
Abstract
One of the most challenging tasks of modern battery management systems is the accurate state of health estimation. While physico-chemical models are accurate, they have high computational cost. Neural networks lack physical interpretability but are efficient. Physics-informed neural networks tackle the aforementioned shortcomings by combining the efficiency of neural networks with the accuracy of physico-chemical models. A physics-informed neural network is developed and evaluated against three different datasets: A pseudo-two-dimensional Newman model generates data at various state of health points. This dataset is fused with experimental data from laboratory measurements and vehicle field data to train a neural network in which it exploits correlation from internal modeled states to the measurable state of health. The resulting physics-informed neural network performs best with the synthetic dataset and achieves a root mean squared error below 2% at estimating the state of health. The root mean squared error stays within 3% for laboratory test data, with the lowest error observed for constant current discharge samples. The physics-informed neural network outperforms several other purely data-driven methods and proves its advantage. The inclusion of physico-chemical information from simulation increases accuracy and further enables broader application ranges.
Export citation and abstract BibTeX RIS

This is an open access article distributed under the terms of the Creative Commons Attribution 4.0 License (CC BY, http://creativecommons.org/licenses/by/4.0/), which permits unrestricted reuse of the work in any medium, provided the original work is properly cited.
The transport sector is responsible for nearly a quarter of the global carbon emissions. 1 The transition to climate friendly mobility is heavily dependent on electric vehicles (EVs) and thus the development and production of lithium-ion batterys (LiBs). While the battery market size has doubled from 2014 to 2019, 2 the development of efficient and highly accurate battery management systems (BMSs) remains a challenge. The BMS monitors and controls the high-voltage storage systems by measuring signals like current, voltage and temperature, in order to estimate the state of charge (SOC) and the state of health (SOH). Accurate state estimation is mandatory to enable long and safe operation. 3 New cell chemistries and more sophisticated systems aggravate the development of universal methods.
This paper refers to the SOH in terms of capacity, i.e., SOHC = C/Cinit. The current capacity is C and Cinit is the initial capacity, which is a measured value at begin-of-life (BOL). This value is usually higher than the nominal capacity CN, issued by the manufacturer. In the case of synthetic data, Cinit is equal to CN. In literature several error metrics can be found to evaluate the accuracy of estimation models, e.g., root mean squared error (RMSE) and mean absolute error (MAE). The necessary definitions are listed in the Appendix, Table XI. Various SOH estimation models exist and can be roughly clustered into physics-based (PB), semi-empirical and data-driven methods. A brief summary of recent implementations and their SOH estimation accuracy is listed in Table I. PB models catch the underlying physical and chemical mechanisms of LiBs. In most cases they are defined as a set of partial differential equations (PDEs) or ordinary differential equations (ODEs). The pseudo-2-dimensional (P2D) model by Doyle, Fuller and Newman is the common way to model a battery with focus on its mass transport and thermodynamics. 4 A detailed description of the P2D model can be found in the Appendix. The model has physico-chemical interpretability, but the numerical solving of the PDEs is computationally cumbersome. The model itself is not capable to describe aging effects. Furthermore the parameter sets of PB models are snapshots of the current degradation state, i.e., the SOH. 4 The implementation of degradation mechanisms into the model architecture leads to further complexity increase. It is nearly impossible to fully describe these numerous mechanisms in mathematical expressions. Reduced P2D models coupled with filter algorithms are often found in SOH estimation methods because they decrease the computational cost heavily. 5–9 The widely used reduced order single particle model (SPM) assumes an uniformly distributed current density along the porous electrode thickness and thus simplifies the P2D model to one single particle per electrode. 9–11 This assumption reduces the amount of PDEs and hence the computational complexity. 11 Different to the P2D model, the SPM neglects the dynamics in the liquid phase and hence fails to fully describe the mass transport in the electrolyte. 12 Recentpublications 5,7–9,13,14 frequently assume solid electrolyte interface (SEI) growth as the dominant degradation mechanism and couple the SPM with adaptive filter algorithms to yield SOH estimation models. For example, Allam and Onori 5 have developed such a model. The SEI growth is implemented into an aging-dependent voltage loss equation in which the relevant degradation parameters are updated via a sliding mode interconnected observer. The parameter update is achieved by fitting the simulated voltage to the measured signal. The updated parameters are directly linked to capacity fade. The model showed high robustness against measurement noise and reached a mean absolute percentage error (MAPE) of 0.92% for a new and 1.65% for an aged cell. 5 Gao et al. 7 introduced a simplified P2D model with integrated degradation modes, 15 i.e., loss of lithium inventory (LLI), loss of active material (LAM) and resistance rise. The internal parameters are updated by comparing measured and calculated voltage responses. The adaptation is directly linked to the SOC and SOH. For constant temperature the method reached a MAE below 1%. 7 Similar, Zhao et al. 9 or Gambhire et al. 8 presented PB reduced order models which achieved MAE below 2% and 1% for constant ambient temperature.
Table I. Recent realizations of PB models and NNs with their SOH estimation accuracy. If not stated otherwise, the datasets were captured on cell level.
| Method | Dataset | Limitation/Remark | Accuracy | References |
|---|---|---|---|---|
| SPM with sliding mode interconnected observer | Experimental dataset with two capacity measurements | — | 1.65% RMSE | 5 |
| Simplified P2D model with integrated degradation modes | Experimental dataset with 21 capacity measurements | Constant temperature | 1% MAE | 7 |
| PB reduced order model | Experimental cyclic aging data | Constant temperature (25, 40, 55 °C) | 2% MAE | 9 |
| PB reduced order model | Experimental cyclic and calendaric aging data | Constant temperature (25, 45 °C) | 1% MAE | 8 |
| LSTM NN | Oxford Battery Degradation dataset | CC charging voltage curves at constant temperature | 0.5% RMSE | 20 |
| LSTM NN | Experimental cyclic aging cell data | CC charging voltage curves at 25 °C | 2.08% RMSE | 21 |
| LSTM NN | NASA Battery Degradation dataset | CC charging voltage, current and temperature curves at temperature from 20 °C to 30 °C | 2.5% RMSE | 22 |
| FNN | Experimental cyclic and calendaric aging data | Only applicable to narrow temperature window (25 °C to 35 °C) | 0.9% RMSE | 23 |
| CNN–FNN | Real-world data from 40 EV buses | Long CC charging windows at low currents mandatory to reach high accuracy | 2.79% RMSE | 25 |
Whereas PB models integrate the underlying electrochemical mechanisms into the architecture, data-driven or machine learning (ML) models are black boxes with a learned mapping from measurable to immeasurable variables. The performance relies on the input training dataset and the user-defined model architecture. A requirement is an existing correlation between input and output. It is simple to set up a data-driven approach for SOC or SOH estimation but very challenging to reach generalization. In the context of ML generalization means that test data is different from training data, i.e., a method works for unknown data in new scenarios. 16 From 2018 to 2022 most of the publications dealing with data-driven state estimation utilize support vector machines (SVMs) or neural networks (NNs). 17 Especially long-short-term memory networks (LSTMs), first introduced by Hochreiter and Schmidhuber, 18 are in the focus because they are the most efficient and widely used sequential networks in the field. 17–19 For example, Gong et al. 20 published a combined SOC and SOH estimation model that uses unprocessed charging voltage curves as input. For the Oxford Battery Degradation dataset the LSTM model reached a RMSE below 0.5% and a maximum absolute error (MAX) below 1% at constant temperature. Similar, Li et al. 21 developed a LSTM model which uses unprocessed voltage charging curves as input and reached a MAPE below 2.08% at constant temperature of 25 °C. Choi et al. 22 have demonstrated up to absolute 3.57% RMSE reduction by utilizing a combined dataset from voltage, current and temperature. In a temperature range from 20 °C to 30 °C the LSTM model achieved a RMSE below 2.5% for the NASA Battery dataset. Rahimian et al. 23 showed a SOH estimation RMSE below 0.9% when training a feedforward neural network (FNN) with partial voltage, current and temperature data from automotive cells.
A more recent publication by She et al. 24 combined multiple equivalent circuit modelss (ECMs) on cell level with incremental capacity analysis (ICA) to build a full battery storage SOH estimation model. By utilizing the features gathered from ICA and a subsequent update of the battery parameters, the model estimated the SOH of an EV fleet with a RMSE of 2.04%. Similar, Wang et al. 25 combined health-indicating features gathered from coulomb-counting and ICA to inform a hybrid deep NN. The combined convolutional neural network (CNN) and FNN reached a SOH MAE of 2.79% for an EV bus fleet. More information about recent SOH estimation models can be drawn from recent review papers, e.g., by Yang et al. 26
Aykol et al. 27 first recognized the potential of the physics-informed neural network (PINN) for SOH estimation in 2021. While PB models require high computational effort, ML models lack physical interpretability. The fusion of both models is promising to eliminate the respective disadvantage and rather strengthen the benefits.
As Fig. 1 shows, Aykol 27 extended the possible model architectures to sequential and hybrid PINNs. Strongly related to PINNs, and often falsely described as such, is physics-informed machine learning (PIML). These methods utilize other ML approaches like a SVM or Gaussian process regression (GPR). Sequential PINNs are generable with existing PB and ML models. The sequential residual learning approach S1 from Fig. 1 feeds the output of a PB degradation model into a ML update model. The ML model learns the residual between the PB model estimation SOHPB and the true label SOHtrue. The learned residual is used to update the estimation and minimize the error. While the PB model captures basic aging effects, the ML model is promising to learn more complex degradation mechanisms. The output SOHest is partially constrained by physics but the application is still limited by the complexity of the PB model and its implemented degradation mechanisms. 27

