
Abstract
Quantum annealing was originally proposed as an approach for solving combinatorial optimization problems using quantum effects. D-Wave Systems has released a production model of quantum annealing hardware. However, the inherent noise and various environmental factors in the hardware hamper the determination of optimal solutions. In addition, the freezing effect in regions with weak quantum fluctuations generates outputs approximately following a Gibbs–Boltzmann distribution at an extremely low temperature. Thus, a quantum annealer may also serve as a fast sampler for the Ising spin-glass problem, and several studies have investigated Boltzmann machine learning using a quantum annealer. Previous developments have focused on comparing the performance in the standard distance of the resulting distributions between conventional methods in classical computers and sampling by a quantum annealer. In this study, we focused on the performance of a quantum annealer as a generative model from a different aspect. To evaluate its performance, we prepared a discriminator given by a neural network trained on an a priori dataset. The evaluation results show a higher performance of quantum annealer compared with the classical approach for Boltzmann machine learning in training of the generative model. However the generation of the data suffers from the remanent quantum fluctuation in the quantum annealer. The quality of the generated images from the quantum annealer gets worse than the ideal case of the quantum annealing and the classical Monte-Carlo sampling.
Similar content being viewed by others
Introduction
Quantum annealing (QA) is an approach for solving combinatorial optimization problems starting form the quantum superpositioned state1. The quantum tunneling effect drives the system and searches the ground state in the lugged energy landscape2,3,4,5,6. The hardware implementation of QA has been developed by D-Wave Systems and performs for production level, attracting much interest from academia and industry7,8,9,10. Quantum annealers have been used in numerous applications, such as portfolio optimization11, protein folding12, molecular similarity problems13, computational biology14, job-shop scheduling15, traffic optimization16, election forecasting17, machine learning18,19,20,21,22,23, web recommendation24, automated guided vehicles in factories25, decoding algorithm26 and Black-box optimization27. By feeding a Hamiltonian-based quadratic unconstrained binary optimization matrix into a quantum annealer, several solutions can be quickly obtained. However, the solution may not always be optimal owing to unavoidable hardware limitations. For instance, connectivity in the hardware graph may be insufficient to represent the optimization matrix. In fact, the original optimization problem is embedded in a hardware chimera (previous hardware version) or a Pegasus graph. The embedding protocol is generally difficult, and many variants have been proposed28. When various problems are embedded in the hardware graph, a chain with interacting redundant spins represent the original problems. Nevertheless, when the strength of the chain interaction is sufficiently high, embedding can be avoided. Another hardware limitation is the nonuniform distribution of the degenerate ground states owing to quantum effects. As an alternative for QA, simulated annealing achieves uniform degenerate ground states29,30. Still, this limitation is not critical, as a degenerate ground state can be found in any case. Another limitation is relatively crucial and related to the freezing effect and environment effect from a heat bath. A real quantum annealer is not isolated from the environment. Thus, it does not reflect the ideal QA case assumed in theory. Hence, if the system is thermalized, the quantum annealer outputs follow a Gibbs–Boltzmann distribution. Consequently, several protocols based on QA do not maintain the system in the ground state as in adiabatic quantum computation. Instead, they employ a nonadiabatic counterpart31,32,33,34 and consider thermal effects35. Recently, the quantum annealer implements a different protocol known as the reverse annealing employing the thermal effect at the middle stage of inverse protocol of the standard QA36,37. Investigation of the environment effect has been reported in the literature38.
In the present study, we focus on the property that the quantum annealer outputs following the Gibbs-Boltzmann distribution. In the quantum annealer, the transverse field gradually decreases and becomes insufficient to change the spin configurations at the last stage of the protocol of QA. Thus the distribution function is rather close to the Gibbs-Boltzmann one with a finite-strength transverse field39. Therefore the quantum annealer can be used for the quantum Boltzmann machine40. In the quantum Boltzmann machine, we consider the Ising model at a finite temperature with the transverse field. It costs highly expensive computational effort to generate the spin configurations following the Gibbs-Boltzmann distribution of the Ising model with a finite-strength transverse field at a non-zero temperature. However, if we have the quantum annealer, the quick generation of the sampling following the Gibbs-Boltzmann distribution in computationally hard regions. In this sense, the quantum annealer can be used as the quantum simulator as in the literature41,42. In addition, even for the classical Boltzmann machine, the quantum annealer is available as the sampling device with regularization in context of machine learning. Since the strength of the residual transverse field is very tiny, the quantum annealer is an approximate sampler for the Gibbs-Boltzmann distribution without the transverse field. The small quantum fluctuation works as the regularization in the classical Boltzmann machine learning. In the previous studies, the previous studies on the classical Boltzmann machine learning by use of the quantum annealer reported better performance than the standard methods in classical computers43. In theoretical aspect, the small quantum fluctuation improves the performance on prediction as shown in several studies44,45.
