact in the representation space, and the dissimilar representation coefficients are separated as much as possible in the representation space. Experiments on the KAGGLE Alzheimer’s dataset verify the advantages of our algorithm. Major contributions of this manuscript are highlighted below: (1) Considering the global information of the data by using the large margin term, the obtained dictionary is discriminative, and the representation coefficient has the small intra-class distance and large inter-class distance. (2) The local structure preservation term is introduced, which can inherit the manifold structure of the original data. (3) The ℓ2,1-norm term on the representation coefficients is used, which can enhance the sparsity and robustness of the representation coefficients.
Backgrounds
Dictionary-Based Sparse Representation Classifier
Using SRC algorithm in image classification, how to design effective dictionary and representation coefficient for feature representation is the key factor to determine the algorithm performance (Wright et al., 2009). There are three aspects considered in the design of SRC algorithm: (1) The reconstruction error of the representation coefficients is small, so that the samples are as close to the original samples as possible in the sparse representation; (2) The representation coefficients are constrained to make the representation coefficients as sparse as possible; (3) The discrimination term should be considered to better extract more discriminative information of data (Jiang et al., 2013).
Let X = [X1,…,XK] ∈ Rd×N be the K-classes training sample set, Xk = [x1,…,xNk] be the k-th class training sample subset, k = 1, 2,…, K,N = N1 + N2 + ⋯ + NK. d is the dimensional of samples. The SRC algorithm for image classification can be represented as,
where Y is the class label matrix of X. D ∈ Rd×m is the learned dictionary, and A ∈ Rm×N is the representation coefficient matrix of X. m is the size of dictionary. In model training, the data reconstruction item is to ensure the representation ability of the dictionary D, so that the reconstruction error of the training data is minimized, and the reconstructed image is as close to the original sample as possible. The regularization term is used to constrain the sparsity of the representation coefficients, which is usually represented as,
where ||⋅||p is the regularization term of the representation coefficient A (p < 2), which makes the representation coefficient as sparse as possible. f(D,A,Y) is the discriminative function term of representation coefficient for classification to ensure the discriminative ability of D and A.
To obtain a discriminative dictionary, Yang et al. (2017) developed a supervised Fisher discrimination dictionary learning (FDDL), which associated the elements in the dictionary with the class labels of the samples based on the Fisher discrimination criterion. Jiang et al. (2013) proposed the discriminative Label consistent K-SVD (LC-KSVD) algorithm. Zhang et al. (2019) proposed a robust flexible discriminative dictionary learning (RFDDL) algorithm based on subspace recovery and enhanced locality. This algorithm improved image representation and classification by enhancing representation coefficient robustness. The computational complexity of the SRC representation coefficient is usually high. To quickly obtain the representation coefficients, Ma et al. (2017) proposed the local sparse representation algorithm, which used the KNN criterion to select k samples adjacent to the current sample to build a dictionary matrix. In this way, the size of the dictionary is reduced and the process of representation coefficient is greatly accelerated. Similarly, inspired by the KNN criterion, Zheng and Ding (2020) developed a sparse KNN classifier based on group lasso strategy and KSVD algorithm. Wang et al. (2018) proposed a SRC algorithm based on the ℓ2-norm, which replaced the ℓ1-norm with the ℓ2-norm to constrain the coefficients. Ortiz and Becker (2014) proposed an approximate linear SRC algorithm. Authors used least square algorithm to select the training samples corresponding to the absolute values of the k largest coefficients to build a sub-dictionary.
KAGGLE Alzheimer’s Image Dataset
The experiments in this manuscript are carried out on the KAGGLE Alzheimer’s image dataset (Loddo et al., 2022). The KAGGLE Alzheimer’s dataset contains a total of four types of MRI images: non AD (3,200 images), very mild AD (2,240 images), mild AD (896 images) and moderate AD (64 images), with the resolution of 176 × 208. The KAGGLE Alzheimer’s dataset does not provide detailed information on patient status. Figure 1 shows some example images of the KAGGLE Alzheimer’s dataset.
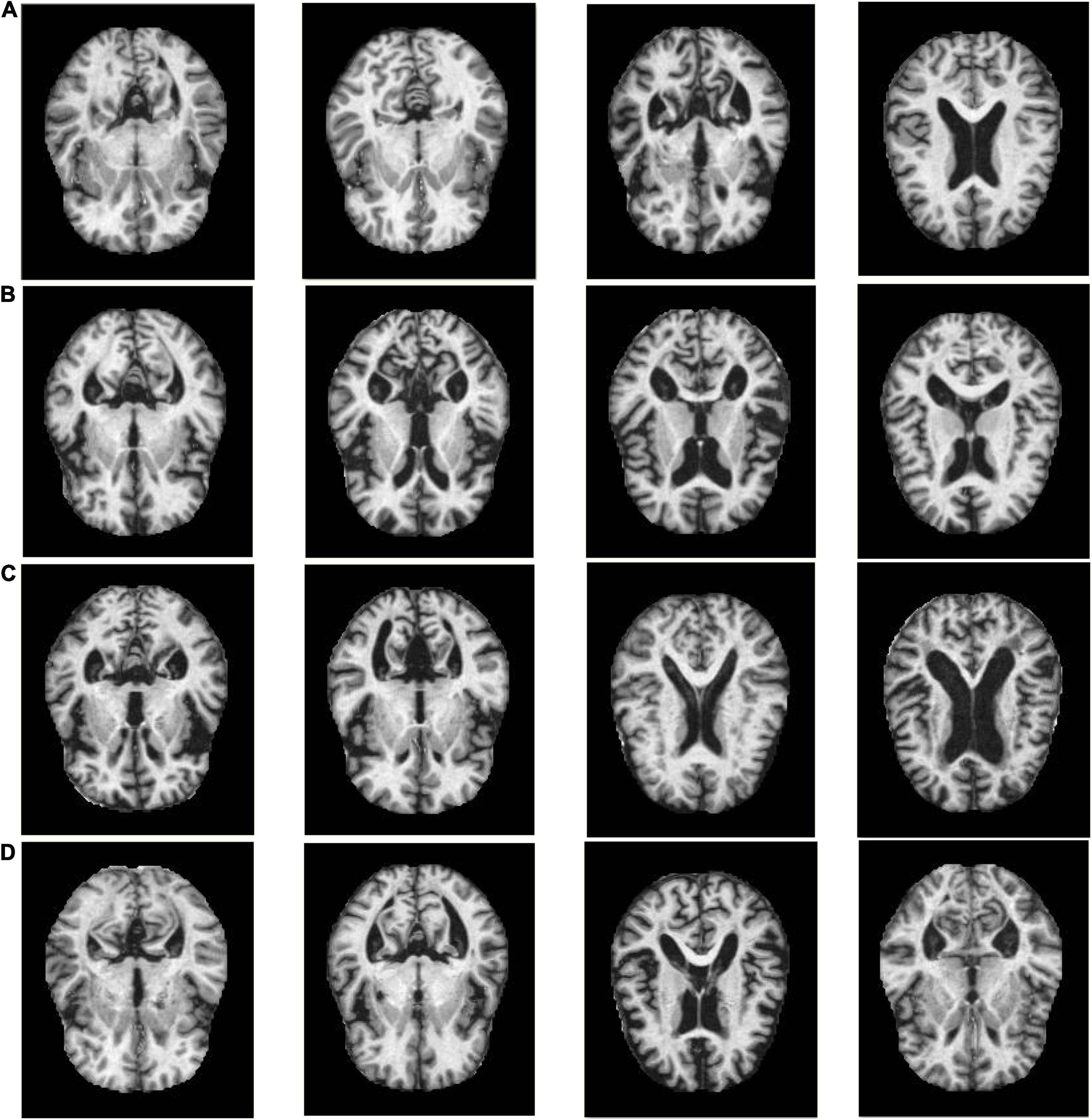
Figure 1. Example samples of the KAGGLE Alzheimer’s dataset, (A) Non AD, (B) Moderate AD, (C) Mild AD, (D) Very Mild AD.
