
Abstract
The urinary microbiome has been increasingly characterized using next-generation sequencing. However, many of the technical methods have not yet been specifically optimized for urine. We sought to compare the performance of several DNA isolation kits used in urinary microbiome studies. A total of 11 voided urine samples and one buffer control were divided into 5 equal aliquots and processed in parallel using five commercial DNA isolation kits. DNA was quantified and the V4 segment of the 16S rRNA gene was sequenced. Data were processed to identify the microbial composition and to assess alpha and beta diversity of the samples. Tested DNA isolation kits result in significantly different DNA yields from urine samples. DNA extracted with the Qiagen Biostic Bacteremia and DNeasy Blood & Tissue kits showed the fewest technical issues in downstream analyses, with the DNeasy Blood & Tissue kit also demonstrating the highest DNA yield. Nevertheless, all five kits provided good quality DNA for high throughput sequencing with non-significant differences in the number of reads recovered, alpha, or beta diversity.
Similar content being viewed by others


Introduction
Resident microbes in multiple niches of the human body are being studied for their impact on health and disease. The microbiome of the urinary tract has not been extensively characterized, though differences in urinary microbiota are evident in urologic conditions such as urgency urinary incontinence1,2,3. It is also likely that the presence of urinary commensals affects the propensity towards development of urinary tract infections4. It is now known that urine is a low microbial biomass (microbe-poor) environment that contains a range of fastidious bacteria that are not detected using standard urine culture, or even with the recently developed enhanced quantitative urine culture (EQUC) techniques1,5. As such, characterization of the urinary microbiome has been accomplished using culture-independent methods, relying on next-generation sequencing methods such as bacterial 16S rRNA gene sequencing, also known as amplicon sequencing or marker gene sequencing.
Despite the fact that the urinary microbiome has been recognized for almost a decade1, many of the technical methods used in marker gene sequencing have not been optimized or standardized for detection of urinary microbiota, as has been done for other microbiome niches6,7. When performing DNA sequencing on biological samples to extract information about the bacterial communities present, multiple technical steps are required in order to name and classify the microbes contained in the sample: sample collection, storage and handling, DNA isolation, amplification, and sequencing8. At each of these steps, bias could influence the final results, and several technical steps have been evaluated in recent studies. The method of sample collection affects the recovered urinary microbiome characteristics, with catheterized sampling offering the most specificity for the bladder environment1,9,10. As for storage and handling steps, high concentrations of certain chemicals in urine result in precipitation of crystalline and amorphous materials such as uric acid, calcium phosphates, calcium oxalate and others11. The presence of crystalline precipitants in urine were recently shown to alter the pelleting and lysis of cells, and biochemical reactions such as amplification via polymerase chain reaction (PCR) prior to sequencing12,13. Storage and handling of urine specimens after collection has also been investigated14, and the study demonstrates that urine samples should be cooled as soon as possible if a stabilizing agent such as Assay Assure® is not used.
In addition to sample collection, handling and storage, the DNA isolation methods used are another important step for microbiome analysis where bias could be introduced prior to sequencing. At this step, human and microbial DNA are extracted from the proteins, salts, and other components of the physiologic sample. This requires lysis of human cells and bacterial cell walls in order to isolate the DNA contained within. When performing marker gene sequencing, the isolated DNA is later subjected to PCR, where the marker gene is amplified and uniquely tagged for sequencing. The bacterial 16S rRNA gene is one of the most commonly used marker genes used for bacterial identification. To date, a range of amplicons encompassing multiple different variable regions of the 16S rRNA gene including V2, V3-V4, V4, V4-V5, and V68,15,16 have been applied to urinary microbiome samples.
