A Study on Intelligent Dialogue Agent for Older Adults’ Preventive Care – Towards Development of a Comprehensive Preventive Care System
A Study on Intelligent Dialogue Agent for Older Adults’ Preventive Care – Towards Development of a Comprehensive Preventive Care System
Volume 5, Issue 6, Page No 09-21, 2020
Author’s Name: Sho Hirose1,a), Daisuke Kitakoshi1, Akihiro Yamashita1, Kentarou Suzuki2, Masato Suzuki1
View Affiliations
1National Institute of Technology, Tokyo College, Tokyo, 193-0997, Japan
2Kyorin University, Mitaka, 181-8612, Japan
a)Author to whom correspondence should be addressed. E-mail: s20613@tokyo.kosen-ac.jp
Adv. Sci. Technol. Eng. Syst. J. 5(6), 09-21 (2020); ![]() DOI: 10.25046/aj050602
DOI: 10.25046/aj050602
Keywords: Intelligent Dialogue Agent, Comprehensive Preventive Care System, Reinforcement Learning

Export Citations
Preventive care approaches have attracted much attention in Japan, which is one of the world’s most super-aged societies. These approaches aim to decrease the number of people who require nursing care or other human support. Our research group has developed several kinds of preventive care systems, including a fall prevention system, a cognitive training system, and an Intelligent Dialogue Agent (IDA). In this paper, we focus on familiarizing older adults with the IDA – a conversational agent that encourages older adults to engage it in natural conversations, while monitoring their health in the process – and we introduce a Speech Content Coordinating Function (SCCF) to the IDA to further improve older adult’s familiarity with and interest in the agent. We also have a plan to develop a Comprehensive Preventive Care System (CPCS) which can encourage proactive conversation and provide effective monitoring of older adults as well as habitual cognitive training. To evaluate the basic characteristics and impressions of the CPCS, a prototype version that consists of the IDA and the Mechanism for Cognitive Training (MCT) is developed. The results of the experiments indicated that the SCCF can adequately adjust speech content depending on the user’s circumstances. We also confirmed that the prototype CPCS achieves synergistic effects (e.g., more detailed monitoring of older adult’s health condition, increased frequency of cognitive training) when its components are used together.
Received: 30 August 2020, Accepted: 18 October 2020, Published Online: 08 November 2020
1. Introduction
This paper is an extension of work originally presented at the 2019 International Conference on Technologies and Applications of Artificial Intelligence [1].
Japan is currently known as the most advanced super-aged soci- ety. In 2018, Japanese people aged 65 and older accounted for 28.1% of the total population [2]. As the aging demographic increases, the number of people requiring long-term care also increases, as does the number of people who need nursing care or other human support, and that number in Japan has reached 6.41 million, as cer- tified by the Long-Term Care Insurance Act [3]. Preventive care approaches, which aim to decrease the number of people who re- quire nursing care or other human support by reducing the decline in individuals’ mental and/or physical functions, have attracted a lot of attention. These approaches also aim to control increasing medical costs and the associated burden because the number of older adults is increasing while the working population is expected to decline due to declining total fertility rates. In recent years, many researchers in various fields have focused on the prevention not only of dementia but also of fall, one of the causes of the need for nursing care, and have shown a certain degree of effectiveness in preventive care [4]– [12]. However, some older adults experience physical and/or psychological distress due to preventive care activities, and therefore have trouble engaging in these activities on a regular basis.
At the same time, in the past decade, various voice-interaction- based devices and softwares (Dialogue Agents) such as smart speak- ers (e.g., Google Home and Amazon Echo) and voice assistants (e.g., Siri and Cortana) [13] have been developed and employed to provide useful information and a variety of services in response to users’ prompts. In addition, there has been much research into the use of Dialogue Agents for older adults with dementia and mild cognitive impairment [14]– [17]. However, it should be noted that these devices and the Dialogue Agents generally do not talk to users without a specific request or prompt. However, we believe that introducing a function that makes it possible for Dialogue Agents to speak to users spontaneously in order to elicit a reaction will play an important role in endowing the agents with a sense of humanity and familiarity.
Against these backgrounds, previous studies examined Intelli- gent Dialogue Agents (IDAs) that allow natural and flexible com- munication with and monitoring of older adults by using a Smart Speaker, a friendly interface, to investigate older adults’ impressions of the Smart Speaker and the basic characteristics of the IDA [18]. The IDA employed a Spontaneous Talking Function (STF) that allows the IDA to talk to older adults without users’ requests to encourage them to actively dialogue. Our research group has shown that the STF is effective in some ways, particularly in providing increased convenience and familiarity to older adults. Our research group is also developing a cognitive training system based on a memory game on a tablet device [19] and a Fall Prevention Sys- tem for regular preventive care exercise [3] to prevent dementia and fall, one of the main factors leading to a need for nursing care. Additionally, our research group is conducting a study to estimate the behavior of older adults who live alone from data gathered by supervision sensors installed in their homes [20]. In this paper, we introduce a Speech Content Coordinating Function (SCCF) into the IDA in order to further improve the user’s familiarity with and interest in the IDA. The SCCF determines the content of speech by using a reinforcement learning algorithm according to the user’s preferences and condition. In order to investigate the basic charac- teristics of the SCCF and users’ impression of it, and to evaluate whether the SCCF was able to acquire appropriate policy depending on its users, several experiments were conducted. In the experi- ments, we developed a text-based agent in the form of a chat-bot and introduced the SCCF into it.
In addition, this paper considers the feasibility of a Comprehen- sive Preventive Care System (CPCS). Although we aim to develop the CPCS by integrating our preventive care systems, it is currently in the conceptual phase. Once fully developed, the CPCS will contribute to the encouragement of active conversation and the pro- vision of not only effective monitoring of the health condition of older adults but also regular cognitive training and fall prevention exercise. As the first step to examine the adequacy and impressions of the CPCS, we conducted the experiment with a prototype version of the CPCS using both the IDA with a sensor and the Mechanism for Cognitive Training (MCT) which is at present equivalent to the cognitive training system.
At present, neither the IDA nor the prototype CPCS has been
(a state-to-action map) based on observations and trial-and-error interactions with its environment. A policy characterizes an agent’s behavior and is described using the function:
![]()
where and denote sets of states and actions, respectively. The pair (s, a)( s , a ) is referred to as a rule, which states that “if an agent observes a state s, it outputs an action a”. At each time step t, an agent observes state st, and selects action at using π.
