
Abstract
While the spatial mode of photons is widely used in quantum cryptography, its potential for quantum computation remains largely unexplored. Here, we showcase the use of the multi-dimensional spatial mode of photons to construct a series of high-dimensional quantum gates, achieved through the use of diffractive deep neural networks (D2NNs). Notably, our gates demonstrate high fidelity of up to 99.6(2)%, as characterized by quantum process tomography. Our experimental implementation of these gates involves a programmable array of phase layers in a compact and scalable device, capable of performing complex operations or even quantum circuits. We also demonstrate the efficacy of the D2NN gates by successfully implementing the Deutsch algorithm and propose an intelligent deployment protocol that involves self-configuration and self-optimization. Moreover, we conduct a comparative analysis of the D2NN gate’s performance to the wave-front matching approach. Overall, our work opens a door for designing specific quantum gates using deep learning, with the potential for reliable execution of quantum computation.
Similar content being viewed by others

Introduction
Quantum logic gates are a fundamental component of quantum information processing1 and reliable quantum computing necessitates quantum operations with high fidelity. To date, quantum gates based on superconducting circuits2,3, trapped ions4,5, defects in solid states6 and spin qubit in silicon7,8,9 have met the error correction threshold of 99% in surface code10. However, similar levels of performance have not yet been observed in photonic quantum logic gates11,12,13,14,15,16,17, which possess unique features that have attracted considerable interest in the field of quantum information processing. Photonic quantum gates are naturally compatible with quantum communications, which result in excellent networkability18,19,20,21,22,23. Benefiting from their weak interactions with the environment, photons often have long decoherence time, low noise and crosstalk, thus demanding fewer overheads for fault-tolerance24. Moreover, photons are low-cost quantum systems that operate at room temperature compared to other quantum systems. By exploiting their abundant physical dimension resources and modulation flexibility, photonic quantum gates have been demonstrated in many degrees of freedom (DoFs)25,26,27,28.
Among all these DoFs, the intrinsic infinity of orthogonal bases in the spatial modes of photons offers an extensive coding alphabet, encouraging creativity in high-dimensional quantum information processing. High-dimensional quantum states increase the information per photon and exhibit robustness against environmental noise29 and quantum cloning. The realization of quantum gates on the spatial modes of photons has garnered significant attention due to these advantages. Discrete optics schemes have already demonstrated the quantum controlled-NOT (CNOT) gate11, four-dimensional X gate13, four-dimensional CNOT gate14, and controlled-SWAP gate15. However, despite these excellent works, achieving high-dimensional unitary transformations in a scalable and compact manner with high fidelities remains a challenge.
Recently, researchers have attempted to achieve coaxial unitary transformations through multi-plane light-conversion with impressive performance16. However, this approach lacks process tomography fidelities and requires further research. In contrast to the traditional method of wave-front matching (WFM)30, more sophisticated approaches based on machine learning have been developed31. One such approach, the all-optical machine learning framework known as diffractive deep neural networks (D2NNs), was originally proposed for optical processing tasks such as image recognition and classification, with low energy costs and at the speed of light32. Many variants of the original design have since been reported to improve its performance and expand its applications33,34,35,36. Recently, it has been shown that D2NNs are capable of performing arbitrary complex-valued linear transformations37.
Here we propose a novel scheme for implementing a variety of quantum gates using the deep-learning-based design of passive diffractive layers placed in sequence to manipulate the spatial modes of photons. To be specific, we demonstrate three-dimensional X gates and H gates, as well as a single-photon CNOT gate through the adoption of specialized coding rules, leading to remarkable process fidelities exceeding 99%. Our compact and reconfigurable implementation displays great scalability and robustness of mode basis and is conducive to intelligent deployment. Moreover, we demonstrate the applicability of our approach by employing the Deutsch algorithm, which validates the feasibility of constructing a spatial mode quantum computer.
Results
Concept of quantum gate assisted by D2NN architecture
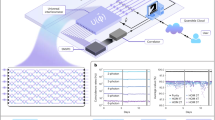
Figure 1a illustrates the quantum gate implementation concept. The spatial mode quantum gate is responsible for converting the spatial modes, where different mapping rules correspond to different logical gate operations. To design a specific quantum gate, the input and output mode correspondence should be determined. As an example, we use three Laguerre-Gaussian modes (\(L{{G}_{0}}^{-2}\), \(L{{G}_{1}}^{0}\) and \(L{{G}_{0}}^{2}\)) as inputs and outputs for the neat axial symmetry of their superposition states and exploiting azimuthal and radial DoFs to show the mapping of the three-dimensional X gate. It should be clarified that the notion of \(L{{G}_{p}}^{\ell }\) represents the LG mode with azimuthal order of \(\ell\) and radial order of p. The mode phases and the mapping between them are represented on the side of the D2NN for clarity, with the yellow line indicating the current working mode conversion in this concept figure. To implement this gate, we need to generate phase layers, which are where the D2NN comes into play. The D2NN, inspired by digital artificial neural networks, uses phase planes as hidden layers to learn the relation between inputs and outputs in an energy- and time-efficient way by harnessing the power of light. In the D2NN, inputs and outputs are optical fields, and the hidden layers are represented by phase planes, whose pixel phase determines the layer weight. Pixels between two layers are linked by the diffraction effect, and multiple phase layers are aligned sequentially along the optical axis to accomplish the desired mode conversion. The model of the spatial mode quantum gate is built and ready to be trained by iterative algorism on a computer. To learn the optimal phase layers that implement the desired operation on the experiment setup, we minimize the loss function of the deviation between the inference output field and the theoretical output field by the Adam gradient-descent algorithm31 while the pixel phase values are updated in diffractive layers. The optimization result is obtained when the loss function converges. See Supplementary Note 1 for more details on the pattern generation.