Although several QA applications to the Boltzmann machine learning have been reported, previous studies have shown that the quantum annealer achieves higher performance in Boltzmann machine learning measured in the standard distance between the target and attained distributions, the Kullback–Leibler (KL) divergence. In this study, we investigated the performance of Boltzmann machine learning using a quantum annealer from a different perspective. We used the quantum annealer during training and generation of the Boltzmann machine. Previously, the performance of the quantum annealer has been investigated with respect to the final value of the KL divergence. However, the trained model has not been considered as a generative model, as its performance is difficult to assess. Thus, we prepared another neural network to measure the quality of the generated data from the Boltzmann machine. Although several measures quantify the similarity between two images, we use another neural network because the generated outputs do not necessarily represent a one-to-one correspondence of images in the training dataset. We evaluate the generated outputs by discriminating them using the discriminator neural network, assuming that these outputs are similar to the training samples. The discriminator model was trained using the same training dataset as that fed to the Boltzmann machine to learn its various features. The discriminator then indicated the similarity between the generated and training samples.
The remainder of this paper is organised as follows. The next section describes the Boltzmann machine and sampling using a quantum annealer. Then, we explain the training and generation method of the Boltzmann machine used in the experiments and the discriminator to assess the generated data. Subsequently, we report the evaluation results of the images generated by the Boltzmann machine and compare different combinations of sampling methods in Boltzmann machine learning. In the last section, we summarise the study.
Problem setting
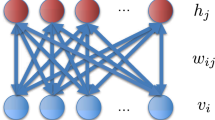
The Boltzmann machine is a neural network model with fully connected and undirected edges. We set a binary variable that can be either 0 or 1 at each node. In Boltzmann machine learning, the binary variables are assumed to follow the Gibbs–Boltzmann distribution:
where \(x_i\) is the binary variable for node i and \(\Phi \) is the energy function of the Boltzmann machine indicating that the state of the node that reduces this energy is likely to appear. In the energy function, \(b_i\) is the bias of node i and \(w_{ij}\) is the weight between nodes i and j on each edge. These are summarised as parameters and are denoted as \(\varvec{\theta }\). \(Z(\varvec{\theta })\) is a partition function used for normalisation. In Boltzmann machine learning, the output data are assumed to follow the Gibbs–Boltzmann distribution defined above. During learning, the maximum likelihood estimation for probability distribution (1) is performed:
where
and N is the number of samples. We use the log-likelihood function instead of the mature quantity for simplicity. To find maximiser \(\varvec{\theta }^*\) of the log-likelihood function, we take its derivative with respect to \(\varvec{\theta }\) to obtain
where \(\langle \ldots \rangle _\text{{data}}\) denotes the empirical mean over the training data and \(\langle \ldots \rangle _\text{{model}}\) denotes the model expectation. The bottleneck of Boltzmann machine learning is estimating the model expectation in the equations above, as it requires \(2^N\) calculations in principle. Therefore, the estimation should be approximated or a sampling method following the Gibbs–Boltzmann distribution should be adopted. For sampling, we prepared several synthetic data samples according to the probability distribution of the model and approximated the expected value using their empirical mean. Sampling methods include Gibbs sampling using the Markov chain Monte Carlo (MCMC) method. Instead of directly manipulating Gibbs sampling, we used a quantum annealer to efficiently obtain output samples following the Gibbs–Boltzmann distribution. We also compared the performance of Boltzmann machine learning for two sampling methods.
