Article Text

Abstract
Introduction Ideally, health conditions causing the greatest global disease burden should attract increased research attention. We conducted a comprehensive global study investigating the number of randomised controlled trials (RCTs) published on different health conditions, and how this compares with the global disease burden that they impose.
Methods We use machine learning to monitor PubMed daily, and find and analyse RCT reports. We assessed RCTs investigating the leading causes of morbidity and mortality from the Global Burden of Disease study. Using regression models, we compared numbers of actual RCTs in different health conditions to numbers predicted from their global disease burden (disability-adjusted life years (DALYs)). We investigated whether RCT numbers differed for conditions disproportionately affecting countries with lower socioeconomic development.
Results We estimate 463 000 articles describing RCTs (95% prediction interval 439 000 to 485 000) were published from 1990 to July 2020. RCTs recruited a median of 72 participants (IQR 32–195). 82% of RCTs were conducted by researchers in the top fifth of countries by socio-economic development. As DALYs increased for a particular health condition by 10%, the number of RCTs in the same year increased by 5% (3.2%–6.9%), but the association was weak (adjusted R2=0.13). Conditions disproportionately affecting countries with lower socioeconomic development, including respiratory infections and tuberculosis (7000 RCTs below predicted) and enteric infections (9700 RCTs below predicted), appear relatively under-researched for their disease burden. Each 10% shift in DALYs towards countries with low and middle socioeconomic development was associated with a 4% reduction in RCTs (3.7%–4.9%). These disparities have not changed substantially over time.
Conclusion Research priorities are not well optimised to reduce the global burden of disease. Most RCTs are produced by highly developed countries, and the health needs of these countries have been, on average, favoured.
- randomised control trial
- geographic information systems
This is an open access article distributed in accordance with the Creative Commons Attribution 4.0 Unported (CC BY 4.0) license, which permits others to copy, redistribute, remix, transform and build upon this work for any purpose, provided the original work is properly cited, a link to the licence is given, and indication of whether changes were made. See: https://creativecommons.org/licenses/by/4.0/.
Statistics from Altmetric.com
Key questions
What is already known?
Prior studies have manually investigated the relationship between published research in different health conditions and the global burden of disease that they impose.
However, these analyses have been mostly limited to estimates of research funding from national funders, or smaller scale analysis of older publication records.
These studies have highlighted disparities in research relative to burden, but they are not sufficient to enable global targeting of research to optimise improvements in disease burden.
What are the new findings?
We automatically process all of PubMed, allowing us to conduct a continually updated, comprehensive analysis of published reports of randomised controlled trials (RCTs), including the number of participants per RCT and the health conditions studied.
We found that considerable disparities exist between the relative volume of evidence on some conditions and the global burden of disease that they impose, as calculated by the Global Burden of Disease study.
Further, our analysis suggests that there exists a smaller amount of evidence for conditions that impose a comparatively large burden of disease in lower-income countries.
What do the new findings imply?
Looking at numbers of RCTs published, and the numbers of participants in these trials, it seems that research priorities are not optimised to reduce the global burden of disease, and that research for conditions affecting higher-income countries has, on average, been favoured.
The findings from this study could help research funders to focus research investment in areas where the largest reductions in disease burden could be made.
Introduction
The Global Burden of Disease (GBD) study has estimated the leading causes of death and disability worldwide.1 A key strategy to reduce death and morbidity is to conduct randomised controlled trials (RCTs) to determine the effects of interventions for improving health.2 However, RCTs are highly expensive to conduct; this cost leads to a risk of health inequality, where the health needs of countries which lack resources are neglected. Health inequalities have been defined as differences in health outcome which are avoidable, remediable and considered unjust.3 From an ethical standpoint (and particularly a concern for justice), health resources should be distributed to help those with the greatest need, and in those who stand to see the greatest benefit. There are very many factors which could affect which health problems are researched, not limited to: the existence of highly effective treatments for certain conditions; national governments prioritising conditions which affect their own country’s population and the unpredictable nature of scientific breakthroughs in therapy. Pharmaceutical companies are likely to develop drugs which have the potential to be sold at profit; this can lead to neglect of conditions (eg, infectious diseases) which disproportionately affect low income countries.4 Nonetheless, a rational and ethical approach to funding research—seeking to reduce health inequalities and maximise global societal benefit—would take account of the global disease burden.