a Conceptual illustration of the D2NN quantum gate’s abstract architecture, showing how the neural networks map quantum states in high-dimensional Hilbert space to other states in that space. The specific three-dimensional X gate scheme is shown in the lower part as an example, including input states, multilayer D2NN, and output states. The mapping between inputs and outputs is indicated on the side of the D2NN, with the currently active mapping highlighted in yellow. b Experimental setup of a 4-layers spatial mode quantum gate. c A heralded single photon source is used. FPC: fiber polarization controller; Col.: collimator; SLM: spatial light modulator; L1-L6: lenses; BS: beam splitter; Cam.: camera; SPD1&2: single photon detector; C.C.: coincidence counting; PPLN1&2: periodically poled lithium niobate; SHG: second harmonic generation; SPDC: spontaneous parametric down-conversion; BPF: bandpass filter. While the heralding photons of the photon pairs are sent to the SPD1, the heralded photons are prepared into input states by complex modulation using SLM1, followed by D2NN-generated phase layers loaded onto SLM2 to perform the desired operation. Output states are analyzed using SLM3, a fiber coupling system, and the SPD2. The coincidence counting of SPD1&2 indicates the single photon passing the entire system. d Second-order correlation function \({g}^{2}(\tau )\) of the heralded single photon source determined using the Hanbury Brown and Twiss setup. The g2(0) = 0.024(2) implies the remarkable performance of the source
To verify the functionality of the generated phase layers, we conduct an experiment in which we imprint them onto a spatial light modulator (SLM), as depicted in Fig. 1b. The device comprises four parts: source, preparation, quantum gate, and measurement. The source is made by a heralded single photon source which detects one photon (known as heralding photon) from a photon pair to announce the arrival of the other one (the heralded photon), as show in Fig. 1c. Here the photon pairs at 1550 nm are generated by spontaneous parametric down-conversion (SPDC) in a type-0 periodically poled lithium niobite bulk crystal (PPLN2). The pump beam at 775 nm are generated via second harmonic generation of PPLN1 (see Method for more details). The second-order correlation function \({g}^{2}(\tau )\) of the heralded single photon source, characterized through the Hanbury Brown and Twiss (HBT) setup, is illustrated in Fig. 1d. The value of \({g}^{2}(0)\) is measured to be 0.024(2) based on the experimental outcomes derived from three-fold coincidences, with delays being varied. When assessed using another commonly employed evaluation method, \({g}^{2}(0)={C}_{123}\times {N}_{3}/{C}_{13}/{C}_{23}\), the value of \({g}^{2}(0)\) could be as low as 2.56 × 10−4. Here, C123 is the coincidence count of channel 1, 2 and 3 in the HBT setup, N3 is the single count of channel 3, and \({C}_{13}({C}_{23})\) denotes the coincidence count of channels 1 and 3 (2 and 3).
The heralded photons are then guided to the preparation stage, where we employ the complex modulation technique38,39 to prepare the desired states and to project output states, and load SLM2 with the generated D2NN phases to implement the quantum gate operation. To optimize the efficiency of SLM usage, simplify the experimental setup, and reduce the footprint of the device, we set a mirror opposing the SLM2 and adjust the incident angle such that the light reflects on the SLM2 the same number of times as the number of layers. We note that the incident angle will affect the alignment since layers are perpendicular to the optical axis in the modeling described in Fig. 1a. But the degradation in this experiment is not significant and thus acceptable here. Further analysis of the effect of the incident angle can be found in ref. 40.
High-dimensional spatial mode gates, single-photon CNOT gate and process tomography
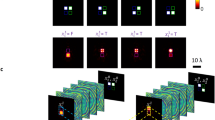
The high-dimensional spatial mode gate performs a crucial function in higher dimensional encoding space. We design and demonstrate three-dimensional X gates, H gates, and a single-photon CNOT gate, as the diagrams depicted in Fig. 2a–c. The three-dimensional X1 gate circularly shifts the basis states forward, while the three-dimensional H1 gate transforms the basis states into superpositions of all basis states with different well-defined phases. For the CNOT gate, we adopted a unique coding method to encode two bits of information, utilizing four orbital angular momentum (OAM) modes of a single photon, which are \(\left|-1\right\rangle\), \(\left|+1\right\rangle\), \(\left|-3\right\rangle\) and \(\left|+3\right\rangle\) corresponding to \(\left|00\right\rangle\), \(\left|01\right\rangle\), \(\left|10\right\rangle\) and \(\left|11\right\rangle\). With this method, input state \(\left|-3\right\rangle\) is flipped to \(\left|+3\right\rangle\) by this CNOT gate and vice versa, while input states \(\left|\pm 1\right\rangle\) remaining unchanged. This method is inspired by the concept of path coding. Consider the scenario where four distinct path states are at disposal; they can be interpreted as a tensor product of two two-dimensional qubits, such as the top/bottom and left/right directions, as depicted in the upper section of Fig. 2d. Similarly, the OAM DoF, also possessing infinite dimensions, can be viewed as the “path” within the mode space. We artificially categorize four OAM states into two types: sign dimensions (referring to phase rotation directions) and order dimensions (indicating phase rotation orders). Each category comprises two levels, effectively forming the dual levels for control and target qubits. This configuration is illustrated in the lower segment of Fig. 2d. The path encoding method has been employed for demonstrating quantum fault-tolerant threshold recently41. Additionally, the mode encoding method has also been utilized, with reference to the azimuthal and radial order of LG modes16. Figure 2e–g display the output mode profiles of these gates, which exhibit a high degree of consistency between the simulations and experimental measurements. The minor deviations in the output modes might be attributed to possible misalignment and imperfections in the apparatus. The corresponding inputs are prepared in all mutually unbiased bases (MUBs) in three-dimension for X and H gates, while for the CNOT gate, an overcomplete state set in 2 × 2-dimension is utilized. Further details about the MUBs can be found in Supplementary Note 2.