We analysed the quality of generation by the Boltzmann machine trained using the outputs from a quantum annealer. To control data generation, we separated the nodes of the Boltzmann machine into sectors A and B. One sector of nodes (\(i \in A\)) represents the data, and the other sector (\(i \in B\)) selects the kind of data. We denote the binary vectors in sector A as \(\mathbf{x}_A\) and those in sector B as \(\mathbf{x}_B\). We used the MNIST dataset, which consists of various images of handwritten digits from zero to nine, as the dataset for assessment. Thus, sector B for selecting the digit label requires at most 10 nodes. Sector A representing the generated images has the remaining nodes of the Boltzmann machine. Although machine learning studies are generally performed for higher-dimensional data even for proofs of concept, we employed the MNIST dataset due to the limited capacity of the quantum annealer. For the experiments, we used the D-Wave 2000Q quantum computer, whose size is restricted to 64 binary variables on the fully connected graph by embedding on a chimera graph. Consequently, the number of nodes in the sector for representing the image in Boltzmann machine learning was seriously restricted using this hardware. We also restricted the number of digits to five, and resized the images to \(8 \times 6 = 48\) pixels from the scaled-down MNIST dataset. In addition, we binarized the original images as shown in Fig. 1 to be suitable for the quantum annealer.

Samples of binarised handwritten digits from MNIST dataset.
To control the generated images, we fixed one of the nodes in sector B during training. For instance, let us consider the generation of five images for digits from 5 to 9. We represented each image \(\mathbf{x}\) with label k from 5 to 9 into image data \(\mathbf{x}_{B} = \mathbf{x}\) using one-hot encoding as \(\mathbf{x}_A = (1,0,0,0,0)\) for \(k=5\), \(\mathbf{x}_A = (0,1,0,0,0)\) for \(k=6\), and so on. The Boltzmann machine was trained using the labelled encoded images and provided the controlled images depending on sector B. In the implementation, we applied a strong magnetic field to the node corresponding to the desired label. Then, the generated output from the Boltzmann machine was conditioned on sector B. In the conventional MCMC approach, we can directly control each bit in sector B. In contrast, the quantum annealer cannot keep each bit. Thus, we applied a strong magnetic field to generate the data. Below, we detail the experiments for assessing the performance of Boltzmann machine learning by using a quantum annealer. Note that the quantum annealer sometimes fails to correctly generate outputs by indirect control of the bit in sector B. However, because we omit the spins in the sector B, we straightforwardly input the resultant spin configurations into the discriminator.
Experiments
The currently available quantum annealer performs QA mainly to solve optimization problems. However, it can also generate different binary variable configurations. The distribution of the configurations approximately follows a Gibbs–Boltzmann distribution with the form of the energy function in Eq. (2). Therefore, we replaced the estimation of the model expectation with the computation of the empirical mean of the QA outputs by setting the same energy function during Boltzmann machine learning. The outputs are classical but follow the Gibbs–Boltzmann distribution with a finite transverse magnetic field controlling the strength of the quantum fluctuation39. For optimization, the remaining quantum fluctuation may lead to obstacles in the solutions. However, for machine learning, it would be helpful to find the parameters providing high performance, as reported in previous studies. Indeed, the possibility of improving the generalisation performance by finite-strength quantum fluctuations during neural network training has been explored25,46.
A previous study used the KL divergence to assess the performance of a Boltzmann machine40. As a result, a lower KL divergence was attained by using the Boltzmann machine and sampling from the quantum annealer, suggesting the superiority of the quantum version of the Boltzmann machine. In this study, we focused on the practical performance of a quantum annealer by directly assessing the quality of generated data from the Boltzmann machine. Besides investigating the data quality, we compared different combinations of sampling methods for Boltzmann machine learning. Specifically, we evaluated Gibbs sampling and direct sampling in the quantum annealer during both training and generation. During training, sampling was used to compute the expectations for assessing the derivatives with respect to the parameters. Finite-strength quantum fluctuations affect the precision of the computation of the derivatives. In other words, quantum fluctuations perform regularisation, as investigated in a previous study. During generation, sampling is used again to generate a new sample. Then, the finite-strength quantum fluctuation was assumed not to be directly related to the quality of the generated data but rather to cause degradation. However, sampling in a quantum annealer provides independent output samples because the annealer quickly repeats the generation of the binary configurations following the Gibbs–Boltzmann distribution by leveraging quantum superposition. In contrast, classical sampling tends to maintain correlation between samples if both the generation of the distribution function is not restarted using different initial conditions and the sampling period is short. Thus, Boltzmann machine learning using quantum annealers is expected to be superior to that using classical computers during generation.
