
Abstract
Topological data analysis (TDA) characterizes the global structure of data based on topological invariants such as persistent homology, whereas convolutional neural networks (CNNs) are capable of characterizing local features in the global structure of the data. In contrast, a combined model of TDA and CNN, a family of multimodal networks, simultaneously takes the image and the corresponding topological features as the input to the network for classification, thereby significantly improving the performance of a single CNN. This innovative approach has been recently successful in various applications. However, there is a lack of explanation regarding how and why topological signatures, when combined with a CNN, improve discriminative power. In this paper, we use persistent homology to compute topological features and subsequently demonstrate both qualitatively and quantitatively the effects of topological signatures on a CNN model, for which the Grad-CAM analysis of multimodal networks and topological inverse image map are proposed and appropriately utilized. For experimental validation, we utilize two famous datasets: the transient versus bogus image dataset and the HAM10000 dataset. Using Grad-CAM analysis of multimodal networks, we demonstrate that topological features enforce the image network of a CNN to focus more on significant and meaningful regions across images rather than task-irrelevant artifacts such as background noise and texture.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Convolutional neural networks (CNNs) have proven their ability to extract complex patterns from images for image classification tasks [1–7]. However, it is well known that CNNs can be biased towards task-irrelevant patterns such as background noise and texture rather than towards the global shape of an object of interest in a given image [8, 9]. This comes from the fact that CNNs extract local features with their limited receptive field and the max pooling operations that tend to preserve high-frequency information such as noise and texture.
Topological data analysis (TDA) is a recent mathematical development that characterizes the global structure of data based on computational topology. Persistence diagram [10] is a way to represent data as a multiset containing topological properties called persistence homology [11]. By the nature of a multiset, it is challenging to feed persistence diagram directly into a neural network. To resolve this difficulty, several vectorization methods for representing persistence diagram with a fixed-size vector have been proposed such as persistence image (PI) [12], persistence landscape (PL) [13], Betti sequence (BS) [14], etc.
With such vectorization methods, several studies have proposed neural network architectures that take topological features as inputs. In [14], a BS was used as an input for a one-dimensional CNN model to solve time-series classification problems. In [15], a concatenated vector of the raw signal and the corresponding persistence vector was fed into a CNN for gravitational wave detection problems. These earlier studies, however, used a unimodal network that accepts only input from one modality (or channel).
Recent studies have shown that multimodal networks, which take original data and the corresponding topological features as inputs, achieve better performance than the original unimodal network without the topology network. In [16], PersLay, a deep learning layer, was proposed, which takes a raw persistence diagram as an input and combines it with a graph feature to solve several graph classification problems. TDA-Net [17], a generic network architecture that combines a two-dimensional CNN and various types of representations for persistence diagram, improves classification performance by taking an image and the corresponding BS simultaneously. It was applied successfully to COVID-19 classification from CXR-images [17].
Despite its successful performance, the multimodal network of combined TDA and CNN lacks an explanation as to how and why topological features enhance the discriminative power of the original CNN. However, it is crucial to understand the effects of topological features on a neural network to effectively integrate TDA with a deep learning framework. To analyze the effects of topological features on a CNN, we, in this paper, demonstrate how the behavior of a CNN changes when topological features are fed into the CNN. For this, we use the method of visualizing the saliency maps of the input image and its topological features. A saliency map of an input image shows the degree of influence of each pixel in the image on model prediction [18]. There have been several approaches to generating a saliency map, which can be categorized into the following two approaches.
The first approach, namely, the input-perturbation-based approach [19–21], perturbs small regions of inputs and measures the changes in the model prediction. If the perturbed region causes a considerable change in the prediction, it is regarded as a significant feature of the model decision. This approach deforms the given image by randomly masking the image regions with small patches. However, the perturbation method is inadequate for analyzing the combined topology net, i.e. CNN-TDA Net for our research. This is because such a deformation in an image could easily lead to a large change in topology, particularly a change in persistent homology used in our research. For persistent homology, the n-dimensional hole structure, such as the number and the size of holes, could be easily changed due to the deformation. Thus, it is difficult to determine whether the resulting change by perturbation reflects the actual significance of the region or is simply due to artifacts.
The second approach, namely, the gradient-based approach, is free of such issues, and we choose this method for our analysis. Gradient-based approaches, [22–26], contrary to the perturbation method, measure the importance of each region of an image by computing the gradient of model prediction with respect to features. The gradient-based method is more desirable for analyzing the influence of topological features because no corruption of the input image is used, and the individual effects of the visual (CNN) and topological features (TDA-Net) can be measured by computing the partial derivatives of the model prediction with respect to both features independently. Furthermore, it can easily be extended to multimodal networks.
One difficulty with the saliency approach is determining whether a saliency map depends on the model parameters, so that it can truly capture the regions affecting the model prediction. In [27], two methods were proposed for determining the sanity of gradient-based saliency maps, and Grad-CAM [25] passed the sanity checks. Thus, saliency methods based on Grad-CAM are suitable for comparing the differences between two networks. There have been advanced variants of Grad-CAM [26, 28]; however, in this paper, we use the original Grad-CAM to focus on showing how the behavior of a CNN changes when additional topological information is given.
In this paper, we are concerned with the question: 'How does the topology network improve model performance when combined with a CNN?'. To answer this question, we first propose a methodology to utilize Grad-CAM analysis for multimodal networks and visually demonstrate the effects of topological signatures on a CNN. Specifically, we apply multimodal Grad-CAM to CNN-TDA Net [17] trained on various image classification datasets. Second, we propose a methodology to transform a feature map obtained from the considered BS and Grad-CAM into the region of the input image. We refer to this transformation as the topological inverse image map. In general, the topological inverse map is not unique; however, in our case, it is well-defined because there is one-to-one correspondence between the constructed complex and the filtration as explained later in this paper. By visualizing the top five individual feature maps of large channel importance, it is shown that there are redundant and meaningless feature maps obtained from a single CNN, whereas a CNN-TDA Net significantly reduces the number of redundant and meaningless feature maps and creates task-relevant feature maps. The results show that topological features from the topology network enforce an image network to focus more on meaningful regions across all images, whereas a single CNN is biased to task-irrelevant artifacts such as background noise and texture.
The rest of this paper is structured as follows. In section 2, we provide an overview of TDA based on persistent homology. Building cubical complexes is a crucial step for persistent homology on images for the combined CNN and TDA multimodal network towards calculating BS. BS is the main vectorization used in this paper. Thus, the building strategies are explained and the definition of BS is provided in this section. The TDA-Net, a multimodal network of combined CNN and TDA, and Grad-CAM, the main analysis tool for the visualization of feature maps, are explained in section 3. In section 4, we explain our main analysis tools for demonstrating the effects of topological features on CNNs, that is, Grad-CAM analysis on multimodal networks and the topological inverse image map. The description of numerical experiments using those two famous datasets, i.e. the transient versus bogus image dataset and the HAM 10000 dataset are presented in section 5. The numerical results are presented in section 6. In this section, the effects of topological features on a CNN are clearly visualized through Grad-CAM and the topological inverse image map. In addition, for quantitative analysis, the Intersection over Union (IoU) scores of both the CNN and CNN-TDA Net are computed and compared. Finally, in section 7, we provide a brief conclusion and discuss future work.
2. TDA on images and Betti sequences
TDA is a technique for characterizing the global structure of given data by using computational topology. Persistent homology is one of the main methodologies of TDA. With this method, the topological feature of the given data is extracted as follows. First, we construct a filtration, a nested sequence of simplicial (or cubical) complexes indexed by filtration values. Second, we compute persistence homology for the filtered complex and represent it as persistence diagram. Persistence diagram is the multiset of the birth-death pairs of each kth homology class. Due to its multiset nature, the persistence diagram is unsuitable for use as an input in a neural network. Thus, persistence diagram is converted into a fixed-size representation using vectorization methods, such as PI [12], PL [13], and BS [14]. In this section, we briefly provide an overview of each component of the procedure above.
2.1. Cubical complex and persistent homology
Images consist of discrete pixels (or voxels) on a fixed uniform grid in Euclidean space  . Intuitively, these pixels have some kind of connection structure. This connection structure may form an edge or a surface of image. With the aid of computational topology, this connectivity can be handled suitably and calculated numerically.
. Intuitively, these pixels have some kind of connection structure. This connection structure may form an edge or a surface of image. With the aid of computational topology, this connectivity can be handled suitably and calculated numerically.
Graphs or simplicial complexes are typical examples, which represent the connection between objects such as edges or planes. Cubical complexes are generally used to represent the connectivity in images. Since images are defined on mesh, cubical complexes, whose bases are elementary cubes, are suitable to represent the topological features of the given image data.
A cubical complex is a collection of vertices, edges, squares, and higher dimensional analogues on a regular grid in  . The formal definition is as follows:
. The formal definition is as follows:
Definition 1 (Cubical complex). An elementary cube  is defined as a product
is defined as a product  where each Ij
is either a singleton set
where each Ij
is either a singleton set  or a unit-length interval
or a unit-length interval ![$[m,m+1]$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn6.gif) for some integers
for some integers  . The number k of the unit-length intervals in the product of Q is called the dimension of cube Q and we call Q a k-cube. If Q and Qʹare two cubes and
. The number k of the unit-length intervals in the product of Q is called the dimension of cube Q and we call Q a k-cube. If Q and Qʹare two cubes and  , then Q is said to be a face of Qʹ. A cubical complex X in
, then Q is said to be a face of Qʹ. A cubical complex X in  is a collection of k-cubes (
is a collection of k-cubes ( ) such that
) such that
- (i)every face of a cube in X is also in X;
- (ii)the intersection of any two cubes of X is either empty or a face of each of them.
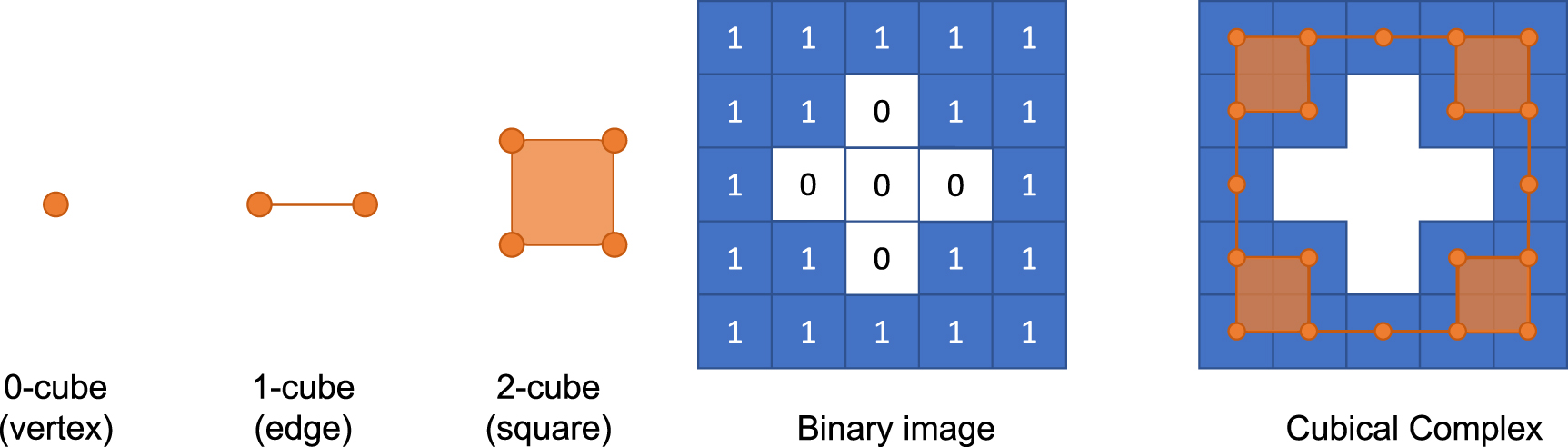
In order to obtain a cubical complex of a given image, choose an appropriate threshold (grayscale value) and obtain a binary image. Those pixels (e.g. figure 1) assigned the value of 1 in the binary image on the grid in  are regarded as a point (vertex). Now one can define a cubical complex on the point set. See figure 1.
are regarded as a point (vertex). Now one can define a cubical complex on the point set. See figure 1.

