
Abstract
We present an analysis of two key sets of data constraining the high x gluon at up to approximate N\({}^3\)LO in QCD within the MSHT global PDF fitting framework. We begin with LHC 7 and 8 TeV inclusive jet and dijet production at both NNLO and aN\({}^3\)LO. This makes use of the formalism established in the previous global MSHT20aN\({}^3\)LO PDF fit, but now considers the role of dijet production for the first time at this order. We present a detailed comparison of the fit quality and PDF impact for both cases, and consider the role that electroweak corrections, and the scale choice for inclusive jet production has. Some mild tension between these data sets in the impact on the high x gluon is seen at NNLO, but this is largely eliminated at aN\({}^3\)LO. While a good fit quality to the dijet data is achieved at both orders, the fit quality to the inclusive jet data is relatively poor. We examine the impact of including full colour corrections in a global PDF fit for the first time, finding this to be relatively mild. We also revisit the fit to the ATLAS 8 TeV Z \(p_T\) data, considering the role that the \(p_T\) cuts, data selection and different aspects of the aN\({}^3\)LO treatment have on the fit quality and PDF impact. We observe that in all cases the aN\({}^3\)LO fit quality is consistently improved relative to the NNLO, indicating a clear preference for higher order theory for these data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Parton distribution functions (PDFs) of the proton are a key element in the LHC precision physics program. As such, recent dedicated efforts to extract these as accurately and precisely as possible have been performed by multiple groups, accompanied by the release of public PDF sets [1,2,3,4]. In these analyses, a wide range of data from HERA and fixed target experiments to the Tevatron and the LHC are included in the fit, while the state-of-the-art in the theoretical calculation entering these fits is now by default next-to-next-to leading order (NNLO) in the QCD perturbative expansion.
More recently the MSHT group undertook the first PDF analysis at approximate \({\textrm{N}}^3\)LO order [5], resulting in the public MSHT20an3lo PDF set. This included the information already known at \({\textrm{N}}^3\)LO for the PDF evolution, heavy flavour transitions and DIS coefficient functions, which constitutes a large amount of information. At the same time it also included approximations and corresponding uncertainties for the unknown parts. A clear impact on the fit quality was observed, with as expected an improvement seen by going to this next (approximate) order, while the impact on the PDFs and LHC phenomenology was in some cases found to be significant. Given the amount of known \({\textrm{N}}^3\)LO information available, these represent a more accurate PDF determination. An analysis of the impact of QED corrections on top of the a\({\textrm{N}}^3\)LO fit was also presented recently [6], though these are not included in this work. Since the publication of the MSHT20an3lo PDF set, there have been a few further theoretical ingredients determined; this includes additional moments and other pieces for several splitting functions [7,8,9,10,11], in addition to progress determining the remaining unknown transition matrix elements [12,13,14]. We expect the impact of such additional information to be small, as we parameterised the effects of missing pieces as sources of theoretical uncertainty on our aN3LO PDFs. Furthermore we have explicitly checked that for the additional splitting function information the effect on the PDFs is mild and within the uncertainties. Therefore the newly calculated ingredients are not included in this work as we wish to analyse with respect to the public MSHT20aN3LO PDFs, for which this information was not yet available. We therefore leave the analysis and inclusion of these few additional theoretical constraints and ingredients to a future, dedicated work.
There are many implications for LHC physics and PDF fitting to investigate. A particularly relevant topic relates to the impact of LHC data on the high x gluon. This is a region where direct information was relatively lacking prior to the inclusion of data from hadronic collisions, and specifically the LHC, in PDF fits. However, with the advent of the LHC and the availability of a range of differential and high precision inputs from, in particular, top quark pair, jet and Z boson \(p_T\) (or Z boson in association with jets) measurements, significant constraints on the high x gluon, as well as other parton flavours, can be placed. The impact of theses data sets and their interplay has been the focus of much discussion, see [1, 15,16,17] for studies in the context of the MSHT PDF fit, as well as elsewhere in [2,3,4, 18,19,20,21,22,23,24,25,26].
In the case of jet production, only inclusive jet data are included in the baseline MSHT20 fit [1], as well as the more recent a\({\textrm{N}}^3\)LO analysis [5]. However, a range of LHC dijet data are available [27,28,29,30,31] along with NNLO theoretical calculations to match them [32, 33]. Indeed, the impact of dijet data on the NNPDF fits has been studied in [2, 24] at up to NNLO. While in [24] full consistency was found between the inclusive jet and dijet data sets, in [2] the CMS 8 TeV triple differential data [29] was found to be in significant tension with the baseline fit excluding it, in particular in terms of the impact on the high x gluon. This is of particular note as these data are the only case so far to be included in a PDF fit that are triple differential in the dijet kinematics; this provides a greater constraining power on the PDFs.
In light of this, it is highly relevant to examine the impact of these dijet data on the MSHT20 fit. As well as providing an assessment of this impact within the context of a distinct PDF fit, a key novel element we will examine here is the effect that going to approximate \({\textrm{N}}^3\)LO will have. By doing so, we can determine to what extent questions of consistency between the jet and dijet case, and between these and other data entering the fit, as well as their PDF impact, changes in going to the more accurate a\({\textrm{N}}^3\)LO order. In the latter case, theoretical uncertainties from missing higher orders in the calculation of the cross sections are also, crucially, included. Indeed, as discussed in [5, 18], the effect of going to a\({\textrm{N}}^3\)LO can be significant in terms of the PDF impact of given data sets and the tensions between them.
A further relatively recent theoretical advance that it is interesting to consider is the impact of including full colour corrections at NNLO, as first calculated in [34]. These are shown in this reference to be moderate but not negligible in particular for the case of triple-differential dijet production. However, thus far they have not been considered within the context of a global PDF fit. We therefore study the impact of these corrections here.
In addition to jet and dijet data, as discussed above a further data set of relevance to the high x gluon is the ATLAS 8 TeV Z \(p_T\) data [35]. This was observed in [1] to be in some tension with other data sets in terms of its impact on the gluon, most notably with differential top quark pair production and inclusive jet data. The fit quality was found to be rather poor at NNLO, but in [5] this was observed to improve dramatically when going to a\({\textrm{N}}^3\)LO. In addition, it was illustrated in [18] that the tension between this data set and others in the fit seemed to reduce at a\({\textrm{N}}^3\)LO. At NNLO, the fit quality and impact of this data set were found in the CT and NNPDF fits [2, 3] to be somewhat different, however here smaller subsets of the data were fit to, as well as there being other differences in the treatment of the theory (in particular the uncertainties in the NNLO K-factors) entering the fit, see [1] for more details. Given this, a more detailed analysis of this data set, and its impact on the MSHT fit, is again well motivated.
In light of the above discussion, in this paper we present the first analysis of inclusive jet and dijet production at up to a\({\textrm{N}}^3\)LO order. We analyse in detail the fit quality, consistency between the jet and dijet cases, and overall PDF impact at up to a\({\textrm{N}}^3\)LO order. We also study the effect of including electroweak (EW) corrections, the choice of scale in the case of inclusive jet production (namely \(p_\perp ^{\textrm{jet}}\) of \(H_\perp \)), and the impact of full colour corrections in the case of dijet production. We in addition investigate the effect of how modifying the manner in which the ATLAS 8 TeV Z \(p_T\) data [35] is treated affects the fit at up to a\({\textrm{N}}^3\)LO order, namely by increasing the lower cut on \(p_T^{ll}\) in order to assess any potential limitations of the NNLO fit to these data, as well providing a rather closer comparison to the data subsets that are fit by the CT and NNPDF groups. We also consider the extent to which the known aN\({}^3\)LO information contributes to the improved fit.
The outline of this paper is as follows. In Sect. 2.1 we present the inclusive jet and dijet data sets that enter the fit, as well as the theoretical calculation corresponding to these. In Sect. 2.2 we discuss the fit quality at up to a\({\textrm{N}}^3\)LO order for both inclusive jet and dijet cases. In Sect. 2.3 we present their impact on the high x gluon. In Sect. 3.1 we discuss the Z \(p_T\) data and the corresponding theory in our study. In Sect. 3.2 we present the relevant fit qualities and in Sect. 3.3 the PDFs that result from this. Finally, in Sect. 4 we conclude.
2 Jet and dijet production at NNLO and aN\({}^3\)LO
2.1 Data and theory
The MSHT20 fit [1] includes inclusive jet data from the Tevatron [36, 37] and CMS at 2.76 TeV [38], as well as data from ATLAS [39] at 7 TeV and CMS [40, 41] at 7 and 8 TeV. In all fits which follow, we continue to include the Tevatron and CMS 2.76 TeV data (for which there are no dijet data counterparts), as well as all other non-jet data sets in the MSHT20 fit. We will supplement this by either the 7 and 8 TeV LHC inclusive jet data or their counterpart dijet data, which cannot be included simultaneously due to their statistical overlap, as discussed later. In this study we wish to compare to the MSHT20 baseline at NNLO and aN3LO, for which 13 TeV data are not included, therefore we focus on 7 and 8 TeV data here. The 13 TeV inclusive jet and dijet data [30, 42, 43] will be included in a more major update of the PDFs in the future.
For the inclusive jet fits, we include the ATLAS 7 TeV and CMS 7 and 8 TeV jet data that are in the MSHT20 fit, and now include also the ATLAS 8 TeV [44] data set. We take the larger of the jet radii available, namely \(R=0.6\) for the ATLAS data, and \(R=0.7\) for the CMS. We choose the larger jet radius as this seems to be slightly more perturbatively convergent, although hadronic corrections are a little larger, see e.g. [44]. For the ATLAS 7 and 8 TeV data we apply a smooth decorrelation of certain systematic error sources, guided by the proposal described in [44]. The implementation of this is exactly as described in [1] for the 7 TeV data, while for the 8 TeV data we use this form of decorrelation, but applied to four sources, as suggested in [44], namely the jet flavour response, the multi-jet balance fragmentation, the jet energy scale pile-up \(\rho \) topology, and the non-perturbative corrections.

