- Research
- Open access
- Published:
A localized fault detection algorithm for mobility management in the strongly t-diagnosable wireless ad hoc network under the comparison model
EURASIP Journal on Wireless Communications and Networking volume 2016, Article number: 218 (2016)
Abstract
Among the many kinds of networking technologies, the wireless ad hoc network is an important one for creating high-performance ubiquitous computing systems. The availability of a wireless ad hoc network (WANET) depends highly upon the level of node reliability. System-level fault diagnosis has long been a subject for the purpose of maintaining system reliability. This paper addresses the comparison-based approach to fault detection, and accordingly, we developed a localized algorithm for detecting faulty nodes in strongly one-step t-diagnosable WANETs. The contributions of this paper are highlighted as follows: (i) A localized fault detection algorithm is proposed for strongly one-step t-diagnosable WANETs under the comparison model, (ii) the proposed algorithm is formally proved, and it incurs only linear time complexity, which is relatively efficient compared to some others in literature, and (iii) some examples are presented for clarifying how to accomplish the comparison-based fault detection process.
1 Introduction
A modern network system contains a large number of computing and storage units, organized in a static or dynamic underlying interconnection topology. Among the many kinds of networking technologies, the wireless ad hoc network (WANET) is a key to high-performance ubiquitous computing systems [2, 3, 9, 22, 26, 28, 31]. A WANET is a type of wireless network in which some nodes are self-organized in a wireless local area network. There are three important properties related to WANETs [7]. First, the WANET is deployed on any topology and managed independently of any preexisting infrastructure. Second, the nodes with mobility property are the most important components of WANET. According to Grossglauser and Tse [11], mobility can increase the capacity of a WANET. Third, it has the scalability property, such that it could be used in a large deployment. Due to the undecided number of nodes even during a short duration, the main difficulties are mobility property and reasons for node failure. The reasons for node failures are caused by some nodes with low battery situations, selfish behavior, or suffering from being compromised as well as attacked events, etc. Therefore, the WANET for any topology is needed to possess strong requirements, which must be able to exploit the high-level reliability linking with scalability and fault tolerance without compromising. In addition, many related issues have been addressed. For example, Kumar et al. [16] and Subramaniyan et al. [27] studied selfish node detection in a MANET; Renugadevi and Mala [24] proposed an improved group key agreement for MANETs. Hence, the maintaining connectivity in the face of node failures or so-called unit failures is a main concern in this paper.
The availability of a WANET depends greatly upon the node reliability, and the system-level fault detection approaches to achieve high system availability. Preparata, Metze, and Chien [23] formalized the notion of fault diagnosis and studied under what condition can a system be one-step t-fault diagnosable. Then, they further proposed a fault-tolerance metric, called the one-step diagnosability, to evaluate the degree of a system’s fault-tolerance capability. According to their formal definition [23], a WANET of n nodes is one-step t-fault diagnosable if all faulty nodes within the WANET can be identified without replacement provided the number of faulty nodes present does not exceed t. Among the various models of fault diagnosis [4, 21, 23], Maeng and Malek [21] proposed one classic approach in a comparison-based strategy, as known as the comparison model. Their approach makes an assumption that any node w is capable of playing the role of a “comparator” in differentiating between responses from two of its neighbors, u and v. The comparison result is 0 if w finds no difference between the returned responses from u,v; otherwise, the comparison result is 1. However, w may be either faulty or normal so that the set of comparison results is not absolutely reliable. Thus, both theoretical and algorithmic issues related to comparison-based fault diagnosis/detection have received the attention of many researchers [6, 8, 12–15, 18, 19, 29, 32].
The one-step diagnosability [23] is a reasonable metric for evaluating a network’s fault-tolerance capability, but it cannot exceed the network’s minimum degree. However, for a number of well-known instances of network topologies with one-step diagnosability being τ, their one-step diagnosability cannot be further increased only when some node happens to have exactly τ faulty neighbors and no normal neighbor. Motivated by such an observation, Lai et al. [20] first proposed the concept of strongly t-diagnosable systems/networks, in which each of any set of no more than t+1 faulty nodes can be correctly distinguished if every node has at least one normal neighbor. The aim of the localized fault detection is to identify the status of any given node in a WANET, which is classified as either “normal” or “faulty.” In this paper, we develop a localized fault detection algorithm under the comparison model for ease of handling scalability and mobility management in a strongly t-diagnosable WANET.
The remainder of this paper is structured as follows: We introduce in advance useful graph-theory terminology about formalizing the process of comparison-based fault diagnosis in Section 2. The localized fault identification algorithm and its mathematical proof are detailed in Section 3. Examples and applications are presented in Section 4. Our concluding remarks are drawn in Section 5.
2 Preliminaries
A WANET is composed of mobile nodes that can communicate directly and bi-directionally with the others via wireless communication if they are in the allowable communication range [3]. Every node is also responsible for forwarding data packets from the other nodes. Therefore, any two individual nodes that are outside their allowable communication range can still communicate indirectly with each other if at least one path, an ordered sequence of communication links, connects them. On this background, a simple, loopless, and undirected graph is an adequate model of a WANET’s network topology. To formalize the process of comparison-based fault diagnosis in a WANET, we have to define some graph-theory notations in advance. The standard terminology of graph theory is also referred to in [5].