Regardless of which segment of DNA is used as the marker gene, reliably isolating all of the DNA in a sample is an important step prior to PCR and sequencing. Many commercial kits and custom protocols for DNA isolation were developed for microbiome analyses specifically for microbe-rich or microbe-poor environments19,22,25,26. This tailoring of DNA isolation methods was required to achieve more representative identification and quantification of the microbial composition for each respective environment. Nevertheless, different methods for DNA isolation show variable efficiencies of DNA recovery and quality. A large number of studies report significant differences in microbial composition identified with the use of different DNA isolation protocols17,18,19,20,21,22,23,24. Biases introduced by the DNA isolation methods to microbial composition persist both in microbe-rich communities such as gut, soil, sewage19,25 and in microbe-poor communities such as water, meconium, and animal larvae22,26. However, there are occasionally studies that do not show notable differences among DNA extraction methods in other microbial niches23.
Most studies that examine differences among DNA extraction protocols note that the main hurdles are incomplete cellular lysis and presence of PCR inhibitors that could interfere with downstream sequencing. Incomplete cellular lysis for some microbes biases the compositional analyses towards more easily lysed taxa. These differences in lysis were repeatedly recorded for Gram positive bacteria and fungi that both have more robust cell walls in comparison with Gram negative bacteria20,26. For the urinary microbiome, researchers have previously found a significant bias in the ability to detect fungi due to the inability to efficiently lyse hardy fungal cells13,27. However, many urinary microbiome studies employ a variety of DNA isolation techniques without considering these potential sources of bias. Furthermore, microbe-poor communities, such as urine, are especially sensitive to potential influence from contaminants, which should be taken into account during analysis6,28. Table S1 summarizes multiple studies to highlight the diversity of the methods of DNA isolation used to date. These studies use both custom and commercially available DNA isolation methods. As there are no studies directly comparing the results obtained when urine samples are subjected to different commercial DNA isolation kits, our primary objective was to assess whether recovered microbes identified by 16S rRNA sequencing differ based on the DNA isolation protocol.
Results
DNA recovery and performance in high throughput sequencing
A total of 11 urine samples and one negative control containing phosphate buffered saline (PBS) were equally divided and subjected to parallel DNA isolation procedures with five DNA isolation kits (Table 1). The total DNA concentration recovered from each DNA isolation kit was highly variable (Fig. 1A, Table S3) with the Qiagen DNeasy Blood and Tissue kit resulting in the highest concentrations and the Promega kit with the lowest (Kruskal–Wallis p = 0.0007 overall, pairwise Wilcoxon rank sum < 0.05). Since each aliquot from urine samples contained the same starting material per kit, and each kit elutes DNA into a 50 µL volume, higher concentrations would reflect a higher total amount of DNA isolated. Of the 60 samples (55 from urine and 5 controls), a total of 7 (11.6%) did not produce identifiable bands on gel electrophoresis after PCR amplification of the V4 region of the 16S rRNA gene (Table S3, Fig. S1A). The majority of these samples were derived from one urine specimen with the lowest quantity of recovered DNA (Sample 11) and negative controls, suggesting truly low quantity DNA in these samples. However, in one instance (Sample 4), no gel band was detected after PCR when DNA was extracted with the Qiagen DNeasy Ultraclean kit though bands were identified when DNA was isolated with all of the other four kits.

Isolation kits produce different total DNA concentrations but similar 16S specific sequencing depth. (A) DNA concentration measured by Qubit varied significantly by DNA isolation kit used (Kruskal–Wallis p = 0.0007), with the Blood & Tissue kit recovering significantly more and the Promega kit recovering significantly less DNA compared to others (pairwise Wilcoxon rank sum < 0.05). (B) Differences in total DNA concentration did not translate to significant differences in the number of sequence reads per sample (Kruskal–Wallis p = 0.806).
Despite the differences in DNA concentrations between isolation kits, DNA isolated from all kits appeared to perform similarly in high throughput sequencing, possibly due to the general normalization of starting DNA amounts in the PCR amplification step prior to library preparation and sequencing.
We did not identify significant differences in the total number of recovered reads based on the DNA isolation kit (Kruskal–Wallis p = 0.806, Fig. 1B). Notably, sequencing reads were obtained even in negative controls and in samples without gel bands after PCR that might have originally been presumed to be devoid of DNA.
