
Abstract
Widespread, debilitating and often treatment-resistant, depression and other stress-related neuropsychiatric disorders represent an urgent unmet biomedical and societal problem. Although animal models of these disorders are commonly used to study stress pathogenesis, they are often difficult to translate across species into valuable and meaningful clinically relevant data. To address this problem, here we utilized several cross-species/cross-taxon approaches to identify potential evolutionarily conserved differentially expressed genes and their sets. We also assessed enrichment of these genes for transcription factors DNA-binding sites down- and up- stream from their genetic sequences. For this, we compared our own RNA-seq brain transcriptomic data obtained from chronically stressed rats and zebrafish with publicly available human transcriptomic data for patients with major depression and their respective healthy control groups. Utilizing these data from the three species, we next analyzed their differential gene expression, gene set enrichment and protein–protein interaction networks, combined with validated tools for data pooling. This approach allowed us to identify several key brain proteins (GRIA1, DLG1, CDH1, THRB, PLCG2, NGEF, IKZF1 and FEZF2) as promising, evolutionarily conserved and shared affective ‘hub’ protein targets, as well as to propose a novel gene set that may be used to further study affective pathogenesis. Overall, these approaches may advance cross-species brain transcriptomic analyses, and call for further cross-species studies into putative shared molecular mechanisms of affective pathogenesis.
Similar content being viewed by others
Introduction
Stress evokes a wide range of behavioral, molecular and physiological responses1,2,3,4,5,6,7 in vivo, also triggering various affective disorders, including anxiety, depression and post-traumatic stress disorder (PTSD) clinically8,9,10,11. While these neuropsychiatric disorders are widespread, debilitating and often treatment-resistant12,13,14, their understanding is complicated by heterogeneity and unclear pathological mechanisms and risk factors15,16. To address these problems, animal (experimental) models are widely used for studying stress pathogenesis and recapitulating clinical affective disorders17,18,19.
Commonly utilizing various chronic unpredictable stress (CUS) protocols20,21,22,23,24, these experimental models typically involve rodents exposed to varying stressors for several weeks22,24,25,26,27, to evoke anxiety- and/or depression-like ‘affective’ behavioral and physiological alterations28,29,30 that resemble those observed clinically31,32. Recognized as an important novel model organism in the central nervous system (CNS) disease modeling, the zebrafish (Danio rerio) is widely used in translational biomedicine33,34,35,36. Complementing rodent neurobehavioral evidence, zebrafish are also becoming popular in stress research37,38. Their growing utility in this field is supported by the fact that zebrafish are highly homologous to humans both genetically and physiologically39,40, and have evolutionarily conserved neurotransmitter systems41,42 and neuromorphology43,44. Like rodents, zebrafish are currently widely used in modeling stress-related affective disorders45,46,47, typically utilizing various aquatic protocols, assays and tests adapted from those in rodents48,49,50,51,52.
However, all animal models are rather difficult to fully parallel in humans, necessitating novel methods of translating experimental modeling results into clinical setting. Aiming to target ‘core’, evolutionarily conserved pathogenesis, and recognizing the importance of cross-species analyses in CNS research53,54, here we performed an in-depth pilot cross-species/cross-taxon analysis of brain transcriptomic data in zebrafish, rats and humans, in order to identify putative novel ‘shared’ molecular targets for affective CNS disorders evoked by chronic stress.
Results
In general, our study aimed to identify common differentially expressed (DE) genes and/or enriched gene sets in contrasts between (1) human subiculum data from patients with major depressive disorder (MDD, based on DSM-IV criteria) vs. healthy controls available from NCBI's Gene Expression Omnibus (GEO) database55, (2) rat hippocampus samples following chronic unpredictable stress (CUS) vs. unexposed controls, and (3) zebrafish whole-brain CUS-exposed samples versus unexposed controls (see the “Methods” section for details, as well as Supplementary Table S1 and Fig. 1). The study utilized several different methods to establish potential relationships between the species-specific and cross-species data.

Schematic summary of the study design and analyses.
Briefly, Experiment 1 aimed to directly search for common patterns in the differential gene expression data (i.e., identifying DE genes for each species) and in gene set enrichment results (i.e., identifying the enriched sets for each species by analyzing the expression of sets of genes instead of individual genes), searching for similar genes (using orthologues) or gene sets (using Kyoto Encyclopedia of Genes and Genomes, KEGG56) in these data. Additionally, Experiment 1 analyzed the enrichment of DE genes for transcription factors DNA-binding sites (TFBSs) down- and up- stream from their genetic sequences.
Experiment 2 pooled all individual species' raw RNA sequencing (RNA-seq) data by their orthologs, generating combined ‘interspecies' data that were further analyzed for comparison between affective pathogenesis (MDD humans + CUS rats + CUS zebrafish) vs. controls (healthy humans + control rat + control zebrafish data). These data were further processed using the DE and gene set enrichment analyses, similar to Experiment 1.
Experiment 3 applied the Fisher’s meta-analysis approach57 to combine interspecies data. Briefly, the individual species-specific data were first processed using the DE or gene set enrichment analyses (using only the genes that have orthologues in all three species), and then the p-values obtained for each species were further included in Fisher’s meta-analysis57. Finally, Experiment 4 utilized another approach, as we generated protein–protein interaction network for selected identified common/shared genes that have orthologous in all three species. We next analyzed the maximal cliques (MCs, subgraphs in which all nodes are connected to each other, as in58) for this network, and used them as gene sets for further enrichment analysis (similar to other enrichment analyses described above, but using MCs instead of Kyoto Encyclopedia of Genes and Genomes (KEGG)56 sets). These sets were analyzed for enrichment for individual species data first and then further combined into interspecies data using the Fisher’s meta-analysis57.
Overall, Experiment 1 focused on direct species-to-species comparisons of brain gene expression data. Specifically, if some genes were DE in the experiment, we next evaluated whether their respective orthologues appear in another animal species or in clinical data. Utilizing traditional direct two-species comparisons of lists of gene orthologues using Venn diagrams, Experiment 1 revealed 25 DE genes for human subiculum, 47 for rat CUS hippocampus and 196 for zebrafish CUS whole brain samples (Supplementary Tables S1–S3). No orthologous DE genes were identified as shared/common between the species using the HomoloGene database59 (www.ncbi.nlm.nih.gov/homologene, see Fig. 2 and Supplementary Material 2 online). Generally Applicable Gene Set Enrichment (GAGE) analyses60, performed on raw data counts similarly to the DE gene analysis, identified 56 altered KEGG sets in human, 69 in rat, and 32 in zebrafish data (Fig. 2 and Supplementary Tables S4–S6). Sets that were simultaneously altered in all three species include calcium signaling, extracellular matrix-receptor (ECM-receptor) interaction, cell adhesion molecules (CAMs), and neuroactive ligand-receptor interaction KEGG pathways (Fig. 2). Notably, one upregulated set (oxidative phosphorylation) was affected in both rat and zebrafish samples, and two downregulated pathways (spliceosomes and RNA transport) were common between humans and rats.

Venn diagrams for differentially expressed (DE) genes or enriched gene sets (GSEA, gene set enrichment analysis) using similar raw RNA-seq data counts comparing subiculum in human major depressive disorder (MDD) vs. control, hippocampi in rats exposed to chronic unpredictable stress (CUS) vs. unexposed controls, and in zebrafish CUS-exposed vs. unexposed control whole brain samples, using 1:1:1 orthologues from the HomoloGene Map59 (Experiment 1, see the “Methods” section for details). Overall, these direct species-to-species comparisons revealed no common DE genes and very few common DE gene sets.
While traditional DE analyses here yielded no common genes between the three species, studying enrichment of significantly altered genes for transcription factors DNA-binding sites (TFBSs) down- and up- stream from their genetic sequences (see the “Methods” section and61 for details) revealed 291 differentially represented (DR) human, 249 rat and 80 zebrafish TFBSs, with 19 DR TFBSs shared by all three species (Fig. 3 and Supplementary Tables S7–S9).

Summary of common/shared over- and under-represented transcription factors DNA binding sites (TFBSs) among differentially expressed (DE) genes with high (p < 0.01) vs. low (p > 0.7) statistical variability in human, rat, and zebrafish data using the CiiiDer TFMs software61 (Experiment 1). Only TFBSs with both p < 0.05 for gene coverage p-value and p < 0.05 for the distribution of the number of TFBS, were considered significantly altered. TFBSs were sorted by their gene coverage p-value. Data are represented as log2-enrichment values, calculated according to the CiiiDer TFMs manual61.
In general, the results of Experiment 1 show that direct comparisons of gene orthologues may not be an efficient approach to find commonalities in RNA-seq data between species-specific samples. Furthermore, given that TFBSs and GSEA analyses were similar to traditional DE gene analyses, utilizing data for a wide range of genes organized within specific established molecular pathways may be more informative to compare gene expression patterns between species.
Instead of comparing gene expression profiles as a post-hoc analysis, Experiment 2 pooled raw RNA-seq data counts, thus combining the species-specific data prior to any differential expression analysis, aiming to achieve better inter-species data compliance. To globally analyze gene expression data in all three species, we compiled a pooled interspecies list of counts for all their common orthologous genes, using the HomoloGene database map59 (see Supplementary Material 2 and www.ncbi.nlm.nih.gov/homologene), thus generating the combined ‘human MDD + rat CUS + zebrafish CUS' dataset of genes to be compared with the pooled control dataset consisting of control groups from all three species. Using such gene list, Experiment 2 yielded no differences in DE human orthologue genes by comparing stressed vs. normal controls for all three species (NS; p adjusted > 0.05). However, this lack of significant effects was rather unsurprising, given high heterogeneity of species-specific data, and the fact that their Principal Component Analysis (PCA) revealed most main effects as species-specific (Fig. 4). In contrast, our GAGE analysis60 of these data was more sensitive, yielding 91 altered molecular pathways (Supplementary Table S10). Importantly, these findings closely parallel data obtained earlier in Experiment 1 (Fig. 2, Supplementary Tables S4–S6), since all 4 sets (found to be enriched in all three species in Experiment 1) were similarly enriched in Experiment 2 (Fig. 2, Supplementary Tables S4–S6 and S10). Furthermore, among these 4 sets, three sets (Neuroactive ligand-receptor interaction, calcium signaling and ECM-receptor interaction) were the most altered in Experiment 2, supporting their likely high impact on affective pathogenesis in all three species.

The principal component analysis (PCA) of Experiment 2 data, studying cross-species samples mapped using 1:1:1 orthologous map pooled into stress (major depressive disorder, MDD/chronic unpredictable stress, CUS) or control groups. Note high data heterogeneity that prevented direct combining cross-species data here, and the lack of clear separation between the groups in other principal components (PC) studied (data not shown). PC 1—principal component 1, PC 2—principal component 2.
Overall, Experiment 2, similarly to Experiment 1, yielded poor DE gene profiling results, hence calling for other tools to be applied to better combine and analyze the brain gene expression data. In contrast, GSEA was efficient in both Experiments 1 and 2, further supporting high efficiency of this approach to detect commonalities in RNA-seq data.
