
Abstract
The use of multiple dyes during histological sample preparation can reveal distinct tissue properties. However, since the slide preparation differs for each dye, the tissue slides are being deformed and a nonrigid registration is required before further processing. The registration of histology images is complicated because of: (i) a high resolution of histology images, (ii) complex, large, nonrigid deformations, (iii) difference in the appearance and partially missing data due to the use of multiple dyes. In this work, we propose a multistep, automatic, nonrigid image registration method dedicated to histology samples acquired with multiple stains. The proposed method consists of a feature-based affine registration, an exhaustive rotation alignment, an iterative, intensity-based affine registration, and a nonrigid alignment based on modality independent neighbourhood descriptor coupled with the Demons algorithm. A dedicated failure detection mechanism is proposed to make the method fully automatic, without the necessity of any manual interaction. The described method was proposed by the AGH team during the Automatic Non-rigid Histological Image Registration (ANHIR) challenge. The ANHIR dataset consists of 481 image pairs annotated by histology experts. Moreover, the ANHIR challenge submissions were evaluated using an independent, server-side evaluation tool. The main evaluation criteria was the target registration error normalized by the image diagonal. The median of median target registration error is below 0.19%. The proposed method is currently the second-best in terms of the average ranking of median target registration error, without statistically significant differences compared to the top-ranked method. We provide an open access to the method software and used parameters, making the results fully reproducible.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Automatic, nonrigid registration of histological images acquired using distinct dyes is an important task (Borovec et al 2020). It makes it possible to fuse information from structures of the same tissue that may be not revealed by one of the applied dyes (Kugler et al 2019). Nevertheless, the problem is extremely challenging due to the following aspects: (i) differences in the tissue appearance due to the use of multiple dyes and sample preparation often leading to the problem of missing data, (ii) enormously large size of the microscopy images (gigapixel resolution), (iii) large and complex nonrigid deformations, (iv) difficulty to find globally unique features due to a repetitive texture (Borovec et al 2020, ANHIR Website 2019).
The importance and difficulty of the problem led to organizing a dedicated challenge named Automatic Non-rigid Histological Image Registration (ANHIR) (Borovec et al 2020, ANHIR Website 2019). The challenge was organized jointly with the IEEE ISBI 2019 conference and the organizers provided an open, annotated dataset containing several tissue types acquired using multiple dyes, and an automatic, independent, server-side evaluation tool. The images were reasonably paired together and landmarks for calculating the target registration error were annotated by histological experts. In total, 256 participating teams from 32 countries registered for the challenge, among which 6 were invited to the dedicated workshop at the IEEE ISBI 2019 conference, including the AGH team with the method described in this article. A full description of the challenge and its outcomes can be found in Borovec et al (2020) and ANHIR Website (2019).
1.1. Related work
There are many works related to the medical image registration including the use of different transformations, optimization algorithms, similarity metrics (Sotiras et al 2013, Oliveira and Tavares 2014) and recently also methods using deep learning approach (Litjens et al 2017). However, due to the mentioned difficulties, the generally applicable methods have limited usefulness for the registration of histological images. Firstly due to the resulting registration accuracy, and secondly due to a high computation time (Borovec et al 2018, 2020). The ANHIR challenge organizers evaluated several openly available nonrigid registration algorithms like bUnwarpJ (Arganda-Carreras et al 2006), RVSS (Arganda-Carreras et al 2006), NiftyReg (Rueckert 1999), Elastix (Klein et al 2010), ANTs (Avants et al 2008) or DROP (Glocker et al 2011). However, all of them provided rather poor results compared to the dedicated algorithms proposed by the challenge participants (Borovec et al 2020).
Majority of the works about registration of histology images involve the registration between histology and magnetic resonance images. There is much less work done for registration of histological images acquired using multiple stains. However, there are some interesting contributions made prior to the ANHIR challenge. An intriguing idea was presented in Song et al (2014) where the authors introduced a concept about an intensity-based nonrigid registration algorithm driven by an unsupervised content classification enhancing the structural similarity. Another important contribution was presented in Shojaii et al (2011) where authors proposed use of fiducial markers to calculate the target registration error and improve the registration evaluation process. The bUnwarpJ, which is an elastic and consistent image registration algorithm is also noteworthy since a lot people working with histology images use it on a daily basis (Arganda-Carreras et al 2006).
Several other methods were proposed directly for the challenge. The best scoring method proposed by the MEVIS team (Lotz et al 2019), similar to our approach, is a multistep procedure and consists of: (i) exhaustive, initial rotation search, (ii) iterative affine registration based on the normalized gradient field (NGF) similarity metric (Haber and Modersitzki 2006), (iii) B-Splines-based nonrigid registration using the NGF similarity metric. The main advantage of their method is a commercial, well optimized, matrix-free implementation which makes it extremely fast. The method is able to register the images in just a few seconds, even using resolution up to 8000 pixels in the larger dimension. However, since the method is commercial, there is no open implementation or free access available. The method proposed by the UPENN team (Venet et al 2019) also consists of three steps: (i) initial preprocessing involving images resampling and background removal by deconvolution, (ii) a random orientation search and a following affine registration, (iii) use of a general-purpose medical image registration tool named 'Greedy' which is an implementation of a greedy diffeomorphic registration algorithm (Joshi et al 2004, Yushkevich et al 2016). Only one of the best scoring teams decided to use a deep learning-based solution. The TUB team used a modified volume tweening network, described by Zhao et al (2020). The network was first unsupervisedly trained and then fine-tuned using the training landmarks which may be controversial. The description of the methods proposed by TUNI and UA teams can be be found in Kartasalo et al (2018) and Punithakumar et al (2017) respectively.