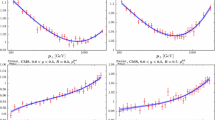
The calculated NNLO to NLO K-factors, including the MC statistical errors, corresponding to a selection of the CMS 8 TeV inclusive jet [41] and dijet [29] data, in the latter case at leading (LC) and full (FC) colour in the NNLO calculation. Also shown is the 4-parameter fit to the K-factors, following the treatment in [15]. The uncertainty band is shown for illustration by summing in quadrature the 68% C.L. fit uncertainties in each bin, i.e. omitting correlations. In the upper plots, the blue (red) bands correspond to the LC (FC) fits
The CMS 7 TeV data correspond to an updated analysis of the earlier 7 TeV data presented in [28]. For this earlier analysis the \(p_\perp \) threshold is higher, with \(p_\perp ^j > 114\) GeV, while for the more recent analysis [40] this extends down to \(p_\perp ^j > 56\) GeV. The \(p_\perp ^j\) binning in the overlapping region is identical in the two cases. For the CMS 8 TeV data [41] we include the full statistical correlations between bins, available on the xFitter website [45], following advice from the relevant analysers [46]. In all cases, the data are presented double differentially in the jet \(p_\perp \) and rapidity, y, and reconstructed using the anti-\(k_\perp \) algorithm [47], while we apply non-perturbative corrections and uncertainties provided by the experimental collaborations.
For the dijet fits, we include ATLAS data [27] at 7 TeV, and CMS data at 7 and 8 TeV [28, 29]. The ATLAS data are presented double differentially in terms of the dijet invariant mass, \(m_{jj},\) and half rapidity separation, \(y^* = |y_1-y_2|/2,\) of the two leading jets. The CMS 7 TeV data are presented double differentially in terms of the dijet invariant mass, \(m_{jj},\) and maximum absolute rapidity, \(|y_\textrm{max}|,\) of the two leading jets. The CMS 8 TeV data are presented triple differentially, in terms of the average transverse momentum, \(p_{\perp \textrm{avg}},\) half rapidity separation, \(y^*,\) and boost of the dijet system, \(y_b=|y_1 + y_2|/2,\) defined in all cases with respect to the leading jets. As we will see, the triple differential nature of the CMS 8 TeV data leads to this set having a particularly significant impact on the fit in comparison to the other dijet sets, due to its ability to isolate specific regions of parton x more precisely. In the ATLAS case we take the \(R=0.6\) data set, while the CMS data use jet radius \(R=0.7.\) In all case the jets are again reconstructed using the anti-\(k_\perp \) algorithm [47], while we apply non-perturbative corrections provided by the experimental collaborations. For the CMS 8 TeV data we note that, as demonstrated in Appendix A.3 of [48], a selection of the correlated systematic errors change sign at a given point in \(p_\perp ^{\textrm{av}},\) however this is not reflected in the corresponding Hepdata entry. Following discussion with the relevant analysers [49], we have corrected these in our fit. As we will see, the impact on the fit quality is relatively minimal, which can be expected as the majority of these error sources change sign at larger \(p_\perp ^{\textrm{av}},\) where the data are less precise.
We note that the inclusive jet fit does not include these dijet data sets, and likewise the dijet fits exclude the ATLAS and CMS 7 and 8 TeV inclusive jet data sets. This is necessary in the case of the CMS inclusive jet data, and the ATLAS 7 TeV inclusive jet data, in order to avoid double counting, given the correlations between the inclusive and dijet measurements are currently not available, and these do not come from distinct underlying data sets. In principle, this is not the case for the ATLAS 8 TeV data, where no dijet measurement is available at the time of this study, but in order to better differentiate between the fitting of jet and dijet data, we continue to exclude this in the dijet fit.
For the theoretical predictions we use NLO APPLGrid [50] and FastNLO [51, 52] grids, supplemented by NNLO K-factors calculated using NNLOJET [32, 33]. For the NNLO corrections, the leading colour (LC) results are used in all cases except for the CMS 8 TeV dijet data [29], where the full colour (FC) predictions [34] are also compared to. For both the leading colour and full colour results we utilise K-factors. As discussed in [34] the impact of FC at NNLO is small in the case of both inclusive jet and double differential dijet production, therefore we only expect any significant effect to occur for this triple differential data set. Moreover for many of the other cases the FC results are not publicly available. Given this, we will take the LC results as our baseline in the dijet fit, although we will examine all relevant differences that come from instead using the FC result in the dijet fit.


The K-factors are, as in [1, 15], fitted to a 4-parameter polynomial in the logarithm of the binned variable. As the NNLO to NLO K-factors are expected to be smoothly varying functions, we argue this provides more control over any assessment of the impact of including NNLO theory in comparison to simply including the quoted MC errors in a bin-by-bin uncorrelated way. Moreover, our default treatment of K-factors at aN\({}^3\)LO is constructed by using the NNLO (and NLO) K-factors in a manner that is based on these being smoothly varying functions, though is not reliant upon this. In Fig. 1 we show the result of this, and the corresponding uncertainty, for a representative selection of the CMS 8 TeV inclusive jet [41] and dijet [29] data (with both the LC and FC cases shown), and the fit is seen to work rather well. A moderate but clear difference in trend is seen between the LC and FC cases for the dijet distributions, as has been observed already in [34]. For the inclusive jet data, we take as our default renormalisation/factorisation scale \(\mu = p_\perp ^j,\) however we will also consider \(\mu = \hat{H_T},\) defined as the scalar sum of the transverse momentum of all partons in the event, see [53]. In Fig. 2 we show the NLO, NNLO and aN\({}^3\)LO QCD K-factors corresponding to a selection of the CMS 8 TeV dijet [29] data, with the aN\({}^3\)LO QCD K-factors corresponding to the default dijet fit described in Sect. 2.2. For concreteness we take the LC NNLO predictions here. The K-factors are determined as described in Section 7.1 of [5]. We can see that the predicted behaviour at aN\({}^3\)LO displays good perturbative convergence, in line with the lower order. Results for the inclusive jet case were presented in Section 7.2. of [5], and so are not repeated here, but are also found to display similarly good perturbative convergence.
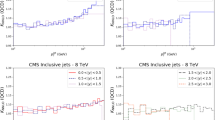
EW corrections are included as K-factors, and computed as in [54]. These include \(O(\alpha \alpha _s)\) and \(O(\alpha ^2)\) and \(O(\alpha \alpha _s^2)\) weak radiative corrections, that is they account for the dominant Sudakov logarithmic effect that becomes more significant at larger jet \(p_\perp \) and dijet \(m_{jj}.\) Photon-initiated production is not included in these, but as discussed in [55] these are negligible for jet production. The EW K-factors corresponding to a representative selection of the CMS 8 TeV inclusive jet [41] and dijet [29] data are shown in Fig. 3. We can see that in one bin these are as large as \(\sim 10{-}20\%\) at larger values of the kinematic variable, \(p_\perp ^j\) or \(p_\perp ^{\textrm{av}}\) in this case, but that for other rapidity bins they are significantly smaller. The magnitude of the EW corrections is moderately larger for the inclusive case, although not significantly so.
2.2 Fit quality
We now consider the fit quality, i.e. \(\chi ^2\) per number of points, for global PDF fits including the jet and dijet data. As described above, the baseline data set is in both cases the same as MSHT20, but with the jet fit including 7 and 8 TeV inclusive jet data from ATLAS and CMS [39,40,41, 44], and the dijet fit including instead the 7 and 8 TeV dijet data from ATLAS and CMS [27,28,29]. The inclusive jet fit then excludes the corresponding dijet data, and vice versa. For the sake of comparison, we will also consider ‘no jets/dijets’ fits, which exclude both of these data sets, although continue to include the lower energy inclusive jet data from the LHC and Tevatron, again as described in the previous section. These provide relatively limited constraints on PDFs.
In Table 1 we show the fit quality at both NNLO and aN\({}^3\)LO for these cases, while in Table 2 we show results at NLO. In all cases, unless otherwise stated, NLO EW corrections are included for the jet and dijet data, with the treatment of the other data sets being as in MSHT20 [1, 55]. We note that in the original MSHT20aN3LO study [5] the CMS 7 TeV inclusive jet data were taken with \(R=0.5,\) rather than \(R=0.7\) that we now take, and moreover NLO EW corrections were omitted in the CMS 7 or 8 TeV inclusive jet data. Therefore our inclusive jet case now corresponds to the QCD only case of the recent aN\({}^3\)LO + QED study [6]. In Table 1 the fit qualities shown in bold are for data sets that are included in the corresponding fit, while the remainder are the predicted fit qualities from the resulting PDF set. In the aN\({}^3\)LO case, for the jet/dijet predictions we apply the K-factors that are extracted from the corresponding fit with these data included, given these are not well determined (or determined at all in the dijet case) from the fit with these data sets excluded.
Considering first the jet fits, we can see that the fit quality to the jet data improves from 1.73 to 1.67, and then to 1.63 from NLO to NNLO and aN\({}^3\)LO, respectively. That is, the fit quality improves with each order, as we would hope for. This improvement from NNLO to aN\({}^3\)LO is not observed in [5], with the inclusion of NLO EW corrections for the CMS 7 and 8 TeV inclusive jet data sets and addition of the ATLAS 8 TeV jet data altering the behaviour. In any case, the improvement with each order is relatively mild, and even at aN\({}^3\)LO the fit quality remains poor. We recall that for the CMS 8 TeV jet data [41] we include statistical correlations between bins; excluding these leads to a rather significant improvement in the fit quality for this data set, by e.g. \(\sim 0.4\) per point at NNLO. For the ATLAS jet data, we find that the impact of the default correlations of the systematic errors is not negligible but relatively mild: at NNLO, the fit quality to the 7 (8) TeV data deteriorates by 0.2 (0.1) per point if these are used. The former result was already observed in [1]. Also shown in the table is the result of a the aN\({}^3\)LO fit but with NNLO K-factors applied for the five classes of data sets described in [5] (namely all hadronic processes and dimuon production in semi-exclusive DIS). We can see that in this case the description of the jet data sets in fact deteriorates mildly with respect to the NNLO cases. It is therefore not the case that a more precise aN\({}^3\)LO treatment of DIS data and DGLAP evolution alleviates some degree of tension with the inclusive jet data, as was also observed in [5]. The inclusion of the aN\({}^3\)LO K-factors does provide sufficient freedom to give a net improvement in fit quality to jet data, but only a mild one.
In the dijet fits we again see an improvement in the fit quality with increasing perturbative order, from 3.14 to 1.21 and 1.06 at NLO, NNLO and aN\({}^3\)LO, respectively. However here the improvement is clearly more significant, with both the NNLO and aN\({}^3\)LO fits being rather good. Again we observe the aN\({}^3\)LO dijets fit with the NNLO K-factors has a very slightly worse fit quality relative to the full aN\({}^3\)LO fit, though in the dijet case, still improved relative to the NNLO fit, indicating a preference for the known aN\({}^3\)LO information included in the fit. For the CMS 8 TeV dijet data, we find that reverting to the correlated systematic errors provided on the Hepdata repository, i.e. with apparently incorrect signs, gives a relatively small impact on the fit quality, with a deterioration of 0.02 per point at NNLO. We note that the combination of the relatively significant size of the 7 and 8 TeV inclusive jet data set with respect to the global data set (about \(15\%\) in terms of the number of data points) and the significantly worse fit in this case results in the global fit quality at NNLO (aN\({}^3\)LO) being significantly improved in the dijet fit in comparisons to the jet fit, by 0.07 (0.08) per point.
At NNLO, if the K-factor points along with their quoted uncorrelated bin-by-bin statistical errors are used instead of the smooth fitting procedure described in the previous section, we find that the inclusive jet fit quality improves by \(\sim 0.2\) per point. Such an improvement is not entirely surprising: the inclusive jet data are to a large extent dominated by systematic experimental errors (and their correlations) rather than statistical errors, and hence the fit quality is driven by the extent to which the theory can match these precise data. When the fit quality is relatively poor, including an additional source of uncorrelated uncertainty can therefore wash this out somewhat, even if the underlying K-factors are scattered by these errors, and lead to a better fit quality; effectively, the statistical errors on the data are being increased. Indeed, at NNLO and aN\({}^3\)LO in the dijet case, where the fit quality is good, the difference between using the direct K-factor points and the fit is in general marginal. The one exception to this is when FC corrections are used for the CMS 8 TeV dijet data (discussed further below), for which the fit quality in fact deteriorates by 0.1 (0.05) per point at NNLO (aN\({}^3\)LO) relative to the K-factor fit we use by default. Looking at Fig. 1 there is perhaps some evidence that the scatter in the K-factors is somewhat larger than the quoted MC uncertainties, which may be driving this effect. Of course, the need to perform smooth fits to bin-by-bin K-factors is eliminated once interpolation tables directly at the desired order are provided, e.g. at NNLO once NNLOJET [61, 62] results become available in such a format rather than via K-factors.
Given these findings, we would therefore argue that fitting the K-factors as smooth functions and including associated uncertainties gives a clearer picture of the overall impact of such higher-order QCD corrections, when these are made available in this way. However, we find that the principle results, namely that the dijet fit quality is better, as well as the impact of EW corrections and the scale choice discussed further below, remain consistent irrespective of the treatment of the K-factors.