However, a key methodological issue of GAGE analyses utilized in Experiments 1 and 2 here was its reliance on the pre-set KEGG pathways, that may have no direct connection to affective pathogenesis per se, and can only partially correspond to the observed phenotypes. For example, while the KEGG calcium signaling pathway may relate to some disturbances in depression, it can neither fully explain nor recapitulate the disorder, and some of the genes within this pathway may have no effect on depression pathogenesis. To account for these limitations, Experiment 3 probed the ability of Fisher’s meta-analysis to combine p-values from different experiments (in order to improve data combination). Likewise, Experiment 4 also applied the graph theory-based MC analysis (see further), to obtain set enrichment results for targets that are more functionally related to the affective pathogenesis.
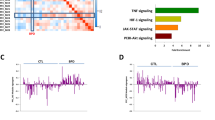
Fisher’s meta-analyses were efficient to compare combined interspecies DE genes' and gene sets enrichment p-values. In summary, examining the potential of Fisher’s meta-analysis57 to compare gene-orthologues data, Experiment 3 yielded 15 human, 29 rat, and 62 zebrafish DE orthologues (Supplementary Tables S11–S13). Fisher’s meta-analysis of these data identified 66 DE genes, including 15 DE genes altered in the same log2 fold change (l2fc) direction in all three species, supporting that they all changed their expression in a similar way across the species (Fig. 5 and Supplementary Table S14). While our GAGE analyses60 revealed 24 altered human, 42 rat and 109 zebrafish pathways (Supplementary Tables S15–S17), their Fisher’s meta-analysis57 identified 112 pathways shared by all three species (Supplementary Table S18).

Heatmap representing log2 fold change of the genes significantly altered according to Fisher’s meta-analysis57 (left panel) or volcano plots for selected genes (right panel) in Experiment 3.
To examine whether Fisher’s meta-analysis data at least partially correspond to direct differentially expressed (DE) gene analyses applied earlier (Experiment 1), we constructed the Protein–Protein Interaction (PPI) network for shared DE genes (identified in Experiment 3) and DR TFBSs (identified in Experiment 1) with high enrichment level (p = 8.31e − 09), using the Search Tool for the Retrieval of Interacting Genes/Proteins (STRING) online database62 (https://www.string-db.org/). Overall, these results support strong inter- and intra-connection between the TFBSs' Experiment 1 and DE meta-analyses' Experiment 3 data (Fig. 6). After ranking all vertices in the PPI networks by the Degree63, BottleNeck64, Betweenness and DMNC||MNC65 approaches (i.e., characterizing their overall ‘hubness’ within the network), we excluded genes with mixed direction (increased or decreased, compared to control) of expression changes in the stressed groups (see the “Methods” section for details), choosing only vertices that were highly ranked by at least two separate graph theory-based methods independently, thus yielding 4 proteins from the TFBS study and two proteins from the meta-analysis study as ‘hub’ vertices (Table 1), including 3 up-regulated or overrepresented (IKZF1, FEZF2, and VWF) and 3 down-regulated or underrepresented proteins (FLI1, ARNT and ERG, Fig. 5, 6).

The network of protein–protein interactions (PPI) constructed for differentially expressed (DE) genes from Experiment 3 or differentially represented (DR) transcription factors (TF) binding sites (TFBSs) from Experiment 1, using the STRING online database62 (https://www.string-db.org/, see the “Methods” section and Fig. 3 and 5 for details).
Experiment 4 aimed to establish novel, functionally more valid (than using the KEGG approach) sets of genes that may better correspond to the pathogenesis of affective disorders. In the graph theory, a clique is a subset of vertices of a graph such that every two distinct vertices in the clique are adjacent (connected), thus forming a complete subgraph66. MCs represent cliques that cannot be extended by including one more adjacent vertex, meaning that it is not a subset of a larger clique58. Applying the clique analyses here, Experiment 4 identified 121219 MCs for the PPI network constructed using the entire set of orthologous genes, including 21938 non-ribosomal MCs (with a maximum size of N = 29) that were further analyzed as gene sets using GAGE60, to compare their enrichment (bidirectionally altered, i.e., including both under- and over-representation in absolute values, regardless the direction of individual gene expression changes) in each species in affective (CUS/MDD) samples vs. control (Fig. 7 and Supplementary Material 3). Fisher’s meta-analysis of these data identified a total of 257 enriched MCs containing 253 unique proteins (Supplementary Table S20 and Fig. S2).

Genes expressed in a similar direction in the enriched sets using Fisher’s meta-analysis 57 on maximal cliques (MCs) Gene Set Enrichment Analysis (GSEA) data of major depressive disorder (MDD) vs. control human or chronic unpredictable stress (CUS) vs. control rat and zebrafish data, mapped to 1:1:1 human orthologue using the HomoloGene database59 (Experiment 4; www.ncbi.nlm.nih.gov/homologene). Data are presented as mean log2 fold change.
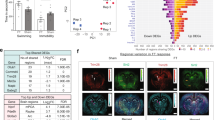
As a proof-of-concept approach, we also applied GAGE analysis60 to the set containing these 253 genes, finding it to be significantly enriched in stress vs. control groups in all three species (Fig. 8 and Supplementary Table S21). Notably, this set was not only enriched in depressed human prefrontal cortex (PFC) data, but was also less enriched following antidepressant treatment in stressed animals, based on both zebrafish and rat data (drug vs. stress groups; Fig. 8 and Supplementary Table S21). Overall, this collectively indicates that this set was enriched in the original datasets even when analyzed using traditional methods (without any data combination), and may also have some predictive validity as well, given its responsivity to antidepressant treatment.

The number of maximal cliques (MCs) in the protein–protein interaction (PPI) network constructed from all orthologous genes mapped using 1:1:1 human:rat:zebrafish HomoloGene59 (www.ncbi.nlm.nih.gov/homologene) map in STRING62 (https://www.string-db.org/) and OmicsNet (www.omicsnet.ca/)67 databases.
To identify the most consistent/stable expression changes across the three species, our further analyses focused on genes from the set with similar changes in expression (increased or decreased) for each species (Fig. 9). In silico Experiment 4 generated a PPI network consisting of a total of 45 proteins, including those encoded by 6 genes (GRIA1, DLG1, CDH1, THRB, PLCG2, and NGEF) most highly altered (assessed by average l2fc absolute values) in all three species (Fig. 10). Five of these genes (except NGEF) were also highly ranked by their l2fc absolute values in fluoxetine-treated zebrafish and rats, further implicating them in both stress pathogenesis and antidepressant effects (Fig. 11). Finally, our graph theory-based analyses of protein-protein interaction (PPI) networks, performed similarly to Experiment 3, helped establish multiple ‘hub’ proteins (Table 1) that may also represent promising targets due to their high impact on the PPI. Overall, these PPI analyses reveal the potential role of the Wnt-signaling pathway, involving multiple wnt proteins (e.g., WNT2, WNT3A, WNT7A and B, WNT8B, WNT10A), a protein with highly altered expression of the corresponding gene among all three species found in Experiment 4 (GRIA1), key hormone receptors (TRHR and OXTR), and some other important cellular proteins (Table 1).

Results of Gene Set Enrichment Analyses (GSEA) comparing the set of 253 genes suggested using maximal cliques (MCs) and significantly altered in Fisher’s meta-analysis 57 (Experiment 4). All data significantly differed from their corresponding controls (p < 0.05). Asterisks denote additional significant differences between the groups (p < 0.05). MDD—major depressive disorder, Sub—subiculum, Hip—hippocampus, Flu—fluoxetine, PFC—prefrontal cortex.

The network of protein–protein interactions (PPI) constructed for genes expressed in a similar direction in the enriched sets using Fisher’s meta-analysis57 on the maximal cliques (MCs) Gene Set Enrichment Analysis (GSEA) data of major depressive disorder (MDD) vs. human control or chronic unpredictable stress (CUS) vs. rat or zebrafish control data, mapped to 1:1:1 human orthologue using HomoloGene database59 (Experiment 4; www.ncbi.nlm.nih.gov/homologene). PPIs were constructed using the STRING online database62 (see the “Methods” section and Figs. 3, 5 for details; www.string-db.org). Data are presented as mean log2 fold change between the stress groups from three species, compared to their respective controls. Black frames denote genes most highly-ranked as differentially expressed (DE) in all three species (see the “Methods” section for details).

Heatmap representing fluoxetine effects in animals on brain genes expressed in a similar direction in the sets deemed ‘enriched' using Fisher’s meta-analysis57 on maximal cliques (MCs) Gene Set Enrichment Analysis (GSEA) data for major depressive disorder (MDD) vs. human control or chronic unpredictable stress (CUS) vs. control rat and zebrafish data, mapped to 1:1:1 human orthologue using the HomoloGene database59 (Experiment 4; www.ncbi.nlm.nih.gov/homologene). Data are presented as mean log2 fold change.
Discussion
The present study was the first cross-species/cross-taxon in-depth analysis of stress-related CNS transcriptomic data from three important organisms (humans, rats and zebrafish), in order to probe their putative shared genomic mechanisms in affective pathogenesis. This study also combined several innovative methods of analyses (Experiments 2–4) to tackle this problem, contrasting these approaches with more common and traditional, direct species-to-species comparisons (Experiment 1). Refining such analyses, Experiments 3 and 4 focused on mapping shared orthologous human, rat, and zebrafish genes before differential expression analyses, and were also further reinforced by meta-analytical methods, becoming more sensitive among all approaches used here. In summary, the results of our analyses are as follows: (1) The use of gene sets-related analysis is highly beneficial to study commonalities in interspecies RNA-seq results relevant to stress-related CNS disorders. (2) Data from different species cannot be directly pooled together due to high heterogeneity of their gene expression. (3) The meta-analytical approach is highly efficient in combining the interspecies RNA-seq results. (4) The value of analyzing gene sets may be increased by using functionally meaningful ways of data extraction, such as finding MCs in the targeted PPI networks.
Interestingly, some potential protein targets that were up-regulated and had high connectedness in PPI networks generated by Experiment 3, include the FEZ Family Zinc Finger 2 (FEZF2) and IKAROS Family Zinc Finger 1 (IKZF1), both having zing-finger Cys2His2-like fold group (zf-C2H2)68 and 36.67-% homology to each other, based on protein sequences assessed by the Basic Local Alignment Search Tool (BLAST) database69. In neurons, both FEZF2 and IKZF1 are important TFs that determine neuroprogenitor cell fate70. FEZF2 also promotes neuroplasticity and neuronal signaling that involves neuroactive ligand-receptor interaction, cell adhesion molecules, and calcium signaling pathways71, thereby strikingly paralleling our KEGG 56 pathways enrichment findings here (Fig. 2 and Supplementary Tables S4–S6 and S10). FEZF2 also controls the expression of Helix-loop-helix (HLH) DNA-binding domain-containing proteins72,73, such as neurogenins, neurogenic differentiation (NEUROD), and ASCL1 orthologues that represent closely related HLH proteins controlling neuronal fate (e.g., temporal switch from neuro- to gliogenesis)68,70,74. Interestingly, NEUROD6 was a DE gene found by meta-analysis in the present study, albeit altered in different directions across species (Fig. 6). Similarly, IKZF1 participates in neuronal differentiation, including the differentiation of the growth hormone releasing hormone (GHRH) cells in mammalian hypothalamus70, and its genetic knockout in mice evokes pronounced antidepressant-like behavior and poorer acoustic startle75. Collectively, this corroborates our present findings identifying this gene as a potential critical ‘shared', evolutionarily conserved candidate CNS ‘affective’ gene (Fig. 6). Notably, IKZF1 is more robustly expressed in microglia than in neurons, oligodendrocytes or astrocytes, as assessed by mean DE TFs in human cortex76. Furthermore, comparison of meta- and TFBS- analyses with this patterned expression data76 suggests that most DE genes and DR TFBSs (Experiments 1 and 3) after stress exposure may be associated with primarily microglial (e.g., IKZF1, PRDM1, ELF1, ELK3, ETS2, and FLI1), and with only a few neuronal (e.g., NEUROD6) and astrocytic (e.g., FEZF2), genes76.
