
Introduction
Performance degradation of aeroengines is an inevitable problem in their regular operations. A timely and accurate grasp of the health status of each component is the basis of formulating a reasonable maintenance plan to ensure flight safety and maintain the economic affordability of engine operation. So far, nonlinear model-based steady state gas path analysis is still a necessary means for aeroengine health monitoring. Compared with steady state data, engine transient state data cover a wider working scope of components, more complex operating conditions, and can provide more abundant engine health information. Therefore, the research of transient state gas path analysis has important theoretical significance and engineering application value.
Parameter selection is an unavoidable fundamental problem in gas path analysis. Therefore, almost synchronous with the introduction of aeroengine gas path analysis, Urban (1975) proposed to match the measured quantities and health parameters based on the inverse of the Influence Coefficient Matrix (ICM), that is, the fault coefficient matrix. Subsequent research focused on the discussion of ICM. Stamatis et al. (1992) proposed a method to quickly select health parameters based on the projection of the health parameter vector on the corresponding singular vector of the Jacobian matrix, and determined the measurement subset according to the results of sensitivity analysis. Provost (1994) proposed a method to distinguish redundant measurements based on parameter correlation analysis. España (1993) pointed out that the necessary condition for an observable system is that the number of measurements is no less than that of the health parameters to be determined. Grönstedt (2002) judged the optimal combinations of health parameters in different dimensions by analysing the condition number of the system Hessian matrix. Ogaji et al. (2002) utilized measurement sensitivity to determine their ability of quantifying implanted faults, and uses the Root Mean Square Error (RMSE) of the estimated results for measurement set evaluation. Mathioudakis and Kamboukos (2006) proposed a method to determine measurements, health parameters and the number of operating points by analysing the condition numbers of the Jacobian matrices based on the data of single or multiple operating points. McCusker and Danai (2010) obtained parameter signatures by performing wavelet analyses on the small disturbance output signals during transient process, and selected the necessary measurements accordingly. In the framework of Systematic Sensor Selection Strategy (S4), Sowers et al. (2008) proposed to determine the optimal combination of measuring points according to their merit value, and used the deviation of the measurements or their root mean square to judge the detectability of each health parameter. Borguet and Léonard (2008) used the figure of merit, which is defined based on the characteristic quantity of the system Fisher information matrix, to select the optimal measurement set, and employed the sensitivity index and observability index to evaluate the set. Simon and Rinehart (2016) commended a measurement selection method on the basis of statistical theory.
Although the above-mentioned research on the selection of gas path analysis parameters has improved the accuracy of engine condition monitoring, they are all based on engine steady state and cannot provide sufficient theoretical support for engine transient state gas path analysis. In this paper, we present the methods for system construction of transient state gas path analysis and their applications.
Methodology
Nonlinear gas path analysis
Aeroengine nonlinear condition monitoring model can be expressed as the following nonlinear equations.
The components of the health parameter vector θ in the above equations are generally defined by the ratio of the performance parameters of the degraded or malfunctioning engine components to those of the clean engine components, and in the form of
In the numerical calculation of health parameter estimation, Equation 2 can be linearized at the currently estimated value of the health parameters
where the Jacobian matrix
Equation 4 can be written in residual form as
where the estimated measurement residual (in relative form)
and the estimated health parameter residual
Then in the kth iterative calculation, we have
Parameter selection
Sensitivity analysis
When a certain health parameter degrades, measurements at different cross-sections or with different properties deviate with different magnitudes or even different signs. Therefore, the traditional method (Urban, 1975) believes that those deviations in the measurements will indicate their ability of identifying this health parameter.
