
Abstract
Manual delineation of liver segments on computed tomography (CT) images for primary/secondary liver cancer (LC) patients is time-intensive and prone to inter/intra-observer variability. Therefore, we developed a deep-learning-based model to auto-contour liver segments and spleen on contrast-enhanced CT (CECT) images. We trained two models using 3d patch-based attention U-Net (\({{\text{M}}}_{{\text{paU}}-{\text{Net}}})\) and 3d full resolution of nnU-Net (\({{\text{M}}}_{{\text{nnU}}-{\text{Net}}})\) to determine the best architecture (\({\text{BA}})\). BA was used with vessels (\({{\text{M}}}_{{\text{Vess}}})\) and spleen (\({{\text{M}}}_{{\text{seg}}+{\text{spleen}}})\) to assess the impact on segment contouring. Models were trained, validated, and tested on 160 (\({{\text{C}}}_{{\text{RTTrain}}}\)), 40 (\({{\text{C}}}_{{\text{RTVal}}}\)), 33 (\({{\text{C}}}_{{\text{LS}}}\)), 25 (CCH) and 20 (CPVE) CECT of LC patients. \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) outperformed \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) across all segments with median differences in Dice similarity coefficients (DSC) ranging 0.03–0.05 (p < 0.05). \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\), and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) were not statistically different (p > 0.05), however, both were slightly better than \({{\text{M}}}_{{\text{Vess}}}\) by DSC up to 0.02. The final model, \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\), showed a mean DSC of 0.89, 0.82, 0.88, 0.87, 0.96, and 0.95 for segments 1, 2, 3, 4, 5–8, and spleen, respectively on entire test sets. Qualitatively, more than 85% of cases showed a Likert score \(\ge\) 3 on test sets. Our final model provides clinically acceptable contours of liver segments and spleen which are usable in treatment planning.
Similar content being viewed by others

Introduction
Liver cancer is the third most common cause of the cancer-related deaths globally and it resulted in roughly 700,000 deaths in 20201. Surgery (resection or lobectomy) is considered the main line of treatment especially in colorectal liver metastases2 in which segment(s) or entire lobe is removed depending upon the extent of tumor3,4. However, the ability to perform liver surgery is largely dependent upon accurate localization of tumor with respect to segments and the volumetric measurement of liver segments as it allows clinician to ensure that the patient would have minimum remnant functional liver volume after the surgery (e.g. 20% in normal liver)4. To quantify the functional liver volume, radiologists/technologists perform manual contouring of segments on the contrast-enhanced CT (CECT) images following the architecture of vessels, ligament and organs5. However, manual contouring is time intensive6 and prone to inter/intra-observer variabilities7 which can affect the volumetric measurement and subsequent clinical use. Therefore, automation of liver segment contouring is crucial to evaluate the eligibility of patient for liver surgery.
Several semi-automatic and automatic segmentation approaches exist but recent advancements in Deep Learning (DL) based models have outperformed other methods in terms of required time and segmentation accuracies across various organ sites8. Recent surveys have reported a plethora of architectures used in medical image segmentation out of which U-Net based architectures are widely used for organ segmentations9,10. In particular, 3D U-Net (the 3D extension of U-Net) is of great importance as it offers two major features (1) training with sparse volumetric data (2) input of 3D volume/patch in the training which allows the architecture to retain more features in contrast to 2D input11. Both of those features make 3D U-Net more applicable in 3D organ segmentation, and resultingly, several studies12,13 have reported reasonable accuracy and clinically translatable performance of organ segmentations with 3D U-Net. Currently, nnU-Net is one of the state-of-art segmentation framework which utilizes U-Net based architectures (combined or individual 2D and 3D U-Net) to train segmentation models14, and has shown excellent translatable clinical performance in abdominal segmentation15. In addition, nnU-Net is a self-configuring framework and automatically performs hyperparameter tuning and data augmentation which promises to result in higher segmentation accuracies14. However, the presence of 3D input patch also implies the inclusion of features from irrelevant regions which involve large number of trainable parameters resulting in excessive requirement of computational resources. To address such issues, Attention based gating has been implemented by Oktay et al. 2018 in the standard 2D U-Net, which uses attention coefficients to identify relevant image features and merge them just before the concatenation operation in the skip-connection phase16. Additionally, Attention U-Net showed consistent significant performance improvements when its performance was compared with 3D U-Net16. However, since 3D input patch would also preserve higher number of relevant features compared to 2D input, it is therefore reasonable to implement attention mechanism in the multiple skip connection of standard “3D U-Net” and test if it would improve the segmentation accuracies.
Additionally, with regard to model training for segment contouring in the patients with primary and metastatic liver disease, the architecture has to face liver specific anatomical challenges which could result in uncertainties in demarcation of liver segments. For example, the occlusion of vessels due to tumor could result in distortion of liver contours and liver segments. Both aforementioned issues could be addressed if we can implement localization of vessels during the training. Another important condition is enlargement of liver and spleen in cancer patients in which spleen is abutted with segment 2 and 3 which result in incorrect separation of segments with spleen. One possible approach to address such issues is training the model with both segments and spleen. Currently, a very few DL based liver segmentation studies exist that investigated the automated segmentation accuracy on CT images of patients with liver tumors. Tian et al. 2019 implemented global and local context U-Nets (GLC-UNet) which first segmented the whole liver and then localized vessel-based slice features are utilized to segment the Couinaud’s segments17. GLC-UNet achieved a mean segment DSC similarity coefficient (DSCs) of 0.92. Additionally, a recent study by Lee et al. 2022 developed two different models to separately contour the liver segments and spleen and achieved a median DSC score around 0.91 across the segments18.
In this study, our central goal is to develop a fully automated segmentation model that can achieve consistent, robust, expert observer-level accuracy in liver segment contouring to guide the liver surgery planning. To achieve this goal, we have established three main aims (1) to determine the best architecture for auto segmentation of liver segments by investigating the performance of 3D patch based attention U-Net (paU-Net) over the gold-standard framework of nnU-Net (2) to determine if addition of vessels and spleen during segmentation training could improve the liver segments segmentations (3) to perform quantitative and qualitative assessment of model across patients undergoing RT, general evaluation for liver surgery, portal vein embolization (PVE), and CT based liver pathologies used in various segmentation challenges.
Materials and methods
Overall framework
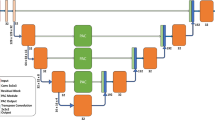
Figure 1 shows the overall workflow of our study which involves three major blocks. Starting in the architecture selection block (block 1), we investigated the best architecture by comparing Attention 3D U-Net and 3D full resolution from nnU-Net. In the uncertainty improvement block (block 2), we investigated whether the addition of vessels and spleen during model training improves the segmentation results while using the best architecture identified from block 1. Lastly, in the Model Assessment (block 3), all the models were evaluated on surgery candidates’ CT scans, patients who received portal vein embolization, non-contrast CT images and on external CT datasets from various segmentation challenges19,20,21,22.

(A) Overall workflow of the study. (B) Architecture for 3D-patch based U-Net with attention mechanism (C) nnU-Net framework which automatically optimizes the architecture based on the type of datasets. *Quantitative analysis were performed by calculating Dice similarity coefficient, 95th percentile Hausdoff’s distance, and percent change in the volume of segments and spleen between AI predicted and ground-truth contours. Statistical analysis was performed using Wilcoxon signed rank test with Bonferroni correction. **All models were assessed on cohorts of Block 3 using both quantitative and qualitative analyses (Figures created using biorender.com).