RL algorithms are roughly classified into two approaches, exploration-oriented and exploitation-oriented approaches. The former approaches, which include Q-leaning, Sarsa, and so on, aim to optimize the total discounted reward typically in environments modeled by Markov Decision Process (MDP). The latter ones, such as Bucket Brigade and REINFORCE, are based on the notion of credit assignment and aim to increase learning speed and to acquire reasonable policies even in non-MDP environments although it is not ensured to acquire the optimal policy by using them. Because the environments we treat in this study seem to be non-MDP ones, the exploitation oriented RL algorithms are applied. Brief explana- tions about REINFORCE and Bucket Brigade, which are employed in the IDA and MCT (described later), respectively, are presented below.
2.1 REINFORCE
REINFORCE [22] is an exploitation-oriented approach based on a policy-gradient reinforcement learning algorithm. Policy- gradient reinforcement learning algorithms such as natural policy gradients [23], and stochastic gradient methods [24] learn policies directly by updating parameters θ that characterize a policy πθ, as opposed to many conventional reinforcement learning algorithms such as Q-learning [25] or Sarsa [26]. The values of θ are related to conditional probabilities p(a s). In other words, the policy-gradient reinforcement learning algorithms aim to acquire a probability dis- tribution that selects the optimal action to take in each state so as to maximize the sum of the rewards. The goal of these algorithms is thus to obtain the parameters θ, which characterize the probabilistic policy πθ that maximizes the sum of rewards, updated according to the following formula (2):
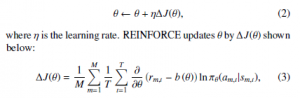
future applicability of the IDA and CPCS for older adults.
2. Preliminaries (Reinforcement Learn- ing)
where sm,t, am,t, and rm,t are state, action and reward at the t-th time step in the m-th episode (t = 1, …, T ; m = 1, …, M), respectively. In the above formula, an episode denotes the sequence of rules selected between rewards, and one time step is counted when the agent selects a rule. The term b(θ) reduces the variance of the esti- mate and serves to stabilize the policy learning process, called the Before describing our study, we will first introduce the con baseline (b(θ) = ΣM rm,t), and πθ denotes the agent’s policy. In concept of Reinforcement Learning (RL). RL is a machine learning method [21]. An RL agent attempts to acquire an appropriate policy the present study, the probability that the IDA will select its action a given a state s is computed by the softmax function (4) with the inverse temperature parameter β, because both the state and action spaces are discrete.
based on their behavior and dialogue history. The IDA talks spon- taneously, using a variety of contents such as notification of daily routines (e.g., taking medicine, walking), trivia, news, weather and traffic information, and food information. The sensor mounted on
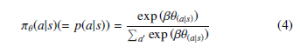
REINFORCE is used to coordinate the IDA’s speech content depending on the user’s circumstances in this study.
2.2 Bucket Brigade
In the Bucket Brigade algorithm [27], a policy is characterized by rule-weights w(st, at), which are used as an agent’s policy π. When an agent acquires reward R after it selects rule (st, at) at time step t, the weights of rule w(st, at) and w(st−1, at−1) are reinforced as follows: the IDA also can monitor older adults within its detection area.
- Architecture of the IDA
Figure 1 shows the final design of the IDA. The IDA consists pri- marily of an input/output (I/O) unit, a learning unit, and a database.
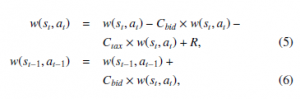
where Cbid and Ctax denote a “bid” parameter specifying a degree of propagating the weight w(st, at) to the weight w(st−1, at−1), in which the rule (st−1, at−1) plays a role of “trigger” to select the next rule (st, at), and a “tax” parameter which determines a discount rate for the weight of the rule selected at step t, respectively.
- I/O Unit
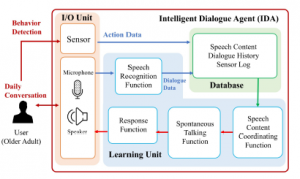
Figure 1: Final design of the IDA
rithms categorized as an exploitation-oriented approach. The above formulae mean that this algorithm updates a rule weight at each step, even when no reward is given, and also that this algorithm is relatively easy to implement compared to other conventional RL methods. Moreover, the agent with the Bucket Brigade can acquire reasonable policies in many cases even if the agents do not have a sufficient number of trials because it actively employ rewarded past experience. This study applies the algorithm to the function for adjusting the difficulty level of cognitive training for respective users in the mechanism providing the users with cognitive training, which is described in the next section.
3. Preventive Care Systems
In this section, we present the preventive care systems that are currently under development or about to start development. We first overview the Intelligent Dialogue Agent (IDA), which our research group is currently developing, then introduce the Mechanism for Cognitive Training (MCT) as another preventive care framework, and finally provide brief outline of the Comprehensive Preventive Care System (CPCS), which will consist of the above two compo- nents and will be developed as our final goal.
3.1 Intelligent Dialogue Agent (IDA)
We have developed the Intelligent Dialogue Agent (IDA) with the aim of encouraging natural and flexible conversation with its users (older adults) and of monitoring older adult’s health condition
The I/O unit is composed of a microphone, a speaker and a sensor. The user’s motion is recorded by the sensor in order to track his or her characteristic behavior, such as lifestyle activities (e.g., waking and sleeping times, regular exercise). The pyroelectric sensor we adopted in this study, and which is embedded in the IDA, is both inexpensive and easy to use. Moreover, our research group has already employed a similar type of sensor and confirmed that it worked effectively to capture the motions of individuals [20]. This sensor can detect objects separate from the user, as well as even the slightest movement of people separate from the user. Although the IDA currently employs a microphone and speaker which are implemented by the included smart speaker (Google Home Mini) as its I/O unit, these components have certain limitations; for example, the smart speaker cannot acquire the user’s response and dialogue history in real time. We thus plan to develop and implement an IDA that includes the highly desirable speech recognition and synthesis functions without using a smart speaker.
- Database
The database stores logs of the user’s activity as detected by the sensors, and the history of dialogue between the IDA and the user, which is converted from speech information into text data by the Speech Recognition Function, a component of the Learn- ing Unit. The data stored in the database are used to estimate the user’s condition and to adjust the behavior of the IDA. We adopted a NoSQL cloud-hosted database known as the Firebase Realtime Database (https://firebase.google.com) for this component because it is compatible with Google Home Mini, which we employed in the IDA.
