1. 引言
相对于研究非常多的负荷而言,电网运行数据中另一个与负荷数据同样海量的电压数据却很少研究。就目前电网数据研究来看,专门针对电压数据的研究只是在过电压问题监测识别及电压数据采集管理 [1] 方面有涉及。
用户用电模式是用户用电的一个非常重要特征,通过用户的用电模式特征了解,不仅更深刻掌握用户用电行为特征,制定针对性强的营销策略,还对负荷管理、电力规划等有指导作用。用户负荷曲线是对用户负荷的详细时序记录,综合体现了用户用电特征。王志勇 [2] 通过对客户用电数据归一化等预处理后进行聚类,得到类族典型负荷曲线,有效区分了各类别的经济类型用电模式。钟伟宽 [3] 采用工作日和休息日对用户日负荷曲线分类,取平均后并进行正规化的曲线作为代表性负荷曲线,进而运用模糊C均值聚类法得到各类典型用户负荷模式特性,并对各类负荷曲线之间进行了对比,表明了模糊聚类在用户的负荷曲线特征提取方面的可行性。冯璐,王成文,申晓留,谭忠富 [4] 基于灰色聚类和层次分析法,对用户风险和价值方面的特征提取进行了研究。
本文根据广州地区不同母线电压在不同时期表现出的规律性,在此利用支持向量机回归进行电压特征曲线研究,使用K-均值聚类对系统表现出的电压特性进行分类研究。通过对电压数据进行探索分析后发现,电压数据也是具备较强规律性和重复性,特别是时间序列的周期性特点、电压数据与时间段的关系以及不同主变之间存在的相似性等方面。
2. 支持向量机回归
本文以当前时刻为研究切面,通过对电压数据建立支持向量机回归 [5] 模型,对前期历史电压数据进行模型训练后,通过回归预测方式给出当前时刻某主变电压特征曲线数据,并对回归后得到的电压曲线进行分析,加深了对主变和电压数据的认识。
考虑样本如下
考虑线性拟合的情况,用下面的函数来拟合以上样本
(2.1)
假设函数(1)能够以精度
零误差地拟合样本,那么得到:
(2.2)
考虑到可能允许出现的拟合误差的情况,引入松弛变量
和
,(2.2)变成
(2.3)
通过最小化
来控制函数集的复杂度。再考虑到拟合误差的情况,线性回归问题转化成二次优化问题
(2.4)
其中,
,为一常数,作为超出拟合精度
的样本的惩罚因子。前一部分代表了函数的推广能力,后一部分代表了经验误差(即拟合函数对训练样本的误差),两个合起来就是统计学理论中提到的结构风险最小化。采用优化方法得到其对偶问题,在约束条件:
(2.5)
下,对拉格朗日因子
,最大化目标函数
(2.6)
可以求得回归函数
(2.7)
当函数
为非线性时,通过一种事先规定好的映射
,将样本投影到的一个特征空间(Hibert空间),进行线性回归。可以通过满足Mercer条件的核函数
代替在其高维特征空间内积运算。公式(2.7)用核函数替换,得到特征空间的线性函数:
3. K-均值聚类
K-均值聚类 [6] 在连续型数据下应用非常广泛,考虑到本文研究电压数据结构为典型时序特征连续型数据,且主要处理日电压特征向量,与层次聚类、DBSCAN聚类等聚类技术相比,采取K-均值较符合数据结构特点。
具体来看,影响指定参数K的K-均值算法分类效果的在于距离定义、聚类目标函数选择、初始质心确定,以及在开始的参数K选择。
1) 压特征曲线距离测度定义
在所有聚类技术中,最基础的工作就是定义距离测度。本文电压特征K均值聚类定义采用欧式距离,设
为分别两条母线
对应的日电压特征向量,则
的日电压特征曲线距离为
(3.1)
2) 类目标函数
聚类的效果需要评估指标进行判断,在此我们选择误差平方和(SSE, sum of the square error)作为评估指标
(3.2)
即计算每根母线与其类中心的距离,再对所有类的距离进行求和得到。其中