Figure 1. An example of cubical complex. A cubical complex consists of elementary cubes (left). After choosing an appropriate threshold, one may obtain a binary image (middle). Each pixel in the binary image corresponds to a vertex. If two pixels are adjacent, connect them by an edge. A square is a filled face made of four edges. A cubical complex of this image is a collection of all these components (right).
Download figure:
Standard image High-resolution imageRepresenting an image as a cubical complex allows us to observe the topological features in the image such as the connected components and loop structures. Moreover, these topological features in the image are characterized by the notion of homology. Hence, one may find the number of connected components or loops in the image by calculating its homology. Homology of an image is obtained through the following steps.
- (i)Choose a threshold and define a cubical complex X.
- (ii)For each
 , define a free abelian group (or vector space over finite field ) whose basis is a set of all k-cubes in X. Each is called kth chain group or chain module. Let .
, define a free abelian group (or vector space over finite field ) whose basis is a set of all k-cubes in X. Each is called kth chain group or chain module. Let . - (iii)For each k, define a homomorphism which maps k-cubes to sum of its faces in . Each is called the kth boundary operator.
- (iv)Now, the kth homology group is defined as the quotient space for each k.










Notice that the composition  is equivalent to the zero map. It follows
is equivalent to the zero map. It follows  and then the homology group
and then the homology group  is well-defined.
is well-defined.
The rank of the kth homology group  is called the kth Betti number or generator. Roughly speaking, the Betti number is the number of k-dimensional holes in X such as connected components (zero-dimensional holes), loops (one-dimensional holes) and so on.
is called the kth Betti number or generator. Roughly speaking, the Betti number is the number of k-dimensional holes in X such as connected components (zero-dimensional holes), loops (one-dimensional holes) and so on.
Using homology, useful topological information can be calculated through matrix computations. For this, we need to select appropriate thresholds to define a cubical complex. Persistent homology, a major tool of TDA, is a generalized concept of homology that helps us to learn how homology changes with increasing thresholds. The topological features used in a CNN-TDA Net considered in this paper are calculated based on persistent homology.
A grayscale image is represented by a function  where Ω is the grid on which the image is defined and
where Ω is the grid on which the image is defined and  is the grayscale value of the pixel
is the grayscale value of the pixel  . In general, the grayscale value of one pixel takes an integer value between 0 and 255. Additionally, let
. In general, the grayscale value of one pixel takes an integer value between 0 and 255. Additionally, let  be an empty set. A sublevel set of a grayscale image for a value
be an empty set. A sublevel set of a grayscale image for a value  is a set of all pixels in the grid with a pixel intensity less than or equal to i, i.e.
is a set of all pixels in the grid with a pixel intensity less than or equal to i, i.e.  . A sublevel set may be realized with a binary image in which 1 is assigned to pixels of the sublevel set and 0 is assigned to pixels on the remaining grid. We note here that we mainly consider the grayscale images in this paper and the colored images will be considered in our future research.
. A sublevel set may be realized with a binary image in which 1 is assigned to pixels of the sublevel set and 0 is assigned to pixels on the remaining grid. We note here that we mainly consider the grayscale images in this paper and the colored images will be considered in our future research.
Let Xi
be the cubical complex defined on the binary image of the sublevel set  . Then a sequence
. Then a sequence  of the sublevel sets induces a nested sequence of cubical complexes
of the sublevel sets induces a nested sequence of cubical complexes  . This sequence is called the filtration.
. This sequence is called the filtration.
The inclusion relation of cubical complexes in the filtration is naturally extended to the inclusion relation of the corresponding homology. More precisely, this idea is based on the functoriality that appears throughout various mathematical applications. That is, the inclusion map  between two cubical complexes
between two cubical complexes  is extended to the inclusion linear map
is extended to the inclusion linear map  between two vector spaces
between two vector spaces  and
and  for fixed k. For
for fixed k. For  , the following holds :
, the following holds :

