
Abstract
We compared the prediction performance of machine learning-based undiagnosed diabetes prediction models with that of traditional statistics-based prediction models. We used the 2014–2020 Korean National Health and Nutrition Examination Survey (KNHANES) (N = 32,827). The KNHANES 2014–2018 data were used as training and internal validation sets and the 2019–2020 data as external validation sets. The receiver operating characteristic curve area under the curve (AUC) was used to compare the prediction performance of the machine learning-based and the traditional statistics-based prediction models. Using sex, age, resting heart rate, and waist circumference as features, the machine learning-based model showed a higher AUC (0.788 vs. 0.740) than that of the traditional statistical-based prediction model. Using sex, age, waist circumference, family history of diabetes, hypertension, alcohol consumption, and smoking status as features, the machine learning-based prediction model showed a higher AUC (0.802 vs. 0.759) than the traditional statistical-based prediction model. The machine learning-based prediction model using features for maximum prediction performance showed a higher AUC (0.819 vs. 0.765) than the traditional statistical-based prediction model. Machine learning-based prediction models using anthropometric and lifestyle measurements may outperform the traditional statistics-based prediction models in predicting undiagnosed diabetes.
Similar content being viewed by others
Introduction
The Diabetes Fact Sheet in Korea 2020 from the Korean Diabetes Association reported that the prevalence of type 2 diabetes (hereafter “diabetes”) in Korean adults aged ≥ 30 years in 2018 was 13.8% (approximately 4.9 million)1. However, detecting diabetes is challenging, given the asymptomatic state at an early stage of diabetes. Consequently, many cases of diabetes are not diagnosed until after one’s diabetes complications have deteriorated2, and the optimal timing of diabetes treatment is often delayed3,4.
Therefore, it is imperative to identify an easy and accessible diabetes prediction at an early stage to effectively treat and manage diabetes and prevent its complications. Growing evidence has suggested some diabetes prediction models using “non-invasive” data, including sociodemographic, clinical, and key health characteristics (e.g., age, waist circumference [WC], family history of diabetes, smoking status, alcohol consumption, and resting heart rate [RHR])5,6. Based on the magnitude of the relationships between candidate diabetes risk factors and diabetes, there are some (early stage) diabetes prediction models using either a self-report survey using the diabetes risk score (DRS)7,8 or applying various algorithms from a machine learning perspective9,10.
In Korea, diabetes prediction models have been established using data from the Korean National Health and Nutrition Examination Survey (KNHANES) and the Korean Genome and Epidemiology Study. However, the previous Korean diabetes prediction models were limited by (1) insufficiently high (i.e., 0.74 to 0.765) the receiver operating characteristic curve area under the curve (AUC) in the models5,6 and (2) low accessibility, given that the models used blood lipid profiles (e.g., fasting glucose, glycated hemoglobin [HbA1c], triglyceride, and total cholesterol)11,12. Furthermore, Jang et al. suggested a previous diabetes prediction model13 may be valid in a specific condition only when adjusting for the proportion of diabetic vs. non-diabetic individuals at 1:1. Additionally, some research was at high risk of “overfitting” because the external validity of models was not examined given that the “training and internal validation set” and “external validation set” were not properly differentiated14.
To fill the knowledge gap in the literature, the objective of this study was to compare the performance of machine learning (ML)-based prediction models and traditional statistics (TS)-based prediction models using non-invasive, highly accessible clinical variables (e.g., age, sex, anthropometry, family history of diabetes, lifestyle behaviors). We hypothesized that the prediction performance of the ML-based undiagnosed diabetes prediction models would be superior to that of the TS-based undiagnosed diabetes prediction models.
Methods
Study population (undiagnosed diabetes)
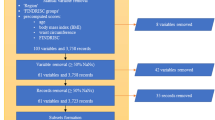
We used the data from the Korean National Health and Nutrition Examination Survey (KNHANES), which is an ongoing nationwide cross-sectional health and nutrition survey, to examine the health status of Koreans and to monitor trends in health risk factors and prevalence of major chronic diseases in Korea15. The details of the KNHANES have been described elsewhere15. Among individuals who participated in the 2014–2020 KNHANES (N = 113,091), we excluded those who were (1) aged < 19 or ≥ 80 years (N = 28,421); (2) diagnosed with diabetes (N = 11,337); and (3) missing data on predictor variables (N = 40,163; e.g., physical activity, family history of diabetes, WC, smoking status, RHR, sleep time, body mass index, alcohol consumption). Therefore, a total of 32,827 participants were examined. Figure 1 presents a flow chart of the study participants’ inclusion process.