为上面定义的欧式距离,
为第i类的类中心,实际上采用上面欧式距离,
可以推得为
(3.3)
实际上,采用欧式距离时,
(3.4)
为类中心
的第j时刻的特征电压值,对(5.4)式子求偏导数可得到(5.3)为最优。
3) 初始中心选择
选择初始中心是K均值聚类中重要一环,初始中心的位置能影响算法迭代次数以及最终能否找到最小SSE聚类。为减少出现算法陷入局部最优情况,我们采用常用的随机初始化中心技术,即多次运行,每次随机选择一组中心,比较选取最小SSE的分类。
4) 最佳分类数确定
确定最佳分类数是聚类分析中还未形成统一解决理论的问题,其中关键的困难是对类的结构和内容难以形成一致的概念。在研究实践中,一般是研究者根据研究目的,根据实际数据和要求,选择适宜分类数。Demirmen (1972)曾提出了根据树状结构图来分类的准则:
a) 每一类须在与其他各类相比是突出的,即各类中心之间距离须足够大;
b) 每一分类不要包含过多元素;
c) 分类数应与分析目的一致;
d) 在使用几种不同聚类技术分析时,聚类结果上应该发现相同的类。
本文研究的主变电压特征分类问题,目前没有相关关于聚类分类数的理论支持,在相近的负荷特征曲线分类问题上,研究者基本上从实验效果上给出分类数 [7],而未从理论高度阐述。本文分类数确定方式也采取从多次实验中选择分类效果较明显的分类数。
4. 实验
在算法具体实现和计算上,本文选择了林智仁等开发的支持向量机(SVM)程序库LIBSVM [8],LIBSVM是一个有关SVM回归与模式识别算法的Matlab软件包,它提供了ν-支持向量机、C-支持向量机、分布估计(one-class SVM)以及两种SVM回归算法ϵ-支持向量回归和ν-支持向量回归问题的具体计算方法和实现细节。
首先我们选择昌岗.10 KV IIA母线(changgang.10MM2A)进行建模分析。通过changgang.10MM2A母线一年电压数据时间序列图,如图1,直观上可以看出电压序列具有明显的周期性特征。
根据上面的讨论,我们需先确定一个合适的训练样本维度m,考虑到电压的周期性,我们先取m = 7进行训练样本提取并建模。
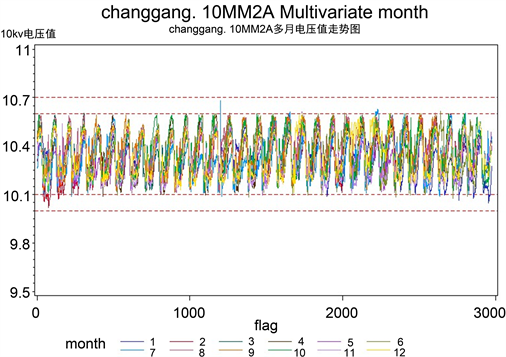
Figure 1. 12 Month voltage data sequence diagram of changgang.10MM2A
图1. changgang.10MM2A母线12个月电压数据时序图
4.1. 数据预处理
首先提取changgang.10MM2A一年电压数据,针对LIBSVM包中对数据格式要求,将电压数据处理为一个矩阵形式。其中,矩阵的行数为96,每一列依次对应一天中从00:00:00开始每隔15分钟的电压数据,而行数为一年中有记录changgang.10MM2A电压值的天数,由于本文源数据中母线changgang.10MM2A只含有363天数据,因此最终得到一个96 × 363矩阵。
接下来我们对矩阵中缺失值进行处理,考虑到电压的规律性,在每天同一时刻数据较为接近,且支持向量机的鲁棒性较好,数据微小波动对模型训练非常有限,因此我们采取用缺失值所在时刻一年平均值
(4.1)
进行填补,当有多个缺失值时,可对全部缺失值赋值为所有不为0的电压数值均值。
4.2. 模型效果测量指标
为了对训练出的模型进行评价以及进一步优化参数,我们需要设定一些模型效果的测量指标。对于分类问题而言,常可以选择预测的正确率来衡量模型优劣,由于本文中电压序列回归数据位连续数据值,因此我们考虑用以下指标评估模型预测性。
设
为测试数据,