The Proposed Algorihtm
Objective Function
The purpose of sparse representation is to represent the sample with as few elements as possible on a given dictionary, so that a more concise representation of the sample can be obtained, and the useful information contained in the sample can be easily obtained. Thus the core problem of sparse representation is how to compute sparse coding coefficients on a given learned dictionary. Compared with the commonly used ℓ1-norm and ℓ2-norm, ℓ2,1-norm can improve the robustness of the model and reduce the computational complexity. Thus, we introduce ℓ2,1-norm constraint on representation coefficients in LMLS-SRC, i.e.,
where λ1 is a constant.
We define a large margin term on representation coefficient that relies on a specific neighborhood size for intra-class and inter-class representation coefficients. The large margin term minimizes the intra-class distance of the representation coefficient and maximizes the inter-class distance of the representation coefficient, so as to improve the difference between the representation coefficients of different classes. The large margin term on representation coefficient can be written as,
where represents the distance between ai and the sparse representation of the same class. represents the distance between ai and the sparse representation of the different class. Ck is the index set of the k-th class sample.
We build the intra-class similarity matrix Qw and inter-class similarity matrix Qb based on representation coefficient. The elements of the matrix Qw and matrix Qb are expressed as,
Then the large margin term on representation coefficient can be expressed as,
where . The matrix is the diagonal matrix with the element being the column-sum of Qb.
Following the principle of local structure preservation, if two images are close in the original space, they should also have similar representation coefficients. To this end, we construct a similarity matrix P that reflects the intrinsic local structure between images. The element of matrix P is defined as,
where N(xj) represents the k nearest neighbors of xj.
The local structure preservation term on representation coefficient is expressed as,
where the graph Laplacian matrix L is , is the diagonal matrix with the element being the row-sum of P.
The LMLS-SRC algorithm is a supervised learning model. Using the class labels of all training samples, we use a linear classifier W for representation coefficient A and dictionary D, i.e.,
In summary, the objective function of the LMLS-SRC algorithm can be written as,
i.e.,
where λ1,λ2,λ3,λ4, and λ5 are trade-off parameters.
By alternately optimizing the representation coefficient A, dictionary D and classifier parameter W, the following performance can be obtained as: (1) the dictionary D has more sparse representation performance, which enhances the reconstruction of the sample by the dictionary. (2) LMLS-SRC maximizes the distance between different classes of representation coefficients and greatly reduces the similarity between different classes of representation coefficients. (3) The representation coefficient is more discriminative, which is beneficial to the performance of image classification.
Optimization
(1) Fix D, W, and update A. Eq. (12) can be written by,
According to the definition of ℓ2,1-norm, . Ω is a diagonal matrix whose elements are setting by Ωii = 1/(2||Ai||2) where Ai represents the i-th row of A.
Equation (12) can be re-written by,
Setting ∂F(A)/∂A = 0, we can obtain,
A can obtained by the updated by,
(2) Fix A, W, and update D. Equation (12) can be written by,
We can solve Eq. (17) by the following Lagrangian dual function,
where γi is the Lagrange multiplier of i-th atoms.
We build a diagonal matrix Θ with the element Θii = γi. Equation (18) can be written by,
Setting ∂F(D,Θ)/∂D = 0, we can obtain,
(3) Fix A and D, and update W. Equation (12) can be written by,
Setting ∂F(W)/∂W = 0, we can obtain,

Experiments
Experimental Settings
In clinical diagnosis, AD classification tasks consist of two categories. The first is the AD binary classification task, which extracts features based on MRI images and uses machine learning models to classify normal individuals and AD patients, which can help doctors diagnose AD patients. The second is the classification of various ADs, especially the diagnosis and identification of mild AD and very mild AD. Early prediction of AD can help to take treatment and intervention measures in the early stage of AD. Therefore, in this manuscript, we design binary, three-class and four-class classification tasks on the KAGGLE Alzheimer’s dataset.
Volume analysis is the commonly used feature extraction method in AD classification. Volumetric feature extraction is divided into two categories: density maps and predefined area methods. AD MRI image is mainly related to the volume of the density map structure, cortical structure, subcortical structure and other regions. In this manuscript, we use FSL (FMRIB software library) toolbox to extract MRI features (Jenkinson et al., 2012). FSL is a library of comprehensive analysis tools for brain imaging data such as MRI, developed by the FMRIB Centre in Oxford. We use the FSL toolbox to calculate the volume, area and thickness characteristics of various brain tissues in brain MRI images. In the comparison experiment, the LMLS-SRC algorithm is compared with SRC (Wright et al., 2009), logistic regression (LR) (Tsangaratos and Ilia, 2016), linear discriminant (LD) (Kim et al., 2011), LC-KSVD, FDDL, and sparse representation-based discriminative metric learning (SRDML) (Zhou et al., 2022). The radial basis function (RBF) kernel is used in LR. The default settings are used to produce test results from these classifiers using the MATLAB classification learner toolbox. The RBF kernel and the regularization parameters for all comparison algorithms range from 10–3 to 103. The number of dictionary atoms in SRC and dictionary learning is set as the number of training samples. Indicators of classification performance include classification accuracy, sensitivity, specificity, precision, F1-score, and G-mean. We carry out 5-fold cross-validation strategy and record the experimental results.
Experimental Results
(1) Binary classification task. The main goal of this work is to classify brain MRI into AD and non AD classes. We utilized 3,200 and 62 MRI images for non AD and AD classes, respectively. We randomly selected 1,000 MRI images from the non AD class images to increase the moderate AD class dataset to 620 MRI images using data augmentation techniques. The comparative training and test results in binary classification task are shown in Tables 1, 2, respectively.