Flowchart of the study data set.
Prediction algorithms and comparison between machine learning-based diabetes prediction model vs. traditional statistics-based diabetes prediction model.
We created ML-based prediction models based on the five ML classification algorithms: logistic regression, Random Forest30, Light Gradient Boosting Machine (Light GBM)31, Extreme Gradient Boosting (XG Boost)32, and Adaptive Boosting (AdaBoost)33. We compared the ML-based and TS-based prediction models using the previously developed diabetes prediction models5,6. These TS-based prediction models5,6 employed the previously established diabetes risk score8 and included easily accessible and publicly available clinical data from KNHANES, including sex, age, WC, family history of diabetes, hypertension status, smoking status, alcohol consumption, and/or RHR. Specifically, to compare ML-based prediction models and TS-based prediction models, we reproduced previous diabetes risk score models5,6 and compared their performance on the same external validation set. We compared ML-based prediction models and TS-based prediction models in four different sets of variables: (1) sex, age, WC, and RHR6; (2) sex, age, WC, hypertension status, alcohol consumption, smoking status, and family history of diabetes5; (3) sex, age, WC, hypertension status, alcohol consumption, smoking status, family history of diabetes, and RHR6; (4) in addition to the variables used in previous studies, features (i.e., predictor variables; e.g., physical activity, sleep time, and body mass index) that can maximize prediction performance were selected using the feature selection algorithm of machine learning. We utilized several methods of feature selection, including the Shapley value method46, the Recursive Feature Elimination Cross-Validation method47, and the Permutation feature selection method48. These approaches were employed to identify and include the main variables commonly selected across the different methods in our analysis. AUC was used to compare the prediction performance of the ML-based and the TS-based prediction models. We used the Hanley and McNeil’s methods16 to test the significant difference between the two AUC scores derived by the ML-based and TS-based prediction models.
Measures
Target variable (undiagnosed type 2 diabetes)
Undiagnosed diabetes was previously defined and described6. Briefly, participants with fasting glucose ≥ 126 mg/dL or HbA1c ≥ 6.5% yet had not been diagnosed or under any diabetes treatments, were considered undiagnosed diabetes.
Features (predictor variables)
The methods of measurement have been previously described in detail. RHR was measured as a radial pulse in the right arm for 15 s after resting for 5 min in a seated position, and then multiplied by 4 and used as an RHR (beats/min). Age (years), family history of diabetes (yes, no), hypertension status (yes, no), smoking status (yes, no), and alcohol consumption (< 1, 1–4.9, 5 drinks/day) were measured using a general questionnaire administered by trained medical staff and interviewers. WC (cm) was measured at the narrowest point between the lower borders of the rib cage and the uppermost borders of the iliac crest at the end of a normal breath, using a standard protocol. The measurements of other features such as waist-to-height ratio (WHtR), body mass index (kg/m2), total physical activity (work-related, leisure-time, walking; metabolic equivalent task/week), and sleep time (h/day) are described in Supplemental Table 1.