Datasets patient population
The study included two major data group, namely, an internal data group (IDG) and external data group (EDG). The IDG consisted of contrast enhanced CT (CECT) scans of patients diagnosed with primary and metastatic liver cancer at our institution. Within IDG, we have four cohorts. The radiotherapy cohort (\({{\text{C}}}_{{\text{RT}}}\)) consisted of 100 patients with a radiotherapy planning and 3-month follow-up CECT image. The surgery cohort (\({{\text{C}}}_{{\text{LS}}}\)) included 33 CT scans of patients that were being evaluated for liver surgery. The non-contrast cohort (\({{\text{C}}}_{{\text{NC}}}\)) included 20 non-contrast CT (non-CECT) scans of patient with contrast scans used in the training. The portal vein embolization cohort (\({{\text{C}}}_{{\text{PVE}}}\)) included 20 CT scans of patient undergoing portal vein embolization for the liver (PVE). All patients from internal data group were retrospectively enrolled in a Health Insurance Portability and Accountability Act-compliant institutional review board approved study (The University of Texas MD Anderson Cancer Center IRB PA18-0832) with a waiver of informed consent. Use of data was approved by the IRB and all experiments were performed in accordance with relevant guidelines and regulations.
The EDG consisted of challenge data (\({{\text{C}}}_{{\text{CH}}}\)) which included a total of 25 patients obtained from 3D-IRCADb-01 (\({{\text{C}}}_{{\text{IRCAD}}-01}\)), 3D-IRCADb-02 \(({{\text{C}}}_{{\text{IRCAD}}-02}\)), task 8 Medical Imaging Decathlon Challenge (\({{\text{C}}}_{{\text{MID}}}\)) and CHAOS (\({{\text{C}}}_{{\text{CHAOS}}}\)) datasets19,20,21. Table 1 shows the detailed technical information regarding the images and patients used in this study.
Manual and AI edited segmentations
Ground-truth segmentations of the patient datasets included liver segments 1, 2, 3, 4, 5–8 (combined), spleen, and vessels. Two major approaches were used to contour the liver segments. In first approach, an in-house nnU-Net model trained on the subset of \({{\text{C}}}_{{\text{RTTrain}}}\) was used to contour liver segments on \({{\text{C}}}_{{\text{RT}}}\) and \({{\text{C}}}_{{\text{LS}}}\). Afterwards, the model generated contours were edited or recontoured fully by a radiologist (MA) as per the need. In second approach, liver segments were manually contoured by the radiologist MA on \({{\text{C}}}_{{\text{PVE}}}\), and \({{\text{C}}}_{{\text{CH}}}\) without any assistance from AI models. Additionally, spleen contours on \({{\text{C}}}_{{\text{RT}}}\) and \({{\text{C}}}_{{\text{CH}}}\) were first created by a nnU-Net model trained on task 9 Medical Imaging Decathlon Dataset20 and were manually edited by a radiologist (MA) or students (SR and ACG). On \({{\text{C}}}_{{\text{PVE}}}\), \({{\text{C}}}_{{\text{LS}}}\), and \({{\text{C}}}_{{\text{NC}}}\) the spleen was manually contoured by ACG without using any AI segmentations. Lastly, the reader is referred to Sect. “Uncertainty improvement-impact of vessels and spleen” for mechanism behind vessels contours.
Architecture selection
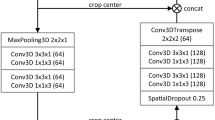
We have investigated two variants of 3D U-Net in this study. First, we developed a 3D patch-based U-Net with attention mechanism based on the standard 3D U-Net11 and attention gate16. As shown in Fig. 1A and B, in the analysis path, a patch size of 256 × 256 × 24 was input to the network. The network consisted of 4 layers with 2 blocks in each layer. A convolution of 3 × 3 × 3 is performed at each block with group normalization and Leaky ReLU followed by a 2 × 2 × 2 max pooling before transitioning to the next layer. In the decoder, blocks within each layer undergo up-sampling through convolution of 3 × 3 × 3. A skip-layer with concatenation is implemented which feeds the feature map from corresponding block in encoder to attention gate. The attention gate suppresses the irrelevant features and noise as per the standard methodology16. The gated feature is then concatenated to the transposed block in the analysis. A final 1 × 1 × 1 convolution is performed in the last layer of the decoder path to produce the image with selected number of classes. Categorical cross entropy is used as the loss function for validation. To identify the best hyperparameters, we performed multiple trainings (epoch = 1000) using stable and cyclic learning rates (rate = 0.0001) for number of blocks = 2 and 3 and number of filters = 16, 32, 48, 64. As a result, 16 models were trained.
Second, we investigated the 3D full-resolution configuration of nnU-Net which is also a patch-based 3D U-Net. nnU-Net automatically generates the segmentation pipeline specific to the dataset through its three major domains: fixed, rule-based, and empirical parameters, which handles all the preprocessing, training and postprocessing for the datasets14. Unlike our in-house architecture, the nnU-Net automatically selects the hyperparameter that is suitable for a dataset. Figure 1C shows an example of nnU-Net architecture which was used to train the model in section. A patch size of 192 × 192 × 48 with a batch size of 2 is input to the architecture with 5 layers, 2 blocks, and 32 filters. In the encoder, there is a convolution of 3 × 3x × 3 followed by Intensity Normalization (IN) and a 2 × 2 × 2 max pooling. In the decoder, blocks undergo up-sampling using the same mechanism as described for the 3D U-Net. Data augmentation was performed automatically as described in the nnU-Net guidelines14. Combined DSC and cross-entropy are used as the loss function.
To identify the best architecture, we trained two models, one based on the patch U-Net (MpaU-Net) and one based on the nnU-Net (MnnU-Net) to predict the segmentation of segments 1, 2, 3, 4, and 5–8. Models were trained for five-fold cross validation using ensemble approach in both architectures. In MpaU-Net, majority vote and STAPLE algorithm from Simple ITK v2.2.1 was implemented to select the best result from five folds. In MnnU-Net, the default configuration of nnU-Net (average ensembling) was used14. Quantitative and statistical analysis were performed (as per Sect. “Data analysis”) to select the best architecture model, MBest-Architecture.
Uncertainty improvement-impact of vessels and spleen
We investigated if the uncertainties in the definition of liver segment boundaries can be improved by incorporating two additional features in the training.
First, we trained a model (\({{\text{M}}}_{{\text{vess}}}\)) using \({{\text{M}}}_{{\text{Best}}-{\text{Architecture}}}\) (from Block 1) to investigate if the incorporation of vessels during the training would improve the segmentation of the liver segments. We began by generating liver vessels using the liver vessel generation algorithms23 available in a commercial treatment planning system (RayStation v12.0.110.72, RaySearch Laboratories, Stockholm, Sweden) on \({{\text{C}}}_{{\text{RT}}}\) (N = 200). The binary label map of vessels was added as an extra input channel using modality function in nnU-Net, and the model was trained to predict the contours of liver segments. Second, we trained a model (\({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\)) using \({{\text{M}}}_{{\text{Best}}-{\text{Architecture}}}\) (from Block 1) to determine if the addition of spleen contours during the training would result in improved segmentation of liver segments, especially segments 2 and 3. The training was optimized to predict the contours of the liver segments (with segments 5–8 combined) and spleen.