Supposing θc is the health parameter of a healthy engine, then θc = I can be generated from Equation 3. Let h be a small percentage constant (say 1%) and define the incremental vector of health parameters as
Substituting θc and δθi into Equation 2, we obtain
Combining Equations 12 and 13, then we obtain the sensitivity of measurement j to health parameter i at sampling time t as
Equation 14 can also be written in matrix form as
Identifiability analysis
When Equation 15 is full column rank, the health parameter corresponding to each column is identifiable. In this paper, the singular value decomposition method is used to obtain the rank of the matrix. Then the matrix in Equation 15 can be decomposed as
The diagonal elements of
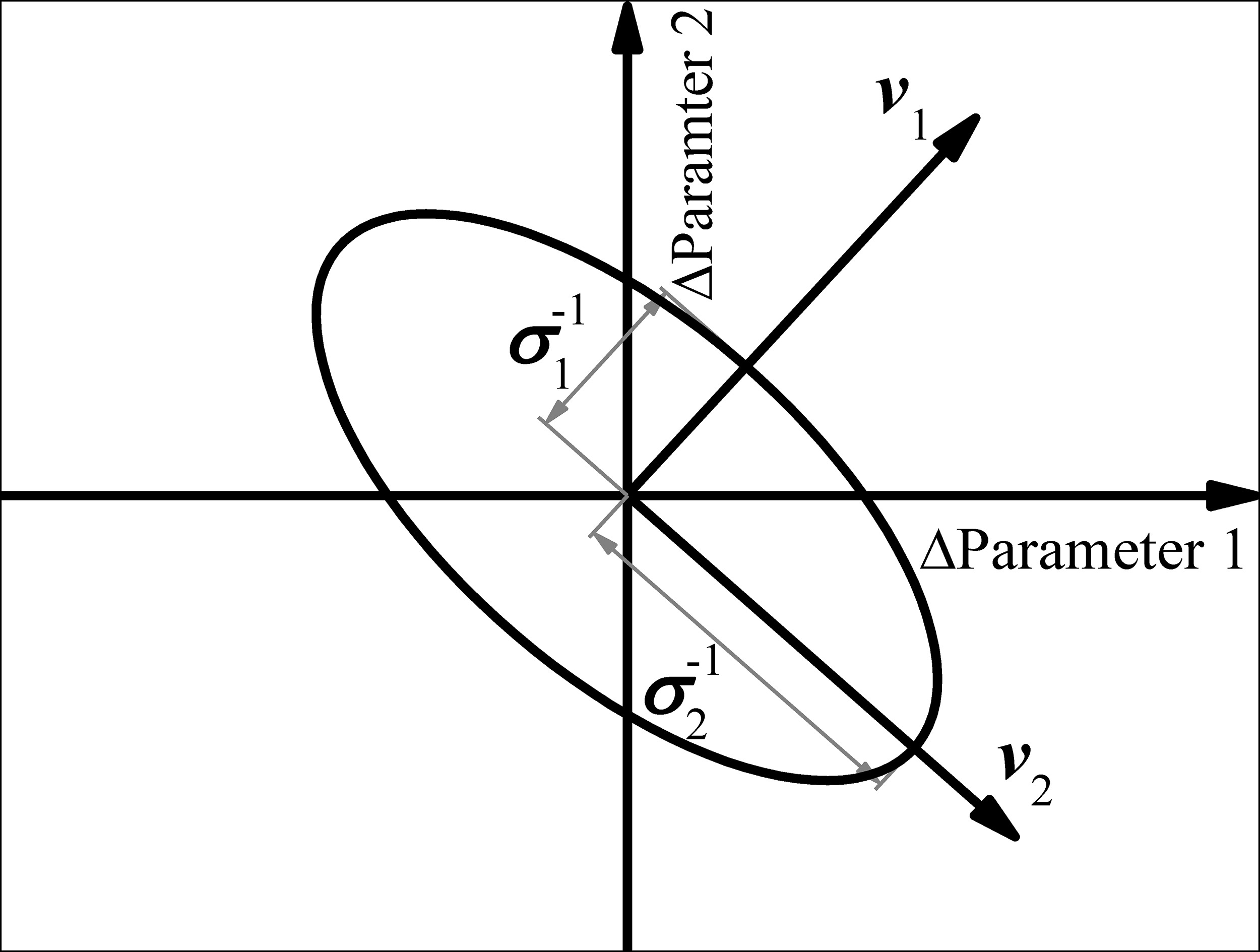
It is obvious that the longest axis of the hyper-ellipsoid determines the maximum span of the health parameter space, which corresponds to the upper bound of system uncertainty. Therefore, the smallest singular value σmin(t) can be used to measure system identifiability.