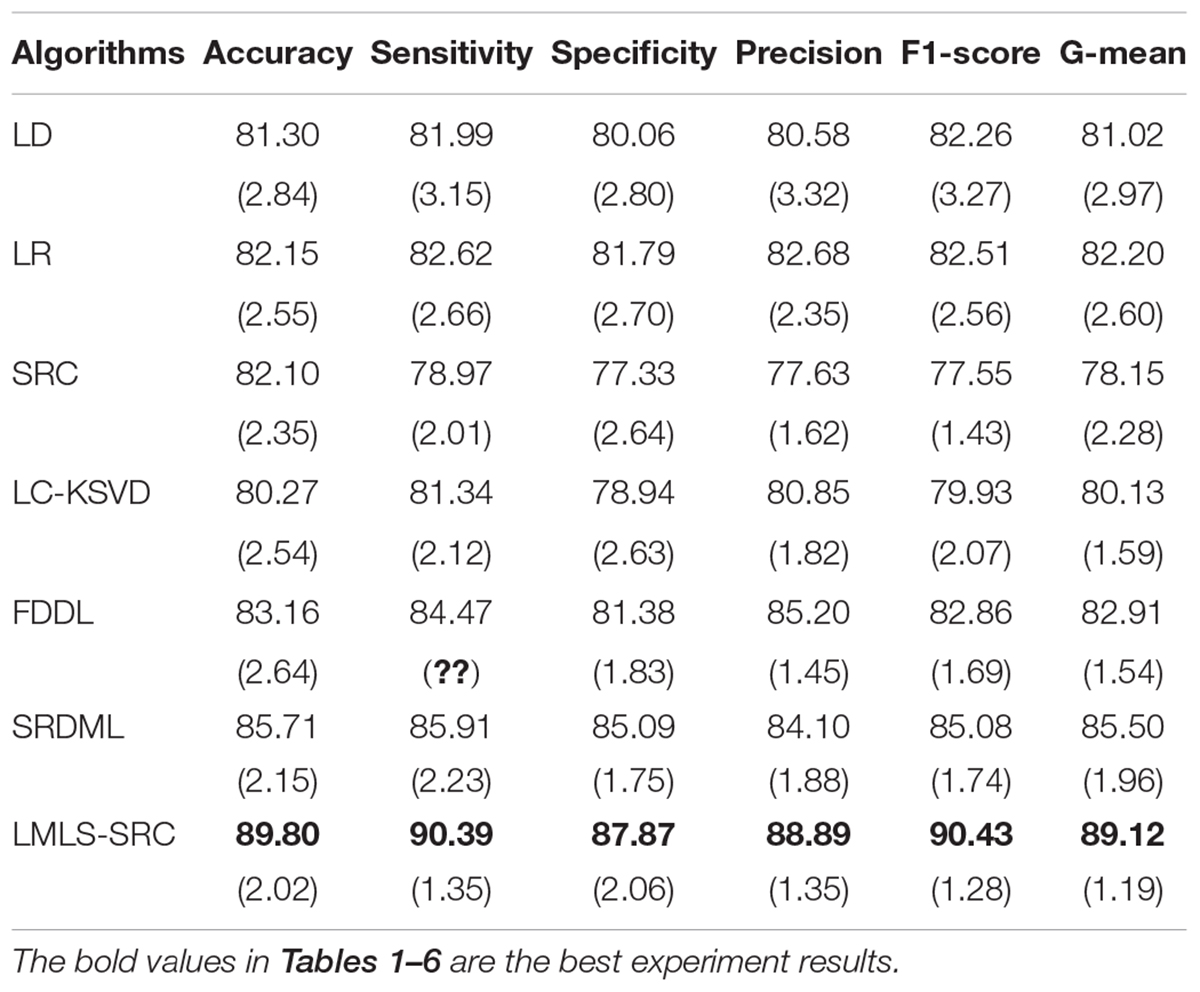
Table 1. The comparative training results (with standard deviation) in binary classification task.
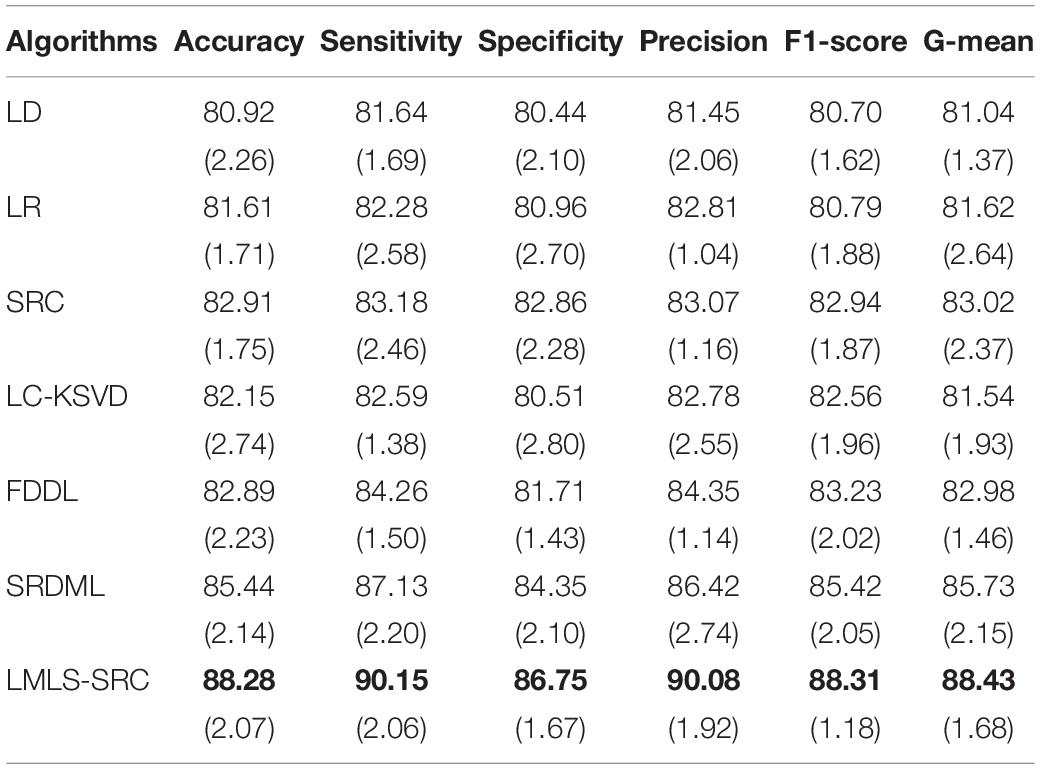
Table 2. The comparative test results (with standard deviation) in binary classification task.
(2) Three-class classification tasks. The main goal of this work was to classify brain MRI into three classes: non AD, mild AD, and moderate AD. Using data augmentation techniques, these three classes of datasets contain 3,200, 700, and 620 images, respectively. We randomly selected 1,000 MRI images from the non AD class. The comparative training and test results in three-class classification task are shown in Tables 3, 4, respectively.