1.2. Contribution
In this work, we describe in detail the method proposed by the AGH team for the ANHIR challenge and provide access to the method software. The method is fully automatic, robust to the applied dye and the tissue type, and is currently the second-best method proposed for the challenge in terms of the average ranking of the median target registration error, without a statistically significant difference to the top-ranked method (according to the one-sided Wilcoxon signed-rank test with p = 0.01) (Borovec et al 2020).
2. Method
2.1. Overview
We propose a method fulfilling all the ANHIR challenge requirements. The method is fully automatic, robust, resistant to staining using multiple dyes, reasonably fast and calculates an accurate dense deformation field. The algorithm works well with predefined parameters, without the necessity to tune them to each image pair separately.
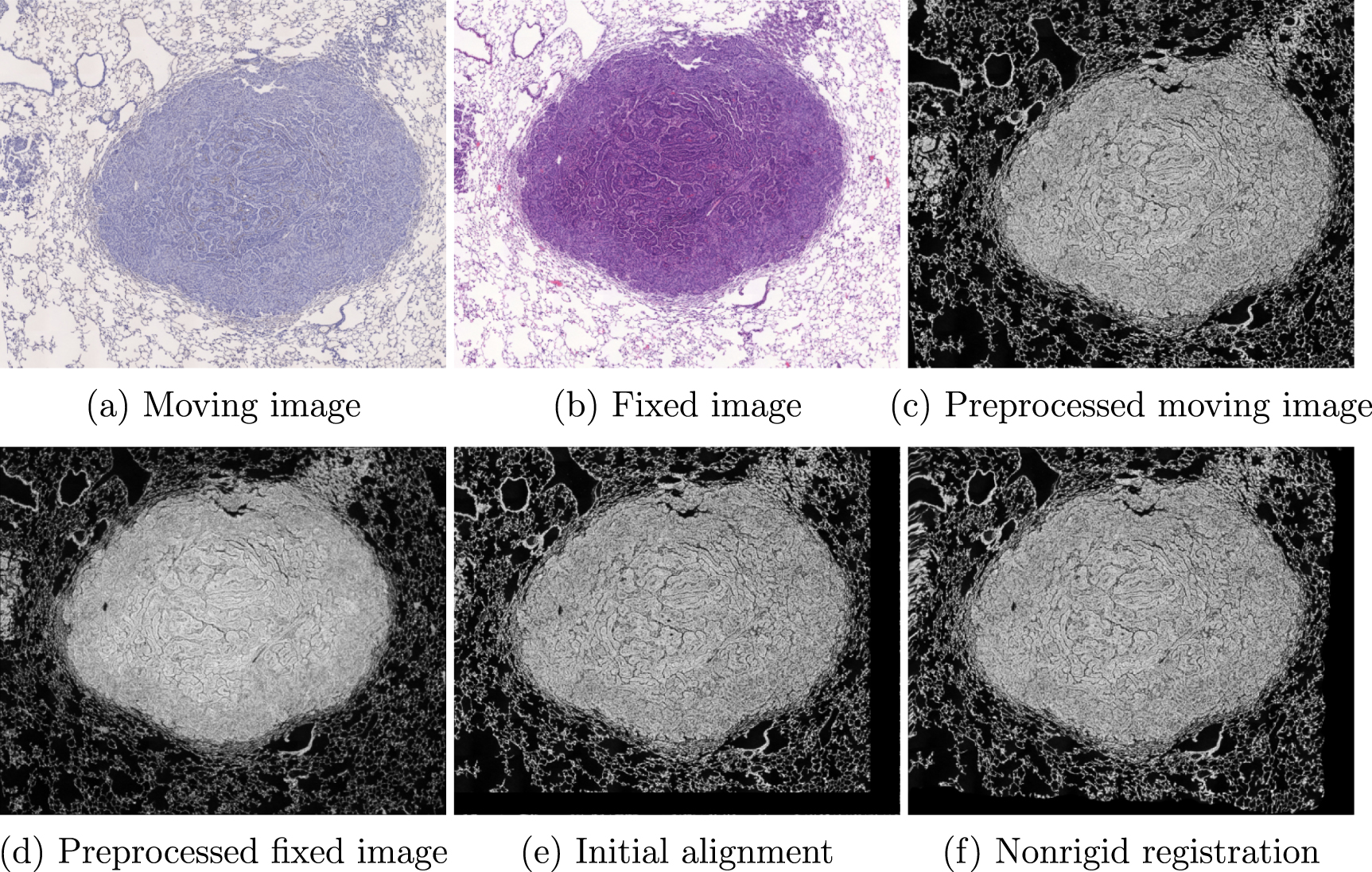
The proposed method consists of several sequential steps. First, both the moving and the fixed images are preprocessed to make the registration process as easy as possible. Then, the algorithm attempts to initially align the images using a feature-based approach. In case of failure, an exhaustive rotation search is performed. As a next step, the initial affine transformation is being refined by a dedicated affine registration resistant to missing data. Finally, a fully nonrigid, multimodal registration is used to calculate the final deformation field. The algorithm flow is presented in algorithm 1. An exemplary visualization of the images after each step is shown in figure 1.