Studies from the USA and the UK have reported that disparities exist in national health research funding for certain conditions. Some conditions, such as diabetes and cancer, have attracted a comparatively generous amount of research funding in these countries relative to their national and global burden, whereas other conditions, such as stroke and respiratory diseases, have been relatively neglected.5–8 In a later study, Evans et al mapped the volume of research (RCTs and systematic reviews) published in 2005 to conditions studied in the GBD study. They concluded that global disability-adjusted life years (DALYs; a measure that incorporates the quality of lived years with respect to physical and mental functioning criteria) in 2004 did not explain any of the topic distribution of research articles published in the following year.9 By contrast, Atal et al examined 117 000 new registrations for clinical trials globally from 2006 to 2015, and reported that trials registered were proportionate to disease burden in high-income countries, but not in non-high income countries.10
To our knowledge, there has been no comprehensive, global study comparing published research (both in terms of trial and participant numbers) with the relative burden of each condition. We address this gap by evaluating the total volume of evidence (numbers of RCTs and trial participants) published for clinical conditions via an automated analysis of all research articles indexed in PubMed (http://pubmed.ncbi.nlm.nih.gov) from 1990 onwards. Our system uses natural language processing to automatically identify text within articles that describes the conditions being studied, and maps these to GBD-defined categories. This permits comparison between the global disease burden and the amount of published evidence that exists for each condition, and could help prioritise research funding to relatively understudied conditions with high burden. Uniquely, as our method is fully automatic, we are able to analyse articles at large scale (classification of 100’s of thousands of documents), and with continuous, live updating—neither of which have been feasible so far with manual methods.
Methods
We developed a machine learning system which maintains a live database of annotated RCT reports, named Trialstreamer. We have described the computational methods and accuracy of the system components in detail elsewhere,11 and summarise the key points relevant to the current study below.
Monitoring PubMed for RCTs in humans
We first downloaded the full PubMed database (annual baseline data, from 11 December 2018) and then subsequently monitored and added all newly published articles daily. This comprises >30 million articles. We automatically identify the subset of articles that describe RCTs using a machine learning system, which operates over the text of the title and abstract, and the Publication Type database index.12 Briefly, we ensemble a Support Vector Machine (SVM)13 and a Convolutional Neural Network.14 These machine learning models are trained1 on 280 000 abstracts manually labelled as being RCTs or not by Cochrane Crowd, (https://crowd.cochrane.org) a collaborative citizen science project. We do not rely on the Publication Type index alone, as we have previously found it to miss a substantial proportion of the 5–7 most recent years of articles11 (due to delay in manual indexing after publication). We next removed any RCTs that were not conducted in humans (eg, animal or agricultural studies) using an SVM model. This model was trained using labelled abstracts from PubMed (labels derived as a function of whether the Medical Subject Headings (MeSH) (MeSH refers to the MeSH vocabulary, maintained by the National Library of Medicine and used for indexing articles in the MEDLINE database) term ‘Humans’ had been applied or not).
Automatic information extraction
To characterise the trial participants and outcomes, we first automatically extract ‘snippets’ of text (typically a few consecutive words within the abstract) describing these components. For this, we use a sequence tagging machine learning model (namely a Long Short-Term Memory network15 followed by a conditional random field.16–18 This model was trained using a publicly available dataset called EBM-NLP (Evidence Based Medicine—Natural Language Processing), which comprises 5000 RCT abstracts in which text spans relevant to the respective characteristics (participants, interventions, comparators and outcomes) were manually annotated.
These text descriptions are then standardised to MeSH terms. This allows us to infer, for example, that ‘myocardial infarction’ and ‘heart attack’ refer to the same condition, and that both are subtypes of cardiovascular disease. To achieve this step, we use an approach similar to that described by Demner-Fushman et al, in their MetaMap software.19 This approach involves generating a large database of text synonyms for MeSH terms, done by finding alternative descriptions for each term in linked vocabularies. These synonyms are then sought in the extracted population and outcomes text spans.
Linking RCTs with data on global disease burden
In this study, we use the 22 level 2 categories defined by the GBD collaboration. These categories describe broad disease areas such as ‘Cardiovascular diseases’ and ‘Mental disorders’ (the full list is provided in table 1). The GBD collaboration makes available International Classification of Diseases (ICD-10) codes which define the scope of each category. We automatically link these ICD-10 codes to the equivalent MeSH terms using a tool and dataset named Metathesaurus, from the Unified Medical Language System.20 In brief, Metathesaurus provides a database of synonyms between different health science vocabularies, and thus lists of synonymous terms between ICD-10 and MeSH can be retrieved. One clinical author (IJM) manually checked all of the automatically generated mappings from MeSH to GBD category (both removing any errors from the automatic mapping, and adding links where they had been missed). This resulted in a final mapping of 5256 parent MeSH terms to one of the 22 GBD categories.
