1. 引言
自改革开放以来,随着经济的发展,福建茶业得到快速发展。福建省气候地理环境十分适宜生产茶叶 [1],山地居多,气候温暖湿润,是我国茶叶的重要产地,有着一千多年的茶叶历史。茶业是福建九大支柱产业之一,对经济发展、农业增效和地区旅游业中起着不可替代的作用 [2]。本文围绕着收集的福建省历年茶叶产量相关数据,进行序列平稳性判断及处理,然后对序列的自(偏)相关系数图进行研究,建立两个ARIMA时间序列模型,再检验分析两个模型的显著性以及参数显著性,根据近年福建省茶叶产量检验对比分析,选择预测效果较好的模型,来对福建省2020~2025年茶叶产量进行较高精度的拟合预测。
2. 茶叶产量数据的预处理
2.1. 平稳性判断
从福建省统计局官网收集到福建省1986~2019年的茶叶产量,如表1所示(单位:万吨):

Table 1. Table of tea production in Fujian Province in 1986~2019
表1. 福建省1986~2019年茶叶产量表
从中挑取2016~2019年的茶叶产量数据用来作为检验数据。
根据茶叶产量表的数据,利用SAS软件 [3],绘制福建省1986~2015年茶叶产量的时序图,如图1所示:
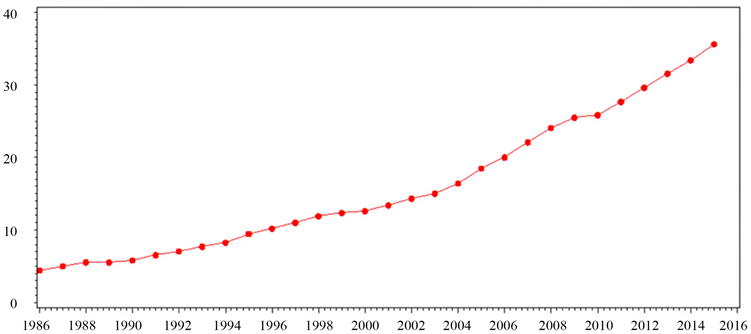
Figure 1. Time sequence of total tea production in Fujian Province from 1986 to 2015
图1. 福建省1986~2015年茶叶总产量的时序图
Cramer分解定理里说明了任何一个序列的波动都可以视为同时受到了确定性影响和随机影响的综合作用 [4]。平稳序列要求这两方面的影响都是稳定的,而非平稳序列产生的机理则在于它所受到的这两方面的影响至少有一方面是不平稳的。
根据图1可以看出,时序图有明显的递增趋势,而非在一个常数值上下波动,可以判断出该序列为非平稳序列。
2.2. 平稳化处理
若要根据序列构建拟合模型,需要先进行差分运算,来通过自回归的方式提取确定性信息,使非平稳序列变为平稳 [5]。运用SAS软件对该时间序列进行一阶差分,并画出时序图,如图2所示:
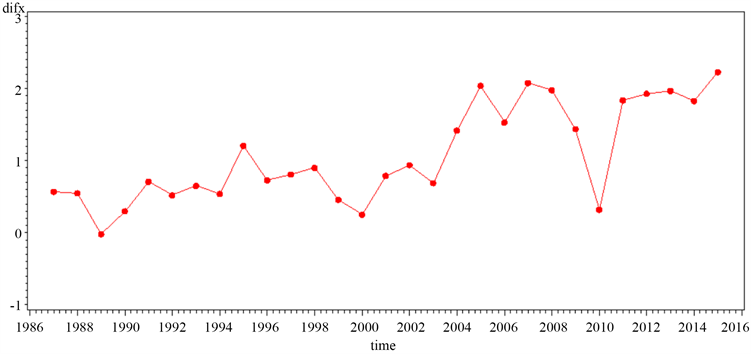
Figure 2. Time sequence diagram of the first-order difference of the total output of tea in Fujian Province from 1986 to 2015
图2. 福建省1986~2015年茶叶总产量一阶差分后的时序图
做一阶差分后,时序图没有明显的递增或者递减趋势,也没有明显周期性的变化,为了准确判断差分后的平稳性,运用Eviews软件 [6] 来对一阶差分后的序列做ADF检验。检验结果如图3所示:
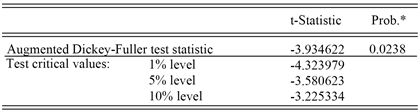
Figure 3. Unit root test after first order difference of sequence
图3. 序列一阶差分后的单位根检验
检验结果显示,P值为0.0238小于显著性水平0.05,拒绝存在单位根的原假设,所以一阶差分后的序列是平稳的。
2.3. 纯随机性检验
纯随机性检验也称为白噪声检验,用来检验一个序列是否为纯随机序列。若一个序列为纯随机序列,那么该时间序列的序列值之间没有任何相关关系,这就意味着序列值之间不会互相影响,也就没有继续研究下去的价值。根据Bartlett定理 [7],Ljung和Box构造了LB统计量来进行检验:
(1)
其中,n为序列观察期数,m为指定延迟期数。
运用SAS软件计算出各个延迟阶数下的LB检验统计值的量和P值,结果如表2所示:
检验结果显示,各阶延迟阶数下的LB统计量的P值都显著小于显著性水平0.05,拒绝为白噪声序列的原假设,所以该序列为平稳非白噪声序列。
3. ARIMA(1,1,0)模型识别及参数估计
3.1. 模型识别
福建省1986~2015年茶叶总产量一阶差分后的自相关图和偏自相关图如图4和图5所示。通过观察自相关图和偏自相关图可以看出:当延迟期数大于1之后,自相关系数都在两倍标准差之内,且呈现指数衰减到零附近,呈现出拖尾性质,所以自相关系数为一阶拖尾;当延迟阶数为1时,偏自相关系数明显大于2倍标准差范围,当延迟阶数大于1后,迅速衰减到两倍标准差之内,且几乎都落在2倍标准差范围以内,呈现截尾性质,所以偏自相关系数为一阶截尾。所以把该模型定阶为ARIMA(1,1,0)模型 [8]。

Figure 4. Autocorrelation graph after first order difference of sequence
图4. 序列一阶差分后的自相关图

Figure 5. Partial autocorrelation graph after first order difference of sequence
图5. 序列一阶差分后的偏自相关图
3.2. 模型参数估计
模型定阶后,对模型未知的参数值进行估计。对于时间序列中的未知参数的估计方法有三种:矩估计、极大似然估计、最小二乘估计 [7]。在实际运用中,最小二乘估计法是最常用的方法。最小二乘估计法在ARMA模型场合中,记
(2)
(3)
当它假定过去未观测到的序列值等于0,那么可以得到它的残差平方和为:
(4)
使此式达到最小值的估计值就为参数
的最小二乘估计。通过SAS软件,运用条件最小二乘估计法来对拟合的模型进行参数估计,结果如表3所示:
由表3可得,拟合的模型为:
(5)
或等价表示为
(6)
4. ARIMA(1,1,0)模型检验及预测
4.1. 模型检验
确定拟合模型的口径后,对模型进行显著性检验和参数显著性检验。显著性检验即通过检验残差序列是否纯随机来检验模型的信息是否提取充分,以来判定模型的估计效果;参数性检验即检验模型各参数是否显著非零,来评估模型的可行性和精简性,不显著非零的参数则表明该参数对应的自变量对因变量影响不明显,需要从拟合的模型中剔除。通过SAS软件获取模型显著性检验表以及参数显著性检验表,结果如表4、表5所示:
Table 4. Model significance test table
表4. 模型显著性检验表
显著性检验表结果显示,各阶延迟阶数下的LB统计量的P值都显著大于0.05,所以认为这个拟合模型的残差序列属于白噪声序列,即该模型显著有效。
Table 5. Parameter significance test table
表5. 参数显著性检验表
参数显著性检验表结果显示,所有参数均通过显著非零检验,说明ARIMA(1,1,0)模型对该序列的拟合显著成立。
4.2. 模型预测及数据对比
根据拟合的模型公式,利用SAS软件对福建省2016~2019年的茶叶总产量进行预测,结果如表6所示:
Table 6. Prediction table of total output value of tea in Fujian Province in 2016~2019
表6. 2016~2019年福建省茶叶总产量值预测表
把福建省2016~2019年茶叶产量数据摘出,用来与预测值作对比,来判断模型预测是否较为成功。对比数据如表7所示:
Table 7. Comparison table of total output value of tea in Fujian Province in 2016~2019
表7. 2016~2019年福建省茶叶总产量值对比表
从表7中可以看出,模型总体的预测精度良好,误差率总体较低,能基本稳定在1%以内。但随着预测步的增加,实际数据与预测数据的误差率逐渐增大。
5. ARIMA(1,2,1)模型识别及参数估计
5.1. 平稳性检验
运用SAS软件,将原始序列进行二阶差分,得到的时序图如图6所示:
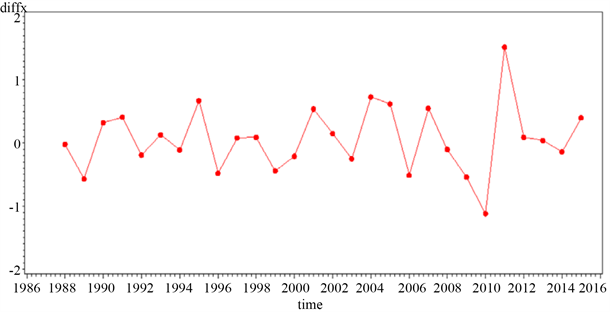
Figure 6. Sequence diagram after second order difference
图6. 序列二阶差分后的时序图
二阶差分后的时序图没有明显的趋势走向,也没有周期性的变化,为了准确判断平稳性,对序列进行ADF检验。检验结果如图7所示。结果显示,P值为0小于0.05,拒绝存在单位根的原假设,所以可以判断二阶差分后的序列为平稳序列。

Figure 7. Unit root test after second order difference of sequence
图7. 序列二阶差分后的单位根检验
5.2. 纯随机性检验
检验序列为平稳序列之后,对序列进行纯随机性检验。利用SAS软件得到二阶差分后序列的纯随机性检验表,自相关图和偏自相关图。纯随机性检验表如表8所示,检验结果显示,各阶延迟阶数下的LB统计量的P值都小于0.05,拒绝原假设,所以该序列为平稳非白噪声序列。
Table 8. Second order difference pure random test table
表8. 二阶差分纯随机检验表
6. ARIMA(1,2,1)模型识别及参数估计
6.1. 模型识别
序列二阶差分后的自相关图和偏自相关图如图8、图9所示,通过观察自相关图和偏自相关图可以看出:自相关系数快速地进入两倍标准差,且延迟一阶之后的自相关系数都在二倍标准差之内,所以自相关系数为一阶截尾。当延迟阶数大于等于1时,偏自相关系数都在两倍标准差之内,所以可以判断该时间序列的偏自相关系数为一阶截尾。所以把该模型定阶为ARIMA(1,2,1)模型。

Figure 8. Autocorrelation graph after second order difference of sequence
图8. 序列二阶差分后的自相关图
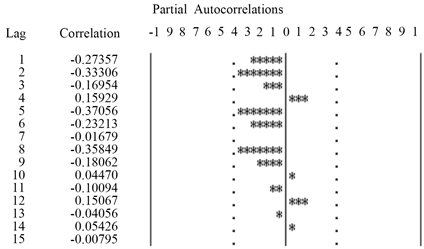
Figure 9. Partial autocorrelation graph after second order difference of sequence
图9. 序列二阶差分后的偏自相关图
6.2. 模型参数估计
将二阶差分后的序列模型定阶后,通过SAS软件,运用条件最小二乘估计法来对拟合的模型进行参数估计,结果如表9所示:
Table 9. Parameter estimation table after second order difference
表9. 二阶差分后的参数估计表
由得到的参数估计表可知,拟合的模型为:
(7)
7. ARIMA(1,2,1)模型检验及预测
确定拟合模型的口径后,对模型进行显著性检验和参数显著性检验,检验结果如表10、表11所示:
Table 10. Significance test table of second-order difference model
表10. 二阶差分后模型显著性检验表
检验结果显示,各阶延迟下的LB统计量的P值都显著大于显著性水平0.05,所以可以认为这个拟合模型的残差序列属于白噪声序列,即该模型显著有效。