- Learning Unit
The learning unit has four functions: the Spontaneous Talking Function (STF), the Speech Recognition Function, the Response Function, and the Speech Content Coordinating Function (SCCF). A brief explanation of the four functions is as follows. The IDA can output its speech content without prompting by the user at the appropriate time by using the STF. The STF triggers speech to the user based on the user’s daily routines and behavioral logs stored in the database. The Speech Recognition Function converts voice information obtained from the microphone, such as questions from the user or the user’s responses to the IDA’s speech, into textual information. The Response Function transforms the next speech content into voice information and transfers it to the speaker. In addition, the SCCF provides appropriate speech content depending on the user’s preferences and condition. We expect that introducing the SCCF into the IDA will improve the convenience and familiarity of the IDA and hence the user’s willingness to continue using the IDA. In order to adjust the content, timing, and frequency of speech, the following history information should be taken into account:
- The behavioral history of the user (i.e., the frequency and number of times the user is detected) obtained by sensors on the I/O
- The history and frequency of dialogue between the user and the
bad, not useful, detrimental), or uninteresting, and the reward values obtained by the IDA are determined according to the feedback cate- gories. Before establishing the reward setting, we asked a speech therapist at a long-term care insurance facility for older adults to comment on “how older adults come to have a good impression of speech content”. She responded as follows:
[Comments of speech therapist]
“Even if older adults express negative responses to the informa- tion provided by the agent’s speech, they may not necessarily have a negative evaluation of the corresponding speech (i.e., any user’s reaction to the speech is evidence of being interested in the speech content).”
Based on this information from the speech therapist, we set up our SCCF to have two reward settings, one employing the speech therapist’s comments and the other based on another assumption under which “the users’ interest in speech directly corresponds to interest in the content of the speech.” When the IDA acquires a reward, the weight parameter θ for each state and action are updated, and the probabilities for selecting actions are changed.
We substituted the softmax function (4) into the REINFORCE updating equation ((2), (3)) and the number of time steps T was set at one because we defined one episode as ending with one instance of speech. The following formula derived from (2), (3), and (4) is applied to the policy learning (parameter update) in the SCCF.
- What kinds of speech content were previously produced by the IDA and at which time
- Basic information about the user (e.g., age, gender, address,
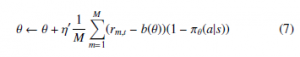
preferred topics for conversation)
- The Speech Content Coordinating Function (SCCF)
The results of the experiments and questionnaires conducted in our previous study confirmed that the provision of appropriate in- formation by the IDA increases the willingness of users to continue participating in dialogue with the IDA [1]. In the present study, we introduced the SCCF into the IDA and investigated its basic characteristics and performance.
In order to acquire the adequate behavior (policy) to determine natural responses depending on the particular user’s preferences and/or circumstances, we apply the REINFORCE algorithm de- scribed in Section 2.1 to the SCCF as the policy learning algorithm. To conduct policy learning, we defined state, action, and reward for the IDA. The IDA’s action is defined as the speech category c C that the agent employs to talk to the user (C: A set of speech categories). There are 13 different speech categories: C = time signal, greeting, today’s weather, weekly weather forecast, today’s trivia, domestic news, international news, economic news, technol- ogy news, science news, entertainment news, sports news, and each user’s daily routine work . The state of the IDA is defined as the pair of speech categories (c1, c2) that constituted the agent’s output in the last two time steps. This state definition is based on the assumption that there is some relationship between past speech content and current content in human-to-human conversation (c1 C, c2 C). The user’s feedback on the speech content spoken by the IDA is employed as the reward. All feedback is classified into one of three categories: positive (e.g., good, useful, beneficial), negative (e.g.,
3.2 The Mechanism for Cognitive Training (MCT)
Our research group has developed the Mechanism for Cogni- tive Training (originally proposed as the cognitive training system) that encourages older adults to engage in cognitive training to help prevent dementia [19]. As shown in Figure 2, the MCT provides older adults with a brain-twister-based memory game as cognitive training, provided in such a way that they can regularly perform this memory game through repetitive interactions with a software agent on a tablet device. The software agent also serves as both an opponent who plays the game with the older adult users and a conversation partner; the goal of the latter function is to increase the familiarity of older adults with the MCT. Our system is expected to prevent dementia by preserving and improving cognitive func- tions such as short-term memory and encouraging and improving the user’s motivations to use them. Furthermore, the MCT has a difficulty adjustment function that can set the appropriate game difficulty level according to differences between users and each individual user’s current circumstances in order to create an envi- ronment that makes it easier for users to continue cognitive training for long periods of time, since they neither get bored because the game is too easy nor give up because it is too difficult. The database stores information on each user’s game-playing conditions, such as memory time, response time, accuracy rate, and difficulty, and uses these data to adjust the difficulty level and provide feedback on the memory game results to the users.
The difficulty adjustment function employs the Bucket Brigade algorithm described in Section 2.2 in order to coordinate the game difficulty level. The Bucket Brigade algorithm is known to have two characteristics: (i) advancing policy learning even when no reward is given; and (ii) additionally acquiring reasonable policies in many cases, even if the agents do not have a sufficient number of trials, by actively employing rewarded past experiences.
The software agent in the MCT is based on the concept of Human-Agent Interaction (HAI), which aims to design an appro- priate framework of interactions between humans and agents. The MCT currently has a function to coordinate speech content depend- ing on the game-playing frequency and/or time interval between bouts of gameplay so that a user can play the game (engage in the cognitive training exercise) comfortably. However, since it is intended that the software agent will be implemented on a tablet device, its functional and performance limitations may prevent it from fully achieving the desired functionality. Therefore, both func- tions for coordinating speech content and sensors for detecting the user’s motions will be implemented in the IDA. In addition, the functions currently embedded in the software agent on the MCT will be implemented in the CPCS as functions of the IDA.
As a result of several experiments, we have confirmed that older adults were able to increase the difficulty level and the accuracy of the cognitive training by using the MCT. Furthermore, introducing the difficulty adjustment function made it possible to appropriately coordinate the training difficulty depending on the circumstances of the older adult playing the game. Although the use of MCT clearly had a positive effect on maintaining/improving the short term mem- ory and cognitive function of older adults, we also confirmed that experiments over a longer period with a much large number of par- ticipants will be needed in order to make a detailed assessment of the MCT’s effectiveness in dementia prevention.