Overall, the observed diversity of the cell types implicated in depression is not surprising, as microglia, astrocytes, endothelial cells and oligodendrocytes have been extensively studied for their association with affective pathogenesis. For example, microglial cells emerge as promising novel targets for depression treatment, representing important modulators of inflammatory activity in the brain, also key for supporting healthy neuronal connectivity24. Moreover, endothelial dysfunction biomarkers are associated with depression pathogenesis clinically, and are normalized following antidepressant treatment77. Similarly, astrocytes regulate glucose metabolism, neurotransmitter uptake (especially glutamate), synaptic development/maturation or the blood brain barrier function, and their role in depression pathogenesis is well supported by clinical and preclinical studies78,79. Finally, postmortem reduction of glial density in amygdala (an important regulator of emotional responses) may be primarily due to oligodendrocyte cell death80, whereas of the down-regulation of oligodendrocytal genes is observed in both depressed patients and animal chronic stress models81. Taken together, the present findings are in line with recent views on depressive pathogenesis implicating multiple brain cell types, and supporting the value of studying whole-brain tissue in addition to cell type-specific samples.
The present study also compared all candidate genes found in meta- and TFBS- analyses with publicly available meta-analyses of cell-specific expression patterns in human and mouse brain82. Several observations can be made based on these analyses. First, as shown in Supplementary Fig. 1, all brain cell types were involved in the development of pathological affective states in all three species here. Second, all neuron-specific genes were altered bidirectionally between these species, confirming some distinct effects of chronic stress on neuronal tissue in various vertebrates reported previously83. Finally, some key microglial (e.g., IKZF1) and astrocytal (e.g., FEZF2) proteins may play an integrative, ‘hub’ role in stress-related ‘affective’ PPI networks generated here (Table 1).
However, the present study also has several clear limitations. First, the Fisher’s meta-analysis57 was oversensitive to highly-DE genes in individual species (e.g., FEZF2 in rats), thus possibly not properly reflecting its potential evolutional conservation, as suggested by other methods used here. Furthermore, our study utilized zebrafish whole brain samples, rat hippocampal samples and online human subiculum data, hence possibly complicating direct inter-species comparisons. Likewise, only male rat and human data, but mixed-sex zebrafish data, were analyzed. However, rat and human data were as close to each other as to zebrafish data in terms of the number of identified conservative genes, sets, TFBS or principal components (Experiment 2), thus supporting the validity of using zebrafish whole-brain and mixed-sex samples in the pilot analysis here.
Importantly, as a proof of concept, in a separate study we also utilized depression patient PFC data to assess the enrichment of the set of 253 genes found here to be altered in all three species (hippocampus in rats and human and whole brain in zebrafish) in Experiment 4. Overall, these analyses yielded pronounced enrichment in depressed vs. healthy patients (Fig. 9), thereby supporting the idea of targeting the effects common in other brain regions. Similarly, an antidepressant exherted opposite effects on the gene set enrichment (Fig. 9) and expression of genes of interest (Fig. 11) in Experiment 4, thus providing further pharmacological validity for the study. However, as already noted, variation in brain regions may also affect the study results, for example, contributing to the lack of common DE genes between species using traditional species-to-species analyses in in Experiment 1. Thus, further follow-up studies may be needed to generate more nuanced insights by focusing on sex- and brain area-specific samples.
Finally, using the HomoloGene database59 (www.ncbi.nlm.nih.gov/homologene) to identify gene orthologues across species also presents some limitations because it is currently incomplete, and not all existing gene orthologues are registered there. For example, the IKZF1 orthologue was not identified in the rat genome, albeit the Ikzf1 gene exists in rats and is highly homological to the respective human and zebrafish genes, as assessed by the BLAST database69. As such, using a curated database of gene orthologues to simplify their identification may also lead to false negatives (e.g., yielding fewer genes due to data deficiency), hence necessitating further manual data curation and updating. Moreover, because teleost fish underwent an additional round of whole-genome duplication, many of the mammalian genes have additional orthologues in zebrafish, resulting in over-representation of zebrafish over human and rat genomes. To mitigate this potential confound, the present study used only one (most homological) zebrafish ortholog for each such duplicated gene. However, this strategy may also impact the results of the study since some of the two gene orthologues may hypothetically have divergent CNS functions, brain localization and/or expression patterns.
Another important aspect to consider is the overall validity of animal modelling for human brain disorders. The translational relevance of animal models of depression has traditionally been evaluated based on their predictive, construct and face validity84. It is generally accepted that CUS paradigms in rodents fulfill all these criteria, since they replicate many symptoms of depression seen in humans (good face validity), show specific and selective responses to antidepressants (good predictive validity), and have sound theoretical basis (good construct validity)85,86. However, as with other animal models of depression, CUS-based paradigms themselves have several important conceptual and methodological limitations. In fact, while stress is one of the key predictors for depression development in humans87, the exact cause-effect relationships between stress and depression are poorly understood. For instance, it is still unclear how stressful events cause pathological changes in the brain of depressed patients, and why some other individuals remain stress-resistant or stress-resilient88. Furthermore, some symptoms of depression cannot in principle be modeled in animals, either due to their high cognitive complexity (e.g., suicidality) or inability of animals to objectively report their internal states (e.g., feelings of worthlessness and guilt).
Depression is also a highly heterogeneous disorder in terms of its clinical manifestations89,90, which further complicates adequate studying its symptoms and their modeling in animals. For example, while dysregulated neuroendocrine axis is often the most consistent physiological sign of depression, it actually occurs only in ~ 50% depressed patients91. Given the high comorbidity between depression and various other affective disorders (especially anxiety)92, it is also unclear whether they represent trully distinct brain disorders or diverse manifestations of some common overlapping pathological process.
As already mentioned, Experiments 1–3 were more sensitive in identifying similar changes in pathways expression than analyses of expression changes in individual genes. However, there are no pathways in the KEGG database56 that have a direct pathological association with CNS affective pathogenesis, since exact molecular pathways that contribute to these disorders remain poorly understood. Therefore, it is logical to specifically focus on the most affected gene sets in all three species observed in the study independently of curated pathways. To address this problem, the present study utilized a novel approach, comparing differences in expression data of MCs identified in orthologous PPI networks. Although MC analyses have already been used in various transcriptomic studies93,94,95,96, here we not only applied this approach to CNS transcriptomic data across the three common model species, but also enhanced its sensitivity, successfully identifying multiple enriched MCs by combining this approach with meta-analytical methods.
Assessing genes that formed significantly altered MCs, we also identified a novel gene set that may be potentially useful for comparing animal and human affective pathological states (used as a curated pathway in databases). For example, this set includes several well-known stress- and affective disorder-related genes, such as FOS-, JUN-, MAPK-, Wnt- and adhesion-related genes, thereby further supporting the validity of our approach. Importantly, we also identified the most conservative ‘stress’ subnetwork consisting of CNS genes that were not only inter-connected (within PPIs), but also changed their expression in the same direction in all three species studied here (Fig. 9, 10, Supplementary Table S14). For example, this subnetwork includes several similarly expressed “core” genes in all three stressed groups (GRIA1, DLG1, CDH1, THRB, NGEF, and PLCG2), likely serving as potential ‘hub’ genes within the subnetwork (Tables 1, 2).
Thus, our analyses successfully identified shared genes that were involved in affective pathology in all three species, hence representing likely evolutionarily conserved biomarkers of affective pathology. Furthermore, the expression of all genes similarly expressed across all three species, except NGEF, was rescued in the respective rat- and zebrafish fluoxetine-treated groups, further implicating their importance not only for CNS stress responses, but also for antidepressant treatment, again strongly supporting the validity of the present study’s approach and findings.
PLCG2 belongs to the phospholipase C gamma (PLC) family, encoding the enzyme 1-phosphatidylinositol-4,5-bisphosphate phosphodiesterase gamma-2 (PLCG2) that cleaves the membrane phospholipid PIP2 (1-phosphatidyl-1D-myo-inositol 4,5-bisphosphate) to the second messengers IP3 (myoinositol 1,4, 5-triphosphate) and DAG (diacylglycerol) playing a key role in signal transduction97,98,99. Another PLC family member, PLCG1 is expressed widely within the brain, especially in the cortex and the hippocampus100, and has been implicated in CNS disorders, such as epilepsy, Huntington's disease, and bipolar and unipolar depression101,102,103. In contrast, PLCG2 is predominantly expressed in the bone marrow and lymphoid organs104 and is responsible for hereditary immune and autoimmune disorders105,106. However, recent mouse studies found PLCG2 expression in the granular cell layer of the dentate gyrus and microglia107, and its mutations are also implicated in Alzheimer's disease107. Together with our present findings, thus implicates both PLCG1 and PLCG2 as potential factors in both neurodegenerative and affective disorders.
The THRB gene generates two alternatively spliced isoforms of the thyroid hormone receptor beta, TRβ1, and TRβ2108. Together with another receptor, TRα, these nuclear receptors act as transcription factors that mediate the genomic effects of thyroid hormone in various tissues109,110. Importantly, while thyroid receptors are highly expressed in the brain111,112, thyroid hormones (e.g., acting via brain TRα and TRβ receptors) may modulate monoaminergic neurotransmission, thereby affecting mood and behavior113,114,115,116, including strong co-morbidity of thyroid dysfunctions with mood disorders117,118,119.
The NGEF (Neuronal Guanine Nucleotide Exchange Factor) gene120 is expressed in the caudate nucleus and is involved in the activation of RhoA, Rac1, and Cdc42 (the Ras superfamily-associated proteins), hence modulating mitogen-activated protein kinase (MAPK) signaling and cell junction121. NGEF is also a downstream signaling component of the ephrin-A (EphA4) tyrosine kinase receptor, responsible for the formation of neural networks, nerve growth, and changes in cell morphology involved in cell motility122,123,124,125,126. Some genetic studies also implicate NGEF in schizophrenia127,128. However, the CNS functions of NGEF remain poorly understood, and its putative role in stress-related affective pathogenesis (as suggested in the present study) merits further study.