RCTs in PubMed with estimates of trial population sizes, and comparison with measures of global disease burden
Descriptive statistics
We report descriptive statistics for RCT counts and participant numbers. We use the country of the first author’s affiliation as a proxy for the country organising or funding the study. In order to capture trials addressing prevention, we also consider RCTs as relevant to the GBD category where rates of the health condition in question are identified as an outcome, even where participants did not have the condition at trial onset. For example, trials that recruited people with diabetes but measured the effects of an intervention on subsequent coronary heart disease were considered as relevant to both the ‘diabetes’ and ‘cardiovascular diseases’ categories. We also present separate estimates based on this distinction, that is, separating instances where a given GBD condition was found in the trial population (‘treatment’ trials) from those where it was inferred to describe an outcome (‘prevention’ trials).
Estimating uncertainty due to prediction error
We randomly sampled articles (titles and abstracts) from the finalised dataset, and two authors independently manually labelled these with respect to study design (RCT in humans vs not; 500 abstracts, done by IJM and BCW), GBD category (250 abstracts, done by IJM and VL), and number of participants randomised (500 abstracts, done by IJM and BCW). Authors then met to resolve discrepancies by consensus. We then used the bootstrap method to estimate 95% prediction intervals for final counts, using the method described by Fox and colleagues.21 22 In short, we use our manually labelled data to calculate 10 000 bootstrap estimates of the precision and recall of each labelling task.23 These precision and recall estimates are then used to adjust the automated results from the full dataset (generating 10 000 adjusted count estimates for each classification task), which can be used to construct a 95% prediction interval. To evaluate uncertainty around extracted sample sizes we use a similar approach, except we used estimates of the absolute error taken from the manually labelled abstracts. We then simulated the effect of this error on the full dataset using the bootstrap method with 10 000 iterations. These intervals permit assessment of the degree to which model misclassification and bias has affected the final results.
Assessing associations between disease burden and published RCTs
To examine associations between global disease burden and volume of evidence (both numbers of RCTs and participants), we used a series of linear regression models with log-transformed global DALYs as the predictor, and the log-transformed numbers of global RCTs as the dependent variable. We evaluate annual data on DALYs for each clinical condition for the full period available from the GBD study (1990–2017), and adjust for trends over time by incorporating the year as a categorical predictive variable. A detailed description alongside statistical code and data for these analyses is available at the Open Science Framework (DOI: 10.17605/osf.io/3db76).
In our first regression analysis, we examined the association of global DALYs on RCT publications in the same year. We explored incorporating the year (as categorical variable) both as a fixed and a random effect, evaluating using the Hausman test. We compare observed RCT counts for each GBD condition with those predicted by the model.
In our second regression analysis, we examine the effect of lag (given that RCTs will publish reports some time after measures of disease burden are known). Here, we use finite length distributed lag models, and evaluate the association of global DALYs with up to 1, 2, 3, 4 and 5 years lag on published RCTs in the index year. We compare models using the adjusted R2 statistic, the Akaike information criterion (AIC) and Bayesian information criterion (BIC).
In our third regression analysis, we add a variable to account for whether a particular condition tends to impose a disproportionate burden in high-income, rather than low-income and middle-income countries.
We examine associations between socioeconomic status and evidence volume, using the Sociodemographic Index (SDI) of the country from the GBD study. As a metric of disparity in disease burden, we used the ratio of DALYs occurring in high SDI countries (the top fifth) to DALYs occurring in low and medium SDI countries (ie, the bottom four fifths).
Finally, we conducted a sensitivity analysis aiming to discover whether our results are sensitive to ‘salami slicing’ (the practice of publishing results from a single trial across multiple publications, which could lead us to overestimate the evidence base). We first estimated the mean number of publications per RCT for each GBD condition, utilising the subset of articles which contained a unique trial registry identifier. Then we use these values to discount our estimate of RCT numbers for each GBD condition. We repeated our regression analyses with these discounted RCT numbers.
Results
We analysed records of 31 367 011 articles indexed in PubMed on 27 July 2020. We estimate that 463 000 articles describing RCTs (95% prediction interval 439 000 to 485 000). We show how these trials are distributed globally (by location of the first author) in figure 1. The number of RCTs published for each of the 22 ‘level 2’ disease categories from the 2017 GBD study is presented in table 1 and figures 2 and 3.