3.3 Comprehensive Preventive Care System (CPCS)
The Comprehensive Preventive Care System (CPCS) aims to allow older adults to enjoy engaging in cognitive training while being monitored by their family and friends through active conver- sation. The CPCS consists of an IDA, which can carry out natural conversation with users, and an MCT (detailed in section 3.3) which provides users with a memory game on a tablet device as a kind of cognitive training (Figure 2).
Our research group is carrying out research on and development of each component with a view towards their eventual integration into the CPCS. Because the integration of the IDA and the MCT will allow the CPCS to employ the data stored in both in parallel, this system will be able to produce a synergistic effect between the cognitive training and monitoring functions. For example, the cognitive training status obtained by the MCT will be combined with the dialogue/behavior history acquired by the IDA, making possible a more detailed understanding of the user’s condition (e.g., the user’s degree of fatigue, whether he or she has taken a break while engaging in cognitive training, and so on). One of the final purposes of the CPCS is to notify family and friends of the circum- stances of an older adult user obtained by the system, which also aims to accomplish the following three goals:
- To maintain and improve the cognitive function of older adults;
- To promote active conversation between older adults and their family, friends and the IDA; and
- To create an effective environment where older adults and their families and/or community groups can be mutually in- volved to better monitor the older adult’s health condition, and promote their care and dementia
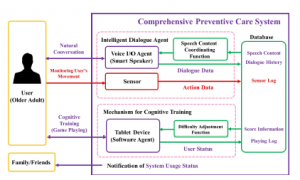
Figure 2: the Diagram of the CPCS
4. Experiments
As described in Section 1, we have not yet had an opportunity to employ older adults in the evaluation of the SCCF and the CPCS. In addition, many aged households lack a Wi-Fi environment which would be needed in order to use and evaluate the CPCS at home. For these reasons, we conducted several experiments with students to confirm that the SCCF can appropriately coordinate the speech content depending on the user’s circumstances and to evaluate the basic characteristics and impressions of the CPCS. Moreover, we used the prototype version of the CPCS (described in a later section) in these experiments, because at present we have not evaluated the full version of the CPCS, but only its respective components (the IDA and the MCT).
Before conducting the experiment, a simple written question- naire was administered to older adults in order to confirm their awareness of smartphones, the internet environment at their home, and the degree of interest/expectation in regard to spontaneous talk- ing by the IDA (smart speaker). The questionnaire results showed that (i) older adults’ degree of recognition of smart speakers was low;
- the majority of them did not have an internet (Wi-Fi) connection that would permit the use of a smart speaker at home; however,
- they had a high level of interest about conversation with the IDA (smart speaker), particularly its spontaneous talking function. Regarding item (iii), the older adults had on average 3 topics that they wanted the IDA to talk about, and no older adults answered that the talking function was “unnecessary” or that they had “no topics which they wanted to make the smart speaker talk about”. The detailed results of the questionnaire are presented in Appendix (A).
4.1 Evaluation of the SCCF
In our first experiment, we aimed to evaluate the basic charac- teristics of the SCCF by employing a prototype of the IDA (hence- forth referred to simply as the IDA) developed as a chat-bot using the Slack message application. The chat-bot periodically talks to provide information and learns from its users’ feedback. The exper- iment was conducted for six days and our subjects were 10 students (average age: 18.9).
As the speech content of the chat-bot, six out of 13 categories were randomly selected before starting the experiment. The total number of states was 6 6 = 36 because the chat-bot had up to two previous categories (c1, c2) as pairs. From the set of selected speech categories Cj ( Cj = 6), the chat-bot selects speech category c according to the current policy. The initial value of the param- eters θ which characterize a policy πθ equals θ0. Therefore, the chat-bot chooses a speech category with uniform probability at the first stage of the experimental period. Each participant responded to the speech content provided by the IDA with one of three kinds of feedback (P/N: positive/negative impression; U: uninterested). Reward values were determined by the collective feedback of users. The following two types of reward settings were utilized based on comments received from the speech therapist.
Under this setting, in accordance with the speech therapist’s assumption that “older adults would be interested in a topic if their evaluation was not U,” a positive reward (+1) was assigned if the participant’s feedback was P or N, and no reward was given other- wise.
Under this setting, positive (+1) reward, negative (-1) reward, or no reward was given if the user’s evaluation of a topic was P, N, or U, respectively.
The participants gave feedback for approximately 300 speech contents for each setting. To avoid any influence of the order of the participants’ evaluations in settings RA and RB, the participants were grouped into two equally sized groups, and the order was changed in different groups. The parameters used in the policy learning and action selection are shown in Table 1.
Table 1: Parameters used in reinforcement learning
| Parameter | Value |
| ηj | 0.22 |
| M | 3 |
| θ0 | 10 |
| β | 15 |
In addition, subjective evaluations was conducted after the end of the experimental period (three days) for each reward setting and after the end of the experiment to examine the participants’ impres- sions of the SCCF. We also administered the questionnaire regarding the level of interest in each category at the end of the experiment because we did not want it to affect the participants’ evaluation of the chat-bot’s speech.
Which speech categories provided by the IDA were most pre- ferred varied among users. The favorite speech categories and/or favored order of talking could also vary within the same user de- pending on the current circumstances (e.g., on holiday, at work, while eating, before bedtime, and so on). For these reasons, it was difficult to acquire a policy for providing optimal speech contents in the experiments; however, we can say that we were able to acquire a policy better expressing the user’s preference by the learning in the SCCF if the speech categories preferred by the user were easy to be provided from the IDA compared to the other categories. The exper- iment thus confirmed the probability of the IDA generating speech for each category after learning the preferences of users while in- vestigating the favorite categories of users via the questionnaire. By comparing the above results, we discuss the adequateness of the SCCF by evaluating whether the SCCF can learn the preference of users and how accurately the learning result matches the actual preference of users.
4.2 Preliminary Experiments with the CPCS
Several experiments were conducted to investigate the synergis- tic effect of using the MCT in conjunction with the IDA. As part of our preparation for conducting the experiment with older adults, we asked 10 students (the same as the participants in section 3.1) to participate in our preliminary experiments. However, after exclud- ing one participant (participant F) due to an equipment malfunction that resulted in incomplete sensor data, a total of nine participants were included in these experiments.