| Algorithm 1: The proposed algorithm. |
|---|
| Input : M (moving image), F (fixed image) |
| Output : u (deformation field) |
 , ,  = preprocess the = preprocess the  , ,  images (algorithm 2) images (algorithm 2) |
u = calculate the feature-based or the exhaustive initial alignment using  , , |
 (algorithm 4) (algorithm 4) |
u = calculate the initial alignment refinement between  and and 
|
| (algorithm 3) |
u = perform the nonrigid registration using  , ,  and u as the initial and u as the initial |
| deformation (algorithm 5) |
| return u |

Figure 1. An exemplary visualization of the images after subsequent registration steps for the case no. 351 from the ANHIR dataset. The median rTRE is: (i) initial: 6.88%, (ii) after initial alignment: 0.61%, (iii) after nonrigid registration: 0.32%.
Download figure:
Standard image High-resolution image2.2. Preprocessing
The preprocessing consists of the following steps. Firstly, the data is converted to the grayscale, smoothed and downsampled to a lower resolution. The downsampling is required because the computation time using the original resolution is extremely high and the improvement of the registration quality is not that significant considering the unacceptable increase of the computational time. The resolution is different for the initial alignment, the exhaustive search, the affine transformation tuning, and the nonrigid registration. The images are resampled in a way that makes the smaller dimension equal to 2048, 512, 1024, 4096 pixels, respectively for the initial alignment, the exhaustive search, the affine transformation tuning, and the nonrigid registration. After the downsampling, the image entropy is calculated for both images and the histogram of the image with a lower entropy is matched to the histogram of the image with higher entropy. This step makes it possible to use a traditional feature-based approach to calculate the similarity or the affine transformation. The step is not required for the following affine transformation tuning or the nonrigid registration. Finally, the images are padded to the same size and the intensity is inverted (so the background is equal to 0). Padding the images to the same shape simplifies operations involving both the images (e.g. the similarity metric calculation) because it limits the necessity to check the boundary conditions and improves the cache memory utilization. The proposed preprocessing is presented in algorithm 2.
| Algorithm 2: Preprocessing. |
|---|
| Input : M (moving image), F (fixed image) |
Output :
 (preprocessed images) (preprocessed images) |
 , ,  = convert both the = convert both the  , ,  images to the grayscale images to the grayscale |
 , ,  = resample the gray = resample the gray  , ,  images to a given resolution images to a given resolution |
 , ,  = calculate the = calculate the  , ,  images entropy images entropy |
 , ,  = match the histogram of the image with a lower entropy to the = match the histogram of the image with a lower entropy to the |
image with the higher entropy based on the  , , 
|
 , ,  = pad the = pad the  , ,  images to the same shape and invert the intensity images to the same shape and invert the intensity |
return
 , , 
|
2.3. Initial alignment
The histological images are often misaligned with a low overlap ratio making the process of the initial alignment essential for the following nonrigid registration. Even though an intensity-based affine or rigid registration is sufficient for many cases, it fails for numerous of them due to large displacements (e.g. due to almost 180 degrees rotation) or missing data resulted from the use of distinct dyes (e.g. 20% of tissue being invisible in the fixed image).
The initial alignment during the proposed algorithm is based on the similarity or the affine transformation. The initial alignment consists of several subsequent steps: (i) the feature-based affine registration, (ii) the exhaustive initial rotation search (in case of a failure of the feature-based registration), and (iii) the iterative, intensity-based affine registration (in all cases). In the first step, three sets of matching features are calculated, using SIFT (Lowe 2004), ORB (Rublee et al 2110), and SURF (Bay et al 2006). The use of three descriptors is motivated by the necessity to make the algorithm fully automatic, without manual method selection or parameter tuning. The use of three feature descriptors is not strictly mandatory but it makes the algorithm more robust, and the computational time is negligible compared to the following registration steps. Then, the RANSAC algorithm is used to calculate the transformation between the filtered keypoints. Finally, the evaluation of the transformation quality is determined using a failure detector (described later in this section). The Dice coefficient is calculated between appropriately thresholded masks, as described in section 2.5. Transformation with the highest coefficient is selected. The use of this procedure successfully aligns more than 70% of the image pairs, the remaining ones are handled by an exhaustive search or skipped because not all pairs require the initial alignment.
The alternative scenario based on the exhaustive search uses the binary version of the moving and fixed images, calculated using the Li thresholding (Li and Tam 1998). Then, the centroid values are calculated for both the binary images and the desired rotation is optimized exhaustively with a fixed angle step equal to 2 degrees. The fixed step size was not tuned because the initial alignment time is negligible compared to the time required for the data loading or the nonrigid registration. The Dice coefficient is used as a similarity measure between the warped moving mask and the fixed mask.