Figure 1. PINN architecture model landscape for SOH estimation (adapted from Aykol et al. 27 ). In architecture S1, S3 and H2 it is assumed that the PB model has degradation mechanisms implemented and is thus able to estimate the SOH. X(t) can be any time-series battery data used to perform the SOH estimation, Xmeas can be any experimental battery data including time-series data, {X} describes the necessary input data including battery parameters for the PB model, ϑ are the battery parameters and yPB can be any output from a PB model.
Download figure:
Standard image High-resolution imageThe transfer learning approach S2 tackles this limitation by running the complex PB model temporally decoupled with arbitrary input data {X} . The output data yPB includes internal battery states such as concentrations and potentials. This data is combined with experimental data Xmeas to train the ML model. During operation, time-series data X(t) can be used to estimate the SOHest with low computational cost and physical constraints. The final PINN does not depend on the complexity of the PB model and is prospective to learn the hidden physics of battery degradation. 27 Relatively few publications exist on sequential PINN or PIML for SOH estimation. Thelen et al. 28 researched the sequential PINN approaches S1 and S2 in two subsequent studies. 28,29 The first transfer learning PINN (S2) was trained to co-estimate the SOH and the primary degradation mode, LAM and LLI, by fusing experimental data with simulated data from a half-cell model. Both datasets were captured at two temperatures and current rates. The half-cell model output the open-circuit-potential (OCP) curves of both electrodes which can be used to reconstruct the open-circuit-voltage (OCV) of the full cell. Finally a differential voltage analysis (DVA) determines the degradation mode. These features were used to train a single hidden layer NN to estimate the SOH and degradation modes. The advantages of the data fusion was confirmed by a comparison to models trained solely with one input dataset. The combined training dataset lead to best performance with a RMSE of 0.74% for SOH and 2.85% for degradation mode estimation. In the consecutive study 29 the first approach was compared to the residual learning approach S1 with almost identical settings. The residual learning approach performed worse with an average RMSE of 2.35% for SOH and 5.09% for degradation mode estimation. Similarly, Kohtz et al. 30 developed a transfer learning PIML with three subsequent steps. SEI-growth was implemented as the major degradation mechanism in the initial PB model to describe capacity loss. It must be noted that SEI growth is yet not fully understood and building accurate models is an ongoing research question. 31 A succeeding GPR was trained to map partial charging voltage, current and temperature curves to SEI-layer thickness. The final multi-fidelity look-up table directly correlated the SEI-thickness with capacity, accepting an initial 1.5% error. Training data consisted of charging curves at 0.2, 0.33, 0.5, 1, 2C and 25, 35, 45 °C, while validation was carried out by samples at 1.5C, 30 °C and avarying duration of 150 s to 400 s. Assuming the exclusion of errors in the upper regions of the SOH, the RMSE of the estimated SEI thickness was found to be 8.97%.
The identification of physico-chemical battery parameters is a well discussed research topic. 27,32,33 First, more information about the influence of degradation on these parameters is necessary in order to implement validated parameter learning PINNs (S3). This approach uses a prior ML model to learn the parameter set of a battery over its lifetime and eventually update the PB model with an accurate parameter set. The PB model uses this information to solve for the internal states and SOHest. Reduced PB models are necessary to reach online applicability. 27 To the best of the authors knowledge, Li et al. 33 were the first to realize a parameter identification ML model. The model estimated degradation dependent PB parameters from voltage and current signals at a constant temperature of 25 °C with a MAPE of 12.5%.
The hybrid PINN approaches integrate one model into the other architecture. Physics-constrained ML (H1) implements PB elements in the ML model, e.g., in the loss function during training. There is optimism to physically constrain the output by following physico-chemical laws. 27 Nascimento et al. contributed with several publications 34–36 to the field of hybrid PINN for SOC estimation and remaining useful life (RUL) prediction. In their studies, they implemented physis-based knowledge into deep NN, for example by embedding it into recurrent neural network (RNN) cells, to simulate the time-dependent response of a battery to applied current. 36
The ML-accelerated PB models (H2) are the original implementation of PINN, first introduced by Raissi et al. 37 Hence in other research areas these models are only referred to as PINNs. The approximation ability of NNs is exploited to solve the underlying PDEs of PB models with less computational burden. Due to the relation of the internal state lithium-ion concentration to the SOC, more H2 PINNs are already developed for SOC estimation. 38 In contrast, the urgency to integrate degradation mechanisms into PB models still limits the application of accurate ML-accelerated PB models for SOH estimation. 27 Pepe et al. 39 introduced a NN which solves the underlying differential equations of a PB system. For training with the NASA and Oxford Battery dataset, the PINN reached an SOH RMSE of 5.81% and 1.55%, respectively. The data was limited to a narrow current and temperature region. Thus, challenges remain to develop accurate, generalizable, ML-accelerated PB models. Recently, Xu et al. 40 set the benchmark for hybrid battery models by publishing a physics-informed deed autoencoder with an SOH RMSE of 0.64%. Similar, Wen et al. 41 proved the ability of NNs to approximate the underlying PDEs of a Verhulst model in order to estimate the SOH and predict the RUL.
While available PINNs show promising results for internal state estimation, 42–45 few publications exist on accurate, robust and generalizable SOH estimation. Especially, there are no studies utilizing these aforementioned immeasurable internal states, such as concentrations and potentials. To the best of the authors knowledge, this is the first publication to develop a transfer learning PINN which fuses experimental data from in-vehicle and laboratory sources with simulation data (including internal states), generated by a P2D model. The developed model fuses data with different dimensions from a broad operational region with a variety of load profiles and charging strategies, including temperatures from 0 °C to 50 °C and currents from −2.5C to 2.5C. The benefit of including synthetic data and especially immeasurable internal states is discussed in detail. The proposed method is further analyzed in regards of its sensitivity to current profiles and temperature and finally benchmarked to purely data-driven models.
Experimental
The outline of the proposed method is illustrated in Fig. 2. For this work a Newman-P2D model is used to generate data which is merged with experimental data. The combined dataset is randomly split into training and testing data.

Figure 2. General approach with subsequent work tasks. Data is collected from simulation and measurement sources and a PINN for SOH estimation is developed.
Download figure:
Standard image High-resolution imageThe initial model is selected based on a literature research and optimized with additional features. The best features are chosen based on the results of a correlation and sensitivity analysis. The NN is finetuned in accordance to the results of a Bayes hyperparameter tuning approach.
Data generation
The simulation of cell internal states over lifetime demands a parameter set, which represents the cell in its aged state. For the investigated cell 16 parameter sets at SOHs ranging from 73% to 100% are developed and validated against laboratory measurements. Table XV in the Appendix offers a more detailed description of the parameter set and the dependencies of single parameters on degradation. Further, a resimulation of the measurement profiles (Fig. 12 in the Appendix) yields an acceptable voltage MAE below 35 mV, even for degraded batteries. Nevertheless, it is crucial to remember that selecting correct parameters is still an open research question. Although the simulated voltage and temperature signals fit the true measurements, it cannot be proven that every physical and electrochemical parameter is correct.
The simulation dataset includes charging events, dynamic driving profiles and check-up tests. Figure 3 summarizes the simulated drive cycles together with the experimental current profiles.

Figure 3. Current profiles of the simulated and measured dataset. For the dynamic profiles DST-3, FUDS-1, US06-2, pulse profile and the in-vehicle measurement just a snippet of the full profile is displayed.
Download figure:
Standard image High-resolution imageThe laboratory data was captured with a battery cycler in a climate chamber at 25 °C. Prior to testing, the cells were acclimatized and set to a default SOC of 50%. The laboratory measurements (Fig. 3i) refer to a predefined check-up-profile with four alternating C/3 charge and discharge sections which are applied within voltage limits. The constant current (CC) charging profiles are followed by a constant voltage (CV) section until the remaining cell current reaches a predefined threshold. The laboratory tests do not include dynamic load profiles. In total almost 150 d of time-series data from laboratory check-ups are used in the proposed method.
The in-vehicle data was collected from a development fleet with 18 EVs in Germany. A mobile data recorder directly accesses and stores the measured signals by the BMS. The recorder collects the signals during driving and charging and checks the SOH of the battery storage before and after the trip. The in-vehicle data (Fig. 3j) consists of dynamic driving profiles and charging sections. An in-vehicle profile is shown in Fig. 3j, as an example of a dynamic driving sample. In total nine days of in-vehicle time series data are available in the dataset. It must be noted that respective SOH labels of the in-vehicle dataset are generated at a test bench with similar measurements as in the laboratory dataset. Hence, the SOH represents the available capacity during a constant current (CC) C/3 discharge.
The simulation covers multi-step constant current (MSCC) fast charge events. Figure 3a illustrates a MSCC profile for a pristine cell at 25 °C. Two out of three sections from the dynamic stress test (DST) are included in the simulation (Figs. 3b and 3c). Similarly one section of the federal urban driving schedule (FUDS, Fig. 3d) and one section of the high acceleration aggressive driving cycle (US06, Fig. 3e) are simulated. The DST, FUDS and US06 are based on public driving profiles which are available at the website of the University of Maryland. 46,47 The 1C CC discharging (Fig. 3f) generally accounts for low current discharging. The pulse profile (Fig. 3g) is a three times repeated test with a 1C discharge section and alternating pulses with 1C, 2C and 2.5C. The step profile (Fig. 3h) includes short CC charge and discharge sections with C/3, 2C/3 and 1C.
Further, Table II displays the simulation profiles, their duration and the varied start SOC and temperature. Some settings must be excluded due to exceeding of safety limits, i.e., minimum or maximum cell voltage or temperature. The simulations run with a time-step resolution of 5 s as a tradeoff between runtime and accuracy. In total almost 7000 simulations with a duration of 250 d are performed.
Table II. Test matrix for the data generation process with the simulated starting SOC, ambient temperature and duration of the drive cycle.
| Start SOC | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | Duration |
|---|---|---|---|---|---|---|---|---|---|---|
| DST-1 a | x | x | x | x | x |

