


Abstract
The accuracy and robustness of vehicle cognition in severe weather have always been the focus and difficulty of intelligent vehicle environment perception. This paper proposes a vehicle cognition method based on radar and infrared thermal camera information fusion in severe weather. The fusion of radar and infrared cameras can greatly enrich the completeness of vehicle cognitive information. First, an attention mechanism based on radar guidance information was proposed to extract the vehicle region of interest (ROI). Unlike the traditional ROI extraction method, this method is not disturbed by the environment and does not need complicated calculations, which can quickly and accurately extract ROI for vehicles. Second, based on ROI information, the infrared thermal image is reconstructed and enhanced, which is of great significance to improve the accuracy of vehicle detection for deep learning. Finally, we propose a vehicle depth estimation method based on pixel regression and use multi-scale cognitive information to fuse radar and image targets. The fusion method considering depth information can reduce target confusion and improve fusion robustness and accuracy, especially when vehicles are adjacent to each other. The experimental results show that the vehicle detection accuracy of this method is 95.2% and the vehicle detection speed is 37 fps, which effectively improves the performance of vehicle detection in severe weather.
Export citation and abstract BibTeX RIS
1. Introduction
Environmental perception is the foundation of intelligent vehicle behavioral decision making and motion planning. The research shows that many traffic accidents related to intelligent vehicles are caused by environmental perception failure, especially in severe conditions such as night, rain, fog and snow [1]. Vehicles are the most important component of the traffic environment. The study confirms that vehicle detection in severe weather is of great significance for improving the safety of intelligent vehicle driving [2]. Accurate and comprehensive vehicle cognitive information (vehicle position, motion state and size) can effectively reduce traffic accidents in severe weather. With the development of sensor technology and artificial intelligence, the accuracy and real time of vehicle cognition have reached a very high level in good weather. However, there are still many challenges in severe weather.
Machine vision, millimeter-wave radar and LiDAR are the most commonly used sensors for intelligent vehicle environment perception. The visible light camera can obtain rich perception information (texture, color, grayscale) from the traffic environment, and has a strong ability to express the details of vehicle targets. However, this kind of camera is sensitive to the change of illumination. The research shows that vehicle lamp information is obvious and stable at night. Therefore, vehicle detection at night can be realized by extracting and identifying vehicle lamps [3–5]. It should be noted that the extraction of lamp features can be easily interfered with by vehicle attitude and environmental light source. At the same time, the lamps of different vehicles are easily confused when the vehicles are adjacent to each other. In addition, raindrops, snowflakes and air-suspended particulates will introduce a lot of noise into the image, which will greatly reduce the accuracy and robustness of vehicle detection. To solve these problems, some researchers have tried to use the image processing method (dark channel theory [6], contrast enhancement [7], GAN network [8]) to remove the raindrops and fog from the image. However, these methods usually require complicated calculations, which will greatly reduce the real-time performance of vehicle detection. It is found that thermal imaging and infrared cameras have good adaptability for severe weather. Various algorithms of machine learning [9, 10] and deep learning [11, 12] have achieved good results in infrared image vehicle detection. However, by relying only on image detection, vehicle cognitive information will be incomplete.
Millimeter-wave radar can detect vehicle targets by receiving and analyzing the echo signal, which has good adaptability to severe weather. However, the radar detection targets are very miscellaneous, and the sensor itself cannot classify the target. In addition, radar can only use a particle model to describe the target without contour and size information. Therefore, millimeter-wave radar is usually used with other sensors to detect vehicles.
LiDAR has good adaptability to most weather (except for heavy rain and fog ). Nowadays, LiDAR vehicle detection based on deep learning has gradually replaced the traditional algorithms [13, 14]. The deep-learning algorithm can automatically learn the point cloud features of the vehicle through a data-driven approach, which has better detection speed and accuracy. The representative LiDAR vehicle detection methods based on deep learning include PointNet [15], BridNet [16], FVNet [17], VoxelNet [18] and PIXOR [19]. However, the detection range and accuracy of radar will also be seriously disturbed on rainy, foggy and snowy days. Besides, multi-line LiDAR is more expensive than other sensors, and there are still many challenges in its wide application for the company.
It is obvious that visible cameras cannot work in severe weather, and the performance of LiDAR will also be greatly limited. Therefore, millimeter-wave radar and infrared thermal cameras are good choices for vehicle detection in severe weather. Infrared thermal cameras convert the heat distribution of the environment into visible images. When a vehicle is running, tires, engines and exhaust pipes generate a lot of heat, and these areas have obvious texture and gray features in infrared thermal images, which is not disturbed by the severe weather. In addition, radar can provide accurate position and motion state information about vehicles for images, which will greatly enrich vehicle cognition information. Therefore, we propose a traffic vehicle cognition method in severe weather based on radar and infrared thermal camera fusion. However, in this study, there are also two extremely challenging problems as follows.