Both the feature-based and the exhaustive initial alignment need further refinement. We noticed that the use of an additional global affine registration resistant to missing data significantly improves subsequent nonrigid registration for many cases, especially ones with significant differences in the appearance. On the other hand, the iterative intensity-based affine registration is unable to address largely misaligned cases (e.g. 180 degrees rotation), therefore it cannot be applied alone and the previous steps are mandatory. The influence of this step alone is shown in the supplementary material (is available online at stacks.iop.org/PMB/66/025006/mmedia). The additional affine registration is based on the method described by Periaswamy and Farid (2006). However, we use it as a global affine registration algorithm. The method is based on an explicit, pyramid-based, iterative optimization of 8 parameters (6 affine and 2 intensity correction parameters). During each iteration the transformation is calculated as a:

where  ,
, ![$\nabla \mathbf{G_y \cdot D_y}, \nabla \mathbf{G_x}, \nabla \mathbf{G_y}, -\mathbf{M}, \mathbf{1}]^\intercal$](https://content.cld.iop.org/journals/0031-9155/66/2/025006/revision4/pmbabcad7ieqn35.gif) ,
,  and
and  ,
,  denotes the image gradient in the x and y direction respectively,
denotes the image gradient in the x and y direction respectively,  ,
,  denotes the image domain in the x and y dimension respectively,
denotes the image domain in the x and y dimension respectively,  is the moving image,
is the moving image,  is the fixed image and · denotes the piecewise multiplication. The image gradient is calculated using filters described by Farid and Simoncelli (2004). Then, the calculated transformation is converted to the velocity field and composed with the actual deformation field. The algorithm is run for a predefined, constant number of iterations and pyramid levels. The more detailed description of the initial alignment refinement is presented in algorithm 3 and the full initial alignment algorithm is described in algorithm 4.
is the fixed image and · denotes the piecewise multiplication. The image gradient is calculated using filters described by Farid and Simoncelli (2004). Then, the calculated transformation is converted to the velocity field and composed with the actual deformation field. The algorithm is run for a predefined, constant number of iterations and pyramid levels. The more detailed description of the initial alignment refinement is presented in algorithm 3 and the full initial alignment algorithm is described in algorithm 4.
| Algorithm 3: Global affine registration. |
|---|
Input : M (moving image), F (fixed image),  (initial deformation field—optionally), (initial deformation field—optionally), |
| number of resolutions, number of iterations per resolution |
| Output: u (the refined initial deformation field) |
 , ,  = create moving and fixed images for each resolution by resampling = create moving and fixed images for each resolution by resampling |
 and and  respectively respectively |
| foreach Resolution do |
| forEach Iteration do |
 = warp the = warp the  moving image with the current deformation field u moving image with the current deformation field u
|
 = As in equation (1) = As in equation (1) |
 = convert = convert  to a velocity field to a velocity field |
u = u ° 
|
| _u = upsample the deformation field u |
| _return u |
| Algorithm 4: Initial alignment summary. |
|---|
| Input : M (moving image), F (fixed image) |
| Output : u (calculated initial deformation field) |
 = calculate SIFT, SURF, ORB keypoints and features using = calculate SIFT, SURF, ORB keypoints and features using  and and  images images |
 = filter only the possible matches between = filter only the possible matches between  and and 
|
 = estimate the initial transformation for each feature = estimate the initial transformation for each feature |
extraction method using RANSAC and 
|
 = choose the best transformation among = choose the best transformation among  or detect the or detect the |
| failure |
| if Failure then |
 = calculate the transformation using the exhaustive search between M = calculate the transformation using the exhaustive search between M
|
| _and F images |
u = convert the transformation  to the deformation field to the deformation field |
| u = refine the initial transformation u using algorithm 3 |
| return u |
2.4. Nonrigid registration
After the initial alignment, a nonrigid registration is used to calculate the final, dense deformation field. The proposed method is based on the Demons algorithm (Thirion 1998) but using modality independent neighborhood (MIND) descriptor (Heinrich et al 2012) instead of the traditional unimodal approach. The sum of squared differences (SSD) between the MIND descriptor evaluated for all corresponding pixels can be used as a multimodal similarity metric. The similarity metric performance is superior compared to the mutual information and can be implemented in an efficient, parallel way (Heinrich et al 2012). We use the compositive and symmetric version of the Demons algorithm due to its fastest convergence and an ability to recover more complex deformations (Reaungamornrat et al 2160). However, we decided to not use the diffeomorphic version because we know that the real deformation field is inherently noninvertible due to the method of sample preparation. The fluid and the diffusion smoothing are applied as in the unimodal approach. The velocity field is calculated as follows:

where  and
and  denote the MIND descriptors of the moving and the fixed image respectively. The MIND Demons algorithm is described in algorithm 5. The proposed nonrigid algorithm is dedicated to relatively small (but complex) deformations. Therefore, the correct initial alignment is crucial to obtain an accurate deformation field. The default parameters can be found in the code repository (Proposed Method Software 2019).
denote the MIND descriptors of the moving and the fixed image respectively. The MIND Demons algorithm is described in algorithm 5. The proposed nonrigid algorithm is dedicated to relatively small (but complex) deformations. Therefore, the correct initial alignment is crucial to obtain an accurate deformation field. The default parameters can be found in the code repository (Proposed Method Software 2019).