Microbial composition
Alpha diversity measures summarize the composition of bacteria in a sample in terms of the numbers of different taxa present (richness) and their distribution (evenness). We did not identify significant differences in alpha diversity measured as the number of observed genera, the Shannon index, or the inverse Simpson index based on DNA isolation kit (Kruskal–Wallis p = 0.292, 0.363, and 0.436, respectively; Fig. 2).

Richness and evenness of the microbial composition does not depend on the DNA isolation kit (Kruskal–Wallis p = 0.292, 0.363, and 0.436, respectively). Box plots depict the median and range of diversity measures.
To evaluate the differences in the overall composition of taxa between DNA isolation kits, we estimated beta diversity using the Bray–Curtis distance and nonmetric multi-dimensional scaling (NMDS, Fig. 3A), and evaluated the relative abundance of recovered bacteria in each sample (Fig. 3B). For most of the samples, the composition appears to be consistent despite the DNA isolation kit that was used. As such, the overall microbial composition was not significantly different based on the DNA isolation protocol (PERMANOVA p = 0.87, permutations = 999), with the exception of Sample 7, which displays high variability in both the relative abundance and NMDS plots. As expected, recovered microbes differed significantly between the 11 urine samples (PERMANOVA p = 0.001, permutations = 999).

Differences in the DNA isolation methods do not result in drastic changes in relative abundances of identified genera. (A) Multidimensional scaling plot using Bray Curtis distance demonstrates that most samples are not significantly different due to DNA isolation kit (p = 0.87 in PERMANOVA analysis), though sample 7 was not tightly clustered, indicating that these samples may have significant variations in microbiome composition by kit. (B) Stacked bar plots represent the microbial composition of each sample after DNA isolation and 16S rRNA gene sequencing. Only sample 4, 7, and negative control PBS exhibit more variability across multiple kits.
Recovery of Gram positive versus Gram negative bacteria
Prior studies comparing methods of DNA isolation from non-urine microbiome samples strongly indicated that the envelope structure of Gram positive organisms represents an impediment for uniform cell lysis17,18,19,20,21,22,23,24. Therefore, we analyzed whether DNA isolation kits biased the identified microbial composition towards Gram negative species. We compared relative abundances among all genera with known Gram staining of representatives (Fig. 4 and Fig. S2 for individual sample results). Four out of five DNA isolation kits yielded comparable overall relative abundances of Gram positive bacteria. The Promega kit resulted in fewer Gram positive bacteria, though this was not statistically significant (Kruskal–Wallis, p = 0.197), likely due to the small sample size and highly variable data.

DNA from Gram positive bacteria was consistently present in four out of five tested DNA isolation kits. The Promega kit recovered Gram positive bacteria, but at lower abundance than the other kits, though this was not significantly different (Kruskal–Wallis, p = 0.197).
Microbiome studies of different niches reveal that overall composition is important for health and disease. However, infectious disease studies also show that specific microbes may be important for an underlying condition. Therefore, we further analyzed the presence of eight specific genera relevant for the urinary niche (Fig. 5). These include genera containing three known urinary pathogens (Escherichia, Klebsiella, Enterococcus) and five genera typically considered as commensals (Lactobacillus, Corynebacterium, Prevotella, Staphylococcus, Gardnerella). This analysis shows a non-significant reduction of Enterococcus, Corynebacterium, and Staphylococcus genera for the Promega kit. It also appears that the PowerSoil kit could recover more ‘easy-to-lyse’ Gram negative organisms such as Klebsiella and Escherichia compared to the other kits. In our study, this phenomenon was driven by approximately half of the samples (see Fig. 3B and Fig. S2, Samples 2,4,7,9, and 11).