Now we can define the persistent module and homology:
Definition 2 (The
k
th persistence module). For the given filtration  and fixed dimension k, the kth persistent module PMk
consists of the pair of the k-dimensional homology groups (or vector spaces) and linear maps
and fixed dimension k, the kth persistent module PMk
consists of the pair of the k-dimensional homology groups (or vector spaces) and linear maps

where  is the kth homology for each Xi
and
is the kth homology for each Xi
and  are the linear maps induced by the inclusions
are the linear maps induced by the inclusions  for all
for all  . The kth persistent homology groups
. The kth persistent homology groups
 are the images of
are the images of  ; that is,
; that is,  .
.
The functoriality of persistent homology plays a critical role to analyze whole scheme for the evolution of the space with respect to the variation of parameters. One can observe overall homology according to the change of the parameter.
Recall that the generators of each homology represent the connectivity of space, such as connected components, loops, voids and so forth. Then for any i and j with  , the generator of the previous homology group
, the generator of the previous homology group  may be maintained as the generator of the latter
may be maintained as the generator of the latter  under the linear map
under the linear map  or no longer be a generator as expressed by the linear combination of the generators of
or no longer be a generator as expressed by the linear combination of the generators of  .
.  may also contain new generators that were not present in
may also contain new generators that were not present in  . This means that information about the connectivity of each space is 'newly born', 'persist', or 'merged away' as the scale changes.
. This means that information about the connectivity of each space is 'newly born', 'persist', or 'merged away' as the scale changes.
The persistent homology  summarizes this information. The rank of
summarizes this information. The rank of  is called the kth persistence Betti number and denoted by
is called the kth persistence Betti number and denoted by  .
.  represents the number of the kth homological classes persisting between i and j.
represents the number of the kth homological classes persisting between i and j.
The decomposition theorem of persistence module tells us that persistent homology can be decomposed algorithmically by a multiset of intervals ![$\left\{[b_n,d_n]\right\}_n$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn60.gif) in which each interval
in which each interval ![$[b,d]$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn61.gif) corresponds to a topological invariant that is born at b and dies at d [29]. Then, the collection of intervals
corresponds to a topological invariant that is born at b and dies at d [29]. Then, the collection of intervals ![$\left\{[b_n,d_n]\right\}_n$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn62.gif) for persistent homology is called persistence barcode. The persistence diagram is a collection of points in
for persistent homology is called persistence barcode. The persistence diagram is a collection of points in  that each point
that each point  corresponds to the interval
corresponds to the interval ![$[b_n,d_n]$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn65.gif) in barcode. Persistence barcode and persistence diagram have exactly the same information.
in barcode. Persistence barcode and persistence diagram have exactly the same information.
Figure 2 shows persistent homology of the left image in (a). (a) shows the filtration of the given image, (b) the corresponding persistence barcode, and (c) the corresponding persistence diagram. For the filtration value i = 0, only five pixels with a zero intensity are activated, and form five connected components. These five connected components correspond to the five solid lines in persistence barcode. For X1, the five connected components are integrated into one so that the four solid lines in the barcode end at i = 1. One connected component remains until X4 as shown in the figure—the first orange lines in the barcode and the point  in the diagram. For one-dimensional homology, one loop enclosed by the connected components is born at X1 and dies at X4 corresponding to the red dashed line in the barcode and the red dot in the diagram.
in the diagram. For one-dimensional homology, one loop enclosed by the connected components is born at X1 and dies at X4 corresponding to the red dashed line in the barcode and the red dot in the diagram.

Figure 2. Example of persistent homology of the left image data of (a). (a) Filtration. (b) The corresponding persistence barcode. (c) The corresponding persistence diagram. Note that the point  in the persistence diagram is a triple point.
in the persistence diagram is a triple point.
Download figure:
Standard image High-resolution imageAs shown above, persistence diagram contains useful topological characteristics of the given data. However, it cannot be fed into the neural networks directly due to its multiset nature. Vectorization is a way of feeding the topological features appearing in persistence diagram into the neural networks. Various vectorization methods have been proposed that convert persistence diagram into a finite size representation, such as BS, persistence landscape, and PI. Let  be a sequence of filtration values and
be a sequence of filtration values and  be a fixed number. Briefly speaking, the kth BS [14] is defined by
be a fixed number. Briefly speaking, the kth BS [14] is defined by  where
where ![$BC(\epsilon) = \left|\left\{(b,c)\in PD : \epsilon \in [b,d]\right\}\right|$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn71.gif) . The kth persistence landscape [13] is defined by
. The kth persistence landscape [13] is defined by  where
where  is the lth largest value of
is the lth largest value of  . A PI [12] is an image-like representation that applies the Gaussian kernel to each point in persistence diagram.
. A PI [12] is an image-like representation that applies the Gaussian kernel to each point in persistence diagram.
2.2. Betti sequences
In this work, we utilized BS for the CNN-TDA Net as the vectorization of topological features. For the given filtered complex Xε
, the BS is constructed by tracking the variation of the Betti numbers of each complex Xε
with the increasing value of ε. In other words, the Betti curve (BC) is a function assigning each ε value to the Betti number  .
.
Definition 3 (Betti curve/Betti sequence). Let  be the equally spaced points in the parameter space. For the persistence diagram PDk
for the kth persistence module
be the equally spaced points in the parameter space. For the persistence diagram PDk
for the kth persistence module  , the kth Betti curve is a function defined by
, the kth Betti curve is a function defined by

The kth Betti sequence is the sequence of the numbers

The BC is easy to compute. One can observe that the BC is the linear combination of the indicator functions ![$\mathbf{1}_{[\epsilon_i,\epsilon_{i+1}]}$](https://content.cld.iop.org/journals/2632-2153/4/3/035019/revision2/mlstace6f3ieqn78.gif) . Thus, the BC is a step function, and its space forms a vector space with Lp
-norm
. Thus, the BC is a step function, and its space forms a vector space with Lp
-norm  . It follows that the BC is suitable to statistical inference and machine learning [30].
. It follows that the BC is suitable to statistical inference and machine learning [30].
By stacking the kth BSs along the dimensions, we can represent them as a multichannel sequential data structure where each data point is a d-dimensional vector, i.e,

This interpretation of the BSs as sequential data motivated us to utilize a one-dimensional CNN for analyzing BSs.
3. TDA-Net and Grad-CAM
3.1. TDA-Net
A CNN-TDA Net (or simply TDA-Net) [17] is a family of neural networks that take an image and the corresponding topological features as inputs to predict its label. TDA-Net consists of three subnetworks: an image network, a TDA network (or a topology network), and a prediction head. An image network fimg is a CNN that takes an image as an input and extracts a fixed-size feature vector. A TDA network ftda is a parameterized nonlinear function that encodes TDA features corresponding to the input image into a feature vector of a fixed size. That is, for the given image  and the corresponding TDA features,
and the corresponding TDA features,  , we have
, we have


where  and
and  are the feature vectors with specific dimensions determined by the input size and the network architecture, respectively. Again, examples of topological features could be PI, PL, and BS. The structure of the TDA network depends on the shape of the vectorization. For example, one can use a two-dimensional CNN for PI because PI is given as a two-dimensional image and a one-dimensional CNN for PL and BS because both PL and BS are basically one-dimensional sequences of numbers. In this paper, we focus on the effects of topological features using BS, simply referred to as a CNN-BS Net.
are the feature vectors with specific dimensions determined by the input size and the network architecture, respectively. Again, examples of topological features could be PI, PL, and BS. The structure of the TDA network depends on the shape of the vectorization. For example, one can use a two-dimensional CNN for PI because PI is given as a two-dimensional image and a one-dimensional CNN for PL and BS because both PL and BS are basically one-dimensional sequences of numbers. In this paper, we focus on the effects of topological features using BS, simply referred to as a CNN-BS Net.
The concatenation of  and
and  is fed into the prediction head. A typical choice for a prediction head fhead is an MLP, but any nonlinear function that produces a prediction can be used:
is fed into the prediction head. A typical choice for a prediction head fhead is an MLP, but any nonlinear function that produces a prediction can be used:

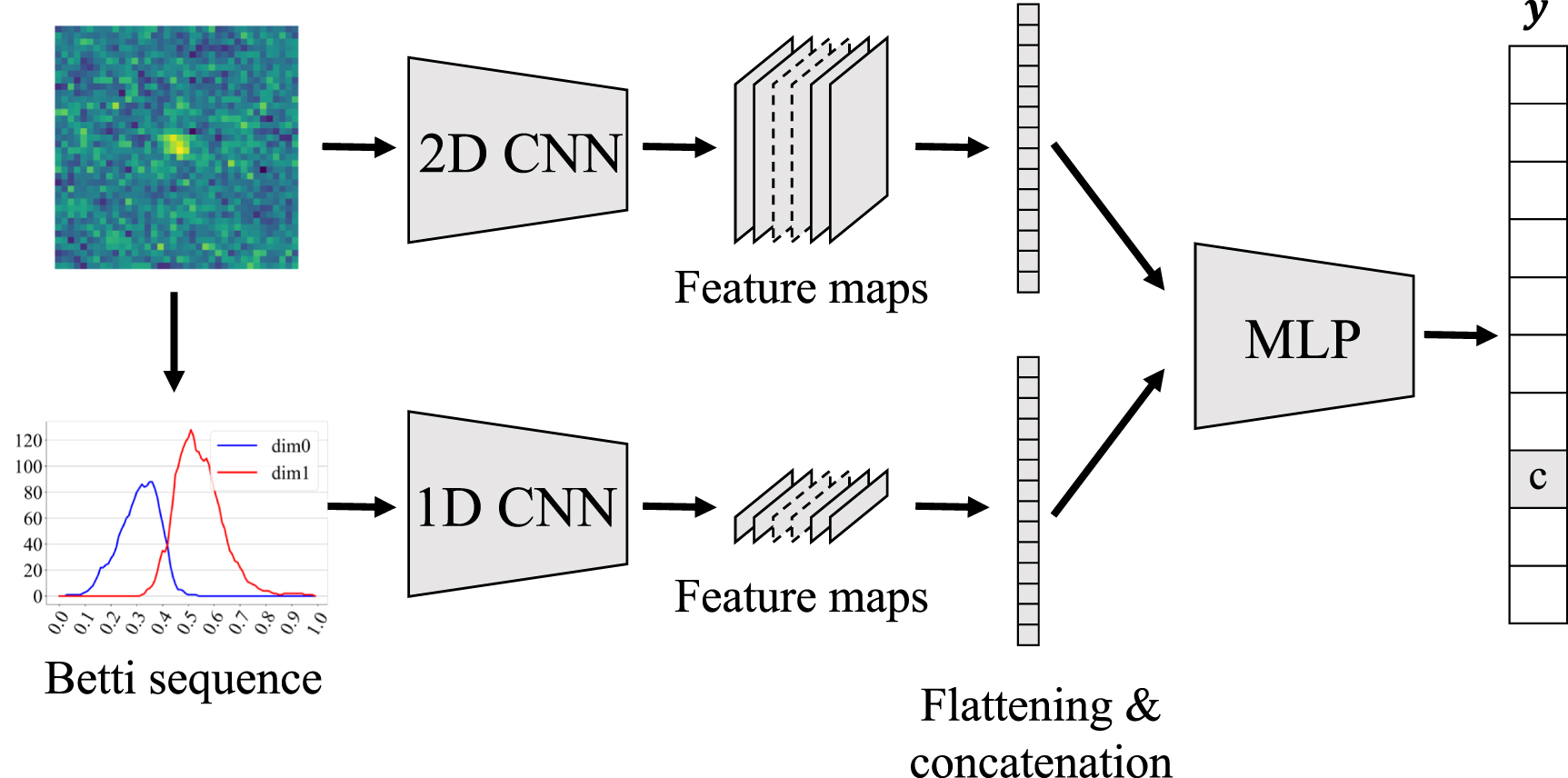
where  is a scalar for a one-dimensional regression task or a vector for a classification task. Figure 3 shows the schematic structure of a TDA-Net, i.e. a CNN-BS Net. The top-left figure shows the original image. The main image source is located at the image center with a noisy background. The bottom left figure shows the BSs; the blue solid line represents the zero-dimensional BS and the red the one-dimensional BS. The image and the BSs are fed into the TDA-Net in the figure. The image passes through the two-dimensional CNN (denoted as the 2D CNN in the figure) to produce feature maps. The BSs go through the one-dimensional CNN (denoted as the 1D CNN in the figure), producing into feature maps. Both the image and topology feature maps are fed into the MLP towards the prediction head.
is a scalar for a one-dimensional regression task or a vector for a classification task. Figure 3 shows the schematic structure of a TDA-Net, i.e. a CNN-BS Net. The top-left figure shows the original image. The main image source is located at the image center with a noisy background. The bottom left figure shows the BSs; the blue solid line represents the zero-dimensional BS and the red the one-dimensional BS. The image and the BSs are fed into the TDA-Net in the figure. The image passes through the two-dimensional CNN (denoted as the 2D CNN in the figure) to produce feature maps. The BSs go through the one-dimensional CNN (denoted as the 1D CNN in the figure), producing into feature maps. Both the image and topology feature maps are fed into the MLP towards the prediction head.

Figure 3. The schematic diagram of TDA-Net for an image with its Betti sequence. TDA-Net is a multimodal neural network that takes an image and the corresponding topological features as its inputs.
Download figure:
Standard image High-resolution image3.2. Grad-CAM
Grad-CAM [25] is a technique for visually explaining the decision of a CNN-based model. It measures the influence of each pixel in the feature maps of the last convolutional layer on the model prediction. Let yc be the prediction of the model for a class c and Ak be the kth feature map of the last convolutional layer. Then, the class-discriminative localization map Grad-CAM, which has the form of a heat map, is computed as follows:

where  is the importance of the kth feature map.
is the importance of the kth feature map.  is defined as the average of the partial derivative values of yc
with respect to each pixel in Ak
:
is defined as the average of the partial derivative values of yc
with respect to each pixel in Ak
:

where (i, j) is the coordinate of each pixel in the feature map Ak
and Z is the number of pixels in Ak
. In (9),  ensures that
ensures that  is greater than or equal to zero. The resolution of
is greater than or equal to zero. The resolution of  is the same as that of the feature maps, which is generally smaller than that of the input image. Thus,
is the same as that of the feature maps, which is generally smaller than that of the input image. Thus,  is upsampled to
is upsampled to  which has the same resolution as the input image by using bilinear interpolation. The visual interpretation of the model is obtained by superimposing
which has the same resolution as the input image by using bilinear interpolation. The visual interpretation of the model is obtained by superimposing  on the input image. Figure 4 shows a schematic illustration of how the heat map is calculated using Grad-CAM applied to the CNN. The figure shows how the gradients of the model prediction with respect to feature maps are integrated through ReLU towards the heat map, which is then displayed on the original image after being upsampled. The area in the warmest color in the bottom-left heat map indicates the main feature that the CNN uses for prediction in the image.
on the input image. Figure 4 shows a schematic illustration of how the heat map is calculated using Grad-CAM applied to the CNN. The figure shows how the gradients of the model prediction with respect to feature maps are integrated through ReLU towards the heat map, which is then displayed on the original image after being upsampled. The area in the warmest color in the bottom-left heat map indicates the main feature that the CNN uses for prediction in the image.