Theory/Data comparison for a selection of the CMS 8 TeV dijet [29] data, at different perturbative orders. The upper (lower) plots correspond to the result before (after) shifting by the correlated systematic errors. The black error bands are the purely statistical errors, while, the grey bands in the upper plot correspond to the statistical and total systematic error added in quadrature, shown for illustration
The improvement from NLO to NNLO in the dijet fit is particularly dramatic, and we can see is driven by the description of the most constraining CMS 8 TeV dijet data, which at NLO is 5.27 per point, i.e. very poor indeed. At NNLO (aN\({}^3\)LO) on the other hand, this improves to 1.22 (0.86). Such a level of improvement from NLO to NNLO is not without precedent; in the MSHT20 analysis [1], for example, the description of the ATLAS high precision W, Z data at 7 TeV [63] is 5.0 per point at NLO and 1.91 at NNLO. The latter admittedly remains a relatively poor fit, but the impossibility for purely NLO QCD to give anything other than an extremely poor description of such high precision data is clear. Indeed, in [5] the fit quality is found to improve again to 1.55 per point at aN\({}^3\)LO, with predicted K-factors that qualitatively follow theoretical expectations [64]. We therefore view this improvement in the dijet case as again indicative of the failure of a NLO QCD analysis to match the increasing high precision and multi-differential data from the LHC, in this case the triple-differential CMS 8 TeV dijet data.
To understand this further, in Fig. 4 we show the theory/data for a selection of the CMS 8 TeV dijet data, at the different perturbative orders. In the upper plots we show results before shifting by the correlated systematic errors, and while there is perhaps some hint that the NLO description will not be good (e.g. in the higher \(p_\perp \) region) this is not completely clear. In the PDF fit the impact of the correlated systematics is incorporated via experimental nuisance parameters, one per correlated systematic, which are then allowed to be shifted in the PDF fitFootnote 1 with an appropriate \(\chi ^2\) penalty, as is standard, see e.g. Section 4.2.1 of [65]. On the other hand, after the PDF fit, once we shift by the correlated systematic errors, as shown in the lower plot, we can clearly see that NLO theory cannot describe the shape of the corresponding distributions. It is therefore only after accounting for the systematic errors, and their appropriate correlations, that the poor fit quality in the NLO case becomes clear, and this is not completely evident by simply looking at data/theory comparisons by eye. We note that the mismatch of the shape when comparing data to theory at NLO in the left of Fig. 4 is roughly opposite to, and hence corrected by, the NNLO correction to the K-factor in Fig. 2, with the latter increasing with \(p_\perp .\)
Turning now to the description of data not in the individual fits, at NNLO we find that the description of the jet/dijet data not included in the fit is \(\sim 50\) points worse in both cases in comparison to the case where these are fit; the prediction of the jet data from the dijet fit is 0.08 per point worse, and the prediction of the dijet data from the jet fit is 0.17 per point worse. This indicates some degree of tension between the pulls of the two sets, even if it is not necessarily dramatic. At aN\({}^3\)LO on the other hand, the difference is significantly reduced, with the description of the jet/dijet data not included in the fit being \(\sim 15\) points worse in both cases. Therefore, although the description of the jet data remains relatively poor at this order, the degree of tension between the jet and dijet data is reduced. If only NNLO K-factors are used the description of the jet data in the dijet fit is \(\sim 40\) worse, which might indicate a larger degree of tension in this case. On the other hand, the description of the dijet data by the jet fit is \(\sim 8\) worse, i.e. less than in the full aN\({}^3\)LO jets fit, so the picture is somewhat mixed.
It it also instructive to consider the fit quality to other LHC data sets that are known to be particularly sensitive to the high x gluon, namely the ATLAS 8 TeV Z \(p_T\) [35] data and the range of differential top quark pair production data from ATLAS and CMS [57,58,59,60] that are included in the baseline MSHT20 fit. The fit qualities of these datasets are also shown in Table 1. At NNLO, we can see that the description of the Z \(p_T\) data improves from 1.87 to 1.66 per point, i.e. \(\sim 22\) points in total, when the dijet rather than jet data are fit. This therefore indicates that some degree of the tension that is known to exist between the inclusive jet and Z \(p_T\) data (e.g. observed in [1, 17]) is reduced when the dijet data are instead considered. The fit quality for the differential top data on the other hand is somewhat worse in the dijet fit, by 0.16 per point, indicating that these data are in somewhat larger tension with the dijet data than the inclusive jets. At aN\({}^3\)LO, on the other hand, the fit quality for the Z \(p_T\) improves dramatically, as observed in [5]; it is close to 1 per point irrespective of whether the jet or dijet data are fit. This will be examined in more detail in Sect. 3. Similarly, any difference in the differential top data is reduced. This is indicative of the fact that the aN\({}^3\)LO tends to reduce such tensions in comparison to the NNLO case. If NNLO K-factors are used, we can see that the description of the Z \(p_T\) data remains significantly improved with respect to NNLO, in both the case of the jet fit (again as observed in [5]) and the dijet fit. However, there is further room for improvement here, and we can see that for the dijet fit the description of the Z \(p_T\) data is 0.13 per point lower. The description of the differential top data is 0.11 per point worse, on the other hand. Therefore, the degree of tension is reduced purely by including aN\({}^3\)LO theory (absent the K-factors), but remains present between the Z \(p_T\) data and the inclusive jets, and the differential top data and the dijets.
We next consider in Table 3 the impact of the scale choice in the jet fits at different perturbative orders. Namely, we consider changing from our default renormalisation/factorisation scale \(\mu = p_\perp ^j,\) to \(\mu = \hat{H_T},\) defined as the scalar sum of the transverse momentum of all partons in the event, see [53]. For the CMS 7 TeV data, NNLO K-factors are only available for the \(p_\perp \) binning of the earlier analysis [28], i.e. not for the lower \(p_\perp \) bins, rather than the updated analysis [41]. In particular, these are only available for \(p_\perp ^j > 114\) GeV, rather than the lower value of \(p_\perp ^j > 56\) GeV corresponding to the later analysis. We therefore impose this higher \(p_\perp ^j\) cut for the \(\mu = \hat{H_T}\) case and, to maintain a direct comparison, the \(\mu = p_\perp ^j\) case presented in Table 3, although not elsewhere. It is argued in [53] that \(\mu = \hat{H_T}\) is a more perturbatively stable scale choice than \(\mu = p_\perp ^j,\) and indeed we can see that at NLO the fit quality is somewhat better for this choice, by 0.08 per point, i.e. \(\sim 50\) points in \(\chi ^2.\) However, at NNLO and aN\({}^3\)LO the difference is marginal, with the \(\mu = \hat{H_T}\) scale giving a slightly worse fit quality. In terms of the trend with increasing perturbative order we can see that while this improves order-by-order for \(\mu = p_\perp ^j\) (albeit to a relatively poor fit quality even at aN\({}^3\)LO), for \(\mu = \hat{H_T}\) no clear trend of this sort is observed. Therefore, at NNLO and beyond there is no clear preference in terms of the fit quality between the two scale choices.

The gluon PDF resulting from the jet and dijet fits, with respect to the no jets/dijets case. The left (right) plot corresponds to the NNLO (aN\(^{3}\)LO) case. The top plots show the PDF ratio, including the 68% C.L. PDF errors, while the bottom plots show the symmetrised errors. Also shown in both top plots are jet and dijet cases at aN\(^{3}\)LO, but with NNLO K-factors
In Tables 4 and 5 we show the impact of excluding NLO EW corrections at both NNLO and aN\(^{3}\)LO in QCD, and for both the jet and dijet fits, respectively. In the dijet case, we can see that the fit quality with the EW corrections is improved by \(\sim 0.22{-}0.23\) per point relative to the case without, i.e. by \(\sim 60\) points in \(\chi ^2,\) at both NNLO and aN\({}^3\)LO orders. The inclusion of EW corrections is therefore relatively significant in achieving an overall very good fit quality in both cases. However, in the jet case we can see that the fit quality at both orders in QCD actually deteriorates upon the inclusion of EW corrections, by 0.1 per point at NNLO and somewhat less (0.04 per point) at aN\(^{3}\)LO. The reason for this deterioration is unclear, but given these EW corrections should certainly be included we would in general expect them to improve the fit quality. Given this, this observation is arguably a further indication of an underlying issue in the fit to the inclusive jet data. We note that if NLO EW corrections are excluded, then the fit quality to the jet data indeed gets mildly worse at aN\(^{3}\)LO in comparison to NNLO, consistent with the differing trend observed in [5] and discussed above.