| ||||
| DST-3 a | x | x | x | x | x | x | x | x |

| |
| FUDS-1 a | x | x |

| |||||||
| US06-2 a | x | x | x | x |

| |||||
| CC 1C a | x | x |

| |||||||
| Pulses a | x | x |

| |||||||
| Steps a | x | x | x |

| ||||||
| Fast Charge b | x | x | x | x | x |

|
aSimulation at 0 °C, 15 °C, 25 °C, 35 °C, 45 °C. bSimulation at 0 °C, 15 °C, 25 °C, 35 °C.
Figure 4 illustrates the data distribution of 1000 random samples from the full data. All datasets inhibit the full and evenly distributed voltage range, which directly correlates to the SOC. While the simulation data is evenly distributed along temperature, current and SOH, the laboratory data is mainly captured at 25 °C and current rates of −C/3 and C/3. The synthetic dataset is distributed at temperatures from 0 °C to 50 °C because the used P2D model was validated for this cell with these boundaries. Nevertheless, it is realistic to apply the method only to data captured at battery temperatures above 0 °C due to preconditioning of the battery pack before operation or charging. The intelligent, anticipating preconditioning–function results in a relatively low probability of operating the battery pack at sub–zero temperature. The in-vehicle measurements include a broader temperature region due to seasonal and daily variety in Germany. Unfortunately, the data is mainly distributed around 100% SOH, even including SOH values above 100%. While the synthetic dataset inhibits highly dynamic driving profiles and thus covers a current range from −2.5C up to 2.5C, the experimental dataset is mainly distributed at low current rates between −C/3 and C/3. For the laboratory cell dataset this is due to the check up profile in Fig. 3i, which refers to a standardized test protocol. Unfortunately, no dynamic driving profiles are available from laboratory cell measurements. On the other side, the in-vehicle dataset reflects real-world driving and charging behavior from our development fleet. Hence, lower current rates show realistic operational strategies. As can be seen in Fig. 4 more than 50% of the in-vehicle data are dynamic load profiles.

Figure 4. Visualization of the three datasets for 1000 random samples. The upper figures show the scatter plot and the lower figures visualize the kernel densities. Both refer to the first y-axis on the left. The second y-axis on the right side refers to the cumulative distribution plots in the diagonal, in golden color. While most of the simulation data is uniformly distributed, laboratory and in-vehicle measurements are mainly captured at fixed temperature and current operating points.
Download figure:
Standard image High-resolution imageThe simulation data has the lowest sampling rate, with one signal per five seconds, and consequently sets the reference. Higher sampling rates increase the computational effort for the P2D data generation heavily. Due to the low frequency, the fast effects during a change in charge direction are not discernible in the signal trajectory. Nevertheless, effects with longer time-constants give enough information about the degradation state to estimate the SOH. This issue is discussed in more depth in the Results and Discussion section. The combined dataset includes over 409 d of time-series including voltage, current, temperature and SOH. Simulation data further includes SOC and internal states, i.e., concentration and potential of the solid and liquid phase.
The full, combined dataset runs through a preprocessing scheme before it is used for model development. First, every signal is normalized to a range between zero and one. This has been shown to be optimal for NN training because it speeds up training and can improve performance. 48 The data is split into 70% of training and 30% of testing data which differ in the SOH label to avoid overfitting. The data split is applied to the simulation, laboratory and in-vehicle dataset. The chosen SOH values are selected randomly at the beginning for every subdataset. The data split, however, is kept during the whole model development process to ensure comparability throughout the development process. Hence, the data split ensures that subsamples from the same source and SOH belong to either the training or testing dataset.
Model optimization
A transfer learning PINN runs the complex PB model simulations temporally decoupled 27 as in Fig. 1 S2. The output data, which includes internal battery states is fused with experimental data and processed in a NN. The final transfer learning PINN inhibits physico-chemical information from battery internal states and reduces the complexity in the application phase to that of the ML model. It is therefore crucial to design an efficient and accurate NN.
Recent publications 17,21 suggest the usage of LSTM networks, a specialized RNN, for processing time-series data and SOH estimation. A promising approach from Li et al. 21 is taken as the initial model and adopted to suit the database. The model complexity is reduced in order to start with a more basic approach. The LSTM takes the three input signals current, voltage and temperature, sampled to 300 s with a time step of 5 s. The sampling routine is further optimized by using 50% sliding windows to increase the amount of data. For example, a full signal of 900 s length leads to five samples with 300 s duration instead of three.
Unfortunately, sampling also generates useless samples that, for example, have no current flow and no subsiding overpotentials, and thus no information. An outlier removal script excludes these samples. Nevertheless, samples with a short duration of applied current are included in the dataset on purpose. These samples are not associated as outliers but rather as data anomalies and hence are important elements of the training data. 49 Prior investigation proves the positive influence of the natural regularization effect of these data anomalies. Indeed, the removing of all these anomalies yields a local optimum where the model overfits on the simulation data and underfits on experimental data.
The model processes the input data with three dimensions, i.e.,  through three LSTM layers with each 50, 50 and three memory cells, a reshape layer and a dense layer with one neuron to the final scalar output, the SOH. The architecture is visualized in Fig. 8a. The model is optimized with the state-of-the-art algorithm Adam (the reader is referred to the publication by Kingma and Ba
50
) and MAE as the loss function. The NN trains with no validation split and a batch size of 128 for 100 epochs.
through three LSTM layers with each 50, 50 and three memory cells, a reshape layer and a dense layer with one neuron to the final scalar output, the SOH. The architecture is visualized in Fig. 8a. The model is optimized with the state-of-the-art algorithm Adam (the reader is referred to the publication by Kingma and Ba
50
) and MAE as the loss function. The NN trains with no validation split and a batch size of 128 for 100 epochs.
Figure 5 visualizes the performance of the initial model for the three test datasets. In Fig. 5, the errorbars visualize the standard deviation of the estimations. Additionally, the distribution of the SOH estimation error is visualized in a histogram.

Figure 5. SOH estimation accuracy of the initial model for each test dataset. In the lower graph, the estimated SOHest is plotted against the true SOH. The upper histograms visualize the error distribution with ΔSOH=SOHest−SOHtrue for every test dataset.
Download figure:
Standard image High-resolution imageMore information can be drawn from Table III, in which the model accuracy is measured in RMSE, MAE and MAX. While the MAE seems acceptable, the RMSE and MAX reveal the bad performance of the model. Most of the samples are estimated around the mean value and due to the low complexity of the model it struggles to fit the training data. This indicates underfitting in ML. 19
Table III. Accuracy of the initial SOH estimation model.
| Evaluation Test Data | RMSE | MAE | MAX |
|---|---|---|---|
| Combined | 5.94% | 4.79% | 23.2% |
| Simulation | 5.92% | 4.99% | 20.9% |
| Laboratory | 5.56% | 3.85% | 21.1% |
| In-Vehicle | 8.89% | 7.58% | 23.2% |
Feature engineering
The preprocessing of training data influences the performance of NNs. So-called features, which can range from arbitrary measured signals to statistical transformations, improve the accuracy and efficiency of the model if they correlate with the desired output. 19 Features with negligible correlation hinder the generalization of model training and slow down the computation. Therefore, the selection of the final feature set is guided by a correlation and sensitivity analysis. Statistical features are calculated via available input data. The available dataset includes voltage, current and temperature signals and even internal states for the simulation data subset. Cell voltage U is defined as the potential difference between both current collectors. The temperature signal T is the cell core temperature in the synthetic dataset and the cell surface temperature for experimental data. The resulting deviation is further analyzed in the Discussion section and visualized in the Appendix, Fig. 12. Table IV summarizes and clusters the available input data. As the internal states have temporal and spatial dependencies, the cell is discretized along its x-dimension. Indices used in Table IV provide information about the spatial characteristics of a time-series signal. It must be noted that the SOC is an internal state, too. For convenience the SOC is defined as the weighted average of the solid concentration cs,NE along the negative electrode with respect to the maximum solid concentration. The SOC is assumed as unknown for the experimental datasets. Further information regarding the spatial discretization and the calculation of respective signals can be found in the Appendix.
Table IV. Input signals, clusters and the availability for each data subset. The solid concentration is distinguished between surface concentrations cs,s and average particle concentrations in the negative and positive electrode along the respective electrode cs,NE, cs,PE.
| Cluster | Signals | Simulation | Laboratory | In-Vehicle |
|---|---|---|---|---|
| U | U | x | x | x |
| I | I | x | x | x |
| T | T | x | x | x |
| SOC | SOC | x | ||
| Φs | Φs,NE, Φs,PE | x | ||
| Φl | Φl,NE/CC, Φl,PE/CC, Φl,SEP, Φl,NE/SEP, Φl,PE/SEP | x | ||
| c s | cs,NE,avg, cs,PE,avg, cs,s,NE/SEP, cs,s,PE/SEP | x | ||
| c l | cl,NE/CC, cl,PE/CC, cl,SEP, cl,NE/SEP, cl,PE/SEP | x | ||
s: solid, l: liquid, s, s: solid surface, NE: negative electrode, PE: positive electrode, SEP: separator, CC: current collector.
Table V shows a comprehensive list of possible features. 41–51,53 They are clustered in scalar and vectorized features. The scalar features include basic and advanced features. The scalar features yield one value per input sample. The vectorized features are generated by scanning the input signal between two adjacent points. Hence, a sample with N data points leads to N − 1 data points for a vectorized feature. To align with the data size of the time-series signals, the last entry is replicated and placed in the final column. Figure 6 illustrates the process of combining the signals with its features in the three dimensional dataset.