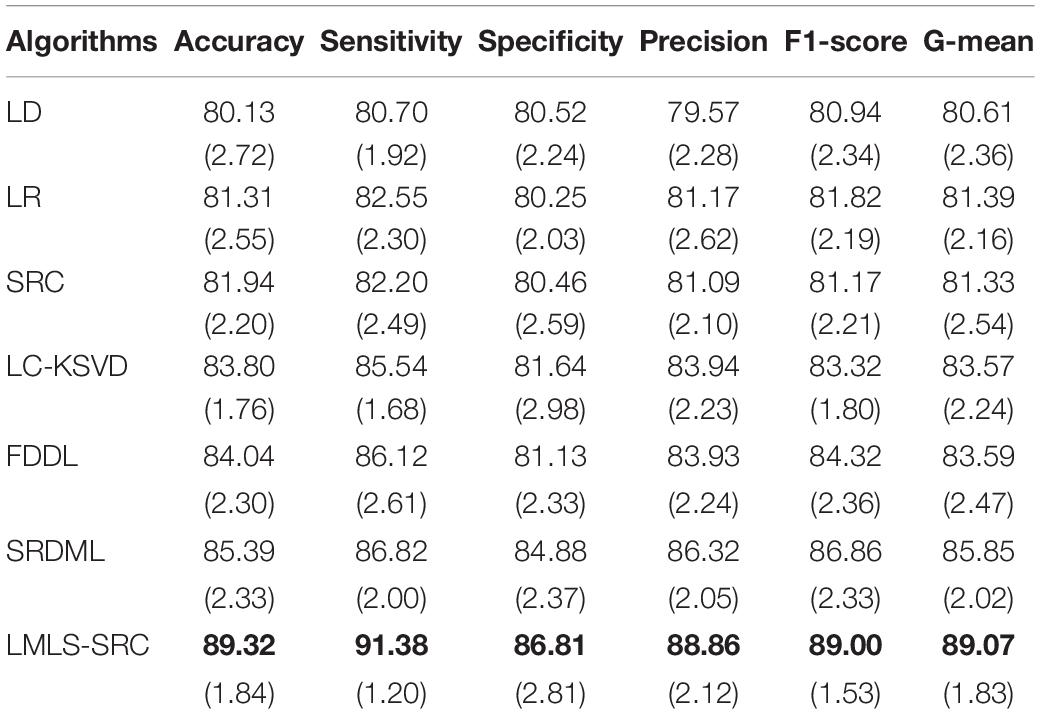
Table 3. The comparative training results (with standard deviation) in three-class classification task.
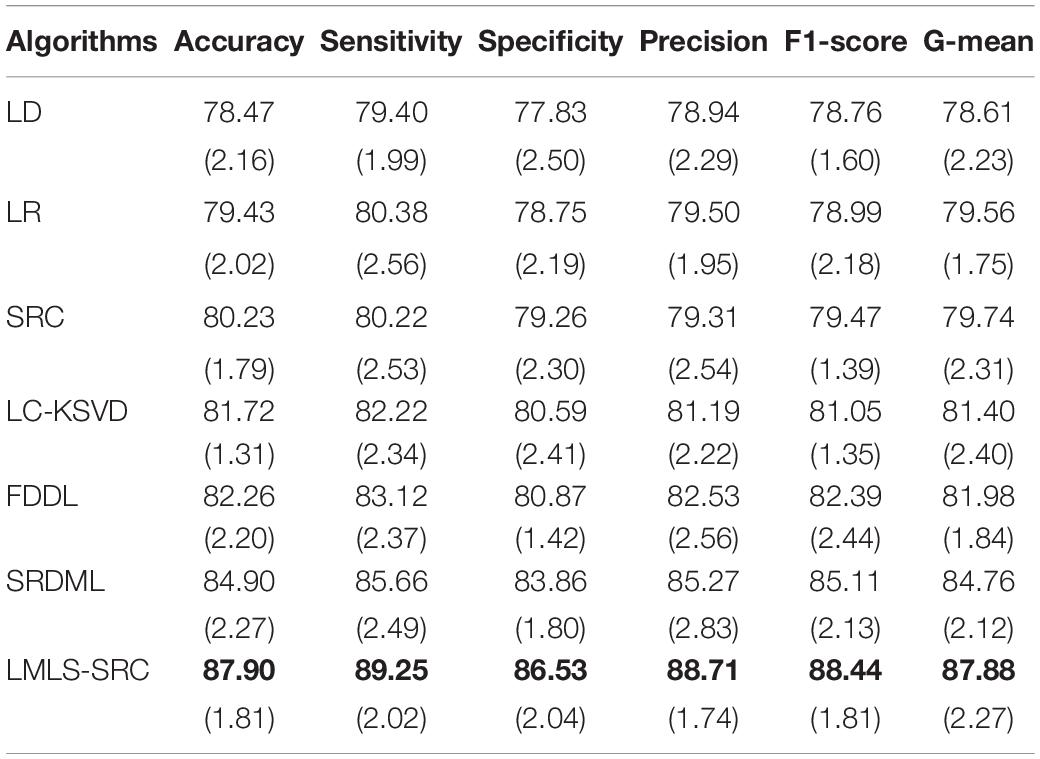
Table 4. The comparative test results (with standard deviation) in three-class classification task.
(3) Four-class classification tasks. The main goal of this work is to classify brain MRI images into four classes: very mild AD, non AD, mild AD, and moderate AD. Similar to the three-class classification task described, we randomly selected 1,000 MRI images each from non AD class images and very mild AD, respectively, and used data augmentation to increase the moderate dementia dataset to 520 MRI images. The number of images in the four categories of very mild AD, non AD, mild AD, and moderate AD are 1,000, 1,000, 700, and 520, respectively. The comparison training and test results in four-class classification task are shown in Tables 5, 6, respectively.
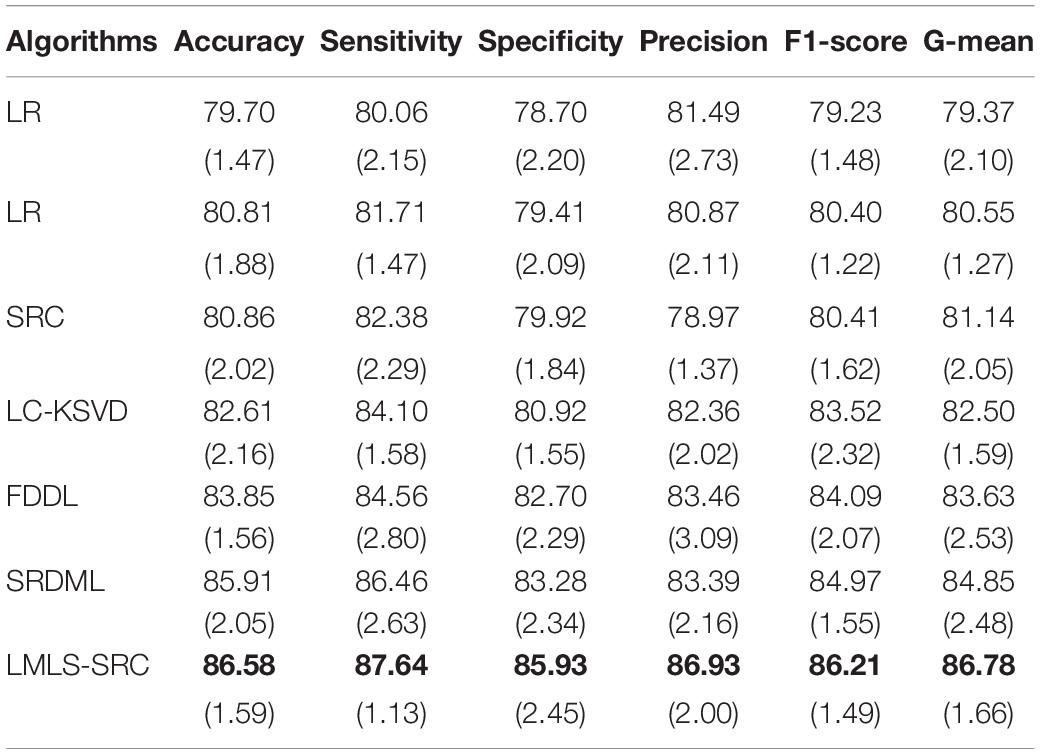
Table 5. The comparative training results (with standard deviation) in four-class classification task.