Table 11. Test table of parameter significance after second-order difference
表11. 二阶差分后参数显著性检验表
检验结果显示,参数显著性检验的常数项
和参数值
未通过显著非零检验,所以这两个参数值为零。把两个不显著非零的参数剔除后,得到了新的参数显著性检验表(表12):
Table 12. Parameter significance test table after parameter elimination
表12. 参数剔除后参数显著性检验表
剔除掉不显著非零的参数之后,再通过SAS软件,运用条件最小二乘估计法来对拟合的模型进行参数估计,结果如表13所示:
Table 13. Parameter estimation table after parameter elimination
表13. 参数剔除后的参数估计表
由二阶差分参数剔除后的参数估计表所知,拟合的模型为:
(8)
根据二阶差分后拟合的模型公式,利用SAS软件对福建省2016年~2019年的茶叶总产量进行预测,结果如表14所示:
Table 14. Prediction table of total output value of tea in Fujian Province in 2016~2019
表14. 2016~2019年福建省茶叶总产量值预测表
和一阶差分一样,把2016~2019的数据摘出,做预测之后与预测值作对比,来判断模型拟合是否较为成功。对比数据如表15所示:
Table 15. Comparison table of total output value of tea in Fujian Province in 2016~2019
表15. 2016~2019年福建省茶叶总产量值对比表
从表15中可以看出,模型的预测值与真实值的误差稳定在0.5内,误差率总体较低,稳定在1%以内,整体的误差比ARIMA(1,1,0)模型的还要小,说明模型ARIMA(1,2,1)的总体预测精度更好。
8. 模型对比及预测
模型结果对比如表16所示,可以看出ARIMA(1,2,1)模型相比ARIMA(1,1,0)模型的福建省2016~2019年茶叶产量预测值,更接近数据的真实值,且ARIMA(1,2,1)模型的AIC值 [9] 小于ARIMA(1,1,0)模型,根据AIC准则,ARIMA(1,2,1)模型会优于ARIMA(1,1,0)模型。
Table 16. Comparison table of model results
表16. 模型结果对比表
结合多种因素进行结合考虑,最终选择拟合较优的ARIMA(1,2,1)模型对未来几年福建省茶叶产量进行预测,结果如表17:
Table 17. Prediction table of total output value of tea in Fujian Province from 2020 to 2025
表17. 2020~2025年福建省茶叶总产量值预测表
根据预测的结果,福建省未来的茶叶产量依旧呈上升趋势,也有可能逐渐趋于平稳。
9. 结论
福建省一直致力茶叶品牌建设与开发,茶业又好又快发展的成因,除了自身环境条件之外,主要还有行业相关和政府部门的重视,予以政策扶持,以及茶叶科技先进技术应用的进步。本文利用SAS软件,运用时间序列分析的理论知识,对福建省的茶叶总产量进行研究,通过建立的两个模型预测福建省茶叶总产量未来趋势,根据数据比对以及各因素综合考虑挑选出拟合较好的一个模型。通过该模型体现的茶叶产量发展,为有效的未来茶业发展提供参考依据。