We evaluated the performance of Boltzmann machine learning using a quantum annealer by preparing a discriminator neural network to measure the quality of the generated data. The discriminator was trained using the MNIST dataset, as for Boltzmann machine learning. The input layer of the discriminator had \(8 \times 6\) nodes receiving the output from the Boltzmann machine representing the resized images. We do not deal with the bits in sector B for selecting the label in generation. The output layer had 5 nodes to express the image label using one-hot encoding. The discriminator architecture is shown in Fig. 2. In addition, we set the cross-entropy as the loss function and used Adam optimization to train the discriminator47 and \(D=896\) images representing digits 5–9. We used all these images for training the discriminator and the Boltzmann machine. The number of training data affects the performance of the Boltzmann machine learning in general48. In our study, to enhance the performance of the Boltzmann machine learning as far as possible, we used all the images for training the discriminator and the Boltzmann machine. Thus, both networks suitably characterised the MNIST dataset. However, the discriminator was not trained using the images generated by the Boltzmann machine.

Discriminator architecture (ReLU, rectified linear unit).
We defined the quality of the generated images as the agreement rate between the obtained labels from discrimination:
where \(D_m\) is the number of matching labels between generation and discrimination and \(D_t\) is the total number of generated images.
We used two sampling methods, namely, Gibbs sampling and direct sampling in the quantum annealer (D-Wave 2000Q) for training. Gibbs sampling was performed with burn-in time \(T_\text{in}\) and sampling interval \(\Delta t\) of \((T_\text{in},\Delta t) = (200, 10)\) and (1000, 50). The number of samples was set to 200. On the other hand, direct sampling in the quantum annealer does not have burn-in time and sampling interval but uses annealing time, this we set to \(\delta t = 5\) \(\mu \)s per sampling. The number of samples was 200, as for Gibbs sampling. During training, while computing the expectation by the empirical mean trough sampling, we updated the parameters using minibatch learning and the momentum method with \(L_2\) norm regularisation following the approach in49. The parameters used during training of the Boltzmann machine are listed in Table 1.
After learning the Boltzmann machine, we used it to synthesise images. For image generation, we also used Gibbs sampling and direct sampling in the quantum annealer. We sampled 100 images per digit (i.e., 500 samples for the five digits) by controlling sector B. In addition to the two sampling methods, we performed low-energy sampling using the quantum annealer. Specifically, we first obtained 1000 samples from the quantum annealer and considered only the 100 images with the lowest energy values as the sampled images. We changed combination of sampling methods for training and generation. For example, we considered training with Gibbs sampling and generation with direct sampling. The sampling combinations are listed in Table 2.
All the experiments performed in this study are summarised in Fig. 3.

Summary of experiments performed in this study.
Results
We show the interaction terms and biases, which are described by the non-diagonal parts and diagonal ones, after performing the Boltzmann machine learning by each sampling method in Fig. 4. Depending on the sampling method, slight difference appears. Basically the biases becomes strong on the location at which most the the digits overlaps and interaction terms also. Compared among the results by QA and MCMCs , the ones by MCMCs contain relatively large values in the parameters. On the other hand, QA yields small values in the resulting parameters. This is due to the nontrivial noise involved in the sampling form the quantum annealer. The noise affects as regularizer in training similarly to the previous studies by use of the quantum annealer. As shown below, the learning from generation from QA actually avoids overfitting to the training images.

Interaction terms (non-diagonal elements) and biases (diagonal ones). The left-hand side panel shows the result of the trained model by the direct sampling from the quantum annealer, the center one is that by the MCMC in short equilibration time and sampling period, and the right-hand side one is that by MCMC in long equilibration time and sampling period.
The training results of the discriminator is shown in Fig. 5. The recognition rate of the discriminator exceeded 99%.

Results of discriminator training. The solid and dotted lines correspond to the results of training and validation, respectively.
We used the discriminator to assess the performance of the Boltzmann machine in terms of agreement rate \(R_{a}\) according to the number of epochs, obtaining the results shown in Fig. 6.

Agreement rate \(R_a\) over 4000 epochs for different sampling methods for image generation. Training used direct sampling with QA (solid line), MCMC \((T_\text{in},\Delta t)=(200,10)\) (dotted line), and MCMC \((T_\text{in},\Delta t)=(1000,50)\) (dashed-dotted line).
For a given sampling method for generation, training using Gibbs sampling provided a \(R_a\) approximately 10% lower than training using direct sampling with QA. When training using Gibbs sampling, \(R_a\) tended to be lower owing to overfitting with increasing number of epochs. This phenomenon did not occur for direct sampling with QA. Thus, training using direct sampling with QA may prevent overfitting in training of the Boltzmann machine. This observation is consistent with previous studies that considered KL divergence40. We confirmed the observation considering the agreement ratio. The agreement ratio reflects the quality of the generated images by comparing the generated and original images. On the other hand, the KL divergence measures the similarity between probability distributions. Therefore, the agreement ratio is homogeneous between different generative models and measures the performance of data generation.