| Algorithm 5: MIND demons algorithm. |
|---|
Input : M (moving image), F (fixed image),  (fluid sigma), (fluid sigma),  (diffusion (diffusion |
sigma),  (MIND sigma), (MIND sigma),  (MIND radius), (MIND radius),  (initial (initial |
| deformation field—optionally), number of resolutions (3), |
| convergence indicator |
| Output: u (calculated deformation field) |
| Ms, Fs = create moving and fixed images for each resolution by resampling |
| M and F images |
 = calculate and cache the MIND descriptor for fixed images = calculate and cache the MIND descriptor for fixed images 
|
u = initialize the deformation field using  or identity transform or identity transform |
| foreach Resolution do |
 , ,  = initialize convolution kernels (typically Gaussian) = initialize convolution kernels (typically Gaussian) |
| while Not Converged do |
 = warp the moving image = warp the moving image  with the current deformation field u with the current deformation field u
|
 = calculate the MIND descriptor for the = calculate the MIND descriptor for the 
|
 = As in equation (2) = As in equation (2) |
 = = 


|
u = u ° 
|
u = 
 u
u
|
| _u = upsample the deformation field u |
| _return u |
Noteworthy, the original algorithm proposed for the ANHIR challenge was a bit different. The locally affine registration was used together with the MIND-based Demons registration and the better result was chosen automatically by the failure detector. However, after extending the research and improving the performance of the MIND-based Demons we decided to skip the local affine registration which improved the results significantly, taking the second instead of third place in the ANHIR competition (Borovec et al 2020, ANHIR Website 2019). It is important to emphasize that both this article, as well as the ANHIR challenge summary (Borovec et al 2020), present the results for the method described here. For a comparison to the locally affine registration we refer reader to a supplementary material.
2.5. Failure detection
One of the most difficult requirement was to make the method fully automatic. It was not allowed to tune parameters individually to a particular case. The methods were supposed to run as-is for all provided image pairs. As a solution to this problem, we proposed failure detection procedures after each registration stage.
For the initial alignment, after several experiments, we decided that the simplest solution is the most successful. Since the intensity histogram easily distinguishes between the image background and the tissue structure, we use adaptive thresholding for both the moving and the fixed image, and then calculate the Dice coefficient between the resulting masks. The adaptive thresholding was performed as in the initial alignment, using the Li method (Li and Tam 1998). If the resulting coefficient is lower than a given, fixed threshold or does not increase compared to the masks of images before the initial alignment, we treat the result as a failure. A similar method but with fixed parameters was used to choose the best output for the exhaustive search. The fixed threshold was chosen experimentally using the desired volume overlap ratio (0.75), without exhaustively tuning this parameter. The results are robust to changes of this parameter, as shown in the supplementary material.
The failure detection for the nonrigid registration or the affine transformation refinement is easier. We experimentally verified that it is enough to use the SSD between the MIND descriptors calculated for the warped moving image and the fixed image. Since the purpose of both the methods is to calculate relatively small deformations, the MIND descriptor can capture beneficial deformations without falling into local minima, as it would be in the initial alignment case.
2.6. Technical details
The proposed algorithm is implemented using Python with standard numerical (NumPy, SciPy) and computer vision libraries (OpenCV), and plain C++ for the MIND-based Demons nonrigid registration. The implementation of the proposed method is made available at a GitHub repository (Proposed Method Software 2019). The MIND-based Demons algorithm is implemented in C++ using the OpenMP library because it is the most expensive part in terms of computational time and a naive, non-parallel Python-based implementation was too slow to take part in the ANHIR challenge. The remaining source code, since the performance is not that essential, is implemented using Python and is calculated using only a single core.
The method parameters were tuned to make the results as good as possible, however, without an exhaustive search over the whole parameter space. We chose the initial parameters using the knowledge about the algorithm behavior and then tuned them using a binary search between reasonable values. Since majority of the parameters describe how particular images, descriptors or deformation fields should be smoothed by the Gaussian filter, it is easy to determine reasonable values due to how Gaussian filtering is being implemented in practice, using the separated 1-D accumulators (the reasonable values for smoothing sigma are in the range [0.5–2.0]). The MIND radius is an integer taking just few reasonable values (from 1 to 3), therefore tuning it is even easier.
Instead of registering the pairs as a source to target (chosen by the challenge organizers) we decided to register targets to sources to avoid the necessity of inverting the calculated deformation field, thus, lowering the target registration error between the target and the warped source landmarks. During all the registration steps, all transformations, both linear and non-linear are composed together, avoiding the addition of vector fields. The moving image is never interpolated more than once to make the interpolation error negligible. The MIND descriptor for the fixed image is calculated once for each resolution and cached to significantly decrease the computation time.
Currently, the whole procedure, including loading the data, all the registration steps and saving the results, takes between 60 and 90 s using i9-9960X, which is the main drawback compared to other methods proposed during the ANHIR challenge (Borovec et al 2020). The algorithm computation time could be lowered significantly by proposing a GPU-based implementation. Since all the algorithm stages are fully parallelizable and there is no need for memory transfers, we forecast that a proper CUDA implementation on a modern GPU (e.g. GeForce RTX 2080 Ti) could result in more than 40 times speedup. This would make registration of a single pair a matter of single seconds resulting in a useful real-time tool for physicians and life scientists. It should be clarified that the processing time reported by the challenge organizers is normalized by the ANHIR evaluation system with respect to the number of cores and the processing power (Borovec et al 2020). It should be considered as processing time relative to other challenge participants, not the real time requires for the analysis, especially considering that all steps of our method, excluding the nonrigid registration, use just a single core.
2.7. Dataset and experimental setup
The dataset consists of 481 image pairs and is split into 230 training and 251 evaluation pairs (Fernandez-Gonzalez et al 2002, Gupta et al 2018, Mikhailov et al 2018, Bueno and Deniz 2019, Borovec et al 2020). For the training pairs, both the source and the target landmarks are widely available, while for the evaluation pairs only the source landmarks can be downloaded and examined. The evaluation is performed server-side, automatically using scripts provided by the ANHIR organizers. The landmarks were annotated by 9 experts and there are on the average 86 landmarks per image. The average error between the same landmarks chosen by two annotators is 0.05% of the image size which can be used as the indicator of the best possible results to achieve by the registration methods, below which the results become indistinguishable (Borovec et al 2018, 2020).