Figure 6. Structure of the three dimensional dataset. In this example one scalar and one vectorized feature are included and calculated for every input signal. After each feature the binary decision (BD) column informs the network about availability. The vectorized feature columns yield 60 data points for a 300 s sample with 61 data points. Thus, the last entry is copied into the empty cell.
Download figure:
Standard image High-resolution imageTable V. Possible features derived from the raw time-series data x(t) = X = {x1, x2,...xN }, where pj describes the probability of occurrence of one event xj . x(t) can be any time-series signal in the input dataset, e.g., voltage u(t) or current i(t).
| Abbreviation | Feature | Formula |
|---|---|---|
| Scalar Features | ||

| Minimum Value |

|

| Maximum Value |

|
| mean() | Mean Value |

|
| mad() | Median Absolute Deviation |

|
| mode() | Mode | Most Frequent Value in the Dataset X |
| Δ() | Delta per Sample |

|
| std() | Standard Deviation |

|

| Maximum Change per Timestep |

|
| rms() | Root Mean Square |

|
| skew() | Skewness 54 |
![$\tfrac{\tfrac{1}{N}{\sum }_{j=1}^{N}{\left({x}_{j}-\mathrm{mean}({\boldsymbol{X}})\right)}^{3}}{{\left[\tfrac{1}{N}{\sum }_{j=1}^{N}{\left({x}_{j}-\mathrm{mean}({\boldsymbol{X}})\right)}^{2}\right]}^{3/2}}$](https://content.cld.iop.org/journals/1945-7111/170/9/090524/revision1/jesacf0efieqn21.gif)
|
| se() | Shannon Entropy 51 |

|
| wv() | Wavelet Variance 52 | Last Coefficient of Wavelet Variance Transform |
| dft() | Discrete Fourier Transform Coefficients 53 |
 for k = 1,...,N − 1 for k = 1,...,N − 1 |
| Vectorized Features | ||
| d/dt() | First Windowed Derivative |
 for k = 1,...,N − 1 for k = 1,...,N − 1 |
| d2/dt2() | Second Windowed Derivative |
 for k = 1,...,N − 1 for k = 1,...,N − 1 |
| rmsvec() | Windowed Root Mean Square |
 for k = 1,...,N − 1 for k = 1,...,N − 1 |
| Additional (vectorized) Features | ||
| R() | Windowed Resistance |
 for k = 1,...,N − 1 for k = 1,...,N − 1 |
| CB() | Charge Balance |
 for k = 1,...,N − 1 for k = 1,...,N − 1 |
Few statistical features demand a more detailed explanation. Skewness (skew()) is an asymmetry measure of the underlying data distribution. 54 Shannon entropy (se()) returns the amount of information contained in a signal, where information refers to the definition in information theory. 51 The wavelet variance (wv()) measures the variability in a signal. 52 The discrete Fourier transform coefficients (dft()) can be used to describe a periodic signal. This means a periodic signal is split into its constituent frequencies, 53 where the first six coefficients are used in this approach. The six coefficients are treated as scalar features in this approach. The windowed resistance feature (R()) calculates the theoretical resistance with respect to the investigated window. The charge balance (CB()) measures the added or removed charge amount and hence directly correlates to the SOC and can work as a substitute for the SOC column in the experimental dataset.
In this study, we utilize snipped time-series signals, such as voltage, current, temperature, and additional internal states, as the base for our input sample. By performing feature engineering, we augment our dataset with multiple vectorized time-series signals, which are added to the original dataframe. Additionally, scalar features are included in each input sample. The final input data can be represented as a three-dimensional dataframe that incorporates three distinct categories of information. It should be noted that, with the exception of the features R() and CB(), all features are computed for every input signal. As a result, the total number of variables in each input sample is given by  , where Nsignals represents the number of signals used, and
, where Nsignals represents the number of signals used, and  represents the number of features employed. Notably, the count of
represents the number of features employed. Notably, the count of  does not include R() or CB(), which are classified as
does not include R() or CB(), which are classified as  .
.
Correlation and sensitivity analysis—feature selection
Before selecting features, a correlation analysis helps to understand the relation between different input features and their relation to the output. After selecting the first set of useful features a sensitivity analysis returns the most promising feature set and leads to the final feature selection.
The correlation analysis uses the Pearson correlation coefficient r to calculate the correlation between two signals X = {x1, x2,...,xN } and Y = {y1, y2,...,yN }, where N is the total number of samples.

Equation 1 can be easily calculated between two scalar features, but it is not directly possible between two time-series datasets or between a time-series signal and a scalar feature, e.g., the voltage time signal to the SOH. The vectorized features in Table V serve as a substitute. The correlation coefficient is computed individually for each value with its corresponding data point in the other signal, followed by averaging.
The feature list in Table V applies to every input signal from Table IV. To decrease the computational effort, all features belonging to one data cluster (see Table IV) are kept together for analysis. Hence, correlation analysis is performed for every feature cluster to the SOH. The cross-correlation between features gives insights about redundant features.
Detailed results regarding the direct correlation of features to the SOH for 300 s samples can be found in the Appendix, Table XII. It must be noted that correlation will increase if the sample length increases. Features derived from
c
s and
c
l show non-negligible correlation to the SOH for basic scalar features mean(),  ,
,  , mode() and rms(). Also more advanced features like wv() and dft() show higher correlation. The evaluation leads to the conclusion to exclude the features std(), Δ(), mad(), skew(),
, mode() and rms(). Also more advanced features like wv() and dft() show higher correlation. The evaluation leads to the conclusion to exclude the features std(), Δ(), mad(), skew(),  and d2/dt2() from further analysis because they show no correlation to the output or have strong cross-correlation to already included features. The remaining features and all possible input data clusters are evaluated in the following sensitivity analysis.
and d2/dt2() from further analysis because they show no correlation to the output or have strong cross-correlation to already included features. The remaining features and all possible input data clusters are evaluated in the following sensitivity analysis.
A sensitivity analysis describes the process of searching the possible feature space for the best combination of input features. The feature space includes the available signals but also the selected statistical features. While the signals current, voltage and temperature are included in any case, the additional input features from the simulation dataset are varied. Those signals are not available for experimental data, hence a so-called binary decision column is introduced. The column is located after the last time step and assigned with the value one in the case of available data, and with a zero in case of unavailable data. This allows the NN to either use or ignore the feature depending on availability. This method was already validated for battery temperature prediction with CNNs. 55 The combined data structure is visualized in Fig. 6.
The statistical features are clustered into four subsets as to reduce computational complexity. The charge balance feature CB() is included in any case, as it works as a substitute for the SOC. The clusters are listed in Table VI.
Table VI. Feature clusters, their abbreviation and content.
| Abbreviation | Feature cluster | Content |
|---|---|---|
| F1 | Statistical, scalar features |
 , mean(), , mean(),  , mode() , mode() |
| F2 | Scalar, physical interpretable features | wv(), rms(), dft() |
| F3 | Vectorized, related features | d/dt(), R() |
| F4 | Vectorized, adapting features | rmsvec() |
Combined with five possible input data signals (SOC, Φs, Φl,
c
s,
c
l) in total  combinations must be evaluated. The trained models are evaluated based on the decision metric in Eq. 4. The RMSE
combinations must be evaluated. The trained models are evaluated based on the decision metric in Eq. 4. The RMSE  RMSE and MAX
RMSE and MAX  for the experimental sub-test dataset are normalized and combined with a weighting factor to attribute the RMSE and MAX with equal importance. Simulation data is excluded from the decision metric. The final score results from both error metrics and yields the highest value for the best performing model.
for the experimental sub-test dataset are normalized and combined with a weighting factor to attribute the RMSE and MAX with equal importance. Simulation data is excluded from the decision metric. The final score results from both error metrics and yields the highest value for the best performing model.



In Fig. 7 the results from the sensitivity analysis are displayed. The shaded areas refer to feature variations with signals from c s, c l, Φs or Φl included. Hence, in total 24 = 16 different signal combinations are displayed. For better readability and to shift the focus toward the influence of signal combinations, the trajectories within a certain area are smoothed with a Savitzky-Golay filter with window size 11 and a polynomial order of three. Note that the final score solely emerges from the laboratory and in-vehicle results.

Figure 7. Resulting score (Eq. 4) from the sensitivity analysis. The final score is calculated only in respect to the laboratory and in-vehicle data. The feature variations include all possible 512 combinations of signals and their respective scalar and vectorized features. The included features are separated into the lower and upper y-range for better readability.
Download figure:
Standard image High-resolution imageIt is challenging to interpret the multidimensional visualization in Fig. 7. The usage of the features from the solid concentration
c
s leads to slight accuracy increase for the experimental data and excellent performance for synthetic data. For the simulation data, however, inclusion of features from both concentrations
c
s and
c
l leads to the best result. This result also supports the correlation analysis findings. The model with highest score includes features from cluster F2, and uses the signals U, I, T, SOC, Φs, Φl and
c
s. Table VII gives the detailed report about estimation accuracy with the relative error  . The accuracy increases for every dataset and metric. In particular the error related to simulation data decreases heavily, due to the inclusion of the internal states as an input variable and its correlation to the SOH.
. The accuracy increases for every dataset and metric. In particular the error related to simulation data decreases heavily, due to the inclusion of the internal states as an input variable and its correlation to the SOH.
Table VII. Accuracy of the best performing model after sensitivity analysis for each test dataset and the relative error change in relation to the initial model.
| Evaluation Test Data | RMSE | Δ
(RMSE) | MAE | Δ
(MAE) | MAX |

|
|---|---|---|---|---|---|---|
| Combined | 3.96% | −33.3% | 3.14% | −34.3% | 12.3% | −47.0% |
| Simulation | 3.48% | −41.2% | 2.89% | −42.1% | 7.98% | −61.8% |
| Laboratory | 5.00% | −10.1% | 3.66% | −4.94% | 12.3% | −42.2% |
| In-Vehicle | 5.45% | −38.7% | 5.17% | −31.8% | 10.0% | −56.9% |
Hyperparameter tuning
Prior to hyperparameter tuning, a sample length analysis is conducted, resulting in 1800 s as the optimal trade-off between training runtime and accuracy. The sample length analysis for the initial model (Fig. 8a) and the priory selected feature set is given in the Appendix, Table XIII. An additional dense layer before the last layer further improves accuracy. These settings are used for hyperparameter tuning.