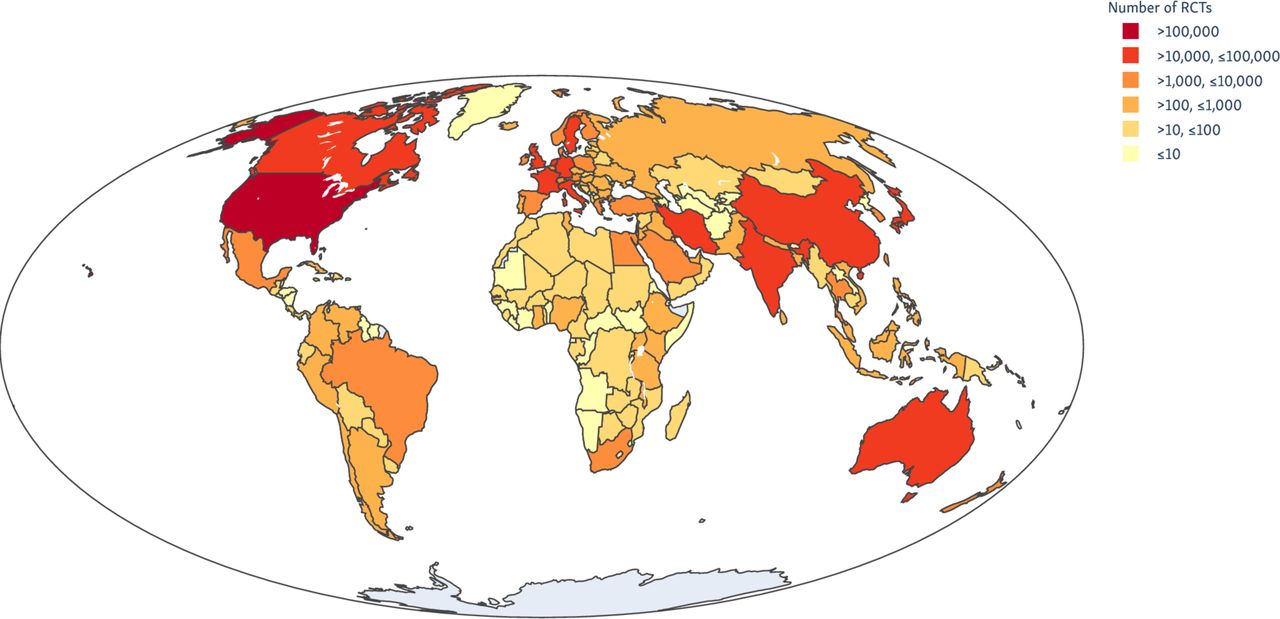
Global clinical trial publications by first author location, 1990–2017.

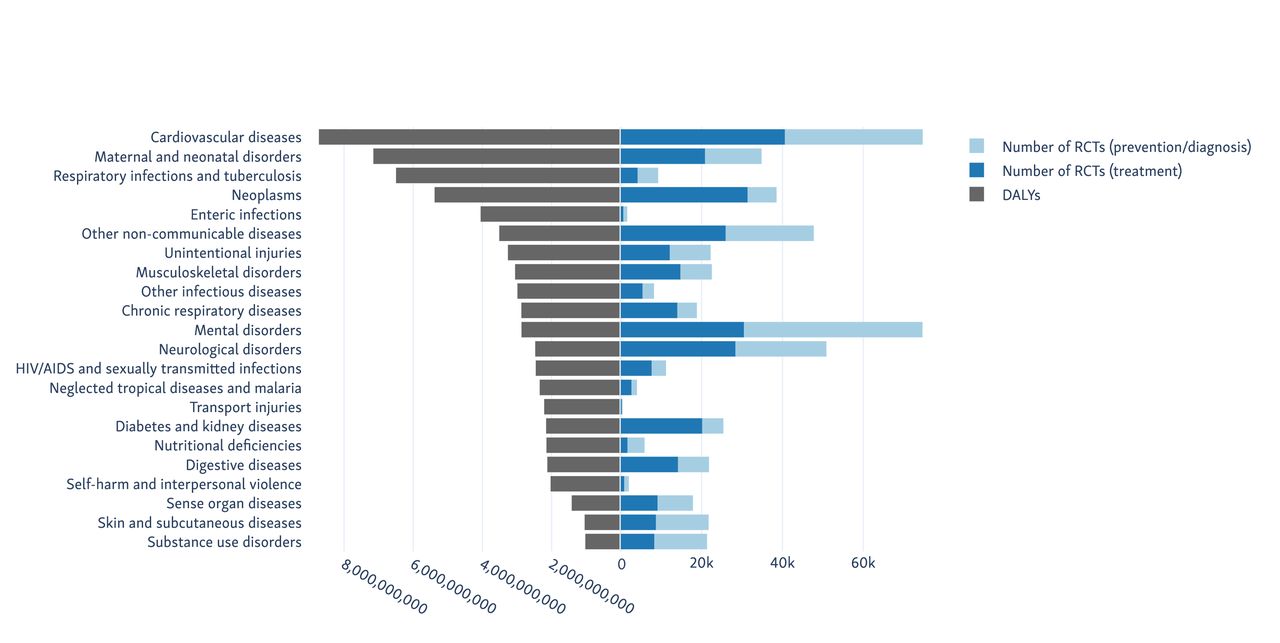
Disease categories causing the highest global burden (by DALY), with the number of RCTs published for each). DALY, disability-adjusted life years; RCT, randomised controlled trial.