a–c Gate diagrams for the three-dimensional X1 gate, three-dimensional H1 gate and CNOT gate, with their input and output states. The phase parameter \(\omega\) is \({e}^{2\pi i/3}\), and the \(|0{\rangle }_{C}\) (\(|0{\rangle }_{T}\)) denotes that the control (target) qubit is in \(|0\rangle\) state. d Comparison between the path encoding and orbital angular momentum (OAM) encoding method. Four distinct states are categorized and can be interpreted as a tensor product of two two-dimensional qubits, such as the top/bottom and left/right directions for the path encoding, and sign dimensions (referring to phase rotation directions) and order dimensions (indicating phase rotation orders) for the OAM encoding. e–g Simulated output mode profiles and experimental profiles captured by a camera, corresponding to input states spanning all mutually unbiased bases (MUBs) in three dimensions for X and H gates, and in a 2 × 2 dimension for the CNOT gate
To obtain a more comprehensive characterization of these gates, it is necessary to employ quantum process tomography (QPT)42. It involves preparing the input states in all MUBs as previously described, applying the gates to this set of states, and performing full state tomography on every output state by means of projective measurements in all MUBs. The resulting normalized measurement outcomes yield the tomography matrices presented in Fig. 3a–c. With these tomography results, we can infer the quantum process \(\varepsilon ({\rho }_{in})\), which can be decomposed as
where \({\rho }_{in}\) is the input state of the system, \(d\) is the dimension, and \(E\) is a set of operators usually being generalized Pauli matrix. We use the Gell–Mann matrices for \(d=3\) and two-qubit generalized Pauli matrices for \(d=4\). The \({d}^{2}\times {d}^{2}\) matrix \(\chi\) is the process matrix, which contains all information about this quantum process \(\varepsilon ({\rho }_{in})\) and can be reconstructed since all other elements in Eq. (1) is known. Figure 3d–f exhibit bar plots of the reconstructed process matrices χ. For a clearer view, the bars with negative values are flipped up and presented with pale gray edges. A physical matrix must be positive semidefinite and trace preserving. Due to inherent experimental noise, however, standard QPT might produce an unphysical matrix with negative eigenvalues. Thus, the maximum-likelihood estimation (MLE) method that always yields physically sensible results is devised for the reconstruction42,43. By introducing the Lagrange multiplier and constructing an appropriate iteration form, MLE method preserves the positive semi-definiteness and trace normalization of the process matrix (see Supplementary Note 3). The conformity between theory and experiment is evaluated by process fidelity \(F={\rm{Tr}}({\chi }_{t}{\chi }_{e})\), which is the trace of the product of theoretical process matrix \({\chi }_{t}\) and experimental process matrix \({\chi }_{e}\). In this experiment, we achieve \({F}_{3DX1}=98.4(2) \%\), \({F}_{3DH1}=99.4(3) \%\) and \({F}_{CNOT}=99.6(2) \%\), respectively. To quantify the comparison between theoretical, simulated and experimental tomography matrices, the mean squared errors (MSEs) of them for different gates are exhibited in Fig. 3g. An intuitive observation emerging from the data comparison is that lower MSE signifies better fidelity, and the experimental imperfections significantly reduce the MSE level. Additionally, the process matrices of X2, H2, H3 are listed in Supplementary Note 2. Our results indicate not only the feasibility of high-dimensional operation in spatial modes of photons using D2NN, but also the high performance which is essential to the reliable execution of quantum algorithms.

a–c Tomography matrices for reconstructing the process matrices of the gates. Each element of the tomography matrix corresponds to the projective measurement outcome for a specific combination of input and projection basis. d–f Reconstructed process matrices χ for the three-dimensional X1 gate, three-dimensional H1 gate and CNOT gate. The X and H gates process matrices are shown in the Gell–Mann matrix basis, while the CNOT gate process matrix is shown on the basis of two-qubit generalized Pauli operators. Theoretical process matrices and experimentally reconstructed process matrices are represented by transparent and colored bars, respectively. The real and imaginary parts are plotted separately, and bars with negative values are flipped up for better visibility and have greyish-white edges. The process fidelities for these three gates are 98.4(2)%, 99.4(3)%, and 99.6(2)%. g Mean squared error (MSE) of simulated and experimental tomography compared to theoretical tomography matrix
Demonstration of the Deutsch algorithm and intelligent deployment
Quantum gates are fundamental components of quantum algorithms, which leverage quantum superposition and interference to achieve computational advantages over classical algorithms. These gates are capable of simultaneously processing all possible states via superposition and achieving the correct outcome via interference. As an application of the D2NN quantum gates, we implement the quantum circuit of the two-bit version of the Deutsch-Jozsa algorithm, known as the Deutsch algorithm44,45. The algorithm’s goal is to determine whether a Boolean function \(f:\{{x}_{1},{x}_{2},\cdots ,{x}_{n}\}\to \{0,1\}\) is constant (\(f({x}_{i})=0\) or \(f({x}_{i})=1\) for all \(x\)), or balanced (\(f({x}_{i})=0\) for half of \(x\) and \(f({x}_{i})=1\) for the other half of \(x\)). In classical computing, the worst-case scenario requires \({2}^{n-1}+1\) query of \(f\) to identify it, since there are \({2}^{n}\) possible outputs.