- (a)Other obstacles and heat sources in the infrared thermal image will cause great interference to vehicle detection. Therefore, the vehicle detection algorithm (deep learning and machine learning) based on traversal search is prone to false detection. Attention mechanism [20], threshold segmentation [21] and visual saliency [22] can be used for vehicle region of interest (ROI) extraction and effectively reduce environmental interference. However, these methods usually rely on complicated calculations, which will reduce the real-time performance of vehicle detection, and the ROI extraction accuracy is poor when the vehicle features are not obvious. It is of great significance to eliminate the interference of invalid obstacles accurately and efficiently to improve the accuracy of vehicle detection.
- (b)Both radar and imaging can provide vehicle detection information, but infrared thermal images can only contain vehicle 2D information. The target fusion based on 2D information is easily confused, especially when vehicles are adjacent to each other [23]. How to improve the accuracy of target fusion is the key to traffic vehicle cognition.
2. The model framework
To solve the above problems and improve the accuracy and robustness of vehicle cognition, we propose a solution as shown in figure 1. As can be seen from figure 1, the model framework mainly includes three parts.
- (a)According to the statistical characteristics of different radar detection targets, we extract effective vehicle targets from radar. These radar targets contain vehicle position and motion state information, which is essential for traffic vehicle cognition.
- (b)To eliminate the interference of traffic environment on vehicle detection, we propose an attention mechanism based on radar guidance information for vehicle ROI extraction. This method does not rely on complicated image processing and is not disturbed by the environment, which can quickly and accurately extract vehicle ROI. In addition, to further enhance the vehicle details and texture features, the infrared thermal images are reconstructed and enhanced based on ROI information, which will effectively improve the accuracy of vehicle detection. Then, we first adopt transfer learning and the excellent deep learning model (YOLO v4) to detect vehicles from infrared thermal images.
- (c)We propose a vehicle depth estimation algorithm from images based on pixel regression and transform the vehicle fusion from 2D space to 3D space. The multi-scale target fusion method considering depth information can effectively improve the accuracy and robustness of vehicle target fusion, especially when vehicles are adjacent to each other. Radar and infrared thermal cameras share vehicle cognitive information through target fusion, and the cognitive information of traffic vehicles includes the vehicle position, vehicle motion state and vehicle size, which can meet the requirements of intelligent vehicle behavior decision-making and motion planning.
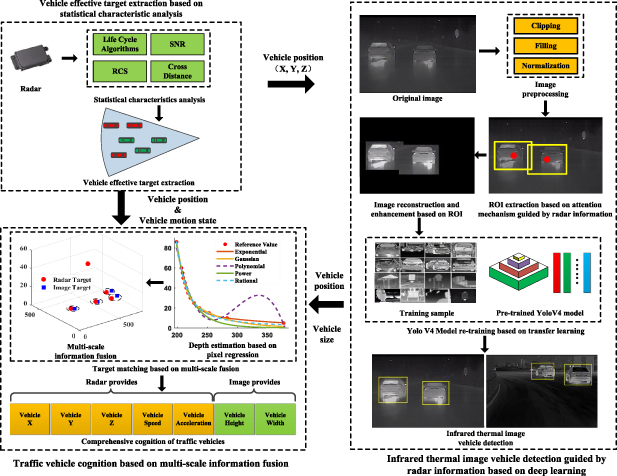
Figure 1. The model framework of this paper.
Download figure:
Standard image High-resolution image3. Vehicle effective target extraction based on statistical characteristic analysis
Radar detection targets are scrambled, and the radar itself cannot classify targets. However, intelligent vehicles are most concerned about vehicles with potential collision risks, such as the red vehicles in figure 2.
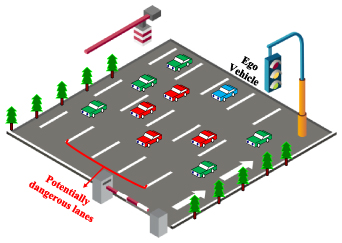
Figure 2. Distribution of vehicles in a road environment.
Download figure:
Standard image High-resolution imageTo extract valid vehicle targets, it is necessary to eliminate other radar detection targets, including invalid targets, stationary targets and non-dangerous targets. According to the characteristics of targets, the statistical analysis method can be used to screen radar targets, as shown in figure 3.
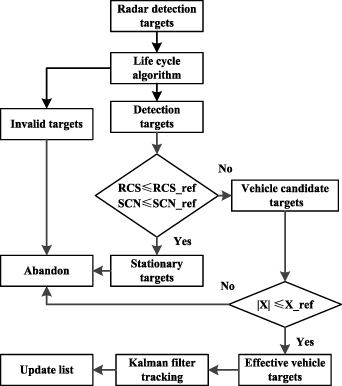
Figure 3. Target screening based on statistical characteristic analysis.
Download figure:
Standard image High-resolution imageAn invalid target usually refers to the radar false target caused by vehicle bumping and electromagnetic interference. This kind of target generally lasts for a short time and can be screened by a life cycle algorithm [24].
Static targets (except vehicles) mainly include trees, road guardrails and streetlamps, etc. Relevant studies show that the radar cross-section (RCS) and signal–noise ratio (SNR) of static targets are quite different from those of vehicles [25, 26]. Generally, the RCS and SNR of static targets are relatively small due to their cross-sectional area and materials. According to radar parameters, the stationary targets can be eliminated by a reasonable threshold setting (RCS_ref and SNR_ref).