Figure 8. Architecture of the initial (a) and final model (b) and corresponding dimensions of output data from each layer with n as the number of samples.
Download figure:
Standard image High-resolution imageDuring model training, the weights of the individual neurons are adopted. These weights generally are referred to as parameters. In contrast, the hyperparameters cannot be learned during training and must be set initially. Hence, the hyperparameters are the settings of the model and must be tuned by the engineer in order to design a useful NN. The process of optimizing hyperparameters is called hyperparameter tuning. Most important, during this process one must not solely rely on the training accuracy. This always leads to deeper, more complex models and finally in overfitting the training data. Instead, test or validation accuracy must be included into the evaluation metric. 19
Manual tweaking is cumbersome and prone to miss the global or even local optimum. Automated tuning scripts promise to ease the application and return global optima. Bayesian optimization is a powerful technique for tuning hyperparameters in a LSTM network. 19,56 It involves selecting a set of hyperparameters to optimize, defining a range of values for each hyperparameter, and then using Bayesian statistical methods to efficiently explore the hyperparameter space and identify the combination of hyperparameters that minimizes the validation loss. During the optimization process, the algorithm learns from previous evaluations and updates its estimate of the hyperparameters that are most likely to produce the best results, while also pruning out non-promising directions of optimization. This approach can significantly reduce the time and effort required to find the optimal set of hyperparameters for a given LSTM network, and has been shown to improve performance compared to manual tuning or other automated methods. 56 The Keras-made solution KerasTuner 57 is used in this paper.
The search space and the maximum number of iterations used for Bayesian optimization are defined beforehand, as listed in Table VIII. The number of neurons and the dropout rate can be set individually for every layer. All resulting models from hyperparameter tuning are trained with the same dataset as the initial model, with the exception of small reversed subset for validation.
Table VIII. Defined hyperparameter search space for Bayesian optimization.
| Hyperparameter | Search space |
|---|---|
| LSTM Layers | 1 to 5 |
| Neurons in LSTM Layers | 32 to 512 |
| Dropout Layers | 0 to 4 |
| Dropout Rate | 0.1 to 0.5 |
| Batch Size | 32 to 256 |
| Epochs | 50 to 2000 |
A fraction of the training dataset from laboratory and in-vehicle data is used as validation data to monitor the model's performance for unknown samples. The simulation data is excluded from validation because the main goal is to minimize the loss for experimental data. The Bayes optimization solves for the best choice of hyperparameters to minimize the validation loss, which means in this case the accuracy at estimating the SOH of experimental data. Every permutation is executed twice and the average validation loss is stored. More than 200 permutations are evaluated. The best hyperparameter set is found to be four LSTM layers, one dropout layer, a batch size of 256 and 1500 epochs. The architecture of the final model is visualized in Fig. 8b. The flattening layer maps a three dimensional input to a two dimensional output. Along with the architecture, the output dimensions of every layer are given.
Results and Discussion
The performance evaluation of the final PINN is visualized in Fig. 9. The individual errors are listed in the first part of Table X. The model is evaluated against the tree different datasets: simulation, laboratory and in-vehicle data. The model performs best with simulation data and estimates the SOH with a RMSE of 1.98%. The SOH of the laboratory test data can be estimated with a RMSE of 2.95%. The standard deviation error bars in Fig. 9 show little deviation from the mean estimate for simulation and laboratory data, indicating increased estimation confidence. Nonetheless, the findings presented in Table X and Fig. 9 demonstrate that the in-vehicle data samples pose a significant challenge to the model. This subset of data is characterized by a higher RMSE of 8.56%. The model's failure to capture the overall degradation trend for the in-vehicle data is evident, resulting in decreased performance solely for this dataset when compared to the post-sensitivity-analysis model. Despite the higher in-vehicle error, the model achieves the lowest validation loss because the in-vehicle dataset represents a small subset of the validation data with less than 5% of the total validation data. Consequently, the worse estimation of in-vehicle samples is compensated by better performance for laboratory samples.

Figure 9. SOH estimation accuracy of the final model for each test dataset. In the lower graph, the estimated SOHest is plotted against the true SOH. The upper histograms visualize the error distribution with ΔSOH=SOHest−SOHtrue for every test dataset.
Download figure:
Standard image High-resolution imageModel sensitivity
The performance of the PINN model is strongly influenced by driving profiles and temperature ranges, as demonstrated in Table IX. While the sensitivity analysis was employed during the model development process to identify the most promising features, we utilize it here to evaluate the PINN's dependency on current and temperature profiles. The selected driving profiles consist of CC charging, CC discharging, and dynamic profiles. Two temperature regions are defined. The first region T1 includes all samples with a measured temperature between 20 °C to 30 °C. The region T2 inhibits all samples outside of T1, which means below 20 °C and above 30 °C.
Table IX. Accuracy of the PINN for different temperature regions and current profiles.
| Simulation | Laboratory | In-Vehicle | ||||
|---|---|---|---|---|---|---|
| T1 | T2 | T1 | T2 | T1 | T2 | |
| MAE | ||||||
| CC Charge | — | — | 2.37% | — | 7.65% | 6.79% |
| CC Discharge | 1.50% | 1.36% | 1.79% | — | 12.2% | — |
| Dynamic Profile | 1.69% | 1.71% | 2.09% | 0.60% | 7.21% | 7.26% |
| Average | 1.68% | 1.69% | 2.08% | 0.60% | 8.12% | 7.23% |
| RMSE | ||||||
| CC Charge | — | — | 3.46% | — | 7.96% | 6.79% |
| CC Discharge | 1.72% | 1.61% | 2.43% | — | 13.6% | — |
| Dynamic Profile | 2.00% | 2.01% | 2.92% | 0.60% | 9.03% | 8.02% |
| Average | 1.98% | 1.99% | 2.95% | 0.60% | 9.57% | 7.93% |
| MAX | ||||||
| CC Charge | — | — | 14.1% | — | 11.6% | 6.98% |
| CC Discharge | 2.73% | 2.71% | 7.54% | — | 23.4% | — |
| Dynamic Profile | 5.60% | 6.73% | 14.1% | 0.60% | 23.4% | 13.0% |
Simulation data is estimated best with samples from CC discharge events in the temperature region T2. It can be seen in Fig. 3 that the simulation data does not include CC charging events. Higher accuracy for CC events is expected, due to more data with similar profiles in the training data. Although more data with dynamic profiles is included in the training set, it is very challenging for data-driven models to transfer knowledge gained from one dynamic profile to another dynamic profile if current rates and gradients differ strongly. Additionally, the time-step of 5 s is too large to differentiate between the instantaneous processes inside the battery like ohmic and charge-transfer overpotentials. The model's performance exhibits a minor temperature dependency, potentially stemming from statistical uncertainty during the training phase. A more detailed analysis yields similar performance even for very low or high temperatures, which is explainable by the evenly distributed simulation dataset (Fig. 4). The worst performance, i.e., the MAX error, originates in both temperature regions from a sample with a negative current pulse of 1C (Steps-Profile from Fig. 3). This high error emerges from a relatively small portion of data with this profile in comparison to CC discharging events which leads to a biased estimation.
As can be seen in Fig. 4, most of the laboratory data is captured for CC charging and discharging events at the temperature region T1. Dynamic profiles also include parts of CC charging and discharging events with at least 360 s of current flow and hence include the overpotential buildup or relaxation process. This additional information allows the PINN to reach high estimation accuracy for dynamic profiles with a RMSE below 3% for both temperature regions even with a large time-step of 5 s. The performance of the model with dynamic profiles within the temperature range T2 lacks statistical significance due to the limited number of samples. In fact, just a single sample from the laboratory dataset lies within temperature range T2. Excluding this data segment, the PINN performs best for CC discharging events, benefiting from additional data obtained during the training process from the simulation dataset. In contrast, less amount of data for CC charging events and possible outliers lead to poorer performance. These outliers are identified by unusual temperature profiles which originate from unknown history. For example the temperature decreases (ΔT < 0.5 K) although the battery is operated due to prior heating. These data anomalies are not included in the CC discharging, nor the dynamic profiles.
Across all data subsets, the RMSE of the in-vehicle estimations exceeds 7%. The performance for all in-vehicle data subsets is insufficient, making the interpretation of the sensitivity analysis unnecessary. The PINN struggles to transfer knowledge from simulation and laboratory data to in-vehicle data, particularly due to significant mismatches in most current profiles. Notably, the highest errors emerge from CC discharging samples with a current rate below 0.1C.
Benchmark
To further investigate the performance and the influence of physico-chemical information on the PINN, it is compared to purely data-driven approaches. The other approaches are chosen as they represent the most common NNs in the field. 17,19 The data-driven approaches are tuned with respect to the proposed hyperparameter–tuning procedure, presented in Table VIII. This allows a fair comparison because the hyperparameters are optimized to their individual best for the specific reduced dataset. They all keep the flattening and the two dense layers with ten and one neuron to produce the final scalar output. Table XIV in the Appendix presents the final architecture for every NN. Table X and Fig. 10 show the benchmark. All other models train with the full dataset but exclude internal states, with the exception of the LSTMexp. The LSTMexp trains solely with experimental data to evaluate the impact of synthetic training data.