An undirected graph G is composed of a vertex set V(G), which stands for mobile nodes in a WANET, coupled with an edge set E(G), which symbolizes communication links between nodes in a WANET. Here, we use {x,y} to denote an edge linking adjacent vertices x and y. Two adjacent vertices are neighbors of each other, denoted by N h d G (v) to the set of all neighbors of a vertex v. Then, the degree of v is equal to |N h d G (v)|, which is denoted by d e g G (v). In this paper, we make the following assumption for a given WANET: every node has the same communication range; that is, each node communicates with others within a unitary circle. Under this assumption, the network topology of a WANET is further simplified as a unit disk graph, which corresponds to a collection of unit disks in 2D or 3D space - circle/spheres of radius 1. Each vertex in a unit disk graph is associated with the center of an individual unit disk. In a unit disk graph, an edge links two vertices v 1 and v 2 if and only if the two disks associated with v 1 and v 2 cover both v 1 and v 2.
2.1 The comparison-based fault detection
For any node in a WANET, its actual status may be either normal or faulty. The fault detection is approached by comparing data generated from two nodes that have overlapped active areas. Our fault detection scheme is on the basis of the comparison model [21]. In this model, each unit w that has at least two neighbors u,v is able to play the role of comparator in differentiating between data transmitted by u and v: w sends an identical test request to u,v and then compares it with the received responses between u and v. The comparison result γ({u,v} w ) is set to be 0 if w finds no difference between the returned responses from u and v; otherwise, γ({u,v} w ) is set to be 1. When γ({u,v} w )=0, it also means that w agrees that both u and v are normal nodes. Because w may be either faulty or normal, the comparison model makes the following two assumptions:
-
1.
If the actual status of the comparator w is faulty, then w may produce an unpredictable comparison result. For example, γ({u,v} w ) may be 0 or 1 at random, and it is unreliable.
-
2.
If the actual status of the comparator w is normal, then w produces a reliable comparison result: γ({u,v} w )=0 indicates that both u and v are normal; otherwise, u or v is a faulty node.
Table 1 lists every validation rule of the comparison model according to the actual statuses of u, v, and w.
The syndrome set is a set of all comparison results collected from a network. However, because a faulty node produces unpredictable comparison results, different syndrome sets may be consistent with an identical fault set F. Let γ[X] be the set of syndrome sets that are consistent with fault set X. Any two different fault sets X 1 and X 2 are called distinguishable (respectively, indistinguishable) if the intersection of γ[X 1] and γ[X 2] is empty (respectively, non-empty). Sengupta and Dahbura [25] proved topological conditions for characterizing any one-step t-fault diagnosable graph G: Every two fault sets X 1 and X 2 in G have to be distinguishable if both X 1 and X 2 contain at most t vertices. Furthermore, the rules for telling whether or not two fault sets are distinguishable are summarized in the following lemma:
Lemma 1
[ 25 ] Any two fault sets X 1,X 2 in a graph G are distinguishable if and only if their topological structures can meet one condition (see Fig. 1):
-
1.
There exist {u,w}⊆V(G)∖(X 1∪X 2) and {v}⊆X 1△X 2 (Fig. 1 a, b ),
Fig. 1 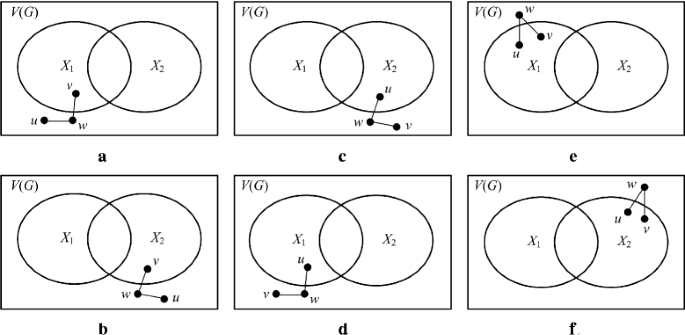
Topological conditions for characterizing a pair X 1,X 2 of two distinguishable fault sets: a & b The first condition of Lemma 1; c & d the second condition of Lemma 1; e the third condition of Lemma 1; f the fourth condition of Lemma 1
-
2.
There exist {v,w}⊆V(G)∖(X 1∪X 2) and {u}⊆X 1△X 2 (Fig. 1 c, d ),
-
3.
There exist {w}⊆V(G)∖(X 1∪X 2) and {u,v}⊆X 1∖X 2 (Fig. 1 e ),
-
4.
There exist {w}⊆V(G)∖(X 1∪X 2) and {u,v}⊆X 2∖X 1 (Fig. 1 f ),

where both u and v are neighbors of w, and X 1△X 2=(X 1∖X 2)∪(X 2∖X 1).
2.2 Strongly one-step t-diagnosable systems
Lai et al. [20] defined the concept of strongly one-step t-diagnosable network systems for investigating potential limitations in the one-step diagnosability. The standard definition of strongly one-step t-diagnosable graphs is presented in Definition 1.
Definition 1
[ 20 ] A graph G is strongly one-step t-diagnosable if it satisfies either condition (1) or (2): For any two fault sets X 1,X 2 in G, subject to |X 1|≤t+1 and |X 2|≤t+1,
-
1.
X 1 and X 2 are distinguishable;
-
2.
X 1 and X 2 are indistinguishable, but there exists an individual vertex x in G such that X 1∩X 2 covers N h d G (x).
Definition 1 implies that two arbitrary fault sets X 1 and X 2, both of which contain at most t+1 elements, are indistinguishable in a strongly one-step t-diagnosable WANET only when X 1 and X 2 happen to cover all neighbors of some individual node. This special case incurs one potential limitation of the one-step diagnosability. In the remainder of this paper, a set F is a restrictive fault set if F∩N h d G (v)≠N h d G (v) for each v∈V(G). Definition 2 is an extension to the original notion of one-step t-fault diagnosable systems for meeting the nature of restrictive fault sets.