Indices definition
To describe the sensitivity of the measurements from the perspective of a whole process, it is defined here that the Root Mean Square (RMS) sensitivity of measurement j to health parameter i as
Two more indices are defined to describe the analysing ability of the engine health status of a given measurement set. One is the Process Averaging Identifiability (PAI) in Equation 18 to indicate its identifiability, the other is Process Averaging Root Mean Square Error (PARMSE) in Equation 19 to indicate its accuracy.
Results and discussion
In this section, two problems will be discussed separately: measurement selection when there is instrumental redundancy, and health parameter selection when the number of measurements is limited.
The engine model
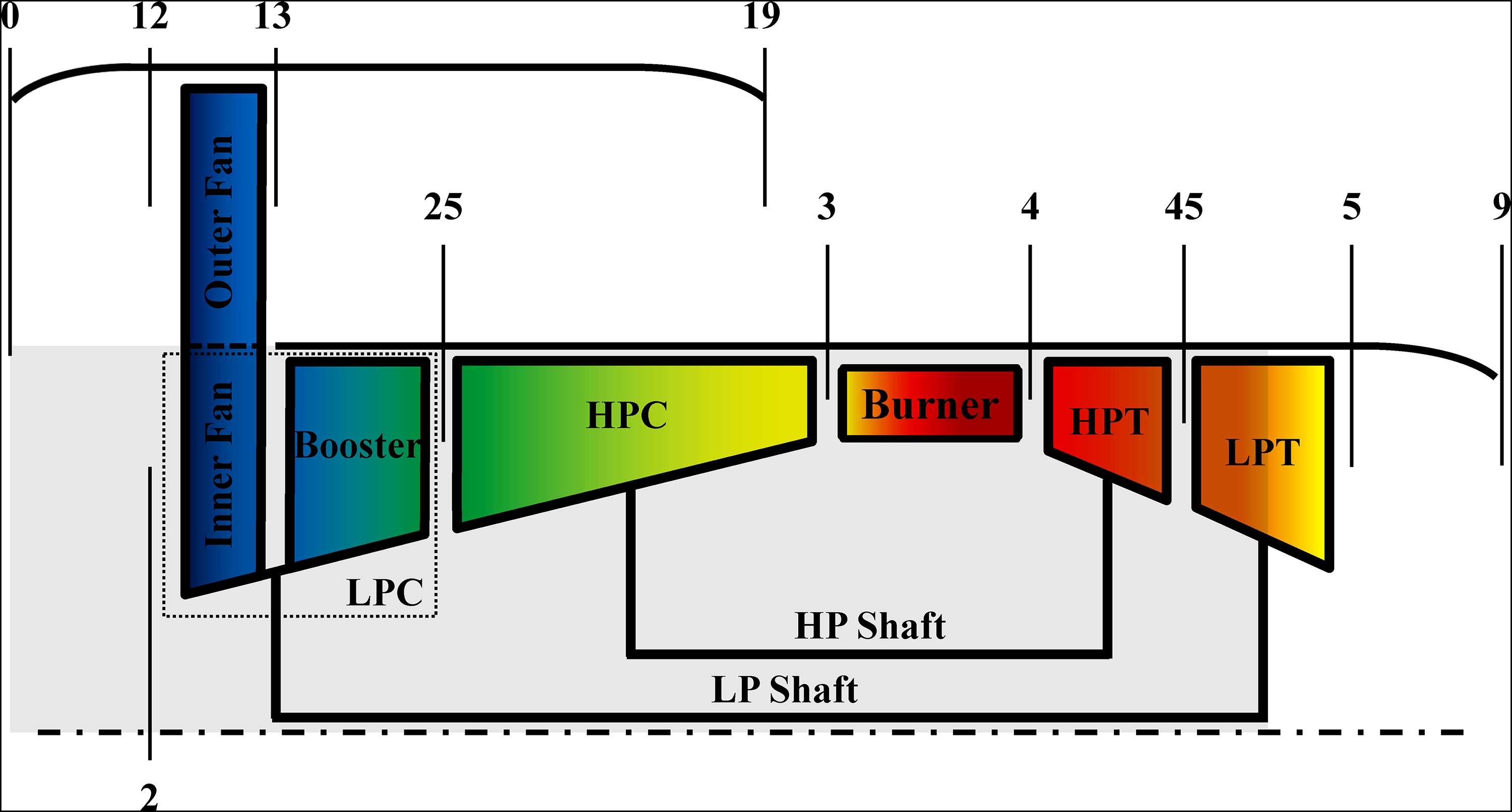
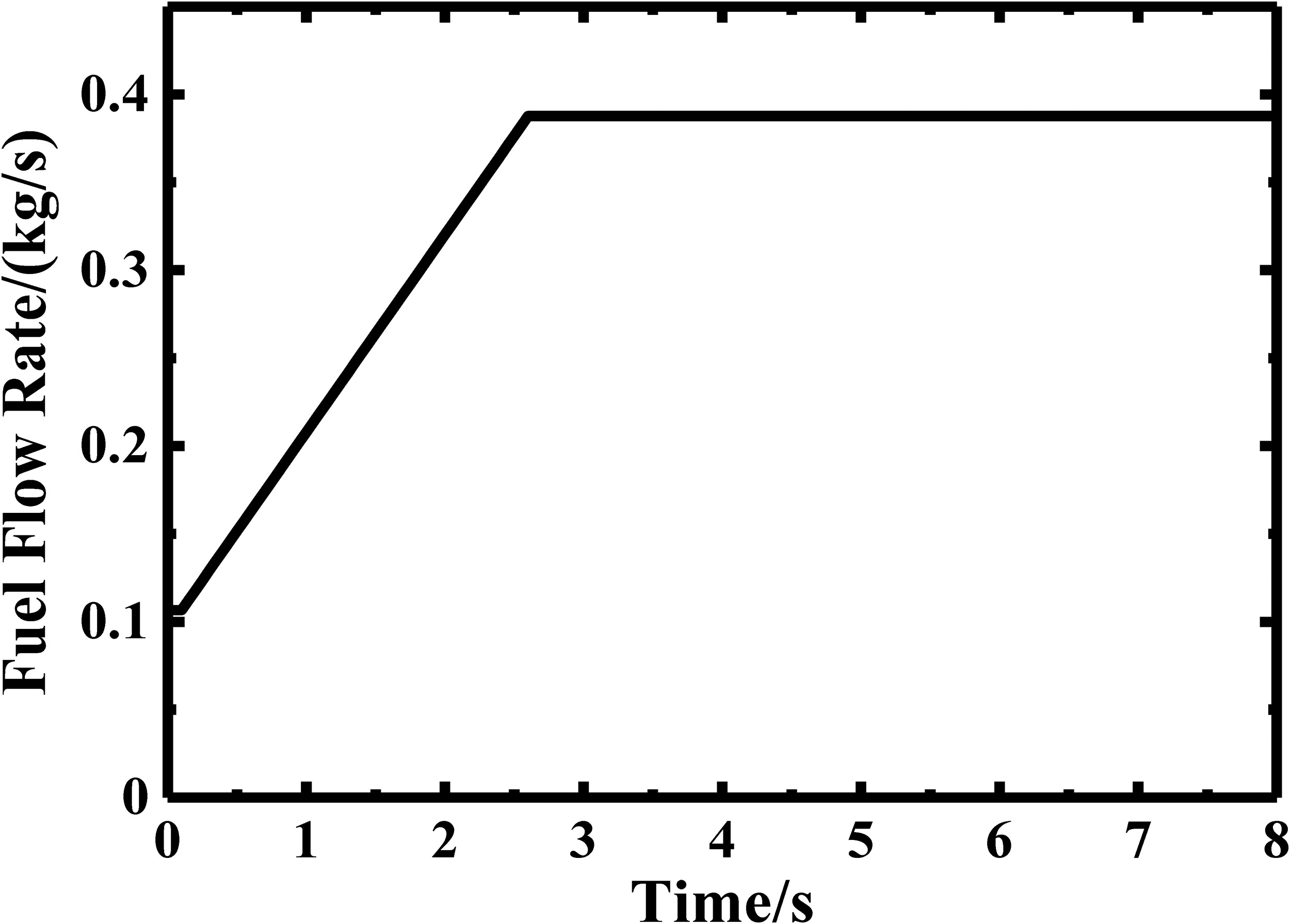
The engine model used for parameter selection is a separated flow turbofan engine. Figure 2 depicts the stations where outputs are simulated. A slam acceleration process using the fuel schedule shown in Figure 3 is chosen for the analysis.