Non-dangerous targets are vehicles outside the lane and adjacent lanes of the ego vehicle, which have no potential collision risks, such as the green vehicle in figure 2. We can set the threshold Xref of cross-range to eliminate non-dangerous vehicles. We assume that the road width is Wroad, and the recommended value is 3.75 m. The average vehicle width is Wvehicle, and the recommended value is 1.8 m. The measurement error of the radar is xerror, and the recommended value is 5%. The threshold Xref of the cross-range can be expressed by equation (1). The parameter n is the road correction coefficient, when the vehicle runs on a straight road, and the value of n is 2. When the vehicle runs on a curve or intersection road, the value of n is 3.5. If the target's cross-range is out of [−Xref, Xref], it will be discarded.
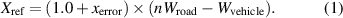
4. Infrared thermal image vehicle detection guided by radar information based on deep learning
4.1. Unification of radar and camera information
There are significant differences in the sampling frequency and the coordinate system of different sensors. Sensor information unification includes time synchronization and space synchronization. The information interaction between radar and infrared camera is at the same system time, so it is a simple and effective method to realize time synchronization by timestamp. To facilitate the mutual transformation of coordinate systems, we define the coordinate systems as shown in figure 4.
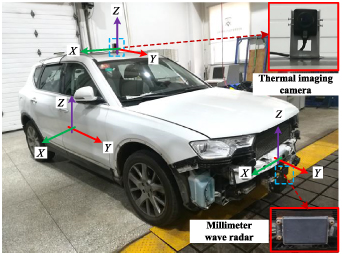
Figure 4. Experimental vehicle and coordinate system definition.
Download figure:
Standard image High-resolution imageThere are three coordinate systems:vehicle coordinate system, camera coordinate system and radar coordinate system. According to geometric constraints and projection transformation [27], the coordinate transformation between radar and image can be expressed by equation (2).
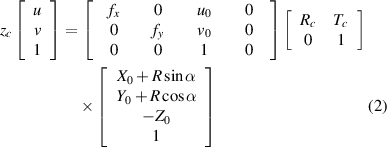
where (u, v) is the projection of the radar target (R, α) in the image coordinate, and [fx, fy, uo, vo ] are the internal parameters (focal length and main coordinate point) of the camera. [Rc, Tc] are two 3 × 3 matrices representing the camera's external parameters (rotation matrix and translation matrix). All these parameters can be obtained by a calibration experiment. [X0, Y0, Z0] represents the offset between the radar coordinate system and the origin of the vehicle coordinate system.
4.2. Attention mechanism of radar guidance information for vehicle ROI extraction and image processing
There is a very challenging problem in infrared thermal image vehicle detection. Vehicle features are easily disturbed by the surrounding heat sources, such as buildings, electronic billboards, streetlamps, etc. These interferences can easily lead to false detection of vehicles and are not conducive to the enhancement of vehicle details and features in infrared thermal images. To solve this problem, we first propose an attention mechanism based on radar guidance information for vehicle ROI extraction. This method can quickly and accurately extract the ROI of vehicles without environmental disturbances and complicated calculations. The infrared thermal image has been reconstructed and enhanced based on the ROI information, which will greatly highlight the features of the vehicle in the image and improve the subsequent vehicle detection. The realization process of the whole method is shown in table 1.
Table 1. Pseudo-code of algorithm.
| Algorithm. Attention mechanism guided by radar information for vehicle ROI extraction and image processing |
|---|
| Input: Original infrared image |
| 1. Convert original image to grayscale image |
| 2. Size = Max(img_heigh, img_width) |
| 3. Filling image to Size × Size |
| 4. Resize image to 512 × 512 |
| 5. [Img_x, Img_y] = Equation (2) (R_radar,α_radar) |
| 6. ROI_height = Equation (3) (Radar_x) |
| 7. ROI_ width = 1.3 × ROI_width |
| 8. ROI_center = [Img_x, Img_y] |
| 9. ROI_area = 1.4×(ROI_width × ROI_heigth) |
| 10. If pixel ∈ ROI |
| 11. Pixel_ value = pixel × 1 |
| 12. else |
| 13. Pixel_ value = Pixel × 0 + 255 |
| 14. end |
| 15. Save image |
| 16. Image_out = ACE_algorithm (image) |
| Out: Image_out |
4.2.1. Vehicle ROI extraction based on attention mechanism guided by radar information.
Attention mechanism, threshold segmentation, selective search and visual saliency can all be used for ROI extraction. However, this kind of algorithm usually requires image processing or complicated calculations, which will reduce the real-time performance. Compared with ordinary images, this kind of method is more likely to cause ROI extraction error, when there is an obvious environmental heat source in infrared thermal images. However, our ROI extraction method can avoid this problem. According to equation (1), the vehicle detection targets of radar are projected to the infrared image, as shown in figure 5. The coordinate of the radar target in the infrared thermal image is the center of the vehicle ROI.

Figure 5. Radar target conversion to image.