Definition 2
A graph G is restrictively one-step t-diagnosable under the comparison model if every two different restrictive fault sets F 1 and F 2 in G, both of which contain at most t elements, are distinguishable.
3 The localized fault detection algorithm
Given a WANET with underlying topology G and any one of its node o, the localized fault identification aims to determine the actual status of o. Kung and Chen [17] first formalized the concept behind the localized fault identification under the PMC diagnostic model. The following definition extends it to the comparison model.
Definition 3
For any positive integer t, a node o is one-step t-identifiable under the comparison model if every two distinct fault sets F 1 and F 2 in G, with |F 1|≤t, |F 2|≤t, and o∈F 1△F 2, are distinguishable; furthermore, o is restrictively one-step t-identifiable under the comparison model if for every two different restrictive fault sets F 1 and F 2 in G, with |F 1|≤t, |F 2|≤t, and o∈F 1△F 2, are distinguishable.
Theorem 1
Under the comparison model, a graph G is one-step t-fault diagnosable if and only if every vertex of G is one-step t-identifiable.
Proof
Suppose that G is one-step t-fault diagnosable under the comparison model. If there is some vertex x not one-step t-identifiable in G, then G contains a pair of indistinguishable fault sets F 1,F 2, both of which have at most t elements so that x is in F 1△F 2 according to Definition 3. Obviously, G is not one-step t-fault diagnosable, which is an trivial contradiction against the assumption.
On the other hand, suppose that all vertices of G are one-step t-identifiable under the comparison model. If G is not one-step t-fault diagnosable, then G contains an indistinguishable pair F 1,F 2 of two fault sets that satisfy |F 1|≤t and |F 2|≤t. Since F 1≠F 2, the set F 1△F 2 is not empty; i.e., it has at least one vertex, say y. Therefore, it follows from Definition 3 that y is not one-step t-identifiable under the comparison model, which is a contradiction against the assumption.
By the argument of contradiction, the proof is completed. □
The next theorem is an extension to the original concept behind Theorem 1 for meeting the condition on restrictive fault sets.
Theorem 2
Under the comparison model, a graph G is restrictively one-step t-diagnosable if and only if all vertices in G are restrictively one-step t-identifiable.
Proof
Suppose that G is restrictively one-step t-diagnosable under the comparison model. If there is some vertex x in G not restrictively one-step t-identifiable, then G contains a pair of indistinguishable fault sets F 1,F 2, both of which have at most t elements so that x is in F 1△F 2, in accordance with Definition 3. Hence, it follows from Definition 2 that G is not restrictively one-step t-diagnosable, which is an obvious contradiction against the assumption.
On the other hand, suppose that all vertices of G are restrictively one-step t-identifiable. If G is not restrictively one-step t-diagnosable, then G contains an indistinguishable pair F 1,F 2 of two restrictive fault sets that satisfy |F 1|≤t and |F 2|≤t in accordance with Definition 2. Since F 1≠F 2, the set F 1△F 2 is not empty; i.e., it has at least one vertex, say v. Consequently, it follows from Definition 3 that v cannot be restrictively one-step t-identifiable, which is a straightforward contradiction against the assumption.
By the argument of contradiction, the proof of this theorem is completed. □
Let t=d e g G (o). For any h≥1, an h-extending star with root o is denoted by \(\mathbb {ES}^{(h)}_{G}(o)\), which is a subgraph of G defined below:
-
\(V\left (\mathbb {ES}^{(h)}_{G}(o)\right) = \{o\} \cup \bigcup ^{h}_{i=1}\bigcup ^{t}_{j=1}\{o_{i,j}\}\).
-
\(E\left (\mathbb {ES}^{(h)}_{G}(o)\right) = \bigcup ^{t}_{j=1} \left \{ \{o, o_{1,j}\} \right \} \cup \left \{ \{o_{i,j},o_{i+1,j}\} \mid h-1 \geq i \geq 1 \right \}\) if h≥2, and
-
\(E\left (\mathbb {ES}^{(h)}_{G}(o)\right) = \bigcup ^{t}_{j=1} \left \{ \{o, o_{1,j}\} \right \}\) if h=1.
Figure 2 a, b illustrates 3- and 4-extending stars, respectively. Chiang and Tan [8] developed an efficient method (Algorithm 1) to execute the comparison-based fault diagnosis based on a 4-extending star.

a 3-extending star \(\mathbb {ES}^{(3)}_{G}(o)\), b 4-extending star \(\mathbb {ES}^{(4)}_{G}(o)\), and c branching star \(\mathbb {BS}_{G}(o)\), where t=d e g G (o)

Theorem 3
[ 8 ] Let \(\mathbb {ES}^{(4)}_{G}(o)\) denote a 4-extending star. The algorithm \(\mathbf {FD}(\mathbb {ES}^{(4)}_{G}(o))\) (Algorithm 1) returns a correct status of the root o if \(\mathbb {ES}^{(4)}_{G}(o)\) contains at most d e g G (o) faulty vertices.
Unfortunately, Algorithm 1 is likely to make an incorrect decision if the number of faults in \(\phantom {\dot {i}\!}\mathbb {ES}^{(4)}_{G}(o)\) is greater than d e g G (o), as shown in the following examples.