By considering the two characteristics of the agreement ratio, we compared all the experimental results. Comparing the different sampling methods for training, we found that a higher agreement ratio is given by direct sampling with QA for all the cases regardless of the generation method. Thus, regularisation is ensured during training of Boltzmann machine learning by direct sampling with QA. Figures 7 and 8 show several images to illustrate the differences between the training methods. The images correctly discriminated are coloured, and those incorrectly classified are shown in black and white.

Images generated using QA with low energy at epoch 4000.

Images generated using MCMC(200, 10) at epoch 4000.
Comparing the different sampling methods during generation, we found that a higher agreement ratio is achieved by MCMC regardless of the burn-in time and sampling interval. Thus, the quantum annealer provides lower generation quality than the classical approach. This lower quality is due to obstacles in sector B for selecting the label because we cannot always fix the binary variable during QA. Instead, we applied a strong magnetic field to fix the binary variables in sector B. Therefore, several samples could not be correctly generated following sector B. This demonstrates some practical difficulty for generating data while controlling outputs using the quantum annealer.
From the experiments, it is clear that training using the quantum annealer improves the performance of the Boltzmann machine, being consistent with the findings from another study40. Regarding generation, QA retains a finite-strength transverse magnetic field at the end, influencing the experimental results. To investigate the effect of the residual transverse magnetic field, we applied the quantum Monte Carlo method with a finite-strength transverse magnetic field for data generation. We used the same trained Boltzmann machines by QA and MCMC(1000, 50) as in the previous experiment. We set the number of Trotter slices to 32 and the inverse temperature to 32. The transverse magnetic field was changed from 0.1 to 1.0 in increments of 0.1 for image generation. \(R_a\) was calculated according to the number of epochs during training, obtaining the results shown in Fig. 9.

\(R_a\) over 4000 epochs for images generated using quantum Monte Carlo method.
As shown in Fig. 9a, the agreement rate is higher than when generating images using QA compared with the results shown in Fig. 6a,b. Consequently, the performance reduces owing to the inherent effects of the quantum annealer and different control methods of sector B. However, the strength of the transverse magnetic field does not improve because the performance saturates in this case. During early training, a slight improvement was observed by inducing the finite-strength transverse magnetic field. Thus, finite-strength quantum fluctuations may affect the quality of data generation, at least for the handwritten digits considered in this study. In addition, looking at the results in the trained case using Gibbs sampling as shown in Fig. 9b, we found substantial effects of the finite-strength transverse magnetic field. The agreement rate considerably improved as the transverse magnetic field increased to 0.3, but it reduced for a stronger field. Therefore, a transverse magnetic field with appropriate strength may contribute to the performance improvement. Compared to the case of the results as in Fig.6c,d, the results with a finite-strength transverse field about 0.3 are very similar. In other words, the D-Wave quantum annealer remains its transverse field about 0.3 in terms of the quantum Monte Carlo simulation. These results suggest that the improvement in \(R_a\) by QA for generation using the Boltzmann machine is due to the slightly remanent transverse magnetic field. Unfortunately, the performance of the quantum annealer hardware for generation is not better than that of Gibbs sampling for generation due to the inherent effects affecting the hardware. We did not analyse the degradation in performance of the Boltzmann machine for data generation. Nevertheless, the last experiment demonstrated that the finite-strength quantum fluctuation in the quantum annealer implementation at the end of the protocol can improve data generation. In the future, the improvement of the quantum annealer can lead to high-quality data generation, as suggested by the results of the last experiment.
Summary
In this study, we performed various experiments to compare different sampling methods during training and generation based on Boltzmann machine learning. Previous studies have mainly focused on the performance of Boltzmann machine learning by evaluating the KL divergence during training. We analysed the effects of different sampling methods during data generation. First, we tested sampling methods, including Gibbs sampling, and the repetition of using a quantum annealer and lower-energy samples from the quantum annealer during training. The performance of the generated images was measured by a discriminator neural network that classified the images into several labels. The highest performance was observed for the quantum annealer during training. This is possibly due to the stochastic output provided by the quantum annealer. The gradient computed during training was assessed by the empirical mean of the output provided by the quantum annealer. Thus, the stochastic outputs result in fluctuating gradients. Consequently, the training escaped from several plateau and saddle points in the energy space of the log-likelihood function. This finding is consistent with observations from previous studies.