Download figure:
Standard image High-resolution imageThe vehicle detection of radar can quickly find the potential area of the vehicle in infrared images through projection transformation. Compared with methods based on image processing, this step does not require complicated calculations. However, it is worth noting that how to determine the size of the dynamic ROI window is a problem that cannot be ignored. We find that the size of ROI is negatively correlated with the distance of the vehicle. When the camera is fixed, the height of vehicles in the image and the actual distance is in one-to-one correspondence, which is negatively correlated with the longitudinal distance and is unrelated to the lateral distance. To verify this discovery, we carried out an experiment as shown in figure 6.

Figure 6. Verification experiment of vehicle pixel height.
Download figure:
Standard image High-resolution imageThe longitudinal distance between the camera and the vehicle is 9.3 m. When the vehicle is located in the middle of the image, the pixel height of the vehicle is 112. We adjust the position of the vehicle, and when the vehicle is located at the right edge of the image, the pixel height of the vehicle is 114. The experimental results show that the pixel height of the vehicle does not change obviously because of the lateral position.
Taking a large SUV with a height of 1.7 m as an experimental vehicle, the change of vehicle height with distance in image is shown in figure 7.
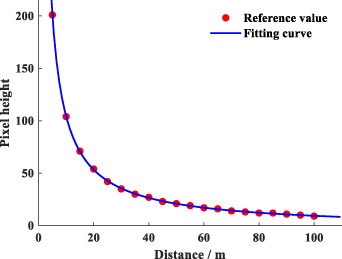
Figure 7. Variation curve of vehicle height with distance.
Download figure:
Standard image High-resolution imageWe have tried many different fitting functions, and it is finally found that the fitting accuracy of the power function is the best. The fitting results show that the SSE is 3.17, the RMSE is 0.43 and the fitting function as shown in equation (3). R is the distance of the vehicle, which can be provided by radar detection information.
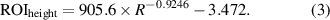
The width of the dynamic ROI window is determined by the vehicle aspect ratio. According to the statistics of 300 different types of vehicles, it is found that the aspect ratio of most vehicles is between 0.8 and 1.3, as shown in figure 8.
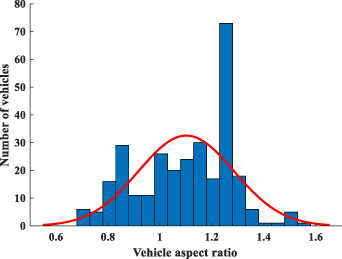
Figure 8. Vehicle aspect ratio statistics.
Download figure:
Standard image High-resolution imageTo prevent the loss of vehicle information in ROI, we adopt the aspect ratio as 1.3. Besides, considering the error of radar detection and sensor fusion, the size of ROI should be expanded by 1.4 times. Then, the area of the vehicle ROI can be expressed by equation (4)
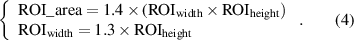
We compare different ROI extraction methods, and the results are shown in figure 9.
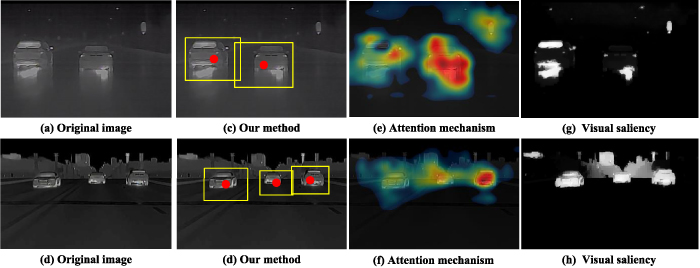
Figure 9. Comparison of different ROI extraction algorithms.
Download figure:
Standard image High-resolution imageIt is obvious that attention mechanism and visual saliency are easy to take other obstacles (buildings, streetlamps) in the environment as vehicle ROI. Moreover, visual saliency will lose effective ROI when the gray features of vehicles are not obvious, such as in figure 9(g).
Our method can not only accurately extract the ROI of vehicles, but also effectively avoid environmental interference. Besides, this method does not depend on complicated image processing and calculation, which can greatly improve the speed of ROI extraction. The calculation time of visual saliency and attention mechanism that we have tried is 10–14 ms, and our method is only 4 ms on the same hardware (CPU: Intel Xeon, GPU: NVIDIA Tesla V100), which can save 60%–70% of the calculation time.
4.2.2. Image reconstruction and enhancement based on ROI information.
To eliminate the interference of traffic environment to vehicle detection and improve the imaging quality of vehicles, the image is reconstructed based on ROI extraction information. We keep the images of ROI unchanged, and set the gray value of the images in other areas to 255, as shown in figure 10.

Figure 10. Infrared thermal image reconstruction.
Download figure:
Standard image High-resolution imageThe reconstructed image is all black except the ROI area. The black area has no gray or texture features of the environmental background, which will not affect the subsequent image enhancement. To further enhance the details of the vehicles in ROI, this paper uses the Automatic Color Enhancement (ACE) algorithm [28] to enhance the vehicle features. A comparison of different vehicle image enhancement algorithms is shown in figure 11.

Figure 11. Comparison of different image enhancement algorithms.