Leveraging the power of the Deutsch algorithm, the question can be solved with just one function evaluation, instead of growing exponentially with the number of qubits. In the state preparation stage, we set the qubit \(x\) as \(|0{\rangle }_{x}\) and qubit \(y\) as \(|1{\rangle }_{y}\), and apply two H gates to each qubit to create a superposition that represents all possible state combinations. By creating a superposition, the oracle function (maps the state \(|x\rangle |y\rangle\) to \(|x\rangle |y\oplus f(x)\rangle\), \(\oplus\) is the XOR operation) can work on all possible configurations simultaneously. After applying the oracle function and the interference (H gates to each qubit after the oracle), we will measure qubit \(x\) as 0 for all constant functions or 1 for balanced functions. The derivation of this process is in Supplementary Note 4. Two kinds of oracle functions that are constant and balanced are constructed using an identity operator and a CNOT operator, respectively, as shown in Fig. 4a. The corresponding output states are presented before measurement. Notably, the oracle function and interference process are implemented with a single SLM, which reduces system complexity and alignment difficulties, enhancing the practicality of our implementation. Although only \(x\) qubit measurement is required, we project and measure the output photon in four bases of two qubits for clarity, as shown in Fig. 4b, and the results are consistent with the theoretical output states in Fig. 4a.

a Circuit diagram of the Deutsch algorithm based on the single-photon quantum gate. The whole circuit is divided into three parts: state preparation, oracle operation followed by interference, and measurement, as marked in three colored blocks on the circuit. These three parts are performed by three separate spatial light modulators (SLMs). The oracle is implemented by an identity operation circuit for a constant function and a CNOT operation for a balanced function. The states after the first and second parts are illustrated in this figure, separately. b Projective measurement results of the circuit output states in four bases for constant (in orange) and balanced (in blue) functions
In addition to demonstrating various gates in the quantum circuit, our reconfigurable implementation showcases more innovative features. We propose a protocol to explore its potential in applications that demand intelligent deployment. This protocol takes advantage of the flexibility offered by the reconfigurable setup and the smooth coordination among preparation, operation, and measurement devices. The task is to configure the gate setup according to preset commands, specifically achieving the automated switch from \({U}_{1}\) to \({U}_{2}\). The entire self-configuration process is illustrated in Fig. 5a, encompassing several steps. First, the current gate’s performance is assessed using process tomography. This tomography matrix is then utilized for reconstructing the gate fidelity via the MLE method mentioned earlier. The MLE method produces different fidelities based on various assumptions about ideal tomography matrices, as depicted in Fig. 5b. Among these assumptions, the one leading to the highest fidelity is most likely to represent the actual gate behavior, thereby allowing the gate to be tested and identified. Subsequently, the system transitions to another desired gate configuration by loading a new layer set, which is H3 here. To confirm the realization of the intended gate, another round of process tomography and reconstruction are performed. The annotations at the initiation and termination points of the tomography arrow in Fig. 5a signify the initial and measured tomography matrices, respectively. Meanwhile, the annotations along the switch arrow denote the previous and updated layers.

a Schematic of the self-configuration and optimization process. Tomo.: tomography; The process involves testing the current gate via process tomography, switching to the desired gate by loading a new layer set. To confirm the realization of the intended gate, another round of process tomography is performed. The annotations at the initiation and termination points of the tomography arrow signify the initial and measured tomography matrices, respectively. The annotations along the switch arrow denote the previous and updated layers. Once the configuration is complete, a spacing optimization process is performed to match the calculation spacing with the physical spacing. b Gate fidelities used to test the gate in the self-configuration demonstration before (H1 gate) and after switching (H3 gate). c Visibility plot of the search steps for the optimal spacing between each layer. A rough range is estimated first, followed by a search process to narrow down the possible interval of maximum visibility. The maximum visibility achieved is ~0.97 at 41 mm
After configuring to the desired gate, the next step involves optimizing the spacing between each layer to match the experimental setup. Adjusting the spacing between SLM2 and the mirror can be a tedious task, but it can be avoided by varying the spacing during pattern generation. This approach is more compatible with automatic protocols. First, a rough estimate of the spacing range is made based on the setup, and then five equally spaced sampling points are selected as the initial condition. The visibilities of these sampling points and their distribution are used to update the sampling points for the next step (see Supplementary Note 5). This iterative process stops when the searching range is below the threshold, where the spacing variance does not correspond to a significant change in visibility. The threshold is presumed to be lower than 0.1 mm, which is supported by the analysis of Z-axis offset effects in Supplementary Note 6 (with some approaches to improve misalignment tolerance). Figure 5c shows the visibilities of different sampling spots in each update, with the highest visibility observed around 0.97 at 41 mm.
Gate performance analysis and comparison with WFM
Optimizing practical parameters inherent to the SLM is of paramount importance to achieve optimal quantum gate performance. To assess the critical pixel number of the SLM, it is essential to explore two distinct scenarios, as diagramed in Fig. 6a, b. The first scenario involves variations in the number of pixels while keeping the physical dimensions of the layers fixed. Alternatively, the second scenario considers changes in the number of pixels while maintaining the pixel dimensions, which, in turn, alter the physical dimensions of the layers.