In this study, we performed additional comparisons of the sampling methods during generation. QA with lower-energy samples showed a relatively stable performance compared with direct sampling by the quantum annealer. In addition, Gibbs sampling exhibited higher performance than the other sampling methods. Thus, we can conclude that Gibbs sampling provides the highest performance for generation. Thus, we applied the quantum Monte Carlo method to realize the ideal computation in the quantum annealer, which is usually polluted by environmental effects. Sampling with the quantum Monte Carlo method showed higher performance than Gibbs sampling. This means that the best generation quality is given by ideal QA implemented by the quantum Monte Carlo method. Unfortunately, the available quantum annealer cannot realize ideal QA and thus shows poor performance during generation.
We varied the strength of the transverse magnetic field and investigated the performance of generation for different sampling methods. We found that a finite-strength transverse magnetic field enhances the quality of the generated images. This is a remarkable discovery in the context of quantum machine learning. Previous studies ensured that finite-strength quantum fluctuations during training improved the generalisation performance, indicating the robustness of the trained model and ability to handle unknown data. On the other hand, we showed that finite-strength quantum fluctuations increase the quality of the generated images. We could not assert any mechanism that explains the higher performance of sampling with finite-strength quantum fluctuations. However, we believe that our findings provide a new direction for studying quantum machine learning. The latest version of the quantum annealer, the D-wave advantage, might show different (possibly higher) performance compared with that achieved in our study. As shown in the results of the quantum Monte Carlo method, sampling affected by the remanent quantum fluctuation at the end of the QA protocol showed a slightly different performance during generation compared with Gibbs sampling. After this study, we expect that future developments will emphasize practical aspects of quantum machine learning, such as generated images and their quality.
References
Kadowaki, T. & Nishimori, H. Quantum annealing in the transverse Ising model. Phys. Rev. E 58, 5355–5363. https://doi.org/10.1103/PhysRevE.58.5355 (1998).
Ray, P., Chakrabarti, B. K. & Chakrabarti, A. Sherrington-kirkpatrick model in a transverse field: Absence of replica symmetry breaking due to quantum fluctuations. Phys. Rev. B 39, 11828–11832. https://doi.org/10.1103/PhysRevB.39.11828 (1989).
Das, A., Chakrabarti, B. K. & Stinchcombe, R. B. Quantum annealing in a kinetically constrained system. Phys. Rev. E 72, 026701. https://doi.org/10.1103/PhysRevE.72.026701 (2005).
Das, A. & Chakrabarti, B. K. Colloquium: Quantum annealing and analog quantum computation. Rev. Mod. Phys. 80, 1061–1081. https://doi.org/10.1103/RevModPhys.80.1061 (2008).
Morita, S. & Nishimori, H. Mathematical foundation of quantum annealing. J. Math. Phys. 49, 125210. https://doi.org/10.1063/1.2995837 (2008).
Masayuki, O. & Hidetoshi, N. Quantum annealing: An introduction and new developments. J. Comput. Theor. Nanosci. 8, 963–971 (2011).
Johnson, M. W. et al. A scalable control system for a superconducting adiabatic quantum optimization processor. Supercond. Sci. Technol. 23, 065004 (2010).
Berkley, A. J. et al. A scalable readout system for a superconducting adiabatic quantum optimization system. Supercond. Sci. Technology 23, 105014 (2010).
Harris, R. et al. Experimental investigation of an eight-qubit unit cell in a superconducting optimization processor. Phys. Rev. B 82, 024511. https://doi.org/10.1103/PhysRevB.82.024511 (2010).
Bunyk, P. I. et al. Architectural considerations in the design of a superconducting quantum annealing processor. IEEE Trans. Appl. Supercond. 24, 1–10. https://doi.org/10.1109/TASC.2014.2318294 (2014).
Rosenberg, G. et al. Solving the optimal trading trajectory problem using a quantum annealer. IEEE J. Sel. Top. Signal Process. 10, 1053–1060. https://doi.org/10.1109/JSTSP.2016.2574703 (2016).
Perdomo-Ortiz, A., Dickson, N., Drew-Brook, M., Rose, G. & Aspuru-Guzik, A. Finding low-energy conformations of lattice protein models by quantum annealing. Sci. Rep. 2, 571 (2012).