The tissues are provided as RGB images in a .png format, without the histological metadata. The tissues were stained using: (i) clara cell 10 protein, (ii) prosurfactant protein C, (iii) hematoxylin and eosin, (iv) anigen KI-67, (v) platelet endothelial cell adhesion molecule, (vi) human epidermal growth factor receptor 2, (vii) estrogen receptor, (viii) progesterone receptor, (ix) cytokeratin, (x) podocin. The images are divided into 8 classes containing: (i) lung lesion tissue, (ii) lung lobes, (iii) mammary glands, (iv) the colon adenocarcinomas (COADs), (v) mice kidney tissues, (vi) gastric mucosa and adenocarcinomas tissues, (vii) breast tissues, (viii) human kidney tissues (Borovec et al 2020, ANHIR Website 2019). All the tissues were acquired in different acquisition settings making the dataset more diverse. Full description of the dataset can be found in ANHIR Website (2019). An exemplary visualization of images are shown in figure 2. The challenge was performed on medium size images which were approximately 25% of the original image scale. The approximate image size after the resampling varied from 8k to 16k pixels (in one dimension).

Figure 2. Visualization of the registered tissues showing the robustness required by the registration method (Borovec et al 2018, 2020).
Download figure:
Standard image High-resolution imageThe target registration error (TRE) was the evaluation metric used for the ANHIR challenge, more concretely a rTRE (dimensionless) defined as:

where TRE denotes the target registration error, w is the image width and h is the image height. The normalization by the image diagonal made it possible to compare TREs between image pairs with different resolutions. The challenge organizers reported following metrics related to the rTRE: (i) average median rTRE, (ii) average rank of median rTRE (the main evaluation metric), (iii) average max rTRE, (iv) average rank of max rTRE. The median rTRE describes the quality of the final nonrigid registration. The average rTRE shows the initial alignment quality and the resistance to failures. The max rTRE presents the ability to recover large deformations. In this article, we focus on the main ANHIR evaluation metric: the average rank of median rTRE. For a full summary of the challenge results, we refer to Borovec et al (2020).
3. Results and discussion
We present the cumulative histograms of the rTRE for all the cases with available landmark pairs in figure 3. It shows the cumulative histograms for all classes together and each class separately. In table 1, we show rTRE statistics for the openly available landmarks for each class and registration phase. The exemplary, visual presentation of the landmarks correspondence before and after the registration is shown in figure 4. The exemplary checkerboard is shown in figure 5. In table 2, we show the rTRE results compared to other teams and algorithms participating in the ANHIR competition (Punithakumar et al 2017, Kartasalo et al 2018, Lotz et al 2019, Venet et al 2019, Borovec et al 2020, Zhao et al 2020). The results in the table 2 come from the ANHIR challenge summary (Borovec et al 2020) and were calculated by the server-side evaluation platform. The methods parameters were tuned by their authors or challenge organizers. For readers interested in an influence of a particular registration step on the final results we refer to the supplementary material where we present the rTRE results e.g. results without the failure detection or without the affine refinement.

Figure 3. The cumulative histograms of the rTRE for all classes together and each class separately for all the ANHIR cases with the available landmark pairs.
Download figure:
Standard image High-resolution image
Figure 4. Visualization of the landmarks correspondence before and after the registration procedure (case no. 232). Note that the moving image is warped by the calculated deformation field. The initial median rTRE is equal to 26.55%, the median rTRE after the registration is equal to 0.37%.
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 5. An exemplary checkerboard visualization for the image pair no. 137. The first row presents the whole images. The second row shows zoomed details inside the tissues (IA denotes the initial alignment). The visualization presents an evaluation case, therefore the rTRE cannot be reported.
Download figure:
Standard image High-resolution image{kind=link}
Table 1. Quantitative results of the rTRE for each class calculated between the openly available landmarks.
| Tissue | Initial rTRE | Initial alignment rTRE | Final rTRE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Median | Average | Max | Median | Average | Max | Median | Average | Max | |
| All tissues | 0.0486 | 0.0715 | 0.0804 | 0.0036 | 0.0086 | 0.1770 | 0.0019 | 0.0068 | 0.1740 |
| COADs | 0.0575 | 0.0773 | 0.6004 | 0.0036 | 0.0058 | 0.1662 | 0.0018 | 0.0038 | 0.1528 |
| Lung lesions | 0.0443 | 0.0472 | 0.1406 | 0.0056 | 0.0076 | 0.1008 | 0.0040 | 0.0063 | 0.0947 |
| Gastric tissues | 0.0792 | 0.1936 | 0.8043 | 0.0014 | 0.0030 | 0.0421 | 0.0006 | 0.0019 | 0.0384 |
| Lung lobes | 0.0268 | 0.0345 | 0.2288 | 0.0032 | 0.0055 | 0.0512 | 0.0012 | 0.0033 | 0.0517 |
| Breast tissues | 0.4202 | 0.4036 | 0.6901 | 0.0048 | 0.0057 | 0.0151 | 0.0043 | 0.0050 | 0.0146 |
| Mammary glands | 0.0486 | 0.0573 | 0.1770 | 0.0061 | 0.0176 | 0.1770 | 0.0028 | 0.0157 | 0.1734 |
| Mice kidneys | 0.0619 | 0.0686 | 0.2347 | 0.0058 | 0.0178 | 0.1770 | 0.0028 | 0.0159 | 0.1740 |
| Human kidneys | 0.0204 | 0.0202 | 0.0301 | 0.0070 | 0.0082 | 0.0242 | 0.0038 | 0.0072 | 0.0239 |
Table 2. Quantitative result of all methods used during the ANHIR challenge on the evaluation data. The table presents part of the results from the ANHIR challenge organizers benchmark Borovec et al (2020). Please note that all the algorithms were evaluated automatically by the server-side evaluation platform and the methods parameters were tuned by their authors or the challenge organizers (* denotes methods evaluated by organizers). The methods were ranked by the average rank of the median rTRE.