The diagrams of a pixel number scaling with layer dimensions fixed, b pixel number scaling with pixel dimensions fixed, c grayscale and d distortion of SLM variations. e–h Corresponding visibility and loss plots corresponding to the parameters explored in a–d. Both visibility and loss metrics demonstrate degradation when either upscaling or downsampling is applied. An increase in pixel numbers enhances performance, but with diminishing marginal returns, validating our choice of 384 pixels as sufficient. Notably, a decrease in grayscale depth exhibits negligible effects on performance until it falls below 16 levels. Furthermore, SLM distortion introduces undesired phase shifts to the D2NN pattern, resulting in reduced performance
In the first scenario, our primary focus is on the influence of pixel density or sampling precision on quantum gates. Our analysis intuitively suggests that higher pixel densities contribute to enhanced quantum gate performance. Additionally, we delve into the consequences of upscaling or downsampling quantum gates with different pixel densities. The findings depicted in Fig. 6e reveal that both upscaling and downsampling have a detrimental effect on performance, although they operate through distinct mechanisms. Upscaling reduces performance by diminishing the effective modulation degrees of freedom, while downsampling leads to performance degradation due to sampling errors arising from pixel merging. In the second scenario, our analysis demonstrates, in Fig. 6f, that increasing the number of pixels can indeed boost performance. However, it’s important to note that the marginal improvement diminishes, and performance changes become less significant after reaching approximately 384 pixels. This suggests that, for the scope of our work, selecting 384 pixels suffices to achieve the desired outcomes.
Moreover, the gray level depth of the SLM can significantly impact quantum gate performance, as illustrated in Fig. 6c, g. Lower gray level depths introduce inaccuracies in pixel values. Surprisingly, our findings indicate that quantum gate performance remains relatively stable within the range of 32 to 512 gray levels, with a noticeable performance drop occurring only when the depth falls below 16 levels. Another critical parameter affecting performance is the presence of phase distortion in the SLM, as shown in Fig. 6d, h. The distortion phase applied is a combination of the fourth and fifteenth terms of Zernike polynomials. Phase distortion introduces additional phase components that render the original design ineffective. Consequently, the necessity of pre-compensating for shape distortions in the SLM becomes evident.
Despite our successful experimental demonstration of the D2NN spatial mode quantum gate, we remain concern about its upper performance limit. Two primary metrics are used to evaluate the device performance: visibility and loss. Visibility characterizes the quality of the output, and is defined as \({V}_{i}=|\langle {\varphi }_{i}|{\varphi }_{i}\rangle {|}^{2}/{\sum }_{i,j}^{d}|\langle {\varphi }_{i}|{\varphi }_{j}\rangle {|}^{2}\), where \(|{\varphi }_{j}\rangle\) is the defined computational basis, and \(d\) is the dimension. Loss, defined as \((|{{\rm{E}}}_{in}{|}^{2}-|{{\rm{E}}}_{out}{|}^{2})/|{{\rm{E}}}_{in}{|}^{2}\), is the normalized energy waste and negatively related to efficiency. It is worth mentioning that the energy loss here referring to the scattering loss that arises from undesired phase pattern design or pattern misalignment, and does not account for Fresnel reflection effects. Several factors might impact visibility and loss, including the number of trainings, the spacing between each layer, and the number of layers with a fixed spacing or a fixed total length, as presented in Fig. 7a–d. Our data indicate that performance generally improves with increasing numbers of training and layers, eventually converging to a certain value. It is intuitive that the D2NN fitness shows positive correlation with the training number, resulting in better visibility and lower loss. Similarly, more layers provide more DoFs to achieve desired conversion, whether fixed spacing or fixed total length. It is worth noting that poor and less reliable performance is observed when the number of trainings or layers is very small, as these designs do not fully function. Specifically, some inputs are not correctly converted, and their energy is lost due to scattering. Of interest, the loss related to spacing between each layer (Fig. 7b) shows a small dip around 10 mm and flattens out as the spacing increases. This discrepancy could be attributed to lower pixel utilization for shorter diffraction distances and larger losses due to scattering for larger diffraction distances.

Simulated visibility (blue) and loss (red) as a function of a the number of trainings (4 layers), b spacing between each layer (4 layers), c number of layers with a fixed spacing, and d number of layers with a fixed total length. b–d are trained for 500 epochs. e, f Performance comparison of D2NN and WFM in visibility and loss. g Introduction of a separate energy loss term to emphasize its expression during the training process. h Visibility and i loss metrics based on varying weights assigned to the energy loss component within the loss function. All 12 states in three-dimensional MUBs are considered. The solid curves represent the average data, and the filled areas show the range of values for different states
To clearly illustrate the improvement of our approach, we compare the performance of D2NN with WFM in Fig. 7e, f. The results indicate that both methods converge within a few dozen iterations in terms of visibility and loss. WFM achieves near-perfect energy conservation, as evidenced by its impressive loss plot. This can be explained by the weight update mechanism in WFM, which is based on the overlap between the forward propagation field and the backpropagation field. In contrast, D2NN allows for arbitrary connections between nodes and uses the Adam algorithm to avoid local optima46. Although D2NN requires more training to reduce its loss, it outperforms WFM in terms of visibility and approaches the ideal value of 1. It is worth noting that in all cases shown in Fig. 7, we use all 12 states in the three-dimensional MUBs as input states, which diminishes the performance of WFM. Overall, the comparison reveals that D2NN significantly improves visibility at a small cost of energy loss.