Hernandez, M. & Aramon, M. Enhancing quantum annealing performance for the molecular similarity problem. Quantum Inf. Process. 16, 133. https://doi.org/10.1007/s11128-017-1586-y (2017).
Li, R. Y., Di Felice, R., Rohs, R. & Lidar, D. A. Quantum annealing versus classical machine learning applied to a simplified computational biology problem. npj Quantum Inf. 4, 14. https://doi.org/10.1038/s41534-018-0060-8 (2018).
Venturelli, D., Marchand, D. J. J. & Rojo, G. Quantum Annealing Implementation of Job-Shop Scheduling. ArXiv e-prints (2015). arXiv:1506.08479.
Neukart, F. et al. Traffic flow optimization using a quantum annealer. Front. ICT 4, 29 (2017).
Henderson, M., Novak, J. & Cook, T. Leveraging Adiabatic Quantum Computation for Election Forecasting. ArXiv e-prints (2018). arXiv:1802.00069.
Crawford, D., Levit, A., Ghadermarzy, N., Oberoi, J. S. & Ronagh, P. Reinforcement Learning Using Quantum Boltzmann Machines. ArXiv e-prints (2016). arXiv:1612.05695.
Arai, S., Ohzeki, M. & Tanaka, K. Deep neural network detects quantum phase transition. J. Phys. Soc. Jpn. 87, 033001. https://doi.org/10.7566/JPSJ.87.033001 (2018).
Takahashi, C. et al. Statistical-mechanical analysis of compressed sensing for Hamiltonian estimation of Ising spin glass. J. Phys. Soc. Jpn. 87, 074001. https://doi.org/10.7566/JPSJ.87.074001 (2018).
Ohzeki, M. et al. Quantum annealing: Next-generation computation and how to implement it when information is missing. Nonlinear Theory Appl. IEICE 9, 392–405. https://doi.org/10.1587/nolta.9.392 (2018).
Neukart, F., Von Dollen, D., Seidel, C. & Compostella, G. Quantum-enhanced reinforcement learning for finite-episode games with discrete state spaces. Front. Phys. 5, 71. https://doi.org/10.3389/fphy.2017.00071 (2018).
Khoshaman, A., Vinci, W., Denis, B., Andriyash, E. & Amin, M. H. Quantum variational autoencoder. Quantum Sci. Technol. 4, 014001 (2018).
Nishimura, N., Tanahashi, K., Suganuma, K., Miyama, M. J. & Ohzeki, M. Item Listing Optimization for E-commerce Websites based on Diversity. arXiv e-printsarXiv:1903.12478 (2019).
Ohzeki, M., Miki, A., Miyama, M. J. & Terabe, M. Control of automated guided vehicles without collision by quantum annealer and digital devices. Front. Comput. Sci. 1, 9. https://doi.org/10.3389/fcomp.2019.00009 (2019).
Ide, N., Asayama, T., Ueno, H. & Ohzeki, M. Maximum-likelihood channel decoding with quantum annealing machine (2020). arXiv:2007.08689.
Koshikawa, A. S., Ohzeki, M., Kadowaki, T. & Tanaka, K. Benchmark test of black-box optimization using d-wave quantum annealer (2021). arXiv:2103.12320.
Okada, S., Ohzeki, M., Terabe, M. & Taguchi, S. Improving solutions by embedding larger subproblems in a d-wave quantum annealer. Sci. Rep. 9, 2098. https://doi.org/10.1038/s41598-018-38388-4 (2019).
Matsuda, Y., Nishimori, H. & Katzgraber, H. G. Ground-state statistics from annealing algorithms: quantum versus classical approaches. New J. Phys. 11, 073021. https://doi.org/10.1088/1367-2630/11/7/073021 (2009).
Yamamoto, M., Ohzeki, M. & Tanaka, K. Fair sampling by simulated annealing on quantum annealer. J. Phys. Soc. Jpn. 89, 025002. https://doi.org/10.7566/JPSJ.89.025002 (2020).
Ohzeki, M. Quantum annealing with the Jarzynski equality. Phys. Rev. Lett. 105, 050401. https://doi.org/10.1103/PhysRevLett.105.050401 (2010).
Ohzeki, M., Nishimori, H. & Katsuda, H. Nonequilibrium work on spin glasses in longitudinal and transverse fields. J. Phys. Soc. Jpn. 80, 084002. https://doi.org/10.1143/JPSJ.80.084002 (2011).