Download figure:
Standard image High-resolution imageAs can be seen from figure 11, the adaptive gray enhancement based on the reconstructed image can improve the image quality to the greatest extent, which will improve the accuracy of subsequent vehicle detection. Compared with the global enhancement algorithm (figures 11(e) and (f)), this method only processes the ROI image, which significantly reduces the computation time. Moreover, the global image enhancement is easily disturbed by the environment heat source, and the vehicle features are still easily confused with the environment.
4.3. Vehicle detection in infrared thermal image based on transfer learning and Yolo V4
YOLO v4 is the latest version of the YOLO series of target detection algorithms. On Tesla V100 it processes images at 65 fps and has a mean average precision of 65.7% on MS COCO dataset [29]. In this paper, YOLO v4 is applied to infrared thermal image vehicle detection for the first time. Vehicles have obvious features in the reconstructed and enhanced infrared thermal images. YOLO v4 is especially suitable for extracting significant vehicle targets from the images and can provide an accurate bounding box for vehicle targets, which is indispensable information for vehicle cognition.
To improve the training efficiency and accuracy, we retrain the pre-trained YOLO v4 based on transfer learning. Transfer learning is used to improve new learning tasks by transferring knowledge from related tasks that have been learnt, which is beneficial to improve the training speed and accuracy of the model when the number of training samples is constant [30]. The specific implementation process is shown in figure 12.
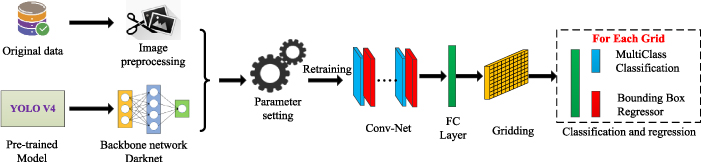
Figure 12. Yolo v4 infrared vehicle detection model training based on transfer learning.
Download figure:
Standard image High-resolution imageThe YOLO v4 model training based on transfer learning can be divided into four steps.
- (a)Extract the backbone network. Darknet is the backbone network of YOLO v4, which is used for image feature extraction. Loading weights from the pre-trained model can accelerate the convergence of the network and reduce the dependence of training samples.
- (b)Image preprocessing. The image is adjusted to a size of 512 × 512 by resizing and filling (the original image size is 800 × 600), ensuring the same dimension as the input layer of the model. In addition, the original image can generate more training samples by rotating, mirroring, image reconstruction and enhancement based on radar information. The number of original training images is 20 000, containing all kinds of severe traffic environments (Night, foggy, snowy and rainy). After image augmentation, there are 52 000 effective training images, including 162 325 vehicle targets. Image augmentation can effectively improve the model training accuracy and prevent overfitting.
- (c)Definition of the loss function. The loss function of YOLO v4 training includes regression-bounding box loss, confidence loss, and classification loss. The definitions of these loss functions are the same as those in the literature [29].
- (d)Parameter setting. Parameter settings mainly include model parameters and training parameters. The partial parameter settings are shown in table 2.
Table 2. Partial parameter settings.
| Symbol | Definition | Value |
|---|---|---|
| Width | Image width | 512 |
| Height | Image height | 512 |
| Channels | Image channel | 1 |
| Batch | Batch size | 32 |
| Classes | Number of categories | 1 |
| Filters | Convolution kernel | 18 |
| Learning rate | Learning rate | 0.001 |
| Scales | Attenuation factor | 0.1 |
| Epoch | Iteration times | 100 |
The development environment of the model is based on python-3.8 and OpenCV-4.4, and the hardware configuration for the model training is as follows: CPU (Intel Xeon), GPU (NVIDIA Tesla V100) and memory (64 G). After repeated training, the accuracy and loss of YOLO v4 gradually meet the requirements of target detection, and the training process is shown in figure 13. It can be seen from figure 13 that with the increase in the training epoch, the accuracy of the model is continuously improved and tends to be stable. The loss value of the model decreases continuously, and the average accuracy of the test PR curve is 0.96, which meets the requirements of the model for vehicle detection accuracy.
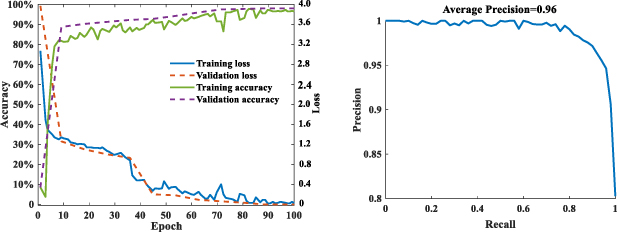
Figure 13. Model iterative training curve and PR curve.
Download figure:
Standard image High-resolution imageIt can be seen from figure 12 that with the increase in the training epoch, the accuracy of the model is continuously improved and tends to be stable. The loss value of the model decreases continuously, which meets the training requirements of the model.
We tried different models and tested them with test sets; the results are shown in table 3.