Fortunately, theoretical energy losses associated with D2NN can be controlled by incorporating them into the optimization loss function, as depicted in Fig. 7g. Originally, the loss function is defined as the MSE between the inferred outputs \(E\) and the corresponding theoretical outputs \(\hat{E}\), which is \({f}_{L}=\frac{1}{{n}^{2}}\mathop{\sum }\limits_{i,j}^{n}({|{E}_{i,j}-{\hat{E}}_{i,j}|}^{2})\). It is worth noting that the original loss function inherently accounts for energy loss to some extent, yet the energy term constraints are not fully expressed during the training process. Instead, greater emphasis is placed on optimizing visibility. The introduction of a separate energy loss term aims to strike a balance of these two parameters. As the weight assigned to the energy loss in the new loss function increases, we observe a slight reduction in output visibility. However, it is noteworthy that the D2NN outputs continue to outperform the optimized visibility achieved with the WFM method. Simultaneously, the energy loss of D2NN converges towards that of the WFM method, as shown in Fig. 7h, i, underscoring the superiority of our approach.
Discussion
In conclusion, we present a universal approach utilizing deep learning to design high fidelity and high-dimensional spatial mode quantum gates. Our scheme is implemented with a group of D2NN-generated phase layers, allowing us to experimentally demonstrate all three-dimensional quantum gates and a single-photon CNOT gate with an average fidelity over 99%, as characterized by quantum process tomography. Compared to discrete optics demonstrations, our implementation is more practical, relatively compact, and capable of integrating multiple operations into a single device, simplifying the physical implementation of quantum circuits and reducing error rates. Moreover, our approach enables the cascading of multiple gates, facilitating the implementation of quantum circuits for other algorithms. Our design is also reconfigurable and allows for closed-loop control, enabling automatic configuration47. Finally, we analyze the theoretical performance upper limit of D2NN gates and compare it with the WFM approach. Although we find some similarities between the two, D2NNs are more general and can achieve higher visibility by varying the loss factor.
The experimental performance of the gates proposed in this work is affected by the gray-level accuracy of the phase modulation device and its diffraction efficiency, both of which are expected to be improved with advancements in device manufacture. Misalignment of the experimental setup is another factor that may lead to deviations from the ideal output states and energy losses. This issue could be addressed through better alignment protocols, auto-alignment algorithms, or self-optimization processes. Other approaches to reduce the impact of misalignment include modeling the entire physical process more precisely and implementing pre-compensation techniques, or introducing random offsets in the D2NN design to improve tolerance48,49 (see Supplementary Note 7 for further details). Regarding the measured experimental loss in the SLM, accounting for the four reflections, the observed 63.44% loss aligns reasonably well with the SLM’s inherent efficiency of approximately 90%. To address this concern in reflective setups, a potential solution involves replacing the SLM with manufactured phase layers coated with high reflection materials50. For configurations with a transmissive nature, it is worth considering potential collaboration between certain anti-reflection techniques and the D²NN architecture51. Moreover, the theoretical upper limit of D2NN constrains the gate performance, but it can be improved by using different D2NN architectures52,53, various layers (e.g., nonlinear layers54,55, transmissivity modulation layers32,56), operations in Fourier space54, or special training strategies57.
Regarding scalability, the spatial-mode-encoding scheme enables access to a high-dimensional Hilbert space in theory58. Previous experiments have achieved dozens or even hundreds of dimensions in the coding space using similar multi-plane devices40,59,60. It has also been shown that the dimensionality is linearly proportional to the number of phase planes61. These findings suggest the potential of our spatial mode gate implementation to handle qudits in higher dimensions at the cost of increasing the number of layers. Furthermore, we test several coding bases for the three-dimensional gates and the CNOT gate, and they all exhibit reliable behavior, indicating that our approach has excellent robustness to different spatial modes of encoding, even with a certain number of dimensions.
Materials and methods
Experimental setup
A 1550 nm laser (~500 mW) and the PPLN1 are used to generate the pump beam at 775 nm (~2 mW) for the SPDC process in PPLN2, as shown in the left bottom of Fig. 1b. A set of bandpass filters are used after the PPLN1 to suppress the residual 1550 nm laser. The 775 nm pump beam is focused by a lens (f = 150 mm, not shown) at the PPLN2 with a radius of 70 μm to enhance SPDC efficiency. To filter out the 775 nm pump beam, two 1550 nm bandpass filters, each with a 10 nm bandwidth, are utilized. Both crystals satisfy type-0 phase matching condition and are mounted on the temperature-controlled stages to uphold the optimal phase matching temperature: 56.6 °C for PPLN1 and 82 °C for PPLN2. Accounting for system losses, detector efficiency, and a heralding efficiency of approximately 14.5%, the characterized source brightness stands at ~\(3.79\times {10}^{6}\) pairs/s/nm/mW. Photon pairs generated via SPDC are separated by a BS, and then one of them is coupled into free-space by a collimator (Thorlabs F260FC-1550) at a beam waist of 1.5 mm. A fiber polarization controller (FPC1) is used to align the photon polarization to the working direction of an SLM (PLUTO-2.1-TELCO-013, SLM1 in Fig. 1b) which carves out required LG modes by imprinting complex modulation phase patterns. A 4-f lens set (L1 and L2) with a pinhole is required by the complex modulation method to filter out the desired diffraction light. A mirror (Thorlabs MRA10-M01) is set opposing the SLM2 so that light bounces off SLM2 four times to transform input modes under the configuration of the generated phase layers on SLM2. The four modulation phase layers are 384 × 384 pixels in size (8 µm) and spaced 41 mm apart. Owning to its reflection implementation and tilted incident light axis, the spacing between SLM2 and mirror is even less than half of 41 mm, making its footprint relatively compact. At the output plane, another 4-f lens set (L3 and L4) is used to image the outputs onto the SLM3, which, together with the third 4-f imaging system, a collimator, a single-mode fiber, and the superconducting nanowire single-photon detector (Eos4 of Single Quantum, 70% efficiency at 1550 nm, ~300 dark counts), constitute a spatial mode analyzer. A multichannel picosecond event timer (HydraHarp 400 of PicoQuant) is used to record all detector clicks for later analysis.