| Method | Average rTRE | Median rTRE | Max rTRE | Median rank rTRE Max rank rTRE | ||||
|---|---|---|---|---|---|---|---|---|
| Average | Median | Average | Median | Average | Median | Average rank | ||
| Initial | 0.1340 | 0.0684 | 0.1354 | 0.0665 | 0.2338 | 0.1157 | – | – |
| MEVIS | 0.0044 | 0.0027 | 0.0029 | 0.0018 | 0.0251 | 0.0188 | 2.84 | 5.04 |
| AGH | 0.0053 | 0.0032 | 0.0036 | 0.0019 | 0.0283 | 0.0225 | 3.42 | 6.00 |
| UPENN | 0.0042 | 0.0029 | 0.0029 | 0.0019 | 0.0239 | 0.0190 | 3.47 | 4.29 |
| CKVST | 0.0043 | 0.0032 | 0.0027 | 0.0023 | 0.0239 | 0.0189 | 4.41 | 5.27 |
| TUB | 0.0089 | 0.0029 | 0.0078 | 0.0021 | 0.0280 | 0.0178 | 4.53 | 3.81 |
| TUNI | 0.0064 | 0.0031 | 0.0048 | 0.0021 | 0.0287 | 0.0204 | 5.32 | 5.80 |
| DROP* | 0.0861 | 0.0042 | 0.0867 | 0.0028 | 0.1644 | 0.0273 | 7.06 | 7.43 |
| ANTs* | 0.0991 | 0.0072 | 0.0992 | 0.0058 | 0.1861 | 0.0351 | 9.23 | 7.79 |
| RVSS* | 0.0472 | 0.0063 | 0.0448 | 0.0046 | 0.1048 | 0.0275 | 9.65 | 8.42 |
| bUnwarpJ* | 0.1097 | 0.0290 | 0.1105 | 0.0260 | 0.1995 | 0.0727 | 9.67 | 9.37 |
| Elastix* | 0.0964 | 0.0074 | 0.0956 | 0.0054 | 0.1857 | 0.0353 | 10.04 | 8.88 |
| UA | 0.0536 | 0.0100 | 0.0506 | 0.0082 | 0.1124 | 0.0353 | 10.28 | 8.83 |
| NiftyReg* | 0.1120 | 0.0372 | 0.1136 | 0.0355 | 0.2010 | 0.0714 | 11.08 | 10.08 |
The proposed method works well for the great majority of the dataset images. As many as 472 from the 481 image pairs can be considered as registered correctly, without a failure. For 414 of the image pairs, the results can be hardly improved at all because they are close to the human annotation error, which mostly includes the COADs, gastric tissues, breast tissues, lung lesions, and lung lobes. However, for the mammary glands, mice kidneys and human kidneys the results could be improved. There are three main sources of error for problematic cases. The first one is connected to possible undetected failures of the initial alignment. For example, the alignment of human kidneys (figure 2(d)) or mice kidneys (figure 2(g)) are prone to fall into local minima due to a lack of distinctive features and a regular shape of the tissues which leads to e.g. 180 degrees initial misalignment. The second one is related to large nonrigid displacements, e.g. for the mammary glands (figure 2(e)). The regularization used in the Demons algorithm (based on the implicit diffusion and fluid regularization terms) is too restrictive for large displacements due to the fixed and constant coefficients. Probably, the use of an optimization algorithm with an explicit, less restrictive regularization term would provide better outcomes. Finally, the third main source of error is connected with the misalignment of the image histograms for some hard cases, where the intensity distribution of the background in one image is more similar to the intensity distribution of the tissue in the second image than to its background, e.g for the mice kidney images (figure 2(g)). This problem could be solved by segmenting the tissue from the background prior to the registration.
Interesting observations can be made based on the results presented in table 2. The current evaluation metric, the median rank of rTRE evaluates how well the fine details are registered. Our method was proposed having this in mind, without focusing on the hard outliers. The final ranking would be completely different if instead of the median rTRE rank, the maximum rTRE rank would be used for evaluation. Such a ranking would evaluate how well the largest deformations are recovered which for some applications can be more important than the pixel-level registration quality. In such case, the method proposed by TUB would be the winner (Zhao et al 2020). Our method is not the best regarding this aspect because the deformation field regularization in the Demons algorithm is not able to recover large, nonrigid deformations which happen e.g. for mammary glands. The current winners' method suffers from the same issue. A second interesting observation is the huge gap between the participants and the state-of-the-art methods performance. The difference between the best three teams (MEVIS, AGH, UPENN) is huge compared to e.g ANTs, RVSS or bUnwarpJ. The gap arises from the fact, that a lot of failures can be observed for these methods due to the initial misalignment which the participants' methods handle quite well, using exhaustive search or random transformations (Lotz et al 2019, Venet et al 2019). This shows that in practical applications the preprocessing and the initial alignment, often incorrectly treated as something obvious and already solved, can be crucial to obtain reasonable results.