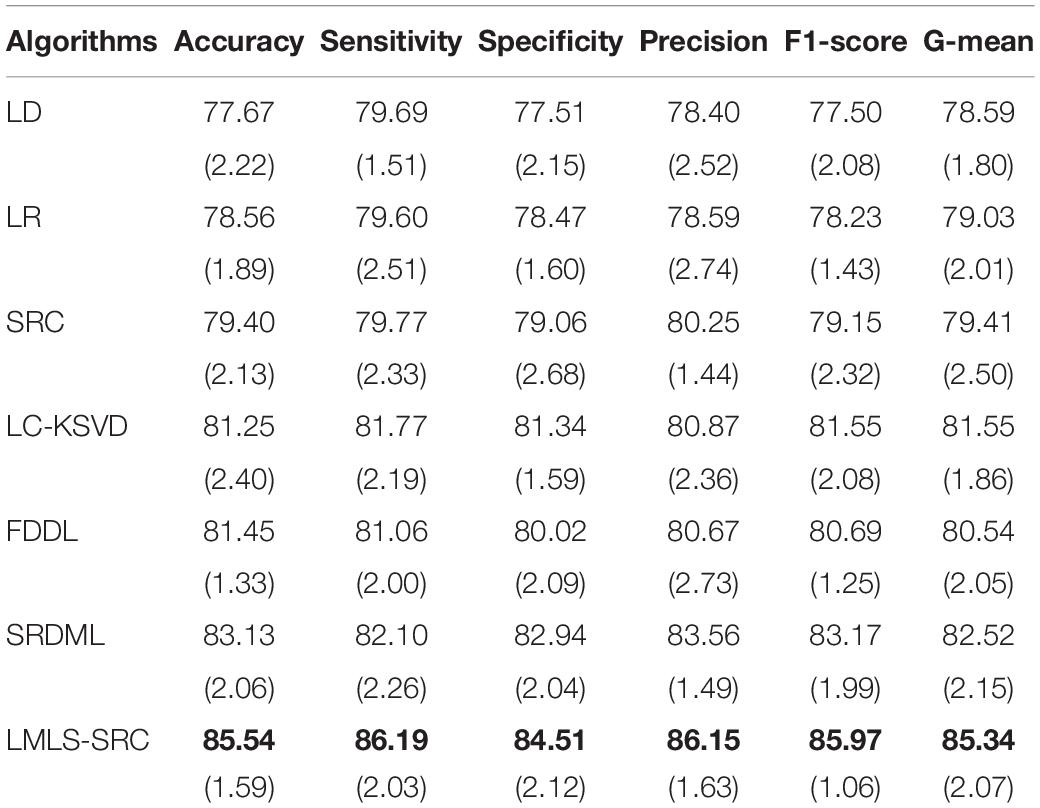
Table 6. The comparative test results (with standard deviation) in four-class classification task.
We can see that all the comparison algorithms have the highest classification accuracy in the binary classification task (AD and non AD). It shows that these machine learning algorithms have excellent performance in the classification and diagnosis of AD. It is more practical to classify patients, very mild AD, non AD, mild AD, and moderate AD into four classes, and this classification task is more difficult. The classification accuracy of all the comparison algorithms on the four-class task is slightly lower than that on the two-class task. However, the LMLS-SRC algorithm achieves the best results in these tables, indicating that our algorithm has a great improvement in the diagnosis of AD.
In Tables 2, 4, 6, the LMLS-SRC algorithm improves the classification accuracy of the second best algorithm by 2.84, 3.00, and 2.41%, respectively. This shows that the dictionary learned in this study has better reconstruction performance for the samples of same class and better discriminative performance for samples of different classes. KSVD, LC-KSVD, and LMLS-SRC are SRC algorithms. The KSVD and LC-KSVD algorithms only constrain the discriminative ability of the representation coefficients, and do not take into account the large margin between the representation coefficients of different classes. Therefore, the discriminative ability of the learned dictionary obtained by KSVD and LC-KSVD is still weak. The dictionary learned by the LMLS-SRC algorithm in this manuscript is combined with the classification large margin criterion, which directly constrains the intra-class distance and inter-class distance of the representation coefficients. Compared with the other three algorithms, the inter-class differences of the dictionary learned by our algorithm are more discriminative.
Parameter Analysis
(1) Convergence analysis. The update of {(D), (A), (W)} in the objective function are three convex optimization problems. That is, when other parameters are fixed, the iterative solution of dictionary D, representation coefficient A and classifier parameter W is the convex problem. The solution of dictionary D is obtained by Eq. (20). The solution of dictionary A is obtained by Eq. (16). The solution of dictionary W is obtained by Eq. (22). Figure 2 shows the convergence of the LMLS-SRC algorithm. As shown in Figure 2, it can be seen that the classification accuracy of the LMLS-SRC algorithm tends to be parallel to the X-axis from the 10th iteration. Here, it can be considered that our algorithm converges after 12 iterations.
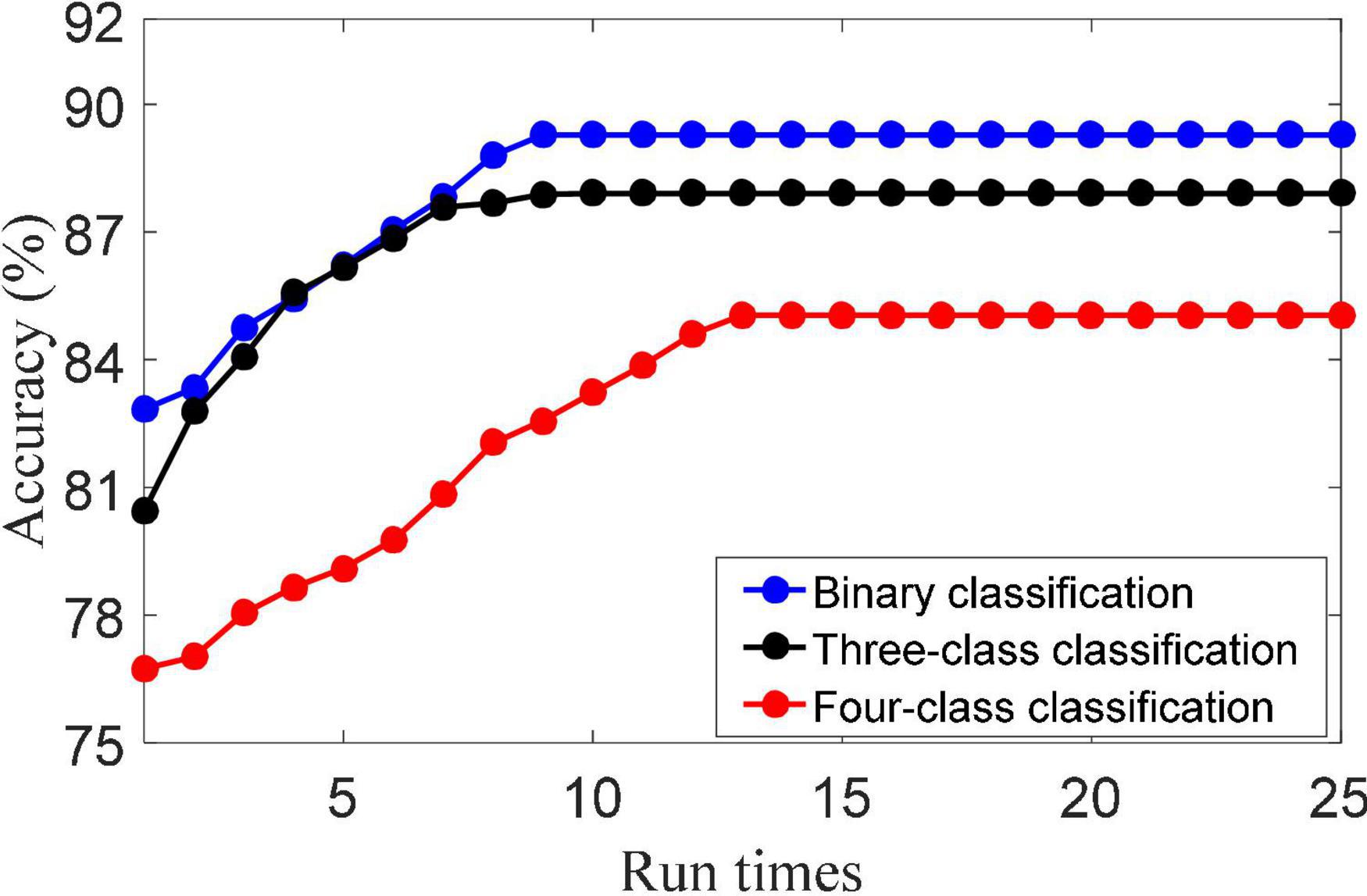
Figure 2. Convergence of the LMLS-SRC algorithm.