Table 3. Comparison of test results of different models.
| Model | Image size | Reconstruction & enhancement | Accuracy% |
|---|---|---|---|
| SSD | 416 × 416 | √ | 91.3 |
| SSD | 512 × 512 | × | 88.6 |
| YOLO v3 | 416 × 416 | √ | 92.1 |
| YOLO v3 | 512 × 512 | √ | 93.6 |
| YOLO v4 | 416 × 416 | √ | 94.2 |
| YOLO v4 | 512 × 512 | √ | 95.7 |
| YOLO v4 | 512 × 512 | × | 91.1 |
It can be seen from table 3 that the vehicle detection accuracy of YOLO v4 is higher than that of other models, and the image processing algorithm of this paper plays an important role in improving the accuracy of vehicle detection, which can improve vehicle detection accuracy by 4%−7%.
5. Traffic vehicle cognition based on multi-scale information fusion
Radar and images can provide different vehicle cognition information, which can complement each other. Therefore, information fusion is an important way to improve the accuracy and completeness of vehicle cognition. Both radar and image can detect vehicle targets, so the object-level fusion usually adopts the late fusion method [31], such as in figure 14.
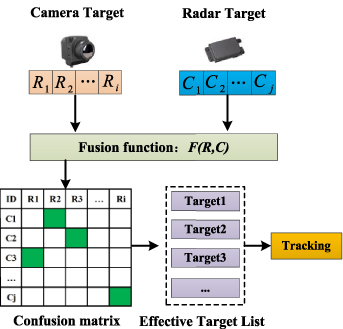
Figure 14. Target-level information fusion and tracking.
Download figure:
Standard image High-resolution image5.1. Limitations of information fusion based on 2D information
The vehicle cognition of infrared thermal images only contains 2D information. Assume that the sets of radar detection targets and infrared camera detection targets in the traffic environment are R_set and C_set as equation (5)
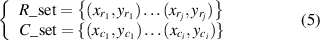
where  represents the coordinates of the radar target in the image, and
represents the coordinates of the radar target in the image, and  represents the central coordinates of the bounding box for vehicle detection target in infrared thermal image.
represents the central coordinates of the bounding box for vehicle detection target in infrared thermal image.
Cost function is a simple and practical method for target-level fusion [32, 33]. The cost function value of any two targets can be calculated by equation (6). The confusion matrix contains the cost function values of all targets. The smaller the cost function value is, the two detection targets will be judged to be the same targets.
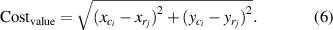
It is worth noting that there are inevitable errors in the vehicle detection and sensor calibration, so it is easy to cause fusion error by calculating the cost matrix using only 2D information (X, Y), especially when the positions of the vehicles are quite adjacent to each other. For example, there are five radar detection targets and four image detection targets in figure 15.
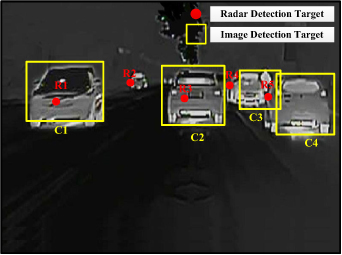
Figure 15. Radar and image vehicle detection target.
Download figure:
Standard image High-resolution imageVehicle cognition information from radar and infrared images is shown in table 4, which only contains the 2D position information of vehicles.
Table 4. Vehicle 2D detection information.
| Radar Target | Camera Target | ||||
|---|---|---|---|---|---|
| ID_R | X | Y | ID_C | X | Y |
| 1 | 130 | 235 | 1 | 150 | 212 |
| 2 | 301 | 194 | 2 | 451 | 221 |
| 3 | 435 | 227 | 3 | 610 | 202 |
| 4 | 539 | 197 | 4 | 716 | 242 |
| 5 | 629 | 223 | — | — | — |
According to equation (6), the fusion result of radar and camera vehicle detection target is shown in figure 16.
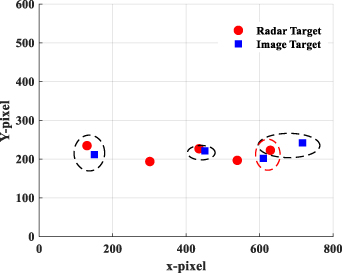
Figure 16. Vehicle target fusion based on 2D information.
Download figure:
Standard image High-resolution imageIt is obvious that there are five vehicle targets in figure 14. However, it has six targets after fusion, including four fusion targets and two isolated radar targets, which is inconsistent with the actual situation. It is not difficult to find that the cost function mistakenly judges the radar target R5 and image target C3 as the same target.
In fact, the position distribution of vehicles in the image is unbalanced, and the changing range of vehicle ordinate is quite narrow, which makes the target easily confused in 2D space. If the depth information of vehicles is considered in target fusion, the accuracy of vehicle fusion can be effectively improved in 3D space. The radar itself can provide distance information about vehicles, so how to accurately estimate vehicle depth information in images is the key to information fusion.