Ohzeki, M. & Nishimori, H. Nonequilibrium work performed in quantum annealing. J. Phys. 302, 012047 (2011).
Somma, R. D., Nagaj, D. & Kieferová, M. Quantum speedup by quantum annealing. Phys. Rev. Lett. 109, 050501 (2012).
Kadowaki, T. & Ohzeki, M. Experimental and theoretical study of thermodynamic effects in a quantum annealer. J. Phys. Soc. Jpn. 88, 061008. https://doi.org/10.7566/JPSJ.88.061008 (2019).
Yamashiro, Y., Ohkuwa, M., Nishimori, H. & Lidar, D. A. Dynamics of reverse annealing for the fully connected \(p\)-spin model. Phys. Rev. A 100, 052321. https://doi.org/10.1103/PhysRevA.100.052321 (2019).
Arai, S., Ohzeki, M. & Tanaka, K. Mean field analysis of reverse annealing for code-division multiple-access multiuser detection (2021). arXiv:2004.11066.
Bando, Y. et al. Probing the universality of topological defect formation in a quantum annealer: Kibble–Zurek mechanism and beyond. Phys. Rev. Res. 2, 033369. https://doi.org/10.1103/PhysRevResearch.2.033369 (2020).
Amin, M. H. Searching for quantum speedup in quasistatic quantum annealers. Phys. Rev. A 92, 052323 (2015).
Amin, M. H., Andriyash, E., Rolfe, J., Kulchytskyy, B. & Melko, R. Quantum boltzmann machine. Phys. Rev. X 8, 021050. https://doi.org/10.1103/PhysRevX.8.021050 (2018).
Kairys, P. et al. Simulating the Shastry–Sutherland Ising model using quantum annealing. PRX Quantum 1, 020320. https://doi.org/10.1103/PRXQuantum.1.020320 (2020).
King, A. D. et al. Scaling advantage over path-integral Monte Carlo in quantum simulation of geometrically frustrated magnets. Nat. Commun. 12, 1113. https://doi.org/10.1038/s41467-021-20901-5 (2021).
Adachi, S. H. & Henderson, M. P. Application of quantum annealing to training of deep neural networks (2015). arXiv:1510.06356.
Ohzeki, M., Okada, S., Terabe, M. & Taguchi, S. Optimization of neural networks via finite-value quantum fluctuations. Sci. Rep. 8, 9950 (2018).
Baldassi, C. & Zecchina, R. Efficiency of quantum vs. classical annealing in nonconvex learning problems. Proc. Natl. Acad. Sci. USA 115, 1457–1462 (2018).
Arai, S., Ohzeki, M. & Tanaka, K. Teacher-student learning for a binary perceptron with quantum fluctuations (2021). arXiv:2102.08609.
Kingma, D. P. & Ba, J. L. Adam: A method for stochastic gradient descent. ICLR: International Conference on Learning Representations 1–15 (2015).
Ohzeki, M. L1-regularized Boltzmann machine learning using majorizer minimization. J. Phys. Soc. Jpn. 84, 054801. https://doi.org/10.7566/JPSJ.84.054801 (2015).
Benedetti, M., Realpe-Gómez, J., Biswas, R. & Perdomo-Ortiz, A. Quantum-assisted learning of hardware-embedded probabilistic graphical models. Phys. Rev. X 7, 041052. https://doi.org/10.1103/physrevx.7.041052 (2017).
Acknowledgements
The authors would like to thank Manaka Okuyama and Masamichi J. Miyama for the fruitful discussions. This work was financially supported by JSPS KAKENHI Grant No. 20H02168, 19H01095 and No. 18H03303, partly supported by JST-CREST (No. JPMJCR1402), the Next Generation High-Performance Computing Infrastructures and Applications R&D Program of MEXT and by MEXT-Quantum Leap Flagship Program Grant Number JPMXS0120352009.
Author information
Authors and Affiliations
Contributions
T.S. performed the experiments and analysed the results; M.O. led the research project and established the experimental design and method for evaluating the results; all the authors contributed to writing and improving the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sato, T., Ohzeki, M. & Tanaka, K. Assessment of image generation by quantum annealer. Sci Rep 11, 13523 (2021). https://doi.org/10.1038/s41598-021-92295-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-92295-9
This article is cited by
-
Efficient low temperature Monte Carlo sampling using quantum annealing
Scientific Reports (2023)
-
Travel time optimization on multi-AGV routing by reverse annealing
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