Example 1
Suppose that the faulty nodes are distributed as those black nodes shown in Fig. 3, whereas white nodes are normal. Since o 1,j is now faulty for every 1≤j≤t, it makes an unreliable comparison. We assume that \(\phantom {\dot {i}\!}\gamma (\{o,o_{2,j}\}_{o_{1,j}})\) is 0 or 1 at random for each j. Because both o 2,j and o 3,j are normal for 1≤j≤t, they are able to make a correct comparison. Thus, we get \(\phantom {\dot {i}\!}\gamma (\{o_{1,j},o_{3,j}\}_{o_{2,j}})=1\) and \(\phantom {\dot {i}\!}\gamma (\{o_{2,j},o_{4,j}\}_{o_{3,j}})=0\) for each j. Accordingly, Algorithm 1 computes n 0=n 1=0 and returns 0 as output. That is, the algorithm identifies o as a normal node, which is an incorrect result.

A scenario that the algorithm \(\mathbf {FD}(\mathbb {ES}^{(4)}_{G}(o))\) (Algorithm 1) makes an incorrect decision, in which black and white nodes are faulty and normal, respectively
Example 2
Suppose that black nodes are faulty and white nodes are normal in Fig. 4. Under the comparison model, faulty nodes make an unreliable comparison. Therefore, Algorithm 1 still computes n 0=n 1=0 and returns 0 as output, which is an incorrect result.

A scenario that the algorithm \(\mathbf {FD}(\mathbb {ES}^{(4)}_{G}(o))\) (Algorithm 1) makes an incorrect decision, in which black and white nodes are faulty and normal, respectively
A branching star architecture with root o is denoted by \(\mathbb {BS}_{G}(o)\), which is a subgraph of G defined below:
-
\(V\left (\mathbb {BS}_{G}(o)\right)=\{o\}\cup \bigcup ^{t}_{k=1}\{o^{k},o^{k}_{1,1},o^{k}_{1,2},o^{k}_{2,1},o^{k}_{2,2},o^{k}_{3,1},o^{k}_{3,2}\}\).
-
\(E\left (\mathbb {BS}_{G}(o)\right) = \bigcup ^{t}_{k=1} \left \{ \{o, o^{k}\} \right \} \cup \left \{ \{o^{k}, o^{k}_{1,1}\},\{o^{k}, o^{k}_{1,2}\}\right \} \cup \left \{ \{o^{k}_{i,j},o^{k}_{i+1,j}\} \mid 1 \leq i,j \leq 2 \right \}\).
See Fig. 2 c for illustration.
To prove the next theorem, we need an additional term - vertex cover, which can be referred to in [5].
Theorem 4
Suppose that d e g G (o)≥2. Under the comparison model, o is restrictively one-step (d e g G (o)+1)-identifiable if there exists a branching star architecture with root o in G.
Proof
We assume that G contains a branching star \(\mathbb {BS}_{G}(o)\) with root o. Throughout this proof, F 1 and F 2 are two different restrictive fault sets satisfying the following conditions: (1) both F 1 and F 2 has at most t+1 elements, and (2) o is in F 1△F 2. By symmetry, we assume that o is in F 1. For the sake of convenience, let F denote the intersection of F 1 and F 2, and p denote the number of elements in F. Obviously, the value of p ranges from 0 to t. Both F 1 and F 2 are restrictive fault sets, so is their intersection F. Because o is not in F, we derive the following inequality: r=|F∩N h d G (o)|≤ min{p,t−1}. Without loss of generality, we can further make an assumption that o r+1,…,o t are normal; that is, {o i∣r+1≤i≤t}∩F=∅. Then, we consider the possibilities of r.
Case I: r=t−1. That is, we have {o 1,…,o t−1}⊆F. Because both F 1 and F 2 are restrictive fault sets, we obtain o t∉F 1∪F 2.
Subcase I.1: \(o^{t}_{1,1}\) or \(o^{t}_{1,2}\) is not in F 1∪F 2. Here we further make an assumption that \(o^{t}_{1,1} \not \in F_{1} \cup F_{2}\). See Fig. 5 a for illustration. Thus, it follows from Lemma 1 that F 1 is distinguishable from F 2, and vice versa.

Illustrating the proof of Theorem 4: a Subcase I.1; b Condition I.2.A; c Condition I.2.B; d Condition I.2.C; e & f Case II
Subcase I.2: Both \(o^{t}_{1,1}\) and \(o^{t}_{1,2}\) are in F 1∪F 2. We take into accounts the following three conditions.
Condition I.2.A: \(o^{t}_{1,1}\) or \(o^{t}_{1,2}\) is in F 1∖F 2. See Fig. 5 b, in which we assume \(o^{t}_{1,1} \in F_{1} \setminus F_{2}\). Consequently, it follows from Lemma 1 that F 1 and F 2 form a pair of distinguishable restrictive fault sets.
Condition I.2.B: Both \(o^{t}_{1,1}\) and \(o^{t}_{1,2}\) are in F 2∖F 1. See Fig. 5 c. By Lemma 1, F 1 and F 2 remain to form a pair of distinguishable restrictive fault sets.
Condition I.2.C: One of \(o^{t}_{1,1}\) and \(o^{t}_{1,2}\) is in F 2∖F 1, and the other is in F 1∩F 2. Without loss of generality, we assume \(o^{t}_{1,1} \in F_{2} \setminus F_{1}\). Then, \(o^{t}_{2,1}\) and \(o^{t}_{3,1}\) are not in F 1∪F 2. See Fig. 5 d. Again, it follows from Lemma 1 that F 1 and F 2 constitute a pair of distinguishable restrictive fault sets.