Strategies for building diabetes prediction models
Figure 2 shows the process of building a diabetes prediction model. We combined the KNHANES data from 2014 to 2020, and the 2014–2018 data (N = 23,369) were used as the training and internal validation sets and the 2019–2020 data (N = 9,458) as the external validation set. We then performed fivefold cross-validation using the training and internal validation sets to select an optimal prediction algorithm, hyper-parameters, and features, and to reduce the variance of the prediction performance (generated by the distribution of data when the data were randomly divided) to prevent overfitting of the model17,18. For the cross-validation, we used “Stratified Cross-Validation”19 after adjusting for the proportion of undiagnosed diabetes in each cross validation set. In the cross-validation process20, first, the prediction model was trained using the “Training set” and the performance of the trained model was examined using the “Internal validation set,” which was not included in the ‘Training set’. Second, we estimated the mean AUC values of the prediction performance level from the mutually exclusive 5 “Internal validation sets” after five iterations. Third, we selected the best prediction algorithm (when the estimated average of the AUC level was highest from the five internal validation sets), hyperparameters, and features for the prediction model. For reference, we utilized the Optuna framework41, which automates the search for the most effective hyperparameter configuration. Optuna offers a user-friendly and adaptable interface for defining search spaces, specifying the objective function for optimization, and choosing optimization algorithms41. Fourth, the highest mean AUC of the prediction model within the “Internal validation set” was validated using the 2019–2020 data (“external validation set”) and was compared with the TS-based Korean diabetes prediction models using risk scores5,6.

Conceptual schematic for prediction model building and performance evaluation.
Evaluation for the prediction performance of diabetes prediction models
We evaluated the performance of the diabetes prediction models using AUC, sensitivity, specificity, Youden index, positive predictive value (PPV), negative predictive value (NPR), positive likelihood ratio (PLR), and negative likelihood ratio (NLR). In general, the cutoff value of prediction models for predicting diabetes is determined when the Youden index (sensitivity + specificity − 1) is the highest21. However, considering the purpose of this study, we excluded the cutoff value of the highest Youden index (when sensitivity was low, and specificity was high) and determined the optimal cutoff value of the prediction model for diabetes when the sensitivity was greater than 80% and the specificity was greater than 50% (when the Youden index was highest).
Shapely additive explanation (SHAP) analysis for interpretable ML models
Unlike traditional statistical methods, ensemble learning22,23, a type of ML algorithm (e.g., bagging and boosting) used in this study, is combined with multiple prediction models. Consequently, the prediction performance is superior to that of a single prediction model owing to the ensemble effect from combining multiple models24. However, it is difficult to clearly examine the features that contribute to prediction results25. To address this limitation, we adopted SHAP26,27, which is a leading unified framework for interpreting the decision-making process of ML models and prediction results28,29. For reference, SHAP analysis operates by assigning significance values, referred to as Shapley values (which represent the importance of each feature; positive values indicate a positive contribution), to the input features of a machine learning model. These values elucidate the extent to which each feature contributes to the model's prediction for a given instance26,27.
Statistical analysis
We used Python version 3.8.8. to develop ML-based models and SPSS version 25.0 (Inc., Chicago, IL) for descriptive statistics, which includes frequency distributions and variability, were used to present the characteristics of the study participants. Differences between the non-diabetic and undiagnosed diabetes groups were examined using the t-test or chi-square test, as appropriate. The statistical difference of AUC between prediction models was examined using Hanley and McNeil’s methods16.
Ethics approval and consent to participate
This study uses information disclosed to the public and was exempted from deliberation because it uses existing data that has already been generated information about the study subjects.
Results
Participant characteristics stratified by data split (training & internal validation, and external validation sets) are shown in Table 1. Participants with undiagnosed diabetes (vs. non-diabetes) were more likely to be older and smokers, have higher body weight, body mass index, WC, RHR, WHtR, systolic and diastolic blood pressures, hypertension, more family history of diabetes, and greater alcohol consumptions (all P < 0.001) in both the “training & internal validation set” and “external validation set.” Furthermore, participants diagnosed with diabetes were more likely to be older and have a family history of diabetes and hypertension than participants with undiagnosed diabetes (all P < 0.05). For additional reference, the participant characteristics stratified by non-diabetes, undiagnosed diabetes, and diagnosed diabetes are presented in Supplemental Table 1.
The prediction performance comparison between the ML-based diabetes prediction model and TS-based prediction model6 using sex, age, WC, and RHR is presented in Table 2. In the external validation set, the AUC and Youden index of the TS-based prediction model developed by Park et al.6 were 0.740 (95% CI 0.721–0.759) and 35.0 respectively. Because the Random Forest showed the highest mean prediction performance in the training and internal validation sets, it was selected when four features (i.e., sex, age, WC, and RHR) were included in the model. In the external validation set, the AUC and Youden index of the ML-based prediction model were 0.788 (95% CI 0.722–0.804), 44.0, respectively. The AUC of the ML-based prediction model was significantly higher than that of the TS-based prediction model (P = 0.008).