Measurement selection
Supposing there is instrumental redundancy. The candidate measurements, the health parameters to be estimated and their implanted deviations are listed in Table 1 (subscripts are described in Figure 1), where Γ and η represent the corrected flow rate and efficiency of the corresponding component. Sensor dynamics and noise are ignored for simplicity in this study.
Table 1.
Candidate measurements and health parameters considered.
| No. | Candidate Measurement | Health Parameter | Implanted Deviation Δθi,d |
|---|---|---|---|
| 1 | P13 | ΓFan | −1% |
| 2 | T13 | ηFan | −1% |
| 3 | P25 | ΓLPC | −1% |
| 4 | T25 | ηLPC | −1% |
| 5 | NLP | ΓHPC | −1% |
| 6 | P3 | ηHPC | −1% |
| 7 | T3 | ΓHPT | 1% |
| 8 | NHP | ηHPT | −1% |
| 9 | P45 | ΓLPT | 1% |
| 10 | T45 | ηLPT | −1% |
| 11 | P5 | ||
| 12 | T5 |
To estimate all health parameters listed in Table 1, simultaneously, and avoid unnecessary instrument installation, we need to select 10 measurements among the 12 candidates in a way that is most conducive to engine health status estimation. There will be two ways involved in this paper for measurement selection: one is sensitivity analysis-based, and the other is identifiability analysis-based.
Sensitivity analysis-based measurement selection
Equation 17 is used to calculate the RMS sensitivity of each measurement corresponding to each health parameter, and the results are listed in Table 2. Data from 80 sampling points (N = 80) in this transient process are chosen for the analysis, and the sampling interval is 0.05 s. According to the data of each column in Table 2, the descending sequence of measurement sensitivity to each health parameter can be obtained (Table 3).
Table 2.
RMS sensitivity of the measurements (10−3).
Table 3.
Descending sequence of measurement sensitivity.
Because the 6 measurements (P25, NLP, P3, NHP, P45 and T5) in the first column of Table 3 have the highest RMS sensitivity to the corresponding health parameter, therefore they are firstly selected. Then we need to determine the optimal measurement set among the remaining
Table 4.
Results of sensitivity analysis-based method.