Case II: r≤t−2. Referring to the definition given in [5], a component in G is the maximal connected subgraph of G. Let C o be the component of \(\mathbb {BS}_{G}(o) - F\) that o belongs to. Thus, C o contains \(\{o\} \cup \bigcup ^{t}_{i=r+1}\{ o^{i} \} \cup \big \{ o^{i}_{1,1},o^{i}_{2,1},o^{i}_{3,1},o^{i}_{1,2},o^{i}_{2,2},o^{i}_{3,2} \big \} \setminus F\). It is straightforward to see that the cardinality of any vertex cover S of C o is at least [2(t−r)−(p−r)]+(t−r)+1=3t−2r−p+1 if S contains o. Comparing this number with the value of |F 1△F 2|≤2(t−p+1), we have (3t−2r−p+1)−(2t−2p+2)=t+p−2r−1≥(p−r)+1≥1. Hence, we get a fact that S has two nodes x,y that are adjacent and reside outside F 1△F 2. So, both x and y are not in F because C o is a component of \(\mathbb {BS}_{G}(o) \setminus F\)). Accordingly, there exists a path in C o connecting edge {x,y} and node o through F 1 or F 2 (see Fig. 5 e, f). Again, it follows from Lemma 1 that F 1 and F 2 form a pair of distinguishable restrictive fault sets.
In summary, o is restrictively one-step (t+1)-identifiable by Definition 3, and the proof is completed. □
On the basis of branching star architectures, we develop a localized fault diagnosis algorithm C F D (Algorithm 2) that can detect restrictive faults under the comparison model.

Theorem 5
Let \(\mathbb {BS}_{G}(o)\) denote a branching star with root o. Suppose that o is linked to a normal neighbor. Then, the proposed method \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) (Algorithm 2) returns a correct status of the root o if \(\mathbb {BS}_{G}(o)\) contains at most d e g G (o)+1 faulty vertices.
Proof
The proof proceeds using arguments of contradiction. Let t=d e g G (o). Suppose that \(\mathbb {BS}_{G}(o)\) contains at most t+1 faulty vertices and F denote the set of all faulty vertices.
If \(\gamma \big (\{ o^{k}_{1,p}, o^{k}_{3,p} \}_{o^{k}_{2,p}} \big) = 1\) for some k∈{1,2,…,t} and p∈{1,2}, then we assume, without loss of generality, \(\gamma (\{o^{1}_{1,2},o^{1}_{3,2}\}_{o^{1}_{2,2}})=1\). Then, at least one of \(o^{1}_{1,2}\), \(o^{1}_{2,2}\), and \(o^{1}_{3,2}\) is faulty. Thus, \(\mathbb {BS}_{G}(o) - \bigcup ^{t}_{i=1} \{o^{i}_{1,2},o^{i}_{2,2},o^{i}_{3,2}\}\), which is isomorphic to \(\mathbb {ES}^{(4)}_{G}(o)\), contains at most t faulty nodes. By Theorem 3, \(\mathbf {FD}(\mathbb {ES}^{(4)}_{G}(o))\) is able to identify the true status of o. Otherwise, we have \(\gamma \big (\{ o^{k}_{1,p}, o^{k}_{3,p} \}_{o^{k}_{2,p}} \big) = 0\) for all k∈{1,2,…,t} and p∈{1,2}.
For the sake of convenience, let n[∗][1]=t−n[0][0]−n[1][0].
Case 1: n[0][0]−n[1][0]≥0.
Subcase 1.1: n[0][0]−n[1][0]≥1 or n[0][0]=n[1][0]≥1. On the contrary, we assume that o is faulty. When \(\big (\gamma (\{o, o^{k}_{1,p}\}_{o^{k}}), \gamma (\{o^{k}, o^{k}_{2,p}\}_{o^{k}_{1,p}}), \gamma (\{o^{k}_{2,p}, o^{k}_{3,p}\}_{o^{k}_{2,p}}) \big) = (0,0,0)\) for some k∈{1,2,…,t} and p∈{1,2}, then all of o k, \(o^{k}_{1,p}\), and \(o^{k}_{2,p}\) are faulty. Thus, we derive the following inequality:
which is a contradiction against the assumption of |F|≤t+1. As a result, the status of o is normal.
Subcase 1.2: n[0][0]=n[1][0]=0. That is, it means \(\gamma (\{o^{k},o^{k}_{2,1}\}_{o^{k}_{1,1}})=\gamma (\{o^{k},o^{k}_{2,2}\}_{o^{k}_{1,2}})=1\) for every 1≤k≤t. We further make an assumption that the status of o t is normal. Obviously, the number of faulty nodes in \(\bigcup ^{t-1}_{k=1}\{o^{k},o^{k}_{1,1},o^{k}_{2,1},o^{k}_{1,2},o^{k}_{2,2}\}\) amounts to at least (t−1). Moreover, \(o^{t}_{1,1}\) or \(o^{t}_{2,1}\) is faulty; \(o^{t}_{1,2}\) or \(o^{t}_{2,2}\) is faulty. Thus, we can deduce that t+1≥|F|≥(t−1)+2=t+1, and the status of o must be normal.
Case 2: n[0][0]−n[1][0]≤−1.