A comparison between the ML-based and TS-based diabetes prediction models5 using sex, age, WC, family history of diabetes, alcohol consumption, smoking status, and hypertension status is presented in Table 3. In an external validation set, the AUC and Youden index of the TS-based prediction model developed by Lee et al.5 were 0.759 (95% CI 0.741–0.777), and 36.0 respectively. Because XGBoost showed the highest mean prediction performance in the training and internal validation sets, XGBoost was selected when seven features (i.e., sex, age, WC, family history of diabetes, alcohol consumption, smoking status, and hypertension status) were included in the model. In the external validation set, the AUC and Youden index of the ML-based prediction model were 0.802 (95% CI 0.787–0.817), and 44.4 respectively. The AUC of the ML-based prediction model was significantly higher than that of the TS-based prediction model (P = 0.015).
A comparison between the ML-based diabetes prediction model and the TS-based prediction model5 using sex, age, WC, family history of diabetes, alcohol consumption, smoking status, hypertension status, and RHR is presented in Table 4. In the external validation set, the AUC and Youden index of the TS-based prediction model developed by Park et al.6 were 0.765 (95% CI 0.738–0.792) and 42.0 respectively. Since LightGBM showed the highest mean prediction performance in the training & internal validation sets, LightGBM was selected when eight features (i.e., sex, age, WC, family history of diabetes, alcohol consumption, smoking status, hypertension status, and RHR) were included in the model. In the external validation set, the AUC and Youden index of the ML-based prediction model were 0.811 (95% CI 0.796–0.826) and 48.3, respectively. The AUC of the ML-based prediction model was significantly higher than that of the TS-based prediction model (P = 0.008).
In addition to the aforementioned features from previous TS-based diabetes prediction models5,6, the feature selection algorithm determined a total of 11 features (previous features plus four additional features: body mass index, WHtR (replacement of WC), physical activity, and sleep time). A comparison between the ML-based diabetes prediction model and TS-based diabetes prediction models5,6 using these 11 features is presented in Table 5. In the external validation set, LightGBM (the highest prediction performance in the training & internal validation sets) showed the highest prediction performance. The AUC and Youden index of this ML-based prediction model were 0.819 (95% CI 0.805–0.833) and 47.4, respectively. The AUC of the ML-based prediction model was significantly higher than that of the TS-based prediction model (P = 0.001).
Figure 3 shows the highest 3 AUC of the ML-based diabetes prediction models and the model with the highest AUC among the previous TS-based diabetes prediction models developed by Park et al. 6 .

AUC Comparison of machine learning prediction models and risk score model.
After validating the prediction performance, we used SHAP framework26,27. Figure 4 shows the SHAP summary results of the top three machine-learning-based models. The SHAP values differed slightly among the prediction algorithms. The WHtR, age, hypertension status, body mass index, family history of diabetes, sex, and RHR were selected as important features with a high contribution to the detection of undiagnosed diabetes. According to the SHAP value, as the WHtR, age, body mass index, and RHR values increased, the probability that the prediction model predicted the participant to have diabetes increased. The contribution of lifestyle features (e.g., alcohol consumption, physical activity, sleep time, and smoking status) to the prediction results was relatively small compared with the anthropometric measures (e.g., WHtR, age, body mass index, and RHR). The lower the levels of physical activity and sleep time and the higher the work physical activity, the higher the probability of being diagnosed with undiagnosed diabetes. In the case of categorical features, the probability of predicting undiagnosed diabetes using the prediction model was higher in male, having a family history of diabetes, hypertension, current smoking, and high alcohol consumption.

SHAP summary plot of the top 3 prediction models: contribution and effect of each feature.
Discussion
We compared the prediction performance of the ML-based prediction models with that of the TS-based diabetes prediction models with an external validation set in a large representative sample of Korean adults, using self-reported clinical data. Our findings suggest that ML-based diabetes prediction models, regardless of the number of features used in developing models, were superior to TS-based prediction models5,6 using the diabetes risk score method8. When the feature selection method was employed in our ML-based model, the AUC was 0.819, which was better than the highest AUC (0.765) among TS-based models6.