(2) Training set size. The size of the training set usually directly determines the performance of machine learning algorithms. Figure 3 shows the classification accuracy of the LMLS-SRC algorithm on binary-class, three-class and four-class classification tasks under different training sets of each subclass. The X-axis represents the training sample size N of each subclass, N = [50, 100,…, 400]. From Figure 3, we can see that the accuracy of LMLS-SRC increases with the increase of training samples. When the training sample size of each subset reaches 200, the performance of the LMLS-SRC algorithm is basically stable, indicating that the LMLS-SRC algorithm can achieve better performance without too many training samples.
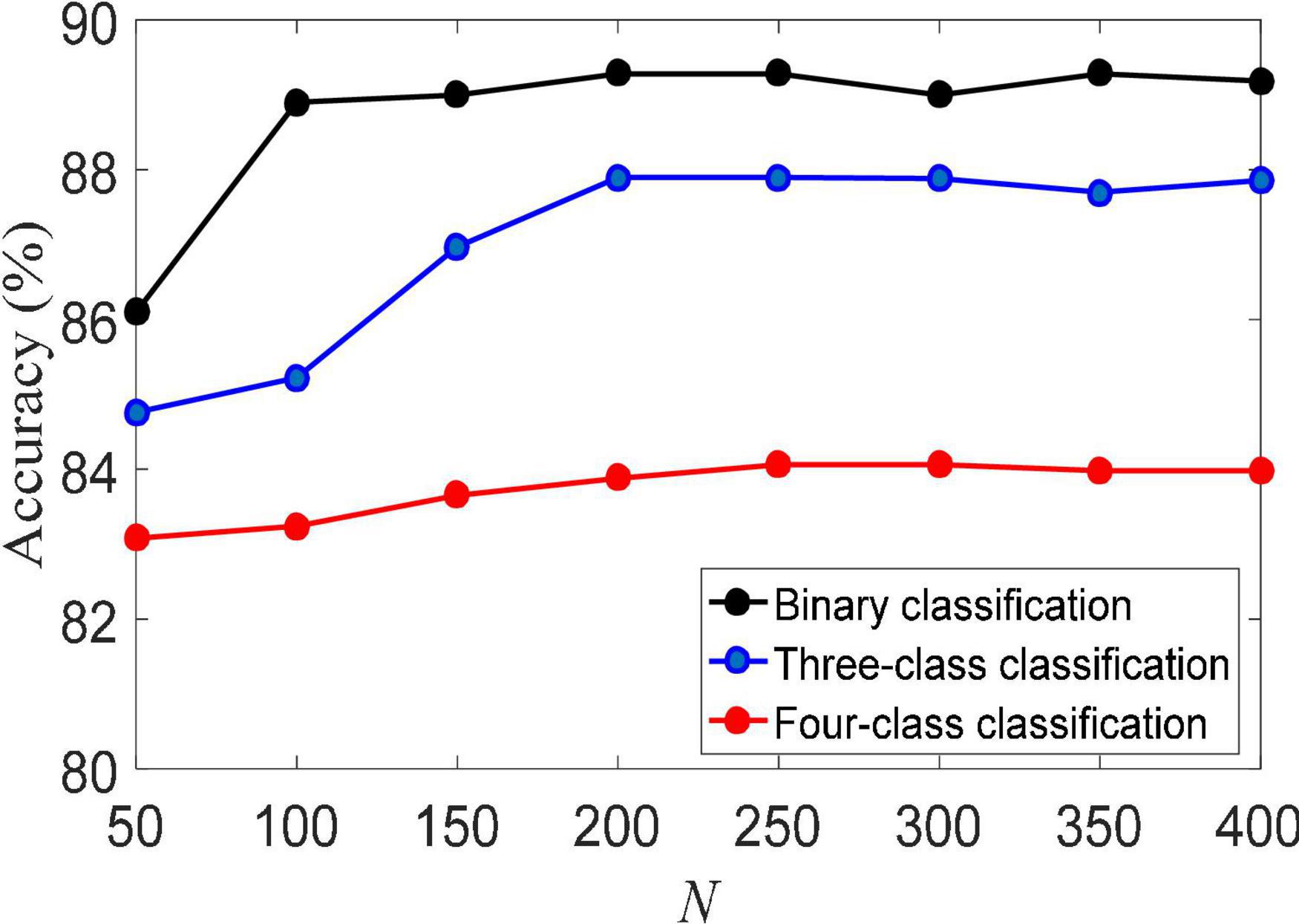
Figure 3. Classification accuracy of local structure preservation sparse representation classifier (LMLS-SRC) under different training sets of each subclass.
(3) Regularization parameters. The LMLS-SRC algorithm has five regularization parameters λ1,λ2,λ3,λ4, and λ5, and the regularization parameters are all obtained in [1.0E-3…, 1.0E+3]. λ2 controls the role of the large margin term. λ3 controls the role of the local structure preservation term. λ4 controls the role of the linear classifier. Figure 4 shows the classification accuracy of the LMLS-SRC algorithm in the binary, three-class and four-class tasks with different λ2, λ3, and λ4, respectively. Figure 4 shows that the performance of the LMLS-SRC algorithm varies greatly with different λ2, λ3, and λ4, while fixing the other parameters. Therefore, it is reasonable to use a grid search strategy to optimize the regularization parameters.