Subcase 2.1: n[ 0][ 0]−n[ 1][ 0]≤ −2. On the contrary, we assume that o is normal. When \(\big (\gamma (\{o, o^{k}_{1,p}\}_{o^{k}}),\gamma (\{o^{k}, o^{k}_{2,p}\}_{o^{k}_{1,p}}), \gamma (\{o^{k}_{2,p}, o^{k}_{3,p}\}_{o^{k}_{2,p}}) \big) = (1,0,0)\) for some k∈{1,2,…,t} and p∈{1,2}, then both \(o^{k}_{1,p}\) and \(o^{k}_{2,p}\) are faulty. Thus, we get a contradiction as follows: |F|≥2n[1][0]+n[∗][1]≥(n[0][0]+2)+n[1][0]+n[∗][1]≥t+2.
Subcase 2.2: n[0][0]−n[1][0]=−1 and n[0][0]≥1. If o is normal, then we get a contradiction since |F|≥4n[1][0]+n[∗][1]=(n[0][0]+1)+3n[1][0]+n[∗][1]=t+1+2n[1][0]≥t+3. Hence, o must be faulty.
Subcase 2.3: n[0][0]=0 and n[1][0]=1. That is, there is exactly one integer k, 1≤k≤t, such that \(\big (\gamma (\{o,o^{k}_{1,1}\}_{o^{k}}), \gamma (\{o^{k},o^{k}_{2,1}\}_{o^{k}_{1,1}}) \big) = (1,0)\) or \(\big (\gamma (\{o,o^{k}_{1,2}\}_{o^{k}}), \gamma (\{o^{k},o^{k}_{2,2}\}_{o^{k}_{1,2}}) \big) = (1,0)\). We make the following assumption: \(\big (\gamma (\{o,o^{k}_{1,1}\}_{o^{k}}), \gamma (\{o^{k},o^{k}_{2,1}\}_{o^{k}_{1,1}}) \big) = (1,0)\). Then, we first claim that o k is normal. If not, then o k, \(o^{k}_{1,1}\), and \(o^{k}_{2,1}\) are all faulty so that |F|≥(t−1)+3=t+2, which is a straightforward contradiction violating the assumption of |F|≤t+1. We further claim that \(\gamma (\{o,o^{k}_{1,2}\}_{o^{k}})=1\). If not, then \(o^{k}_{1,1}\), \(o^{k}_{2,1}\), and \(o^{k}_{2,2}\) are all faulty so that |F|≥(t−1)+3=t+2. By contradiction, the claim holds. Since \(\gamma (\{o,o^{k}_{1,2}\}_{o^{k}})=1\), o has to be faulty. Suppose, by contradiction, that o is normal. Then \(o^{k}_{1,1}\), \(o^{k}_{2,1}\), \(o^{k}_{1,2}\), and \(o^{k}_{2,2}\) are all faulty and |F|≥(t−1)+4=t+3, which is an obvious contradiction violating the assumption of |F|≤t+1.
As a consequence, the algorithm \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) returns a correct status of o, provided that \(\mathbb {BS}_{G}(o)\) contains at most t+1 faulty vertices, and o is linked to a normal neighbor. □
The time complexity of \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) is analyzed below. We make an assumption that a comparator takes constant time differentiating responses from any two of its neighbors. Then, the time complexity of \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) is \(O(|V(\mathbb {BS}_{G}(o))|)\). Since \(|V(\mathbb {BS}_{G}(o))|=7deg_{G}(o)+1\), the time taken for determining the status of node o is O(d e g G (o)). We can apply this algorithm to every node in a WANET one after another. Let Δ denote the maximum degree of a WANET with underlying topology G. In general, the total time for identifying all nodes is O(N Δ), where N is the amount of nodes. In literature, Sengupta and Dahbura [25] first presented a diagnosis algorithm whose time complexity is O(N 5). Later, Yang and Tang [30] addressed a more efficient fault identification under the comparison model and developed an O(N Δ 3 δ) algorithm with respect to N-node networks, where δ is the minimum node degree. Compared with these previous results, our approach contributes a significant improvement.
4 Applications
This section presents some examples to show how \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) (Algorithm 2) does accomplish the fault detection. In the first example, suppose that
is a set of six faulty nodes in \(\mathbb {BS}_{G}(o)\). A possible syndrome set on \(\mathbb {BS}_{G}(o)\) is illustrated in Fig. 6 a. According to the decision flow (the leading if-else block) of \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\), since \(\gamma \big (\{ o^{1}_{1,2}, o^{1}_{3,2} \}_{o^{1}_{2,2}} \big) = \gamma \big (\{ o^{3}_{1,1}, o^{1}_{3,1} \}_{o^{3}_{2,1}} \big) = \gamma \big (\{ o^{5}_{1,1}, o^{5}_{3,1} \}_{o^{5}_{2,1}} \big) = 1\), it may run \(\mathbb {ES}^{(4)}_{G}(o) \leftarrow \mathbb {BS}_{G}(o) - \bigcup ^{5}_{i=1} \{o^{i}_{1,2},o^{i}_{2,2},o^{i}_{3,2}\}\), as illustrated in Fig. 6 b. According to the decision flow of \(\mathbf {FD}(\mathbb {ES}^{(4)}_{G}(o))\) (Algorithm 1), \(\mathbf {FD}(\mathbb {ES}^{(4)}_{G}(o))=1\) is returned since n 0=0<2=n 1; that is, o is a faulty node.