Comparison of relative abundances of genera with biologically-significant representatives. We compared relative abundances of bacteria recovered from eight genera with high biologic relevance including urinary pathogens (Escherichia, Klebsiella, Enterococcus) and commensals (Lactobacillus, Corynebacterium, Prevotella, Staphylococcus, Gardnerella). The Promega kit tended to recover fewer Gram positive Corynebacteria, Enterococci, and Staphylococci compared to other kits while the PowerSoil kit recovered more Escherichia and Klebsiella compared to other kits. In follow up experiments, we did not confirm a bias in favor of Gram negative organisms for the PowerSoil kit. Rather, the PowerSoil kit was substantially influenced by contaminants in low biomass environments (See Fig. S3 and S4).
To assess the trend towards bias in recovery of specific types of bacteria, we further tested DNA isolation results in a subset of kits using a well characterized mock microbial community (ZymoBIOMICS Microbial Community Standard, Zymo Research, Irvine, CA). This community contains known quantities of 8 bacteria, including both Gram positive and Gram negative microbes. In this secondary experiment, we did not confirm differences among kits based on Gram staining status, though we were unable to include the Promega kit due to a loss of proprietary instruments in our facility. Rather, we observed that results were highly variable by kit in extremely low microbial biomass samples. DNA isolation kits performed similarly with undiluted or slightly diluted bacteria. However, when bacteria were substantially diluted, replicating the bacterial cell content of urine, only DNA extracted with the DNeasy Blood & Tissue kit resulted in all of the expected organisms after sequencing (Fig. S3A). When substantially diluted, other kits showed varying amounts of expected organisms with a substantial amount of additional contaminant bacterial DNA (Fig. S3B, Fig. S4).
Discussion
The field of urinary microbiome research is still relatively new. As such, studies benchmarking DNA isolation kits and their performance in recovering urinary microbial composition data are lacking. This study aimed to compare several methods of isolating microbial DNA from human urine. In particular, we compared five commercially available DNA isolation kits and estimated not only the quantity of DNA, but also the quality of DNA when utilized in downstream compositional analyses.
It has previously been shown that biases are introduced to microbial composition analysis based on the DNA isolation technique in both high biomass and low biomass communities of microbes19,22,26. Our results echo those found in oral microbial communities, where the DNA isolation method may result in significantly different DNA yield, though overall non-significant differences in downstream sequencing23. Though many of our downstream assessments showed non-significant differences, our data do not support the assumption that all DNA isolation kits perform equally in urinary microbiome studies, as we identified some qualitative differences in recovery of Gram positive versus Gram negative organisms, and some differences in overall performance with low biomass samples. Since microbiome data are typically presented in terms of relative abundance, if one type of microbe is absent due to a technical bias, it will artificially make other microbes appear more abundant. This is evident when viewing graphs in Figure S2, where relative abundances of Gram positive and Gram negative bacteria are inversely proportional to each other.
In our study, after initial PCR amplification, four samples and three controls derived from extremely low quantities of DNA failed to show a band on electrophoresis. The lack of amplified DNA after beginning with extremely low quantities of DNA could be expected. However, in one instance a sample extracted with the UltraClean kit had normal quantities of starting DNA with no evident PCR product on electrophoresis. This one result could have been spurious or possibly indicative of the presence of PCR inhibitors in the sample, as have been identified in other studies12,13.
Our findings are strengthened by the multiple ways in which we assessed quality of DNA after isolation. This included evaluation of PCR products, assessment of the number of sequencing reads after high-throughput sequencing, as well as detailed compositional analyses of microbial data. We utilized an updated and rigorous bioinformatics pipeline to identify the genera corresponding to recovered sequences. We then utilized this information to assess the quality of sequencing information, which revealed some initial differences based on Gram staining characteristics and in urogenital genera that are highly relevant to the urinary microbiome field. However, these initial differences were not confirmed in a secondary experiment with a mock microbial community. Rather, we established that high variability and potential contaminants can be observed in dilute, low biomass environments. These results confirm the importance of including a dilution series of positive controls when performing sequencing, as has been previously described, to control for potential contaminants during bioinformatic processing of low biomass sequencing data28.