References
Nielsen, M. A. & Chuang, I. L. Quantum Computation and Quantum Information. (Cambridge: Cambridge University Press, 2010).
Barends, R. et al. Superconducting quantum circuits at the surface code threshold for fault tolerance. Nature 508, 500–503 (2014).
Xu, Y. et al. High-fidelity, high-scalability two-qubit gate scheme for superconducting qubits. Phys. Rev. Lett. 125, 240503 (2020).
Ballance, C. J. et al. High-fidelity quantum logic gates using trapped-ion hyperfine qubits. Phys. Rev. Lett. 117, 060504 (2016).
Srinivas, R. et al. High-fidelity laser-free universal control of trapped ion qubits. Nature 597, 209–213 (2021).
Rong, X. et al. Experimental fault-tolerant universal quantum gates with solid-state spins under ambient conditions. Nature Communications 6, 8748 (2015).
Noiri, A. et al. Fast universal quantum gate above the fault-tolerance threshold in silicon. Nature 601, 338–342 (2022).
Mądzik, M. T. et al. Precision tomography of a three-qubit donor quantum processor in silicon. Nature 601, 348–353 (2022).
Xue, X. et al. Quantum logic with spin qubits crossing the surface code threshold. Nature 601, 343–347 (2022).
Wang, D. S., Fowler, A. G. & Hollenberg, L. C. L. Surface code quantum computing with error rates over 1%. Phys. Rev. A 83, 020302 (2011).
O’Brien, J. L. et al. Demonstration of an all-optical quantum controlled-NOT gate. Nature 426, 264–267 (2003).
Okamoto, R. et al. Demonstration of an optical quantum controlled-NOT gate without path interference. Phys. Rev. Lett. 95, 210506 (2005).
Babazadeh, A. et al. High-dimensional single-photon quantum gates: concepts and experiments. Phys. Rev. Lett. 119, 180510 (2017).
Wang, Y. L. et al. Experimental demonstration of efficient high-dimensional quantum gates with orbital angular momentum. Quantum Sci. Technol. 7, 015016 (2022).
Wang, F. R. et al. Experimental demonstration of a quantum controlled-SWAP gate with multiple degrees of freedom of a single photon. Quantum Sci. Technol. 6, 035005 (2021).
Brandt, F. et al. High-dimensional quantum gates using full-field spatial modes of photons. Optica 7, 98–107 (2020).
Chen, Z. & Segev, M. Highlighting photonics: looking into the next decade. eLight 1, 2 (2021).
Ding, Y. H. et al. High-dimensional quantum key distribution based on multicore fiber using silicon photonic integrated circuits. npj Quantum Inform. 3, 25 (2017).
Boaron, A. et al. Secure quantum key distribution over 421 km of optical fiber. Phys. Rev. Lett. 121, 190502 (2018).
Mao, Y. Q. et al. Integrating quantum key distribution with classical communications in backbone fiber network. Optics Express 26, 6010–6020 (2018).
Liu, J. et al. Multidimensional entanglement transport through single-mode fiber. Sci. Adv. 6, eaay0837 (2020).
Wang, Q. K. et al. High-dimensional quantum cryptography with hybrid orbital-angular-momentum states through 25 km of ring-core fiber: a proof-of-concept demonstration. Phys. Rev. Appl. 15, 064034 (2021).
Da Lio, B. et al. Path-encoded high-dimensional quantum communication over a 2-km multicore fiber. npj Quantum Inform. 7, 63 (2021).
Cozzolino, D. et al. High-dimensional quantum communication: benefits, progress, and future challenges. Adv. Quantum Technol. 2, 1900038 (2019).
Kagalwala, K. H. et al. Single-photon three-qubit quantum logic using spatial light modulators. Nat. Commun. 8, 739 (2017).
Zeuner, J. et al. Integrated-optics heralded controlled-NOT gate for polarization-encoded qubits. npj Quantum Inform. 4, 13 (2018).
Larsen, M. V. et al. Deterministic multi-mode gates on a scalable photonic quantum computing platform. Nat. Phys. 17, 1018–1023 (2021).
Shi, S. et al. High-fidelity photonic quantum logic gate based on near-optimal Rydberg single-photon source. Nat. Commun. 13, 4454 (2022).
Ecker, S. et al. Overcoming noise in entanglement distribution. Phys. Rev. X 9, 041042 (2019).
Sakamaki, Y. et al. New optical waveguide design based on wavefront matching method. J. Lightwave Technol. 25, 3511–3518 (2007).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. Preprint at https://doi.org/10.48550/arXiv.1412.6980 (2017).
Lin, X. et al. All-optical machine learning using diffractive deep neural networks. Science 361, 1004–1008 (2018).
Luo, Y. et al. Design of task-specific optical systems using broadband diffractive neural networks. Light Sci. Appl. 8, 112 (2019).