a A syndrome set on \(\mathbb {BS}_{G}(o)\) and b the remaining syndromes on \(\mathbb {ES}^{(4)}_{G}(o)\), in which black and white nodes are faulty and normal, respectively, and the number next to each node is the comparison result
In the second example, suppose that
is a set of six faulty nodes in \(\mathbb {BS}_{G}(o)\). A possible syndrome set on \(\mathbb {BS}_{G}(o)\) is illustrated in Fig. 7 a. According to the decision flow (the leading if-else block) of \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\), since \(\gamma \big (\{ o^{k}_{1,p}, o^{k}_{3,p} \}_{o^{k}_{2,p}} \big) = 0\) for every 1≤k≤5 and p∈{1,2}, it runs the else-block and computes n[0][0]=3 and n[1][0]=0. Consequently, \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) returns 0 since n[0][0]−n[1][0]≤0; that is, o is a normal node.

Two syndrome sets on \(\mathbb {BS}_{G}(o)\), in which black and white nodes are faulty and normal, respectively, and the number next to each node is the comparison result: a The syndrome set consistent with F 2, and b the syndrome set consistent with F 3
In the third example, suppose that
is a set of six faulty nodes in \(\mathbb {BS}_{G}(o)\). A possible syndrome set on \(\mathbb {BS}_{G}(o)\) is illustrated in Fig. 7 b. Since \(\gamma \left (\{ o^{k}_{1,p}, o^{k}_{3,p} \}_{o^{k}_{2,p}} \right) = 0\) for every 1≤k≤5 and p∈{1,2}, it runs the else-block and computes n[0][0]=1 and n[1][0]=2. Accordingly, \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) returns 1 since n[0][0]−n[1][0]<0. That is, o is a faulty node.
The proposed algorithm is also capable of identifying faults in some static network structures including two of the most popular ones, hypercubes and star-graph networks. These two networks have been approved for their promising topological properties. To apply the proposed algorithm, it suffices to show that branching star architectures can be embedded into them.
Lai [19] developed an O(n)-time procedure for creating 4-extending stars within an n-dimensional bijective connection graph B C n , n≥5. One important instance of B C n is surely the n-dimensional hypercube Q n [10]. Below, we show how to build branching star architectures in the hypercube: A unique n-bit binary string is assigned to each node of Q n . An edge links two nodes in Q n if and only if they differ at one and only one position. When two nodes differ at ith bit with i∈{1,2,…,n}, the edge linking these two nodes is called an (i)-edge. Figure 8 is a systematic framework to obtain branching star architectures in Q n .

a A branching star architecture with root 000000 in Q 6; b a branching star architecture in Q n for n≥6
For n≥3, S G n stands for the star-graph network that has the set of all permutations over {1,2,…,n} to form its vertex set [1]. In S G n , each vertex is labeled by an individual permutation x 1 x 2…x n and is linked to the other (n−1) vertices x i x 2…x i−1 x 1 x i+1…x n for every 2≤i≤n. The edge linking vertices x 1 x 2…x n and x i x 2…x i−1 x 1 x i+1…x n is an (i)-edge. Figure 9 depicts an instance of branching star architecture in S G n for any n≥5.

a A branching star architecture in S G n for n≥5; b a branching star architecture with root 12345 in S G 5
5 Conclusions
Among various networking technologies, the WANET is critical for creating high-performance ubiquitous computing systems. A WANET is a kind of wireless network in which some nodes are self-organized in a wireless local area network. Node mobility is the most important property for WANETs. According to Grossglauser and Tse [11], mobility can increase the capacity of a WANET. Due to the undecided number of nodes even during a short duration, main difficulties of maintaining a WANET result from the properties of node mobility and frequent node failure. In this paper, a comparison-based approach to system-level fault detection is addressed, and accordingly, we developed a localized fault detection algorithm for WANETs. The contributions are highlighted as follows:
-
1.
A localized fault detection algorithm, \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\), is proposed for strongly t-diagnosable WANETs under the comparison model.
-
2.
The proposed algorithm is formally proved to assure its validity.
-
3.
The algorithm \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) incurs only linear time complexity, which is relatively efficient compared to some others in literature.
-
4.
Examples are presented to clarify how \(\mathbf {CFD}(\mathbb {BS}_{G}(o))\) does accomplish the comparison-based fault detection.
References
SB Akers, B Krishnamurthy, A group-theoretic model for symmetric interconnection networks. IEEE Trans. Comput. 38(4), 555–566 (1989).
I Ambika, V Pillai Sadasivam, P Eswaran, An effective queuing architecture for elastic and inelastic traffic with different dropping precedence in MANET. EURASIP J. Wirel. Commun. Netw. 2014:, 155 (2014).
M Barbeau, E Kranakis, Principles of ad hoc networking (Wiley, New York, 2007).
F Barsi, F Grandoni, P Maestrini, A theory of diagnosability of digital systems. IEEE Trans. Comput. 25(6), 585–593 (1976).
G Chartrand, OR Ollermann, Applied and algorithmic graph theory (McGraw-Hill, New York, 1993).
C-A Chen, S-Y Hsieh, (t,k)-Diagnosis for component composition graphs under the MM* model. IEEE Trans. Comput. 60(12), 1704–1717 (2011).
H-C Chen, TCABRP: A trust-based cooperation authentication bit-map routing protocol against insider security threats in wireless ad hoc networks. IEEE Syst. J (2015). doi:http://dx.doi.org/10.1109/JSYST.2015.2437285.
C-F Chiang, JJM Tan, Using node diagnosability to determine t-diagnosability under the comparison diagnosis model. IEEE Trans. Comput. 58(1), 251–259 (2009).
F-T Chien, K-G Wu, Y-W Chan, M-K Chang, Y-S Su, An effective routing protocol with guaranteed route preference for mobile ad hoc networks. Int. J. Distrib. Sens. Netw. 2014(532049), 2014 (2014). doi:http://dx.doi.org/10.1155/2014/532049.