5.2. Vehicle depth estimation based on pixel regression
To improve the accuracy and speed of vehicle depth estimation in infrared images, this paper proposes an efficient method based on vehicle pixel regression. We find that when the position of the camera and the size of the image are determined, the distance between vehicles can be directly reflected by the coordinates of the lower edge of the vehicle in the image, and the coordinate information can be directly extracted from the bounding box as shown in figure 17. The farther the vehicle distance is, the larger the ordinate of the bottom edge is. Vehicles with different distances and their ordinates are in one-to-one correspondence. The distance of the vehicle is inversely proportional to the ordinate of the image and is unrelated to the abscissa. As shown in figure 17, there are two vehicles in the position of image Y3, which are distributed on the left and right sides, but their longitudinal distance is the same as the ego vehicle.
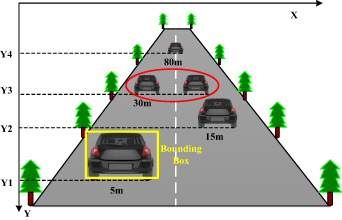
Figure 17. Relationship between vehicle distance and its ordinate.
Download figure:
Standard image High-resolution imageBased on this discovery, we obtained the mapping relationship between vehicle distance and Y coordinate by calibration experiment and used different functions to fit the experimental data, as shown in figure 18. It can be seen from figure 18 that the experimental data changes smoothly, and it is negatively correlated.
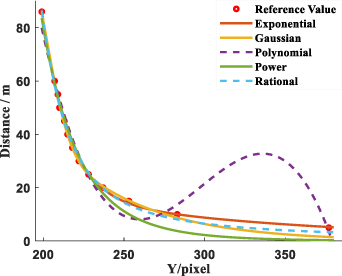
Figure 18. The fitting results of different functions.
Download figure:
Standard image High-resolution imageWe have evaluated and analyzed the fitting results of different functions, and the fitting results of different functions are shown in table 5.
Table 5. Analysis of fitting results for different functions.
| Function | SSE | R-square | RMSE | Mean error |
|---|---|---|---|---|
| Exponential | 11.65 | 0.9981 | 1.138 | 2.51% |
| Gaussian | 17.61 | 0.9972 | 1.586 | 7.35% |
| Polynomial | 149 | 0.9759 | 4.08 | 13.41% |
| Power | 116.5 | 0.9813 | 3.255 | 17.78% |
| Rational | 20.79 | 0.9967 | 1.723 | 6.67% |
It can be seen from table 5 that the exponential function has the best fitting result with a mean error of only 2.51%, and the expression of the fitting function is as follows:
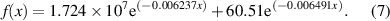
We used 20 sets of test data to test different distance estimation methods, including the isometric mapping method, geometric method and our method. It can be seen from figure 19 that with the increase in measurement distance, the estimation error of all algorithms has generally increased. The mean errors of isometric mapping and geometric methods are 11.7% and 7.5%, and the mean error of our method is only 4.2%, which has greatly improved the measurement accuracy.
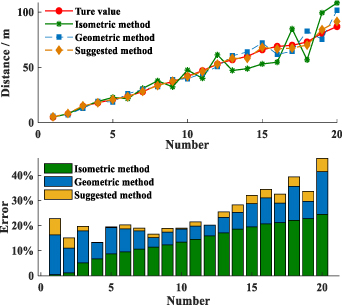
Figure 19. Comparison of different measurement algorithms.
Download figure:
Standard image High-resolution imageThe vehicle depth estimation algorithm based on pixel regression expands the cognitive information about images from 2D space to 3D space, which will provide a basis and data support for multi-scale information fusion.
5.3. Multi-scale cognitive information fusion considering depth information
YOLO v4 model uses bounding boxes to locate vehicles in infrared thermal images. The distance of the vehicle can be obtained by substituting the Y coordinate of the lower edge of the bounding box into equation (7). The set of radar and image detection vehicles containing depth information can be expressed as equation (8)
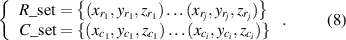
There are differences in the distribution of vehicles on x–y–z, and these differences are manifested in two aspects. First, the data variation range is different. To eliminate the calculation error, this paper uses min–max normalization to normalize the data. Second, the weights of the three directions in fusion are different. Therefore, the cost function considering depth information is defined by equation (9)
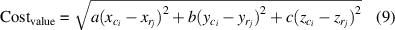
where a, b, c represents x–y–z fusion weights and Z is the depth information of vehicles.
The fusion weight can be determined by the genetic algorithm [34]. After many iterations, a, b and c are 2.39, 0.86 and 3.74 respectively. The cost matrix considering the target depth information is shown in table 6.
Table 6. Vehicle detection target cost matrix.
| Id | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|
| C1 | 0.48 | 1.73 | 0.76 | 1.03 | 1.18 |
| C2 | 0.82 | 1.81 | 0.12 | 0.64 | 0.43 |
| C3 | 1.38 | 1.57 | 0.73 | 0.20 | 0.56 |
| C4 | 1.42 | 2.24 | 0.75 | 1.09 | 0.45 |
According to the cost matrix, there are five vehicle targets, including four fused targets (F1–F4) and one single radar target (R2), as shown in figure 20. There is no image detection target that can be fused with the single radar target R2, but it will also be output to the target list as an effective target, which completely conforms to the actual traffic environment in figure 15.