A prototype version of the CPCS was employed for these exper- iments. The system consists primarily of the MCT and the IDA, but does not have functions that allow the two mechanisms to commu- nicate or that allow either of the components to use data collected by the other. Using both mechanisms in parallel would contribute to the combined use of the log data obtained by each. We conducted two kinds of experiments to investigate differences in impressions of the CPCS when the IDA talked spontaneously and when it did not. This experiment was conducted in two periods, a speech period and a nonspeech period, of three days each for a total experimental duration of six days. However, to ensure that the order of the two periods did not affect the subjects’ impressions of the CPCS, the order was randomized for each participant. The IDA employed in the experiment had a simple STF consisting of a smart speaker (Google Home Mini) and a pyroelectric sensor without introducing the SCCF, and provided information (speech content c Cjj = C each user’s daily routine work ) selected randomly every 15 min between 9:00 and 23:00 during the speech period. Additionally, we asked participants to listen to the IDA’s speech at least eight times
a day. Sensors detected the participants’ behavior throughout the experimental period (sampling interval: 1 s; detection range: 115◦ within a 2-m view range). The difficulty adjustment function was included in the MCT. We asked the participants to play a 10-min memory game every day near the location where the sensor was installed.
Written questionnaires were also administered after the first half of the experiment and at the end of the experiment to inquire about the number of times participants heard the IDA speaking, whether the difficulty level of the memory game was appropriate, and their willingness to continue to use the CPCS.
Table 2: The actual speech probability of the chat-bot’s speech at the end of the experiment for each participant.
| Reward setting | RA | RB | ||||||||||
| Participant / ranking | 1st place | 2nd place | 3rd place | 4th place | 5th place | 6th place | 1st place | 2nd place | 3rd place | 4th place | 5th place | 6th place |
| A | 0.680 | 0.040 | 0.050 | 0.060 | 0.080 | 0.090 | 0.300 | 0.280 | 0.180 | 0.090 | 0.040 | 0.110 |
| B | 0.505 | 0.257 | 0.040 | 0.099 | 0.059 | 0.030 | 0.310 | 0.380 | 0.140 | 0.030 | 0.070 | 0.070 |
| C | 0.030 | 0.000 | 0.050 | 0.416 | 0.040 | 0.455 | 0.300 | 0.180 | 0.210 | 0.150 | 0.120 | 0.040 |
| D | 0.198 | 0.139 | 0.208 | 0.238 | 0.079 | 0.129 | 0.416 | 0.069 | 0.238 | 0.079 | 0.079 | 0.109 |
| E | 0.108 | 0.206 | 0.235 | 0.157 | 0.118 | 0.167 | 0.168 | 0.218 | 0.129 | 0.139 | 0.139 | 0.208 |
| F | 0.109 | 0.059 | 0.327 | 0.119 | 0.218 | 0.168 | 0.168 | 0.149 | 0.208 | 0.099 | 0.267 | 0.099 |
| G | 0.300 | 0.260 | 0.100 | 0.180 | 0.080 | 0.080 | 0.139 | 0.287 | 0.119 | 0.257 | 0.119 | 0.069 |
| H | 0.000 | 0.000 | 0.000 | 0.020 | 0.980 | 0.000 | 0.149 | 0.129 | 0.228 | 0.277 | 0.099 | 0.119 |
| I | 0.190 | 0.170 | 0.120 | 0.100 | 0.250 | 0.170 | 0.304 | 0.127 | 0.147 | 0.196 | 0.157 | 0.069 |
| J | 0.240 | 0.256 | 0.112 | 0.096 | 0.088 | 0.208 | 0.160 | 0.260 | 0.080 | 0.070 | 0.200 | 0.230 |
| Average | 0.236 | 0.139 | 0.124 | 0.148 | 0.199 | 0.150 | 0.241 | 0.208 | 0.168 | 0.139 | 0.129 | 0.112 |
Similarly to the case of IDA, how efficiently the CPCS prototype can monitor a user’s behavior would be influenced by its installation site and the daily habits of the user. However, synergistic effects are also expected through the concomitant use of the IDA and the MCT, and could have a positive impact on the frequency with which users engage in cognitive training. To clarify these issues, we evalu- ated and discussed the impressions of users, the effectiveness of the system at monitoring users, and the relationships between dialogue with the IDA and the frequency of cognitive training by examining data such as the sensor log, the result of the questionnaire/interview with the participants, and the training frequency in parallel.
5. Results and Discussion
This section describes our experimental results and discusses our investigation of the basic characteristics and performance of the SCCF as well as the effectiveness of the CPCS prototype presented in Section 4.
5.1 Performance Evaluation of the SCCF
Let us first discuss the performance and adequacy of the SCCF in providing appropriate information according to the user’s pref- erences and condition. Table 2 lists the probability of the chat-bot talking about each category over the last 100 times in the three-day experimental period. This table shows the results for all participants. In this table, “ranking” corresponds to the participants’ interest lev- els for each speech category obtained by the questionnaire adminis- tered after the experiment. This table revealed that the probability of talking acquired by the learning tends to be high when the rank of the interest level is high, especially under the reward setting RB. The bold digits in the table indicate areas in which probability increased from its initial value (16.66…%). Table 3 represents the results of the questionnaire concerning the participants’ interest levels for each category on a five-point scale (the other questionnaire results are shown in Appendix (B)). Digits in boldface indicate areas with an interest level greater than 3. Table 2 shows that, for reward setting RB, the probabilities of the top three speech categories tend to be larger than the initial probability value while the probabilities of the bottom three categories tend to be smaller. Additionally, the results presented in Tables 2 and 3 show that, under reward setting RB, there is a positive correlation between the probabilities of speech from
the chat-bot at the end of the experiment and interest in the actual content of the speech under reward setting RB. In other words, the probability that the chat-bot provides the participants with topics of interest increased throughout the experiment, while the probability that it provided topics for which many participants’ feedback was U (no interest) decreased. Therefore, we believe that the chat-bot with reward setting RB was able to provide information that reflected the users’ thoughts and states.
On the other hand, the chat-bot with reward setting RA failed to acquire the appropriate policy. An important feature in the chat-bot with setting RA was that the probability of a particular category being provided was too large (up to 98%) when targeting a specific participant compared to the results obtained with setting RB (up to 41%). Critically, reward setting RA does not include negative rewards; regardless of whether the user’s feedback is positive or negative, a positive reward is given. Thus, it is much more likely that the chat-bot with the reward setting RA will be given a posi- tive reward than the chat-bot with reward setting RB. However, it seems that the speech probability was changed too drastically for the chat-bot with reward setting RA under the current parameter settings.