Our study certainly has multiple limitations, which are mainly related to technical factors. After assessing recovered DNA quantity using Qubit, we did not perform additional testing to assess the proportion of microbial versus human DNA contained in each sample. Thus, it is unclear if differences identified in total DNA recovery actually translate to differences in microbial DNA within different samples, which is the component of interest in microbiome studies. Another limitation was inherent in the need to divide urine samples. Though one urine sample was produced, we needed to ensure that it was equally divided prior to performing parallel testing with five kits. Since the biomass (e.g. cellular material containing DNA) may not be evenly distributed within the fluid of a urine sample, we addressed this issue by first centrifuging whole urine to produce a cell pellet containing the biomass. This cell pellet was then reconstituted in a smaller volume, thoroughly mixed, and then divided into five aliquots. However, it is still possible that due to pipetting or mixing errors, slightly different amounts of starting material were present in aliquots, which could have contributed to some of the variability seen in our results. However, we believe this factor is less important since urine volume did not correlate with biomass. For example, as shown in Tables S2 & S3, a 50 mL sample (Sample 3) had the highest amount of recovered DNA while another 100 mL sample had the lowest amount of recovered DNA. We utilized a negative control (PBS buffer) that was processed and sequenced in parallel to the urine samples. Though there was no starting DNA added to this sample, we recovered a small number of sequences (Fig. S1) suggesting presence of low level contaminants. Unfortunately, we did not use separate controls at each analytic step and thus we are unable to distinguish the sources of the observed contamination, which could come from plastics in the laboratory, reagents within the DNA isolation kits, or during multiple technical steps prior to sequencing.
This study utilized voided urine, which is more reflective of the urogenital microbiome than the bladder microbiome. Since we are not attempting to characterize a niche, the method of urine sample acquisition is less important. However, microbes from the vagina are found in higher abundance in voided compared to catheterized urinary samples, and thus may have higher representation in the compositional data presented here. Since vaginal and urinary microbes are highly related in terms of the genera and species represented, vaginal contamination theoretically should not negatively impact the results of this benchmarking study29,30. Nevertheless, studies such as this one would ideally be replicated numerous times to confirm the findings.
Conclusions
When considering the totality of our findings, DNA extracted with the Qiagen Biostic Bacteremia and DNeasy Blood & Tissue kits showed the fewest technical issues in downstream analyses, with the DNeasy Blood & Tissue kit also demonstrating the highest DNA yield. Nevertheless, all five kits provided good quality DNA for high throughput sequencing with non-significant differences in the number of reads recovered, alpha, or beta diversity. In qualitatively assessing the types of bacteria, the Promega and DNeasy PowerSoil kits appear to have some biases towards over-representing certain Gram negative bacteria of biologic relevance within the urinary microbiome. This bias in the DNeasy PowerSoil kit was not confirmed in follow up analysis of a mock microbial community. Rather, analyses in a mock microbial community confirmed that kits may perform differently when applied to high versus low biomass environments, and that we should anticipate and control for potential contaminants in low biomass samples. These findings have implications for research teams wishing to maximize utility of low biomass samples, particularly for sequencing strategies where more DNA is required. Furthermore, these findings are relevant for interpretation of microbiome studies. The results presented here are certainly in line with other microbiome niches suggesting that the DNA isolation methods used could potentially bias downstream results. As such, we urge caution to investigators when selecting which DNA isolation method is used in future urinary microbiome studies, caution to the scientific community when assessing findings from studies where isolation methods with known bias were used, and further urge a high level of caution in general when trying to compare or extrapolate results from studies where different DNA isolation methodologies were used.
Materials and methods
Sample collection and processing
This study was deemed exempt by the Duke University Institutional Review Board (Pro00085111). Following all relevant guidelines, de-identified voided urine samples were collected in sterile cups from the Duke Urogynecology clinic, refrigerated (4 °C), and processed within 4–10 h (Table S2). As the study was deemed exempt by IRB no consent was obtained.