Last, we individually compared the performance of the models \({{\text{M}}}_{{\text{ves}}}\) and \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) with our best architecture model \({{\text{M}}}_{{\text{Best}}-{\text{Architecture}}}\) to determine if individual features improved the segmentation performance. Additionally, we compared \({{\text{M}}}_{{\text{vess}}}\) and \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) models to determine if one features would result in greater impact on segmentation. To select a single best model (\({{\text{M}}}_{{\text{Best}}-{\text{Model}}})\), all the model comparisons were performed on the external validation set \({{\text{C}}}_{{\text{RT}}}{\text{val}}\) using quantitative and qualitative assessment described in Sect. “Quantitative analysis” and “Qualitative analysis”. After the optimal model was selected, all models were evaluated on all test sets to determine if the optimal model ranking was held in the test environment.
Training, validation and test set for model creation
Our framework includes training, validation, and test sets. As shown in Fig. 1A, CRT was used for training and validation, and CLS, CCH, CPVE were used for test set. CRT datasets were split into training (N = 160), and validation (N = 40) by randomizing planning and 3 month follow up images of patients. The optimization of models during training was performed using cross entropy and dice as a loss function (see Sect. “Manual and AI edited segmentations” for more details). Hyperparameters were tuned manually and automatically according to architecture as described in Sect. “Manual and AI edited segmentations”. All models in our study were trained for 1000 epochs and with five-fold cross-validation. All models were evaluated on both validation (\({{\text{C}}}_{{\text{RTVal}}}\)) and test sets (\({{\text{C}}}_{{\text{LS}}}, {{\text{C}}}_{{\text{CH}}}, {{\text{C}}}_{{\text{PVE}}}\)). While the main purpose of validation set was to select the best model, the assessment of models on test set was used to further establish the discrimination among the model performance.
Table 2 shows the labels used in the study and data separation for training, validation, and test across the models.
Assessment of the models on patients withheld from training/validation
Assessment of the final model on the liver surgery patients
To assess the accuracy of the models in clinical practice, we retrospectively obtained 33 CT scans of patients for whom the segment volume was assessed to determine the eligibility of the patient for liver surgery. AI predicted contours from each model were quantitatively and qualitatively evaluated as per Sect. “Qualitative analysis”.
Assessment of the models on challenge datasets
This test set was developed by randomly selecting 25 CT images from each cohort \({{\text{C}}}_{{\text{IRCAD}}-01}, {{\text{C}}}_{{\text{IRCAD}}-02}, {{\text{C}}}_{{\text{MID}}},\) and \({{\text{C}}}_{{\text{CHAOS}}}\). A radiologist (MA) contoured the liver segments and spleen on each CT. The liver segment and spleen contours generated by all of the models were qualitatively and quantitatively compared with the ground-truth contours.
Assessment of the models on post-portal vein embolization images
This test set was developed by obtaining 20 patients who received Portal vein embolization at our institution. This analysis's main purpose was to quantify the model's performance in presence of liver hypertrophy and metallic artifacts. All images included some form of metallic artifacts due to embolization coil. AI predicted contours from all models were assessed against the ground-truth using both quantitative and qualitative analysis.
Perturbation analysis of the model using non-contrast images
Here, we investigated the adaptability of our models on the perturbed images of patients using non-contrast images which is one of the clinical scenarios. We randomly selected CECT images of 20 patients used in training and then obtained their corresponding pre-contrast CT (i.e., non-CECT) images from the same four-phase liver CT protocol examination. To generate the ground-truth contours of liver segments, we first contoured the whole liver on the both CECT and non-CECT using our deep-learning based model24, and then performed whole liver based biomechanical deformable image registration using an algorithm previously validated25,26. We used models \({{\text{M}}}_{{\text{Best}}-{\text{Architecture}}}\) and \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) to predict the liver segments and spleen.\({{\text{M}}}_{{\text{vess}}}\) was not assessed because non-contrast images lack the vessels in the image. Further, no qualitative analysis was performed due to absence of vessel information on the image. In addition to quantitative metrics mentioned in Sect. “Qualitative analysis”, mean distance to agreement (MDA) was also evaluated to further quantify the adaptability of our model when presented with perturbation.
Data analysis
Quantitative analysis
The performance of the model was evaluated on all validation (N = 40), entire test (N = 78 total) and perturbation sets (N = 20) using Sorenson-DSC similarity coefficients (DSC), average Hausdorff Distance (HDA), 95th Percentile Hausdorff Distance (HD95), Percent Difference in the Volume (PDV).
For further comparison, we calculated the individual DSC differences (\({{\text{DSC}}}_{{{\text{M}}}_{1}-{{\text{M}}}_{2}}\)) between the corresponding cases of models of interests using Eq. (1a) and binned the results in [0.025, 0.05), [0.05, 0.1), and [0.1, 1) under respective models based on the sign (Eq. (1b)). Lastly, the ratio of the frequency of cases within each bin from two models of interests was used to evaluate the models (Eq. (2)).
where \({{\text{M}}}_{1}\) and \({{\text{M}}}_{2}\) are two models of interests and could be any models from {\({{\text{M}}}_{{\text{paU}}-{\text{Net}}}, {{\text{M}}}_{{\text{nnU}}-{\text{Net}}}, {{\text{M}}}_{{\text{vess}}}, {{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\)}. \({{{\text{N}}}_{{\text{M}}}}_{1}\) and \({{{\text{N}}}_{{\text{M}}}}_{2}\) are number of cases from each model meeting the criteria in Eq. (2). All parameters discussed above were assessed for segmentations corresponding to the models in Table 2.
Qualitative analysis
Unipolar Likert scale survey on the scale of 1–5 was performed by radiologists to evaluate the contours from various datasets. To avoid the inherent biasness in observer, the assessments were performed by two radiologist who did not participate in delineating any contours in our study. A radiologist (SY) evaluated the contours of all models on \({{\text{C}}}_{{\text{LS}}}\) and \({{\text{C}}}_{{\text{CH}}}\). Another radiologist (US) evaluated the contours of all models on \({{\text{C}}}_{{\text{RTVal}}}\) and \({{\text{C}}}_{{\text{PVE}}}\). Likert scoring criteria with the definition of rating is shown in the Table 3 below.
Intra- and inter-observer analysis
We selected 10 images that were used in our model training. Radiologist MA contoured the segments twice in the gap of two weeks and relative inter-observer variability in DSC was estimated. Additionally, another radiologist, JAMS, contoured the liver segments on the same patients, and relative interobserver variability in DSC were calculated with respect to the contours of MA.
Statistical analysis
Wilcoxon signed-rank test was performed to determine if the models were statistically different (p < 0.05). For comparison involving more than 2 models, Bonferroni correction was performed to adjust the p-values.
Results
Selection of best architecture
The best tuned hyperparameters for paU-Net were obtained for the model with 3 blocks and 64 filters. This model showed highest validation DSC of 0.75 and a low difference between training and validation DSC of 0.14 among all paU-Net models.
In paU-Net’s ensembling method comparison, the majority vote and STAPLE based contours showed overall similar mean DSCs of 0.86 and 0.87, respectively. However, when we compared minimum DSC of segments altogether, STAPLE showed improvement of 0.052 or 5.2% on average (see Table S1). Additionally, our visual assessment revealed that the majority vote contours had increased zero voxels at the boundaries of segments compared to STAPLE results (see Fig. S1). Therefore, we selected STAPLE based prediction as our final ensembling method for \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\).