The impact of excluding EW corrections and taking \(\mu = H_T\) on the gluon PDF resulting from the jet NNLO fits, with respect to the default (\(\mu = p_\perp ^j,\) with EW corrections) fit. The 68% C.L. PDF errors are shown for the baseline fit only
Next, in Table 6 we examine the impact of including FC corrections at NNLO in case of the CMS 8 TeV dijet data [29]. We can see that this in fact leads to some moderate deterioration in the fit quality at NNLO, by 0.07 per point. This is not in general what we would expect, given these FC corrections should be included in the theoretical prediction. However, the deterioration corresponds to less than \(1\sigma \sim 0.13 \) per point for this data set, so is of relatively limited statistical significance. Moreover, at aN\(^{3}\)LO the difference is very mild, with the fit quality in the FC case in fact being slightly better. At aN\(^{3}\)LO we utilise fitted K-factors for different process categories, as described in Section 7 of [5], to incorporate the uncertainty from the missing higher order corrections for hadronic processes at N3LO into the PDF fit. These are allowed to be constrained and fit by the data as for other theoretical nuisance parameters, see [5] for more details. Interestingly, if NNLO K-factors are used (i.e. we set the aN3LO fitted K-factors for dijets to zero so they reduce to the known NNLO results), the difference is also rather less than at NNLO, although in this case the FC fit quality is slightly worse than the LC. This therefore indicates that difference between the NNLO and aN\(^{3}\)LO fits is not entirely driven by the freedom one has in the approximate N\(^{3}\)LO K-factors to absorb in a large part differences between FC and LC results and NNLO; while the aN\(^{3}\)LO K-factor will be constructed from a different NNLO K-factor in the FC case, there remains a freedom in the corresponding nuisance parameters at this order, see [5]. However this does play some role, with the aN\(^{3}\)LO K-factor giving an improvement of 0.04 per point in comparison to the NNLO K-factor, i.e. aN\(^{3}\)LO (\(K_\textrm{nnlo}\)), case. In other words going from the FC fit quality being 0.02 per point better in the full aN\(^{3}\)LO fit to 0.02 worse when the K-factors are fixed.

The impact of including full colour (FC) corrections at NNLO for the CMS 8 TeV dijet data [29] in the dijet fits at NNLO and aN\(^{3}\)LO in QCD, with respect to the default fit to both data sets. The 68% C.L. PDF errors are shown for the baseline and LC fits only

The impact of including only the ATLAS or CMS data on the gluon PDF in the jet and dijet fits at NNLO and aN\(^{3}\)LO in QCD, with respect to the default fit to both data sets. The 68% C.L. PDF errors are shown for the baseline fit only
We find that taking the FC result does not change any of the relevant conclusions above: that is, the fit quality in the dijet case remains significantly better at NNLO and aN\(^{3}\)LO, with a moderate improvement seen between these orders, while the impact of EW corrections remains that of improving the fit quality. We also note that there is some change in the fit quality to other data sets in the fit when a refit is performed with FC corrections included instead of LC, although this is rather small; the total improvement in \(\chi ^2\) upon refitting at NNLO is \(\sim 4\) points, with \(\sim 3\) of this being in the CMS 8 TeV dijet data. However we recall that FC corrections are not available for and thus also not included for any of the other jet data sets, and so it is difficult to draw firm conclusions here.

The quark PDFs resulting from the jet and dijet fits, with respect to the no jet case, with 68% C.L. PDF errors given. The left (right) plots show the NNLO (aN\(^{3}\)LO) fits
We finish this section by commenting on the results of the earlier study in the NNPDF fit [24], where largely the same 7 and 8 TeV jet and dijet data sets were fit at up to NNLO order in QCD. In terms of the inclusive jet fits, a completely direct comparison is not in all cases possible, as the baseline fit there only includes one rapidity bin in the ATLAS 7 TeV jet data [39], while for the CMS 7 TeV data the older analysis of [28] is used rather than the update [40] that we take by default, and for the CMS 8 TeV data statistical correlations are not included. Nonetheless, in terms of the overall trends we can observe some consistency but also some differences. In particular, the fit quality to the ATLAS jet data is relatively poor, similar to here for the 7 TeV and in fact rather worse at 8 TeV (although in the later NNPDF4.0 analysis [2] this is significantly lower), while the fit quality to the CMS data is better, but consistent with what we find when we cut out the lower \(p_\perp \) bins of the 7 TeV data and do not account for statistical correlations in the 8 TeV data. Although a fit to both 7 and 8 TeV data sets at NLO is not performed, when fit individually it is found in the NNPDF analysis that the fit quality to the inclusive jet data deteriorates from NLO to NNLO. This is not observed in this study, but given the various differences in the manner in which the inclusive jet data are treated and lack of a like-for-like comparison fit to both 7 and 8 TeV data, there are many potential reasons for this. The fit quality upon the inclusion of EW corrections is on the other found broadly to deteriorate, as we find.
For the dijet data, the fit quality to the CMS 8 TeV dijets [29] is in fact rather worse in [24] than what is found here, being 1.58 per point in the default fit, in comparison to 1.22. The reason for this is not straightforward to determine, but is most likely due to the underlying differences between the MSHT and NNPDF fits, and most importantly the other data sets that are included in the fit, and the treatment of them. The fit quality at NLO is also found to be very poor (3.69 per point in a fit to 8 TeV dijet data) and to improve significantly upon the inclusion of NNLO theory. On the other hand, the fit quality is found to deteriorate upon the inclusion of EW corrections, contrary to our result here. Therefore, our results indeed display some similarities with the study of [24], but also some differences. This highlights that the interpretation of a given set of data cannot always be evaluated in isolation, but is rather tied up with the other data in the PDF analysis and the manner in which these are treated, as well as other methodological differences. As an example, the treatment of the ATLAS 8 TeV Z \(p_T\) [35] data, which impact on the gluon PDF in a similar (large) x region, is rather different between the NNPDF and MSHT analyses, with NNPDF including somewhat less data and treating the uncertainties slightly differently, see Sect. 3 for a detailed discussion.
In conclusion, we observe that the fit quality to the dijet data is greatly improved with respect to the inclusive jet case at NNLO, and that this remains true at aN\(^{3}\)LO, where the fit quality to the inclusive jets remains relatively poor. This conclusion is unaffected if we take \(\mu = H_T\) rather than \(\mu = p_\perp ^j\) for the renormalisation/factorisation scale in the inclusive jet theory, while the impact of FC corrections in the triple differential data is mild but not negligible. Moreover, we find that the fit quality to the inclusive jet data becomes worse when we include NLO EW corrections, in contrast to the dijet case, where we see an improvement, as we would in general expect. The underlying issue that is present in achieving a good fit to the jet data when binned inclusively is therefore not present in the dijet measurements, including the triple differential and highly constraining CMS 8 TeV data. This indicates that it may be preferable to include dijet rather than inclusive jet data in the fit, when both options are available. However when and if the full correlations between the two data sets become available, this conclusion will need to be reassessed.
2.3 Impact on PDFs
We next consider the impact of the fits described in the previous section on the PDFs. We begin in Fig. 5 with the gluon PDF, as we expect jet and dijet data to have the largest impact in this case, in particular at high x. We can see from the top left plot that at NNLO, while they are consistent within errors, the jet and dijet data have somewhat different pulls on the gluon, with the dijet data preferring a somewhat larger gluon. This is consistent with the reasonable degree of tension observed in the two fits in Table 1, as well as with the fact that the dijet fit give a rather better description of the ATLAS Z \(p_T\) data [35], which is found to prefer a larger high x gluon in the MSHT20 fit [1, 17, 18]. At aN\(^{3}\)LO, on the other hand, the pull on the gluon is more consistent, which is again as expected from the smaller degree of tension observed between the two fits in Table 1.
To investigate this further, we also show in Fig. 5 (right) the impact on the gluon at aN\(^{3}\)LO, but with NNLO K-factors. In this case the jet and dijet results show larger deviations at high x. Indeed, in the left plot we also include the same \(K_\textrm{nnlo}\) curves for comparison, and the difference between the jet and dijet case with NNLO K-factors is more similar to that at NNLO. For the jet fit, the majority of the change in going to aN\(^{3}\)LO can be seen to come from the other aN\(^{3}\)LO information in the fit, as in the right figure we can see that the full aN\(^{3}\)LO and \(K_\textrm{nnlo}\) results are very similar. For the dijet fit, the trend is different, and the inclusion of aN\(^{3}\)LO K-factors does have some impact on the gluon. Overall, while we can see in the left figure that the aN\(^{3}\)LO (with NNLO K-factor) curves are somewhat closer than the pure NNLO case, the impact of including aN\(^{3}\)LO K-factors is more significant, bringing the jet and dijet gluons into closer agreement. Thus, to a large extent the reduction in the (mild) tension between the jet and dijet fits with respect to the high x gluon at aN\(^{3}\)LO is due to the freedom allowed by the parameterised K-factors at this order, and results in a gluon in the dijet fit that lies closer to the jet case.
In terms of the PDF uncertainties, shown in the lower plots after symmetrising, a clear but moderate reduction with respect to the no jets/dijets fit is observed. This reduction is comparable between the jet and dijet fits, but overall the dijet fits give a larger reduction, at both orders. While this relative improvement is quite small, it is worth noting that in terms of the bare number of data points, the dijet data are over a factor of 2 less. Indeed, most of the constraint comes from the CMS 8 TeV dijet data, which has a factor of \(\sim 5\) less data points. Although such a measure only provides a rough guide, it is clearly notable that even given this the reduction of the gluon PDF uncertainty is slightly greater for the dijet fit; for a larger data set we may expect further improvements.
In Fig. 6 we show the impact of excluding NLO EW corrections and separately of using \(\mu = H_T\) rather than \(\mu = p_\perp ^j\) for the renormalisation/factorisation scale in the inclusive jet case, corresponding to a subset of the fits in Tables 3, 4 and 5. We can see that the effects are small and always within the PDF uncertainties, but not entirely negligible, such that the central values can approach close to the edge of the PDF uncertainty band of the baseline fit in some regions. There is no particular trend for a reduced impact at aN\(^{3}\)LO.
In Fig. 7 we show the impact of including FC corrections at NNLO to the CMS 8 TeV dijet data, in the dijet fits at NNLO and aN\(^{3}\)LO. The impact is mild and well within PDF uncertainties, though not entirely negligible at high enough x.
In Fig. 8 we show the impact of only fitting the ATLAS or CMS jet/dijet data, to examine any difference in pull between these. In the left plots the results of the jet fits are shown, and we can see that the ATLAS and CMS data do indeed show some difference in pulls on the higher x gluon (a similar effect was observed in [15] at NNLO), indicating a degree of tension. This remains true at aN\(^{3}\)LO, as see in the bottom left plot. In the right plots the corresponding dijet cases are shown, and here we can see that the ATLAS and CMS data tend to pull in a more similar direction, indicating less of a degree of tension. Overall, the CMS curve follows the baseline (ATLAS + CMS) curve very closely, due to the fact that the 8 TeV triple differential CMS data are driving the fit in this case.
Finally, in Fig. 9 we show the impact on the quark flavour decomposition, at both NNLO (left figures) and aN\(^{3}\)LO (right figures). Overall, the impact on these PDFs is indeed less than in the gluon case at high x. However, interestingly at NNLO the dijet fit leads to some rearrangement of the quark flavour decomposition at intermediate x. The down quark and antiquark are particularly affected, and indeed have rather smaller uncertainties. The reason for this is not obvious, but appears to be simply due to the fact that the location of the global PDF minimum in the dijet case is such that the down type quarks are rather better constrained. At aN\(^{3}\)LO, on the other hand, this effect is rather smaller, although the uncertainty on the d remains somewhat smaller in comparison to the jet, and no jet/dijet, cases. We note that the aN\(^{3}\)LO with NNLO K-factors gives rather similar results in comparison to the full aN\(^{3}\)LO fit, and hence are not shown.
3 ATLAS 8 TeV Z \(p_T\) data at NNLO and aN\(^{3}\)LO
3.1 Data and theory
A further source of constraints on the high x gluon in the MSHT20 NNLO [1] and aN\({}^3\)LO [5] PDFs is the ATLAS 8 TeV measurement of the dilepton transverse momentum distribution [35], which we refer to for brevity as the Z \(p_T\) data set, although it extends beyond the peak region. Different groups have reported slightly different impacts of this data [2, 3], though different amounts of data are included. In the MSHT20 NNLO and aN\({}^3\)LO PDF fits we choose to fit the maximum amount of data possible for this data set and include the absolute cross sections. Therefore we include the data double-differential in the lepton pair transverse momentum, \(p_T^{ll},\) and rapidity, \(y_{ll},\) in the Z peak mass bin ([66,116] GeV). For all other mass bins we take the available single differential distributions in \(p_T^{ll}.\) We include a \(p_T^{ll}>30\,{{\textrm{GeV}}}\) cut in order to exclude the region influenced by transverse momentum resummation and non-perturbative corrections. Finally, no maximum \(p_T^{ll}\) cut is applied as electroweak corrections (which are relevant here) are included as provided in [25]. We therefore include a total of 104 data points, more than included by default by other global fitting groups. Our theory predictions are calculated using MCFM [66] with APPLgrid at NLO [50] with NNLO K-factors determined from NNLOJET [61, 62] and using the factorisation scale as the transverse mass of the vector boson, as is standard. Further details are given in [1] and in the next section. For the baseline data set we choose, for simplicity and ease of comparison with earlier studies, to fit to the same inclusive jet data described in the previous sections. However, we may expect broadly similar conclusions if instead the dijet baseline data set were fit.
3.2 Fit quality
It was noted in [5] and earlier in Sect. 2.2 (see Table 1) that there was a significant improvement in the fit quality of this ATLAS 8 TeV Z \(p_T\) data at aN\({}^3\)LO relative to NNLO, with the latter quite poorly fit whilst the former was able to fit these data without issues. This suggested a clear preference in this precision data for aN\({}^3\)LO QCD corrections to the PDFs. The significant improvement at aN\({}^3\)LO relative to NNLO was also observed to be largely independent of the choice of inclusive jet or dijet data in the fit and therefore unconnected to potential tensions between these data sets. Nonetheless, it was noted in Sect. 2.2 that in absolute terms the fit quality of the Z \(p_T\) data set was notably better in the dijet fit at NNLO, indicating greater tension between the Z \(p_T\) and inclusive jet data than the dijet data, also observed in the pulls in Fig. 5 (upper left). This difference is absent at aN\({}^3\)LO. In this section, we therefore investigate these ATLAS 8 TeV Z \(p_T\) data further in the context of the updated NNLO and aN\({}^3\)LO baseline PDFs used in this paper with the addition of the ATLAS 8 TeV inclusive jet data relative to our MSHT20 [1] baseline.
Table 7 provides the fit qualities in terms of the \(\chi ^2\) per datapoint at NNLO and aN\({}^3\)LO for these data, first in our default setup with a \(p_T^{ll}\) cut removing the resummation region below \(30\,\text {GeV}.\) The fit qualities of 1.87 and 1.04 for the NNLO and aN\({}^3\)LO fits respectively follow the pattern previously noted of a poor fit quality at NNLO being significantly ameliorated at aN\({}^3\)LO. In order to investigate whether this improvement at aN\({}^3\)LO is associated with a particular part of the \(p_T^{ll}\) spectrum, and thereby assess any potential limitations of the NNLO fit to this data, we systematically increase the \(p_T^{ll}\) minimum cut incrementally and analyse the fit quality of these data at each order. Table 7 shows a gradual improvement of the fit quality of the NNLO fit from 1.87 (default \(p_T^{ll} > 30\,{\textrm{GeV}}\)) to 1.24 (for \(p_T^{ll} > 105\,{{\textrm{GeV}}}\)). By way of comparison there is also a small improvement in the fit quality of the aN\({}^3\)LO fit from 1.04 to 0.83 over the same range. Nonetheless the fit quality at NNLO remains poor and is always considerably worse than at aN\({}^3\)LO. There is therefore no clear evidence of issues associated with any particular part of the \(p_T^{ll}\) spectrum at NNLO. In particular the fit remains comparatively poor even with quite high values of \(p_T^{ll}\) cut. Thus, there is no evidence that sensitivity to resummation or other effects at low \(p_T^{ll}\) higher than our default \(p_T^{ll} > 30\,{{\textrm{GeV}}}\) cut is responsible for the poor fit quality at NNLO. In addition, the final column of Table 7 shows the effect of imposing a maximum \(p_T^{ll} < 150\,{{\textrm{GeV}}}\) cut, which removes the larger \(p_T^{ll}\) region where there is sensitivity to electroweak corrections (though these are included for these data). A poor fit quality of 1.91 remains at NNLO, and is again significantly improved to 1.08 at aN\({}^3\)LO, indicating sensitivity to electroweak or other effects in the high \(p_T^{ll}\) region are also not responsible for the poor fit quality at NNLO.