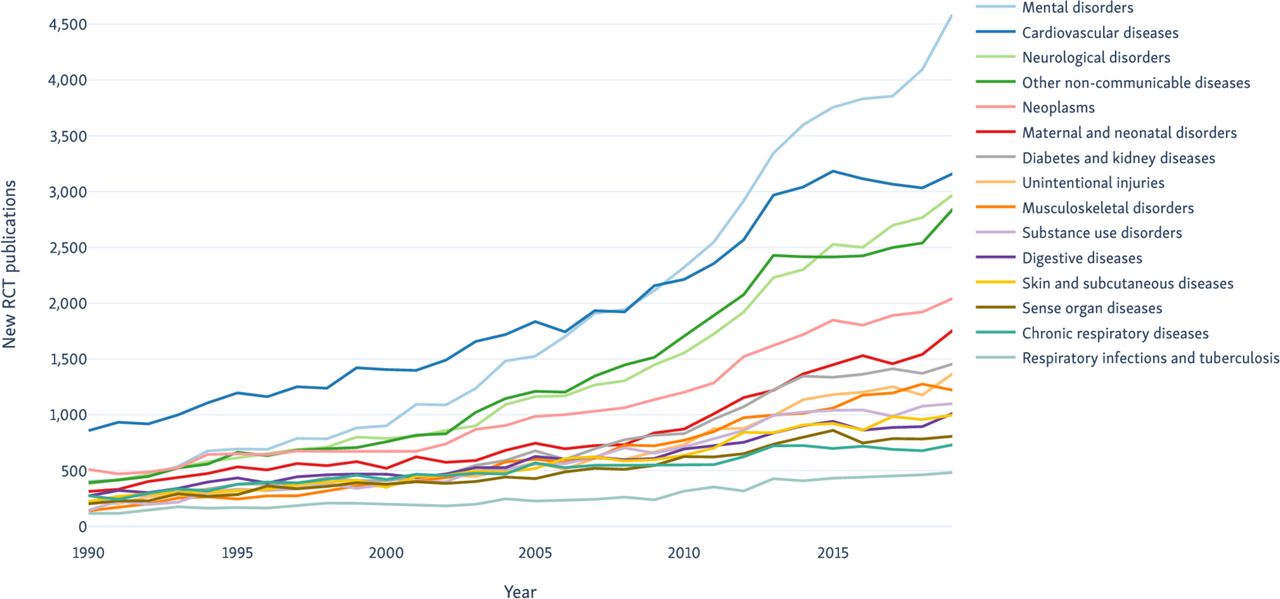
Trends over time in RCT publications of the top fifteen categories by publication rates from 1990 to 2019. RCT, randomised controlled trials.
Mental disorders (ranked 11th in terms of total DALYs) had the largest number of RCTs with 55 000, followed by cardiovascular diseases (ranked first) with 54 000. We separate the results from trials where the clinical condition occurred in the trial population (generally trials of treatment strategies for), and where the condition was a trial outcome (typically trials looking at prevention or diagnosis of the condition) in table 1 and figure 2. In all cases except for mental disorders, the numbers of trials and participants in the ‘treatment’ trials exceeded those in the ‘prevention’ trials.
Overall, we estimate the median number of participants randomised per RCT was 72, with IQR 32–195. We show how the distribution of RCT sample sizes varies for each of the GBD categories in figure 4.

Number of participants recruited to RCTs pertaining to each of the Global Burden of Disease categories. RCTs, randomised controlled trials.