Table 4 shows the volumetric and overlap metric comparison between the results of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\). \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) showed overall mean (average of median) DSC of 0.87 (0.87) and 0.89 (0.92), respectively, when assessed across all segments. The individual mean DSC values of \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) for segments 1, 2, 3, and 4 were greater than that of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) by 0.03, 0.04, 0.02, and 0.05, respectively. The ratio of number of cases meeting binned differences (Eq. (3)) i.e., \({{\text{f}}}_{{{\text{M}}}_{{\text{nnU}}-{\text{Net}}}:{{\text{M}}}_{{\text{paU}}-{\text{Net}}}}\) was > 3 for segments 2, 3, and 5–8 and were > 10 for segments 2 and 4 (see Table S2 for details). Additionally, \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) demonstrated lower mean and median HD95 values than \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) for each segment. The difference in mean and median HD95 between \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) were within 1 mm for all segments except segment 4 where the differences were 16.3 mm (mean) and 2.7 mm (median), with \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) having superior performance. PDV comparison showed that differences in mean and median were mostly within \(\pm\) 1.5% with few exceptions; segment 1 showed differences of − 5.3% and − 3.2% for mean and median, respectively, with \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) having superior performance, segment 2 showed − 5.8% (mean) and segment 4–3.9%(mean), with \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) having superior performance. Statistically, Wilcoxon signed-rank showed that performance difference of the models were significant for DSC values of all segments with \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) having superior performance. Further, except segments 2 and 5–8 in \({{\text{HD}}}_{{\text{A}}}\) and \({{\text{HD}}}_{95}\), all other metrics/segments showed statistical significance in the comparison. Lastly, as per the qualitative assessment (Table 5), 99% of cases from \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) received an overall score \(\ge\) 3 whereas 88% of cases from \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) received an overall score of \(\ge\) 3. Considering the better agreement with \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) qualitatively and quantitatively, we selected nnU-Net as the best architecture, i.e. \({{\text{M}}}_{{\text{Best}}-{\text{Architecture}}}={{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\). Hereafter, \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) is also used to represent the best architecture which is nnU-Net model trained with segments only.
Impact of vessels and spleen on segment contouring/selection of best model
Tables 5 and 6 shows the comparison of models \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\), \({{\text{M}}}_{{\text{vess}}}\), and \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) using quantitative and qualitative approach described in Sects. “Quantitative analysis” and “Qualitative analysis”, respectively. For \({{\text{M}}}_{{\text{vess}}}\) vs.\({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\), \({{\text{M}}}_{{\text{vess}}}\) showed DSC values of 0.89 (mean) and 0.91 (average of median), which are similar to mean DSC of 0.89 and average of median DSC of 0.92 of \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\). Individual DSC difference (\({{\text{M}}}_{{\text{vess}}}- {{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\)) were within -0.01 (mean) for segments 2, 3, 4, 5–8 and − 0.02 (median) for segments 2 and 4. All other segments had mean and median DSC difference of 0. \({{\text{f}}}_{{\text{M}}_{{\text{vess}}}:{{\text{M}}}_{{\text{nnU-Net}}}}\) was \(\le 1:3 (0.33)\) (see Table S3 for details) for all except segment 5–8 where the ratio was 1:1. With regard to \({{\text{HD}}}_{{\text{95}}}\), the difference in mean and median values (\({{\text{M}}}_{{\text{vess}}}- {{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\)) were within \(\pm 1mm\) for all cases except mean values of segments 3, 4, and 5–8 where the differences were 2.6 mm,1.50 mm, and 1.67 mm, respectively. Additionally, the overall differences in the mean and median PDV values were within \(\pm 2.5\%.\) Most of the differences were \(>0\), indicating a reduction in performance for \({{\text{M}}}_{{\text{vess}}}\). Qualitatively, the difference between the cases of \({{\text{M}}}_{{\text{vess}}}\) and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) receiving score \(\ge\) 3 is within 1% in all segments except segments 2 and 3 where \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) leads by 3% and 5% respectively. Overall, the metrics of \({{\text{M}}}_{{\text{vess}}}\) were equivalent or slightly worse than of that of \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\).
In \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) vs.\({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\), \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) showed DSC values of 0.89 (mean) and 0.91 (average of median) which are similar to mean DSC of 0.89 and average of median DSC of 0.92 of \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\). Individual DSC difference between (\({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}- {{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\)) were 0 for all segments except the median of segment 4 where \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\)>\({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) by 0.01. \({{\text{f}}}_{{{\text{M}}}_{{{\text{seg+spleen}}}}:{{\text{M}}}_{{\text{nnU-Net}}}}\) was negligible or 1:1) (see Table S4 for details). The difference in the mean and median \({{\text{HD}}}_{{\text{95}}}\) of the two models were negligible (range = − 0.62 to 0.01 mm). Lastly, the difference in the mean and median PDV of the two models ranged from -1.7% to 0.6%. Qualitatively, the difference between percent of cases receiving score \(\ge\) 3 across two models were within 1% except segment 5–8 where \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) led by 5%. Overall, the results from two models were equivalent.
Lastly, the Wilcoxon signed-rank test showed that \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) were not significantly different in their metrics (p > 0.05). Comparison of \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) with \({{\text{M}}}_{{\text{vess}}}\) showed no significance in most cases with few exceptions (see footer of Table 7). Furthermore, \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) showed better agreement than \({{\text{M}}}_{{\text{vess}}}\) in terms of \({{\text{HD}}}_{{\text{95}}}\). Therefore, in overall comparison, we establish that \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\sim {{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}} >{{\text{M}}}_{{\text{vess}}}\). We selected \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) as our best model due to its wider application as the mean/median DSC of spleen is 0.99.
Assessment of the models on the liver surgery patients
Table 7 shows the results from quantitative assessment of our models on the pre-surgery CTs. The mean and average of median DSC values of \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) across all segments were 0.91 and 0.92, respectively, and those for spleen were 0.91 and 0.96. Individually, the mean and median DSCs of all segments from \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) were \(\ge 0.90\) except segment 2 where median and mean DSC were 0.86 and 0.85, respectively. With regards to distance metrics, segment 2 from \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) showed a mean and median \({{\text{HD}}}_{95}\) values of 8.5 mm and 9.4 mm which was the highest among all other segments. The best \({{\text{HD}}}_{95}\) were obtained in case of segment 1 with mean and median values of 2.8 mm and 3.2 mm. Additionally, spleen showed mean \({{\text{HD}}}_{95}\) of 2.2 mm. With regard to volumetric comparison, \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) vs radiologist ground-truth contours, the overall mean and average median values across all segments were 8.2% and 5.6%. Likewise, mean and median PDV for spleen were within 2%. Lastly, stratification of DSC based on the cancer type showed no performance change in segments (\(\pm\) 1%) but spleen of CC (N = 5) showed 2% lesser DSC than CRM (N = 22) cases.
In comparison to \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\), \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{vess}}}\) showed poor performance in case of segment 1 as mean DSC of \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) were greater than other two models by 7% and 6%, respectively. On segment 3 and 4, \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) outperformed \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) by 2% and 5%, respectively. Moreover, the mean DSC value of \({{\text{M}}}_{{\text{Vess}}}\) was around 5% less that other models on segments 2, 3, and 4 which supports that vessels architectures and segments 2 and 3 boundary are sensitive to each other. The mean DSC of other three models were within 2% of one another. With regards to HD, \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) showed the largest HD but all other models showed similar performance.