During processing, samples were handled aseptically, transferred to 50 mL conical tubes and spun without any buffer pretreatment to collect all of the biomass, including human and microbial cells (4 °C, Eppendorf 5810R centrifuge, 15 min, 3220 rcf) represented in the “cell pellet”. Supernatants were decanted and the remaining cell pellets with residual urine were transferred into sterile 1.5 mL tubes, then spun again at 10,000 rcf in the Eppendorf 5340R centrifuge for 5 min at 4 °C. The total cell pellet per sample was resuspended in sterile filtered phosphate buffered saline (PBS) on ice. Re-suspended pellets were divided into 5 identical aliquots, and stored at -80 °C until DNA isolation.
DNA isolation procedures
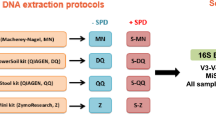
This step started with the five identical aliquots and thus the same starting material was processed in parallel with five commercially available DNA isolation kits. Each kit had differing levels of chemical, mechanical, and enzymatic cell lysis, as summarized in Table 1. PBS buffer was used as a negative control sample with each DNA isolation kit. For the Qiagen DNeasy Blood & Tissue kit we performed the optional steps as recommended in the protocol for optimizing recovery of Gram positive bacteria. All samples were assessed using the Agilent 2100 Bioanalyzer, Promega GlowMax spectrophotometer and ThermoFisher Qubit HR reagents to determine the quality and quantity of recovered DNA. Recovered DNA concentrations are provided in Table S3.
Bacterial ribosomal DNA amplification and sequencing
DNA samples and negative control were subjected to PCR in order to amplify the V4 variable region of the 16S rRNA gene. For PCR, forward primer 515 and reverse primer 806 were used following the Earth Microbiome Project protocol (http://www.earthmicrobiome.org/). These primers (515F and 806R) carry unique barcodes allowing for construction of a library of pooled samples for sequencing. PCR products were quantified and pooled. In instances where no PCR product was detected (see Table S3), equivalent volumes of the final PCR amplification solution were pooled with the others. Combined pooled samples were then submitted for sequencing on an Illumina MiSeq sequencer configured for 150 base-pair paired-end sequencing runs. DNA samples for all kits were prepared and sequenced together to avoid processing and sequencing batch variations.
Sequencing data processing and analysis
Raw sequences were trimmed and de-multiplexed prior to being processed with DADA2 (v.1.14.0) to provide amplicon sequence variants (ASVs) per sample31. ASVs were compared against the SILVA reference database (v.132) using the RDP classifier implemented in DADA2 for identification of taxa prior to being analyzed with phyloseq and vegan in R32,33,34. Overall microbial composition was assessed by estimating alpha diversity (number of observed genera, Shannon Index, and Inverse Simpson Index) as well as beta diversity using the Bray–Curtis distance. Comparisons across the 5 isolation kits were statistically evaluated using the Kruskal–Wallis rank sum tests followed by pair-wise comparisons using Wilcoxon-rank sum tests, and PERMANOVA for Bray–Curtis distances. The analysis code is available at https://github.com/KarstensLab/urobiome_dna_kits.
Data availability
All sequences are available for download in the Sequence Read Archive under Accession Number PRJNA662669 (http://www.ncbi.nlm.nih.gov/bioproject/662669).
References
Wolfe, A. J. et al. Evidence of uncultivated bacteria in the adult female bladder. J. Clin. Microbiol. https://doi.org/10.1128/JCM.05852-11 (2012).
Karstens, L. et al. Does the urinary microbiome play a role in urgency urinary incontinence and its severity?. Front. Cell. Infect. Microbiol. https://doi.org/10.3389/fcimb.2016.00078 (2016).
Pearce, M. M. et al. The female urinary microbiome in urgency urinary incontinence. Am. J. Obstet. Gynecol. https://doi.org/10.1016/j.ajog.2015.07.009 (2015).