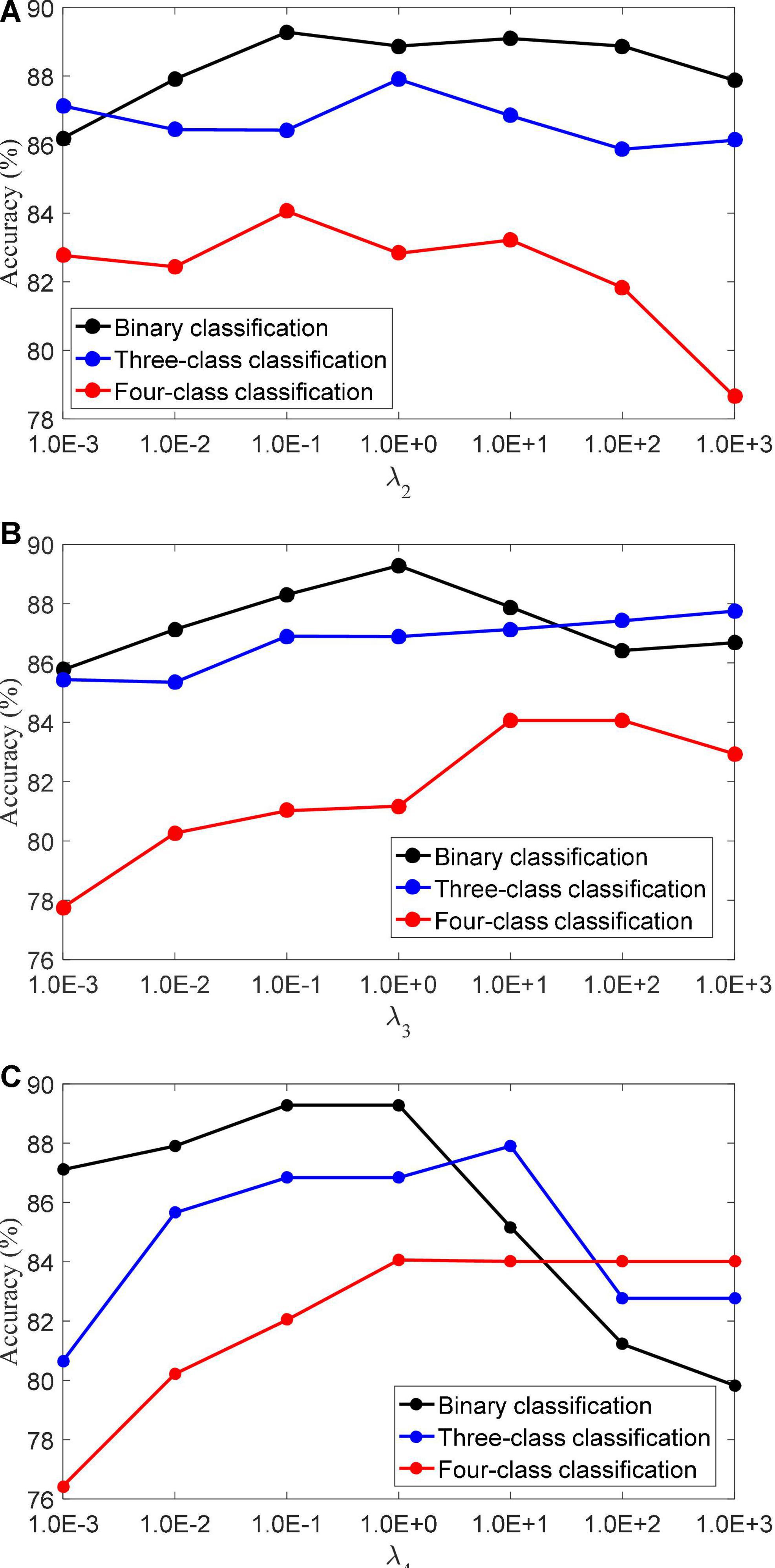
Figure 4. Classification accuracy of LMLS-SRC with different regularization parameters, (A)λ2, (B)λ3, and (C) λ4.
Conclusion
With the acceleration of the global aging trend, one of the problems brought about is the rapid increase in the number of AD patients. The pathogenesis and effective treatment of AD are still unclear at present. Early detection, classification, and prediction of AD, and targeted care and treatment of patients on this basis can delay the progression of AD. Machine learning algorithms that can automatically extract information and complete inference have good application prospects in AD classification and prediction. Therefore, this manuscript conducts research based on the application of SRC algorithm in AD classification. The research content mainly includes two aspects: model construction and model performance evaluation. The proposed LMLS-SRC algorithm introduces the large margin term and local constraint term in the traditional SRC model, and obtains the dictionary and representation coefficients with discriminative ability while maintaining the data manifold structure. The effectiveness of the LMLS-SRC algorithm is validated on the KAGGLE Alzheimer’s dataset.
Although the LMLS-SRC algorithm shows the advantages compared with some excellent algorithms, there are still some problems to be solved. In the future, we will mainly focus on the following aspects: (1) The LMLS-SRC algorithm belongs to the shallow model. How to design the deep model of the sparse representation algorithm needs to be further studied. (2) In this manuscript, brain MRI images are used as the basic data to study the application of AD classification. Multimodal data can provide richer information, and how to extract AD-related features from multimodal data can be studied in the future. (3) This manuscript uses the volume features extracted by using FSL tool. Extracting various features for AD classification can be done in the next future. (4) In practical applications, image classification often encounters small samples or even a single training sample, and traditional SRC algorithms cannot effectively handle such situations. How to deal with the single training sample is the work to be further studied in the future.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.kaggle.com/datasets/tourist55/alzheimers-dataset-4-class-of-images.