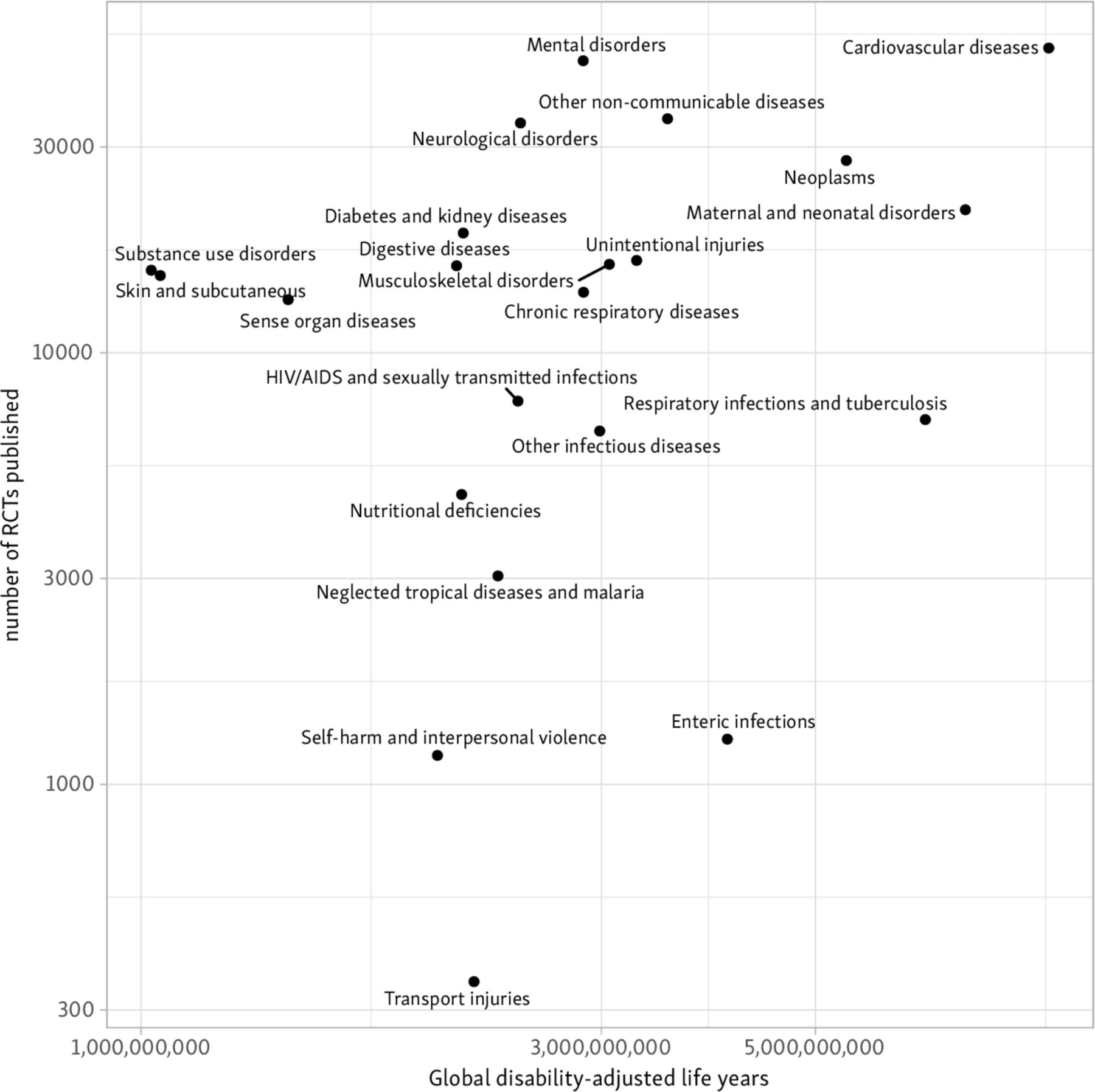
In figure 5 we scatter the volume of evidence estimated for conditions against the global burden that they impose (totals in period 1990–2017) for the 22 ‘level 2’ GBD categories.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Total RCTs published globally from 1990 to 2017 against disability-adjusted life years in the same period. RCTs, randomised controlled trials.
Our primary analysis found that, on average, increasing DALYs were associated with a statistically significant increase in RCT publication in the same year, but that variance was not well explained by the model (β=0.52 for log DALYs, 95% CI 0.33 to 0.70; R2=0.13). This translates to an average increase in the number of RCTs published of 5% (3.2% to 6.9%) for each 10% increase in DALYs in the same year. We report differences between the expected vs observed number of RCTs and trial participants based on this model in table 2.
Difference between measured number of RCTs, and number predicted based on global disease burden (negative numbers=fewer RCTs were published than predicted)
We found that models incorporating between 3 and 5 years of lag had improved fit compared with the equivalent model with no lag effects (demonstrated by reduction in AIC, BIC, and increase in adjusted R2). The model incorporating lag up to 3 years found an average 7.2% increase in published RCTs for every 10% increase in DALYs (adjusted R2=0.29). The models with lag up to 4, and up to 5 years gave near identical estimates and fit (full analysis results provided in the statistical appendix).