Brubaker, L. & Wolfe, A. J. The female urinary microbiota, urinary health and common urinary disorders. Ann. Transl. Med. https://doi.org/10.21037/atm.2016.11.62 (2017).
Hilt, E. E. et al. Urine is not sterile: use of enhanced urine culture techniques to detect resident bacterial flora in the adult female bladder. J. Clin. Microbiol. https://doi.org/10.1128/JCM.02876-13 (2014).
Kim, D. et al. Optimizing methods and dodging pitfalls in microbiome research. Microbiome https://doi.org/10.1186/s40168-017-0267-5 (2017).
Kerckhof, F. M. et al. Optimized cryopreservation of mixed microbial communities for conserved functionality and diversity. PLoS ONE https://doi.org/10.1371/journal.pone.0099517 (2014).
Karstens, L. et al. Community profiling of the urinary microbiota: considerations for low-biomass samples. Nat. Rev. Urol. https://doi.org/10.1038/s41585-018-0104-z (2018).
Pohl, H. G. et al. The urine microbiome of healthy men and women differs by urine collection method. Int. Neurourol. J. https://doi.org/10.5213/inj.1938244.122 (2020).
Pryles, C.V. Percutaneous bladder aspiration and other methods of urine collection for bacteriologic study. Pediatrics (1965).
Fogazzi, G. B. Crystalluria: a neglected aspect of urinary sediment analysis. Nephrol. Dial. Transpl. 11, 379–387 (1996).
Munch, M. M. et al. Optimizing bacterial DNA extraction in urine. PLoS ONE https://doi.org/10.1371/journal.pone.0222962 (2019).
Ackerman, L. A. et al. Optimization of DNA extraction from human urinary samples for mycobiome community profiling. PLoS ONE https://doi.org/10.1371/journal.pone.0210306 (2019).
Jung, C. E. et al. Benchmarking urine storage and collection conditions for evaluating the female urinary microbiome. Sci. Rep. https://doi.org/10.1038/s41598-019-49823-5 (2019).
Moustafa, A. et al. Microbial metagenome of urinary tract infection. Sci. Rep. https://doi.org/10.1038/s41598-018-22660-8 (2018).
Wojciuk, B. et al. Urobiome: In sickness and in health. Microorganisms https://doi.org/10.3390/microorganisms7110548 (2019).
Claassen, S. et al. A comparison of the efficiency of five different commercial DNA extraction kits for extraction of DNA from faecal samples. J. Microbiol. Methods https://doi.org/10.1016/j.mimet.2013.05.008 (2013).
Henderson, G. et al. Effect of DNA extraction methods and sampling techniques on the apparent structure of cow and sheep rumen microbial communities. PLoS ONE https://doi.org/10.1371/journal.pone.0074787 (2013).
Knudsen, B. E. et al. Impact of sample type and DNA isolation procedure on genomic inference of microbiome composition. mSystems (2016). doi:https://doi.org/10.1128/msystems.00095-16
Lim, M.Y., Song, E.J., Kim, S.H., Lee, J. & Nam, Y.D. Comparison of DNA extraction methods for human gut microbial community profiling. Syst. Appl. Microbiol. (2018). doi:https://doi.org/10.1016/j.syapm.2017.11.008
McOrist, A. L., Jackson, M. & Bird, A. R. A comparison of five methods for extraction of bacterial DNA from human faecal samples. J. Microbiol. Methods https://doi.org/10.1016/S0167-7012(02)00018-0 (2002).
Stinson, L. F., Keelan, J. A. & Payne, M. S. Comparison of Meconium DNA extraction methods for use in microbiome studies. Front. Microbiol. https://doi.org/10.3389/fmicb.2018.00270 (2018).
Vesty, A., Biswas, K., Taylor, M. W., Gear, K. & Douglas, R. G. Evaluating the impact of DNA extraction method on the representation of human oral bacterial and fungal communities. PLoS ONE https://doi.org/10.1371/journal.pone.0169877 (2017).