Since every parameter estimation process takes 90% of the implanted deviation in Table 1 as the initial value, the initial PARMSE of all estimations is
Identifiability analysis-based measurement selection
Inevitably, measurement selection results based on sensitivity analysis is susceptible to subjective factors. Therefore, a large number of validation calculations are required. On the other hand, traditional identifiability analysis-based methods usually adopt exhaustive strategy, so the amount of calculation would also be considerable. This paper proposes the Minimum Identifiability Loss (MIL) method, which uses identifiability as the objective criterion and adopts exclusive strategy. Thus it avoids the influence of subjective factors and reduces the amount of calculations.
The procedures of MIL are:
Calculate the PAI of the measurement set which includes all 12 candidate measurements in Table 1.
Calculate the PAI of the measurement set consist of 11 candidate measurements in Table 1, which means a certain measurement will be excluded each time.
Find the q-p measurement sets with the highest PAI in step 2 and exclude the measurements that are excluded by these sets, then the remaining candidate measurements will constitute the optimal measurement set.
Table 5.
Results of MIL method.
In Table 5, set 1 contains all 12 candidate measurements, while set 2 to 13 contain 11 candidate measurements. Results show that set 1 has the highest PAI, and the PAI of the other sets decline diversely, among which set 2 and set 3 have the least decline relative to set 1. Therefore, compared to other candidate measurements, T13 and T45 have the least contribution to system identifiability and are excluded firstly. Thereby we obtain an optimal measurement set as same as the set 1 in Table 4.
Compared with sensitivity analysis-based method and traditional identifiability-based method adopting exhaustive strategy, the MIL method adopts a simpler selecting logic, and avoids the calculation of a large number of measurement combinations. Especially, when the number of the candidate measurements increases, the calculation amount of the MIL method would only grow linearly.
Health parameter selection
Supposing the number of measurements is limited. A typical 7 gas path measurements set is listed in Table 6.
It is not possible to estimate all the health parameters shown in Table 1 simultaneously using the measurement set given in Table 6, obviously. Therefore, we have to select the health parameter combinations that can be better identified. The health parameter selection problem considering here has the following features:
Due to the varying engine nonlinearity with the operating process, the nature and quantity of the health parameters that can be estimated at different sampling points may also change.
Because the selection process involves changes in the health parameter space, the applicability of traditional sensitivity analysis-based and identifiability analysis-based methods would be greatly restricted.
Construct the
Construct the
Then the health parameter combinations corresponding to the full rank subsystem are regarded as feasible combinations.
Table 7.
Full rank subsystem results at sampling point t = 1 s
Results show that the maximum number of identifiable health parameters at t = 1 s is 7, and there are 10 feasible combinations, among which combination 3 has the highest identifiability

It also shows that there are slightly differences of the maximum number of identifiable health parameters at different sampling points, that is, 7 for the majority of the sampling points except 6 at t = 1.7 s and t = 1.8 s.
Smearing effect analysis
Considering the identifiability of the engine health status on a component level by the measurement set shown in Table 6. According to the health parameters listed in Table 1, the health status of each main gas path component is described by two health parameters. So the maximum number of components that can be analysed simultaneously by the measurement set shown in Table 6 is 3 at each sampling point. Therefore, theoretically, the number of identifiable component combinations is
By constructing the subsystem matrix of the 25 component combinations at a certain sampling point and calculating their rank, we can obtain the identifiability of these subsystems. The results are shown in Figure 5. The left part of Figure 5 shows the component combinations, with colour black and white represent “include” and “not include”, respectively. The right part of Figure 5 shows the identifiability of the corresponding component combination, with colour blue and white represent “identifiable” and “unidentifiable”, respectively.