Theory and data comparison at NNLO (dotted lines), NNLO with a\(\textrm{N}^3\)LO K-factors added (dot dashed lines), a\(\textrm{N}^3\)LO with NNLO K-factors (dashed lines) and a\(\textrm{N}^3\)LO (solid lines). The ratio of theory/data is shown and the points are the datapoints with their total uncorrelated error only shown by the errorbars. The left figure is the data pre-fit, whilst the right figure is after the correlated systematic pulls are accounted for. Representative bins are shown in each figure, with the top being the \(M_{ll}=[66,116]~{\textrm{GeV}}, y_{ll}=[0.0,0.4]\) and the bottom being the \(M_{ll}=[46,66]~{\textrm{GeV}}\) \(y_{ll}=[0.0,2.4]\) bin

The effect on the gluon PDF of cutting data below a given \(p_T^{ll}\) from the ATLAS 8 TeV Z \(p_T\) data at NNLO (left) and aN\({}^3\)LO (right) at \(Q=100~{\textrm{GeV}}.\) The numbers in brackets give the number of datapoints included
There is also evidence of reduced tension of the Z \(p_T\) data with other data sets in the global fit at aN\({}^3\)LO in comparison with those at NNLO. The rest of the global fit data at NNLO changes by \(\Delta \chi ^2 = -35.9\) upon the removal of the ATLAS 8 TeV Z \(p_T\) data.Footnote 2 This reflects the tensions of these data at NNLO with a range of other data sets, as shown further in Table 16 of [1]. In contrast the corresponding change at aN\({}^3\)LO of the remainder of the data once the ATLAS 8 TeV Z \(p_T\) is removed is \(\Delta \chi ^2 = -22.0,\) demonstrating a reduced sensitivity to the presence of this data at aN\({}^3\)LO and indicative of reduced tensions between it and other data in the aN\({}^3\)LO fit. Table 8 demonstrates how this improvement is spread across a selection of data sets in the global fit. The data sets showing the greatest absolute improvements in \(\chi ^2\) once the ATLAS 8 TeV Z \(p_T\) data are removed in the NNLO fit are the NMC deuteron data, the HERA \(e+p\) NC 920 GeV data, the ATLAS 7 TeV inclusive jets data, the ATLAS 7 TeV precision W, Z data, the ATLAS 8 TeV Z data and the ATLAS 8 TeV inclusive jets data. These all show reduced \(\Delta \chi ^2\) improvements, or in some cases no improvement, upon removal of the Z \(p_T\) data at aN\({}^3\)LO. Similar reduced tensions were also noted in [18], for example see Fig. 17. Consistency is observed with the trends seen there with the NMC deuteron, HERA \(e+p\) NC 920 GeV data and the ATLAS 7 TeV inclusive jets data being amongst those shown to oppose the ATLAS 8 TeV Z \(p_T\) pull on the gluon. We therefore observe the improvement in the fits, though often mild, of several of the inclusive jet data sets when the Z \(p_T\) data are removed, the same is true to a lesser extent for some of the \(t\bar{t}\) data sets, indicating some tension between these data sets and the ATLAS 8 TeV Z \(p_T\) data.
In addition to comparing the different fit qualities with and without the ATLAS 8 TeV Z \(p_T\) data set, or with differing minimum and maximum \(p_T^{ll}\) cuts applied, we can also compare the treatments of different global fitting groups of these data. In MSHT we by default include 104 datapoints for the ATLAS 8 TeV Z \(p_T\) data set. As outlined in the previous section, this corresponds to including all data with \(p_T^{ll} > 30\, {\textrm{GeV}}\) with single differential results in the dilepton transverse momentum \(p_T^{ll}\) for the mass bins not including the Z boson invariant mass peak - i.e. [12,20], [20,30], [30,46], [46,66] and [116,150] where \([a,b] = a\, {\textrm{GeV}}< m_{ll} < b\, {\textrm{GeV}}.\) In addition, double differential results in \(p_T^{ll}\) and the rapidity of the dilepton pair \(y_{ll}\) are utilised in the [66,116] mass bin incorporating the Z mass peak. In contrast, NNPDF and CT take slightly different data subsets. NNPDF (from 3.1 onwards) additionally cut datapoints with \(p_T^Z > 150 \,{\textrm{GeV}}\) in the Z mass bin [66,116], resulting in 12 fewer datapoints, the justification being to remove sensitivity to large \(p_T^Z\) where electroweak corrections become large [2, 19]. CT18 apply the same large \(p_T^{ll}\) cut as NNPDF, however they also cut the region \(p_T^{ll} < 45 \,{\textrm{GeV}}\) (compared to \(p_T^{ll} < 30\, {\textrm{GeV}}\) in MSHT20 and NNPDF4.0), to be more conservative in reducing sensitivity to the low \(p_T^{ll}\) resummation region. On top of this they only fit the data in the mass bins [46,66], [66,116] and [116,150] (with the argument being to eliminate lower \(M_{ll}\) bins where higher order corrections are potentially more significant) and treat the central Z peak mass bin only single differentially in \(p_T^{ll},\) i.e. not including the rapidity dependence. This therefore results in significantly fewer datapoints, with only 27 ultimately being fitted. There are additionally differences in the treatment of the uncertainties which also impact the fit quality and pulls on the PDFs observed, with uncorrelated uncertainties included in the CT and NNPDF cases, as discussed in [1]. In the latter NNPDF case the size of these is significantly larger than the quoted MC uncertainties on the K-factors and the improvement in the fit quality was found to be dramatic. These other differences will not be further examined in this work.
In Table 9 we summarise the fit qualities obtained fitting different subsets of the data, including the exact data set fit by NNPDF and approximating the data set fit by CT. In the latter case for simplicity we still take the data as double differential in the Z peak invariant mass bin for ease (resulting in 48 datapoints in total), whereas this is treated single differentially by CT. The uncertainty treatment remains as in MSHT20 in all cases, though as noted earlier this also varies between groups. A similar exercise was performed in the context of the MSHT20 NNLO PDF set in [1], and we repeat it here in the context of an updated fit and extend it to aN\({}^3\)LO. We can then make a direct comparison of the aN\({}^3\)LO fit qualities obtained this way with like-for-like NNLO fit qualities. It can be seen that the fit quality at NNLO remains poor also for the data subset fit by NNPDF and the CT-like data subset. Some further improvement might be expected if the data in the Z peak bin were rapidity integrated, which would reduce our CT-like fit from 48 to 27 datapoints (to match exactly the datapoints included in CT), as this places less constraints on the PDFs. Nonetheless, the fit qualities observed in Table 9 again suggest that the poor fit quality is not associated with the exact data points included at NNLO. At NNLO, CT and NNPDF quote fit qualities of \(\sim 1.1\) [3] and \(\sim 0.9\) [2] (also similar to that quoted in NNPDF3.1 [19]) respectively and it was demonstrated in [1] that similar fit qualities could be obtained by adding an additional uncorrelated uncertainty of \(1\%\) to the fit in the way is done in NNPDF for example. This suggests that differences seen between groups at NNLO reflect, rather than the data points included, instead other differences in the setups between the groups, including in the uncertainty treatment. In any case, returning to Table 9 we now observe that in all data selections the fit quality substantially improves at aN\({}^3\)LO, emphasising it is the higher order (aN\({}^3\)LO rather than NNLO) of the fit performed that leads to the possibility to fit these data well.
We can further examine the nature of the better fit quality at aN\(^{3}\)LO to the ATLAS 8 TeV Z \(p_T\) data set by making further intermediate PDF fits, with certain aspects of the aN\(^{3}\)LO theory incorporated or not and then comparing the fit qualities of these intermediate fits with the full NNLO or aN\(^{3}\)LO. One particular question to address, is the extent to which the fit quality improvement is associated to the genuine and largely known included aN\(^{3}\)LO effects in the splitting functions (as well as indirectly from the known N\(^{3}\)LO ingredients included for the transition matrix elements and DIS coefficient functions – for more information see [5]) or the K-factor freedom allowed for the unknown N\(^{3}\)LO vector boson plus jets K-factor, which contains theoretical nuisance parameters in the aN\(^{3}\)LO fit. The details of the procedure for the aN\(^{3}\)LO (fitted) K-factors included in the aN\(^{3}\)LO PDFs and their uncertainties are given in Section 7 of [5]. It was observed in [5], see e.g. Table 4, as well as earlier in this work in the context of the jets and dijet analysis (see Table 1 of Sect. 2.2), that the fit to the Z \(p_T\) data at aN\(^{3}\)LO even with NNLO K-factors (the final columns) is notably better, indicating a preference not only for the shape and normalisation freedom provided by our fitted aN\(^{3}\)LO K-factors (see Section 7 of [5]) but also for the known N\(^{3}\)LO information encoded in the higher order splitting functions, DIS coefficient functions and transition matrix elements of the aN\(^{3}\)LO PDF fit. We examine this in greater detail here.
In Table 10 the fit qualities of the ATLAS 8 TeV Z \(p_T\) data in a full NNLO global PDF fit (second column) and the full aN\(^{3}\)LO global PDF fit (last column) are therefore compared with two intermediate PDF fits; in the fourth column with an aN\(^{3}\)LO fit with the purely known NNLO K-factors (as provided previously), whilst the third column provides the “inverse case” of an NNLO fit with additional aN\(^{3}\)LO K-factors (determined by the fit). The total fit qualities of these fits are given in the bottom row. This comparison demonstrates that the aN\(^{3}\)LO K-factor freedom and the remainder of the largely known aN\(^{3}\)LO ingredients both contribute relatively equally to the fit quality improvement. The NNLO fit has a relatively poor fit quality of 1.87 per point, the two intermediate cases both have very similar and notably improved fit qualities of \(\approx 1.4\) per point, whilst the full aN\(^{3}\)LO fit improves to 1.04 per point. This demonstrates that whilst the aN\(^{3}\)LO K-factor freedom is able to account for some of the data and theory differences which result in a poor fit at NNLO, it is not able to account for much of the difference due presumably to non-trivial shape or normalisation differences. These cannot be absorbed into the unknown N3LO K-factors and so the fit quality is only improved further by the inclusion of the other largely known aN\(^{3}\)LO theory ingredients, as one would hope. Corresponding improvements in the global PDF fit quality are also seen, as provided in the bottom row of Table 10.
This observation is further elucidated by the direct comparisons of the theoretical predictions obtained in the various PDF fits with the data. Ratios of theory to data, both for the raw pre-fit data unaltered by the correlated systematics and with the data post-fit after these are taken into account by the fit, are shown for two representative cases are shown in Fig. 10. Specifically the two cases shown are for the Z peak \(M_{ll}=[66,116]~{\textrm{GeV}},\) \(y_{ll}=[0.0,0.4]\) bin and the \(M_{ll}=[46,66]~{\textrm{GeV}}\) rapidity integrated (\(y_{ll}=[0.0,2.4]\)) bin. The left figure displays the comparison for the raw pre-fit data, and the right figure after allowing the correlated systematic shifts. The same four PDF fits considered in Table 10 are shown. The comparison plots for all of the six double-differential rapidity bins in the Z peak mass bin of [66,116] GeV and all of the five single-differential other mass bins, before and after the correlated systematic pulls are applied in the fit, are given in Appendix A. The solid line is the full aN\(^{3}\)LO theory/data ratio, for comparison against the datapoints with their uncorrelated uncertainty shown by their errorbars. In the pre-fit case, it is visible by eye in several of the bins that this is more closely following the datapoints, though differences still remain. The full NNLO (dotted line), NNLO + aN\(^{3}\)LO K-factor case (dot dashed line), and aN\(^{3}\)LO + NNLO fixed K-factors (dashed line) are not able to follow the data to the same degree. After accounting for the correlated systematic pulls in the fit, all four cases naturally move closer to the datapoints, as must occur, though it is still visible even by eye that the full aN\(^{3}\)LO appears better able to describe the datapoints in several of the bins. This is reflected in the fit qualities given in Table 10. This further highlights the need for the aN\(^{3}\)LO theory to describe this precise data.
This is also reflected by the average theory/data ratio across all 104 datapoints, which whilst a relatively crude measure, is also closer to 1 in the full aN\(^{3}\)LO case both for the pre-fit data and after shifting by the correlated systematics in the fit than for any of the other 3 fits shown in the figure. As a result of the better agreement of the aN\(^{3}\)LO fit, even for the pre-fit, it also has the smallest contribution to the \(\chi ^2\) from the correlated systematic experimental nuisance parameter penalties, whereas the NNLO fit has the largest. The penalties from the correlated systematic pulls at NNLO account for \(+37.0\) of the \(\Delta \chi ^2 = +85.4\) deterioration in the fit quality at NNLO relative to aN\(^{3}\)LO. In the two intermediate cases (NNLO + aN\(^{3}\)LO K-factors or aN\(^{3}\)LO + NNLO K-factors) where we observe approximately half the improvement in fit quality, as seen previously in Table 10, the penalties from the correlated systematic pulls are also approximately halved relative to the NNLO case. This indicates that the pulls of these in the lower order (not full aN\(^{3}\)LO) cases attempt to absorb some of the theory – data difference, which is substantially reduced by the aN\(^{3}\)LO theory. All in all, these observations demonstrate the need for the aN\(^{3}\)LO theory to describe this Z \(p_T\) data, with a preference for not simply the freedom associated with our treatment of the unknown aN\(^{3}\)LO K-factors, but rather the full aN\(^{3}\)LO fit. This indicates that the inclusion of the known aN\(^{3}\)LO information in the full global PDF fit is required to obtain a good fit of this data.

The effect on the gluon PDF at NNLO of varying the Z \(p_T\) datapoints included to match those included by NNPDF (NNPDF-like) or to approximate those included by CT (CT-like), more details are given in the text. The numbers in brackets give the number of datapoints included
3.3 Impact on PDFs
It is also instructive to examine the effects of these Z \(p_T\) data on the PDFs, in particular the high x gluon PDF, on which it places constraints. It was demonstrated that for NNLO PDFs this data resulted in a net upward pull on the gluon at high x in [1], and similar effects are seen at aN\({}^3\)LO (this is also shown later in Fig. 11). Ultimately this has a significant impact on the resulting gluon at high x. This is also noted at NNLO albeit to a lesser degree by NNPDF4.0 [2], and CT18 [3] see smaller effects still – though both groups include fewer datapoints than in MSHT and there are additional differences in their treatments of the uncertainties, as discussed in the previous section. The ATLASpdf21 fit also reported qualitatively similar effects for Z + jets data on the high x gluon [4]. The pulls of these Z \(p_T\) data on the MSHT20 PDF fits were also shown in [18], though in this section we will examine this in more detail, in the context of the various fits with different data cuts and selections described in the previous section (Sect. 3.2).

The effect on the gluon PDF uncertainty of removing the ATLAS 8 TeV \(Zp_T\) data set at NNLO (left) and aN\({}^3\)LO (right) at \(Q=100~{\textrm{GeV}}\)

The effect of the ATLAS 8 TeV \(Zp_T\) data set at NNLO on the (upper left) up valence, (upper right) down valence, (lower left) strangeness ratio \(R_s = \frac{s+\bar{s}}{\bar{u}+\bar{d}},\) and (lower right) gluon PDFs at \(Q=100~{\textrm{GeV}}\)