Figure 4. Illustration of Grad-CAM adapted from [25]. Grad-CAM is computed as the weighted sum of feature maps of the last convolutional layer. Each weight is the average of the partial derivative values of the predicted probability with respect to pixels in each feature map. With upsampling Grad-CAM provides the visual interpretation of the given convolutional network.
Download figure:
Standard image High-resolution image4. Proposed analysis
4.1. Grad-CAM on multimodal networks
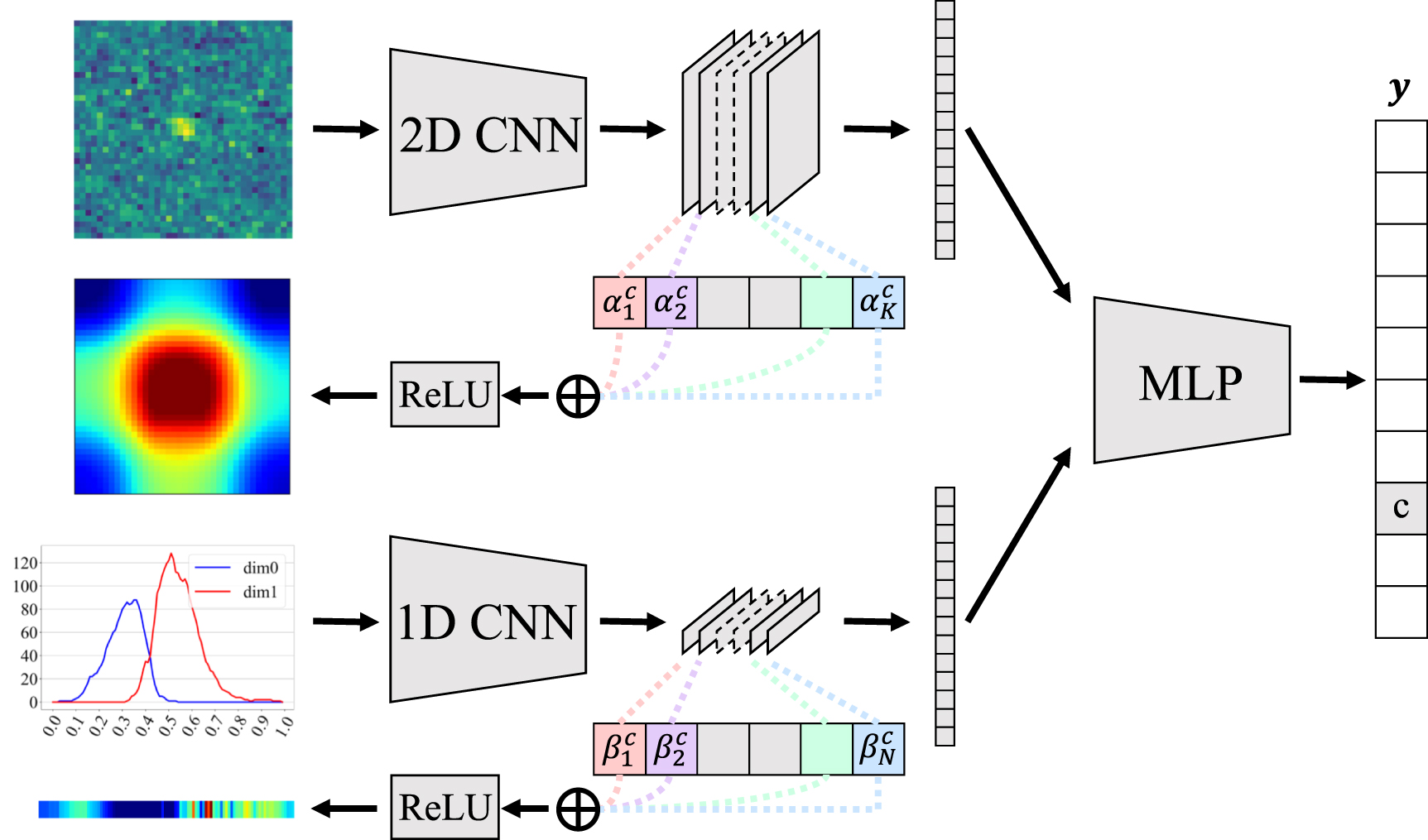
To the best of our knowledge, the current work is the first approach to apply Grad-CAM to CNN-TDA Nets and analyze the role of TDA features on a CNN. The application of Grad-CAM to a multimodal network was initially implemented in [31]. Here, we first provide an elaborated formulation. We perform Grad-CAM on the last feature maps A of an image network and the last feature maps B of a TDA network, respectively, i.e.


where Ak
is the kth feature map of the image network and  is the total number of pixels in Ak
. And
is the total number of pixels in Ak
. And


where Bn
is the nth feature map of the TDA network in the one-dimensional CNN and  is the total number of pixels in Bn
. Then,
is the total number of pixels in Bn
. Then,  and
and  are upsampled to
are upsampled to  and
and  so that they have the same resolution as the input image and the computed BS, respectively. Figure 5 illustrates the procedure of Grad-CAM analysis on the multimodal network. In figure 5, the top-left figure shows the original input image, which has the main image source at the center in a noisy background. The middle left figure shows the heat map obtained by Grad-CAM applied to the image network and displaced on the original image after being upsampled. The bottom left figure shows the zero- and one-dimensional BSs of the original image through the steps of building cubical complexes. The blue solid line represents the zero-dimensional BS and the red solid line the one-dimensional BS, as shown in figure 3. Unlike figure 3, the figure shows the heat map by Grad-CAM applied to the topology network. Figure 5 shows how those heat maps for the image and topology networks are obtained in the CNN-TDA Net. As shown in the figure, the prediction head is a nonlinear function of those two feature maps from the image and topology networks. Thus, the heat map of the image network is obviously affected by the topology network.
so that they have the same resolution as the input image and the computed BS, respectively. Figure 5 illustrates the procedure of Grad-CAM analysis on the multimodal network. In figure 5, the top-left figure shows the original input image, which has the main image source at the center in a noisy background. The middle left figure shows the heat map obtained by Grad-CAM applied to the image network and displaced on the original image after being upsampled. The bottom left figure shows the zero- and one-dimensional BSs of the original image through the steps of building cubical complexes. The blue solid line represents the zero-dimensional BS and the red solid line the one-dimensional BS, as shown in figure 3. Unlike figure 3, the figure shows the heat map by Grad-CAM applied to the topology network. Figure 5 shows how those heat maps for the image and topology networks are obtained in the CNN-TDA Net. As shown in the figure, the prediction head is a nonlinear function of those two feature maps from the image and topology networks. Thus, the heat map of the image network is obviously affected by the topology network.

Figure 5. Illustration of Grad-CAM analysis on a multimodal TDA-Net. Every subnetwork of each input modality should be a CNN-based network to apply Grad-CAM. Multimodal Grad-CAM is simply the collection of multimodal Grad-CAMs using the feature maps of the last convolutional layer of each subnetwork.
Download figure:
Standard image High-resolution imageHere we note that there are no cross-effects of both feature maps in the MLP after the concatenation of the two flattened vectors of A and B. With ReLU activation function, it is guaranteed that there is no nonlinear term between any  and
and  when yc
is a predicted logit (before applying the Softmax function). Hence, the partial derivative with respect to
when yc
is a predicted logit (before applying the Softmax function). Hence, the partial derivative with respect to  or
or  is either zero or the linear weight corresponding to each of them.
is either zero or the linear weight corresponding to each of them.
4.2. Topological inverse image analysis
In order to interpret the Grad-CAM results of a TDA network, we define the topological inverse image of a range of filtration values. Let  be the grayscale image of the height h and width w, and
be the grayscale image of the height h and width w, and  be two filtration values. We define the sublevel image
be two filtration values. We define the sublevel image  of I at ta
as follows:
of I at ta
as follows:

for  , and
, and  . Then, the topological inverse image of I of the range
. Then, the topological inverse image of I of the range  is defined as the subtraction of
is defined as the subtraction of  from
from  , i.e.
, i.e.

That is,  is the image I where the region that has intensities out of the range
is the image I where the region that has intensities out of the range  is set to be zeros. The visual explanation of the inverse image is shown in figure 6. The left figure (a), in figure 6, is the original grayscale image of a point source with noisy background. As shown in the figure, the main object of interest is located in the image center. As the noise intensity in the background is non-negligible compared to the intensity of the main object in the center, CNN could be biased to such high-frequency noise in the background. Figure (b) shows two filtration values ta
and tb
with
is set to be zeros. The visual explanation of the inverse image is shown in figure 6. The left figure (a), in figure 6, is the original grayscale image of a point source with noisy background. As shown in the figure, the main object of interest is located in the image center. As the noise intensity in the background is non-negligible compared to the intensity of the main object in the center, CNN could be biased to such high-frequency noise in the background. Figure (b) shows two filtration values ta
and tb
with  . Figures (c) and (d) show
. Figures (c) and (d) show  and
and  , respectively, where it is clear that background noise is still significant. Figure (e) shows the topological inverse image,
, respectively, where it is clear that background noise is still significant. Figure (e) shows the topological inverse image,  , in the range of
, in the range of  . As shown in (e), the main image source is more outstanding than in (c) and (d). As shown later, the heat map by Grad-CAM indicates well the main image characteristics through the topological inverse image map.
. As shown in (e), the main image source is more outstanding than in (c) and (d). As shown later, the heat map by Grad-CAM indicates well the main image characteristics through the topological inverse image map.