Table 3: Degree of interest in participants’ speech categories (on a 5-point scale).
| Participant / ranking | 1st place | 2nd place | 3rd place | 4th place | 5th place | 6th place |
| A | 5 | 4 | 4 | 3 | 2 | 2 |
| B | 5 | 4 | 3 | 3 | 3 | 2 |
| C | 4 | 4 | 4 | 3 | 1 | 2 |
| D | 5 | 5 | 4 | 1 | 2 | 1 |
| E | 5 | 3 | 3 | 4 | 3 | 2 |
| F | 5 | 5 | 4 | 3 | 2 | 1 |
| G | 4 | 4 | 4 | 4 | 3 | 2 |
| H | 4 | 4 | 3 | 2 | 1 | 1 |
| I | 5 | 4 | 4 | 2 | 1 | 1 |
| J | 4 | 4 | 5 | 4 | 3 | 3 |
| Average | 4.6 | 4.1 | 3.8 | 2.9 | 2.1 | 1.7 |
5.2 Basic Characteristics of the CPCS
This section discusses whether the prototype version of the CPCS can monitor and/or understand a user’s circumstances in de- tail using the log data collected by the IDA and MCT, and evaluates users’ impressions of the system as well. The sensor data of partici- pant F were incomplete due to an equipment malfunction and are therefore not included in these results.
- Differences in the Participants’ Amounts of Activity
Let us consider the amount of activity detected by the pyroelec- tric sensor on the CPCS. A participant’s amount of activity Actx is defined as the number of times the sensor detects his/her motion for x min. The maximum and minimum values of Actx equal 60x and 0, respectively. Since the sensor may also detect objects other than the user, the value of Actx must be corrected depending on the experimental circumstances. Table 4 shows the maximum amount of activity per 30 min for each participant over the course of the experiment. As shown in the table, Participant B had the greatest amount of activity (number in red) while Participant A had the low- est amount (blue). Figure 3 also shows sketches of the rooms usually used by Participants A and B, and the location and orientation of the sensor in those rooms.
Installation of the sensor in a location where it can detect the participant’s motion appropriately is essential in order for behavior to be estimated accurately. Since Participant B answered in the interview after the experimental period that she often reads for long periods of time at her desk, we believe that this caused her amount of activity to be greater than that of the other participants because she was active within the detection range of the sensor. These results suggest that environmental factors, such as the location and direc- tion of the sensor, may influence the recorded amount of activity (some noise and error in sensing may also influence the results).
Therefore, in the case that the CPCS in its current form would be employed in practice by older adults, it is necessary to consider in advance where the sensors should be installed to effectively track the older adults’ amount of activity. At the same time, if the CPCS could be installed at the appropriate location, we can expect to properly understand their behavior.
Table 4: Maximum amount of activity per 30 min for each participant.
| Participant | Act30 | Participant | Act30 |
| A | 1210 | G | 1301 |
| B | 1800 | H | 1353 |
| C | 1312 | I | 1711 |
|
D E |
1386 1672 |
J | 1503 |
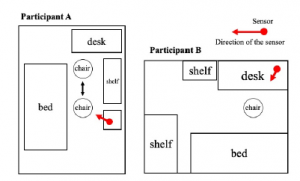
Figure 3: Diagram of the rooms where the experiment was conducted for Participants A and B
- Sensor Logs and Time Spent on the Memory Game
Figure 4 depicts the average number of cognitive training mem- ory games played every 30 min on weekdays (bar graph) and activity patterns (i.e., transition in the amount of activity) recorded by the sensor (line graph). The results shown in this figure are the aver- age values for seven participants who showed similar behavioral trends. Participant I was excluded because his academic year and life patterns were different from those of the others. Here, interval
(b) in Figure 4 is characterized by low activity because the partic-
ipants were at school and not near the CPCS installation site. In addition, as can be seen at interval (c), there was an overall tendency for the participants to play the memory game more often at night, increasing their activity level at the same time. In contrast, interval
(a) shows a larger amount of activity compared to interval (b), but almost no gameplay history except for Participant E. This result indicates that the participants were preparing to go to school during the corresponding period.
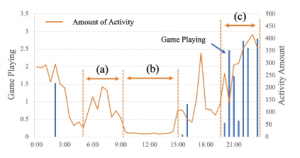
Figure 4: Average amount of game playing and activity patterns on weekdays.
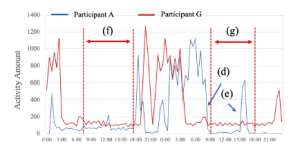
Figure 5: Weekend activity patterns for Participants A and G
At the same time, we can also see significant differences be- tween the participants’ behavior on weekday vs. weekends in terms of their life rhythms, such as sleeping hours and daily habits. Fig- ure 5 shows the weekend activity patterns for Participants A and G, which were particularly distinctive. These patterns allow us to estimate the participants’ awakening time and bedtime. For exam- ple, Participant A’s activity decreased early Sunday morning ((d) in Figure 5) and increased around 15:00 ((e) in Figure 5). In the interview after the experiment, Participant A confirmed that this activity pattern corresponded to his sleep pattern. Similarly, the other participants’ sleep patterns could also be estimated from their activity logs. These results demonstrate the usefulness of the users’ stored behavioral log data.
On the other hand, it was not possible to fully estimate Partici- pant G’s weekend sleep pattern. Figure 5 suggests that Participant G’s bedtime was 3:00 on Saturday, and her waking time was around 19:00. However, in the interview after the experiment, we learned that she was awake but not in the room with the sensor at certain times of the day, such as from 7:30 to 17:00 (interval (f) in Figure 5) on Saturday and from 8:00 to around 18:00 (interval (g) in Figure 5) on Sunday. The fact that Participant G spent less time in the room where the CPCS was installed may have contributed to her lower amount of activity.
These results demonstrate that the use of sensor logs and game- play histories obtained by the CPCS allows us to estimate not only daily habits such as waking and sleeping times but also whether users go out for long periods of time.