The effect of the ATLAS 8 TeV \(Zp_T\) data set at aN\({}^3\)LO on the (upper left) Up valence, (upper right) Down valence, (lower left) Strangeness ratio \(R_s = \frac{s+\bar{s}}{\bar{u}+\bar{d}},\) and (lower right) gluon PDFs at \(Q=100~{\textrm{GeV}}\)
In Fig. 11 the effect of these Z \(p_T\) data on the high x gluon PDF at NNLO (left figure) and aN\({}^3\)LO (right figure) are shown. The denominators of the ratios are the new PDFs at their respective orders with the ATLAS 8 TeV inclusive jet data included on top of the MSHT20 PDFs, with the uncertainty band on this new baseline also shown. The dotted light green lines indicate the impact of removing this ATLAS 8 TeV Z \(p_T\) data set completely is a reduction in the high x gluon for \(x > rsim 0.035.\) It is immediately clear that the impact of the removal of the data set at aN\({}^3\)LO is smaller than at NNLO, with the latter producing a gluon around the edge of (or in places beyond) the uncertainty band whilst the former lies well inside the gluon PDF uncertainty. Moreover, gradually cutting out more of the data by increasing the \(p_T^{ll}\) cut smoothly transitions from the default fit towards the case with no Z \(p_T\) data, again reinforcing the fact that no issues with particular \(p_T^{ll}\) regions are seen. In the context of our investigations mimicking the NNPDF and CT datapoint selections (“CT-like” and “NNPDF-like”) in the previous Sect. 3.2, we also observe that the CT-like and NNPDF-like fits show similar pulls on the high x gluon PDF, though analogously reduced in magnitude due to the fewer number of datapoints included. This is shown in Fig. 12 at NNLO, a similar effect is seen at aN\({}^3\)LO and so is not shown here, though with slightly reduced pulls.
Figure 13 illustrates the impact of these data on the gluon PDF uncertainty. At NNLO, the impact of the presence or absence of the ATLAS 8 TeV Z \(p_T\) data set on the high x gluon uncertainty is very small, despite the notable constraints it offers on the central value, as a result of the significant tensions it shows with other data in the global fit. In contrast, at aN\({}^3\)LO there is a somewhat clearer reduction on the gluon uncertainty in the \(x\sim 0.05\) region from the inclusion of the ATLAS 8 TeV Z \(p_T\) data set. The reduced tensions between it and other data at aN\({}^3\)LO enable it to further constrain the gluon PDF uncertainty.
Finally, in Figs. 14 and 15 the effect of the inclusion of the ATLAS 8 TeV Z \(p_T\) data set on several other PDFs is shown, including the gluon but now also the up and down valence quarks and the strangeness ratio \(R_s = \frac{s+\bar{s}}{\bar{u}+\bar{d}}.\) In addition to the pull on the high x gluon, the Z \(p_T\) data also have a pull on the quark PDFs, as these initiate the production of a Z boson at leading order. The quark PDFs are relatively well constrained and so the impact is smaller but there are visible pulls downwards on the up and down valence PDFs and the strangeness ratio at \(x > rsim 0.01\) at NNLO. On the other hand, the effect is again milder at aN\({}^3\)LO, perhaps due to the reduced tension in this fit. The strangeness ratio nonetheless remains lowered once the Z \(p_T\) data is included at intermediate to large x. This may be due to the momentum sum rule. The Z \(p_T\) data prefers a gluon which is larger at higher x values, and hence carries more momentum. This must come from somewhere, and the high-x strange quark is the least well-constrained PDF carrying appreciable momentum.
4 Conclusions
In this paper we have presented analyses of two key sets of data for constraining the high x gluon, comparing their impacts at both NNLO and a\({\textrm{N}}^3\)LO.
First we have presented the first analysis of LHC inclusive jet and dijet production in a global PDF fit at up to a\({\textrm{N}}^3\)LO order. We have analysed in detail the fit quality, consistency between the jet and dijet cases, and overall PDF impact of these data sets. We have observed that at NNLO a good fit quality to LHC 7 and 8 TeV data on dijet production can be achieved, in contrast to the case of inclusive jet production, where the fit quality is rather poor, consistent with earlier studies. This remains true at a\({\textrm{N}}^3\)LO, i.e. the fit to the inclusive jet data continues to be poor. In addition, we have observed that the inclusion of EW corrections in fact leads to some deterioration in the fit quality at either QCD order in the inclusive jet case, in contrast to what we might expect. For dijet production, on the other hand, the fit quality does improve upon the inclusion of EW corrections. The above results are found to be stable under a change of the choice of scale for the inclusive jet case, namely between \(p_\perp ^j\) and \(H_\perp ;\) some improvement is observed when using the former scale at NLO, but at NNLO order and higher the fit quality is rather stable. At NNLO, we have also found evidence for a reduced tension between the dijet data and the ATLAS 8 TeV Z \(p_T\) data, which is also sensitive to the high x gluon, although at a\({\textrm{N}}^3\)LO this tension is largely eliminated in both the jet and dijet fits.
We have also observed that at NLO the fit quality to the CMS 8 TeV triple differential dijet data (the only data of this type so far included in a PDF fit) is extremely poor; it is only by going to at least NNLO that a good fit can be achieved. This highlights the importance of having high precision theoretical calculations to match such high precision and multi-differential data.
In terms of the impact on the gluon PDF, we note some moderate difference in pull between the inclusive jet and dijet fits at NNLO, although these are statistically compatible. Therefore at this order the choice of which data set to include in the fit will have some effect on the extracted PDFs. On the other hand, at a\({\textrm{N}}^3\)LO this difference is largely eliminated and the resulting PDFs are rather compatible, in particular in the case of the gluon. A further interesting observable to consider is the impact on the fit value of the strong coupling, \(\alpha _S,\) which will be the topic of a future study.
A further issue that we have made the first study of within the context of a global PDF fit is that of full colour corrections at NNLO in the theoretical predictions. We have studied the impact of these when they are included for the most relevant data set, namely the CMS 8 TeV triple-differential dijet data. We find that at NNLO there is in fact a relatively mild deterioration in the fit quality, but which is not present at a\({\textrm{N}}^3\)LO. The impact on the gluon PDF is found to be mild, but not completely negligible. Therefore, in general the impact of FC corrections is found to be relatively mild, but not necessarily insignificant. Until these are available for the full range of jet and dijet data considered it is arguably difficult to draw completely firm conclusions about this.
From these results, we conclude that at NNLO it may be preferable to include dijet rather than inclusive jet production data in future PDF fits, when a choice must be made between the two, as is currently the case for all existing jet and dijet measurements that derive from the same data set. This choice is found to have some impact on the PDFs at NNLO, and it will therefore be of great interest for experimental collaborations to provide the full correlations between the jet and dijet data sets, such that a simultaneous analysis can be performed. Absent this, the increased stability of the PDFs with respect to this choice at a\({\textrm{N}}^3\)LO is further evidence that going to this order (and/or including missing higher order uncertainties in the cross section calculations) may be preferable. The above conclusions are found to be independent of whether FC corrections are applied at NNLO for the most sensitive CMS 8 TeV dijet data set.
We have in addition revisited the analysis of the ATLAS 8 TeV Z \(p_T\) data. At NNLO, we find the fit quality to this data set remains poor, regardless of the particular cuts and datapoint selections made. The fit quality at aN\({}^3\)LO is not only always improved relative to NNLO but also well fit regardless of the datapoints included. We therefore conclude that we find no evidence that the poor fit quality at NNLO is related to issues with particular parts of the \(p_T^{ll}\) spectrum but rather the general need to go to higher orders in the fit. Moreover, we demonstrate that the improvement in fit quality is associated not only with the additional freedom provided by the unknown a\({\textrm{N}}^3\)LO K-factors, but also to a significant extent with the known a\({\textrm{N}}^3\)LO information included in the fit. The impact on the fit of these ATLAS 8 TeV Z \(p_T\) data is consistent between NNLO and aN\({}^3\)LO, both resulting in an upward pull on the gluon at high x, though the pull is somewhat reduced at aN\({}^3\)LO. Greater tensions between the Z \(p_T\) data and other data in the global fit are also seen at NNLO than at aN\({}^3\)LO. As a result, these restrict the ability of the Z \(p_T\) data to further constrain the gluon PDF uncertainty at high x at NNLO to the extent seen at aN\({}^3\)LO. Overall we therefore conclude that the improvement of the fit quality and reduction in tensions of these precise Z \(p_T\) data at aN\({}^3\)LO relative to NNLO is a sign of a genuine preference for higher order QCD effects.