Figure 10. Benchmark of the PINN to other state-of-the-art machine learning (ML) models. The estimated SOHest is plotted against the true SOH for every model and dataset.
Download figure:
Standard image High-resolution imageTable X. Benchmark of the PINN with other state-of-the-art machine learning (ML) models for each test dataset. For every test dataset and every error metric the lowest error value is printed bold.
| Evaluation Test Data | RMSE | MAE | MAX |
|---|---|---|---|
| PINN | |||
| Combined | 3.03% | 2.11% | 23.4% |
| Simulation | 1.98% | 1.69% | 6.73% |
| Laboratory | 2.95% | 2.08% | 14.1% |
| In-Vehicle | 8.56% | 7.28% | 23.4% |
| LSTMexp | |||
| Combined | 4.81% | 3.29% | 20.9% |
| Simulation | — | — | — |
| Laboratory | 4.65% | 3.01% | 20.9% |
| In-Vehicle | 5.76% | 5.10% | 13.1% |
| LSTM | |||
| Combined | 3.36% | 2.30% | 29.5% |
| Simulation | 2.97% | 1.97% | 13.86% |
| Laboratory | 3.33% | 2.45% | 15.1% |
| In-Vehicle | 6.65% | 5.52% | 29.5% |
| FNN | |||
| Combined | 6.09% | 4.97% | 52.9% |
| Simulation | 6.08% | 5.24% | 15.5% |
| Laboratory | 6.11% | 4.41% | 52.9% |
| In-Vehicle | 6.17% | 4.99% | 11.4% |
| RNN | |||
| Combined | 7.00% | 4.64% | 30.4% |
| Simulation | 8.25% | 5.45% | 30.4% |
| Laboratory | 3.81% | 3.00% | 15.3% |
| In-Vehicle | 4.98% | 4.60% | 9.79% |
In Fig. 10 it is clearly visible, that the FNN and the RNN underfit the training data and hence fail to accurately estimate the SOH of any test dataset. It is evident that FNNs fail to capture the temporal context and are thus not qualified to process the dependencies of time-series signals. 18,58 The findings further support the initial statement, that LSTMs are superior to RNNs. The LSTM solves the vanishing gradient problem 18,59 and thus estimates the SOH with an average RMSE of 3.36%. Nevertheless, it has a worse performance than the PINN and estimates the laboratory samples with a RMSE of 3.33%. The error further increases to 4.65% if simulation data is completely excluded, as in the LSTMexp.
Discussion
The present study aims to investigate the effect of physical information and synthetic data on the performance of machine learning SOH estimation models. The main research question was whether incorporating such data can improve the accuracy and generalization ability of these models. Our results provide strong evidence that physical information and synthetic data indeed have a positive impact on model performance. Table X supports the statement by giving the accuracy of the PINN in comparison to the same model architecture trained without simulation data, nor internal states (LSTMexp) and trained without internal states (LSTM). The PINN model trained with both types of data consistently outperforms other models for laboratory test data. The inclusion of synthetic data to the LSTM provides more training data and hence improves the accuracy for laboratory test data. Additional information from internal states further boosts performance.
Our results confirm previous findings by Thelen et al., 28 who showed that a sequential PINN trained on a combined dataset achieved the best performance in estimating the SOH. Thelen et al., 28 however, used less but more detailed data, including a DVA of half cells, and hence, reported a lower RMSE of 0.74% at estimating the SOH at 37 °C or 55 °C. Similarly, Son et al. 60 demonstrated that incorporating more detailed features, such as mechanical and electrochemical responses, in the form of health indicators optimized a PINN to estimate the SOH with a lower RMSE of 0.49%. In contrast, the current study utilizes easily derivable signals during operation and does not require complex measurements to initialize the method, thereby competing with the PIML model developed by Kohtz et al. 30 The latter model processes charging voltage segments and estimates the SEI thickness, which is directly mapped to the SOH, with an RMSE of 8.97% at an unseen test case at 30 °C. Notably, the developed PINN in the present study outperforms the PIML by Kohtz et al. 30 for any given laboratory test dataset. Furthermore, this study first introduces internal states from a P2D model as additional features in the synthetic dataset. The model is forced to link the measurable states to the internal variables that correlate to the SOH due to the binary decision column. This work thus extends previous research by demonstrating the efficacy of utilizing easily obtainable signals and internal states in estimating the SOH of batteries.
Nevertheless, the data and the method must be critically discussed. The following paragraphs are structured to align with the workflow of the model development process. Initially, a thorough analysis of the data sources is presented, encompassing aspects such as sampling methodologies, parameter validity, potential imperfections in the experimental data, and the integration of multiple data sources. Subsequently, the focus shifts toward a critical evaluation of the model, including an assessment of hyperparameter tuning and feature selection techniques.
First, the sampling itself reduces the signal duration and makes the model generalizable to snippets with constant length from any SOC window. On the other hand, by sampling the data, the previous history of operation is unknown and may lead to scenarios in which important information is missing. For example, the worst performance for laboratory data (Table IX) is due to a decreasing temperature signal, which is falsely interpreted by the model because the previous history is unknown. A more similar data structure eventually leads to higher performance, especially the usage of full CC charging events. The sampling further leads to a loss of information in the experimental datasets due to the low sampling rate of 0.2 Hz, which is set by the simulation data. Dynamic samples with relaxation processes profit from higher sampling rates because more information about the overpotentials with fast time-constants are included. 61 The additional information from higher sampling rates positively contributes to the final performance. In other works, 28,30,42,43,60,62 the sample rate is not explicitly stated.
Second, the validity of the P2D parameter set, particularly under degraded conditions, is limited to predefined measurements. For this particular cell, the degraded parameter set is fitted to a repeated C/3 CC charge–discharge test, as in Fig. 3i. In general, several parameter sets lead to accurate result due to the ambiguity of the combination. A perfect alignment between the observed battery response, voltage and temperature, does not necessarily guarantee the uniqueness of the assumed parameter set. The precise measurement of all internal states and parameters during operation is still a challenge. Nevertheless, the experimental data shows good agreement between the measurable signals and the simulation results (see Fig. 12).
Third, the accuracy is influenced by imperfections in the experimental dataset, i.e., noise or varying ambient temperature. Especially, the in-vehicle dataset presents these challenges for the PINN. More important, the in-vehicle dataset only comprises of 2.20% of the total data amount, whereas laboratory data makes up to 36.7% and simulation data 61.1%. Hence, it is reasonable for the model to be biased toward the other data sources and further to disregard the in-vehicle training loss during optimization. The model is likely to end in a local optimum with underfitted in-vehicle training data. The possibility to achieve comparable results with even sparser experimental data should be addressed in future studies.
This work tries to combine signals from cell level, which is simulation and laboratory data, with signals from storage level. The current flow into the storage is divided by the number of parallel cells to yield the average cell current. The voltage and temperature signal is only captured for the minimum, maximum and average value per signal. The average values are used in this approach. Hence, giving rise to various error sources. The samples from the in-vehicle dataset itself statistically vary from the other data sources, as can be seen in Fig. 4. Most of the data is distributed at high SOHs, even above 100%. The in-vehicle dataset includes more aggressive profiles with higher current rates than the other data sources. Hence, a large amount of the in-vehicle dataset is poorly represented in the training data. The interaction of these challenges leads to the reduced performance for in-vehicle data.
The model itself might be prone to overfitting because it trains with a large batch size of 256 for 1500 epochs and is relatively deep, i.e., many neurons and layers. Generally, more complex models are rather prone to overfit on training data. 19 To assess this problem, the data has been split independently priorly. This strategy ensures to use test data with different SOH labels than the training data. Bayes optimization uses the validation loss as the cost function and hence stops training before overfitting on training data occurs. Further, the dropout layer and the inclusion of data anomalies act as regularization techniques and thus prevent overfitting. 19
Feature selection plays a vital role in determining the accuracy and interpretability of the final PINN. Although a comprehensive feature selection process including correlation and sensitivity analysis was performed, the initial selection of possible features may not be ideal, and there are several limitations to the process. In this study, the final feature selection indeed reduced the error, but it cannot be disproven that there exist another feature set that truly result in the global optimum of the feature space.
Finally, it is very challenging to prove the cause of superior performance of the PINN over the LSTM in Table X. It is most plausible and there is strong evidence that the NN exploits correlation between the measurable signals current, voltage, temperature, and the internal states which increase the correlation to the SOH. In other words, there are connections from the first layer with current, voltage and temperature as input to the hidden layers, which fuses this information with knowledge from internal states. Previous analyses support the statement about feature correlation from both signal types, corroborating this assertion.
To improve the efficacy of the proposed method, it is desired to employ an advanced synthetic dataset containing full CC charging events with higher sampling rates. Furthermore, to enhance the performance, more precise P2D parameters are required that exhibit improved conformity with experimental data, even at degraded state. In order to facilitate the utilization of PINNs in the context of in-vehicle or field data, it is imperative to minimize the discrepancies between combined datasets. To this end, processing the signals of individual cells holds promise as an alternative to relying on mean cell voltage and temperature.
The proposed method demonstrates its suitability for real-time SOH estimation in many applications. Especially the low requirement on signals allow the realization in EVs because only one current, voltage and temperature signal with a sampling rate of 0.2 Hz are mandatory. If we assume that one signal value equals one integer with two bytes, the whole data package comprises of 2.06 kB. A cloud connection and frequent data exchange further enable a BMS to monitor the SOH with remote updates, i.e., the 2.06 kB package is sent to the backend where the model is employed, the resulting scalar SOH is returned to the BMS. The final model demands 17.7 MB of storage in H5-format and estimation of one sample takes 55 ms with CPU-computing on a 11th generation Intel i7 core (3.00 GHz, 8 CPUs, 16 GB RAM).
PB simulations have the capability to enhance existing data-driven approaches through the provision of additional physico-chemical battery data or to establish new PINNs, even with sparse experimental data. The utilization of a synthetic dataset facilitates the acquisition of comprehensive information concerning cell-internal states, including the previously unknown degradation states. It enables a reduction in the number of required experiments and ultimately reduces associated time and cost requirements.
The utilization of conventional transfer learning for the PINN model presents a promising avenue for improving its usability and accuracy. In this context, transfer learning describes the training of base models with big data and the followed retraining with individual, sparse data. Transfer learning enables pre-training and publication of data-driven models with large-scale synthetic data, which can include internal states. The usability of conventional transfer learning for capacity estimation in lithium-ion batteries was exemplary proven by Shen et al. 63 and Zou et al. 64
Conclusions
This research paper presents an analysis of the key challenges in the development process of ML projects, with a focus on the critical role of data and their preprocessing in optimizing model architecture. Physico-chemical simulations act as a powerful tool for generating large quantities of highly accurate data, including both measurable and non-measurable internal states in synthetic datasets, to yield improved results. Nevertheless, this study highlights the need for a detailed understanding of the limitations and development process of PINN. The developed sequential PINN architecture, which temporally decouples the complex P2D model, enables fast estimation using  samples from current, voltage, and temperature signals. The PINN achieves estimation errors below 2% RMSE and 3% RMSE for simulation and laboratory data, respectively. The fusion of experimental data with synthetic data leads to increased accuracy and through inclusion of internal states in the simulation dataset, the performance is further improved. The comparison of the PINN with state-of-the-art NNs highlights the positive impact of incorporating physical information. Moreover, comparable current profiles, e.g., CC events, improve the estimation accuracy. The developed PINN demonstrates high accuracy for laboratory data, particularly for comparable samples to those in the simulation dataset. Unfortunately, it fails to generalize to in-vehicle data due to dataset size, differences in current profiles, and signal acquisition. Furthermore, the performance of the model is constrained by the sample rate of 5 s, which does not capture relaxation behavior in the high frequency domain. Ultimately, this study shows that a well chosen combination of experimental and synthetic data, equal data splits and structure, improves the performance of data-driven SOH estimation models. Hence, physical informing a NN is a low complex solution to boost performance of ML models, not limited to battery state estimation.
samples from current, voltage, and temperature signals. The PINN achieves estimation errors below 2% RMSE and 3% RMSE for simulation and laboratory data, respectively. The fusion of experimental data with synthetic data leads to increased accuracy and through inclusion of internal states in the simulation dataset, the performance is further improved. The comparison of the PINN with state-of-the-art NNs highlights the positive impact of incorporating physical information. Moreover, comparable current profiles, e.g., CC events, improve the estimation accuracy. The developed PINN demonstrates high accuracy for laboratory data, particularly for comparable samples to those in the simulation dataset. Unfortunately, it fails to generalize to in-vehicle data due to dataset size, differences in current profiles, and signal acquisition. Furthermore, the performance of the model is constrained by the sample rate of 5 s, which does not capture relaxation behavior in the high frequency domain. Ultimately, this study shows that a well chosen combination of experimental and synthetic data, equal data splits and structure, improves the performance of data-driven SOH estimation models. Hence, physical informing a NN is a low complex solution to boost performance of ML models, not limited to battery state estimation.
Acknowledgments
This work was funded by the BMW Group AG and was performed in cooperation with the University of Bayreuth and the Technical University of Munich.
Appendix A.: Error Metrics
Table XI lists the most widely used error metrics. In the context of SOH estimation, Y is equal to the true SOH, while  is the estimated SOHest. The MAPE exhibits a more pronounced violation of errors around zero compared to the MAE or the RMSE.
is the estimated SOHest. The MAPE exhibits a more pronounced violation of errors around zero compared to the MAE or the RMSE.
Table XI. Common error metrics, their abbreviations and formula. 65
| Error Metric and Abbreviation | Formula |
|---|---|
| Mean Absolute Error (MAE) |