- Using Sensor Logs to Capture Users’ Lifestyle Habits
This section focuses on the sensor logs obtained in the IDA, a component of the CPCS, while playing the memory game on the MCT, and before and after playing. Figure 6 shows the amount of activity recorded every one minute for about 20 min while Partici- pant B was playing the memory game. The memory game has 13 levels of difficulty and records three degrees of fatigue: 0, Bad; 1, Normal; 2, Good. Figure 7 shows the transitions in difficulty level and degrees of fatigue during the time that Participant B played the memory game. Note that all the intervals in Figure 7 correspond to interval (h) in Figure 6. The red circles on the red line plot in Figure 7 indicate the times at which the memory game was started. In Par- ticipant B’s interview after the experimental period, she noted that she played the memory game at her desk (near the location where the CPCS was installed). During and after the gameplay (interval
(h) and the second half of (h) in Figure 6), the amount of activity increased compared to the period of time before play, while after 22:12 (interval (i) in Figure 7), the participant temporarily stopped playing the memory game. Figure 6 confirms that the amount of activity remains high. We can speculate that the cause of this pattern was that Participant B was feeling fatigued from the memory game and may have stopped playing the game to do some other task or take a break.
Figure 8 depicts the amount of activity recorded every one min for about 20 min while Participant E was playing the memory game. In contrast to the results obtained for Participant B, Participant E’s activity tended to decrease during the game-playing time ((j) in Figure 8) compared to his activity before and after playing. The interviews revealed that Participant E tended to play memory games on the bed. We inferred that this position was responsible for the low activity levels recorded by the system, since the location of the sensor would have made it difficult to detect someone on a bed. The interviews of the other participants indicated that the sensor logs adequately expressed their behaviors. It was clear from these results that the data obtained from the IDA and the MCT can be used to extrapolate detailed information about the user’s circumstances.
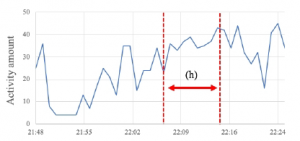
Figure 6: Activity before, during, and after Participant B’s game playing.
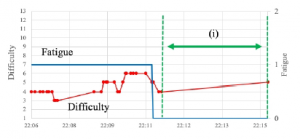
Figure 7: Changes in difficulty and fatigue during the memory game (Participant B).
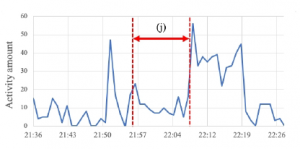
Figure 8: Activity patterns for Participant E.
- Questionnaire Investigation of the CPCS
Next we will discuss the participants’ impressions of the CPCS and the synergistic effects of combining the IDA and the MCT based on the results of subjective evaluations of the nine participants (col- lege students) conducted after the experimental period. Among the nine participants, five stated that they felt there was a need to use the CPCS; however, there was only one participant who wanted to use both the IDA and the MCT as individual components of the CPCS. Thus, although in some cases the student participants expressed interest in the components of the CPCS, it can be said that, on the whole, they did not have a positive impression of the prototype version of the CPCS. One reason for this may be that students attend classes on a daily basis and have frequent opportunities to talk with the people around them. Further research needs to be conducted to investigate differences in the trends across age groups.
Table 5 shows the average number of times the memory game provided by the MCT was played per day by each participant with
Table 5: Differences in the number of times the memory game was played with and without speech from the IDA.
| Participant | A | B | C | D | E | G | H | I | J | Average |
| Not talking | 14.7 | 5.0 | 23.0 | 21.0 | 0.0 | 37.0 | 21.0 | 31.0 | 30.0 | 20.3 |
| Talking | 20.7 | 10.0 | 26.7 | 31.0 | 15.7 | 41.0 | 29.0 | 40.3 | 41.3 | 28.4 |
| Difference (talking – not talking) | 6.0 | 5.0 | 3.7 | 10.0 | 15.7 | 4.0 | 8.0 | 9.3 | 11.3 | 8.1 |
and without speech from the IDA. When the IDA spoke, the number of times each participant played was greater than that when the IDA did not speak (average: 8.1 times). We consider that the above result was caused by the synergy of the combination of the IDA and the MCT, because the dialogue between the IDA and the participant promoted their habitual game playing. The other questionnaire results can be seen in Appendix (C).
6. Conclusion
In the present study, we introduced the Speech Content Coordi- nating Function (SCCF) into the Intelligent Dialogue Agent (IDA), and developed a prototype version of the Comprehensive Preventive Care System (CPCS) consisting of the IDA and the Mechanism for Cognitive Training (MCT). The SCCF was developed as a text- based agent in the form of a chat-bot that employed reinforcement learning based on the policy gradient method. This system was tested in an experiment with student participants. The experimental results confirmed that the SCCF acquires appropriate policies based on the user’s preferences and conditions. Furthermore, the results of experiments using the prototype version of the CPCS confirmed that taking advantage of data obtained from both the IDA and the MCT can lead to synergistic effects to monitor users in greater detail, better understand their circumstances, and increase the frequency of cognitive training.
In future research, we will further improve the convenience and familiarity of the SCCF by determining not only the content of speech but also the appropriate frequency and timing of speech based on the user’s circumstances at any given time. At the same time, because this improvement may cause an exponential increase in the number of states and actions compared to the learning environ- ment of the experiments conducted in the present study, we plan to improve the current learning algorithm or apply more powerful ones, such as deep reinforcement learning algorithms. The adaptability and familiarity of the improved SCCF will need to be evaluated through more practical experiments with older adults in a setting that more closely replicates real-life circumstances.
We also expect that further synergistic effects will occur by allowing the components of the prototype CPCS to communicate and share their data. It will also be necessary investigate the effects of the CPCS on older adults and their impressions of this system by fully examining the different trends in people of different age groups. We also plan to integrate a fall prevention system, which is currently being developed in parallel by our research group, into the CPCS; however, since this system involves physical exercise and a certain risk of injury, we will proceed with its integration in stages, starting with older adults who are at little risk of injury. Similarly, we will continue to work on the introduction of other preventive care systems and expect to see synergies similar to those obtained in the present study.
Acknowledgment
The authors would like to thank the staff of the Fujisawa Care Center, and the members of the Hachioji Senior Citizens’ Club and Cafe Kajiyashiki for their cooperation.
- D. Kitakoshi, S. Hirose, A. Yamashita, M. Suzuki, K. Suzuki, “Development of an Intelligent Dialogue Agent for Older Adults: Evaluation of Functions to Control Spontaneous Talk and Coordinate Speech Content,” in 2019 Interna- tional Conference on Technologies and Applications of Artificial Intelligence (TAAI), 1–6, IEEE, 2019, doi:10.1109/TAAI48200.2019.8959870.
- S. Bureau, The Statistical Handbook of Japan 2019, Ministry of Internal Affairs and Communications, 2019.