Figure 6. Illustration of a topological inverse image. (a) The original image. (b) 3D visualization of the image where z-axis represents the pixel intensity for two filtration values ta
and tb
. (c)  . (d)
. (d)  . (e)
. (e)  .
.
Download figure:
Standard image High-resolution imageWe investigate the topological inverse image of the range near the filtration value that has the maximum in Grad-CAM, that is, the filtration value where the heat map by Grad-CAM has the warmest color. Here, the range is determined by the receptive field of the TDA network. We recall that the receptive field of a pixel in feature maps is the region in the input involved in the calculation of that pixel. Hence, we consider the topological inverse image  such that
such that

and

where  , lrf is the length of the receptive field of the TDA network, and lbc is the length of the BS. Therefore, the topological inverse image can be interpreted as a transformation from a feature map obtained from the BS and Grad-CAM into the region of the input image. While the inverse of a given BS may not be unique in general, the definition of our topological inverse image ensures that it can always be obtained when an image and two filtration values are given. As shown in the following section, Grad-CAM analysis shows that the topological inverse image identified by the heat map is well-matched with the main image of interest. This implies that the topology network is less sensitive to background noise than the image network. The reproducible codes for the experiments with the HAM1000 dataset can be found at https://github.com/HiddenBeginner/cnntdanet_gradcam.
, lrf is the length of the receptive field of the TDA network, and lbc is the length of the BS. Therefore, the topological inverse image can be interpreted as a transformation from a feature map obtained from the BS and Grad-CAM into the region of the input image. While the inverse of a given BS may not be unique in general, the definition of our topological inverse image ensures that it can always be obtained when an image and two filtration values are given. As shown in the following section, Grad-CAM analysis shows that the topological inverse image identified by the heat map is well-matched with the main image of interest. This implies that the topology network is less sensitive to background noise than the image network. The reproducible codes for the experiments with the HAM1000 dataset can be found at https://github.com/HiddenBeginner/cnntdanet_gradcam.
5. Experiments
In this section, we provide the results of the Grad-CAM analysis of CNN-TDA Net. Among the possible vectorization methods for persistence diagrams, we mainly focus on the BS explained in section 2. Specifically, for the following experiments, we used Giotto-TDA [32], a topological machine learning toolbox in Python, to generate topological features, and TensorFlow [33] to build and train the combined neural networks.
5.1. Dataset
We consider the grayscale image classification problem; the cubical complex explained in section 2 can be directly applied to grayscale images. We conducted experiments using those two famous image classification datasets, i.e. the transient versus bogus image dataset and the HAM10000 dataset.
5.1.1. Transient-vs-bogus dataset
One of the most important challenges in astrophysics today is to detect transients in given images. This problem is particularly important for the identification of the electromagnetic (EM) counterpart of a detected gravitational wave [34]. More precisely, transients are astrophysical objects that appear for just milliseconds to days in their brightness in a sequence of astrophysical images in time. Transient candidates include kilonovae, supernovae, gamma-ray explosions, etc. Among the transient candidates, a kilonova is an event caused by the emission of gravitational waves from a compact binary system. Thus, identifying the kilonova as a transient is a key tool for identifying the EM counterpart of the detected gravitational wave. Meanwhile, bogus are events in the images that appear briefly as transient but are not actual transients of interest. The desired classification model is to detect the true positives (transients) and identify the false positives (bogus). In this study, we used the transient-vs-bogus dataset generated and provided by IMSNG at Seoul National University. It contains a set of  grayscale images composed of 307 transient images and 3424 bogus images. Notice that the considered dataset is an imbalanced dataset.
grayscale images composed of 307 transient images and 3424 bogus images. Notice that the considered dataset is an imbalanced dataset.
5.1.2. The HAM10000 dataset
The HAM10000 [35] dataset consists of  dermatoscopic images collected from different skin populations. The dataset provides
dermatoscopic images collected from different skin populations. The dataset provides  grayscale and RGB images, as well as raw RGB dermatoscopic images. Among them, we used
grayscale and RGB images, as well as raw RGB dermatoscopic images. Among them, we used  grayscale images for our experiments. Each image is labeled with one of the seven pigmented skin lesions. The proportion of each lesion varies from approximately
grayscale images for our experiments. Each image is labeled with one of the seven pigmented skin lesions. The proportion of each lesion varies from approximately  for the major class to
for the major class to  for the minor class, indicating a typical class imbalance.
for the minor class, indicating a typical class imbalance.
For both datasets, we generated the BS for each image. We used the filtered cubical complexes and computed both the zero- and one-dimensional persistence diagrams. Then, we obtained the BS with n_bins = 100, i.e. the range of filtration values is divided into 100 intervals so that the resulting BS has the form of a  matrix. We used
matrix. We used  of the data for training and the rest for validation.
of the data for training and the rest for validation.
5.2. Network architecture and training configuration
We conducted Grad-CAM analysis on the CNN-BS Net. The architecture of the image network follows that of O'TRAIN [36]. O'TRAIN performs well on various grayscale images, particularly on the transient versus bogus image classification problem, and is widely used in the astrophysical image analysis community. For the topology network, we selected WaveNet [37], which is suitable for sequential data because the BS can also be regarded as sequential data, as explained in section 2.2. Table 1 shows the optimized image network of O'TRAIN architecture (top) and the topology network adopted from the architecture of WaveNet (bottom). Here, we note that all convolutional operations are applied after zero padding. The concatenation of the two flattened feature maps is fed into the classification head. The classification head is an MLP with two hidden layers with 512 and 256 neurons. More training details and learning curves are provided in appendix
Table 1. The architecture of O'TRAIN [36] (top) and WaveNet [37] (bottom) before the classification head. (i: the layer number, k: the filter size,  : the number of filters, p: the dropout rate, rdilated: the rate of dilation).
: the number of filters, p: the dropout rate, rdilated: the rate of dilation).
| i | Operator |

|
|---|---|---|
| 1 | Conv2D 
| 16 |
| 2 | Conv2D 
| 32 |
| 3 | AvgPooling2D 
| 32 |
| 4 | Conv2D 
| 64 |
| 5 | MaxPooling2D 
| 64 |
| 6 | Dropout 
| 64 |
| 7 | Conv2D 
| 128 |
| 8 | MaxPooling2D 
| 128 |
| 9 | Dropout 
| 128 |
| 10 | Conv2D 
| 256 |
| 11 | MaxPooling2D 
| 256 |
| 12 | Flatten | — |
| i | Operator |

| rdilated |
|---|---|---|---|
| 1 | Conv1D 
| 20 | 1 |
| 2 | Conv1D 
| 20 | 2 |
| 3 | Conv1D 
| 20 | 4 |
| 4 | Conv1D 
| 20 | 8 |
| 5 | Conv1D 
| 20 | 1 |
| 6 | Conv1D 
| 20 | 2 |
| 7 | Conv1D 
| 20 | 4 |
| 8 | Conv1D 
| 20 | 8 |
| 9 | Conv1D 
| 10 | — |
| 10 | Flatten | — | — |
6. Result
6.1. Transient-vs-bogus dataset
Figures 7 and 8 show the Grad-CAM analysis of the transient versus bogus image datasets. Figure 7 shows the results of the multimodal Grad-CAM analysis of the image that contains the transient in the image center. In the figure, (a) is the image that contains a single transient. As shown in the figure, the transient, a round and bright object, is located at the image center. The heat maps, those color images in the top row in columns (b) through (g), are the Grad-CAM heat maps over the single CNN (i.e. without the topology network). The heat maps in the bottom row are the Grad-CAM heat maps over the CNN-BS Net, that is, the heat maps when the topology network is combined with the original CNN. The images in column (b) are the aggregated Grad-CAM heat maps displayed over the input image, (a), with (top) and without (bottom) the topology network, respectively. Those images in column (b) show slight differences between the networks with and without the topology network. The bottom figure in Column (b) shows that the heat map is concentrated around the transient and more symmetric than that of the single CNN shown in the top. Here notice that the images in column (b) are the aggregated images of all the individual feature maps obtained by the network as indicated in (9) and (10). Thus, it is worth investigating how the heat map of each individual feature map changes when combined with the topology network. Those images in columns (c) through (g) are the heat maps of the top five feature maps that have the highest channel importance values defined in (10). As shown in the figure, the heat map of each feature map with the topology network is more centered around the transient than the heat map of the single CNN except for the 5th feature map in Column (g). Although there are differences between the single CNN and CNN-BS Net, the aggregated heat maps in column (b) indicate that both the single CNN and the CNN-BS Net capture the desired transient features reasonably. The image in column (h) is the topological inverse image  where ta
and tb
are defined in (17) and (18) for the length of the receptive field
where ta
and tb
are defined in (17) and (18) for the length of the receptive field  , the dimension of the BSs
, the dimension of the BSs  , and the filtration value
, and the filtration value  that has the maximum in Grad-CAM on the BS shown in column (i). The blue line in the image of (i) is the zero-dimensional BS and the red the one-dimensional BS. The heat map by Grad-CAM is displayed in the x-axis. The feature image of (h) is obtained from the heat map of (i) using the topological inverse image map. As shown in the figure, the topological inverse image captures well the overall shape of the transient in the center. As shown in the following results as well, the CNN-BS Net explicitly captures the shape of the desired object through the topological inverse map, (15) and (16).
that has the maximum in Grad-CAM on the BS shown in column (i). The blue line in the image of (i) is the zero-dimensional BS and the red the one-dimensional BS. The heat map by Grad-CAM is displayed in the x-axis. The feature image of (h) is obtained from the heat map of (i) using the topological inverse image map. As shown in the figure, the topological inverse image captures well the overall shape of the transient in the center. As shown in the following results as well, the CNN-BS Net explicitly captures the shape of the desired object through the topological inverse map, (15) and (16).