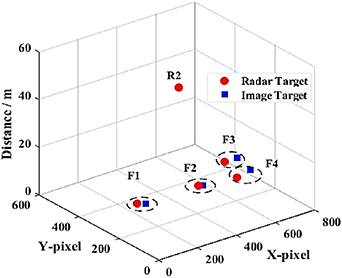
Figure 20. Multi-scale vehicle target fusion.
Download figure:
Standard image High-resolution imageCompared to 2D fusion, the multi-scale fusion model considering depth information can effectively improve the accuracy and robustness of target fusion. The fused vehicle targets can share the vehicle's cognitive information, radar can provide vehicle position (x, y, z) information and motion state (velocity and acceleration), and images can provide the vehicle size (width and height), which greatly enriches the vehicle cognition information. Besides, the effective working range of radar is wider than that of camera. Sometimes the camera cannot recognize the distant vehicle target (target R2 is in figure 20), but the radar can complete the long-distance vehicle detection task. Moreover, when vehicles are adjacent to each other or even blocked, image-based detection methods may not be able to distinguish targets. However, radar can distinguish targets according to their longitudinal distance distribution, which effectively improves the accuracy of vehicle detection.
6. Experimental results and analysis
To verify the performance of the vehicle detection model, we selected different severe weather conditions to test the model, and some experimental results are shown in figure 21.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 21. Test results of different severe weather.
Download figure:
Standard image High-resolution image{kind=link}
There are 418 vehicles in the test set. Within the working range of the sensors, the effective vehicle detection target is 398 (accuracy, 95.2%), missed vehicles is 20 (missing rate, 4.8%), which are the vehicles mainly concentrated in the far distance, and the false detection of vehicles is 5 (false positive rate, 1.2%). In addition, the average vehicle detection speed is 37 fps. It is obvious that the method of this paper can fully meet the requirements of real-time and accuracy for vehicle detection in severe weather.
To further illustrate the performance of this method, we compare it with other infrared thermal image vehicle detection methods. The comparison results are shown in table 7.
Table 7. Performance comparison of different vehicle detection methods.
| Ref | Accuracy(%) | Speed (fps) | Ref | Accuracy (%) | Speed (fps) |
|---|---|---|---|---|---|
| [35] | 76.47 | 30 | [11] | 64.5 | 53 |
| [36] | 92.1 | 5 | [22] | 92.3 | 25 |
| [37] | 94.6 | 10 | [21] | 93.9 | 21 |
| [9] | 96.2 | — | Our A | 95.2 | 37 |
| [38] | 91.7 | — | Our B | 90.4 | 43 |
| [12] | 94.3 | 35 | Our C | 92.2 | 39 |
Method A represents the vehicle detection algorithm based on radar and camera fusion. Method B is pure image vehicle detection based on YOLO v4 without image reconstruction and enhancement. Method C is pure image vehicle detection based on YOLO v4 with global adaptive enhancement. The fusion of sensors may slightly reduce the speed of vehicle detection, but it can greatly improve the accuracy of vehicle detection on the premise of ensuring real-time performance. In summary, method A proposed in this paper shows good performance in both real-time and accuracy, and fully meets the requirements of vehicle detection in severe weather. However, it should be noted that the application environment, computing hardware and programming language of these methods are quite different. Therefore, the comparison results are for reference only.
7. Conclusions and future works
To improve the accuracy and robustness of traffic vehicle cognition in severe weather, a new method based on radar and infrared thermal camera information fusion is proposed. Through the research, we can draw the following main conclusions.
- (a)A ROI extraction method based on an attention mechanism guided by radar information can accurately and quickly extract the ROI of the vehicles from the infrared thermal image. The radar information can directly provide the potential location information of vehicles for infrared thermal images by projection transformation and dynamic programming. This method is not only free from environmental interference, but also can save 60%–70% ROI extraction time compared with other algorithms.
- (b)The reconstruction and enhancement of infrared thermal images based on ROI information can avoid environmental interference and greatly highlight the grayscale and texture features of vehicles, which can improve the detection accuracy of vehicles by 4%–7%.
- (c)The multi-scale fusion method considering depth information can effectively improve the accuracy of vehicle fusion, especially when vehicles are adjacent to each other. Vehicle depth information and fusion weight can eliminate the unbalanced distribution of vehicles in 2D space, which makes the vehicles easier to distinguish.
- (d)The accuracy of vehicle detection based on radar and infrared thermal camera information fusion is 95.2% and the detection speed is 37 fps in severe weather. The accuracy and real-time performance can easily meet the requirements of traffic vehicle cognition.
It should be noted that the vehicle cognition range of a single infrared thermal camera is limited. We consider adding different kinds of radar and infrared thermal cameras in future research, which can realize omnidirectional vehicle cognition.
Acknowledgments
Thanks to the State Key Laboratory of Automobile Simulation and Control which provided many experiments and help with data labeling. Thanks to the financial support provided by various funds: National Natural Science Foundation of China (U1664261), Natural Science Foundation of Jilin Province (20170101209JC), National College Students' Innovation and Entrepreneurship Training Program (202010183258), Jilin University Postgraduate Innovation Fund Project (101832018C205), and Jilin University Postgraduate Innovation Fund Project (101832020CX137).
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.