Walden, C., Carbonero, F. & Zhang, W. Assessing impacts of DNA extraction methods on next generation sequencing of water and wastewater samples. J. Microbiol. Methods https://doi.org/10.1016/j.mimet.2017.07.007 (2017).
Whiteside, S. A., Razvi, H., Dave, S., Reid, G. & Burton, J. P. The microbiome of the urinary tract: a role beyond infection. Nat. Rev. Urol. https://doi.org/10.1038/nrurol.2014.361 (2015).
Xue, M., Wu, L., He, Y., Liang, H. & Wen, C. Biases during DNA extraction affect characterization of the microbiota associated with larvae of the Pacific white shrimp, Litopenaeus vannamei. PeerJ https://doi.org/10.7717/peerj.5257 (2018).
Ackerman, A. L. & Underhill, D. M. The mycobiome of the human urinary tract: Potential roles for fungi in urology. Ann. Transl. Med. https://doi.org/10.21037/atm.2016.12.69 (2017).
Karstens, L. et al. Controlling for contaminants in low-biomass 16S rRNA gene sequencing experiments. mSystems (2019). doi:https://doi.org/10.1128/msystems.00290-19
Thomas-White, K. et al. Culturing of female bladder bacteria reveals an interconnected urogenital microbiota. Nat. Commun. https://doi.org/10.1038/s41467-018-03968-5 (2018).
Komesu, Y. M. et al. Methodology for a vaginal and urinary microbiome study in women with mixed urinary incontinence. Int. Urogynecol. J. https://doi.org/10.1007/s00192-016-3165-7 (2017).
Callahan, B. J. et al. DADA2: High-resolution sample inference from Illumina amplicon data. Nat. Methods https://doi.org/10.1038/nmeth.3869 (2016).
Quast, C. et al. The SILVA ribosomal RNA gene database project: Improved data processing and web-based tools. Nucleic Acids Res. https://doi.org/10.1093/nar/gks1219 (2013).
McMurdie, P. J. & Holmes, S. Phyloseq: an R package for reproducible interactive analysis and graphics of microbiome census data. PLoS ONE https://doi.org/10.1371/journal.pone.0061217 (2013).
Oksanen, J. et al. Package vegan. R Packag ver (2013).
Acknowledgements
We thank the clinical research coordinators (Shantae McLean, M.P.H., Robin Gilliam, M.S.W., Akira Hayes, M.S.) at the Duke Urogynecology Clinic who assisted in collecting urine samples for this study. We also thank the Duke University School of Medicine for the use of the Microbiome Shared Resource (in particular to Holly Dressman, Ph.D.), which provided Promega kit isolation and all the library preparation services, as well as the Sequencing and Genomic Technologies Core Facility of the Duke University Center for Genomic and Computational Biology. This study was funded by: K12 Duke KURe (DK100024) NIDDK and UAH Startup fund to TAS; career development awards K23 DK110417, R03 AG060082, and P30 AG028716 to NYS; UL1TR002369 and K01 DK116706 to LK.
Author information
Authors and Affiliations
Contributions
TAS conceived the study and performed the experiments; TZ and AB assisted with literature review, analysis and data annotation; TAS, LK, and NYS analyzed the data; CLA contributed in discussing the results and editing the manuscript. TAS, LK and NYS interpreted the data and wrote the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Karstens, L., Siddiqui, N.Y., Zaza, T. et al. Benchmarking DNA isolation kits used in analyses of the urinary microbiome. Sci Rep 11, 6186 (2021). https://doi.org/10.1038/s41598-021-85482-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-85482-1
This article is cited by
-
Current Trends and Challenges of Microbiome Research in Bladder Cancer
Current Oncology Reports (2024)
-
Benchmarking DNA isolation methods for marine metagenomics
Scientific Reports (2023)
-
Longitudinal urinary microbiome characteristics in women with urgency urinary incontinence undergoing sacral neuromodulation
International Urogynecology Journal (2023)
-
The pediatric urobiome in genitourinary conditions: a narrative review
Pediatric Nephrology (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