为根据支持向量机回归估计出的模型计算得到的预测值。
均方差
(4.2)
以及平方相关系数
(4.3)
4.3. 模型参数确定和优化
采用支持向量机求解回归问题,在使用进行模型训练前,关键是核函数与参数的选择。
本质上SVM是基于核的方法,因此核函数选择对模型效果有相当重要影响,有时候选择不同核对结果预测差别很大,而对于核函数的选择并无统一理论进行指导,一般以经验和实验结果进行选择,本文中选择具备良好性态和较小运算复杂度 [9] [10] 的RBF核函数
(4.4)
作为模型核函数。
接下来对惩罚参数C和核函数
选择,我们在设定的一个较大的范围内将参数取值C和
的离散值,以较大步长对全体离散点组合进行格点搜索。在每个点上采取K-fold cross Validation (K-CV)交叉验证方法进行实验,即将原始分拆成K组,将每组子集做一次验证集,同时其余K-1组作为训练集训练模型,用验证集进行性能评价,最后取K组的均方差的均值
(4.5)
以及K组平方相关系数的均值
(4.6)
作为此组参数(C,
)的性能评价标准,对所有格点搜索完后,取在交叉验证法思想下测试集上表现最好的组合。虽然有可能此时的参数选择不是全局最优,但是结合时间和准确度考虑,目前交叉验证算法是非常理想的参数选择方法。
进一步,在大致得出一个粗略的优化参数组合(
,
)后,我们以此参数组合为中心划出一个小范围区域,再利用小的搜索步长对此小区域进行格点搜索,同样利用K-CV交叉验证法得到进一步优化的参数组合(
,
)。将此过程循环N次,可以得到效果相对最优的参数组合(
,
)。
本次实验针对changgang.10MM2A母线训练集参数选择过程如下表1,考虑到样本数不多,K取K-CV交叉验证法的下限值3。

Table 1. Parameter selection process of changgang.10MM2A training set ( C , γ )
表1. changgang.10MM2A母线训练集
参数选择过程
通过七次对区域范围和步长的缩小搜索,我们得到了一个较优化的参数组合
。
再考虑对损失函数参数
进行确定,在此我们不妨设定上一步得到的优化参数组合
,同时对损失函数参数赋不同值进行计算比较,选取最优的组合,分别取
,0.5,0.3,0.1,0.05,0.01,0.005,如表2。
Table 2. Parameter selection process of changgang.10MM2A training set ε
表2. changgang.10MM2A母线训练集
参数选择过程
由表2实验结果数据可知,在参数
取值(0.0625, 6.9644)情况下,
取值较大时,对损失函数几乎无约束力,取值
减少至0.1附近时模型效果显著增强。在
取值逐渐减少时,平方相关系数表现出先增大后减小的趋势。这是由于当损失函数取值较大时,参与回归的支持向量数量较少,使得模型没有得到较高程度的拟合,而随着
取值减少,这时参与回归的支持向量数量增加,模型复杂化后出现过拟合。因此我们取损失函数参数
,这时拟合效果在几组实验数据中表现最佳,平方相关系数最高。
综合上述实验,我们初步确定本次特征提取实验模型,模型核函数为RBF核函数,损失函数参数
,惩罚参数
,核函数参数
。
4.4. 电压特征曲线提取
根据上节确定的模型参数,即取RBF核函数,损失函数参数
,惩罚参数
,核函数参数
,我们对基于2012年12月31日时间截面对电压特征曲线进行提取,并将数据按照96个时间点序列绘图如下图2。
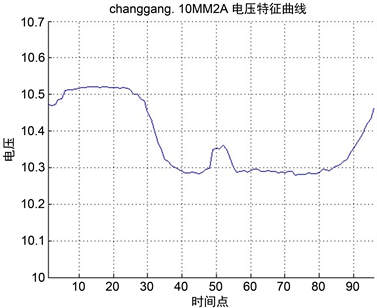