Ethics Statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
RL conceived and developed the theoretical framework of the manuscript. All authors carried out experiment and data process, drafted the manuscript, and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Al-Khuzaie, F., and Duru, A. D. (2021). Diagnosis of Alzheimer disease using 2D MRI slices by convolutional neural network. Appl. Bion. Biomech. 2:6690539. doi: 10.1155/2021/6690539
Altaf, T., Anwar, S. M., Gul, N., Majeed, M. N., and Majid, M. (2018). Multi-class Alzheimer’s disease classification using image and clinical features. Biomed. Signal Process. Control 43, 64–74. doi: 10.1016/j.bspc.2018.02.019
Chang, H., Zhou, Y., Borowsky, A., Barner, K., Spellman, P., and Parvin, B. (2015). Stacked predictive sparse decomposition for classification of histology sections. Int. J. Comput. Vis. 113, 3–18. doi: 10.1007/s11263-014-0790-9
Gao, S. S. (2021). Gray level co-occurrence matrix and extreme learning machine for Alzheimer’s disease diagnosis. Int. J. Cogn. Comput. Eng. 2, 116–129. doi: 10.1016/j.ijcce.2021.08.002
Gu, X., Zhang, C., and Ni, T. G. (2021). A hierarchical discriminative sparse representation classifier for EEG signal detection. IEEE/ACM Trans. Comput. Biol. Bioinform. 18, 1679–1687. doi: 10.1109/TCBB.2020.3006699
He, T. (2019). Image classification based on sparse coding multi-scale spatial latent semantic analysis. EURASIP J. Image Video Process. 2019:38. doi: 10.1186/s13640-019-0425-8
Hett, K., Ta, V. T., Manjón, J. V., and Coupé, P. (2018). Adaptive fusion of texture-based grading for Alzheimer’s disease classification. Comput. Med. Imag. Graph. 70, 8–16. doi: 10.1016/j.compmedimag.2018.08.002
Jenkinson, M., Beckmann, C. F., Behrens, T. E. J., Woolrich, M. W., and Smith, S. M. (2012). FSL. Neuroimage 62, 782–790. doi: 10.1016/j.neuroimage.2011.09.015
Jiang, Y., Chen, L., Zhang, H., and Xiao, X. (2019). Breast cancer histopathological image classification using convolutional neural networks with small SE-ResNet module. PLoS One 14:e0214587. doi: 10.1371/journal.pone.0214587
Jiang, Z., Lin, Z., and Davis, L. S. (2013). Label consistent K-SVD: learning a discriminative dictionary for recognition. IEEE Trans. Pattern Analys. Mach. Intell. 35, 2651–2664. doi: 10.1109/TPAMI.2013.88
Katabathula, S., Wang, Q., and Xu, R. (2021). Predict Alzheimer’s disease using hippocampus MRI data: a lightweight 3D deep convolutional network model with visual and global shape representations. Alzheimers Res. Ther. 13:104. doi: 10.1186/s13195-021-00837-0
Kim, K. S., Choi, H. H., Moon, C. S., and Mun, C. W. (2011). Comparison of k-nearest neighbor, quadratic discriminant and linear discriminant analysis in classification of Electromyogram signals based on the wrist-motion directions. Curr. Appl. Phys. 11, 740–745. doi: 10.1016/j.cap.2010.11.051
Kruthika, K. R., Maheshappa, H. D., Rajeswari, and Alzheimer’s Disease Neuroimaging Initiative (2019). Multistage classifier-based approach for Alzheimer’s disease prediction and retrieval. Inform. Med. Unlocked 14, 34–42. doi: 10.1016/j.imu.2018.12.003
Lee, S., Lee, H., and Kim, K. W. (2020). Magnetic resonance imaging texture predicts progression to dementia due to Alzheimer disease earlier than hippocampal volume. J. Psychiatry Neurosci. 45, 7–14. doi: 10.1503/jpn.180171
Liu, M., Zhang, D., Adeli, E., and Shen, D. G. (2015). Inherent structure-based multiview learning with multitemplate feature representation for Alzheimer’s disease diagnosis. IEEE Trans. Biomed. Eng. 63, 1473–1482. doi: 10.1109/TBME.2015.2496233
Loddo, A., Buttau, S., and Ruberto, C. D. (2022). Deep learning based pipelines for Alzheimer’s disease diagnosis: a comparative study and a novel deep-ensemble method. Comput. Biol. Med. 141:105032. doi: 10.1016/j.compbiomed.2021.105032
Ma, H., Gou, J., Wang, X., Ke, J., and Zeng, S. (2017). Sparse coefficient-based k-nearest neighbor classification. IEEE Access 5, 16618–16634. doi: 10.1109/ACCESS.2017.2739807
Ortiz, E. G., and Becker, B. C. (2014). Face recognition for web-scale datasets. Comput. Vis. Image Understand. 118, 153–170. doi: 10.1016/j.cviu.2013.09.004
Pan, X., Adel, M., Fossati, C., Gaidon, T., and Guedj, E. (2019). Multilevel Feature Representation of FDG-PET Brain Images for Diagnosing Alzheimer’s Disease. IEEE J. Biomed. Health Inform. 23, 1499–1506. doi: 10.1109/JBHI.2018.2857217
Porsteinsson, A. P., Isaacson, R. S., Knox, S., Sabbagh, M. N., and Rubino, I. (2021). Diagnosis of Early Alzheimer’s Disease: clinical Practice in 2021. J. Prevent. Alzheimers Dis. 8, 371–386. doi: 10.14283/jpad.2021.23
Shi, Y. H., Gao, Y., Yang, Y. B., Zhang, Y., and Wang, D. (2013). Multimodal sparse representation-based classification for lung needle biopsy images. IEEE Trans. Biomed. Eng. 60, 2675–2685. doi: 10.1109/TBME.2013.2262099
Tsangaratos, P., and Ilia, I. (2016). Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: the influence of models complexity and training dataset size. Catena 145, 164–179. doi: 10.1016/j.catena.2016.06.004
van Oostveen, W. M., and de Lange, E. (2021). Imaging Techniques in Alzheimer’s Disease: A Review of Applications in Early Diagnosis and Longitudinal Monitoring. Int. J. Mol. Sci. 22:2110. doi: 10.3390/ijms22042110
Venugopalan, J., Tong, L., Hassanzadeh, H. R., and Wang, M. D. (2021). Multimodal deep learning models for early detection of Alzheimer’s disease stage. Sci. Rep. 11:3254. doi: 10.1038/s41598-020-74399-w
Wang, K., Hu, H., and Liu, T. (2018). Discriminative kernel sparse representation via l2 regularisation for face recognition, Image and vision processing and display technology. IET Inst. Eng. Technol. 54, 1324–1326. doi: 10.1049/el.2018.6727
Wong, W. (2020). Economic burden of alzheimer disease and managed care considerations. Am. J. Manag. Care 26, S177–S183. doi: 10.37765/ajmc.2020.88482
Wright, J., Yang, A. Y., Ganesh, A., Sastry, S. S., and Ma, Y. (2009). Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 31, 210–227. doi: 10.1109/TPAMI.2008.79
Yang, M., Chang, H., Luo, W., and Yang, J. (2017). Fisher discrimination dictionary pair learning for image classification. Neurocomputing 269, 13–20. doi: 10.1016/j.neucom.2016.08.146
Yao, D., Calhoun, V. D., Fu, Z., Du, Y., and Shi, J. (2018). An ensemble learning system for a 4-way classification of Alzheimer’s disease and mild cognitive impairment. J. Neurosci. Methods 302, 75–81. doi: 10.1016/j.jneumeth.2018.03.008
Zhang, X. F., Dou, H., Ju, T., Xu, J., and Zhang, S. T. (2016). Fusing heterogeneous features from stacked sparse autoencoder for histopathological image analysis. IEEE J. Biomed. Health Inform. 20, 1377–1383. doi: 10.1109/JBHI.2015.2461671
Zhang, Z., Ren, J., Jiang, W., Zhang, Z., Hong, R., Yan, S., et al. (2019). Joint subspace recovery and enhanced locality driven robust flexible discriminative dictionary learning. IEEE Trans. Circuits Syst. Video Technol. 30, 2430–2446. doi: 10.1109/TCSVT.2019.2923007
Zheng, S., and Ding, C. (2020). A group lasso based sparse KNN classifier. Pattern Recogn. Lett. 131, 227–233. doi: 10.1016/j.patrec.2019.12.020
Keywords: Alzheimer’s disease, sparse representation classifier, image classification, magnetic resonance imaging, KAGGLE Alzheimer’s dataset
Citation: Liu R, Li G, Gao M, Cai W and Ning X (2022) Large Margin and Local Structure Preservation Sparse Representation Classifier for Alzheimer’s Magnetic Resonance Imaging Classification. Front. Aging Neurosci. 14:916020. doi: 10.3389/fnagi.2022.916020
Received: 08 April 2022; Accepted: 09 May 2022;
Published: 25 May 2022.
Edited by:
Yuanpeng Zhang, Nantong University, ChinaReviewed by:
Lijun Xu, Nanjing Institute of Technology (NJIT), ChinaMin Shi, Fuzhou University of International Studies and Trade, China
Copyright © 2022 Liu, Li, Gao, Cai and Ning. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guangjun Li, liguangjun@whsu.edu.cn