Li, J. X. et al. Class-specific differential detection in diffractive optical neural networks improves inference accuracy. Adv. Photon. 1, 046001 (2019).
Kuschmierz, R., Scharf, E., Ortegón-González, D. F., Glosemeyer, T. & Czarske, J. W. Ultra-thin 3D lensless fiber endoscopy using diffractive optical elements and deep neural networks. Light. Adv. Manuf. 2, 415–424 (2021).
Li, Y., Luo, Y., Mengu, D., Bai, B. & Ozcan, A. Quantitative phase imaging (QPI) through random diffusers using a diffractive optical network. Light. Adv. Manuf. 4, 1–16 (2023).
Kulce, O. et al. All-optical synthesis of an arbitrary linear transformation using diffractive surfaces. Light Sci. Appl. 10, 196 (2021).
Davis, J. A. et al. Encoding amplitude information onto phase-only filters. Appl. Opt. 38, 5004–5013 (1999).
Bolduc, E. et al. Exact solution to simultaneous intensity and phase encryption with a single phase-only hologram. Opt. Lett. 38, 3546–3549 (2013).
Fontaine, N. K. et al. Laguerre-gaussian mode sorter. Nat. Commun. 10, 1865 (2019).
Sun, K. et al. Optical demonstration of quantum fault-tolerant threshold. Light Sci. Appl. 11, 203 (2022).
Fiurášek, J. & Hradil, Z. Maximum-likelihood estimation of quantum processes. Phys. Rev. A 63, 020101 (2001).
Ježek, M., Fiurášek, J. & Hradil, Z. Quantum inference of states and processes. Phys. Rev. A 68, 012305 (2003).
Deutsch, D. & Jozsa, R. Rapid solution of problems by quantum computation. Proc. R. Soc. A: Math. Phys. Eng. Sci. 439, 553–558 (1992).
Perez-Garcia, B. et al. Quantum computation with classical light: implementation of the Deutsch-Jozsa algorithm. Phys. Lett. A 380, 1925–1931 (2016).
Hashimoto, T. Wavefront matching method as a deep neural network and mutual use of their techniques. Opt. Commun. 498, 127216 (2021).
Zhou, T. K. et al. Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit. Nat. Photon. 15, 367–373 (2021).
Mengu, D. et al. Misalignment resilient diffractive optical networks. Nanophotonics 9, 4207–4219 (2020).
Mengu, D., Rivenson, Y. & Ozcan, A. Scale-, shift-, and rotation-invariant diffractive optical networks. ACS Photonics 8, 324–334 (2021).
Zhang, Y. H. et al. An ultra-broadband polarization-insensitive optical hybrid using multiplane light conversion. J. Lightwave Technol. 38, 6286–6291 (2020).
Horodynski, M. et al. Anti-reflection structure for perfect transmission through complex media. Nature 607, 281–286 (2022).
Chang, J. L. et al. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification. Scientific Reports 8, 12324 (2018).
Dou, H. K. et al. Residual D2NN: training diffractive deep neural networks via learnable light shortcuts. Optics Lett. 45, 2688–2691 (2020).
Yan, T. et al. Fourier-space diffractive deep neural network. Phys. Rev. Lett. 123, 023901 (2019).
Zuo, Y. et al. All-optical neural network with nonlinear activation functions. Optica 6, 1132–1137 (2019).
Xiong, W. J. et al. Optical diffractive deep neural network-based orbital angular momentum mode add-drop multiplexer. Optics Express 29, 36936–36952 (2021).
Rahman, M. S. S. et al. Ensemble learning of diffractive optical networks. Light Sci. Appl. 10, 14 (2021).
Gao, X. Q. et al. Arbitrary d-dimensional Pauli X gates of a flying qudit. Phys. Rev. A 99, 023825 (2019).
Wen, H. et al. Scalable non-mode selective Hermite-Gaussian mode multiplexer based on multi-plane light conversion. Photon. Res. 9, 88–97 (2021).
Rademacher, G. et al. Peta-bit-per-second optical communications system using a standard cladding diameter 15-mode fiber. Nat. Commun. 12, 4238 (2021).
Kulce, O. et al. All-optical information-processing capacity of diffractive surfaces. Light Sci. Appl. 10, 25 (2021).
Acknowledgements
The authors would like to extend sincere thanks to Dr. Carmelo Rosales-Guzmán and Dr. Xiang Cheng for their invaluable insights and thoughtful discussion during the development of this work. This work was supported by the National Natural Science Foundation of China (62125503, 62261160388, 62001182, 62371202), the Natural Science Foundation of Hubei Province of China (2023AFA028, 2023AFB814), the Key R&D Program of Guangdong Province (2018B030325002), the Key R&D Program of Hubei Province of China (2021BAA024, 2020BAB001), and the Innovation Project of Optics Valley Laboratory (OVL2021BG004).
Author information
Authors and Affiliations
Contributions
J.W. and Q.W. developed the concept and conceived the experiments. Q.W. and J.L. designed the optical system. Q.W. and D.L. simulated the system and carried out the experiment with J.L. Q.W., D.L., and J.L. prepared the experimental data analyses. Q.W. drafted the manuscript with support by all co-authors. J.W. finalized the paper. J.W. supervised the project.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Q., Liu, J., Lyu, D. et al. Ultrahigh-fidelity spatial mode quantum gates in high-dimensional space by diffractive deep neural networks. Light Sci Appl 13, 10 (2024). https://doi.org/10.1038/s41377-023-01336-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41377-023-01336-7

{kind=link}