The GRIA1 gene encodes the GluR1 (GluA1) protein, a subunit of glutamate α-amino-3-hydroxy-5-methyl-4-isoxazolepropionic acid (AMPA) receptor, critical for synaptic plasticity, learning, and memory129,130,131. GRIA1 is ubiquitously expressed throughout the rat and human brain, with the highest expression in the hippocampus132,133. Interestingly, GRIA1-/-knockout mice display hyperlocomotion, increased anxiety, exacerbated novelty response, and impaired spatial working memory and object recognition134,135,136,137,138. Mounting evidence implicates GluR1 dysregulation in uni- and bipolar depression, and schizophrenia 139,140,141, hence calling for further studies of its role in stress in vivo. Rodent GluR1 activity alters in various brain areas following both acute142,143,144,145 and chronic stress143,146,147,148,149,150,151,152,153,154, with usually downregulated GRIA1/GluR1 expression/protein content. However, patterns of GluR1 regulation depend on both the duration of stress and the specific brain area examined. For example, hippocampal GluR1 is upregulated after shorter-term (< 21 days)143,149,150, but downregulated under longer-term (> 28 days), chronic stress151,153,154. Furthermore, treatment with classical antidepressants (e.g., fluoxetine, desipramine, and maprotiline), as well as with atypical fast-acting antidepressant ketamine, elevates GRIA1 expression and restores GluR1 level in chronically stressed rodents155,156,157,158,159. Together with our present cross-species genomic findings (Figs. 9, 10, and Supplementary Table S14), this strongly suggests GluR1 as a ‘core’, an evolutionarily conserved gene involved in affective pathogenesis.
Discs large homolog 1 (DLG1) is a scaffolding protein from the membrane-associated guanylate kinase (MAGUK) family that regulates the activation of both B- and T-lymphocytes, encoded in humans by the DLG1 gene160,161. Rat Dlg1 localizes in the presynaptic nerve endings of excitatory synapses, as well as in (and along with) the bundles of unmyelinated axons162. In addition to mammalian DLG1, there are several other types of DLGs (DLG2 (PSD-93), DLG3 (NE-dlg), and DLG4 (PSD-95)) expressed almost exclusively in the nervous system163 and likely contributing to rodent affective pathogenesis (e.g., Dlg4, but not Dlg1 or Dlg2, decreases in mouse hippocampus two days after the forces swim test164). DLG1 also regulates the activity of the glutamate N-methyl-D-aspartic acid (NMDA) and AMPA receptors165,166. NMDA receptor antagonists like ketamine exert both anxiolytic and antidepressant properties167, whereas antagonism of AMPA receptors is linked to depression168.
Perhaps the most interesting finding here (Table 2) in the context of affective pathology involves Epithelial-cadherin (E-cadherin; CDH1), a Ca2+-dependent cell adhesion molecule169, whose extracellular region acts as an adhesion anchor binding to cadherins on other cells170, and intracellular region interacts with catenins (e.g., α- and β-catenins) and other regulatory proteins171. Since β-catenin is an important signaling protein in the Wnt-signaling pathway, the cadherin/catenin complex modulates cellular signal transduction172. Wnt signaling has long been associated with affective pathogenesis173 and downregulated E-cadherin expression has been reported in vitro by ketamine, a novel rapid-acting antidepressant174. Similarly, a classical antidepressant, fluoxetine, impairs CDH1-mediated cell adhesion175. Unlike other genes, CDH1 is overexpressed in PFC of human MDD patients vs. controls (assessed using protocol similar to Experiment 4 here), supporting its important interspecies and inter-tissue (including different brain regions) conservation.
In conclusion, translational multidisciplinary approaches remain a cornerstone for innovative CNS research. Here, we applied several novel analyses aiming to reveal evolutionarily conserved transcriptomic phenotypes across three different vertebrate animal models (zebrafish, rat and human clinical data). Using these approaches, we identified GRIA1, DLG1, CDH1, THRB, PLCG2, NGEF, IKZF1, FEZF2 as promising and shared affective ‘hub’ targets (Table 2), whose further experimental studies may markedly foster translational research of affective disorders.
Methods
Animals, housing, and chronic unpredictable stress modeling
Wild-type adult zebrafish (n = 6, 1:1 sex ratio) and Wistar male rats (n = 3; NCBI's Gene Expression Omnibus (GEO)55 accession number GSE205325 www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE205325) were subjected to the CUS protocols reported elsewhere32,176, utilizing the 5-week (zebrafish) or 12-week (rats) protocols. Behavioral studies reconfirmed the evoked anxiety- and depression-like phenotypes in both species32,176 induced by CUS. All animals were kept in standard conditions, according to national and institutional guidelines32,176. Additional statements regarding ethical data use are available in Ethical Confirmation statements section and in the original published studies32,176.
Human subjects
Human transcriptomic data were obtained from the open source177 (NCBI's Gene Expression Omnibus (GEO)55 accession number GSE102556 www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE102556), the Douglas Bell Canada Brain Bank (DBCBQ, Douglas Mental Health Institute, Verdun, Québec). The subjects (males, n = 3 for subiculum, n = 4 for PFC study, average age 45) were of European ancestry and French-Canadian descent who died suddenly, without prolonged agony177. Diagnoses were obtained using Diagnostic and Statistical Manual of Mental Disorders-IV (DSM-IV) criteria using the Structured Clinical Interview for DSM-IV Axis I Disorders (SCID-I) interviews178 adapted for psychological autopsies177. While the original study177 included numerous suicide attempters in the control group, and many samples were from patients treated with antidepressants, we excluded these samples from the present in-silico analyses (see Statistical analyses for details), aiming at more homogenous groups. All methods involving human subjects in the cited study were carried out in accordance with relevant guidelines and regulations, as well as in accordance with the Declaration of Helsinki. Additional statements regarding ethical data use are available in Ethical Confirmation statements section and in the original study177.
RNA-sequencing
RNA-sequencing procedures were performed as reported previously32,176,177. Briefly, animal brains were dissected on ice following standard procedures, and hippocampus were dissected from the whole rat brains using Waxholm Space atlas179. RNA isolation was performed using the TRI-reagent (Evrogen JSC, Moscow, Russia), according to manufacturer instructions. RNA quality was examined using Quantus (Promega Corporation, Madison, USA), electrophoresis, and QIAxcel (QIAGEN, Venlo, Netherlands). Sequencing was performed on Illumina HiSeq2500 (Illumina Inc., San Diego, USA) with 140 bp paired-read (zebrafish) and Illumina HiSeq4000 (Illumina Inc., San Diego, USA) with 151 bp paired-read (rat), with at least 20 million reads generated for each sample. Human samples from the referenced study177 involved dorsolateral PFC (BA8/9; dlPFC) and ventral subiculum (vSUB) carefully dissected at 4 °C after being flash-frozen in isopentane at − 80 °C by highly trained histopathologists using reference neuroanatomical maps177,180,181. Similar to our rat and fish experiments, RNA isolation in clinical samples was performed with TRI-reagent, according to manufacturer instructions177. Samples were sequenced at 50 bp paired-read on Illumina HiSeq2500 with at least 50 million reads per sample after two sequential sequencing177.
Statistical analyses and data handling
Data on human RNA-seq postmortem subiculum and PFC expression were obtained from the NCBI's Gene Expression Omnibus (GEO)55 accession number GSE102556 http://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE102556. Only male control and MDD patients that did not receive any treatment and died from natural or accident causes were included in the present analyses, resulting in n = 3 for subiculum and n = 4 for PFC. Reads were mapped to zebrafish GRCz11, rat Rnor_6.0, and human GRCh38 using RNA STAR182 and further processed in featureCounts183 (https://usegalaxy.org/)184. For inter-species transcriptomic data comparison, we applied four different approaches (summarized in Fig. 1) utilizing the R software185, Bioconductor software186, and the DESeq2 package187. The DESeq2 was chosen as a tool efficient for experiments with 12 or fewer replicates, stable within 0.5 fold-change thresholds, and as an approach consistent with other tools, such as EdgeR (when using exact test), Limma, and EBSeq32,188. All genes with less than 10 counts per all samples were removed from the analysis. DE gene data analyses were next performed using the DESeq function. The p-values were adjusted using the Benjamini–Hochberg correction189. P-value and false discovery rate (FDR) were set at 0.05 in all analyses here.
GSEA is a widely used method to study gene expression data in terms of molecular sets, allowing for better detection of expression changes190,191,192,193. However, classical GSEA has some limitations, including the inability to handle datasets of different sizes and some experimental designs60. A sub-type of GSEA, GAGE for the set analysis addresses these limitations60, also enabling to choose independent databases to be analyzed depending on research goals, and consistently outperforming classical GSEA methods60. The KEGG56 (www.genome.jp/kegg/) pathway enrichment analyses were performed on normalized and log2-transformed counts by the GAGE package60, using two-sample Student’s t-test for group comparison of differential expression of gene sets. Both up- and downregulated, as well as bidirectionally (using absolute values) altered pathways were analyzed here. The p-values were adjusted using the Benjamini–Hochberg correction189, with the FDR cut-off set at 0.05.
In Experiment 1, we compared DE and enriched gene sets for each species separately. Briefly, the resultant gene expression counts mapped to zebrafish GRCz11 (n = 6), rat Rnor_6.0 (n = 3) and human GRCh38 (n = 3) were analyzed independently using DESeq2 and GAGE functions comparing stress or MDD to control groups for each species (p adjusted < 0.05, Fig. 1). Lists of significantly DE genes in these species were further compared by searching orthologues using the HomoloGene function59 (http://www.ncbi.nlm.nih.gov/homologene) and Venn diagrams. Lists of significantly altered GAGE sets were also compared using their KEGG56 names. Finally, we studied TFBS over- and under-represented in genes with high variability (p values < 0.01 in DE analysis) vs. low variability (p > 0.7) using the CiiiDer TFMs software (http://www.ciiider.com/) for each species61 (only TFBSs with p < 0.05 simultaneously for gene coverage p-value and for the distribution of the number of TFBS were considered statistically significant). The potential binding sites were established using position frequencies matrices from the Jaspar 2020 core vertebrates matrix194 (https://jaspar.genereg.net/) and searched in the genomes of the respective species targeting 1500 bp upstream and 500 bp downstream of the specific genes 61. The resulting lists of DR binding sites were similarly compared between the species.
In Experiment 2, we performed interspecies comparison of stress (CUS/MDD) versus control effects using raw RNA-seq data counts mapped to human orthologues pooled in combined affective disorder groups (CUS + MDD) or in combined control group (animal control + healthy patients) prior to any differential analysis, aiming to achieve better inter-species data compliance (Fig. 1). Because all hypotheses in this experiment closely resembled each other (i.e., probing the effects of affective pathology on CNS transcriptome in vertebrates), we combined all RNA-seq data in one experiment, designing it as a study of affective pathology effects on human transcriptome orthologues in vertebrates. Briefly, all counts were mapped 1:1:1 to human orthologues using the HomoloGene59 database (http://www.ncbi.nlm.nih.gov/homologene), resulting in 10353 genes and 24 samples (n = 12) which were next assessed for stress (and MDD) vs. control group effects using the DESeq2 and GAGE analyses (p adjusted < 0.05).
Experiment 3 used cross-species comparison of stress/MDD vs. control samples using counts mapped to human orthologues in separate DE and GSEA analyses for each species, that were further compared using the meta-analysis (Fig. 1). Again, because hypotheses from DE and GSEA analyses in different species were similar (i.e., probing the effects of affective pathology on transcriptome in human orthologues), it was possible to compare different species using meta-analysis. Briefly, DESEq2 analysis was conducted for each species data separately, using only the genes successfully mapped 1:1:1 to human orthologues (similar to Experiment 2). The resulting 3 DESeq2 analyses were next meta-analyzed using the Fisher’s method (that utilizes one-sided p-values combination)57 and the metaRNASeq package in R195. Significantly altered genes (Benjamini–Hochberg correction p adjusted value < 0.05), as assessed by meta-analyses, were further selected based on their consistent unidirectional expression changes across all three species. Overall, the Experiment 3 design closely resembled RNA-seq meta-analysis in other biological studies (e.g., salt stress–responsive genes and pathways in microalga Dunaliella196), hence supporting the efficiency of cross-species meta-analyses of orthologues expression to identify evolutionarily conserved “core” changes.