In summary, both the studies of jet and dijet data and the ATLAS 8 TeV Z \(p_T\) data have demonstrated the need for precise theory to match experimental precision. The aN\({}^3\)LO theoretical accuracy provided by the MSHT PDFs is found in both cases to be a key ingredient in this.
DataAvailability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: We refer the reader to earlier studies for the release of public LHAPDF grids, as described in the text.]
Notes
The same occurs implicitly if a covariance matrix is used instead of nuisance parameters.
Note this is slightly different to that reported in [1] due to the addition of the ATLAS 8 TeV inclusive jets data to the baseline here, as well as other minor alterations.
References
S. Bailey, T. Cridge, L.A. Harland-Lang, A.D. Martin, R.S. Thorne, Eur. Phys. J. C 81, 341 (2021). arXiv:2012.04684
NNPDF, R.D. Ball et al., Eur. Phys. J. C 82, 428 (2022). arXiv:2109.02653
T.-J. Hou et al., Phys. Rev. D 103, 014013 (2021). arXiv:1912.10053
ATLAS, G. Aad et al., Eur. Phys. J. C 82, 438 (2022). arXiv:2112.11266
J. McGowan, T. Cridge, L.A. Harland-Lang, R.S. Thorne, Eur. Phys. J. C 83, 185 (2023). arXiv:2207.04739
T. Cridge, L.A. Harland-Lang, R.S. Thorne (2023). arXiv:2312.07665
G. Falcioni, F. Herzog, S. Moch, A. Vogt, Phys. Lett. B 842, 137944 (2023)
G. Falcioni, F. Herzog, S. Moch, A. Vogt, Four-loop splitting functions in qcd—the gluon-to-quark case (2023). arXiv:2307.04158
S. Moch, B. Ruijl, T. Ueda, J. Vermaseren, A. Vogt, Additional moments and x-space approximations of four-loop splitting functions in qcd (2023). arXiv:2310.05744
G. Falcioni, F. Herzog, S. Moch, J. Vermaseren, A. Vogt, The double fermionic contribution to the four-loop quark-to-gluon splitting function (2023). arXiv:2310.01245
T. Gehrmann, A. von Manteuffel, V. Sotnikov, T.-Z. Yang, Complete \(n_f^2\) contributions to four-loop pure-singlet splitting functions (2024). arXiv:2308.07958
J. Ablinger et al., J. High Energy Phys. 2022 (2022)
J. Ablinger et al., Nucl. Phys. B 999, 116427 (2024)
J. Ablinger et al., The non-first-order-factorizable contributions to the three-loop single-mass operator matrix elements \(a_{Qg}^{(3)}\) and \(\delta a_{Qg}^{(3)}\) (2024). arXiv:2403.00513
L.A. Harland-Lang, A.D. Martin, R.S. Thorne, Eur. Phys. J. C 78, 248 (2018). arXiv:1711.05757
S. Bailey, L. Harland-Lang, Eur. Phys. J. C 80, 60 (2020). arXiv:1909.10541
R. Thorne, S. Bailey, T. Cridge, L. Harland-Lang, A.D. Martin, SciPost Phys. Proc. 8, 018 (2022)
X. Jing et al., Phys. Rev. D 108, 034029 (2023). arXiv:2306.03918
NNPDF, R.D. Ball et al., Eur. Phys. J. C 77, 663 (2017). arXiv:1706.00428
PDF4LHC Working Group, R.D. Ball et al., J. Phys. G 49, 080501 (2022). arXiv:2203.05506
PDF4LHC21 Combination Group, T. Cridge, SciPost Phys. Proc. 8, 101 (2022). arXiv:2108.09099
S. Amoroso et al., Acta Phys. Pol. B 53, 12 (2022). arXiv:2203.13923
A. Ablat et al., Exploring the impact of high-precision top-quark pair production data on the structure of the proton at the lhc (2023). arXiv:2307.11153
R. Abdul Khalek, Eur. Phys. J. C 80, 797 (2020). arXiv:2005.11327
R. Boughezal, A. Guffanti, F. Petriello, M. Ubiali, JHEP 07, 130 (2017). arXiv:1705.00343
E.R. Nocera, M. Ubiali, Constraining the gluon pdf at large x with lhc data (2019). arXiv:1709.09690
ATLAS, G. Aad et al., JHEP 05, 059 (2014). arXiv:1312.3524
CMS, S. Chatrchyan et al., Phys. Rev. D 87, 112002 (2013). arXiv:1212.6660. [Erratum: Phys. Rev. D 87, 119902 (2013)]
CMS, A.M. Sirunyan et al., Eur. Phys. J. C 77, 746 (2017). arXiv:1705.02628
ATLAS, M. Aaboud et al., JHEP 05, 195 (2018). arXiv:1711.02692
CMS, CMS-PAS-SMP-21-008 (2022)
J. Currie, E.W.N. Glover, J. Pires, Phys. Rev. Lett. 118, 072002 (2017). arXiv:1611.01460
A. Gehrmann-De Ridder, T. Gehrmann, E.W.N. Glover, A. Huss, J. Pires et al., Phys. Rev. Lett. 123, 102001 (2019). arXiv:1905.09047
X. Chen, T. Gehrmann, E.W.N. Glover, A. Huss, J. Mo, JHEP 09, 025 (2022). arXiv:2204.10173
ATLAS, G. Aad et al., Eur. Phys. J. C 76, 291 (2016). arXiv:1512.02192
D0, V.M. Abazov et al., Phys. Rev. D 85, 052006 (2012). arXiv:1110.3771
CDF, A. Abulencia et al., Phys. Rev. D 75, 092006 (2007). arXiv:hep-ex/0701051. [Erratum: Phys. Rev. D 75, 119901 (2007)]
CMS, V. Khachatryan et al., Eur. Phys. J. C 76, 265 (2016). arXiv:1512.06212
ATLAS, G. Aad et al., JHEP 02, 153 (2015). arXiv:1410.8857. [Erratum: JHEP 09, 141 (2015)]
CMS, S. Chatrchyan et al., Phys. Rev. D 90, 072006 (2014). arXiv:1406.0324
CMS, V. Khachatryan et al., JHEP 03, 156 (2017). arXiv:1609.05331
CMS, A. Tumasyan et al., JHEP 02, 142 (2022). arXiv:2111.10431. [Addendum: JHEP 12, 035 (2022)]
CMS, A. Hayrapetyan et al. (2023). arXiv:2312.16669
ATLAS, M. Aaboud et al., JHEP 09, 020 (2017). arXiv:1706.03192
E. Eren, K. Lipka, Private communication
M. Cacciari, G.P. Salam, G. Soyez, JHEP 04, 063 (2008). arXiv:0802.1189
G. Sieber, Measurement of triple-differential dijet cross sections with the CMS detector at 8 TeV and PDF constraints. PhD thesis, KIT, Karlsruhe (2016)
K. Rabbertz, Private communication
T. Carli et al., Eur. Phys. J. C 66, 503 (2010). arXiv:0911.2985
T. Kluge, K. Rabbertz, M. Wobisch, FastNLO: fast pQCD calculations for PDF fits, in 14th International Workshop on Deep Inelastic Scattering, pp. 483–486 (2006). arXiv:hep-ph/0609285
fastNLO, D. Britzger, K. Rabbertz, F. Stober, M. Wobisch, New features in version 2 of the fastNLO project, in 20th International Workshop on Deep-Inelastic Scattering and Related Subjects, pp. 217–221 (2012). arXiv:1208.3641
J. Currie et al., JHEP 10, 155 (2018). arXiv:1807.03692
S. Dittmaier, A. Huss, C. Speckner, JHEP 11, 095 (2012). arXiv:1210.0438
T. Cridge, L.A. Harland-Lang, A.D. Martin, R.S. Thorne, Eur. Phys. J. C 82, 90 (2022). arXiv:2111.05357
CMS, V. Khachatryan et al., Eur. Phys. J. C 76, 265 (2016). arXiv:1512.06212
CMS, V. Khachatryan et al., Eur. Phys. J. C 75, 542 (2015). arXiv:1505.04480
ATLAS, G. Aad et al., Eur. Phys. J. C 76, 538 (2016). arXiv:1511.04716
ATLAS, M. Aaboud et al., Phys. Rev. D 94, 092003 (2016). arXiv:1607.07281. [Addendum: Phys. Rev. D 101, 119901 (2020)]
CMS, A.M. Sirunyan et al., Eur. Phys. J. C 77, 459 (2017). arXiv:1703.01630
A. Gehrmann-De Ridder, T. Gehrmann, E.W.N. Glover, A. Huss, T.A. Morgan, JHEP 07, 133 (2016). arXiv:1605.04295
W. Bizoń et al., JHEP 12, 132 (2018). arXiv:1805.05916
ATLAS, M. Aaboud et al., Eur. Phys. J. C 77, 367 (2017). arXiv:1612.03016
X. Chen et al., Phys. Rev. Lett. 128, 052001 (2022). arXiv:2107.09085
J. Gao, L. Harland-Lang, J. Rojo, Phys. Rep. 742, 1–121 (2018)
J.M. Campbell, R. Ellis, Phys. Rev. D 65, 113007 (2002). arXiv:hep-ph/0202176
NMC, M. Arneodo et al., Nucl. Phys. B 483, 3 (1997). arXiv:hep-ph/9610231
NuTeV, M. Tzanov et al., Phys. Rev. D 74, 012008 (2006). arXiv:hep-ex/0509010
NuSea, R.S. Towell et al., Phys. Rev. D 64, 052002 (2001). arXiv:hep-ex/0103030
NuTeV, M. Goncharov et al., Phys. Rev. D 64, 112006 (2001). arXiv:hep-ex/0102049
H1, ZEUS, F. Aaron et al., JHEP 01, 109 (2010). arXiv:0911.0884
D0, V.M. Abazov et al., Phys. Rev. D 88, 091102 (2013). arXiv:1309.2591
LHCb, R. Aaij et al., JHEP 02, 106 (2013). arXiv:1212.4620
LHCb, R. Aaij et al., JHEP 06, 058 (2012). arXiv:1204.1620
ATLAS, G. Aad et al., Phys. Lett. B 725, 223 (2013). arXiv:1305.4192
LHCb, R. Aaij et al., JHEP 05, 109 (2015). arXiv:1503.00963
CMS, S. Chatrchyan et al., JHEP 02, 013 (2014). arXiv:1310.1138
ATLAS, M. Aaboud et al., Eur. Phys. J. C 77, 367 (2017). arXiv:1612.03016
D0, V.M. Abazov et al., Phys. Rev. Lett. 112, 151803 (2014). arXiv:1312.2895. [Erratum: Phys. Rev. Lett. 114, 049901 (2015)]
ATLAS, G. Aad et al., Eur. Phys. J. C 76, 538 (2016). arXiv:1511.04716
ATLAS, M. Aaboud et al., JHEP 05, 077 (2018). arXiv:1711.03296
CMS, A.M. Sirunyan et al., Eur. Phys. J. C 77, 459 (2017). arXiv:1703.01630
ATLAS, G. Aad et al., Eur. Phys. J. C 79, 760 (2019). arXiv:1904.05631
CMS, V. Khachatryan et al., Eur. Phys. J. C 76, 265 (2016). arXiv:1512.06212
CMS, V. Khachatryan et al., Eur. Phys. J. C 75, 542 (2015). arXiv:1505.04480
ATLAS, M. Aaboud et al., JHEP 12, 059 (2017). arXiv:1710.05167
Acknowledgements
We thank Jamie McGowan, whose invaluable work on the original a\({\textrm{N}}^3\)LO fit provided the groundwork for this study. We thank the NNPDF collaboration and Emmanuele Nocera in particular for providing NLO theory grids for certain jet and dijet data sets. We thank Alex Huss for providing NNLO K-factors for the jet and dijet data. We thank Engin Eren and Katerina Lipka for help with CMS data, in particular the statistical correlations for the 8 TeV inclusive jet data. We thank Klaus Rabbertz for helpful correspondence about the experimental error definitions, and their signs, in the CMS 8 TeV dijet data. We also thank our co-authors on Ref. [18] for discussions of the Z \(p_T\) pulls. TC acknowledges that this project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant agreement no. 101002090 COLORFREE). L. H.-L. and R.S.T. thank STFC for support via grant awards ST/T000856/1 and ST/X000516/1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Code availability
My manuscript has no associated code/software. [Author’s comment: Code/Software sharing not applicable to this article.]
Appendix A: ATLAS 8 TeV Z \(p_T\) theory-data comparison
Appendix A: ATLAS 8 TeV Z \(p_T\) theory-data comparison
Here we provide theory data comparison plots for all bins, including all 104 datapoints, for the ATLAS 8 TeV Z \(p_T\) data set, first for the pre-fit data before accounting for the correlated systematic pulls and then for the data shifted by the fits by the correlated systematics (Figs. 16 and 17).