Qualitatively, regarding \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\), 97% of segments showed a score \(\ge 3\) with 69% showing a score of \(\ge 4\) and 27% showing a score of 5. Individually, at least 64% of each segment showed a score of 4 or more. Segments 1, 4, and 5–8 received higher scores than segments 2 which is highlighted by the lower value of 15% (score of 5) in Table 5. Compared with other models, contours from \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) included 14% more cases of Likert score \(\ge 3\) than \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\). However, the other two models received similar scores as the \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\).
Assessment of the models on challenge datasets
Tables 6 and 8 shows the results from quantitative and qualitative assessment of all models on the challenge dataset (CCH). With regards to the best model (\({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\)), both overall mean and median DSC values of segments were 0.87. The individual mean and median DSC values were \(\ge\) 0.96 for segment 5–8 and spleen whereas the mean/median DSC for segments 1, 2, 3, 4 ranged 0.80 to 0.88. Segment 2 had the lowest mean and median DSCs of 0.80. For distance metrics, segment 1 and spleen had a mean and median \({{\text{HD}}}_{95}\) within 5 mm which was better than all other segments. The largest mean and median \({{\text{HD}}}_{95}\) values were \(\ge 10\) mm which was observed in the segment 2. Lastly, the overall mean and average median PDV were 11% and 9.5% for segment and 2% for spleen. Largest PDVs were observed in segment 2 with mean/median of 19%. Lastly, since the cancer types of challenge datasets are not available, we could not perform stratified DSC analysis. Comparatively, both \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{Vess}}}\) showed mean and median DSC/HD95/PDV within 1%/1 mm/2% of our best model. On the other hand, \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) showed mean and median HD95/PDV of 5 mm/6% higher than the that of the best model.
Qualitatively, 100% of cases in \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) received an overall Likert score \(\ge\) 3 with more than 80% received score \(\ge\) 4. Lower Likert scores were localized to segments 2 and 3 contours. Regarding other models, Likert scores of \({{\text{M}}}_{{\text{Vess}}}\) and \({{\text{M}}}_{{\text{Seg}}}\) showed similar trend as the \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\). In contrast, the percentage of cases of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) receiving score \(\ge\) 3 was 64% with only 20% showing overall score \(\ge\) 4. Lastly, more than 97% of spleen from \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) received score \(\ge\) 4.
Assessment of the models on post-portal vein embolization images
As per Table 9, \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) showed mean and median DSCs ≥ 0.87 for all segments and spleen except segment 2 where the mean and median DSCs were 0.82 and 0.80 in the case of segment 2. Furthermore, segments 2, 3, 4, 5–8, showed mean/median DSCs \({{\text{HD}}}_{95}\)≥7 mm. Segment 1 and Spleen showed mean/median \({{\text{HD}}}_{95}\) within 5 mm. Mean and median PDVs of segments 1, 3, 4, 5–8 were within 10% but that of segment 2 was ≥ 15%. The stratified DSC analysis using cancer types showed CC (N = 3) larger DSC CRM (N = 17) by 2 to 4%. With regards to other models, all of the models showed mean and median DSCs within 1% of \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) with the exception of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) in case of segment 4 where DSCs were less than that of \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) by 7%. Similar trends were observed in \({{\text{HD}}}_{95}\) with the exception of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) showing mean \({{\text{HD}}}_{95}\) up to 18% in the case of segment 5–8. Except \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\), PDVs of all models were within 4% of one another. Mean PDVs of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) were greater than that of \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) by 16%.
Qualitatively, at least 90% of cases received a score \(\ge 3\) and at least 85% received a score of \(\ge 4\) across all models in each segment with the exception of segment 4 and 5–8. For segments 4 and 5–8, only 5% and 10% cases of \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) received score \(\ge\) 4 whereas at least 25% cases of \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) received score \(\ge\) 4. Additionally, a score ≥ 3 was received by more than 45% of cases of segment 5–8 across all models. Lastly, all cases of spleen received a score of 5. Examples of Likert scores with the specific images are shown in Fig. 2.

Example cases of three different Likert score (5, 4, and 3) is shown for two different cohorts. Blue arrow highlights the uncertainties in boundaries between the manual and model predicted contours. For score 4 and 3 in the images of \({{\text{C}}}_{{\text{PVE}}}\), the arrow highlights the hole in segment 5–8 due to metal artifacts. In \({{\text{C}}}_{{\text{PVE}}}\), a score of 4 is given when image has a hole, but segments boundaries follow the vessels.
Assessment of the model on non-contrast images
As per Table 10, \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) showed mean and median DSCs \(\ge\) 0.83 across all segments and spleen with the exception of segment 1 and 2 where the mean DSCs were 0.70 and 0.78 respectively. Further, mean, and median \({{\text{HD}}}_{95}\) were \(\ge 5{\text{mm}}\) across all segments but spleen showed \({{\text{HD}}}_{95}\) <5 mm. Segment 1 showed a mean and median PDVs of 18% and 30% which was the largest PDV compared to other segments. Next, The mean MDA ranged from 1.6–3.6 mm for segments and was 1.3 mm for spleen.
\({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\), showed similar performance as \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\), across all metrics in all segments. Specifically, the agreement between the models were within 2%, 1.5 mm, and 3% and 0.2 mm in terms of DSC, \({{\text{HD}}}_{95}\), PDV, and MDA, respectively, with \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) showing underperformance. On the other hand, \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) showed slightly improved performance than \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) and \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) in case of segment 1 and 2. Specifically, mean DSC of segment 1 from \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) was greater than that of \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) by 8%. Similarly, mean DSC of segment 2 from \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) was greater than that of \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) by 5%. However, such magnitude of discrimination was not observed in segment 1 and 4 in terms of \({{\text{HD}}}_{95}\). \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) showed mean \({{\text{HD}}}_{95}\) greater than that of other two models by 10 mm and 6 mm in case of segments 1 and 4, respectively. Likewise, the mean PDV were larger than two models by 9% for segment 4. Additionally, \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) showed MDA was within 1 mm for all segments when compared with the \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\).
No \({{\text{M}}}_{{\text{Vess}}}\) model was trained, and no qualitative evaluation was performed because there is no vessel information on the non-CECT images.
Intra- and inter-observer analysis
The intraobserver mean DSCs on contours drawn by radiologist MA were of 0.88, 0.88, 0.94, 0.92, and 0.99 in segments 1, 2, 3, 4, 5–8, respectively. Likewise, the interobserver mean DSCs in between the contours drawn by radiologists JAMS and MA were 0.82, 0.85, 0.91, 0.88, and 0.96, respectively.
Discussion
In this study, we have developed a clinically translatable model that can be used to auto-contour the liver segments and spleen on abdominal CT images. We validated all models on a validation set (\({{\text{C}}}_{{\text{RTVal}}}\)) of 40 CECT of patients with primary and metastatic liver tumors to identify the best model. We also assessed all models on various test sets (N = 78) shown in Fig. 1. First, we demonstrated that 3D full resolution architecture of nnU-Net outperformed 3D attention U-Net (paU-Net) by 2–5% in DSC across all liver segments. We also investigated the impact of adding segmentation of the vessels and spleen to aid in segmenting the liver segments and observed no major performance change between the models. Our final model can segment liver segments 1, 2 ,3 ,4 and 5–8 and the spleen with an average mean DSC of 0.89 and 0.99 across liver segments and spleen, respectively. We demonstrated that our model can be used in the clinical environment for surgical planning (mean DSC = 0.91) and for PVE patients (overall Likert score \(\ge 4\) for 95%). To our knowledge, this is the first study to develop a single model to contour liver segments and spleen which is validated across primary/secondary liver cancers patients and across both contrast and non-contrast images.