We also generated a human PPI network in the STRING database (https://www.string-db.org/) for Homo sapiens62 using TFBSs enriched in Experiment 1 and DE genes from Experiment 3, resulting in 74 proteins connected to any other protein, with the largest network consisting of 67 vertices. We used a minimal interaction score of 0.15 and use all active interaction sources, except text-mining, to construct the network in the STRING database. The network was further processed in the CytoScape software197 (https://cytoscape.org/) and the CytoHubba198 packages to target ‘hub’ genes, using vertices’ degree63, bottleneck64, and DMNC||MNC65 approaches. Among proteins and TFBSs ranked as top 10 hub vertices by any of these approaches, we excluded those showing different l2fc directions in meta-analysis, to focus only on conserved hubs that cause similar effects in all species studied.
The MC data in transcriptomic analyses is widely used in biomedicine93,94,95,96. Here, we performed an interspecies comparison of MC enrichment in stress/MDD versus control PPI networks using the OmicsNet (https://www.omicsnet.ca/) 67 and STRING databases62 from counts mapped to human orthologues in three different experiments for each species (10,353 proteins, resulting in the largest PPI network of 7933 proteins; Fig. 1). In the resultant PPI network, we identified all MCs using the Cytoscape plugin MClique197, finding a total of 121219 MCs (Supplementary Material 3). The majority (82%) of these MCs consisted of nodes (genes) that all originated from the same few ribosomal genes that were further excluded from analyses as non-specific, thus yielding 21938 (18%) non-ribosomal MCs of interest (Fig. 7). Ribosomal MCs were identified as cliques containing S or L Ribosomal Proteins genes (RPS or RPL) as vertices. The final 21,938 non-ribosomal MCs were further analyzed as gene sets using GAGE for each species, comparing the bidirectional expression of MC in stress versus control.
Resulting DE MCs were further compared using a meta-analysis to identify MCs with conserved expression among species, like DE genes and enriched gene sets in Experiment 3. We then used all the genes composing MCs that were significantly enriched in meta-analysis, to generate a single novel gene set (containing 253 genes) and, as a proof-of-concept, compared its expression changes as a whole using the GAGE approach in the individual species-specific (non-pooled) stress sample groups. Additionally, we also compared the expression of the same 253-gene set in human PFC, in rat CUS + fluoxetine hippocampal , and in zebrafish CUS + fluoxetine whole-brain samples vs. their corresponding stress-free controls (Fig. 8 and Supplementary Table S21). To further process these data, we excluded from the set the genes with different expression directions in the species-specific groups, compared to their respective control groups. Finally, we built a PPI network for the remaining 45 genes (45 proteins) and attempted to identify core pathology-related proteins using two additional approaches. One was similar to Experiment 3 techniques of graph analyses, identifying vertices degree63, bottleneck64, and DMNC||MNC65 of the vertex. Another approach ranked all vertices using l2fc of each original group, taking top 10 over- and top 10 under-expressed genes in each group, and then analyzed the lists of genes, identifying 6 genes that are stably highly over- or under-expressed across all 3 species. We further compared these gene lists for fluoxetine versus stress effects, identifying pronounced antidepressant effects on the expression of 5 of these genes, thus further corroborating our findings.
Analyses of all in vivo data in this study were performed online and offline without blinding the analysts to the treatments, since all animals and samples were included in analyses, data were analyzed in a fully unbiased automated method, and the analysts had no ability to influence the results of the experiments. The study experimental design and its description here, as well as data analysis and presenting, adhered to the Animal Research: Reporting of In Vivo Experiments (ARRIVE) guidelines for reporting animal research and the Planning Research199 and Experimental Procedures on Animals: Recommendations for Excellence (PREPARE) guidelines for planning animal research and testing200.
The graph theory-based analyses
The graph theory-based analyses of gene expression data were performed using the Cytoscape software for biomolecular interaction networks construction and analyses version 3.8.0197 (https://cytoscape.org/). The PPI networks were constructed using the STRING (Search Tool for the Retrieval of Interacting Genes/Proteins) database62 (https://www.string-db.org/). The resultant PPI networks were analyzed by the Cytoscape application cytoHubba198 to probe essential vertices/hubs in PPI networks for top 10-degree63 vertices, top 10 bottleneck64 vertices, or top 10 vertices by the Double Screening Scheme (DSS), combining Density of Maximum Neighborhood Component (DMNC) and Maximum Neighborhood Component (MNC)198, as in32. The degree of the vertex v was defined as the number of edges of vertex v, thus representing the number of a protein’s connections to other proteins63, similar to32. The bottleneck vertices were determined using the betweenness centrality of the vertex, based on the measuring of the number of shortest passes going through the vertex64, similar to32. Bottleneck proteins likely represent essential ‘hubs’ in the network functioning as connectors bridge-like proteins201. MNC of the vertex v was defined as a size of the maximum connected component of subnetwork N(v) constructed by vertices adjacent to v65, similar to32. DMNC of a vertex v was defined as E/Nε where N is vertex number and E is the edge number of MNC(v), and ε is defined as 1.765. DSS was further calculated as follows: for n most possible essential proteins that were expected in the output (n is an empirical value), 2n top-ranked proteins were selected by DMNC method65, similar to32. The selected proteins were then ranked by the MNC values, selecting top n proteins for analyses. The DSS (DMNC||MNC) method was chosen here as an effective tool to identify essential proteins within molecular networks65.
Ethics approval
The study does not include any direct animal or human experimentation and uses previously published datasets32,176 from animal experiments approved by the Institutional animal care and use committee (IACUC) of St. Petersburg State University and/or the Institute of Experimental animal of Almazov National Medical Research Center, that fully adhered to the National and Institutional guidelines and regulations on animal experimentation, as well as to the 3Rs principles of humane animal experimentation. The human data used here resulted from publicly available datasets in published studies (approved by the research ethics boards of McGill University and UT Southwestern), with necessary written informed consents obtained from all participants177.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding authors upon reasonable request.
References
McEwen, B. S. Physiology and neurobiology of stress and adaptation: Central role of the brain. Physiol. Rev. 87(3), 873–904 (2007).
Sapolsky, R. M. The endocrine stress-response and social status in the wild baboon. Horm. Behav. 16(3), 279–292 (1982).
Walker, E., Mittal, V. & Tessner, K. Stress and the hypothalamic pituitary adrenal axis in the developmental course of schizophrenia. Annu. Rev. Clin. Psychol. 4, 189–216 (2008).
Kyrou, I. & Tsigos, C. Stress mechanisms and metabolic complications. Horm. Metab. Res. 39(06), 430–438 (2007).
Elenkov, I. J. & Chrousos, G. P. Stress hormones, proinflammatory and antiinflammatory cytokines, and autoimmunity. Ann. N. Y. Acad. Sci. 966(1), 290–303 (2002).
Golovatscka, V., Ennes, H., Mayer, E. A. & Bradesi, S. Chronic stress-induced changes in pro-inflammatory cytokines and spinal glia markers in the rat: A time course study. NeuroImmunoModulation 19(6), 367–376 (2012).
Yang, P. et al. Changes in proinflammatory cytokines and white matter in chronically stressed rats. Neuropsychiatr. Dis. Treat. 11, 597 (2015).
Charmandari, E., Tsigos, C. & Chrousos, G. Endocrinology of the stress response. Annu. Rev. Physiol. 67, 259–284 (2005).
Chrousos, G. P. Stress and disorders of the stress system. Nat. Rev. Endocrinol. 5(7), 374 (2009).
Thomson, F. & Craighead, M. Innovative approaches for the treatment of depression: Targeting the HPA axis. Neurochem. Res. 33(4), 691–707 (2008).
Barden, N. Implication of the hypothalamic–pituitary–adrenal axis in the physiopathology of depression. J. Psychiatry Neurosci. 29(3), 185 (2004).
Bale, T. L. et al. The critical importance of basic animal research for neuropsychiatric disorders. Neuropsychopharmacology 44(8), 1349–1353 (2019).
Török, B., Sipos, E., Pivac, N. & Zelena, D. Modelling posttraumatic stress disorders in animals. Prog. Neuropsychopharmacol. Biol. Psychiatry 90, 117–133 (2019).
Meier, S. M. et al. Genetic variants associated with anxiety and stress-related disorders: A genome-wide association study and mouse-model study. JAMA Psychiat. 76(9), 924–932 (2019).
Sandi, C. & Richter-Levin, G. From high anxiety trait to depression: A neurocognitive hypothesis. Trends Neurosci. 32(6), 312–320 (2009).
Krishnan, V. & Nestler, E. J. The molecular neurobiology of depression. Nature 455(7215), 894–902 (2008).
Sgoifo, A. & Meerlo, P. Animal models of social stress: Implications for the study of stress related pathologies in humans. Stress 5(1), 1–2 (2002).
Scharf, S. H. & Schmidt, M. V. Animal models of stress vulnerability and resilience in translational research. Curr. Psychiatry Rep. 14(2), 159–165 (2012).
Czéh, B., Fuchs, E., Wiborg, O. & Simon, M. Animal models of major depression and their clinical implications. Prog. Neuropsychopharmacol. Biol. Psychiatry 64, 293–310 (2016).
Bondi, C. O., Rodriguez, G., Gould, G. G., Frazer, A. & Morilak, D. A. Chronic unpredictable stress induces a cognitive deficit and anxiety-like behavior in rats that is prevented by chronic antidepressant drug treatment. Neuropsychopharmacology 33(2), 320–331 (2008).
Cox, B. M., Alsawah, F., McNeill, P. C., Galloway, M. P. & Perrine, S. A. Neurochemical, hormonal, and behavioral effects of chronic unpredictable stress in the rat. Behav. Brain Res. 220(1), 106–111 (2011).
Otabi, H., Goto, T., Okayama, T., Kohari, D. & Toyoda, A. The acute social defeat stress and nest-building test paradigm: A potential new method to screen drugs for depressive-like symptoms. Behav. Proc. 135, 71–75 (2017).
Monteiro, S. et al. An efficient chronic unpredictable stress protocol to induce stress-related responses in C57BL/6 mice. Front. Psych. 6, 6 (2015).
Ma, L. et al. Animal inflammation-based models of depression and their application to drug discovery. Expert Opin. Drug Discov. 12(10), 995–1009 (2017).
Willner, P. Validity, reliability and utility of the chronic mild stress model of depression: A 10-year review and evaluation. Psychopharmacology 134(4), 319–329 (1997).
Katz, R. J. Animal models and human depressive disorders. Neurosci. Biobehav. Rev. 5(2), 231–246 (1981).
Katz, R. J. Animal model of depression: Pharmacological sensitivity of a hedonic deficit. Pharmacol. Biochem. Behav. 16, 965–968 (1982).
Echandia, E. R., Gonzalez, A., Cabrera, R. & Fracchia, L. A further analysis of behavioral and endocrine effects of unpredictable chronic stress. Physiol. Behav. 43(6), 789–795 (1988).