We provide full results for our sensitivity analysis (where we adjust for the differential impact of RCTs producing multiple publications in each disease in our statistical appendix (https://osf.io/zf97n/). We found that RCTs with a registry identifier produced a mean of 1.3 articles, but that there was variation between GBD categories (from 1.2 articles/RCT in nutritional deficiencies to 1.5 articles/RCT in cardiovascular diseases). Compared with our primary results, our sensitivity analysis found a near identical relationship between DALYs and published trials (β=0.48, 95% CI 0.30 to 0.66; R2=0.13). Adjusting for multiple publications did not affect which conditions were found to have relatively high or low associated RCT publications.
In our final model, which examined the effect of the DALY location (ratio of DALYs in the top fifth of countries by SDI vs the bottom four fifths), we found that DALYs, and the DALY location were both associated with increased RCT publications (βDALY=0.75, 95% CI 0.56 to 0.91, βlocation=0.44, 95% CI 0.38 to 0.51; adjusted R2=0.33). This may be interpreted that for every 10% shift in DALYs towards high-income countries, the number of RCTs increased by 4% (3.7% to 4.9%), and for every 10% increase in DALYs globally, RCTs increased by 7% (5.7% to 9.1%).
Discussion
We present the results from a natural language processing system that we used to perform a large-scale, comprehensive, automated analysis of all published RCTs indexed in the PubMed database. We find the number of published RCTs covering health conditions correlates only weakly with the burden that they inflict globally. Some conditions (particularly respiratory infections and tuberculosis, enteric infections and transport injuries) attract substantially fewer published RCTs than expected based on the global burden.
Conditions with fewer RCTs and participants than expected tend to disproportionately affect countries with low and medium socioeconomic status. For instance, respiratory infections and tuberculosis, which had the largest disparity between global burden and number of published RCTs disproportionately affects populations in lower income countries.24 By contrast, cancers and diabetes, for which there appears to be a relative abundance of evidence, are comparatively common in high-income countries, although this picture is changing over time.25 26 In other words, the top fifth of countries by SDI, who conduct the vast majority of RCTs, are more closely matching RCT conduct with disease burden within their own countries (although still weakly). These findings suggest that a research funding strategy based on individual countries priorities does not optimally meet global needs. However, the picture is complex: global development has meant that the most important diseases affecting high-income countries (ie, cardiovascular disease and cancers) have also become the top health priorities in low-income and middle-income countries a number of years later.
The median number of participants per RCTs was 72 (ie, a typical trial is likely to have around 36 participants per arm, or fewer for trials with >2 arms). Smaller trials can be conducted faster and at lower cost, and thus can be more responsive to need, but have important limitations.27 Small trials are more susceptible to the effects of publication bias, and have a high likelihood of generating false positive, and false negative findings.28 Meta-epidemiological studies have shown that trials with fewer than 100 participants per arm tend to exaggerate treatment effects, compared with larger ones.29 30 Twenty-five years after Yusuf et al called for larger, simpler RCTs,31 unfortunately we find that a majority of published trials are likely to be too small to provide useful or definitive information.
Prior work has investigated the relationship between burden of disease and National Institutes of Health funding.5 8 These efforts relied on manual compilation of data, which necessarily limited the scope of analysis. Additionally, these efforts could only analyse conditions for which funding data was available. The authors of the landmark 1999 New England Journal of Medicine study noted that data were not available for conditions making up 38% of the total DALY estimate at that time.5 Conducting this analysis manually additionally precludes the realisation of a ‘living’ view of the evidence base. By contrast, we have developed a fully automated approach that facilitates comprehensive, real-time analysis of the published RCT literature. For illustration, at the time of writing (September 2020), our system has indexed 158 RCTs examining treatments for COVID-19. This contrasts with PubMed, which has indexed (largely manually) 58 with the equivalent MeSH terms.
Because our coverage of diseases is broader than prior work on the relationship between funding and burden of disease, the results are not directly comparable. However, some findings do qualitatively align with findings from prior analyses of research funding. For example, we also find that diabetes generated a relatively generous number of RCTs, as do cancers (in general). Future analyses using the methods and data could examine specific conditions within the categories presented here, investigating, for example, whether stroke is adequately researched compared with coronary artery disease, or the distribution of trials relevant to different subtypes of cancer.