|
| Root Mean Squared Error (RMSE) |

|
| Mean Absolute Percentage Error (MAPE) |

|
| Maximum Absolute Error (MAX) |

|
Y: True value,  : Estimated value, N: Number of samples.
: Estimated value, N: Number of samples.
Appendix B.: Results from the Correlation Analysis
Table XII gives insights about the results from the correlation analysis performed to derive the best suitable features for SOH estimation. All scalar features are calculated on the 300 s samples from the combined dataset. The features derived from internal states solely utilize the synthetic data samples. The correlation between the vectorized feature CB() and the SOH is not calculated, because it is assumed to directly correlate with the SOC. Hence, CB() acts as a substitute for the SOC signal in the experimental dataset. The Pearson correlation coefficient between the windowed resistance R() and the SOH is 2.16% for a window length of 10 s.
Table XII. Pearson correlation coefficient between the SOH and every feature of every signal from a 300 s sample. All values are given in percent in a range between −100% to 100%, where −100% indicates indirect proportionality and 100% direct proportionality.
| Feature | U | I | T | SOC | Φs | Φl | c s | c l |
|---|---|---|---|---|---|---|---|---|

| 5.11 | 1.04 | −1.20 | 4.15 | 9.08 | 4.17 | 28.8 | 8.94 |

| 1.60 | 1.16 | 2.16 | 3.81 | 11.0 | 8.18 | 29.0 | 9.00 |
| mean() | 3.75 | 1.94 | −1.48 | 3.47 | 10.9 | 6.59 | 29.0 | 7.46 |
| mad() | −6.26 | 0.36 | −6.90 | −5.50 | 8.35 | 8.54 | 3.65 | 11.0 |
| mode() | 3.12 | 2.01 | −1.31 | 2.99 | 10.5 | 6.07 | 28.3 | 6.57 |
| Δ() | −4.84 | 0.54 | −6.36 | −6.24 | 7.19 | 6.53 | 4.02 | 10.8 |
| std() | −5.67 | −0.22 | −5.94 | −6.27 | 7.61 | 7.98 | 4.07 | 10.5 |

| −1.24 | −0.81 | 2.15 | −3.81 | 1.96 | 1.07 | 3.13 | 1.21 |
| rms() | 3.72 | 2.24 | −1.48 | 3.45 | 11.2 | 8.65 | 29.0 | 7.37 |
| skew() | 0.87 | −0.32 | −1.23 | −0.20 | 0.82 | 1.15 | 1.90 | 1.12 |
| se() | 0.99 | 1.77 | 0.95 | 0.99 | 0.99 | 3.27 | 11.6 | 9.09 |
| wv() | −0.78 | 1.93 | −1.49 | 3.49 | 2.08 | 1.47 | 29.0 | 7.56 |
| dft() | 2.03 | 0.55 | 2.99 | 3.69 | 10.8 | 6.57 | 29.1 | 7.57 |
| d/dt() | 1.30 | 0.56 | 2.93 | 3.13 | 2.1 | 2.13 | 2.72 | 3.02 |
| d2/dt2() | 1.50 | 0.74 | 1.73 | 2.39 | 2.14 | 2.24 | 1.83 | 2.27 |
| rmsvec() | 3.89 | 2.63 | 1.49 | 3.68 | 11.4 | 8.65 | 29.2 | 7.54 |
Appendix C.: Results from the Sample Length Analysis
The initial model from Fig. 8a is trained with the final feature set and samples with varying duration from 300 s to 2400 s. Table XIII lists the RMSE of the individual models for every sub dataset and the training duration normalized to the training duration for the model with 300 s samples. A sample duration of 1800 s is selected due to its optimal accuracy in laboratory samples while ensuring reasonable runtime.
Table XIII. Results of the sample length analysis. For a sample length between 300 s to 2400 s the relative training duration and the accuracy for each test dataset is listed for the initial model.
| Sample Length | Δttrain/Δttrain,300 s | Sim. RMSE | Lab. RMSE | Veh. RMSE |
|---|---|---|---|---|
| 300 s | 1.00 | 3.48% | 5.00% | 5.45% |
| 600 s | 1.23 | 2.14% | 4.40% | 7.50% |
| 900 s | 1.52 | 4.76% | 4.34% | 7.10% |
| 1200 s | 2.02 | 2.28% | 4.41% | 6.74% |
| 1500 s | 3.63 | 2.03% | 4.73% | 7.58% |
| 1800 s | 3.74 | 2.86% | 4.11% | 6.51% |
| 2100 s | 3.87 | 3.26% | 4.45% | 6.89% |
| 2400 s | 3.97 | 1.56% | 4.60% | 8.37% |
Appendix D.: Results from the Bayes Optimization of the Benchmarked Models
The benchmarked NNs were tuned to their respective optimum by Bayes optimization. For all models, the search space is defined as in Table VIII. The resulting hyperparameters for every NN are listed in Table XIV.
Table XIV. Results of the Bayes hyperparameter tuning for all benchmarked NNs. The first dropout–layer is placed after the second neural layer.
| Hyperparameters | LSTM | LSTMexp | FNN | RNN |
|---|---|---|---|---|
| Layers | 2 | 2 | 4 | 4 |
| Neurons | 352, 32 | 256, 128 | 480, 256, 64, 128 | 192, 384, 96, 480 |
| Dropout Layers | 1 | 1 | 3 | 3 |
| Dropout Rate | 0.2 | 0.4 | 0.3, 0.1, 0.4 | 0.3, 0.4, 0.2 |
| Batch Size | 265 | 64 | 256 | 96 |
| Epochs | 891 | 1437 | 1426 | 1303 |
Appendix E.: Newman Pseudo Two-dimensional Model
The pseudo-2-dimensional (P2D) model, introduced by Doyle, Fuller and Newman, 4,66,67 describes the cell on a macroscopic scale with two porous electrodes, an insulating separator and liquid electrolyte, as depicted in Fig. 11. The model solves the mass and charge balance and the electrode kinetics along the x-dimension of the full cell. The insertion of lithium-ions into the particle, i.e., diffusion, is modelled with the second pseudo-dimension in r-direction. The two dimensions are coupled via the mass balance and the electrode kinetics.