Mineur, Y. S., Belzung, C. & Crusio, W. E. Effects of unpredictable chronic mild stress on anxiety and depression-like behavior in mice. Behav. Brain Res. 175(1), 43–50 (2006).
Paolo, S., Brain, P. & Willner, P. Effects of chronic mild stress on performance in behavioural tests relevant to anxiety and depression. Physiol. Behav. 56(5), 861–867 (1994).
Hill, M. N., Hellemans, K. G., Verma, P., Gorzalka, B. B. & Weinberg, J. Neurobiology of chronic mild stress: Parallels to major depression. Neurosci. Biobehav. Rev. 36(9), 2085–2117 (2012).
Demin, K. A. et al. Understanding complex dynamics of behavioral, neurochemical and transcriptomic changes induced by prolonged chronic unpredictable stress in zebrafish. Sci. Rep. 10(1), 1–20 (2020).
Lakstygal, A. M. et al. Zebrafish models of diabetes-related CNS pathogenesis. Prog. Neuropsychopharmacol. Biol. Psychiatry 92, 48–58 (2019).
De Abreu, M. S. et al. Non-pharmacological and pharmacological approaches for psychiatric disorders: Re-appraisal and insights from zebrafish models. Pharmacol. Biochem. Behav. 193, 172928 (2020).
Zabegalov, K. N. et al. Abnormal repetitive behaviors in zebrafish and their relevance to human brain disorders. Behav. Brain Res. 367, 101–110 (2019).
Volgin, A. D. et al. Understanding central nervous system effects of deliriant hallucinogenic drugs through experimental animal models. ACS Chem. Neurosci. 10(1), 143–154 (2018).
Stewart, A. M., Braubach, O., Spitsbergen, J., Gerlai, R. & Kalueff, A. V. Zebrafish models for translational neuroscience research: From tank to bedside. Trends Neurosci. 37(5), 264–278 (2014).
Kalueff, A. V., Echevarria, D. J. & Stewart, A. M. Gaining Translational Momentum: More Zebrafish Models for Neuroscience Research (Elsevier, 2014).
Barbazuk, W. B. et al. The syntenic relationship of the zebrafish and human genomes. Genome Res. 10(9), 1351–1358 (2000).
Howe, K. et al. The zebrafish reference genome sequence and its relationship to the human genome. Nature 496(7446), 498–503 (2013).
Rico, E. et al. Zebrafish neurotransmitter systems as potential pharmacological and toxicological targets. Neurotoxicol. Teratol. 33(6), 608–617 (2011).
Panula, P. et al. Modulatory neurotransmitter systems and behavior: Towards zebrafish models of neurodegenerative diseases. Zebrafish 3(2), 235–247 (2006).
Panula, P. et al. The comparative neuroanatomy and neurochemistry of zebrafish CNS systems of relevance to human neuropsychiatric diseases. Neurobiol. Dis. 40(1), 46–57 (2010).
Wulliman, M. F., Rupp, B. & Reichert, H. Neuroanatomy of the Zebrafish Brain: A Topological Atlas (Birkhäuser, 2012).
Egan, R. J. et al. Understanding behavioral and physiological phenotypes of stress and anxiety in zebrafish. Behav. Brain Res. 205(1), 38–44 (2009).
Steenbergen, P. J., Richardson, M. K. & Champagne, D. L. The use of the zebrafish model in stress research. Prog. Neuropsychopharmacol. Biol. Psychiatry 35(6), 1432–1451 (2011).
Demin, K. A. et al. Understanding neurobehavioral effects of acute and chronic stress in zebrafish. Stress 24, 1–18 (2020).
Zimmermann, F. et al. Unpredictable chronic stress alters adenosine metabolism in zebrafish brain. Mol. Neurobiol. 53(4), 2518–2528 (2016).
Manuel, R. et al. Unpredictable chronic stress decreases inhibitory avoidance learning in Tuebingen long-fin zebrafish: Stronger effects in the resting phase than in the active phase. J. Exp. Biol. 217(21), 3919–3928 (2014).
Rambo, C. L. et al. Gender differences in aggression and cortisol levels in zebrafish subjected to unpredictable chronic stress. Physiol. Behav. 171, 50–54 (2017).
Marcon, M. et al. Prevention of unpredictable chronic stress-related phenomena in zebrafish exposed to bromazepam, fluoxetine and nortriptyline. Psychopharmacology 233(21), 3815–3824 (2016).
Piato, Â. L. et al. Unpredictable chronic stress model in zebrafish (Danio rerio): Behavioral and physiological responses. Prog. Neuropsychopharmacol. Biol. Psychiatry 35(2), 561–567 (2011).
Dubbelaar, M. et al. Transcriptional profiling of macaque microglia reveals an evolutionary preserved gene expression program. Brain Behav. Immun.-Health 15, 100265 (2021).
Connolly, N. P. et al. Cross-species transcriptional analysis reveals conserved and host-specific neoplastic processes in mammalian glioma. Sci. Rep. 8(1), 1–15 (2018).
Edgar, R., Domrachev, M. & Lash, A. E. Gene expression omnibus: NCBI gene expression and hybridization array data repository. Nucl. Acids Res. 30(1), 207–210 (2002).
Kanehisa, M. & Goto, S. KEGG: Kyoto encyclopedia of genes and genomes. Nucl. Acids Res. 28(1), 27–30 (2000).
Fisher, R. A. Statistical methods for research workers. Stat. Methods Res. Work. (10th. ed.) (1946).
Akkoyunlu, E. A. The enumeration of maximal cliques of large graphs. SIAM J. Comput. 2(1), 1–6 (1973).
Mancarci, O. & French, L. Homologene: Quick access to homologene and gene annotation updates. R Package Version 1, 68 (2019).
Luo, W., Friedman, M. S., Shedden, K., Hankenson, K. D. & Woolf, P. J. GAGE: Generally applicable gene set enrichment for pathway analysis. BMC Bioinform. 10, 161 (2009).
Gearing, L. J. et al. CiiiDER: A tool for predicting and analysing transcription factor binding sites. PLoS ONE 14(9), e0215495 (2019).
Szklarczyk, D. et al. STRING v11: Protein–protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucl. Acids Res. 47(D1), D607–D613 (2019).
Diestel, R. Graph theory 3rd ed. Grad. Texts Math. 173, 33 (2005).
Freeman, L. C. A set of measures of centrality based on betweenness. Sociometry 35–41 (1977).
Lin, C.-Y. et al. Hubba: Hub objects analyzer—A framework of interactome hubs identification for network biology. Nucl. Acids Res. 36(suppl_2), W438–W443 (2008).
Luce, R. D. & Perry, A. D. A method of matrix analysis of group structure. Psychometrika 14(2), 95–116 (1949).
Zhou, G. & Xia, J. OmicsNet: A web-based tool for creation and visual analysis of biological networks in 3D space. Nucl. Acids Res. 46(W1), W514–W522 (2018).
Mistry, J. et al. Pfam: The protein families database in 2021. Nucl. Acids Res. 49(D1), D412–D419 (2021).
Boratyn, G. M. et al. Domain enhanced lookup time accelerated BLAST. Biol. Direct 7(1), 1–14 (2012).
Alvarez-Bolado, G. Development of neuroendocrine neurons in the mammalian hypothalamus. Cell Tissue Res. 375(1), 23–39 (2019).
Clare, A. J., Wicky, H. E., Empson, R. M. & Hughes, S. M. RNA-sequencing analysis reveals a regulatory role for transcription factor Fezf2 in the mature motor cortex. Front. Mol. Neurosci. 10, 283 (2017).
Shimizu, T. et al. Zinc finger genes Fezf1 and Fezf2 control neuronal differentiation by repressing Hes5 expression in the forebrain. Development 137(11), 1875–1885 (2010).
Yang, N., Dong, Z. & Guo, S. Fezf2 regulates multilineage neuronal differentiation through activating basic helix-loop-helix and homeodomain genes in the zebrafish ventral forebrain. J. Neurosci. 32(32), 10940–10948 (2012).
Dennis, D. J. et al. Neurog2 and Ascl1 together regulate a postmitotic derepression circuit to govern laminar fate specification in the murine neocortex. Proc. Natl. Acad. Sci. 114(25), E4934–E4943 (2017).
Kiehl, T.-R., Fischer, S. E., Ezzat, S. & Asa, S. L. Mice lacking the transcription factor Ikaros display behavioral alterations of an anti-depressive phenotype. Exp. Neurol. 211(1), 107–114 (2008).
Nott, A., Holtman, I. R., Coufal, N. G., Schlachetzki, J. C., Yu, M., Hu, R. et al. Cell type-specific enhancer-promoter connectivity maps in the human brain and disease risk association. bioRxiv 778183 (2019).
Lopez-Vilchez, I. et al. Endothelial damage in major depression patients is modulated by SSRI treatment, as demonstrated by circulating biomarkers and an in vitro cell model. Transl. Psychiatry 6(9), e886–e886 (2016).
Rajkowska, G. & Stockmeier, C. A. Astrocyte pathology in major depressive disorder: Insights from human postmortem brain tissue. Curr. Drug Targets 14(11), 1225–1236 (2013).
Demin, K. A. et al. CNS genomic profiling in the mouse chronic social stress model implicates a novel category of candidate genes integrating affective pathogenesis. Prog. Neuropsychopharmacol. Biol. Psychiatry 105, 110086 (2021).
Hamidi, M., Drevets, W. C. & Price, J. L. Glial reduction in amygdala in major depressive disorder is due to oligodendrocytes. Biol. Psychiatry 55(6), 563–569 (2004).
Edgar, N. & Sibille, E. A putative functional role for oligodendrocytes in mood regulation. Transl. Psychiatry 2(5), e109–e109 (2012).
McKenzie, A. T. et al. Brain cell type specific gene expression and co-expression network architectures. Sci. Rep. 8(1), 1–19 (2018).
Song, C. et al. Modeling consequences of prolonged strong unpredictable stress in zebrafish: Complex effects on behavior and physiology. Prog. Neuropsychopharmacol. Biol. Psychiatry 81, 384–394 (2018).
Willner, P. The validity of animal models of depression. Psychopharmacology 83(1), 1–16 (1984).
Nollet, M., Guisquet, A. M. L. & Belzung, C. Models of depression: Unpredictable chronic mild stress in mice. Curr. Protoc. Pharmacol. 61(1), 56561–656517 (2013).
Willner, P. The chronic mild stress (CMS) model of depression: History, evaluation and usage. Neurobiol. Stress 6, 78–93 (2017).
Hammen, C. Stress and depression. Ann. Rev. Clin. Psychol. 1(1), 293–319 (2005).
Richter-Levin, G. & Xu, L. How could stress lead to major depressive disorder?. IBRO Rep. 4, 38–43 (2018).
Goldberg, D. The heterogeneity of “major depression”. World Psychiatry 10(3), 226 (2011).
Milaneschi, Y. et al. Polygenic dissection of major depression clinical heterogeneity. Mol. Psychiatry 21(4), 516–522 (2016).
Du, X. & Pang, T. Y. Is dysregulation of the HPA-axis a core pathophysiology mediating co-morbid depression in neurodegenerative diseases?. Front. Psych. 6, 32 (2015).