Our final model is applicable in four clinical scenarios. First, the model can be used to auto-contour the segments of liver surgery patients where it can aid in estimating the volumetric change due to PVE and in overall resection planning, demonstrating an accuracy of 5.6% in overall median volume. Second, the model can be used to auto-contour liver segments in patients undergoing RT for liver cancer as studies5,27,28 have highlighted the importance of understanding liver segment regeneration for the optimization of RT plans. Third, the volume estimation from the model can be used in the prediction of cirrhosis and fibrosis as studies have reported that segment-volume ratio are significant predictors of cirrhosis/fibrosis18,29. Last, for the pathologies leading to hepatosplenomegaly, our model can be used to segment liver and spleen with higher accuracies in the case where segment 2 and 3 is abutted with spleen. Once our model is fully translated in the clinic, the utilization of model will allow improve efficiency, as the model can generate all its structure in 30–75 s per patient. The required time is very efficient compared to 90 min required in manual segmentation at our clinic and up to three minutes required in some of the semi-automatic segmentation methods30.
With regard to technical results, our first major observation was in the comparison of STAPLE vs. majority vote where we hypothesized that STAPLE > majority vote. This was confirmed based upon visual assessment that all 40 images in test set from \({{\text{C}}}_{{\text{RT}}}\) has at least one slice with increased zero valued pixel at the segment demarcation than STAPLE. The observation was expected because STAPLE assigns the label based on the probability values compared to a majority voting in SimpleITK (used in our study), which utilizes frequency of label which could lead to large number of undecided pixels. Second, in our architecture selection study, we observed that the nnU-Net architecture was superior with the paU-Net architecture demonstrating over segmentation of segment 1 including volume of segments 4, 5–8, and inferior venacava, and under segmentation in segment 3 with volume classified as segments 2 and 4. This could be due to less options in data augmentation in paU-Net than nnU-Net which greatly impacted the performance in the cases where vessel defining the segment boundaries deviated from the majority of the training data. Lastly, the paU-Net often failed to accurately contour segment 4, typically failing at the interface of the portal vein. The nnU-Net did not suffer from this uncertainty and therefore the accuracy improvement for segment 4 was the most significant, compared to the paU-Net model.
With regard to improvement in uncertainty, the statistical test showed no differences in models when spleen were added to the best architecture model. Specifically, in \({{\text{C}}}_{{\text{RT}}}\), for \({{\text{M}}}_{{\text{vess}}}\mathrm{ vs }{{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\), 91% of the cases showed DSC differences within [-0.025,0.025]. The cases where DSC differences were larger (\({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\)>\({{\text{M}}}_{{\text{vess}}}\)) corresponded to errors in \({{\text{M}}}_{{\text{vess}}}\) due to over segmentation of segment 3 to segment 2 in two cases, over segmentation and under segmentation of segments 5–8 over 4 in one case. Similar trends were observed for \({{\text{M}}}_{{\text{vess}}}\mathrm{ vs }{{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\), to suggest a preference for \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\). However, most of the contrast in performance was observed in segment 1, 2, and 4 (Table S5). In \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) vs. \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\), we argued \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) was similar to \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) (Table 7 and Table S4), however, we selected \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) because of slightly improved performance. Quantitatively, we observed in Table 7 that descriptive statistics of the results were similar except segment 5–8 of \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) where minimum DSC and maximum \({{\text{HD}}}_{95}\) improved by 0.05 and ~ 9 mm upon addition of spleen. Upon qualitative assessment of those cases, the improvement in \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) was due to lesser under segmentation of segment 5–8 compared to \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\). Next, our validation set included N = 8/40 cases of segment 2 and 3 hypertrophy. In N = 7/8, there was no difference in segment 2 and 3 i.e., both models showed reasonable segmentation without any over or under segmentations. In N = 1/7, \({{\text{M}}}_{{\text{nnU}}-{\text{Net}}}\) showed under segmentation of segment 2 next to spleen but segmentations from \({{\text{M}}}_{{\text{seg}}+{\text{spleen}}}\) were improved on the same slices. Although our hypothesis that including the spleen in the model would be better than one without spleen was not supported because both models showed reasonable performance on cases with segment 2/3 hypertrophy we still selected model with spleen as our final model as this model has wider application and can be also used to estimate the severity of cirrhosis/fibrosis if needed in the patient undergoing liver surgery or RT.
\({{\text{M}}}_{{\text{seg}}+\mathrm{spleen }},\) the final model showed excellent performance on the \({{\text{C}}}_{{\text{LS}}}\) patients for all segments except segment 2 where mean DSC was 0.85 and mean \({{\text{HD}}}_{95}\) was 9.4 mm. Furthermore, the subjective analysis showed that except segment 2/3, more than 70% of all cases received overall score \(\ge 4\) on Likert score. This is likely due to the uncertainties in the boundary of segment 2/3. While the uncertainties are primarily attributed to performance of the model, it is also important to note that the opacification of the veins plays a great role in the ability of radiologist to evaluate the segmentation. The radiologist (SY) reported that N = 16/33 images were arterial phase images leading to a reduced confidence level in the evaluation of the contours as the portal venous branches are not well opacified and localized on the arterial phase images. Additionally, the visual assessment also showed that 5/33 of \({{\text{C}}}_{{\text{LS}}}\) showed holes or under segmentation in segment 5–8 due to photon starvation from metal artifact of the embolization coil/stent (N = 4/5) and tumor hole (N = 1/5).Furthermore, another N = 2/33 cases showed holes and under segmentation in segment 4 due to photon starvation from metal artifacts. Lastly, we observed slightly lower DSC in CC compared to CRM primarily because of portal hypertension in CC which could lead to enlarged spleen and could affect the contour performance. This was supported when obtained a difference of 13 cc between mean volume of both cancer types. Comparatively, since our final model showed better DSC in the case of CC opposed to HCC by approximately 2%, it could be argued that the severity of underlying disease which affects liver texture on CT across different cancer types could also impact vessels and hence the contours. Therefore, one would expect a DSC performance trend of colorectal metastasis patients > Cholangiocarcinoma > Hepatocellular carcinoma. However, since the number of patients in Cholangiocarcinoma in \({{\text{C}}}_{{\text{LS}}}\) is smaller (5 vs. 22), we cannot state a robust conclusion. In comparison with other models, our best model outperformed paU-Net and vessel-based model mostly on segment 1, 4 and 2, 3, 4, respectively but not on segment 5–8. This could be because segment 5–8 is the largest structure which means it is less sensitive to change in the vessel structures and includes more features. This requires lesser optimization in the model which means model less robust models such \({{\text{M}}}_{{\text{paU}}-{\text{Net}}}\) could also show better performance.