Some assumptions explain why the ML-based diabetes prediction models used in this study were superior to the TS-based prediction models. First, the ML methods we used in our study were bagging34 and boosting35 algorithms22, which developed multiple prediction models, aggregated to determine the final prediction result. Since the final prediction result is determined by voting for various prediction results, an unbiased prediction result can be obtained23,36. Compared with a single prediction model, these methods result in a more accurate prediction34,35,36,37,38,39. Second, when compared to the ML-based approach, the TS-based approach5,6,8 is challenging for researchers to develop prediction models by considering all possible cases that may result from multiple features and algorithms. In contrast, an ML-based method can select the optimal features to maximize the prediction performance using feature selection algorithms40. In addition, by using hyperparameter tuners such as Optuna41 and Hyperopt42, it is possible to determine how many single prediction models are combined to develop a final prediction model to maximize prediction performance while avoiding overfitting. Our findings suggest that diabetes prediction models developed by the ML-based method may be more time-efficient, cost-effective, and superior to the previous TS-based method.
For these reasons, there is growing evidence for the application of the ML-based approach and artificial neural network, a type of ML, to develop prediction models for diabetes11,12,14,43,44. However, these prediction models11,12,43 may be less accessible because they were developed using blood lipid variables (e.g., fasting glucose, HbA1c, triglyceride, and total cholesterol). In addition, another study14 using XGBoost, an algorithm similar to our approach, reported a high AUC score of 0.92. However, this prediction model14 may be at high risk of overfitting45 given that the prediction model was developed without using the ‘external validation set’. In addition, the prediction performance of this model14 was not assured, given that there was no verified result for unseen data. On the other hand, our ML-based prediction model developed using non-invasive data may be more accessible. Furthermore, the external validity of our prediction model was tested from the external validation set and we used the SHAP analysis to determine the predictive power of each predictor (feature) and to generate explainable models, while the previous artificial neural network prediction model for undiagnosed diabetes44, deemed a black-box model, using non-invasive data (e.g., age, WC, body mass index, sex, smoking status, hypertension, and family history of diabetes) did not validate their model through the application of SHAP analysis.
In addition, the aforementioned prediction models only mentioned the prediction performance and did not explain the importance or effect of the features that contributed to the prediction results. Therefore, it was impossible to interpret the prediction models used in these studies. To address this limitation, the ML-based prediction model of this study calculated the contribution and effect of each feature using SHAP and presented it to interpret its prediction results. Additionally, the sensitivity of our prediction model using age, WC, and RHR was 83.3%, which may be sufficiently valid.
This study has several limitations. First, given the nature of the cross-sectional study design, we could not determine causality between the features and undiagnosed diabetes. Thus, future studies on diabetes prediction models should employ longitudinal cohort data to examine the temporal relationships between features and incident diabetes. Additionally, RHR is highly affected by sleep quality, smoking status, alcohol consumption, and/or major health characteristics; therefore, interpretation should be made with caution. Lastly, findings cannot be generalized to wider populations given that our study examined Korean data only. Thus, additional research with racially/ethnically diverse population data is needed to confirm our preliminary findings.
In conclusion, our study suggests that ML-based undiagnosed type 2 diabetes prediction models may improve the prediction performance of TS-based prediction models and methods. The continuous increase in the number of diagnosed and undiagnosed diabetes epidemics is a major public health concern. The study findings will inform public health researchers and healthcare professionals to apply efficient new diabetes prediction models for the prevention of diabetes and its adverse health consequences. A clear next step in future research is to identify our preliminary findings in a different setting of data with wider populations in order to better generalize the findings.
Data availability
All data generated or analyzed during this study are included in this published article and are available from the Korean National Health & Nutrition Examination Survey repositories.