Merikangas, K. et al. Comorbidity and boundaries of affective disorders with anxiety disorders and substance misuse: Results of an international task force. Br. J. Psychiatry 168(30), 58–67 (1996).
Zheng, C. H., Yuan, L., Sha, W., Sun, Z. L. Gene differential coexpression analysis based on biweight correlation and maximum clique. In Prodings of the BMC Bioinformatics (Springer, 2014).
Jiao, Q. J., Shen, H. B. Maximum-clique algorithm: An effective method to mine large-scale co-expressed genes in arabidopsis anther. In Proceedings of the Proceedings of the 30th Chinese Control Conference (IEEE, 2011).
Amgalan, B. & Lee, H. WMAXC: A weighted maximum clique method for identifying condition-specific sub-network. PLoS ONE 9(8), e104993 (2014).
Pradhan, M. P., Nagulapalli, K. & Palakal, M. J. Cliques for the identification of gene signatures for colorectal cancer across population. BMC Syst. Biol. 6(3), 1–17 (2012).
Hernandez, D., Egan, S. E., Yulug, I. G. & Fisher, E. M. Mapping the gene that encodes phosphatidylinositol-specific phospholipase C-gamma 2 in the human and the mouse. Genomics 23(2), 504–507 (1994).
Koss, H., Bunney, T. D., Behjati, S. & Katan, M. Dysfunction of phospholipase Cgamma in immune disorders and cancer. Trends Biochem. Sci. 39(12), 603–611 (2014).
Yang, Y. R. et al. Primary phospholipase C and brain disorders. Adv. Biol. Regul. 61, 80–85 (2016).
Jang, H. J. et al. Phospholipase C-gamma1 involved in brain disorders. Adv. Biol. Regul. 53(1), 51–62 (2013).
Giralt, A. et al. Brain-derived neurotrophic factor modulates the severity of cognitive alterations induced by mutant huntingtin: Involvement of phospholipaseCgamma activity and glutamate receptor expression. Neuroscience 158(4), 1234–1250 (2009).
Rantamaki, T. et al. Pharmacologically diverse antidepressants rapidly activate brain-derived neurotrophic factor receptor TrkB and induce phospholipase-Cgamma signaling pathways in mouse brain. Neuropsychopharmacology 32(10), 2152–2162 (2007).
Turecki, G. et al. Evidence for a role of phospholipase C-gamma1 in the pathogenesis of bipolar disorder. Mol. Psychiatry 3(6), 534–538 (1998).
Mao, D., Epple, H., Uthgenannt, B., Novack, D. V. & Faccio, R. PLCgamma2 regulates osteoclastogenesis via its interaction with ITAM proteins and GAB2. J. Clin. Invest. 116(11), 2869–2879 (2006).
Ombrello, M. J. et al. Cold urticaria, immunodeficiency, and autoimmunity related to PLCG2 deletions. N. Engl. J. Med. 366(4), 330–338 (2012).
Zhou, Q. et al. A hypermorphic missense mutation in PLCG2, encoding phospholipase Cgamma2, causes a dominantly inherited autoinflammatory disease with immunodeficiency. Am. J. Hum. Genet. 91(4), 713–720 (2012).
Magno, L. et al. Alzheimer’s disease phospholipase C-gamma-2 (PLCG2) protective variant is a functional hypermorph. Alzheimers Res. Ther. 11(1), 16 (2019).
Lazar, M. A. Thyroid hormone receptors: Multiple forms, multiple possibilities. Endocr. Rev. 14(2), 184–193 (1993).
Yen, P. M. Physiological and molecular basis of thyroid hormone action. Physiol. Rev. 81(3), 1097–1142 (2001).
Brent, G. A. Mechanisms of thyroid hormone action. J. Clin. Investig. 122(9), 3035–3043 (2012).
Mellström, B., Naranjo, J. R., Santos, A., Gonzalez, A. M. & Bernal, J. Independent expression of the α and β c-erb A genes in developing rat brain. Mol. Endocrinol. 5(9), 1339–1350 (1991).
Bernal, J. Thyroid hormone receptors in brain development and function. Nat. Clin. Pract. Endocrinol. Metab. 3(3), 249–259 (2007).
Rahman, M. H. & Ali, M. Y. The relationships between thyroid hormones and the brain serotonin (5-HT) system and mood: Of synergy and significance in the adult brain-A review. Faridpur Med. Coll. J. 9(2), 98–101 (2014).
Kirkegaard, C. & Faber, J. The role of thyroid hormones in depression. Eur. J. Endocrinol. 138, 1–9 (1998).
Bauer, M., Heinz, A. & Whybrow, P. Thyroid hormones, serotonin and mood: Of synergy and significance in the adult brain. Mol. Psychiatry 7(2), 140–156 (2002).
Whybrow, P. C. & Prange, A. J. A hypothesis of thyroid-catecholamine-receptor interaction: Its relevance to affective illness. Arch. Gen. Psychiatry 38(1), 106–113 (1981).
Bathla, M., Singh, M. & Relan, P. Prevalence of anxiety and depressive symptoms among patients with hypothyroidism. Indian J. Endocrinol. Metabol. 20(4), 468 (2016).
Ittermann, T., Völzke, H., Baumeister, S. E., Appel, K. & Grabe, H. J. Diagnosed thyroid disorders are associated with depression and anxiety. Soc. Psychiatry Psychiatr. Epidemiol. 50(9), 1417–1425 (2015).
Demet, M. M. et al. Depression and anxiety in hyperthyroidism. Arch. Med. Res. 33(6), 552–556 (2002).
Rodrigues, N. R. et al. Characterization of Ngef, a novel member of the Dbl family of genes expressed predominantly in the caudate nucleus. Genomics 65(1), 53–61 (2000).
Shamah, S. M. et al. EphA receptors regulate growth cone dynamics through the novel guanine nucleotide exchange factor ephexin. Cell 105(2), 233–244 (2001).
Van Eekelen, M., Runtuwene, V., Masselink, W. & den Hertog, J. Pair-wise regulation of convergence and extension cell movements by four phosphatases via RhoA. PLoS ONE 7(4), e35913 (2012).
Schmucker, D. & Zipursky, S. L. Signaling downstream of Eph receptors and ephrin ligands. Cell 105(6), 701–704 (2001).
Sahin, M. et al. Eph-dependent tyrosine phosphorylation of ephexin1 modulates growth cone collapse. Neuron 46(2), 191–204 (2005).
Norris, J. M. et al. Genome-wide association study and follow-up analysis of adiposity traits in hispanic Americans: The IRAS family study. Obesity 17(10), 1932–1941 (2009).
Knöll, B. & Drescher, U. Src family kinases are involved in EphA receptor-mediated retinal axon guidance. J. Neurosci. 24(28), 6248–6257 (2004).
Birnbaum, R. et al. Investigation of the prenatal expression patterns of 108 schizophrenia-associated genetic loci. Biol. Psychiat. 77(11), e43–e51 (2015).
Sun, Y. et al. Association of MAD1L1 polymorphism (rs871925) with prenatal famine exposure and schizophrenia in a Chinese population: A case–control study. IUBMB Life 72(2), 259–265 (2020).
Sanderson, D. J. et al. The role of the GluR-A (GluR1) AMPA receptor subunit in learning and memory. Prog. Brain Res. 169, 159–178 (2008).
Frey, M. C., Sprengel, R. & Nevian, T. Activity pattern-dependent long-term potentiation in neocortex and hippocampus of GluA1 (GluR-A) subunit-deficient mice. J. Neurosci. 29(17), 5587–5596 (2009).
Kessels, H. W. & Malinow, R. Synaptic AMPA receptor plasticity and behavior. Neuron 61(3), 340–350 (2009).
Keinanen, K. et al. A family of AMPA-selective glutamate receptors. Science 249(4968), 556–560 (1990).
Sjöstedt, E. et al. An atlas of the protein-coding genes in the human, pig, and mouse brain. Science 367(6482), eaay5947 (2020).
Sanderson, D. J. et al. Deletion of the GluA1 AMPA receptor subunit impairs recency-dependent object recognition memory. Learn. Mem. 18(3), 181–190 (2011).
Wiedholz, L. M. et al. Mice lacking the AMPA GluR1 receptor exhibit striatal hyperdopaminergia and ‘schizophrenia-related’ behaviors. Mol. Psychiatry 13(6), 631–640 (2008).
Maksimovic, M., Vekovischeva, O. Y., Aitta-aho, T. & Korpi, E. R. Chronic treatment with mood-stabilizers attenuates abnormal hyperlocomotion of GluA1-subunit deficient mice. PLoS ONE 9(6), e100188 (2014).
Bannerman, D. M. et al. A comparison of GluR-A-deficient and wild-type mice on a test battery assessing sensorimotor, affective, and cognitive behaviors. Behav. Neurosci. 118(3), 643 (2004).
Schmitt, W. B. et al. Spatial reference memory in GluR-A-deficient mice using a novel hippocampal-dependent paddling pool escape task. Hippocampus 14(2), 216–223 (2004).
Zhang, J. & Abdullah, J. M. The role of GluA1 in central nervous system disorders. Rev. Neurosci. 24(5), 499–505 (2013).
Alt, A., Nisenbaum, E. S., Bleakman, D. & Witkin, J. M. A role for AMPA receptors in mood disorders. Biochem. Pharmacol. 71(9), 1273–1288 (2006).
Freudenberg, F., Celikel, T. & Reif, A. The role of α-amino-3-hydroxy-5-methyl-4-isoxazolepropionic acid (AMPA) receptors in depression: Central mediators of pathophysiology and antidepressant activity?. Neurosci. Biobehav. Rev. 52, 193–206 (2015).
Bartanusz, V. et al. Stress-induced changes in messenger RNA levels of N-methyl-D-aspartate and AMPA receptor subunits in selected regions of the rat hippocampus and hypothalamus. Neuroscience 66(2), 247–252 (1995).
Rosa, M. L. N. M., Guimarães, F. S., Pearson, R. C. A. & Del Bel, E. A. Effects of single or repeated restraint stress on GluR1 and GluR2 flip and flop mRNA expression in the hippocampal formation. Brain Res. Bull. 59(2), 117–124 (2002).
Yuen, E. Y. et al. Acute stress enhances glutamatergic transmission in prefrontal cortex and facilitates working memory. Proc. Natl. Acad. Sci. 106(33), 14075–14079 (2009).
Yuen, E. Y. et al. Mechanisms for acute stress-induced enhancement of glutamatergic transmission and working memory. Mol. Psychiatry 16(2), 156–170 (2011).
Moench, K. M., Breach, M. R. & Wellman, C. L. Prior stress followed by a novel stress challenge results in sex-specific deficits in behavioral flexibility and changes in gene expression in rat medial prefrontal cortex. Horm. Behav. 117, 104615 (2020).
Li, N. et al. Glutamate N-methyl-D-aspartate receptor antagonists rapidly reverse behavioral and synaptic deficits caused by chronic stress exposure. Biol. Psychiat. 69(8), 754–761 (2011).
Gao, L. et al. Folic acid exerts antidepressant effects by upregulating brain-derived neurotrophic factor and glutamate receptor 1 expression in brain. NeuroReport 28(16), 1078–1084 (2017).
Schwendt, M. & Ježová, D. Gene expression of two glutamate receptor subunits in response to repeated stress exposure in rat hippocampus. Cell. Mol. Neurobiol. 20(3), 319–329 (2000).