Next, in \({{\text{C}}}_{{\text{CH}}},\) \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) showed overall mean DSC of 0.87 which was smaller than the observed results on the \({{\text{C}}}_{{\text{LS}}}\) and \({{\text{C}}}_{{\text{RT}}}{\text{Val}}\) sets. Specifically, poor results were confined to segment 1 thru 4. The reason behind such observation was uncertainties in the boundaries of the segments in most of the cases. The images in challenge dataset also include cases with large and multiple tumors in the which could potentially lead to vessel occlusion and/or unremarkable opacification of the vessels on CT scans. Further, upon visual assessment, N = 4/25 cases of \({{\text{C}}}_{{\text{CH}}}\) showed under and over segmentation. Specifically, N = 3/4 showed under segmentation in segment 2, 4, and 5–8 dues to tumor and diseases, and N = 1/4 segment showed over segmentation to heart.
In \({{\text{C}}}_{{\text{PVE}}}\), we observed that the overall mean DSC of segments was 0.87 which is primarily because of poor performance in the segment 2. Upon visual assessment, we found N = 20/20 images showed inconsistency between the segment 2–3 boundary of ground-truth and prediction. The boundary of segments 2 and 3 is dictated by the portal veins in the left liver, and the architecture of those veins exhibit higher variation across patient population due to disease in liver. Another reason is segmental hypertrophy which could result in under and over segmentation of a specific segments. The volume of segment 2 from our best model in \({{\text{C}}}_{{\text{PVE}}}\) is 148 \(\pm\) 73 cc and the ground-truth volume of normal liver from CHAOS dataset is 88 \(\pm\) 36 cc which supports there is hypertrophy of segment 2. Next, regarding the effect of metallic artifacts, we found that N = 17/20 patients of \({{\text{C}}}_{{\text{PVE}}}\) had embolization coils spanning segment 5–8 and 4 with mostly localized in segment 5–8. N = 2/17 were immune from the impact of metal artifacts. However, in the remaining N = 15/17, both segments 4 (N = 3/15) and 5–8 (N = 15/15) showed holes in contours due to photon starvation arising from metal artifacts. This was expected because our training dataset did not include patients undergoing portal vein embolization. Lastly, the stratified DSC analysis for different cancer types showed the model performed better on CC (N = 3) patients than CRM (N = 17) patients by 2–4% which is not consistent with our observation in the \({{\text{C}}}_{{\text{RTVal}}}\).
Next, in the perturbation analysis, we observed that \({{\text{M}}}_{{\text{Seg}}+{\text{Spleen}}}\) was still better than the other two models in terms of DSC, HD95, and PDV across all segments except segment 1 and 2. In segment 1, and 2, \({{\text{M}}}_{{\text{paUNet}}}\) showed slightly better performance (p < 0.05). However, this was contradicted when we assessed the MDA which was higher for \({{\text{M}}}_{{\text{paUNet}}}\). Therefore, we attribute the observation of DSC for segment 1 mostly because of attention mechanism due to absence of contrast and randomness in the data. Overall, we argue that our best model could be potentially used on non-contrast images of same examination in clinic for segments 3, 4, 5–8 and spleen. For segments 1, and 2, minimum interventions from radiologist would be required to correct the contours. Lastly, since the non-contrast images are hardly used to discriminate tumor types, we did not perform stratified DSC analysis on non-contrast cases.
Comparing the performance of final model across validation and various test sets in Tables 6, 7, 8 and 9, we found that model performs best on \({{\text{C}}}_{{\text{LS}}}\) as evidenced by improved segment mean DSC (2–6%) than other cohorts. This could be attributed to the fact that surgery patients have less severe pathologies (e.g., surgery is typically a first-line therapy for smaller tumors) and minimal fewer artifacts than patients undergoing radiotherapy or portal vein embolization or patients in challenge cohorts. Further, we also observed that mean segmental DSC of \({{\text{C}}}_{{\text{RTVal}}}\) and \({{\text{C}}}_{{\text{LS}}}\) were slightly better than \({{\text{C}}}_{{\text{CH}}}\) and \({{\text{C}}}_{{\text{PVE}}}\). Specifically, while performance in segment 1 is within mean DSC of 2% across the datasets, segments 2, 3, and 4 showed lesser mean DSCs (up to 6%) which is attributed to fact that \({{\text{C}}}_{{\text{CH}}}\) dataset has larger and numerous tumors, larger slice thickness. For segment 5–8, \({{\text{C}}}_{{\text{PVE}}}\) showed lesser mean DSC by 3–5% due to presence of under segmentation or holes in segment 5–8 arising from metallic artifacts.
Considering the above analysis, our study has three limitations (1) segmentation of combined segments 5–8, (2) failure of the model on segments with metal artifacts, and (3) uncertainty in the segment 2 and 3 boundaries. For (1), clinical practice for surgical planning dictated our segmentation selection and the combination of segments 5–8. In addition, in our experience, there is substantial variability in the manual contouring of these segments individually. For (2), the issue can be addressed by manually editing the failed contours in the cases with severe photon starvation and increasing the number of such cases in our training datasets. For the last issue, we could implement post-processing methods to automatically optimize the boundary of segment 2 and 3. In our clinic, the segmental boundaries are separated based on the branching of portal veins and the regions above the left portal vein branch are segment 2 whereas regions below the left portal vein branches are segment 331. We can use our in-house tool to generate liver vessels on CT scans in post-processing phase23 and also implement vessel enhancements and active contour methods, as reviewed by Ciecholewski et. al. 202132, to further enhance the vessels at the periphery of segment 2 and 3. Despite the limitations, our model performs comparable or improved accuracy in comparison with studies as shown in Table 11. Tian et al. 2019 reported the mean values across all segments and our results are in close agreement with their result, In comparison with Lee et al. 2022, our model demonstrated superior results on \({{\text{C}}}_{{\text{LS}}}\) in all segments (except segment 2) by 3–30%. For segment 2, our model showed inferior results by up to 6% which is attributed to the variability in the boundaries of the segments 2 and sensitivity of our model to the vessel architecture. Another reason is the difference in the underlying pathology of the literature compared to our datasets. Lee et al. 202218 assessed their model performance on the patients with hepatitis C and cirrhosis, however, our \({{\text{C}}}_{{\text{LS}}}\) is dominantly CRM and CC patients (see Table 1). The severity of cancer is also known to cause cavernous transformation of the vessels which also leads to uncertainties in the segment 2 contours.
Conclusion
In this study, we developed and validated to a clinically acceptable accuracy, a fully automated model that can auto-contour liver segments and spleen on CECT images. We found that implementing the attention mechanism in 3D U-Net did not improve the performance when compared with the 3D full-resolution nnU-Net. We also identified that the addition of segmenting the vessels and spleen did not have large impact on accuracy of segment contours. The application of the model is primarily intended for use with patients undergoing assessment for liver surgery or liver radiotherapy, but the model can be used in any clinical scenario where there is a need for segment contouring on CECT. Upon assessing our model on patients undergoing portal-vein embolization, we conclude that contouring is significantly impacted by presence of metallic artifacts leading to holes in the contours. However, inclusion of such patients in the training may improve performance in the future. Lastly, with regard to non-contrast images, we conclude that our final model can contours segments with accuracies sufficient enough for clinical use with review and possibly moderate interventions from radiologist.