Abbreviations
- WC:
-
Waist circumference
- WHtR:
-
Waist to height ratio
- RHR:
-
Resting heart rate
- DRS:
-
Diabetes risk score
- KNHANES:
-
Korean National Health and Nutrition Examination Survey
- ROC:
-
Receiver operating characteristic
- AUC:
-
Area under the ROC curve
- ML:
-
Machine learning
- TS:
-
Traditional statistics
- PPV:
-
Positive predictive value
- NPV:
-
Negative predictive value
- PLR:
-
Positive likelihood ratio
- NLR:
-
Negative likelihood ratio
- SHAP:
-
Shapely additive explanation
- LightGBM:
-
Light gradient boosting machine
- XGBoost:
-
Extreme gradient boosting machine
- AdaBoost:
-
Adaptive boosting
- Bagging:
-
Bootstrapping and aggregating
References
Jung, C. H. et al. Diabetes fact sheets in Korea, 2020: An appraisal of current status. Diabetes Metab. J. 45, 1–10 (2021).
DECODE Study Group on behalf of the European Diabetes Epidemiology Study Group. Will new diagnostic criteria for diabetes mellitus change phenotype of patients with diabetes? Reanalysis of European epidemiological data. BMJ 317, 371–375 (1998).
Kim, S. R. The effects of diabetes self-awareness on diabeteic patients' subjective health level [Master's dissertation]: Ajou University (2013).
Harris, M. I. et al. Prevalence of diabetes, impaired fasting glucose, and impaired glucose tolerance in US adults: The Third National Health and Nutrition Examination Survey, 1988–1994. Diabetes Care 21, 518–524 (1998).
Lee, Y. H. et al. A simple screening score for diabetes for the Korean population: Development, validation, and comparison with other scores. Diabetes Care 35, 1723–1730 (2012).
Park, D. H., Cho, W., Lee, Y. H., Jee, S. H. & Jeon, J. Y. The predicting value of resting heart rate to identify undiagnosed diabetes in Korean adult: Korea National Health and Nutrition Examination Survey. Epidemiol. Health. 44, e2022009 (2022).
Franciosi, M. et al. Use of the diabetes risk score for opportunistic screening of undiagnosed diabetes and impaired glucose tolerance: The IGLOO (Impaired Glucose Tolerance and Long-Term Outcomes Observational) study. Diabetes Care 28, 1187–1194 (2005).
Lindstrom, J. & Tuomilehto, J. The diabetes risk score: A practical tool to predict type 2 diabetes risk. Diabetes Care 26, 725–731 (2003).
Hasan, M. K., Alam, M. A., Das, D., Hossain, E. & Hasan, M. Diabetes prediction using ensembling of different machine learning classifiers. IEEE Access. 8, 76516–76531 (2020).
Naim, I., Singh, A. R., Sen, A., Sharma, A. & Mishra, D. Healthcare CHATBOT for diabetic patients using classification. Soft Comput. Theor. Appl. 479, 427–437 (2022).
Ha, K. H. et al. Development and validation of the Korean diabetes risk score: A 10-year national cohort study. Diabetes Metab. J. 42, 402–414 (2018).
Lim, N. K., Park, S. H., Choi, S. J., Lee, K. S. & Park, H. Y. A risk score for predicting the incidence of type 2 diabetes in a middle-aged Korean Cohort-the Korean genome and epidemiology study. Circ J. 76, 1904–1910 (2012).
Jang, J. S., Lee, M. J. & Lee, T. R. Development of T2DM prediction model using RNN. J. Digt. Converg. 17, 249–255 (2019).
Kim DH, Jwa MK, Lim SJ, Park SM, Joo JW. A study on the prediction algorithm of diabetes based on XGBoost: Data from the 2016~2018 Korea National Health and Nutrition Examination Survey. J. Korean Inst. Commun. Inf. Sci. (Abstract). 965–6 (2021).
Kweon, S. et al. Data resource profile: the Korea national health and nutrition examination survey (KNHANES). Int. J. Epidemiol. 43, 69–77 (2014).
Hanley, J. A. & McNeil, B. J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 148, 839–843 (1983).
Moore, A. W. Cross-validation for detecting and preventing overfitting. School Comput Sci Carneigie Mellon University (2001). http://www.autonlab.org/tutorials/overfit10.pdf
Santos, M. S., Soares, J. P., Abreu, P. H., Araujo, H. & Santos, J. Cross-validation for imbalanced datasets: avoiding overoptimistic and overfitting approaches [research frontier]. IEEE Comput. Intell. Mag. 13, 59–76 (2018).