Qin, Y., Karst, H. & Joels, M. Chronic unpredictable stress alters gene expression in rat single dentate granule cells. J. Neurochem. 89(2), 364–374 (2004).
Toth, E. et al. Age-dependent effects of chronic stress on brain plasticity and depressive behavior. J. Neurochem. 107(2), 522–532 (2008).
Yuen, E. Y. et al. Repeated stress causes cognitive impairment by suppressing glutamate receptor expression and function in prefrontal cortex. Neuron 73(5), 962–977 (2012).
Duric, V. et al. Altered expression of synapse and glutamate related genes in post-mortem hippocampus of depressed subjects. Int. J. Neuropsychopharmacol. 16(1), 69–82 (2013).
Kallarackal, A. J. et al. Chronic stress induces a selective decrease in AMPA receptor-mediated synaptic excitation at hippocampal temporoammonic-CA1 synapses. J. Neurosci. 33(40), 15669–15674 (2013).
Li, N. et al. mTOR-dependent synapse formation underlies the rapid antidepressant effects of NMDA antagonists. Science 329(5994), 959–964 (2010).
Tan, C.-H., He, X., Yang, J. & Ong, W.-Y. Changes in AMPA subunit expression in the mouse brain after chronic treatment with the antidepressant maprotiline: A link between noradrenergic and glutamatergic function?. Exp. Brain Res. 170(4), 448–456 (2006).
Martínez-Turrillas, R., Del Río, J. & Frechilla, D. Sequential changes in BDNF mRNA expression and synaptic levels of AMPA receptor subunits in rat hippocampus after chronic antidepressant treatment. Neuropharmacology 49(8), 1178–1188 (2005).
Martinez-Turrillas, R., Frechilla, D. & Del Río, J. Chronic antidepressant treatment increases the membrane expression of AMPA receptors in rat hippocampus. Neuropharmacology 43(8), 1230–1237 (2002).
Barbon, A. et al. Chronic antidepressant treatments induce a time-dependent up-regulation of AMPA receptor subunit protein levels. Neurochem. Int. 59(6), 896–905 (2011).
Zanin-Zhorov, A. et al. Scaffold protein Disc large homolog 1 is required for T-cell receptor-induced activation of regulatory T-cell function. Proc. Natl. Acad. Sci. U. S. A. 109(5), 1625–1630 (2012).
Liu, W. et al. The scaffolding protein synapse-associated protein 97 is required for enhanced signaling through isotype-switched IgG memory B cell receptors. Sci. Signal 5(235), 54 (2012).
Muller, B. M. et al. Molecular characterization and spatial distribution of SAP97, a novel presynaptic protein homologous to SAP90 and the Drosophila discs-large tumor suppressor protein. J. Neurosci. 15(3 Pt 2), 2354–2366 (1995).
Funke, L., Dakoji, S. & Bredt, D. S. Membrane-associated guanylate kinases regulate adhesion and plasticity at cell junctions. Annu. Rev. Biochem. 74, 219–245 (2005).
Freudenberg, F. Quantitative analysis of Gria1, Gria2, Dlg1 and Dlg4 expression levels in hippocampus following forced swim stress in mice. Sci. Rep. 9(1), 14060 (2019).
Kim, E. & Sheng, M. PDZ domain proteins of synapses. Nat. Rev. Neurosci. 5(10), 771–781 (2004).
Nakagawa, T. et al. Quaternary structure, protein dynamics, and synaptic function of SAP97 controlled by L27 domain interactions. Neuron 44(3), 453–467 (2004).
Berman, R. M. et al. Antidepressant effects of ketamine in depressed patients. Biol. Psychiatry 47(4), 351–354 (2000).
Gould, T. D. et al. Involvement of AMPA receptors in the antidepressant-like effects of lithium in the mouse tail suspension test and forced swim test. Neuropharmacology 54(3), 577–587 (2008).
Berx, G., Becker, K. F., Höfler, H. & Van Roy, F. Mutations of the human E-cadherin (CDH1) gene. Hum. Mutat. 12(4), 226–237 (1998).
Shapiro, L. & Weis, W. I. Structure and biochemistry of cadherins and catenins. Cold Spring Harb. Perspect. Biol. 1(3), a003053 (2009).
Perez-Moreno, M. & Fuchs, E. Catenins: Keeping cells from getting their signals crossed. Dev. Cell 11(5), 601–612 (2006).
Tian, X., Liu, Z., Niu, B., Zhang, J., Tan, T. K., Lee, S. R. et al. E-cadherin/β-catenin complex and the epithelial barrier. J/ Biomed. Biotechnol. 2011 (2011).
Teo, C. H., Soga, T. & Parhar, I. S. Brain beta-catenin signalling during stress and depression. Neurosignals 26(1), 31–42 (2018).
Wang, J. et al. Ketamine-induced bladder fibrosis involves epithelial-to-mesenchymal transition mediated by transforming growth factor-β1. Am. J. Physiol.-Renal Physiol. 313(4), F961–F972 (2017).
Chang, H.-Y. et al. Selective serotonin reuptake inhibitor, fluoxetine, impairs E-cadherin-mediated cell adhesion and alters calcium homeostasis in pancreatic beta cells. Sci. Rep. 7(1), 1–13 (2017).
Demin, K. A., Kolesnikova, T. O., Galstyan, D. S., Krotova, N. A., Ilyin, N. P., Derzhavina, K. A. et al. Modulation of behavioral and hippocampal transcriptomic responses in rat prolonged chronic unpredictable stress model by fluoxetine, eicosapentaenoic acid and lipopolysaccharide. bioRxiv (2021).
Labonté, B. et al. Sex-specific transcriptional signatures in human depression. Nat. Med. 23(9), 1102–1111 (2017).
Spitzer, R. L., Williams, J. B., Gibbon, M. & First, M. B. The structured clinical interview for DSM-III-R (SCID): I: History, rationale, and description. Arch. Gen. Psychiatry 49(8), 624–629 (1992).
Papp, E. A., Leergaard, T. B., Calabrese, E., Johnson, G. A. & Bjaalie, J. G. Waxholm Space atlas of the Sprague Dawley rat brain. Neuroimage 97, 374–386 (2014).
Haines, D. E. Neuroanatomy: An Atlas of Structures, Sections, and Systems Vol. 153 (Lippincott Williams & Wilkins, 2004).
Nolte, J. The Human Brain: An Introduction to Its Functional Neuroanatomy (Mosby, 2002).
Dobin, A. et al. STAR: Ultrafast Universal RNA-seq Aligner. Bioinformatics 29(1), 15–21 (2013).
Liao, Y., Smyth, G. K. & Shi, W. featureCounts: An efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics 30(7), 923–930 (2014).
Afgan, E. et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update. Nucl. Acids Res. 46(1), 537–544 (2018).
R Core Team. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing (2017).
Huber, W. et al. Orchestrating high-throughput genomic analysis with Bioconductor. Nat. Meth. 12(2), 115–121 (2015).
Love, M. I., Huber, W. & Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15(12), 550 (2014).
Schurch, N. J. et al. How many biological replicates are needed in an RNA-seq experiment and which differential expression tool should you use?. RNA 22(6), 839–851 (2016).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. Roy. Stat. Soc. Ser. B (Methodol.) 57(1), 289–300 (1995).
Subramanian, A. et al. Gene set enrichment analysis: A knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl. Acad. Sci. 102(43), 15545–15550 (2005).
Kim, S.-Y. & Volsky, D. J. PAGE: Parametric analysis of gene set enrichment. BMC Bioinform. 6(1), 144 (2005).
Nam, D. & Kim, S.-Y. Gene-set approach for expression pattern analysis. Brief. Bioinform. 9(3), 189–197 (2008).
Tian, L. et al. Discovering statistically significant pathways in expression profiling studies. Proc. Natl. Acad. Sci. 102(38), 13544–13549 (2005).
Fornes, O. et al. JASPAR 2020: Update of the open-access database of transcription factor binding profiles. Nucl. Acids Res. 48(D1), D87–D92 (2020).
Marot, G., Jaffrézic, F. & Rau, A. metaRNASeq: Differential meta-analysis of RNA-seq data. Dim (param) 1(26408), 3 (2020).
Panahi, B., Frahadian, M., Dums, J. T. & Hejazi, M. A. Integration of cross species RNA-Seq meta-analysis and machine-learning models identifies the most important salt stress–responsive pathways in microalga Dunaliella. Front. Genet. 10, 752 (2019).
Shannon, P. et al. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 13(11), 2498–2504 (2003).
Chin, C.-H. et al. cytoHubba: Identifying hub objects and sub-networks from complex interactome. BMC Syst. Biol. 8(4), 1–7 (2014).
McGrath, J. C., Drummond, G., McLachlan, E., Kilkenny, C. & Wainwright, C. Guidelines for reporting experiments involving animals: The ARRIVE guidelines. Br. J. Pharmacol. 160(7), 1573–1576 (2010).
Smith, A. J., Clutton, R. E., Lilley, E., Hansen, K. E. A. & Brattelid, T. PREPARE: guidelines for planning animal research and testing. Lab. Anim. 52(2), 135–141 (2018).
Yu, H., Kim, P. M., Sprecher, E., Trifonov, V. & Gerstein, M. The importance of bottlenecks in protein networks: Correlation with gene essentiality and expression dynamics. PLoS Comput. Biol. 3(4), e59 (2007).
Acknowledgements
This work was financially supported by the Ministry of Science and Higher Education of the Russian Federation (Agreement No. 075-15-2022-301). AVK is the Chair of the International Zebrafish Neuroscience Research Consortium (ZNRC) and President of the International Stress and Behavior Society (ISBS, www.stress-and-behavior.com) that coordinated this collaborative multi-laboratory project. The consortium provided a collaborative idea exchange platform for this study. It is not considered as affiliation and did not fund the study. The funders had no role in the design, analyses, and interpretation of the submitted study, or decision to publish.
Author information
Authors and Affiliations
Contributions
K.A.D. (Conceptualization) (Data curation) (Formal analysis) (Funding acquisition) (Investigation) (Methodology) (Project administration) (Resources) (Software) (Validation) (Visualization) (Writing—original draft) (Writing—review and editing), N.A.K. (Investigation) (Writing—original draft) (Writing—review and editing), N.P.I. (Investigation) (Writing—original draft) (Writing—review and editing), D.S.G. (Investigation) (Writing—original draft) (Writing—review and editing), T.O.K. (Investigation) (Writing—original draft) (Writing—review and editing), T.S. (Investigation) (Writing—original draft) (Writing—review and editing), M.S.d.A. (Investigation) (Writing—original draft) (Writing—review and editing), E.V.P. (Investigation) (Writing—original draft) (Writing—review and editing), K.N.Z. (Investigation) (Writing—original draft) (Writing—review and editing), A.V.K. (Conceptualization) (Funding acquisition) (Methodology) (Project administration) (Resources) (Supervision) (Validation) (Visualization) (Writing—review and editing).
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Demin, K.A., Krotova, N.A., Ilyin, N.P. et al. Evolutionarily conserved gene expression patterns for affective disorders revealed using cross-species brain transcriptomic analyses in humans, rats and zebrafish. Sci Rep 12, 20836 (2022). https://doi.org/10.1038/s41598-022-22688-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-22688-x
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