- D. Kitakoshi, T. Okano, M. Suzuki, “An empirical study on evaluating ba- sic characteristics and adaptability to users of a preventive care system with learning communication robots,” Soft computing, 21(2), 331–351, 2017, doi: 10.1007/s00500-015-1631-7.
- T. Suzuki, H. Kim, H. Yoshida, T. Ishizaki, “Randomized controlled trial of exercise intervention for the prevention of falls in community-dwelling elderly Japanese women,” Journal of bone and mineral metabolism, 22(6), 602–611, 2004, doi:10.1007/s00774-004-0530-2.
- A. Sixsmith, N. Johnson, “A smart sensor to detect the falls of the elderly,” IEEE Pervasive computing, 3(2), 42–47, 2004, doi:10.1109/MPRV.2004.1316817.
- N. K. Suryadevara, S. C. Mukhopadhyay, “Wireless sensor network based home monitoring system for wellness determination of elderly,” IEEE sensors journal, 12(6), 1965–1972, 2012, doi:10.1109/JSEN.2011.2182341.
- W.-H. Wang, P.-C. Chung, Y.-L. Hsu, M.-C. Pai, C.-W. Lin, “Inertial-sensor- based balance analysis system for patients with Alzheimer’s disease,” in 2013 Conference on Technologies and Applications of Artificial Intelligence, 128– 133, IEEE, 2013, doi:10.1109/TAAI.2013.36.
- R. Naqvi, D. Liberman, J. Rosenberg, J. Alston, S. Straus, “Preventing cog- nitive decline in healthy older adults,” CMAJ, 185(10), 881–885, 2013, doi: 10.1503/cmaj.121448.
- Y. S. Delahoz, M. A. Labrador, “Survey on fall detection and fall prevention using wearable and external sensors,” Sensors, 14(10), 19806–19842, 2014, doi:10.3390/s141019806.
- T. Watanabe, K. Kamata, S. A. Hasan, S. Shibusawa, M. Kamada, T. Yonekura,
M. Yamada, “Design of an antagonistic exercise support system using a depth image sensor,” in Proceedings of the 10th EAI International Conference on Pervasive Computing Technologies for Healthcare, 162–169, 2016. - A. Chelli, M. Patzold, “A Machine Learning Approach for Fall Detection and Daily Living Activity Recognition,” IEEE Access, 7, 38670–38687, 2019, doi:10.1109/ACCESS.2019.2906693.
- D. Yacchirema, J. DePuga, C. Palau, M. Esteve, “Fall detection system for elderly people using IoT and ensemble machine learning algorithm,” Per- sonal and Ubiquitous Computing, 23(5-6), 801–817, 2019, doi:10.1007/ s00779-018-01196-8.
- G. Lo´pez, L. Quesada, L. A. Guerrero, “Alexa vs. Siri vs. Cortana vs. Google Assistant: a comparison of speech-based natural user interfaces,” in Inter- national Conference on Applied Human Factors and Ergonomics, 241–250, Springer, 2017, doi:10.1007/978-3-319-60366-7 23.
- M. K. Wolters, F. Kelly, J. Kilgour, “Designing a spoken dialogue interface to an intelligent cognitive assistant for people with dementia,” Health Informatics Journal, 22(4), 854–866, 2016, doi:10.1177 3329.
- S. Nakatani, S. Saiki, M. Nakamura, K. Yasuda, “Generating Personalized Vir- tual Agent in Speech Dialogue System for People with Dementia,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), volume 10917 LNCS, 326– 337, 2018, doi:10.1007/978-3-319-91397-1 27.
- A. Russo, G. D’Onofrio, A. Gangemi, F. Giuliani, M. Mongiovi, F. Riccia- rdi, F. Greco, F. Cavallo, P. Dario, D. Sancarlo, V. Presutti, A. Greco, “Dia- logue Systems and Conversational Agents for Patients with Dementia: The Human-Robot Interaction,” Rejuvenation Research, 22(2), 109–120, 2019, doi:10.1089/rej.2018.2075.
- F. Tang, I. Uchendu, F. Wang, H. H. Dodge, J. Zhou, “Scalable diagnostic screening of mild cognitive impairment using AI dialogue agent,” Scientific Reports, 10(1), 2020, doi:10.1038/s41598-020-61994-0.
- S. Yamada, D. Kitakoshi, A. Yamashita, K. Suzuki, M. Suzuki, “Devel- opment of an Intelligent Dialogue Agent with Smart Devices for Older Adults: A Preliminary Study,” in 2018 Conference on Technologies and Applications of Artificial Intelligence (TAAI2018), 50–53, IEEE, 2018, doi: 10.1109/TAAI.2018.00020.
- D. Kitakoshi, R. Hanada, K. Iwata, M. Suzuki, “Cognitive training system for dementia prevention using memory game based on the concept of human-agent interaction,” Journal of Advanced Computational Intelligence and Intelligent Informatics, 19(6), 727–737, 2015, doi:10.20965/jaciii.2015.p0727.
- H. Eguchi, S. Yoshikawa, A. Yamashita, D. Kitakoshi, Y. Ho, Y. Hujimoto,T. Yamaguchi, M. Kanae, T. Sato, “Analysis of pyroelectric sensor data in- stalled in thehomes of elderly individuals,” in Proc. the First International Symposium on AI for ASEAN Development, 2018.
- R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, MIT press Cambridge, 1998.
- R. J. Williams, “Simple Statistical Gradient-Following Algorithms for Connec- tionist Reinforcement Learning,” Machine Learning, 8(3-4), 229–256, 1992, doi:10.1007/BF00992696.
- S. M. Kakade, “A natural policy gradient,” in Advances in neural information processing systems, 1531–1538, 2002.
- H. Kimura, K. Miyazaki, S. Kobayashi, “Reinforcement learning in POMDPs with function approximation,” in International Conference on Machine Learn- ing, volume 97, 152–160, 1997.
- C. J. Watkins, P. Dayan, “Q-learning,” Machine learning, 8(3-4), 279–292, 1992, doi:10.1007/BF00992698.
- G.A. Rummery, M. Niranjan, On-line Q-learning using connectionist systems, volume 37, University of Cambridge, Department of Engineering Cambridge, UK, 1994.
- R. Nakano, “Efficient learning of behavioral rules,” in From Animals to Ani- mats 6: SAB2000 Proceedings Supplement of the Sixth International Conference on Simulation of Adaptive Behavior, p178-184. Paris, France, 2000.