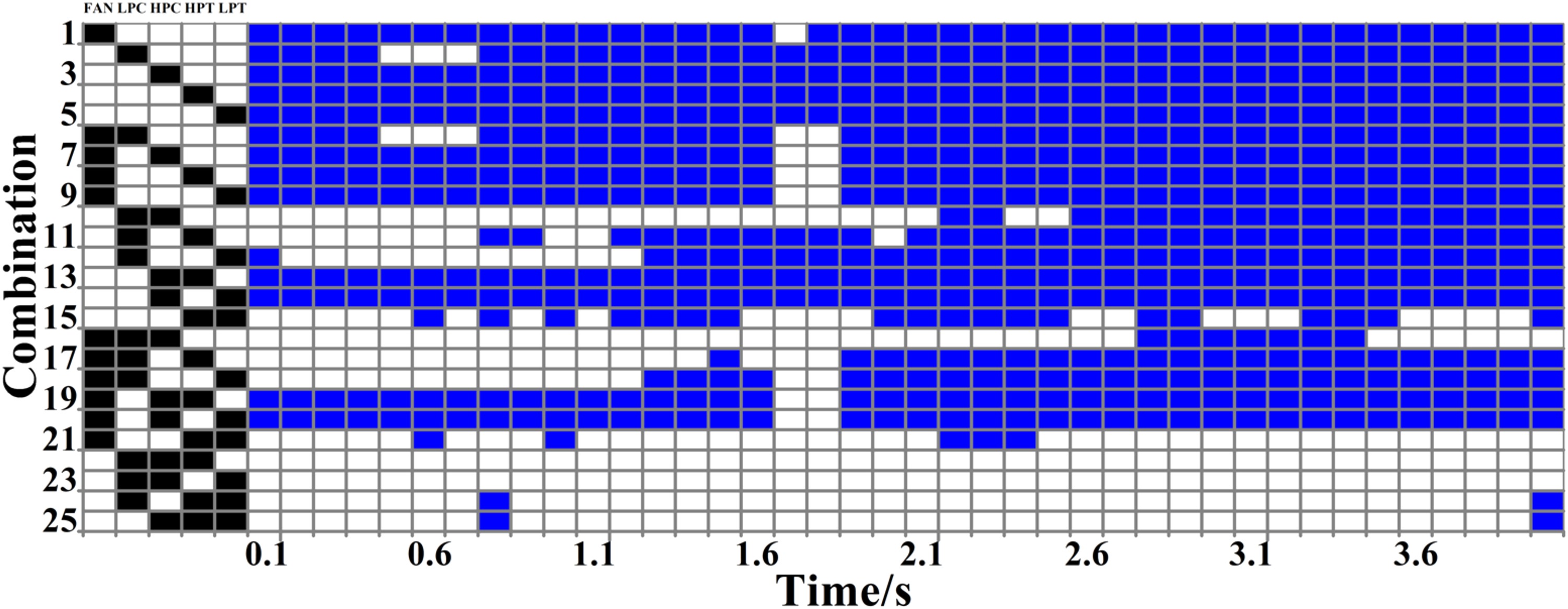
Figure 5 shows that the identifiability of the component combinations vary with sampling time as well as the number of components. In general, an increase in the number of components leads to a decrease in identifiability.
Take combination 10 and combination 15 as examples, the estimation results of these two combinations are shown in Figure 6. The number of combinations and sampling points are consistent with Figure 5, and the colour green, yellow, and red represent “converged with high precision”, “converged with low precision” and “diverged”, respectively.

Combining the results in Figures 5 and 6, unsatisfactory estimation result only occurs when the corresponding component combination is unidentifiable. Take the results of combination 10 at t = 0.9 s and combination 15 at t = 0.1 s as examples (Figure 7).
Figure 7.
Estimation results of combination 10 at t = 0.9 s (left) and combination 15 at t = 0.1 s (right).