Zeng, X. & Martinez, T. R. Distribution-balanced stratified cross-validation for accuracy estimation. J. Experim. Theor. Aftif. Intell. 12, 1–12 (2000).
Browne, M. W. Cross-validation methods. J Math Psychol. 44, 108–132 (2000).
Fluss, R., Faraggi, D. & Reiser, B. Estimation of the Youden Index and its associated cutoff point. Biom. J. 47, 458–472 (2005).
Dietterich, T. G. Ensemble methods in machine learning. Mult. Classif. Syst. 1–15 (2000).
Bühlmann, P. Bagging, Boosting and Ensemble Methods. In Handbook of Computational Statistics 985–1022 (Springer, 2012).
Bauer, E. & Kohavi, R. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants. Mach. Learn. 36, 105–139 (1999).
Watson DS et al. Clinical applications of machine learning algorithms: beyond the black box. BMJ. 364 (2019).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process Syst. 30, 4768–4777 (2017).
Lundberg, S. M., Erion, G. G., & Lee, S.I. Consistent individualized feature attribution for tree ensembles. Preprint at https://arxiv.org/abs/1802.03888v3 (2018).
Yang, J. Fast TreeSHAP: Accelerating SHAP Value Computation for Trees. Preprint at https://arxiv.org/abs/2109.09847 (2021).
Ribeiro, M. T., Singh, S., & Guestrin, C. Model-agnostic interpretability of machine learning. Preprint at http://arxiv.org/abs/1606.05386 (2016)
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 30, 3146–3154 (2017).
Chen, T., & Guestrin, C. Xgboost: A scalable tree boosting system. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. Preprint at https://arxiv.org/abs/1603.02754 (2016).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comp. Syst. Sci. 55, 119–139 (1997).
Breiman, L. Bagging predictors. Mach Learn. 24, 123–140 (1996).
Schapire, R. E. The strength of weak learnability. Mach. Learn. 5, 197–227 (1990).
Sutton, C. D. Classification and regression trees, bagging, and boosting. Handbook Statist. 24, 303–329 (2005).
Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 33, 1–39 (2010).
Sagi, O. & Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 8, 1249 (2018).
Opitz, D. & Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 11, 169–198 (1999).
Chandrashekar, G. & Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 40, 16–28 (2014).
Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2623–2631 (2019).
Bergstra, J., Yamins, D., & Cox, D. D. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference SciPy, 13–19 (2013).
Dinh, A., Miertschin, S., Young, A. & Mohanty, S. D. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med. Inform. Decis. Mak. 19, 1–15 (2019).
Ryu, K. S. et al. A deep learning model for estimation of patients with undiagnosed diabetes. Appl. Sci. 10, 421 (2020).
Hawkins, D. M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 44, 1–12 (2004).
Marcílio, W. E., & Eler, D. M. From explanations to feature selection: assessing SHAP values as feature selection mechanism. In Proceedings of the 2020 33rd SIBGRAPI Conf Graph Patterns Images (SIBGRAPI). 340–347 (2020).
Misra, P. & Yadav, A. S. Improving the classification accuracy using recursive feature elimination with cross-validation. Int. J. Emerg. Technol. 11, 659–665 (2020).
Altmann, A., Toloşi, L., Sander, O. & Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 26, 1340–1347 (2010).
Funding
This study was funded by Yonsei Signature Research Cluster Program of 2022-22-0010.
Author information
Authors and Affiliations
Contributions
S.G.C., D.-H.P. and J.Y.J. contributed to the study ideation and design. S.G.C. and M.O. contributed to drafting of the manuscript and verification of statistical methods. S.G.C., M.O, and B.L. contributed to the overall review of machine learning methodology and data analysis. S.G.C. and M.O. contributed equally to this work as first authors. All autohros read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Choi, S., Oh, M., Park, D. et al. Comparisons of the prediction models for undiagnosed diabetes between machine learning versus traditional statistical methods. Sci Rep 13, 13101 (2023). https://doi.org/10.1038/s41598-023-40170-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-40170-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