Our analysis has some limitations. First, our primary analysis examines publications and not RCTs themselves. Our sensitivity analysis confirms previous findings that RCTs may generate more than one publication,32 and so our estimates of publication numbers are likely to be an overestimate of the number of trials conducted. However, we found adjusting for estimates of duplicate publication made little difference to estimates of research done as a function of global burden. Second, the automated data extraction methods used here are only able to count explicit mentions of a disease or disorder, and explicit descriptions of participant numbers from the abstract, but abstracts do not always contain all the necessary information (in this study, for example, 34% of articles publications did not report the number of study participants). There is evidence of improvement over time after the publication of the Consolidated Standards of Reporting Trials recommendations in 1996.33
Last, we restrict our enquiry to PubMed and therefore have not counted RCTs which have produced publications in journals not indexed in PubMed. PubMed tends to under-represent articles published in non-English languages (though includes some where an English-language translations abstracts exist). PubMed also does not index conference presentations or pharmaceutical company data repositories. By focusing on published articles, this analysis will by construction miss RCTs whose results are never published (although unpublished trial results are arguably not effectively contributing to reducing the global disease burden). Nonetheless, PubMed is reasonably comprehensive; and those RCT publications that it misses have been found to comprise a relatively small fraction of the available health research.34 35
Why and how do some conditions attract relatively high numbers of RCTs and trial participants? We have described above how the priorities of research funders (nation states, pharmaceutical companies and disease-specific charities) may not align with the global need. But disparities in funding may not be the sole explanation: organisational and cultural differences within medical subdisciplines could plausibly play a role. National strategies exist for increasing participation in oncology research (eg, 2008 guidance from the American Society of Clinical Oncology which set a target of >10% of patients participating in clinical trials36); a large proportion of research looking at how best to increase trial recruitment has arisen from cancer RCTs.37 Further investigation of how the better performing medical disciplines achieve their high recruitment rates might uncover strategies which are more widely applicable.
Clinical trials are one small part of tackling the global disease burden and the UN sustainable development goals, and this wider landscape needs to be considered when determining research priorities. For example, the provision of clean water is likely to be more important for preventing enteric infections than any specific health intervention, and probably does not require an RCT to prove it.38 There may be other conditions (eg, HIV39) where established treatments can enable those with the condition to have a normal lifespan without significant disability. This contrasts with some types of cancer (eg, pancreatic cancer40), where we still lack reliably effective treatments. For pharmacological research, the ability to run new trials depends on the availability of new candidate drugs to test.41 Such new candidate drugs depend on unpredictable scientific breakthroughs, which will not neatly tally with global disease burden rankings.
Nonetheless, these data on the relative attention attracted by different health conditions may provide a useful metric to consider alongside other indicators of research need. Given that the vast majority of trials are being conducted by the wealthiest 20% of countries, targeting national health priorities is not sufficient, and a global approach is needed. We publish daily updates of the figures in this paper at www.robotreviewer.net/stateoftheevidence, and make the source code and dataset freely available via the Open Science Framework (DOI: https://dx.doi.org/10.17605/osf.io/3DB76).
Acknowledgments
We are enormously grateful to the volunteers from the Cochrane Crowd, who labelled hundreds of thousands of articles manually, enabling us to develop the machine learning system. Our grateful thanks to Danielle Wenner from the Department of Philosophy, Carnegie Mellon University, who reviewed early drafts and provided us with valuable feedback on the ethics of research funding distribution. We thank the Global Burden of Disease collaboration for making their data freely available for academic use.
References
Footnotes
Handling editor Seye Abimbola
Twitter @ijmarshall
Contributors Initial study conceived by IJM and BCW, with intellectual input from all authors. Automatic information extraction system created by: IJM, BCW, BN, AN and FS. Curation of data for training machine learning models: JT, AN-S, BCW, BN, AN and IJM. Statistical analysis designed and conducted by IJM, VL and BCW. Initial draft of manuscript by IJM and BCW. Critical revisions for important intellectual content: all; Approval of final manuscript: all.
Funding This work is funded by the UK Medical Research Council (MRC), through its Skills Development Fellowship programme (IJM), MR/N015185/1, and the US National Institutes of Health (NIH) under the National Library of Medicine, 2R01-LM012086-05 (IJM, FS and BCW). VL is funded by a National Institute for Health Research (NIHR), (Doctoral Research Fellow- DRF-2017-10-13). JT received grants from Cochrane during the conduct of the study.
Disclaimer The views expressed are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health and Social Care.
Map disclaimer The depiction of boundaries on this map does not imply the expression of any opinion whatsoever on the part of BMJ (or any member of its group) concerning the legal status of any country, territory, jurisdiction or area or of its authorities. This map is provided without any warranty of any kind, either express or implied.
Competing interests None declared.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Patient consent for publication Not required.
Provenance and peer review Not commissioned; externally peer reviewed.
Data availability statement Data are available in a public, open access repository. All data are available in a public, open access repository (DOI 10.17605/osf.io/3db76).
↵Model ‘training’ describes the process of adjusting model parameters to align with (typically large amounts of) data. Here, the models consume text documents (abstracts), with manual labels designating whether these are RCTs or not. Once trained (ie, once the parameters are estimated) the model can be applied to new, unseen abstracts to provide predictions.