Noteworthy, the proposed method is not learning-based. The risk for overfitting to the training set still exists but is much lower compared to the learning-based algorithms. First, because the number of hyperparameters is lower, and second, because the cost function is optimized for all cases during the registration, unlike in the learning-based scenario. What is more, it can be observed that the results for the evaluation set are even better than the results obtained using the training set. In our opinion, the training cases are more difficult than the evaluation cases due to more complex, larger deformations and a lower number of distinctive features.
One of the limitations related to the ANHIR evaluation system was the fact that to some degree the parameters of the proposed methods could be tuned to the evaluation set. The participants were allowed to upload the results more than once (several times per day) and verify how particular change in parameters affects the final results. This issue was somehow limited by the maximum available submission per day and inability to see the results at the case-level. Nevertheless, this approach could be used to gain a strong advantage over other participants and impact the final ranking. A report of the number of participants attempts to tune the parameters would be beneficial, however, it is unavailable due to the limitations of the challenge design and hosting platform. In general, all teams tuned the parameters to some extent, e.g. UPENN performed an exhaustive grid search, and the TUB team used the training landmarks to tune the deep network parameters. Based on the available materials (Borovec et al 2020), we think that among the competitive methods only the MEVIS method may be considered as more automatic with lower number of tuneable hyperparameters and easier parameter tuning.
It turned out that the key component to the successful, automatic registration of the histological images is the proper initial alignment. The following nonrigid registration is also important, however, without a proper initialization it will most probably fail into local minima and will be unable to converge correctly. The manual or semi-automatic initial alignment is easy, but due to the requirement to make the methods fully automatic, without any parameter tuning, it turned out that proposing the initial alignment method for all cases was unexpectedly difficult. All three best-scoring teams made the same observations and the correct initial alignment was the key to success during the challenge (Borovec et al 2020).
Noteworthy, the nonrigid registration is a bit different than the one used during the challenge. The reason for that was an observation that after improving the MIND Demons' performance, the results were much better than the ones used by the locally affine partial data registration (Periaswamy and Farid 2006). Therefore, we decided to simplify the procedure and use only a single nonrigid registration method. In general, increasing the resolution of images being the input to the locally affine registration would probably make the results similar to the MIND Demons, however, the computational complexity of the method is unacceptable. It is important to emphasize that both this article, as well as the ANHIR summary (Borovec et al 2020), present the same results, for the version using the MIND Demons. The results for the locally affine alignment are presented in the supplementary material. Interestingly, we also attempted to use the MIND-SSD during the exhaustive rotation search and the affine registration, however, it did not provide results better than the proposed approach. Both the rTRE after the affine registration and the number of failures were higher when using the MIND descriptor. It turned out that the MIND-based similarity measure was not a good choice for the global alignment while it improved the nonrigid registration. For the comparison of the MIND Demons to classical, unimodal Demons we refer to the supplementary material.
The intensity matching based on entropy level during preprocessing deserves an additional comment. One could argue that the intensity distributions could be very different and thus an attempt to match then is inherently wrong. This argument is valid, however, we did not notice intensity distribution mismatch in the ANHIR dataset. Another argument might apply to the bijectivity of the intensity matching. In general, the transformation is bijective and we could as well match images with higher-entropy to the images with lower-entropy. However, based on our experience, using the higher entropy improves the registration results.
Undoubtedly, the main drawback of the proposed method is computation time. The time between 60 and 90 s would be rather frustrating for practical use by physicians or life scientists. However, by inspection of the method proposed by the best scoring team (Borovec et al 2020) which was fully parallel, matrix-free and greatly optimized, we think that a similar optimization is possible in the proposed algorithm. Furthermore, a GPU-based implementation would make the method significantly faster resulting in the registration time in the range of single seconds.
An interesting observation made during the challenge was the lack of success for the deep learning-based techniques (Borovec et al 2020). Even though the target registration error achieved on the training set was the lowest, the method was not generalizing that well resulting in poor outcomes on the evaluation dataset, most probably due to overfitting or strong diversity of the dataset. Maybe a better data augmentation or not using the landmarks during training would provide a better generalization ability.
In future work, we plan to look closer at the deep learning-based registration. Maybe an attention-based image registration with a proper, strong dataset augmentation, working on the full resolution of the histological images, would be even more successful nonrigid registration method, and deep methods to extract the keypoints and features could lead to even better initial alignment. What is more, since the inference time is much lower than the training time, the use of deep learning could significantly decrease the computation time.
4. Conclusion
To conclude, we proposed a fully automatic, robust, multi-step, nonrigid image registration algorithm dedicated to histological images, which is currently the second-best method on the ANHIR challenge evaluation dataset in terms of the average ranking of the median target registration error, without statistically significant differences compared to the top-ranked method (Borovec et al 2020). In this article, we described the proposed algorithm and provided access to the method software (Proposed Method Software 2019). In future, we plan to propose a deep learning-based method working on the full resolution images.
Acknowledgment
The work was supported by the National Science Centre in Poland, under the Preludium project UMO-2018/29/N/ST6/00143.