Figure 2. Voltage characteristic curve of changgang.10MM2A
图2. changgang.10MM2A电压特征曲线
我们可以选取每个主变的一根代表母线。之后我们需要提取每个主变的电压特征曲线,即采取支持向量机回归算法对选取出的母线进行电压预测。
4.5. 特征曲线建模聚类
依据上两节数据预处理提取数据后,我们得到了广州市AVC系统574个10 KV主变在本次数据最新时间点截面的日电压特征曲线,即含96个时间点的日电压特征向量。
待聚类对象574个主变的集合
(4.7)
其中对象参数为
(4.8)
按照上节原理定义其距离测度
(4.9)
为对比聚类效果,我们同时给出按照余弦向量定义的距离进行测试
(4.10)
考虑到具体应用问题,分类数不宜太多,另一方面,由于数据样本不小,且特征曲线差异性较大,也不能太少。结合本文对数据的分析角度,经过综合比较,我们选择6类,即指定K = 6,结果如下表3:
Table 3. Data of clustering results
表3. 聚类结果数据
5. 聚类结果及分析
上节我们对广州AVC系统中主变的电压特征曲线进行了聚类分析,得到6类电压运行模式。每类主变及其类中心的电压特征曲线如图3,其中红色为类中心曲线。
从各聚类组的叠加效果上看,聚类效果不错,聚类中心能较好的反映本聚类组的形态特征。
由图4:各主变聚类中心特征曲线图可见,第三类的电压特征曲线总体位于最高位,第五类电压特征曲线总体位于低位,这两类的组内标准差较小,说明这两组组内特征一致,聚类效果较好。第一类特征曲线总体介于第三到第四之间,居于中间位置,标准差最大,区别较大,存在继续细分的可能。第六类特征曲线凌晨时间居于中间位置,其余时间居于最低位置,标准差较大,样本数量较少。第二类、第四类电压特征曲线居于中间位置,组内标准差适中。
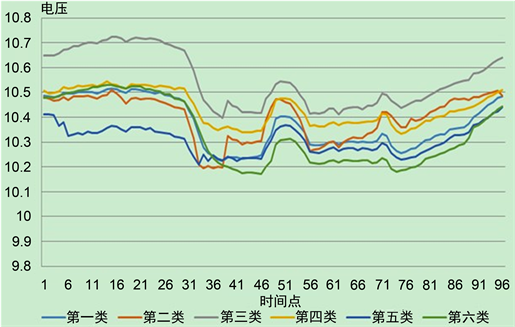
Figure 4. Characteristic curve of main transformer cluster center
图4. 各主变聚类中心特征曲线图
第三类电压特征曲线需要重点关注,原因在于此类特征电压曲线具备非常明显的越限特征,从凌晨开始电压一直处于高位状态,在第三十一个时间点之前都大于10.6 KV,即都高于AVC系统设定的电压调整上限。由于AVC系统具备自动调节功能,当电压高于设定上限时,会调节设备,使得电压降低,而第三类电压曲线一直处于高于调整上限甚至高于合格电压状态,说明具有此类电压特征模型的主变调节设备不能完全满足本区域内平衡电压的要求,相关单位需要加强监测此类主变辖区内电压运行状态,完善调控方案。
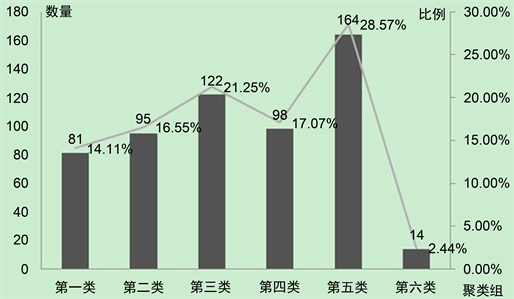
Figure 5. Quantitative distribution of clustering characteristic curves
图5. 各聚类特征曲线数量分布
由图5:各类聚类特征曲线数量分布图,可知,在本文聚类研究的时间点上,第三类特征曲线有122个,占比为21.25%,在整个电力系统中占比较大,需要重点关注,及时调整,以保证整个片区电压合格率。
6. 结论
综上所述,第三类和第五类组内标准差较小,聚类效果较好;第一类组内标准差较大,可以进一步细分;第六类组内标准差较大,但是样本数量较少,可以不用考虑再细分;第二类和第四类组内标准差适中,可以根据划分精度的要求,决定是否进一步细分。
基金项目
中国南方电网科技项目《基于BART算法和超吸收壁Brown运动的AVC系统定值智能学习与过程控制技术研究》。