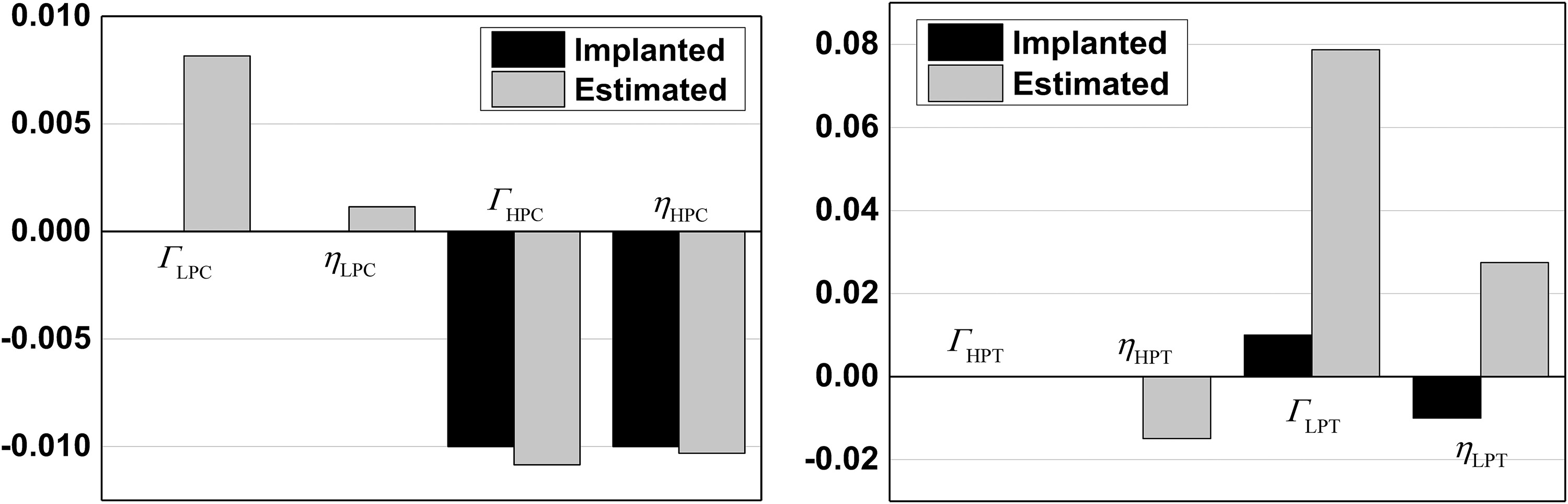
It is shown that there are large deviations in both cases, which means “smearing effect” occurs. Aretakis et al. (2002) and Mathioudakis et al. (2004) firstly pointed out this phenomenon in fault diagnosis, and they also provided a solution for this problem, that is, addition of measured quantities between the corresponding components. Based on the above results, it can be concluded that “smearing effect” is caused by the measurement set as well as the engine nonlinearity at a certain operating point, which means only when the combination of these two factors leads to a singular system, may this phenomenon occur. From the perspective of system identification, “smearing effect” means an increase in system uncertainty.
Conclusions
The methods on how to choose the proper measurements and health parameters when constructing an aeroengine gas path analysis system using transient data have been presented. The traditional sensitivity analysis-based measurement selection has been conducted, and a new measurement selection method adopting exclusive strategy has been proposed. A health parameter selection method based on maximal linearly independent group analysis has been proposed. The root cause of “smearing effect” has been revealed. The applicability of the proposed method has been demonstrated on a separated flow turbofan engine, and the results show that:
The indices defined in this paper is effective.
The MIL method adopts a simple selecting logic, and avoids the calculation of a large number of measurement combinations.
Maximal linearly independent group analysis is effective to determine the optimal combination of health parameters at each sampling point under the condition of limited measurements.
“Smearing effect” is caused by measurement settings as well as engine nonlinearity, and it occurs only when the combination of these two factors leads to a singular system at a specific working point.
Nomenclature
process averaging root mean square error
h
small percentage constant
MIL
minimum identifiability loss
N
rotational speed
P
total pressure
p
number of health parameters
q
number of measurements
RMSE
root mean square error
r
rank
T
total temperature
t
time
u
engine input vector
x
engine performance vector
z
measurement vector
Γ
health parameter (corrected flow rate)
η
health parameter (efficiency)
θ
health parameter vector
process averaging identifiability