Figure 7. The result of true positive data. The top and bottom rows indicate the single CNN and the CNN-BS Net, respectively. (a) An input image. (b) Grad-CAM heat map over the image. (c)–(g): Individual feature maps that have top-5 channel importance. (h) The topological inverse image. (i) Grad-CAM heat map of the TDA network over the Betti sequence.
Download figure:
Standard image High-resolution image
Figure 8. The results of true negative data. The descriptions are the same as in figure 7. We note that there are many redundant or meaningless feature maps in the case of the single CNN (top rows), while the image network of the CNN-BS Net yields non-trivial feature maps (bottom rows).
Download figure:
Standard image High-resolution imageThe difference between the single CNN and the CNN-BS Net becomes clearer in the bogus image datasets shown in figure 8. Each column represents the same as that shown in figure 7. In figure 8, we consider three different bogus images, as shown in column (a). The bogus images are different from the transient images—they are not necessarily round or symmetric due to the nature of the bogus objects in the image. None of them looks similar to the transient shown in (a) of figure 7. We observe extreme differences between the single CNN and the CNN-BS Net in the results of the bogus image datasets. The aggregated heat maps in column (b) are significantly different between the single CNN and the CNN-TDA Net. In columns (c) through (g), the top five individual feature maps are displayed. From those feature maps, we observe that the single CNN has multiple redundant and zero feature maps, even though each of those feature maps has a high channel importance value. Notably, the feature maps in columns (c), (d) and (g) of the top and middle bogus images in column (a) have simply zero values. Similarly, those feature maps in columns (c) and (f) of the bottom bogus image in column (a) also have zero values. However, as shown in the figure, the heat maps of the feature maps of the CNN-BS Net show more consistent and regularized images than the single CNN. Obviously, almost every feature maps of the CNN-BS Net focus on the center of the image. These results show that the topology network helps the original single CNN to focus on the critical region of interest and that the topological inverse map captures the shape of the bogus image well as shown in the figures in column (h). As in figure 7, those images in column (h) are obtained from the heat maps over the BS in column (i) through the topological inverse map. As shown in the figure, the heat map over the BS clearly captures the shape of the bogus image. Such a clear capture of the shape of the desired image plays a crucial role in classification, which in turn results in enforcing the feature maps over the combined network more distinct and meaningful. Overall, these experiments show how the heat map of each feature map of the original single CNN change when the topology network is combined and how they are regularized towards more meaningful feature maps.
6.2. The HAM10000 dataset
Figure 9 shows the results for the HAM10000 dataset. The images in column (a) show two different skin lesions. The following images in columns (b) through (i) are the same as those explained in the previous example. We used the second-last feature maps of the single CNN and the image network to compute the importance of the kth feature maps,  , in (10) and (12) because the last feature maps have too small resolution of
, in (10) and (12) because the last feature maps have too small resolution of  . For this example, notice that the black artifacts around the skin lesion exist in the image. The top image shows that there are sharp black artifacts near the four corners of the image. The bottom image in column (a) has the artifacts, black and broad, near the left and right boundaries. These black artifacts in both images are not the main skin lesions of our interest but just meaningless background or device artifacts. The problem is that these artifacts are structured in their shape and could be incorrectly interpreted as the main source of the skin lesion in the feature map for classification. In fact, it is well known that CNNs can be easily biased to high-frequency information or task-irrelevant artifacts in the input images [8, 9]. As observed in the feature map images in columns (b) through (g) in the top rows (by the single CNN without the topology network), the artifacts are highlighted in the heat map more than in the region where the actual skin lesion of interest exits. In other words, the CNN-based model constitutes the classification network by focusing more on such artifacts. It is interesting that no feature map by the single CNN highlights the skin lesion in its heat map. In contrast, we observe that the heat map of each feature map of the CNN-BS Net in the bottom rows is totally different. Regardless of the class it predicts, the CNN-BS Net yields the heat map that highlights the skin lesions and does not exploit artifacts except the heat map in column (c) of the top image of (a). Similarly, for the bottom image of (a), the CNN-BS Net highlights the skin lesions rather than the artifacts. Only the heat maps in Columns (f) and (g) highlight the main lesion and the artifacts at a similar level. The images in column (h) show that the black artifacts were also captured by the topology network allowing the image network to focus more on the task-relevant areas—the feature map of the image network in column (b) when combined with the topology network focuses on the skin lesion in the center. This also shows that the one-dimensional Grad-CAM of the BS in column (i) yields the warmest color in the heat map around which the corresponding filtration values provide the well-matched topological inverse image map with the skin lesion towards the meaningful feature maps. The results of other vectorization methods can be found in figures B1 and B2.
. For this example, notice that the black artifacts around the skin lesion exist in the image. The top image shows that there are sharp black artifacts near the four corners of the image. The bottom image in column (a) has the artifacts, black and broad, near the left and right boundaries. These black artifacts in both images are not the main skin lesions of our interest but just meaningless background or device artifacts. The problem is that these artifacts are structured in their shape and could be incorrectly interpreted as the main source of the skin lesion in the feature map for classification. In fact, it is well known that CNNs can be easily biased to high-frequency information or task-irrelevant artifacts in the input images [8, 9]. As observed in the feature map images in columns (b) through (g) in the top rows (by the single CNN without the topology network), the artifacts are highlighted in the heat map more than in the region where the actual skin lesion of interest exits. In other words, the CNN-based model constitutes the classification network by focusing more on such artifacts. It is interesting that no feature map by the single CNN highlights the skin lesion in its heat map. In contrast, we observe that the heat map of each feature map of the CNN-BS Net in the bottom rows is totally different. Regardless of the class it predicts, the CNN-BS Net yields the heat map that highlights the skin lesions and does not exploit artifacts except the heat map in column (c) of the top image of (a). Similarly, for the bottom image of (a), the CNN-BS Net highlights the skin lesions rather than the artifacts. Only the heat maps in Columns (f) and (g) highlight the main lesion and the artifacts at a similar level. The images in column (h) show that the black artifacts were also captured by the topology network allowing the image network to focus more on the task-relevant areas—the feature map of the image network in column (b) when combined with the topology network focuses on the skin lesion in the center. This also shows that the one-dimensional Grad-CAM of the BS in column (i) yields the warmest color in the heat map around which the corresponding filtration values provide the well-matched topological inverse image map with the skin lesion towards the meaningful feature maps. The results of other vectorization methods can be found in figures B1 and B2.

Figure 9. The results of the HAM10000 dataset. The descriptions are the same as in figure 7. The two images have black artifacts around the boundaries (a). The single CNN exploits the artifacts, while the image network of the CNN-BS Net focuses on the skin lesions of interest.
Download figure:
Standard image High-resolution image6.3. Comparison of the localization ability of Grad-CAM
In order to verify our conjecture that the topology network enforces the image network to focus on the regions of interest, we calculated the localization abilities of the heat maps of both the single CNN and CNN-BS Net. We randomly sampled 100 images and manually labeled the segmentation mask for the regions of skin lesions. In figure 10, column (b) shows the segmentation masks corresponding to the images in column (a). The CNN and CNN-BS Net were trained on the remaining images except for the 100 samples. After training, we binarized the Grad-CAM of the two networks with a threshold as illustrated in columns (c) and (d) in figure 10. The images in columns (c) and (d) show the binarized Grad-CAM of the single CNN and the CNN-BS Net with the threshold value of 0.2. We then calculated the IoU score between the segmentation mask and the binarized heat map. We trained the two networks 30 times with different random seeds, binarized the heat maps with the threshold values of  and 0.5, and computed the average IoU scores for each threshold.
and 0.5, and computed the average IoU scores for each threshold.

Figure 10. (a) Two sample images. (b) The corresponding segmentation masks to the images in (a). (c) The binarized Grad-CAM of the single CNN with the threshold value of 0.2. (d) The binarized Grad-CAM of the CNN-BS Net with the threshold value of 0.2.
Download figure:
Standard image High-resolution imageFigure 11 shows the average IoU scores between the segmentation masks and the binarized heat maps of the single CNN (blue solid line) and the CNN-BS Net (red solid line). As shown in the figure, the CNN-BS Net, which has higher IoU scores than the single CNN, captures the regions of interest more accurately than the single CNN. For the single CNN, the average IoU score decreases linearly as the threshold increases. However, it is interesting to observe that, for the CNN-BS Net, the average IoU score changes nonlinearly. That is, the score increases with the threshold, reaches the local maximum near the threshold value of 0.2, and then decreases linearly. The fact that the IoU score increases even though the threshold increases indicates that the CNN-BS Net could also give attention to the artifacts, but the level of the significance of attention is low, so such attention disappears quickly as the threshold value increases. This implies that the image network of the CNN-BS Net focuses on the regions of interest more efficiently than the single CNN.