J Fan, L He, BC Interconnection networks and their properties. Chin. J. Comput. 26(1), 84–90 (2003).
M Grossglauser, DNC Tse, Mobility increases the capacity of ad hoc wireless networks. IEEE/ACM Trans. Netw. 10(4), 477–486 (2002).
S-Y Hsieh, Y-S Chen, Strongly diagnosable product networks under the comparison diagnosis model. IEEE Trans. Comput. 57(6), 721–732 (2008).
S-Y Hsieh, Y-S Chen, Strongly diagnosable systems under the comparison diagnosis model. IEEE Trans. Comput. 57(12), 1720–1725 (2008).
S-Y Hsieh, C-W Lee, Diagnosability of two-matching composition networks under the MM* model. IEEE Trans. Dependable Secure Comput. 8(2), 246–255 (2011).
G-H Hsu, C-F Chiang, L-M Shih, L-H Hsu, JJM Tan, Conditional diagnosability of hypercubes under the comparison diagnosis model. J. Syst. Archit. 55(2), 140–146 (2009).
J Kumar, A Kathirvel, N Kirubakaran, P Sivaraman, M Subramaniam, A unified approach for detecting and eliminating selfish nodes in MANETs using TBUT. EURASIP J. Wirel. Commun. Netw. 2015:, 143 (2015).
T-L Kung, H-C Chen, Toward the fault identification method for diagnosing strongly t-diagnosable systems under the PMC model. Int. J. Commun. Netw. Distrib. Syst. 15(4), 386–399 (2015).
T-L Kung, H-C Chen, L-H Hsu, in Proc. 2015 International Congress on Natural Sciences and Engineering (2015 ICNSE), Kyoto, Japan, May 7–9 2015, Higher Education Forum (HEF). A topological condition for recognizing strongly diagnosable systems under the comparison model, (2015), pp. 314–319.
P-L Lai, A systematic algorithm for identifying faults on hypercube-like networks under the comparison model. IEEE Trans. Reliab. 61(2), 452–459 (2012).
P-L Lai, JJM Tan, C-P Chang, L-H Hsu, Conditional diagnosability measures for large multiprocessor systems. IEEE Trans. Comput. 54(2), 165–175 (2005).
J Maeng, M Malek, in Proc.11th Int. Symp. Fault-Tolerant Comput. (FTCS’81), Portland, USA, June 24-26, 1981, IEEE CS. A comparison connection assignment for self-diagnosis of multiprocessors systems, (1981), pp. 173–175.
S Palaniappan, K Chellan, Energy-efficient stable routing using QoS monitoring agents in MANET. EURASIP J. Wirel. Commun. Netw. 2015:, 13 (2015).
FP Preparata, G Metze, RT Chien, On the connection assignment problem of diagnosis systems. IEEE Trans. Electron. Comput. 16(12), 848–854 (1967).
N Renugadevi, C Mala, Improved group key agreement for emergency cognitive radio mobile ad hoc networks. J. Wirel. Mob. Netw. Ubiquit. Comput. Dependable Appl.6(3), 73–86 (2015).
A Sengupta, A Dahbura, On self-diagnosable multiprocessor systems: diagnosis by the comparison approach. IEEE Trans. Comput. 41(11), 1386–1396 (1992).
V Sharma, R Kumar, N Rathore, Topological broadcasting using parameter sensitivity-based logical proximity graphs in coordinated ground-flying ad hoc networks. J. Wirel. Mob. Netw. Ubiquit. Comput. Dependable Appl. 6(3), 54–72 (2015).
S Subramaniyan, W Johnson, K Subramaniyan, A distributed framework for detecting selfish nodes in MANET using record- and trust-based detection (RTBD) technique. EURASIP J. Wirel. Commun. Netw. 2014:, 205 (2014).
W Xiong, J Xu, Y Li, N Zhao, X Wan, J Liang, Minimum node degree of k-connected vehicular ad hoc networks in highway scenarios. EURASIP J. Wirel. Commun. Netw. 2016:, 32 (2016).
M-C Yang, Conditional diagnosability of matching composition networks under the MM* model. Inf. Sci. 233:, 230–243 (2013).
X Yang, YY Tang, Efficient fault identification of diagnosable systems under the comparison model. IEEE Trans. Comput. 56(12), 1612–1618 (2007).
XM Zhang, Y Zhang, F Yan, AV Vasilakos, Interference-based topology control algorithm for delay-constrained mobile ad hoc networks. IEEE Trans. Mob. Comput. 14(4), 742–754 (2015).
Q Zhu, G Guo, D Wang, Relating diagnosability, strong diagnosability and conditional diagnosability of strong networks. IEEE Trans. Comput. 63(7), 1847–1851 (2014).
Acknowledgements
The authors would like to thank the anonymous referees and the editors for their thorough review. The suggested comments help us improve the present manuscript significantly. In particular, our gratitude also goes to Prof. Michael Burton, Asia University, for his effort into language editing. This work is supported in part by the Ministry of Science and Technology, Taiwan, Republic of China, under Grants MOST 104-2221-E-468-002 and MOST 104-2221-E-468-003.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kung, TL., Teng, YH., Lin, CK. et al. A localized fault detection algorithm for mobility management in the strongly t-diagnosable wireless ad hoc network under the comparison model. J Wireless Com Network 2016, 218 (2016). https://doi.org/10.1186/s13638-016-0714-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13638-016-0714-1