Theory and data comparison at NNLO (dotted lines), NNLO with aN\(^{3}\)LO K-factors added (dot dashed lines), aN\(^{3}\)LO with NNLO K-factors (dashed lines) and aN\(^{3}\)LO (solid lines). The ratio of theory/data is shown and the points are the datapoints with their total uncorrelated error (quadrature sum of their statistical and uncorrelated systematic errors) only shown by the errorbars. On the left are the 6 double differential bins in \(p_T^{ll}\) and \(y_{ll}\) the Z peak region, and on the right are the 5 single differential bins in \(p_T^{ll}\) for the other mass bins. In this figure the data are before shifting by the fit of the correlated systematic pulls

Theory and data comparison at NNLO (dotted lines), NNLO with aN\(^{3}\)LO K-factors added (dot dashed lines), aN\(^{3}\)LO with NNLO K-factors (dashed lines) and aN\(^{3}\)LO (solid lines). The ratio of theory/data is shown and the points are the datapoints with their total uncorrelated error (quadrature sum of their statistical and uncorrelated systematic errors) only shown by the errorbars. On the left are the 6 double differential bins in \(p_T^{ll}\) and \(y_{ll}\) the Z peak region, and on the right are the 5 single differential bins in \(p_T^{ll}\) for the other mass bins. In this figure the data are after shifting by the fit of the correlated systematic pulls
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3.
About this article

Cite this article
Cridge, T., Harland-Lang, L.A. & Thorne, R.S. The impact of LHC jet and Z \(p_T\) data at up to approximate N\({}^3\)LO order in the MSHT global PDF fit. Eur. Phys. J. C 84, 446 (2024). https://doi.org/10.1140/epjc/s10052-024-12771-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-024-12771-0