Data availability
The 3D-IRCADb-01 data can be accessed at https://www.ircad.fr/research/data-sets/liver-segmentation-3d-ircadb-01/. The 3D-IRCADb-02 dataset can be accessed at https://www.ircad.fr/research/data-sets/respiratory-cycle-3d-ircadb-02/. The task 8 Medical Imaging Decathlon Challenge dataset can be accessed at http://medicaldecathlon.com/dataaws/. The CHAOS dataset can be accessed at https://chaos.grand-challenge.org/Download/. The internal liver CT data used during our study are available upon reasonable request in compliance with instuitutional IRB requirements.
References
Sung, H. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71(3), 209–249 (2021).
Akgül, Ö. et al. Role of surgery in colorectal cancer liver metastases. World J. Gastroenterol. 20(20), 6113–6122 (2014).
Clavien, P.-A. et al. Strategies for safer liver surgery and partial liver transplantation. N. Engl. J. Med. 356(15), 1545–1559 (2007).
Guglielmi, A. et al. How much remnant is enough in liver resection?. Dig. Surg. 29(1), 6–17 (2012).
Jabbour, S. K. et al. Upper abdominal normal organ contouring guidelines and atlas: A radiation therapy oncology group consensus. Pract. Radiat. Oncol. 4(2), 82–89 (2014).
Vorwerk, H. et al. Protection of quality and innovation in radiation oncology: The prospective multicenter trial the German Society of Radiation Oncology (DEGRO-QUIRO study). Evaluation of time, attendance of medical staff, and resources during radiotherapy with IMRT. Strahlenther Onkol. 190(5), 433–43 (2014).
Bernhard, P. & Charl, B. Chapter 4—Image analysis for medical visualization. In Visual Computing for Medicine 2nd edn (eds Bernhard, P. & Charl, B.) 111–175 (Elsevier, 2014).
Chen, W. et al. Deep learning vs. atlas-based models for fast auto-segmentation of the masticatory muscles on head and neck CT images. Radiat. Oncol. 15(1), 176 (2020).
Wang, R. et al. Medical image segmentation using deep learning: A survey. IET Image Process. 16(5), 1243–1267 (2022).
Litjens, G. et al. A survey on deep learning in medical image analysis, medical image analysis. Med. Image Anal. 42, 60–88 (2017).
Çiçek, Ö., et al. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. Preprint at https://arXiv.org/quant-ph/1606.06650 (2016).
Cardenas, C. E. et al. Auto-delineation of oropharyngeal clinical target volumes using 3D convolutional neural networks. Phys. Med. Biol. 63(21), 215026 (2018).
Rigaud, B. et al. Automatic segmentation using deep learning to enable online dose optimization during adaptive radiation therapy of cervical cancer. Int. J. Radiat. Oncol. Biol. Phys. 109(4), 1096–1110 (2021).
Isensee, F. et al. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18(2), 203–211 (2021).
Yu, C. et al. Multi-organ segmentation of abdominal structures from non-contrast and contrast enhanced CT images. Sci. Rep. 12(1), 19093 (2022).
Oktay, O., et al. Attention U-Net: Learning Where to Look for the Pancreas. Preprint at https://arXiv.org/quant-ph/1804.03999 (2018).
Tian, J., et al., Automatic Couinaud Segmentation from CT Volumes on Liver Using GLC-UNet. Springer Nature Switzerland.
Lee, S. et al. Fully automated and explainable liver segmental volume ratio and spleen segmentation at CT for diagnosing cirrhosis. Radiol. Artif. Intell. 4(5), e210268 (2022).
Soler, L., et al. 3D image reconstruction for comparison of algorithm database: A patient specific anatomical and medical image database. [cited 2023; https://www.ircad.fr/research/data-sets/liver-segmentation-3d-ircadb-01/ (2010).
Antonelli, M. et al. The medical segmentation decathlon. Nat. Commun. 13(1), 4128 (2022).
Kavur, A. E. et al. CHAOS challenge—Combined (CT-MR) healthy abdominal organ segmentation. Med. Image Anal. 69, 101950 (2021).
Kavur, A. E. et al. Comparison of semi-automatic and deep learning-based automatic methods for liver segmentation in living liver transplant donors. Diagn. Interv. Radiol. 26(1), 11–21 (2020).
Cazoulat, G. et al. Detection of vessel bifurcations in CT scans for automatic objective assessment of deformable image registration accuracy. Med. Phys. 48(10), 5935–5946 (2021).
Anderson, B. M. et al. Automated contouring of contrast and noncontrast computed tomography liver images with fully convolutional networks. Adv. Radiat. Oncol. https://doi.org/10.1016/j.adro.2020.04.023 (2020).
He, Y. et al. Optimization of mesh generation for geometric accuracy, robustness, and efficiency of biomechanical-model-based deformable image registration. Med. Phys. 50(1), 323–329 (2023).
Brock, K. K. et al. Accuracy of finite element model-based multi-organ deformable image registration. Med. Phys. 32(6), 1647–1659 (2005).
Su, T.-S. et al. A prospective study of liver regeneration after radiotherapy based on a new (Su’S) target area delineation. Front. Oncol. https://doi.org/10.3389/fonc.2021.680303 (2021).
Polan, D. F. et al. Implementing radiation dose-volume liver response in biomechanical deformable image registration. Int. J. Radiat. Oncol. Biol. Phys. 99(4), 1004–1012 (2017).
Bezerra, A. S. et al. Determination of splenomegaly by CT: Is there a place for a single measurement?. AJR Am. J. Roentgenol. 184(5), 1510–1513 (2005).
Zhang, Q. et al. An efficient and clinical-oriented 3D liver segmentation method. IEEE Access 5, 18737–18744 (2017).
Ryu, M. & Cho, A. New Liver Anatomy: Portal Segmentation and the Drainage Vein (Springer, 2009).
Ciecholewski, M. & Kassjański, M. Computational methods for liver vessel segmentation in medical imaging: A review. Sensors 21, 2027. https://doi.org/10.3390/s21062027 (2021).
Acknowledgements
Research reported in this publication was supported in part by Pauline Altman-Goldstein Discovery Fellowship, Helen Black Image Guided Fund, Image Guided Cancer Therapy Research Program at The University of Texas MD Anderson Cancer Center, a generous gift from the Apache Corporation, National Cancer Institute of the National Institutes of Health under award numbers R01CA221971 and R01CA235564, Tumor Measurement Initiative through the MD Anderson Strategic Initiative Development Program (STRIDE), National Cancer Institute of the National Institutes of Health under award number 1P01CA261669 and National Institutes of Health/NCI under award number P30CA01667.
Author information
Authors and Affiliations
Contributions
All authors in this manuscript have adequately contributed to the research to be an author on this manuscript. A.C.G., G.C., B.C.O., A.K.J., E.J.K., and K.K.B. participated in the research design and data collection. M.A. performed manual contouring of liver segments and spleen on contrast enhanced CT images. S.Y. directed the manual contouring and evaluated the quality of AI predicted contours. U.S. and J.A.M.S. performed qualitative evaluation and segment contouring, respectively. B.R. and C.Y. contributed to development of infrastructures for model training. A.C. and J.W. helped in model deployment and streamlining the workflow. M.M. contributed to data collection. A.C.G. wrote the manuscript. All authors reviewed and edited the manuscript before submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gupta, A.C., Cazoulat, G., Al Taie, M. et al. Fully automated deep learning based auto-contouring of liver segments and spleen on contrast-enhanced CT images. Sci Rep 14, 4678 (2024). https://doi.org/10.1038/s41598-024-53997-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-53997-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