Figure 11. The average IoU scores between the segmentation masks and the binarized heat maps of the single CNN (blue) and the CNN-BS Net (red) versus the threshold values of  and 0.5. The average IoU scores are calculated over the 30 replications and the 100 samples. The vertical error bars indicate the 95% confidence intervals.
and 0.5. The average IoU scores are calculated over the 30 replications and the 100 samples. The vertical error bars indicate the 95% confidence intervals.
Download figure:
Standard image High-resolution image6.4. Comparison with a wide CNN
We investigate whether the enhanced classification performance and localization ability of CNN-BS Net is possibly a result of the increased number of trainable parameters. To this end, we consider a wide CNN that has a comparable number of parameters to the CNN-BS Net. Specifically, we doubled the number of channels of the first four convolutional layers of the 2D-CNN presented in table 1. The number of parameters of each network can be found in table A2. As shown in figure 12, increasing the number of parameters did not enable the single CNN to focus on the region of interest, supporting our hypothesis that topology features enforce the image network of a CNN to focus on meaningful regions.

Figure 12. (a) Four sample images. (b) Grad-CAM of the single CNN. (c) Grad-CAM of the Wide CNN. (d) Grad-CAM of the image network of CNN-BS Net.
Download figure:
Standard image High-resolution image7. Conclusion
Recently, it has been reported that the performance of a single CNN can be significantly improved by combining it with a topology network based on persistent homology. By nature, the concatenation of a CNN and topology network constitutes a multimodal network. Despite the success of various applications, there is a lack of explanation as to how and why such topological signatures when combined with CNN improve the discriminative power of the original CNN.
In this work, we visually demonstrated the effects of topological features on CNNs using numerical experiments with two famous examples: the transient versus bogus image dataset and the HAM10000 dataset. We proposed a methodology to apply Grad-CAM analysis to multimodal networks, particularly for the combined CNN-TDA network. We used BS as topological feature. Thus the Grad-CAM was applied to the combined CNN-BS network. Furthermore, to interpret the behavior of the TDA network on the image network of CNN, we defined the topological inverse image map with a specific range composed of two filtration values. The experimental results show that the single CNN produces multiple meaningless or redundant feature maps that are biased to high-frequency artifacts or that have all zero values. Meanwhile, the topology network properly captures the shape of the object of interest in the input image and the corresponding image network focuses more on the critical regions throughout the images than the single CNN. This was verified with the topological inverse image map through the heat map obtained by Grad-CAM of the topology network.
We hypothesized that the topology network characterizes the structure of an object and helps the image network to focus on specific regions of interest more efficiently than the single CNN. We qualitatively and quantitatively verified our hypothesis with experiments, and we could understand how and why the topology network improves the performance of the original CNN. From the qualitative results via the visualization, we showed that the topological features can help the original CNN to focus on more task-relevant features of the given image than task-irrelevant artifacts or noise. Moreover, our quantitative analysis based on IoU scores revealed that the topological features not only enforce the image network to focus on the regions of interest more accurately and efficiently.
For the current work, our experiments were limited to domain-specific grayscale images. It is not known whether the CNN-TDA Net will behave similarly on more general images. Furthermore, a detailed mathematical analysis was not provided in this work. Our future work will extend our CNN-TDA Net to RGB image datasets such as CIFAR-10 or ImageNet with Grad-CAM analysis and the topological inverse image map. Furthermore, we will provide a mathematical analysis of the effects of topological features on CNN in our future work.
Acknowledgments
This research was supported by the National Research Foundation (NRF) of Korea under the Grant Number 2021R1A2C3009648. This work was also supported (in part) by the research grant from the NRF to the Center for the Gravitational-Wave Universe under the Grant Number 2021M3F7A1082053.
Data availability statement
The data cannot be made publicly available upon publication because no suitable repository exists for hosting data in this field of study. The data that support the findings of this study are available upon reasonable request from the authors.
Appendix A: Training details and results for the HAM100 dataset
We carried out a stratified five-fold cross-validation scheme to evaluate the consistent superiority of CNN-TDA Nets over single CNNs. Afterwards, we employed a hold-out training method to conduct Grad-CAM analysis. We initially considered several vectorization methods for representing persistence diagrams, including persistence image (PI), persistence landscape (PL), and Betti sequence (BS). The results in table A1 show that CNN-TDA Nets outperformed single CNNs in most of all evaluated metrics.
Table A1. The result of the evaluation on the HAM10000 dataset. For the multi-class setting, we calculate metrics for each label and take the average weighted by the number of true data in each class. The mean  and standard deviation
and standard deviation  of each metric over five-fold cross-validation are reported. Maximum value for each metric is bolded.
of each metric over five-fold cross-validation are reported. Maximum value for each metric is bolded.
| Accuracy | Recall | Precision | F1 score | |
|---|---|---|---|---|
| CNN |

|

|

|

|
| Wide CNN |

|

|

|

|
| CNN-PL |

|

|

|

|
| CNN-BS |

|

|

|

|
| CNN-PI |

|

|

|

|
After validating the superiority of the CNN-TDA Nets through cross-validation, we re-trained the CNN, Wide CNN, and CNN-BS Net using a hold-out method to obtain networks for Grad-CAM analysis. Specifically, we randomly split the data into training and validation sets using an 80/20 ratio while keeping the ratio of each class consistent between the two datasets. We used Adam optimizer with a learning rate of 10−3 and a batch size of 32 to train the networks for 25 epochs. We did not utilize any techniques to address the issue of imbalanced datasets to see the impact of topological features on the training process.
Figure A1 and table A3 present the learning curves and evaluation metrics of the CNN, Wide CNN, and CNN-BS Net during hold-out training. We would like to note that increasing the number of parameters did not result in performance improvement, which in fact led to overfitting. In contrast, the CNN-BS Net exhibited more stable learning, as evidenced by the lower variance of loss values, and had a smaller generalization gap, which is the difference between the training and validation losses. We selected the networks trained up to epoch 20 since all networks exhibit overfitting after this point.

Figure A1. The learning curves of the single CNN (left), Wide CNN (middle), and CNN-BS Net (right). The curves represent the cross-entropy loss for both training (gray) and validation (blue) datasets, plotted over the number of epochs.
Download figure:
Standard image High-resolution imageTable A2. The number of trainable parameters in the CNN, Wide CNN, and CNN-BS Net. We denote the image network, topology network, and prediction head as fimg, ftda and fhead, respectively.
| fimg | ftda | fhead | Total | |
|---|---|---|---|---|
| CNN | 392 320 | — | 264 711 | 657 031 |
| Wide CNN | 977 920 | — | 264 711 | 1242 631 |
| CNN-BS Net | 392 320 | 6058 | 776 711 | 1175 089 |
Table A3. The result of the evaluation on the HAM10000 dataset. For the multi-class setting, we calculate metrics for each label and take the average weighted by the number of true data in each class.
| Accuracy | Recall | Precision | F1 score | |
|---|---|---|---|---|
| CNN | 72.69 | 28.43 | 67.33 | 68.60 |
| Wide CNN | 72.19 | 30.07 | 67.10 | 68.08 |
| CNN-BS Net | 73.09 | 33.19 | 68.86 | 69.70 |
Appendix B: Grad-CAM results for other vectorization methods

Figure B1. The results of the CNN-TDA Net with persistence landscapes (CNN-PL Net). (a) Sample image. (b) Grad-CAM of the single CNN. (c) Grad-CAM of the image network of CNN-PL Net. (d) the topological inverse image. (e) Grad-CAM of the topology network of CNN-PL Net.
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure B2. The results of the CNN-TDA Net with persistence images (CNN-PI Net). (a) Sample image. (b) Grad-CAM of the single CNN. (c) Grad-CAM of the image network of CNN-PI Net. (d) one-dimensional persistence image. (e) Two-dimensional persistence image. (f) Grad-CAM of the topology network of CNN-PI Net.
Download figure:
Standard image High-resolution image{kind=link}