Figure 11. Domains and geometry of the Newman P2D model (adapted from Jokar et al. 68 ).
Download figure:
Standard image High-resolution imageTable XV presents a summary of the input parameters required for the Newman P2D model, including their dependencies on the proposed model and literature. The theoretical range of parameter variations over degradation is also included when available. The assumed parameter variations over degradation are in good agreement with the literature references. 33,69,70
Table XV. P2D parameter set and their dependencies on SOH, SOC and geometry x for the investigated cell. If a value range cannot be stated, the parameter is described by a function. Begin-of-life (BOL) refers to the pristine state with 100% SOH, end-of-life (EOL) refers to 73% SOH. Table taken from Hamar et al., 44 extended with the aid of Li et al., 33 Andersson et al. 69 and Uddin et al. 70
| Parameter | Unit | Geometry | Dependencies | ||||
|---|---|---|---|---|---|---|---|
| Anode | Separator | Cathode | |||||
| BOL | EOL | BOL | EOL | ||||
| Thickness L | m | 7.3 × 10−5 | 1.4 × 10−5 | 5.5 × 10−5 | SOH 69 | ||
| Particle radius Rp | m | 7 × 10−6 | 7 × 10−6 | x 69 , SOH 69 | |||
| Bruggeman exponent αB | 2.6 | 2.5 | 2.1 | ||||
| Porosity εl | 0.24 | 0.15 | 0.39 | 0.256 | x 33,69 , SOHM,33,69 | ||
| Active material volume fraction εs | 0.7164 | 0.65 | 0.48 | SOH 33,69 | |||
| Electrode equilibrium potential Eeq | V vs Li/Li+ |

|

| T 69 , SOCM,69 , SOHM,69 | |||
Entropic coefficient 
| V K−1 |

| 1 × 10−4 | T 69 , SOCM,69 , SOHM,69 | |||
| Stoichiometry at 0% SOC θ0% | 0.037 | 0.0076 | 0.93 | 0.81 | SOHM,70 | ||
| Stoichiometry at 100% SOC θ100% | 0.83 | 0.59 | 0.19 | 0.19 | SOHM,70 | ||
Max. lithium-ion concentration 
| molm−3 | 31085.2 | 49240 | SOH 69 | |||
| Electrical conductivity of the solid matrix σ | S m−1 | 25 | 0.225 | ||||
| Film resistance Rf | Ω m2 | 0.13 × 10−3 | 7.1 × 10−3 | 0.1 × 10−3 | 11 × 10−3 | SOHM | |
| Reference diffusion coefficient Ds,ref | m2 s−1 | 1.6 × 10−14 | 1 × 10−13 | ||||
| Diffusion coefficient Ds | m2 s−1 |

|

| TM,69 , SOCM,69 , SOHM,69 | |||
| Reference reaction rate kref | m s−1 | 6.4016 × 10−9 | 1.6839 × 10−9 | ||||
| Reaction rate activation energy Ea,k | J mol−1 | 6.8 × 104 | 5 × 104 | ||||
| Charge transfer coefficient αa/c | 0.5 | 0.5 | |||||
| Electrolyte | |||||||
| Initial concentration cl,0 | mol m−3 | 1120 | |||||
| Reference concentration cl,ref | mol m−3 | 1120 | |||||
| Transport number t+ | 0.38 | T 69 , cl 69 | |||||
| Ionic conductivity κ | S m−1 | κ(T, cl) | TM,69 , cl M,69 | ||||
| Diffusion coefficient Dl | m2 s−1 | Dl(T, cl) | TM,69 , cl M,69 , SOH 69 | ||||
Activity coefficient 
|

| TM,69 , cl M,69 | |||||
| Full Cell | |||||||
| Specific double layer capacitance Cdl | F m−2 | 0.2 | |||||
| Reference temperature Tref | K | 298.15 | |||||
Diffusion coefficient activation energy 
| J mol−1 | 3 × 104 | |||||
| Reaction rate ka/c | m s−1 | ka/c(T) | TM,69 , SOC 69 | ||||
| Contact resistance Rc | Ω m2 | 1.2 × 10−3 | |||||
| Grid resistance outside the cell Rext | Ω m2 | 3 × 10−4 | |||||
| Specific heat capacity cp | J kg−1 K−1 | 880 | |||||
M Model.
The accuracy of the aged parameter set is validated by laboratory measurements that include CC C/3 charge–discharge tests as in Fig. 3i. These tests are conducted at 25 °C and various SOHs during a cyclic and calendar lifetime study with varying boundary conditions. Figure 12 shows the resimulation of random samples from both laboratory and in-vehicle datasets. The absolute voltage error for laboratory data remains below 50 mV, except for very low SOC, due to the definition of stoichiometries in the P2D model referring to relaxed voltage data points. As a result, the deposited OCV curve in the model is not defined between 2.8 V to 4.2 V, but rather between 3.1 V to 4.2 V. A full discharge, as in the laboratory check-up, hence leads to slight deviation from measurement to simulation. The temporal signal course, however, aligns well. Similarly, the simulated cell core temperature and the measured cell surface temperature align well, although larger gradients build up during discharge, resulting in minor deviations. In contrast to the laboratory check-ups, the selected in-vehicle samples exhibit highly dynamic driving profiles in both pristine and aged states. For both samples, the voltage simulation agrees well with the measurement, and the absolute error remains below 100 mV at all times. Although the simulated temperature is close to reality for higher ambient temperatures (Fig. 12d), the error increases for lower temperatures (Fig. 12c). Nevertheless, the temporal courses align well, with a maximum error of less than 3 K.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 12. Random samples from the laboratory (12a and 12b) and in-vehicle dataset (12c and 12d) and their simulation results from the P2D model. The figures include the respective voltage and temperature estimation error. (a) Laboratory Data, SOH = 100%. (b) Laboratory Data, SOH = 94%. (c) In-Vehicle Data, SOH = 100%. (d) In-Vehicle Data, SOH = 92%.
Download figure:
Standard image High-resolution image{kind=link}
The model solves for the concentrations cs(x, r, t), cl(x, t) and potentials Φs(x, t), Φl(x, t) within the active material (solid phase, index s) and electrolyte (liquid phase, index l). The surface concentration  is considered as cs,s(x, t) in this paper. The simplification of a porous structure and the assumption of an infinite expansion in y- and z-direction lead to the interpretation of an available active material particle with radius Rp at every point along the x-direction in the electrodes. Hence, the concentrations and potentials can be calculated at every point along the x-dimension. The current densities in the liquid and solid phase il, is and further the ionic flux in
are dependent variables.
is considered as cs,s(x, t) in this paper. The simplification of a porous structure and the assumption of an infinite expansion in y- and z-direction lead to the interpretation of an available active material particle with radius Rp at every point along the x-direction in the electrodes. Hence, the concentrations and potentials can be calculated at every point along the x-dimension. The current densities in the liquid and solid phase il, is and further the ionic flux in
are dependent variables.
The subsequent description of the model equation does not aim to be comprehensive but rather to give the main limitations and assumptions of the model. The interested reader is referred to Refs. 4, 44, 66, 67, 71, 72 for more details.
The mass balance in the liquid phase which is deduced from diffusion and migration yields

with the porosity εl, the effective diffusivity in the liquid phase Dl,eff and the transference number of cations in the solution  . Further, it must be assumed that the gradient of the liquid concentration is zero at the boundaries of the electrodes to the current collectors.
. Further, it must be assumed that the gradient of the liquid concentration is zero at the boundaries of the electrodes to the current collectors.

The potential in the liquid phase Φl is linked to the lithium-ion concentration in the liquid phase cl via
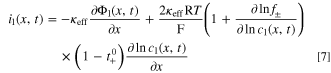
where κeff is the effective conductivity and f± is the activity coefficient. Again, the gradient of the liquid potential is zero toward the electrode—current collector boundary and the value itself is zero for the boundary at the positive electrode.

In both electrodes the charge balance applies

which couples the current density in the solid and liquid phase. In the separator the current in the liquid phase il(x, t) is equal to the applied current iapp. The x- and r-dimension are coupled via the correlation of the pore wall flux jn and the divergence of the current density

where the specific surface as expresses the geometrical coupling. The specific surface is defined as the ratio of surface to volume in the spherical active particles with the volume fraction of the active material εs and the radius of the particles Rp.
The ionic pore-wall flux jn of lithium-ions is related to the surface overpotential η by the Butler-Volmer relation

where i0 is the exchange current density and cl,ref is the reference lithium-ion concentration in the liquid phase. The reaction rate constants are ka, kc; and αa, αc are the charge transfer coefficients for the anodic and cathodic path, respectively. The surface overpotential η is the driving force of the electrochemical reaction and can be expressed with the electrode and electrolyte potentials, the equilibrium potential and the potential drop across a film resistance Rf

The equilibrium potential depends on the surface concentration and thus on the SOC.
The potential in the solid phase of the electrodes is finally derived by Ohm's law as

with σs,eff as the effective electrical conductivity. The gradient of the solid potential is zero at the boundary between electrodes and separator.

Further, the gradient can be explicitly stated for the boundary of the positive electrode to the current collector

The particle mass balance is described with spherical coordinates as

The solid diffusion coefficient is given as Ds. The concentration gradient of lithium-ions is assumed to be zero at the center of particles, i.e.,

In contrast, on the particle surface it is expressed by the pore-wall flux perpendicular to its surface

The presented P2D model is coupled with a zero-dimensional thermal model to account for the temperature-dependent character of electrochemical reactions. The thermal model includes heat generation within the cell and convective heat transfer with the environment. The local temperature distribution is neglected and hence all equations are calculated without dependency on x or r. The simplified energy balance is given by

where ρ, V and cp are the cell's density, volume and specific heat capacity. The irreversible heat generation

depends on the potential difference between cell voltage Vcell and the open-circuit-voltage (OCV) VOCV, and the applied current I. The reversible heat generation is directly related to the entropy and depends on the absolute temperature T, the applied current I and the temperature dependency of the OCV

The convective heat transfer between the cell's surface and the environment calculates as

where h is the heat transfer coefficient, A is the intersectional area and Tamb is the ambient temperature. The simplified energy balance is coupled with the electrochemical model by introducing temperature dependent parameters, as indicated in Table XV. While the temperature dependency of the solid phase diffusion Ds and the reaction rate constants ka, kc are expressed by the general Arrhenius equation, the diffusion coefficient of the liquid phase Dl,eff, the ionic conductivity κ and the activity coefficient f± depend on an empirical fitting. For a more detailed explanation and the equations, the interested reader is referred to Ref. 44.